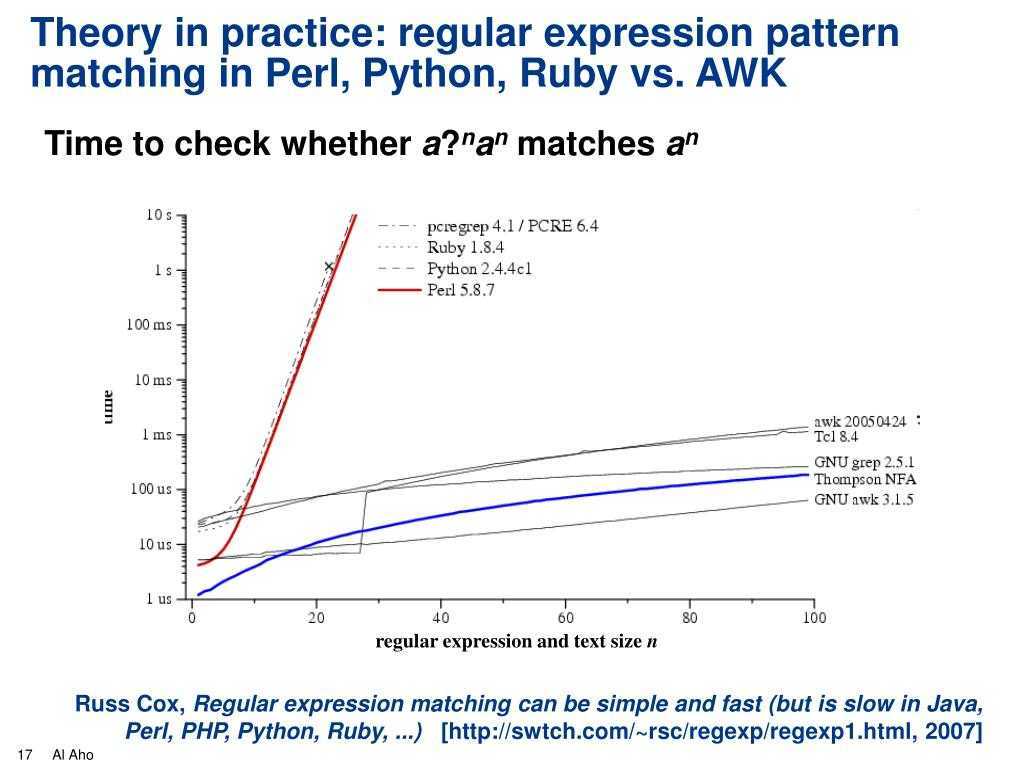
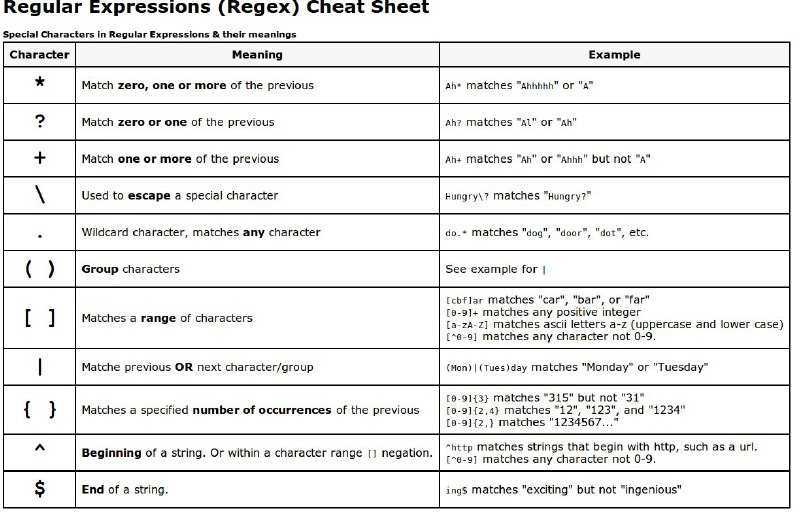
Conclusion
awk is a powerful pattern search and processing command in Linux/Unix. Complicated search task can be done easily using it.Hope you like this article on awk command in Linux with examples
Related articles5 Must have Unix books to enrich your brain and arsenal : This page consists of 5 Must have Unix books to enrich your brain and arsenal.These books will challenge to think and grow moreFunctions in Shell Script :How to write Functions in Shell Script .Step by step tutorial to write and execute function in Shell Script. Unix command prompt.sed command : sed command is a Stream Editor – works as a filter processing input line by line And here are 32 Useful sed command examples in Linux/UnixBasic unix command : Unix Script Tutorial for basic unix command which are used many times . Complete description is given for each of the commandfind command : find command in Unix with example,How to use find command in Unix.Unix find directory command,how to find find based on modified timeunix shell scripting interview questions : Great compilation of unix shell scripting interview questions for success in any interviews.Examples are given for the command alsoawk command Print examples
Часть седьмая: AWK и оболочки (sh/ksh/bash/csh)
Иногда функционала AWK может быть недостаточно. В этом случае можно интегрировать awk в скрипт оболочки. Далее несколько примеров как это можно сделать.
