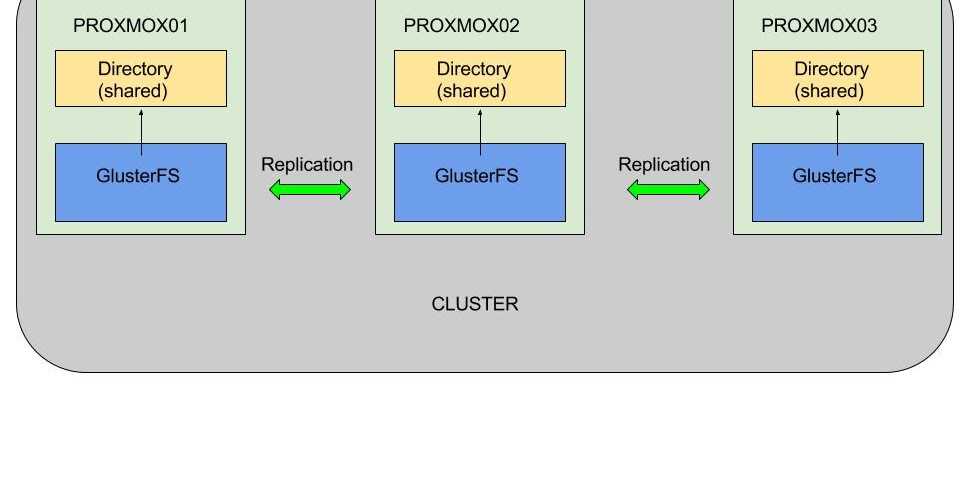
2) Install GlusterFS on Debian (Both nodes)
Then install GlusterFS on both nodes. The good thing is that it’s in the official Debian repositories, so it’s pretty easy to do.
On the terminal, run the following:
:~# apt install glusterfs-server
Then, start and check the service status.
:~# systemctl start glusterd :~# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/lib/systemd/system/glusterd.service; disabled; vendor preset: enabled) Active: active (running) since Thu 2019-08-08 15:22:29 EDT; 27s ago Docs: man:glusterd(8) Process: 8708 ExecStart=/usr/sbin/glusterd -p /run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS) Main PID: 8709 (glusterd) Tasks: 8 (limit: 893) Memory: 2.8M CGroup: /system.slice/glusterd.service └─8709 /usr/sbin/glusterd -p /run/glusterd.pid --log-level INFO Aug 08 15:22:26 osradar systemd: Starting GlusterFS, a clustered file-system server... Aug 08 15:22:29 osradar systemd: Started GlusterFS, a clustered file-system server.
So, GLusterFS is running.
5) Install GlusterFS on Debian 10 (Client)
On the server-side everything is done, just do a little configuration on the client.
First, install the glusterfs package.
:~# apt install glusterfs-client
Then, create a folder to locate the GlusterFS volume data. After this, mount the volume.
:~# mkdir -p /mnt/glusterfsvolume :~# mount -t glusterfs gluster1.osradar.local:/glusterfsvolume /mnt/glusterfsvolume
Remember open the right ports and incoming host.
It is recommended to have it automatically mounted to have immediate availability. You can do it with the following command:
:~# echo "gluster1.osradar.local:/glusterfsvolume /mnt/glusterfsvolume/ glusterfs defaults,_netdev 0 0" | tee --append /etc/fstab
And that is it. You can start to replicate. To test it, just create some files in the volume folders and see how they replicate on the other server and on the client.
Please share this post and join our Telegram Channel.
Настройка разрешения имен для приватной сети
В рамках настройки будем полагать, что все узлы соединены доверенной приватной сетью, в которой они доступны по доменными именам:
- server1.private 10.0.0.1/24
- server2.private 10.0.0.2/24
- server3.private 10.0.0.3/24
Убедитесь, что серверы находятся в разных доменах отказа, чтобы не столкнуться с ситуацией, когда авария затронет сразу две или больше машин.
В ходе настройки будем предполагать, что используются серверы под управлением Debian 9, Ubuntu 16.04 или 18.04 или CentOS7.
Сначала на каждом сервере сформируем файл /etc/hosts, чтобы серверы «видели» друг друга по доменным именам:
cat | sudo tee -a /etc/hosts >/dev/null 10.0.0.1 server1.private 10.0.0.2 server2.private 10.0.0.3 server3.private Ctrl^D
После добавления этих строк убедитесь, что все серверы «видят» друг друга по доменным именам.
Step 4: Remove LVM Filter
Now, remove all the LVM filters applied earlier. This is accomplished by editing the /etc/lvm/lvm.conf config file as follows:
-filter = [ "a|/dev/sd|", "r/.*/"] +filter = [ "a/.*/" ]
After, run vgscan to display the list of volume groups available:
# vgscan Reading all physical volumes. This may take a while... Found volume group "vg_userbackup" using metadata type lvm2 Found volume group "vg_gluster" using metadata type lvm2 Found volume group "vg_userbackup_original" using metadata type lvm2 Found volume group "vg_gluster_original" using metadata type lvm2 Found volume group "vg_sys" using metadata type lvm2
Here we can see we now have both the original “corrupted” volume and the restored volumes.
