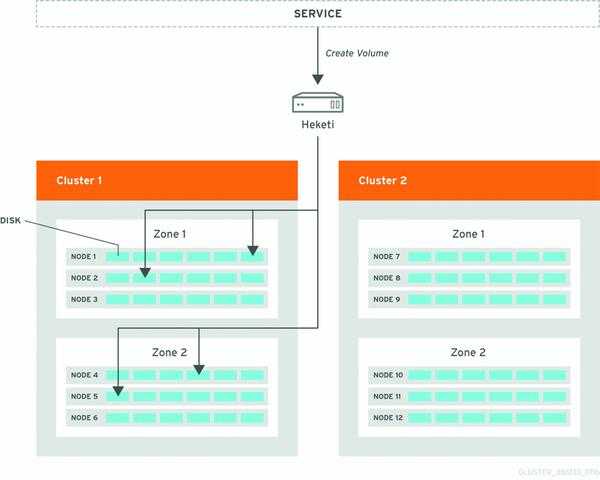
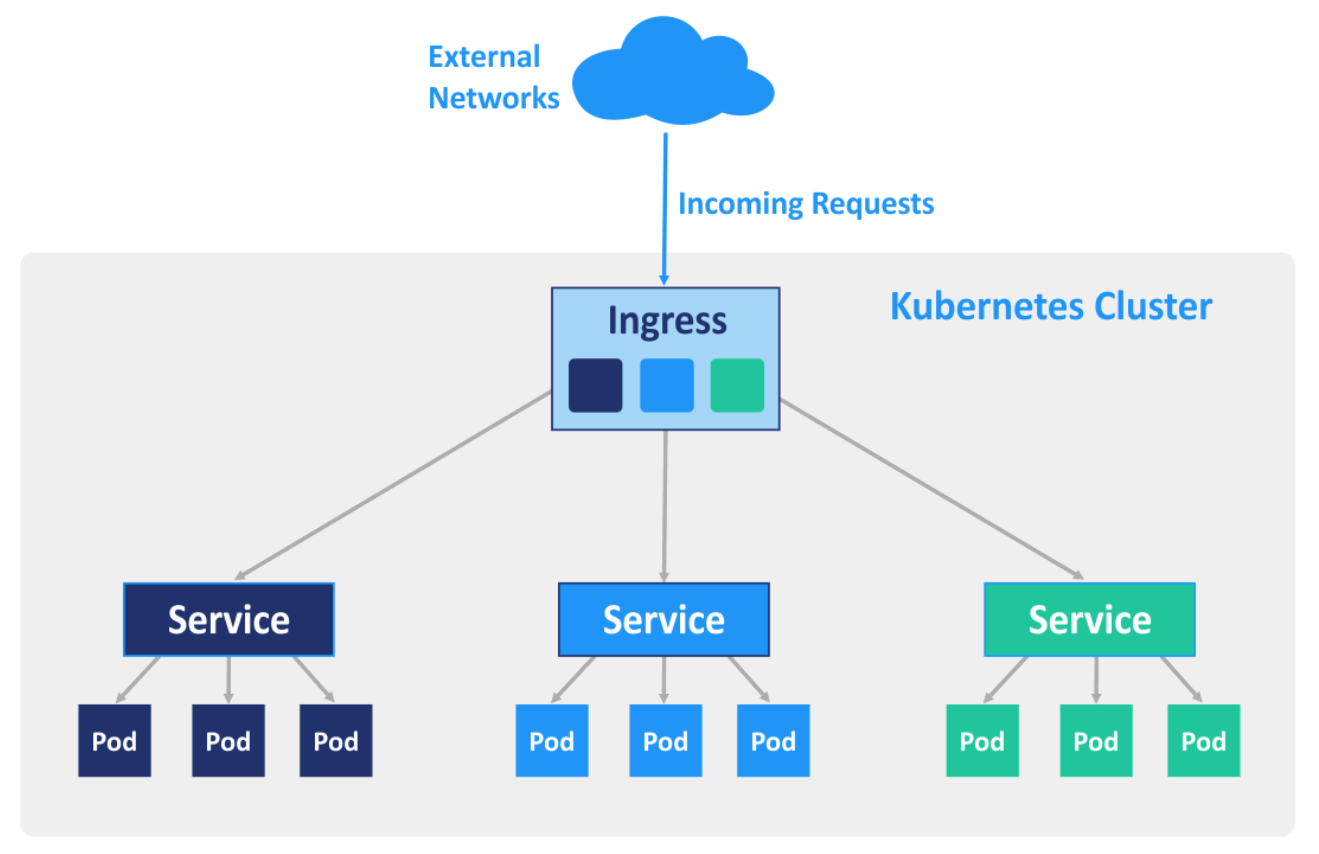
Назначение Kubernetes
Контейнеры упрощают блочную разработку продуктов и их последующую сборку перед запуском. Такой подход дает возможность дорабатывать отдельные модули без влияния на работу остальных функций, и все это происходит на платформе фреймворка Kubernetes. Она обрабатывает ошибки в приложениях, занимается масштабированием, содержит шаблоны развертывания и пр.
Перечень возможностей:
- Обнаружение контейнера происходит по имени DNS или IP-адресу.
- Система самостоятельно балансирует нагрузку и распределяет трафик в сети.
- Подключение выбранного типа хранилища происходит в автоматическом режиме.
- Платформа перезапускает отказавшие контейнеры или блокирует к ним доступ.
- Конфиденциальная информация хранится изолированно от других данных.
Развертывание или откат изменений происходит по заданному сценарию, без участия пользователя. То же относится к резервированию аппаратных ресурсов, количеству процессорных ядер, оперативной памяти (на каждый отдельно взятый контейнер). Единственное ограничение Kubernetes заключается в отсутствие встроенных компонентов вроде базы данных, модуля обработки данных и организации кэша.
Как работают сетевые политики
Несмотря на то что и сетевых политик весьма сложны для понимания, мне удалось выделить несколько простых правил:
- Если в NetworkPolicy выбран под, то предназначенный для этого пода трафик будет ограничиваться.
- Если для пода не определен объект NetworkPolicy, к этому поду смогут подключаться все поды из всех пространств имен. То есть, если для конкретного пода не определена сетевая политика, по умолчанию неявно подразумевается поведение «разрешить все (allow all)».
- Если трафик к поду А ограничен, а под Б должен к нему подключиться, необходимо создать объект NetworkPolicy, в котором выбран под А, а также есть ingress-правило, в котором выбран под Б.
Дело усложняется в том случае, когда надо настроить сетевое взаимодействие между различными пространствами имен. В двух словах это работает так:
- Сетевые политики действуют только на сетевые подключения к тем подам, которые находятся в одном пространстве имен с NetworkPolicy.
- В разделе ingress-правила можно выбрать только поды из того же пространства имен, в котором развернут объект NetworkPolicy.
- Если поду А необходимо подключиться к находящемуся в другом пространстве имен поду Б и сетевые подключения к поду Б ограничены сетевой политикой, под А должен быть выбран в поле сетевой политики пода Б.
Вступление:
Для кого предназначены данные статьи? В первую очередь, для тех, кто только начинает свой путь в изучении Kubernetes. Также данный цикл будет полезен для инженеров, которые думают переходить от монолита к микросервисам. Все описанное — это мой опыт, в том числе полученный и при переводе нескольких проектов из монолита в Kubernetes. Возможно, что какие-то части публикаций будут интересны и опытным инженерам.
Что я не буду подробно рассматривать в данной серии публикаций:
- подробно объяснять, что такое примитивы kubernetes, такие как: pod, deployment, service, ingress и тд.
- CNI (Container Networking Interface) я рассмотрю очень поверхностно, мы используем callico поэтому другие решения, я только перечислю.
- процесс сборки docker образов.
- процессы CI\CD. (Возможно отдельной публикацией, но после всего цикла)
- helm; про него написано уже достаточно много, я затрону лишь процесс его инсталляции в кластер и настройку клиента.
