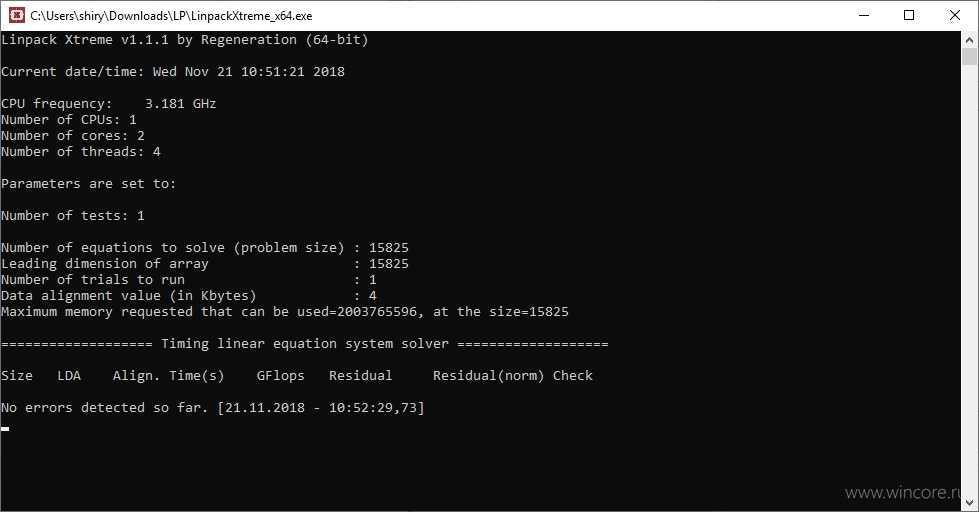
Зачем суживать количество открытых файлов
Поскольку операционной системе требуется память для управления каждым файлом, вы сможете столкнуться с ограничением количества файлов, которые можно открыть. Поскольку программа также сможет закрывать обработчики файлов, она может создавать множество файлов любого размера, пока все вразумительное дисковое пространство не будет заполнено. В этом случае одним из аспектов безопасности является предупреждение исчерпания ресурсов путем введения ограничений.
В Linux существует два вида ограничений:
- Soft Limit Свойство, которое может быть изменено процессом в любое время.
- Hard Limit обозначает наибольшее значение, которое не может быть превышено путем установки мягкого ограничения
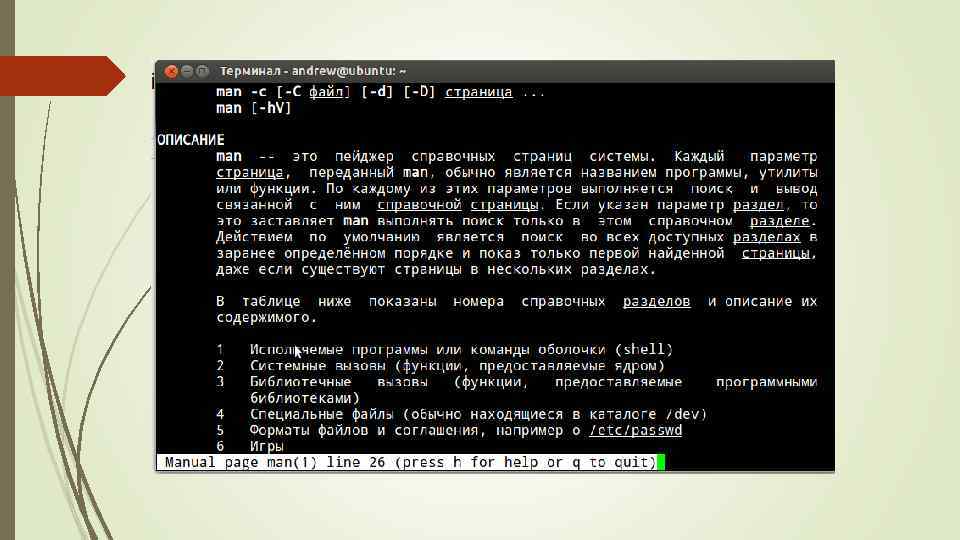
Вы можете увидать максимальное количество открытых файловых дескрипторов в вашей системе Linux, как показано ниже:
Свойство показывает количество файлов, которые пользователь может открыть за сеанс входа в систему, но вы обязаны заметить, что результат может отличаться в зависимости от вашей системы. По некоторым причинам может понадобиться увеличить значение набора ограничений. Вот почему ваша система Linux предлагает возможность (повышая или уменьшая) изменять эти ограничения, изменяя максимальное количество открытых файлов на процесс и на систему.
