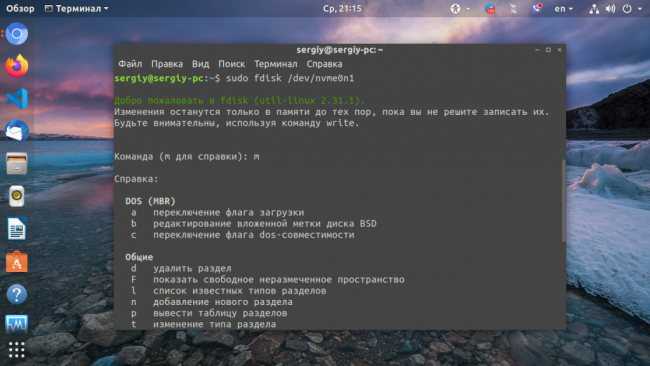
Создать сразу несколько файлов
Чтобы создать одновременно несколько файлов с именами идущими по порядку выполните
touch с {}
touch files/file{1..5}
ls -l files
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:46 file1
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:46 file2
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:46 file3
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:46 file4
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:46 file5
Чтобы скопировать директорию files в директорию sites со всем содержимым выполните
cp -R files sites
ls -l sites/files/
total 0
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:49 file1
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:49 file2
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:49 file3
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:49 file4
-rw-rw-r—. 1 andrei andrei 0 Nov 19 13:49 file5
Директория files была скопирована в директорию sites, то есть теперь у sites есть
поддиректория files.