Простой вывод
Иногда хочется использовать awk просто как программу форматирования, и сбрасывать вывод прямо пользователю Следующий скрипт принимает в качества аргумента имя пользователя и использует awk для дампа информации о нём из /etc/passwd.
Примечание: обратите внимание, что в скрипте одинарные кавычки раскрываются (а не являются вложенными) и между двумя раскрытыми парами одинарных кавычек стоит переменная $1 (вторая), которая в данном случае является аргументом скрипта, в то время как $1 является частью синтаксиса $1 (означает первое поле в строке).
#!/bin/sh
while ; do
awk -F: '$1 == "'$1'" { print $1,$3} ' /etc/passwd
shift
done
Присвоение переменным оболочки вывода awk
Иногда мы хотим использовать awk просто для быстрого способа установить значение переменной. Используя тему passwd, у нас есть способ узнать шелл для пользователя и увидеть, входит ли он в список официальных оболочек.
И опять, обратите внимание, как происходит закрытие одинарных кавычек в выражении awk, После закрытой (второй) кавычки, $1 является переменной, в которую передано значение первого аргумента скрипта, а не частью синтаксиса awk.
#!/bin/sh
user="$1"
if ; then echo ERROR: need a username ; exit ; fi
usershell=`awk -F: '$1 == "'$1'" { print $7} ' /etc/passwd`
grep -l $usershell /etc/shells
if ; then
echo ERROR: shell $usershell for user $user not in /etc/shells
fi
Другие альтернативы:
# Смотрите "man regex"
usershell=`awk -F: '/^'$1':/ { print $7} ' /etc/passwd`
echo $usershell;
# Только современные awk принимают -v. Вам может понадобиться использовать "nawk" или "gawk"
usershell2=`awk -F: -v user=$1 '$1 == user { print $7} ' /etc/passwd`
echo $usershell2;
Объяснение дополнительных вышеприведённых методов остаётся домашним заданием читателю
Передача данных в awk по трубе
Иногда хочется поместить awk в качестве фильтра данных, в большую программу или команду в одной строке, вводимую в запрос оболочки. Пример такой команды в скрипте (в качестве аргументов скрипта передаётся список файлов логов веб-сервера, поскольку запись в журнал настраивается и логи могут иметь различную структуру, для работоспособности в конкретных случаях может понадобиться подправить команды):
#!/bin/sh
grep -h ' /index.html' $* | awk -F\" '{print $4}' | sort -u
Часть третья: Специальные переменные
Мы уже сказали про обычный синтаксис awk. Сейчас давайте начнём рассматривать модные штуки.
awk имеет «специальные» строки соответствия: «BEGIN» и «END»
Директива BEGIN вызывается однажды перед чтением каких-либо строк из данных, никогда снова.
Директива END вызывается после прочтения всех строк. Если дано несколько файлов, то она вызывается только после завершения самого последнего файла.
Обычно вы будете использовать BEGIN для различной инициализации, а END для подведения итогов или очистки.
