
Фильтры в Linux
Фильтры — это способ получения необработанных данных, созданных другой программой или сохраненных в файле.
Эти фильтры имеют различные параметры командной строки, которые изменяют их поведение. В результате, всегда полезно проверить страницу руководства для фильтра.
В приведенных ниже примерах мы будем предоставлять данные для этих программ с помощью файла.
Для каждой из демонстраций ниже будет использоваться следующий файл в качестве примера. Этот файл примера содержит список содержимого, чтобы немного облегчить понимание примеров. Кроме того, файл фактически указан как путь, и поэтому вы можете использовать абсолютные и относительные пути, а также подстановочные знаки.
СКРИН
head
Head — это программа, которая печатает первые строки ввода. По умолчанию он напечатает первые 10 строк, но мы можем изменить это с помощью аргумента командной строки.
head

tail
Данная команда противоположна head. Tail — это команда, которая печатает последние строки ввода. По умолчанию он напечатает последние 10 строк, но мы можем изменить это с помощью аргумента командной строки.
tail

Выше было поведение tail по умолчанию. А ниже указывается заданное количество строк.
sort
Сортировка — это красиво и просто. По умолчанию сортировка выполняется в алфавитном порядке. Между тем, существует множество параметров, позволяющих изменить механизм сортировки. Кроме того, не забудьте проверить справочную страницу, чтобы увидеть все, что он может сделать.
sort
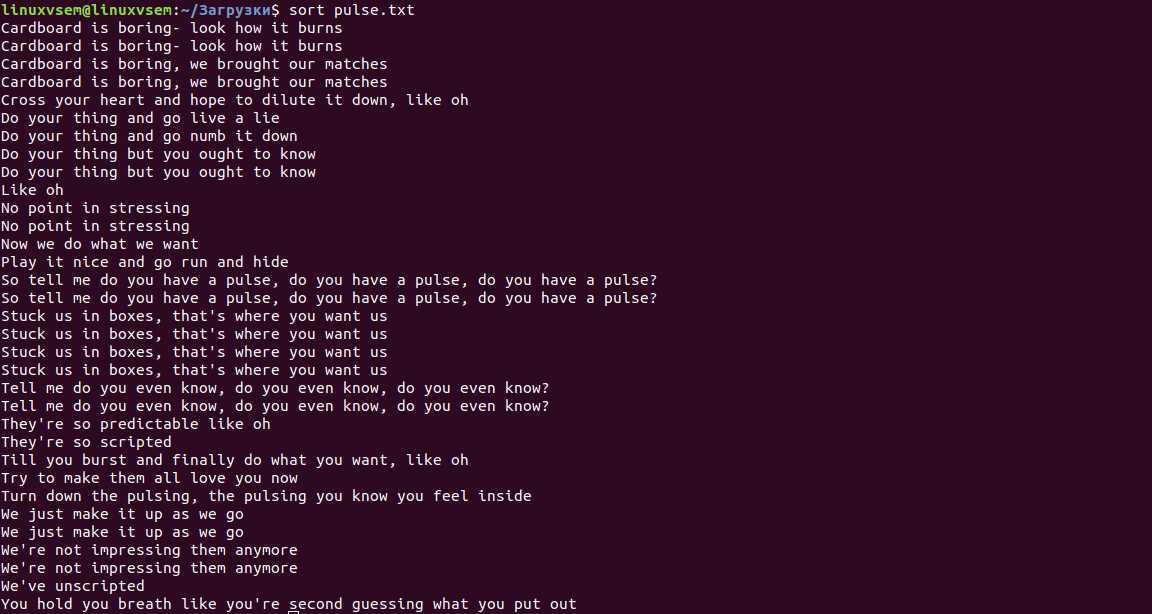
nl
Обозначение чисел в Linux реализуется за счет команды nl.
nl
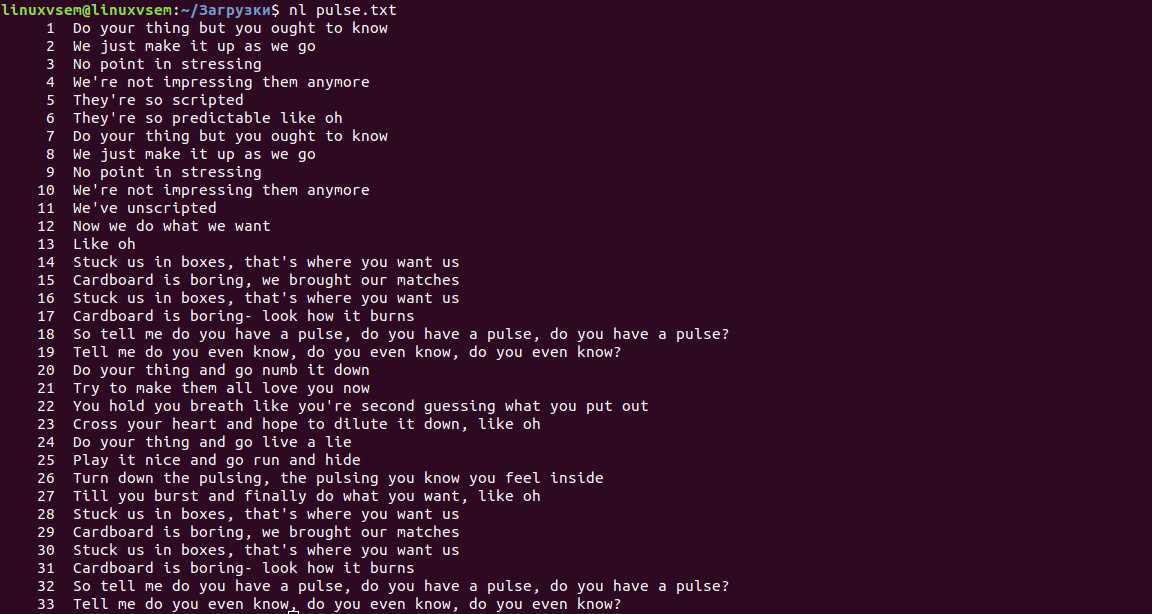
Вот еще несколько полезных опций командной строки.
