
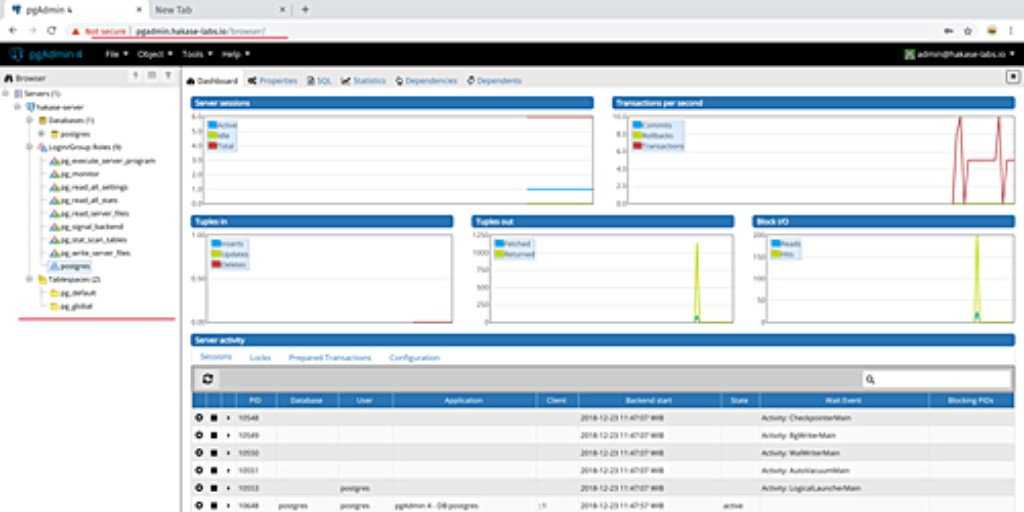
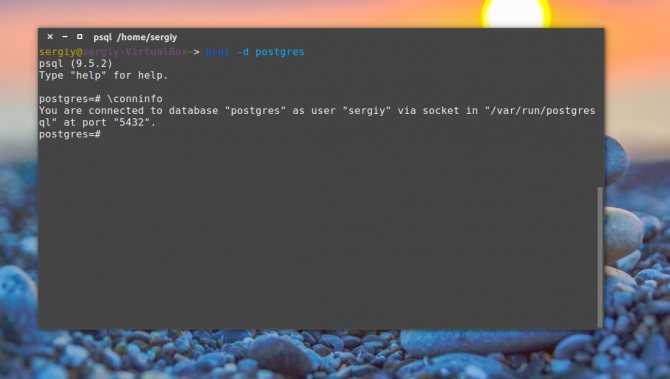
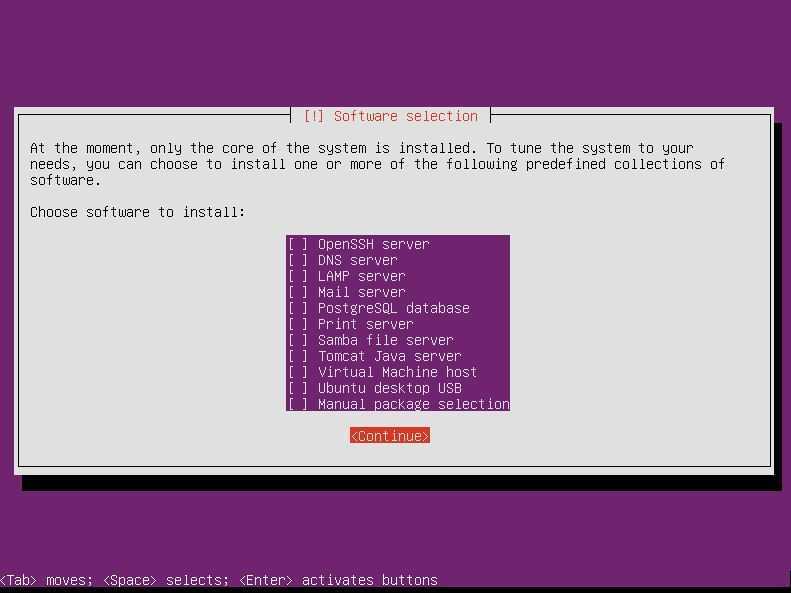
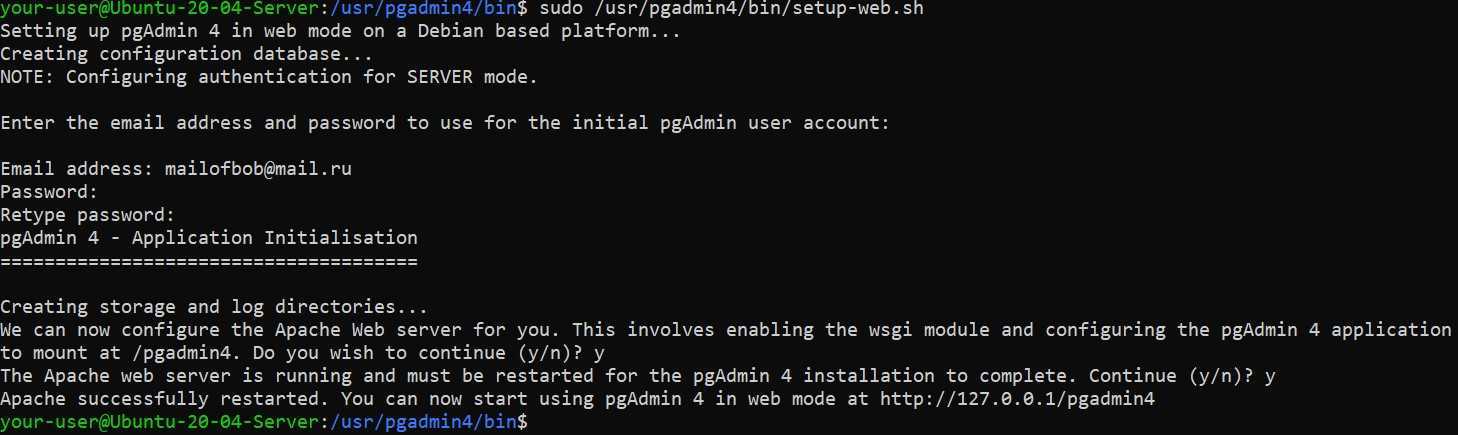
Установка PostgreSQL из исходников
Работаем из под пользователя root, поэтому будьте осторожны!
