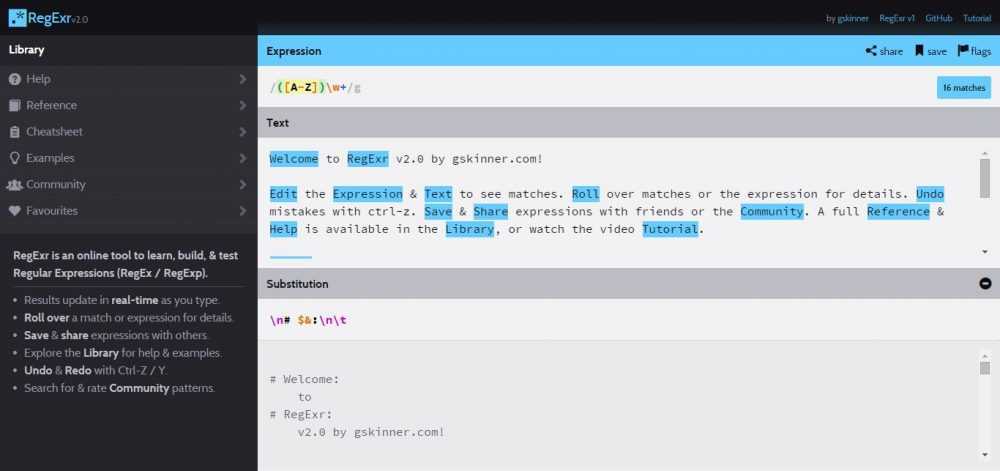
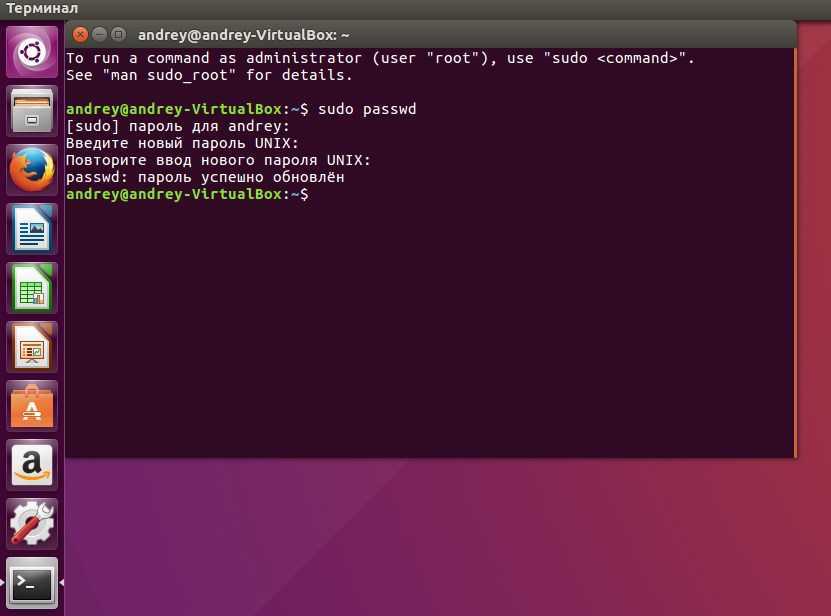
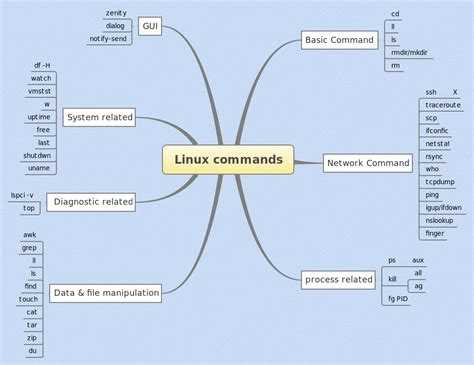
Что такое Select-String и его параметры
Представьте, что вы пишете фрагменты кода в PowerShell и потеряли из виду определенные строки и текст в этом файле PowerShell. Вам нужно найти это во многих тысячах строк кода в тысячах строк и слов. Появляется команда Select-String, которая позволяет вам искать строки и текст в этих входных файлах PowerShell. Он похож на grep в Linux.
Select-String — это командлет, который используется для поиска текста и шаблонов во входных строках и файлах. Он похож на grep в Linux и FINDSTR в Windows. При использовании Select-String для поиска некоторого текста он находит первое совпадение в каждой строке и отображает имя файла, номер строки и всю строку, в которой произошло совпадение. Его можно использовать для поиска нескольких совпадений в строке или для отображения текста до или после совпадения или для получения результатов в логических выражениях, таких как True или False. Вы также можете использовать его для отображения всего текста, кроме совпадения с выражением, которое вы используете в команде. Подстановочные знаки, которые вы используете в FINDSTR, также можно использовать в Select-String. Кроме того, Select-String работает с различными кодировками файлов, такими как ASCII, Unicode и т. Д. Он использует Byte-Order-Mark (BOM) для определения кодировки файла. Если спецификация отсутствует в файле, Select-String примет файл как UTF8.
Параметры Select-String
Microsoft предусмотрел и разработал следующие параметры, которые будут использоваться в синтаксисе.
-Все совпадения
Он используется для поиска всех совпадений в строке, в отличие от первого совпадения в строке, которое обычно выполняет Select-Sting.
-Деликатный случай
Это означает, что совпадение чувствительно к регистру. По умолчанию Select-String не чувствителен к регистру.
-Контекст
Он используется для захвата указанного количества строк, которые вы вводите до и после строки соответствия. Если вы введете 1, будет зафиксирована одна строка до и после матча.
-Культура
В кодировании существуют определенные культуры, такие как порядковый, инвариантный и т. Д. Этот параметр используется для указания культуры в синтаксисе.
-Кодирование
Он используется для указания формата кодировки текста в таких файлах, как ASCII, UTF8, UTF7, Unicode и т. Д.
-Исключать
Этот параметр используется для исключения определенного текста из файла.
-Включают
Этот параметр используется для включения определенного текста в файл.
-InputObject
Он используется для указания текста для поиска.
-Список
Он используется для получения списка файлов, соответствующих тексту.
-LiteralPath
Он используется для указания пути поиска.
