
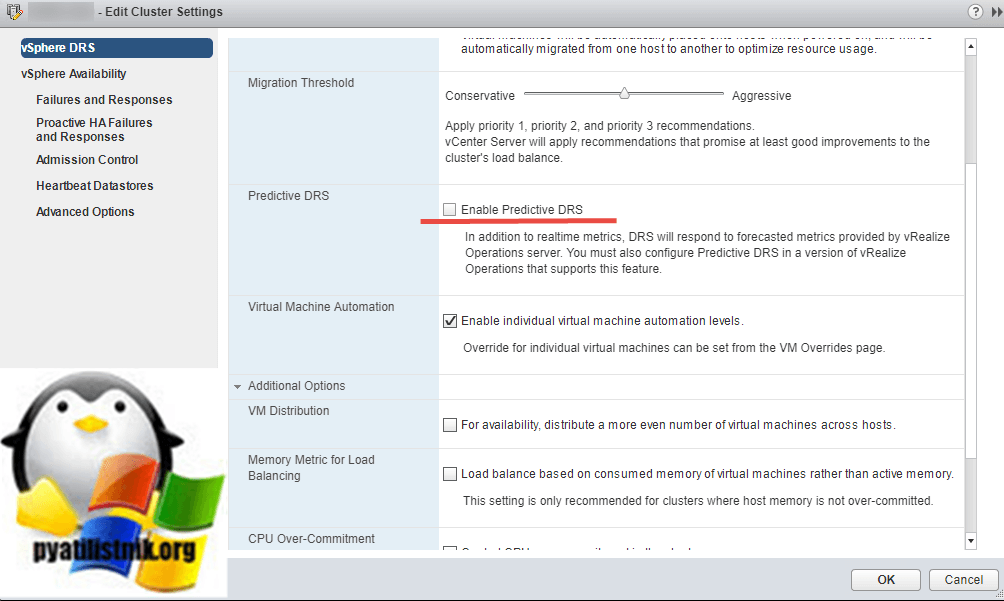
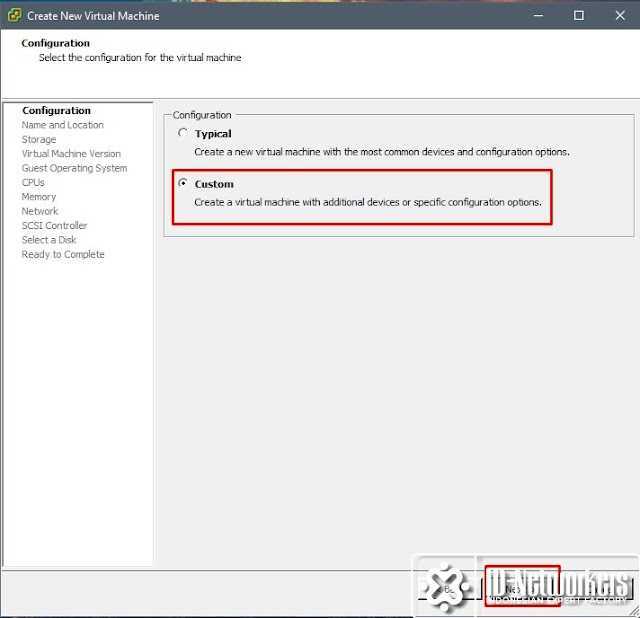
Опция Predictive DRS
Predictive — это новая функция, представленная в vSphere 6.5. Это функция, которая будет использовать vROps для предоставления решений о размещении и распределении нагрузки. Если в вашей среде запущены vROps, он начнет предоставлять прогнозируемую информацию DRS, а затем будет использовать эти показатели для балансировки кластера.
Прогнозируемая по умолчанию информация, получаемая DRS, составляет 60 минут (3600 секунд), и ее можно изменить с помощью расширенного параметра «ProactiveDrsLookaheadIntervalSecs».
Это действительно круто, представьте, что вы знаете, что у виртуальной машины будет рабочая нагрузка, которая увеличит использование ресурсов этой виртуальной машины, а DRS обеспечит миграцию этой виртуальной машины на хост с достаточными ресурсами.
Обратите внимание, что, конечно, DRS будет продолжать использовать данные, предоставленные vCenter Server, но, кроме того, он также использует VROps для прогнозирования того, как будет выглядеть использование ресурсов, и все это на основе исторических данных. Вы можете представить себе виртуальную машину, которая в настоящее время использует 4 ГБ памяти (по требованию), однако каждый день примерно в одно и то же время запускается задание SQL, в результате чего спрос на память увеличивается до 8 ГБ. Эти данные теперь доступны через VROps, и поэтому при составлении рекомендаций по размещению / балансировке этот прогнозируемый всплеск ресурсов теперь может быть принят во внимание. Чтобы включить «Predictive DRS», вам просто в настройках нужно выставить галочку «Enable Predictive DRS»
Чтобы включить «Predictive DRS», вам просто в настройках нужно выставить галочку «Enable Predictive DRS»
Как удалить виртуальную машину через PowerCLI
Чем плохи графические методы, это отсутствием автоматизации и невозможностью массового удаления виртуальных машин. Предположим, что вам нужно бахнуть 50 серверов, сколько времени вы потратите на это и графики, а если вообще нужно выполнить удаленно. Поэтому вы должны использовать оболочку PowerCLI. Он устанавливается в систему отдельно, как это сделать я рассказывал вот тут.
Подключаемся к нашему vCenter серверу или ESXI хосту. Для этого введите в оболочке команду:
Connect-VIServer vcenter.pyatilistnik.org
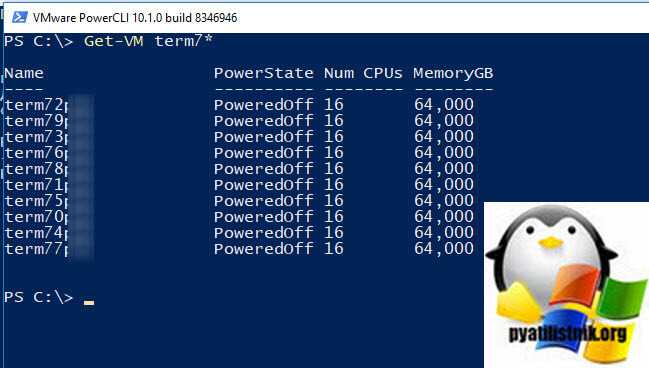
Далее есть такой командлет Get-VM, который может вам показать наличие нужных виртуальных машин. Мои виртуальные машины все называются term70-80. Зная это я могу вывести полный список.
Get-VM term7*
Далее для удаления виртуальной машины есть командлет Remove-VM со своими ключами:
- VM — Задает виртуальные машины, которые вы хотите удалить.
- Confirm — Если значение равно $true, это означает, что командлет запрашивает подтверждение перед запуском. Если значение равно $false, командлет запускается без запроса подтверждения пользователя.
- DeletePermanently — Указывает, что вы хотите удалить виртуальные машины не только из инвентаря, но и из хранилища данных.RunAsync — Указывает, что команда немедленно возвращается, не дожидаясь завершения задачи. В этом режиме выходом командлета является объект Task. Для получения дополнительных сведений о параметре RunAsync запустите «help About_RunAsync» в консоли VMware PowerCLI.
- Server — Указывает сервер vCenter Server, на котором вы хотите запустить командлет. Если этому параметру не задано значение, команда выполняется на серверах по умолчанию.
- WhatIf — Указывает, что командлет запускается только для отображения изменений, которые будут внесены, и на самом деле никакие объекты не изменяются.
Дополнительно можно посмотреть вот тут — https://vdc-repo.vmware.com/vmwb-repository/dcr-public/85a74cac-7b7b-45b0-b850-00ca08d1f238/ae65ebd9-158b-4f31-aa9c-4bbdc724cc38/doc/Remove-VM.html
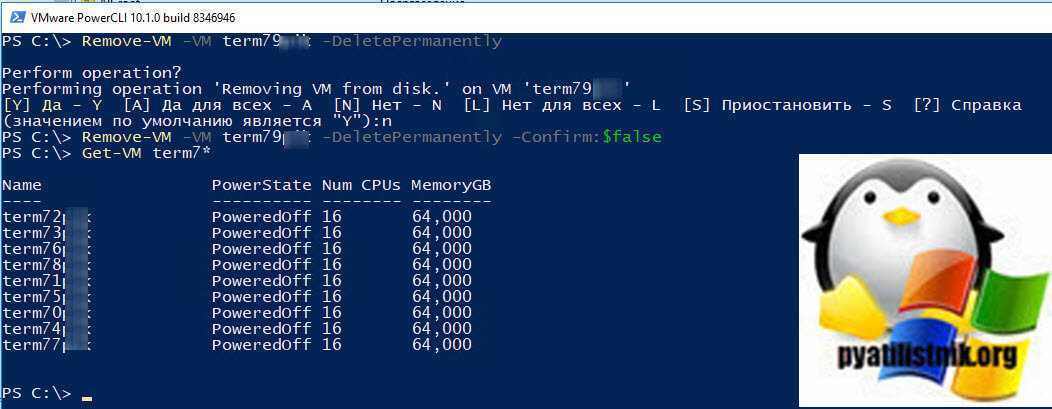
Давайте теперь для примера удалим виртуальную машину term79, для этого введите:
Remove-VM -VM term79
У вас появится подтверждение на удаление, говорим «Y».

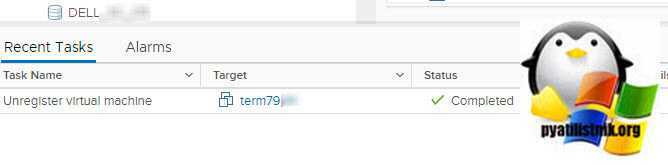
Н на самом деле ваша виртуальная машина не удалена, а просто теперь не зарегистрирована на vCenter, об этом говорит задание «Unregister virtual machine».
Файлы сервера все также продолжают лежать на датасторе.
Давайте теперь используем ключ -DeletePermanently, это позволит полностью с датасторов удалить виртуальный сервер.
Remove-VM -VM term79 -DeletePermanently
У вас выскочит подтверждение ваших действия, если нажмете «Y», то файлы VM будут полностью удалены.

Если не хотите видеть подтверждения, то воспользуемся ключом -Confirm:$false
Remove-VM -VM term79 -DeletePermanently -Confirm:$false
В веб интерфейсе вы увидите задание по удалению сервера.
Как вернуть активную опцию «migrate»
У компании VMware есть KB в которой описаны вот такие симптомы:
- Параметр миграции неактивен на выключенной виртуальной машине в vSphere Client.
- Вы не можете перенести выключенную виртуальную машину.
