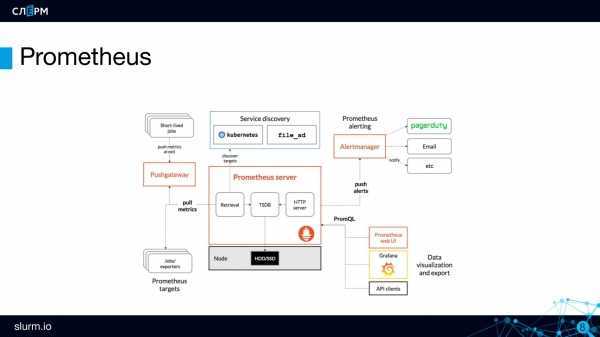
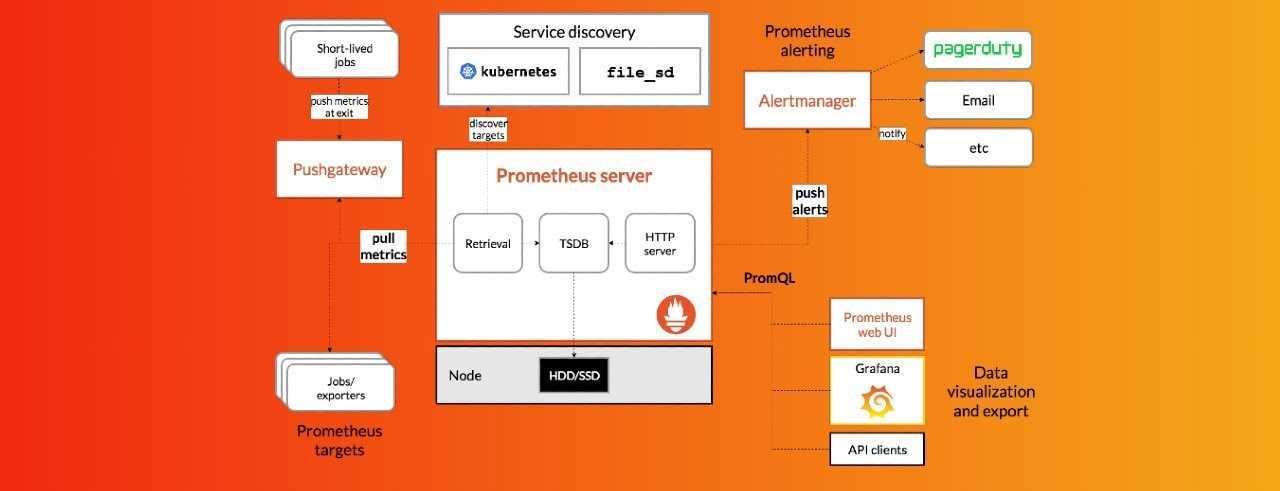
TSDB Admin APIs
These are APIs that expose database functionalities for the advanced user. These APIs are not enabled unless the is set.
Snapshot
Snapshot creates a snapshot of all current data into under the TSDB’s data directory and returns the directory as response.
It will optionally skip snapshotting data that is only present in the head block, and which has not yet been compacted to disk.
URL query parameters:
skip_head=: Skip data present in the head block. Optional.
The snapshot now exists at
New in v2.1 and supports PUT from v2.9
Delete Series
DeleteSeries deletes data for a selection of series in a time range. The actual data still exists on disk and is cleaned up in future compactions or can be explicitly cleaned up by hitting the endpoint.
If successful, a is returned.
URL query parameters:
- : Repeated label matcher argument that selects the series to delete. At least one argument must be provided.
- : Start timestamp. Optional and defaults to minimum possible time.
- : End timestamp. Optional and defaults to maximum possible time.
Not mentioning both start and end times would clear all the data for the matched series in the database.
Example:
NOTE: This endpoint marks samples from series as deleted, but will not necessarily prevent associated series metadata from still being returned in metadata queries for the affected time range (even after cleaning tombstones). The exact extent of metadata deletion is an implementation detail that may change in the future.
New in v2.1 and supports PUT from v2.9
Clean Tombstones
CleanTombstones removes the deleted data from disk and cleans up the existing tombstones. This can be used after deleting series to free up space.
If successful, a is returned.
This takes no parameters or body.
New in v2.1 and supports PUT from v2.9
This documentation is . Please help improve it by filing issues or pull requests.
3. Примеры использования Prometheus Monitoring
Как вы уже знаете, каждое подробное руководство заканчивается проверкой реальности . Как я люблю говорить, технология не является самоцелью и всегда должна служить определенной цели.
Об этом мы и поговорим в этой главе.
а — Отрасль DevOps
Поскольку все экспортеры созданы для систем, баз данных и серверов, основная цель Prometheus явно нацелена на отрасль DevOps.
Как мы все знаем, многие поставщики конкурируют за эту отрасль и предоставляют для нее индивидуальные решения.
Прометей — идеальный кандидат на DevOps.
Необходимые усилия для запуска и запуска ваших экземпляров очень малы, и каждый вспомогательный инструмент можно легко активировать и настроить по запросу.
Обнаружение целей , например, с помощью экспортера файлов, также делает его идеальным решением для стеков, которые в значительной степени зависят от контейнеров и распределенных архитектур.
В мире, где экземпляры создаются так же быстро, как и уничтожаются, обнаружение сервисов необходимо для каждого стека DevOps.
б — Здравоохранение
В настоящее время решения по мониторингу предназначены не только для ИТ-специалистов. Они также предназначены для поддержки крупных отраслей, обеспечивая отказоустойчивые и масштабируемые архитектуры для здравоохранения.
По мере того, как спрос растет все больше и больше, развернутые ИТ-архитектуры должны соответствовать этому спросу. Без надежного способа мониторинга всей вашей инфраструктуры вы можете столкнуться с риском массовых сбоев в работе ваших сервисов . Излишне говорить, что эти опасности должны быть сведены к минимуму для решений в области здравоохранения.
Этот пример изначально обсуждался на сайте opensource.com в следующей статье: https://opensource.com/article/18/9/prometheus-operational-advantage
c — Финансовые услуги
Последний пример был выбран из конференции, проведенной InfoQ, на которой обсуждалась возможность использования Prometheus для финансовых учреждений.
Речь была представлена Джейми Кристианом и Аланом Стрейдером, которые продемонстрировали, как именно они используют Prometheus для мониторинга своей инфраструктуры в Northern Trust. Определенно поучительно и стоит посмотреть.
Отображение метрик с node_exporter в консоли prometheus
Открываем конфигурационный файл prometheus:
vi /etc/prometheus/prometheus.yml
В разделе scrape_configs добавим:
scrape_configs:
…
— job_name: ‘node_exporter_clients’
scrape_interval: 5s
static_configs:
— targets:
* в данном примере мы добавили клиента с IP-адресом 192.168.0.14, рабочее название для группы клиентов node_exporter_clients. Для примера, мы также добавили клиента 192.168.0.15 — чтобы продемонстрировать, что несколько клиентов добавляется через запятую.
Чтобы настройка вступила в действие, перезагружаем наш сервис prometheus:
systemctl restart prometheus
Заходим в веб-консоль prometheus и переходим в раздел Status — Targets:
… в открывшемся окне мы должны увидеть нашу группу хостов и сам компьютер с установленной node_exporter:
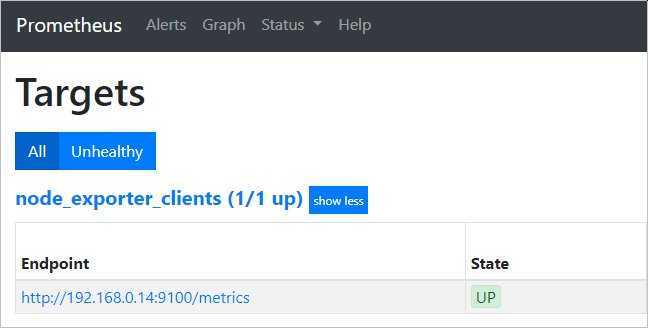
* статус также должен быть UP.
Бонус
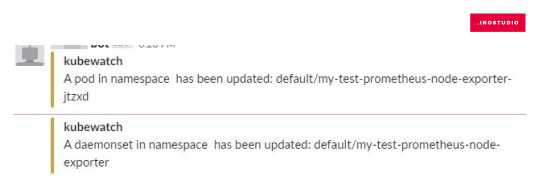
Плюсы данного метода — простая настройка, быстрое оповещение. Минус — если выбрать все resourcesToWatch:, то KubeWatch будет слать много сообщений. Как я понял, это происходит по причине того, что, например, некоторые объекты в Kubernetes могут самостоятельно обновиться, а KubeWatch это фиксирует и сразу оповещает.
В итоге мы рассмотрели установку и настройку одного метода мониторинга для визуального отображения информации о кластере Kubernetes и два метода для оповещения о возникших проблемах в кластере. Моей целью было кратко описать рабочую схему установки и настройки мониторинга. Надеюсь, я справился. Мониторинг в данном виде работает и выполняет свое предназначение. Но нет предела совершенству.
Есть мысли по небольшому дополнению/модернизации этого стека. Причина — кластеров Kubernetes становится больше и устанавливать весь стек целиком на каждый кластер стало казаться не очень хорошей идеей, так как заходить на каждый кластер в Grafana для анализа графиков становится все большей рутиной. Есть желание объединять мониторинг в одном Grafana. Рассмотренный плагин для Grafana поддерживает подключение нескольких кластеров, но пока стоит вопрос о правильной настройке со стороны безопасности. Объединять мониторинг кластеров разных сред, да и к тому же разных проектов — не самая лучшая идея.
как реализовать выкладку приложения CI/CD в Kubernetess.
3: Настройка Prometheus
Следуя стандартным соглашениям Linux, создайте каталог в /etc для конфигурационных файлов Prometheus и каталог в /var/lib для других данных.
Передайте права на каталоги пользователю prometheus:
В каталоге /etc/prometheus создайте файл конфигурации prometheus.yml. На данный момент этот файл будет содержать достаточно информации для запуска Prometheus.
Важно! Конфигурационный файл Prometheus использует формат YAML, который строго запрещает табы и требует двух пробелов для отступов. Prometheus не удастся запустить, если конфигурационный файл некорректно отформатирован
В глобальных настройках (раздел global) задайте интервал по умолчанию для сбора метрик
Обратите внимание, что Prometheus будет применять эти настройки для каждого экспортера, если только глобальные переменные не переопределяются индивидуальными настройками отдельного экспортера
Согласно этому значению scrape_interval Prometheus будет собирать метрики своих экспортеров каждые 15 секунд, что достаточно для большинства экспортеров.
Теперь добавьте Prometheus в список экспортеров, чтобы собирать его метрики. Для этого используйте директиву scrape_configs:
С помощью job_name Prometheus маркирует экспортеры в запросах и графах, потому тут лучше выбрать описательное имя.
Поскольку Prometheus экспортирует важные данные о себе, которые используются для мониторинга производительности и отладки, можно переопределить глобальную директиву scrape_interval с 15 секунд до 5 секунд, чтобы данные обновлялись чаще.
С помощью директив static_configs и targets Prometheus определяет, где запускать экспортеры. Поскольку этот конкретный экспортер запущен на том же сервере, что и Prometheus, можно использовать localhost вместо IP-адреса и порт по умолчанию 9090.
Теперь конфигурационный файл выглядит так:
Сохраните и закройте файл.
Передайте права на этот файл пользователю prometheus.
По завершении конфигурации можно запустить и протестировать Prometheus.
Exporters
prometheus-node-exporter
- В Debian ставится как зависимость к пакету prometheus и добавлен в конфигурацию
Примеры счетчиков
node_filesystem_free_bytes
$ df /
...
/dev/mapper/debian--vg-root 15662008 1877488 12969212 13% /
...
# TYPE node_filesystem_free_bytes gauge
node_filesystem_free_bytes{device="/dev/mapper/debian--vg-root",fstype="ext4",mountpoint="/"} = (15662008 - 1877488) * 1024
node_network_receive_bytes_total
$ cat /sys/class/net/eth1/statistics/rx_bytes
# TYPE node_network_receive_bytes_total counter
node_network_receive_bytes_total{device="eth1"}
Подключение к prometheus
# less /etc/prometheus/prometheus.yml
...
- job_name: node
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets:
Запросы PromQL
8*rate(node_network_receive_bytes_total)
8*rate(node_network_receive_bytes_total{device="eth1"})
8*rate(node_network_receive_bytes_total{device="eth1",instance="localhost:9100",job="node"})
prometheus-blackbox-exporter
# apt install prometheus-blackbox-exporter
Пример конфигурации
# cat /etc/prometheus/blackbox.yml
...
http_2xx:
prober: http
http:
preferred_ip_protocol: "ip4"
...
# service prometheus-blackbox-exporter restart # cat /etc/prometheus/prometheus.yml
...
- job_name: check_http
metrics_path: /probe
params:
module:
static_configs:
- targets:
- https://google.com
- https://ya.ru
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
- job_name: check_ssh
metrics_path: /probe
params:
module:
static_configs:
- targets:
- switch1:22
- switch2:22
- switch3:22
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
probe_success... probe_duration_seconds... probe_http_duration_seconds...
Пример использования file-based service discovery и сервиса ping
# cat /etc/prometheus/prometheus.yml
...
- job_name: check_ping
metrics_path: /probe
params:
module:
file_sd_configs:
- files:
# - switchs.yml
# - switchs.json
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
# cat /etc/prometheus/switchs.json
} ]
# cat /etc/prometheus/switchs.yml
- targets: - switch1 - switch2 - switch3
Проверка конфигурации и перезапуск
prometheus-snmp-exporter
# apt install prometheus-snmp-exporter # cat /etc/prometheus/snmp.yml
#if_mib: # по умолчанию, позволяет не указывать module в http запросе
snmp_in_out_octets:
version: 2
auth:
community: public
walk:
- 1.3.6.1.2.1.2.2.1.10
- 1.3.6.1.2.1.2.2.1.16
- 1.3.6.1.2.1.2.2.1.2
metrics:
- name: if_in_octets
oid: 1.3.6.1.2.1.2.2.1.10
type: counter
indexes:
- labelname: ifIndex
type: Integer
lookups:
- labels:
- ifIndex
labelname: ifDescr
oid: 1.3.6.1.2.1.2.2.1.2
type: DisplayString
- name: if_out_octets
oid: 1.3.6.1.2.1.2.2.1.16
type: counter
indexes:
- labelname: ifIndex
type: Integer
lookups:
- labels:
- ifIndex
labelname: ifDescr
oid: 1.3.6.1.2.1.2.2.1.2
type: DisplayString
# service prometheus-snmp-exporter restart
http://server.corpX.un:9116/

# curl --noproxy 127.0.0.1 'http://127.0.0.1:9116/snmp?target=router&module=snmp_in_out_octets'
# cat /etc/prometheus/prometheus.yml
...
- job_name: 'snmp'
static_configs:
- targets:
- router
metrics_path: /snmp
params:
module:
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9116
Проверка конфигурации и перезапуск
rate(if_in_octets{ifDescr="FastEthernet1/1",ifIndex="3",instance="router",job="snmp"})
8*rate(if_in_octets{ifDescr="FastEthernet1/1",instance="router"})
Система резервного копирования
Система резервного копирования предоставит возможность регулярно создавать резервные копии данных и восстанавливать данные из этих резервных копий. Также это позволит вам откатить данные до предыдущего состояния в случае нежелательных изменений. Все компьютерное оборудование может рано или поздно отказать, что может привести к потере данных. Чтобы этого не случилось, вы должны поддерживать актуальные резервные копии всех важных данных.
Роль систем резервного копирования в среде производства очень важна.
Система резервного копирования может смягчить последствия потери данных, что необходимо для восстановления и, следовательно, для обеспечения доступности приложения в случае потери данных. Но такие системы должны использоваться в сочетании с планами восстановления, которые мы рассмотрим в следующем разделе.
Сервер резервного копирования находится в том же центре обработки данных, что и серверы приложений, на которых создаются исходные резервные копии. Позже копии данных можно переместить на сервер, который находится в другом центре обработки данных, что может гарантировать сохранение данных в случае сбоя в первом ЦОД.
Для настройки резервного копирования нужно выбрать:
- Данные, которые следует регулярно копировать. Как минимум, создайте резервные копии любых данных, которые невозможно воспроизвести из альтернативного источника
- Расписание резервного копирования: когда и как часто вы будете выполнять полные или инкрементные резервные копии.
- Период хранения данных: как долго вы будете хранить резервные копии, прежде чем они будут удалены.
- Дисковое пространство для резервных копий: комбинация трех предыдущих элементов влияет на объем требуемого дискового пространства. Воспользуйтесь сжатием и инкрементными резервными копиями, чтобы уменьшить дисковое пространство, необходимое для хранения копий.
- Сторонний ЦОД для хранения копий данных: это необходимо для того, чтобы защитить сайт от сбоев в первом ЦОД.
- Тестирование резервного копирования: периодически проверяйте процесс восстановления резервной копии, чтобы убедиться, что ваши резервные копии работают правильно.
- Как выбрать стратегию резервного копирования для VPS
- Установка сервера Bacula в Ubuntu 14.04
- Использование Rsync для синхронизации локального и удаленного каталогов на VPS
9: Тестирование установки
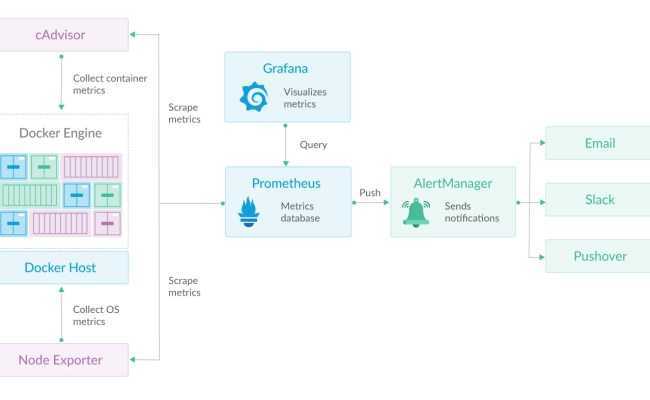
Prometheus предоставляет базовый веб-интерфейс для мониторинга состояния самого себя и своих экспортеров, выполнения запросов и создания графиков. Но из-за простоты и ненадежности интерфейса команда Prometheus рекомендует устанавливать и использовать Grafana для задач более сложных, чем тестирование и отладка.
В этом мануале используется встроенный интерфейс, с помощью которого можно убедиться, что Prometheus и Node Exporter запущены, а также просмотреть простые запросы и графы.
Откройте в браузере:
В появившемся диалоговом окне укажите имя пользователя и пароль, которые вы выбрали в разделе 8.
Затем откройте Expression Browser, где вы сможете выполнять и визуализировать пользовательские запросы.
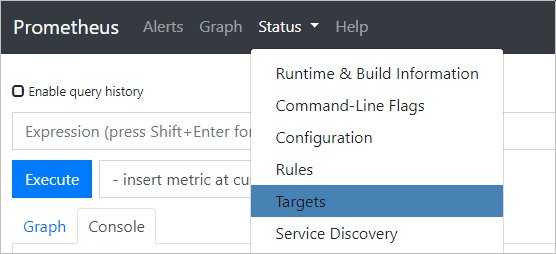
Для начала проверьте статус Prometheus и Node Explorer, открыв меню Status в верхней части экрана, а затем выбрав Targets. Поскольку Prometheus собирает и свои данные, и метрики Node Exporter, в состоянии UP вы должны увидеть обе цели.
Если экспортера нет или вы видите сообщение об ошибке, проверьте состояние сервисов с помощью следующих команд:
В выводе должна быть строка Active: active (running). Если это не так, или активный сервер работает некорректно, следуйте подсказкам на экране, чтобы исправить ошибки.
Чтобы убедиться, что экспортеры работают правильно, выполните несколько выражений Node Exporter.
Сначала перейдите в меню Graph в верхней части экрана, чтобы вернуться в Expression Browser.
В поле Expression введите node_memory_MemAvailable и нажмите кнопку Execute, чтобы обновить вкладку Console и вывести доступный объем памяти сервера.
По умолчанию Node Exporter сообщает эту сумму в байтах. Чтобы преобразовать ее в мегабайты, используйте математические операторы для деления на 1024 два раза.
В поле Expression введите node_memory_MemAvailable/1024/1024, а затем нажмите кнопку Execute.
Вкладка Console отобразит результаты в мегабайтах.
Если вы хотите проверить результаты, выполните команду free в терминале. Флаг -h отображает вывод free в удобочитаемом формате и выводит сумму в мегабайтах.
Этот вывод содержит сведения об использовании памяти, включая доступную память в столбце available.
Помимо базовых операторов язык запросов Prometheus также предоставляет множество функций для агрегирования результатов.
В поле avg_over_time(node_memory_MemAvailable)/1024/1024 и нажмите кнопку Execute. В результате вы увидите среднюю доступную память в мегабайтах за последние 5 минут.
Теперь откройте вкладку Graph, чтобы отобразить выполненное выражение в виде графика, а не текста.
Наведите указатель мыши на график, чтобы получить дополнительную информацию о какой-либо конкретной точке вдоль осей X и Y.
Чтобы узнать больше о создании выражений во встроенном веб-интерфейсе Prometheus, обратитесь к официальной документации.
Чтобы узнать больше о расширениях Prometheus, ознакомьтесь со списком доступных экспортеров, а также с официальным веб-сайтом Grafana.
PrometheusUbuntu 16.04
Оптимизация с помощью обновления
Каждое новое обновление программы 1С сопровождается оптимизацией, совершенствованием и модернизацией. Добавляются новые функции, улучшаются работоспособные системы всей платформы и появляются новые возможности, которые повышают производительность программы, что позволяет уменьшать восприятие от различных внешних факторов (объем хранимой памяти, количество подключаемых пользователей и прочее).
Следует учесть, что программа сама по себе не обновляется, поэтому необходимо самому следить за наличием обновлений или обратиться за помощью к нашим профессионалам. Обновление может выполняться для определенной конфигурации программы или самой платформы в целом.



Не загружаются данные из внешних источников на сервере
Скрипты сайта, выполняемые на веб-сервере, тоже могут обращаться к внешним источникам, например, за курсами валют. Если на стороннем сервисе неполадки, ваш сайт тоже начнет работать медленнее.
Еще одна частая проблема — сайт обращается сам к себе. Например, на сайте с условным именем TEST.RU может встречаться код, при помощи которого разработчик хочет подключить еще один файл к скрипту на языке PHP:
require_once(“https://test.ru/somefile.txt”).
Таких обращений следует избегать, так как они выполняются дольше, чем считывание файла локально с диска.
Диагностировать подобные проблемы через консоль браузера не получится. Потребуется подключение к хостингу по SSH и диагностика с помощью netstat — утилиты, которая собирает и выводит состояния сетевых соединений. Без специальных навыков это будет довольно сложно сделать, лучше пригласить веб-мастера или обратиться в поддержку хостинга.
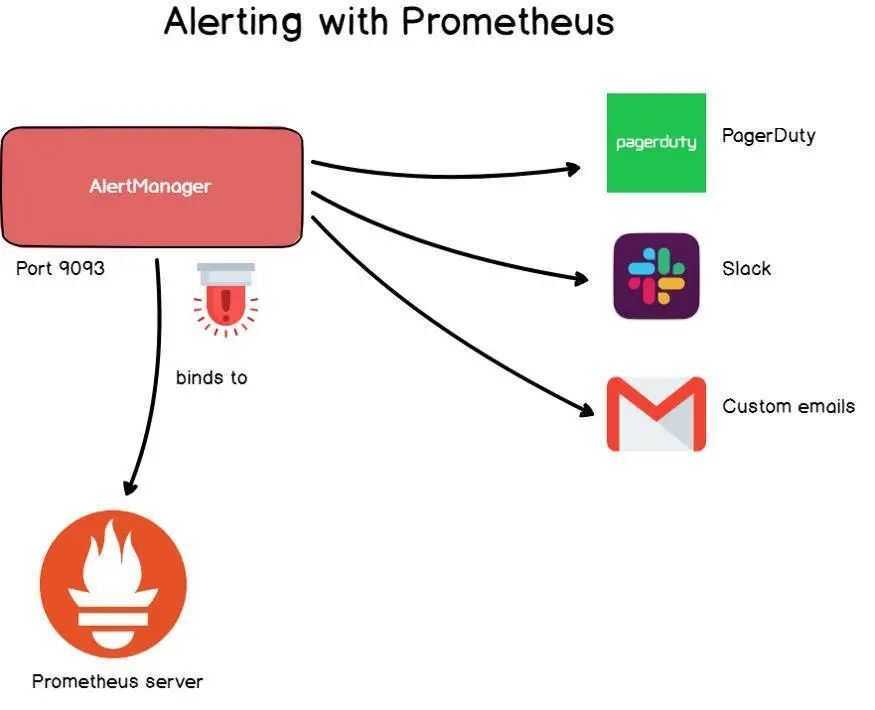
Отправка уведомлений
Теперь настроим связку с алерт менеджером для отправки уведомлений на почту.
Настроим alertmanager:
vi /etc/alertmanager/alertmanager.yml
В секцию global добавим:
global:
…
smtp_from: monitoring@dmosk.ru
Приведем секцию route к виду:
… далее добавим еще один ресивер:
* в данном примере мы отправляем сообщение на почтовый ящик alert@dmosk.ru с локального сервера
Обратите внимание, что для отправки почты наружу у нас должен быть корректно настроенный почтовый сервер (в противном случае, почта может попадать в СПАМ)
Перезапустим сервис для алерт менеджера:
systemctl restart alertmanager
Теперь настроим связку prometheus с alertmanager — открываем конфигурационный файл сервера мониторинга:
vi /etc/prometheus/prometheus.yml
Приведем секцию alerting к виду:
alerting:
alertmanagers:
— static_configs:
— targets:
— 192.168.0.14:9093
* где 192.168.0.14 — IP-адрес сервера, на котором у нас стоит alertmanager.
Перезапускаем сервис:
systemctl restart prometheus
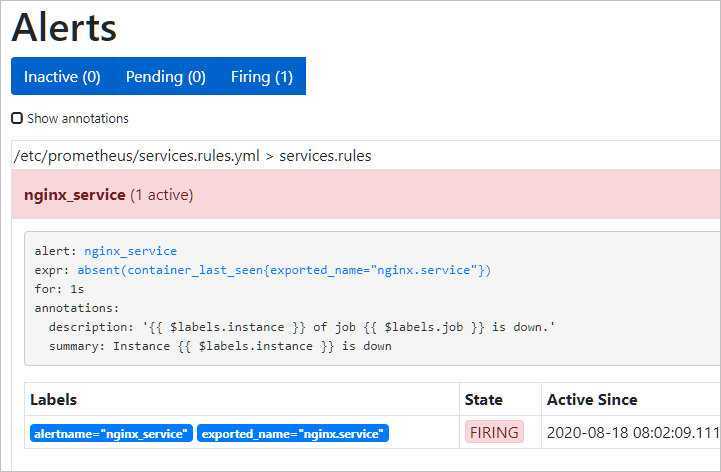
Немного ждем и заходим на веб интерфейс алерт менеджера — мы должны увидеть тревогу:
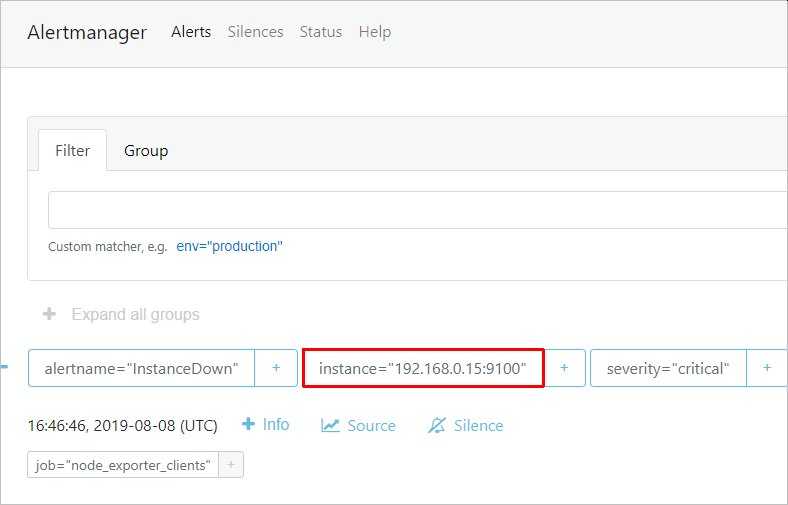
… а на почтовый ящик должно прийти письмо с тревогой.
Имплементация конечной точки:
Есть два формата «изложения». Давайте посмотрим на результат предыдущего примера , посетив http://localhost:9090/metrics.
«`# HELP go_goroutines Number of goroutines that currently exist.
TYPE go_goroutines gauge
go_goroutines 92 «`
Использование клиентской библиотеки
Доступно несколько библиотек для экспонирования показателей, большинство из которых могут выводить текст или более эффективный двоичный формат (Protobuf), упомянутый выше.
Привязки к языку Golang, Java, Python и Ruby поддерживаются проектом, но также доступно множество других привязок с открытым исходным кодом. Полный список можно найти здесь:
Стоит ли составлять собственный протокол?
Формат текста настолько прост, что вы можете легко реализовать протокол, следуя форматам изложения Prometheus. Перед тем как составлять протокол, убедитесь, что действительно не сможете воспользоваться проверенными клиентскими библиотеками.

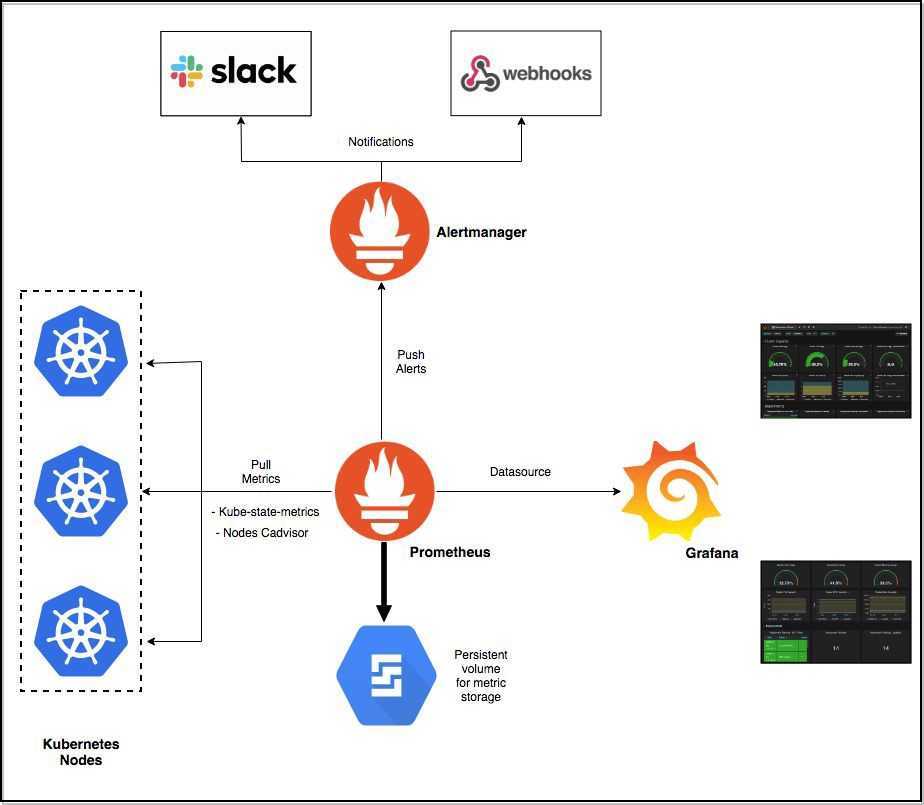
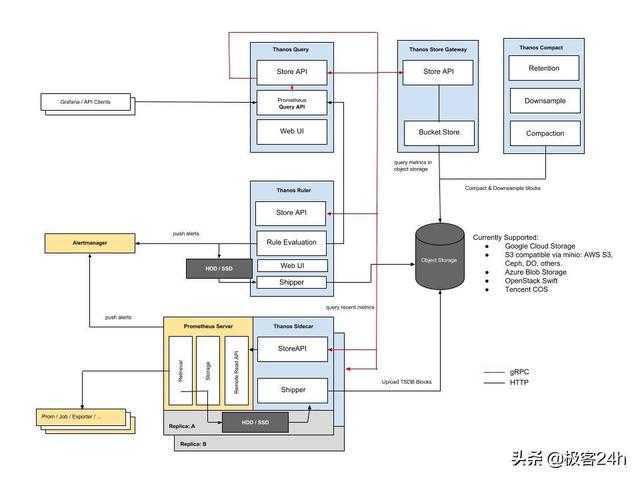
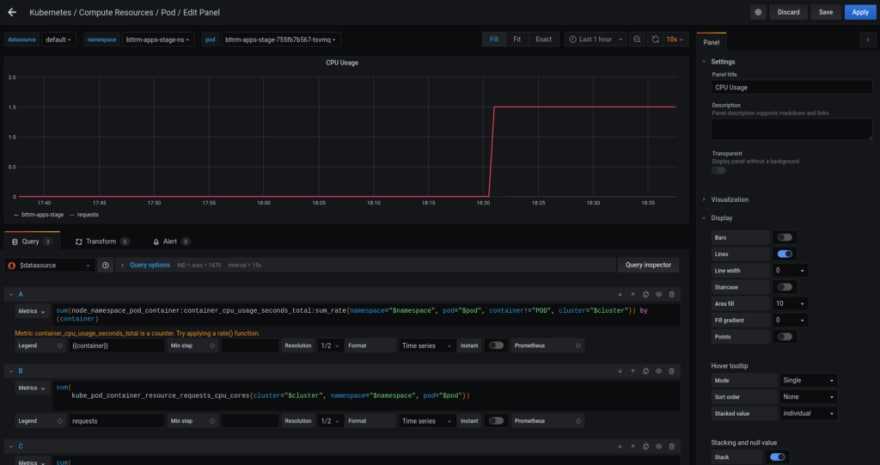
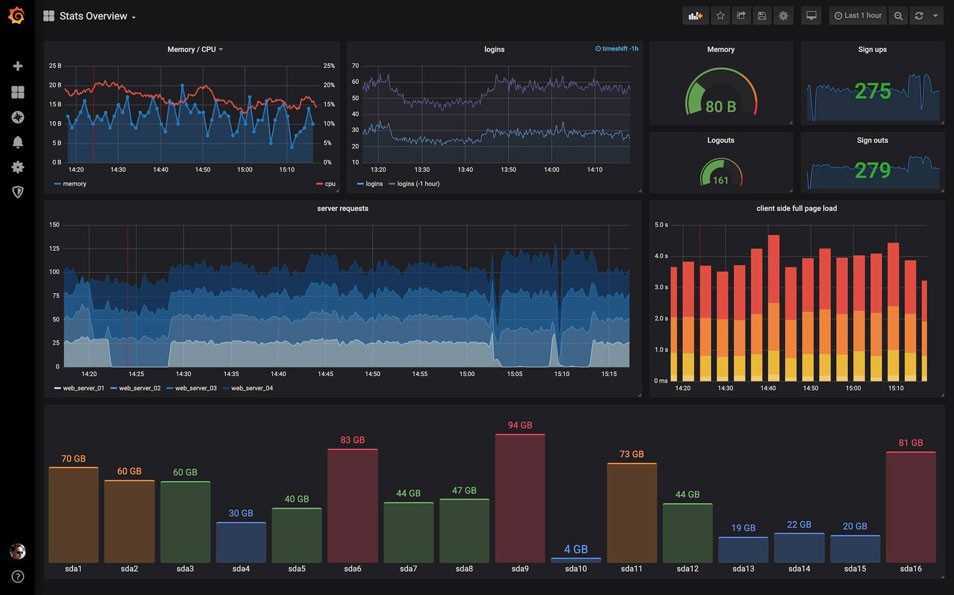
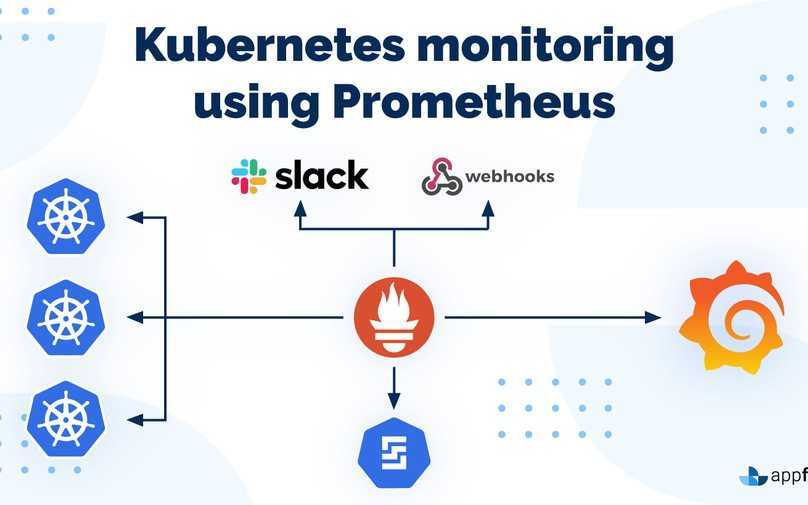
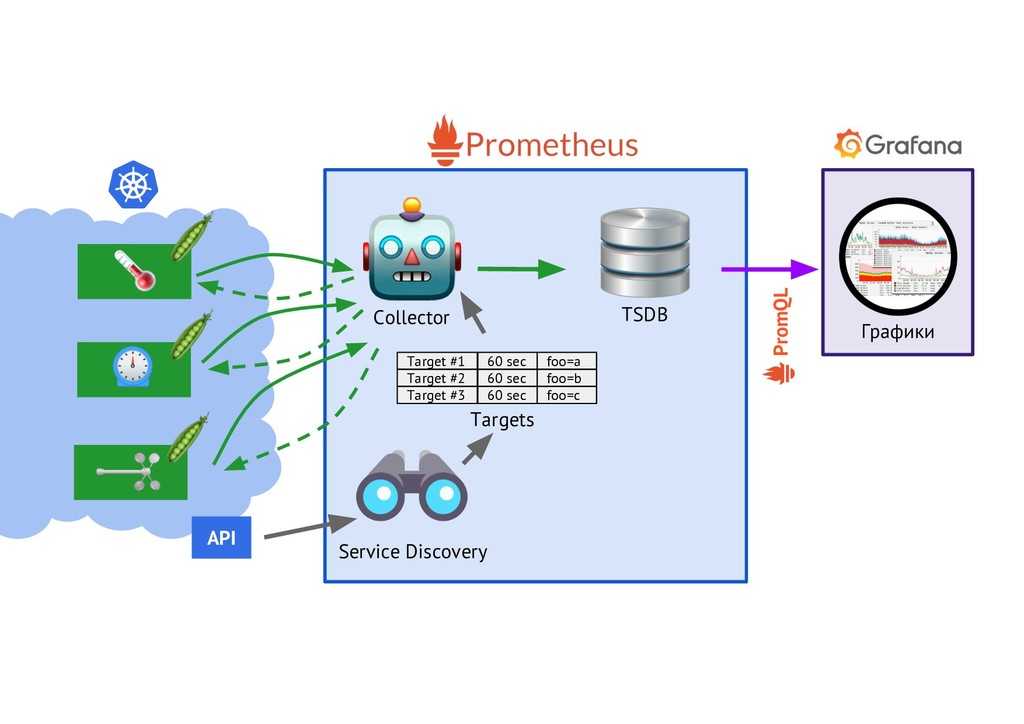

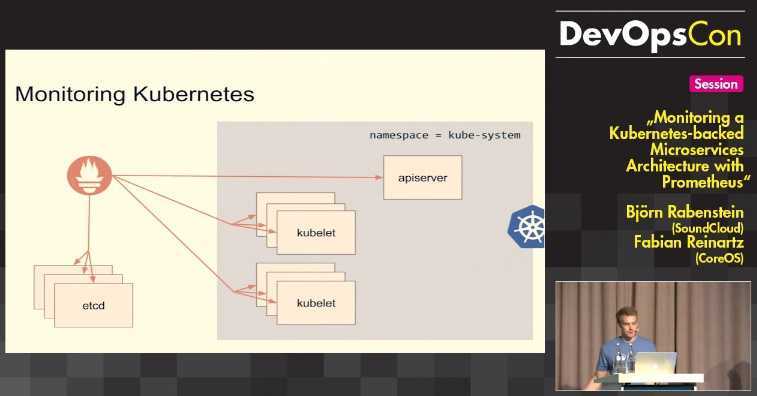
III — Создание полной панели управления Grafana для Node Exporter
Теперь, когда все ваши инструменты настроены, осталось не так много работы, чтобы иметь наши информационные панели.
Для этого мы не собираемся создавать свои дашборды самостоятельно. Вместо этого мы собираемся использовать функцию Импорт панели инструментов » Grafana.
В верхнем левом меню наведите указатель мыши на значок Плюс » и щелкните элемент Импорт » в раскрывающемся списке.
Вам будет представлено следующее окно:
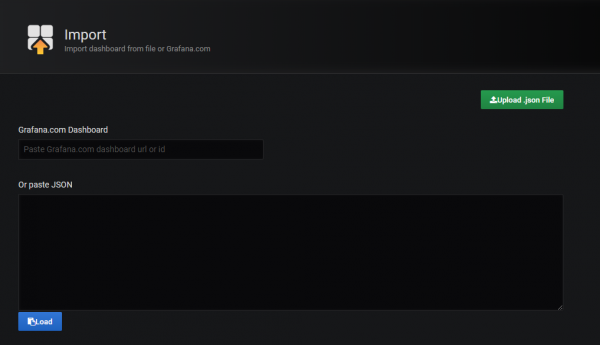
В этом окне у вас есть несколько вариантов. Вы также можете:
- Введите URL-адрес или идентификатор панели инструментов, и он будет автоматически импортирован в ваш экземпляр Grafana.
- Загрузите файл JSON (напомним, что панели управления Grafana экспортируются как файлы JSON, и таким образом ими можно легко поделиться)
- Вставьте непосредственно необработанный JSON
В нашем случае мы собираемся использовать первый вариант, введя идентификатор панели инструментов непосредственно в текстовое поле.
б — Вдохновение для информационных панелей
Нам не нужно самостоятельно создавать информационные панели.
Это особенно верно, когда вам нужно искать десятки показателей.
Вам придется потратить много времени на изучение различных показателей и построений из них.
Мы собираемся использовать для этого Grafana Dashboards. Grafana Dashboards — это репозиторий, принадлежащий Grafana, в котором хранятся сотни информационных панелей, из которых вы можете выбирать.
В нашем случае мы собираемся сосредоточиться на информационных панелях Node Exporter .
Введите « Node Exporter » в поле поиска и прокрутите, пока не дойдете до панели «Node Exporter Full».
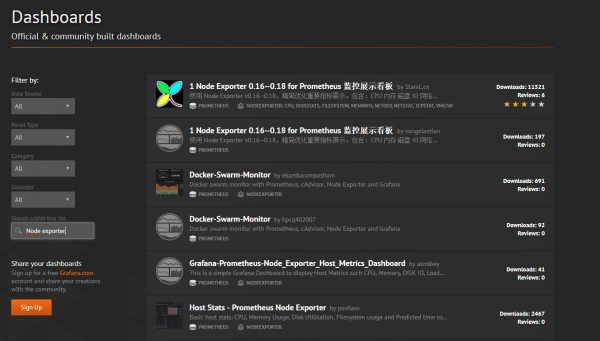
Как вы, наверное, заметили, на панели управления есть ID 1860 (информация доступна в URL-адресе веб-сайта).
Это идентификатор, который мы собираемся скопировать для мониторинга нашей системы.
При импорте введите «1860» в текстовое поле панели управления Grafana.com и нажмите «Загрузить».
Вам будет представлен второй экран для настройки панели инструментов.
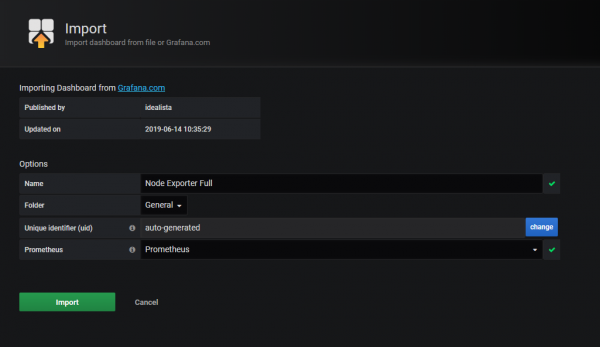
Каждое поле заполняется автоматически .
Однако вам нужно будет выбрать источник данных, в моем случае « Прометей(вы должны привязать его к источнику данных, который вы создали в разделе 2)
Когда закончите, нажмите « Импорт
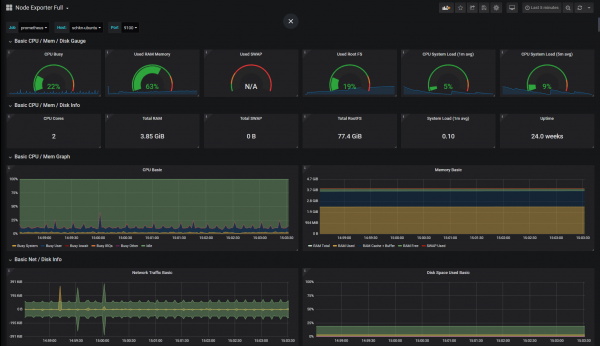
Менее чем за секунду все панели будут построены для вас!
Это 29 категорий, из которых более 192 панелей создаются автоматически. Потрясающий.
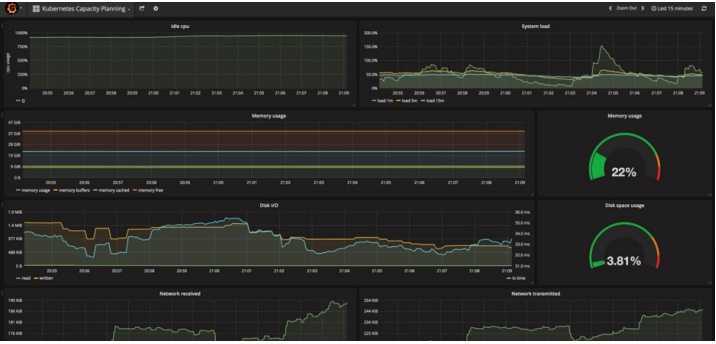
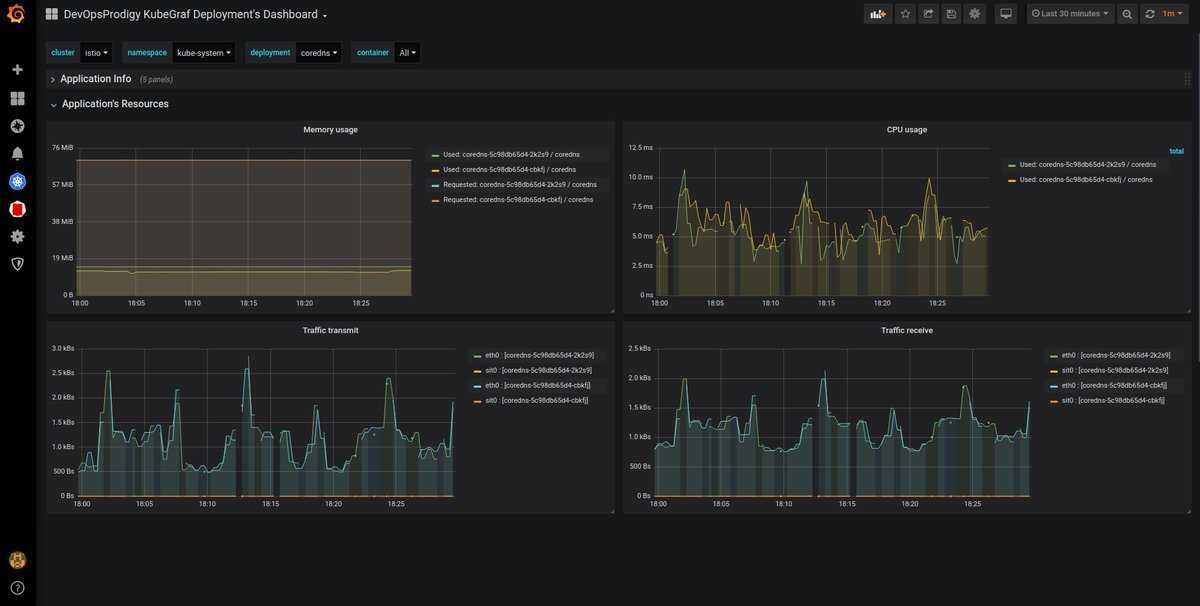
Вот несколько примеров того, как выглядят дашборды:
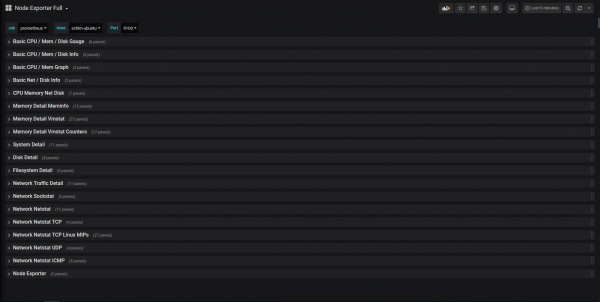
Вы также можете просмотреть все параметры, доступные на всей этой панели.
IV — Дальше
Освоение Node Exporter, безусловно, является обязательным навыком для инженеров, желающих начать работу с Prometheus.
Однако вы можете копнуть немного глубже, используя Node Exporter.
а — Дополнительные модули
Не все модули включены по умолчанию, и если вы запустите простую установку экспортера узлов, скорее всего, вы не используете какие-либо дополнительные плагины.
Вот список дополнительных модулей
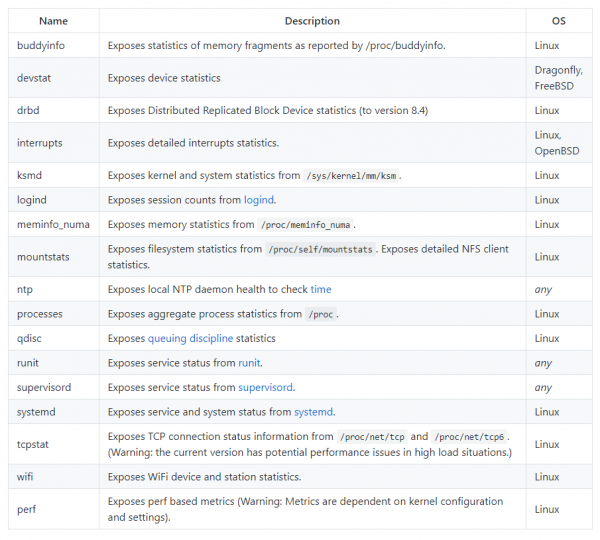
Чтобы активировать их, просто добавьте флаг –collector. <name> при запуске экспортера узлов, например:
ExecStart=/usr/local/bin/node_exporter --collector.processes --collector.ntp
Это должно активировать процессы и сборщики ntp .
b — Сборщик текстовых файлов
Полное руководство по Node Exporter было бы неполным без упоминания сборщика текстовых файлов, по крайней мере, для небольшого раздела.
Подобно Pushgateway, сборщик текстовых файлов собирает метрики из текстовых файлов и сохраняет их прямо в Prometheus.
Он разработан для пакетных заданий или краткосрочных заданий, которые не отображают показатели непрерывно.
Некоторые примеры сборщика текстовых файлов доступны здесь:
- Использование сборщика текстовых файлов из сценария оболочки.
- Мониторинг размеров каталогов с помощью сборщика текстовых файлов.
Implementation
Why are all sample values 64-bit floats? I want integers.
We restrained ourselves to 64-bit floats to simplify the design. The
IEEE 754 double-precision binary floating-point
format
supports integer precision for values up to 253. Supporting
native 64 bit integers would (only) help if you need integer precision
above 253 but below 263. In principle, support
for different sample value types (including some kind of big integer,
supporting even more than 64 bit) could be implemented, but it is not
a priority right now. A counter, even if incremented one million times per
second, will only run into precision issues after over 285 years.

![Сервис_prometheus [методические материалы лохтурова вячеслава]](https://smartshop124.ru/wp-content/uploads/8/f/9/8f96f4e599a8eb6897b890d00055a7b1.jpeg)
Why don’t the Prometheus server components support TLS or authentication? Can I add those?
TLS and basic authentication is gradually being rolled out to the different
components. Please follow the different releases and changelogs to know which
components have already implemented it.
The components currently supporting TLS and authentication are:
- Prometheus 2.24.0 and later
- Node Exporter 1.0.0 and later
This applies only to inbound connections. Prometheus does support
, and other
Prometheus components that create outbound connections have similar support.
This documentation is . Please help improve it by filing issues or pull requests.
Планирование восстановления
Планы восстановления – это наборы документированных процедур для восстановления среды после возможных сбоев или ошибок администрирования. Как минимум, вам понадобится план восстановления после каждого потенциального сбоя, который, по вашему мнению, неизбежно произойдет (например, сбоя аппаратного обеспечения сервера или случайного удаления данных).
Например, очень простой план восстановления после отказа сервера может состоять из списка шагов, предпринятых вами для первоначального развертывания сервера, с дополнительными процедурами восстановления данных приложения из резервных копий. Более эффективный план восстановления может, помимо хорошей документации, использовать сценарии развертывания и инструменты управления конфигурацией, такие как Ansible, Chef или Puppet, чтобы помочь автоматизировать и ускорить процесс восстановления.
Роль планирования восстановления в среде производства очень важна.
Хотя планы восстановления не существуют в серверной среде в качестве программного обеспечения, они являются необходимым компонентом для настройки среды производства. Они позволяют эффективно использовать резервные копии и обеспечивают планомерное восстановление среды и возврат в нужное состояние.
Для создания планов восстановления нужно предусмотреть:
- Документацию процедур: набор документов, которые должны выполняться в случае сбоя. Хорошим стартом будет создание пошагового документа, который можно выполнить для восстановления отказавшего сервера. Затем такой базовый документ можно расширить с помощью блоков для восстановления различных данных и конфигурации приложения из резервных копий.
- Инструменты автоматизации: сценарии и программное обеспечение для управления конфигурацией обеспечивают автоматизацию, которая может улучшить процессы развертывания и восстановления. Хотя для простого восстановления после сбоя вполне подходят пошаговые руководства, они должны выполняться человеком, а это не так быстро и последовательно, как автоматизированный процесс.
- Критические компоненты: компоненты, необходимые для правильной работы приложения. К примеру, таким компонентом может быть сервер приложений и баз данных – если они дадут сбой, приложение станет недоступным.
- Единую точку отказа: так называются критические компоненты, которые не имеют автоматического механизма восстановления сбоев. Вы должны попытаться устранить единые точки отказа, насколько это возможно, чтобы улучшить доступность приложения.
- Постоянные ревизии: своевременно обновляйте свою документацию по мере улучшения процесса развертывания и восстановления.
Параметры компьютера и сети
Бывает так, что отключение ненужных модулей и фоновых процессов может быть недостаточно, чтобы повысить производительность программы 1С. Всему виной могут быть характеристики компьютера. Если они слабые и их недостаточно для минимальных требований программы, то это может повлиять за собой значительное замедление работоспособности софта. Это касается не всех составляющих ПК
Особое внимание следует уделить процессору и оперативной памяти
Системные требования программы 1С можно посмотреть на странице официального сайта 1С. Чтобы посмотреть параметры компьютера, необходимо при помощи кнопки «Пуск» выбрать правой кнопкой мыши пункт «Компьютер». Появиться небольшое меню, где следует выбрать «Свойства». Появится новое окно, которое будет содержать техническую информацию о компьютере.
Помимо процессора и оперативной памяти, также должны соответствовать следующие параметры:
- свободное место на жестком диске не меньше 2 Гб;
- скорость интернет-соединения не меньше 100 мБит за секунду.
Важно отметить, что существует особый пакет программы 1С, который ориентирован на передачу большого объема информации
Здесь следует отдельное внимание уделить пропускной сетевой способности ПК. Если возникнуть какие-либо торможения или другие проблемы, то данную скорость можно увеличить
Для передачи незначительного объема информации вполне достаточно будет 100 мБит/сек.
![Сервис_prometheus [методические материалы лохтурова вячеслава]](http://smartshop124.ru/wp-content/uploads/1/f/8/1f806d1969da0e4af99d57839b388d6f.jpeg)