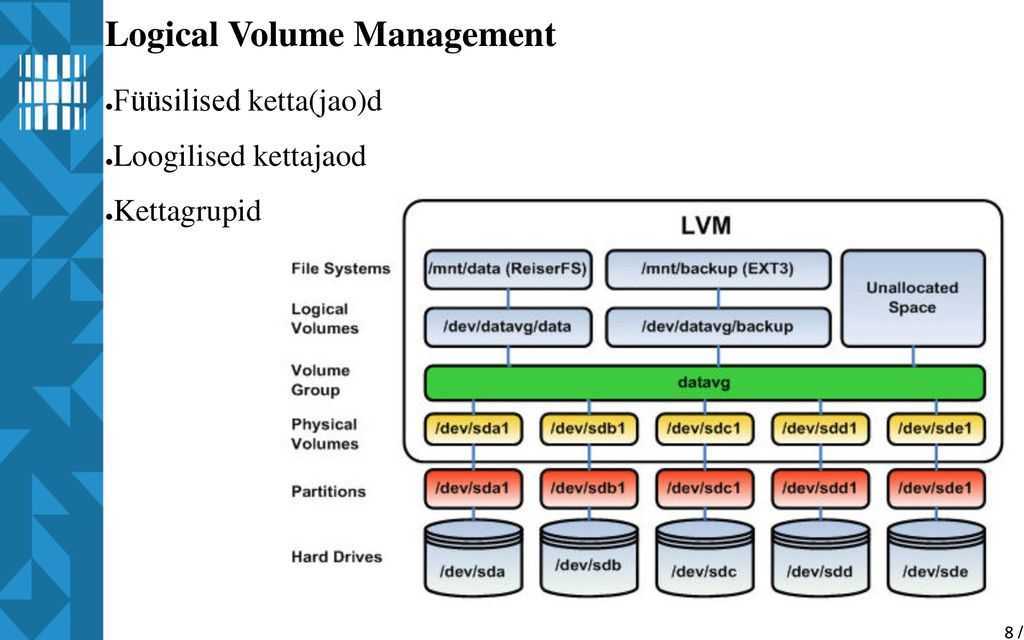
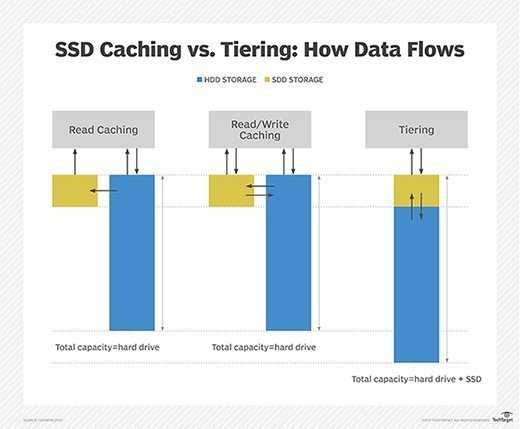
USAGE
Both kinds of caching use similar lvm commands:
1. Identify main LV that needs caching
A main LV exists on slower devices.
$ lvcreate -n main -L Size vg /dev/slow
2. Identify fast LV to use as the cache
A fast LV exists on faster devices. This LV will be used to hold the
cache.
$ lvcreate -n fast -L Size vg /dev/fast $ lvs -a LV Attr Type Devices fast -wi------- linear /dev/fast main -wi------- linear /dev/slow
3. Start caching the main LV
To start caching the main LV using the fast LV, convert the main LV to the
desired caching type, and specify the fast LV to use:
using dm-cache: $ lvconvert --type cache --cachevol fast vg/main using dm-writecache: $ lvconvert --type writecache --cachevol fast vg/main using dm-cache (with cachepool): $ lvconvert --type cache --cachepool fast vg/main
4. Display LVs
Once the fast LV has been attached to the main LV, lvm reports the main LV
type as either cache or writecache depending on the type used.