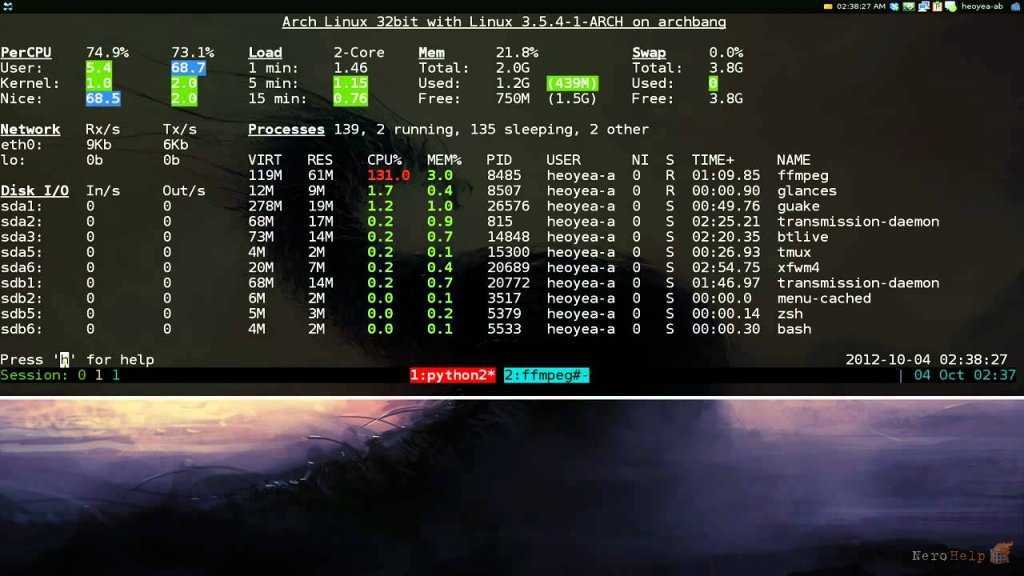
Вычисление средней загрузки
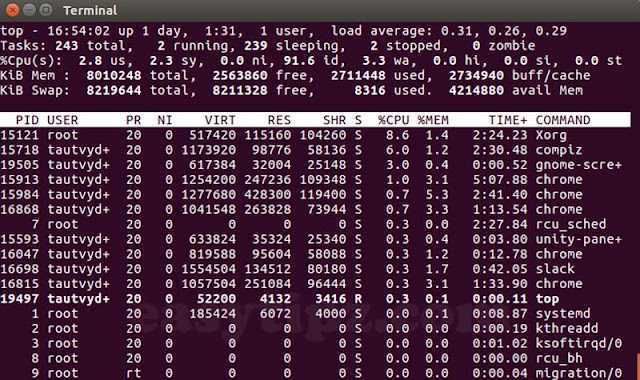
Средняя загрузка (Load Average, LA) — усредненная мера использования ресурсов компьютера запущенными процессами. Величина LA пропорциональна числу процессоров в системе и на ненагруженной системе колеблется от нуля до значения, равного числу процессоров. Высокие значения LA (10*число ядер и более) говорят о чрезмерной нагрузке на систему и потенциальных проблемах с производительностью.
В классическом Unix LA имеет смысл среднего количества процессов в очереди на исполнение + количества выполняемых процессов за единицу времени. Т.е. LA == 1 означает, что в системе считается один процесс, LA > 1 определяет сколько процессов не смогли стартовать, поскольку им не хватило кванта времени, а LA < 1 означает, что в системе есть незагруженные ядра.
В Linux к к количеству процессов добавили ещё и процессы, ожидающих ресурсы. Теперь на рост LA значительно влияют проблемы ввода/вывода, такие как недостаточная пропускная способность сети или медленные диски.
LA усредняется по следующей формуле LAt+1=(LAcur+LAt)/2. Где LAt+1 — отображаемое значение в момент t+1, LAcur — текущее измеренное значение, LAt — значение отображавшееся в момент t. Таким образом сглаживаются пики и после резкого падения нагрузки значение LA будет медленно снижаться, а кратковременный пик нагрузки будет отображен половинной величиной LA.