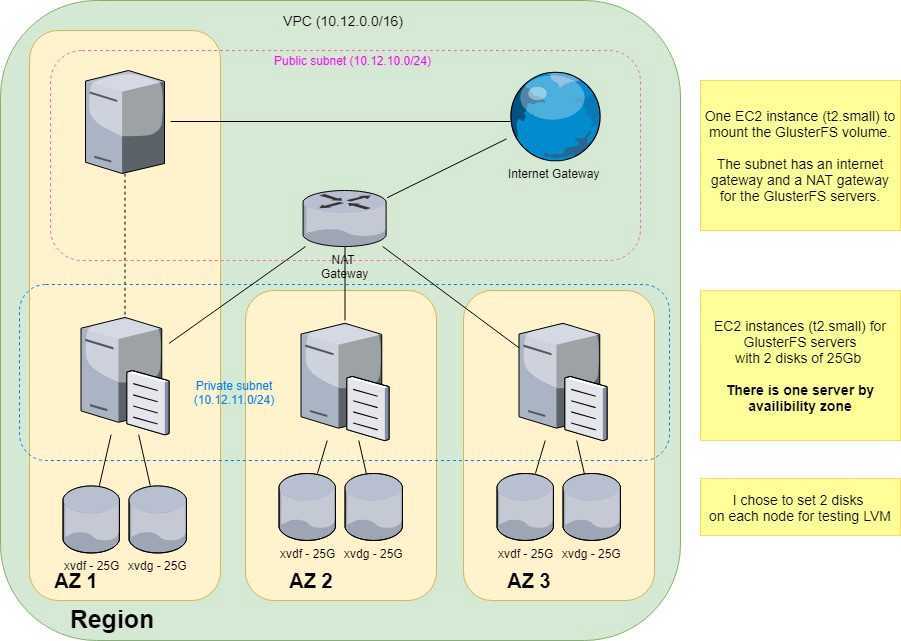
Предварительные требования
Для выполнения данного обучающего руководства вам понадобится три сервера, работающих на Ubuntu 20.04. Каждый сервер должен иметь пользователя non-root user с правами администратора, а также брандмауэр, настроенный с помощью UFW. Чтобы выполнить настройку, воспользуйтесь руководством по начальной настройке сервера Ubuntu 20.04.
Примечание. Как указано в разделе «Цели», это обучающее руководство покажет вам, как настроить два ваших сервера Ubuntu для работы в качестве серверов пула хранения данных, а оставшийся сервер — в качестве клиента, который вы будете использовать для доступа к этим узлам.
Для ясности в этом обучающем модуле будут использоваться компьютеры со следующими именами хостов:
| Имя хоста | Роль в пуле хранения данных |
|---|---|
| gluster0 | Сервер |
| gluster1 | Сервер |
| gluster2 | Клиент |
Команды, которые следует запускать в gluster0 или gluster1, записываются на голубом или розовом фоне соответственно:
Команды, которые следует запускать исключительно на клиенте (gluster2), имеют зеленый фон:
Команды, которые могут или должны запускаться на нескольких компьютерах, записываются на сером фоне:
Обработка отказов
Мы уже познакомились немного с архитектурой двух решений и теперь можем поговорить о том, как с этим жить и какие есть особенности при обслуживании.
Предположим, у нас отказал sda на S1 — обычное дело.
В случае с gl:
- копия данных на оставшемся в группе живом диске не перераспределяется автоматически на другие группы;
- пока диск не будет заменен, останется только одна копия данных;
- при замене сбойного диска на новый репликация выполняется с исправного диска на новый (1 на 1).
Это похоже на обслуживание полки с несколькими RAID-1. Да, с тройной репликацией, при отказе одного диска останется не одна копия, а две, но все равно у такого подхода есть серьезные недостатки, и я покажу их на хорошем примере с RADOS.
Предположим, у нас отказал sda на S1 (OSD-0) — обычное дело:
- PG, которые находились на OSD-0, будут автоматически перемаплены на другие OSD через 10 минут (по умолчанию). В нашем примере на OSD 1 и 2. Если бы серверов было больше, то на большее число OSD.
- PG, которые хранят вторую, уцелевшую копию данных, начнут автоматически реплицировать их на те OSD, куда перенесены восстанавливаемые PG. Получается репликация «многие-ко-многим», а не «один-к-одному» как у gl.
- При введении нового диска взамен сломанного на новую OSD будут намаплены какие-то PG в соответствии с ее весом и постепенно перераспределены данные с других OSD.
Думаю, архитектурные преимущества RADOS пояснять нет смысла. Вы можете не дергаться при получении письма о том, что отказал диск. А придя утром на работу обнаружите, что все недостающие копии уже восстановлены на десятках других OSD или в процессе этого. На больших кластерах, где сотни PG размазаны по куче дисков, восстановление данных одной OSD может проходить на скоростях сильно больших скорости одного диска за счет того, что вовлечены (читают и пишут) десятки OSD. Ну и про распределение нагрузки тоже забывать не стоит.
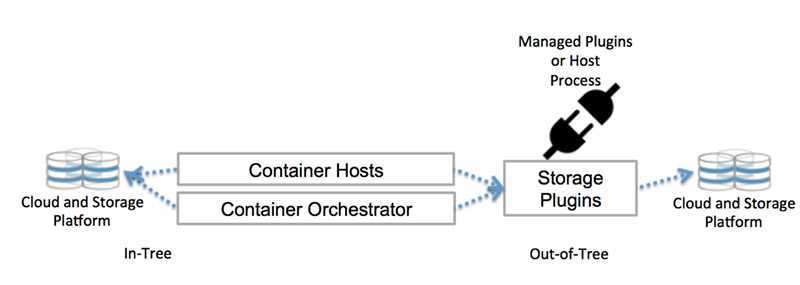
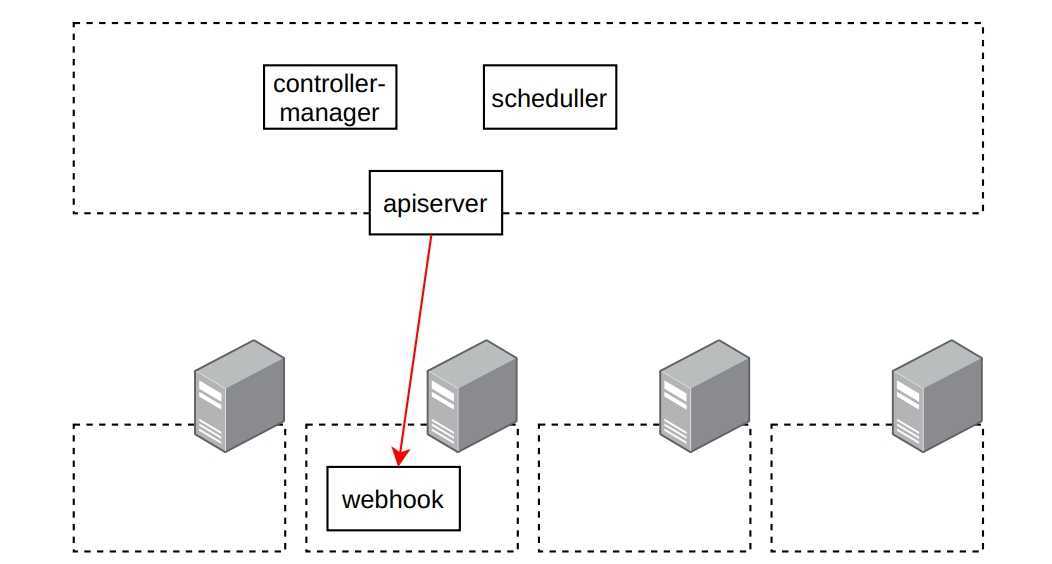
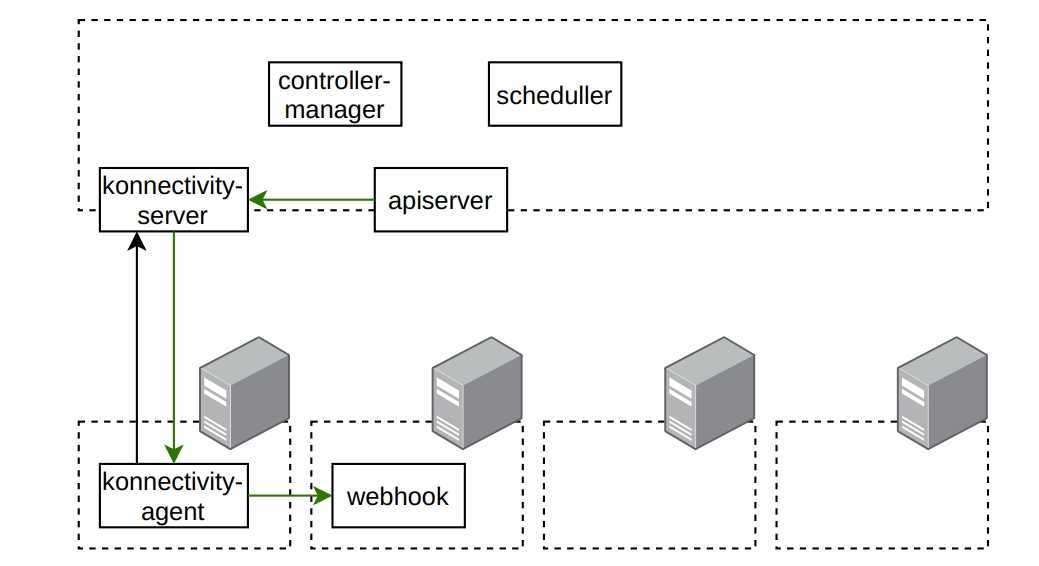
А че по клиентам?
Нативный API двух систем реализован в виде библиотек libgfapi (gl) и libcephfs (CephFS). Биндинги для популярных языков тоже есть. В целом, с библиотеками все примерно одинаково хорошо. Вездесущая NFS-Ganesha поддерживает в качестве FSAL обе библиотеки, что тоже норм. Qemu также поддерживает нативный API gl через libgfapi.
А вот fio (Flexible I/O Tester) давно и успешно поддерживает libgfapi, но поддержки libcephfs в нем нет. Это плюс gl, т.к. с помощью fio очень приятно тестировать gl «напрямую». Только работая из userspace через libgfapi вы получите от gl все, что она может.