Что я хочу рассмотреть подробно:
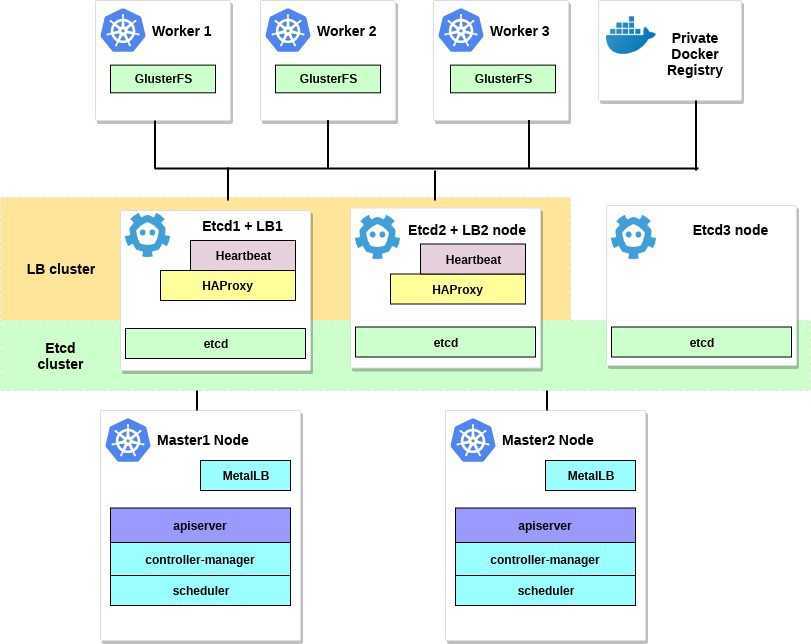
- пошаговый процесс развертывания кластера Kubernetes. Я буду использовать kubeadm. Но при этом я подробно шаг за шагом рассмотрю процесс инсталляции кластера на голое железо, различные виды инсталляции ETCD, составление конфигфайлов для kube admina. Постараюсь разъяснить все варианты балансировки для Ingress контроллера и отличие в разнообразных схемах доступа worknodes до api сервера.
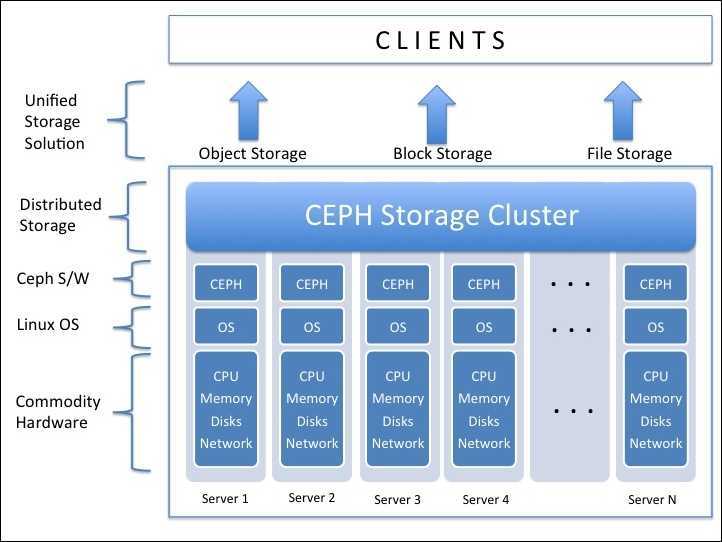
Я знаю, что сегодня для развертывания kubernetes есть много прекрасных инструментов, например, kubespray или тот же rancher. Возможно, кому-то будет более удобно использовать их. Но, я думаю, найдется немало инженеров которые захотят рассмотреть вопрос более детально. - терминологию CEPH и пошаговую инсталляцию кластера CEPH, а также пошаговую инструкцию подключение хранилища ceph к созданному Kubernetes кластеру.
- local-storages, подключение к кластеру kubernetes, а также отличия от подключений типа hostpath и тд.
- kubernetes операторы и развертывание Percona XtraDB Cluster с помощью оператора, а также постараюсь рассказать про плюсы и минусы такого решения после полугодового опыта использования в продакшене. А также немного поделюсь планами по доработке оператора от percona.
Настройка Kubernetes
Сначала указывается сервер, на который был инсталлирован Kubernetes. Он становится первичным, где будут запускаться остальные операции. Инициализация выполняется при помощи команды:
kubeadm init --pod-network-cidr=10.244.0.0/16
В результате создается адрес виртуальной сети Pods (цифры выбираются по желанию пользователя). По умолчанию используется указанный IP. При правильной обработке команды на дисплее будет отображаться команда для присоединения остальных Nods-кластеров к первичному серверу, чтобы создать в итоге рабочую систему.
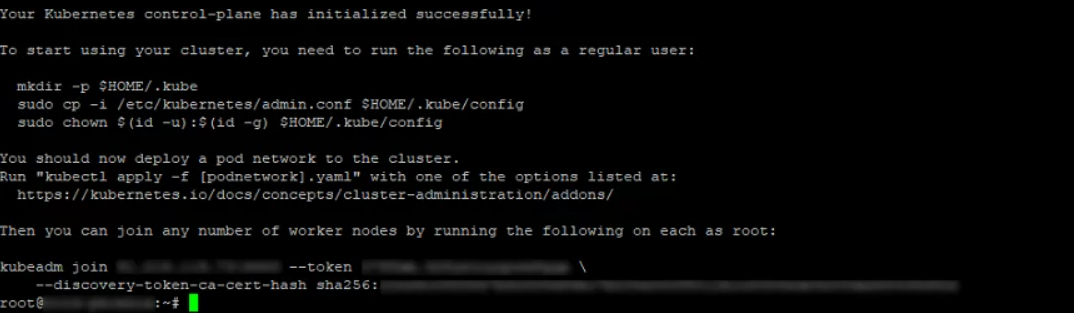
Следующие команды задают пользователя, который будет управлять работой комплекса:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Теперь можно настраивать Container Network Interface (CNI, сетевой интерфейс контейнера). Чтобы избавить себя от рутины ручного ввода команд, рекомендуется установить плагин Flannel или ему подобный (Weave Net, Calico). Первый устанавливается так:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
После ввода команды на экране отображаются имена всех созданных ресурсов.
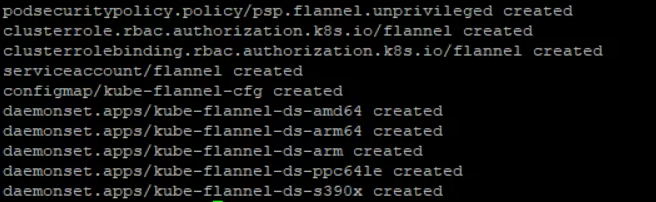
Теперь пользователь добавляет Nods в существующий кластер. Для этого требуется подключение к серверу через SSH, установка модулей Docker, Kubelet, Kubeadm (вопрос рассматривался выше). Выполнение команды:
kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
Остается получить токен авторизации кластера. Если подключение SSH еще не прервано, повторно заходить на сервер не нужно. Токен выдается после ввода команды:
kubeadm token list
По умолчанию он действует 24 часа. Если поставлена задача добавить новый узел по завершении периода, новый создается командой:
kubeadm token create
Вывод выглядит примерно так:
5didvk.d09sbcov8ph2amjw
На этом все. Система готова к эксплуатации. Дальнейшие действия пользователя зависят от стоящих задач и опыта.
Установка и первый запуск
Для начала нужно создать кластер Kubernetes. Чтобы сделать это локально, авторы предлагают воспользоваться minikube, K3s и Kind, а для облака — EKS или GKE. Для каждого типа инфраструктуры с K8s есть своя инструкция по установке Kalm.
К слову, также для облачных кластеров доступна платная услуга — Kalm Cloud. Это специальная онлайн-панель для управления приложениями в кластерах, предусматривающая минимальные действия по установке/конфигурации Kalm и техническую поддержку. Тарифы по работе с Kalm Cloud есть здесь: вкратце, они начинаются от 600 USD в месяц, но стартапы могут получить скидку в 90% на год.
Теперь к самой установке. Перед её началом убедитесь, что указывает на правильный кластер Kubernetes, так как установка производится в текущий контекст (через ).
Я выбрал minikube. Установка выполняется в два шага. Сначала клонируем репозиторий:
Затем устанавливаем утилиту:
В кластере при этом у нас развернулось несколько компонентов:
-
istio-operator + сам Istio;
-
kalm-operator + Kalm;
-
cert-manager.
Стоит обратить внимание, что непосредственно управлять кластером при помощи Kalm нельзя, но можно заходить в контейнеры, выполнять команды, править ConfigMaps и т.д. По кластеру можно также видеть служебную информацию: общее количество потребляемых ресурсов, нагруженность каждого узла в кластере, потребление ресурсов отдельными приложениями
Если в кластер уже установлены какие-то приложения, в Kalm они отображаться не будут. Утилита понимает только свой синтаксис и «видит» приложения, установленные только через kalm-operator.
После установки пробрасываем порт из кластера в localhost:
Если установка прошла успешно, дашборд Kalm будет доступен по адресу http://localhost:3010.
Если возникли проблемы с запуском, не лишним будет заглянуть в .
Способ 1. Указание PV в манифесте пода
Типичный манифест, описывающий под в кластере Kubernetes:
Цветом выделены части манифеста, где описано, какой том подключается и куда.
В разделе volumeMounts указывают точки монтирования (mountPath) — в какой каталог внутри контейнера будет монтироваться постоянный том, а также имя тома.
В разделе volumes перечисляют все тома, которые используются в поде. Указывают имя каждого тома, а также тип (в нашем случае: awsElasticBlockStore) и параметры подключения. Какие именно параметры перечисляются в манифесте, зависит от типа тома.
Один и тот же том может быть смонтирован одновременно в несколько контейнеров пода. Таким образом разные процессы приложения могут иметь доступ к одним и тем же данным.
Этот способ подключения придумали в самом начале, когда Kubernetes только зарождался, и на сегодня способ устарел.
При его использовании возникает несколько проблем:
- все тома надо создавать вручную, Kubernetes не сможет создать ничего за нас;
- параметры доступа к каждому из томов уникальные, и их надо указывать в манифестах всех подов, которые используют том;
- чтобы поменять систему хранения (например, переехать из AWS в Google Cloud), надо менять настройки и тип подключённых томов во всех манифестах.
Всё это очень неудобно, поэтому в реальности подобным способом пользуются для подключения только некоторых специальных типов томов: configMap, secret, emptyDir, hostPath:
-
configMap и secret — служебные тома, позволяют создать в контейнере том с файлами из манифестов Kubernetes.
-
emptyDir — временный том, создаётся только на время жизни пода. Удобно использовать для тестирования или хранения временных данных. Когда pod удаляется, том типа emptyDir тоже удаляется и все данные пропадают.
-
hostPath — позволяет смонтировать внутрь контейнера с приложением любой каталог локального диска сервера, на котором работает приложение, — в том числе /etc/kubernetes. Это небезопасная возможность, поэтому обычно политики безопасности запрещают использовать тома этого типа. Иначе приложение злоумышленника сможет замонтировать внутрь своего контейнера каталог /etc/kubernetes и украсть все сертификаты кластера. Как правило, тома hostPath разрешают использовать только системным приложениям, которые запускаются в namespace kube-system.
приведены в документации.
Чиним ServiceAccounts
Есть ещё один момент. Так как мы потеряли — это тот самый ключ которым были подписаны jwt-токены для всех наших ServiceAccounts, то мы должны пересоздать токены для каждого из них.
Сделать это можно достаточно просто, удалив поле token изо всех секреты типа :
После чего kube-controller-manager автоматически сгенерирует новые токены, подписаные новым ключом.
К сожалению далеко не все микросервисы умеют на лету перечитывать токен и скорее всего вам потребуется вручную перезапустить контейнеры, где они используются:
Например эта команда сгенерирует список команд для удаления всех подов использующих недефолтный serviceAccount. Рекомендую начать с неймспейса , т.к. там установлены kube-proxy и CNI-плагин, жизненно необходимые для настройки коммуникации ваших микросервисов.
На этом восстановление кластера можно считать оконченным
Спасибо за внимание! В следующей статье мы подробнее рассмотрим бэкап и восстановление etcd-кластера
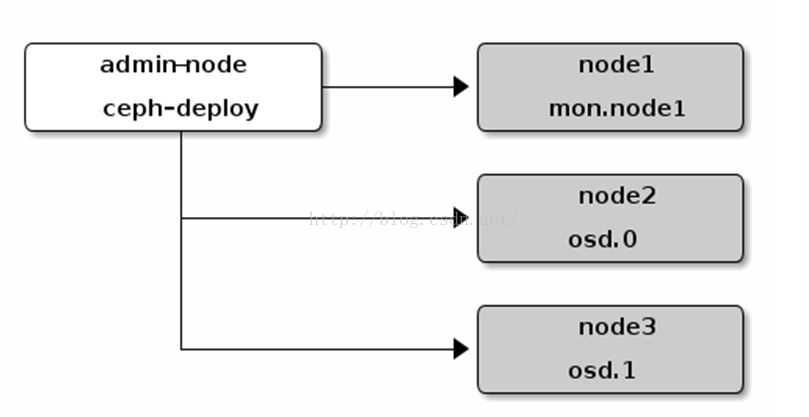
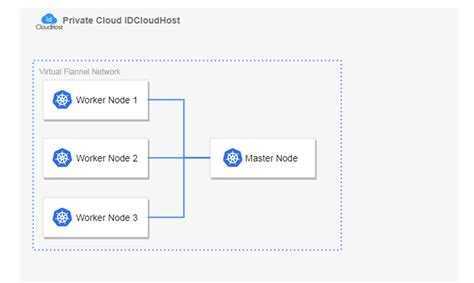
Планирование кластера
Kubernetes очень гибкий, поэтому кластер можно адаптировать к вашим потребностям. Здесь мы не будем рассматривать разные варианты кластеров. Об этом можно почитать в документации Kubernetes в разделе Создание кастомного кластера с нуля. Для примера мы создадим кластер из мастера с etcd и двух рабочих узлов. У кластера не будет плавающего IP, поэтому из интернета он будет недоступен.
Еще нам нужно выбрать CNI (Container Network Interface). Вариантов несколько (cilium, calico, flannel, weave net и т. д.), но мы возьмем flannel, который не нужно настраивать. Calico тоже подойдет, но нужно будет настроить порты OpenStack Neutron для подсетей сервисов и pod’ов.
Чтобы управлять кластерами на панели мониторинга Kubernetes после развертывания, нам нужно установить эту панель.
Kubewise
- Страница проекта;
- Лицензия: проприетарная (станет Open Source);
- Вкратце: «Простой мультиплатформенный клиент для Kubernetes».
Electron
- Взаимодействие в интерфейсе с самыми часто используемыми сущностями Kubernetes: узлами, пространствами имен и т.п.
- Поддержка нескольких файлов kubeconfig для разных кластеров.
- Терминал с возможностью установки переменной окружения .
- Генерация кастомных файлов kubeconfig для заданного пространства имен.
- Расширенные возможности безопасности (RBAC, пароли, service accounts).
6. OpenShift Console
- Раздел документации OpenShift;
- Репозиторий (~150 звёзд GitHub);
- Лицензия: Apache 2.0;
- Вкратце: «UI для кластеров OpenShift».
специального оператора
- Разделяемый подход к интерфейсу — две «перспективы» доступных в Console возможностей: для администраторов и для разработчиков. Режим Developer perspective группирует объекты в более понятном разработчикам виде (по приложениям) и ориентирует интерфейс на решение таких типовых задач, как деплой приложений, отслеживание статуса сборки/деплоя и даже редактирование кода через Eclipse Che.
- Управление рабочими нагрузками, сетью, хранилищами, правами доступа.
- Логическое разделение для рабочих нагрузок на проекты и приложения. В одном из последних релизов — v4.3 — появился специальный Project dashboard, отображающий привычные данные (количество и статусы deployment’ов, pod’ов и т.п.; потребление ресурсов и прочие метрики) в срезе проектов.
- Обновляемое в реальном времени отображение состояния кластера, произошедших в нем изменений (событий); просмотр логов.
- Просмотр данных мониторинга, основанного на Prometheus, Alertmanager и Grafana.
- Управление операторами, представленными в OperatorHub.
- Управление сборками, которые выполняются через Docker (из указанного репозитория с Dockerfile), S2I или произвольные внешние утилиты.
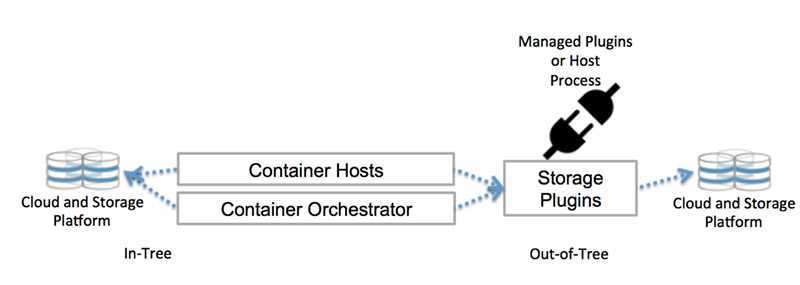
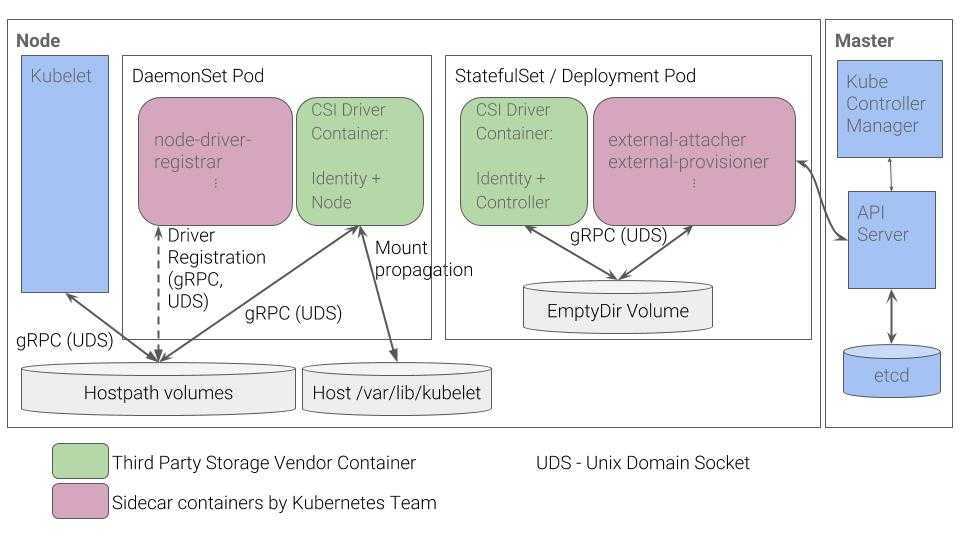
Способ 3. Container Storage Interface
Весь код, который взаимодействует с различными системами хранения данных, является частью ядра Kubernetes. Выпуск исправлений ошибок или нового функционала привязан к новым релизам, код приходится изменять для всех поддерживаемых версий Kubernetes. Всё это тяжело поддерживать и добавлять новый функционал.
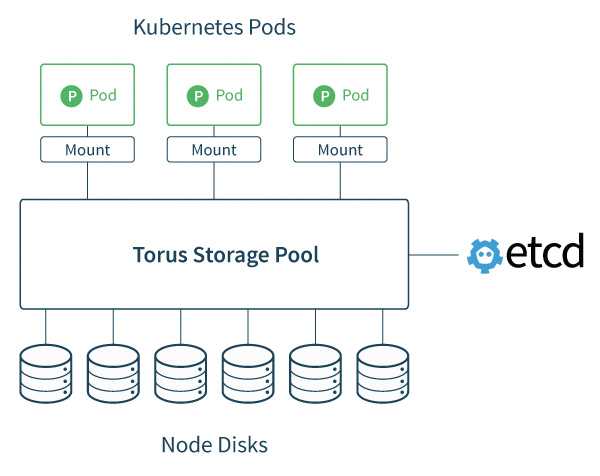
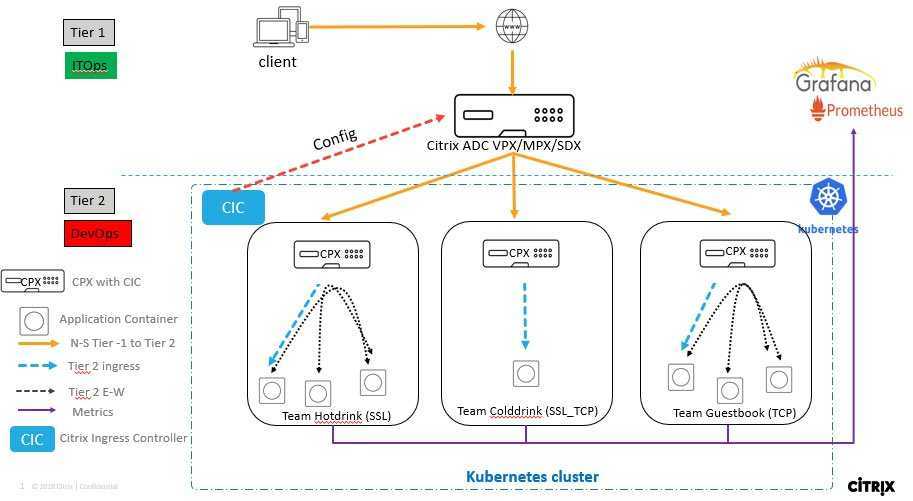
Чтобы решить проблему, разработчики из Cloud Foundry, Kubernetes, Mesos и Docker создали Container Storage Interface (CSI) — простой унифицированный интерфейс, который описывает взаимодействие системы управления контейнерами и специального драйвера (CSI Driver), работающего с конкретной СХД. Весь код по взаимодействию с СХД вынесли из ядра Kubernetes в отдельную систему.
Как правило, CSI Driver состоит из двух компонентов: Node Plugin и Controller plugin.
Node Plugin запускается на каждом узле и отвечает за монтирование томов и за операции на них. Controller plugin взаимодействует с СХД: создает или удаляет тома, назначает права доступа и т. д.
Пока в ядре Kubernetes остаются старые драйверы, но пользоваться ими уже не рекомендуют и всем советуют устанавливать CSI Driver конкретно для той системы, с которой предстоит работать.
Нововведение может напугать тех, кто уже привык настраивать хранение данных через Storage class, но на самом деле ничего страшного не случилось. Для программистов точно ничего не меняется — они как работали только с именем Storage class, так и продолжат. Для администраторов добавилась установка helm chart и поменялась структура настроек. Если раньше настройки вводились в Storage class напрямую, то теперь их сначала надо задать в helm chart, а потом уже в Storage class. Если разобраться, ничего страшного не произошло.
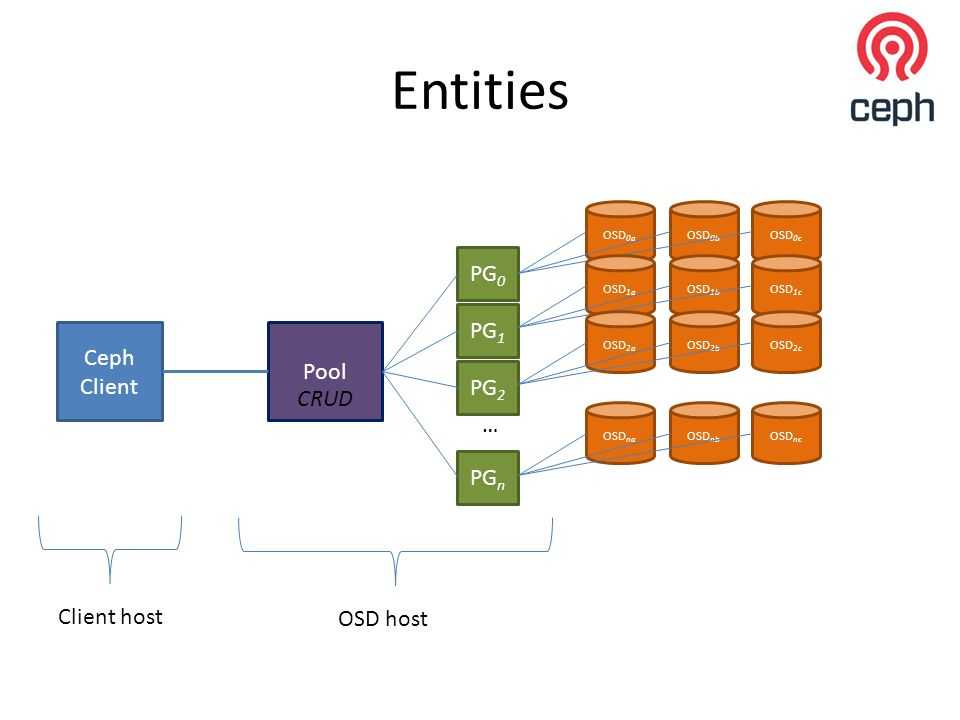
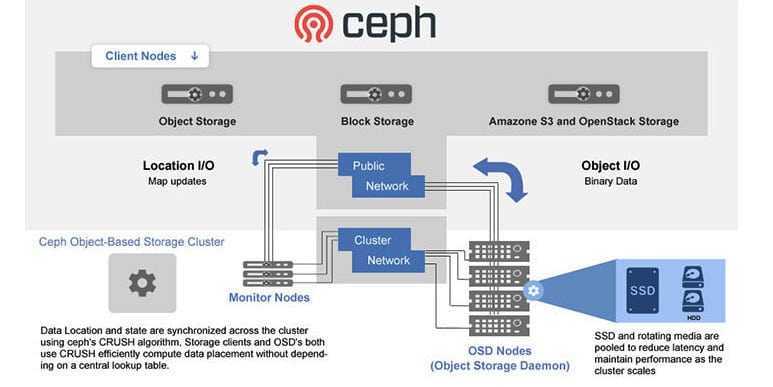
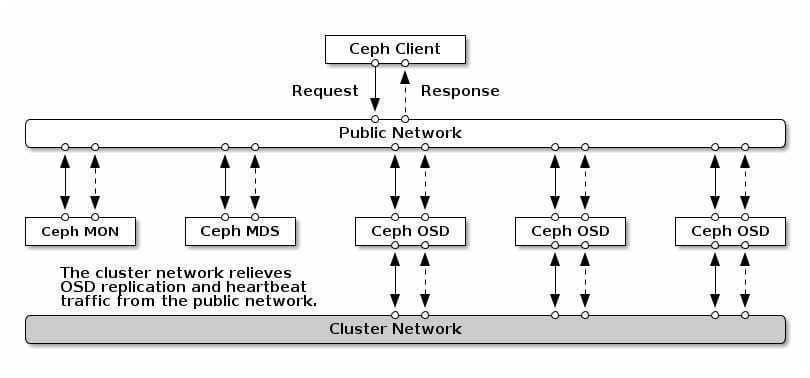
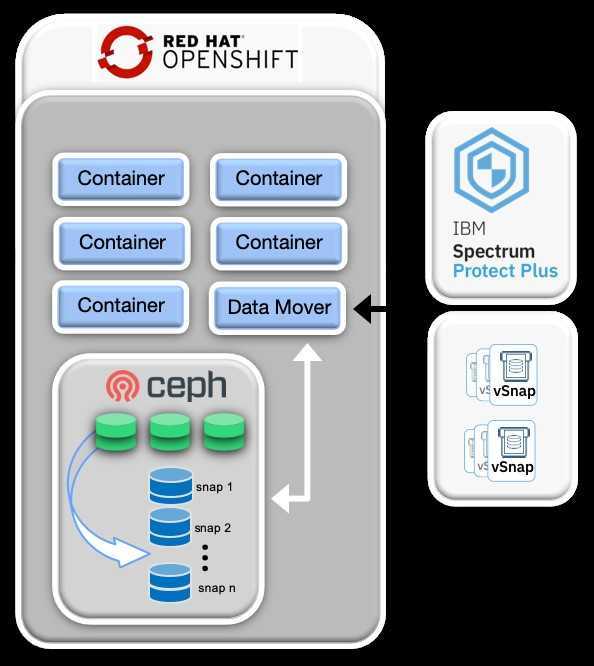
Давайте, на примере, рассмотрим какие преимущества можно получить, перейдя на подключение СХД Ceph с помощью CSI драйвера.
При работе с Ceph плагин CSI даёт больше возможностей для работы с СХД, чем встроенные драйверы.
- Динамическое создание дисков. Обычно диски RBD используются только в режиме RWO, а CSI для Ceph позволяет использовать их в режиме RWX. Несколько pod’ов на разных узлах могут смонтировать один и тот же RDB-диск к себе на узлы и работать с ними параллельно. Справедливости ради, не всё так лучезарно — этот диск можно подключить только как блочное устройство, то есть придётся адаптировать приложение под работу с ним в режиме множественного доступа.
- Создание снапшотов. В кластере Kubernetes можно создать манифест с требованием создать снапшот. Плагин CSI его увидит и сделает снапшот с диска. На его основании можно будет сделать либо бэкап, либо копию PersistentVolume.
- Увеличение размера диска на СХД и PersistentVolume в кластере Kubernetes.
- Квоты. Встроенные в Kubernetes драйверы CephFS не поддерживают квоты, а свежие CSI-плагины со свежим Ceph Nautilus умеют включать квоты на CephFS-разделы.
- Метрики. CSI-плагин может отдавать в Prometheus множество метрик о том, какие тома подключены, какие идут взаимодействия и т. д.
- Topology aware. Позволяет указать в манифестах, как географически распределён кластер, и избежать подключения к подам, запущенным в Лондоне системы хранения данных, расположенной в Амстердаме.
Как подключить Ceph к кластеру Kubernetes через CSI, смотрите в практической части лекции вечерней школы Слёрм. Так же можно подписаться на видео-курс Ceph, который будет запущен 15 октября.
Автор статьи: Сергей Бондарев, практикующий архитектор Southbridge, Certified Kubernetes Administrator, один из разработчиков kubespray.
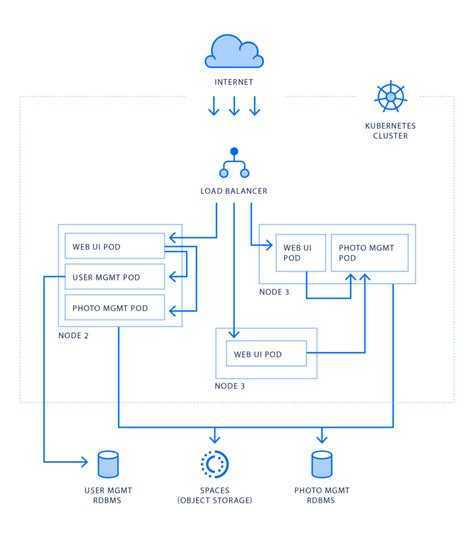
Модель развертывания приложений
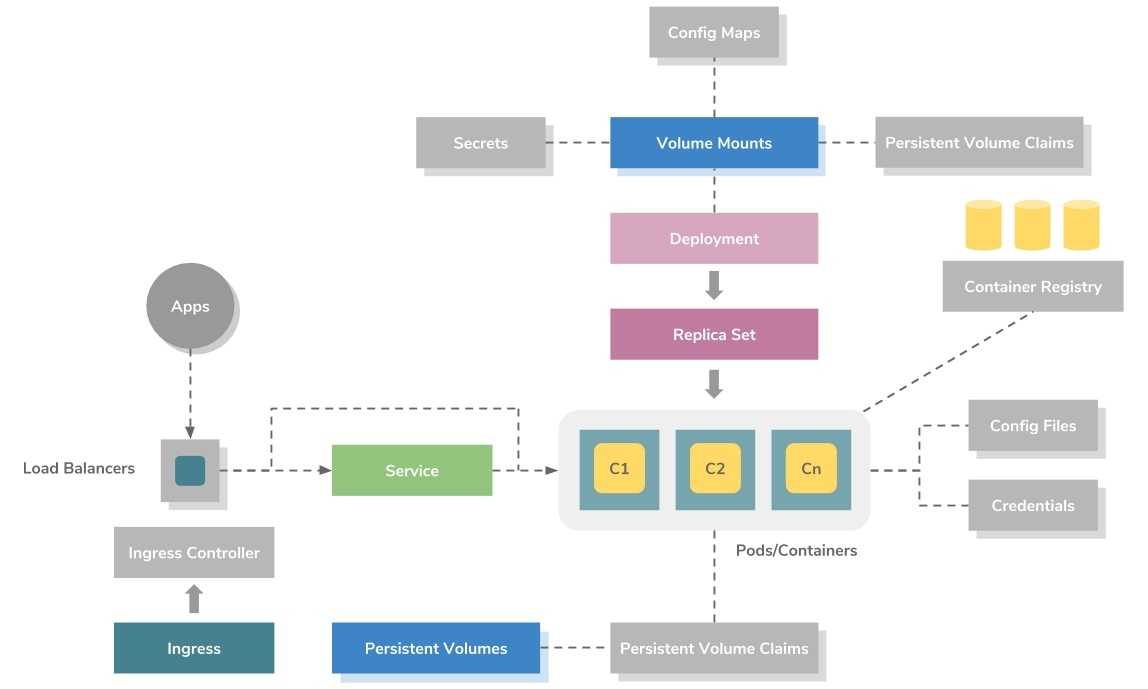
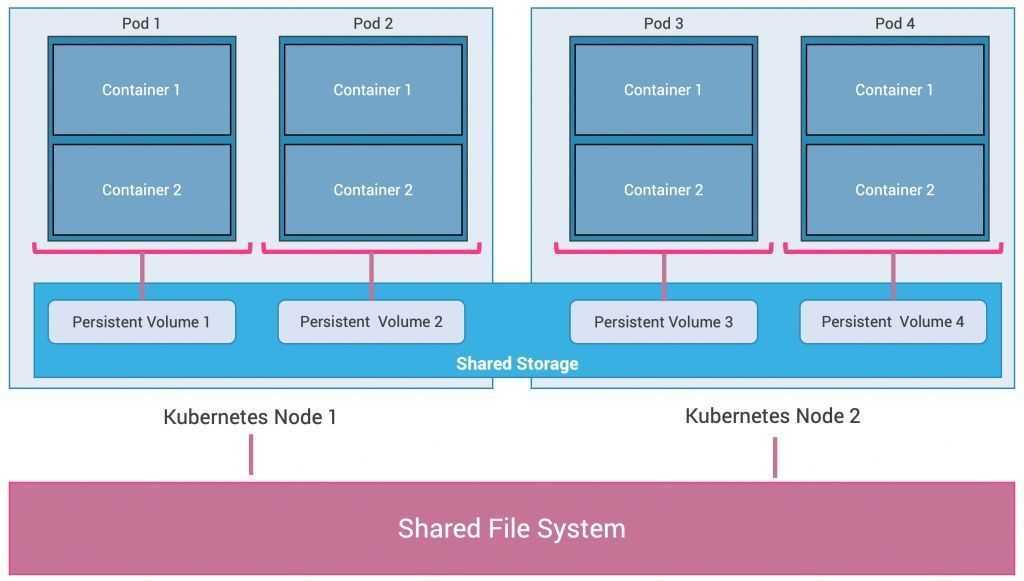
На приведенном выше рисунке показана модель развертывания приложений высокого уровня в Kubernetes. Он использует ресурс ReplicaSet для оркестровки контейнеров.
ReplicaSet можно рассматривать как файл метаданных на основе YAML или JSON, который определяет образы контейнеров, порты, количество реплик, проверки работоспособности активации, проверки работоспособности, переменные среды, монтирование томов, правила безопасности и т.д.
Контейнеры всегда создаются в Kubernetes как группы, называемые подами (pod), которые являются Kubernetes metadata definition или resource. Каждый pod позволяет совместно использовать файловую систему, сетевые интерфейсы, пользователей операционной системы и т.д.
Основные термины, которые нужны для понимания Kubernetes
- pod — контейнер / набор контейнеров + ресурсы хранения + уникальный IP + локальные параметры
- volume — иногда совместно используемое постоянное хранилище
- replicaSet — гарантирует, что определенное количество подов запущено
- deployment — декларативно управляет
- loadBalancer — предоставляет сервис с балансировщиком нагрузки облачного провайдера
-
Volume — Каталог, содержащий данные, доступные для контейнеров в Pod
- Secrets предназначены для хранения и управления конфиденциальной информацией, такой как пароли базы данных, ключи SSH и т.д.
-
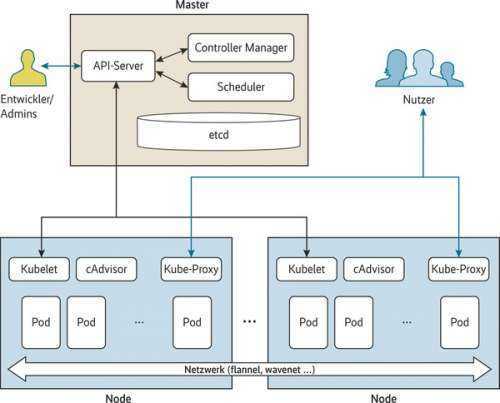
master — объект, ответственный за управление состоянием кластера. Он состоит из 3-х основных компонентов:
- kube-apiserver — предоставляет контроль и состояние кластера
- kube-controller-manager — здесь живет «мозг» контроллеров
- kube-scheduler — подбирает ресурсы для работы
Kubernetes Helm
Helm — это менеджер пакетов для Kubernetes, аналог NPM или YARN. Однако это не только диспетчер пакетов, это еще и средство управления развертыванием Kubernetes. Для простоты Helm Chart можно сравнить с Docker Image.
Helm chart— это просто набор файлов шаблонов YAML, организованных в определенную структуру каталогов.
project-chart/
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── rbac.yaml
│ └── service.yaml
└── values.yaml
|
1 |
project-chart ├──Chart.yaml ├──templates │├──deployment.yaml │├──rbac.yaml │└──service.yaml └──values.yaml |
Helm charts можно дополнительно публиковать в репозиториях. Это могут быть частные репозитории для внутреннего использования или публично размещенные, например hub.kubeapps.com.
Release: экземпляр helm chart загружен в Kubernetes. Его можно рассматривать, как версию приложения Kubernetes, работающую на основе Chart и связанную с определенной конфигурацией.
Настройка Ingress
Описанные выше сервисы решают задачу взаимодействия внутри кластера kubernetes, но нам нужно еще и c внешними пользователями взаимодействовать. Для этого настроим Ingress, который мы установили ранее в виде отдельной роли на ноде. По своей сути это обычный nginx, который будет получать конфигурацию из yaml файла. Рисуем конфиг для ingress, который будет пробрасывать запросы из вне на сервис service-nginx, который мы создали на предыдущем шаге.
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-nginx
spec:
rules:
- host: nginx.cluster.local
http:
paths:
- backend:
serviceName: service-nginx
servicePort: 80
Загружаем конфиг в кластер кубернетиса.
# kubectl apply -f ingress.yaml ingress.extensions/ingress-nginx configured
Смотрим, что получилось.
# kubectl get ingress -o wide NAME HOSTS ADDRESS PORTS AGE ingress-nginx nginx.cluster.local 10.1.4.39 80 3m20s
10.1.4.39 — ip адрес ноды ingress. В принципе, это сразу же может быть внешний ip, который будет принимать на себя все запросы. Так как это nginx, должно быть безопасно и надежно. На практике, я не знаю, делают ли так, но не вижу каких-то весомых причин в типовых сценариях этого не делать. Чтобы проверить работу ingress, нам надо добавить dns запись.
10.1.4.39 nginx.cluster.local
Я просто в локальный hosts машины добавил и проверил.
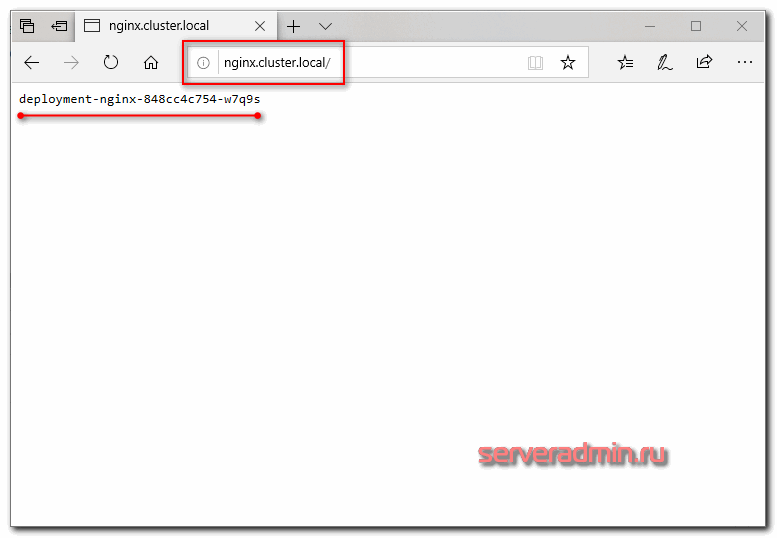
Если обновлять страничку, имя пода будет меняться в соответствии с настройкой балансировки. Она выполняется по алгоритму .