-Нет
Как правило, Select-String выделяет совпадение в файле. Этот параметр используется, чтобы избежать выделения.
-Не соответствует
Он используется для поиска текста, не соответствующего указанному шаблону.
-Дорожка
Он используется для указания пути для поиска вместе с использованием подстановочных знаков.
-Шаблон
Параметр используется для поиска совпадения в каждой строке в качестве шаблона.
-Тихий
Этот параметр используется для получения вывода в виде логических значений, таких как True или False.
-Сырой
Он используется, чтобы видеть только совпадающие объекты, а не информацию о совпадении.
-SimpleMatch
Параметр используется для указания простого совпадения, а не совпадения по регулярному выражению.
Пример 4
C:\PS>function search-help
{
$pshelp = "$pshome\es\about_*.txt", "$pshome\en-US\*dll-help.xml"
select-string -path $pshelp -pattern $args
}
Описание
-----------
Эта простая функция использует командлет Select-String для поиска заданной строки в файлах справки Windows PowerShell. В данном примере функция осуществляет поиск по каталогу en-US, в котором содержатся файлы справки на английском (США) языке.
Чтобы найти с помощью этой функции строку, например "psdrive", введите "search-help psdrive".
Чтобы использовать эту функцию в произвольной консоли Windows PowerShell, замените путь на расположение файлов справки Windows PowerShell в конкретной системе, а затем скопируйте функцию в профиль Windows PowerShell.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
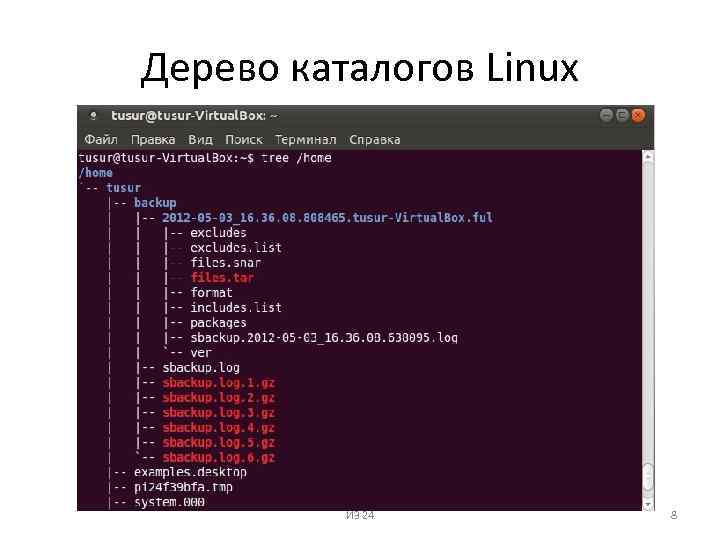
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».

Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Проверка позиций и зависимостей
Если нужно найти слово рядом с другим, то мы можем это сделать с помощью специальных символов:
- (?=Слово) — поиск слова слева;
- (?<=Слово) — поиск слова справа;
- (?!Слово) — не совпадает со словом слева;
- (?<!Слово) — не совпадает со словом слева.
Для примера мы знаем, что после слова ‘зарплату’ будут идти числа и мы хотим узнать их:

Шаблон выше обозначает:
- (?<=зарплата) — поиск слова справа от ‘зарплата’;
- \s — затем содержится символ пробела;
- \w+ — содержится число или буква один или множество раз;
- \b — слово закачивается.
Аналогичное можно сделать и со словом ‘руб’:

В этом шаблоне:
- \d+ — говорит, что у нас есть число повторяющееся один или более раз;
- \s — после числа следует пробел;
- (?=руб) — после пробела находится слово ‘руб’.
Остальные варианты нужны, когда вам нужно исключить совпадения по определенному значению.
2.2, набор метасимволов регулярных выражений grep (базовый набор)
| Режим | Описание | пример |
|---|---|---|
| Начало якорной линии | Такие как:Сопоставить всеНачало строки. | |
| Конец якорной линии | Такие как:Сопоставить всеКонечная строка. | |
| Соответствует не-символу новой строки | Такие как:соответствиеЗатем следует произвольный символ, а затем。 | |
| Совпадение нуля или более предыдущих символов | Такие как:Сопоставляет все строки с одним или несколькими пробелами, за которыми следует grep.Используется вместе для обозначения любого персонажа. | |
| Совпадение символа в указанном диапазоне | Такие как:соответствиес участием。 | |
| Совпадение с символом не в указанном диапазоне | Такие как:Совпадение не содержитс участиемНачиная с буквыЛиния. | |
| Пометить совпадающие символы | Такие как:,Быть отмеченным как。 | |
| Прикрепить начало слова | Такие как:Матч содержитСтрока начального слова. | |
| Закрепить конец слова | Такие как:Матч содержитСтрока конечного слова. | |
| Повторяйте символы последовательно,раз | Такие как:Матчи включают 5 подрядЛиния. | |
| Повторяйте символы последовательно,по крайней мерераз | Такие как:Не менее 5 матчей подрядЛиния. | |
| Повторяйте символы последовательно,по крайней мереРаз, не болеераз | Такие как:Матч 5-10 подрядЛиния. | |
| Соответствует буквенному и числовому символу, то есть | Такие как:Совпадать сЗатем следует ноль или более текстовых или числовых символов, затем。 | |
| Перевернутая форма соответствует несловесному символу | Таких как: период, период и т. Д.Вы можете сопоставить несколько. | |
| Блокировка слова | Такие как: Только матчКоторый может быть толькоЭто слово имеет пробелы с обеих сторон. |
Описание
Командлет Select-String осуществляет поиск текста и текстовых шаблонов во входных строках и файлах. Его можно использовать, как команду Grep в UNIX и Findstr в Windows.
Работа командлета Select-String основана на текстовых строках. По умолчанию Select-String находит первое совпадение в каждой строке и отображает для каждого совпадения имя файла, номер строки и полный текст найденной строки.
Однако можно сделать так, чтобы командлет искал несколько совпадений в строке, выводил текст до и после совпадения или выводил только логическое значение (true или false), указывающее, было ли найдено совпадение.
Командлет Select-String использует поиск по регулярным выражениям, но он также позволяет находить простые совпадения, выполняя поиск введенного фрагмента текста.