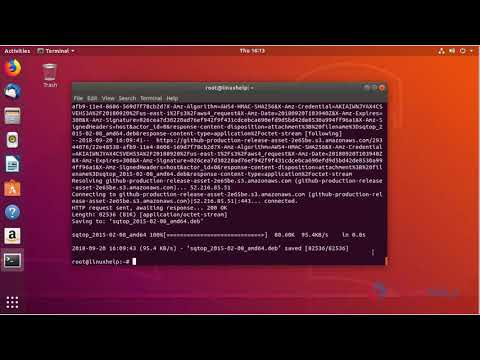
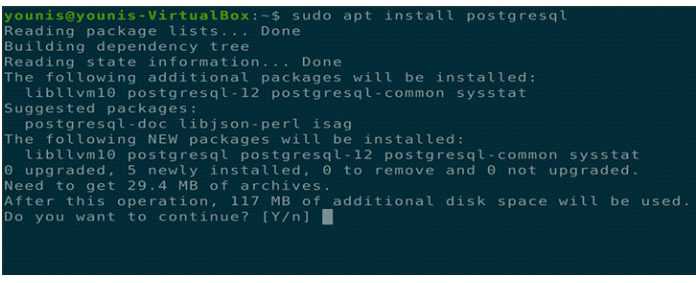
Прежде всего скачаем и распакуем архив:
# mkdir pg # cd pg/ # wget https://ftp.postgresql.org/pub/source/v13.3/postgresql-13.3.tar.gz # tar xf postgresql-13.3.tar.gz # cd postgresql-13.3/
Далее, установим необходимые пакеты, соберем из исходников postgresql и установим его:
# apt install gcc make # apt install libreadline-dev # apt install zlibc zlib1g-dev # ./configure # make # make install
В результате, PostgreSQL у нас установится в каталог /usr/local/pgsql/, здесь лежат сами бинарники.
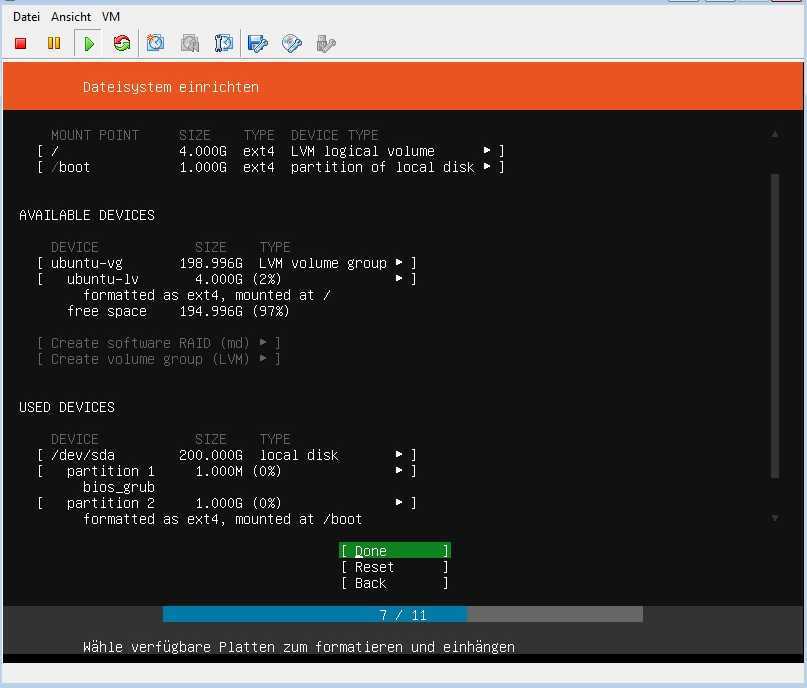
Теперь нам нужно создать каталог для хранения данных. В PostgreSQL он называется PGDATA по имени переменной $PGDATA в которой содержится путь к каталогу кластера PostgreSQL. Создадим такой каталог а также пользователя “postgres“. Дополнительно сделаем этого пользователя владельцем этого каталога и установим права (750):
# mkdir /usr/local/pgsql/data # adduser postgres # chown postgres /usr/local/pgsql/data/ # chmod 750 /usr/local/pgsql/data/
Подробности
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- Каждый элемент таблицы является одним элементом данных
- Каждый столбец обладает своим уникальным именем
- Одинаковые строки в таблице отсутствуют
- Все столбцы в таблице однородные, то есть все элементы в столбце имеют одинаковый тип
- Порядок следования строк и столбцов может быть произвольным
Реляционные СУБД, ориентированные на реализацию систем операционной обработки данных, менее эффективны в задачах аналитической обработки, чем многомерные базы данных. Это связано, во-первых, с наличием достаточно жестких ограничений накладываемых существующей реализацией языка SQL. Примером такого реально существующего ограничения является предположение о том, что данные в реляционной базе неупорядочены (или более точно, упорядочены случайным образом). При этом их упорядочивание требует дополнительных затрат времени на сортировку при каждом обращении к базе данных. В аналитических системах ввод и выборка данных осуществляется большими порциями. В свою очередь данные, после того как они попадают в базу данных, остаются неизменными в течение длительного периода времени. И здесь более эффективным оказывается хранение данных в форме частично денормализованных таблиц, в которых для увеличения производительности могут храниться не только детализированные, но и предварительно вычисленные агрегированные значения. А для навигации и выборки могут использоваться специализированные, основанные на предположении о малой изменчивости и малоподвижности данных в базе данных, методы адресации и индексации. Такой способ организации данных, иногда называют предвычисленным, подчеркивая тем самым, его отличие от нормализованного реляционного подхода, предполагающего динамическое вычисление различного вида итогов (агрегация) и установление связей между реквизитами из разных таблиц (операции соединения).
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд.
Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Всем мета-командам предшествует обратная косая черта , за которой следует фактическая команда.