Просматриваем содержимое файла по шаблону в Linux
На практике зачастую нам необходим не весь текстовый файл, а лишь несколько строк из него. Используя grep, мы можем вывести Linux-файл, предварительно отсеяв лишнее:
grep опции шаблон файл
Команду можно применять и совместно с cat:
cat файл | grep опции шаблон
Давайте выведем из лога лишь предупреждения:
cat /var/log/Xorg.0.log | grep WW
Вывод:
(WW) warning, (EE) error, (NI) not implemented, (??) unknown. (WW) Hotplugging is on, devices using drivers 'kbd', 'mouse' or 'vmmouse' will be disabled. (WW) Disabling Keyboard0 (WW) Disabling Mouse0 (WW) evdev: A4TECH USB Device: ignoring absolute axes.
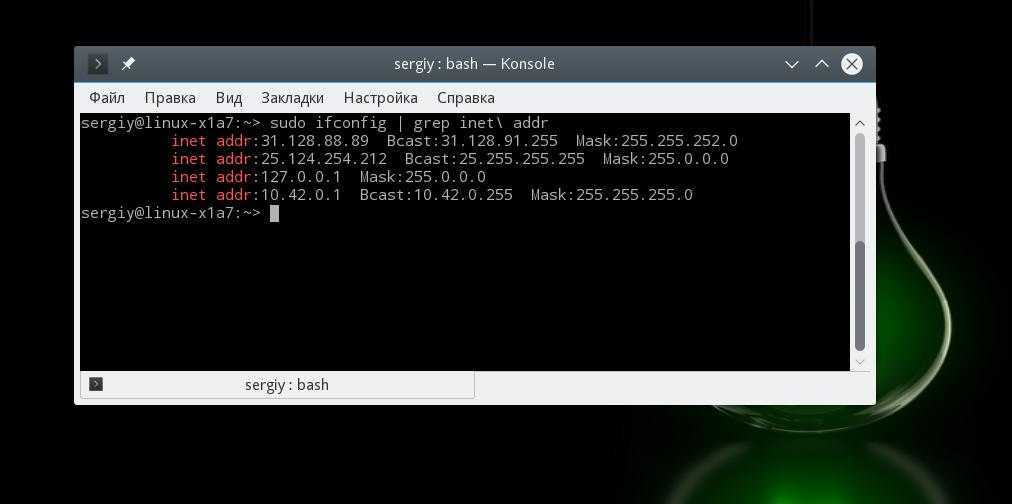
Есть и ряд полезных опций: -A, -B, -C. Допустим, нам надо выполнить вывод двух строк после вхождения enp2s0:
$ ifconfig | grep -A2 enp2s0
Вывод из файла:
enp2s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::beae:c5ff:febe:8bb7 prefixlen 64 scopeid 0x20<link>
А теперь, то же самое, но до вхождения loop:
ifconfig | grep -B2 loop
Вывод:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback)
Можно по две строки как до, так и после loop:
ifconfig | grep -C2 loop
Вывод из файла:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback) RX packets 9810 bytes 579497 (565.9 KiB) RX errors 0 dropped 0 overruns 0 frame
Просматриваем начало или конец файла в Linux
Порой, нам не нужно выводить содержимое всего файла и мы хотим, к примеру, посмотреть лишь несколько строчек лога. Такое часто бывает, если мы подозреваем, что в начале или в конце конфигурационного файла есть ошибки. Для решения данного вопроса у нас существуют команды head и tail (как вы уже догадались, это голова и хвост).
Команда head по умолчанию показывает лишь 10 первых строчек в текстовом файле в Linux:
head /etc/passwd
Вот, что мы увидим:
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false adm:x:3:4:adm:/var/adm:/bin/false lp:x:4:7:lp:/var/spool/lpd:/bin/false sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt news:x:9:13:news:/var/spool/news:/bin/false uucp:x:10:14:uucp:/var/spool/uucp:/bin/false
Кстати, тут мы тоже можем открыть сразу несколько текстовых файлов в Linux одновременно. Вот просмотр сразу двух файлов:
head /etc/passwd /etc/shadow
Если же вас не интересуют все 10 строчек, то, как и в случае с cat, можно использовать опцию –n, цифрой указывая число строк к выводу:
head -n5 /var/log/emerge.log
В итоге мы вывели только пять строк:
1394924012: Started emerge on: Mar 15, 2014 22:53:31 1394924012: *** emerge --sync 1394924012: === sync 1394924012: >>> Synchronization of repository 'gentoo' located in '/usr/portage'... 1394924027: >>> Starting rsync with rsync://212.113.35.39/gentoo-portage
По правде говоря, букву n можно и не использовать, достаточно просто передать цифру:
head -5 /var/log/emerge.log
Кстати, выводить содержимое текстового файла в Linux можно не построчно, а посимвольно. Давайте зададим число символов, которое нужно вывести (используем опцию -с):
head -c45 /var/log/emerge.log
Итак, выводим 45 символов:
1394924012: Started emerge on: Mar 15, 2014 2
Не верите, что их действительно 45? Проверить можно командой wc:
head -c45 /var/log/emerge.log | wc -c 45
С «головой» разобрались, давайте поговорим про «хвост». Очевидно, что команда tail работает наоборот, выводя десять последних строк текстового Linux-файла:
tail /var/log/emerge.log
Количество строк при выводе тоже можно менять. Однако в tail есть такая полезная опция, как -f. С её помощью содержимое текстового файла будет постоянно обновляться, в результате чего вы станете видеть изменения сразу (постоянно открывать и закрывать файл не придётся). Это весьма удобно, если вы хотите просматривать логи Linux в реальном времени:

tail -f /var/log/emerge.log
Просмотр файлов и папок в Linux
Более точная и подробная статья по поиску занятого места на диске.
Проверяем свободное место на всём диске:
df -h
Узнаём какие файлы хранятся в директории
ls
Список папок с занимаемыми размерами в корне сервера (сортировка директорий по алфавиту):
du -hs /*
Выводит список директорий и файлов построчно, сортируя их по возрастанию размера, а также показывает права доступа, размер файлов и дату изменения:
ls -lSr |more
Показывает размер и имена директорий и файлов (сортировка по размеру). В примере сортировка по размеру директории var.
du -sk /var/* | sort -rn
Ещё одна команда (показывает в мб) сортирует по размеру (в данном случае сортировка каталога с логами):
du -k /var/log/* | sort -nr | cut -f2 | xargs -d ‘\n’ du -sh
Бригада ulimit
Команду ulimit можно использовать для увеличения количества файлов, которые можно раскрыть в оболочке. Эта команда является встроенной командой bash, поэтому она влияет только на bash и програмки, запускаемые из него. Синтаксис ulimit следующий:
Параметры определяют, что довольствуется. Вы можете увидеть некоторые варианты, как показано ниже
- (Передача текущих настроек): заставляет ulimit извещать о своих текущих настройках.
- (Ограничения файлов) ограничивает размер файлов, которые могут быть сделаны оболочкой.
- Ограничивает количество открытых файловых дескрипторов.
- и (Жесткие и мягкие ограничения) параметры меняют другие параметры, в результате чего они устанавливаются как жесткие или мягкие ограничения соответственно. Жесткие ограничения смогут впоследствии не увеличиваться, но мягкие ограничения могут быть. Если ни один из вариантов не предусмотрен, ulimit ставит как жесткие, так и мягкие ограничения для указанной функции.
Итак, чтобы увидеть текущее ограничение, вы сможете сделать, как показано ниже:
Вы можете проверить жесткий предел, как показано ниже:
И мягкий предел, как показано ниже:
Вы можете изменить ограничение, как представлено ниже
И вы можете проверить это ниже:
Проблема сейчас в том, что если вы выйдете из системы и войдете в систему или перезагрузите пк, значение будет сброшено. Помните, что для того, чтобы сделать эти ограничения более постоянными, нужно отредактировать один из файлов конфигурации пользователя ( or ) или общесистемные файлы конфигурации ( or ) приплюсовав командную строку ulimit в конец файла, как показано ниже.
Теперь, простонар если вы перезагрузитесь, ограничение, установленное пользователем, будет постоянным. Вы можете увеличить только твердый лимит () или мягкий лимит (), но вы должны заметить, что мягкие ограничения могут быть установлены другым пользователем, в то время как жесткие ограничения могут быть изменены только пользователем root после его аппараты.