Командлет Select-String может выводить все найденные совпадения или останавливаться после первого совпадения для каждого входного файла. Кроме того, он может выводить весь текст, который не соответствует заданному шаблону.
Можно также установить для командлета Select-String конкретную кодировку, например при поиске по файлам в кодировке Юникод.
Назначение операторов find и grep
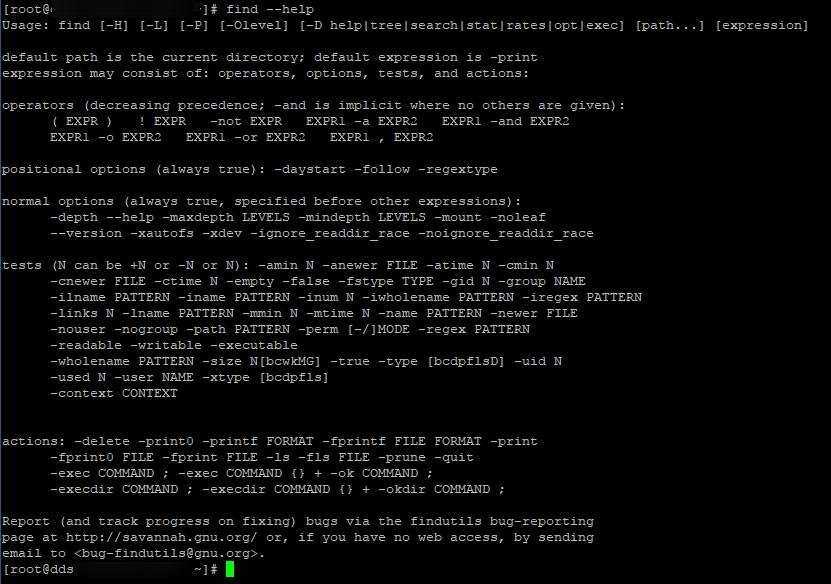
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Выражения в скобках
Выражения в квадратных скобках позволяют сопоставить группу символов, заключив их в квадратные скобки . Например, найдите строки, содержащие «принять» или «акцент», вы можете использовать следующее выражение:
Если первый символ внутри скобок — это курсор , то он соответствует любому одиночному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, начинающихся с «co», за которыми следует любая буква, кроме «l», за которой следует «la», например «coca», «cobalt» и т. Д., Но не будет соответствовать строкам, содержащим «cola». ”:
Вместо того, чтобы помещать символы по одному, вы можете указать диапазон символов внутри скобок. Выражение диапазона создается путем указания первого и последнего символов диапазона, разделенных дефисом. Например, эквивалентно а эквивалентно .
Следующее выражение соответствует каждой строке, начинающейся с заглавной буквы:
также поддерживает предопределенные классы символов, заключенные в скобки. В следующей таблице показаны некоторые из наиболее распространенных классов символов:
| Квантификатор | Классы персонажей |
|---|---|
| Буквенно-цифровые символы. | |
| Буквенные символы. | |
| Пробел и табуляция. | |
| Цифры. | |
| Строчные буквы. | |
| Заглавные буквы. |
Использование sed в Linux
sed (от англ. Stream EDitor) — потоковый текстовый редактор (а также язычок программирования), использующий различные предопределённые текстовые преобразования к последовательному потоку текстовых этих. Sed можно утилизировать как grep, выводя строки по шаблону базового регулярного выражения:
Может быть использовать его для удаления строк (удаление всех пустых строк):
Основным инструментом работы с sed является выражение типа:
Так, образчик, если выполнить команду:
Выше рассмотрены различия меж «grep», «egrep» и «fgrep». Невзирая на различия в наборе используемых регулярных представлений и скорости выполнения, параметры командной строчки остаются одинаковыми для всех трех версий grep.
![Gnu grep [айти бубен]](https://smartshop124.ru/wp-content/uploads/2/d/0/2d00bc29858c4395c3309f545d5a683a.jpeg)
Как мне использовать grep для поиска файла в Linux?
Найдите /etc/passwd для пользователя boo, введите:
Примеры выходных данных::
foo:x:1000:1000:boo,,,:/home/boo:/bin/ksh
Мы можем использовать fgrep/grep тобы найти все строки файла, содержащие определенное слово. Например, чтобы перечислить все строки файла с именем address.txt в текущем каталоге, которые содержат слово “California” выполните:
Обратите внимание, что приведенная выше команда также возвращает строки, в которых “California” является частью других слов, например “Californication” или “Californian”. Следовательно, передайте -w параметр с помощью команды grep/fgrep чтобы получить только строки, в которых “California” включено как целое слово:
Вы можете заставить grep игнорировать регистр слов, то есть сопоставить boo, Boo, BOO и все другие комбинации с -i параметром. Например, введите следующую команду:. Последнийgrep -i «boo» /etc/passwd
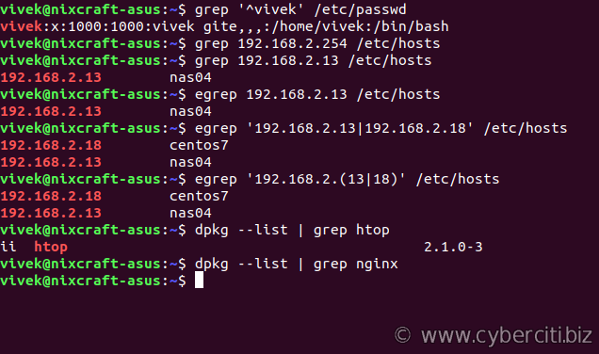 Последнийgrep -i "boo" /etc/passwd
Последнийgrep -i "boo" /etc/passwd
Как использовать grep рекурсивно
Вы можете выполнять поиск рекурсивно, т.е. читать все файлы в каждом каталоге по строке “192.168.1.5”
ИЛИ
Примеры выходных данных:
/etc/ppp/options:# ms-wins 192.168.1.50 /etc/ppp/options:# ms-wins 192.168.1.51 /etc/NetworkManager/system-connections/Wired connection 1:addresses1=192.168.1.5;24;192.168.1.2;
Вы увидите результат для 192.168.1.5 в отдельной строке, перед которой будет указано имя файла (например /etc/ppp/options) в котором он был найден. Включение имен файлов в выходные данные можно подавить, используя -h следующее:
ИЛИ
Примеры выходных данных:
# ms-wins 192.168.1.50 # ms-wins 192.168.1.51 addresses1=192.168.1.5;24;192.168.1.2;
Пример 9
C:\PS>$a = get-childitem $pshome\en-us\about*.help.txt | select-string -pattern transcript
C:\PS> $b = get-childitem $pshome\en-us\about*.help.txt | select-string -pattern transcript -allmatches
C:\PS> $a
C:\Windows\system32\WindowsPowerShell\v1.0\en-us\about_Pssnapins.help.txt:39: Start-Transcript and Stop-Transcript.
