Syntax
sort [OPTION]... [FILE]...
sort [OPTION]... --files0-from=F
Options
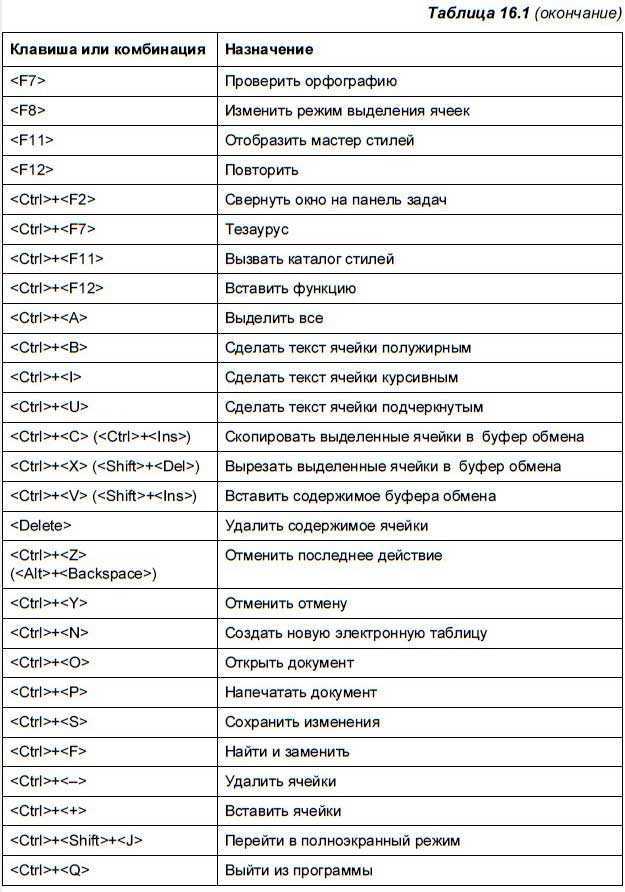
| -b,—ignore-leading-blanks | Ignore leading blanks. |
| -d, —dictionary-order | Consider only blanks and alphanumeric characters. |
| -f, —ignore-case | Fold lower case to upper case characters. |
| -g,—general-numeric-sort | Compare according to general numerical value. |
| -i, —ignore-nonprinting | Consider only printable characters. |
| -M, —month-sort | Compare (unknown) < `JAN‘ < … < `DEC‘. |
| -h,—human-numeric-sort | Compare human readable numbers (e.g., «2K«, «1G«). |
| -n, —numeric-sort | Compare according to string numerical value. |
| -R, —random-sort | Sort by random hash of keys. |
| —random-source=FILE | Get random bytes from FILE. |
| -r, —reverse | Reverse the result of comparisons. |
| —sort=WORD | Sort according to WORD: general-numeric -g, human-numeric -h, month -M, numeric -n, random -R, version -V. |
| -V, —version-sort | Natural sort of (version) numbers within text. |
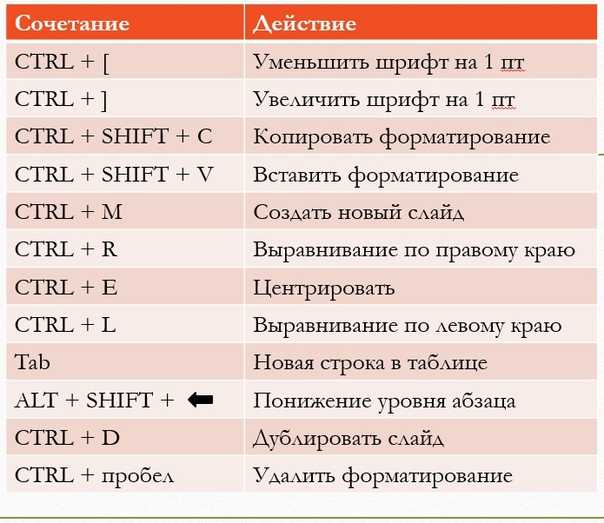
Other options
| —batch-size=NMERGE | Merge at most NMERGE inputs at once; for more use temp files. |
| -c, —check,—check=diagnose-first | Check for sorted input; do not sort. |
| -C, —check=quiet,—check=silent | Like -c, but do not report first bad line. |
| —compress-program=PROG | Compress temporaries with PROG; decompress them with PROG -d. |
| —debug | Annotate the part of the line used to sort, and warn about questionable usage to stderr. |
| —files0-from=F | Read input from the files specified by NUL-terminated names in file F; If F is ‘-‘ then read names from standard input. |
| -k, —key=POS1[,POS2] | Start a key at POS1 (origin 1), end it at POS2 (default end of line). See POS syntax below. |
| -m, —merge | Merge already sorted files; do not sort. |
| -o, —output=FILE | Write result to FILE instead of standard output. |
| -s, —stable | Stabilize sort by disabling last-resort comparison. |
| -t, —field-separator=SEP | Use SEP instead of non-blank to blank transition. |
| -T,—temporary-directory=DIR | Use DIR for temporaries, not $TMPDIR or /tmp; multiple options specify multiple directories. |
| —parallel=N | Change the number of sorts run concurrently to N. |
| -u, —unique | With -c, check for strict ordering; without -c, output only the first of an equal run. |
| -z, —zero-terminated | End lines with 0 byte, not newline. |
| —help | Display a help message, and exit. |
| —version | Display version information, and exit. |
POS takes the form F[.C][OPTS], where F is the field number and C the character position in the field; both are origin 1. If neither -t nor -b is in effect, characters in a field are counted from the beginning of the preceding whitespace. OPTS is one or more single-letter ordering options, which override global ordering options for that key. If no key is given, use the entire line as the key.