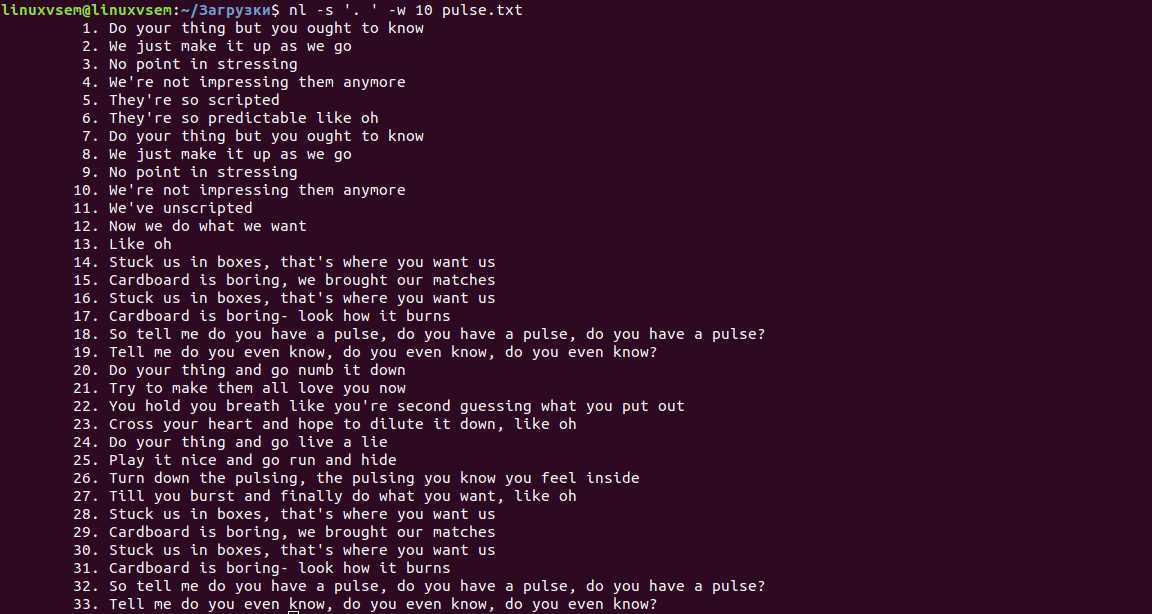
В приведенном выше примере мы использовали 2 параметра командной строки. Первый -s указывает, что следует печатать после числа. С другой стороны, второй -w указывает, сколько отступов ставить перед числами. Для первого нам нужно было включить пробел как часть того, что было напечатано.
Поскольку пробелы обычно используются в качестве символов-разделителей в командной строке, нам нужен был способ указать, что пробел является частью нашего аргумента, а не просто между аргументами. Мы сделали это, включив аргумент в кавычки.
wc
wc обозначает количество слов, а также символы и строки. По умолчанию он подсчитывает все вышеперечисленное. Между тем, используя параметры командной строки, мы можем ограничить его только тем, что нам нужно.
wc
![]()
Иногда вам просто нужно одно из этих значений. -l даст нам только строки, -w даст нам слова, а -m даст нам символы.


![]()
Кроме того, Вы можете комбинировать аргументы командной строки.
![]()
cut
Cut — это хорошая команда, которую можно использовать, если ваш контент разделен на столбцы и вам нужны только определенные поля.
вырезать
В нашем примере файла у нас есть данные в 3 столбцах. Допустим, мы хотели только первый столбец.
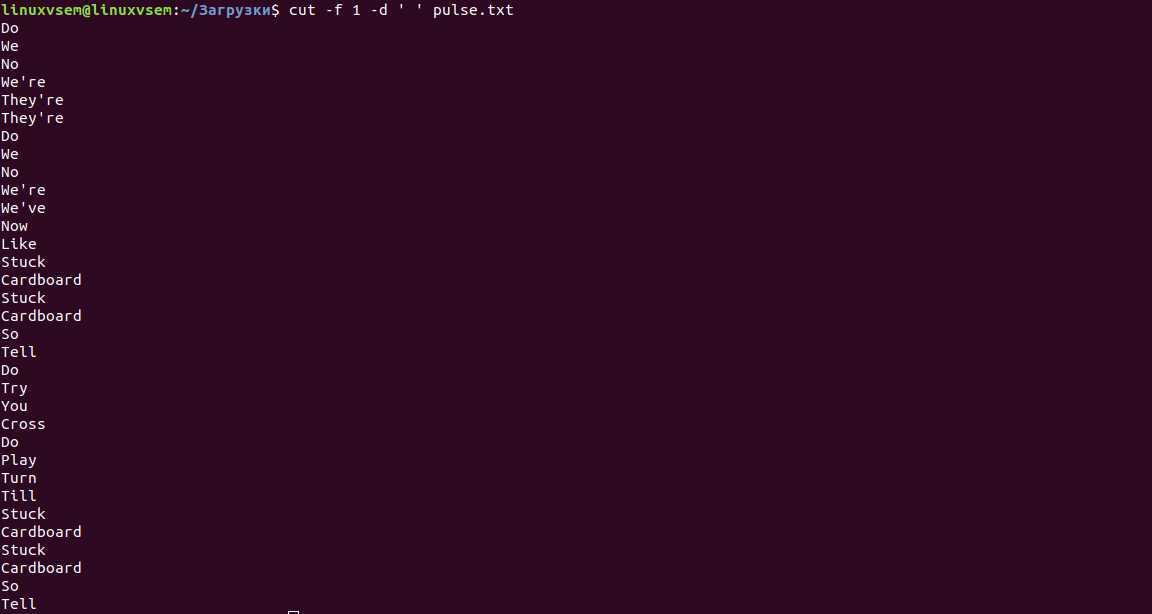
