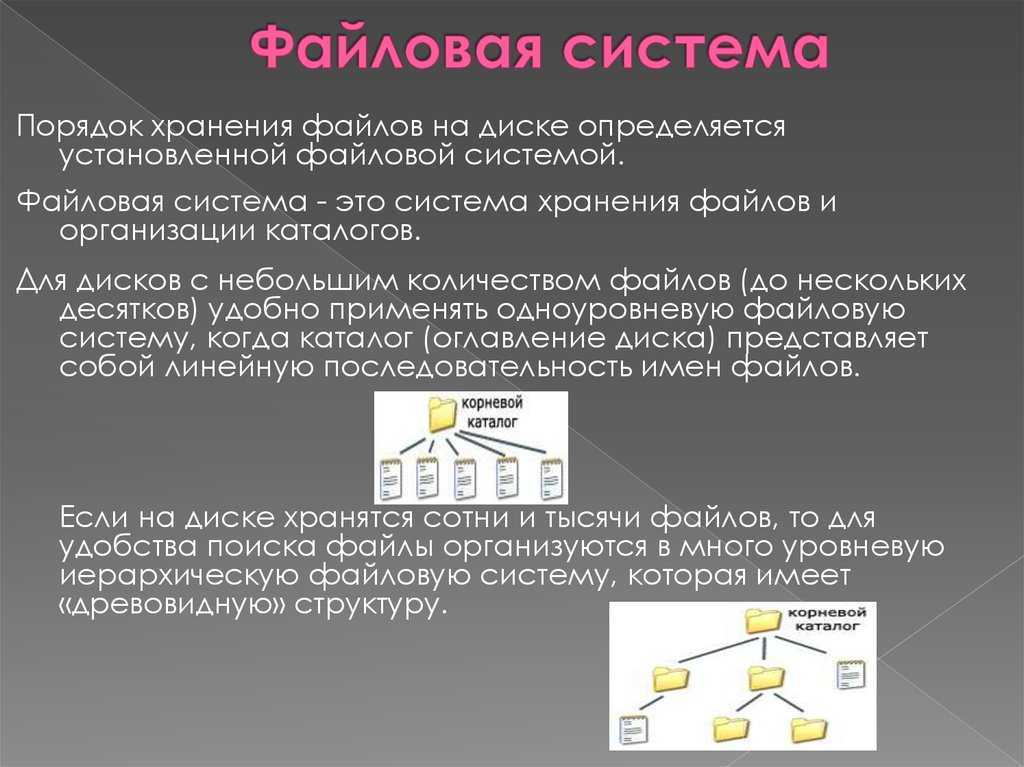
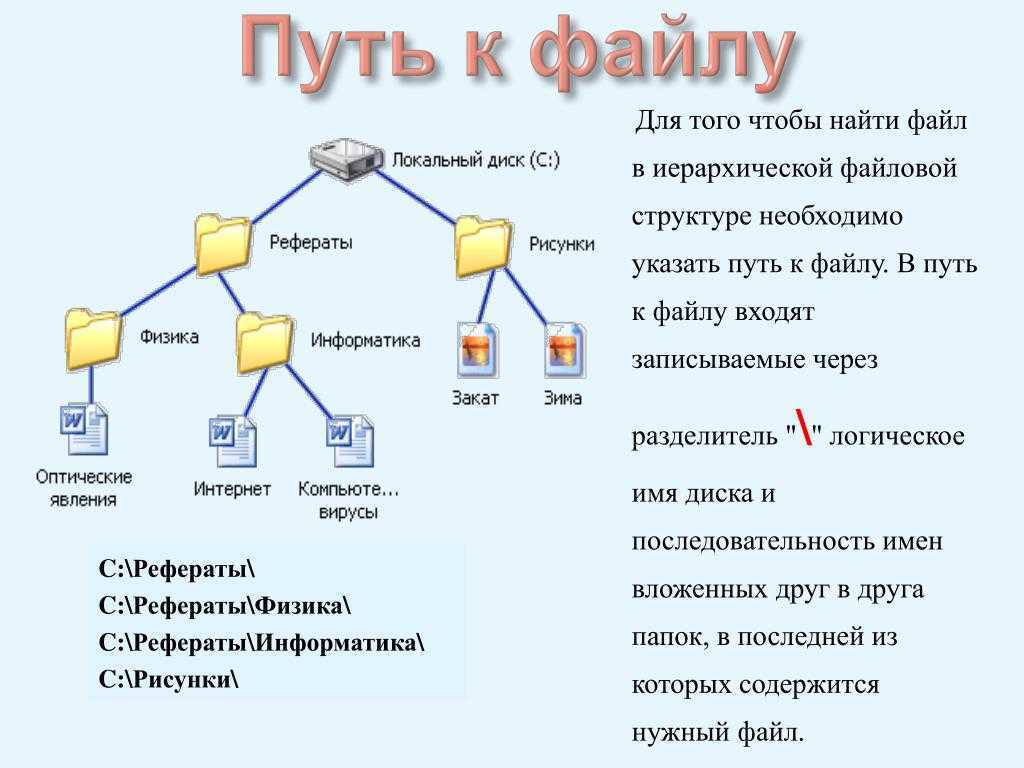
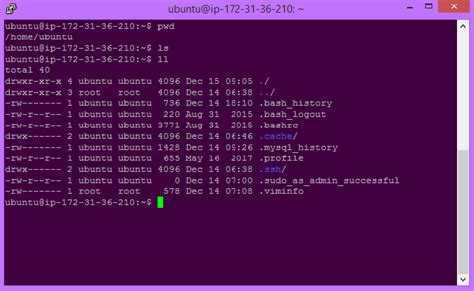
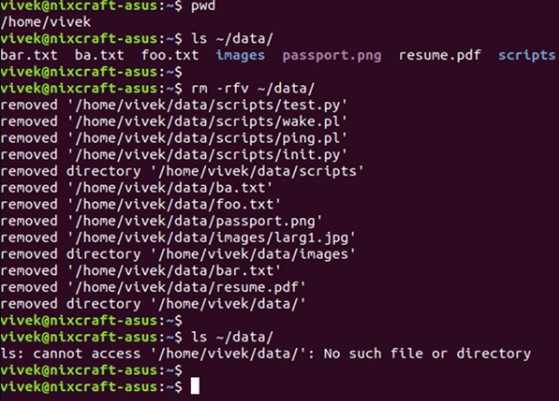
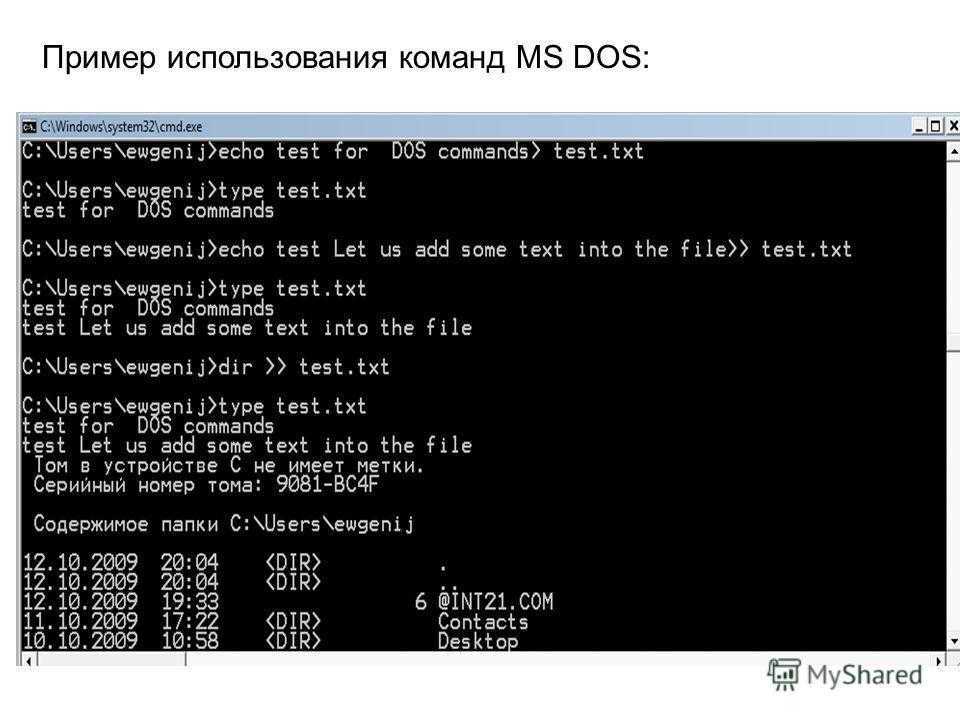
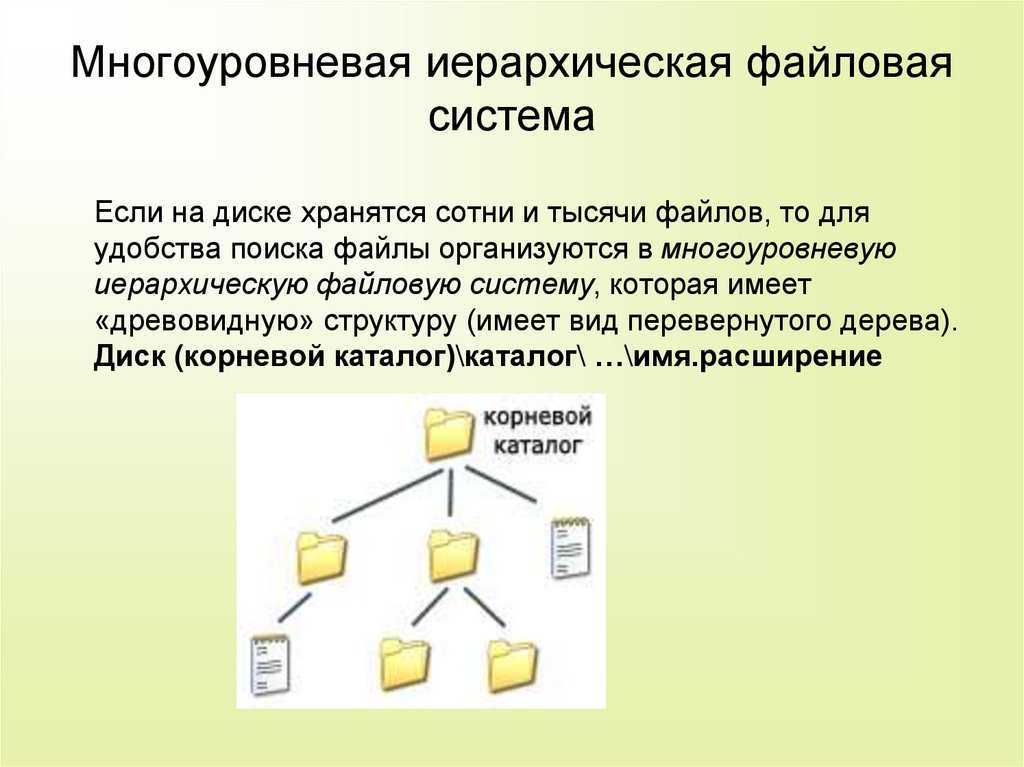
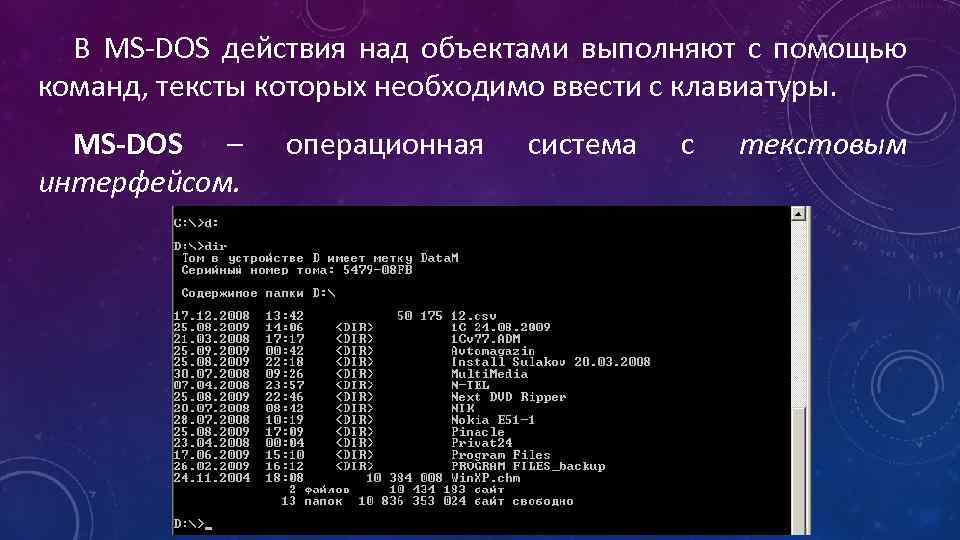
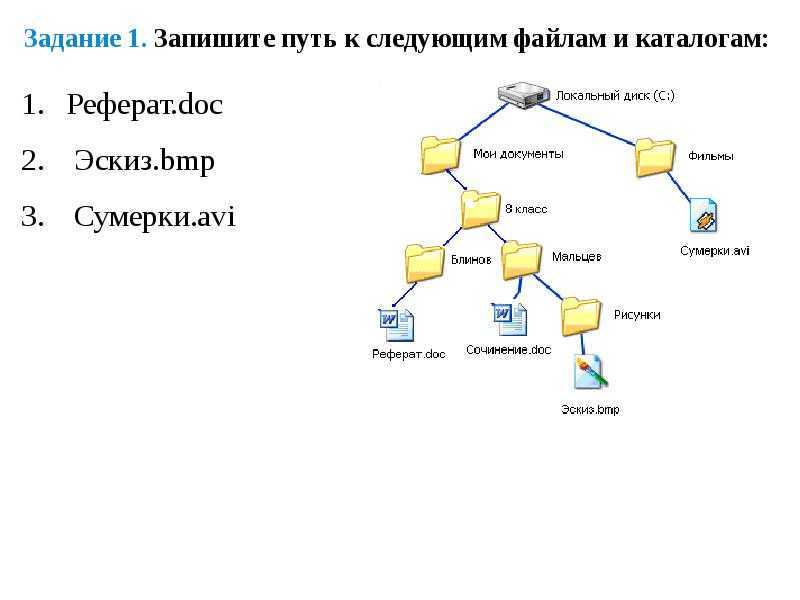
Что такое Bash?
Как я уже говорил, Bash — это интерпретатор команд. По сути, это обычная программа, которая запускается при старте сеанса оболочки. Мы могли бы запускать не Bash, а скажем, интерпретатор python или ruby, и тогда нам пришлось бы выполнять методы этих языков вместо команд Bash для администрирования системы.
Bash принимает команды от пользователя и передает их системному загрузчику, а также обеспечивает взаимодействие между командами, обмен информацией и потоками ввода-вывода. Также оболочка предоставляет пользователю удобный интерфейс для работы с историей команд, поиска и замены, а также исправления ранее выполненных команд, а также автодополнение путей.
Чтение из STDIN
Это общепринятое в Linux для труб серии простой, одной цели команды вместе , чтобы создать большее решение , отвечающее наши точные потребности. Способность делать это — одна из реальных задач Linux. Оказывается, мы можем легко разместить этот механизм и с нашими скриптами. Поступая таким образом, мы можем создавать скрипты, которые действуют как фильтры для изменения данных по определенным для нас способам.
Баш вмещает трубопроводы и перенаправление посредством специальных файлов. Каждый процесс получает собственный набор файлов (один для STDIN, STDOUT и STDERR соответственно), и они связаны при вызове или перенаправлении. Каждый процесс получает следующие файлы:
- STDIN — /proc/<processID>/fd/0
- STDOUT — /proc/<processID>/fd/1
- STDERR — /proc/<processID>/fd/2
Чтобы сделать жизнь более удобной, система создает для нас несколько ярлыков:
- STDIN — /dev/stdin or /proc/self/fd/0
- STDOUT — /dev/stdout or /proc/self/fd/1
- STDERR — /dev/stderr or /proc/self/fd/2
fd в дорожках выше обозначает дескриптор файла.
Поэтому, если мы хотим, чтобы наш скрипт мог обрабатывать данные, которые были отправлены на него, все, что нам нужно сделать, это прочитать соответствующий файл. Все файлы, упомянутые выше, ведут себя как обычные файлы.
summary
Shell
#!/bin/bash
# Основное резюме моего отчета о продажах
echo Here is a summary of the sales data:
echo ====================================
echo
cat /dev/stdin | cut -d’ ‘ -f 2,3 | sort
|
1 |
#!/bin/bash echoHere isasummary of the sales data echo==================================== echo catdevstdin|cut-d’ ‘-f2,3|sort |
Давайте разберем это:
- Строки 4, 5, 6 — Распечатайте заголовок для вывода
- Строка 8 — cat файл, представляющий STDIN, вырезает установку разделителя на пробел, поля 2 и 3 затем сортируют вывод.
Команда head в Linux
Синтаксис у команды head следующий:
$ head опции файл
Здесь:
- Опции — это параметр, который позволяет настраивать работу команды таким образом, чтобы результат соответствовал конкретным потребностям пользователя.
- Файл — это имя документа (или имена документов, если их несколько). Если это значение не задано либо вместо него стоит знак «-», команда будет брать данные из стандартного вывода.
Чаще всего к команде head применяются такие опции:
- -c (—bytes) — позволяет задавать количество текста не в строках, а в байтах. При записи в виде —bytes=NUM выводит на экран все содержимое файла, кроме NUM байт, расположенных в конце документа.
- -n (—lines) — показывает заданное количество строк вместо 10, которые выводятся по умолчанию. Если записать эту опцию в виде —lines=NUM, будет показан весь текст кроме последних NUM строк.
- -q (—quiet, —silent) — выводит только текст, не добавляя к нему название файла.
- -v (—verbose) — перед текстом выводит название файла.
- -z (—zero-terminated) — символы перехода на новую строку заменяет символами завершения строк.
Переменная NUM, упомянутая выше — это любое число от 0 до бесконечности, задаваемое пользователем. Оно может быть обычным либо содержать в себе множитель.
Двойные скобки
Результат выполнения команды можно легко сохранить в переменную.
На основе этого механизма можно выполнять арифметические действия. Достаточно вместо одной пары скобок использовать две.
Рассмотрим примеры в скрипте
expansion_example.sh
Разберём этот скрипт:
Строка 4 — Базовый синтаксис. Можно ставить пробелы без использования кавычек.
Строка 7 — Работает и без пробелов.
Строка 10 — Можно использовать переменные без $ перед ними.
Строка 13 — А можно и с $
Строка 16 — Увеличение переменной на 1. Символ $ не нужен.
Строка 19 — Увеличение переменной на 3. Это краткая форма записи b = b + 3.
Строка 19 — В отличие от других способов символ * не нужно экранировать.
./expansion_example.sh
981112131620
Двойные скобки дают довольно много свободы в форматировании кода.
Они доступны в Bash по умолчанию и их эффективность немного выше. Хотя заметить разницу на современных компьютерах будет непросто.
Стандартный for цикл в Bash
Цикл выполняет итерацию по списку элементов и выполняет заданный набор команд.
Цикл Bash имеет следующую форму:
Список может быть серией строк, разделенных пробелами, диапазоном чисел, выводом команды, массивом и т. Д.
Оберните струны
В приведенном ниже примере цикл будет перебирать каждый элемент в списке строк, и переменный будет установлен на текущий элемент:
Цикл выдаст следующий результат:
Цикл по диапазону чисел
Вы можете использовать выражение последовательности, чтобы указать диапазон чисел или символов, задав начальную и конечную точки диапазона. Выражение последовательности принимает следующую форму:
Вот пример цикла, который перебирает все числа от 0 до 3:
Начиная с Bash 4, также можно указывать приращение при использовании диапазонов. Выражение принимает следующий вид:
Вот пример, показывающий, как увеличить на 5:
Перебирать элементы массива
Вы также можете использовать цикл для перебора массива элементов.
В приведенном ниже примере мы определяем массив с именем и перебираем каждый элемент массива.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
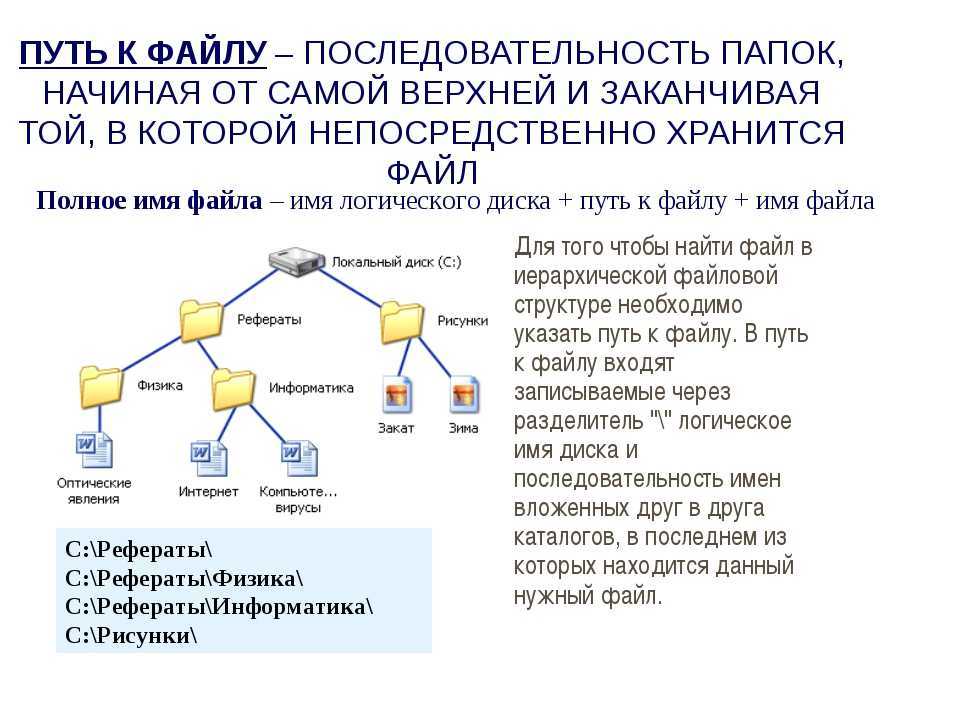
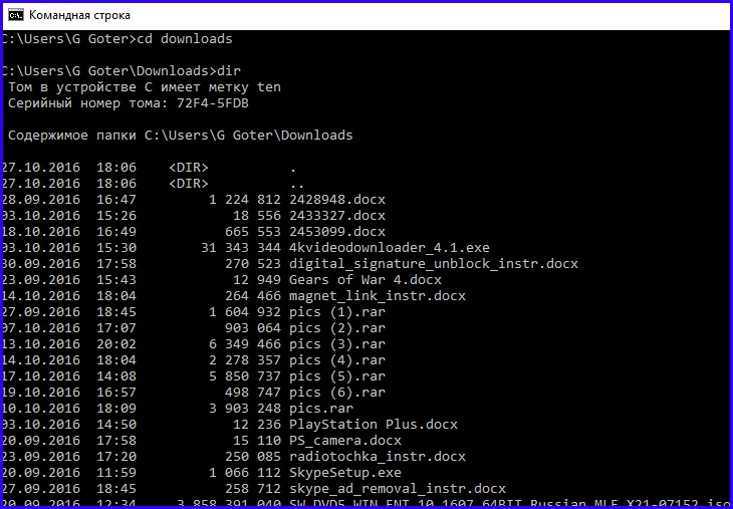
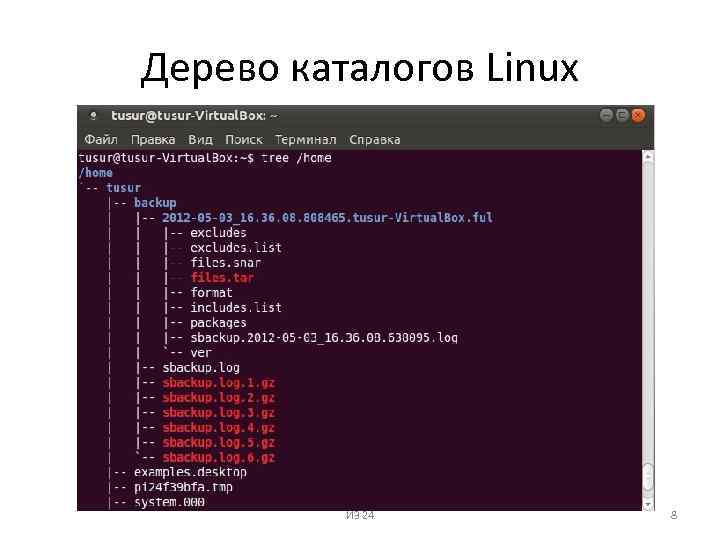
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Параметры скриптов
Для того, чтобы обеспечить некоторую универсальность, существует возможность при вызове передавать скрипту параметры. В этом случае вызов скрипта будет выглядеть так: , например .


![[в закладки] bash для начинающих: 21 полезная команда / хабр](https://smartshop124.ru/wp-content/uploads/5/f/9/5f904252d0ab42019bdadbc18aa88ec8.jpeg)
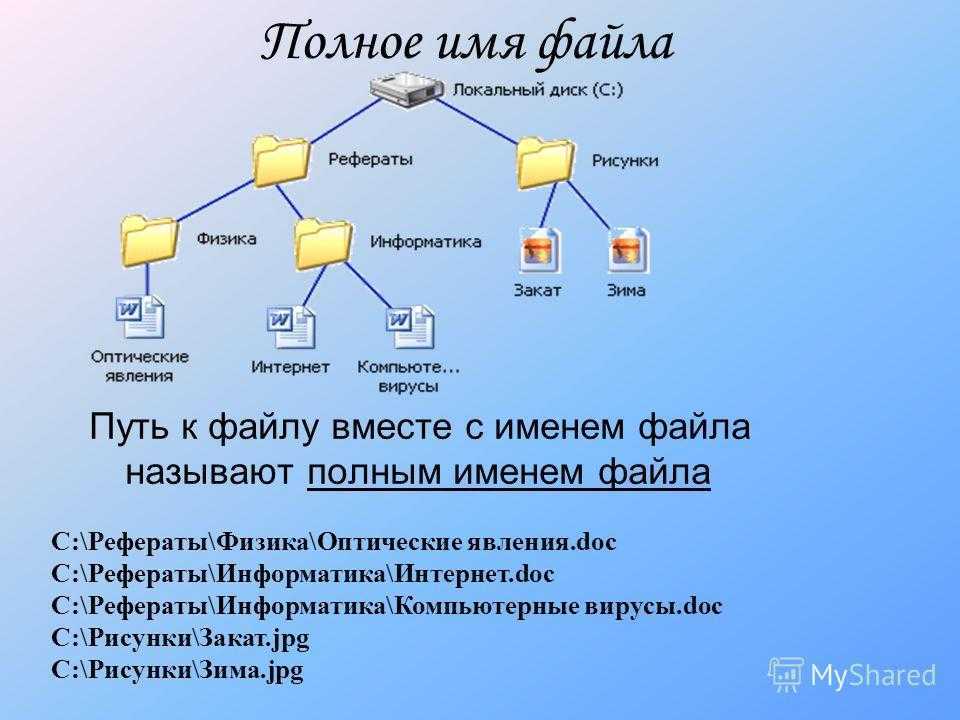
Для того, чтобы получить значение первого параметра, необходимо в скрипте указать , второго — , и т.д. Существует также ряд других переменных, значения которых можно использовать в скрипте: – имя скрипта – количество переданных параметров – PID(идентификатор) процесса, выполняющего скрипт – код завершения предыдущей команды
Создадим файл script1.sh следующего содержания:
Выдадим права на выполнение и выполним скрипт с параметрами:
Мы передали 2 параметра, указывающие город и страну, и использовали их в скрипте, чтобы сформировать строку, выводимую командой printf. Также для вывода в строке Hello использовали имя пользователя из переменной USER.
Для того, чтобы передать значения параметров, состоящие из нескольких слов (содержащие пробелы), нужно заключить их в кавычки:
При этом нужно доработать скрипт, чтобы в команду printf параметры также передавались в кавычках:
Из приведенных примеров видно, что при обращении к переменной для получения её значения используется символ $. Для того, чтобы сохранить значение переменной просто указывается её имя:
Примеры работы echo
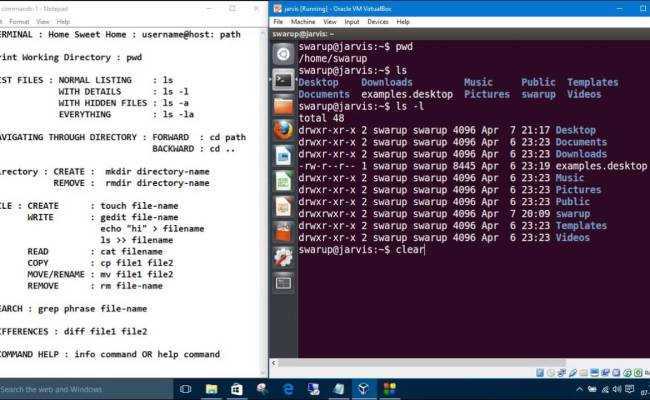
Давайте рассмотрим как пользоваться echo. Сначала просто выведем строку на экран:
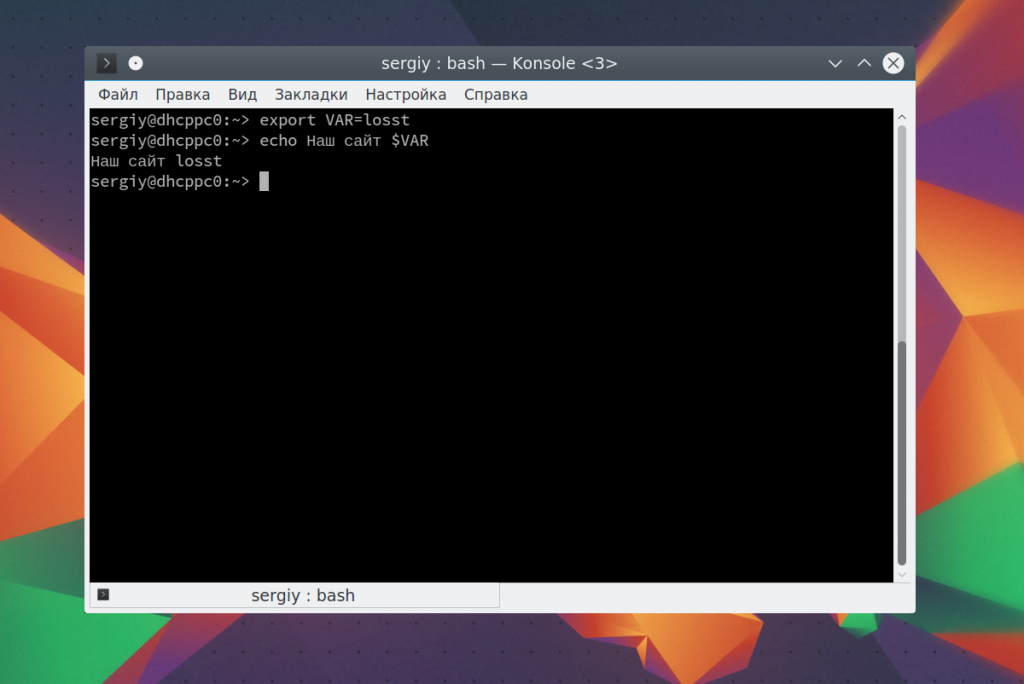
Также можно вывести значение переменной. Сначала объявим переменную:
Затем выведем ее значение:
Как уже говорилось, с помощью опции -e можно включить интерпретацию специальных последовательностей. Последовательность \b позволяет удалить предыдущий символ. Например, удалим все пробелы из строки:
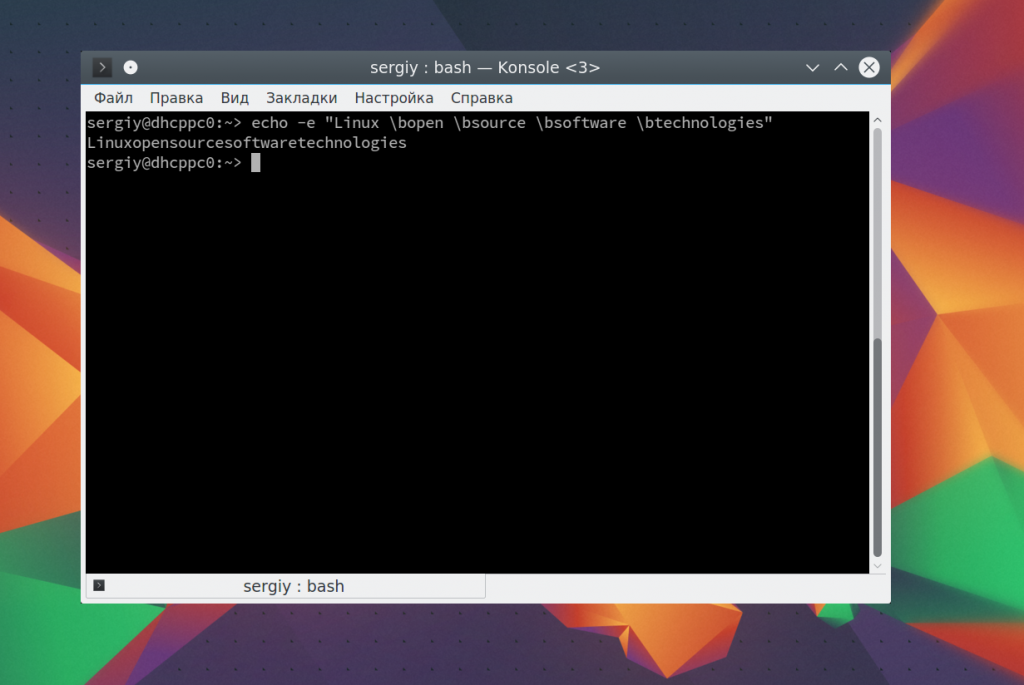
Последовательность \n переводит курсор на новую строку:
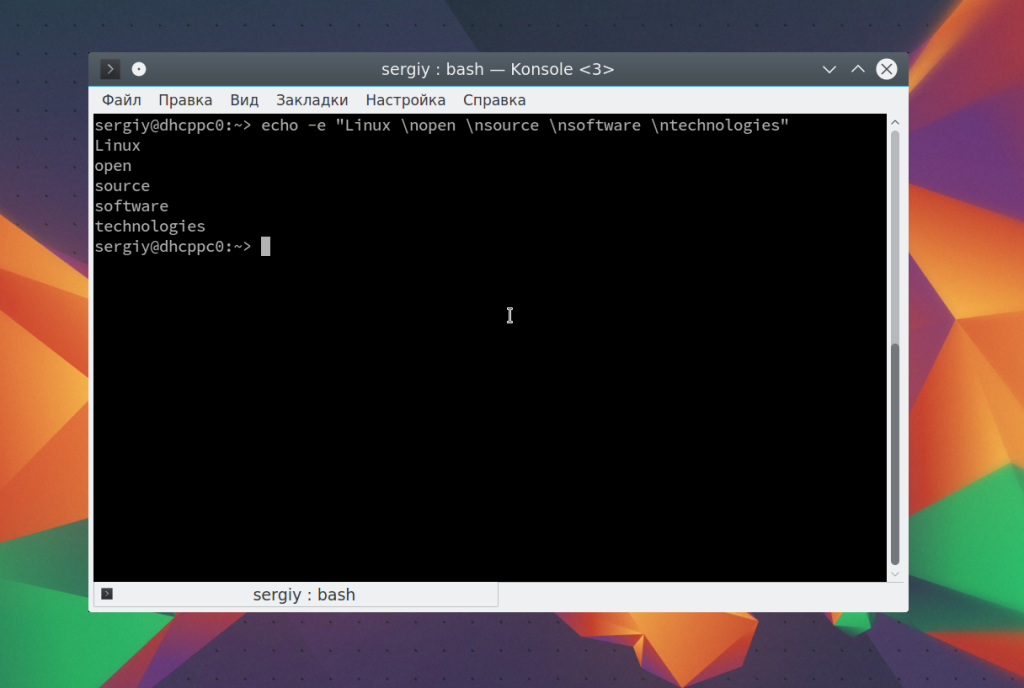
С помощью \t вы можете добавить горизонтальные табуляции:
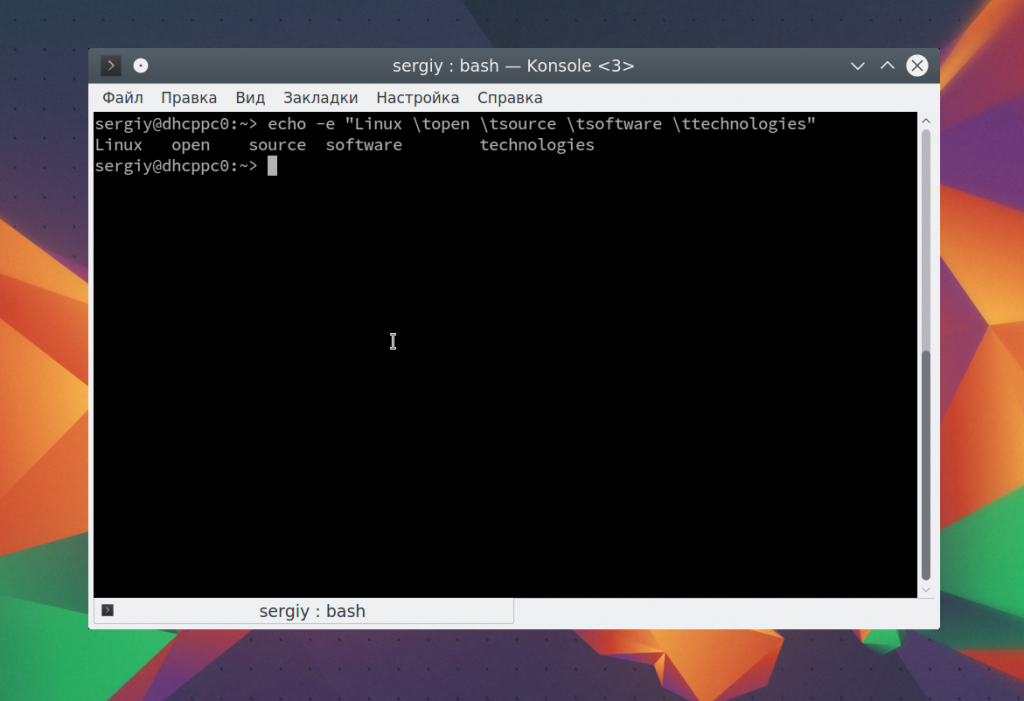
Можно совместить переводы строки и табуляции:
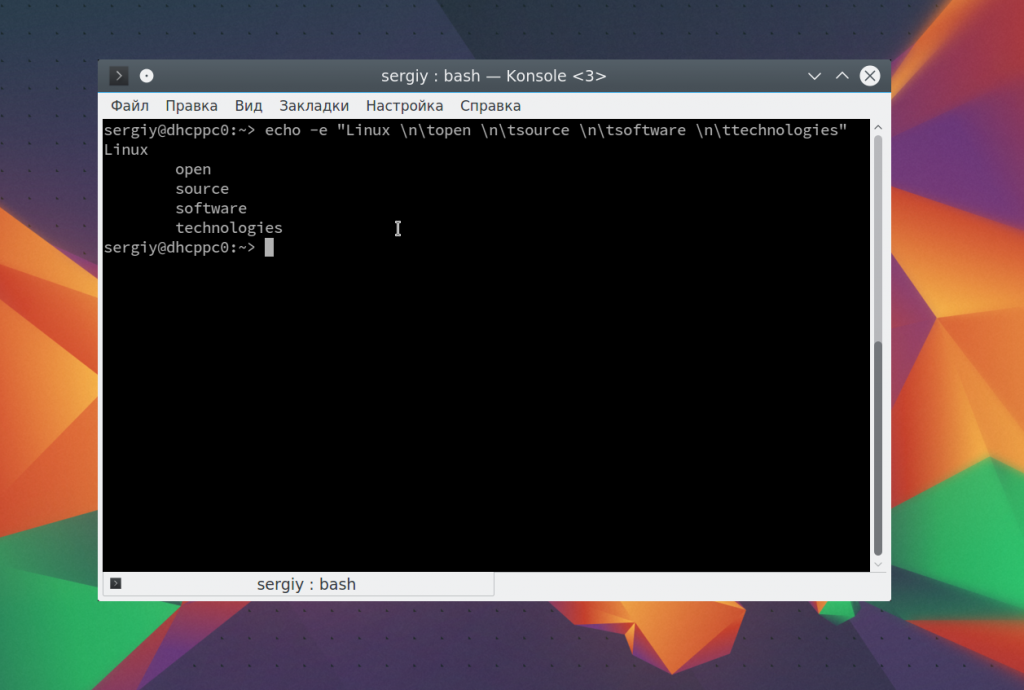
Точно так же можно применить вертикальную табуляцию:
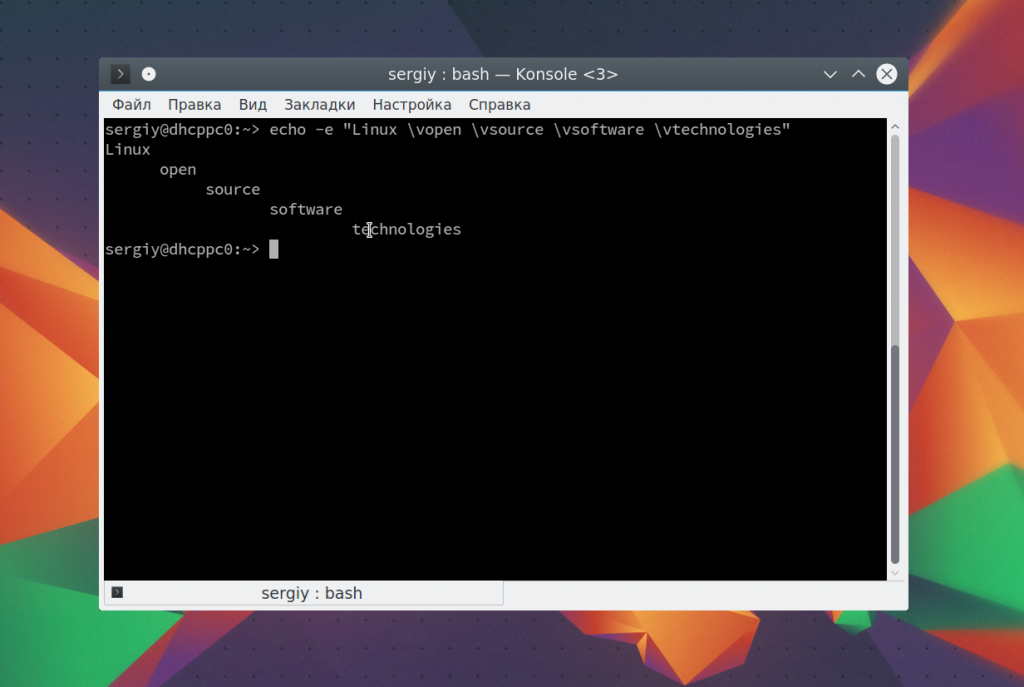
С помощью последовательности \r можно удалить все символы до начала строки:
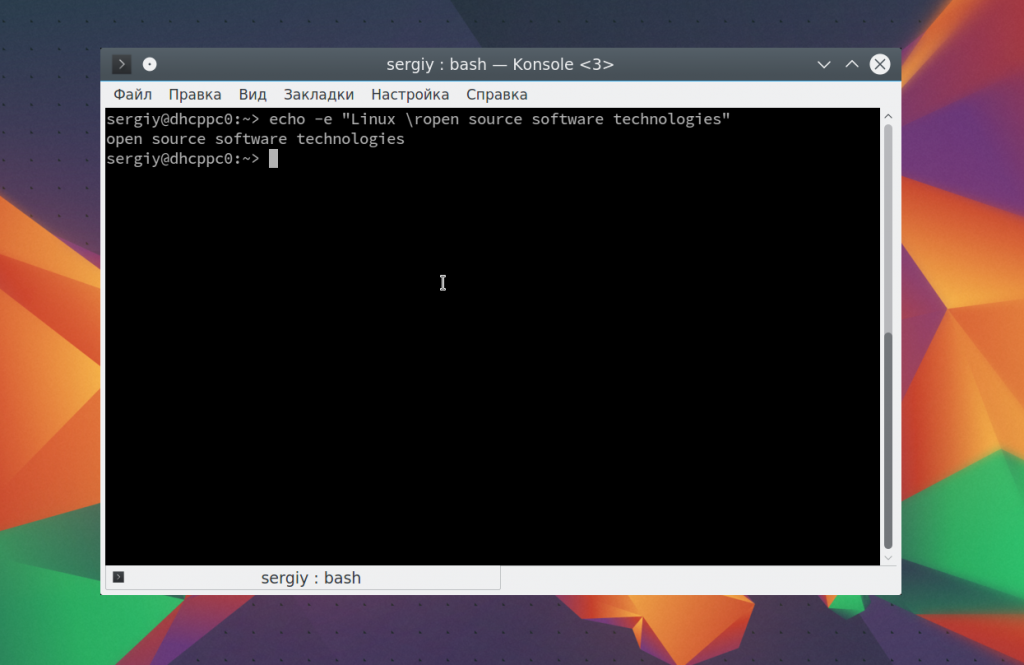
Последовательность -c позволяет убрать перевод на новую строку в конце сообщения:
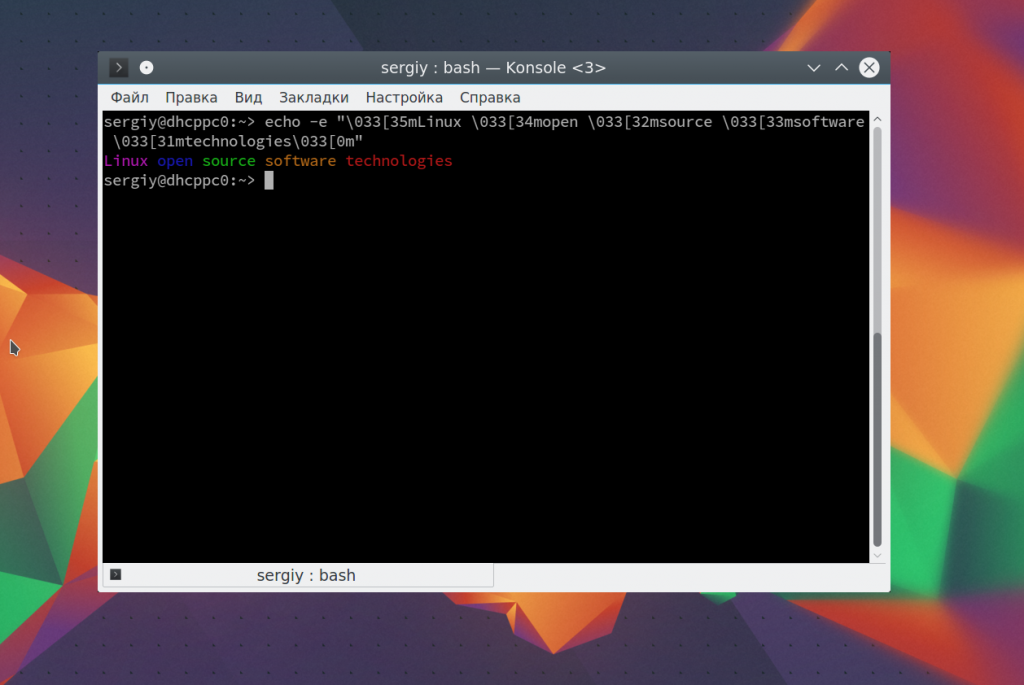
Дальше — больше. Вы можете разукрасить вывод echo с помощью последовательностей управления цветом Bash. Для доступны такие цвета текста:
- \033[30m — чёрный;
- \033[31m — красный;
- \033[32m — зелёный;
- \033[33m — желтый;
- \033[34m — синий;
- \033[35m — фиолетовый;
- \033[36m — голубой;
- \033[37m — серый.
И такие цвета фона:
- \033[40m — чёрный;
- \033[41m — красный;
- \033[42m — зелёный;
- \033[43m — желтый;
- \033[44m — синий;
- \033[45m — фиолетовый;
- \033[46m — голубой;
- \033[47m — серый;
- \033[0m — сбросить все до значений по умолчанию.
Например. раскрасим нашу надпись в разные цвета:
С основными параметрами команды echo разобрались, теперь рассмотрим еще некоторые специальные символы bash. Вы можете вывести содержимое текущей папки просто подставив символ *:
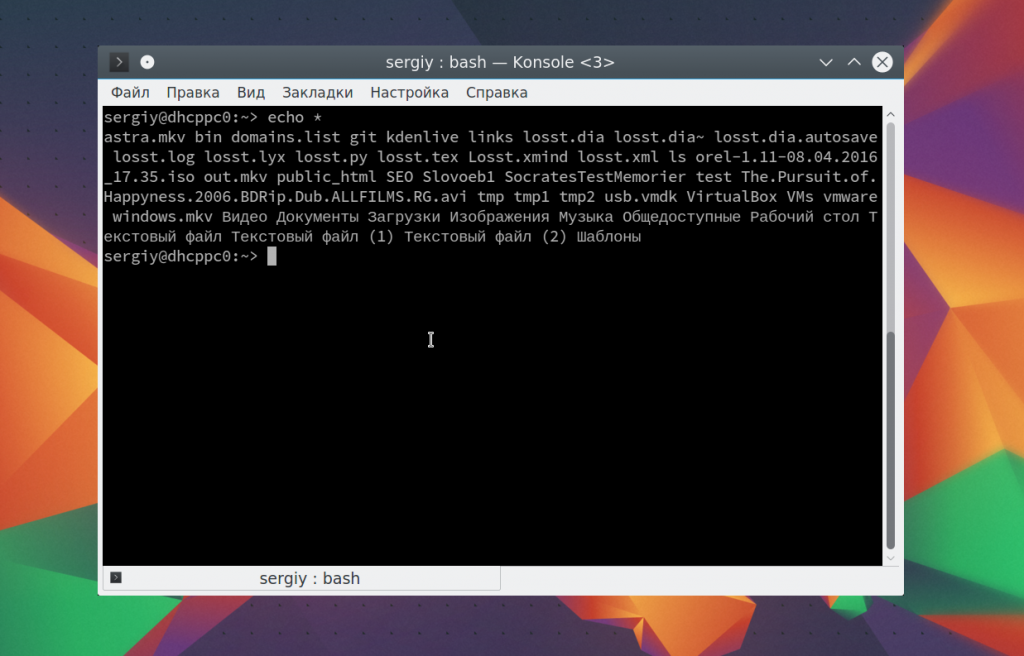
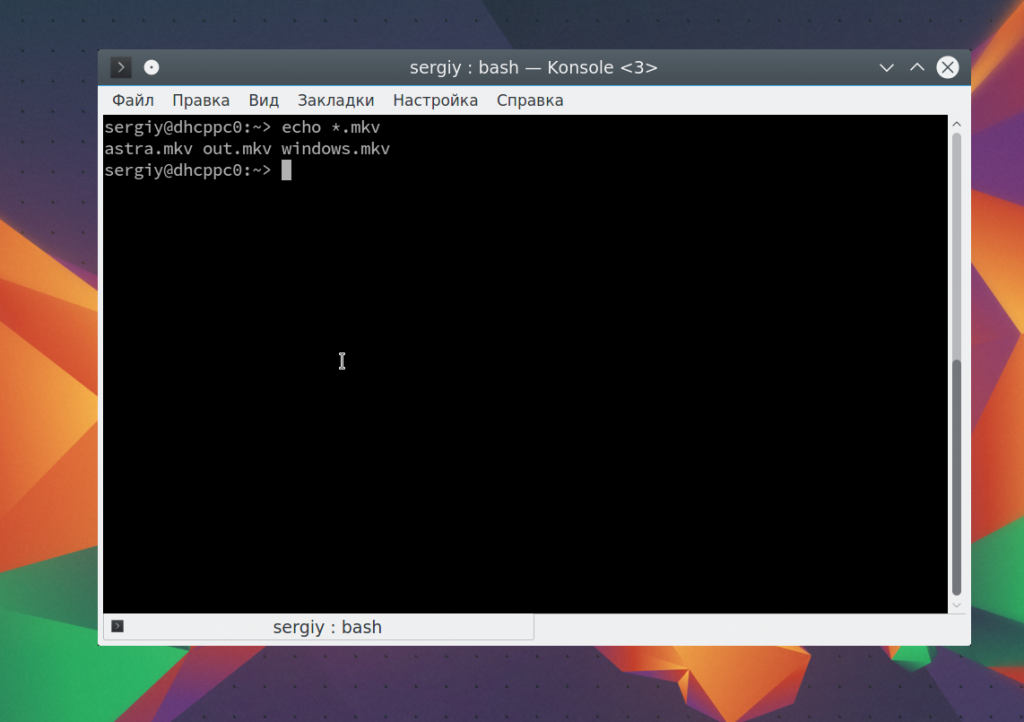
Также можно вывести файлы определенного расширения:
Я уже говорил, что echo можно использовать для редактирования конфигурационных файлов. Вы можете использовать запись echo в файл linux, если он пуст:
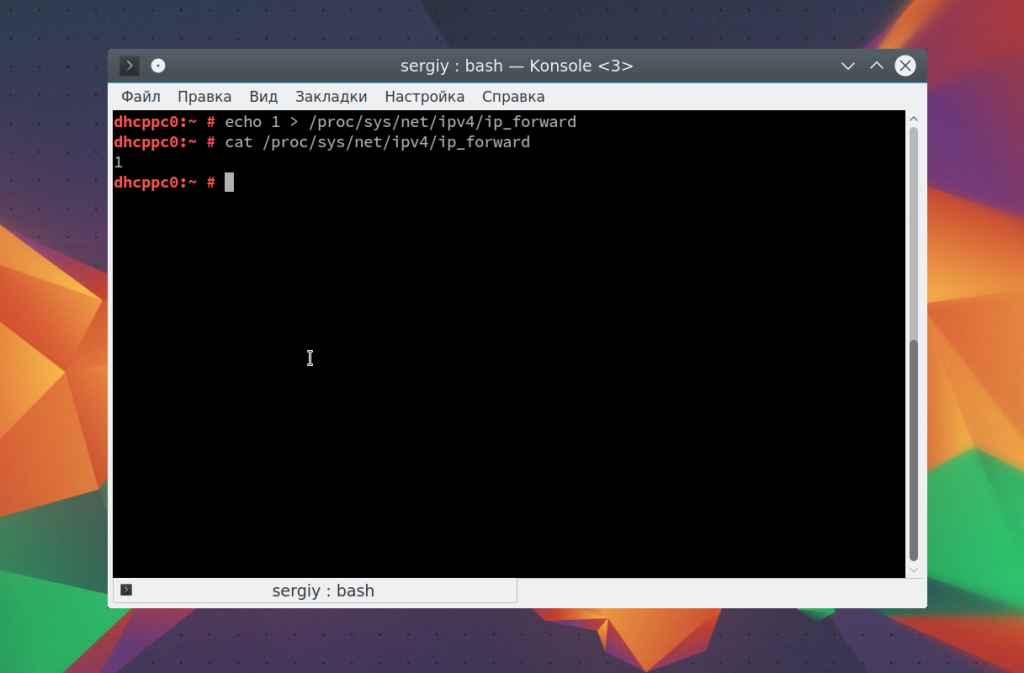
Если файл не пуст, и вам необходимо добавить свою строчку в конец файла используйте символ перенаправления вывода >>:
Если строка содержит какие-либо специальные символы или может быть понята интерпретатором неоднозначно, следует заключить ее в кавычки.
Так что я должен использовать?
Итак, теперь у нас есть 3 метода ввода данных от пользователя:
- Аргументы командной строки
- Чтение ввода во время выполнения скрипта
- Принять данные, которые были перенаправлены в скрипт Bash через STDIN
Какой метод лучше всего зависит от ситуации.
Как правило, вы предпочитаете аргументы командной строки. Они наиболее удобны для пользователей, поскольку данные будут храниться в истории команд, чтобы они могли легко вернуться к нему. Это также лучший подход, если ваш скрипт может быть вызван другими скриптами или процессами (например, возможно, вы хотите, чтобы он периодически запускался с использованием CRON).

![[в закладки] bash для начинающих: 21 полезная команда](https://smartshop124.ru/wp-content/uploads/3/9/f/39fcdfb0306333f699ef8ff5e6325fca.jpeg)
![[в закладки] bash для начинающих: 21 полезная команда / хабр](https://smartshop124.ru/wp-content/uploads/3/f/a/3fa3a9f9470ca9ddbe85dd47e2bf86c1.jpeg)
Иногда характер данных таков, что было бы не идеально для его хранения в истории команд людей и т. д. Хорошим примером этого являются учетные данные для входа (имя пользователя и пароль). В этих обстоятельствах лучше всего читать данные во время выполнения скрипта.
Если весь скрипт выполняет обработку данных определенным образом, то, вероятно, лучше всего работать с STDIN. Таким образом, его можно легко добавить в конвейер.
Иногда вы можете обнаружить, что комбинация идеальна. Пользователь может предоставить имя файла в качестве аргумента командной строки, а если нет, то скрипт обработает то, что он найдет в STDIN (когда мы посмотрим на операторы If, мы увидим, как это может быть достигнуто). Или, возможно, аргументы командной строки определяют определенное поведение, но чтение также используется для запроса дополнительной информации, если требуется.
Ультимативно вы должны думать о 3 факторах при принятии решения о том, как пользователи будут предоставлять данные вашему сценарию Bash:
- Простота использования — какой из этих методов облегчит пользователям использование моего сценария?
- Безопасность. Есть ли конфиденциальные данные, которые я должен обрабатывать надлежащим образом?
- Надежность. Могу ли я сделать так, чтобы моя работа скриптов была интуитивно понятной и гибкой, а также усложнять ошибки?
Часть 2. Переменные в Bash
Часть 4. Сложение, вычитание, умножение, деление, модуль в Bash
Основы скриптов
Скрипт или как его еще называют — сценарий, это последовательность команд, которые по очереди считывает и выполняет программа-интерпретатор, в нашем случае это программа командной строки — bash.
Скрипт — это обычный текстовый файл, в котором перечислены обычные команды, которые мы привыкли вводить вручную, а также указанна программа, которая будет их выполнять. Загрузчик, который будет выполнять скрипт не умеет работать с переменными окружения, поэтому ему нужно передать точный путь к программе, которую нужно запустить. А дальше он уже передаст ваш скрипт этой программе и начнется выполнение.
Простейший пример скрипта для командной оболочки Bash:
Утилита echo выводит строку, переданную ей в параметре на экран. Первая строка особая, она задает программу, которая будет выполнять команды. Вообще говоря, мы можем создать скрипт на любом другом языке программирования и указать нужный интерпретатор, например, на python:
Или на PHP:
В первом случае мы прямо указали на программу, которая будет выполнять команды, в двух следующих мы не знаем точный адрес программы, поэтому просим утилиту env найти ее по имени и запустить. Такой подход используется во многих скриптах. Но это еще не все. В системе Linux, чтобы система могла выполнить скрипт, нужно установить на файл с ним флаг исполняемый.
Этот флаг ничего не меняет в самом файле, только говорит системе, что это не просто текстовый файл, а программа и ее нужно выполнять, открыть файл, узнать интерпретатор и выполнить. Если интерпретатор не указан, будет по умолчанию использоваться интерпретатор пользователя. Но поскольку не все используют bash, нужно указывать это явно.
Чтобы сделать файл исполняемым в linux выполните:
Теперь выполняем нашу небольшую первую программу:
Все работает. Вы уже знаете как написать маленький скрипт, скажем для обновления. Как видите, скрипты содержат те же команды, что и выполняются в терминале, их писать очень просто. Но теперь мы немного усложним задачу. Поскольку скрипт, это программа, ему нужно самому принимать некоторые решения, хранить результаты выполнения команд и выполнять циклы. Все это позволяет делать оболочка Bash. Правда, тут все намного сложнее. Начнем с простого.
Изменение разделителя
По умолчанию при строка разбивается на слова с использованием одного или нескольких пробелов, табуляции и новой строки в качестве разделителей. Чтобы использовать другой символ в качестве разделителя, присвойте его переменной (внутренний разделитель полей).
Когда установлен на символ, отличный от пробела или табуляции, слова разделяются ровно одним символом:
Строка разделена четырьмя словами. Второе слово — это пустое значение, представляющее отрезок между разделителями. Он создан, потому что мы использовали два символа-разделителя рядом друг с другом ( .
Для разделения строки можно использовать несколько разделителей. При указании нескольких разделителей присваивайте символы переменной без пробела между ними.
Вот пример использования и качестве разделителей:
Управляющие конструкции в скриптах
Создание bash скрипта было бы не настолько полезным без возможности анализировать определенные факторы, и выполнять в ответ на них нужные действия. Это довольно-таки сложная тема, но она очень важна для того, чтобы создать bash скрипт.
В Bash для проверки условий есть команда Синтаксис ее такой:
if команда_условие thenкомандаelse командаfi
Эта команда проверяет код завершения команды условия, и если 0 (успех) то выполняет команду или несколько команд после слова then, если код завершения 1 выполняется блок else, fi означает завершение блока команд.
Но поскольку нам чаще всего нас интересует не код возврата команды, а сравнение строк и чисел, то была введена команда [[, которая позволяет выполнять различные сравнения и выдавать код возврата зависящий от результата сравнения. Ее синтаксис:
]
Для сравнения используются уже привычные нам операторы <,>,=,!= и т д. Если выражение верно, команда вернет 0, если нет — 1. Вы можете немного протестировать ее поведение в терминале. Код возврата последней команды хранится в переменной $?:
Теперь объединением все это и получим скрипт с условным выражением:
Конечно, у этой конструкции более мощные возможности, но это слишком сложно чтобы рассматривать их в этой статье. Возможно, я напишу об этом потом. А пока перейдем к циклам.
Объединение команд
Оболочка Bash позволяет не только выполнять команды, но и объединять их в сложные конструкции для получения нужного эффекта. Использование Bash таким способом очень эффективно. Как вы знаете, система Linux создает три потока для каждой программы — поток ввода, поток вывода и поток ошибок. Оболочка позволяет перенаправить поток одной программы прямо в другую с помощью специальных операторов. Читайте более подробно обо всем этом в статье перенаправление ввода вывода в Bash.
Кроме того, Bash позволяет объединять команды по времени выполнения. Существуют такие операторы для объединения команд:
- && — выполнить первую команду, а вторую выполнять только если первая завершится успешно;
- || — выполнить первую команду, а вторую выполнять только если первая завершится неудачей;
- ; — выполняет последовательно каждую следующую команду, как только завершится предыдущая;
- & — запустить команду в фоне и сразу же вернуть управление в командную оболочку для выполнения следующей команды.
Например, сначала выполняем загрузку файла, а затем открываем его в плеере, если загрузка прошла успешно:
Чтобы продолжить этот пример, мы можем удалить загруженный файл, если произошла ошибка:
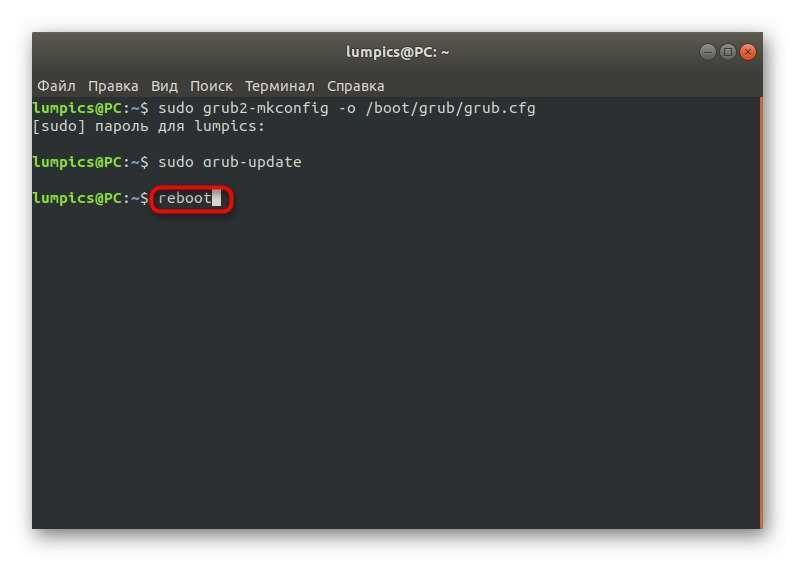
Чтобы выполнить обновление системы, а затем завершить работу выполните:
И наконец, вы можете запустить какой-либо сервис или приложение, например, браузер в фоне и свободно продолжить работу в терминале:
Редактирование текстовых файлов
Чтобы отредактировать текстовый файл нужно открыть его в одном из редакторов.
Скорее всего у вас уже установлен либо nano либо
vi
Создать новый файл можно командой touch
touch new_file
Удалить файл можно командой rm
rm new_file
Создать сразу несколько файлов:
touch file1 file2 file3 file4
Чтобы создать файл с пробелами в имени нужно взять имя в кавычки:
touch ‘file with spaces in name’
Создать новую директорию можно командой mkdir
mkdir расшифровывается как Make Directory
mkdir new_folder
Если нужно создать вложенные директории — воспользуйтесь флагом -p (parent)
mkdir -p city/district/street
Чтобы создать директорию и сразу туда перейти используйте
mkdir example && cd $_
Чтобы выйти из текущего процесса нажмите CTRL + C
Лучше не использовать следующие символы для названий файлов и папок:
‘ » ` { } ( ) < > ! ? & ] : ; \ ^
$ @ ~ * #
Попробуйте открыть файл с помощью cat -vet
cat -vet somefile
Можно увидеть, что в конце строки стоит $ а также кодировку кириллических символов.
Автоматическое дополнение
При выполнении cd писать полное название директории необязательно.
Если из домашней директории вы хотите перейти в Documents, достаточно набрать
Doc и нажать Tab.
Если вы наберете просто D и нажмёте Tab, то Bash не поймёт куда вы хотите перейти —
в Desktop, Documents или в Downloads, поэтому ничего не произойдёт (в Zsh сразу появится подсказка).
Но если вы
нажмёте Tab ещё раз — появится подсказка, а именно список всех директорий, название
которых начинается на D

cd D
Desktop/ Documents/ Downloads/
Чтобы перейти в родительскую директорию выполните
cd ..
Чтобы узнать полный путь до текущей директории выполните
pwd
Просматриваем содержимое файла по шаблону в Linux
На практике зачастую нам необходим не весь текстовый файл, а лишь несколько строк из него. Используя grep, мы можем вывести Linux-файл, предварительно отсеяв лишнее:
grep опции шаблон файл
Команду можно применять и совместно с cat:
cat файл | grep опции шаблон
Давайте выведем из лога лишь предупреждения:
cat /var/log/Xorg.0.log | grep WW
Вывод:
(WW) warning, (EE) error, (NI) not implemented, (??) unknown. (WW) Hotplugging is on, devices using drivers 'kbd', 'mouse' or 'vmmouse' will be disabled. (WW) Disabling Keyboard0 (WW) Disabling Mouse0 (WW) evdev: A4TECH USB Device: ignoring absolute axes.
Есть и ряд полезных опций: -A, -B, -C. Допустим, нам надо выполнить вывод двух строк после вхождения enp2s0:
$ ifconfig | grep -A2 enp2s0
Вывод из файла:
enp2s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255 inet6 fe80::beae:c5ff:febe:8bb7 prefixlen 64 scopeid 0x20<link>
А теперь, то же самое, но до вхождения loop:
ifconfig | grep -B2 loop
Вывод:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback)
Можно по две строки как до, так и после loop:
ifconfig | grep -C2 loop
Вывод из файла:
inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 0 (Local Loopback) RX packets 9810 bytes 579497 (565.9 KiB) RX errors 0 dropped 0 overruns 0 frame
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Как работает перенаправление ввода вывода
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках — информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата — число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux — файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 — этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 — это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 — все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов «<» и «>».






Перенаправление ввода/вывода
Практически все операционные системы обладают механизмом перенаправления ввода/вывода.
Linux не является исключением из этого правила. Обычно программы вводят текстовые данные с
консоли (терминала) и выводят данные на консоль. При вводе под консолью подразумевается клавиатура, а при выводе — дисплей терминала. Клавиатура и дисплей — это, соответственно, стандартный ввод и вывод (stdin и stdout). Любой ввод/вывод можно интерпретировать как ввод из некоторого файла и вывод в файл. Работа с файлами производится через их дескрипторы. Для организации ввода/вывода в UNIX используются три файла: stdin (дескриптор 1), stdout (2) и stderr(3).
Символ > используется для перенаправления стандартного вывода в файл.
Пример:
$ cat > newfile.txt
Стандартный ввод команды cat будет перенаправлен в файл newfile.txt, который будет создан после выполнения этой команды. Если файл с этим именем уже существует, то он будет перезаписан. Нажатие Ctrl + D остановит перенаправление и прерывает выполнение команды cat.
Символ < используется для переназначения стандартного ввода команды. Например, при выполнении команды cat Символ >> используется для присоединения данных в конец файла (append) стандартного вывода команды. Например, в отличие от случая с символом >, выполнение команды cat >> newfile.txt не перезапишет файл в случае его существования, а добавит данные в его конец.
Символ | используется для перенаправления стандартного вывода одной программы на стандартный ввод другой. Напрмер, ps -ax | grep httpd.