Если у вас установлен модуль tree вы можете наглядно изучить вложенность. Если нет — выполните
сперва
sudo yum install tree
tree sites
sites
└── files
├── file1
├── file2
├── file3
├── file4
└── file5
1 directory, 5 files
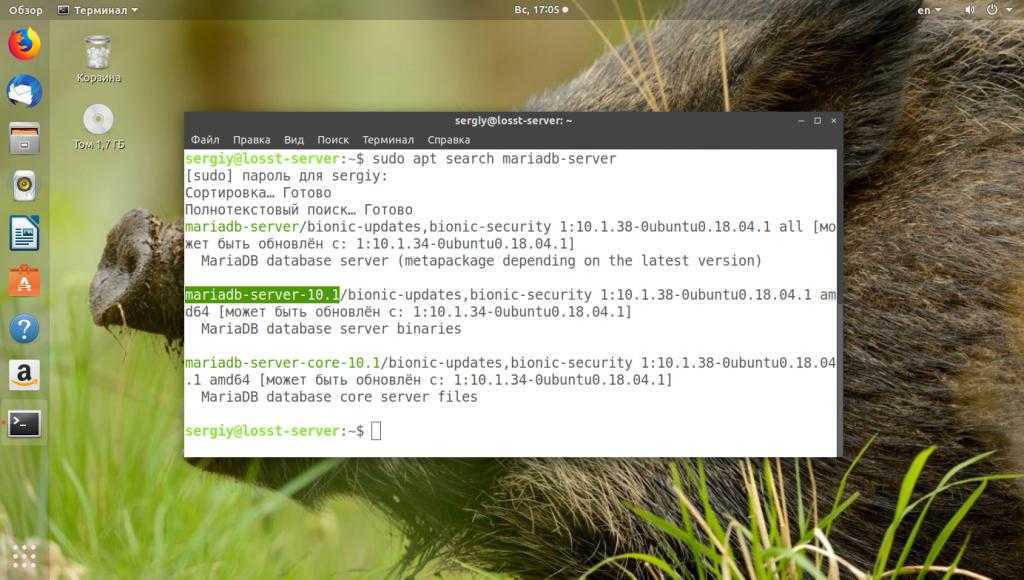
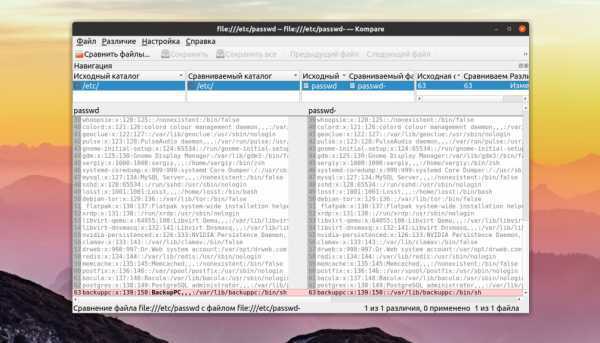
Создать ссылку можно командой ln, символьную ссылку ln -s
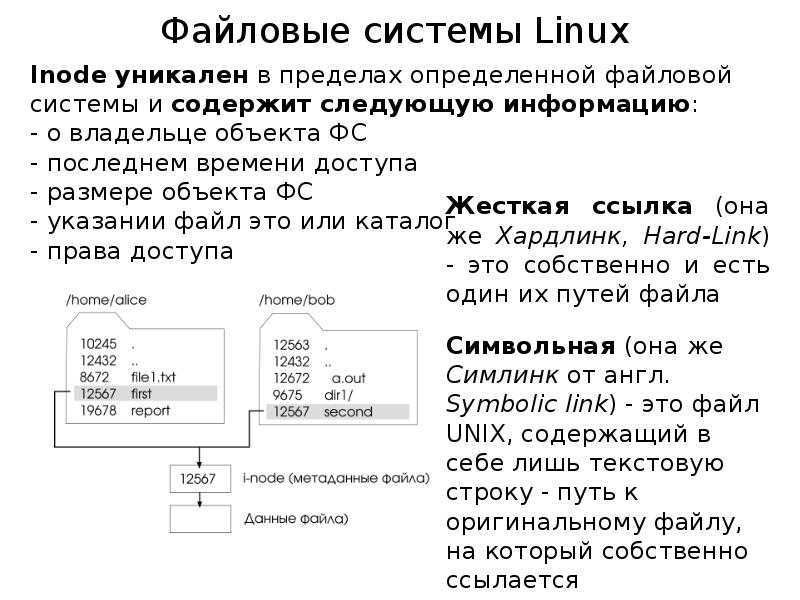
Иноды и ссылки
являются хорошо известной особенностью Linux. Но что происходит с инодами, когда мы создаем символьную ссылку? На следующем скриншоте у меня есть файл с именем file1, каталог под названием dir1, внутри которого расположилась символьная ссылка под названием slink1, которая указывает на :
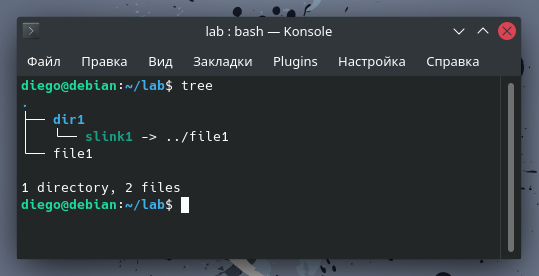
Теперь сравним их номера инодов:
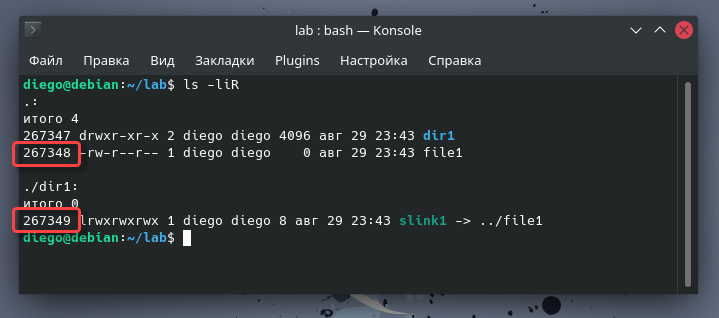
Как и ожидалось, dir1 и file1 имеют разные номера инодов. Но то же самое относится и к символьной ссылке. Когда вы определяете символьную ссылку, то тем самым создаете новый файл. В своих метаданных он указывает на целевой объект. Для каждой создаваемой вами символьной ссылки вы используете новый инод.
Теперь давайте создадим и посмотрим, что произойдет с инодами:
Выводим список номеров инодов:
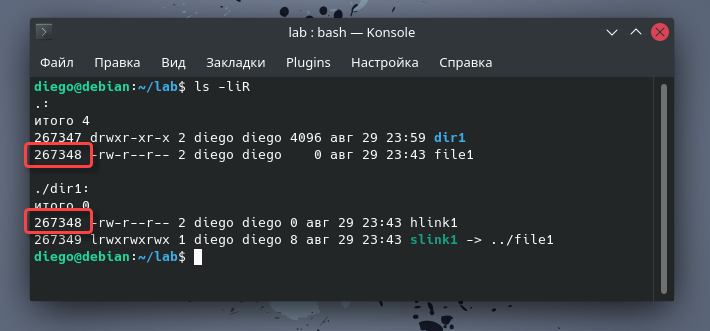
Вы можете видеть, что file1 и hlink1 имеют одинаковый номер инода. Жесткая ссылка не создает новый файл, она лишь предоставляет новое имя для тех же данных. Такое возможно благодаря введению механизма инодов.

Примечание: В более старых версиях Linux можно было создать жесткую ссылку на каталог. Было даже возможно сделать так, чтобы каталог стал родительским самому себе. Но теперь установлены некоторые ограничения, чтобы пользователи не создавали очень запутанную структуру каталогов.
Что такое файловая система
Обычно вся информация записывается, хранится и обрабатывается на различных цифровых носителях в виде файлов. Далее, в зависимости от типа файла, кодируется в виде знакомых расширений – *exe, *doc, *pdf и т.д., происходит их открытие и обработка в соответствующем программном обеспечении. Мало кто задумывается, каким образом происходит хранение и обработка цифрового массива в целом на соответствующем носителе.
Операционная система воспринимает физический диск хранения информации как набор кластеров размером 512 байт и больше. Драйверы файловой системы организуют кластеры в файлы и каталоги, которые также являются файлами, содержащими список других файлов в этом каталоге. Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные.
Запись файлов большого объема приводит к необходимости фрагментации, когда файлы не сохраняются как целые единицы, а делятся на фрагменты. Каждый фрагмент записывается в отдельные кластеры, состоящие из ячеек (размер ячейки составляет один байт). Информация о всех фрагментах, как части одного файла, хранится в файловой системе.
Файловая система связывает носитель информации (хранилище) с прикладным программным обеспечением, организуя доступ к конкретным файлам при помощи функционала взаимодействия программ API. Программа, при обращении к файлу, располагает данными только о его имени, размере и атрибутах. Всю остальную информацию, касающуюся типа носителя, на котором записан файл, и структуры хранения данных, она получает от драйвера файловой системы.
На физическом уровне драйверы ФС оптимизируют запись и считывание отдельных частей файлов для ускоренной обработки запросов, фрагментации и «склеивания» хранящейся в ячейках информации. Данный алгоритм получил распространение в большинстве популярных файловых систем на концептуальном уровне в виде иерархической структуры представления метаданных (B-trees). Технология снижает количество самых длительных дисковых операций – позиционирования головок при чтении произвольных блоков. Это позволяет не только ускорить обработку запросов, но и продлить срок службы HDD. В случае с твердотельными накопителями, где принцип записи, хранения и считывания информации отличается от применяемого в жестких дисках, ситуация с выбором оптимальной файловой системы имеет свои нюансы.
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
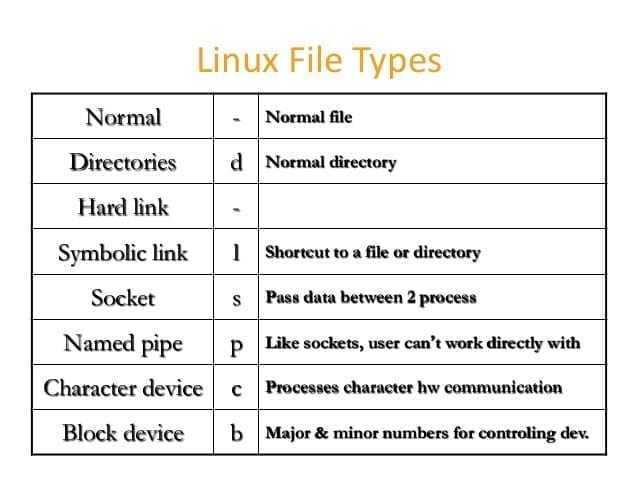
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);
Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
JFS
JFS — это журналированная файловая система. На момент выхода в свет в 1999 году была наиболее производительной из существовавших файловых систем. Сейчас по функциональности сравнима с ext4, но менее популярна.
Вот некоторые её особенности:
- максимальная длина имени файла 255 B;
- максимальный размер файла 4 PB (4000 TB);
- максимальный размер раздела 32 PB (32000 TB);
- контрольные суммы;
- поддержка acl.
Так как по функциональности эта файловая система сравнима с ext4, но по характеристикам и популярности отстаёт, то в Ubintu установщик уже не предлагает использовать её. Можно использовать, если у вас будут храниться файлы размером более 16 ТБ, хотя и в этом случае лучше выбрать XFS.
btrfs
btrfs – это более функциональная и сложная файловая система чем ext4. Начали разрабатывать для Linux в 2007 году, а в 2014 году признали стабильной. Вот некоторые интересные функции:
снимки состояния, которые позволяют запомнить состояние на определенный момент времени всех файлов и вернуться к этому состоянию в последующем
Полезно когда вы случайно удалили что-то важное или какой-то вирус зашифровал все ваши данные на компьютере;
создание RAID конфигурации на уровне файловой системы;
сжатие данных, когда данные при создании автоматически сжимаются экономя свободное место на диске;
дедупликация данных. Когда есть два или более одинаковых файла, то они занимают размер только одного файла, что очень экономит пространство на жестком диске;
контрольные суммы для данных и метаданных, что повышает надежность файловой системы;
дефрагментация данных на лету;
квоты на разделы;
динамическая аллокация inode;
максимальный размер файла 16 EB;
наибольший размер раздела 16 EB;
максимальный размер имени файла 255 B;
Из минусов: файловая система не так проверена временем как ext4, активно использует оперативную память и работает медленнее чем ext4.
Взаимоблокировка процессов
Блокировкой процессов называют состояние системы, при котором 2 или более процессов не могут продолжать свое выполнение из-за отсутствия необходимых для этого ресурсов.
Взаимоблокировка возникает в многозадачных многопользовательских ОС. Чем большее количество различных задач выполняется на машине, и чем меньше ее ресурсы, тем больше вероятность возникновение взаимоблокировок. При этом ситуация напоминает подающий с горы снежный ком. Количество блокированных процессов быстро возрастает до тех пор, пока в системе не останется не одного работающего процесса. ОС практически полностью прекращает полезное функционирование а ЭВМ простаивает.
Блокировки процессов возникают либо сами собой, либо инициализируются внешними атаками. Например: атаки вирусов (хакеров) на определенный сайт приводят к возникновению блокировки на обслуживающим этот сайт ЭВМ. Это вызвано перегрузкой работы соответствующей ЭВМ, когда в условии ограниченности ресурсов (хотя эти ресурсы у майнфреймов могут быть очень большими: несколько сотен дисков, десятки терабайт ОП и т.д. ) ЭВМ должна одновременно обработать очень большое количество запросов.
В итоге ЭВМ нужно будет заново перезагружать. Для майнфрейма каждая перезагрузка аналогична потере нескольких миллионов долларов, такова цена за невыполненные вовремя различные запросы.
Имеются различные способы выхода из блокировок:
- Снятие оператором выполняющихся процессов до тех пор, пока не исчезнет взаимоблокировка. Этот путь эффективен лишь в том случае, когда количество выполняющихся процессов не очень велико (не превышает 100). При большом количестве выполняющихся процессов этот путь чаще всего не помогает преодолеть блокировку.
- Перезагрузка системы этот путь преодоления блокировок наиболее радикальный, но и наиболее дорогой.
- Рестарт системы с так называемой контрольной точки.
Контрольная точка — это полное состояние ЭВМ запомненное на внешнем носители. Для больших ЭВМ организация контрольной точки требует больших ресурсов и времени, поскольку на внешний носитель нужно будет запомнить полное состояние всех регистров ЭВМ, всей ее ОП (несколько десятков терабайт на майнфреймах), а так же полное состояние регистров и ОП каждого из устройств ЭВМ (несколько десятков тысяч устройств на майнфреймах). Несмотря на то что организация контрольной точки требует большого количества времени и ресурсов, ее регулярно проводят с различной периодичностью (раз в час) для того чтобы уменьшить неизбежные финансовые потери от рестарта ЭВМ.
Имеются два противоположных способа борьбы с взаимоблокировками:
- Полное игнорирование угроз возникновения взаимоблокировок.
- Построение такой ОС, которая просчитывает на несколько шагов вперед ситуацию, которая может возникнуть в ЭВМ после запуска определенного процесса. Такое построение ОС ведет к существенному усложнению ее структуры, однако не решает проблемы на 100%, так как любая сложная программа имеет большое количество не выявленных ошибок.
На построение ОС безопасных по отношению к взаимоблокировкам идут лишь в некоторых случаях, в которых возникновение блокировок может привести к катастрофическим последствиям. Например: на ЭВМ управляющих системами стратегических ракет и противоракетной обороны.
Игнорирование угрозы взаимоблокировок приводит к тому, что ОС плохо контролирует последовательность выделения ресурсов отдельным процессам, поэтому с течением времени неизбежно возникновение блокировки.
Почти все ОС построены по такому принципу. На майнфреймах, при проектировании, такая структура ОС была принята , что при среднем количестве запросов на ЭВМ и большом объеме ее ресурсов возникновение блокировок было маловероятным. Затраты на написание сложной безопасной ОС представлялись проектировщиками гораздо больше чем экономические потери возникающие из-за редких возникновении взаимоблокировок. Однако с появлением вирусов и хакерских атак вероятность перегрузки ЭВМ и возникновение блокировок очень сильно возросла.
Польза от инодов
Принцип работы инодов также объясняет, почему невозможно создать жесткую ссылку из одной файловой системы в другую. Разрешение такой задачи открыло бы возможность наличия конфликтующих номеров инодов. В то же время, символьная ссылка может быть создана в разных файловых системах.
Поскольку жесткая ссылка имеет тот же номер инода, что и исходный файл, то вы можете удалить исходный файл, и данные по-прежнему будут доступны по жесткой ссылке. Всё, что вы сделали в этом случае, — это удалили одно из имен, указывающих на заданный номер инода. Данные, связанные с этим инодом, будут оставаться доступными до тех пор, пока все имена, связанные с ним, не будут удалены.
Иноды также являются важной причиной, по которой Linux-системы могут обновляться без необходимости перезагрузки: один процесс может использовать библиотечный файл, в то время как другой процесс заменяет этот файл новой версией. Уже запущенный процесс будет продолжать использовать старый файл, в то время как каждый новый вызов к нему приведет к использованию новой версии
Еще одна интересная функция, которая поставляется с инодами, — это возможность хранить данные в самом иноде. Это называется встраиванием (англ. «inlining»). Этот метод хранения имеет преимущество в экономии места, поскольку не требует использования блоков данных, но при этом также увеличивает время поиска, избегая дополнительного доступа к диску для получения данных.


В некоторых файловых системах, таких как , есть опция под названием inline_data, которая позволяет операционной системе хранить данные вышеописанным способом. Из-за ограничения размера встраивание работает только для очень маленьких файлов.
File Linux
Linux — это система без расширения
Возможно это звучит странно, но по мере проработки разделов это станет более понятным. Расширение файла обычно представляет собой набор из 2 — 4 символов в конце файла, который обозначает тип файла.
Например:
- exe — исполняемый файл или программа.
- txt — простой текстовый файл.
- png, file.gif, file.jpg — изображение.
В других системах, таких как Windows, расширение имеет важное значение, и система использует его для определения типа файла. Под Linux система фактически игнорирует расширение и смотрит в файл, чтобы определить, какой это тип файла
Так, например, я мог бы иметь файл ФОТО.png, который представляет собой мою фотографию. Я мог бы переименовать файл в ФОТО .txt или просто ФОТО. В этом случае, Linux все равно с радостью рассматривает файл как изображение.
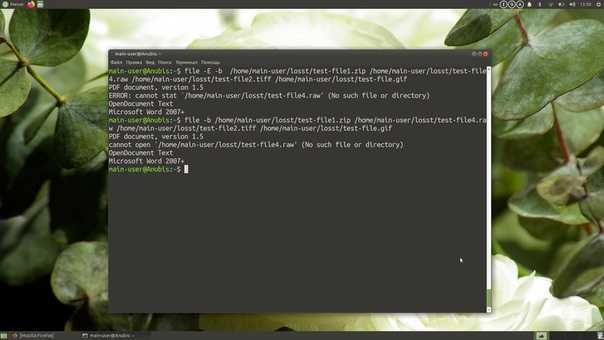
В итоге, иногда бывает трудно точно определить, к какому типу файла относится конкретный файл. К счастью, есть команда file, которую мы можем использовать, чтобы выяснить это.
Всякий раз, когда мы указываем файл или каталог в командной строке, это фактически путь. Кроме того, каталоги на самом деле являются просто особым типом файла. Соответственно, путь — это средство для достижения определенного местоположения в системе.
Linux чувствителен к регистру
Это очень важный и распространенный источник проблем для новичков в Linux. Другие системы, такие как Windows, нечувствительны к регистру при обращении к файлам. Но только не Linux. Таким образом, можно иметь два или более файлов и каталогов с одинаковыми именами, но с разными буквами.

В итоге, Linux видит все это как отдельные и отдельные файлы.
Кроме того, следует учитывать чувствительность к регистру при работе с параметрами командной строки. Например, с помощью команды ls есть две опции s и S, которые делают разные вещи.
Распространенная ошибка — видеть опцию, которая является заглавной, но вводить ее как строчную, и удивляться, почему вывод не соответствует вашим ожиданиям.
Пробелы в наименовании
Пробелы в именах файлов и каталогов вполне допустимы, но мы должны быть немного осторожны с ними. Как вы помните, пробел в командной строке — это то, как мы разделяем элементы. Они, как мы знаем, как называется программа, и могут идентифицировать каждый аргумент командной строки. Если бы мы захотели перейти в каталог с названием «LV Photos» следующее не сработало бы.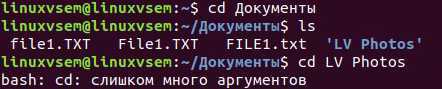 «LV Photos» рассматриваются как два аргумента командной строки. cd перемещается в любой каталог, указанный в первом аргументе командной строки. Чтобы обойти это, нам нужно указать терминалу, чтобы «LV Photos» рассматривались как один аргумент командной строки. Есть два способа сделать это, так же как и в любом случае.
«LV Photos» рассматриваются как два аргумента командной строки. cd перемещается в любой каталог, указанный в первом аргументе командной строки. Чтобы обойти это, нам нужно указать терминалу, чтобы «LV Photos» рассматривались как один аргумент командной строки. Есть два способа сделать это, так же как и в любом случае.
Кавычки («»)
Первый подход предполагает использование кавычек вокруг всего элемента. Вы можете использовать одинарные или двойные кавычки. При этом, между ними есть небольшая разница, но она незначительна. Все, что находится внутри кавычек, считается одним элементом.

Слэш (\)
Другой метод заключается в использовании так называемого escape-символа, который является обратной косой чертой (\). То, что делает обратная косая черта, это экранирование (или аннулирование) специального значения следующего символа.

В приведенном выше примере пространство между «LV» и «Photos» имеет особое значение. В итоге, оно разделяет их как отдельные аргументы командной строки. Поскольку мы поставили перед ним обратную косую черту, это особое значение было удалено.





Узнать расположение файла
Узнать где находится файл lsb_release можно командой which lsb_release. Чтобы сразу получить
дополнительную информацию выполните
ls -lF $(which lsb_release)
-rwxr-xr-x. 1 root root 15929 Mar 27 2015 /usr/bin/lsb_release*
Опция -F означает показать тип файлов. Поэтому нам удалось увидеть * после lsb_release. * означает, что файл
исполняемый.
Чтобы узнать откуда взялся файл можно воспользоваться командой rpm с опциями
q (query) и f (file)
rpm -qf $(which lsb_release)
redhat-lsb-core-4.1-27.el7.centos.1.x86_64
Чтобы скопировать файл в интерактивном режиме воспользуйтесь командой cp с опцией i (interactive)
interactive означает, что если файл с таким имененм существует, вас спросят прежде чем затирать его
cp -i /etc/hosts .
cp -i /etc/hosts .
cp: overwrite ‘./hosts’?
Чтобы создать директорию сразу же с поддиректорией внутри воспользуйтесь командлой
mkdir с опцией p (parent)
mkdir -p sites/heiheiru
ls -l sites
total 0
drwxrwxr-x. 2 andrei andrei 6 Nov 19 13:40 heiheiru
Порождение нового процесса
Порождение нового процесса это длительная процедура, так как ОС должна выполнить множество действий:
- Выделить процессу необходимые ресурсы (адресное пространство, файлы, устройство и т.д.);
- Произвести инициализацию этих ресурсов (загрузить выполняемую программу в ОП, инициализировать первое начальное значение регистров и стеков, открыть файлы и т.д.);
- Занести всю необходимую информацию в специальную таблицу, описывающую процессу в системе;
- Передать управление новому процессу.
Переключение между отдельными выполняющимися процессами так же длительная процедура. В этом случи ОС должна произвести дополнительные (обычно в таблице соответствующей выполняемому процессу) от регистров соответствующих выполняемому процессу, карту отображения в памяти процесса на реальную физическую память, сохранить состояние всех файлов и устройств используемых процессом. После этого ОС должна выбрать полное описание процесса на который она переключается из таблицы (инициализировать регистры, карту отображения памяти процесса на физическую память, состояние файлов и устройств). Переключение между процессами осуществляется в том числе по прерыванию таймера. Обычно системному программисту предоставляется возможность задания максимального времени выполнения одного процесса, после которого произойдет прерывание по таймеру и переключение на другой процесс. При задании маленького значения этого времени у системы будет мало времени на отклик на возникающие события, однако при этом значительная часть процессорного времени будет тратиться на переключение между процессами. При задании большого времени таймера накладные расходы, связанные с переключениями между процессами будут уменьшаться, однако будет ухудшаться отклик системы на возникающие события.
При завершении процесса происходит закрытие всех файлов, освобождение всех ресурсов, занятых всех ресурсов и вычеркивании его из таблицы процессов.