По умолчанию cut использует символ TAB в качестве разделителя для идентификации полей. Опция -f позволяет нам указать, какое поле мы бы хотели. Если нам нужно 2 или более полей, мы разделяем их запятой, как показано ниже.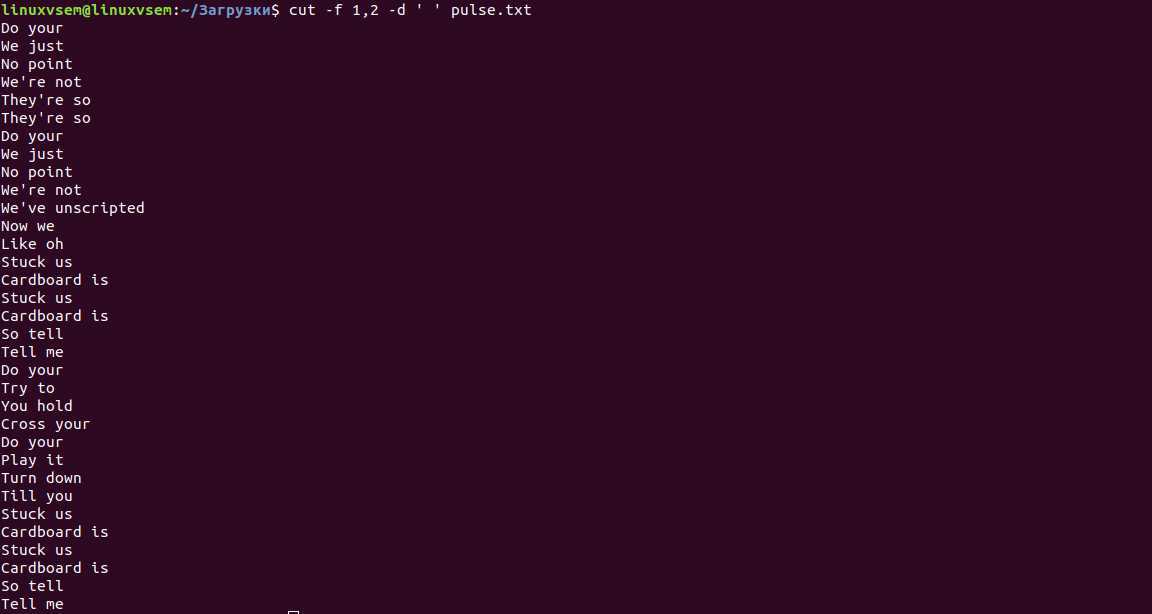
sed
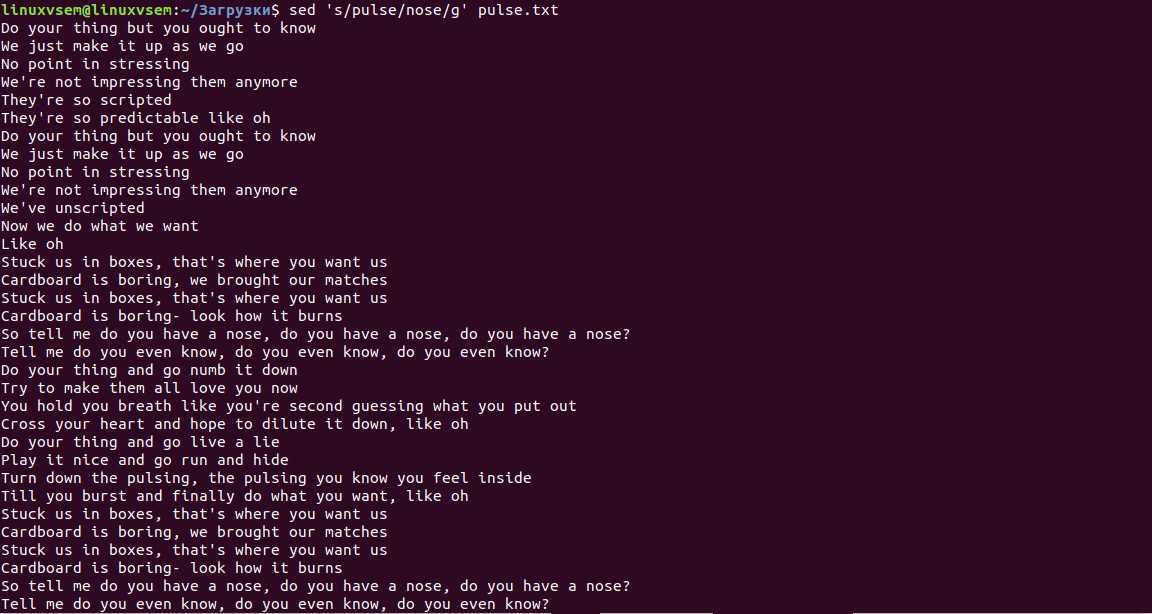
Sed расшифровывается как Stream Editor и позволяет эффективно выполнять поиск и замену наших данных. Это довольно мощная команда, но мы будем использовать ее здесь в ее базовом формате.
sed <выражение>
Инициал s обозначает замену и определяет действие, которое нужно выполнить. Между первой и второй косой чертой (/) мы размещаем то, что ищем. Затем между вторым и третьим слэшем, чем мы хотим его заменить.
uniq
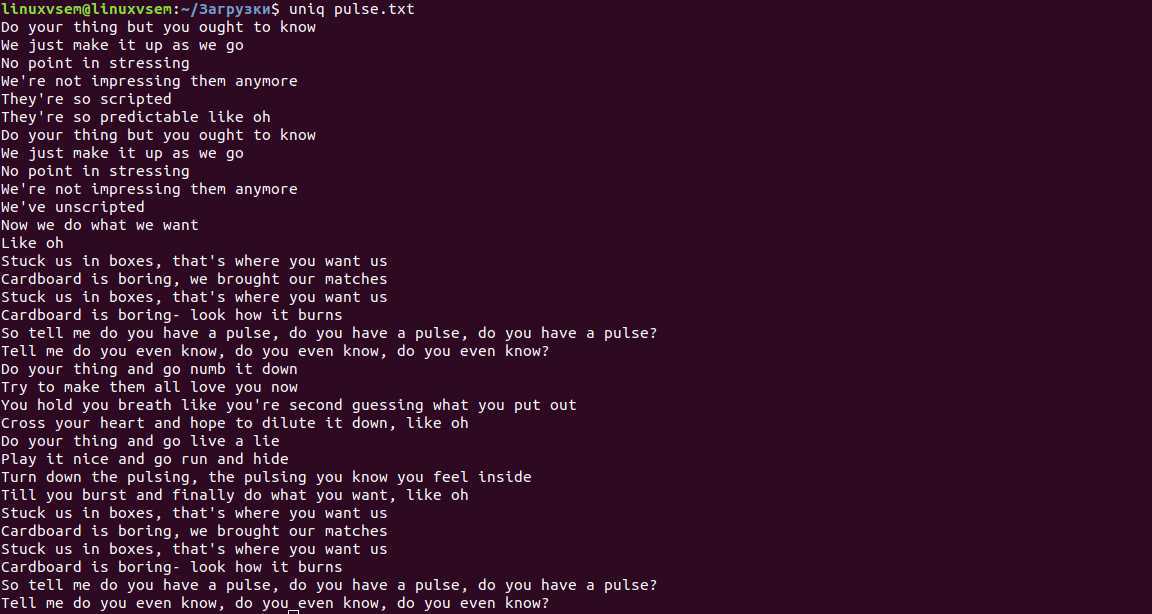
Uniq означает уникальный, и его работа заключается в удалении повторяющихся строк из данных. Однако одно ограничение заключается в том, что эти линии должны быть смежными.
uniq
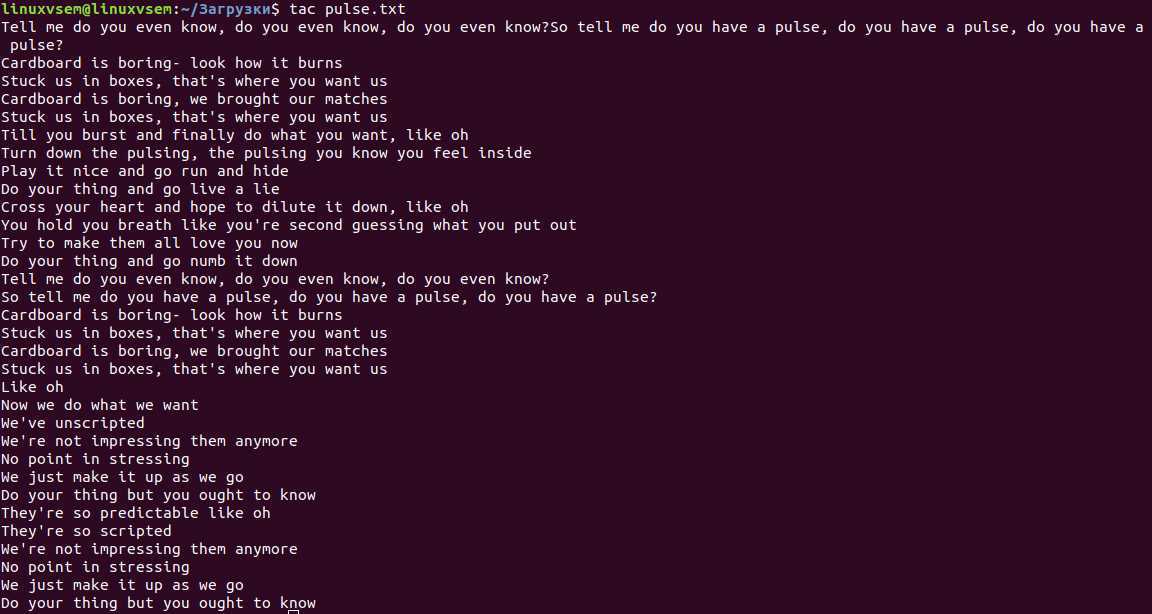
tac
Ребята из Linux известны своим забавным чувством юмора. Программа TAC на самом деле является CAT наоборот. Это было названо так, как это делает противоположность CAT. Получив данные, он напечатает последнюю строку первой, вплоть до первой строки.