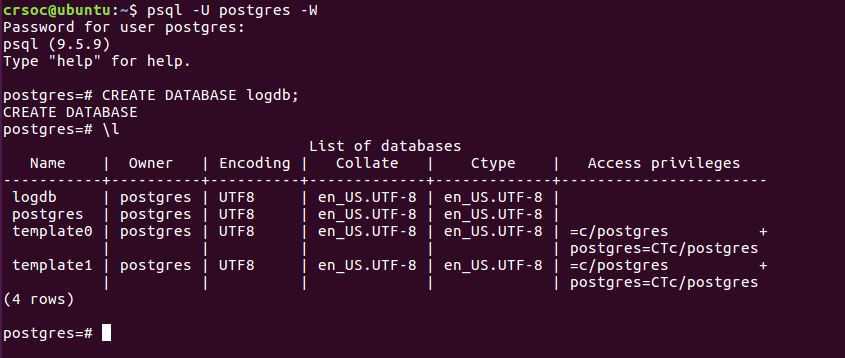
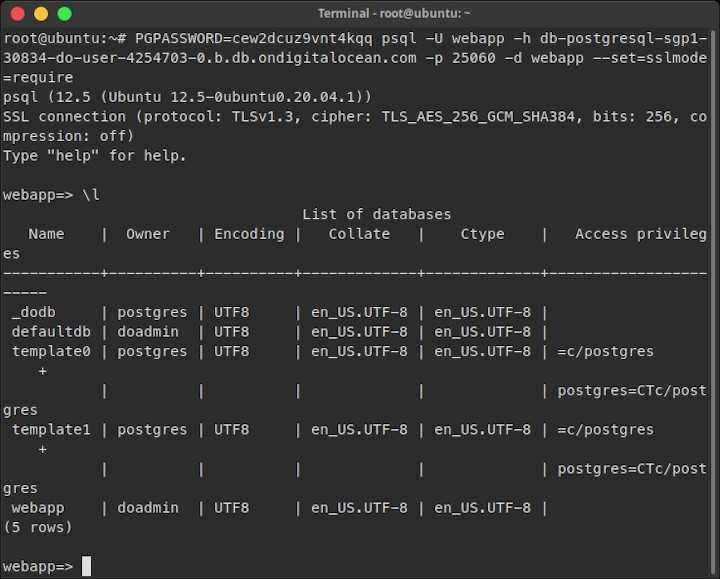
Список всех баз данных
Чтобы получить список всех баз данных на сервере, ты можешь использовать команду .
Ввод этой мета-команды в оболочке Postgres выведет:
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
На данный момент мы пока ничего не создали, а базы данных которые ты видишь на экране — создаются по умолчанию при установке Postgres.
- postgres — это просто пустая база данных.
- «template0» и «template1» — это служебные базы данных, которые служат шаблоном для создания новых баз.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы).
Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.
Когда ты находишься внутри оболочки (shell), то можешь использовать команду (или ), за которой следует имя
базы данных. Если бы у тебя была другая база данных под названием , то подключиться к ней можно было бы так:
Полностью в терминале у тебя получится что-то такое:
Обрати внимание, что приглашение оболочки изменилось с на. Это значит, что теперь ты
подключен к базе данных , а не
Получить список всех таблиц в базе данных
Как и в случае со списком существующих баз данных, ты можешь получить список таблиц внутри конкретной базы данных
с помощью команды .
Перед выполнением этой команды вам необходимо войти в базу данных.
Предположим, ты уже находишься внутри базы , и в ней есть таблица с именем. Набрав , ты
получишь следующее:
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных
руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
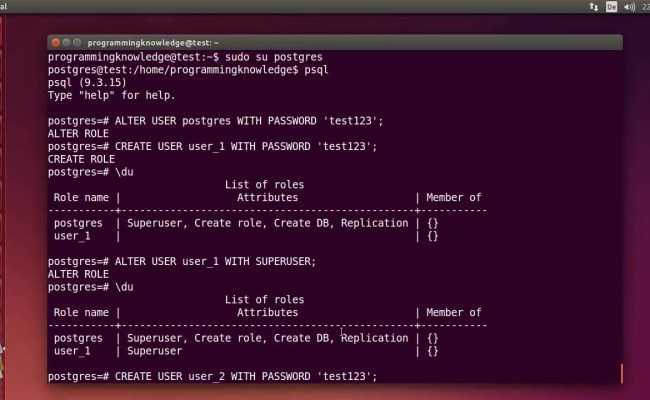
Список пользователей и ролей
Как ты уже знаешь, при установке Postgres создается суперпользователь с именем .
Список всех пользователей базы данных можно вывести на экран используя команду .
Обрати внимание, что первый столбец называется — роль (role name).
И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей. В PostgreSQL пользователи и роли практически
одинаковы
В PostgreSQL пользователи и роли практически
одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание
других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно.
Вместо этого создают другие роли с меньшими привилегиями.
Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
Advantages and Disadvantages of PostgreSQL
PostgreSQL is a feature-rich application, offering advanced features such as materialized views, triggers, and stored procedures. It can handle a very high workload, including data warehouses or highly-scaled web applications, and is noted for its stability. PostgreSQL can be extended with custom data types and functions, and can integrate with code from different languages. However, due to its focus on compatibility, it does not always match other database systems in terms of performance. In addition, not all open source applications support PostgreSQL.
With a large database schema, PostgreSQL can consume a substantial amount of disc space. To store large amounts of data, we recommend hosting PostgreSQL on a
High Memory Linode.
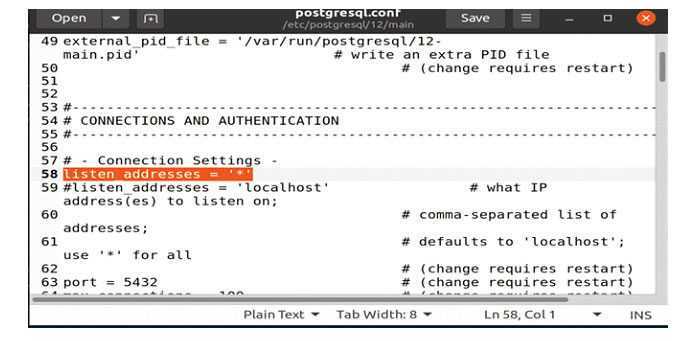
Включить удаленный доступ к серверу PostgreSQL
По умолчанию сервер PostgreSQL прослушивает только локальный интерфейс ( ).
Чтобы включить удаленный доступ к серверу PostgreSQL, откройте файл конфигурации и добавьте в раздел .
/etc/postgresql/12/main/postgresql.conf
Сохраните файл и перезапустите службу PostgreSQL:
Проверьте изменения с помощью утилиты :
Вывод показывает, что сервер PostgreSQL прослушивает все интерфейсы ( ):
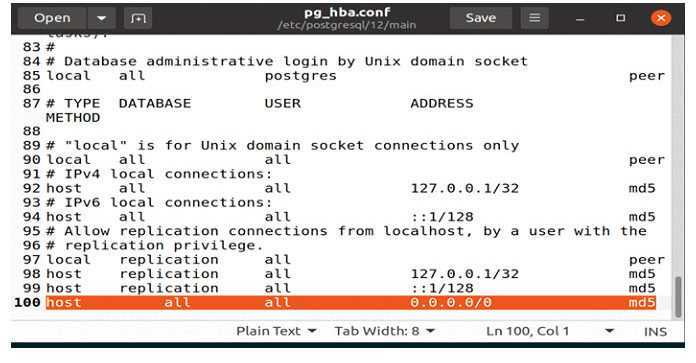
Следующим шагом является настройка сервера для приема удаленных подключений путем редактирования файла .