Но если мы говорим о POSIX файловой системе и о способах ее монтирования, то тут gl может предложить только FUSE-клиент, а CephFS реализацию в апстримном ядре. Понятно, что в модуле ядра можно такого наворотить, что FUSE будет показывать лучшую производительность. Но на практике FUSE — это всегда оверхед на контекстных переключениях. Я лично не раз видел, как FUSE нагибал двухсокетный сервер одними CS.
Как-то на этот счет Линус сказал:
Разработчики gl наоборот считают, что FUSE это круто. Говорят, что это дает больше гибкости и отвязывает от версий ядра. Как по мне, они используют FUSE, потому что gl это не про скорость. Как-то пишется — ну и нормально, и заморачиваться с реализацией в ядре действительно странно.
Что такое ReFS
Аббревиатура от «Resilient File System», ReFS – это новая файловая система, созданная с использованием кода текущей файловой системы NTFS. На данный момент ReFS – это не просто замена NTFS. Она имеет свои преимущества и недостатки. У Вас не получиться просто использовать ReFS вместо NTFS на вашем системном диске.
Поскольку ReFS – новейшая файловая система Microsoft, она предназначена для решения нескольких основных проблем с NTFS. ReFS призвана быть более устойчивой к повреждению данных, лучше работать с определенными рабочими нагрузками и лучше масштабироваться для очень больших файловых систем. Давайте посмотрим, что именно это означает.
Настройка Glusterfs
Мы будем настраивать распределение данных GlusterFS между двумя системами, сервис должен быть установлен и настроен на обоих из них. На обоих компьютерах наши устройства хранения смонтированы в /storage. Перед тем как начать работать с Glusterfs, давайте добавим ip адреса наших серверов /etc/hosts, чтобы обращаться с ними было легче:
Это необходимо сделать на обоих машинах. Дальше нам нужно создать пул
Неважно какую машину вы выберете для этого все будет работать одинаково. Мы будем использовать gluster1
Чтобы комьпютеры могли получить доступ друг к другу, нужно открыть несколько портов в брандмауэре:
Для подключения машины gluster2 выполните команду:
Локальная система автоматически добавляется к пулу, поэтому дополнительно ничего делать не нужно. С помощью следующей команды мы создадим хранилище с репликацией на двух подключенных системах:
По умолчанию используется протокол TCP/IP для взаимодействия, но вы можете вручную указать InfiniBand. Если вы попытаетесь создать хранилище на корневом разделе, то у вас ничего не получиться, для его создания нужно добавить в конец команды опцию force. Далее смотрим информацию о созданном хранилище:
Дальше можно запустить созданную группу:
Существует несколько способов получить доступ к хранилищу GlusterFS. Работа через FUSE будет наиболее быстрой. Также можно использовать Samba или NFS. Кроме того, преимущество использование официального клиента, в том, что вы можете получить доступ к отдельным хранилищам. Для подключения Glusterfs с помощью официального инструмента используйте mount:
Для настройки автоматического монтирования вам понадобится добавить строку в /etc/fstab. Вы можете очень легко расширить существующий пул при необходимости, для этого просто добавьте новый раздел:
Естественно, что ip адрес узла gluster3 должен быть добавлен в файл /etc/hosts. Сначала мы добавляем его в список пиров, затем инициализируем на нем наш раздел. После выполнения команды наше хранилище будет состоять из трех устройств. Вы можете очень просто удалить один из разделов и открепить устройство:
Когда вы добавляете или удаляете разделы, необходимо пересортировать данные, система работала наиболее эффективно. Для этого выполните:
Чтобы посмотреть статус балансировки используйте команду status:
Step 5: Mount Original Bricks
Before we can create the Gluster volume for the original bricks we need to mount all the original bricks.
Step 5 A: Create Mount Points
First, we need to create the brick mount points:
# mkdir -p /brick/home_01_original # mkdir -p /brick/home_02_original # mkdir -p /brick/home_03_original # mkdir -p /brick/home_04_original
Step 5 B: Reboot Server
It is now safe to reboot and recommended to reboot the server to validate the server is ready for the last steps (it also rebuilds the device mappers list in /dev).
Step 5 C: Modify /etc/fstab
Next, add the following lines to the /etc/fstab file:
# Temporary for DR compare /dev/vg_gluster_original/lv_home_01 /brick/home_01_original xfs defaults /dev/vg_gluster_original/lv_home_02 /brick/home_02_original xfs defaults /dev/vg_gluster_original/lv_home_03 /brick/home_03_original xfs defaults /dev/vg_gluster_original/lv_home_04 /brick/home_04_original xfs defaults # End DR Compare
Step 5 D: Mount File Bricks
# mount -a -t xfs
At this point you can begin any brick level comparison or repairs prior to the creation of the Gluster volume and the use of the self-healing within Gluster to repair the volume. Once you are ready to proceed (and have both servers at this point) move on to Step 6.
Mounting Volumes
After installing the Gluster Native Client, you need to mount Gluster
volumes to access data. There are two methods you can choose:
Manually Mounting Volumes
To mount a volume, use the following command:
# mount -t glusterfs HOSTNAME-OR-IPADDRESS:/VOLNAME MOUNTDIR
For example:
# mount -t glusterfs server1:/test-volume /mnt/glusterfs
Note
The server specified in the mount command is only used to fetch
the gluster configuration volfile describing the volume name.
Subsequently, the client will communicate directly with the
servers mentioned in the volfile (which might not even include the
one used for mount).
If you see a usage message like «Usage: mount.glusterfs», mount
usually requires you to create a directory to be used as the mount
point. Run «mkdir /mnt/glusterfs» before you attempt to run the
mount command listed above.
Mounting Options
You can specify the following options when using the
command. Note that you need to separate all options
with commas.
For example:
If option is added while mounting fuse client,
when the first volfile server fails, then the server specified in
option is used as volfile server to mount the
client.
In option, specify the number of
attempts to fetch volume files while mounting a volume. This option is
useful when you mount a server with multiple IP addresses or when
round-robin DNS is configured for the server-name..
If is set to ON, it forces the use of readdirp
mode in fuse kernel module
Automatically Mounting Volumes
You can configure your system to automatically mount the Gluster volume
each time your system starts.
The server specified in the mount command is only used to fetch the
gluster configuration volfile describing the volume name. Subsequently,
the client will communicate directly with the servers mentioned in the
volfile (which might not even include the one used for mount).
To mount a volume, edit the /etc/fstab file and add the following
line:
HOSTNAME-OR-IPADDRESS:/VOLNAME MOUNTDIR glusterfs defaults,_netdev 0 0
For example:
server1:/test-volume /mnt/glusterfs glusterfs defaults,_netdev 0 0
Mounting Options
You can specify the following options when updating the /etc/fstab file.
Note that you need to separate all options with commas.
For example:
Testing Mounted Volumes
To test mounted volumes
-
Use the following command:
If the gluster volume was successfully mounted, the output of the
mount command on the client will be similar to this example: -
Use the following command:
The output of df command on the client will display the aggregated
storage space from all the bricks in a volume similar to this
example: -
Change to the directory and list the contents by entering the
following:
For example,
NFS
You can use NFS v3 to access to gluster volumes. Extensive testing has
be done on GNU/Linux clients and NFS implementation in other operating
system, such as FreeBSD, and Mac OS X, as well as Windows 7
(Professional and Up), Windows Server 2003, and others, may work with
gluster NFS server implementation.
GlusterFS now includes network lock manager (NLM) v4. NLM enables
applications on NFSv3 clients to do record locking on files on NFS
server. It is started automatically whenever the NFS server is run.
You must install nfs-common package on both servers and clients (only
for Debian-based) distribution.
This section describes how to use NFS to mount Gluster volumes (both
manually and automatically) and how to verify that the volume has been
mounted successfully.
Creating Distributed Dispersed Volumes
Distributed dispersed volumes are the equivalent to distributed replicated
volumes, but using dispersed subvolumes instead of replicated ones.
To create a distributed dispersed volume
-
Create a trusted storage pool.
-
Create the distributed dispersed volume:
To create a distributed dispersed volume, the disperse keyword and
<count> is mandatory, and the number of bricks specified in the
command line must must be a multiple of the disperse count.redundancy is exactly the same as in the dispersed volume.
If the transport type is not specified, tcp is used as the default. You
can also set additional options if required, like in the other volume
types.volume create: : failed: Multiple bricks of a replicate volume are present on the same server. This setup is not optimal.
Do you still want to continue creating the volume? (y/n)«`
Переименование файлов
Снова возвращаемся к хеш-функциям. Мы разобрались с тем, как конкретные файлы роутятся на конкретные диски, и теперь уместным становится вопрос, а что же будет при переименовании файлов?
Ведь если мы меняем имя файла, то хеш от его имени тоже поменяется, а значит, и место этому файлу на другом диске (в другом хеш-диапазоне) или на другой PG/OSD в случае RADOS. Да, мы мыслим правильно, и тут у двух систем снова все перпендикулярно.
А вот у RADOS вообще нет метода для переименования объектов как раз из-за необходимости в последующем их перемещении. Для переименования предлагается использовать честное копирование, что приводит к синхронному перемещению объекта. А CephFS, которая работает поверх RADOS, имеет козырь в рукаве в виде пула с метаданными и MDS. Изменение имени файла не затрагивает содержимое файла в data-пуле.
Другие команды GlusterFS
Просмотр списка пулов в кластере
# gluster pool list
Добавить новый пул в кластер
# gluster peer probe glusterfs-srv3.local
Удалить пул из кластера
# gluster peer detach glusterfs-srv3.local
Просмотр списка томов
# gluster volume list
Просмотр состояния тома
# gluster volume status
Остановка работы тома
# gluster volume stop volume-name
Удаление тома
# gluster volume delete volume-name
Запуск ребалансировки тома
# gluster volume rebalance volume-name start
Просмотр состояния ребалансировки тома
# gluster volume rebalance volume-name status
Добавить раздел к тому
# gluster volume add-brick replica 3 volume-name glusterfs-srv3.local:/mnt/data/volume-data-2/
Удалить раздел из тома
# gluster volume remove-brick volume-name glusterfs-srv3.local:/mnt/data/volume-data-2/
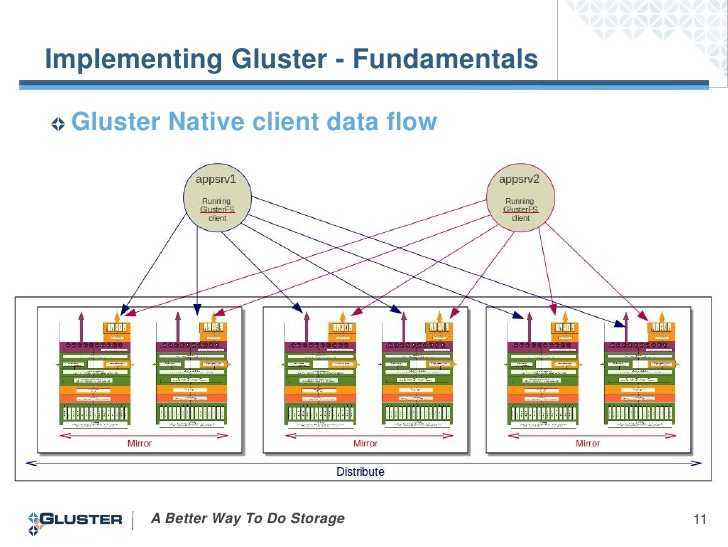
Creating Distributed Striped Replicated Volumes
Distributed striped replicated volumes distributes striped data across
replicated bricks in the cluster. For best results, you should use
distributed striped replicated volumes in highly concurrent environments
where parallel access of very large files and performance is critical.
In this release, configuration of this volume type is supported only for
Map Reduce workloads.

To create a distributed striped replicated volume
-
Create a trusted storage pool.
-
Create a distributed striped replicated volume using the following
command:For example, to create a distributed replicated striped volume
across eight storage servers:If the transport type is not specified, tcp is used as the
default. You can also set additional options if required, such as
auth.allow or auth.reject.volume create: : failed: Multiple bricks of a replicate volume are present on the same server. This setup is not optimal. Use ‘force’ at the end of the command if you want to override this behavior.«`
ReFS не может заменить NTFS
Все эти функции звучат неплохо, но вы не можете просто переключиться на ReFS из NTFS. Windows не может загружаться из файловой системы ReFS и требует NTFS.
ReFS также исключает другие функции, доступные в NTFS, включая сжатие и шифрование файловой системы, жесткие ссылки, расширенные атрибуты, дедупликацию данных и дисковые квоты. Тем не менее, ReFS совместима с различными функциями. Например, если вы не можете выполнять шифрование определенных данных на уровне файловой системы, ReFS будет совместима с полным типом шифрования BitLocker.
Windows 10 не позволит вам форматировать любой старый раздел как ReFS. В настоящее время вы можете использовать ReFS только для пространства хранения, где её функции помогают защитить данные от повреждений. В Windows Server 2016 вы можете форматировать тома с помощью ReFS вместо NTFS. Возможно, вы захотите сделать это для тома, на котором планируете хранить виртуальные машины. Однако, вы по-прежнему не сможете использовать ReFS для загрузочного тома. Windows может загружаться только с диска NTFS.
Непонятно, какое будущее ждёт ReFS. Возможно, Microsoft в один прекрасный день улучшит её, пока она не сможет полностью заменить NTFS во всех версиях Windows. Неясно, когда это может произойти. Но, на данный момент ReFS может использоваться только для конкретных задач.
Централизованное хранение журналов приложений
Вы можете захотеть хранить журналы приложений в общем каталоге GlusterFS, чтобы иметь возможность их совместной обработки. В этом случае вам необходимо изменить параметры Nginx, добавив в них имя хоста или его адрес:
access_log /var/log/nginx/access-10.0.0.1.log; error_log /var/log/nginx/error-10.0.0.1.log;
Не забудьте организовать ротацию журналов — в общем каталоге это сделать несколько сложнее. Другой способ организации централизованного хранения записей журналов — отправлять их в общее хранилище, например, в Elasticsearch с помощью Filebeat и анализировать их в Kibana.
Создание тома хранения данных
Теперь, когда все серверы находятся в пуле, можно создать том для хранения данных. Поскольку в нашем примере том создается в корневой файловой системе, нам придется использовать аргумент force.
sudo gluster volume create gfs replica 3 server{1,2,3}.private:/opt/gluster-volume force
volume create: gfs: success: please start the volume to access data
Убедиться в том, что том создан можно с помощью команды:
sudo gluster volume list gfs
Для активации тома его необходимо запустить:
sudo gluster volume start gfs volume start: gfs: success
Теперь можно запросить состояние тома gfs:
sudo gluster volume status gfs Status of volume: gfs Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick server1.private:/opt/gluster-volume 49152 0 Y 6741 Brick server2.private:/opt/gluster-volume 49152 0 Y 6558 Brick server3.private:/opt/gluster-volume 49152 0 Y 7504 Self-heal Daemon on localhost N/A N/A Y 6764 Self-heal Daemon on server2.private N/A N/A Y 6581 Self-heal Daemon on server3.private N/A N/A Y 7527 Task Status of Volume gfs ------------------------------------------------------------------------------ There are no active volume tasks
Информация о томе:
sudo gluster volume info gfs Volume Name: gfs Type: Replicate Volume ID: d1408265-bc67-4501-b255-efd165fba094 Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: server1.private:/opt/gluster-volume Brick2: server2.private:/opt/gluster-volume Brick3: server3.private:/opt/gluster-volume Options Reconfigured: transport.address-family: inet nfs.disable: on performance.client-io-threads: off
Gluster Server Docker container:
Although Setting up a glusterfs environment is a pretty simple and straight forward procedure, Gluster community do maintain docker images of gluster both Fedora and CentOS as base image in the docker hub for the ease of users. The community maintains docker images of GlusterFS release in both Fedora and CentOS distributions.
The following are the steps to run the GlusterFS docker images that we maintain:
To pull the docker image from the docker hub run the following command:
CentOS:
This will pull the glusterfs docker image from the docker hub.
Alternatively, one could build the image from the Dockerfile directly. For this, clone the gluster-containers source repository and build the image using Dockerfiles in the repository. For getting the source, One can make use of git:
This repository consists of Dockerfiles for GlusterFS to build on both CentOS and Fedora distributions. Once you clone the repository, to build the image, run the following commands:
For Fedora,
For CentOS,
This command will build the docker image from the Dockerfile and will be assigned the name gluster-fedora or gluster-centos respectively. ‘-t’ option is used to give a name to the image we built.
Once the image is built in either of the above two steps, now we can run the container with gluster daemon running.
Before this, ensure the following directories are created on the host where docker is running:
- /etc/glusterfs
- /var/lib/glusterd
- /var/log/glusterfs
Ensure all the above directories are empty to avoid any conflicts.
Also, ntp service like chronyd / ntpd service needs to be started in the host.
This way all the gluster containers started will be time synchronized.
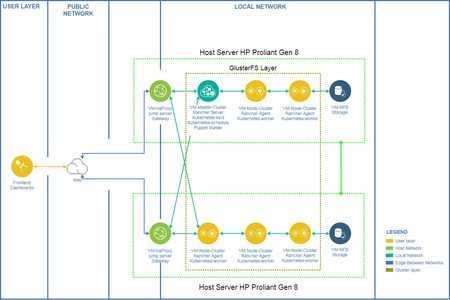
Now run the following command:
( is either gluster-fedora or gluster-centos as per the configurations so far)
Where:
Bind mounting of following directories enables:
Systemd has been installed and is running in the container we maintain.
Once issued, this will boot up the Fedora or CentOS system and you have a container started with glusterd running in it.
Capturing coredumps
/var/log/core directory is already added in the container.
Coredumps can be configured to be generated under /var/log/core directory.
User can copy the coredump(s) generated under /var/log/core/ directory
from the container to the host.
For example:
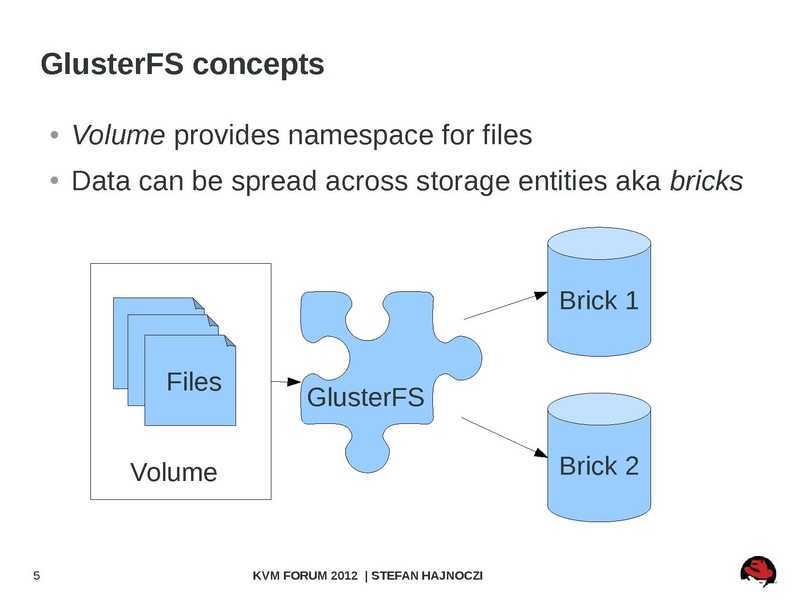
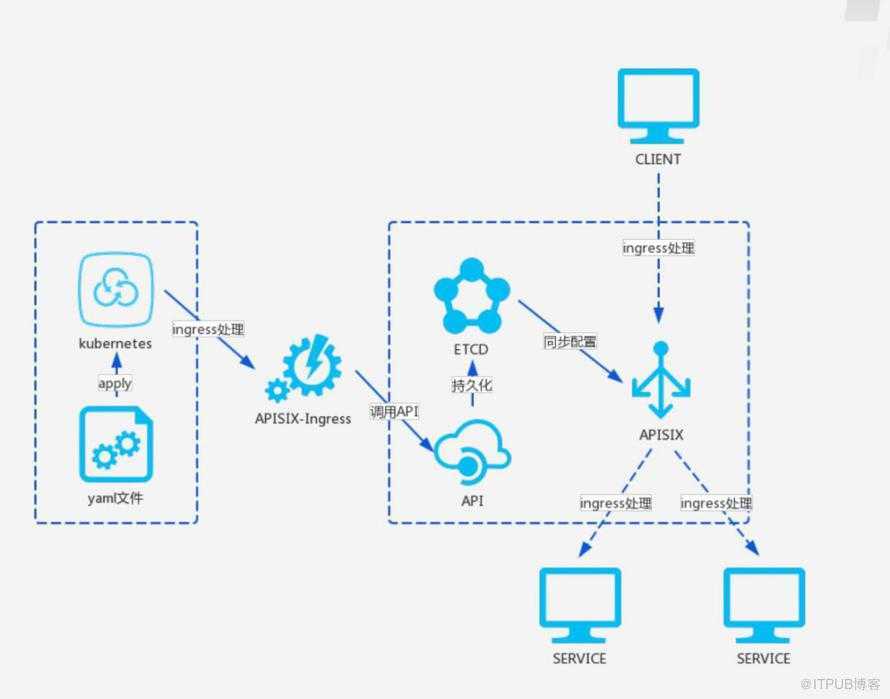
GlusterFS
GlusterFS ― это масштабируемая сетевая файловая система, подходящая для задач с интенсивным использованием данных, таких как облачное хранилище и потоковая передача мультимедиа.
