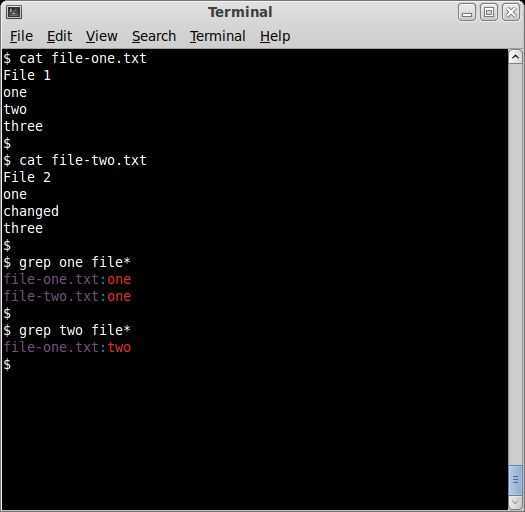
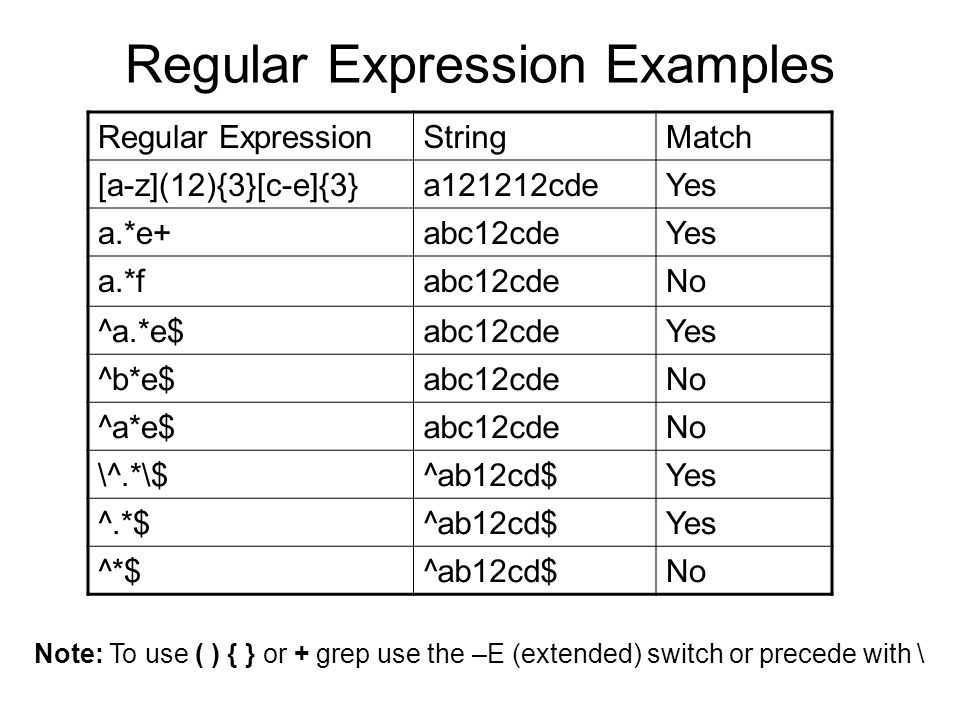
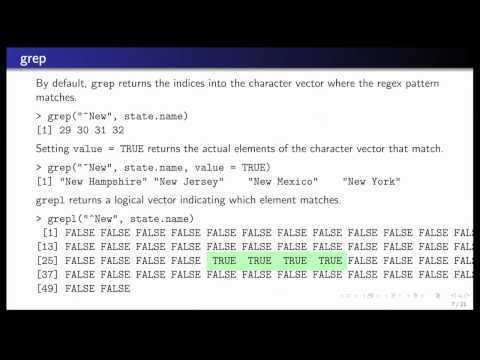
Anchor characters
To locate the beginning of a line in a text, use the caret character (^).
You can use it like this:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}'
$ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

The caret character (^) matches the start of the text:
$ awk '/^this/{print $0}' myfile

What if you use it in the middle of the text?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

It’s printed as it is like a normal character.
When using awk, you have to escape it like this:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

This is about looking at the beginning of the text, what about looking at the end?
The dollar sign ($) checks for the end a line:
$ echo "Testing regex again" | awk '/again$/{print $0}'

You can use both the caret and dollar sign on the same line like this:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
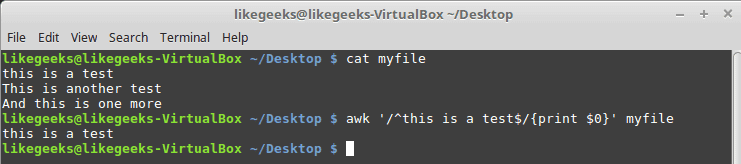
As you can see, it prints only the line that has the matching pattern only.