SIZE may be followed by the following multiplicative suffixes:
| % | 1% of memory |
| b | 1 |
| K | 1024 (default) |
…and so on for M, G, T, P, E, Z, Y.
With no FILE, or when FILE is a dash («—«), sort reads from the standard input.
Also, note that the locale specified by the environment affects sort order; set LC_ALL=C to get the traditional sort order that uses native byte values.
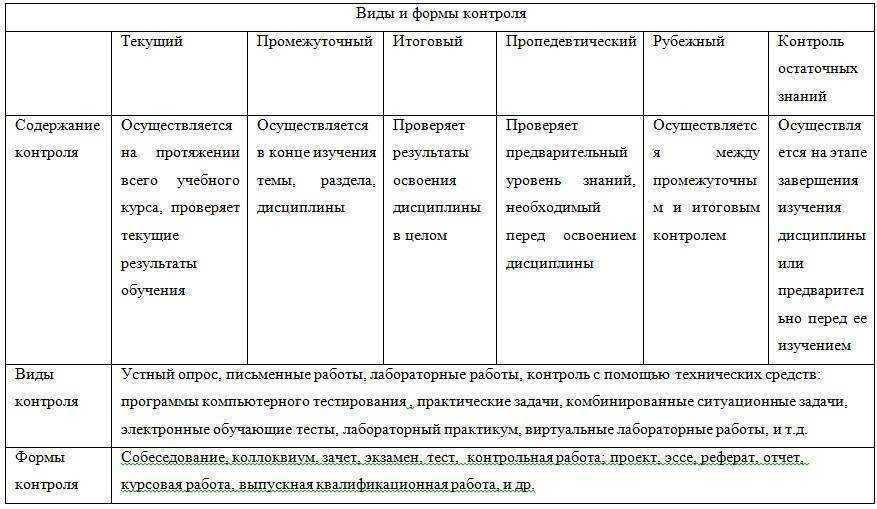
Что такое процесс?
Чтобы понять что отображает команда ps сначала надо разобратся что такое процесс. Процесс Linux — это экземпляр программы, запущенный в памяти. Все процессы можно разделить на обычные и фоновые. Более подробно об этом написано в статье управление процессами Linux. Linux — это многопользовательская система, каждый пользователь может запускать одни и те же программы, и даже один пользователь может захотеть запустить несколько экземпляров одной программы, поэтому ядру нужно как-то идентифицировать такие однотипные процессы. Для этого каждому процессу присваивается PID (Proccess Identificator).
Каждый из процессов может находиться в одном из таких состояний:
- Запуск — процесс либо уже работает, либо готов к работе и ждет, когда ему будет дано процессорное время;
- Ожидание — процессы в этом состоянии ожидают какого-либо события или освобождения системного ресурса. Ядро делит такие процессы на два типа — те, которые ожидают освобождения аппаратных средств и приостановление с помощью сигнала;
- Остановлено — обычно, в этом состоянии находятся процессы, которые были остановлены с помощью сигнала;
- Зомби — это мертвые процессы, они были остановлены и больше не выполняются, но для них есть запись в таблице процессов, возможно, из-за того, что у процесса остались дочерние процессы.
А теперь давайте перейдем ближе к практике.
Получение информации о системе
df
— отчет об использовании пространства дисковых накопителей.
df
df -h
— вывод отчета в удобном виде.
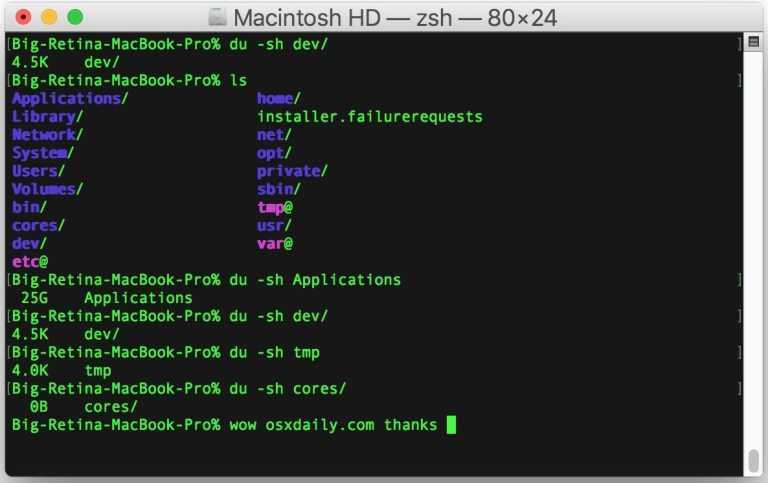
du
— отображение дискового пространства, занятого файлами и каталогами.
du
du -ah /home/janedoe
— отображение размера файлов и каталогов.
du -sh /home/janedoe
— отображение общего размера всех файлов и каталогов.
du -h -d0 *.txt /home/janedoe
— отображение размера только текстовых файлов без заглядывания в подкаталоги (-d0).
du —time -h /home/janedoe
— дополнить вывод временем последнего изменения файла.
free
— отображение занятого пространства оперативной памяти.
free
free -mt
— занятая оперативная память в мегабайтах со строкой Total.
free -th -s1
— отображение результата каждую секунду.
watch free
— отображение занятой оперативной памяти в реальном времени.
hostname
— имя текущего хоста.
iostat
— статистика использования CPU и операций ввода/вывода.
iostat
iostat -m
— выводить статистику в мегабайтах.
iostat -N
— вывод имен устройств в статистике.
iostat -p sda
— вывод статистики для группы блочных устройств.
iostat -x
— вывод расширенной статистики.
screenfetch
— информация о системе (не везде предустановлена).
uptime
— время прошедшее после запуска системы.
uname
— информация об ОС.
uname
uname -a
— полная информация об ОС.
vmstat
— информация об использовании виртуальной памяти.
vmstat
vmstat 2
— обновление данных каждые 2 секунды.
vmstat -d
— статистика использования дисков.
Управление процессами
ps
— выводит информацию о выполняемых в данный момент процессах.
ps
ps -fp 1256 1886 1887
— полная информация о процессах с id 1256, 1886, 1887.
ps aux
— выводит полный список запущенных процессов в системе.
ps -ejH
— вывести дерево процессов.
ps axjf
— вывести расширенное дерево процессов.
ps -p 15 -o comm=
— вывести имя процесса по id.
ps -C sshd -o pid=
— вывести id процесса по его имени.
ps axo pid,pcpu,comm
— вывести информацию о процессах в пользовательском формате.
pstree
— вывод дерева процессов.
pstree
pstree -p
— вывод дерева процессов совместно с их идентификаторами PID.
top
— выводит информацию в реальном времени о запущенных процессах в системе.
jobs
— вывод запущенных задач, остановленных или выполняемых в фоновом режиме.
bg
— перевод задачи (остановленной) на выполнение в фоновом режиме.
bg
bg
— перевод последней (остановленной) задачи в фоновый режим
bg %2
— перевод задачи %2 в фоновый режим.
fg
— вывод задач (остановленных) из фонового режима работы на передний план.
fg
fg
— перевод последней фоновой (остановленной) задачи на передний план.
fg %3
— перевод задачи 3 на передний план.
процесс &
— запуск процесса в фоновом режиме.
firefox &
— запуск браузера Mozilla Firefox в фоновом режиме.
kill
— принудительное завершение работы процессов.
kill
kill 6478
— послать сигнал Terminate (завершить) процессу с идентификатором PID=6478.
kill %2
— послать сигнал Terminate (завершить) задаче под номером 2 в списке jobs.
kill -2 45211
— послать сигнал Interrupt (прервать) процессу с идентификатором PID=45211. Аналог работы Ctrl + C.
kill -19 6478
— послать сигнал Stop (приостановить). Грубо говоря, процесс ставится на паузу.
kill -18 6478
— послать сигнал Continue (продолжить). Грубо говоря, снять процесс с паузы.
kill -28 6478
— послать сигнал Window Changed (сменен размер окна).
kill -20 6478
— послать сигнал Stop (остановить). Аналог работы Ctrl + Z.
kill -l
— получить полный список доступных сигналов.
killall
— принудительное завершение работы для нескольких одноименных процессов.
killall
killall -9 top
— принудительное завершение работы для всех процессов с именем top.
