
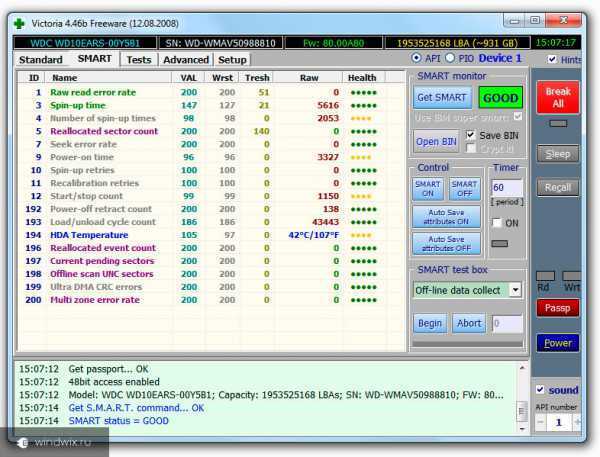
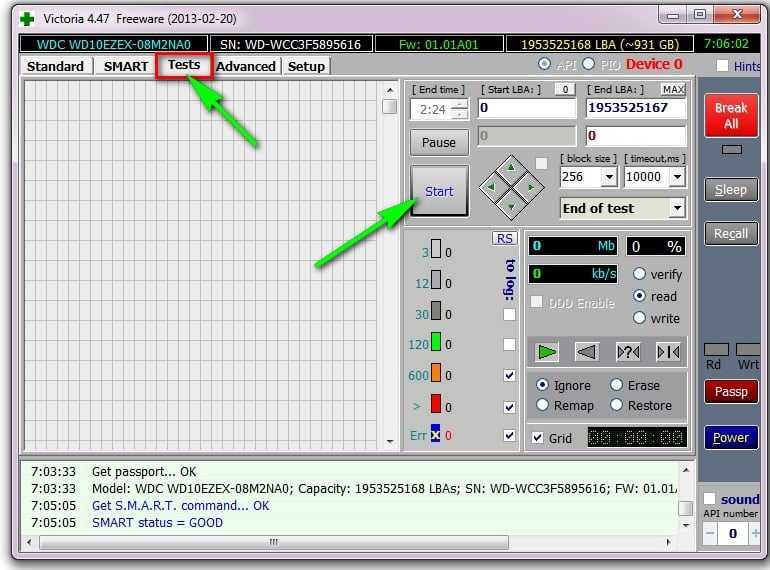
Три лучших программы для анализа занятого дискового пространства
Здесь достаточно удобный интерфейс и вся информация представлена в графической форме визуализации, что достаточно удобно воспринимается. Программа не только помогает проводить анализ дискового пространства, но и при помощи неё можно сразу удалять ненужные выявленные файлы. Установка всегда идет на английском языке но в процессе можно выбрать русский.
После запуск необходимо открыть главное окно программы. Для того чтобы проводить анализ необходимо в окне под названием «выбор дисков» выбрать нужный диск для анализа и просто кликнуть «ок». Во время сканирования окно программы всегда будет отображать информацию об идущем процессе. Есть возможность также приостанавливать при необходимости этот процесс. По окончании такой проверки все результаты будут отображаться в данном окне.
Скачать WinDirStat
— https://windirstat.net/
Эта очередная бесплатная программка, которая также входит в доверие многих пользователей. Это не случайно, поскольку она абсолютно не требует установки, плюс у неё достаточно широкие возможности по фильтрации данных, и она готова справится с альтернативными потоками данных даже файловой системы NTFS.
Пользоваться этой программой легко, достаточно просто открыть её и выбрать диск или раздел который необходимо проверить, далее просто нажать кнопку в углу с многоточием и проверка запустится. В течение работы видно и прогресс сканирования и сами файлы. Окно, где после проверки будут отображаться результаты, будет разделено на специальные блоки. Блок справа покажет результаты по файлам, там всегда показатель процента памяти и расширения в папке. Левый блок содержит уже информацию по папкам. Всё удобно для анализа и осмотра результатов.
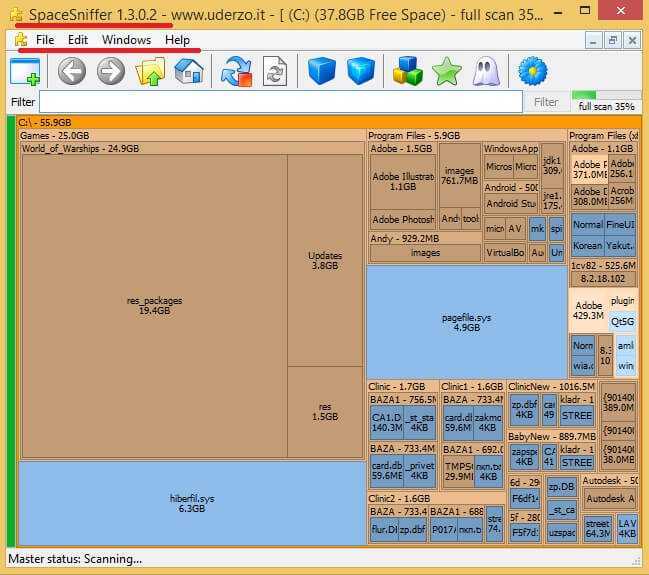
Скачать SpaceSniffer Portable
— http://www.uderzo.it/main_products/space_sniffer
Последняя из списка программа под названием TreeSize Free. Она также предоставляется в бесплатной версии. Может моментально сканировать содержимое с любого носителя. Результаты тут видны в виде раскрывающегося дерева.
Интерфейс такой программы хоть и на английском языке, но разобраться с ней можно и работать с этой программой также приятно. Кнопка под названием «Scan» отвечает в этой программе за само сканирование. Необходимо только выбрать диск для проверки и можно начать процесс сканирования. Программа может также печатать отчеты по результатам текущего сканирования.
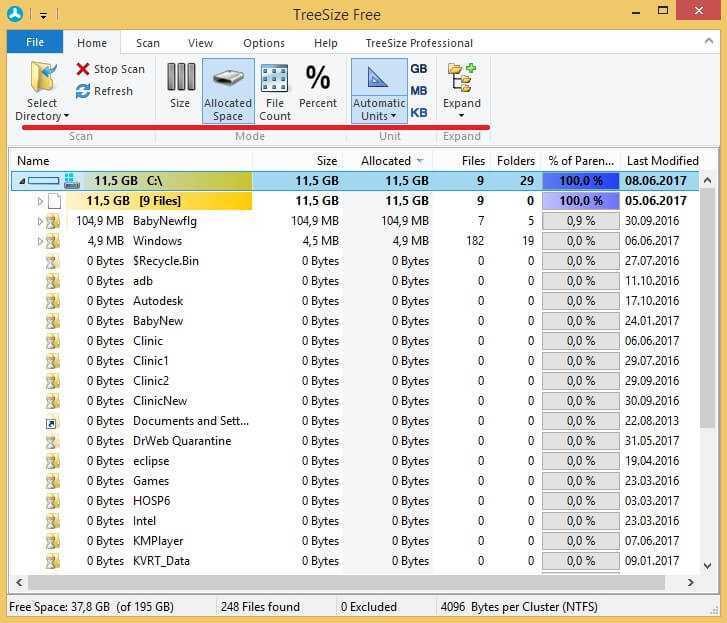
Скачать TreeSize Free
— https://www.jam-software.com/treesize_free/.
Вот такие полезные программы, которые абсолютно бесплатные помогают анализировать место на диске и также проводить чистку ненужных файлов, которые только занимают место на устройстве и делают его работу медленнее.
Вы никогда не задумывались, чем забит ваш жесткий диск? Средство анализа дискового пространства, иногда называемое анализатором хранилища — это программа, специально разработанная для того, чтобы рассказать вам об этом.
Конечно, вы можете легко проверить, сколько свободного места на диске из Windows, но понимание того, что занимает больше всего места, совершенно другое дело — то, с чем может помочь анализатор дискового пространства.
Эти программы выполняют сканирование и интерпретацию всего, что занимает место на диске, например, сохраненных файлов, видео, установочных файлов программы — всего — и затем предоставляют вам один или несколько отчетов, которые помогают четко определить, что занимает все ваше пространство хранения.
Если ваш жесткий диск (или флэш-диск, или внешний диск, и т. д.) переполнился, и вы не совсем уверены, почему, один из этих полностью бесплатных инструментов анализатора дискового пространства действительно пригодится.
Автоматическая диагностика в smartd
Автоматическая диагностика HDD в Linux настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
Здесь:
- -m <email адрес> — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
Сохраните изменения и перезапустите smartd:
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.
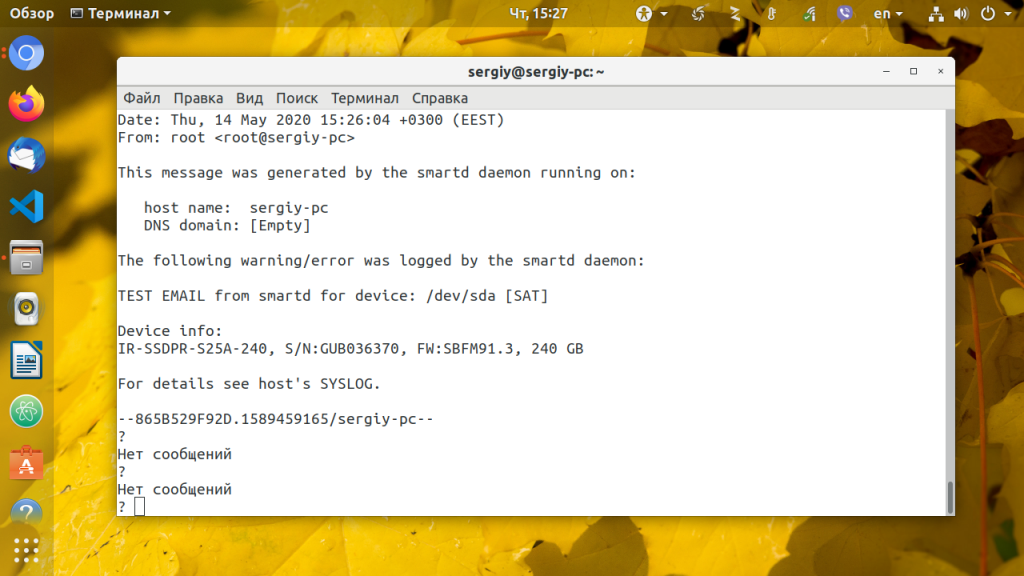
Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Здесь T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещения (ATA);
- O — оффлайн тест.