Проблематика
Если по ходу своей деятельности вы обращаете внимания на такие атрибуты как даты создания, изменения, последнего доступа, то эта статья может быть вам полезна. После опроса нескольких людей я увидел, что на самом деле каверзные вопросы о временных метках многих ставят в тупик. В самом деле, казалось бы, нет ничего проще – дата создания – когда файл создан. Дата изменения – когда изменён. Дата последнего доступа – когда к файлу осуществлялся доступ. Просто? Если вам кажется это просто, то предлагаю ответить на ряд вопросов для самоконтроля. Если вопросы для вас оказались просты и не вызвали некого замешательства, то смело можете читать другие статьи – здесь для вас ничего полезного нет. Но если вопросы заставили вас задуматься, то милости прошу…
Управление владением файлами
Это происходит в следующем порядке:
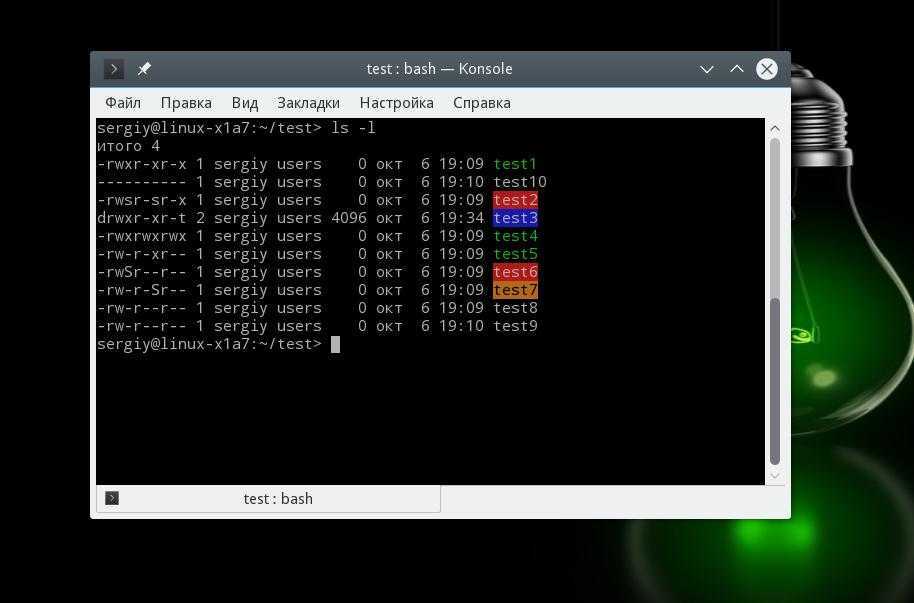
- Оболочка проверяет, являетесь ли вы владельцем файла, к которому вы хотите получить доступ. Если вы являетесь этим владельцем, вы получаете разрешения и оболочка прекращает проверку.
- Если вы не являетесь владельцем файла, оболочка проверит, являетесь ли вы участником группы, у которой есть разрешения на этот файл. Если вы являетесь участником этой группы, вы получаете доступ к файлу с разрешениями, которые для группы установлены, и оболочка прекратит проверку.
- Если вы не являетесь ни пользователем, ни владельцем группы, вы получаете права других пользователей (Other).
ls -l
lsfindfind -user
find users
chown
chown -R
chownchgrpchown.
chown
- chown lisa myfile1 устанавливает пользователя lisa владельцем файла myfile1.
- chown lisa.sales myfile устанавливает пользователя lisa владельцем файла myfile, а так же устанавливает группу sales владельцем этого же файла.
- chown lisa:sales myfile то же самое, что и предыдущая команда.
- chown .sales myfile устанавливает группу sales владельцем файла myfile без изменения владельца пользователя.
- chown :sales myfile то же самое, что и предыдущая команда.
chgrpchgrp
chown-Rchgrp
Как изменить дату создания содержимого файла FileDate Changer
FileDate Changer — бесплатная программа от известного разработчика программного обеспечения NirSoft. Скачайте программу FileDate Changer с сайта разработчика здесь.

Распакуйте ZIP-архив с программой, а затем запустите приложение на компьютере.
Выполните следующие шаги:
- Перетащите файл в окно программы, или нажмите на кнопку «Add Files», для добавления файла с ПК. Поддерживается работа с файлами в пакетном режиме.
- В полях «Created Date» (дата создания), «Modified Date» (дата изменения), «Accessed Date» (дата доступа) установите подходящие значения для даты и времени.
- Нажмите на кнопку «Change Files Date» для применения изменений.
- Закройте программу FileDate Changer, проверьте результат работы.
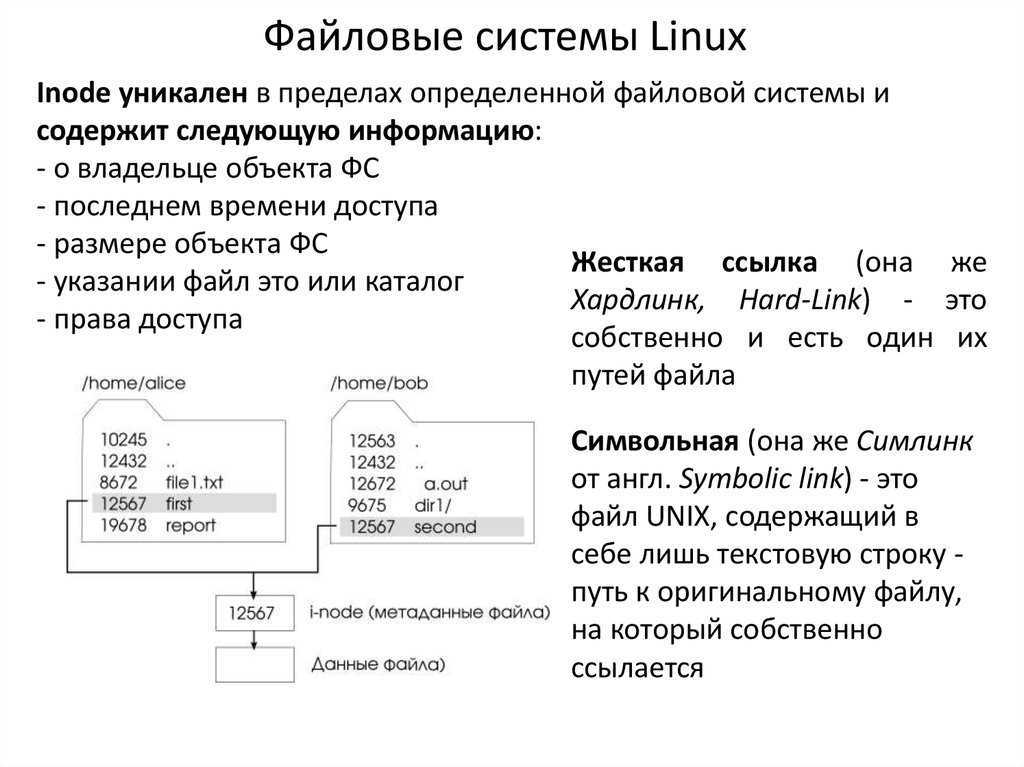
Польза от инодов
Принцип работы инодов также объясняет, почему невозможно создать жесткую ссылку из одной файловой системы в другую. Разрешение такой задачи открыло бы возможность наличия конфликтующих номеров инодов. В то же время, символьная ссылка может быть создана в разных файловых системах.
Поскольку жесткая ссылка имеет тот же номер инода, что и исходный файл, то вы можете удалить исходный файл, и данные по-прежнему будут доступны по жесткой ссылке. Всё, что вы сделали в этом случае, — это удалили одно из имен, указывающих на заданный номер инода. Данные, связанные с этим инодом, будут оставаться доступными до тех пор, пока все имена, связанные с ним, не будут удалены.
Иноды также являются важной причиной, по которой Linux-системы могут обновляться без необходимости перезагрузки: один процесс может использовать библиотечный файл, в то время как другой процесс заменяет этот файл новой версией. Уже запущенный процесс будет продолжать использовать старый файл, в то время как каждый новый вызов к нему приведет к использованию новой версии
Еще одна интересная функция, которая поставляется с инодами, — это возможность хранить данные в самом иноде. Это называется встраиванием (англ. «inlining»). Этот метод хранения имеет преимущество в экономии места, поскольку не требует использования блоков данных, но при этом также увеличивает время поиска, избегая дополнительного доступа к диску для получения данных.
В некоторых файловых системах, таких как , есть опция под названием inline_data, которая позволяет операционной системе хранить данные вышеописанным способом. Из-за ограничения размера встраивание работает только для очень маленьких файлов.
высокоуровневый
- Обычно — пакеты программного обеспечения, которые реализуют промежуточный слой между системной платформой и приложением. Эти пакеты предназначены для переноса уже испытанных протоколов коммуникации приложения на более новую архитектуру. Примером можно привести: DIPC, MPI и др. (мне не знакомы, честно говоря)
Итак. Подведем маленький итог:
- В Linux есть процессы,
- каждый процесс может запускать подпроцессы (нити),
- создание нового процесса создается клонированием исходного,
- прородителем всех процессов в системе является процесс init, запускаемый ядром системы при загрузке.
- процессы взаимодействуют между собой по средствам можпроцессного взаимодействия:
- каналы
- сигналы
- сокеты
- разделяемая память
- каждый процесс обладает свойствами (читай: обладает следующим контекстом):
- PID — идентификатор процесса
- PPID — идентификатор процесса, породившего данный
- UID и GID — идентификаторы прав процесса (соответствует UID и GID пользователя, от которого запущен процесс)
- приоритет процесса
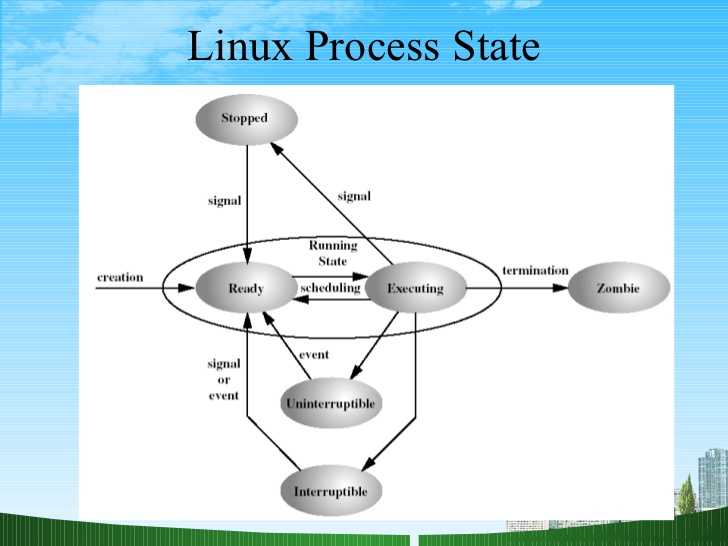
- состояние процесса (выполнение, сон и т.п.)
- так же у процесса есть таблица открытых (используемых) файлов
Далее поговорим о том, как посмотреть состояние процессов в Linux и о том, как же ими управлять.
удаленный;
— удаленные вызовы процедур (Remote Procedure Calls — RPC)
RPC — разновидность технологий, которая позволяет компьютерным программам вызывать функции или процедуры в другом адресном пространстве (как правило, на удалённых компьютерах). Обычно, реализация RPC технологии включает в себя два компонента: сетевой протокол (чаще TCP и UDP, реже HTTP) для обмена в режиме клиент-сервер и язык сериализации объектов (или структур, для необъектных RPC).
— сокеты Unix
Сокеты UNIX бывают 2х типов: локальные и сетевые. При использовании локального сокета, ему присваивается UNIX-адрес и просто будет создан специальный файл (файл сокета) по заданному пути, через который смогут сообщаться любые локальные процессы путём простого чтения/записи из него. Сокеты представляют собой виртуальный объект, который существует, пока на него ссылается хотя бы один из процессов. При использовании сетевого сокета, создается абстрактный объект привязанный к слушающему порту операционной системы и сетевому интерфейсу, ему присваивается INET-адрес, который имеет адрес интерфейса и слушающего порта.
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);
Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.
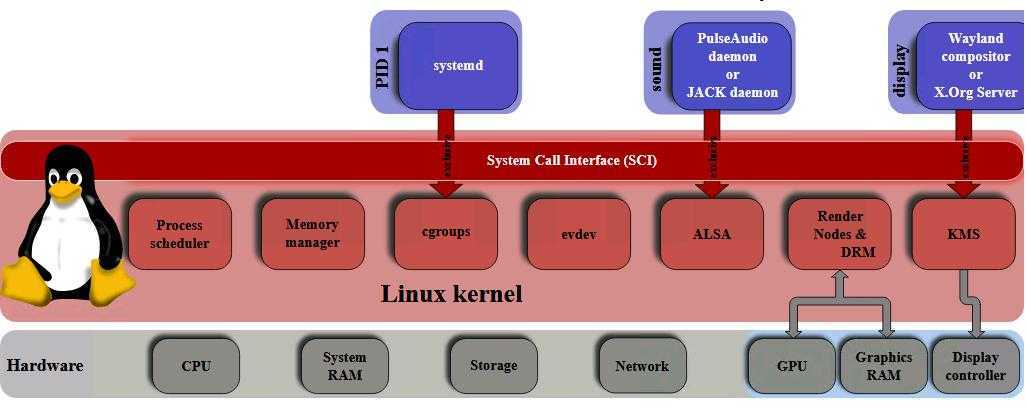
Общие сведения о файлах
Каждый файл в системе Windows имеет один или несколько штампов времени. Три первичных штампа, с которыми мы будем работать, включают:
- Дата создания: дата и время создания текущего экземпляра файла. Это предустановленное значение, и система Windows не меняет этого значения. Некоторые сторонние инструменты позволяют вам изменять это значение.