- В vSphere Client, когда вы выбираете опцию «Migrate» на вкладке «Summary» для виртуальной машины, вы видите ошибку:
Call «VirtualMachine.Relocate» for object «Virtual Machine-NAME» on vCenter Server «vCenter-Name» failed
Подробнее можно почитать вот тут — https://kb.vmware.com/s/article/2044369
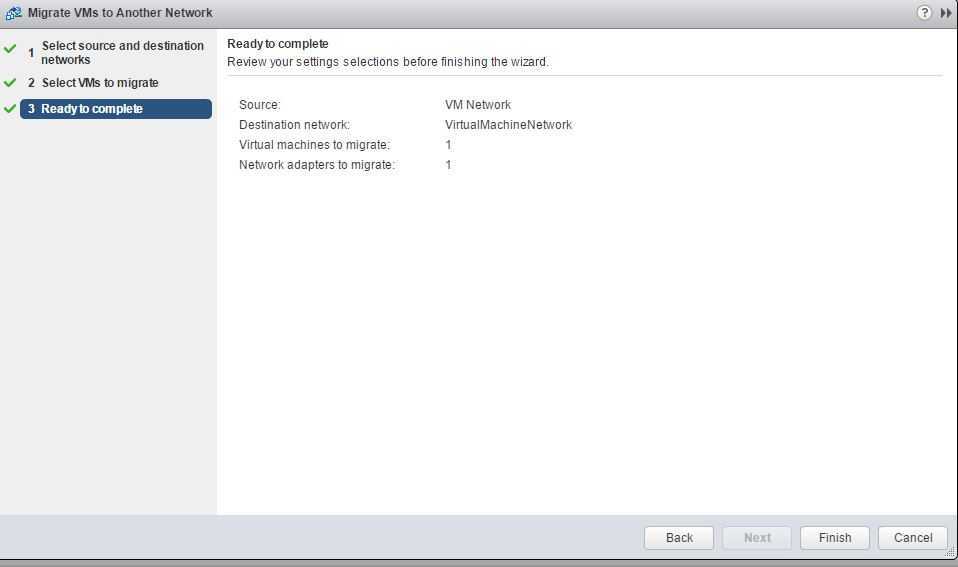
Перед тем как мы все исправим мне стало интересно, а есть ли у меня еще виртуальные машины имеющие данную проблему, чтобы это определить среди множества серверов, можно воспользоваться помощью PowerCLI. Откройте оболочку и подключитесь к вашему vCenter. Далее выполните вот такой код:
Get-vm | Select name,@{Name=»RelocateVM»;Exp={$_| get-view | Select-Object –ExpandProperty DisabledMethod | %{$_ -like «RelocateVM_Task»} | Sort-Object -Unique| Measure-Object | Select-Object -ExpandProperty Count}} | where{$_.RelocateVM -ne 1}
В результате я получил список из двух серверов. Понимая, что это не массовая проблема идем к самому решению.
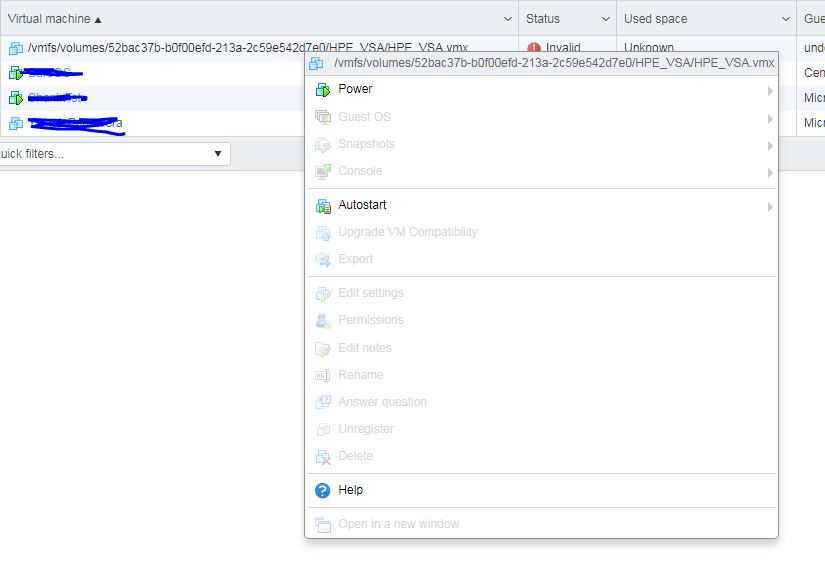
Нам нужно удалить регистрацию виртуальной машины из vCenter Server Inventory. Для этого через правый клик вызовите на сбойном сервере контекстное меню и найдите там пункт «Remove from iventory», это не удалит сервер с датасторов, а просто уберет его из списка зарегистрированных.
Перед удалением из vCenter Server Inventory выключите виртуальную машину и запомните на каком датасторе она у вас располагалась
Соглашаемся с тем, что отменяем ее регистрацию в vCenter.
Далее вы открываете ваш датастор с виртуальными дисками вашего сервера, находите там файл конфигурации, он имеет формат vmx. Далее нажимаем кнопку «Register VM».
У вас откроется мастер регистрации «Register Virtual Machine», на первом шаге вам нужно указать имя виртуальной машины, я оставлю как есть и по возможности вы можете ее сразу положить в контейнер.
Далее выбираем в каком кластере оно будет работать.
Завершаем нашу регистрацию.
Теперь проверьте, что у вас стал активен пункте «Migrate» у виртуальной машины.
Еще у сбойной машины я вам советую обновить VMware Tools, точнее удалить текущие и потом установить свежие.
На этом у меня все. Мы починили кнопку миграции, с вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Как настроить VM Encryption
Поскольку есть множество KMS серверов с поддержкой KMIP (у VMware даже есть документ, описывающий «сертифицированные KMS»), я не буду рассматривать конкретную реализацию KMS, выбор и настройку также обойду стороной. В моей тестовой среде уже есть кластер KMS из трёх нод, в котором каждая нода реплицирует данные с другими нодами.
Если у вас нет KMS, можете взять любой из списка «сертифицированных». Бесплатных решений в этом списке нет, если требуется что-то такое, смотрите в сторону PyKMIP. Кластер на PyKMIP построить нельзя, но с vCenter он работает. Проверял.
Для кластера KMS не требуется Load Balancer. Все ноды кластера равнозначны, содержат одинаковую базу данных и vCenter может запросить ключ у любой ноды KMS, а KMS, который выдал ключ, реплицирует этот ключ на другие ноды.
Установка доверительных отношений между vCenter и KMS
Давайте подключим наши vCenter к кластеру KMS. Процедуру подключения необходимо повторить на каждом vCenter.
Создаём новый кластер, указываем адрес нашей первой ноды и порт 5696 (стандартный порт KMIP). В моем случае логин и пароль указывать не требуется, но это может зависеть от реализации KMS.
Говорим vCenter доверять KMS.
На следующем шаге нам нужно, чтобы KMS доверял vCenter. Нажимаем MAKE KMS TRUST VCENTER.
На выбор есть несколько вариантов установки доверия KMS к vCenter. В случае с нашим кластером используется способ загрузки в vCenter ключевой пары KMS.
Указываем пару публичного и приватного ключей, сгенерированных KMS сервером. Эта пара ключей генерируется специально для настройки доверительных отношений между KMS и KMIP клиентом.
После установки доверия KMS к vCenter, кластер KMS будет доверять этому vCenter. Добавляем в vCenter остальные ноды KMS (загрузка пары ключей этих нод не потребуется) и на этом настройка KMS завершена.
Создание Storage Policy с шифрованием
Следующим шагом будет создание Storage Policy, использующей шифрование.
VM Encryption позволяет хранить VM с шифрованием и без шифрования на одной СХД. У нас уже есть Storage Policy vcd-default-policy. Создадим аналогичную vcd-default-encrypted-policy и включим шифрование в параметрах Host based services.
Отказоустойчивость
Что будет, если упадёт кластер KMS
Очевидно, что ничего хорошего. В окне конфигурации Key Management Servers в vCenter будет такая картина.
Падение KMS не повлияет на уже запущенные VM, которые продолжать работать (и их можно будет выключать, включать, мигрировать на другие хосты) до тех пор, пока в ОЗУ ESXi хранятся KEK, ранее полученные у KMS. KEK будут храниться в памяти до перезагрузки ESXi хоста.
При попытке включить VM Encryption при неработающем KMS пойдут ошибки генерации ключа.
Что произойдёт при перезагрузке ESXi хоста
Хост будет требовать включить шифрование вручную
VM, будучи зарегистрированной на хосте, который не хранит в ОЗУ KEK для этой VM (например, если ESXi хост был перезагружен или был добавлен в кластер после первичной инициализации шифрования), будет требовать разблокировать её, передав KEK на ESXi хост.
Недокументированная фича
vTPM для *nix систем
Существует недокументированный способ подключить vTPM для *nix, или для Windows, использующей BIOS. Этим способом можно подключить vTPM к любой виртуальной машине.
Для этого нужно подключить vTPM, используя PowerCLI. Установим PowerCLI и выполним скрипт через PowerShell.
После выполнения скрипта мы увидим, что конфигурационные файлы VM зашифрованы, но диск использует Storage Policy без шифрования.
vTPM на Linux VM
Также отобразится подключенный vTPM.
vTPM на Linux VM
Проверим работу vTPM в Ubuntu 1804.
На Ubuntu установим пакеты:
Проверим наличие TPM
Проверим работу TPM
Проверка загрузки процессора в пуле ресурсов (Resource Pool CPU Saturation).
Если используете пулы ресурсов и лимит на процессорные ресурсы пула, то читайте дальше. В противном случае сразу идите в следующий блок Host CPU Saturation.
- Выберите пул ресурсов и перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «CPU»;
- Оцените текущую загрузку в MHz (Usage);
- Сравните значение лимита пула ресурсов и текущую загрузку. Если текущая загрузка близка к лимиту, возможно, имеет место нехватка процессорных ресурсов и вам необходимо оценить значение CPU Ready отдельных виртуальных машин в этом пуле;
Проверка CPU Ready:
- Для измерения CPU Ready выберите одну из виртуальных машин (далее ВМ) в пуле, перейдите на вкладку Performance, выберите режим «Advanced» и переключитесь в обзор «CPU» (если вы решаете проблему производительности определенной ВМ, начните с нее);
- Оцените значение Ready для всех «объектов» ВМ. Отдельным «объектом» является каждый виртуальный процессор ВМ. Вам будет необходимо изменить свойства графика «Chart Options…» для отображения этого графика;
- Среднее или максимальное значение Ready для любого виртуального процессора превышает 2000мс? Если да, то у вас наблюдается нехватка процессорных ресурсов из-за установленного лимита на пул ресурсов;
- Повторите для всех ВМ этого пула.
На следующем рисунке проиллюстрирован этот пример
Как устранять потерю пакетов у виртуальной машины
Первое с чего следует начать диагностику, это посмотреть текущую загрузку ESXI хоста на котором располагается ваша виртуальная машина. Может быть ситуация, что на хосте все ресурсы утилизируются по максимуму и он вам об этом пишет «Host CPU usage и host memory usage».
Если на уровне хоста все хорошо и другие виртуальные машины работаю корректно и за ними не замечено потери пакетов, то проверяем уже саму виртуальную машину. Я вам советую открыть командную строку и запустить постоянный пинг через утилиту ping -t. Это нужно для того, чтобы сразу смотреть изменения при нашей диагностике.
Перейдем теперь к самой гостевой операционной системе, тут вам нужно проверить две вещи:
Первая это нагрузка на CPU. Если она под 100%, то вас сетевой интерфейс будет не успевать обрабатывать пакеты, тем более если вы используете устаревший вид интерфейса E1000. Сделать это можно в диспетчере задач. Для этого нажмите одновременно CTRL+SHIFT+ESC. Перейдите на вкладку производительности и выберите пункт «ЦП (CPU)». Убедитесь, что здесь нет всплеском под 100%, если они есть, то перейдите на вкладку «Процессы».
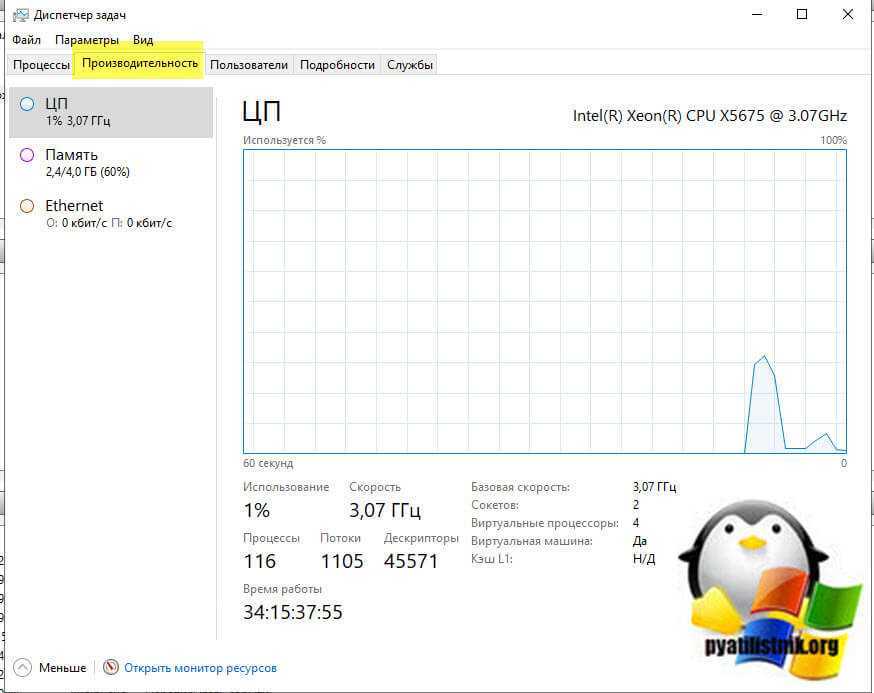
На данной вкладке произведите фильтрацию по загрузке CPU, для этого один раз щелкните по столбцу. В самом верху посмотрите, что за процесс потребляет ваши мощности, если он не нужен, то завершите его, если нужен, то нужно наращивать ресурсов или оптимизировать ПО, которое за него отвечает.
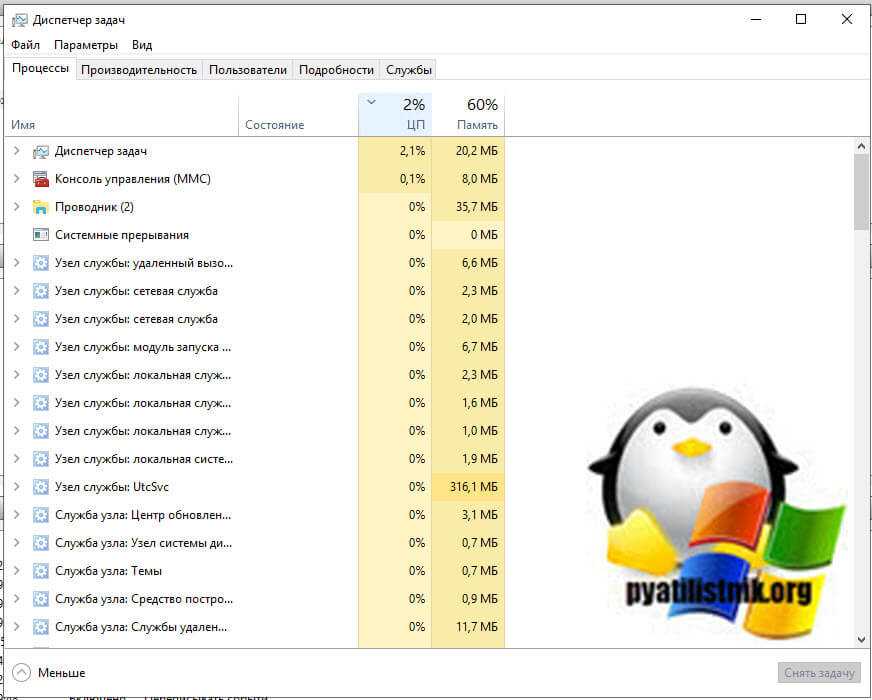
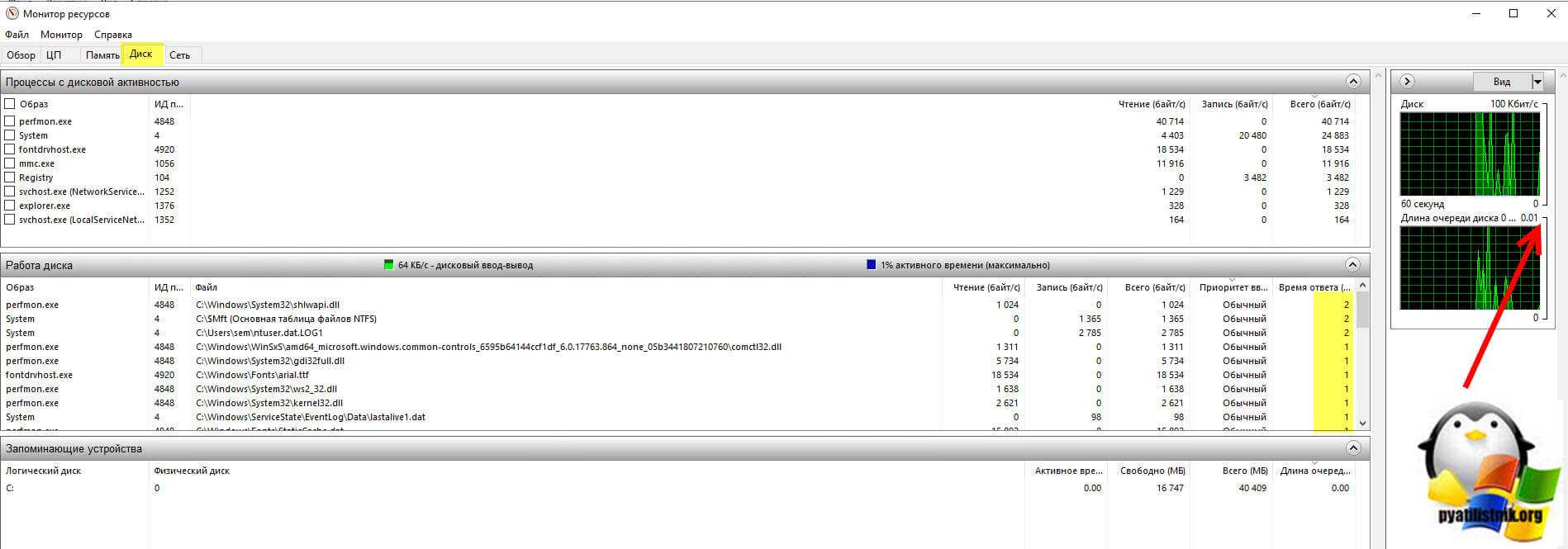
Далее так же посмотрите нагрузку на вашу дисковую подсистему. Для этого запустите монитор ресурсов из диспетчера процессов.
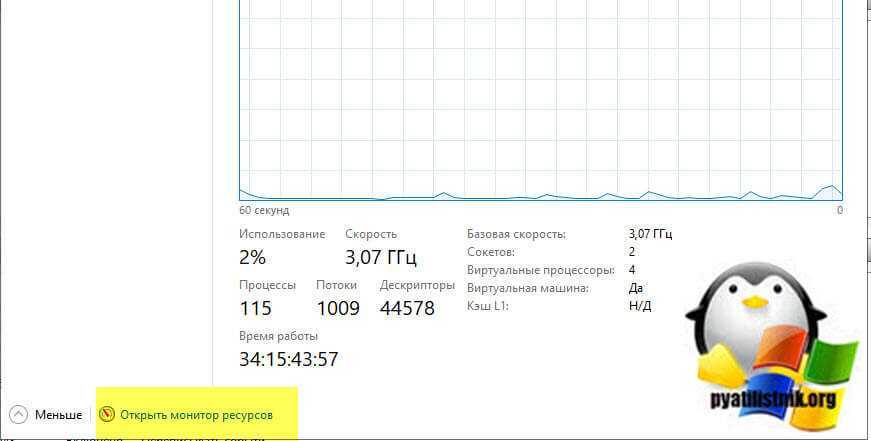
Перейдите на вкладку «Диск», тут вам нужно посмотреть два параметра:
- Длина очереди, которая не должна быть больше единицы
- Время ответов, которое для ssd не должно быть более 20 и для HDD не более 100.
Если у вас значения выше или существенно выше, то нужно искать проблему низкой производительности дисков или самого датастора на котором лежит виртуальная машина.
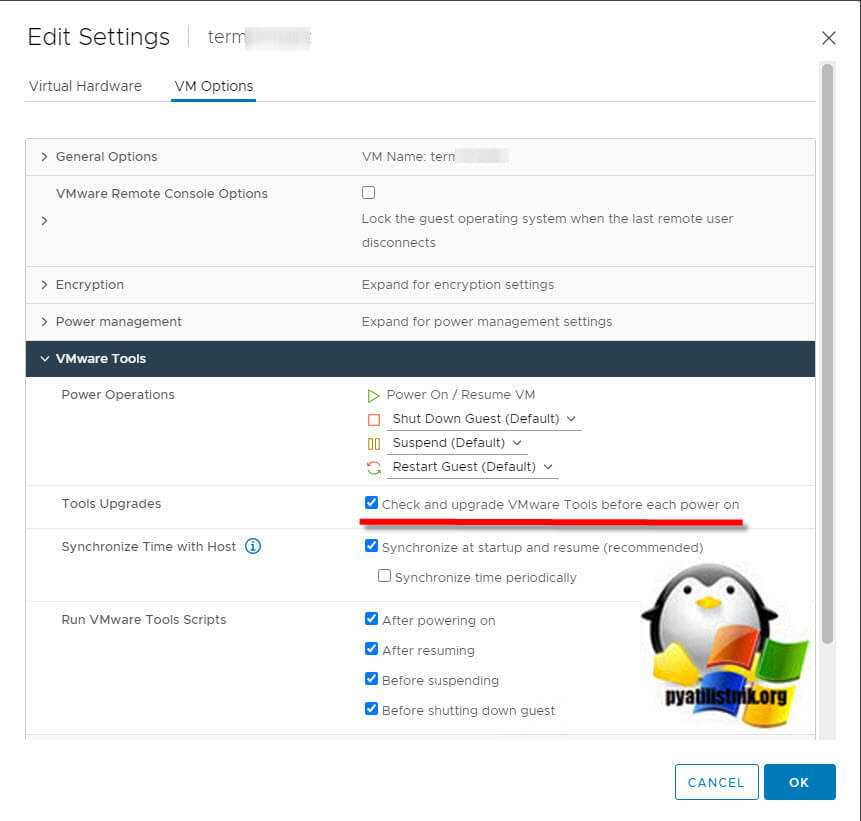
Включение автоматического обновления инструментов при перезагрузке в web-клиенте
Использование параметров виртуальных машин для обновления VMware Tools, также является еще одним методом автоматического обновления оборудования у виртуальных машин. Включение расширенного параметра “Check and upgrade VMware Tools before each power on” нельзя использовать из-за дополнительной перезагрузки виртуальных машин. Помните, что с Windows Server 2016, VMware Tools больше не требует перезагрузки при обновлении, можно безопасно включить этот параметр, и виртуальные машины будут обновляться при каждой перезагрузке. Однако это может быть применимо не ко всем ситуациям, поэтому еще одна рекомендация — включить это для лабораторной среды или некритических рабочих нагрузок. Самый простой способ включить эту опцию — войти в vSphere Client, отредактировать настройки виртуальной машины и включить настройку.
При следующем включении ваша версия виртуального оборудования будет обновлена до последней версии.
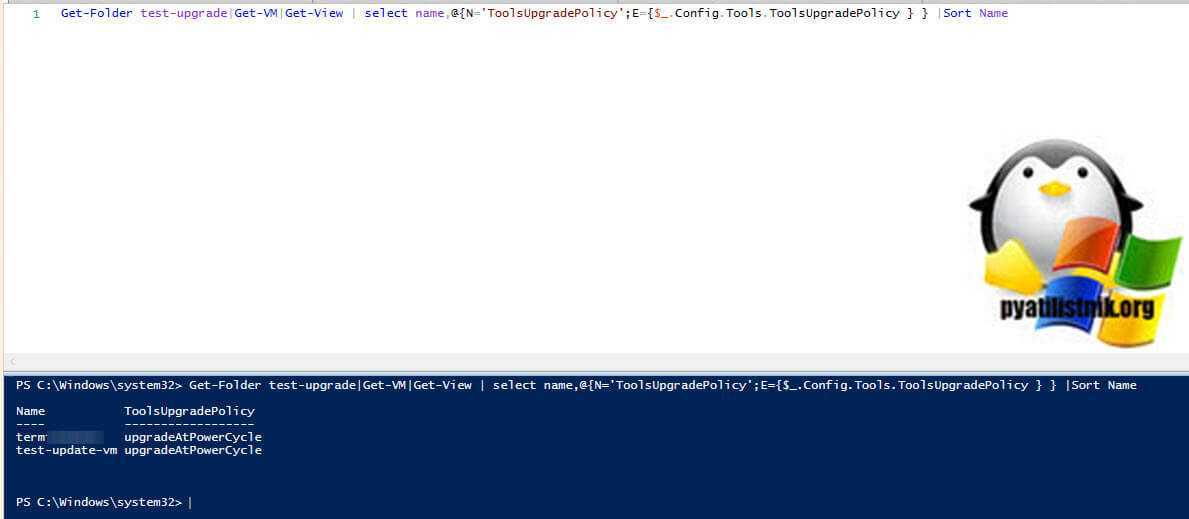
У нас пост об автоматизации, так что давайте посмотрим, сможем ли мы найти способ использовать PowerCLI для изменения настроек виртуальной машины, чтобы это стало проще, когда у нас есть большая среда. Задача выставить списку серверов галку “Check and upgrade VMware Tools before each power on”. Для начала возьмем список виртуальных серверов из папки и посмотрим текущие статусы.
Get-Folder test-upgrade|Get-VM|Get-View | select name,@{N=’ToolsUpgradePolicy’;E={$_.Config.Tools.ToolsUpgradePolicy } } |Sort Name
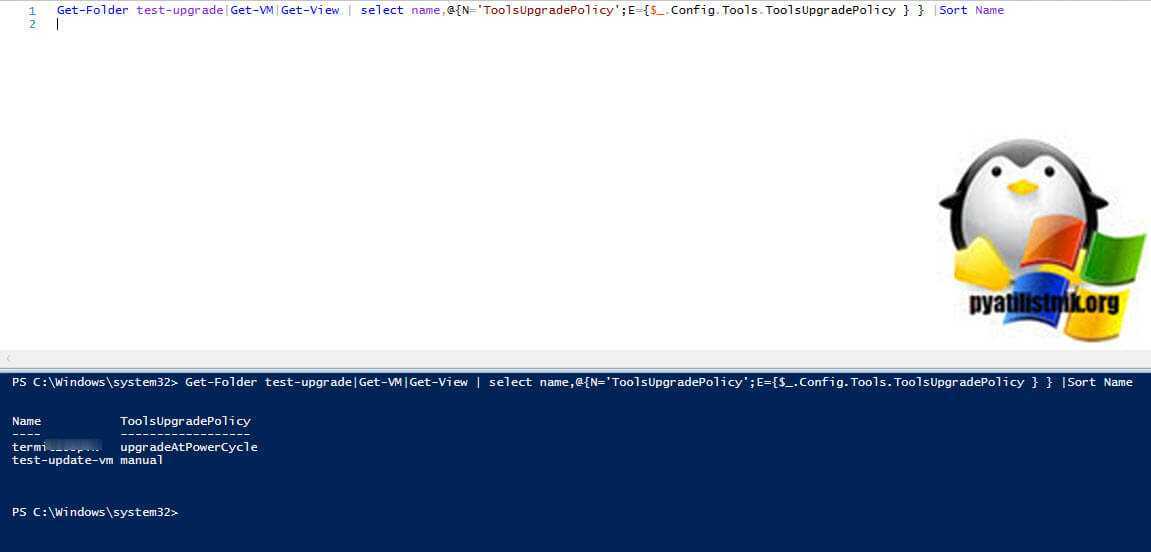
Здесь мы можем увидеть, для каких виртуальных машин установлено автоматическое обновление, а для каких — вручную. Используя фильтр, мы можем искать объекты, которые настроены вручную, а затем настраивать их для установки на upgradeAtPowerCycle. Теперь давайте зададим те кто был вручную, сделать все автоматически.
$ManualUpdateVMs = Get-Folder test-upgrade|Get-VM|Get-View | Where-Object {$_.Config.Tools.ToolsUpgradePolicy -like «manual»}|select name,@{N=’ToolsUpgradePolicy’;E={$_.Config.Tools.ToolsUpgradePolicy } }
Foreach ($VM in ($ManualUpdateVMs)) { $VMConfig = Get-View -VIObject $VM.Name $vmConfigSpec = New-Object VMware.Vim.VirtualMachineConfigSpec $vmConfigSpec.Tools = New-Object VMware.Vim.ToolsConfigInfo $vmConfigSpec.Tools.ToolsUpgradePolicy = «UpgradeAtPowerCycle» $VMConfig.ReconfigVM($vmConfigSpec) }
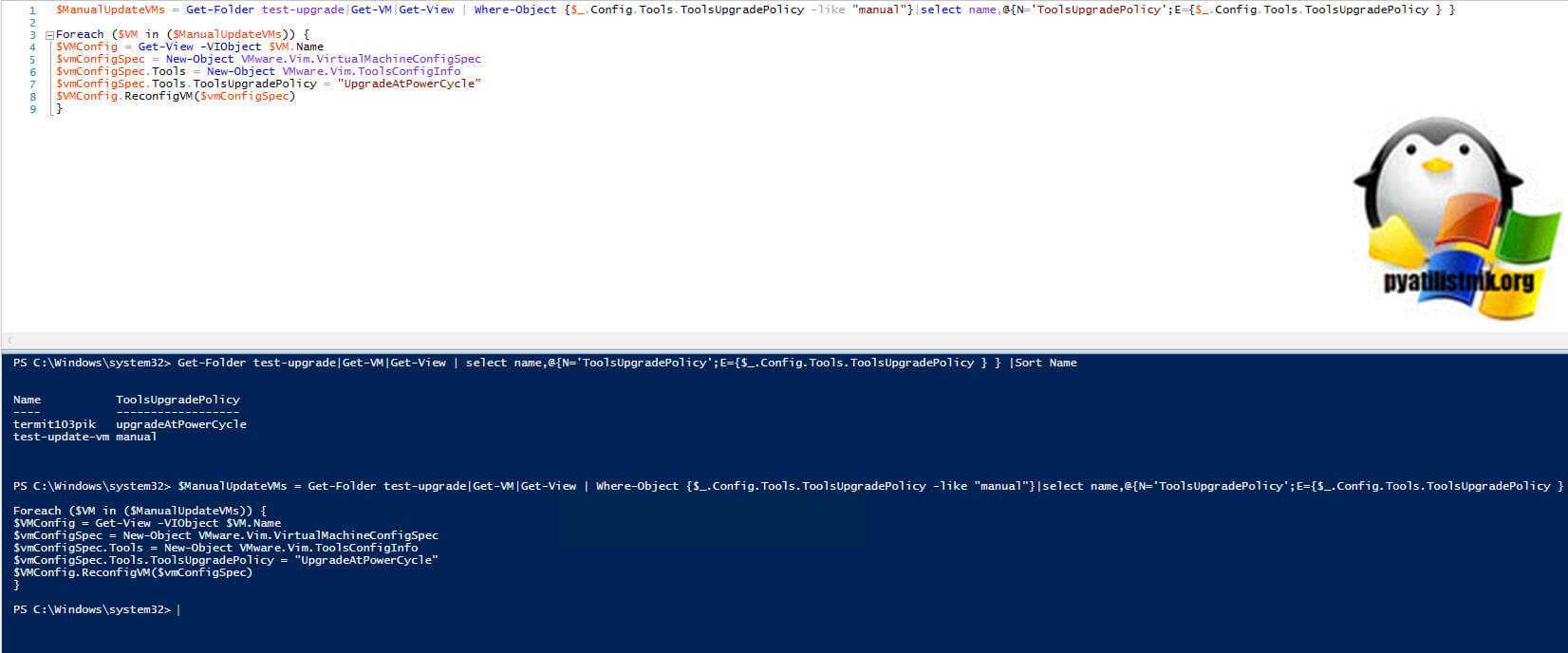
Проверим, что теперь у всех выставлен статус в «ToolsUpgradePolicy» как «UpgradeAtPowerCycle».
Проверка большого времени отклика у ВМ со снапшотами.
- Запускаем esxtop/resxtop;
- Выбираем экран виртуальных дисков, нажав «v»;
- Если не отображаются задержки, включим их отображение, нажав «f», а затем «g» и «h». Нажмите любую кнопку, чтобы вернуться в основной экран esxtop;
- Оцените значения «LAT/rd» и «LAT/wr» для ВМ со снапшотами. Данные значения отражают средние величины задержек при операциях ввода-вывода;
- Перейдите на экран с дисковыми устройствами, нажав «u»;
- Если задержки не отображаются по умолчанию, добавьте требуемые поля, нажав «f», а затем «j» и «k». Нажмите любую кнопку, чтобы вернуться в основной экран esxtop;
- Оцените значения «QUED», «DAVG/rd» и «DAVG/wr». «QUED» показывает текущее значение дисковой очереди на LUN. DAVG/* — среднее время отклика устройства;
- Значение очереди равно нулю? Задержки на экране «виртуального диска» значительно превышают задержки физического LUN? Если да, то проблема в снапшотах ВМ.
To be continued…
Рекомендации по решению проблем ждите в следующей статье/переводе.
Ремонт работающей виртуальной машины со статусом Invalid (Unknown)
В ситуации, когда виртуалка работает и хотелось бы вернуть возможность ее редактировать и взаимодействовать из самого ESXI, вы можете выполнить ряд действий, которые устранят статус Invalid (Unknown). Во первых, вы можете попробовать выполнить из консоли ssh, такие команды:
vim-cmd vmsvc/reload 97 (97 Это ID, мы его получили выше), после этого минуты через две, обновите интерфейс в вашем ESXI клиенте, чтобы проверить статус машины
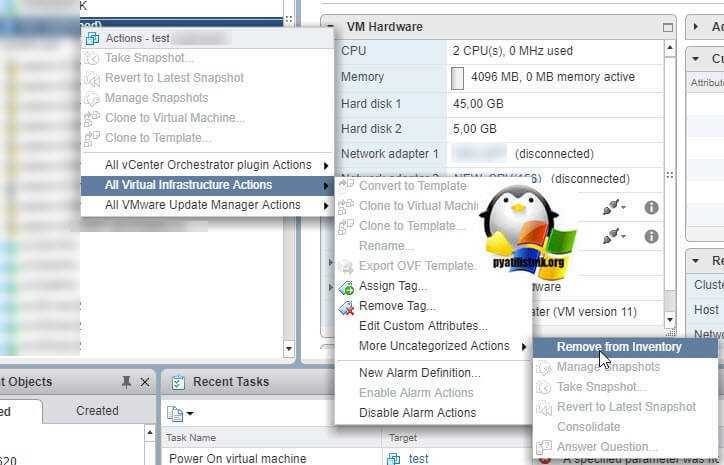
Если новая перерегистрация не помогла, то делаем вот что, тушим по возможности виртуальную машину из самой ОС. Далее, щелкаем по ней правым кликом и удаляем ее из инвентории. В vCenter 6.5 это выглядит так, «All Virtual infrastructure Actions — More Custom Atrtributes — Remove From Inventory».
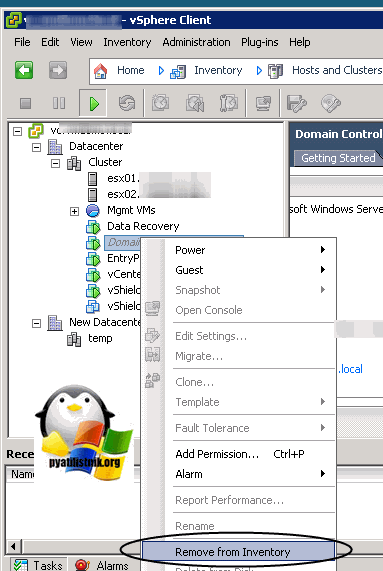
В ESXI 5.5, это выглядит вот так.
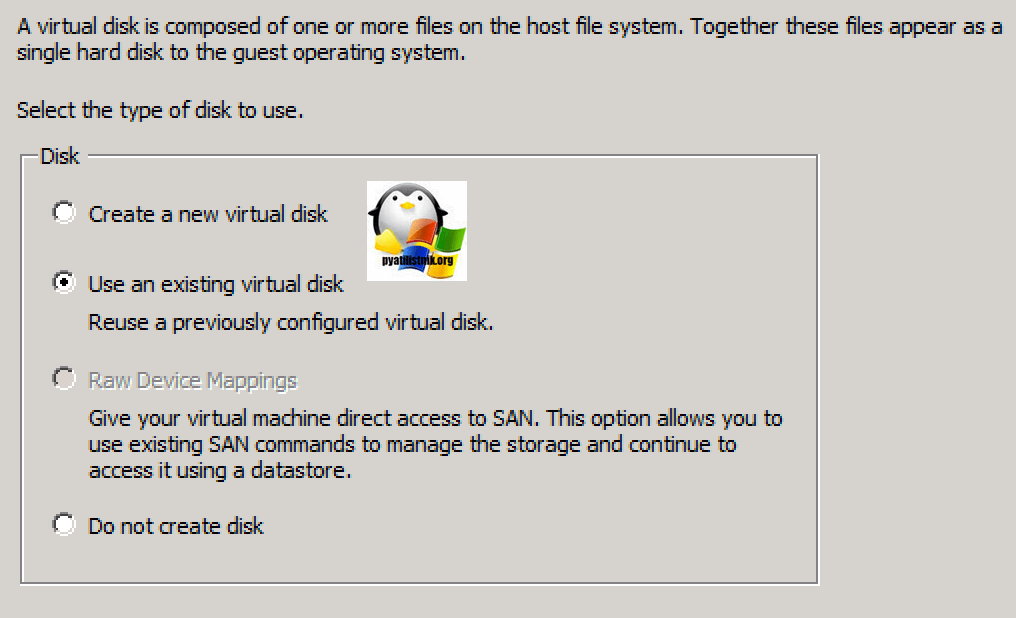
Если виртуалка работает и нет возможности ее выключить, перезагружаем ESXI хост. После чего создаем новую виртуальную машину. На этапе «Customize Hardware», где нужно указывать размер ваших ресурсов, удалите стандартно созданный диск, и нажмите кнопку Add. Выберите пункт «Существующий виртуальный диск (Existing Hard Disk).
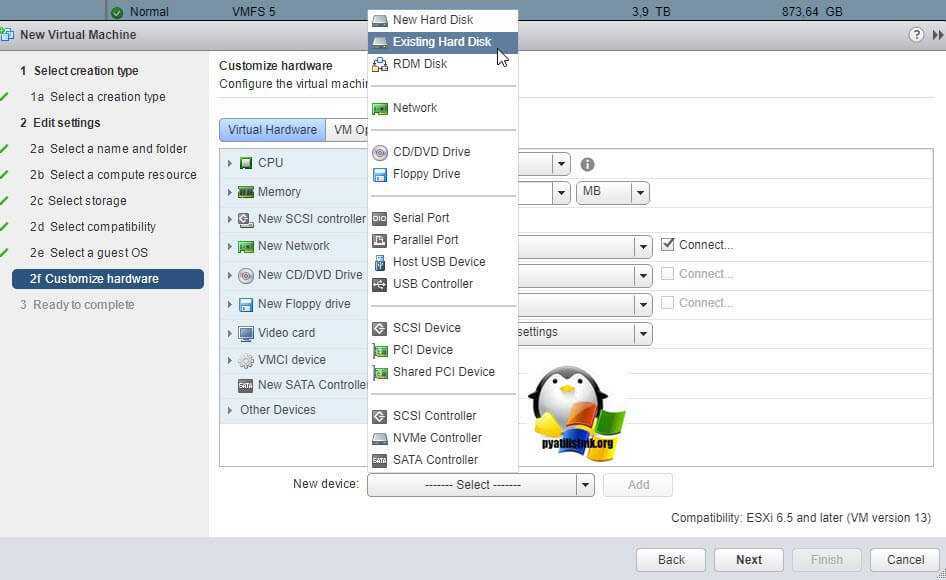
И добавьте все ваши существующие диски, от прежней виртуальной машины. Запустите ее и проверьте, что все работает.
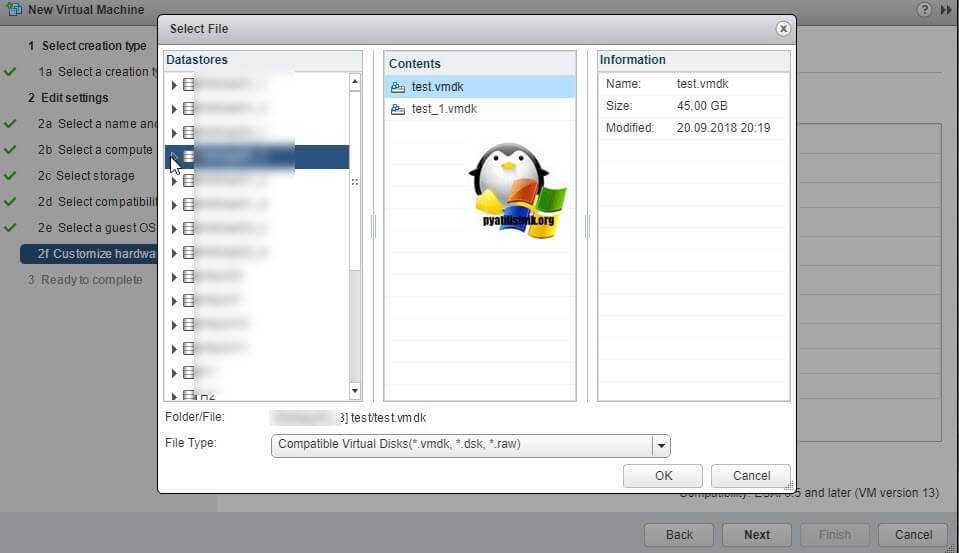
В ESXI 5.5, это выглядит так же, там нужно выбрать «Use an existing virtual disk».
Как только вы удостоверились, что все в порядке, осталось еще выполнить миграцию этих дисков в папку с виртуальной машиной, чтобы все было в одном месте. Для этого два пути, тупое копирование файлов и заново передобавлять их из конфигурации мастера или же сделать Storage VMotion.

Дополнительные возможности для Windows
Virtualization Based Security
Для Windows 10, Windows Server 2016 и новее мы можем использовать Virtualization Based Security. Включение VBS принудительно установит механизм загрузки в UEFI и включит Secure Boot. Если VM использовала BIOS, она, скорее всего, не загрузится после включения.
Про VBS можно прочитать в документации Microsoft или блоге VMware. VBS недостаточно включить в настройках виртуальной машины, его необходимо настроить в гостевой ОС. Процедура настройки описана здесь и в документации Microsoft.
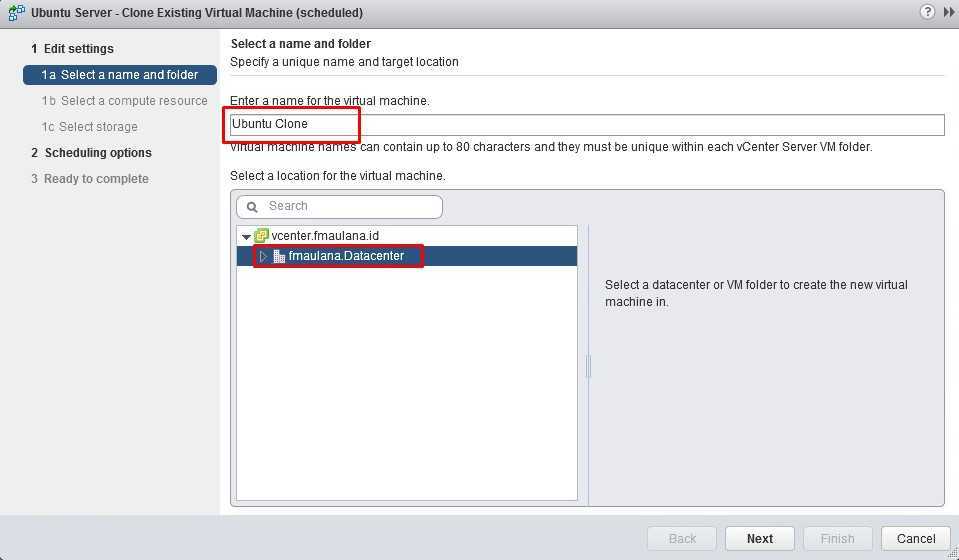
Virtual Trusted Platform Module
Для Windows 10 и Windows Server 2016 и новее, включив шифрование конфигурационных файлов VM и используя для загрузки UEFI (Secure boot можно не включать), в настройках VM становится доступна установка vTPM.
Данные vTPM хранятся в файле *.nvram в зашифрованном виде.
В гостевой ОС vTPM определяется как обычный физический TPM 2.0.
vTPM в Windows определяется как обычный TPM 2.0
Bitlocker
С vTPM мы можем использовать Windows Bitlocker без ввода пароля при загрузке Windows.
Windows будет загружаться автоматически и разблокировать диски с помощью ключей в vTPM. Если такую VM вынести за пределы площадки облачного провайдера, (или, если vTPM будет изменён, а такое происходит даже при восстановлении бэкапа VM, кроме восстановления поверх) то Bitlocker будет требовать ввести ключ восстановления Bitlocker. Перенести ключи из vTPM невозможно (такой кейс не описан в документации и простых способов извлечения ключей из vTPM я не вижу).
После ввода ключа восстановление Bitlocker диск останется зашифрован и начнёт использовать новый vTPM, т.е., в случае изменения vTPM, ключ восстановления Bitlocker нужно будет ввести только 1 раз.
Кейс использования vTPM + Bitlocker может быть компромиссом между удобством (VM включается автоматически без ввода пароля Bitlocker) и безопасностью данных (данные зашифрованы средствами гостевой ОС).
Через панель управления VMware Cloud Director 10.1 и новее есть возможность выбрать Storage Policy, использующую шифрование.
Можно изменять как VM default policy, и в этом случае, изменится политика всех дисков VM, у которых Storage policy не задана явно (задана как VM default policy), а также изменится политика хранения конфигурационных файлов VM.
Также можно задавать Storage Policy индивидуально для каждого диска.
Необходимо придерживаться правила, чтоб все диски VM были или зашифрованы, или были без шифрования. При попытке использования дисков с шифрованием и без шифрования на одной виртуальной машине VMware Cloud Director не позволит это сделать.
При зашифрованных конфигурационных файлах виртуальной машины мы увидим напротив VM Storage Policy надпись (Encrypted). При зашифрованных дисках надпись (Encrypted) будет отображаться напротив каждого виртуального диска.
vTPM без шифрования диска средствами VM Encryption
Чтобы подключить vTPM, конфигурационные файлы VM нужно зашифровать (также, должен быть включен Secure Boot и использовать Windows в качестве гостевой ОС). Если использовать Bitlocker, то шифрование дисков VM средствами VM Encryption приведёт к двойному шифрованию и может негативно сказаться на производительности. Чтобы зашифровать конфигурационные файлы и не шифровать диски VM,необходимо назначить VM Storage Policy c шифрованием, а для дисков использовать Storage Policy без шифрования.
Подключить vTPM из интерфейса VMware Cloud Director нельзя, но это возможно сделать через vSphere Client силами инженеров облачного провайдера.
Для чего пробрасывают в vmware usb
Ну в vmware usb устройства, пробрасывают в конкретные виртуальные машины, для сервисов которые используют аппаратные ключи для своей работы или те же самые модемы, для службы оповещения например. Данный режим прокидывания называется Host-Connected USB Passthrough, ниже я хочу определиться с требованиями, которые должны быть выполнены.
Требования для проброса
- Первое правило весьма логичное, что одно usb устройство, может быть добавлено, только в одну виртуальную машину. У данной машины может быть не более 20 юсби устройств, этого и так за глаза.
- Версия Virtual Hardware должна быть не ниже 8
- На хосте должен быть USB-контроллер. USB arbitrator хоста ESXi может управлять 15-ю контроллерами
- С данными виртуальными машинами, можно проводить процедуру миграции (vMotion), но usb с ней не переедет, это нужно учитывать.
- Перед, добавлением юсби устройства, нужно добавить USB-контроллер в устройства виртуалки
- Перед отключением проброшенного в ВМ ЮСБИ-устройства рекомендуется отключать проброс контроллера в Virtual Machine
- Если у вас используется горячее добавление памяти и CPU, то перед добавлением выключите USB-устройства от ВМ, иначе при увеличении ресурсов usb отвалятся, что может привести к потере данных
- Виртуальная машина не может загружаться с проброшенного устройства USB
Официально Vmware поддерживает вот такие устройства, но это не означает, что если вашего в списке нет, то работать не будет.
Как перезапустить зависшую виртуальную машину
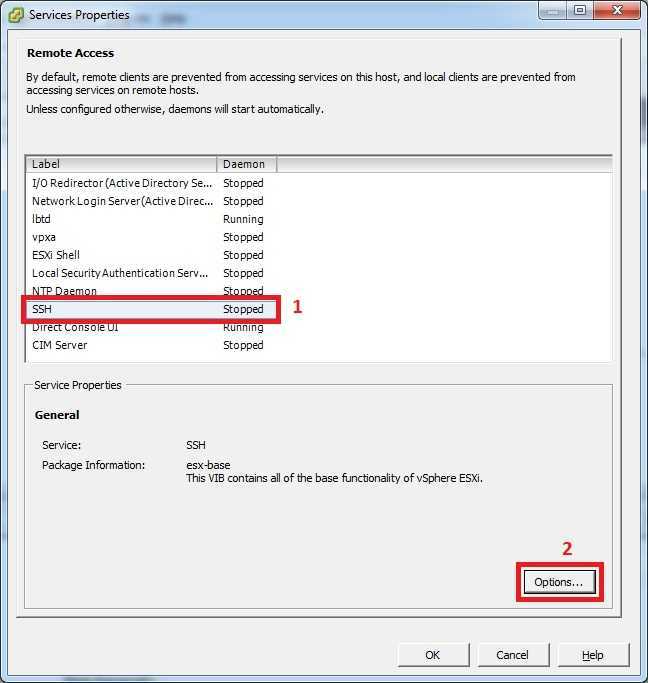
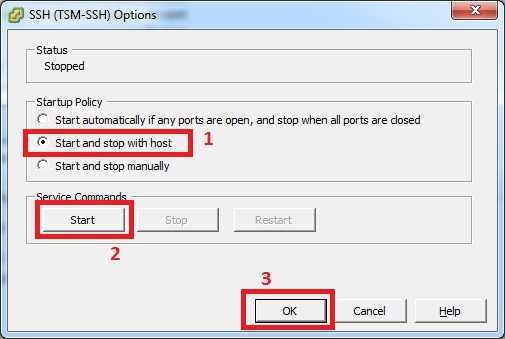
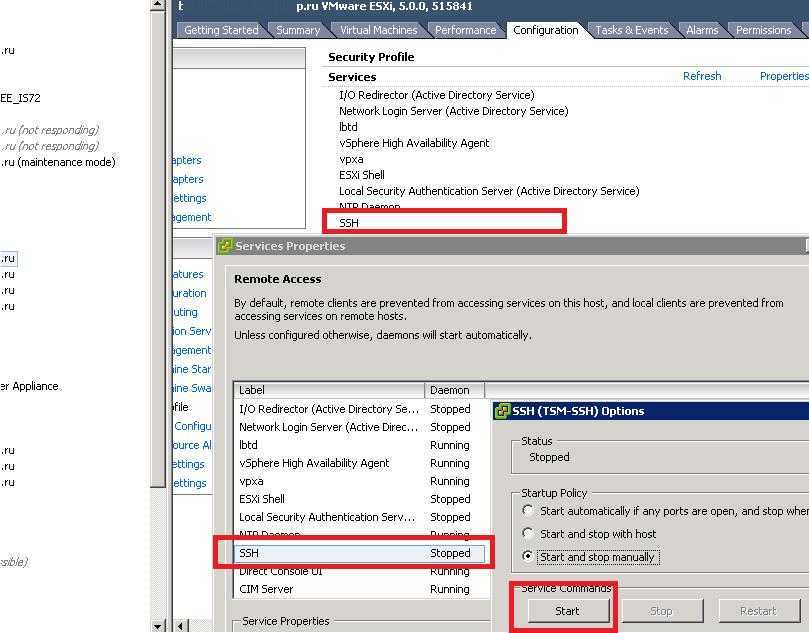
Сразу хочу отметить, что если в графическом интерфейсе у вас не выходит, что либо сделать, то у вас остается только командная строка ssh. Включаем на ESXI хосте SSH службу. Далее подключаемся через Putty или MremoteNG. Я подключаюсь через MremoteNG. Первое, что вам необходимо сделать, это как посмотреть список активных процессов, все как в Windows. Для этого есть команда:
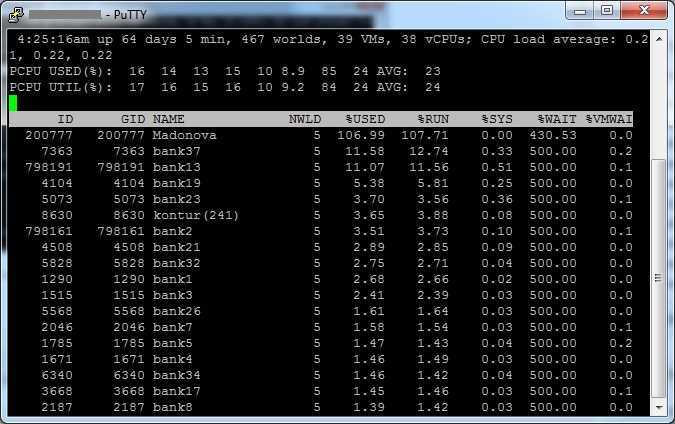
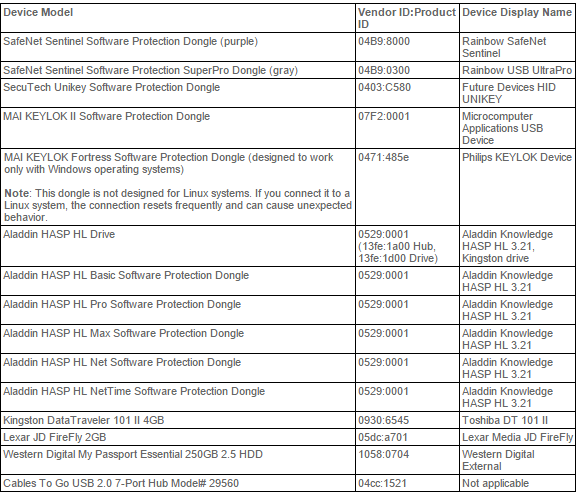
esxtop (Список всех команд в ssh на ESXI)
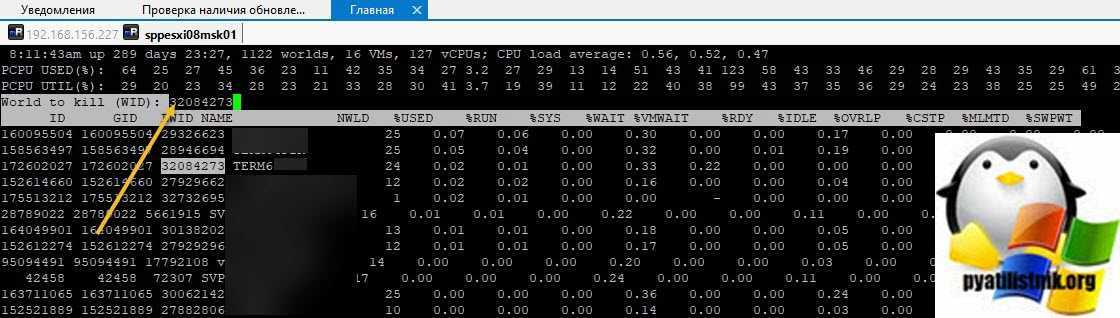
В моем примере, я вижу свою виртуальную машину TERM6. Если системные процессы мозолят вам глаза, то вы можете одновременно нажать SHIFT+V, что оставит отображение только виртуальных машин.