Ниже приведены несколько примеров, показывающих различные варианты использования:
/etc/postgresql/12/main/pg_hba.conf
Последний шаг — открыть порт в вашем брандмауэре.
Предполагая, что вы используете для управления брандмауэром и хотите разрешить доступ из подсети , вы должны выполнить следующую команду:
Убедитесь, что ваш брандмауэр настроен на прием подключений только из доверенных диапазонов IP-адресов.
Step 2 — Using PostgreSQL Roles and Databases
By default, Postgres uses a concept called “roles” to handle authentication and authorization. These are, in some ways, similar to regular Unix-style accounts, but Postgres does not distinguish between users and groups and instead prefers the more flexible term “role”.
Upon installation, Postgres is set up to use ident authentication, meaning that it associates Postgres roles with a matching Unix/Linux system account. If a role exists within Postgres, a Unix/Linux username with the same name is able to sign in as that role.
The installation procedure created a user account called postgres that is associated with the default Postgres role. In order to use Postgres, you can log into that account.
There are a few ways to utilize this account to access Postgres.
Switching Over to the postgres Account
Switch over to the postgres account on your server by typing:
You can now access the PostgreSQL prompt immediately by typing:
From there you are free to interact with the database management system as necessary.
Exit out of the PostgreSQL prompt by typing:
This will bring you back to the Linux command prompt.
Accessing a Postgres Prompt Without Switching Accounts
You can also run the command you’d like with the postgres account directly with .
For instance, in the last example, you were instructed to get to the Postgres prompt by first switching to the postgres user and then running to open the Postgres prompt. You could do this in one step by running the single command as the postgres user with , like this:
This will log you directly into Postgres without the intermediary shell in between.
Again, you can exit the interactive Postgres session by typing:
Many use cases require more than one Postgres role. Read on to learn how to configure these.
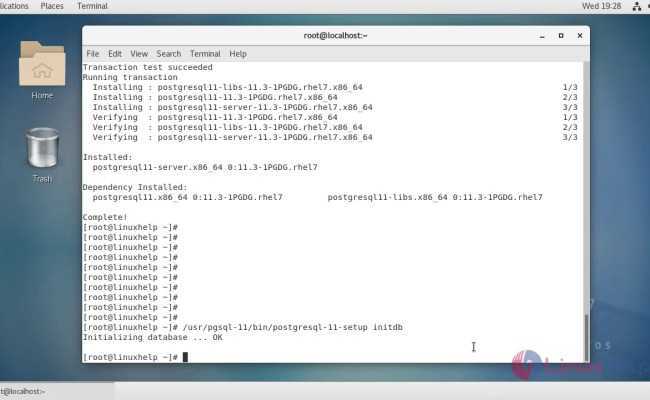
Installing PostgreSQL
Installing the Latest Version of PostgreSQL From the Ubuntu Packages
The easiest way to install PostgreSQL on Ubuntu is with the package installation program . This method installs the latest version of PostgreSQL that is included in the Ubuntu packages. At the time of writing this guide the version is 12.5.
-
Update and upgrade the existing packages.
-
Install PostgreSQL and all dependencies, along with the module that provides additional functionality.
-
Ensure PostgreSQL is running with .
-
To automatically launch PostgreSQL upon system boot-up, register it with .
-
Verify PostgreSQL is running as expected.
This returns a summary of the application and its status. PostgreSQL should be listed as .
Installing PostgreSQL From the PostgreSQL Apt Repository
Installing PostgreSQL from the PostgreSQL repository allows you more control over what version to choose. The following process installs the latest stable version of PostgreSQL. As of early 2021, this is version 13.1. You can also choose to install an earlier release of PostgreSQL.
-
Update and upgrade the existing packages.
-
Add the new file repository configuration.
-
Import the signing key for the repository.
-
Update the package lists.
-
Install the latest version of PostgreSQL.
-
Ensure PostgreSQL is running with .
-
To automatically launch PostgreSQL upon system boot-up, register it with .
-
Verify the status of PostgreSQL with . The status of PostgreSQL should be listed as .
-
![Установка postgresql в ubuntu 20.04 [краткое руководство] | digitalocean](https://smartshop124.ru/wp-content/uploads/a/5/c/a5c1bf4bb71f2785e3d1f455c04e82ed.jpeg)
Create and Delete Tables
Now that you know how to connect to the PostgreSQL database system, we will start to go over how to complete some basic tasks.
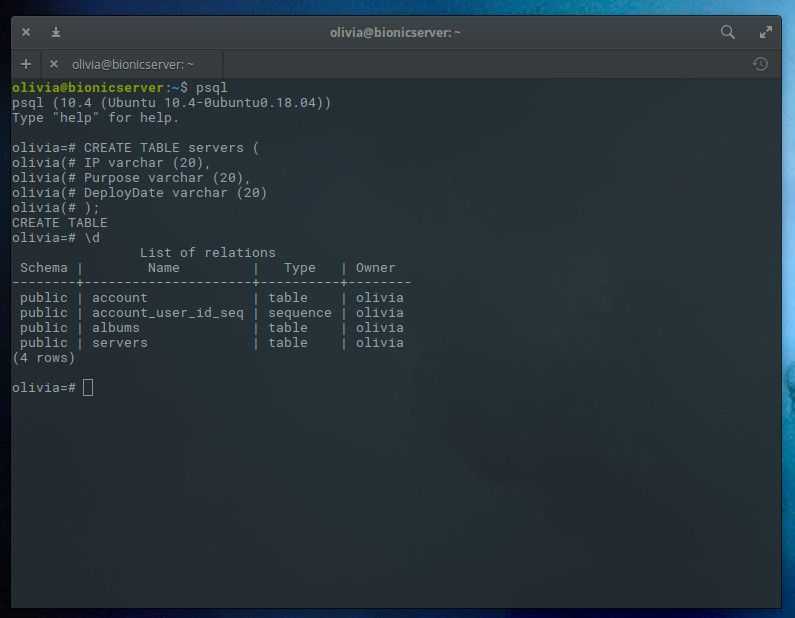
First, let’s create a table to store some data. Let’s create a table that describes playground equipment.
The basic syntax for this command is something like this:
<pre>
CREATE TABLE <span class=“highlight”>tablename</span> (
<span class=“highlight”>columnname1</span> <span class=“highlight”>coltype</span> (<span class=“highlight”>fieldlength</span>) <span class=“highlight”>columnconstraints</span>,
<span class=“highlight”>columnname2</span> <span class=“highlight”>coltype</span> (<span class=“highlight”>fieldlength</span>),
<span class=“highlight”>columnname3</span> <span class=“highlight”>coltype</span> (<span class=“highlight”>field_length</span>)
);
</pre>
As you can see, we give the table a name, and then define the columns that we want, as well as the column type and the max length of the field data. We can also optionally add table constraints for each column.
You can learn more about how to create and manage tables in Postgres here.
For our purposes, we’re going to create a simple table like this:
We have made a playground table that inventories the equipment that we have. This starts with an equipment ID, which is of the type. This data type is an auto-incrementing integer. We have given this column the constraint of which means that the values must be unique and not null.
For two of our columns, we have not given a field length. This is because some column types don’t require a set length because the length is implied by the type.
We then give columns for the equipment type and color, each of which cannot be empty. We then create a location column and create a constraint that requires the value to be one of eight possible values. The last column is a date column that records the date that we installed the equipment.
We can see our new table by typing this:
As you can see, we have our playground table, but we also have something called that is of the type . This is a representation of the “serial” type we gave our column. This keeps track of the next number in the sequence.
If you want to see just the table, you can type:
Шаг 2 — Использование ролей и баз данных в PostgreSQL
По умолчанию Postgres использует концепцию «ролей» для выполнения аутентификации и авторизации. В некоторых аспектах они напоминают обычные учетные записи в Unix, однако Postgres не делает различий между пользователями и группами и предпочитает использовать более гибкий термин “роль”.
После установки Postgres настроена на использование аутентификации ident, что значит, что выполняется привязка ролей Postgres с соответствующей системной учетной записью Unix/Linux. Если роль существует внутри Postgres, пользователь Unix/Linux с тем же именем может выполнить вход в качестве этой роли.
В ходе установки была создана учетную запись пользователя postgres, которая связана с используемой по умолчанию ролью Postgres. Чтобы использовать Postgres, вы можете войти в эту учетную запись.
Существует несколько способов использования этой учетной записи для доступа к Postgres.
Переключение на учетную запись postgres
Вы можете переключиться на учетную запись postgres на вашем сервере с помощью следующей команды:
Теперь вы можете немедленно получить доступ к командной строке PostgresSQL с помощью следующей команды:
Теперь вы можете свободно взаимодействовать с СУБД по мере необходимости.
Закройте командную строку PostgreSQL с помощью следующей команды:
В результате вы вернетесь в командную строку в Linux.
Доступ к командной строке Postgres без переключения учетных записей
Также вы можете запустить необходимую вам команду с учетной записью напрямую с помощью sudo.
Например, в последнем примере от вас требовалось перейти в командную строку Postgres с помощью переключения на пользователя postgres и последующего запуска , чтобы открыть командную строку Postgres. Вы можете сделать это в один прием с помощью отдельной команды , используя пользователя postgres с следующим образом:
Это позволит выполнить вход в Postgres без необходимости использования промежуточной командной строки .
Вы снова сможете выйти из интерактивной сессии Postgres с помощью следующей команды:
Многие варианты использования требуют использования сразу нескольких ролей Postgres. Ниже вы узнаете, как выполнить настройку в таких случаях.
Создание и удаление таблиц
Теперь, когда вы уже знаете, как подключиться к системе управления базами данных PostgreSQL, можно переходить к знакомству с основными задачами по управлению, которые решает Postgres.
Базовый синтаксис создания таблиц выглядит следующим образом:
Как видите, эти команды дают таблице имя, а затем определяют столбцы, тип столбцов и максимальную длину поля данных. Кроме того, вы можете добавить ограничения таблицы для каждой колонки.
Для демонстрационных целей необходимо создать следующую таблицу:
Эта команда создает таблицу с описью оборудования для установки на игровых площадках. В первом столбце таблицы хранятся идентификационные номера оборудования типа. Эти номера представляют собой целые числа с автоматическим инкрементальным увеличением. В этом столбце также содержится константа , и это означает, что значения в нем должны быть уникальными и ненулевыми.
Следующие две строки создают столбцы и оборудования соответственно, и ни один из них не может быть пустым. Следующая строка создает столбец и ограничение, требующее, чтобы значение было одним из восьми возможных вариантов. Последняя строка создает столбец , которая указывает дату установки оборудования.
Для двух из столбцов ( и ) команда не указывает длину поля. Это связано с тем, что для некоторых типов данных не требуется заданная длина, поскольку длина или формат являются подразумеваемыми.
Вы можете просмотреть вашу новую таблицу, введя следующую команду:
Ваша таблица игрового оборудования готова, но здесь есть что-то под названием с типом данных . Это представление типа , который присвоен столбцу . Оно отслеживает следующий номер последовательности и создается автоматически для столбцов данного типа.
Если вы хотите только просмотреть таблицу без последовательности, можете ввести следующую команду:
Мы подготовили таблицу и теперь можем использовать ее для тренировки управления данными.
Использование ролей и баз данных PostgreSQL
По умолчанию Postgres использует понятие “роли” для обработки аутентификации и авторизации. В чем-то они похожи на обычные учетные записи в стиле Unix, но Postgres не делает различий между пользователями и группами и предпочитает более гибкий термин “роль”.
После установки Postgres настраивается на использование аутентификации ident, что означает, что он связывает роли Postgres с соответствующей системной учетной записью Unix/Linux. Если роль существует в Postgres, пользователь Unix/Linux с тем же именем сможет войти в систему в качестве этой роли.
Есть несколько способов использовать эту учетную запись для доступа к Postgres.
Выгрузка баз 1С в dt из командной строки
Частенько бывает нужно сделать выгрузку базы 1С в dt файл. Это можно сделать прямо из консоли ubuntu server с помощью автономного сервера 1С. При этом даже пользователей не придётся выгонять из базы.
sudo /opt/1cv8/x86_64/8.3.19.1264/ibcmd infobase dump --db-server=localhost --dbms=postgresql --db-name=basa1 --db-user=postgres --db-pwd=parol /mnt/backup/basa1.dt

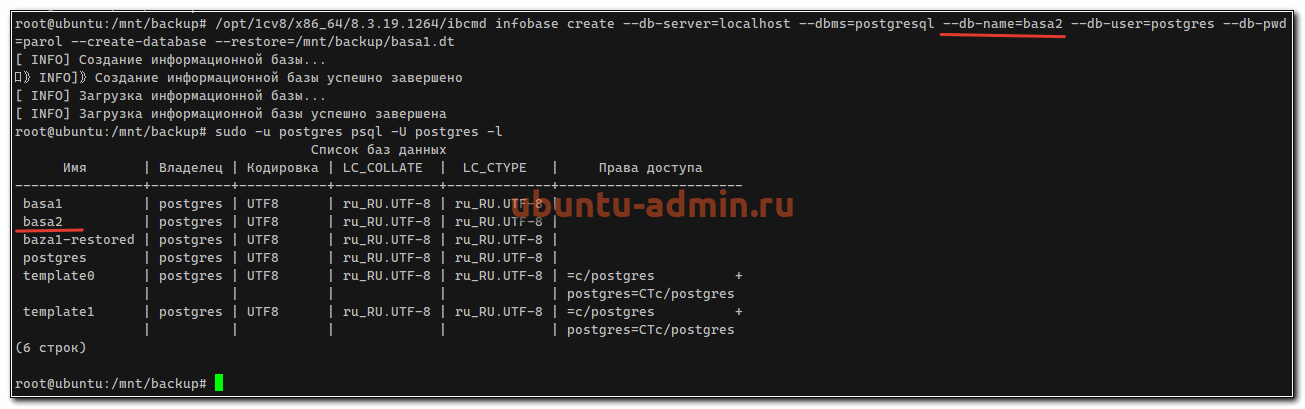
Так же через консоль можно загрузить данные в базу 1С из dt файла. К примеру, загрузим предыдущую выгрузку в новую базу — basa2:
sudo /opt/1cv8/x86_64/8.3.19.1264/ibcmd infobase create --db-server=localhost --dbms=postgresql --db-name=basa2 --db-user=postgres --db-pwd=parol --create-database --restore=/mnt/backup/basa1.dt
С помощью автономного сервера можно проверить базу 1С на ошибки. Опять же, прямо в консоли linux:
sudo /opt/1cv8/x86_64/8.3.19.1264/ibcmd infobase config check --db-server=localhost --dbms=postgresql --db-name=basa2 --db-user=postgres --db-pwd=parol
Все возможности автономного сервера можно посмотреть в руководстве администратора.
Включить удаленный доступ к серверу PostgreSQL
По умолчанию сервер PostgreSQL прослушивает только локальный интерфейс . Чтобы включить удаленный доступ к серверу PostgreSQL, откройте файл конфигурации и добавьте в раздел .
/etc/postgresql/10/main/postgresql.conf
сохраните файл и перезапустите службу PostgreSQL с помощью:
Проверьте изменения с помощью утилиты :
Как видно из выходных данных выше, сервер PostgreSQL прослушивает все интерфейсы (0.0.0.0).
Последний шаг — настроить сервер на прием удаленных подключений путем редактирования файла .
Ниже приведены несколько примеров, показывающих различные варианты использования:
/etc/postgresql/10/main/pg_hba.conf
Загрузка и установка PostgreSQL
PostgreSQL поддерживает все основные операционные системы. Процесс установки прост, поэтому я постараюсь рассказать
о нем как можно быстрее.

Для Windows и Mac ты можешь загрузить установщик
с
веб-сайта EDB
.
EDB больше не предоставляет пакеты для систем GNU/Linux. Вместо этого они рекомендуют вам использовать диспетчер
пакетов твоего дистрибутива.
Установщики включают в себя разные компоненты.
Вот самые важные из них:
- Сервер PostgreSQL (очевидно)
- pgAdmin, графический инструмент для управления базами данных
- Менеджер пакетов для загрузки и установки дополнительных инструментов и драйверов
Windows
Скачав установщик, запусти его как любой другой исполняемый файл. Процесс довольно прямолинеен,
но некоторые вещи все же заслуживают внимания.
Диалоговое окно «Выбрать компоненты» позволяет выборочно устанавливать компоненты.
Если у тебя нет веской причины что-то менять — оставляй все как есть.
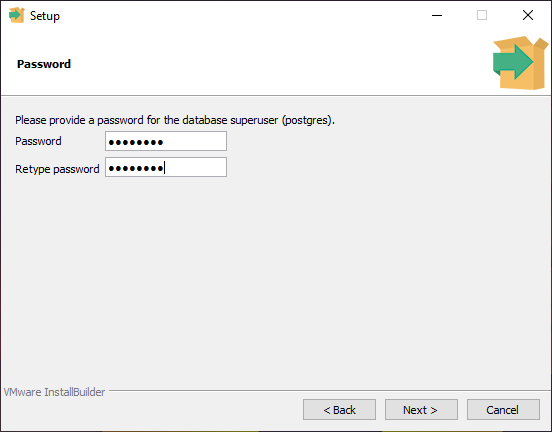
По умолчанию PostgreSQL создает суперпользователя с именем (воспринимай его как учетную запись
администратора сервера базы данных).
Во время установки тебе нужно будет указать пароль для суперпользователя (root).
Позже ты сможешь создать других пользователей и назначать им отдельные доступы и роли.
Мы вернемся к этому позже, а сейчас тебе понадобится учетная запись суперпользователя, чтобы начать использовать СУБД.
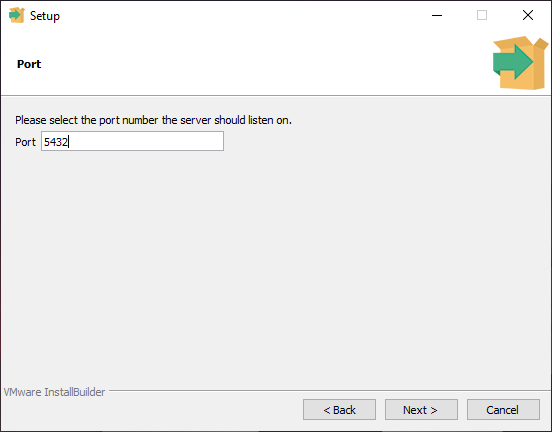
Чтобы запустить сервер разработки на твоем компьютере или , необходимо
назначить ему порт.
Порт по умолчанию — 5432. Если ты устанавливаешь PostgreSQL впервые, то он скорее всего свободен.
Если окажется, что этот порт уже занят другим экземпляром PostgreSQL, ты можешь указать другое значение, например 5433.
После завершения установки ты сможешь запустить SQL Shell, поставляемый с Postgres.