C:\PS> $b
C:\Windows\system32\WindowsPowerShell\v1.0\en-us\about_Pssnapins.help.txt:39: Start-Transcript and Stop-Transcript.
C:\PS>> $a.matches
Groups : {Transcript}
Success : True
Captures : {Transcript}
Index : 13
Length : 10
Value : Transcript
C:\PS> $b.matches
Groups : {Transcript}
Success : True
Captures : {Transcript}
Index : 13
Length : 10
Value : Transcript
Groups : {Transcript}
Success : True
Captures : {Transcript}
Index : 33
Length : 10
Value : Transcript
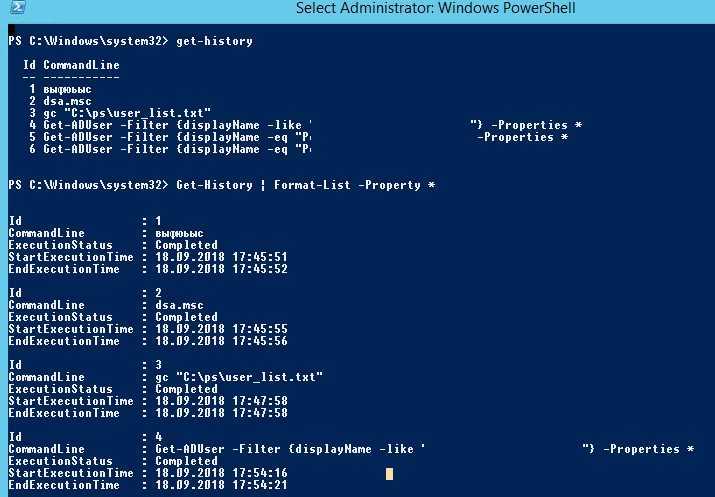
Описание
-----------
В этом примере показано действие параметра AllMatches командлета Select-String. Параметр AllMatches позволяет находить все совпадения в строке, а не по одному совпадению.
Первая команда в этом примере ищет вхождения слова "transcript" в файлах концептуальной справки Windows PowerShell (справка "about"). Вторая команда идентична первой за исключением того, что в ней используется параметр AllMatches.
Вывод первой команды сохраняется в переменной $a. Вывод второй команды сохраняется в переменной $b.
При выводе значений переменных по умолчанию они отображаются одинаково, как показано в примере вывода.
Однако пятая и шестая команда отображают значение свойства Matches каждого из объектов. Свойство Matches для первой команды содержит только одно совпадение (т. е. один объект System.Text.RegularExpressions.Match), в то время как свойство Matches второй команды содержит объекты для обоих совпадений в строке.
Учет регистра
По умолчанию Powershell не чувствителен к регистру, а это значит что все следующие значения будут правдивы:

В большинстве языков у нас вернулось бы только одно значение так как регулярные выражения ассоциируются с учетом регистра. Что бы это исправить это в Powershell есть два варианта. Первый — использование других параметров:
- cmatch — (case sensitive match) учет регистра;
- cnotmatch — (case sensitive not match) учет регистра и поиск не совпадающих значений;
Продолжая пример и изменив ключ мы получим верный результат:

Второй вариант — использование возможностей регулярных выражений, где:
- ‘?i’ — не учитывает регистр;
- ‘?-i’ — учитывает регистр.
Отличия от параметра cmatch в том, что он работает с места объявления:

Если использовать ключ исключающий учет регистра с cmatch, то в случае ниже вернуться все значения:

Поиск целого и обособленного слова используя шаблоны с boundaries
Я не помню что бы я использовал это на практике, но в Powershell есть возможность искать целое слово по шаблону или его часть. Такая возможность называется границами.
Представим, что нам нужно найти имя Ян в следующем предложении:
Если искать просто ‘Ян’ — мы получим неверный результат. Мы так же можем не знать, что имя упоминается с восклицательным знаком (мы можем искать это в 100 файлах). Использование точки (обозначает любой следующий символ) тоже никак не поможет:

Избежать таких ситуаций можно поместив слово между метасимволами ‘\b’, которые позволяют искать не часть, а целое слово:
![]()
Противоположный вариант, когда мы ищем не отдельное, а часть слова — в таких случаях строка экранируется в ‘\B’. В отличие от предыдущего случая этот метасимвол ставится там, где мы ожидаем продолжение или окончание слова. Хороший пример это окончания:

Эти метасимволы можно сочетать вместе для того что бы указать, где слово заканчивается и где начинается:
![]()
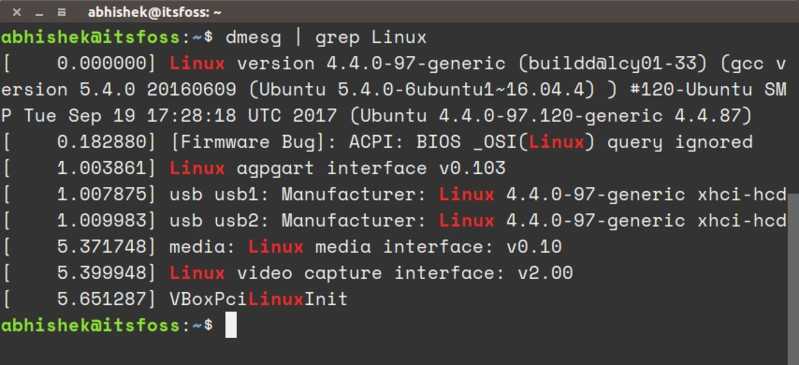
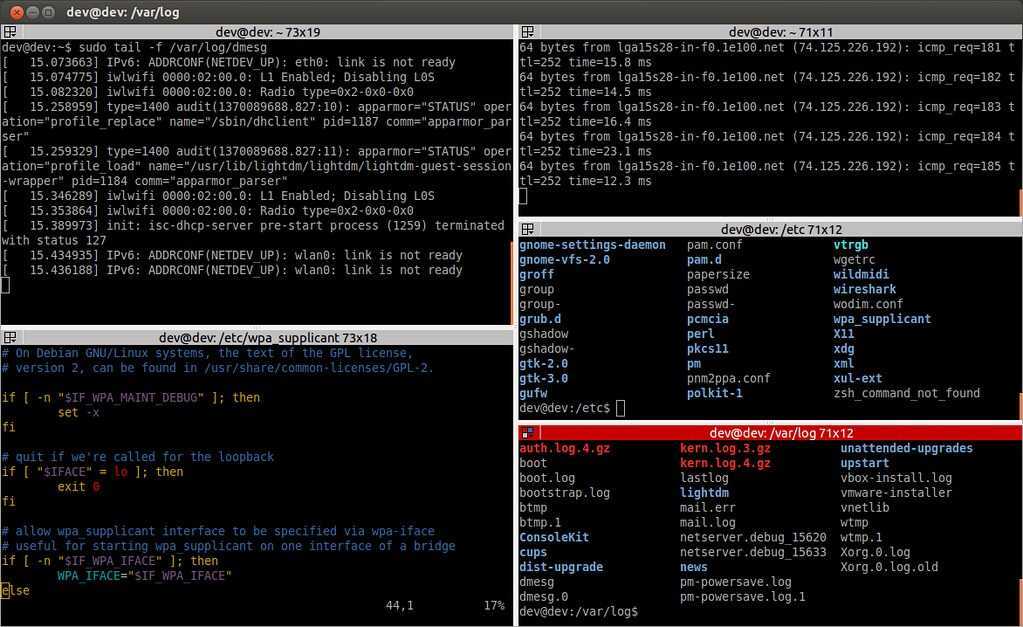
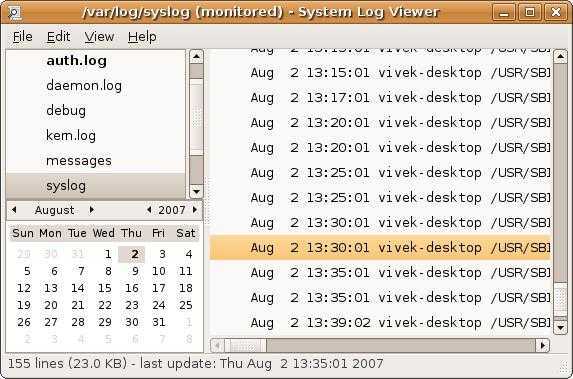
Расположение логов в Linux
Все основные логи Linux находятся в папке /var/log/ вы можете список файлов логов для вашей системы с помощью команды ls:
Дальше рассмотрим 20 различных файлов логов Linux, размещенных в каталоге /var/log/. Некоторых из этих логов встречаются только в определенных дистрибутивах, например, dpkg.logвстречается только в системах, основанных на Debian:
- /var/log/dmesg — содержит сообщения, полученные от ядра. Регистрирует много сообщений еще на этапе загрузки, в них отображается информация об аппаратных устройствах, которые инициализируются в процессе загрузки. Можно сказать это еще один лог системы Linux. Количество сообщений в логе ограничено, и когда файл будет переполнен, с каждым новым сообщением старые будут перезаписаны. Вы также можете посмотреть сообщения из этого лога с помощью команды dmseg;
- /var/log/auth.log — содержит информацию об авторизации пользователей в системе, включая пользовательские логины и механизмы аутентификации, которые были использованы;
- /var/log/messages — содержит глобальные системные логи Linux, включая те, которые регистрируются при запуске системы. В этот лог записываются несколько типов сообщений — почта, cron, различные сервисы, ядро, аутентификация;
- /var/log/boot.log — содержит информацию, которая регистрируется при загрузке системы;
- /var/log/daemon.log — влючает сообщения от различных фоновых демонов;
- /var/log/kern.log — содержит сообщения от ядра, полезны при устранении ошибок пользовательских модулей, встроенных в ядро;
- /var/log/lastlog — отображает информацию о последней сессии всех пользователей. Это нетекстовый файл, для его просмотра необходимо использовать команду lastlog;
- /var/log/maillog /var/log/mail.log — журналы сервера электронной почты, запущенного в системе;
- /var/log/user.log — информация из всех журналов на уровне пользователей;
- /var/log/Xorg.x.log — лог сообщений Х сервера;
- /var/log/alternatives.log — Информация о работе программы update-alternatives. Это символические ссылки на команды или библиотеки по умолчанию;
- var/log/mysqld.log — файлы логов Linux от сервера баз данных MySQL;
- /var/log/httpd/ или /var/log/apache2 — лог файлы linux11 веб-сервера Apache. Логи доступа находятся в файле access_log, а ошибок в error_log;
- /var/log/lighttpd/ — логи linux веб-сервера lighttpd;
- /var/log/conman/ — файлы логов клиента ConMan;
- /var/log/mail/ — в этом каталоге содержатся дополнительные логи почтового сервера;
- /var/log/prelink/ — программа Prelink связывает библиотеки и исполняемые файлы, чтобы ускорить процесс их загрузки. /var/log/prelink/prelink.log содержит информацию о .so файлах, которые были изменены программой;
- /var/log/audit/- содержит информацию, созданную демоном аудита auditd;
- /var/log/setroubleshoot/ — SE Linux использует демон setroubleshootd (SE Trouble Shoot Daemon) для уведомления о проблемах с безопасностью. В этом журнале находятся сообщения этой программы;
- /var/log/samba/ — содержит информацию и журналы файлового сервера Samba, который используется для подключения к общим папкам Windows;
- /var/log/sa/ — содержит .cap файлы, собранные пакетом Syssta;
- /var/log/sssd/ — используется системным демоном безопасности, который управляет удаленным доступом к каталогам и механизмами аутентификации;
- /var/log/btmp — лог файл Linux содержит информацию о неудачных попытках входа. Для просмотра файла удобно использовать команду last -f /var/log/btmp;
- /var/log/cups — сообщения, связанные с печатью и принтерами;
- /var/log/anaconda.log — все сообщения, зарегистрированные при установке сохраняются в этом файле;
- /var/log/yum.log — регистрирует всю информацию об установке пакетов с помощью Yum;
- /var/log/cron — всякий раз когда демон Cron запускает выполнения программы, он записывает отчет и сообщения самой программы в этом файле;
- /var/log/secure — содержит информацию, относящуюся к аутентификации и авторизации. Например, SSHd регистрирует здесь все, в том числе неудачные попытки входа в систему;
- /var/log/wtmp или /var/log/utmp — системные логи Linux, содержат журнал входов пользователей в систему. С помощью команды wtmp вы можете узнать кто и когда вошел в систему;
- /var/log/faillog — лог системы linux, содержит неудачные попытки входа в систему. Используйте команду faillog, чтобы отобразить содержимое этого файла.