- Дата изменения: дата и время последнего редактирования файла (т.е. когда его содержимое было изменено). Переименование файла не изменяет эту отметку времени. Также метка не изменятся, если в файл не было внесено ни каких изменений.
- Дата доступа: дата и время последнего обращения к файлу для чтения или записи.
В Windows также есть несколько других меток времени, которые используются для определенных типов файлов или при определенных обстоятельствах. Например, отметка времени «Дата съёмки» записывается, когда изображение захватывается камерой. Другие метки времени могут быть созданы и использованы определенными приложениями. Например, программное обеспечение резервного копирования может использовать штамп времени с архивированием даты, а в некоторых офисных приложениях используется отметка времени «Дата завершения» для маркировки готового документа.
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Расширенные права
Понимание расширенных прав SUID, GUID и sticky bit
ls -ls x
accountls -lds
- Пользователь является владельцем файла;
- Пользователь является владельцем каталога, в котором находится файл.
ls -ldt
Применение расширенных прав
chmodchmod
chmod
- Для SUID используйте chmod u+s.
- Для SGID используйте chmod g+s.
- Для sticky bit используйте chmod +t, а затем имя файла или каталога, для которого вы хотите установить разрешения.
Пример работы со специальными правами
Откройте терминал, в котором вы являетесь пользователем linda. Создать пользователя можно командой useradd linda, добавить пароль passwd linda.
Создайте в корне каталог /data и подкаталог /data/sales командой mkdir -p /data/sales. Выполните cd /data/sales, чтобы перейти в каталог sales. Выполните touch linda1 и touch linda2, чтобы создать два пустых файла, владельцем которых является linda.
Выполните su — lisa для переключения текущего пользователя на пользователя lisa, который также является членом группы sales.
Выполните cd /data/sales и из этого каталога выполните ls -l. Вы увидите два файла, которые были созданы пользователем linda и принадлежат группе linda. Выполните rm -f linda*. Это удалит оба файла.
Выполните touch lisa1 и touch lisa2, чтобы создать два файла, которые принадлежат пользователю lisa.
Выполните su — для повышения ваших привилегий до уровня root.
Выполните chmod g+s,o+t /data/sales, чтобы установить бит идентификатора группы (GUID), а также sticky bit в каталоге общей группы.
Выполните su — linda. Затем выполните touch linda3 и touch linda4. Теперь вы должны увидеть, что два созданных вами файла принадлежат группе sales, которая является владельцем группы каталога /data/sales.
Выполните rm -rf lisa*. Sticky bit предотвращает удаление этих файлов от имени пользователя linda, поскольку вы не являетесь владельцем этих файлов
Обратите внимание, что если пользователь linda является владельцем каталога /data/sales, он в любом случае может удалить эти файлы!
Планировщик процессов
Задачей планировщика процессов процессов является извлечение процессов, готовых на выполнение, в соответствии с некоторыми правилами. Планировщик старается распределить процессорные ресурсы так, чтобы ни один из процессов не простаивал длительное время, и чтобы процессы, считающиеся приоритетными, получали процессорное время в первую очередь. В многопроцессорных системах желательно, чтобы в последовательных квантах времени процесс запускался на одном и том же процессоре, чтобы максимально использовать процессорный кэш. При этом сам планировщик должен выполнять выбор как можно быстрее.
Простейшая реализация очереди в виде FIFO очень быстра, но не поддерживает приоритеты и многопроцессорность. В Linux 2.6 воспользовались простотой FIFO, добавив к ней несколько усовершенствований:
- Было определено 140 приоритетов (100 реального времени + 40 назначаемых динамически), каждый из которых получил свою очередь FIFO. На запуск выбирается первый процесс в самой приоритетной очереди.
- В многопроцессорных системах для каждого ядра был сформирован свой набор из 140 очередей. Раз в 0,2 секунды просматриваются размеры очередей процессоров и, при необходимости балансировки, часть процессов переносится с загруженных ядер на менее загруженные
- Динамический приоритет назначается процессу в зависимости от отношении времени ожидания ресурсов к времени пребывания в состоянии выполнения. Чем дольше процесс ожидал ресурс, тем выше его приоритет. Таким образом, диалоговые задачи, которые 99% времени ожидают пользовательского ввода, всегда имеют наивысший приоритет.
Прикладной программист может дополнительно понизить приоритет процесса функцией (в Linux — интерфейс к вызову ). Большее значение означает меньший приоритет. В командной строке используется «запускалка» с таким же именем: