
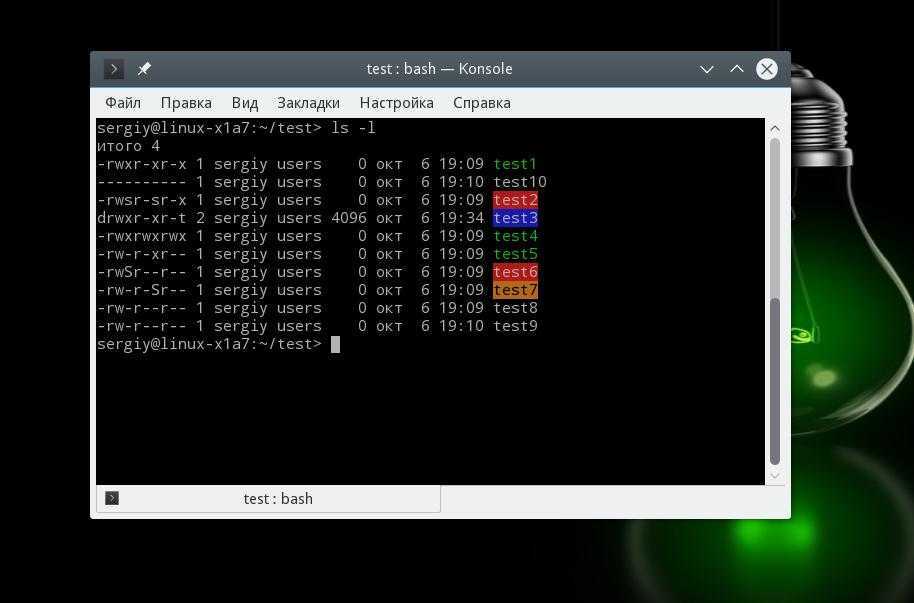
ПРОСМОТР ФАЙЛА В LINUX ПОЛНОСТЬЮ
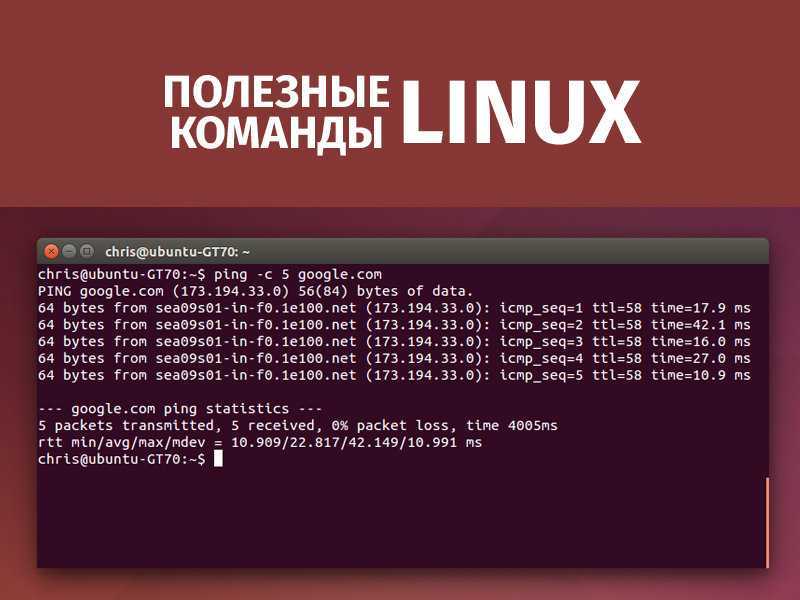
Самая простая и в то же время наиболее часто используемая утилита для просмотра содержимого файла linux — cat. Выводит все содержимое файла в стандартный вывод. В параметре нужно передать только адрес файла, или нескольких файлов. Идеально подходит для просмотра небольших файлов. Общий синтаксис команды cat такой:
Например просмотр содержимого файла linux /etc/passwd:
Также можно посмотреть сразу несколько файлов:
Опция -n включает нумерацию строк:
Для удобства, можно включить отображение в конце каждой строки символа $
А также отображение табуляций, все табуляции будут заменены на символ ^I:
Больше о ней говорить не будем, потому что большинство ее опций направлены на форматирование вывода, и вы сможете их легко изучить выполнив:
Есть еще одна очень похожая на cat утилита — tac. Принимает те же параметры и делает то же самое, только наоборот — выполняет вывод содержимого файла linux в обратном порядке — с конца:
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
find / -name «file.txt»
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня .
2. Поиск файла по части имени:
find / -name «*.tmp»
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
find . -name «sess_*» -a -name «*cd»
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
find . -name «sess_*» -o -name «*cd»
в) Более компактный вид имеют регулярные выражения, например:
find . -regex ‘.*/\(sess_.*cd\)’
find . -regex ‘.*/\(sess_.*\|.*cd\)’
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
4. Найти все файлы, кроме .log:
find . ! -name «*.log»
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
find . -type f -mtime +60
* данная команда найдет файлы, которые менялись более 60 дней назад.
2. Поиск файлов с помощью newer. Данная опция доступна с версии 4.3.3 (посмотреть можно командой find —version).
а) дате изменения:
find . -type f -newermt «2019-11-02 00:00»
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.

find . -type f -newermt 2019-10-31 ! -newermt 2019-11-02
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
б) дате обращения:
find . -type f -newerat 2019-10-08
* все файлы, к которым обращались с 08.10.2019.
find . -type f -newerat 2019-10-01 ! -newerat 2019-11-01
* все файлы, к которым обращались в октябре.
в) дате создания:
find . -type f -newerct 2019-09-07
* все файлы, созданные с 07 сентября 2019 года.
find . -type f -newerct 2019-09-07 ! -newerct «2019-09-09 07:50:00»
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50
Искать в текущей директории и всех ее подпапках только файлы:
find . -type f
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
find / -perm 0666
2. Находим файлы, доступ к которым имеет только владелец:
find / -perm 0600
Поиск файла по содержимому
find / -type f -exec grep -i -H «content» {} \;
* в данном примере выполнен рекурсивный поиск всех файлов в директории и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r | head -n 1
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
find . -name «sess_*» -type f -print -exec rm {} \;
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
find . -name «sess_*» -type f -exec mv {} new_name \;
или:
find . -name «sess_*» -type f | xargs -I ‘{}’ mv {} new_name
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:

find . -name «*.tmp» | wc -l
4. Изменить права:
find /home/user/* -type d -exec chmod 2700 {} \;
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
find /etc -name ‘*.conf’ -follow -type f -exec cat {} \; | grep ‘test’
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
find /opt/project -type f -exec sed -i -e «s/test/production/g» {} \;
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
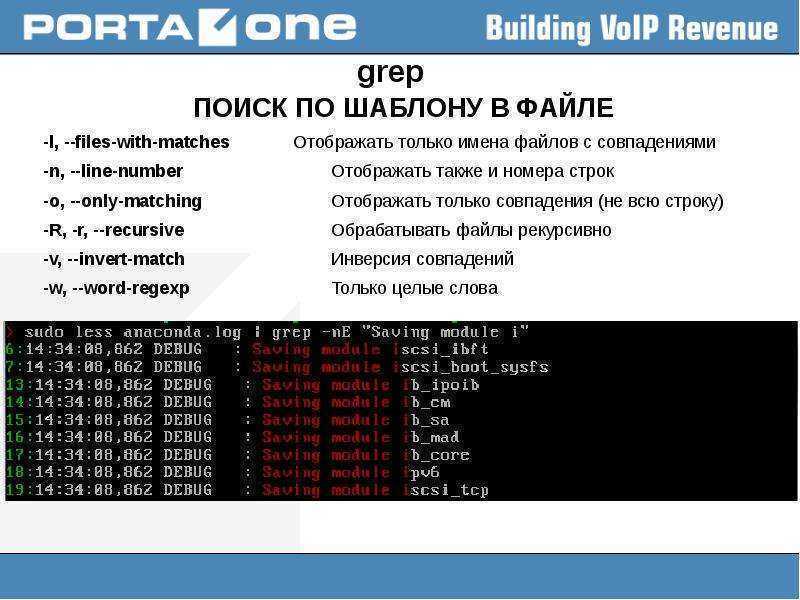
grep примеры использования
В принципе для работы grep не обязательно указывать даже файл или директорию, но это крайне желательно, если Вы хотите найти всё быстрее и точнее. Например:
Найдет файлы с упоминанием меня любимого, если таковые есть. Точнее не файлы, а строки с упоминанием указанного слова, т.е в данном случае sonikelf. Здесь стоит упомянуть, что строкой grep считает все символы, находящиеся между двумя символами новой строки.
| grep sonikelf file.txt | поиск sonikelf в файле file.txt, с выводом полностью совпавшей строкой |
| grep -o sonikelf file.txt | поиск sonikelf в файле file.txt и вывод только совпавшего куска строки |
| grep -i sonikelf file.txt | игнорирование регистра при поиске |
| grep -bn sonikelf file.txt | показать строку (-n) и столбец (-b), где был найден sonikelf |
| grep -v sonikelf file.txt | инверсия поиска (найдет все строки, которые не совпадают с шаблоном sonikelf) |
| grep -A 3 sonikelf file.txt | вывод дополнительных трех строк, после совпавшей |
| grep -B 3 sonikelf file.txt | вывод дополнительных трех строк, перед совпавшей |
| grep -C 3 sonikelf file.txt | вывод три дополнительные строки перед и после совпавшей |
| grep -r sonikelf $HOME | рекурсивный поиск по директории $HOME и всем вложенным |
| grep -c sonikelf file.txt | подсчет совпадений |
| grep -L sonikelf *.txt | вывести список txt-файлов, которые не содержат sonikelf |
| grep -l sonikelf *.txt | вывести список txt-файлов, которые содержат sonikelf |
| grep -w sonikelf file.txt | совпадение только с полным словом sonikelf |
| grep -f sonikelfs.txt file.txt | поиск по нескольким sonikelf из файла sonikelfs.txt, шаблоны разделяются новой строкой |
| grep -I sonikelf file.txt | игнорирование бинарных файлов |
| grep -v -f file2 file1 > file3 | вывод строк, которые есть в file1 и нет в file2 |
| grep -in -e ‘python’ `find -type f` | рекурсивный поиск файлов, содержащих слово python с выводом номера строки и совпадений |
| grep -inc -e ‘test’ `find -type f` | grep -v :0 | рекурсивный поиск файлов, содержащих слово python с выводом количества совпадений |
| grep . *.py | вывод содержимого всех py-файлов, предваряя каждую строку именем файла |
| grep «Http404» apps/**/*.py | рекурсивный поиск упоминаний Http404 в директории apps в py-файлах |
grep — что это и зачем может быть нужно
Про «репку» (как я её называю) почему-то в курсе не многие, что печалит. «Унылая» (не в обиду) формулировка из Википедии звучит примерно так:
grep — утилита командной строки, которая находит на вводе строки, отвечающие заданному регулярному выражению, и выводит их, если вывод не отменён специальным ключом.
Не сильно легче, но доступнее, можно сформулировать так:
grep — утилита командной строки, используется для поиска и фильтрации текста в файлах, на основе шаблона, который (шаблон) может быть регулярным выражением.
Если всё еще ничего не понятно, то условно говоря это удобный поиск текста везде и всюду, в особенности в файлах, директория в и тп. Удобно распарсивать логи и их содержимое, не прибегая к софту, как это бывает в Windows.
Справку можно вычленить так же как по find, т.е методом pgrep, fgrep, egrep и черт знает что еще:
Или:
Расписывать все ключи и даже основные тут (вы еще помните, что это блоговая часть сайта?) не буду, так как в отличии от find’а, последних тут вообще страшное подмножество, особенно учитывая, что существуют pgrep, fgrep, egrep и черт знает что еще, которые, в некотором смысле тоже самое, но для определенных целей.
Потрясающе удобная штука, которая жизненно необходима, особенно, если Вы что-то когда-то где-то зачем-то администрировали. Взглянем на примеры.
Исключить директорию из поиска
Из предыдущего параграфа понятно, что с помощью
можно исключить директорию из поиска.
Пример: найти в ./code все файлы, заканчивающиеся на index.php
но проигнорировать поддиректории на p, то есть в директориях python и php не искать.
find ./code -path «./code/p*» -prune -false -o -name «*index.php»
./code/js/errors/index.php
./code/js/index.php
./code/c/index.php
./code/cpp/index.php
./code/go/pointers/index.php
./code/go/declare_variable/index.php
./code/go/constants/index.php
./code/go/index.php
./code/java/index.php
./code/dotnet/index.php
./code/ruby/index.php
./code/theory/index.php
./code/index.php
-false нужен чтобы не выводить проигнорированные директории.
Ещё один способ исключить директорию из поиска
find ./code -name «*.php« -not -path «./code/p*»
GUI
Графический интерфейс во многом облегчает жизнь новичкам, которые только установили дистрибутив Linux. Данный метод поиска очень похож на тот, что осуществляется в ОС Windows, хотя и не может дать всех тех преимуществ, что предлагает «Терминал». Но обо всем по порядку. Итак, рассмотрим, как сделать поиск файлов в Linux, используя графический интерфейс системы.
Способ 1: Поиск через меню системы
Сейчас будет рассмотрен способ поиска файлов через меню системы Linux. Проводимые действия будут выполняться в дистрибутиве Ubuntu 16.04 LTS, однако инструкция общая для всех.
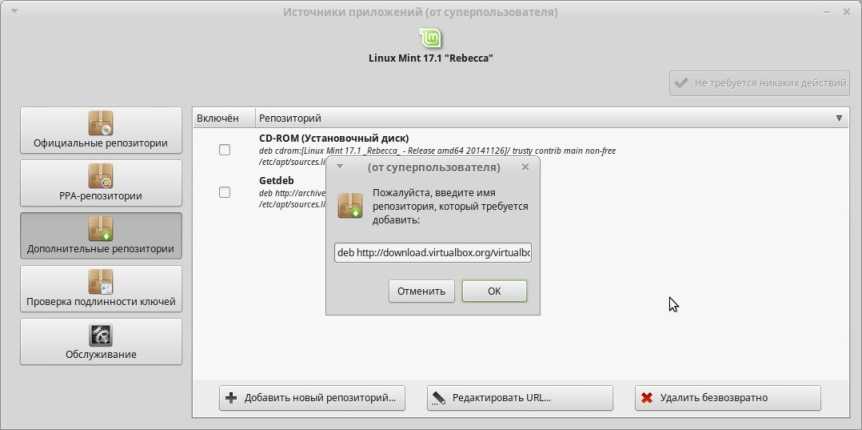
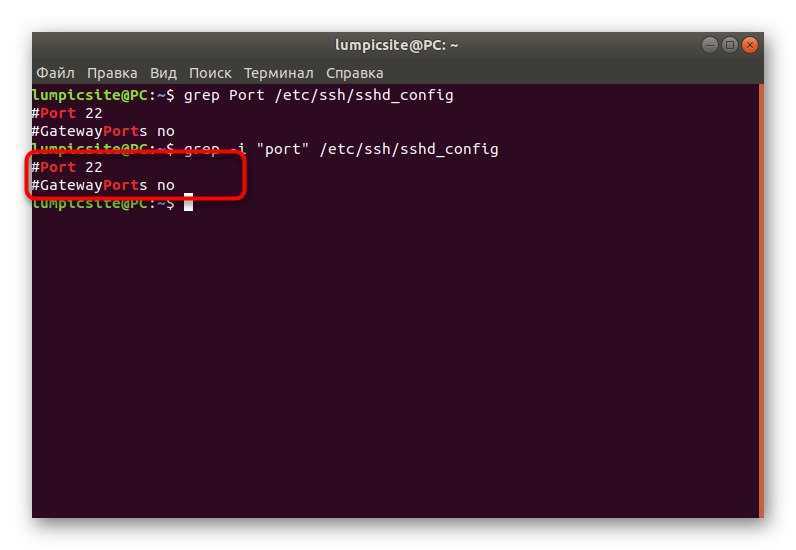
Допустим, вам необходимо найти в системе файлы под именем «Найди меня», также этих файлов в системе два: один в формате «.txt», а второй — «.odt». Чтобы их отыскать, необходимо изначально нажать на иконку меню (1), и в специальном поле для ввода (2) указать поисковый запрос «Найди меня».
Отобразится результат поиска, где будут показаны искомые файлы.
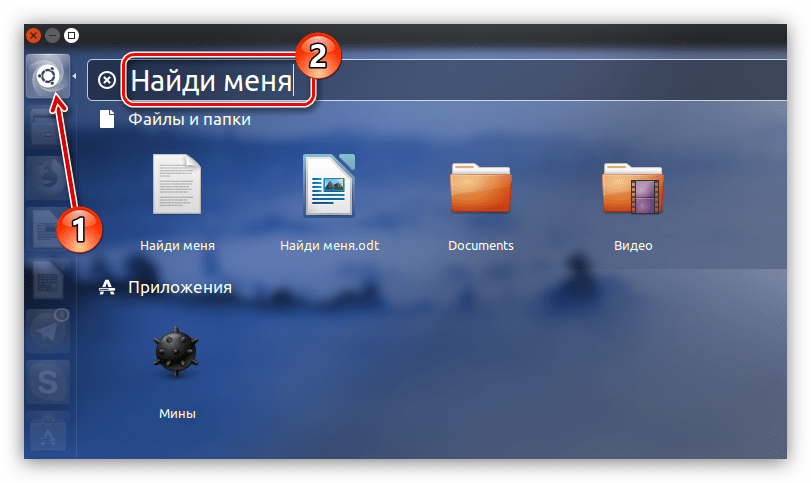
Но если в системе было бы много таких файлов и все они отличались расширениями, то поиск бы усложнился. Для того чтобы исключить в выдаче результатов ненужные файлы, например, программы, лучше всего воспользоваться фильтром.
Расположен он в правой части меню. Фильтровать вы можете по двум критериям: «Категории» и «Источники». Разверните эти два списка, нажав по стрелочке рядом с названием, и в меню уберите выделения с ненужных пунктов. В данном случае разумнее будет оставить лишь поиск по «Файлы и папки», так как мы ищем именно файлы.
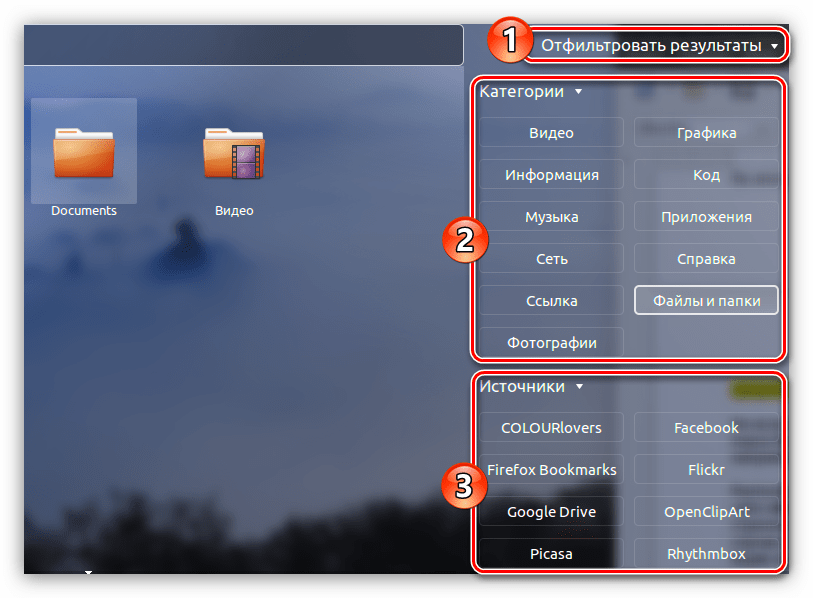
Сразу можно заметить недостаток этого способа — нельзя детально настроить фильтр, как в «Терминале». Так, если вы ищите текстовый документ с каким-то названием, в выдаче вам могут показать картинки, папки, архивы и т. п. Но если вы знаете точное наименование нужного файла, то сможете быстро отыскать его, не изучая многочисленные способы команды «find».
Способ 2: Поиск через файловый менеджер
Второй способ имеет существенное преимущество. Используя инструмент файлового менеджера, можно произвести поиск в указанном каталоге.
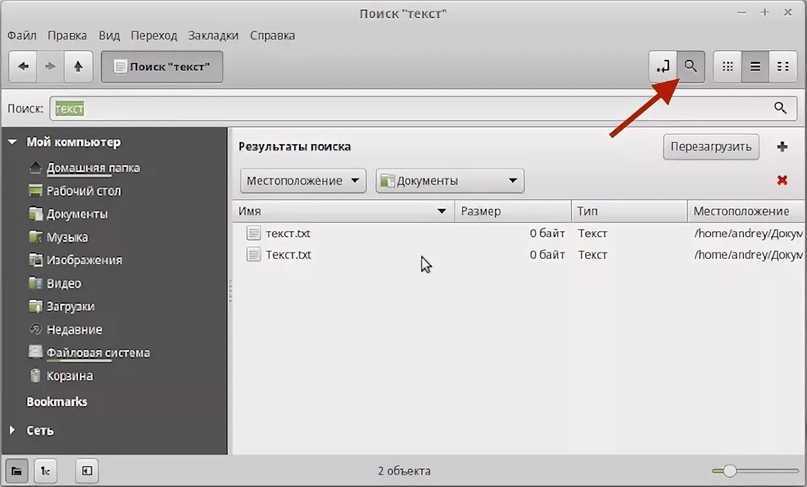
Выполнить данную операцию проще простого. Вам необходимо в файловом менеджере, в нашем случае Nautilus’е, войти в папку, в которой предположительно находится искомый файл, и нажать кнопку «Поиск», расположенную в верхнем правом углу окна.
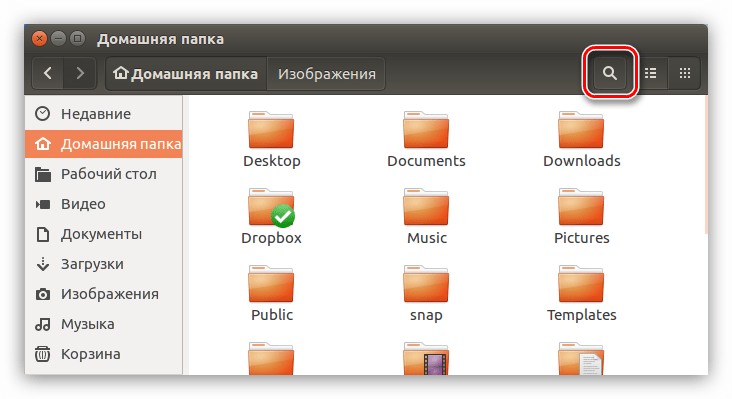
В появившееся поле для ввода вам нужно ввести предполагаемое название файла. Также не забывайте, что поиск может быть проведен не по целому имени файла, а лишь по его части, как показано на примере ниже.
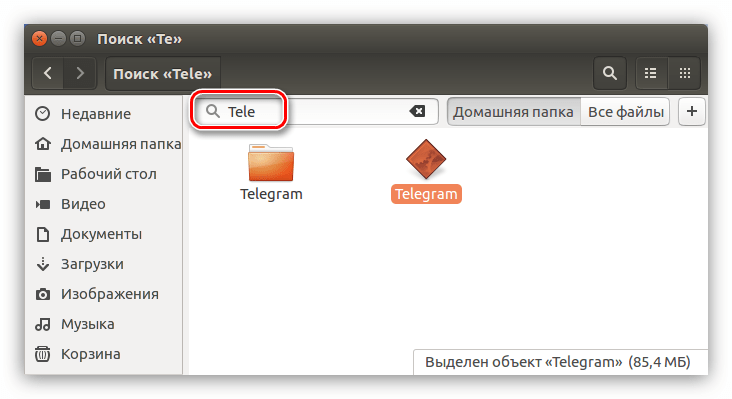
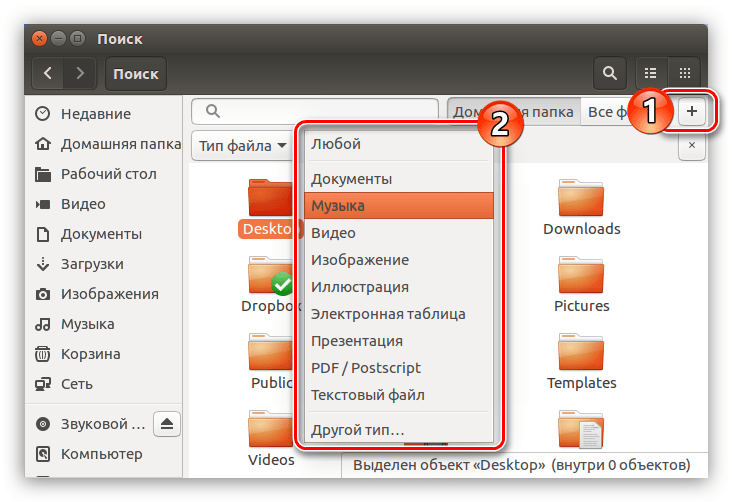
Как и в предыдущем способе, в этом точно так же можно использовать фильтр. Для его открытия нажмите на кнопку со знаком «+», расположенную в правой части поля ввода поискового запроса. Откроется подменю, в котором вы можете из выпадающего списка выбрать искомый тип файла.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».



grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Квантификаторы
Квантификаторы позволяют указать количество вхождений элементов, которые должны присутствовать, чтобы совпадение произошло. В следующей таблице показаны квантификаторы, поддерживаемые GNU :
| Квантификатор | Описание |
|---|---|
| Сопоставьте предыдущий элемент ноль или более раз. | |
| Соответствует предыдущему элементу ноль или один раз. | |
| Сопоставьте предыдущий элемент один или несколько раз. | |
| Сравните предыдущий элемент ровно раз. | |
| Сопоставьте предыдущий элемент не менее раз. | |
| Соответствовать предыдущему элементу не более раз. | |
| Сопоставьте предыдущий элемент от до раз. |
Символ (звездочка) соответствует предыдущему элементу ноль или более раз. Следующее будет соответствовать «right», «sright», «ssright» и так далее:
Ниже представлен более сложный шаблон, который соответствует всем строкам, которые начинаются с заглавной буквы и заканчиваются точкой или запятой. Регулярное выражение Соответствует любому количеству любых символов:
(знак вопроса) символ делает предыдущий элемент необязательным и может соответствовать только один раз. Следующие будут соответствовать как «ярким», так и «правильным». Символ экранирован обратной косой чертой, потому что мы используем базовые регулярные выражения:
Вот то же регулярное выражение с использованием расширенного регулярного выражения:
Символ (плюс) соответствует предыдущему элементу один или несколько раз. Следующее будет соответствовать «sright» и «ssright», но не «right»:
Фигурные скобки позволяют указать точное число, верхнюю или нижнюю границу или диапазон вхождений, которые должны произойти, чтобы совпадение произошло.
Следующее соответствует всем целым числам, содержащим от 3 до 9 цифр:
Grep IP-адреса
Greping для IP-адресов может быть немного сложным, потому что мы не можем просто сказать, что grep ищет 4 числа, разделенных точками — ну, мы могли бы, но эта команда также может вернуть недопустимые IP-адреса.
Следующая команда найдет и изолирует только действительные адреса IPv4 :
$ grep -E -o "(25|2|??)\.(25|2|??)\.(25|2|??)\.(25|2|??)" /var/log/auth.log
Мы использовали это на нашем сервере Ubuntu только для того, чтобы увидеть, откуда были сделаны последние попытки SSH.
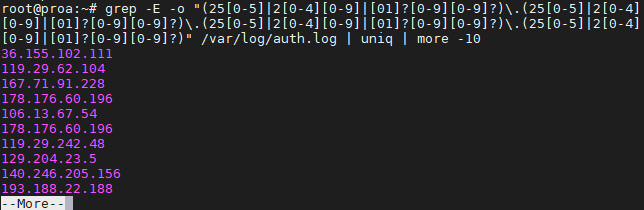
Чтобы избежать повторной информации и захламления вашего экрана, вы можете направить ваши команды grep в «uniq» и «more», как мы делали на скриншоте выше.
Что такое grep?
Команда grep (расшифровывается как global regular expression print) — одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Секрет популярности — её мощь, она даёт возможность пользователям сортировать и фильтровать текст на основе сложных правил.

Утилита grep решает множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.
Просматриваем начало или конец файла в Linux
Порой, нам не нужно выводить содержимое всего файла и мы хотим, к примеру, посмотреть лишь несколько строчек лога. Такое часто бывает, если мы подозреваем, что в начале или в конце конфигурационного файла есть ошибки. Для решения данного вопроса у нас существуют команды head и tail (как вы уже догадались, это голова и хвост).
Команда head по умолчанию показывает лишь 10 первых строчек в текстовом файле в Linux:
head /etc/passwd
Вот, что мы увидим:
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false adm:x:3:4:adm:/var/adm:/bin/false lp:x:4:7:lp:/var/spool/lpd:/bin/false sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt news:x:9:13:news:/var/spool/news:/bin/false uucp:x:10:14:uucp:/var/spool/uucp:/bin/false
Кстати, тут мы тоже можем открыть сразу несколько текстовых файлов в Linux одновременно. Вот просмотр сразу двух файлов:
head /etc/passwd /etc/shadow
Если же вас не интересуют все 10 строчек, то, как и в случае с cat, можно использовать опцию –n, цифрой указывая число строк к выводу:
head -n5 /var/log/emerge.log
В итоге мы вывели только пять строк:
1394924012: Started emerge on: Mar 15, 2014 22:53:31 1394924012: *** emerge --sync 1394924012: === sync 1394924012: >>> Synchronization of repository 'gentoo' located in '/usr/portage'... 1394924027: >>> Starting rsync with rsync://212.113.35.39/gentoo-portage
По правде говоря, букву n можно и не использовать, достаточно просто передать цифру:
head -5 /var/log/emerge.log
Кстати, выводить содержимое текстового файла в Linux можно не построчно, а посимвольно. Давайте зададим число символов, которое нужно вывести (используем опцию -с):
head -c45 /var/log/emerge.log
Итак, выводим 45 символов:
1394924012: Started emerge on: Mar 15, 2014 2
Не верите, что их действительно 45? Проверить можно командой wc:
head -c45 /var/log/emerge.log | wc -c 45
С «головой» разобрались, давайте поговорим про «хвост». Очевидно, что команда tail работает наоборот, выводя десять последних строк текстового Linux-файла:
tail /var/log/emerge.log
Количество строк при выводе тоже можно менять. Однако в tail есть такая полезная опция, как -f. С её помощью содержимое текстового файла будет постоянно обновляться, в результате чего вы станете видеть изменения сразу (постоянно открывать и закрывать файл не придётся). Это весьма удобно, если вы хотите просматривать логи Linux в реальном времени:
tail -f /var/log/emerge.log
find — синтаксис и зачем оно нужно
find — утилита поиска файлов по имени и другим свойствам, используемая в UNIX‐подобных операционных системах. С лохматых тысячелетий есть и поддерживаться почти всеми из них.
Базовый синтаксис ключей (забран с Вики):
-name — искать по имени файла, при использовании подстановочных образцов параметр заключается в кавычки
Опция `-name’ различает прописные и строчные буквы; чтобы использовать поиск без этих различий, воспользуйтесь опцией `-iname’;
-type — тип искомого: f=файл, d=каталог, l=ссылка (link), p=канал (pipe), s=сокет;
-user — владелец: имя пользователя или UID;
-group — владелец: группа пользователя или GID;
-perm — указываются права доступа;
-size — размер: указывается в 512-байтных блоках или байтах (признак байтов — символ «c» за числом);
-atime — время последнего обращения к файлу (в днях);
-amin — время последнего обращения к файлу (в минутах);
-ctime — время последнего изменения владельца или прав доступа к файлу (в днях);
-cmin — время последнего изменения владельца или прав доступа к файлу (в минутах);
-mtime — время последнего изменения файла (в днях);
-mmin — время последнего изменения файла (в минутах);
-newer другой_файл — искать файлы созданные позже, чем другой_файл;
-delete — удалять найденные файлы;
-ls — генерирует вывод как команда ls -dgils;
-print — показывает на экране найденные файлы;
-print0 — выводит путь к текущему файлу на стандартный вывод, за которым следует символ ASCII NULL (код символа 0);
-exec command {} \; — выполняет над найденным файлом указанную команду; обратите внимание на синтаксис;
-ok — перед выполнением команды указанной в -exec, выдаёт запрос;
-depth или -d — начинать поиск с самых глубоких уровней вложенности, а не с корня каталога;
-maxdepth — максимальный уровень вложенности для поиска. «-maxdepth 0» ограничивает поиск текущим каталогом;
-prune — используется, когда вы хотите исключить из поиска определённые каталоги;
-mount или -xdev — не переходить на другие файловые системы;
-regex — искать по имени файла используя регулярные выражения;
-regextype тип — указание типа используемых регулярных выражений;
-P — не разворачивать символические ссылки (поведение по умолчанию);
-L — разворачивать символические ссылки;
-empty — только пустые каталоги.
Примерно тоже самое, только больше и в не самом удобочитаемом виде, т.к надо делать запрос по каждому ключу отдельно, можно получить по
Результатам будет нечто такое из чего можно вычленять справку по отдельному ключу или команде (кликабельно):
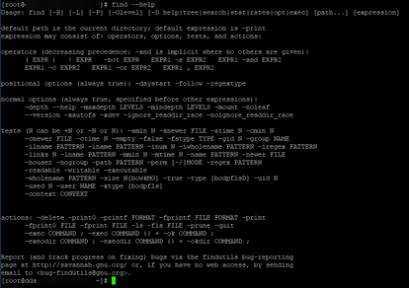
В качестве развлечения можно использовать:
Дабы получить мануал из самой системы по базису и ключам (тоже кликабельно);

Немного о примерах использования. Точно так же, оттуда же и тп. Просто для понимания как оно работает вообще. Наиболее просто, конечно, осознать это потренировавшись в той же консоли на реальной системе.