TAC
Примеры использования tr
1. Замена символов через аргументы
Программа по умолчанию работает со стандартным вводом/выводом.
Пример 1. Заменить все x на z.
Далее следует ввести строку и нажать Enter. Ниже будет выведен обработанный результат и представлена возможность повторного ввода.

Для выхода из программы нажмите Ctrl + D.
Пример 2. Удалить все буквы в нижнем регистре.

Пример 3. Уплотнить повторяющиеся буквы большого и малого регистров.





2. Работа с потоками
Команда tr может принимать на вход результат работы другой программы с использованием пайпа.
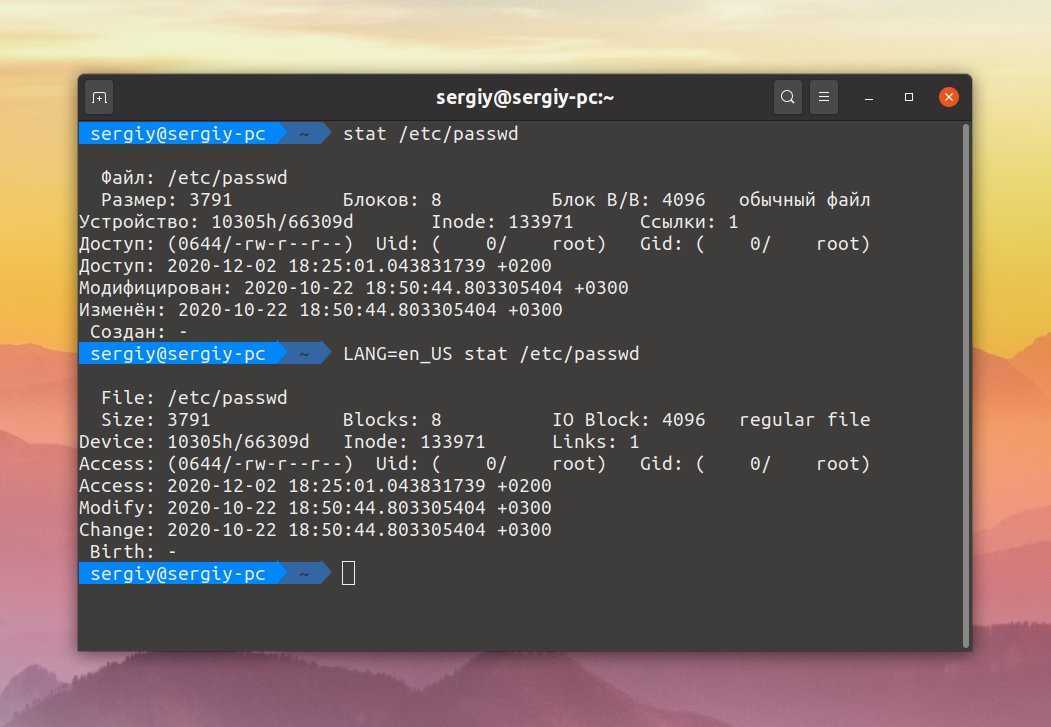
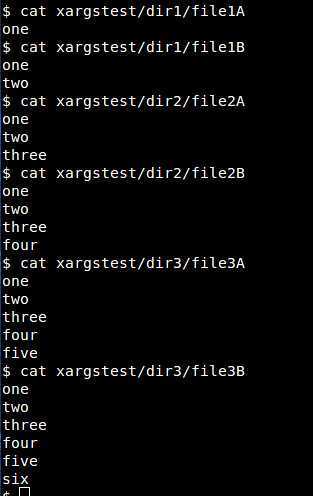
Пример 4. Вывести первые три строки файла /etc/passwd, заменив двоеточия (используемые в качестве разделителя данных) на пробелы.

Также можно использовать перенаправление потока ввода и вывода.
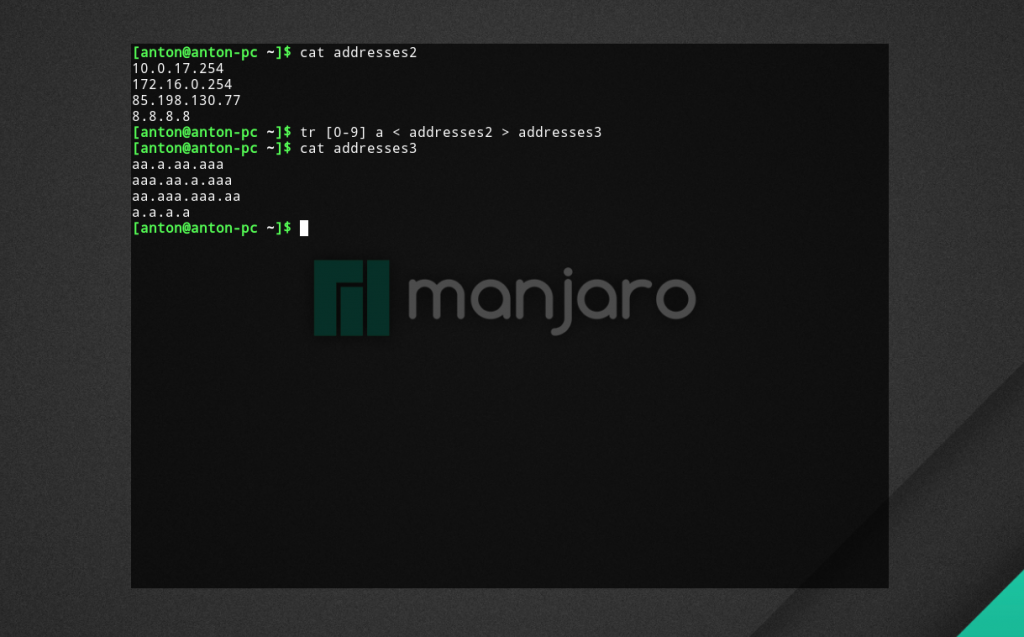
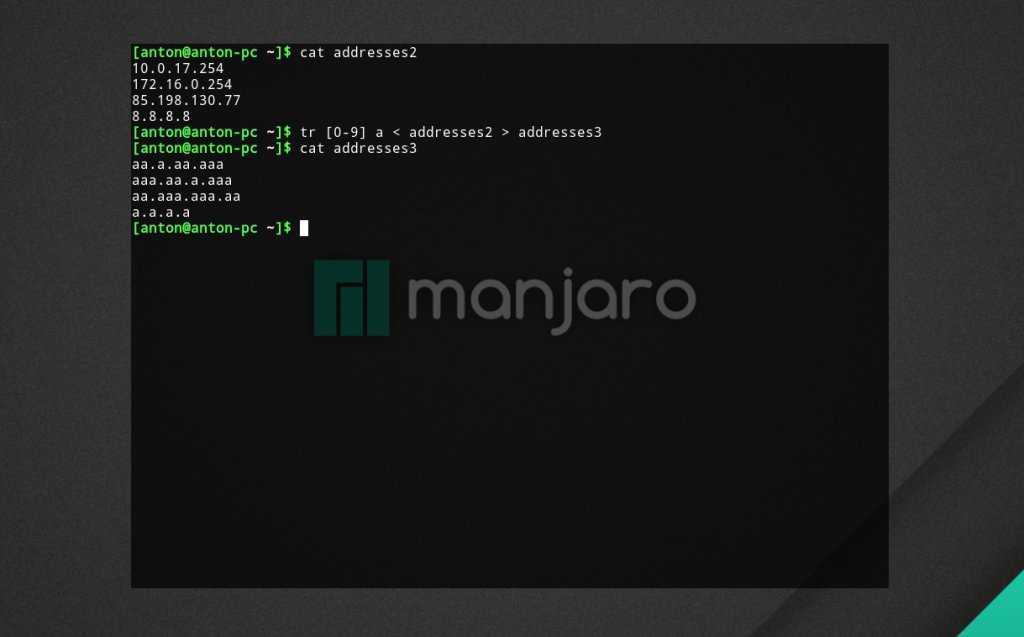
Пример 5. Заменить цифры IP-адреса файла addresses2 на буквы a, и результат записать в файл addresses3.
Как использовать wc команду
Синтаксис команды следующий:
Команда может принимать ноль или более входных имен. Если не указано, или когда есть , будет читать стандартный ввод. Слово — это строка символов, разделенных пробелом, символом табуляции или новой строкой.
В простейшей форме, когда она используется без каких-либо параметров, команда напечатает четыре столбца, число строк, слова, количество байтов и имя файла для каждого файла, переданного в качестве аргумента. При использовании стандартного ввода четвертый столбец (имя файла) не отображается.
Например, следующая команда отобразит информацию о виртуальном файле :
- 448 — количество строк.
- 3632 — количество слов.
- 22226 — это количество символов.
При использовании стандартного ввода имя файла не отображается:
Чтобы отобразить информацию о нескольких файлах, передайте имена файлов в качестве аргументов через пробел:
Команда предоставит вам информацию о каждом файле и строку, включая общую статистику:
Параметры ниже позволяют вам выбрать, какие счетчики будут напечатаны.
- , — Вывести количество строк.
- , — Вывести количество слов.
- , — Вывести количество символов.
- , — Вывести количество байтов.
- , — Вывести длину самой длинной строки.
При использовании нескольких опций счетчик печатается в следующем порядке: новая строка, слова, символы, байты, максимальная длина строки.
Например, для отображения только того количества слов, которое вы бы использовали:
Вот еще один пример, который напечатает количество строк и длину самой длинной строки.
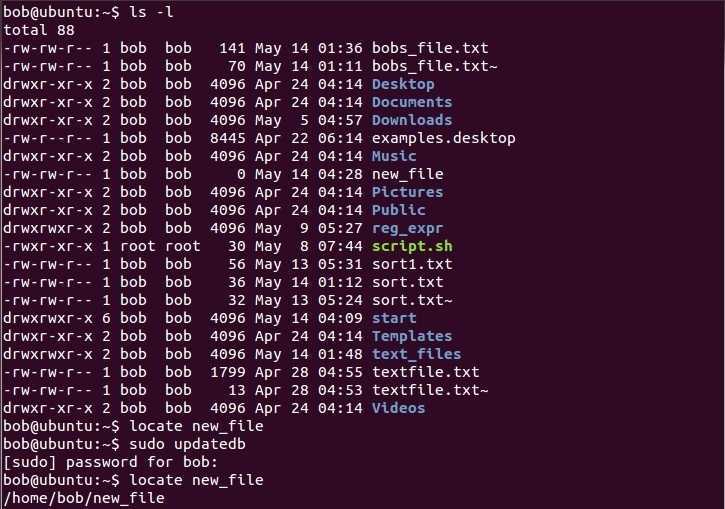
Опция позволяет читать входные данные из файлов , указанных NUL-прерванных имен в файле . Если есть, то читать имена из стандартного ввода. Например, вы можете искать файлы с помощью команды и предоставлять эти файлы в качестве входных данных для :
Вывод покажет количество строк для всех файлов в каталоге, имена которых начинаются с «host»:
Как увидеть новую строку?
od файлы дампа в восьмеричном и других форматах -c выбрать символы ASCII или экранирование обратной косой черты
А вот пример файла и использования od

- echo «Это мой ввод». Хорошо. В этой строке вы вводили или нет
- в этом случае вы должны ввести
- но с -n вам не нужно вводить
- +1 Не совсем. Рассматривать . В строке нет новой строки, НО если вы попытаетесь подсчитать ее символы с помощью , новая строка добавляется команда. Чтобы подсчитать символы в строке в bash, используйте .
- 1 @FattanehTalebi Я не сказал, что это неправильно. Это правильно. У меня вопрос «wc -c a.txt». Результат — 17. Но ожидаемый результат — 16. Я также использую следующий метод. od -c a.txt. В то время отображается только 16. Здесь ‘\ n’ не добавляется. Итак, почему туалет показывает 17. какой лишний символ. Это из файла или ‘\ n’, который мы вводим для выполнения команды в терминале.
В Linux, когда VIM сохранить буферы, он завершит каждую строку добавлением конца строки к новой строке. Шестнадцатеричный дамп VIM отредактированный файл.
Вы можете открыть свой файл и ввести смотреть шестнадцатеричный дамп или напрямую использовать команда.
Там вы можете видеть, что файл добавлен в конце файла.
поэтому, когда вы используете чтобы получить номер этого файла, он вернет 17 которые включают символ новой строки.
У вас есть из-за персонаж.
У вас здесь пара опечаток /0 вместо \0 и chaeracter против character. Дополнительный символ считается туалет -c не является нулем (0) это терминатор строки, скорее всего \n. В файле в формате DOS вы получите 18, потому что это будет двухбайтовый терминатор строки. \r\n.



строка ввода, которую вы указываете как ввод, не имеет ввода / новой строки, но echo назначает ей ввод / новую строку. И wc -c читает ввод или новую строку из заданной командой echo.
например
возвращает 2, потому что 1 для k и 1 для новой строки, добавленной echo
в то время как
возвращает 1, потому что -n подавляет перевод строки.
но wc -c всегда читает новую строку.
Ты можешь попробовать
возвращает 1
посмотреть, что он делает в файле
- Но я передаю ввод только через файл. например «wc -c a.txt»
- 1 хорошо, попробуй это. echo «Это мой ввод»> a.txt, затем запустите wc -c a.txt и printf «Это мой ввод»> a.txt, а затем wc -c a.txt. Вы знаете разницу, о которой я говорю.
- Я использую Ubuntu. Редактор vim
- Я использую Linux, а оболочка — ksh и редактор vi. Вы можете проверить это в командной строке. Выполните echo «My», в выводе вы получите следующее приглашение в новой строке и выполните echo -n «My» или printf «My», на выходе вы получите приглашение сразу после строки My.
Команда watch в Linux
Синтаксис и опции
Синтаксис команды watch крайне прост:
watch опции команда_для_вывода
Перечень опций невелик, но их достаточно для эффективного использования команды:
- -d (—differences) — служит для выделения тех данных в выводе команды, которые отличаются от предыдущих.
- -n (—interval seconds) — позволяет установить желаемый интервал запуска команды.
- -t (—no-title) — выключает отображение заголовков.
- -b (—beep) — если при выполнении команды возникнет ошибка, будет подан звуковой сигнал.
- -e (—errexit) — при возникновении ошибки вывод данных будет заморожен, команда watch прекратит работу после нажатия комбинации клавиш.
- -g (—chgexit) — выход при условии, что в выводе команды обнаружатся изменения.
- -c (—color) — интерпретирует последовательность цветов и стилей ANSI.
- -x (—exec) — выполнение команды будет передано интерпретатору sh -c поэтому, возможно, вам придется использовать дополнительные кавычки чтобы добиться желаемого эффекта. При использовании полной версии написания (—exec) команда будет выполняться в с помощью утилиты exec.
Примеры использования watch
Проще всего продемонстрировать работу команды watch, наблюдая за тем, как компьютер использует оперативную память:
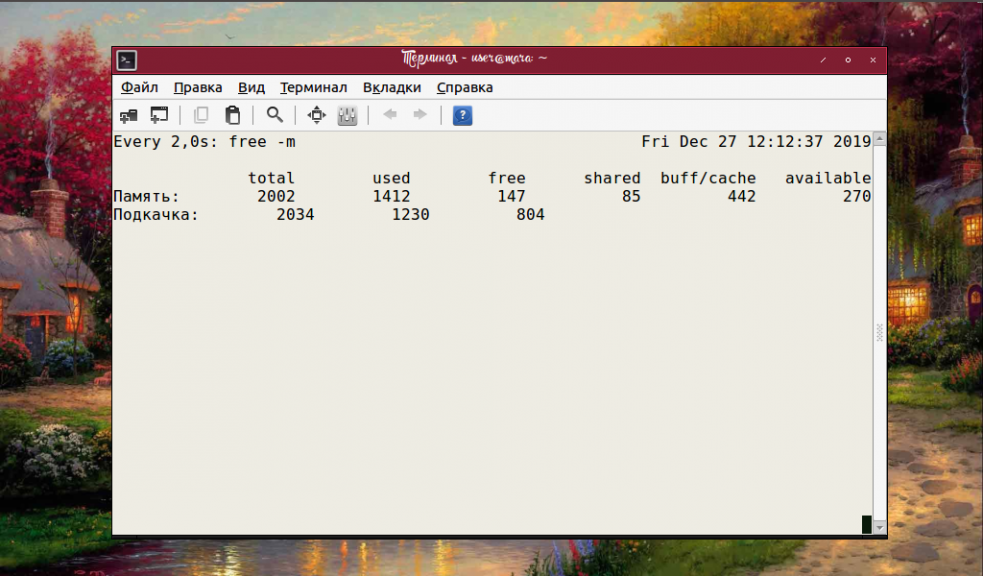
В данном случае не были использованы опции команды watch, зато к выполняемой команде free пришлось добавить параметр -m, который отвечает за отображение свободной памяти RAM. Так тоже можно и нужно делать, чтобы получить искомый результат.
Чтобы не запоминать каким был предыдущий результат вывода и не отслеживать изменения самостоятельно, стоит поручить эту работу опции -d. Она подсвечивает ту информацию, которая отличается от предыдущей:
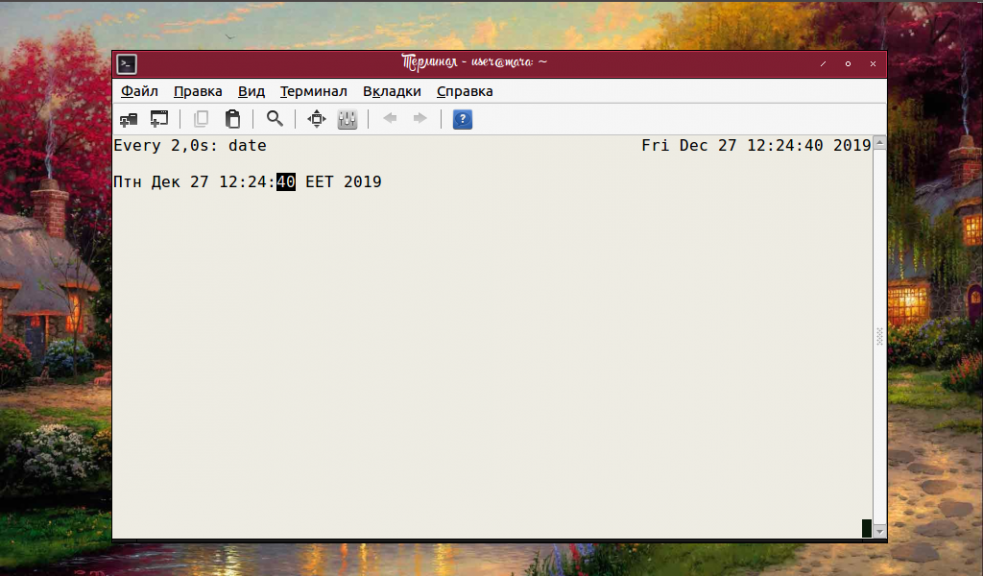
На каждом из скриншотов в верхней строке есть надпись «Every 2,0s». Она означает, что программа перезапускается каждые 2 секунды. Этот интервал установлен по умолчанию, но его можно изменить, используя опцию -n.
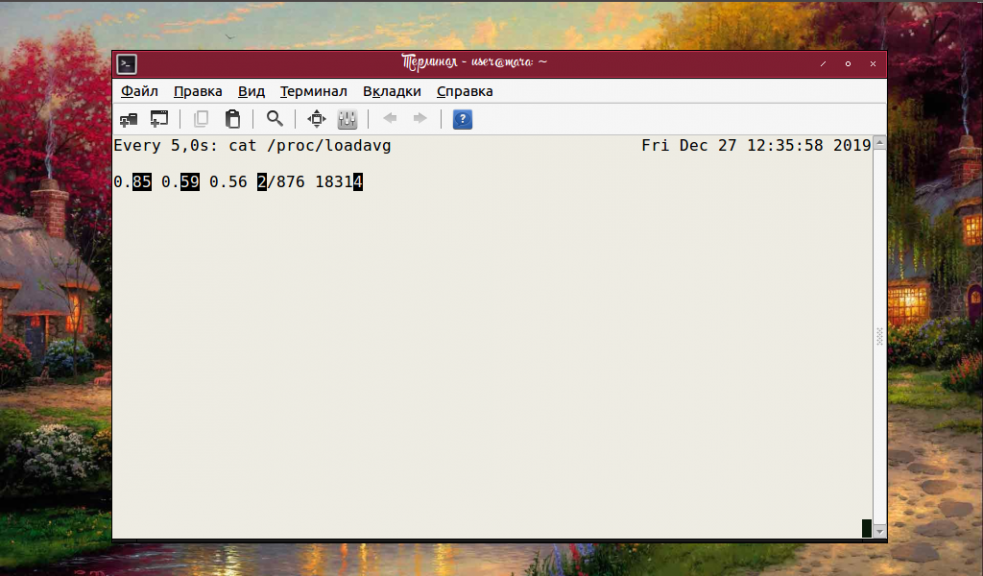
Обратите внимание на то, что значение -n не может быть меньше 1. Верхняя планка не ограничена
Если возникла необходимость получить на экране терминала больше места для полезных данных, можно убрать заглавную информацию. Для этого предназначена опция -t.
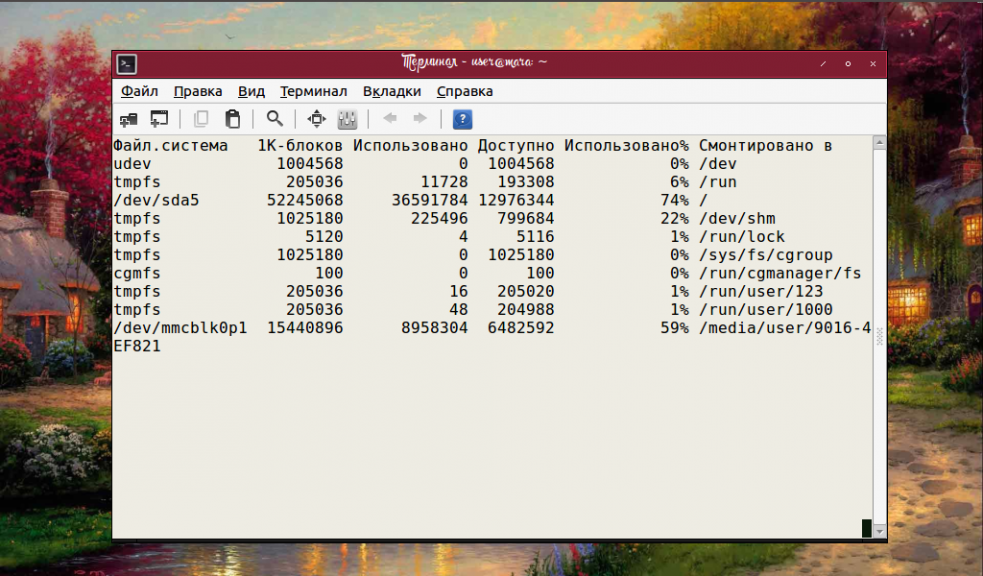
Интервал обновления, опции команды и текущая дата больше не отображаются.
Что касается выхода из утилиты watch, то он осуществляется при нажатии клавиш Ctrl+C или Ctrl+Z. Пока пользователь не воспользуется одной из этих комбинаций, команда будет выполняться с заданными параметрами.
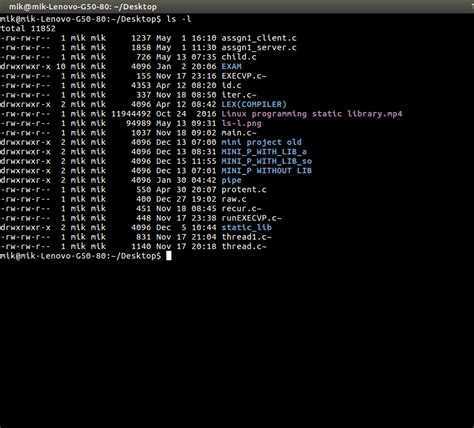

Как посмотреть количество файлов в папке Linux
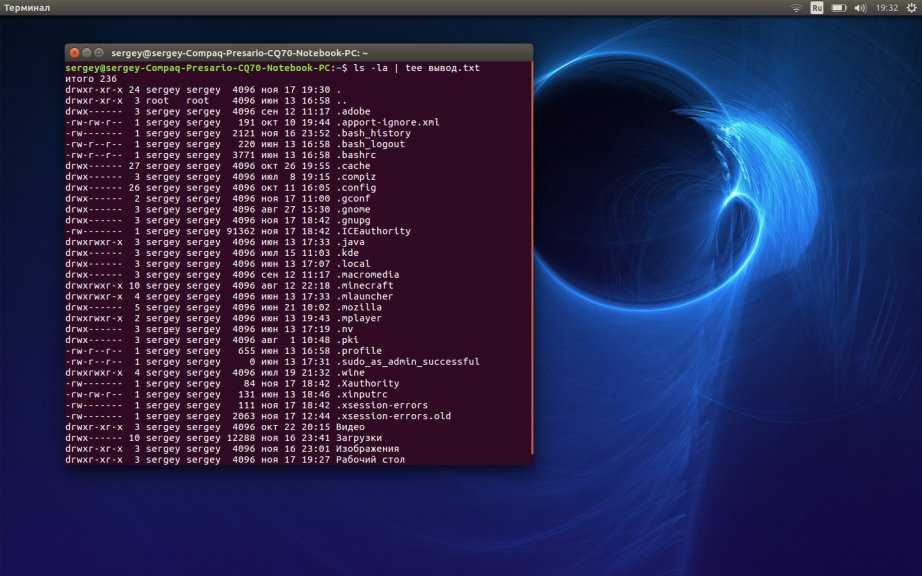
Самый простой способ решить эту задачу — использовать утилиту ls вместе с утилитой wc. Они покажут сколько файлов находится в текущей папке:
В моем случае утилита выдала результат 21, но поскольку ls выводит размер всех файлов в папке строкой total, то у нас файлов на один меньше. Нужно учесть, что тут отображаются еще и директории. Каждая директория начинается с символа «d», а каждый файл с «-«. Для символических ссылок используется «l». Посмотрите внимательно на вывод ls:
Чтобы их отсеять используйте grep:
Эта конструкция выберет только те строки, которые начинаются на дефис. Если вас интересуют не только обычные файлы, но и скрытые, то можно использовать опцию -a:
Так можно подсчитать количество папок:
А так символических ссылок:
Если вам нужно подсчитать количество файлов во всех подпапках, то можно использовать опцию -R:
С фильтром только файлы нам уже не страшно, что команда будет выводить служебную информацию. Если вы не хотите использовать ls, можно воспользоваться утилитой find:
Если нужно смотреть не только количество файлов в папке, но и подпапок, просто не нужно использовать -type f:
Только папки отдельно:
А в случае, когда необходимо перебрать все файлы во всех подпапках, не устанавливайте параметр -maxdepth:
Все эти команды это очень хорошо, но есть еще одно, более удобное средство посчитать количество файлов linux, это утилита tree.
Как использовать команду ps
Общий синтаксис команды следующий:
По историческим причинам и из соображений совместимости команда принимает несколько различных типов параметров:
- Параметры стиля UNIX, которым предшествует одиночный дефис.
- Параметры стиля BSD, используемые без тире.
- Параметры GNU с двумя дефисами перед ними.
Можно смешивать разные типы опций, но в некоторых конкретных случаях могут возникать конфликты, поэтому лучше придерживаться одного типа опций.
Опции BSD и UNIX можно сгруппировать.
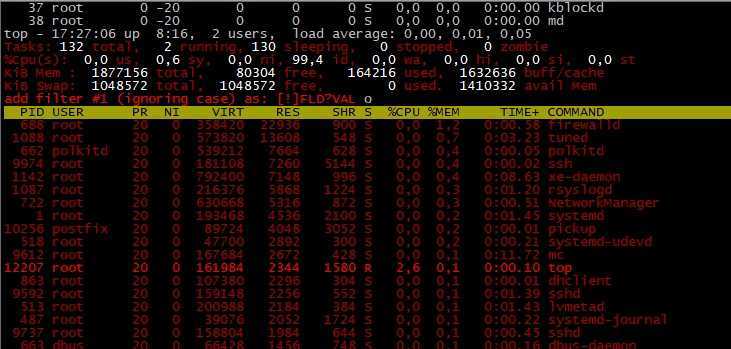
В простейшей форме, при использовании без какой-либо опции, напечатает четыре столбца информации как минимум для двух процессов, запущенных в текущей оболочке, самой оболочки и процессов, запущенных в оболочке при вызове команды.
Вывод включает информацию о оболочке ( ) и процессе, запущенном в этой оболочке ( , команда, которую вы ввели):
Четыре столбца помечены как , , и .
— идентификатор процесса
Обычно при запуске команды наиболее важной информацией, которую ищет пользователь, является PID процесса. Знание PID позволяет устранить неисправный процесс .
— имя управляющего терминала для процесса.
— совокупное время ЦП процесса в минутах и секундах.
— имя команды, которая использовалась для запуска процесса.
Приведенный выше вывод не очень полезен, поскольку не содержит много информации. Настоящая мощь команды проявляется при запуске с дополнительными параметрами.

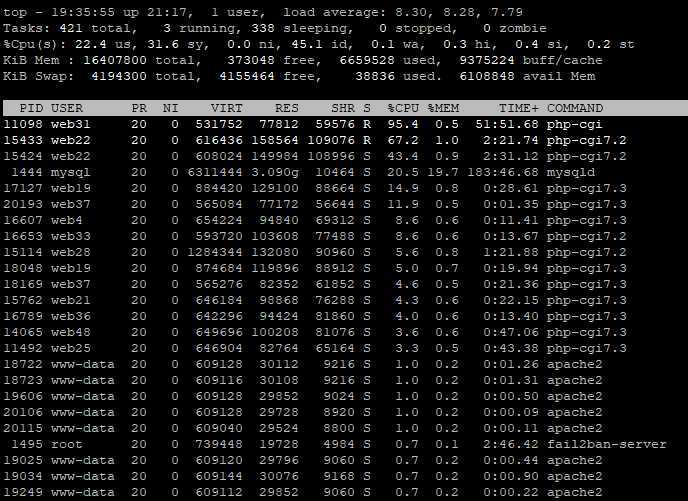
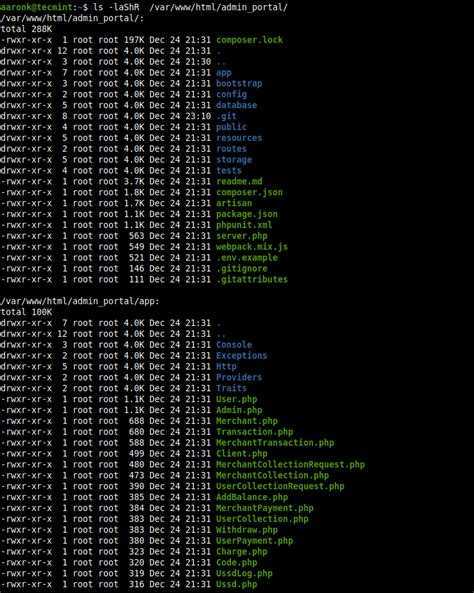
Команда принимает огромное количество параметров, которые можно использовать для отображения определенной группы процессов и различной информации о процессе, но при повседневном использовании требуется лишь несколько.
чаще всего используется со следующей комбинацией параметров:
Форма BSD :
- Параметр указывает отображать процессы всех пользователей. Не отображаются только процессы, не связанные с терминалом, и процессы руководителей групп.
- обозначает ориентированный на пользователя формат, который предоставляет подробную информацию о процессах.
- Параметр указывает перечислить процессы без управляющего терминала. В основном это процессы, которые запускаются во время загрузки и работают в фоновом режиме .
Команда отображает информацию в одиннадцати столбцах, обозначенных , , , , , , , , , и .
Мы уже объяснили метки , , и . Вот объяснение других этикеток:
- — пользователь, запускающий процесс.
- — загрузка процессора процессом.
- — процентное отношение размера резидентного набора процесса к физической памяти на машине.
- — размер виртуальной памяти процесса в КиБ.
- — размер физической памяти, которую использует процесс.
- — код состояния процесса, например (зомби), (спящий) и (запущенный).
- — время начала команды.
Параметр указывает отображать древовидное представление родительских и дочерних процессов:
Команда также позволяет сортировать вывод. Например, чтобы отсортировать вывод на основе использования памяти , вы должны использовать:
Форма UNIX :
- Параметр указывает отображать все процессы.
- обозначает полноформатный список, который предоставляет подробную информацию о процессах.
Команда отображает информацию в восьми столбцах, обозначенных , , , , , и .
Метки, которые еще не объяснены, имеют следующее значение:
- — то же самое, что и , пользователь, запускающий процесс.
- — идентификатор родительского процесса.
- — То же, что и , загрузка процессора процессом.
- — то же самое, что и , время начала команды.
Чтобы просмотреть только процессы, запущенные от имени конкретного пользователя, введите следующую команду, где — это имя пользователя:
Опции who
Используя различные опции, можно получать именно ту информацию, которая нужна здесь и сейчас:
- -a (—all) — включает в себя все основные опции.
- — b (—boot) — показывает время загрузки операционной системы.
- -d (—dead) — выводит перечень зомби-процессов.
- — H (—heading) — никак не влияет на получаемую информацию, зато добавляет колонкам заголовки и помогает понять что где находится.
- -m — показать пользователя, который сейчас работает в терминале.
- -r — вывести текущий уровень запуска (runinit);
- -t — показать последнее изменение системных часов;
- -s — вывести только имя, терминальную сессию и время.
- -q — вывести количество авторизованных пользователей.
- -T — данные о терминальной сессии.
- -u — показать активных пользователей.
- —ips — вместо названия хостов показывает ips.
- —lookup — используется в сочетании с —ips, выводит данные, которые основываются на сохраненном IP, если он доступен, а не на названии хоста.
![[в закладки] bash для начинающих: 21 полезная команда](http://smartshop124.ru/wp-content/uploads/9/5/9/959a561c0741b52538a2801144dc744e.jpeg)