Шаг за шагом ты выберешь сервер, какую базу данных использовать, порт, имя пользователя и пароль.
Используй данные, которые ты вводил на предыдущих шагах.
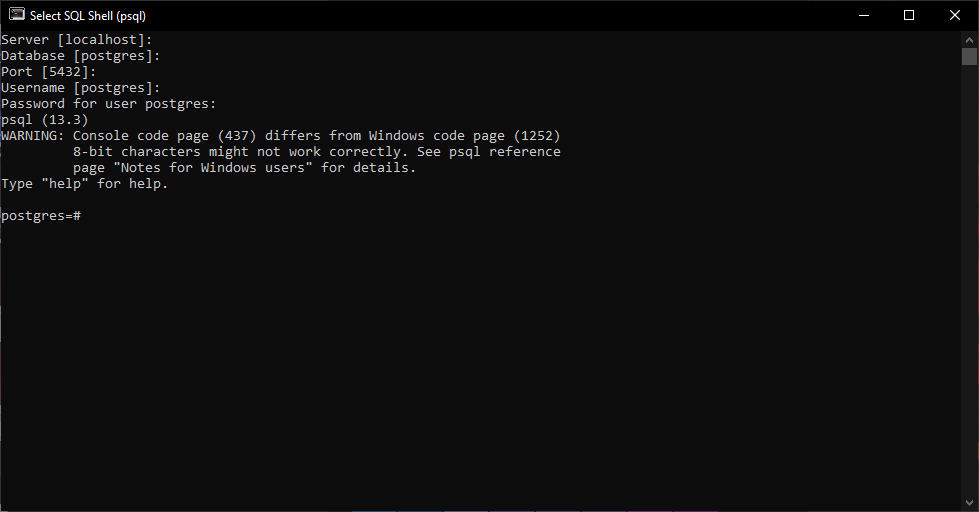
Поздравляю! Настройка для Windows завершена, и скоро мы начнем писать первые SQL запросы.
Ниже список вариантов установки для других операционных систем.
macOS
Для macOS у тебя есть разные варианты. Можно скачать установщик с сайта EDB и запустить его.
![Установка postgresql в ubuntu 20.04 [краткое руководство]](https://smartshop124.ru/wp-content/uploads/8/2/8/828dfa2debc8b24c9bec71a124b2a0b1.jpeg)
Кроме того, можно использовать , простое приложение для macOS.
После запуска у тебя появится сервер PostgreSQL, готовый к использованию.
Завершить работу сервера можно просто закрыв приложение.
Кроме того, ты также можете использовать , менеджер пакетов для macOS.
GNU/Linux
Ты можешь найти PostgreSQL в репозиториях большинства дистрибутивов Linux. Установить его можно одним щелчком мыши
из выбранного графического диспетчера пакетов.
Альтернативно, можно использовать установку через терминал.
Ты можешь обратиться к документации твоего дистрибутива для получения дополнительных сведений.
Arch
Запуск оболочки PostgreSQL
После установки PostgreSQL, нужно запустить оболочку(shell), с помощью которой ты получишь возможность управлять базой данных.
Открой терминал и введи:
— это оболочка Postgres, аргумент используется для указания пользователя.
Поскольку ты еще не создавал других
пользователей, ты войдешь в систему как суперпользователь .
После этого нужно будет ввести пароль
суперпользователя, который ты выбрал во время установки.
Как только пароль установлен, база данных PostgreSQL готова к работе!
Если сервер PostgreSQL по какой-то причине не запускается, можешь попробовать запустить его вручную.
Действия после установки postgres
Если мы установили PostgreSQL Pro версию, выполним только первую настройку.
Пароль для пользователя postgres
Задаем пароль для пользователя postgres:
sudo -u postgres psql -U postgres -d template1 -c «ALTER USER postgres PASSWORD ‘password'»; history -d $((HISTCMD-1))
* данную команду мы запускаем под пользователем postgres; мы задаем пароль password для postgresql-пользователя postgres. Дополнительная команда history -d $((HISTCMD-1)) удалить из истории строку с паролем.
Остальные настройки выполняем для PostgreSQL не Pro версии.
Разрешаем автозапуск сервиса баз данных и стартуем его:
systemctl enable postgresql —now
Блокировка обновлений PostgreSQL
Так как для 1С устанавливается специальная сборка СУБД, необходимо запретить ее обновление. В противном случае будет установлен обычныйpostgresql, что приведет к потери работоспособности сервера.
Смотрим версию установленного сервера баз данных:
dpkg -l | grep postgresql
Пример ответа:
ii postgresql-10 10.10-4.1C …
ii postgresql-client-10 10.10-4.1C …
…
И так, у нас установлена версия 10.10-4.1C. Вводим:
dpkg -l | grep 10.10-4.1C | awk -F’ ‘ ‘{print $2}’ | xargs apt-mark hold
* где 10.10-4.1C — версия установленного PostgreSQL. Команда apt-mark hold блокируем установку обновлений для пакетов версии 10.10-4.1C.
Также добавим:
apt-mark hold postgresql-common postgresql-client-common
Шаг 6: Добавление и удаление данных
Для добавления новой информации используется команда INSERT INTO. Можно использовать два варианта команды: короткий и длинный.
Синтаксис короткого варианта команды:
INSERT INTO название_таблицы VALUES (1, 'Milk', 9.99);
В этом случае вам нужно помнить последовательность столбцов, чтобы ввести правильное значение для каждого столбца.
Второй вариант – использовать команду с указанием столбцов:
INSERT INTO название_таблицы (product_no, name, price) VALUES (1, 'Cheese', 9.99);
INSERT INTO название_таблицы (name, price, product_no) VALUES ('Cheese', 9.99, 1);
В этом случае данные будут записаны в соответствующие указанные столбцы.
Для удаления данных используйте команду DELETE FROM. Если вы введете команду…
DELETE FROM название_таблицы WHERE название_столбца = значение;
…будут удалены все строки, в которых значение выбранного столбца равняется заданному значению.
Пример команды:
DELETE FROM products WHERE price = 10;
Тут важно помнить, что команда без указания уточняющих данных удалит все строки таблицы:
DELETE FROM products;
Доля рынка
По данным DB-Engines, в мае 2017 года наиболее популярными системами являются Oracle, MySQL (с открытым исходным кодом), Microsoft SQL Server, PostgreSQL (с открытым исходным кодом), IBM DB2, Microsoft Access и SQLite (с открытым исходным кодом).