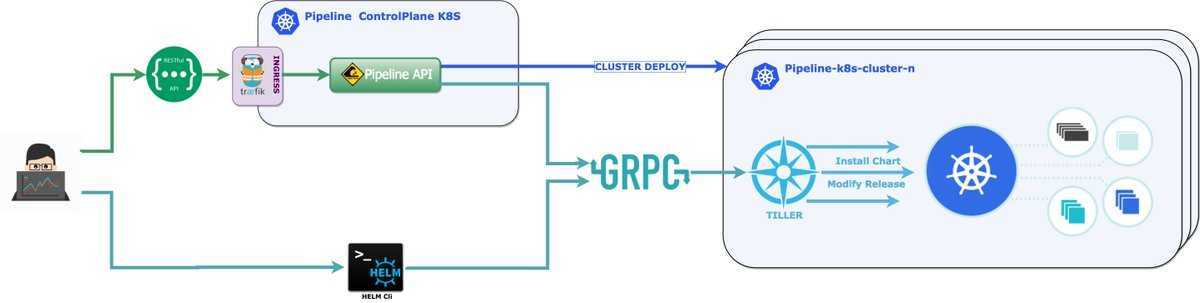
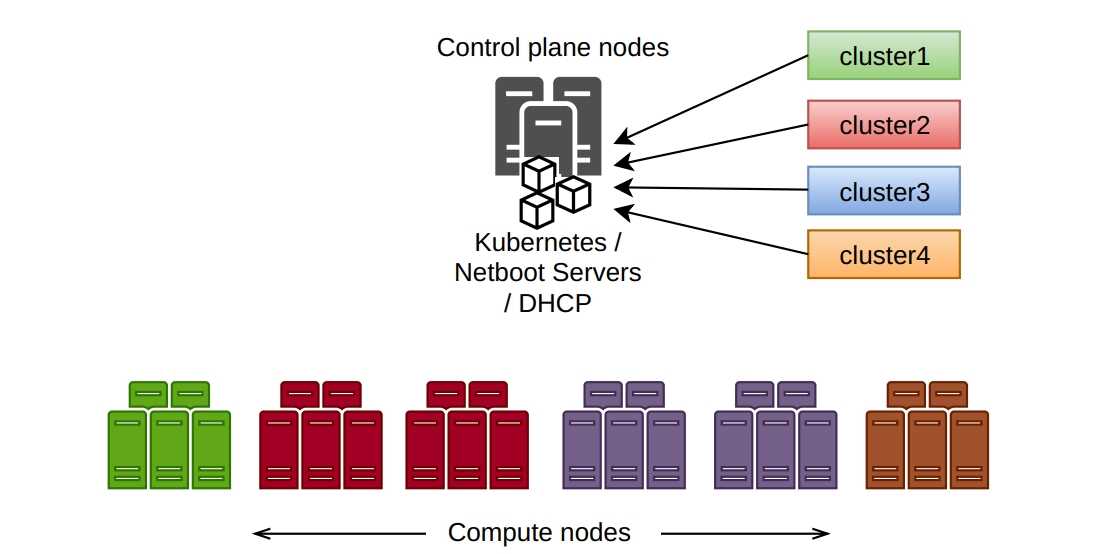
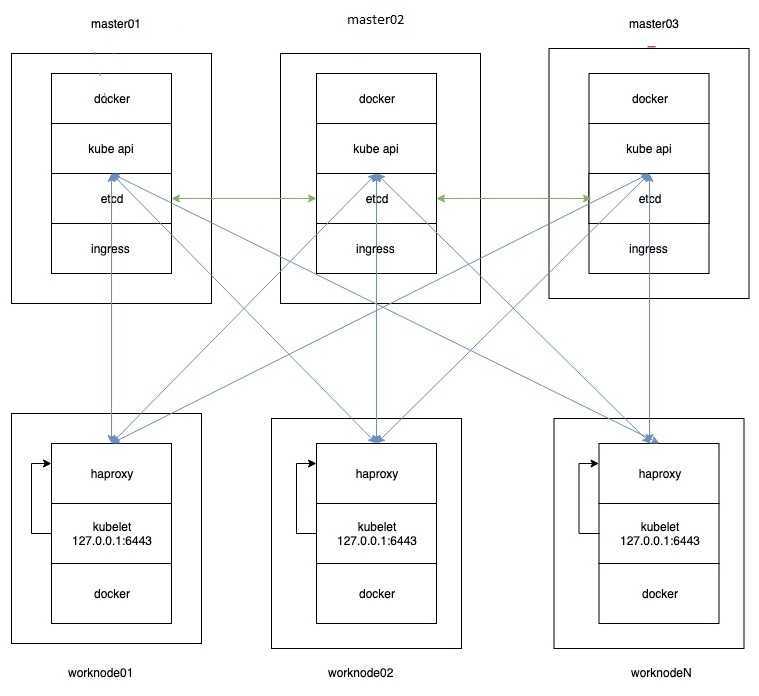

Более подробно настройку ingress контроллера я рассмотрел в отдельной статье.
На этом я прерываюсь и заканчиваю текущее повествование по работе с кластером kubernetes. В таком виде в нем уже можно осмысленно что-то запускать и эксплуатировать. Надеюсь, вам было хоть немного понятно и вы сможете начать экспериментировать с кластером и пытаться на нем запускать какую-то полезную нагрузку. В таком виде он уже пригоден к ограниченной эксплуатации.
Установка ELK стека
Классическая цепочка логирования в ELK стеке.
Вместо Logstash будем использовать стандартного для Kubernetes агента Fluentd и поэтому у нас получится не ELK, а EFK стек. Также в Kubernetes есть несколько схем развертывания логирования. Они описаны в официальной документации . Мы будем реализовывать следующую стандартную схему:
Начнем установку EFK стека с базы данных Elastic Search.
Установка Elastic Search
Создаем namespace efk в Kubernetes:
Добавляем репозиторий:
Обновляем список чартов:
Для минимизации ресурсов делаем конфигурацию с одной Master Node, одной репликой и ограничиваем объём диска в 10Gb. При промышленном развёртывании, конечно, параметры должны быть рассчитаны из реальных требований к надежности Elastic Search кластера и предполагаемого объёма данных:
Если с первого раза не получилось, смотрим логи, удаляем chart и persistent volume:
Правим параметры, запускаем заново.
После успешной установки проверяем, для этого делаем форвард потов:
Запускаем в браузере: http://127.0.0.1:9200/
В ответ должен вернуться JSON с версией Elastic Search.
Установка Fluentd
Чтобы разобраться с Fluentd я использовал несколько материалов:
Краткий алгоритм, который при удачном стечении обстоятельств должен привести к успеху:
Клонируем Helm чарты для fluentd из Git Hub:
-
Создаем ServiceAccount в namespace kube-system с именем fluentd.
-
Создаем ClusterRole и записываем в него конфигурацию с правилами доступа:
Создаем ClusterRoleBinding, в которой связываем ServiceAccount и ClusterRole.
-
Далее в файле fluentd-daemonset-elasticsearch.yaml в параметре FLUENT_ELASTICSEARCH_HOST указываем внутренний IP сервиса elasticsearch-master.
-
Там же правим на настройки с путями.
-
После нескольких неудачных попыток у меня получился следующий работоспособный YAML:
Устанавливаем Helm чарт:
Если попытка не получилось, разбираемся, удалям:
Правим, устанавливаем заново.
Установка Kibana
Установка оказалось на удивление проста. В параметрах сразу подрезаем требуемые системные ресурсы:
При ошибках, как всегда, разбираемся, удаляем:
Запускаем заново. После успешной установки проверяем, делаем порт-форвардинг:
Запускаем GUI в браузере: http://127.0.0.1:5601
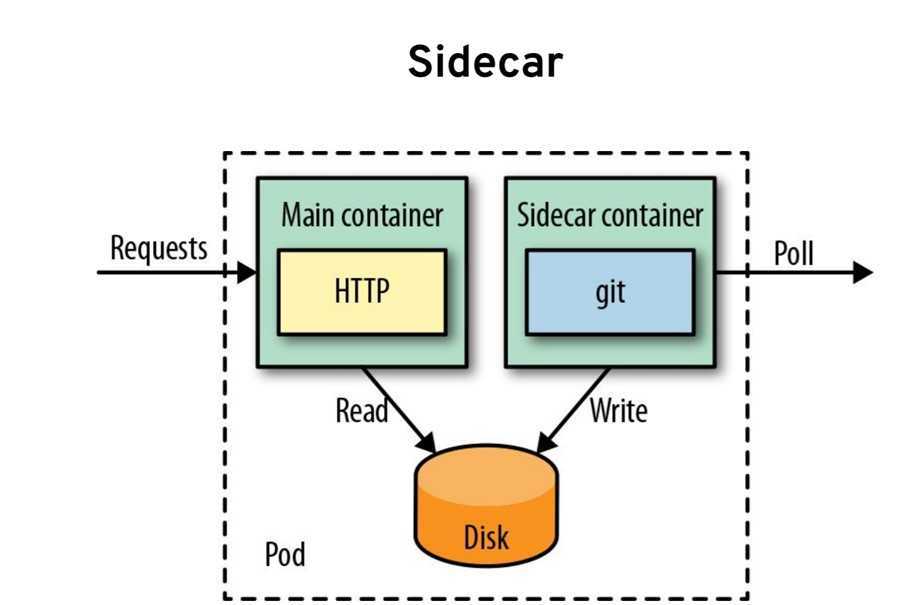
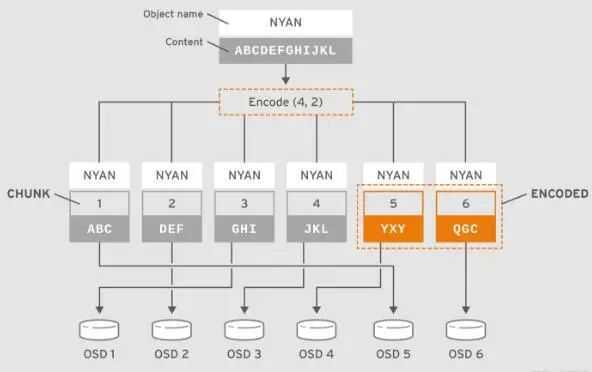
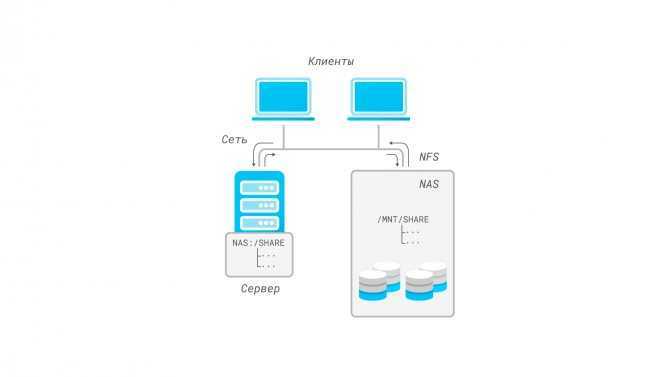
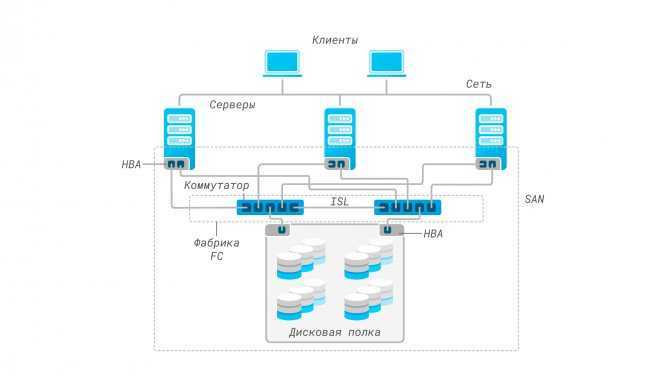

А вот с конфигурированием Kibana все оказалось не очевидно. Чтобы разобраться, установил EFK стек локально под Windows, прошел там всю цепочку и потом вернулся в Kubernetes. Но для тех, кто до этого работал с Kibana, разумеется, все просто:
После захода в GUI Kibana делаем новую Index Pattern (Management -> Index Patterns -> Create New Index Pattern).