Пример:
BEGIN { maxerrors=3 ; logfile=/var/log/something ; tmpfile=/tmp/blah}
... { blah blah blah }
/^header/ { headercount += 1 }
END { printf("всего подсчитано заголовков=%d\n", headercount);
Этот пример посчитает количество раз, которое встречается «header» в файле ввода и напечатает общее количество только после завершения обработки всего файла.
AWK также имеет множество других специальных величин, которые вы можете использовать в секции { }. Например,
print NF
даст вам общее количество колонок (Number of Fields – Количество полей) в текущей строке. FILENAME будет текущим именем файла, подразумевается, что имя файла было передано в awk, а не использована труба.
Вы НЕ МОЖЕТЕ ИЗМЕНИТЬ NF самостоятельно.
Аналогично с переменной NR, которая говорит, как много строк вы обработали. («Number of Records» – Количество записей)
Есть и другие специальные переменные, вы даже такие, которые вы МОЖЕТЕ изменить в середине программы.
Синтаксис команды awk
Сначала надо понять как работает утилита. Она читает документ по одной строке за раз, выполняет указанные вами действия и выводит результат на стандартный вывод. Одна из самых частых задач, для которых используется awk — это выборка одной из колонок. Все параметры awk находятся в кавычках, а действие, которое надо выполнить — в фигурных скобках. Вот основной её синтаксис:








$ awk опции ‘условие {действие}’
$ awk опции ‘условие {действие} условие {действие}’
С помощью действия можно выполнять преобразования с обрабатываемой строкой. Об этом мы поговорим позже, а сейчас давайте рассмотрим опции утилиты:
- -F, —field-separator — разделитель полей, используется для разбиения текста на колонки;
- -f, —file — прочитать данные не из стандартного вывода, а из файла;
- -v, —assign — присвоить значение переменной, например foo=bar;
- -b, —characters-as-bytes — считать все символы однобайтовыми;
- -d, —dump-variables — вывести значения всех переменных awk по умолчанию;
- -D, —debug — режим отладки, позволяет вводить команды интерактивно с клавиатуры;
- -e, —source — выполнить указанный код на языке awk;
- -o, —pretty-print — вывести результат работы программы в файл;
- -V, —version — вывести версию утилиты.
Это далеко не все опции awk, однако их вам будет достаточно на первое время. Теперь перечислим несколько функций-действий, которые вы можете использовать:
- print(строка) — вывод чего либо в стандартный поток вывода;
- printf(строка) — форматированный вывод в стандартный поток вывода;
- system(команда) — выполняет команду в системе;
- length(строка) — возвращает длину строки;
- substr(строка, старт, количество) — обрезает строку и возвращает результат;
- tolower(строка) — переводит строку в нижний регистр;
- toupper(строка) — переводить строку в верхний регистр.
Функций намного больше, но чтобы не загромождать статью я привел только те, которые мы будем использовать сегодня, а также ещё несколько для чтобы вы могли оценить масштаб возможностей утилиты.
В функциях-действиях можно использовать различные переменные и операторы, вот несколько из них:
- FNR — номер обрабатываемой строки в файле;
- FS — разделитель полей;
- NF — количество колонок в данной строке;
- NR — общее количество строк в обрабатываемом тексте;
- RS — разделитель строк, по умолчанию символ новой строки;
- $ — ссылка на колонку по номеру.
Кроме этих переменных, есть и другие, а также можно объявлять свои.
Условие позволяет обрабатывать только те строки, в которых содержатся нужные нам данные, его можно использовать в качестве фильтра, как grep. А ещё условие позволяет выполнять определенные блоки кода awk для начала и конца файла, для этого вместо регулярного выражения используйте директивы BEGIN (начало) и END (конец). Там ещё есть очень много всего, но на сегодня пожалуй достаточно. Теперь давайте перейдем к примерам.
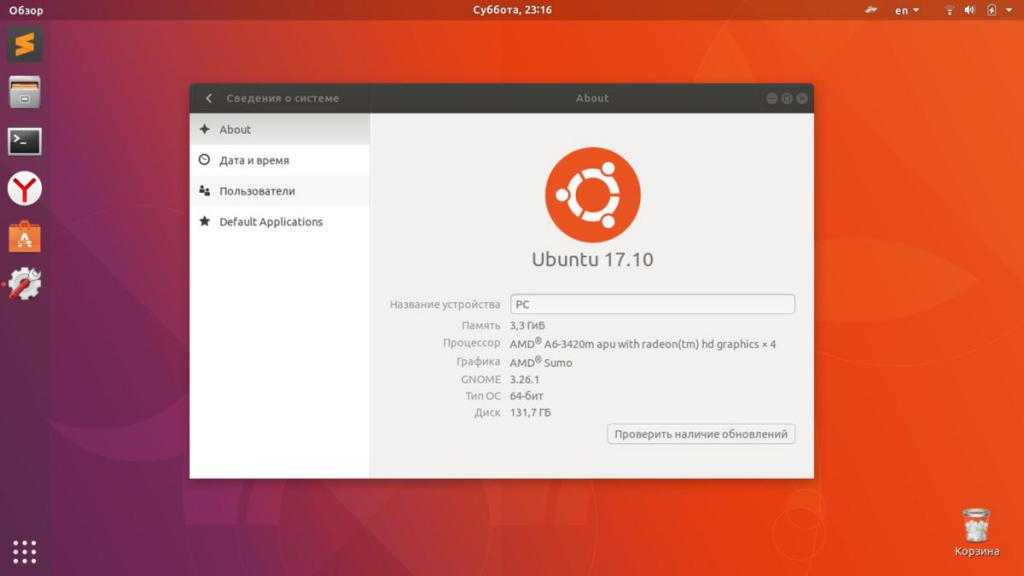
What is Awk command Working Methodology
(a)Awk reads the input files one line at a time.Each line is called record and Each record is splits into the field(b) For each line, it matches with given pattern in the given order, if matches performs the corresponding action.
| cat file1|awk ‘pattern { action }’ |
(c) If no pattern matches, no action will be performed.(d) In the above syntax, either search pattern or action are optional, But not both.(e) If the search pattern is not given, then Awk performs the given actions for each line of the input.
| cat file1|awk ‘ { action }’ |
(f)If the action is not given, print all that lines that matches with the given patterns which is the default action.(e)Empty braces with out any action does nothing. It wont perform default printing operation.
Some important function in unixFunctions:length function to compute length of a string e.g. { print length, $0}substr(s, m, n) produces the sub-string of s that begins at position m and is at most n characters long.
Dmesg Command in Linux
21 Декабря 2019
|
Терминал
В этом руководстве мы рассмотрим основы dmesg команды.
Ядро Linux — это ядро операционной системы, которое контролирует доступ к системным ресурсам, таким как процессор, устройства ввода-вывода, физическая память и файловые системы. Ядро записывает различные сообщения в кольцевой буфер ядра в процессе загрузки и во время работы системы. Эти сообщения содержат различную информацию о работе системы.
Кольцевой буфер ядра — это часть физической памяти, которая содержит сообщения журнала ядра. Он имеет фиксированный размер, что означает, что после заполнения буфера старые записи журналов перезаписываются.
Утилита командной строки используется для печати и управления кольцевого буфера ядра в Linux и других Unix-подобных операционных систем. Это полезно для изучения загрузочных сообщений ядра и устранения проблем, связанных с оборудованием.
Использование команды
Синтаксис команды следующий:
При вызове без каких-либо параметров записывает все сообщения из кольцевого буфера ядра в стандартный вывод:
По умолчанию все пользователи могут запускать команду. Однако в некоторых системах доступ к ним может быть ограничен для пользователей без полномочий root. В этой ситуации при вызове вы получите сообщение об ошибке, как показано ниже:
Параметр ядра указывает, могут ли непривилегированные пользователи просматривать сообщения из буфера журнала ядра. Чтобы снять ограничения, установите его на ноль:
Обычно выходные данные содержат много строк информации, так что только последняя часть выходных данных является видимой. Чтобы увидеть одну страницу за раз, перенаправьте вывод в утилиту пейджера, такую как или :
Используется для сохранения цветного вывода.
Если вы хотите фильтровать сообщения буфера, используйте . Например, чтобы просмотреть только сообщения, связанные с USB, вы должны набрать:
читает сообщения, сгенерированные ядром, из виртуального файла. Этот файл предоставляет интерфейс к кольцевому буферу ядра и может быть открыт только одним процессом. Если в вашей системе запущен процесс, и вы пытаетесь прочитать файл с помощью , или , команда зависнет.
Демон отвалов сообщения ядра , так что вы можете использовать этот файл журнала:
Команда предоставляет ряд опций, которые помогут вам отформатировать и отфильтровать вывод.
Одна из наиболее часто используемых опций — это ( ), которая обеспечивает удобочитаемый вывод. Эта опция направляет вывод команды в пейджер:
Для печати удобочитаемых временных меток используйте опцию ( ):
Формат отметок времени также может быть установлен с помощью параметра, который может быть ctime, reltime, delta, notime или iso. Например, чтобы использовать дельта-формат, введите:
Вы также можете объединить два или более вариантов:
Чтобы просмотреть вывод команды в режиме реального времени, используйте параметр ( ):
Фильтрация вывода
Вы можете ограничить вывод данными объектами и уровнями.
Средство представляет процесс, который создал сообщение. поддерживает следующие возможности журнала:
- — сообщения ядра
- — сообщения уровня пользователя
- — почтовая система
- — системные демоны
- — сообщения безопасности / авторизации
- — внутренние сообщения syslogd
- — подсистема линейного принтера
- — подсистема сетевых новостей
Опция ( ) позволяет ограничить вывод определенными объектами. Опция принимает одно или несколько разделенных запятыми объектов.





Например, для отображения только сообщений ядра и системных демонов вы должны использовать:
Каждое сообщение журнала связано с уровнем журнала, который показывает важность сообщения. поддерживает следующие уровни журнала:
- — система неработоспособна
- — действие должно быть предпринято немедленно
- — критические условия
- — условия ошибки
- — условия предупреждения
- — нормальное, но значимое состояние
- — информационный
- — сообщения уровня отладки
Опция ( ) ограничивает вывод определенными уровнями. Опция принимает один или несколько уровней, разделенных запятыми.
Следующая команда отображает только сообщения об ошибках и критические сообщения:
Очистка кольцевого буфера
Опция ( ) позволяет очистить кольцевой буфер:
Только root или пользователи с привилегиями sudo могут очистить буфер.
Чтобы распечатать содержимое буфера перед очисткой, используйте параметр ( ):
Если вы хотите сохранить текущие журналы в файле перед его очисткой, перенаправьте вывод в файл:
Вывод
Команда позволяет вам просматривать и контролировать кольцевой буфер ядра. Это может быть очень полезно при устранении проблем с ядром или оборудованием.
Введите в своем терминале информацию о всех доступных опциях.
Синтаксис
Для awk существуют понятия команды и действий, выполняемых этой командой. Действия, которые необходимо выполнить, заключаются в фигурные скобки {}, а сама команда (в которую и входят действия) содержится в одинарных кавычках ‘ ‘:
awk '{action1;action2;actionN}'
Несколько действий разделяются (в соответствии с семантикой языка AWK) символом точки с запятой.
Следующая команда выведет весь файл file.txt подобно команде cat
awk '{print}' file.txt
Вывод строки содержащую ‘string’
awk '/'string'/{print}' file.txt
Оператор print принимает выражения $0, $1, $2… Эти выражения указывают какие поля следует выводить, например. Оператор $0 выведет весь файл. Например
awk '{print $0}' file.txt
Аналогично awk ‘{print}’ file.txt выведет весь файл

Если нам нужно получить только первый столбец
awk '{print $1}' file.txt

Второй awk ‘{print $2}’ file.txt и т.д.
Следующие примеры демонстрируют использование awk в самых распространённых ситуациях:
$ dpkg -l | awk '{print $2}'
В результате будет выведен список с именами установленных пакетов. Если же нужно узнать, к примеру, какие пакеты PHP или Apache установлены в системе. Следует дать команду:
$ dpkg -l | awk '/'php'/{print $2}'
или для Apache:
$ dpkg -l | awk '/'apache'/{print $2}'
Выражение для поиска/сортировки/отбора заключается, как можно видеть, между символами /’ ‘/.
Structured Commands
The awk scripting language supports if conditional statement.
The testfile contains the following:
10
15
6
33
45
$ awk '{if ($1 > 30) print $1}' testfile

Just that simple.
You should use braces if you want to run multiple statements:
$ awk '{
if ($1 > 30)
{
x = $1 * 3
print x
}
}' testfile

You can use else statements like this:
$ awk '{
if ($1 > 30)
{
x = $1 * 3
print x
} else
{
x = $1 / 2
print x
}}' testfile
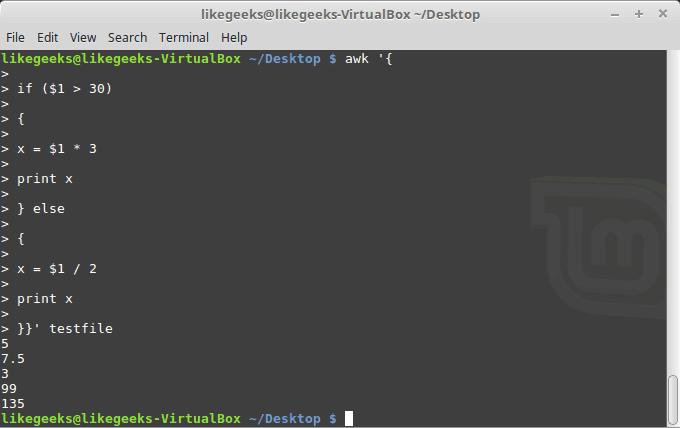
Or type them on the same line and separate the if statement with a semicolon like this:

While Loop
You can use the while loop to iterate over data with a condition.
cat myfile
124 127 130
112 142 135
175 158 245
118 231 147
$ awk '{
sum = 0
i = 1
while (i < 5)
{
sum += $i
i++
}
average = sum / 3
print "Average:",average
}' testfile

The while loop runs and every time it adds 1 to the sum variable until the i variable becomes 4.
You can exit the loop using break command like this:
$ awk '{
tot = 0
i = 1
while (i < 5)
{
tot += $i
if (i == 3)
break
i++
}
average = tot / 3
print "Average is:",average
}' testfile

The for Loop
The awk scripting language supports the for loops:
$ awk '{
total = 0
for (var = 1; var < 5; var++)
{
total += $var
}
avg = total / 3
print "Average:",avg
}' testfile

curl
Утилита curl извлекает информацию и файлы с url-страниц.
Будет полезна тем, кто часто загружает:
- Скрипты.
- Исполняемые файлы программ.
- Архивы.
С помощью команды curl это можно делать не через браузер, а прямо из терминала, что дает возможность автоматизировать процесс.
На самом деле curl является не просто утилитой, а целым набором библиотек, способными реализовать все основные возможности по работе c передачей файлов и url-страницами.
Curl поддерживает работу с протоколами:
- FTP
- FTPS
- HTTP
- HTTPS
- TFTP
- SCP
- SFTP
- Telnet
- DICT
- LDAP
- POP3
- IMAP
- SMTP
Загрузка файлов с помощью curl
Самая распространенная задача для утилиты curl – это загрузка файлов. Чтобы скачать файл достаточно передать утилите имя файла или адрес страницы, например:
Таким образом содержимое файла будет отправлено на стандартный вывод. Для записи его в файл (для примера ex.txt) нужно ввести:




Чтобы скачанный файл назывался так же, как и на сервере необходимо использовать опцию -O:
Стоит отметить, что не во всех дистрибутивах Linux утилита предустановлена по умолчанию.
9.5.3 Арифметические функции
В awk имеются арифметические функции.
- atan2(y, x)
-
Возвращает значение arctan(y/x) в радианнах.