While attached, the fast LV is hidden, and renamed with a _cvol or _cpool
suffix. It is displayed by lvs -a. The _corig or _wcorig LV represents
the original LV without the cache.
using dm-cache:
$ lvs -a
LV Pool Type Devices
main cache main_corig(0)
linear /dev/fast
linear /dev/slow
using dm-writecache:
$ lvs -a
LV Pool Type Devices
main writecache main_wcorig(0)
linear /dev/fast
linear /dev/slow
using dm-cache (with cachepool):
$ lvs -a
LV Pool Type Devices
main cache main_corig(0)
cache-pool fast_pool_cdata(0)
linear /dev/fast
linear /dev/fast
linear /dev/slow
5. Use the main LV
Use the LV until the cache is no longer wanted, or needs to be changed.
6. Stop caching
To stop caching the main LV, separate the fast LV from the main LV. This
changes the type of the main LV back to what it was before the cache was
attached.

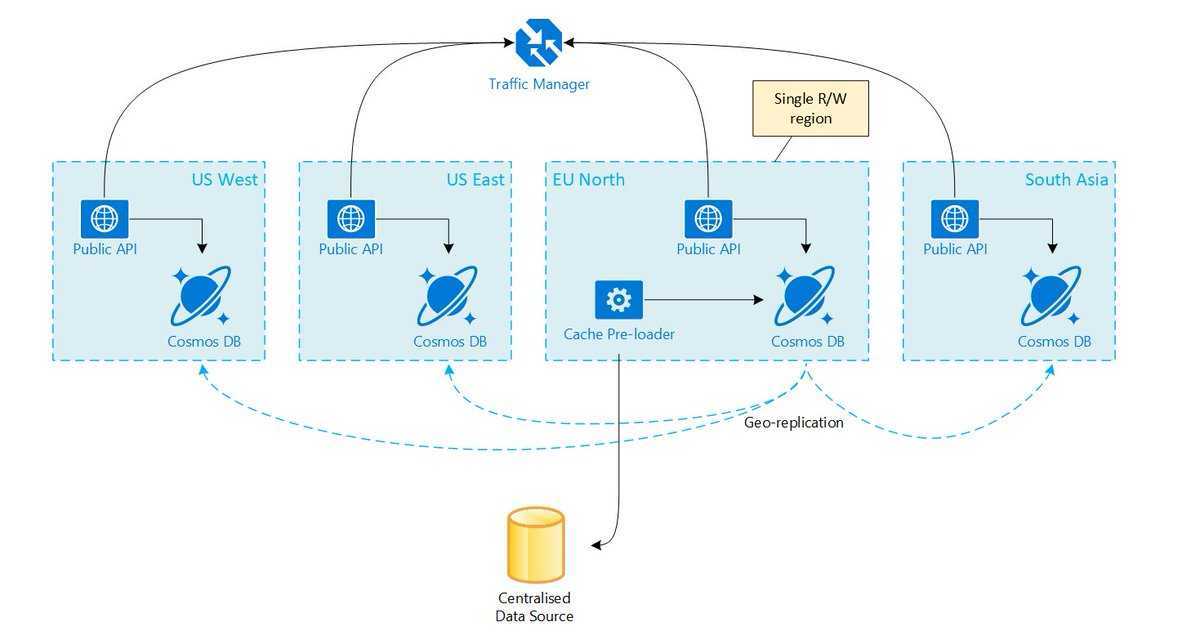
$ lvconvert --splitcache vg/main $ lvs -a LV VG Attr Type Devices fast vg -wi------- linear /dev/fast main vg -wi------- linear /dev/slow
1.Самый действенный способ — использовать Redis
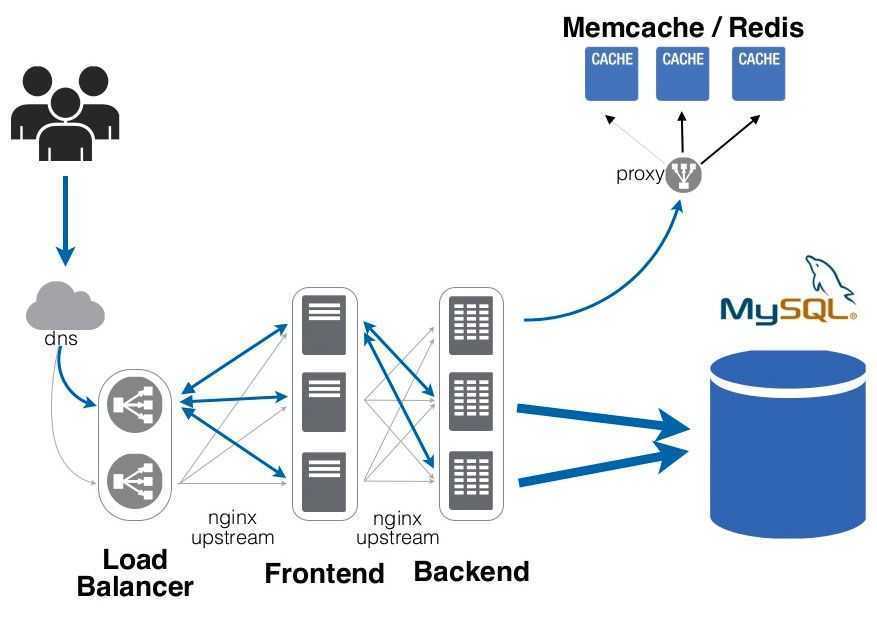
Если у вас уже есть готовая инфраструктура с серверами VMware vSphere, и вы приобретаете NAS только для хранения бэкапов или в качестве основной СХД, посмотрите на память: Synology RackStation RS18017xs+ имеет в базе 16 ГБ ОЗУ, которые можно расширить до 128 ГБ. Вся операционная система DSM (DiskStation Manager) редко требует более 2 ГБ ОЗУ, поэтому неиспользуемую память можно отдать под Redis. Это NoSQL сервер, который хранит данные в памяти, периодически сбрасывая свою базу на диск. При перезагрузке Redis восстанавливает базу с диска, загружая данные в ОЗУ, и даже при отключении электроэнергии, после перезагрузки вам доступны все данные с момента последней синхронизации. Внутрь Redis можно запихнуть не только строки, но и файлы, и если ваше приложение постоянно обращается к каталогу с десятками тысяч маленьких файликов (например при машинном обучении), то вы наверняка знаете, что в этом случае тормозит любая современная файловая система, а Redis — нет.
Redis можно установить через пакет Synology DSM, подключив репозиторий Synocommunity, но там лежит старая версия 3.0.5-5, поэтому лучше использовать Docker или виртуалку, запущенную на NAS-е. Устанавливаем пакет Synology Virtual Machine Manager и внутри разворачиваем 5-ю версию Redis-а на операционной системе Debian.
Давайте протестируем скорость доступа, используя встроенный бенчмарк Redis-а. Полтора миллиона транзакций в секунду в конвейерном режиме и пятьсот тысяч с настройками по умолчанию. Сам по себе Redis — однопоточный, так что вы можете клонировать виртуалку, чтобы задействовать более 1 ядра процессора NAS-а.
Пример с Redis наглядно демонстрирует, что сегодня рассматривать СХД только в качестве файлохранилки можно в двух случаях: когда речь идёт о домашнем 2-дисковом NAS-е или наоборот, когда мы говорим о мощной инфраструктуре банков или авиакомпаний. В остальном же — пожалуйста, вот вам централизованная кэширующая система: подключайтесь к ней и экономьте ресурсы ваших хостов. Вам даже не потребуется 10-гигабитное сетевое подключение: в типичных случаях использования, 1-гигабитной сети вполне достаточно для быстрой работы подключенных клиентов.
Ну и не забывайте, что Synology DSM может использовать защиту данных Redis-а снэпшотами на уровне файловой системы Btrfs. Конечно, использование Redis потребует от вас небольшую переработку приложения, что не всегда возможно, поэтому давайте посмотрим работу встроенного кэширования Synology DSM.
Тест Sysbench OLTP
Возьмём базу данных MariaDB в виртуалке с небольшим объёмом памяти, ну например 8 ГБ. Создадим таблицу в 50 миллионов записей с таким расчетом, чтобы её объём в 11.2 ГБ был больше ОЗУ, доступной для гостевой системы, но меньше ОЗУ NAS-а (16 ГБ) и заставим машину активно использовать диск в режиме транзакционной нагрузки, используя случайные запросы чтения. Проведём этот тест трижды: сначала виртуалка работает на хосте под VMware ESXi 6.7, подключенном по iSCSI, потом то же самое, но с NFS, а затем перенесём виртуалку в Synology Virtual Machine Manager, используя для миграции пакет Synology Active Backup for Business.
Тесты показывают, что сетевой трафик составляет 500-600 Мбит/с, но дисковая активность проявляется только в операциях записи, а значит Synology DSM одинаково хорошо кэширует и операции блочного доступа и операции файлового доступа, что не удивительно, поскольку iSCSI LUN-ы хранятся в виде файлов. Напомню, что наша тестовая RackStation RS18017xs+ имеет базовые 16 ГБ ОЗУ.
В данном случае SSD кэширование не даёт особых преимуществ из-за того, что часть виртуального диска, на котором лежит файл базы данных, легко умещается в ОЗУ NAS-а. Давайте создадим ситуацию, в которой объём базы данных сильно превышает свободную память Rackstation RS18017xs+. Увеличивать количество строк в тестовой таблице до миллиардов не получается: сильно начинает тормозить сама база данных, делая результаты не репрезентативными. Гораздо проще отнять лишнюю память у Synology DSM, для чего запустим в гипервизоре Synology VMM виртуальную машину с 12 ГБ ОЗУ, в результате под кэш останется всего около 2.5 ГБ.
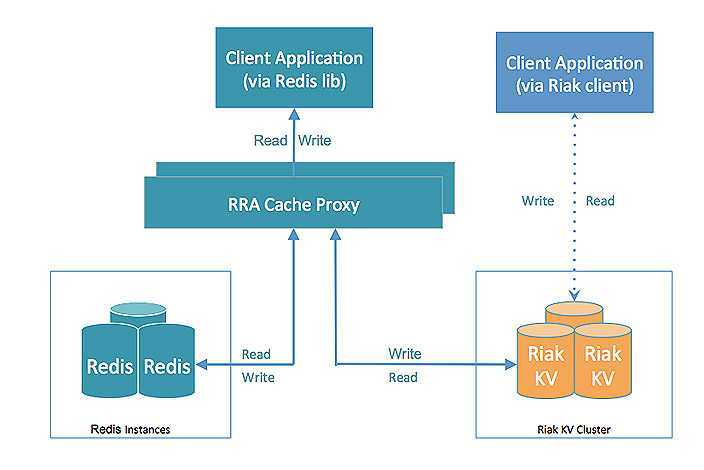


И вот здесь SSD кэш сглаживает негативный эффект от нехватки памяти, хотя всё равно показатели чтения хуже, чем в предыдущем тесте. Нам нужно убедиться, что на скорость влияет именно отсутствие лишней памяти, а не гипервизор Synology VMM, для чего мы должны запустить тот же самый тест на самом NAS-е.
Переместив базу данных в гипервизор Synology VMM, нам пришлось добавить в RS18017xs+ ещё 16 ГБ памяти для того, чтобы сохранить возможность кэширования в ОЗУ NAS-а. Тесты показывают ту же производительность, что не удивительно, поскольку для всех файловых операций в СХД используется общий пул. То есть для практического использования базы данных можно вполне обойтись средствами Synology VMM, сократив количество серверов в вашей компании.
Углубляясь в настройки буферизации на уровне приложения и экспериментируя с параметром InnoDB Buffer Pool Size, я заметил, что при значениях от 1 ГБ до 6 ГБ, производительность существенно не меняется, так что выгоднее отдавать этот объём памяти NAS-у. Так поступают хостинг-провайдеры, предлагая в аренду виртуальные машины с небольшим объёмом памяти: база данных активно работает с дисковой подсистемой, в роли которой выступает СХД с SSD и большим объёмом памяти.
Причём, стоит отметить, что далеко не каждый SAN-массив имеет функцию кэширования в ОЗУ: буферизация LUN на уровне блоков — это редкая особенность, но у Synology сейчас даже iSCSI LUN-ы хранятся в виде файлов, поэтому помимо снапшотов по расписанию, DSM легко ориентируется в том, что нужно держать в памяти, а что — нет. Вот вам ещё один плюс NAS-ов перед SAN-ами.
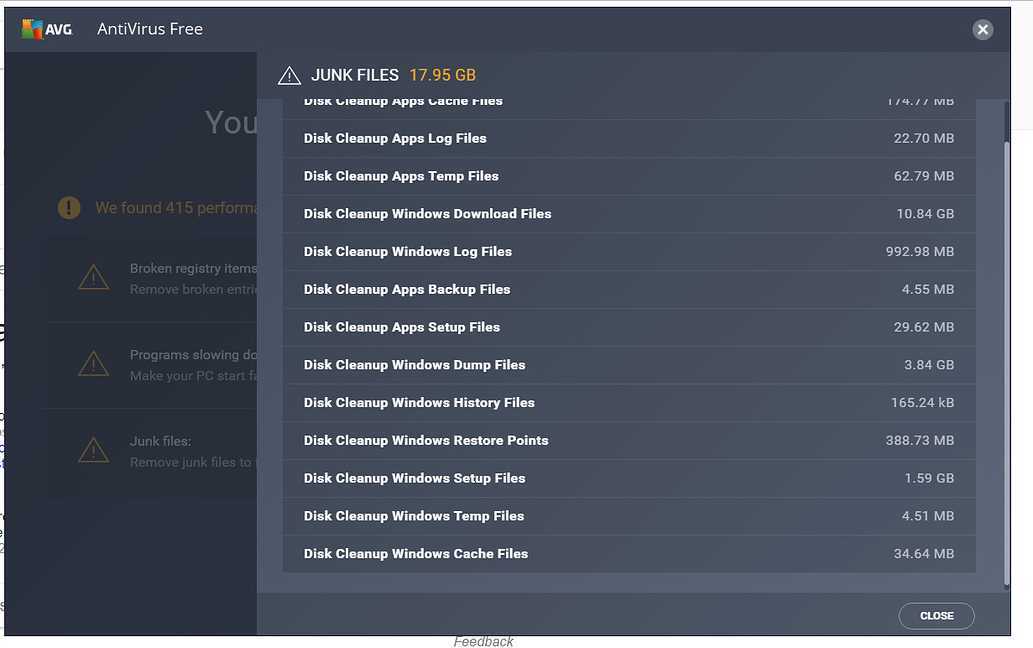
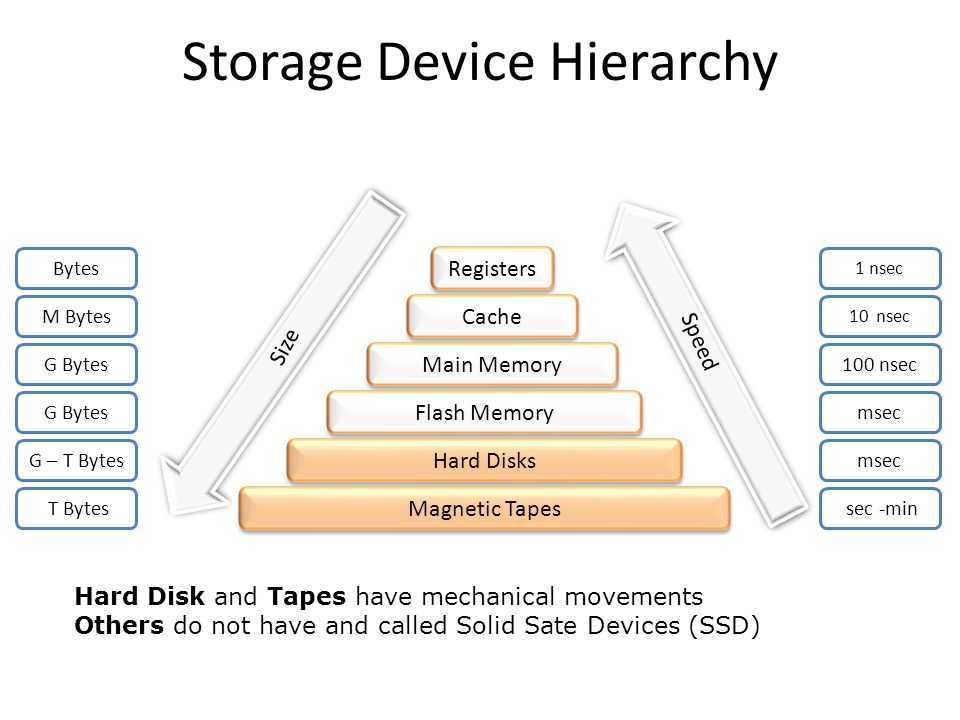
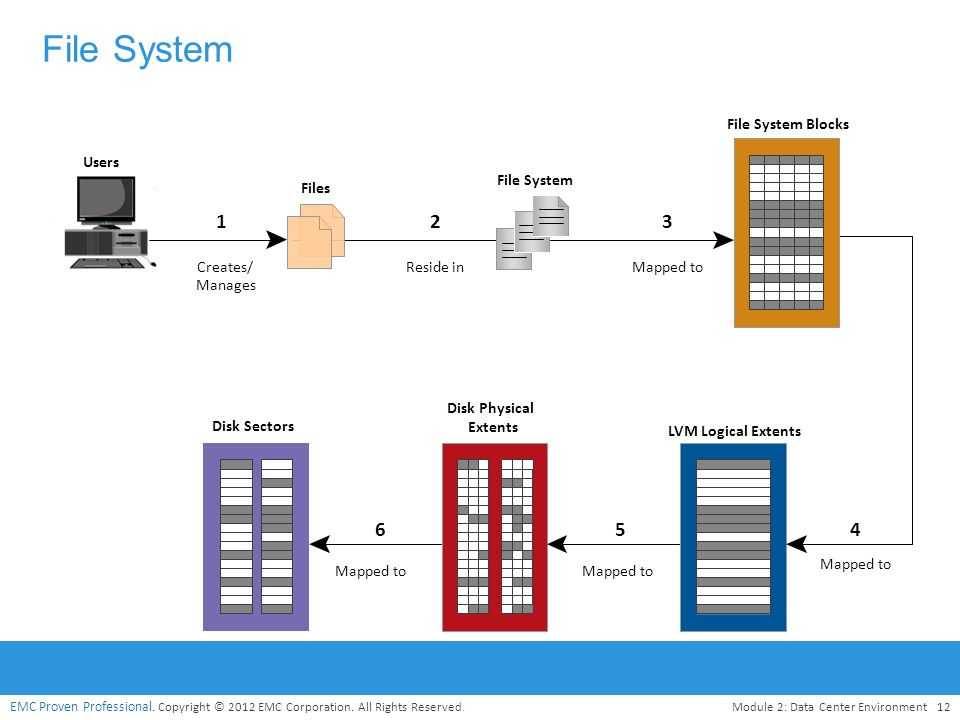
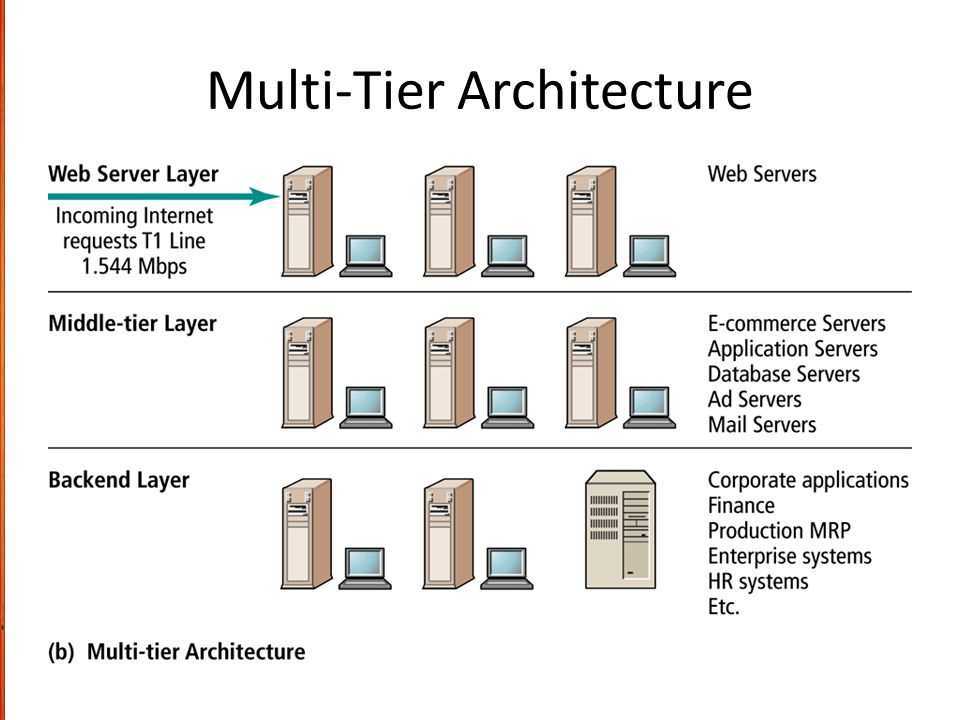
DESCRIPTION
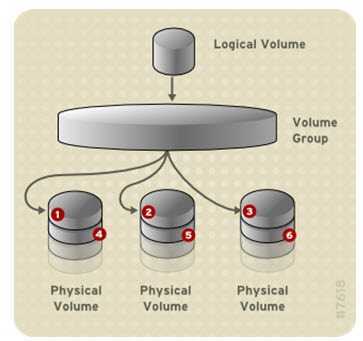
lvm(8) includes two kinds of caching that can be used to improve the
performance of a Logical Volume (LV). Typically, a smaller, faster device
is used to improve i/o performance of a larger, slower LV. To do this, a
separate LV is created from the faster device, and then the original LV is
converted to start using the fast LV.
The two kinds of caching are:
- •
-
A read and write hot-spot cache, using the dm-cache kernel module. This
cache is slow moving, and adjusts the cache content over time so that the
most used parts of the LV are kept on the faster device. Both reads and
writes use the cache. LVM refers to this using the LV type cache. - •
-
A streaming write cache, using the dm-writecache kernel module. This
cache is intended to be used with SSD or PMEM devices to speed up all
writes to an LV. Reads do not use this cache. LVM refers to this using
the LV type writecache.
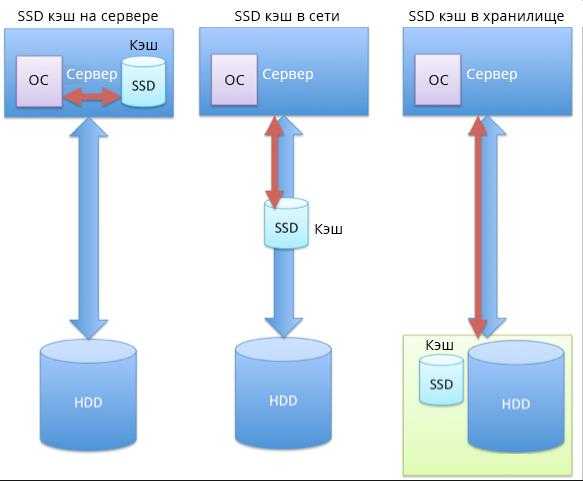
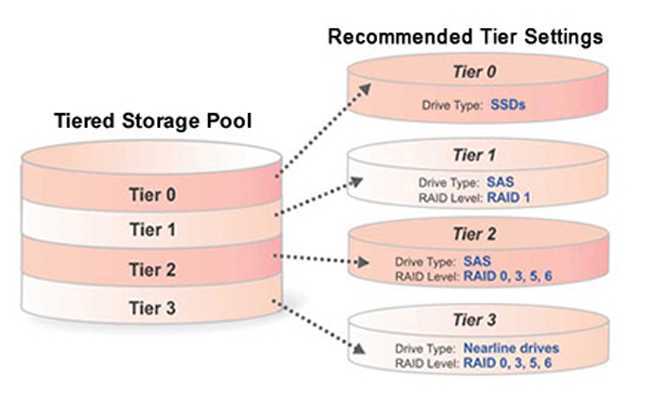
SSD кэш в реализации Synology
SSD-кэш может работать в двух режимах: только чтение и чтение/запись. В первом случае вам достаточно и 1 твердотельного накопителя, а во втором случае — потребуется как минимум пара для объединения в «зеркало». Кэширующие SSD можно объединить и в более сложные массивы, в том числе RAID 5, главное чтобы для кэширования записи поддерживалась отказоустойчивость.
В текущей версии DiskStation Manager содержимое SSD кэша чтения не сохраняется после перезагрузки NAS-а. То есть, после ребута вас ждёт некий период прогрева, хотя DSM начинает пихать данные на SSD буквально с первых минут после запуска. Для кэша чтения/записи такой проблемы нет.
Повторим наш тест, для чего сначала будем использовать 1 SSD в режиме кэша чтения, а затем 2 SSD в режиме кэша чтения/записи, объединив их в зеркальный RAID 1.