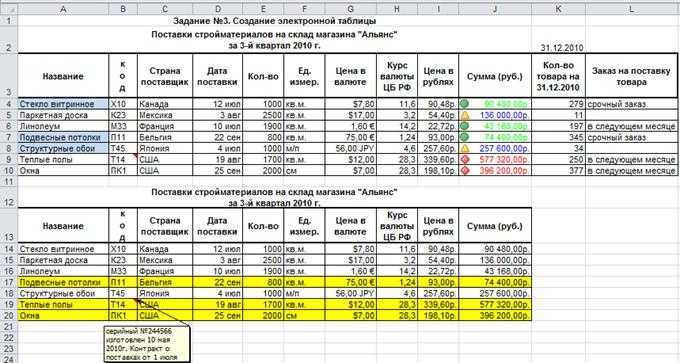
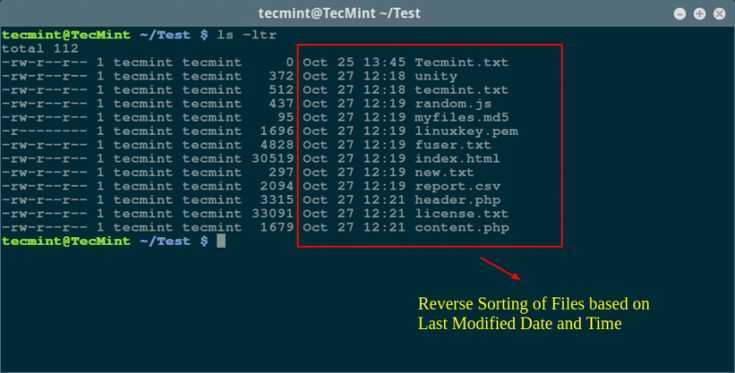
5) Список в обратном порядке по алфавиту
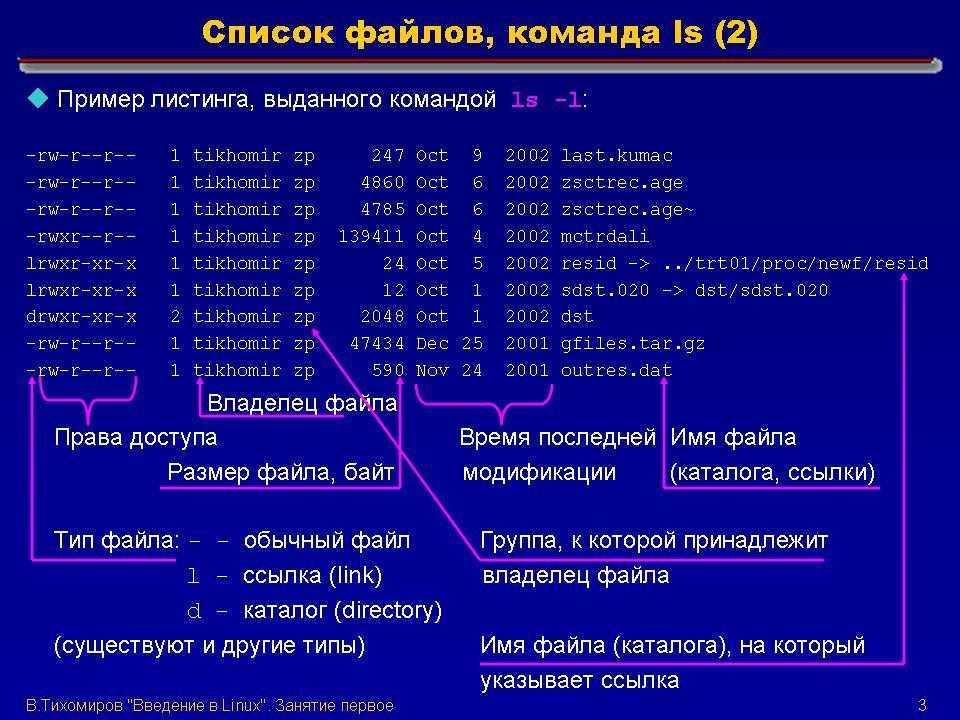
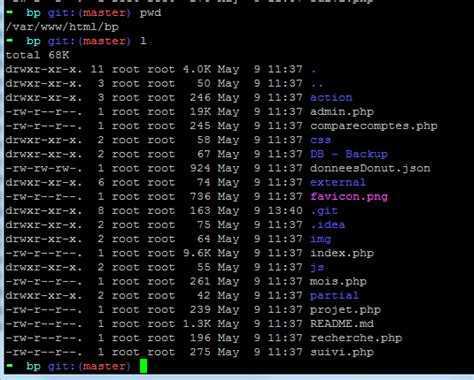
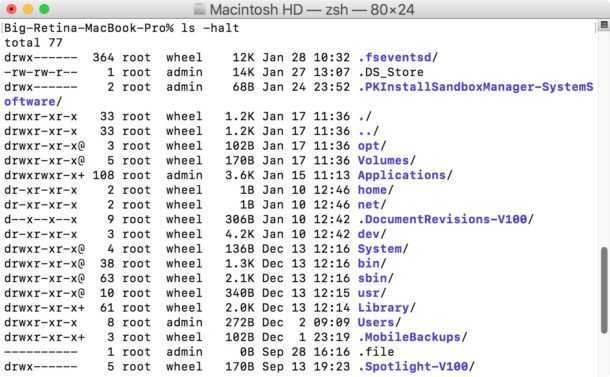
Чтобы перечислить содержимое определенного каталога с подробными сведениями в обратном порядке сортировки по алфавиту, мы будем использовать опции -lr с командой ls.