Дальше рассмотрим, как просмотреть эти логи в операционной системе.
Примеры использования
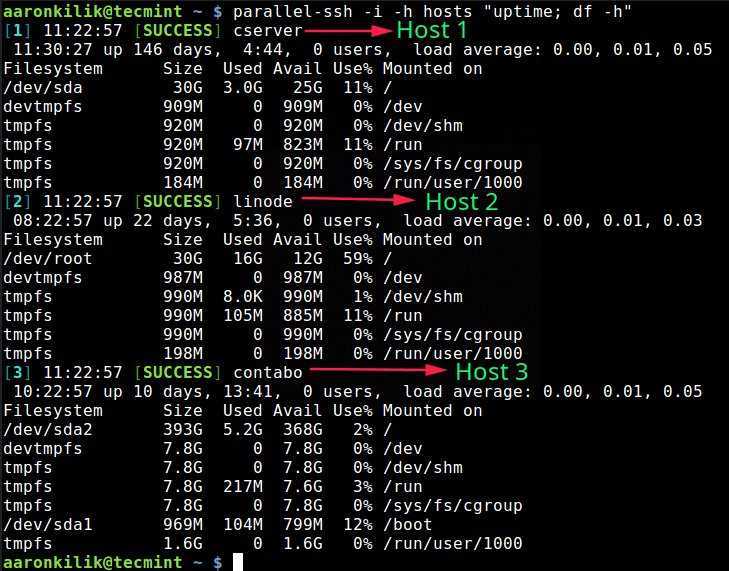
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
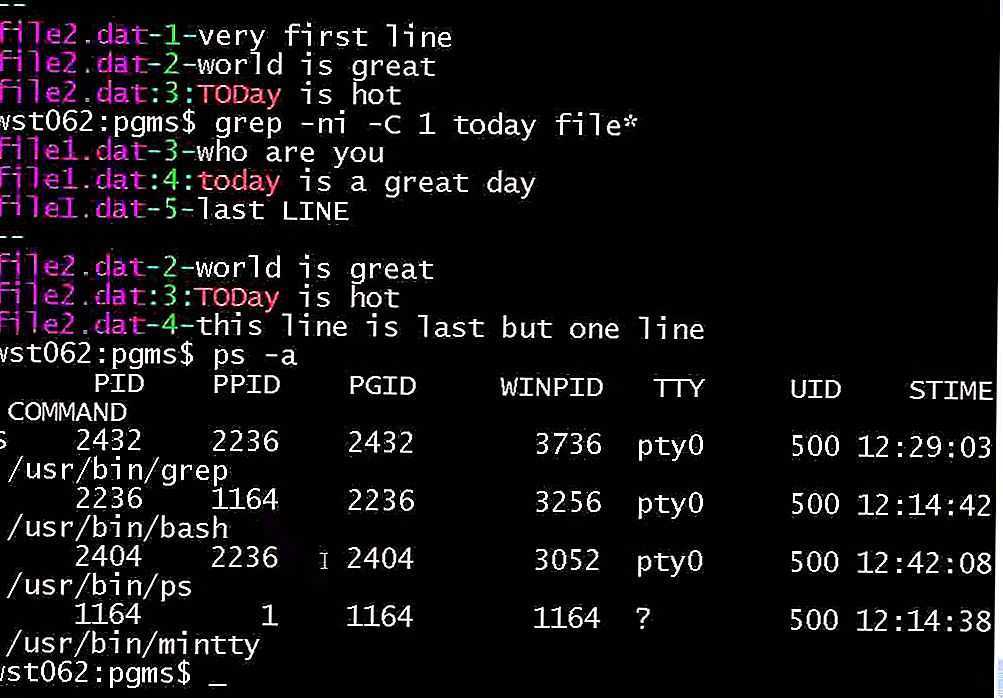
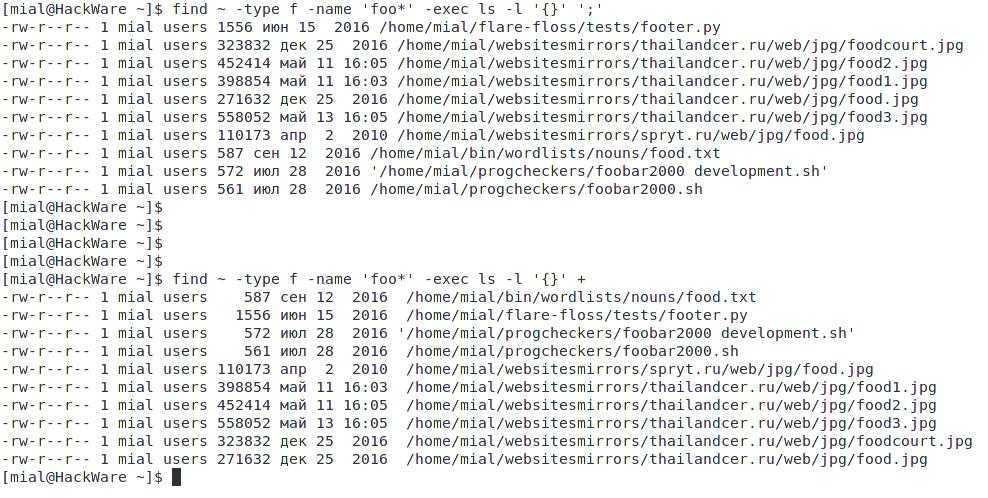
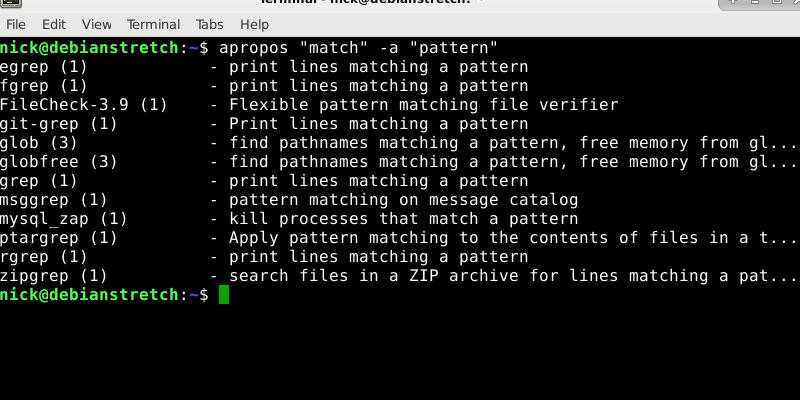
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
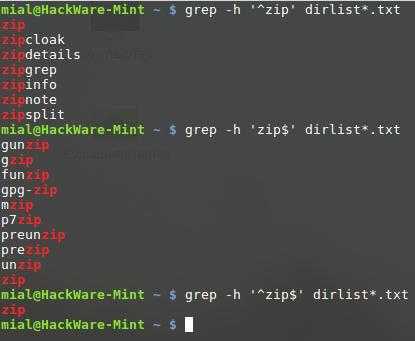
Поиск слов в grep
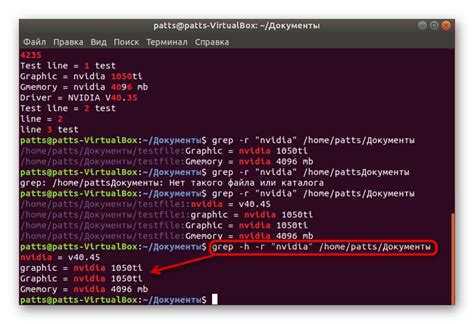
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Примеры команды grep в Linux и Unix
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep 'word' filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i 'bar' file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R 'httpd' .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c 'nixcraft' frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep 'word' filename fgrep 'word-to-search' file.txt grep 'word' file1 file2 file3 grep 'string1 string2' filename cat otherfile | grep 'something' command | grep 'something' command option1 | grep 'data' grep --color 'data' fileName grep -options pattern filename fgrep -options words file |
grep ‘word’ filename
fgrep ‘word-to-search’ file.txt
grep ‘word’ file1 file2 file3
grep ‘string1 string2’ filename
cat otherfile | grep ‘something’
command | grep ‘something’
command option1 | grep ‘data’
grep —color ‘data’ fileName
grep pattern filename
fgrep words file
Поиск совпадений одного из нескольких символов
Когда мы не уверены в конкретном символе — мы можем указать несколько использовав квадратные скобки [] . Значения, которые будут помещены в эти скобки будут соответствовать одному значению:

В примере выше ищутся совпадения либо по букве R или P. Можно указывать диапазон значений. Например такое написание говорит, что мы ищем цифры от 1 до 9. Если написать у нас будут искаться числа с 5 до 9, затем с 6 по 9 и т.д.
Ниже мы ищем значения, где есть буквы от ‘с’ до ‘я’, после которых есть буква ‘е’. Во втором примере мы ищем элементы массива, которые начинаются с букв ‘д’ до ‘с’:

Можно использовать любые метасимволы. В примере ниже у нас идет поиск числа или буквы, затем пробела и опять число-буквенное значение:
![]()
Вы часто можете увидеть написание похоже на следующее, что обозначает любую букву а A до z, от 0 до 9:
Понимание ролей rsyslogd и journald
journalctlrsyslogd добавляет к нему некоторые сервисы. В частности, он заботится о записи данных журнала в определенные файлы (которые будут постоянными между перезагрузками) и позволяет настраивать удаленные журналы и серверы журналов.
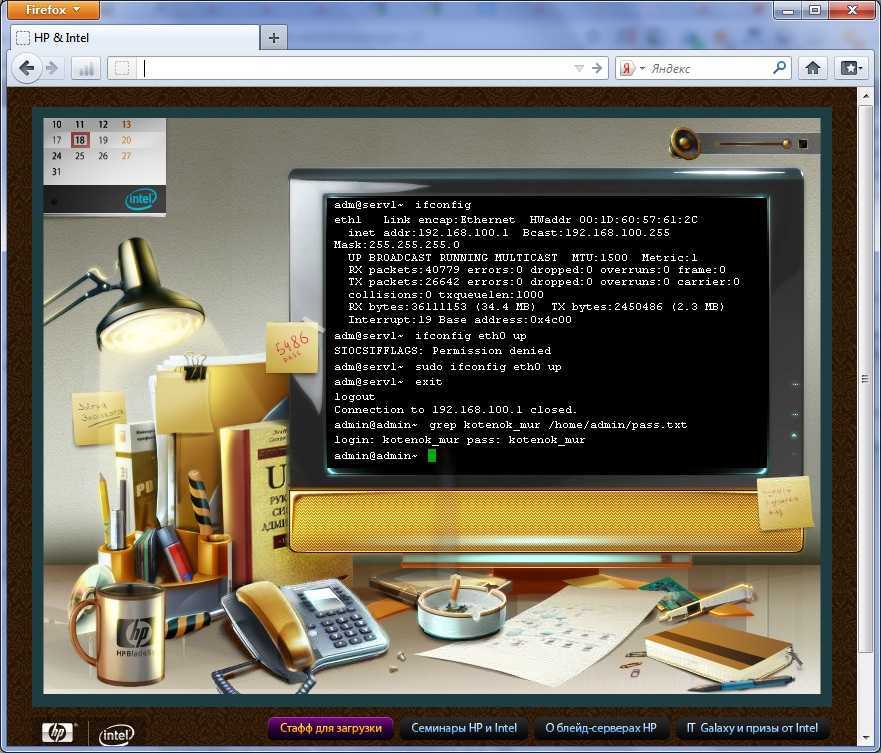
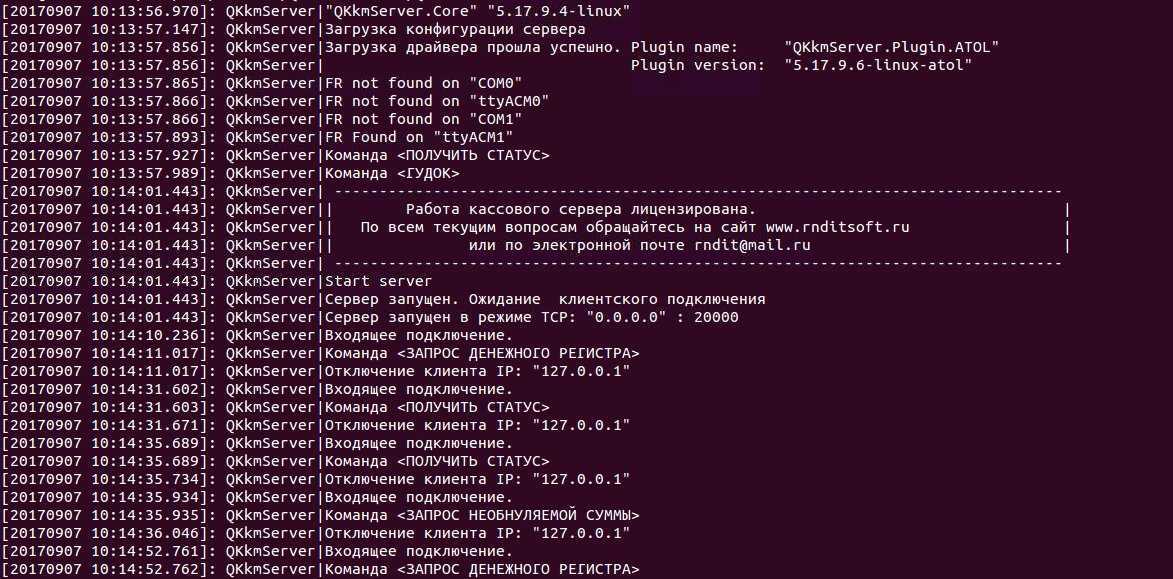
![Gnu grep [айти бубен]](https://smartshop124.ru/wp-content/uploads/b/0/9/b091518167b9055ac7f8fec171dc7283.jpeg)
- Файлы в /var/log, которые пишутся rsyslogd, должны контролироваться.
- Команда journalctl может использоваться для получения более подробной информации из журнала.
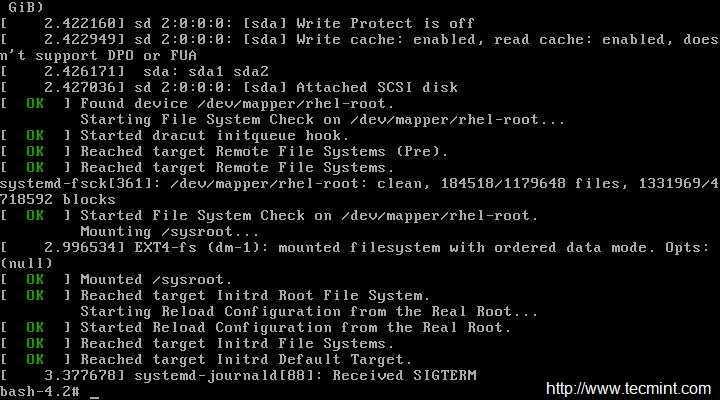
- Для краткого обзора последних значимых событий, которые были зарегистрированы модулями systemd через journald, администраторы могут использовать команду systemctl status <unit>. Эта команда показывает состояние сервисов, а также последние пару строк, которые были логированы. В листинге 1 показан пример, в котором эта команда четко указывает, что пошло не так при запуске сервиса.
Чтение лог-файлов
journalctlless
log-файл
Объяснение
/var/log/messages
Наиболее часто используемый файл журнала, это общий файл журнала, в который записывается большинство сообщений.
/var/log/dmesg
Содержит сообщения журнала ядра.
/var/log/secure
Содержит сообщения, связанные с аутентификацией.
/var/log/boot.log
Сообщения, связанные с запуском системы.
/var/log/audit/audit.log
Содержит сообщения аудита. SELinux пишет в этот файл.
Сообщения, связанные с почтой.
/var/log/samba
Предоставляет файлы журналов для сервиса Samba
Обратите внимание, что по умолчанию Samba не управляется через rsyslog, а записывается непосредственно в каталог /var/log.
/var/log/sssd