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
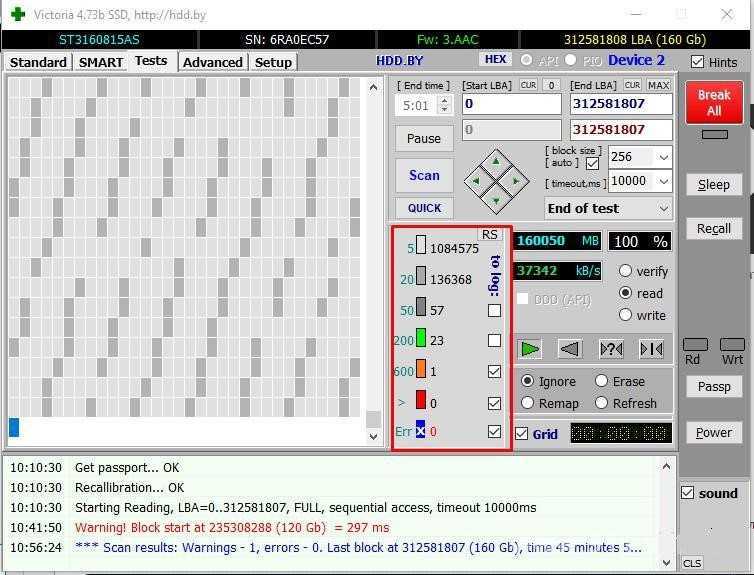
Как проверить состояние жесткого диска и избежать потери данных
Сегодня я расскажу о наиболее простом и доступном способе диагностики жесткого диска. Как проверить состояние жесткого диска и своевременно предотвратить потерю данных? В этом нам поможет программа Crystal Disk Info.
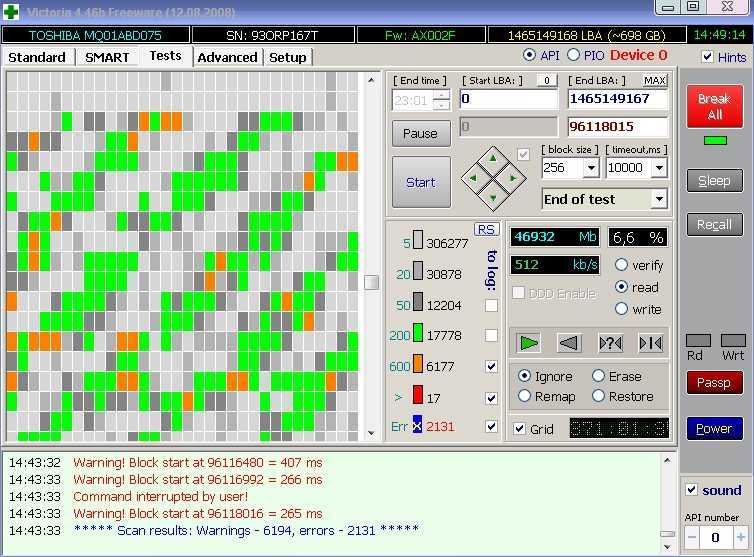
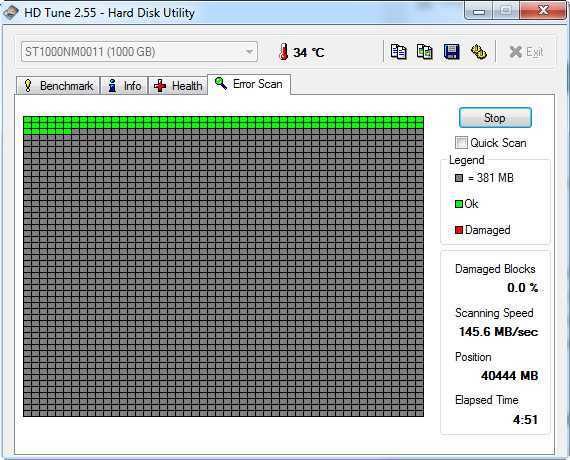
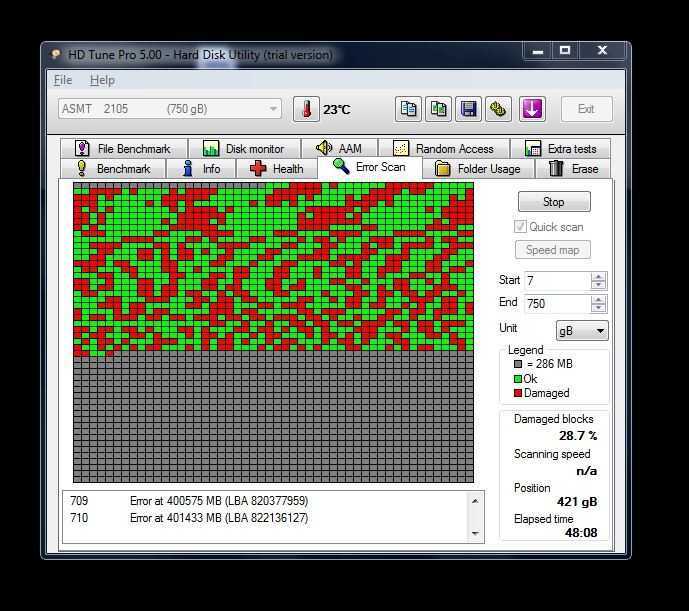
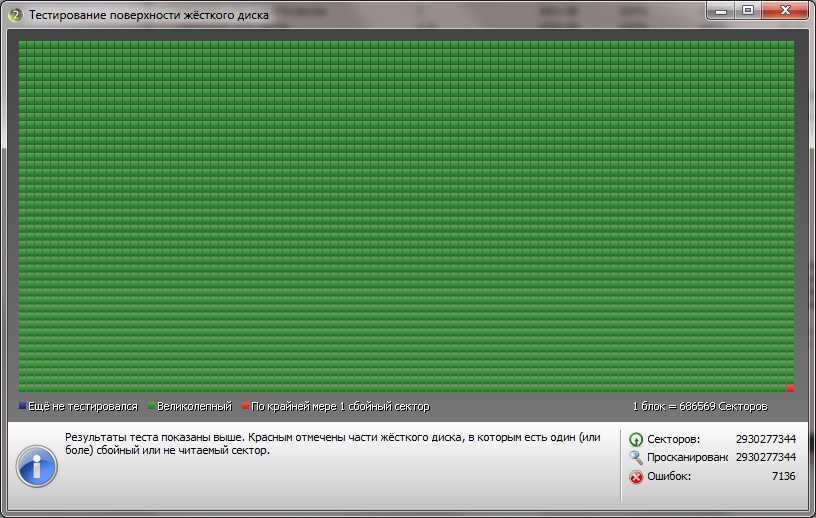
Не смотря на свое название жесткие диски не так уж практичны. К сожалению, в следствии элементарного перегрева, HDD может внезапно выйти из строя, что повлечет за собой потерю личных дынных. Знать о состоянии жесткого диска и проводить его периодический анализ нужно всем, кому не безразличны личные данные и другая важная информация, хранящаяся на компьютере.
Разберем наиболее простой и доступный способ диагностики HDD с помощью бесплатной программы Crystal Disk Info. Программа отслеживает состояние жестких дисков и дает общую оценку «здоровья» вашего диска.
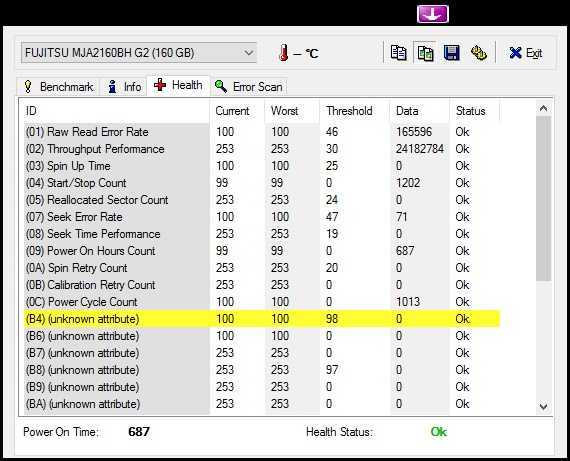
Запускаем установочный файл CrystalDiskInfo.exe и производим установку. Интерфейс программы довольно прост и понятен. В окне программы размещена только самая важная информация о состоянии жесткого диска. Благодаря технологии SMART (от англ. self-monitoring, analysis and reporting technology → технология самоконтроля, анализа и отчётности) программа получает данные о состоянии вашего HDD, считывая параметры аппаратной самодиагностики.
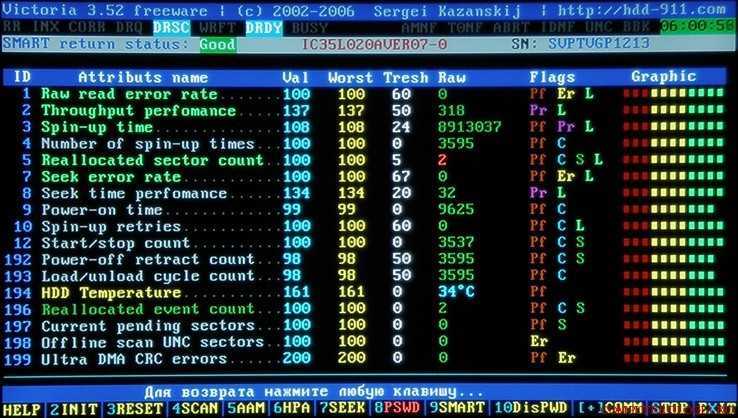
В верхней части окна размещены данные о модели (см. отметку 3), техническом состоянии и температуры (см. отметку 2), кроме этого, если в компьютере несколько жестких дисков, доступно перемещение между ними с помощью вкладки Диск (см. отметку 1). В нижней части расшифровка показателей smart (см. отметку 4). Кстати, если программа запустилась на английском, включить русский можно так, вкладка меню Language — O-Z — Русский.
Что бы сделать общие выводы о состоянии жесткого диска, достаточно посмотреть на индикатор → Техническое состояние (см. отметку 2). Синий цвет говорит, что все в порядке и беспокоится пока не о чем. Как пример, скриншот выше, это данные с моего жесткого диска. Все параметры обозначены синим цветом, температура жесткого диска в пределах нормы. Красный цвет → это предупреждение об имеющихся проблемах. Расшифровка показателей smart (см. отметку 4) показывает причину сбоев.
Повышенное внимание следует обращать на следующие параметры:
— Нестабильные сектора — Неисправимые ошибки секторов — CRC-ошибки и UltraDMA
— Ошибки записи.
Если эти параметры отмечены красным цветом, пришло время заменить винчестер, как это сделать самостоятельно я привел пример в этой статье.
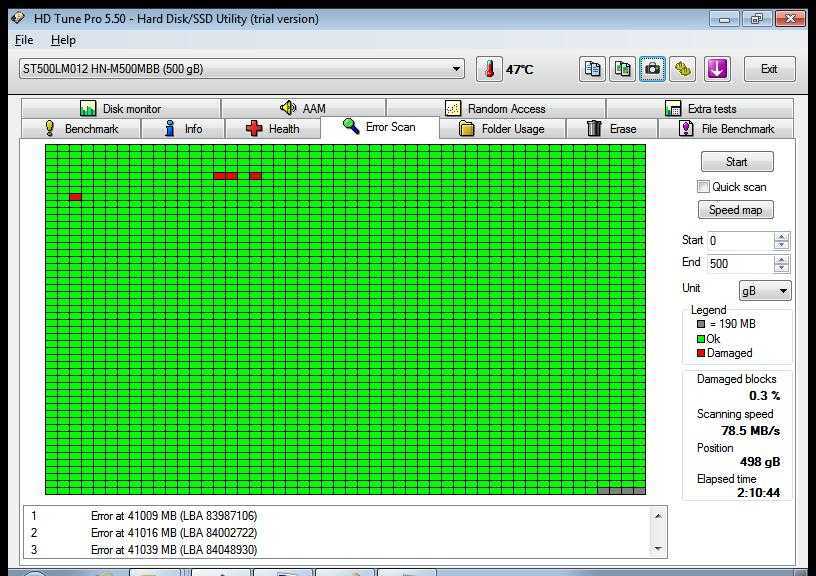
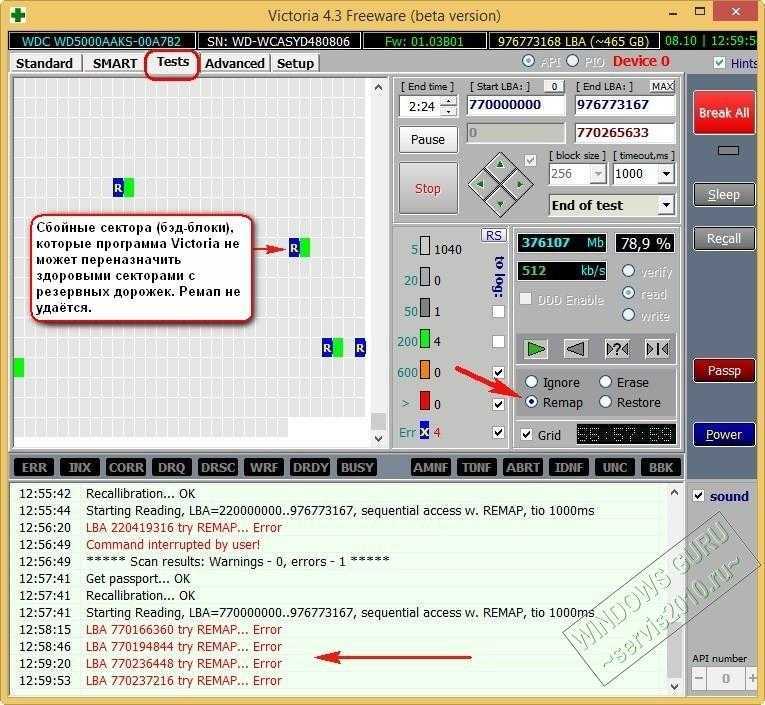
Небольшое количество поврежденных секторов (примерно до 5) отмеченных желтым цветом еще не повод паниковать и бежать за новым жестким диском. Если же количество поврежденных секторов более пяти, как на скриншоте ниже (см. значение Raw), наблюдайте за поврежденными секторами в динамике.
Если с каждым днем число таких секторов растет, то велика вероятность, что такой винчестер уже очень скоро вас подведет. В моем случае Raw-значение для переназначенного сектора равно семи и этот показатель стабилен, что дает повод пока не беспокоиться, чего не скажешь о температуре.
Не маловажным показателем состояния жесткого диска является его рабочая температура. Если жесткий диск перегревается свыше 50°С стоит обеспечить дополнительное охлаждение. Будет правильно, проверить рабочую температуру не сразу после включения системы, а спустя небольшой промежуток времени.
Как улучшить охлаждение для жесткого диска
Если речь идет о системном блоке, то, прежде всего это дополнительное охлаждение за счет установки вентиляторов напротив корзины для жестких дисков или по бокам. Для ноутбуков — это охлаждающие приставки и очистка внутренних компонентов от пыли, которая препятствует нормальному проникновению воздуха. Ноутбук старше 2 лет требует профилактической очистки компонентов не зависимо от наличия или отсутствия проблемы.
Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы, если не на порядок-другой, дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы.
Любой повод вызывающий беспокойство за целостность и сохранность важных файлов на вашем компьютере требует задуматься о необходимости своевременного домашнего бекапа, т.е создании резервных копий наиболее важных файлов. Все жесткие диски делятся на две категории — мертвые и пока еще живые. Не упускайте момент. Что такое бекап данных, способы и варианты бекапа, разберем в ближайших выпусках, не пропустите, подпишитесь на новости прямо сейчас. На этом сегодня все. До встречи в новых статьях!
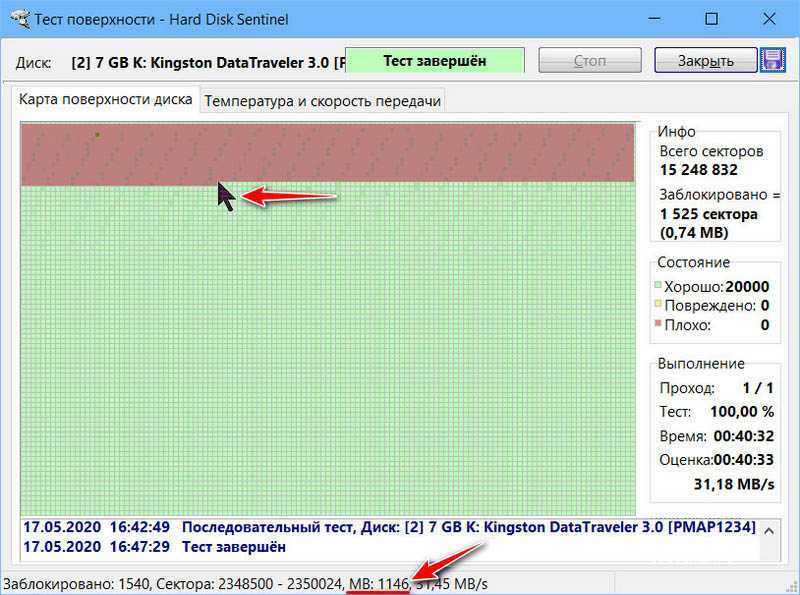
Проверка диска на битые секторы
Перед проверкой разделы необходимо отмонтировать. Как правило я загружаю операционную систему на базе Linux c Live образа или использую подготовленный PXE сервер на котором присутствуют и другие программы для проверки жестких дисков.
Можно сразу запустить проверку с исправлением, но мне кажется это неправильно. Гораздо логичней вначале проверить диск и собрать информацию обо всех битых секторах и только после этого принять решение о дальнейшей судьбе диска.
При появлении хотя бы нескольких плохих секторов я больше диск не использую. Пометку плохих секторов с попыткой забрать из них информацию использую только для того чтобы сохранить данные на другой диск.
Создадим файл указав для удобства имя проверяемого раздела.
touch "/root/bad-sda1.list"
Проверка диска утилитой badblocks
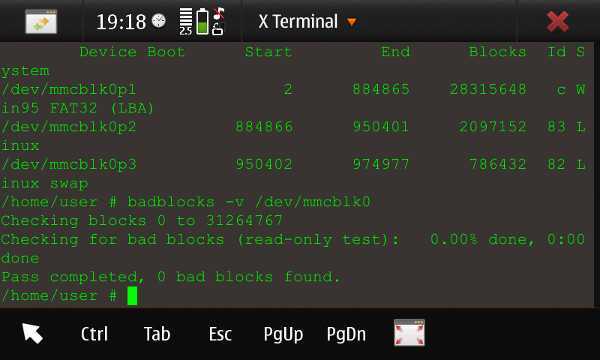
Запустим проверку с информацией о ходе процесса с подробным выводом. Чем больше диск тем дольше проверка!
badblocks -sv /dev/sda1 > /root/bad-sda1.list = Информация о ходе процесса = badblocks -sv /dev/sda1 > /root/bad-sda1.list Checking blocks 0 to 976761542 Checking for bad blocks (read-only test): 0.91% done, 1:43 elapsed. (0/0/0 errors) = Подробный вывод результата = badblocks -sv /dev/sda1 > /root/bad-sda1.list Checking blocks 0 to 156289862 Checking for bad blocks (read-only test): done Pass completed, 8 bad blocks found. (8/0/0 errors)
В нашем случае диск с 8 плохими секторами.
Пометка плохих секторов диска
Запустим утилиту e2fsck, указав ей список битых секторов. Программа пометит плохие сектора и попытается восстановить данные.
![Проверка состояния жестких дисков в linux [colobridge wiki]](https://smartshop124.ru/wp-content/uploads/4/b/4/4b4c7e27ae6cf1375bcd3f41bc9cfad9.jpeg)
Указывать формат файловой системы нет надобности. Утилита сделает всё сама.
e2fsck -l /root/bad-sda1.list /dev/sda1 = Вывод команды = e2fsck -l /root/bad-sda1.list /dev/sda1e2fsck 1.43.3 (04-Sep-2016) Bad block 44661688 out of range; ignored. Bad block 44661689 out of range; ignored. Bad block 44661690 out of range; ignored. Bad block 44911919 out of range; ignored. Bad block 44958212 out of range; ignored. Bad block 44958213 out of range; ignored. Bad block 44958214 out of range; ignored. Bad block 44958215 out of range; ignored. /dev/sda1: Updating bad block inode. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/sda1: ***** FILE SYSTEM WAS MODIFIED ***** /dev/sda1: 11/9773056 files (0.0% non-contiguous), 891013/39072465 blocks
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
В выводе будет что-то подобное:
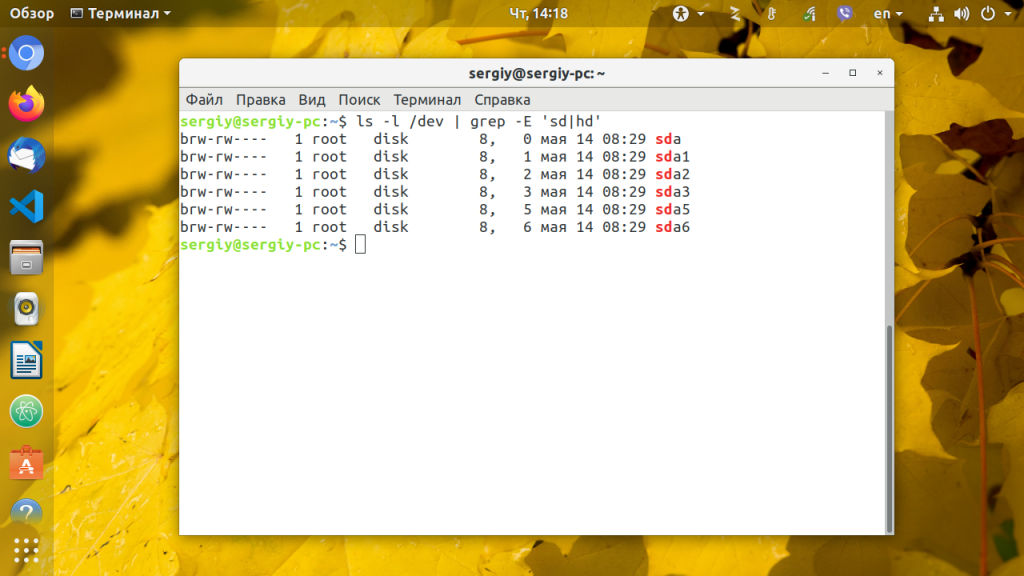
Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
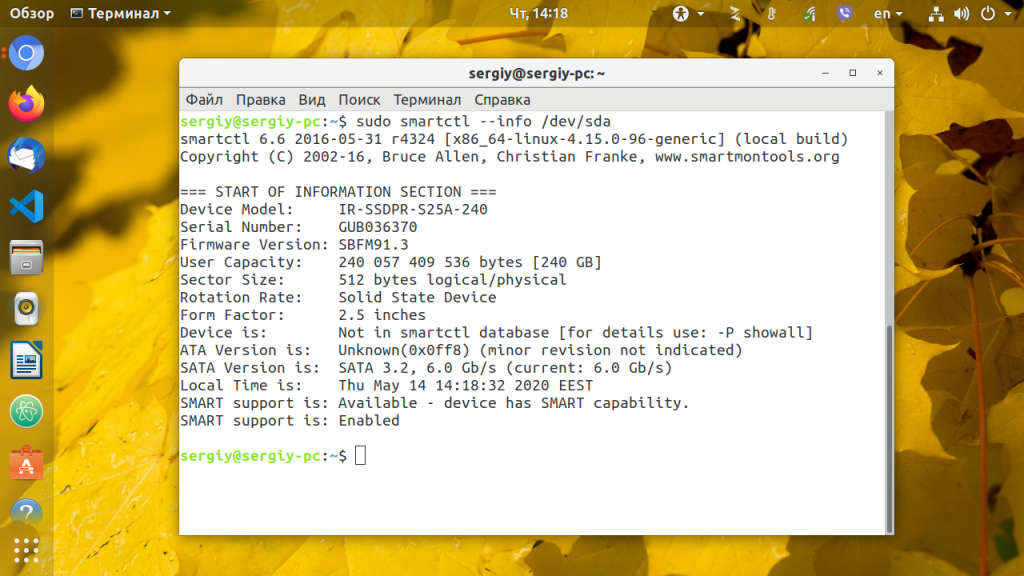
Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:
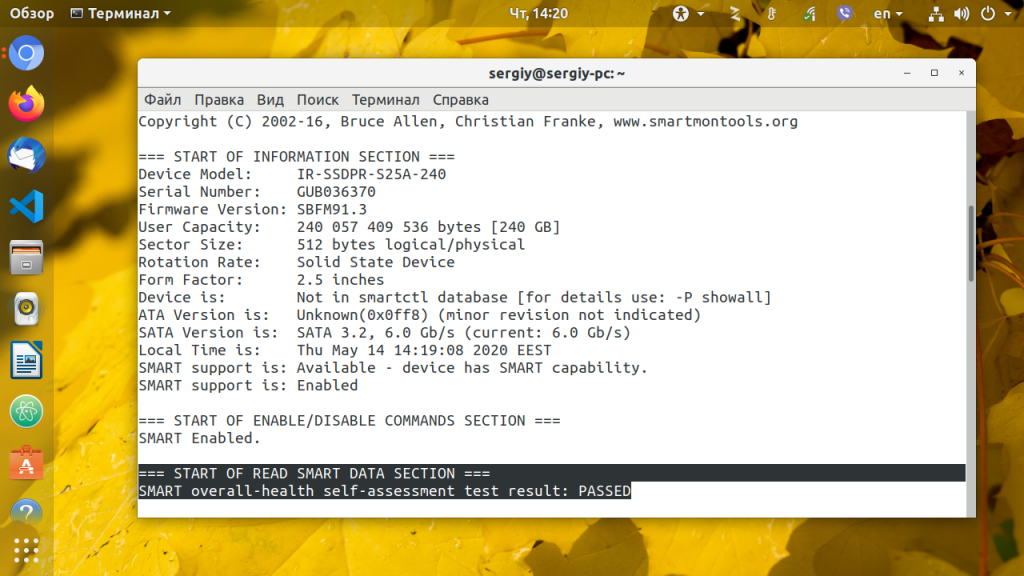
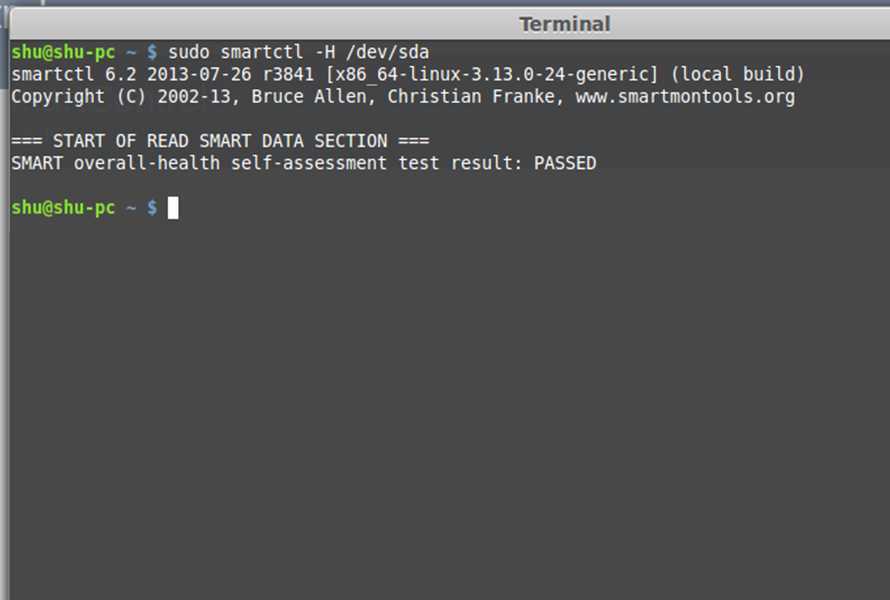
Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.
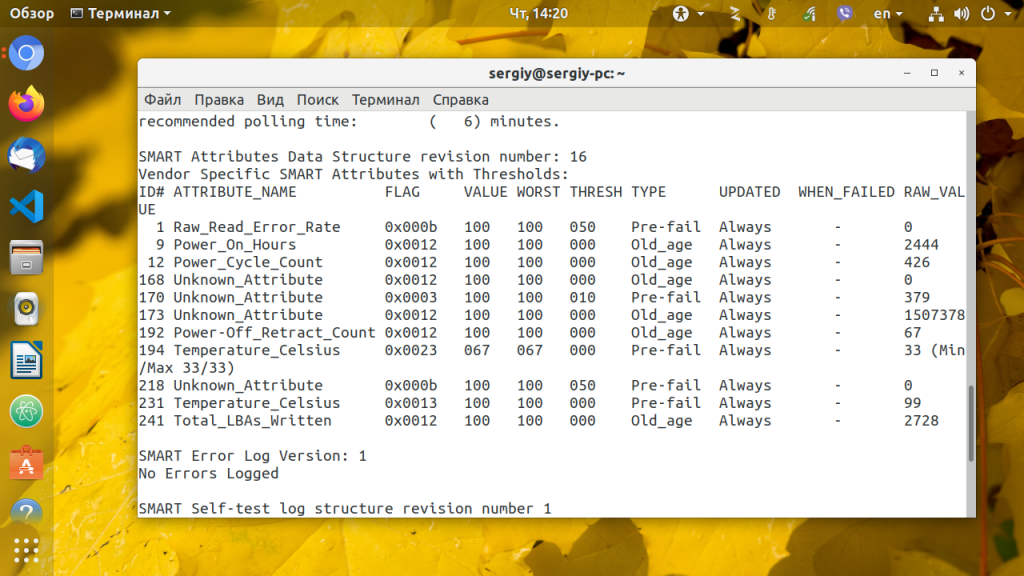
В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — идентификатор атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «-» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
top
top — утилита, с помощью которой можно вывести список работающих в системе процессов и информацию о них. Данная утилита установлена в РЕД ОС по умолчанию.
Для запуска утилиты необходимо в терминале выполнить команду:
$ top
После запуска в терминале можно увидеть вывод, примерно следующего содержания:
Где первая строка:
— текущее время (15:53:43);
— время работы системы (up 9 min);
— количество открытых пользовательских сессий (1 users);
— среднюю загрузку системы (load average: 1.39, 0.71, 0.42).
Вторая строка:
— общее количество процессов в системе (157 total);
— количество работающих в данный момент процессов (2 running);
— количество ожидающих событий процессов (115 sleeping);
— количество остановленных процессов (0 stopped);
— количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie).
Третья строка выводит информацию о работе процессора:
— использование центрального процессора (в процентах) пользовательскими процессам (1.7 us);
— использование центрального процессора (в процентах) системными процессами (0.3 sy);
— использование центрального процессора (в процентах) процессами с приоритетом, повышенным при помощи вызова nice (0.0 ni);
— время (в процентах), когда центральный процессор не используется (97,7 id);
— использование центрального процессора (в процентах) процессами, ожидающими завершения операций ввода-вывода (0.3 wa);
— использование центрального процессора (в процентах) обработчиками аппаратных прерываний (0.0 hi — Hardware IRQ (аппаратные прерывания));
— использование центрального процессора (в процентах) обработчиками программных прерываний (0.0 si — Software Interrupts (программные прерывания));
— количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины), это значение будет равно нулю на настольных компьютерах и серверах, не использующих виртуальные машины (0.0 st — Steal Time (заимствованное время)).
Четвертая и пятая строка показывает информацию об использовании физической оперативной памяти и раздела подкачки (swap):
— общее количество памяти (в килобайтах);
— количество используемой памяти (в килобайтах);
— количество свободной памяти (в килобайтах);
— количество памяти в кэше буферов (в килобайтах).
Далее идет список процессов, отсортированных по величине использования центрального процессора:PID – идентификатор процесса;USER — имя пользователя, который является владельцем процесса;PR — приоритет процесса;NI — значение «NICE», влияющие на приоритет процесса;VIRT — объем виртуальной памяти, используемый процессом;RES — объем физической памяти, используемый процессом;SHR — объем разделяемой памяти процесса;S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс);%CPU — процент использования центрального процессора данным процессом;%MEM — процент использования оперативной памяти данным процессом;TIME+ — общее время активности процесса;COMMAND — имя процесса.
Далее приведено описание наиболее часто используемых интерактивных команд, которые вы можете выполнять во время работы программы:h — вывод справки по утилите;q (Ctrl+C) — выход из top;A — выбор цветовой схемы;d или s — изменить интервал обновления информации;H — выводить потоки процессов;k — послать сигнал завершения процессу;W — записать текущие настройки программы в конфигурационный файл;Y — посмотреть дополнительные сведения о процессе, открытые файлы, порты, логи и т д;Z — изменить цветовую схему;l — скрыть или вывести информацию о средней нагрузке на систему;m — выключить или переключить режим отображения информации о памяти;x — выделять жирным колонку, по которой выполняется сортировка;y — выделять жирным процессы, которые выполняются в данный момент;z — переключение между цветным и одноцветным режимами;c — переключение режима вывода команды, доступен полный путь и только команда;F — настройка полей с информацией о процессах;o — фильтрация процессов по произвольному условию;u — фильтрация процессов по имени пользователя;V — отображение процессов в виде дерева;i — переключение режима отображения процессов, которые сейчас не используют ресурсы процессора;n — максимальное количество процессов, для отображения в программе;L — поиск по слову;<> — перемещение поля сортировки вправо и влево.
Для получения более подробной справки необходимо нажать клавишу «h» во время работы утилиты.
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
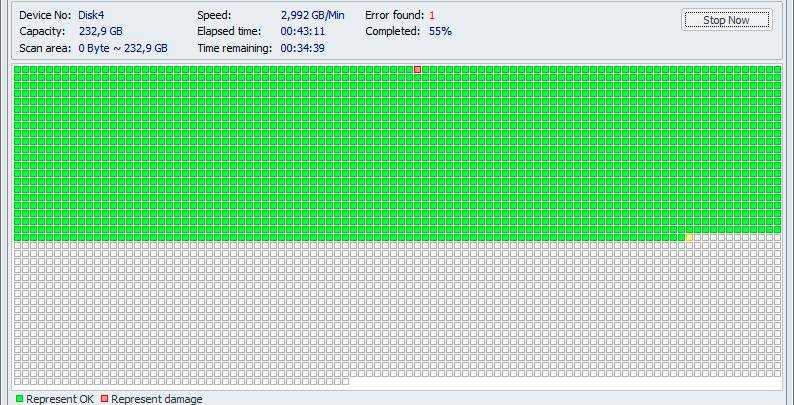
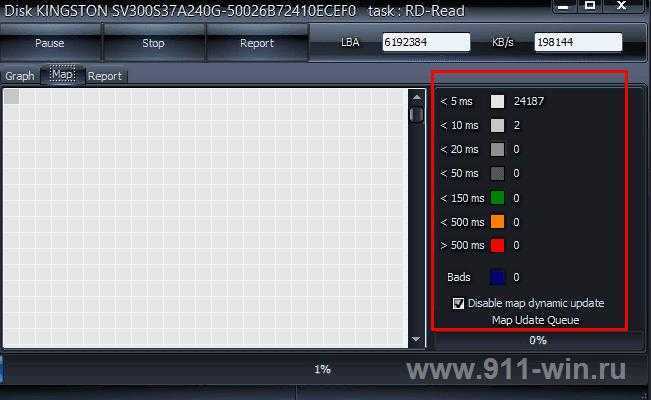
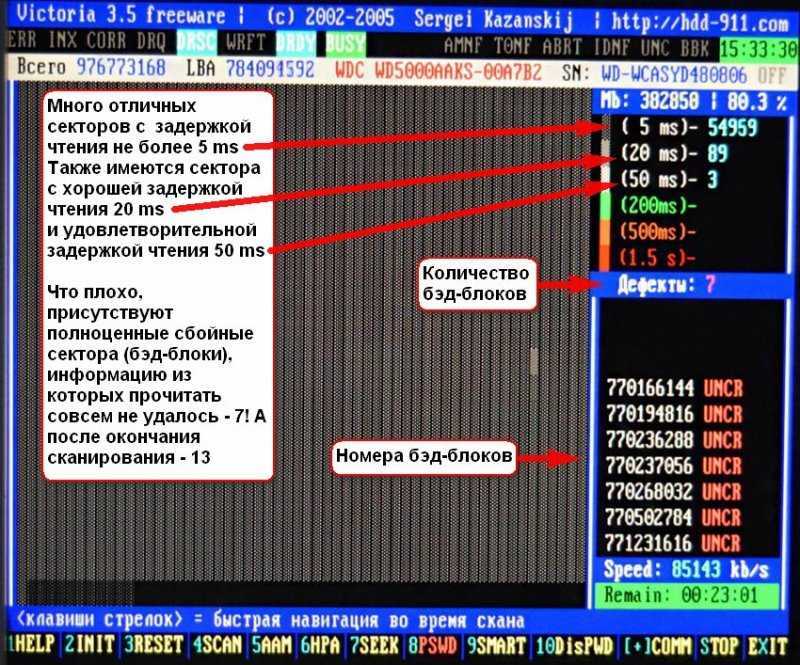
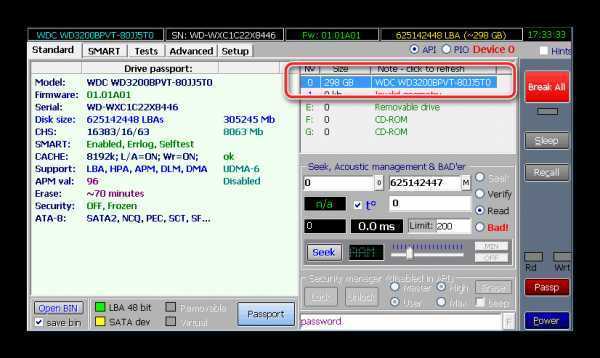
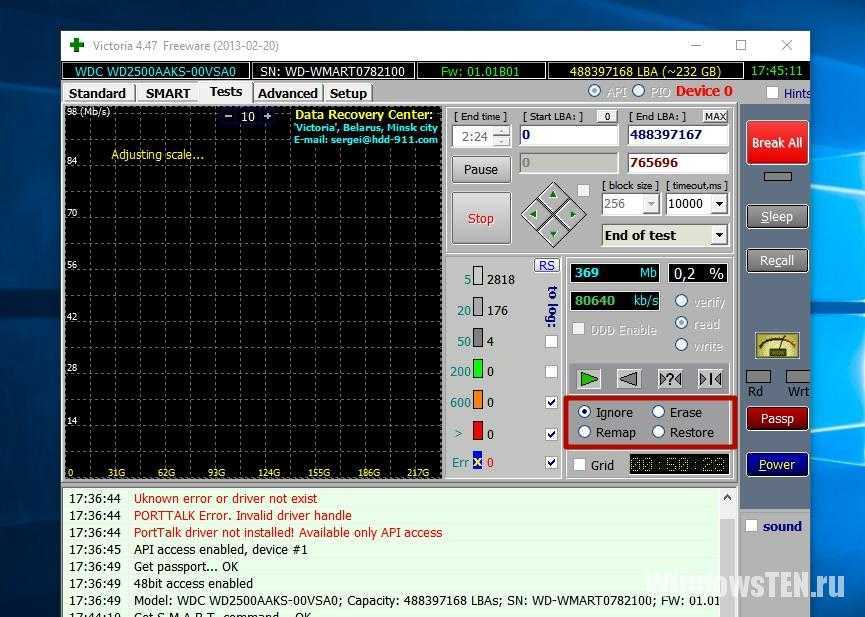
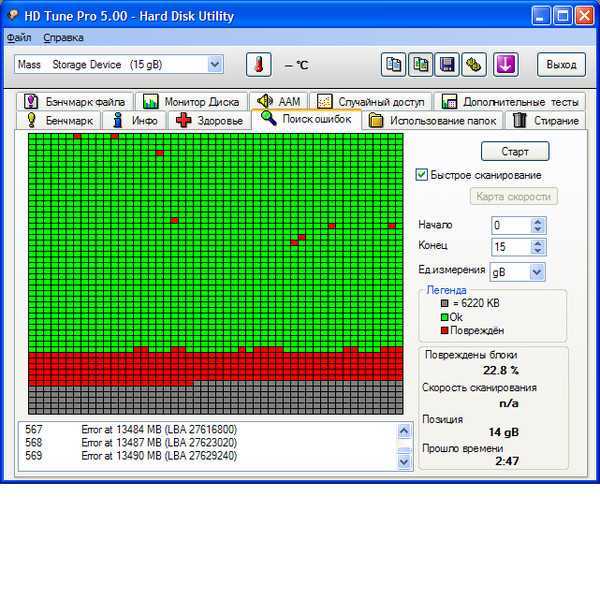
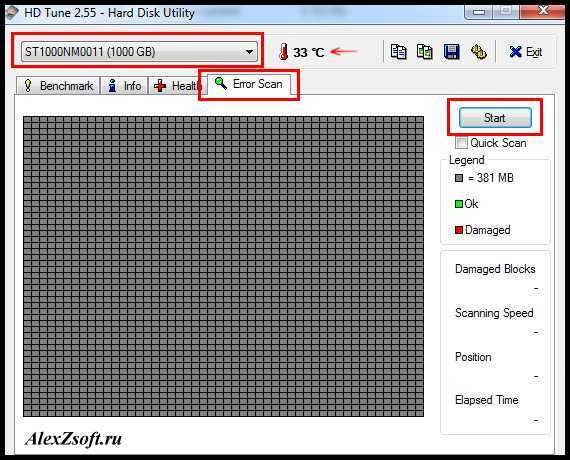
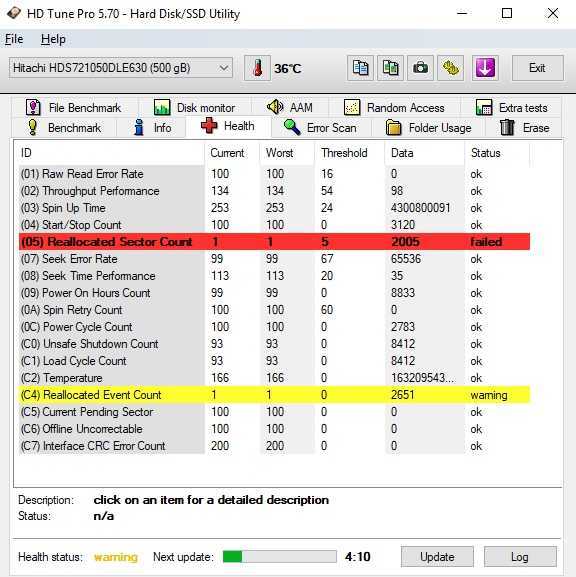
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
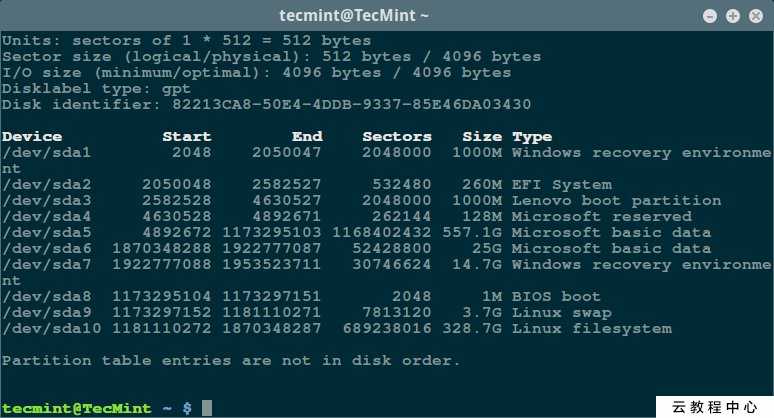
Чтобы получить список подключенных HDD в систему, выполнить:
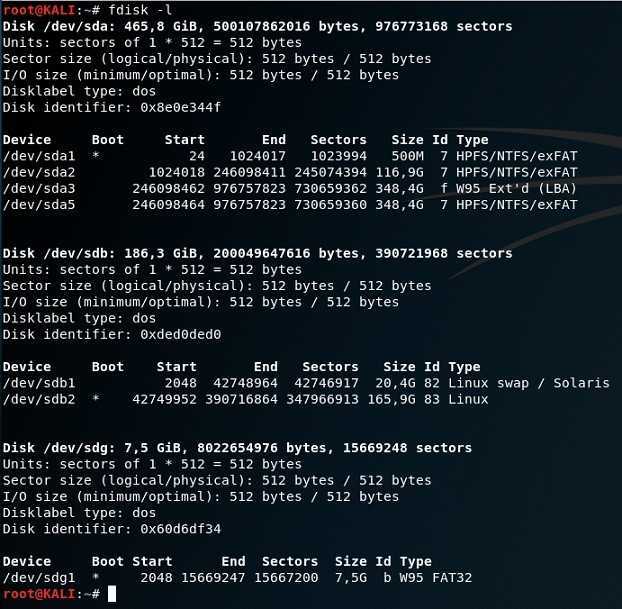
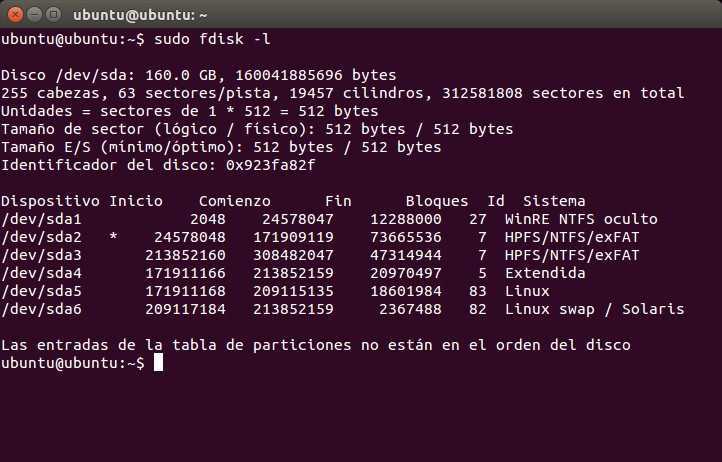
fdisk -l
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
mount
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
df -h
Если мы используем софтовый RAID, его состояние мы можем проверить следующей командой:
cat /proc/mdstat
Если всё в порядке, то мы увидим что-то подобное:
Personalities : md0 : active raid1 sdb1 sdc1 488383352 blocks super 1.2 [2/2]
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1 sdc1), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] )
Ставим hdparm
apt-get install hdparm
Смотрим скорость чтения с накопителя
hdparm -t /dev/sdX
Где /dev/sdX — имя устройства которое необходимо проверить.
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat
Ставим:
apt-get install sysstat
Теперь смотрим вывод iostat по всем дискам в системе:
iostat -x
С интервалом 10 секунд:
iostat -x 10
Или по определённому накопителю:
iostat -x /dev/sdX
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
badblocks -v /dev/sdX
Где /dev/sdX — имя устройства которое необходимо проверить. Если программа обнаружит наличие сбойных блоков, она выведет их количество на консоль. Выполнение данной операции может занять продолжительное время (до нескольких часов) и желательно её выполнение на размонтированной файловой системе, либо в режиме read-only.
Для того, чтобы записать сбойные блоки, выполняем:
badblocks /dev/sdX > /tmp/badblock
Где /tmp/badblock — файл куда программа запишет номера сбойных блоков.
Теперь при помощи программы e2fsck мы можем пометить сбойные блоки и они будут в дальнейшем игнорироваться системой
ВНИМАНИЕ! Данная операция должна проводиться на размонтированной файловой системе, либо в режиме read-only! Проверенное устройство и устройство на накотором будут помечаться сбойные блоки должно быть одно и тоже!
e2fsck -l /tmp/badblock /dev/sdX
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
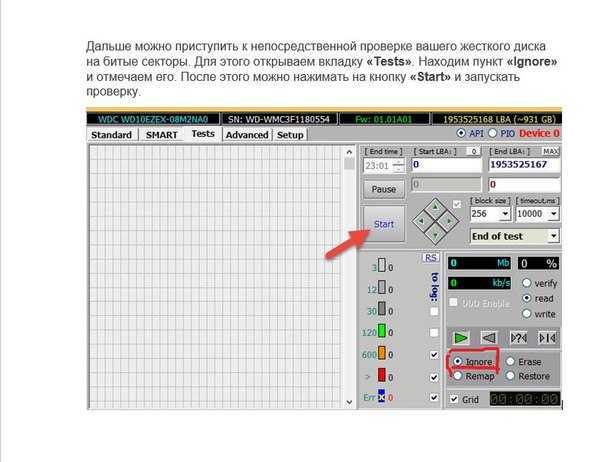
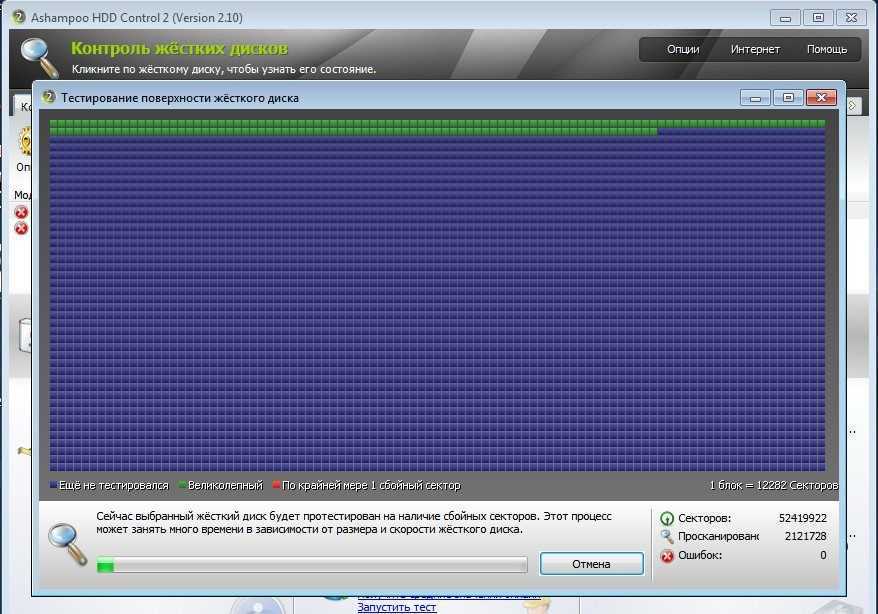
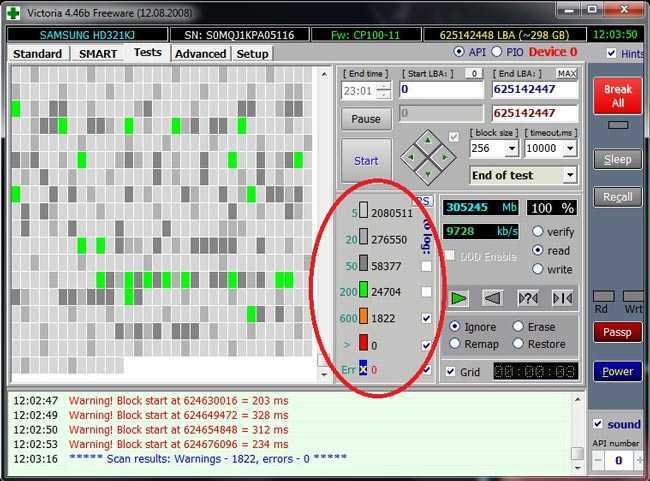
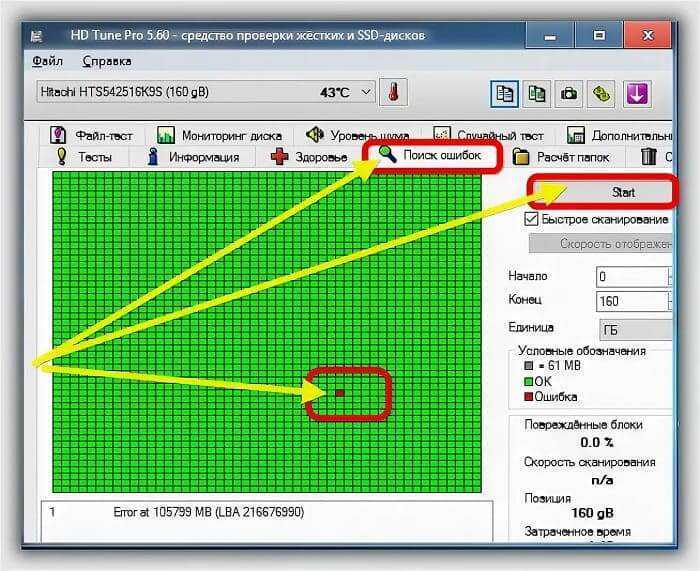
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
apt-get install smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
smartctl -a /dev/sdX
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
—-
Актуальность: 2012/02/29
Safecopy
Это уже та программа,
которую впору использовать на тонущем судне. Если мы осведомлены, что с
нашим диском что-то не так, и нацелены спасти как можно больше выживших
файлов, то Safecopy придёт на помощь. Её задача как раз заключается в
копировании данных с повреждённых носителей. Причём она извлекает файлы
даже из битых блоков.
Устанавливаем Safecopy:
Переносим
файлы из одной директории в другую. Выбрать можно любую другую. В
данном случае мы переносим данные с диска sda в папку home.
Также можете вступить в Телеграм канал, ВК или подписаться на Twitter. Ссылки в шапки страницы. Заранее всем спасибо!!!
Автоматический запуск
Задание на автоматический запуск создается по умолчанию в файле /etc/cron.daily/logrotate. Если изучить его содержимое, мы увидим, что идет запуск logrotate, который читает все файлы в директории /etc/logrotate.d/ и выполняющий для каждого из них ротацию.
Если для какого-то приложения необходимо выполнять ротацию лога по особому расписанию, узнаем полный путь до утилиты logrotate:
which logrotate
* в моем случае, это было /usr/sbin/logrotate.
Получив путь, создаем правило в cron:
crontab -e
0 0 * * * /usr/sbin/logrotate -f /etc/logrotate.d/logstash
* в данном примере в 00:00 будет запускаться logrotate и чистить логи с нашей настройкой для logstash-forwarder.