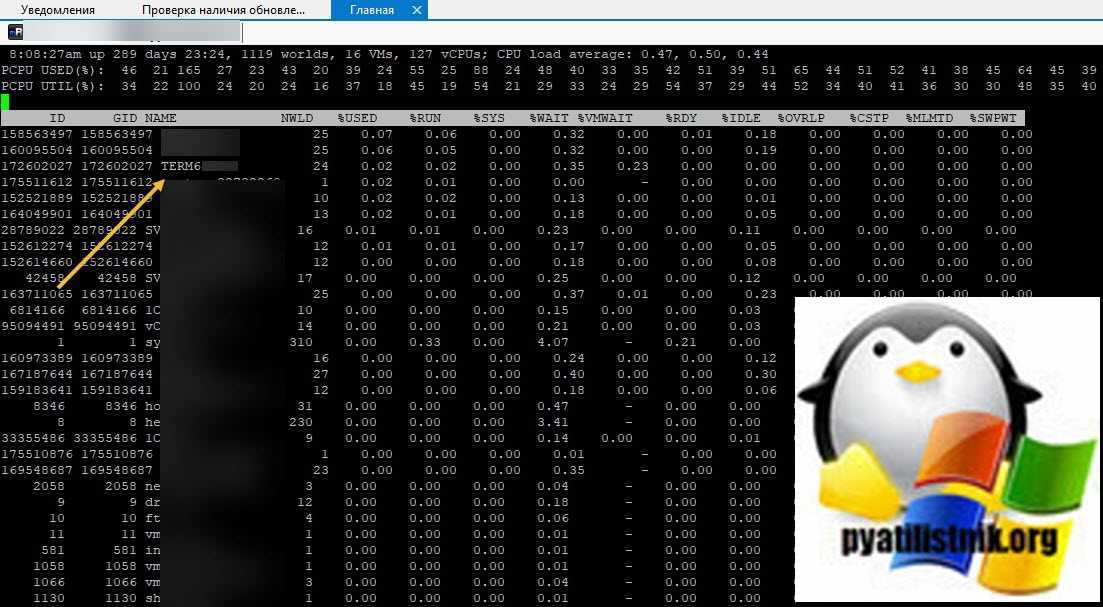
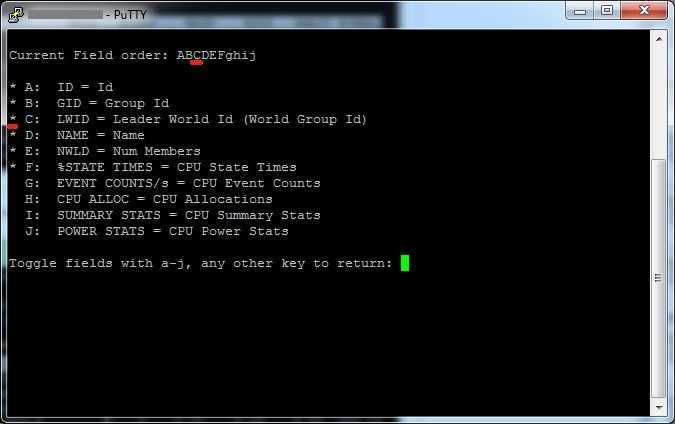
Теперь нам нужно вычислить LWID — Leader World Id, завершив который вы завершите работу нужной виртуалки. ПО умолчанию LWID не отображается, чтобы его включить нажмите клавишу F. У вас откроется меню, где можно добавлять или скрывать поля. Видим, что если нажать клавишу «C», то у вас будет добавлен LWID- Leader World Id. Нажимаем «C» и «Enter».
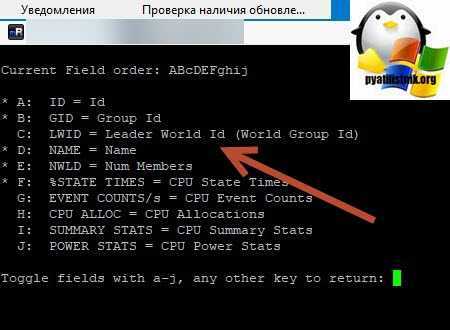
Теперь зная LWID, нажмите клавишу «K», она вызовет меню «World to kill (WID)», данная операция поможет принудительно завершить процесс LWID. Вбиваем наш LWID и нажимаем «Enter».
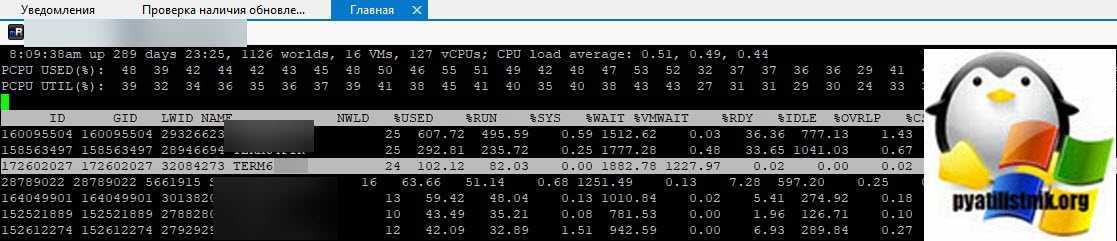
Тут у вас два варианта, чудо произошло (80% вероятности) и чудо не произошло, часто бывает в случаях с ошибкой «Another task is already in progress»
Кстати World ID можно вычисли и просто введя команду:
esxcli vm process list
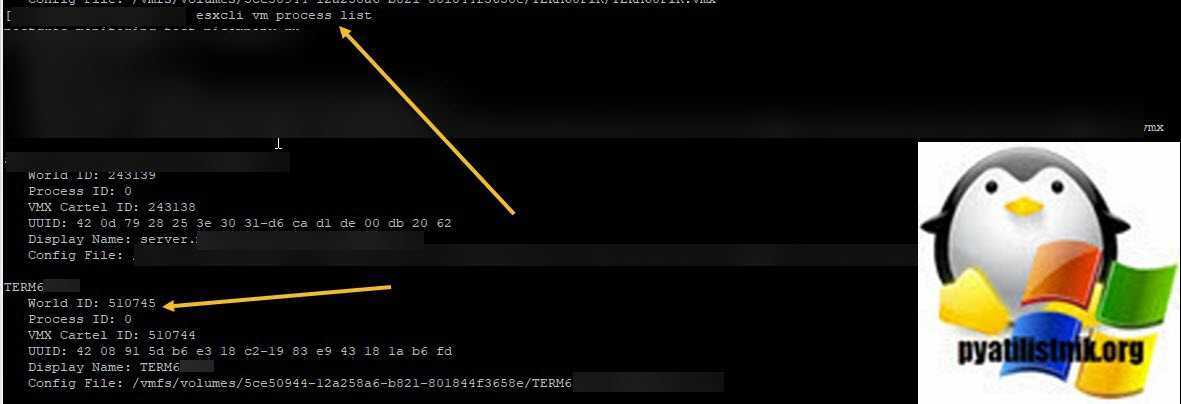
Там вы сможете увидеть World ID, после чего его можно убить командой:
esxcli vm process kill —type=hard —world-id=имя id
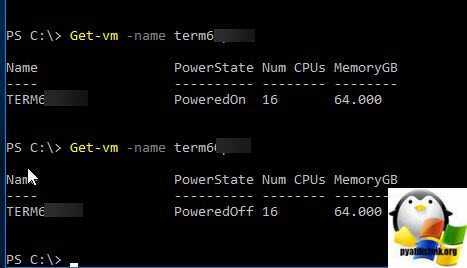
В моем случае чудо произошло, виртуалка перешла в состояние Power OFF, я это вижу в Power-CLI.
Если принудительное завершение процесса вам не помогло, то делаем вот что, по возможности мигрируйте все остальные виртуальные машины с данного хоста, у вас из-за ошибки останется только сбойная. Все в том же SSH. введите:
ps | grep vmx | grep имя виртуалки
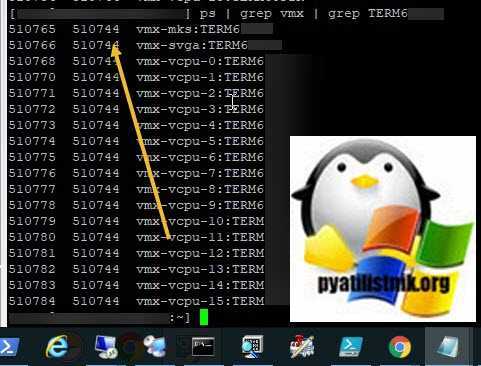
В итоге у вас будет выведен список, где первая колонка это PID процесса, вторая PID родительского процесса, убиваем его для вашей виртуальной машины.
После чего пишем kill PID-родительского процесса. Если не помогло, то пробуем выполнить вот, что (по возможности перевезите другие сервера с данного хоста на другие хосты)
services.sh restart
В результате действий хост стал работать нормально, единственное может быть ситуация, что виртуалку придется удалить из inventory и добавить заново. Если и это не помогло, то попробуйте выполнить:
/etc/init.dhostd restart && /etc/init.dvpxa restart
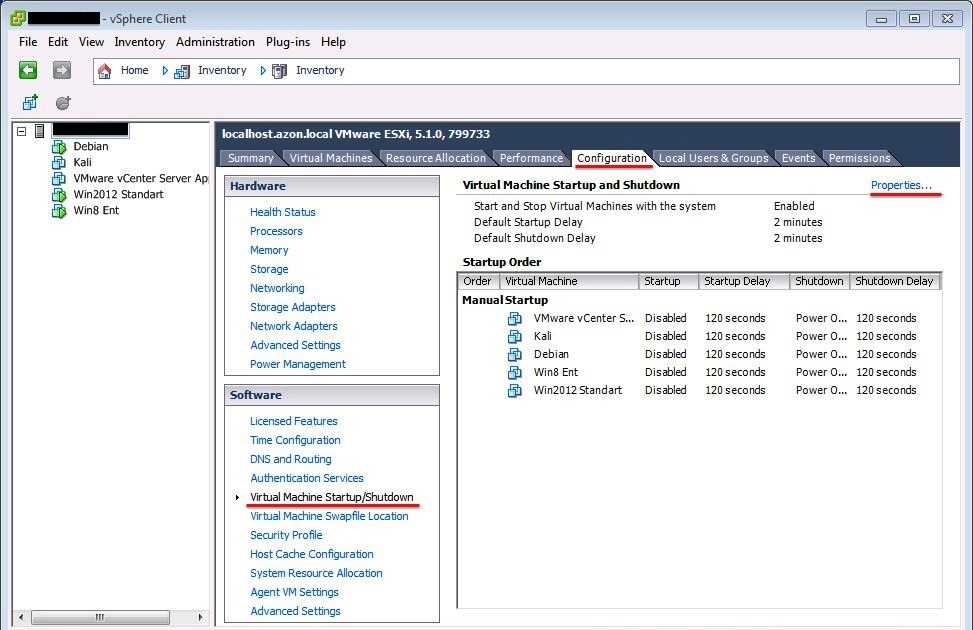
Параметры DRS в vCenter 6.5
Изучив данный вопрос, я понял, что это связано с новым алгоритмом DRS, представленным в vCenter Server 6.5, который можно исправить, но перед этим давайте я напомню какие есть режимы работы DRS кластера. Выберите ваш кластер и перейдите на вкладку «Configure», далее вкладка «vSphare DRS» и в правой части найдите кнопку «Edit».
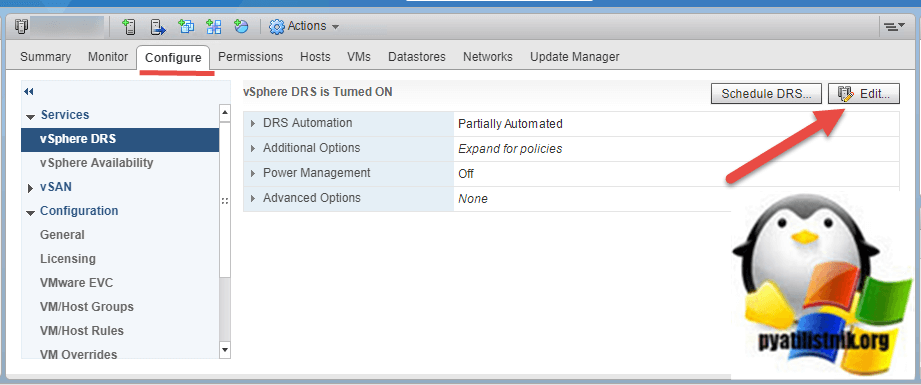
Вы можете определить, будет ли DRS просто отображать рекомендации по миграции или автоматически выполнять миграцию, когда кластер становится несбалансированным, определяя уровень автоматизации. DRS принимает решения, о размещении виртуальных машин, когда виртуальная машина включена и когда виртуальные машины должны быть перебалансированы по хостам в кластере DRS. Доступны три уровня автоматизации:
- Вручную (Manual)- при включении виртуальной машины DRS отобразит список рекомендуемых хостов, на которых вы можете разместить виртуальную машину. Если кластер DRS становится несбалансированным, DRS отобразит рекомендации по миграции виртуальной машины.