Классификация файлов
Содержимое файлов
Файлы могут содержать в себе любую информацию. Это могут быть как программы, выполняемые под управлением какой-либо операционной системы, либо файлы с данными для этих программ. Независимо от операционных систем персональных компьютеров все файлы можно разделить на текстовые и бинарные (по другому — двоичные ) файлы. Текстовыми файлами называют файлы, в которых используются в качестве информационных символы с шестнадцатеричными кодами 20h-7Eh (32 -126 десятичными) и 80h-7Eh (128 — 254 десятичными). В качестве служебных кодов и только в качестве них допускается использовать символы с кодами:
- 09h (9) (HT) — горизонтальная табуляция.
- 0Ah (10) (LF,EOL) — новая строка (перевод строки).
- 0Bh (11) (VT) — вертикальная табуляция.
- 0Ch (12) (FF) — новая строка (перевод страницы).
- 0Dh (13) (CR) — возврат каретки.
- 1Ah (26) (SUB,EOF) — конец файла.
Примечание: При визуализации текстового файла символ горизонтальной табуляции заменяется несколькими (обычно восемью) проблемами, символ вертикальной табуляции — несколькими пустыми строками. Символ возврата каретки переводит курсор (или позицию вывода нового символа) на первый элемент начала строки. Символ перевода строки выводит следующий символ на своем месте, только строкой ниже. Поэтому символ EOL (End-of-Line) действительности — это последовательность символов CR/LF. Все символы, расположенные после символа конца файла, при выводе игнорируются.
Среди всех текстовых файлов можно выделить подмножество чистых ASCII файлов , информационные символы которых имеют только коды с номерами 20h — 7Eh. Двоичные же файлы представляют из себя последовательность из любых символов. Их длина определяется из заголовка файла. Это разделение является важным для различных операционных систем, поскольку назначение и обработка бинарных и текстовых файлов в операционных системах различаются.
Другие виды классификации файлов
Также файлы можно разделить на исполняемые (программы) и неисполняемые ( файлы данных и документов). Исполняемые файлы могут запускаться операционной системой на выполнение, а неисполняемые файлы могут только изменять свое содержимое в процессе выполнения программ. Далее можно разделить файлы на основные , присутствие которых обязательно для работы операционной системы и программных продуктов, служебные , хранящие конфигурацию и настройки основных файлов, рабочие , содержимое которых изменяется в результате работы основных программных файлов и собственно ради которых и создаются все остальные файлы, а также временные файлы , создающиеся в момент работы основных и хранящие промежуточные результаты.






Синтаксис и опции file
Синтаксис команды file достаточно простой. Записывать её в эмуляторе терминала или консоли следует так:
file опции название_документа
Что же касается опций, то их у этой команды несколько десятков. Мы рассмотрим лишь основные:
- -b, —brief — запрет на демонстрацию имен и адресов файлов в выводе команды;
- -i, —mime — определение MIME-типа документа по его заголовку;
- —mime-type, —mime-encoding — определение конкретного элемента MIME;
- -f, —files-from — анализ документов, адреса которых указаны в простом текстовом файле;
- -l, —list — список паттернов и их длина;
- -s, —special-files — предотвращение проблем, которые могут возникнуть при чтении утилитой специальных файлов;
- -P — анализ определенной части файла, которая обозначается различными параметрами;
- -r, —raw — отказ от вывода /ooo вместо непечатных символов;
- -z — анализ содержимого сжатых документов.
Для того, чтобы ознакомиться с полным списком опций, выполните в терминале команду:
Сортировка вывода
Как мы уже упоминали, по умолчанию команда перечисляет файлы в алфавитном порядке.
Параметр позволяет сортировать вывод по расширению, размеру, времени и версии:
- (или ) — отсортировать в алфавитном порядке по расширению.
- (или ) — сортировать по размеру файла.
- (или ) — сортировать по времени модификации.
- (или ) — естественный вид номеров версий.
Если вы хотите получить результаты в обратном порядке сортировки, используйте параметр .
Например, чтобы отсортировать файлы в каталоге по времени модификации в обратном порядке, вы должны использовать:
Стоит отметить, что команда не показывает общее пространство, занятое содержимым каталога. Чтобы узнать размер каталога , используйте команду .