Мы видим, что SSD, мягко говоря, работают-то побыстрее, и зеркальный массив дополнительно увеличивает производительность за счёт чтения с двух накопителей одновременно. Но помимо того, что кэш SSD работает быстрее, он ещё и заполняется быстрее, что хорошо видно на логарифмической диаграмме.
Получается, что NAS не нужно упрашивать сохранить данные в кэше: SSD выходят на максимальную скорость уже через 3-4 минуты, а ОЗУ — через 10-15 минут. Кроме того, SSD-кэш активнее освобождает данные и перестраивается между нагрузками, хотя на диаграммах этого не показать. Но, как говорится, только чтением жив не будешь, и очень интересно, как поведут себя кэши в паттернах VDI и SQL задач. Мы будем использовать 2 размера области теста: 16 ГБ, сопоставимую с объёмом ОЗУ и 96 ГБ, в три раза больше, чем есть памяти в NAS-е.
Там где добавляется запись, уже нужно грамотнее подходить к выбору самих SSD, учитывая, что скорее всего они будут постоянно заполнены данными, и их скорость будет отличаться от максимальной. Увеличим тестовую область в 6 раз:
Интересно, что в SQL-нагрузке при заполнении кэша снижается амплитуда колебаний производительности. Давайте сравним средние значения в разных паттернах.
Внимательные читатели заметили, что для SQL-паттерна мы не приводим диаграмму для 16-гигабайтной области раздела. Конечно, можно было бы махнуть рукой и сказать: «итак всё понятно — нужно ставить минимум 2 SSD», но мы не будем торопиться с выводами, а запустим OLTP тест в реальном приложении в виртуальной машине.
Кэширование в ОЗУ самого NAS-а
Даже если виртуалка под Windows или Linux занимает на диске сотни гигабайт, активно используются единицы или десятки гигабайт дискового пространства: логи и файлы баз данных, часто запрашиваемые файлы, в общем всё то, что не кэшируется в памяти самой гостевой операционной системы или приложения. Часто запрашиваемые блоки данных хранятся в ОЗУ самой Synology DSM, что мы многократно видели в синтетических тестах прямого файлового доступа. Механизм кэширования в ОЗУ лучше всего наблюдать на дисковых операциях случайного чтения.
На этой диаграмме — идеальный вариант доступа к тестовой области объёмом 16 ГБ. Почти вся она может поместиться в ОЗУ NAS-а, что и происходит в процессе теста
Обратите внимание: «раскачивается» NAS достаточно долго — около 10 минут, после чего выходит на максимальную производительность
Когда кэш заполняется, скорость чтения вырастает в 3 раза, но всё равно остаётся небольшой по меркам того, что можно выжать из ОЗУ. Имеет ли смысл добавлять SSD для операций, использующих небольшую активную область раздела, способную уместиться в памяти СХД?
Выводы
Какие выводы можно сделать из нашего тестирования? Прежде всего, обратите внимание на то, насколько агрессивно Synology DSM записывает данные на SSD. Буквально считанные минуты под нагрузкой — и они копируются на SSD накопители, ускоряя и NFS подключения, и iSCSI LUN-ы
По синтетическим тестам, SSD работают даже быстрее ОЗУ, но на деле выходит совсем иначе: чем большое объём горячих данных в вашей инфраструктуре, тем больше памяти нужно установить в NAS, не важно, используются ли в нём жесткие диски, SSD или гибридные массивы. Ну и наш пример с Redis-ом показывает, что если вы вступили на путь добра и решили вместо старой SAN-СХД установить современный умный NAS с виртуализацией, то используйте его возможности по-максимуму: совсем не обязательно стараться забить все отсеки хранилища твердотельными дисками — можно просто добавить поддержку NoSQL баз данных в ваш софт и на самой простой модели Synology серии Rackstation получить чудо-скорость, которую ещё очень много лет не дадут никакие SSD
Ну и наш пример с Redis-ом показывает, что если вы вступили на путь добра и решили вместо старой SAN-СХД установить современный умный NAS с виртуализацией, то используйте его возможности по-максимуму: совсем не обязательно стараться забить все отсеки хранилища твердотельными дисками — можно просто добавить поддержку NoSQL баз данных в ваш софт и на самой простой модели Synology серии Rackstation получить чудо-скорость, которую ещё очень много лет не дадут никакие SSD.
Михаил Дегтярёв (aka LIKE OFF)
07/03.2019