По данным исследовательской компании Gartner, в 2011 году доходы пяти ведущих коммерческих поставщиков реляционных баз данных составили: Oracle (48,8%), IBM (20,2%), Microsoft (17,0%), SAP, включая Sybase (4,6%) и Teradata (3,7% ).
По данным Gartner, в 2008 году доля сайтов баз данных, использующих любую технологию, была:.
- База данных Oracle — 70%
- Microsoft SQL Server — 68%
- MySQL (Oracle Corporation) — 50%
- IBM DB2 — 39%
- IBM Informix — 18%
- SAP Sybase Adaptive Server Enterprise — 15%
- SAP Sybase IQ — 14%
- Teradata — 11%
Conclusion
You are now set up with PostgreSQL on your Ubuntu 14.04 server. However, there is still much more to learn with Postgres. Here are some more guides that cover how to use Postgres:
![Установка postgresql в ubuntu 20.04 [краткое руководство] | digitalocean](https://smartshop124.ru/wp-content/uploads/8/b/2/8b2141ef7192526c9a5fe528fd898db5.jpeg)
- A comparison of relational database management systems
- Learn how to create and manage tables with Postgres
- Get better at managing roles and permissions
- Craft queries with Postgres with Select
- Install phpPgAdmin to administer databases from a web interface
- Learn how to secure PostgreSQL
- Set up master-slave replication with Postgres
- Learn how to backup a Postgres database
<div class=“author”>By Justin Ellingwood</div>
Шаг 3: Создание новой роли
Для создания ролей используется команда createrole. Если использовать ключ —interactive, то у вас будет запрошено имя новой роли. Кроме того, этой роли можно выдать и права суперпользователя.
После авторизации под аккаунтом postgres создайте нового пользователя:
$ createuser --interactive
Если вам удобнее использовать вариант без переключения аккаунтов, тогда команда будет выглядеть следующим образом:
$ sudo -u postgres createuser --interactive
Затем вам нужно будет выбрать имя для роли и решить, будут ли у нее права суперпользователя.
Enter name of role to add: testuser Shall the new role be a superuser? (y/n) y
Если вам нужно еще больше настроек для создаваемой роли, посмотрите все возможные ключи при помощи команды:
$ man createuser
Итак, у вас появился новый пользователь, но пока нет ни одной добавленной базы данных. Далее рассмотрим, как добавить новую БД.
Установите PostgreSQL в Ubuntu
На момент написания этой статьи последней версией PostgreSQL, доступной в официальных репозиториях Ubuntu, была PostgreSQL версии 10.4.
Чтобы установить PostgreSQL на свой сервер Ubuntu, выполните следующие действия:
-
Установка PostgreSQL
Обновите локальный индекс пакета и установите сервер PostgreSQL вместе с пакетом Contrib PostgreSQL, который предоставляет несколько дополнительных функций для базы данных PostgreSQL:
-
Проверка установки PostgreSQL
После завершения установки служба PostgreSQL запустится автоматически.
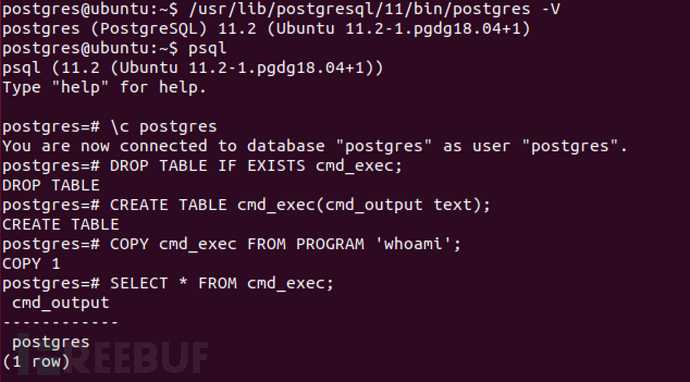
Чтобы проверить установку, мы попытаемся подключиться к серверу базы данных PostgreSQL с помощью и распечатать версию сервера :
psql — это интерактивная утилита командной строки, которая позволяет вам взаимодействовать с сервером PostgreSQL.
Основные недостатки
Помимо невысокой эффективности, о которой было сказано ранее, к недостаткам традиционных реляционных СУБД можно отнести факт того, что в качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
Реляционные СУБД все еще доминируют в системах обработки финансовых транзакций, но сегодня компании все шире применяют СУБД новой архитектуры NoSQL — горизонтально масштабируемые, распределенные и разрабатываемые в открытых кодах. Примеры таких систем — Hadoop, MapReduce и VoltDB. По оценкам аналитиков Forrester, около 75% данных на предприятиях это либо полуструктурированная информация (XML, электронная почта и EDI), либо неструктурированная (текст, изображения, аудио и видео), и лишь 5% от этих данных хранится в реляционных СУБД, а остальное — в базах других типов или в виде файлов, и неподвластно обработке реляционными системами.
По мнению Блора, реляционные СУБД «могут умереть так, что этого никто не заметит» — например, если Oracle в своей СУБД попросту заменит SQL-механизм на NoSQL. Таким механизмом, считает аналитик, могла бы стать одна из существующих сегодня столбцовых СУБД.
Add, Query, and Delete Data in a Table
Now that we have a table, we can insert some data into it.
Let’s add a slide and a swing. We do this by calling the table we’re wanting to add to, naming the columns and then providing data for each column. Our slide and swing could be added like this:
You should take care when entering the data to avoid a few common hangups. First, keep in mind that the column names should not be quoted, but the column values that you’re entering do need quotes.
Another thing to keep in mind is that we do not enter a value for the column. This is because this is auto-generated whenever a new row in the table is created.
We can then get back the information we’ve added by typing:
Here, you can see that our has been filled in successfully and that all of our other data has been organized correctly.
If the slide on the playground breaks and we have to remove it, we can also remove the row from our table by typing:
If we query our table again, we will see our slide is no longer a part of the table:
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
How To Update Data in a Table
We know how to add records to a table and how to delete them, but we haven’t covered how to modify existing entries yet.
You can update the values of an existing entry by querying for the record you want and setting the column to the value you wish to use. We can query for the “swing” record (this will match every swing in our table) and change its color to “red”. This could be useful if we gave it a paint job:
<pre>
UPDATE playground SET color = ‘red’ WHERE type = ‘swing’;
</pre>
We can verify that the operation was successful by querying our data again:
| equip_id | type | color | location | install_date |
|---|---|---|---|---|
| 2 | swing | red | northwest | 2010-08-16 |
As you can see, our slide is now registered as being red.