You can filter blank lines with the following pattern:
$ awk '!/^$/{print $0}' myfile
Here we introduce the negation which you can do it by the exclamation mark !
The pattern searches for empty lines where nothing between the beginning and the end of the line and negates that to print only the lines have text.
Описание формата внутреннего представления данных 1С в контексте обмена данными
Фирма 1С не рекомендует использовать внутреннее представление данных для любых целей, которые отличны от обмена с 1С:Предприятием 7.7. Но сама возможность заглянуть на «внутреннюю кухню» платформы с помощью функций ЗначениеВСтрокуВнутр(), ЗначениеВФайл(), ЗначениеИзСтрокиВнутр() и ЗначениеИзФайла(), дала возможность сообществу программистов 1С разработать новые приемы разработки и анализа.
Так, именно на использовании внутреннего представления был построен алгоритм «быстрого массива», который позволяет практически мгновенно создать массив в памяти на основании строки с разделителями. С помощью разбора внутреннего представления можно «на лету» программным кодом выполнить анализ обычной формы и даже сделать редактор графической схемы. Во внутреннем формате сохраняют свои данные между сеансами различные популярные внешние обработки. А еще это возможность сделать быстрый обмен с внешними системами.
1 стартмани
Теперь по шагам
1. Установим wine (https://wiki.winehq.org/Debian).
wine ставится на i386 архитектуру.
Проверим, что она у нас стоит:
Если нет, то установим (за подробностями сюда https://wiki.debian.org/ru/Multiarch/HOWTO):
Установим репозиторий для установки:
Добавим в список пакетов (/etc/apt/sources.list или отдельным файлом в папку /etc/apt/sources.list.d) строчку:
deb https://dl.winehq.org/wine-builds/debian/ DISTRO main




где DISTRO — имя вашего дистрибутива (у меня wheezy)
Собственно установка:
При попытке установить пакет wine на wheezy возникла ошибка:
«The method driver /usr/lib/apt/methods/https could not be found.»
Репозиторий winehq использует протокол https для загрузки.
Решается установкой нужного транспорта на apt:
Установим полезный скрипт winetricks (с сайта, т.к. в репозитории может быть сильно устаревшим):
Для пользователя (usr1cv8), от которого запущен сервер 1С и будет запускаться wine настраиваем его окружение:
Установим библиотеку для работы с VBScript.
Со временем может выйти более новая версия библиотеки, тогда будет сообщение типа: «Calling wsh56 is deprecated, please use wsh57 instead».
В этом случае устанавливаем указанную версию библиотеки (в данном случае wsh57vb).
Для платформы x64 сперва создаем окружение win32 (требуется для VBScript).
Здесь создается отдельная папка (на свой вкус, я сделал в домашней папке пользователя 1С) ~/.wine32 с библиотеками своей архитектуры.
Скобочные группы ― ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя ), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте. То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
всем текстомвсего текстастрочкой текста
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Начало всего текста или начало строчки текста, если |
|||
| Конец всего текста или конец строчки текста, если |
|||
| Строго начало всего текста | |||
| Строго конец всего текста | |||
| Начало или конец слова (слева пусто или не-буква, справа буква и наоборот) | вал, перевал, Перевалка | ||
| Не граница слова: либо и слева, и справа буквы, либо и слева, и справа НЕ буквы |
перевал, вал, Перевалка | ||
| перевал, вал, Перевалка |
Сложные шаблоны, соответствующие позиции (lookaround и Co)
Следующие шаблоны применяются в основном в тех случаях, когда нужно уточнить, что должно идти непосредственно перед или после шаблона, но при этом
не включать найденное в match-объект.
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
|
lookahead assertion, соответствует каждой позиции, сразу после которой начинается соответствие шаблону … |
Isaac Asimov, Isaac other | ||
|
negative lookahead assertion, соответствует каждой позиции, сразу после которой НЕ может начинаться шаблон … |
Isaac Asimov, Isaac other | ||
|
positive lookbehind assertion, соответствует каждой позиции, которой может заканчиваться шаблон … Длина шаблона должна быть фиксированной, то есть и — это ОК, а и — нет. |
abcdef, bcdef | ||
|
negative lookbehind assertion, соответствует каждой позиции, которой НЕ может заканчиваться шаблон … |
abcdef, bcdef |
На всякий случай ещё раз. Каждый их этих шаблонов проверяет лишь то, что идёт непосредственно перед позицией или непосредственно после позиции. Если пару таких шаблонов написать рядом, то проверки будут независимы (то есть будут соответствовать AND в каком-то смысле).