$ ls -lr /run
output total 24 -rw-------. 1 root root 0 Aug 21 13:18 xtables.lock -rw-rw-r--. 1 root utmp 2304 Sep 8 14:58 utmp drwxr-xr-x. 3 root root 60 Sep 7 23:11 user drwxr-xr-x. 7 root root 160 Aug 26 14:59 udev drwxr-xr-x. 2 root root 60 Aug 21 13:18 tuned drwxr-xr-x. 2 root root 60 Aug 21 13:18 tmpfiles.d drwxr-xr-x. 16 root root 400 Aug 21 13:18 systemd -rw-------. 1 root root 3 Aug 21 13:18 syslogd.pid drwx--x--x. 3 root root 60 Aug 21 13:18 sudo -rw-r--r--. 1 root root 4 Aug 21 13:18 sshd.pid drwxr-xr-x. 2 root root 40 Aug 21 13:18 setrans drwxr-xr-x. 2 root root 40 Aug 21 13:18 sepermit drwxr-xr-x. 2 root root 40 Aug 21 13:18 plymouth .......
6) Список скрытого содержимого каталога в алфавитном порядке сортировки
Examples of the sort command
 Sort Command Linux
Sort Command Linux
Let me show you some examples of sort command that you can use in various situations.
1. Sort in alphabetical order
The default sort command makes it easy to view information in alphabetical order. No options are necessary and even with mixed-case entries, A-Z sorting works as expected.
I am going to use a sample text file named filename.txt and if you view the content of the file, this is what you’ll see:
Now if you use sort command on it:
Here’s the alphabetically sorted output:
2. Sort on numerical value
Let’s take the same list we used for the previous example and sort in numerical order. In case you were wondering, the list reflects the most popular Linux distributions (July, 2019) according to distrowatch.com.
I will modify the contents of the file so that the items are numbered, but out of order as shown below.
After sorting, the result is:
Looks good, right? Can you rely on this method to arrange your data accurately, though? Probably not. Let’s look at another example to find out why.
Here’s my new sample text:
Now, if I use the sort command without any options, here’s what I get:
NOTE: Numbers are sorted by their leading characters only.
When you add the option, the numerical value of the string is now being evaluated rather than only the first character. Now, you can see below that our list is properly sorted.



Now you’ll have the correctly sorted output:
3. Sort in reverse order
For this one, I am going to use our distro list again. The reverse function is self-explanatory. It will reverse the order of whatever content you have in your file.
And here you have the output text in reverse order:
4. Random sort
If you accidentally mashed your shift key while attempting the reverse function, you might have gotten some strange results. rearranges output in randomized order.
Here’s the randomly sorted output:
5. Sort by months
Sort also has built in functionality to arrange by month. It recognizes several formats based on locale-specific information. I tried to demonstrate some unqiue tests to show that it will arrange by date-day, but not year. Month abbreviations display before full-names.
Here is the sample text file in this example:
Let’s sort it by months using the -M option:
Here’s the output you’ll see:
6. Save the sorted results to another file
As I mentioned earlier, sort does not change the original file by default. If you need to save the sorted content, it can be done.
For this example, I’ve created a new file where I want the sorted information to be printed and saved with the name filename_sorted.txt.
Caution: If you try to direct your sorted data to the same file, it will erase the contents of your file.
If you use cat command on the output file, this will be its contents:
7. Sort Specific Column
If you have a table in your file, you can use the option to specify which column to sort. I added some arbitrary numbers as a third column and will display the output sorted by each column. I’ve included several examples to show the variety of output possible. Options are added following the column number.
This will sort the text on the second column in alphabetical order:
This will sort the text by the numerals on the third column.
Same as the above command just that the sort order has been reversed.
8. Sort and remove duplicates
If you have a file with potential duplicates, the option will make your life much easier. Remember that sort will not make changes to your original data file. I chose to create a new file with just the items that are duplicates. Below you’ll see the input and then the contents of each file after the command is run.
Here’s the output files sorted and without duplicates.
9. Ignore case while sorting
Many modern distros running sort will implement ignore case by default. If yours does not, adding the option will produce the expected results.
Here’s the output where cases are ignored by the sort command:
10. Sort by human numeric values
This option allows the comparison of alphanumeric values like 1k (i.e. 1000).
Here’s the sorted output:
I hope this tutorial helped you get the basic usage of the sort command in Linux. Sort command is often used in conjugation with the uniq command in Linux for uniquely sorting text files.
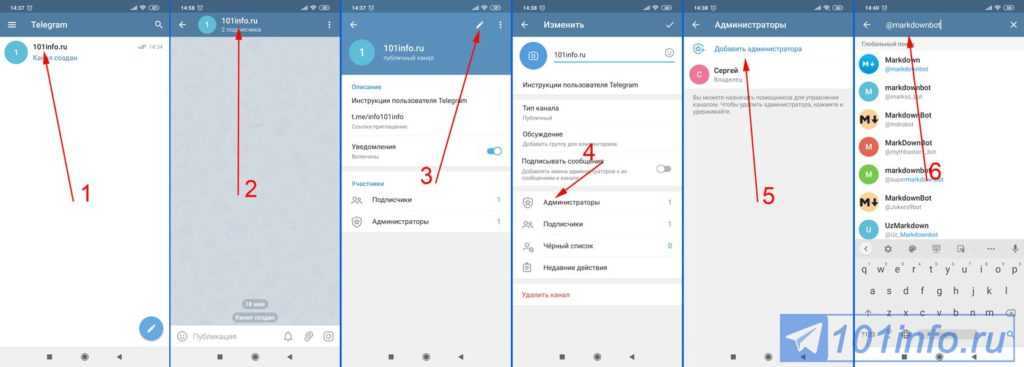


Опции whereis
Вот основные опции whereis:
- -b — поиск бинарных файлов.
- -B <папки> — ведет поиск исключительно в указанных пользователем директориях.-m — поиск мануалов.
- -M <папки> — ищет справочные файлы в тех директориях, которые выбрал пользователь.-s — поиск исходников.
- -S <папки> — будет искать исходные файлы только там, где нужно пользователю
- -u — запрашивает вывод тех команд, у которых отсутствует указанный тип файлов либо имеется в наличии два и больше таковых. К примеру, whereis -m -u* пригодится для поиска команд без мануала или с двумя мануалами.
- -f — должна завершать перечень директорий, поскольку сигнализирует о том, что набор символов, идущий сразу после нее, является названием файла.
- -l — показывает каталоги, в которых по умолчанию происходит поиск.
Вместо <папки> следует прописывать путь к требуемой директории.
Sort command in Linux
The sort command arranges text lines in useful ways. This simple tool can help you quickly sort information from the command line.
Syntax
You should note a few thing:
- When you use sort without any options, the default rules are enforced. It helps to understand the default rules to avoid unexpected outcomes.
- When using sort, your original data is safe. The results of your input are displayed on the command line only. However, you can specify output to a separate file if you wish. More on that later.
- Sort was originally designed for use with ASCII characters. I did not test for this, but it is possible that different encodings may produce unexpected results.
The default rules in the sort command
These are the default rules when using sort. The first few examples will clarify how these priorties are managed. Then we will look at specialized options.
- numbers > letters
- lowercase > uppercase
COLOPHON top
This page is part of the coreutils (basic file, shell and text
manipulation utilities) project. Information about the project
can be found at ⟨http://www.gnu.org/software/coreutils/⟩. If you
have a bug report for this manual page, see
⟨http://www.gnu.org/software/coreutils/⟩. This page was obtained
from the tarball coreutils-8.32.tar.xz fetched from
⟨http://ftp.gnu.org/gnu/coreutils/⟩ on 2021-08-27. If you
discover any rendering problems in this HTML version of the page,
or you believe there is a better or more up-to-date source for
the page, or you have corrections or improvements to the
information in this COLOPHON (which is not part of the original
manual page), send a mail to man-pages@man7.org
GNU coreutils 8.32 March 2020 SORT(1)
Pages that refer to this page:
column(1),
grep(1),
look(1),
procps(1),
ps(1),
uniq(1),
qsort(3),
environ(7)
Что такое метод sort() в Python?
Этот метод берет список и сортирует его. То есть на выходе мы получаем тот же список, только отсортированный. Этот метод не возвращает никакого значения.
В этом примере у нас есть список чисел, и мы можем использовать метод для сортировки списка в порядке возрастания.
my_list =
# Выводим неупорядоченный список:
print("Unordered list: ", my_list)
# Сортировка списка
my_list.sort()
# Выводим упорядоченный список
print("Ordered list: ", my_list)
Выполним наш код и получим следующий результат:
Unordered list: Ordered list:
Однако если список уже отсортирован, то мы получим None.
my_list = # Это строка вернет None, потому что список уже отсортирован print(my_list.sort())
Метод может принимать два необязательных аргумента: и .
Значением выступает функция, которая будет вызываться для каждого элемента в списке.
От редакции Pythonist. О функциях и их аргументах у нас есть отдельная статья — «Функции и их аргументы в Python 3».
В следующем примере давайте используем функцию в качестве значения аргумента key. Таким образом, скажет компьютеру отсортировать список имен по длине, от наименьшего к наибольшему.
names =
print("Unsorted: ", names)
names.sort(key=len)
print("Sorted: ", names)
Вот, что мы получим:
Unsorted: Sorted:
Аргумент может иметь логическое значение: (Истина) или (Ложь).
В следующем примере укажет компьютеру отсортировать список в обратном алфавитном порядке.
names =
print("Unsorted: ", names)
names.sort(reverse=True)
print("Sorted: ", names)
# Результат:
# Unsorted:
# Sorted:
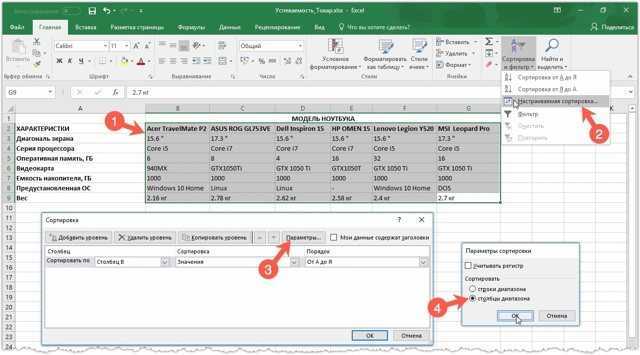
Разница между меню СОРТИРОВКИ и функцией SORT
В Google Таблицах есть два способа сортировки данных:
- С помощью меню «Сортировка» (находится в меню «Данные»).
- Использование функции СОРТИРОВКИ
В то время как меню «Сортировка» можно открыть с помощью пары щелчков мышью, функция СОРТИРОВКА позволяет ввести формулу в строке формул, что дает вам больше контроля над процессом сортировки.
Основное различие между двумя вышеуказанными методами заключается в том, что меню «Сортировка» работает и изменяет исходный диапазон данных. С другой стороны, функция SORT отображает отсортированные данные в новый диапазон данных, тем самым сохраняя исходные данные неизменными.



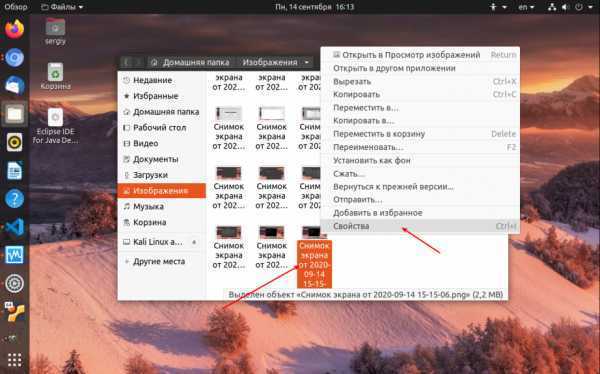
Команда ps в Linux
Сначала рассмотрим общий синтаксис команды, здесь все очень просто:
$ ps опции
$ ps опции | grep параметр
Во втором варианте мы используем утилиту grep для того, чтобы отобрать нужные нам процессы по определенному критерию. Теперь рассмотрим опции утилиты. Они делятся на два типа — те, которые идут с дефисом Unix и те, которые используются без дефиса — BSD. Лучше пользоваться только опциями Unix, но мы рассмотрим и одни и другие. Заметьте, что при использовании опций BSD, вывод утилиты будет организован в BSD стиле.
- -A, -e, (a) — выбрать все процессы;
- -a — выбрать все процессы, кроме фоновых;
- -d, (g) — выбрать все процессы, даже фоновые, кроме процессов сессий;
- -N — выбрать все процессы кроме указанных;
- -С — выбирать процессы по имени команды;
- -G — выбрать процессы по ID группы;
- -p, (p) — выбрать процессы PID;
- —ppid — выбрать процессы по PID родительского процесса;
- -s — выбрать процессы по ID сессии;
- -t, (t) — выбрать процессы по tty;
- -u, (U) — выбрать процессы пользователя.
Опции форматирования:
- -с — отображать информацию планировщика;
- -f — вывести максимум доступных данных, например, количество потоков;
- -F — аналогично -f, только выводит ещё больше данных;
- -l — длинный формат вывода;
- -j, (j) — вывести процессы в стиле Jobs, минимум информации;
- -M, (Z) — добавить информацию о безопасности;
- -o, (o) — позволяет определить свой формат вывода;
- —sort, (k) — выполнять сортировку по указанной колонке;
- -L, (H)- отображать потоки процессов в колонках LWP и NLWP;
- -m, (m) — вывести потоки после процесса;
- -V, (V) — вывести информацию о версии;
- -H — отображать дерево процессов;
Теперь, когда вы знаете синтаксис и опции, можно перейти ближе к практике. Чтобы просто посмотреть процессы в текущей оболочке используется такая команда терминала ps:
Все процессы, кроме лидеров групп, в том же режиме отображения:
Все процессы, включая фоновые и лидеры групп:
Чтобы вывести больше информации о процессах используйте опцию -f:
При использовании опции -f команда выдает такие колонки:
- UID — пользователь, от имени которого запущен процесс;
- PID — идентификатор процесса;
- PPID — идентификатор родительского процесса;
- C — процент времени CPU, используемого процессом;
- STIME — время запуска процесса;
- TTY — терминал, из которого запущен процесс;
- TIME — общее время процессора, затраченное на выполнение процессора;
- CMD — команда запуска процессора;
- LWP — показывает потоки процессора;
- PRI — приоритет процесса.
Например, также можно вывести подробную информацию обо всех процессах:
Больше информации можно получить, использовав опцию -F:
Эта опция добавляет такие колонки:
- SZ — это размер процесса в памяти;
- RSS — реальный размер процесса в памяти;
- PSR — ядро процессора, на котором выполняется процесс.
Если вы хотите получить еще больше информации, используйте вместо -f опцию -l:
Эта опция добавляет отображение таких колонок:
- F — флаги, ассоциированные с этим процессом;
- S — состояние процесса;
- PRI — приоритет процесса в планировщике ядра Linux;
- NI — рекомендованный приоритет процесса, можно менять;
- ADDR — адрес процесса в памяти;
- WCHAN — название функции ядра, из-за которой процесс находится в режиме ожидания.
Дальше мы можем отобрать все процессы, запущенные от имени определенного пользователя:
С помощью опции -H можно отобразить дерево процессов:
Если вас интересует информация только об определенном процессе, то вы можете использовать опцию -p и указать PID процесса:
Через запятую можно указать несколько PID:
Опция -С позволяет фильтровать процессы по имени, например, выберем только процессы chrome:
Дальше можно использовать опцию -L чтобы отобразить информацию о процессах:
Очень интересно то, с помощью опции -o можно настроить форматирование вывода, например, вы можете вывести только pid процесса и команду:
Вы можете выбрать такие колонки для отображения: pcpu, pmem, args, comm, cputime, pid, gid, lwp, rss, start, user, vsize, priority. Для удобства просмотра можно отсортировать вывод программы по нужной колонке, например, просмотр процессов, которые используют больше всего памяти:
Или по проценту загрузки cpu:
Ещё одна опция — -M, которая позволяет вывести информацию про права безопасности и флаги SELinux для процессов:
Общее количество запущенных процессов Linux можно узнать командой:
Мы рассмотрели все основные возможности утилиты ps. Дальше вы можете поэкспериментировать с её параметрами и опциями чтобы найти нужные комбинации, также можно попытаться применить опции BSD.

Метод close()
После того, как все операции будут выполнены с файлом, мы должны закрыть его с помощью нашего скрипта Python, используя метод close(). Любая незаписанная информация уничтожается после вызова метода close() для файлового объекта.
Мы можем выполнить любую операцию с файлом извне, используя файловую систему, которая в данный момент открыта в Python; поэтому рекомендуется закрыть файл после выполнения всех операций.
Синтаксис использования метода close() приведен ниже.
fileobject.close()
Рассмотрим следующий пример.
# opens the file file.txt in read mode
fileptr = open("file.txt","r")
if fileptr:
print("file is opened successfully")
#closes the opened file
fileptr.close()
После закрытия файла мы не можем выполнять какие-либо операции с файлом. Файл необходимо правильно закрыть. Если при выполнении некоторых операций с файлом возникает какое-либо исключение, программа завершается, не закрывая файл.
Мы должны использовать следующий метод, чтобы решить такую проблему.
try:
fileptr = open("file.txt")
# perform file operations
finally:
fileptr.close()
Как работает awk
Существует несколько различных реализаций awk. Мы будем использовать GNU-реализацию awk, которая называется gawk. В большинстве систем Linux интерпретатор — это просто символическая ссылка на .
Записи и поля
Awk может обрабатывать текстовые файлы данных и потоки. Входные данные разделены на записи и поля. Awk работает с одной записью за раз, пока не будет достигнут конец ввода. Записи разделяются символом, который называется разделителем записей. Разделителем записей по умолчанию является символ новой строки, что означает, что каждая строка в текстовых данных является записью. Новый разделитель записей может быть установлен с помощью переменной .
Записи состоят из полей, разделенных разделителем полей. По умолчанию поля разделяются пробелом, включая один или несколько символов табуляции, пробела и новой строки.
Поля в каждой записи обозначаются знаком доллара ( ), за которым следует номер поля, начинающийся с 1. Первое поле представлено с помощью , второе — с помощью и так далее. На последнее поле также можно ссылаться с помощью специальной переменной . На всю запись можно ссылаться с помощью .
Вот визуальное представление, показывающее, как ссылаться на записи и поля:
Программа awk
Чтобы обработать текст с помощью , вы пишете программу, которая сообщает команде, что делать. Программа состоит из ряда правил и пользовательских функций. Каждое правило содержит одну пару шаблон и действие. Правила разделяются новой строкой или точкой с запятой ( ). Обычно awk-программа выглядит так:
Когда обрабатывает данные, если шаблон соответствует записи, он выполняет указанное действие с этой записью. Если у правила нет шаблона, все записи (строки) совпадают.
Действие awk заключено в фигурные скобки ( ) и состоит из операторов. Каждый оператор определяет операцию, которую нужно выполнить. В действии может быть несколько операторов, разделенных новой строкой или точкой с запятой ( ). Если правило не имеет действия, по умолчанию выполняется печать всей записи.
Awk поддерживает различные типы операторов, включая выражения, условные операторы, операторы ввода, вывода и т. Д. Наиболее распространенные операторы awk:
- — останавливает выполнение всей программы и выходит.
- — останавливает обработку текущей записи и переходит к следующей записи во входных данных.
- — Печать записей, полей, переменных и настраиваемого текста.
- — дает вам больше контроля над форматом вывода, аналогично C и bash .
При написании программ awk все, что находится после решетки и до конца строки, считается комментарием. Длинные строки можно разбить на несколько строк с помощью символа продолжения, обратной косой черты ( ).
Выполнение программ awk
Программа awk может быть запущена несколькими способами. Если программа короткая и простая, ее можно передать непосредственно интерпретатору из командной строки:
При запуске программы в командной строке ее следует заключать в одинарные кавычки ( ), чтобы оболочка не интерпретировала программу.
Если программа большая и сложная, лучше всего поместить ее в файл и использовать параметр для передачи файла команде :
В приведенных ниже примерах мы будем использовать файл с именем «team.txt», который выглядит примерно так: