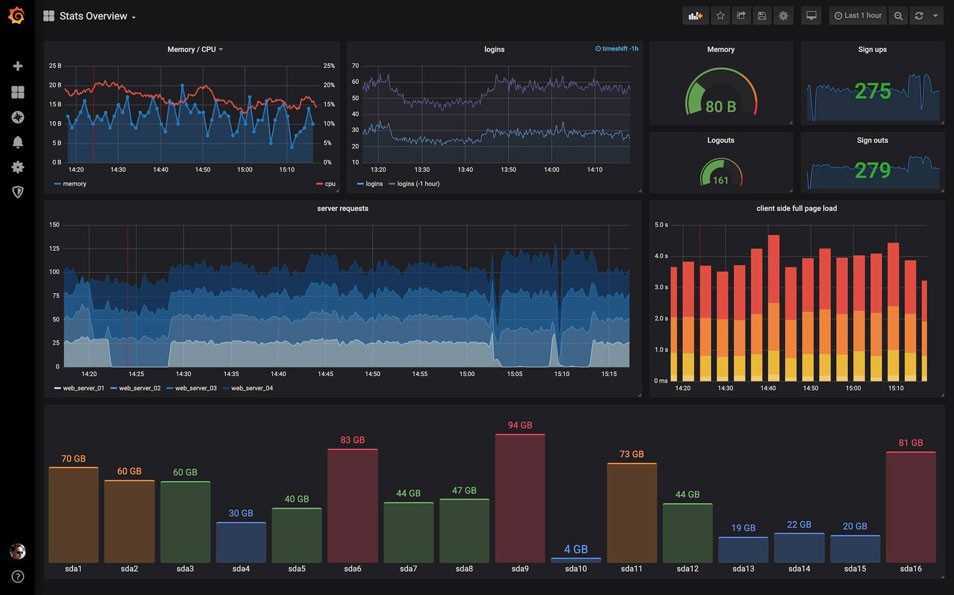
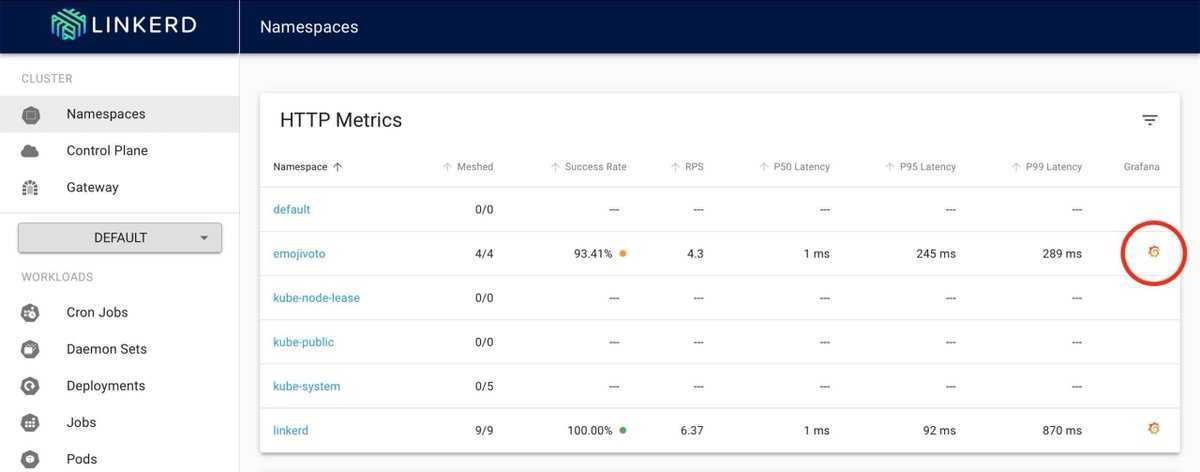
Система мониторинга открытых источников PROMETHEUS Базовое введение и отображение приложений
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>yle=»margin-bottom:5px;»>Теги: Другие Prometheus Grafana
PrometheusЭто система мониторинга службы с открытым исходным кодом Google, которая собирает данные обслуживания через протокол HTTP и сохраняется на локальных базах данных времени.
В качестве нового поколения систем мониторинга PROMETHEUS имеет следующие особенности:
-
Многоценция модели данных: временные ряды определены и настройки ключа / значения по имени индикатора;
-
PROMSQL: гибкий язык запроса, который может быть завершен с использованием многомерных данных;
-
Не полагайтесь на распределенное хранилище, могут работать отдельные узлы;
-
Данные временных серий коллекции на основе режима тяги HTTP;
-
Поддержка вспомогательной последовательности на промежуточных шлюзах
-
Обнаружение целей через открытие услуг или статической конфигурации
-
Поддержка богатых графиков и приборной панели
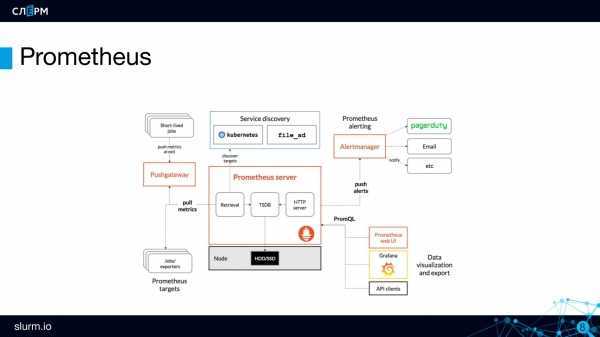
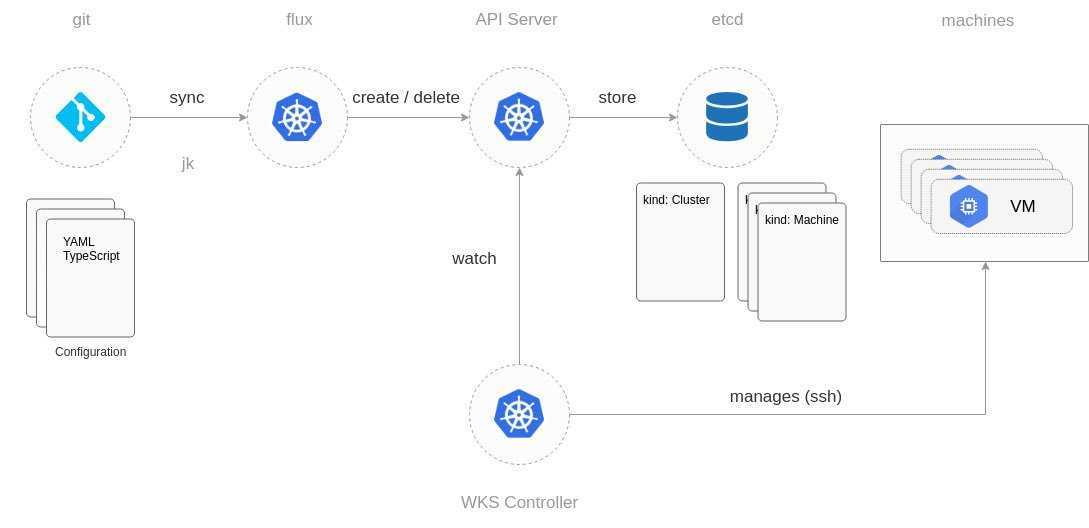
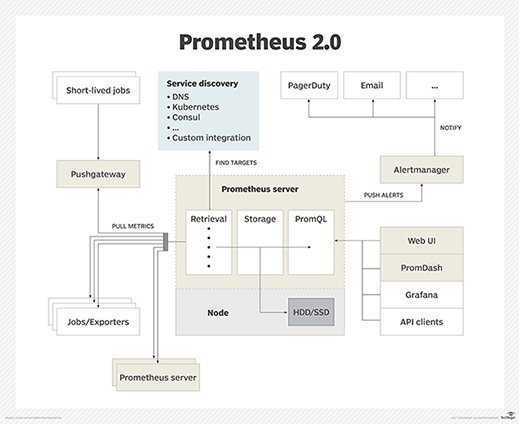
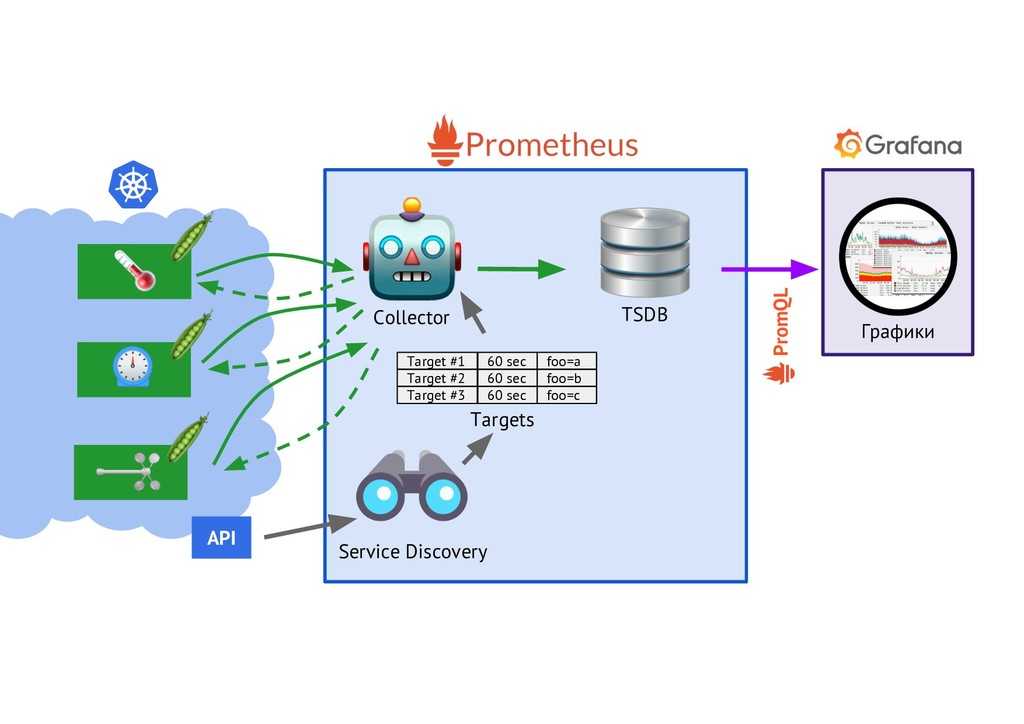
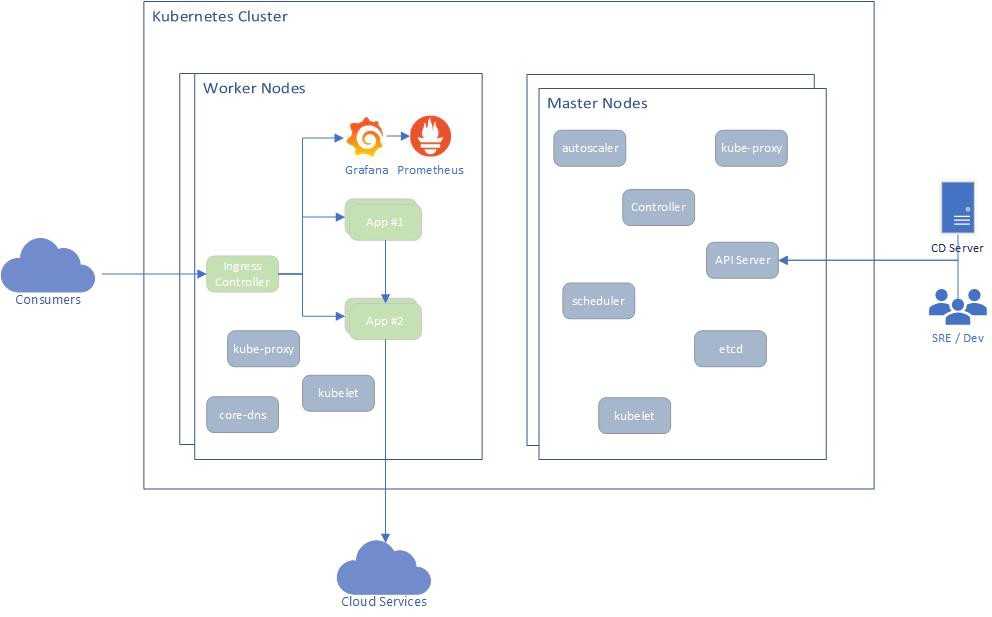
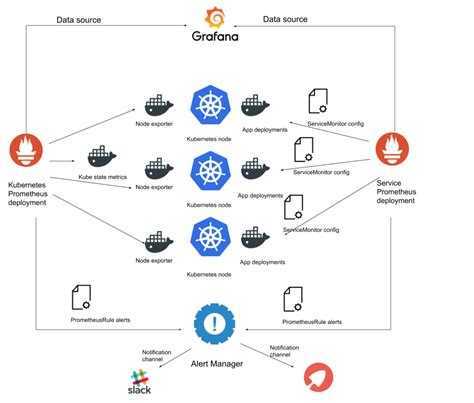
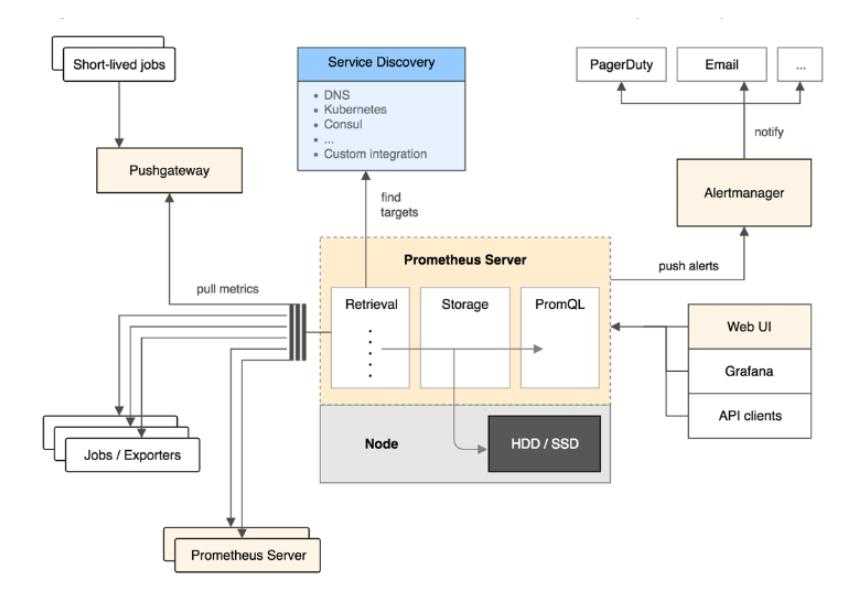
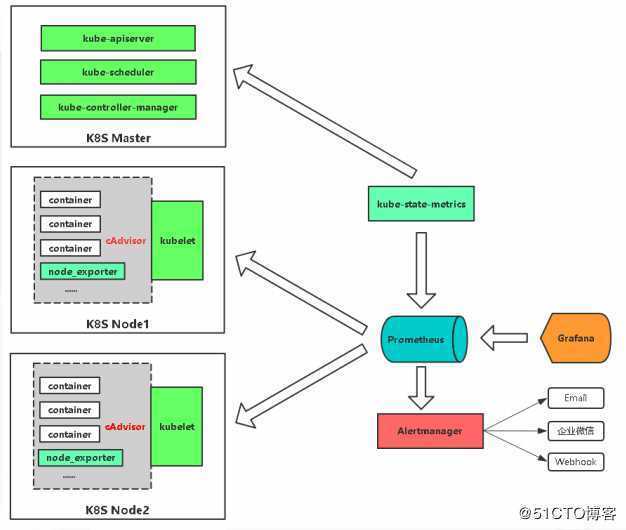
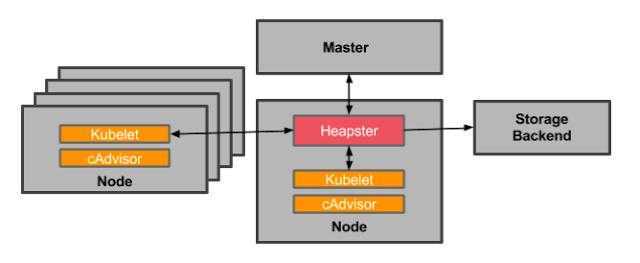
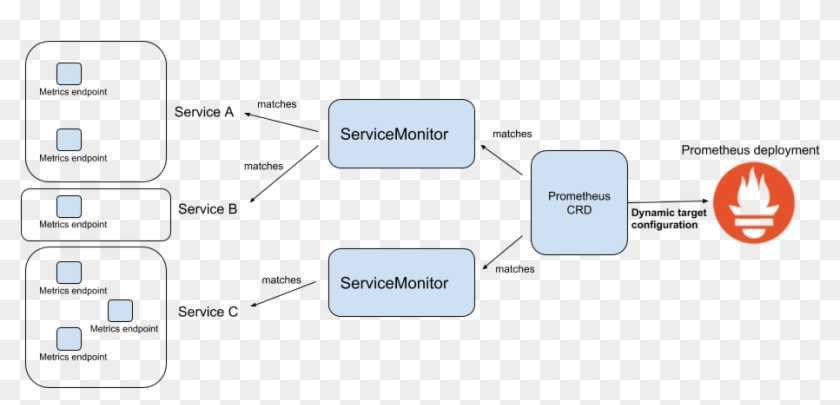
Архитектура Prometheus
В зависимости от данных, сконфигурированных для вытягивания данных каждого узла в соответствии с синхронизацией конфигурации, точку также можно использовать в способе промежуточного шлюза PushGateway, и процесс фактически используемый, как правило, выясняет данные измерений для PROMETHEUS, используя экспортер (например, , mysqld_exporterer, redis_exporter и т. Д.). AlertManager используется для аварийных сигналов, а веб-интерфейс обычно использует Grafana.
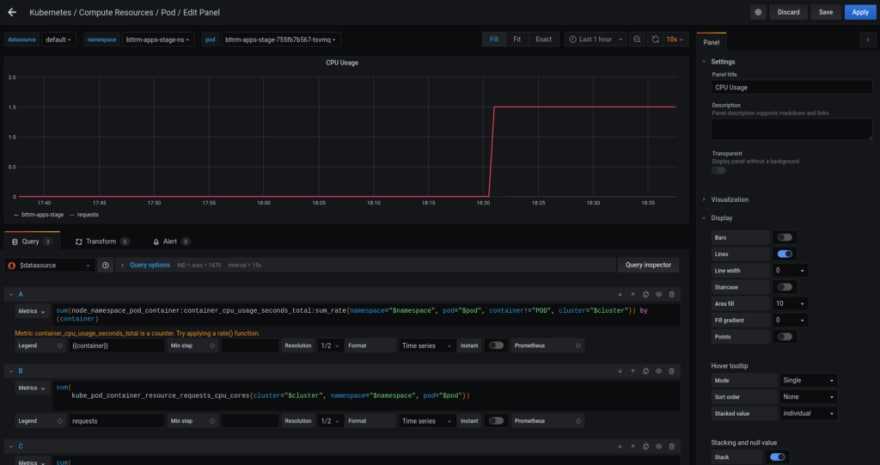
Модель данных PROMETHEUS
Данные мониторинга, собранные PROMETHEUS, сохраняются в базе данных синхронизации в виде метрических показателей.TSDBсередина.
Метрический формат:
<metric name>{<label name>=<label value>, ...}
Пример:
api_http_requests_total{method="GET", handler="/index"}
Индикатор «api_http_requests_total«Указывает на общее количество первой страницы API через метод получения.
Метод установки
Prometheus
docker pull prom/prometheus docker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus
Grafana
docker pull grafana/grafana docker run -d --name=grafana -p 3000:3000 grafana/grafana
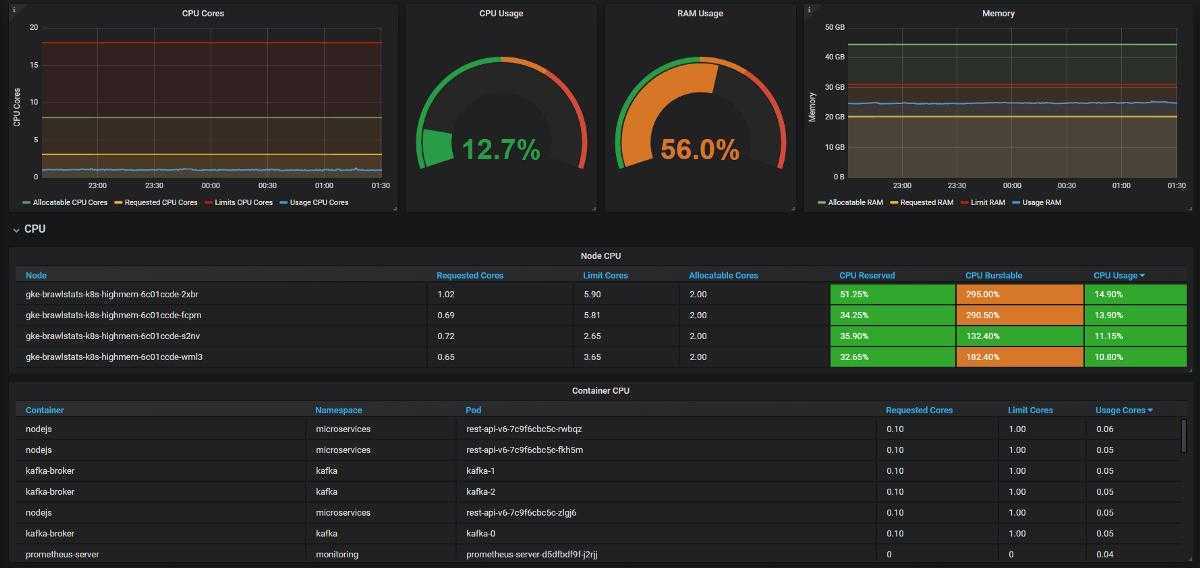
Grafana предоставит нам стереоскопический мониторинг для нас в качестве источника данных, с мощными функциями приборной панели.
Благодаря этой системе с открытым исходным кодом мы можем легко завершить мониторинг ежедневных услуг, таких как Nginx, MySQL, Redis.
Сканируйте свой код, чтобы обратить внимание на моего публичное число, получите последнюю статью!
Интеллектуальная рекомендация
…
1. Определите класс узла: 2. Класс реализации алгоритма: 3. Просмотрите двоичное дерево на следующем рисунке….
Последовательность развития 1. Создать сущность для реализации хозяйствующего субъекта. 2. Создайте IDAL для реализации интерфейса. 3. Создайте DAL для реализации методов в интерфейсе. 4. Увеличьте ин…
pinyin4j действительно сложно, вот простое приложение …
Создать проект взломанная версия pycharm -> новый проект -> django. Project Interpreter использует среду New Virtualenv по умолчанию. settings.py Часовой пояс и язык Статические файлы Зарегистри…
Вам также может понравиться
1. Загрузите исходный код https://github.com/tzutalin/labelImg, После скачивания разархивируйте его. 2. Установите Python3.5. Не используйте 3.6! Не используйте 3.6! Не используйте 3.6! Пока что при в…
Я столкнулся с бизнес-сценарием в недавнем проекте: Перенесите таблицы из текущей базы данных в другую базу данных. Для обеспечения эффективности миграции требуется одновременная миграция данных. Для …
…
С развитием технологии виртуализации все больше и больше веб-проектов используют докер для развертывания и обслуживания. Мы попытались использовать docker-compose для организации веб-проекта, основанн…
После того, как язык задан, режим интерпретатора может определять представление его грамматики и одновременно предоставлять переводчика. Клиент может использовать этот интерпретатор для интерпретации …
Настройка Prometheus
Необходимо добавить задание в Prometheus для подключения к серверу Pushgateway и получения с него метрик. Это делается по такому же принципу, что и получение метрик с экспортеров.
Открываем конфигурационный файл:
vi /etc/prometheus/prometheus.yml
В секцию scrape_configs добавим задание:
…
scrape_configs:
…
— job_name: ‘pushgateway’
honor_labels: true
static_configs:
— targets:
* в данном задании мы говорим серверу Prometheus забирать метрики с сервера localhost (локальный сервер) на порту 9091.
Для применения настроек перезапускаем сервис прометея:
systemctl restart prometheus
Проверяем, что сервис работает корректно:
systemctl status prometheus
Можно попробовать отправить метрики в Pushgateway.
Exporters
prometheus-node-exporter
- В Debian ставится как зависимость к пакету prometheus и добавлен в конфигурацию
Примеры счетчиков
node_filesystem_free_bytes
$ df /
...
/dev/mapper/debian--vg-root 15662008 1877488 12969212 13% /
...
# TYPE node_filesystem_free_bytes gauge
node_filesystem_free_bytes{device="/dev/mapper/debian--vg-root",fstype="ext4",mountpoint="/"} = (15662008 - 1877488) * 1024
node_network_receive_bytes_total
$ cat /sys/class/net/eth1/statistics/rx_bytes
# TYPE node_network_receive_bytes_total counter
node_network_receive_bytes_total{device="eth1"}
Подключение к prometheus
# less /etc/prometheus/prometheus.yml
...
- job_name: node
# If prometheus-node-exporter is installed, grab stats about the local
# machine by default.
static_configs:
- targets:
Запросы PromQL
8*rate(node_network_receive_bytes_total)
8*rate(node_network_receive_bytes_total{device="eth1"})
8*rate(node_network_receive_bytes_total{device="eth1",instance="localhost:9100",job="node"})
prometheus-blackbox-exporter
# apt install prometheus-blackbox-exporter
Пример конфигурации
# cat /etc/prometheus/blackbox.yml
...
http_2xx:
prober: http
http:
preferred_ip_protocol: "ip4"
...
# service prometheus-blackbox-exporter restart # cat /etc/prometheus/prometheus.yml
...
- job_name: check_http
metrics_path: /probe
params:
module:
static_configs:
- targets:
- https://google.com
- https://ya.ru
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
- job_name: check_ssh
metrics_path: /probe
params:
module:
static_configs:
- targets:
- switch1:22
- switch2:22
- switch3:22
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
probe_success... probe_duration_seconds... probe_http_duration_seconds...
Пример использования file-based service discovery и сервиса ping
# cat /etc/prometheus/prometheus.yml
...
- job_name: check_ping
metrics_path: /probe
params:
module:
file_sd_configs:
- files:
# - switchs.yml
# - switchs.json
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9115
# cat /etc/prometheus/switchs.json
} ]
# cat /etc/prometheus/switchs.yml
- targets: - switch1 - switch2 - switch3
Проверка конфигурации и перезапуск
prometheus-snmp-exporter
# apt install prometheus-snmp-exporter # cat /etc/prometheus/snmp.yml
#if_mib: # по умолчанию, позволяет не указывать module в http запросе
snmp_in_out_octets:
version: 2
auth:
community: public
walk:
- 1.3.6.1.2.1.2.2.1.10
- 1.3.6.1.2.1.2.2.1.16
- 1.3.6.1.2.1.2.2.1.2
metrics:
- name: if_in_octets
oid: 1.3.6.1.2.1.2.2.1.10
type: counter
indexes:
- labelname: ifIndex
type: Integer
lookups:
- labels:
- ifIndex
labelname: ifDescr
oid: 1.3.6.1.2.1.2.2.1.2
type: DisplayString
- name: if_out_octets
oid: 1.3.6.1.2.1.2.2.1.16
type: counter
indexes:
- labelname: ifIndex
type: Integer
lookups:
- labels:
- ifIndex
labelname: ifDescr
oid: 1.3.6.1.2.1.2.2.1.2
type: DisplayString
# service prometheus-snmp-exporter restart
http://server.corpX.un:9116/
# curl --noproxy 127.0.0.1 'http://127.0.0.1:9116/snmp?target=router&module=snmp_in_out_octets'
# cat /etc/prometheus/prometheus.yml
...
- job_name: 'snmp'
static_configs:
- targets:
- router
metrics_path: /snmp
params:
module:
relabel_configs:
- source_labels:
target_label: __param_target
- source_labels:
target_label: instance
- target_label: __address__
replacement: localhost:9116
Проверка конфигурации и перезапуск
rate(if_in_octets{ifDescr="FastEthernet1/1",ifIndex="3",instance="router",job="snmp"})
8*rate(if_in_octets{ifDescr="FastEthernet1/1",instance="router"})
DevOps
Со всеми этими экспортерами для разных систем, баз данных и серверов очевидно, что Prometheus предназначен, в основном, для сферы DevOps.
Мы знаем, что в этой сфере множество конкурирующих поставщиков и персонализированных решений.
Prometheus идеально подходит для DevOps.
Для настройки и запуска экземпляров почти не требуется усилий, и можно легко активировать и настроить любой вспомогательный инструмент.
Благодаря обнаружению целевых объектов — например, через файловый экспортер, —это отличное решение для стеков, где широко используются контейнеры и распределенные архитектуры.
В среде, где экземпляры то и дело создаются и удаляются, ни один стек DevOps не обойдется без обнаружения сервисов.
2. Здравоохранение
Сегодня решения для мониторинга нужны не только в ИТ. Они используются и в крупных отраслях, которые предоставляют гибкие и масштабируемые архитектуры для здравоохранения.
Спрос растет, и ИТ-архитектуры обязаны ему соответствовать. Если у вас нет надежного инструмента для мониторинга всей инфраструктуры, вы рискуете столкнуться с серьезными перебоями в обслуживании. Уж в сфере здравоохранения такую опасность точно надо свести к минимуму.
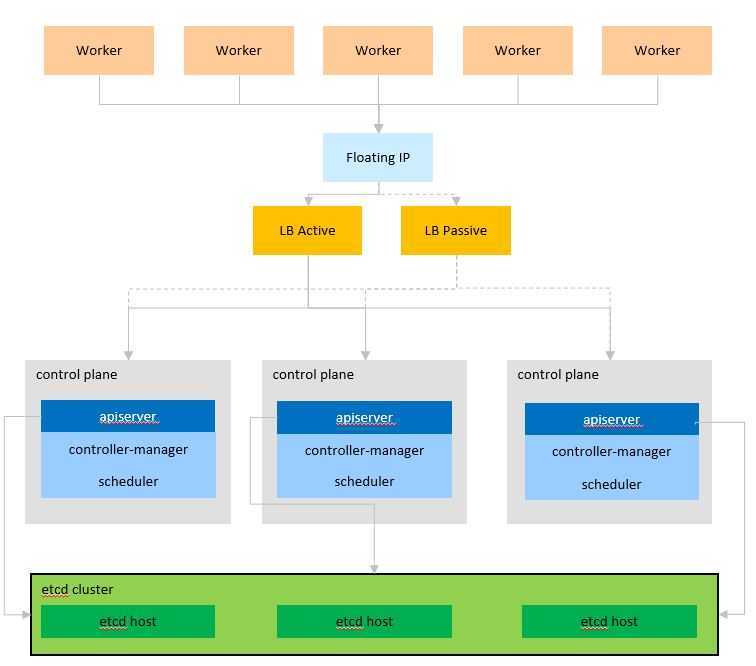
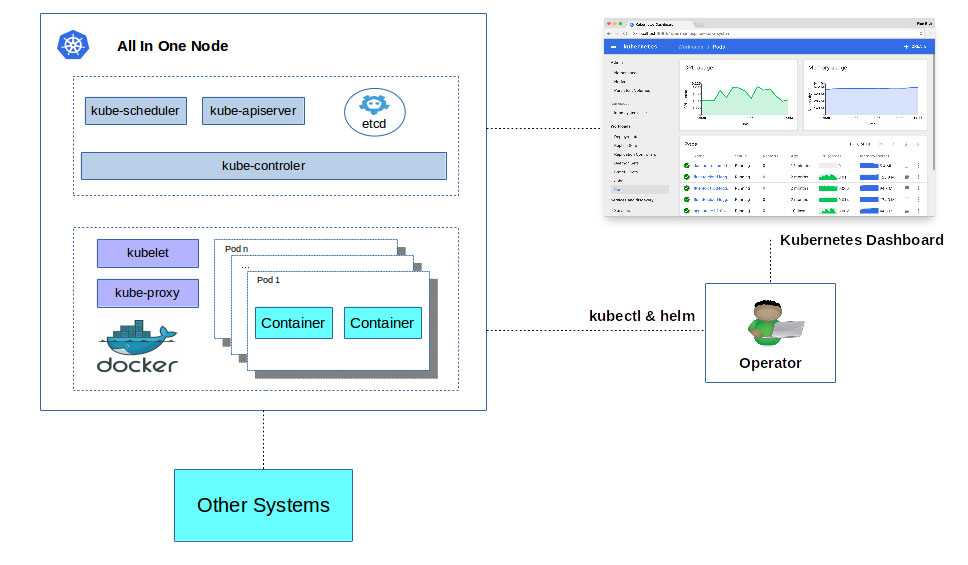
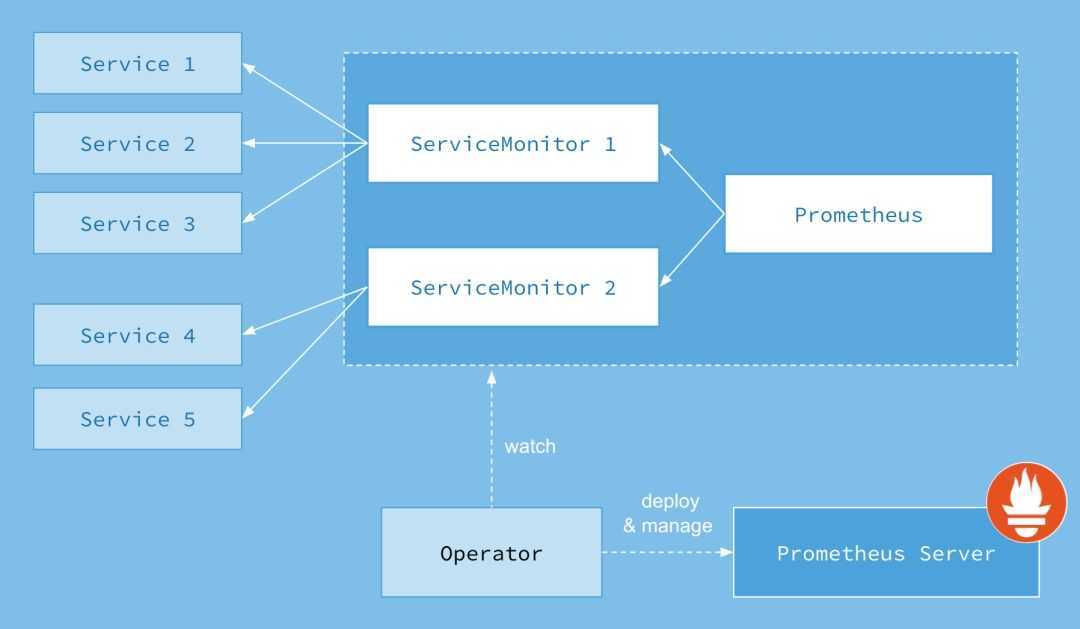
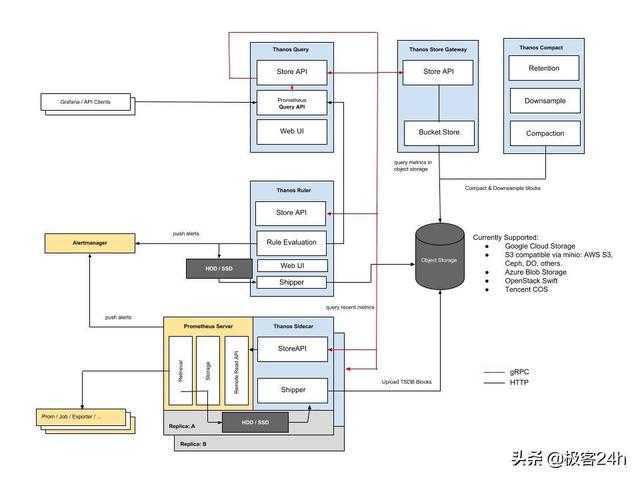
![Сервис_prometheus [методические материалы лохтурова вячеслава]](https://smartshop124.ru/wp-content/uploads/1/f/8/1f806d1969da0e4af99d57839b388d6f.jpeg)
Этот пример обсуждался на opensource.com в следующей статье.
3. Финансовые услуги
Последний пример приводился на конференции InfoQ, где обсуждалось использование Prometheus в финансовых учреждениях.
Джейми Кристиан (Jamie Christian) и Алан Стрейдер (Alan Strader) показывали, как они используют Prometheus для мониторинга своей инфраструктуры в Northern Trust. Очень содержательно, советую посмотреть.
Часть X. Что дальше?
Пора переходить от теории к практике.
Сегодня вы познакомились с основами Prometheus, узнали, какие функции он выполняет, с какими инструментами и системами работает и какие термины использует.
Теперь у вас есть все необходимое, чтобы создать свое решение для мониторинга.
Чтобы приступить к работе с Prometheus, изучите все доступные экспортеры.
Потом установите нужные инструменты, создайте свою первую панель мониторинга — и вперед!
Если вам нужно вдохновение, почитайте мою статью о том, как мониторить машину Linux с Prometheus и Grafana. Там есть инструкции по настройке инструментов и первой панели мониторинга.
Надеюсь, вы узнали что-то новое.
Если у вас есть тема для моей следующей статьи, поделитесь.
Счастливо оставаться!
Prometheus
Prometheus не устанавливается из репозитория и имеет, относительно, сложный процесс установки. Необходимо скачать исходник, создать пользователя, вручную скопировать нужные файлы, назначить права и создать юнит для автозапуска.
Загрузка
Переходим на официальную страницу загрузки и копируем ссылку на пакет для Linux:
и используем ее для загрузки пакета на Linux:
wget https://github.com/prometheus/prometheus/releases/download/v2.17.2/prometheus-2.17.2.linux-amd64.tar.gz
* если система вернет ошибку, необходимо установить пакет wget.
Установка (копирование файлов)
После того, как мы скачали архив prometheus, необходимо его распаковать и скопировать содержимое по разным каталогам.
Для начала создаем каталоги, в которые скопируем файлы для prometheus:
mkdir /etc/prometheus
mkdir /var/lib/prometheus
Распакуем наш архив:
tar zxvf prometheus-*.linux-amd64.tar.gz
… и перейдем в каталог с распакованными файлами:
cd prometheus-*.linux-amd64
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
Назначение прав
Создаем пользователя, от которого будем запускать систему мониторинга:
useradd —no-create-home —shell /bin/false prometheus
* мы создали пользователя prometheus без домашней директории и без возможности входа в консоль сервера.
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
Задаем владельца для скопированных файлов:
chown prometheus:prometheus /usr/local/bin/{prometheus,promtool}
Запуск и проверка
Запускаем prometheus командой:
/usr/local/bin/prometheus —config.file /etc/prometheus/prometheus.yml —storage.tsdb.path /var/lib/prometheus/ —web.console.templates=/etc/prometheus/consoles —web.console.libraries=/etc/prometheus/console_libraries
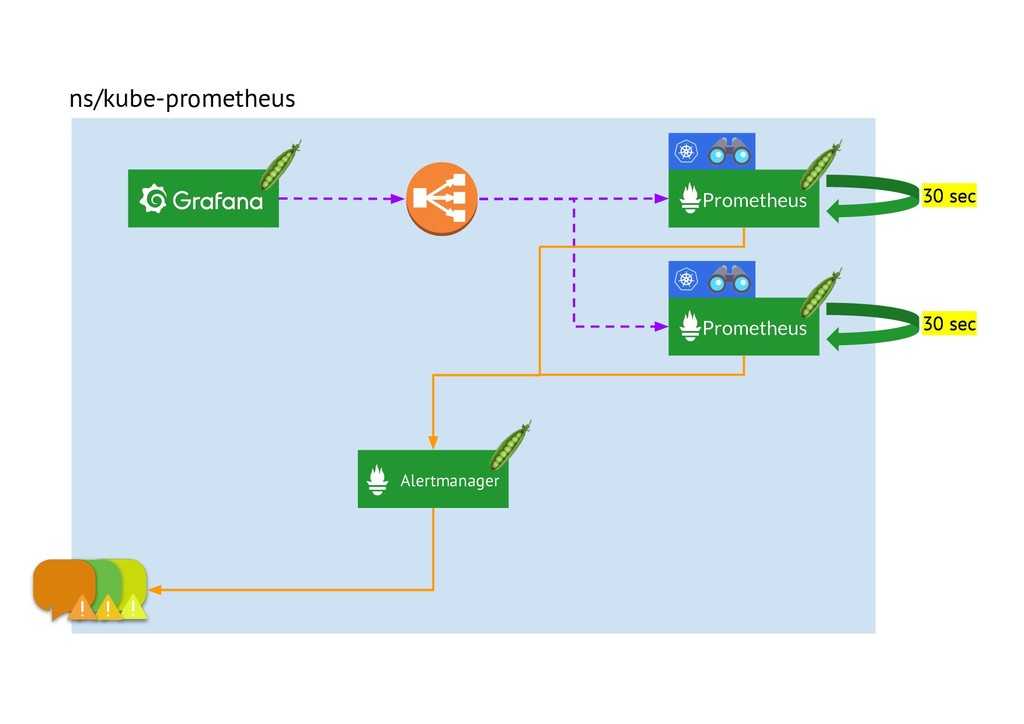
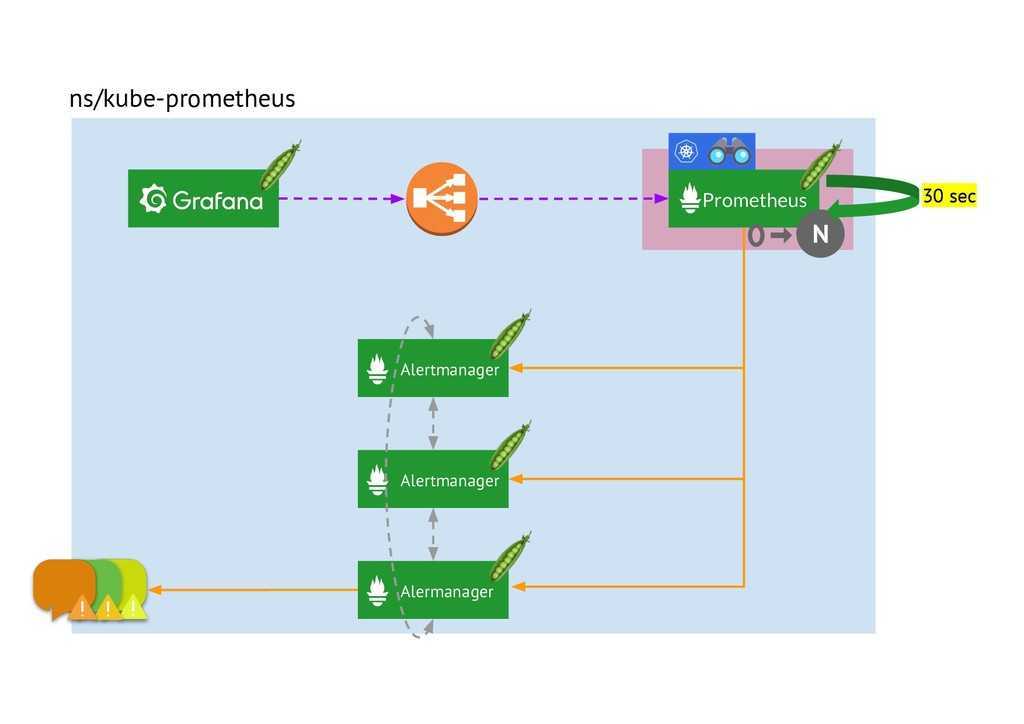
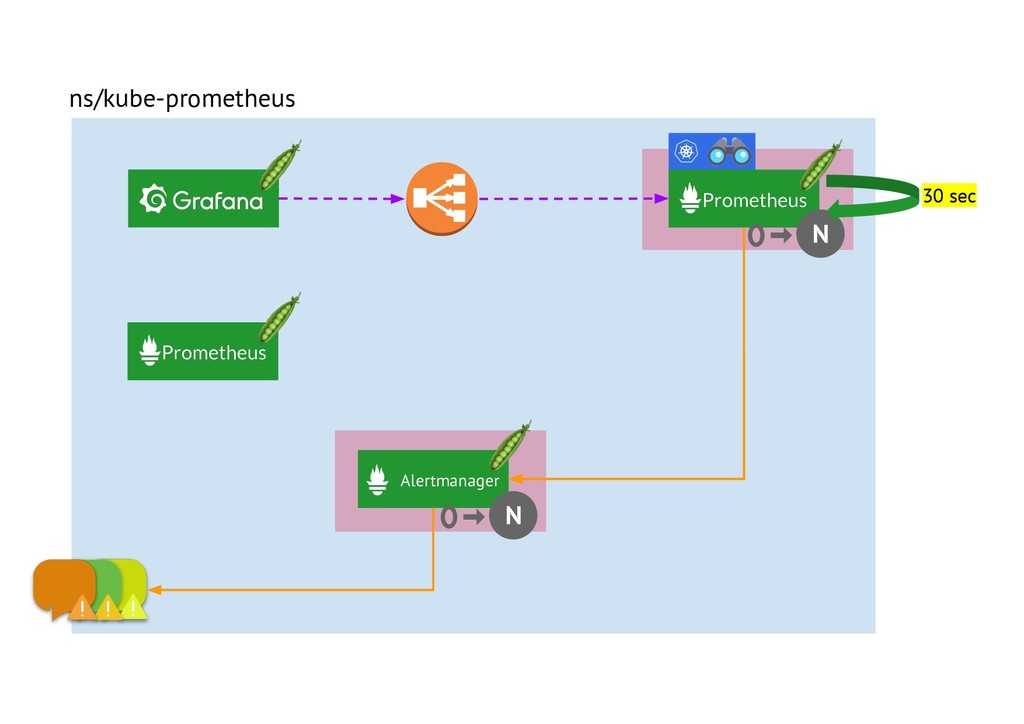
… мы увидим лог запуска — в конце «Server is ready to receive web requests»:
level=info ts=2019-08-07T07:39:06.849Z caller=main.go:621 msg=»Server is ready to receive web requests.»
Открываем веб-браузер и переходим по адресу http://<IP-адрес сервера>:9090 — загрузится консоль Prometheus:
Установка завершена.
Автозапуск
Мы установили наш сервер мониторинга, но его необходимо запускать вручную, что совсем не подходит для серверных задач. Для настройки автоматического старта Prometheus мы создадим новый юнит в systemd.
Возвращаемся к консоли сервера и прерываем работу Prometheus с помощью комбинации Ctrl + C. Создаем файл prometheus.service:
vi /etc/systemd/system/prometheus.service
Description=Prometheus Service
After=network.target
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
—config.file /etc/prometheus/prometheus.yml \
—storage.tsdb.path /var/lib/prometheus/ \
—web.console.templates=/etc/prometheus/consoles \
—web.console.libraries=/etc/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
systemctl daemon-reload
Разрешаем автозапуск:
systemctl enable prometheus
После ручного запуска мониторинга, который мы делали для проверки, могли сбиться права на папку библиотек — снова зададим ей владельца:
chown -R prometheus:prometheus /var/lib/prometheus
Запускаем службу:
systemctl start prometheus
… и проверяем, что она запустилась корректно:
systemctl status prometheus
Процессор
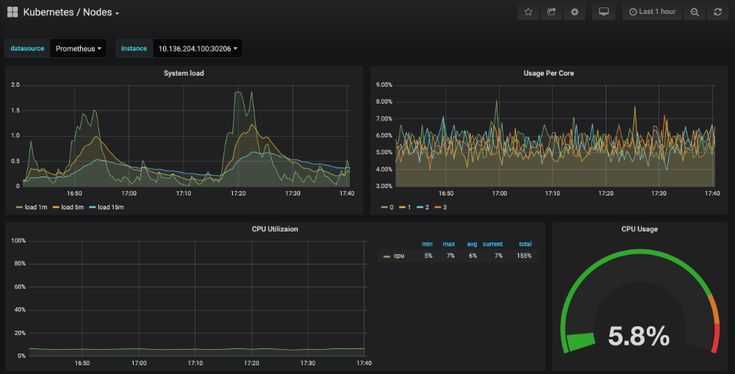
Для получения нужных нам показателей будем использовать метрику node_cpu_seconds_total.
Количество процессоров
1. Общее количество всех процессоров всех узлов:
sum(count(node_cpu_seconds_total{mode=’system’}) by (cpu))
2. Для некоторых инстансов:
sum(count(node_cpu_seconds_total{instance=~’192.168.0.15:9100|192.168.0.20:9100′,mode=’system’}) by (cpu))
* для 192.168.0.15 и 192.168.0.20.
3. По отдельности:
count(node_cpu_seconds_total{mode=’system’}) by (instance)
Нагрузка
1. На все ядра всех узлов:
(irate(node_cpu_seconds_total{job=»node_exporter_clients»,mode=»idle»})) * 100
100 — ((irate(node_cpu_seconds_total{job=»node_exporter_clients»,mode=»idle»})) * 100)
* первый запрос для отображения процента свободного процессорного времени, второй — процент утилизации.
Пример ответа:
{cpu=»0″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.6000000238418579
{cpu=»0″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.9999999403953552
{cpu=»1″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.6000000238418579
{cpu=»1″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 1.5999999642372131
{cpu=»2″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.8000000193715096
{cpu=»2″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.8000001311302185
{cpu=»3″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 1.0000000149011612
{cpu=»3″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.6000000238418579
{cpu=»4″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.19999999552965164
{cpu=»4″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.2000001072883606
{cpu=»5″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.40000002831220627
{cpu=»5″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.3999999165534973
{cpu=»6″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.6000000238418579
{cpu=»6″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.2000001072883606
{cpu=»7″, instance=»192.168.0.15:9100″, job=»node_exporter_clients», mode=»idle»} 0.19999999552965164
{cpu=»7″, instance=»192.168.0.20:9100″, job=»node_exporter_clients», mode=»idle»} 0.3999999165534973

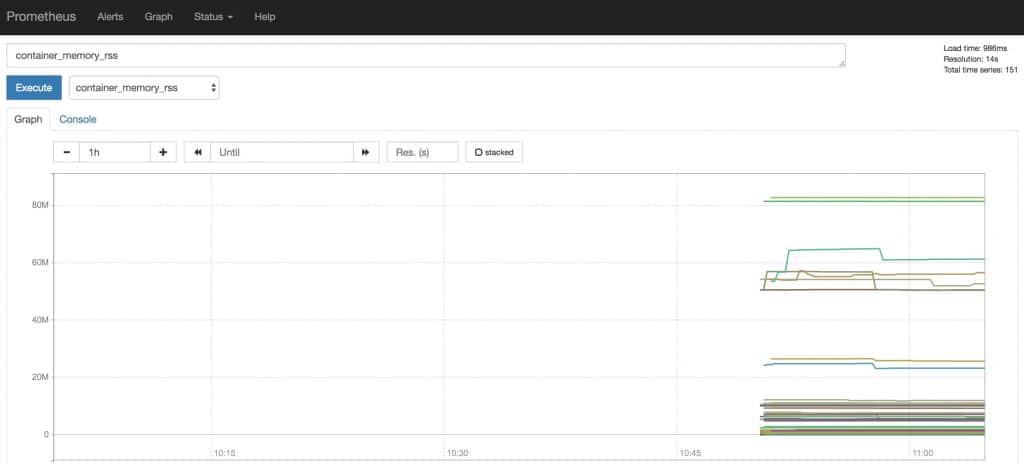

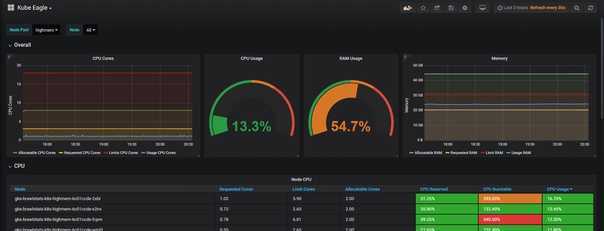
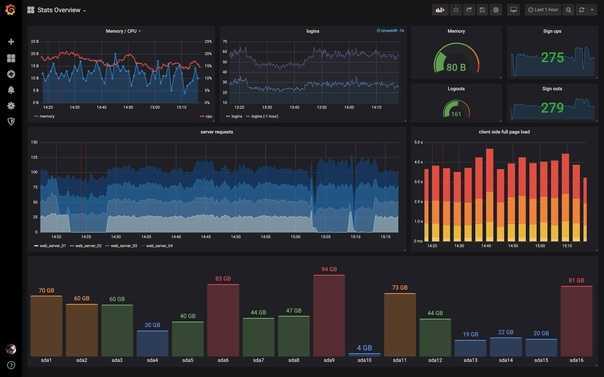
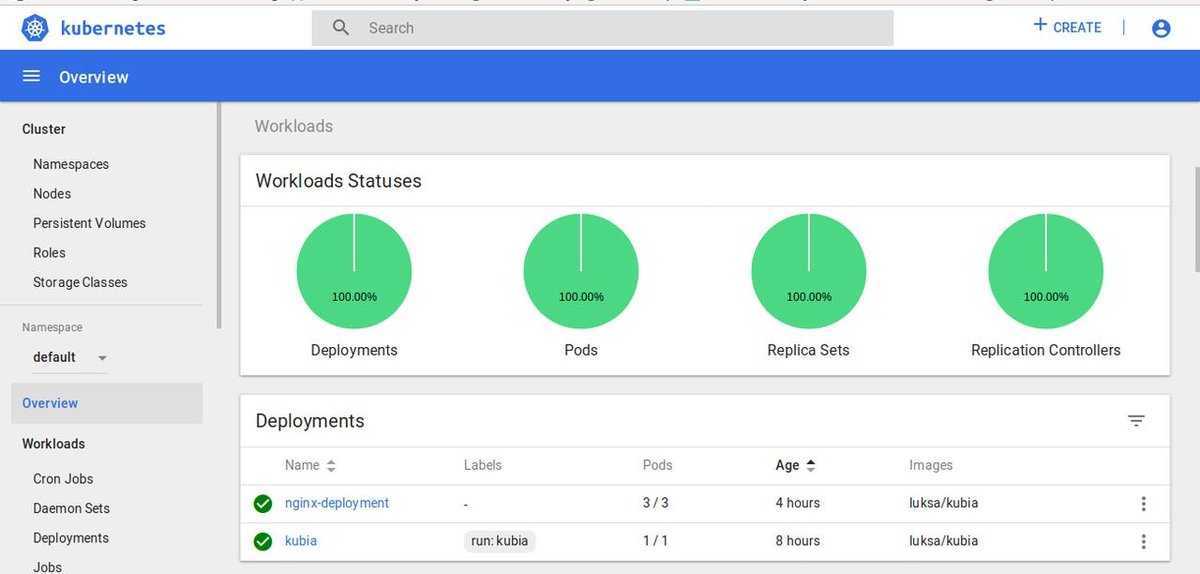
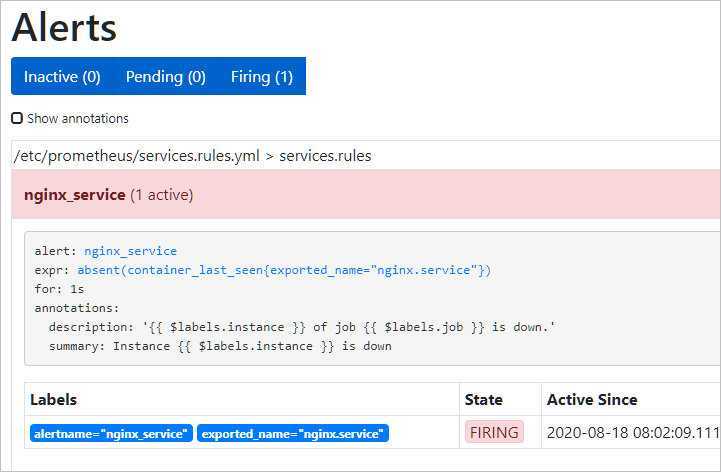
2. Средняя величина по ядрам для всех узлов:
avg by (instance)(irate(node_cpu_seconds_total{job=»node_exporter_clients»,mode=»idle»})) * 100
100 — (avg by (instance)(irate(node_cpu_seconds_total{job=»node_exporter_clients»,mode=»idle»})) * 100)
* первый запрос для отображения процента свободного процессорного времени, второй — процент утилизации.
Пример ответа:
{instance=»192.168.0.15:9100″} 0.7999999960884452
{instance=»192.168.0.20:9100″} 0.9500000253319598
3. Средняя величина по ядрам для конкретного узла:
avg by (instance)(irate(node_cpu_seconds_total{instance=»192.168.0.15:9100″,job=»node_exporter_clients»,mode=»idle»})) * 100
100 — (avg by (instance)(irate(node_cpu_seconds_total{instance=»192.168.0.15:9100″,job=»node_exporter_clients»,mode=»idle»})) * 100)
* первый запрос для отображения процента свободного процессорного времени, второй — процент утилизации.
Пример ответа:
{instance=»192.168.0.15:9100″} 1.100000003352747
Время ожидания
Запрос показывает значение в процентном эквиваленте для времени ожидания процессора. На практике, идеально, когда он равен нулю.
1. Среднее значение за 30 минут для всех узлов:
avg(irate(node_cpu_seconds_total{mode=»iowait»})) * 100
2. Для конкретного узла:
avg(irate(node_cpu_seconds_total{instance=~»192.168.0.15:9100|192.168.0.20:9100″,mode=»iowait»})) * 100
3. Отдельно по каждой ноде:
irate(node_cpu_seconds_total{mode=»iowait»}) * 100
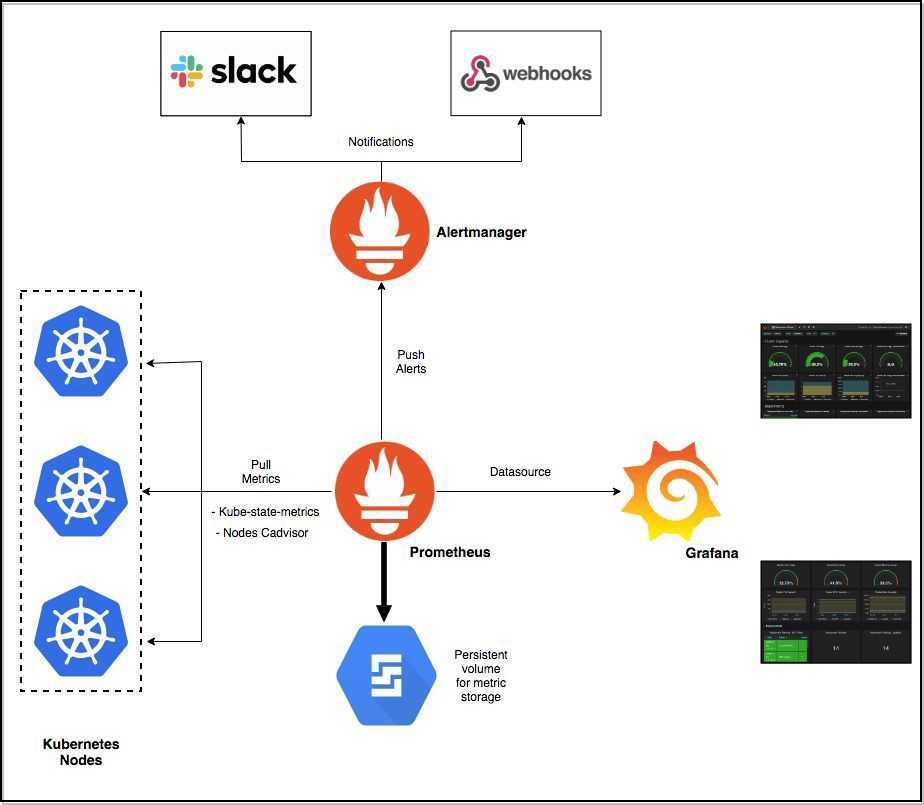
Отправка уведомлений
Теперь настроим связку с алерт менеджером для отправки уведомлений на почту.
Настроим alertmanager:
vi /etc/alertmanager/alertmanager.yml
В секцию global добавим:
global:
…
smtp_from: monitoring@dmosk.ru
Приведем секцию route к виду:
… далее добавим еще один ресивер:
* в данном примере мы отправляем сообщение на почтовый ящик alert@dmosk.ru с локального сервера
Обратите внимание, что для отправки почты наружу у нас должен быть корректно настроенный почтовый сервер (в противном случае, почта может попадать в СПАМ)
Перезапустим сервис для алерт менеджера:
systemctl restart alertmanager
Теперь настроим связку prometheus с alertmanager — открываем конфигурационный файл сервера мониторинга:
vi /etc/prometheus/prometheus.yml
Приведем секцию alerting к виду:
alerting:
alertmanagers:
— static_configs:
— targets:
— 192.168.0.14:9093
![Сервис_prometheus [методические материалы лохтурова вячеслава]](https://smartshop124.ru/wp-content/uploads/b/b/e/bbe9e7d11b9a91590eca524e2dabc7b6.jpeg)
* где 192.168.0.14 — IP-адрес сервера, на котором у нас стоит alertmanager.
Перезапускаем сервис:
systemctl restart prometheus
Немного ждем и заходим на веб интерфейс алерт менеджера — мы должны увидеть тревогу:
… а на почтовый ящик должно прийти письмо с тревогой.
Installing Alertmanager
Start off by creating a seperate user for alertmanager:
useradd -M -r -s /bin/false alertmanager
Next, we need a directory for the configuration:
mkdir /etc/alertmanager chown alertmanager:alertmanager /etc/alertmanager
Then download Alertmanager and verify its integrity:
cd /tmp wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz wget -O - -q https://github.com/prometheus/alertmanager/releases/download/v0.21.0/sha256sums.txt | grep linux-amd64 | shasum -c -
The last command should result in . If it doesn’t, the downloaded file is corrupted, and you should try again.
Next we unpack the file and move the various components into place:
tar xzf alertmanager-0.21.0.linux-amd64.tar.gz
cp alertmanager-0.21.0.linux-amd64/{alertmanager,amtool} /usr/local/bin/
chown alertmanager:alertmanager /usr/local/bin/{alertmanager,amtool}
And clean up our downloaded files in /tmp:
rm -f /tmp/alertmanager-0.21.0.linux-amd64.tar.gz rm -rf /tmp/alertmanager-0.21.0.linux-amd64
global:
smtp_from: 'AlertManager <alertmanager@example.com>'
smtp_smarthost: 'smtp.example.com:587'
smtp_hello: 'alertmanager'
smtp_auth_username: 'username'
smtp_auth_password: 'password'
smtp_require_tls: true
route:
group_by:
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: myteam
receivers:
- name: 'myteam'
email_configs:
- to: 'user@example.com'
Save this in a file called and set permissions:
chown alertmanager:alertmanager /etc/alertmanager/alertmanager.yml
To be able to start and stop our alertmanager instance, we will create a systemd unit file. Use you favorite editor to create the file and add the following to it (replacing with the IP or resolvable FQDN of your server):
Description=Alertmanager
Wants=network-online.target
After=network-online.target
User=alertmanager
Group=alertmanager
Type=simple
WorkingDirectory=/etc/alertmanager/
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yml \
--web.external-url http://<server IP>:9093
WantedBy=multi-user.target
Activate and start the service with the following commands:
systemctl daemon-reload systemctl start alertmanager systemctl enable alertmanager
The command should now indicate that our service is up and running:

Now we need to alter the configuration of our Prometheus server to inform it about our Alertmanager instance. Edit the file . There should already be a section. All we need to do change the section so it looks like this:
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
We also need to tell Prometheus where our alerting rules live. Change the section to look like this:
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "/etc/prometheus/rules/*.yml"
Save the changes, and create the directory for the alert rules:
mkdir /etc/prometheus/rules chown prometheus:prometheus /etc/prometheus/rules
Restart the Prometheus server to apply the changes:
systemctl restart prometheus