Ниже перечислены объекты GlusterFS, которые встречаются в данной статье.
- Node. Сервер хранения, который участвует в доверенном пуле хранения.
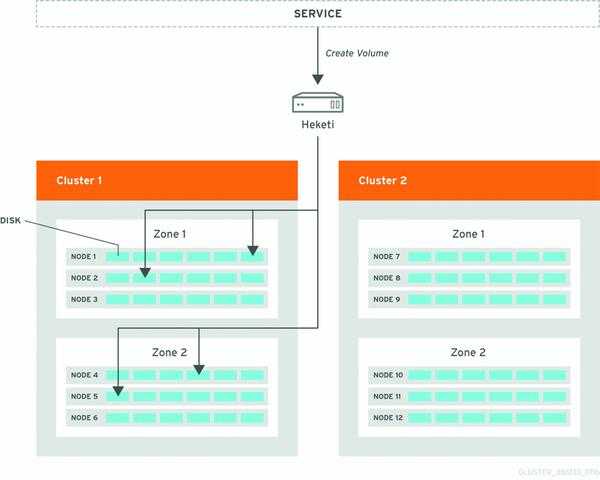
- Brick. Файловая система XFS (512-байтовые inode) на основе LVM (не обязательно, но Heketi поддерживает только такую конфигурацию), смонтированная в папке или каталоге.
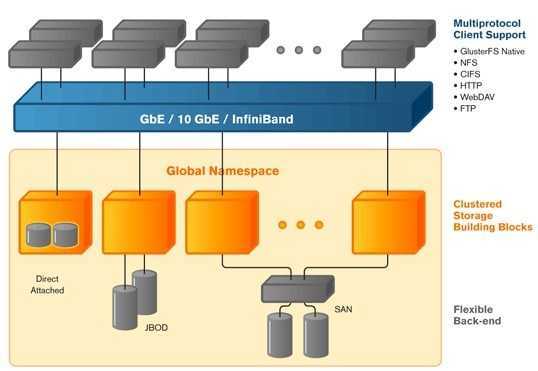
- Volume. Файловая система, которая предоставляется клиентам по сети. Volume можно смонтировать, используя Gluster Native Client (рекомендуемый способ подключения). Также поддерживается подключение по протоколам NFS и CIFS.
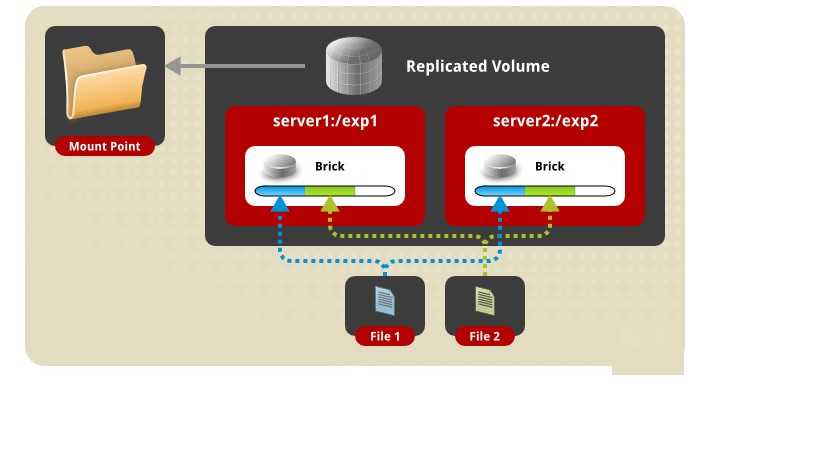
GlusterFS поддерживает различные типы реплицируемых томов, но в этой статье мы рассмотрим его работу на примере Replicated Gluster Volume. В данном случае каждый файл имеет N реплик, которые хранятся на Bricks, входящих в состав одного Volume.
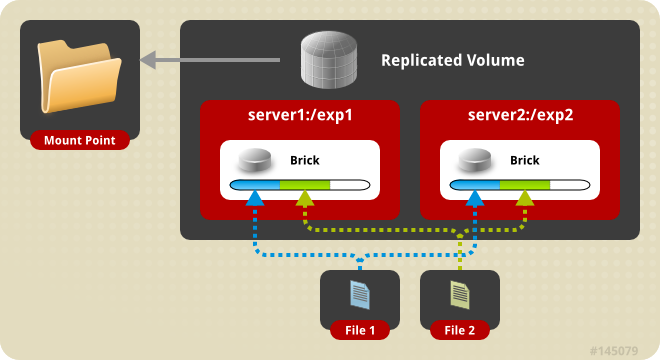
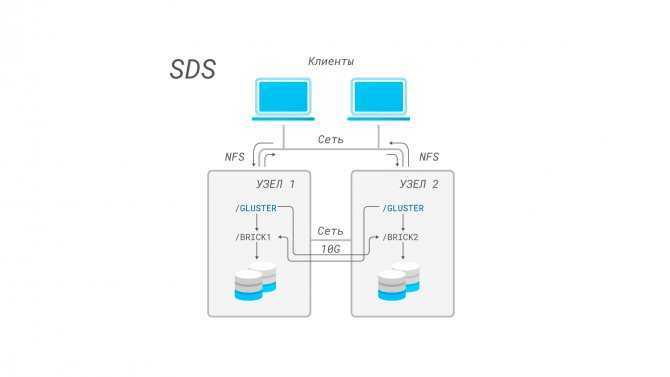
Схема работы Replicated Gluster Volume
В случае выхода из строя одного из серверов для клиента будет доступна вся информация со второго сервера. Для лучшей отказоустойчивости рекомендуется использовать не менее трех реплик для каждого Volume. Именно такой вариант мы используем для некоторых компонентов Targetprocess, поэтому его и рассмотрим в данной статье.