- cos(expr)
-
Возвращает значение cos(expr) в радианнах.
- exp(expr)
-
Возвращает значение экспоненциальной функции.
- int(expr)
-
Возвращает целое от expr.
- log(expr)
-
Возвращает значение натурального логарифма от expr.
- rand()
-
Возвращает случайное значение в интервале .
- sin(expr)
-
Возвращает значение sin(expr).
- sqrt(expr)
-
Возвращает значение sqrt(expr) (квадратный корень из expr).
- srand()
-
Устанавливает новое исходное значение для генератора случайных чисел.
Возвращает предыдущее исходное значение. Если
expr опущено, то используется текущее время в секундах. Таким
образом, если вы
желаете, чтобы у вас при каждом новом запуске awk,
генерировалась
новая псевдослучайная последовательность в функции rand(), то вам
полезно вызвать функцию srand() перед циклом обращений к функции
rand().
Встроенная таблица переменных
| собственности | объяснение |
|---|---|
| $0 | Текущая запись (как одна переменная) |
| N-е поле текущей записи, разделенное ФС | |
| FS | Разделитель поля ввода — это пространство по умолчанию |
| NF | Количество полей в текущей записи — это количество столбцов |
| NR | Количество прочитанных записей — это номер строки, начиная с 1. |
| RS | Введенная запись отделяется разрывом строки и рассматривается как разрыв строки |
| OFS | Разделитель выходного поля также является пробелом по умолчанию |
| ORS | Разделитель выходных записей, по умолчанию — перевод строки |
| ARGC | Количество параметров командной строки |
| ARGV | Массив параметров командной строки |
| FILENAME | Имя текущего входного файла |
| IGNORECASE | Если true, совпадать независимо от регистра |
| ARGIND | ARGV идентификатор обрабатываемого файла |
| CONVFMT | Формат преобразования чисел% .6g |
| ENVIRON | Переменные среды UNIX |
| ERRNO | UNIX системные сообщения об ошибках |
| FIELDWIDTHS | Разделенная пробелами строка ширины поля ввода |
| FNR | Текущие записи |
| OFMT | Формат вывода чисел (по умолчанию% .6g) |
| RSTART | Первая строка соответствует функции соответствия |
| RLENGTH | Длина строки соответствует функции соответствия |
| SUBSEP | Разделитель нижнего индекса массива (значение по умолчанию \ 034) |
Вопросы и ответы по awk
Как вывести только строку определённого номера в awk
Чтобы вывести строки с определённым номером, используйте if() и переменную NR.
Например, чтобы вывести только вторую строку:
free | awk '{ if (NR == 2) print $7 }'
Чтобы вывести вторую и все последующие строки:
free | awk '{ if (NR >= 2) print $7 }'
Чтобы вывести все строки с 10 по 20:
awk '{ if (NR >= 10 && NR <= 20) print }' /etc/passwd
Как перенаправить вывод в файл в awk
Команду print можно использовать с перенаправлением вывода в файл.
К примеру, следующая команда сохранит строки с 10 по 20 из файла /etc/passwd в файл pswd.txt:
awk '{ if (NR >= 10 && NR <= 20) print>"pswd.txt" }' /etc/passwd
Следующая команда ищет в строке слово «mial» и если оно там встречается, то сохраняет всю строку в файл pswd.txt:
awk '/mial/{ print>"pswd.txt" }' /etc/passwd
Как использовать переменные в awk
Следующая команда посчитает количество строк содержащих слово «bash» в файле /etc/passwd, выведет каждую из этих строк и затем выведет общее количество найденных строк:
awk -v y=0 '/bash/{ y++; print $0 } END { print "Всего найдено строк с bash: " y }' /etc/passwd
При запуске программы инициируется переменная y со значением 0. При каждом совпадении (найдена строка «bash»), значение y увеличивается на единицу и выводится найденная строка. В конце выводится значение y.
Как вывести скобки и другие специальные в awk
Скобки и другие специальные символы необходимо помещать в двойные кавычки.
awk -F ',' '{ print "(" $1, $2 ")" }'
В предыдущих примерах имя файла также помещено в двойные кавычки из-за содержащейся в нём точки, которая является специальным символом.
Функции, определяемые программистом
awk
function FunctionName(a, b, ..., z)
{
... тело функции ...
}
awk
Тело функции представляет собой набор awk-команд, применяемых к
списку параметров заголовка функции.
Функция может быть »реккурсивной», вызывая самое себя.
Количество аргументов в фактическом вызове функции может отличаться
от количества аргументов в описании.
»Лишние» переменные получают в качестве значений пустую строку
.
При вызове функции в awk-программе не должно быть никаких символов
( в том числе и пробельных ) между
именем функции и списком аргументов в скобках.
В awk используется механизм передачи параметров »по значению»,
так что всякие изменения, происходящие с аргументами в функции,
не изменяют значений этих переменных вне функции.
Однако, если аргументом функции является массив,
значения его элементов могут быть изменены внутри тела функции.
Основной синтаксис
Команда awk включена во все современные дистрибутивы Linux по умолчанию, ее не нужно устанавливать.
Лучше всего аwk справляется с файлами, отформатированными предсказуемым образом. К примеру, эта команда особенно сильна в анализе и обработке табличных данных. Она работает путем построчного разбора всего файла.


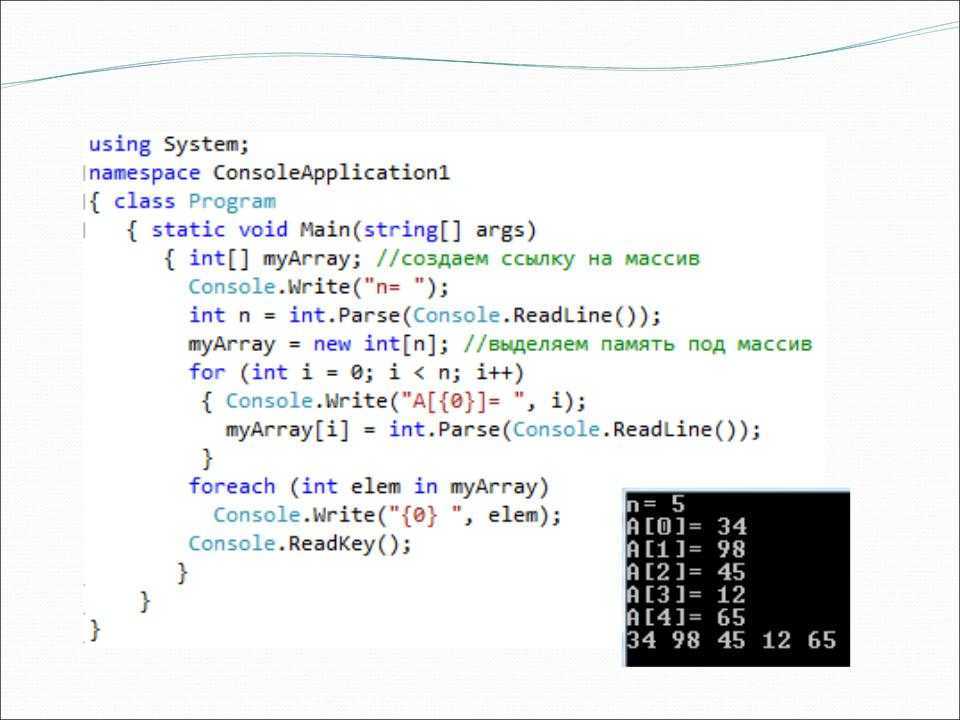





По умолчанию для разделения полей она использует пробельные символы и символы табуляции. К счастью, большинство систем Linux используют такой формат.
Базовый формат команды awk:
Поисковый шаблон или действие можно опустить. Если действие не указано, по умолчанию команда awk выведет результат на экран, то есть, просто выведет все совпавшие с шаблоном строки.
Если был пропущен шаблон, awk выполнит указанное действие для всех строк.
Если обе части были указаны, awk использует поисковый шаблон, чтобы вывести совпавшие с ним строки, а затем выполняет над этими строками указанное действие.