При создании индекса указываем Logstash index, который сгенерировал Fluentd.
-
Идем в Discover, выбираем созданный индекс.
-
Ставим фильтр на определенную дату / время .
-
Выбираем поля kubernetes.container_name и log и смотрим на логи от fluentd и самой Kibana:
Создание Service для Kibana
Для удобного доступа к GUI Kibana делаем сервис, как мы ранее сделали для GUI Grafana. Шаги те же, тут просто перечислю без подробностей:
-
В Pod Kibana делаем метку, по которой Service будет его находить.
-
Далаем и запускаем файл kibana-loadbalancer-svc.yaml для сервиса с типом LoadBalancer. В селектор записываем нашу метку. Внутренний и внешний порт указываем стандартный для Kibana 5601.
-
Смотрим выданный Kubernetes внешний IP адрес, с помощью него получаем доступ к GUI Kibana.
Полная схема Pods в Kubernetes
В результате получили классическую цепочку для централизованного логирования в Kubernetes. Полная схема, развернутых в Kubernetes стеков:
Запускаем машину VirtualBox как службу Windows с помощью программы VBoxVmService
Качаем на странице разработчика
Из плюсов — нет привязки к конкретной версии VirtualBox. С программой VBoxVmService виртуальная машина запускается как сервис даже без логина пользователя в систему.
Далее, далее….
Видим финишное окно установки
На всё соглашаемся, читаем файл Howto.txt
Краткий вольный перевод:
- Part 1 — проверить, как работают виртуальные машины VirtualBox и все закрыть
- Part 2, Step 1 — запустить установщик (уже сделано)
- Part 2, Step 2 — внести свои параметры в файл VBoxVmService.ini
- Part 2, Step 3 — Reboot your system
Подробнее про параметры.
Переходим в папку с установленной программой (по умолчанию — C:\vms), открываем там файл VBoxVmService.ini и меняем нужные нам параметры.
Ниже описаны обязательные для редактирования настройки:
VBOX_USER_HOME — тут нужно указать путь к папке с виртуальными машинами.
VmName — указываем имя виртуальной машины;ShutdownMethod=savestate — метод завершения работы виртуальной машины, которых может быть два:
- «savestate«
- «acpipowerbutton» — вот просто выключение
Первый при выключении сохраняет состояние виртуальной машины, и при включении как бы продолжит её работу, второй является как бы полноценным выключением компьютера
AutoStart — запускать виртуальную машину автоматом при включении компьютера. Возможные варианты — yes и no, в переводе думаю не нуждаются.
Допустим, если целью стоит запуск виртуальной машины с названием XPprint, то файл настроек будет выглядеть следующим образом:
После сохранения файла и перезагрузки видим в трее
XPprint запущена. В службах уже ничего корректировать не надо — служба в автоматическом режиме.
А как собственно в машину попасть? Интерфейс же не запущен.
Мы можем зайти в машину:
- или через удаленный рабочий стол RDP (необходимо заранее на нашей машине настроить сеть)
- или через доступ SSH (на машине заранее должен быть поднят сервер SSH)
Конечно, достаточно чудно бегают пакеты TCP для доступа к гостевой машине (с использованием RDP).
С хостовой машины через реальный сетевой адаптер пакет идет на роутер, он их отправляет на «нарисованный» сетевой адаптер гостевой машины (хм, а виртуальный сетевой адаптер сделан на базе реального хостовой машины — т.е. фактически и физически пакет TCP возвращается обратно по тем же самым проводам витой пары в ту же самую сетевую карту), и в конце концов пакет попадает в гостевую машину (которая «нарисована» внутри реальной хостовой машины).
Пикассо отдыхает…. Достаточно сильный уровень абстракций….
Осталось попробовать самый простой вариант
Заключение
Если у вас нет возможности или желания настраивать кластер Kubernetes самостоятельно на своем железе, можете купить его в готовом виде как сервис в облаке Mail.ru Cloud Solutions.
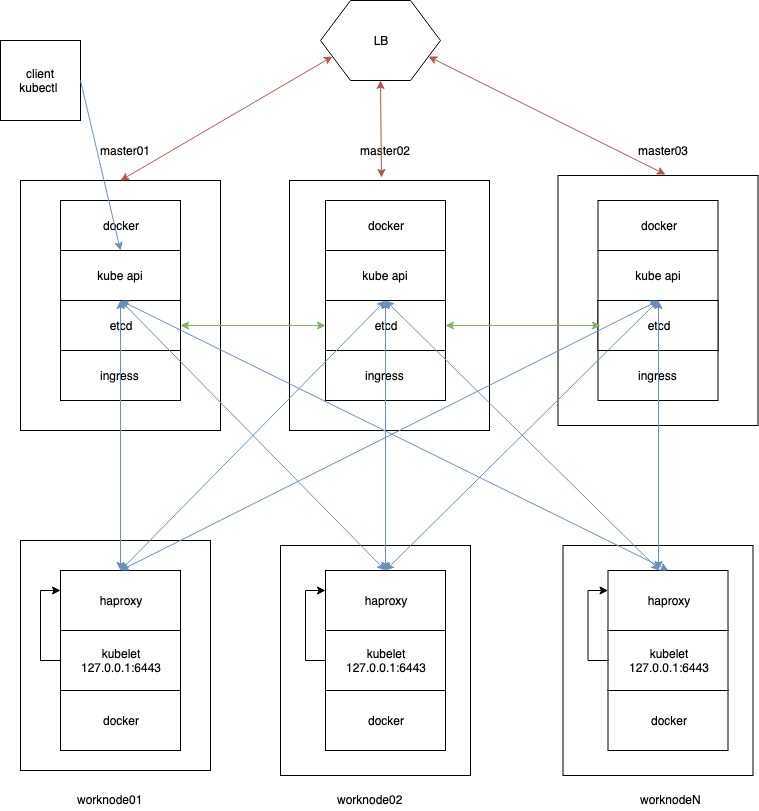
На этом начальную статью по Kubernetes заканчиваю. На выходе у нас получился рабочий кластер из трех мастер нод, двух рабочих нод и ingress контроллера. В последующих статьях я расскажу об основных сущностях kubernetes, как деплоить приложения в кластер с помощью Helm, как добавлять различные стореджи, как мониторить кластер и т.д. Да и в целом, хочу много о чем написать, но не знаю, как со временем будет.
В планах и git, и ansible, и prometeus, и teamcity, и кластер elasticsearch. К сожалению, доход с сайта не оправдывает временных затрат на написание статей, поэтому приходится писать их либо редко, либо поверхностно. Основное время уходит на текущие задачи по настройке и сопровождению.