Как отключить или включить ReFS или Resilient File System в Windows 10
С тех пор как NTFS была разработана и сформулирована в ОС Windows, требования к хранилищу данных резко изменились. Существовала острая необходимость в файловой системе следующего поколения, которая могла бы хорошо работать и решать проблемы, которые присутствовали в NTFS.
Именно тогда Microsoft в 2012 году назвала снимки и разработала ReFS (Resilient File System) — и была представлена в Windows 8.1 и Windows Server 2012 .
ReFS была разработана для максимизации доступности и надежности данных , даже если соответствующие устройства хранения данных испытали аппаратный сбой.
С тех пор, как запоминающие устройства вошли в игру, потребность в дисковом пространстве увеличилась в геометрической прогрессии. В наши дни распространены даже мульти-терабайты накопителей. Следовательно, потребность в постоянно надежной структуре продолжала возникать одновременно.
ReFS имеет архитектуру, которая хорошо работает с чрезвычайно большими наборами данных без какого-либо влияния на производительность.
В этом руководстве мы увидим, как включить или отключить файловую систему ReFS в Windows 10 и попытаться отформатировать диск, используя его, но перед этим давайте рассмотрим некоторые ключевые функции этой величественной файловой системы.
В этой статье мы поговорим о функциях отказоустойчивой файловой системы и узнаем, как включить или отключить файловую систему ReFS в операционной системе Windows Server, а также попробуем отформатировать диск, использующий эту файловую систему.
Особенности отказоустойчивой файловой системы
Доступность данных . Файловая система ReFS расширяет доступность данных, демонстрируя устойчивость к повреждению или сбоям данных. Автоматические проверки целостности данных помогают поддерживать ReFS в сети, и вы вряд ли будете испытывать какое-либо время простоя.
Масштабируемость при растяжении: Требования к увеличению объема и размера данных постоянно растут в связи с изменяющейся технологией. ReFS предлагает возможность бросать вызов чрезвычайно большим наборам данных и работать с ними без проблем с производительностью.
Острое исправление ошибок: файловая система ReFS поставляется с автоматическим сканером целостности данных, известным как скруббер , который периодически сканирует том данных, выявляет потенциальные поврежденные сектора и обрабатывает их для восстановления. ,
ОБНОВЛЕНИЕ . Пожалуйста, прочитайте комментарии ниже, прежде чем продолжить. Дэн Гюль говорит: Опубликовать годовое обновление , это в основном сделает систему непригодной для использования, и по-прежнему невозможно будет выполнять форматирование в ReFS.
Какую файловую систему использует Windows 10?
Если это стандартная установка по умолчанию, ОС использует структуры NTFS. При сбое операционной системы Windows 10 с включенным дисковым пространством это файловые системы ReFS + NTFS.
Включить файловую систему ReFS в Windows 10
Теперь, когда вы знаете, что ReFS появился, чтобы справиться с ограничениями файловой системы NTFS, давайте посмотрим, как вы можете включить его в своей системе Windows 10 и использовать его для форматирования внешнего диска.
Прежде чем приступить к изменениям, обязательно создайте точку восстановления системы. Если в будущем возникнет какая-либо проблема, вы можете использовать эту точку восстановления для отката изменений.
1. Нажмите Windows Key + R на клавиатуре, чтобы запустить приглашение «Выполнить». Введите и нажмите Enter, чтобы открыть редактор реестра.
2. Перейдите по указанному ниже пути на левой боковой панели редактора реестра.
HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Control \ FileSystem
3. Создайте DWORD и назовите его RefsDisableLastAccessUpdate. Установите его значение как 1 , чтобы включить его.
4. Далее, перейдите к указанному ниже пути на левой боковой панели.
HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Control \ MinInt
5. Если ключ MiniNT не существует, его можно создать, щелкнув правой кнопкой мыши> Создать> Ключ.
Теперь под этим ключом создайте новый DWORD и назовите его AllowRefsFormatOverNonmirrorVolume и установите его значение как 1 , чтобы включить его.
6. Выйдите и войдите снова, чтобы изменения вступили в силу. Теперь вы можете подключить внешнее устройство и выбрать файловую систему ReFS для его форматирования. Кроме того, вы можете открыть лист Свойства любого диска, чтобы увидеть, с какой файловой системой он связан.
Создание Replicated-тома
Пожалуй самая простая конфигурация.
gluster volume create rep01 replica 2 gl01:/gluster/gv01 gl02:/gluster/gv01_x000D_ _x000D_ _x000D_ volume create: rep01: success: please start the volume to access data
Здесь rep01 — это имя создаваемого тома, а replica 2 — его конфигурация которая говорит о том, что данные будут храниться в двух экземплярах, на gl01:/gluster/gv01 и gl02:/gluster/gv01 соответственно.
Далее запускаем том;
gluster volume start rep01 _x000D_ _x000D_ _x000D_ volume start: gv01: success
Получить информацию о конфигурации тома можно с помощью команды info:
gluster volume info rep01_x000D_ _x000D_ _x000D_ Volume Name: rep01_x000D_ Type: Replicate_x000D_ Volume ID: 5895cdd2-c56f-440b-b176-6be4ab8cd80c_x000D_ Status: Started_x000D_ Number of Bricks: 1 x 2 = 2_x000D_ Transport-type: tcp_x000D_ Bricks:_x000D_ Brick1: gl01:/gluster/gv01_x000D_ Brick2: gl02:/gluster/gv01

![Сервис_prometheus [методические материалы лохтурова вячеслава]](http://smartshop124.ru/wp-content/uploads/1/f/8/1f806d1969da0e4af99d57839b388d6f.jpeg)