lookaround на примере королей и императоров Франции
— Людовик, за которым идёт VI
| Шаблон | Комментарий | Применяем к тексту |
|---|---|---|
| Цифра, окружённая не-цифрами | Text ABC 123 A1B2C3! | |
| Текст от #START# до #END# | text from #START# till #END# | |
| Цифра, после которой идёт ровно одно подчёркивание | 12_34__56 | |
| Строка, в которой нет boo (то есть нет такого символа, перед которым есть boo) |
a foo and boo and zooand others |
|
| Строка, в которой нет ни boo, ни foo | a foo and boo and zoo and others |
Реализации[править]
- NFA (Nondeterministic Finite State Machine; Недетерминированные Конечные Автоматы) используют «жадный» алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA, выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (Deterministic Finite-state Automaton; Детерминированные Конечные Автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть, не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
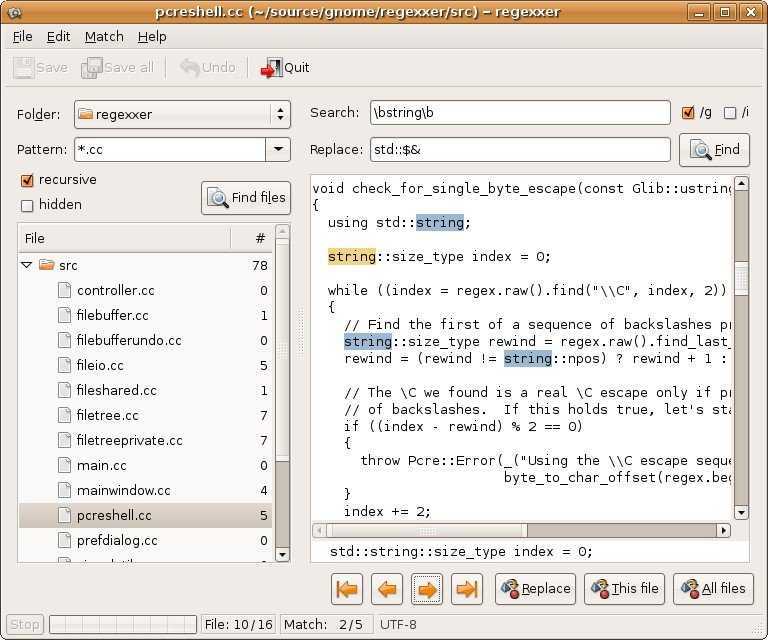
Использование групп при заменах
Использование групп добавляет замене (, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи . Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида .
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена. Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию. Например, «зацензурим» все слова, начинающиеся на букву «Х»:
Ссылки на группы при поиске
При помощи и можно ссылаться на найденную группу и при поиске. Необходимость в этом встречается довольно редко, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок! Регулярные выражения для этого не подходят. Используйте другие инструменты. Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок. Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы. Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае ![]() Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом. Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
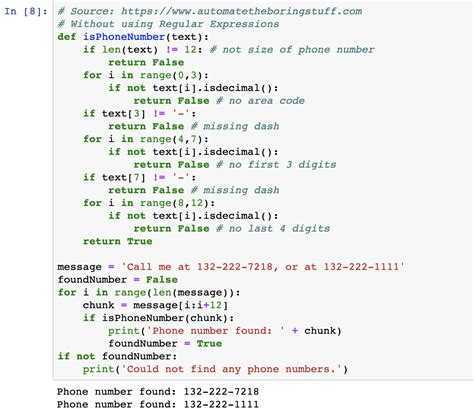
Back References
The ampersand metacharacter is useful, but even more useful is the ability to define specific regions in regular expressions. These special regions can be used as reference in your replacement strings. By defining specific parts of a regular expression, you can then refer back to those parts with a special reference character.
To do back references, you have to first define a region and then refer back to that region. To define a region, you insert backslashed parentheses around each region of interest. The first region that you surround with backslashes is then referenced by \1, the second region by \2, and so on.



Assuming phone.txt has the following text −
(555)555-1212 (555)555-1213 (555)555-1214 (666)555-1215 (666)555-1216 (777)555-1217
Try the following command −
$ cat phone.txt | sed 's/\(.*)\)\(.*-\)\(.*$\)/Area \ code: \1 Second: \2 Third: \3/' Area code: (555) Second: 555- Third: 1212 Area code: (555) Second: 555- Third: 1213 Area code: (555) Second: 555- Third: 1214 Area code: (666) Second: 555- Third: 1215 Area code: (666) Second: 555- Third: 1216 Area code: (777) Second: 555- Third: 1217
Note − In the above example, each regular expression inside the parenthesis would be back referenced by \1, \2 and so on. We have used \ to give line break here. This should be removed before running the command.
Previous Page
Print Page
Next Page
Ссылки на группы при поиске
При помощи и можно ссылаться на найденную группу и при поиске (backrefs).
Необходимость в этом встречается не так часто, но это бывает полезно при обработке простых xml и html.
Только пообещайте, что не будете парсить сложный xml и тем более html при помощи регулярок!
Регулярные выражения для этого не подходят. Используйте другие инструменты.
Каждый раз, когда неопытный программист парсит html регулярками, в мире умирает котёнок.
Если кажется «Да здесь очень простой html, напишу регулярку», то сразу вспоминайте шутку про две проблемы.
Не нужно пытаться парсить html регулярками, даже Пётр Митричев не сможет это сделать в общем случае ![]()
Использование регулярных выражений при парсинге html подобно залатыванию резиновой лодки шилом.
Закон Мёрфи для парсинга html и xml при помощи регулярок гласит: парсинг html и xml регулярками иногда работает, но в точности до того момента, когда правильность результата будет очень важна.
Используйте lxml и beautiful soup.
Some Examples
We’ll start with something simple. Let’s say we wish to identify any line with two or more vowels in a row. In the example below the multiplier {2,} applies to the preceding item which is the range.
- egrep ‘{2,}’ mysampledata.txt
- Robert pears 4
- Lisa peaches 7
- Anne mangoes 7
- Greg pineapples 3
How about any line with a 2 on it which is not the end of the line. In this example the multiplier + applies to the . which is any character.
- egrep ‘2.+’ mysampledata.txt
- Fred apples 20
The number 2 as the last character on the line.
- egrep ‘2$’ mysampledata.txt
- Mark watermellons 12
- Susy oranges 12
- Oliver rockmellons 2
And now each line which contains either ‘is’ or ‘go’ or ‘or’.
- egrep ‘or|is|go’ mysampledata.txt
- Susy oranges 5
- Terry oranges 9
- Lisa peaches 7
- Susy oranges 12
- Anne mangoes 7
Maybe we wish to see orders for everyone who’s name begins with A — K.
- egrep ‘^’ mysampledata.txt
- Fred apples 20
- Anne mangoes 7
- Greg pineapples 3
- Betty limes 14
The sed Addresses
The sed also supports addresses. Addresses are either particular locations in a file or a range where a particular editing command should be applied. When the sed encounters no addresses, it performs its operations on every line in the file.
The following command adds a basic address to the sed command you’ve been using −
$ cat /etc/passwd | sed '1d' |more daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh $
Notice that the number 1 is added before the delete edit command. This instructs the sed to perform the editing command on the first line of the file. In this example, the sed will delete the first line of /etc/password and print the rest of the file.
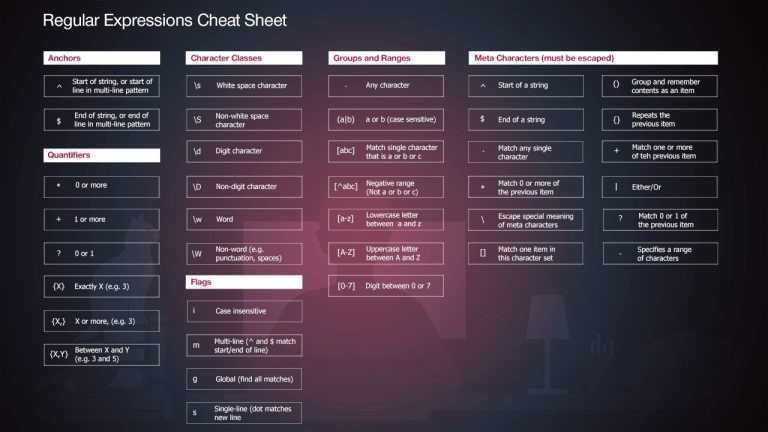
Повторители
Повторитель используется для указания одного или нескольких экземпляров группы. Ниже приведены некоторые часто используемые повторители.
Символ `*`
Оператор звездочка указывает 0 или более повторений предыдущего элемента, насколько это возможно. «ab *» будет соответствовать «a», «ab», «abb» или «a», за которым следует любое количество b.
Символ `+`
Оператор «плюс» указывает на 1 или более повторений предыдущего элемента, насколько это возможно. ‘ab +’ будет соответствовать ‘a’, ‘ab’, ‘abb’ или ‘a’, за которым следует как минимум 1 вхождение ‘b’; он не будет соответствовать «а».