Содержит сообщения, записанные сервисом sssd, который играет важную роль в процессе аутентификации.
/var/log/cups
Содержит сообщения, сгенерированные службой печати CUPS.
Каталог, содержащий лог-файлы, которые записываются веб-сервером Apache. Обратите внимание, что Apache пишет сообщения в эти файлы напрямую, а не через rsyslog.
Понимание содержимого лог-файла
Дата и время: каждое сообщение начинается с отметки времени. В целях фильтрации метка времени записывается как военное время.
Хост: хост, с которого отправлено сообщение
Это важно, потому что rsyslogd также может быть настроен для обработки удаленных логов.
Имя службы или процесса: имя сервиса или процесса, сгенерировавшего сообщение.
Содержимое сообщения: содержимое сообщения, которое содержит точное сообщение, которое было зарегистрировано.
lesstail -ftail -f /var/log/messages
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -b — показывать номер блока перед строкой;
- -c — подсчитать количество вхождений шаблона;
- -h — не выводить имя файла в результатах поиска внутри файлов Linux;
- -i — не учитывать регистр;
- — l — отобразить только имена файлов, в которых найден шаблон;
- -n — показывать номер строки в файле;
- -s — не показывать сообщения об ошибках;
- -v — инвертировать поиск, выдавать все строки кроме тех, что содержат шаблон;
- -w — искать шаблон как слово, окружённое пробелами;
- -e — использовать регулярные выражения при поиске;
- -An — показать вхождение и n строк до него;
- -Bn — показать вхождение и n строк после него;
- -Cn — показать n строк до и после вхождения;
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Что такое grep?
Команда grep (расшифровывается как global regular expression print) — одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Секрет популярности — её мощь, она даёт возможность пользователям сортировать и фильтровать текст на основе сложных правил.
Утилита grep решаем множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл в с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.