- Частично автоматизировано (Partially Automated)- когда виртуальная машина включается, DRS разместит ее на наиболее подходящем хосте без запроса пользователя. Если кластер DRS становится несбалансированным, DRS отобразит рекомендации по миграции виртуальной машины.
- Полностью автоматизированный (Fully Automated) — когда виртуальная машина включается, DRS разместит ее на наиболее подходящем хосте без запроса пользователя. Если кластер DRS становится несбалансированным, DRS автоматически мигрирует виртуальные машины с чрезмерно загруженных хостов на недостаточно используемые хосты.
Порог миграции (Migration Threshold) — этот ползунок определяет, насколько агрессивно DRS будет мигрировать виртуальные машины. Для полностью автоматизированного уровня доступны пять вариантов:
- Уровень 1 (Консервативный) (Level 1 (Conservative)) — применять только рекомендации 1-го приоритета. vCenter Server применяет только рекомендации, которые должны быть приняты для удовлетворения ограничений кластера, таких как правила соответствия (affinity rules) и обслуживание хоста (maintenance).
- Уровень 2 (Level 2) — применять рекомендации 1 и 2 приоритета. vCenter Server применяет рекомендации, которые обещают значительное улучшение баланса нагрузки кластера.
- Уровень 3 (Level 3) — применять рекомендации 1,2 и 3 приоритета. vCenter Server применяет рекомендации, которые обещают хорошее улучшение баланса нагрузки кластера. Это значение по умолчанию.
- Уровень 4 (Level 4) — применять рекомендации 1,2,3 и 4 приоритета. vCenter Server применяет рекомендации, которые обещают умеренное улучшение баланса нагрузки кластера.
- Уровень 5 (Агрессивный) (Level 5 (Aggressive)) — применить все рекомендации. vCenter Server применяет рекомендации, которые обещают даже небольшое улучшение баланса нагрузки кластера.
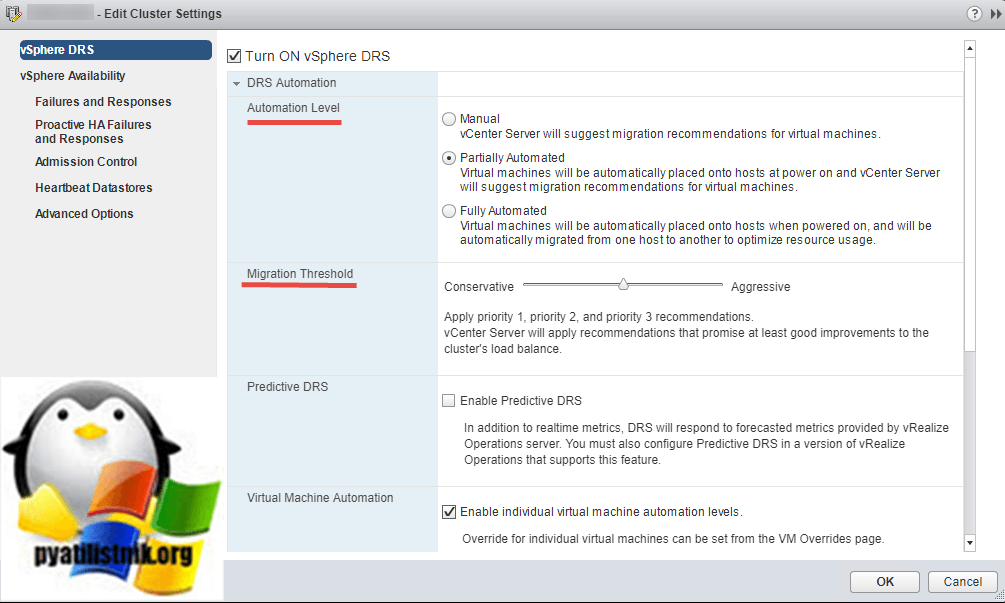
Что по факту в vCenter 6.5, если стоит режим «Manual», то при запуске виртуальной машины, кластер не предлагает на выбор несколько ESXI хостов, хотя должен. Он все так же предлагает только один ESXI хост. В режиме «Partially Automated» виртуальная машина должна автоматически быть запущена на наиболее подходящем хосте, но в итоге это один и тот же. Режим «Fully Automated» не подходит, так как начнет двигать сервера в рабочее время, чем будет создавать дополнительную нагрузку на сервисы, так же есть ряд технологий, которые требуют размещение определенных виртуальных машин на одном ESXI хосте, например технология NLB.
Когда может быть заметен stun виртуальной машины
- Во время выполнения процедуры приостановки виртуальной машины (suspend). Тут происходит такое подмораживание, чтобы скинуть память VM на диск, после чего перевести ее в приостановленное состояние.
- Ну как все уже поняли во время создания снапшота, нужно закрыть старый диск и начать писать в новый.
- Консолидация (удаление) снапшота, подробно описано выше.
- При выполнении миграции с помощью vMotion. Слегка напомню данный механизм, во первых оперативная память передается от одной машины к целевой VM без подмораживания, но затем происходит такой же stun, как и при операции suspend, с тем только отличием, что маленький остаток памяти (минимальная дельта) передается не на диск, а по сети. После этого происходит операция resume уже на целевом хосте. Пользователь этого переключения, как правило, не замечает, так как время этого переключения очень жестко контролируется и чаще всего не достигает 1 секунды. Если память гостевой ОС будет меняться очень быстро, то vMotion может затянуться именно во время этого переключения (нужно передать последнюю дельту).
- Горячая миграция хранилищ Storage vMotion. Здесь stun случается дважды: сначала vSphere должна поставить Mirror Driver, который будет реплицировать в синхронном режиме операции ввода-вывода на целевое хранилище. При постановке этого драйвера происходит кратковременный stun (нужно также закрыть диски). Но и при переключении работы ВМ на второе хранилище происходит stun, так как нужно удалить mirror driver, а значит снова пере открыть диски уже на целевом хранилище.
Как создать снапшот в VMware vSphere
Сама процедура очень простая и сейчас будет описана. Если же вы захотите ее автоматизировать, то советую почитать Как создать snapshot виртуальной машины по расписанию в VMware vCenter 5.5.
сразу подчеркиваю shapshot это не замена бэкапа, запомните это
Выбираете любую виртуальную машину, щелкаете по ней правым кликом и из контекстного меню выбираете Snapshot > Take Snapshot
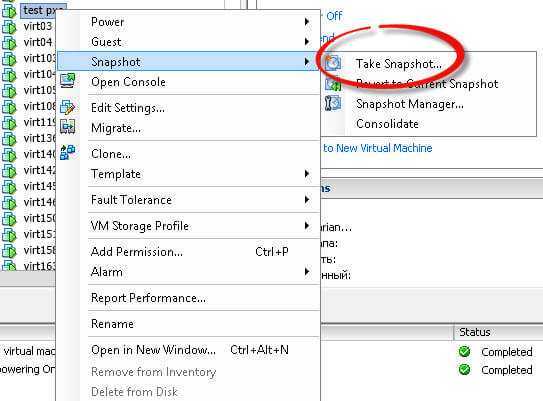
В следующем окне задаем имя snapshot и при желании описание в поле description
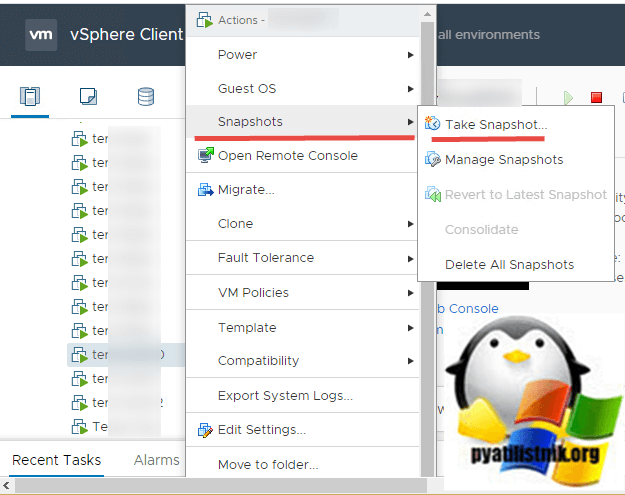
Обратите внимание на две возможные галки. В ESXI 6.5 и выше, создание снимка виртуальной машины делается подобным образом, но уже из веб-интерфейса
Вы так же выбираете нужный сервер, вызываете его контекстное меню «Snaphots — Tale Snapshot»
В ESXI 6.5 и выше, создание снимка виртуальной машины делается подобным образом, но уже из веб-интерфейса. Вы так же выбираете нужный сервер, вызываете его контекстное меню «Snaphots — Tale Snapshot»
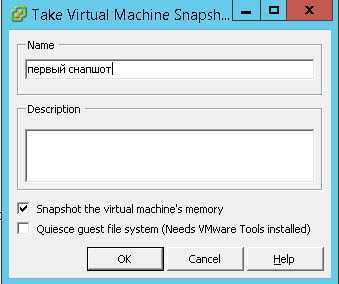
Описание параметров снимка
- Snapshot the virtual machine’s memory > данная опция нужна для того, чтобы во время снятия snapshot esxi виртуалки было состояние оперативной памяти, что при откате даст работающую виртуальную машину. Если вы ее снимите, то вернувшись из снапшота виртуальная машина будет выключена, но зато такой снапшот будет создаваться быстрее, так как нет необходимости сохранять оперативную память в файл, особенно если память большая и постоянно обновляется.
- Quiesce guest file system (need VMware Tools installed) > Это процесс при котором подготавливаются данные на виртуальном диске в состояние требуемое для резервного копирования. Заморозить гостевую файловую систему (требуется установка VMware Tools и ее драйвер Sync Driver) позволяет гарантировать, что данные гостевой операционной системы останутся не поврежденными в снимке.
В итоге VMware Tools с помощью VMware Snapshot Provider запускает создание VSS snapshot внутри гостевой ОС. После чего все VSS writers (смотрим их командой «vssadmin list writers») в гостевой ОС получают запрос и подготавливают соответствующие приложения к бэкапу (происходит запись всех транзакций из памяти на диск). Когда все VSS writers заканчивают работу, они сообщают службе VMware Tools через VMware Snapshot Provider, который, в свою очередь, говорит VMware о том, что снапшот можно снять. Таким образом все приложения резервного копирования для VMware vSphere используют следующие комбинации при отдании команды на создание снапшота VMware (заметьте, что процесс непосредственно создания снапшота целиком и полностью контролируется самой VMware)
Если делать бэкап без опции Quiesce guest file system, то могут быть большие проблемы при восстановлении контроллера домена или Exchange сервера.



![Оптимизация операционной системы vmware esxi 6 для работы с схд [colobridge wiki]](http://smartshop124.ru/wp-content/uploads/e/e/5/ee5ae5780bed4513eda67c2cc6c318ce.jpeg)