Символ `?`
Этот символ указывает, что предыдущий элемент встречается не более одного раза, т.е. он может присутствовать или не присутствовать в строке для сопоставления. Например, «ab +» будет соответствовать «a» и «ab».
Фигурные скобки `{n}`
Фигурные скобки указывают, что предыдущий элемент должен быть сопоставлен ровно n раз. b {4} будет соответствовать ровно четырем символам ‘b’, но не более или менее 4.
Символы *, + ,? и {} называются повторителями, поскольку они определяют, сколько раз повторяется предыдущий элемент.
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Квантификаторы — * + ? и {}
abc* соответствует строке, в которой после ab следует 0 или более символов c -> тестabc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bc
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования
Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы. C#
C#
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку
В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.


JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Basic Regular expressions
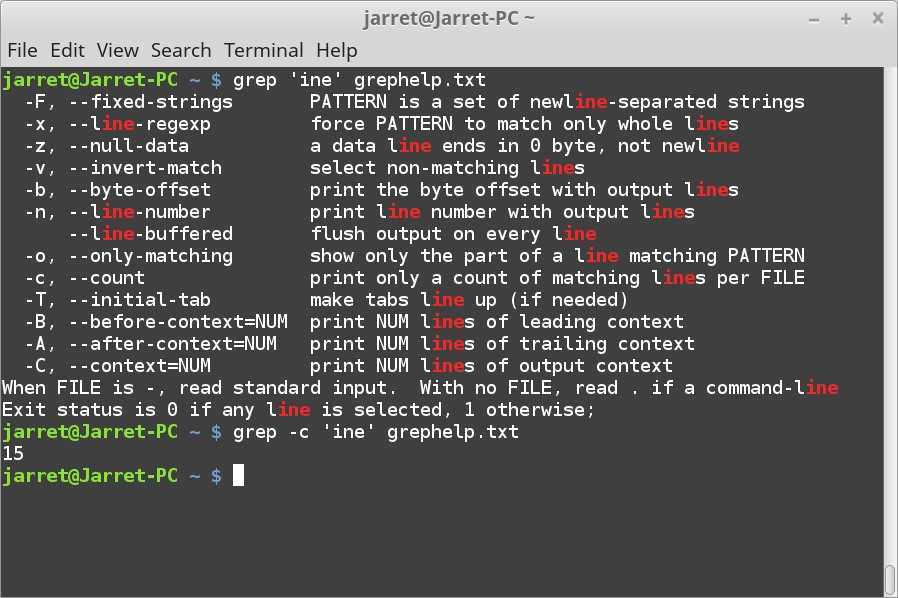
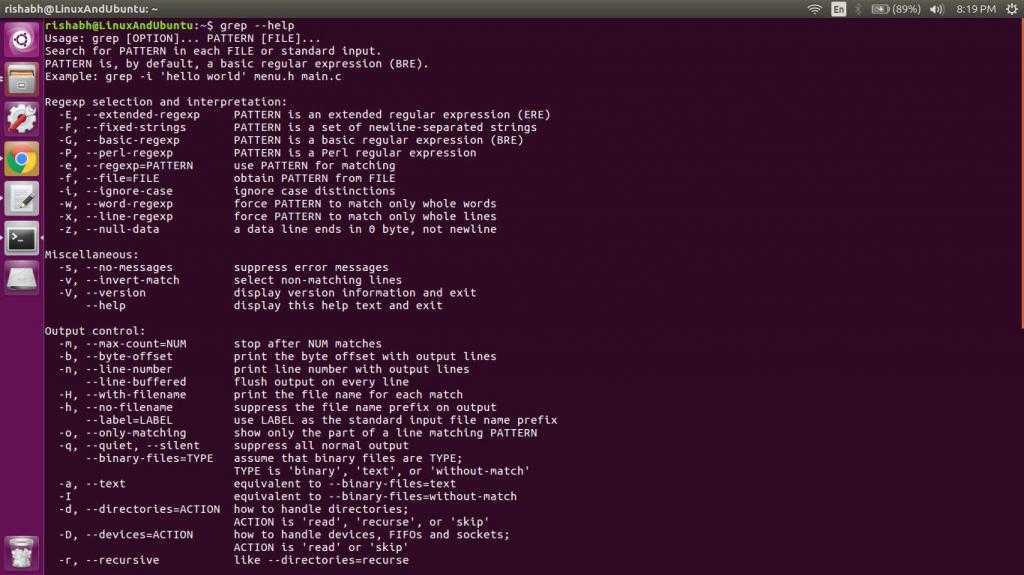
Some of the commonly used commands with Regular expressions are tr, sed, vi and grep. Listed below are some of the basic Regex.
| Symbol | Descriptions |
|---|---|
| . | replaces any character |
| ^ | matches start of string |
| $ | matches end of string |
| * | matches up zero or more times the preceding character |
| \ | Represent special characters |
| () | Groups regular expressions |
| ? | Matches up exactly one character |
Let’s see an example.
Execute cat sample to see contents of an existing file
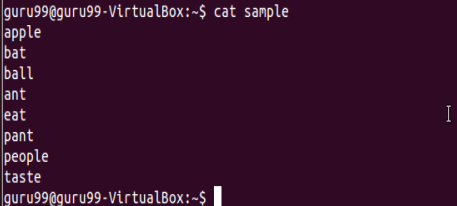
Search for content containing letter ‘a’.
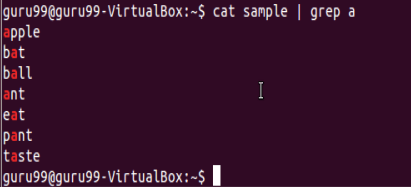
‘^‘ matches the start of a string. Let’s search for content that STARTS with a

Only lines that start with character are filtered. Lines which do not contain the character ‘a’ at the start are ignored.
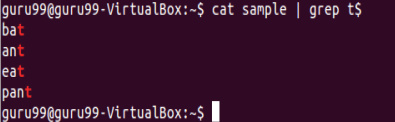
Let’s look into another example –
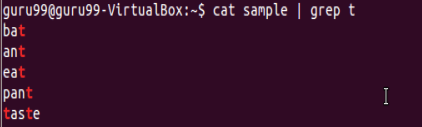
Select only those lines that end with t using $
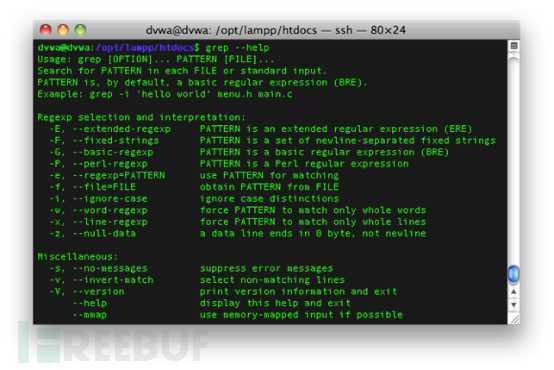
Special characters
regex patterns use some special characters. And you can’t include them in your patterns, and if you do so, you won’t get the expected result.
These special characters are recognized by regex:
.*[]^${}\+?|()
You need to escape these special characters using the backslash character (\).
For example, if you want to match a dollar sign ($), escape it with a backslash character like this:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile

If you need to match the backslash (\) itself, you need to escape it like this:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Although the forward-slash isn’t a special character, you still get an error if you use it directly.
$ echo "3 / 2" | awk '///{print $0}'

So you need to escape it like this:
$ echo "3 / 2" | awk '/\//{print $0}'

Использование групп при заменах
Использование групп добавляет замене (, работает не только в питоне, а почти везде) очень удобную возможность: в шаблоне для замены можно ссылаться на соответствующую группу при помощи .
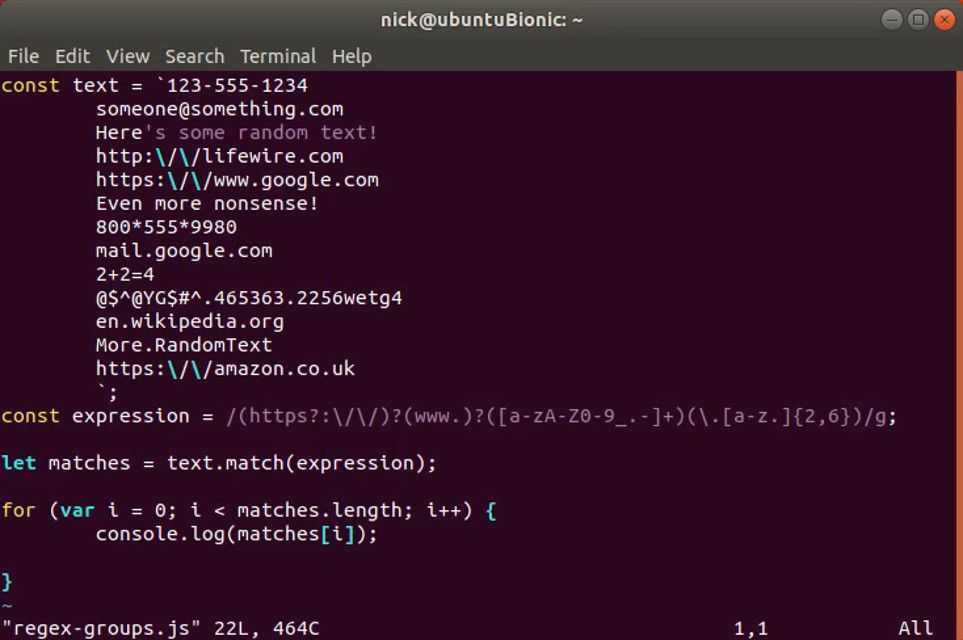
Например, если нужно даты из неудобного формата ММ/ДД/ГГГГ перевести в удобный ДД.ММ.ГГГГ, то можно использовать такую регулярку:







import re
text = "We arrive on 03/25/2018. So you are welcome after 04/01/2018."
print(re.sub(r'(\d\d)/(\d\d)/(\d{4})', r'\2.\1.\3', text))
# -> We arrive on 25.03.2018. So you are welcome after 01.04.2018.
Если групп больше 9, то можно ссылаться на них при помощи конструкции вида .
Замена с обработкой шаблона функцией в питоне
Ещё одна питоновская фича для регулярных выражений: в функции вместо текста для замены можно передать функцию, которая будет получать на вход match-объект и должна возвращать строку, на которую и будет произведена замена.
Это позволяет не писать ад в шаблоне для замены, а использовать удобную функцию.
Например, «зацензурим» все слова, начинающиеся на букву «Х»:
Основы синтаксиса
Любая строка (в которой нет символов ) сама по себе является регулярным выражением. Так, выражению будет соответствовать строка “Хаха” и только она.
Регулярные выражения являются регистрозависимыми, поэтому строка “хаха” (с маленькой буквы) уже не будет соответствовать выражению выше.
Подобно строкам в языке Python, регулярные выражения имеют спецсимволы ,
которые в регулярках являются управляющими конструкциями.
Для написания их просто как символов требуется их экранировать, для чего нужно поставить перед ними знак .
Так же, как и в питоне, в регулярных выражения выражение соответствует концу строки, а — табуляции.
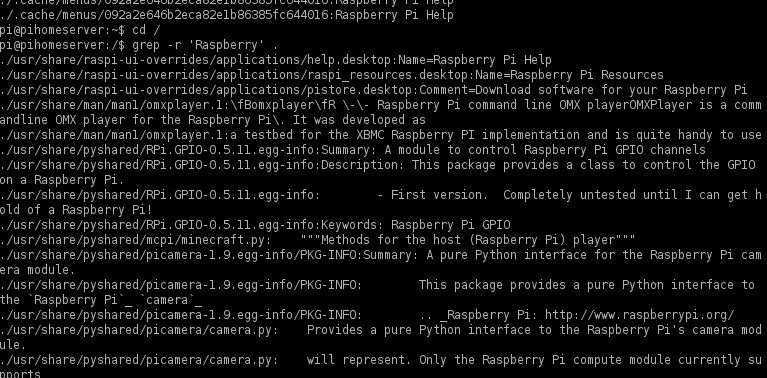
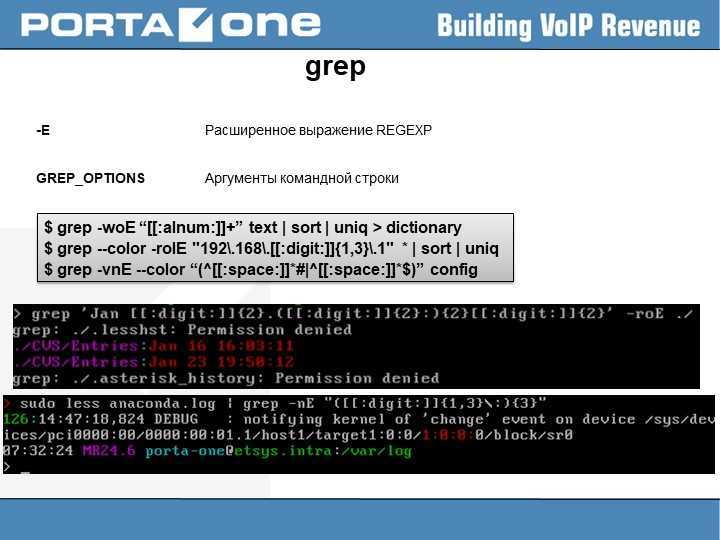
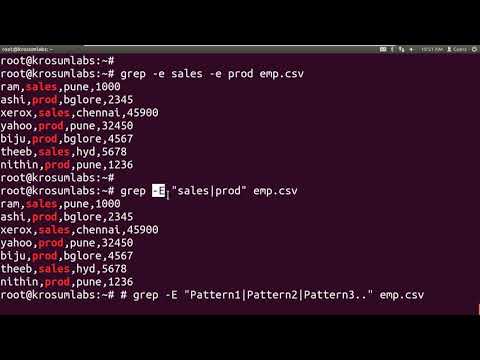
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
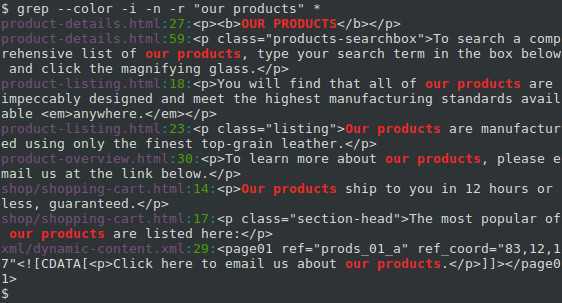
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Централизованное управление кластером 1С Предприятия, состоящим из нескольких рабочих серверов, работающих на платформе GNU/Linux
При эксплуатации крупных информационных систем, в состав которых могут входить десятки серверов 1С Предприятия, зачастую возникают ситуации, требующие однотипных действий на всех серверах кластера 1С Предприятия или на всех серверах контура. В настоящей статье представлен способ централизованного управления серверами 1С Предприятия, работающими на платформе GNU/Linux. Подобный подход может быть использован и для других задач, возникающих в процессе эксплуатации крупных систем, с целью сокращения как временных затрат специалистов, так и времени простоя системы.
1 стартмани
Types of regex
Many different applications use different types of regex in Linux, like the regex included in programming languages (Java, Perl, Python,) and Linux programs like (sed, awk, grep,) and many other applications.
A regex pattern uses a regular expression engine that translates those patterns.
Linux has two regular expression engines:
- The Basic Regular Expression (BRE) engine.
- The Extended Regular Expression (ERE) engine.
Most Linux programs work well with BRE engine specifications, but some tools like sed understand some of the BRE engine rules.
The POSIX ERE engine comes with some programming languages. It provides more patterns, like matching digits and words. The awk command uses the ERE engine to process its regular expression patterns.
Since there are many regex implementations, it’s difficult to write patterns that work on all engines. Hence, we will focus on the most commonly found regex and demonstrate how to use it in the sed and awk.
Идентификаторы
Идентификатор соответствует подмножеству символов, например строчным буквам, числовым цифрам, пробелам и т.д. Regex предоставляет список удобных идентификаторов для соответствия различным подмножествам. Некоторые часто используемые идентификаторы:
- \ d = соответствует цифрам (числовым символам) в строке;
- \ D = соответствует чему угодно, кроме цифры;
- \ s = соответствует пробелу (например, пробел, TAB и т. д.);
- \ S = соответствует чему угодно, кроме пробела;
- \ w = соответствует буквам или цифрам алфавита;
- \ W = соответствует чему угодно, кроме буквы;
- \ b = соответствует любому символу, который может разделять слова (например, пробел, дефис, двоеточие и т. д.);
- . = соответствует любому символу, кроме новой строки. Следовательно, он называется оператором с подстановочными знаками. Таким образом, «. *» будет соответствовать любому символу, любое количество раз.
Примечание. В приведенном выше примере регулярного выражения и во всех других в этом разделе мы опускаем ведущую букву r в строковом литерале регулярного выражения для удобства чтения. Любой приведенный здесь литерал должен быть объявлен как необработанный строковый литерал при использовании в коде Python.
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Address Substitution
If you want to substitute the string sh with the string quiet only on line 10, you can specify it as follows −
$ cat /etc/passwd | sed '10s/sh/quiet/g' root:x:0:0:root user:/root:/bin/sh daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/quiet
Similarly, to do an address range substitution, you could do something like the following −
$ cat /etc/passwd | sed '1,5s/sh/quiet/g' root:x:0:0:root user:/root:/bin/quiet daemon:x:1:1:daemon:/usr/sbin:/bin/quiet bin:x:2:2:bin:/bin:/bin/quiet sys:x:3:3:sys:/dev:/bin/quiet sync:x:4:65534:sync:/bin:/bin/sync games:x:5:60:games:/usr/games:/bin/sh man:x:6:12:man:/var/cache/man:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh backup:x:34:34:backup:/var/backups:/bin/sh
As you can see from the output, the first five lines had the string sh changed to quiet, but the rest of the lines were left untouched.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.