или запуск чистки всех логов:
0 0 * * * /usr/sbin/logrotate -f /etc/logrotate.conf
Проверка диска на битые секторы Linux
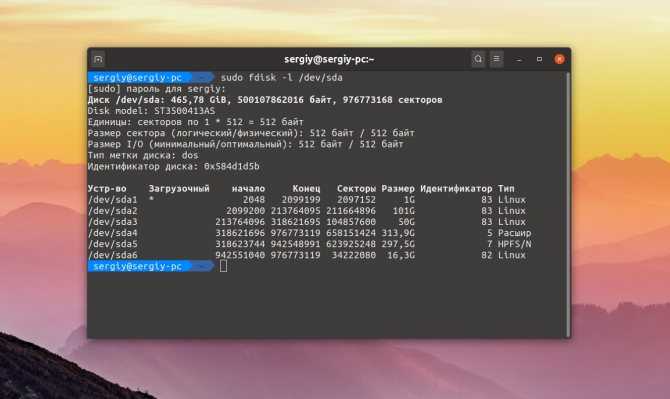
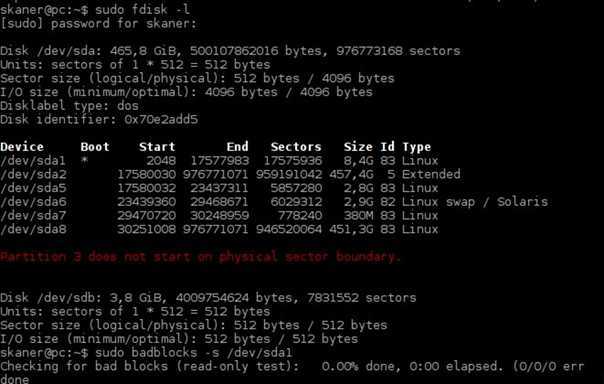
Для поиска битых секторов можно использовать утилиту badblocks. Если вам надо проверить корневой или домашний раздел диска, то лучше загрузится в LiveCD, чтобы файловая система не была смонтирована. Все остальные разделы можно сканировать в вашей установленной системе. Вам может понадобиться посмотреть какие разделы есть на диске. Для этого можно воспользоваться командой fdisk:
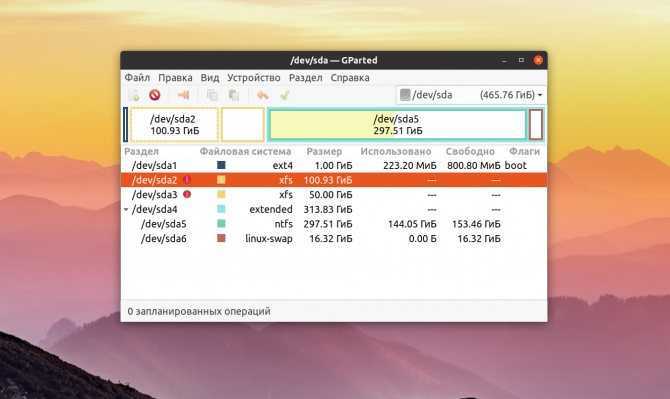
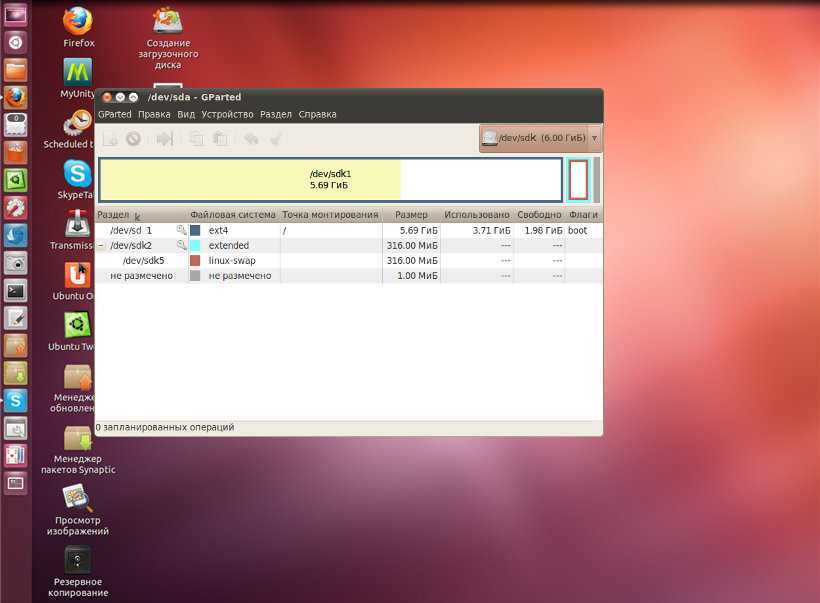
Или если вы предпочитаете использовать графический интерфейс, это можно сделать с помощью утилиты Gparted. Просто выберите нужный диск в выпадающем списке:
В этом примере я хочу проверить раздел /dev/sda2 с файловой системой XFS. Как я уже говорил, для этого используется команда badblocks. Синтаксис у неё довольно простой:
$ sudo badblocks опции /dev/имя_раздела_диска
Давайте рассмотрим опции программы, которые вам могут понадобится:
- -e — позволяет указать количество битых блоков, после достижения которого дальше продолжать тест не надо;
- -f — по умолчанию утилита пропускает тест с помощью чтения/записи если файловая система смонтирована чтобы её не повредить, эта опция позволяет всё таки выполнять эти тесты даже для смонтированных систем;
- -i — позволяет передать список ранее найденных битых секторов, чтобы не проверять их снова;
- -n — использовать безопасный тест чтения и записи, во время этого теста данные не стираются;
- -o — записать обнаруженные битые блоки в указанный файл;
- -p — количество проверок, по умолчанию только одна;
- -s — показывать прогресс сканирования раздела;
- -v — максимально подробный режим;
- -w — позволяет выполнить тест с помощью записи, на каждый блок записывается определённая последовательность байт, что стирает данные, которые хранились там раньше.
Таким образом, для обычной проверки используйте такую команду:
Это безопасно и её можно выполнять на файловой системе с данными, она ничего не повредит. В принципе, её даже можно выполнять на смонтированной файловой системе, хотя этого делать не рекомендуется. Если файловая система размонтирована, можно выполнить тест с записью с помощью опции -n:
![Проверка состояния жестких дисков в linux [colobridge wiki]](https://smartshop124.ru/wp-content/uploads/f/b/3/fb3de1136d7d7e9ce7bba9b22eca6bcf.jpeg)
После завершения проверки, если были обнаружены битые блоки, надо сообщить о них файловой системе, чтобы она не пыталась писать туда данные. Для этого используйте утилиту fsck и опцию -l:
Если на разделе используется файловая система семейства Ext, например Ext4, то для поиска битых блоков и автоматической регистрации их в файловой системе можно использовать команду e2fsck. Например:
Параметр -с позволяет искать битые блоки и добавлять их в список, -f — проверяет файловую систему, -p — восстанавливает повреждённые данные, а -v выводит всё максимально подробно.
How to repair a boot disk with disk utility
In this case all you need to do is reboot into the Recovery HD partition and run Repair Disk from there, here’s how to do that in Modern MacOS versions including macOS Sierra, High Sierra, Mac OS X El Capitan, Mavericks, Yosemite, OS X Lion, Mountain Lion, and OS X Mavericks.
Before proceeding it’s a good idea to backup your drive quickly with Time Machine.
- Reboot the Mac and hold down Command R (hold own Option key on some Macs)
- Select “Recovery HD” from the boot menu
- Choose “Disk Utility” from the Mac OS X Utilities screen
- Click the hard drive that reported the error, click the “First Aid” tab, and now click on “Repair Disk”
After Repair Disk has ran successfully, you are free to boot OS X as normal and the drives issues should be resolved.
A few final notes: relying on a hard drive being healthy is not an alternative to having backups, you need to backup your Mac with regularity using Time Machine or some other method if you choose. Hard drives fail, it’s a fact of computing life. It’s also important to note Disk Utility isn’t a 100% conclusive test suite to determine drive health, and if you hear weird sounds coming out of the hard drive it’s probably a good time to head down to Apple and prepare for a drive swap because that drive is likely going to croak soon.
Finally, if you need to perform further maintenance on the disk, then you may need to use fsck to repair the drive, which is a bit more complex and requires the usage of the command line.
SSD + HDD[править]
| Команда | Описание |
|---|---|
| systemctl status fstrim.timer | Проверить включен ли TRIM |
| lsblk | Посмотреть подключённые жёсткие диски |
| lsblk -o NAME,SIZE,UUID,TYPE,MOUNTPOINT | Посмотреть информацию о дисках |
| cat /proc/partitions | Посмотреть информацию о дисках |
| inxi -plo | Информация о разбиении диска. разделы диска |
| inxi -h | Посмотреть флаги разделов жесткого диска |
| mount | Посмотреть информацию о подключенных устройствах и параметрах подключения |
| df -H | Посмотреть список партиций, их точки монтирования, использование места, тип файловой системы |
| df -h | Узнать размер свободного пространства на разделах диска |
| du -hs * 2>/dev/null | sort -h | Отсортировать файлы по размеру |
| fdisk -l | Все партиции, названия устройств и геометрия hdd |
| hdparm -iv /dev/sda | Посмотреть идентификационную информацию, собранной во время загрузки ОС |
| hdparm -Tv /dev/sda | Измерить время чтения из кэша, для верности показателей — повторить 2-3 раза на неактивном диске |
| hdparm -Tt /dev/sda | Сравнение времени чтения устройства. Полная статистика. Для получения значимых результатов эту операцию следует повторить 2-3 раза в неактивной системе |
| hddtemp -uC /dev/sda | Отображение температуры в Цельсиях для винчестера /dev/sda (установочный пакет hddtemp) |
| hdparm -I /dev/sda | Информация о диске (модель, прошивка, атрибуты и пр) |
| smartctl -d ata -a -i /dev/sda | Информация о диске (модель, прошивка, атрибуты и пр) |
| smartctl -a /dev/sda | Вывод SMART информация для винчестера /dev/sda (необходим пакет smartmontools) |
| baobab | Графическая утилита для анализа места на жестком диске в GNOME |
| ncdu / | Консольная утилита для анализа места на жестком диске |
| ls -lh /var/log/ | Посмотреть содержимое папки с выводом в мегабайтах, килобайтах и пр. |
| parted /dev/sdX print | Информация о жестком диске — sdX, X заменить на букву диска — a,b,c |
| gdisk -l /dev/sda | Покажет раздел загрузчика с кодом раздела EF00 |
| tree -L 3 /boot | Вывод структуры ввиде дерева |
| df -h | awk ‘$NF==»/»{printf «Disk Usage: %d/%dGB (%s)\n», $3,$2,$5}’ | Расчет использования жесткого диска |
| e2fsck -cfpv /dev/sda1 | для восстановления битых секторов жесткого диска и подождать несколько часов |
| whdd | Консольная Ncurses утилита для диагностики жёстких дисков и восстановления данных с нихДиагностика жесткого диска и восстановление данных |
| find -type f -printf «%k\t%p\n» | sort -n | tail | Найти десять самых больших файлов. Размер в блоках по килобайту |
| ls -1 /dev/sd? | Получить список устройств |
| fdisk -l /dev/sda | Посмотреть какие разделы есть на диске «sda» |
| Узнать, что переполняет диск | |
| konqueror с плагинами | Свободный веб-браузер и файловый менеджер, являющийся ключевым компонентом графической среды KDE |
| du <путь> | sort -n. В альте можно отключить резервное копирование (bacula-fd) и почистить /var |
| gparted | Графическая утилита для работы с дисками и разделами |
| filelight | Графическое представление использования дисков/флешек |
| baobab | Графическое представление использования дисков/флешек в Gnome |
| ncdu | Консольный анализатор использования дисков/флешек |
Жёсткие диски имеют особенные названия. В зависимости от интерфейса, через который подключён жёсткий диск, название может начинаться на: sd — устройство, подключённое по SCSI; hd — устройство ATA; vd — виртуальное устройство; mmcblk — обозначаются флешки, подключённые через картридер; В наше время большинство блочных устройств Linux подключаются через интерфейс SCSI. Сюда входят жёсткие диски, USB-флешки, даже ATA-диски теперь тоже подключаются к SCSI через специальный переходник. Поэтому в большинстве случаев вы будете иметь дело именно с дисками sd. Третья буква в имени диска означает его порядковый номер в системе. Используется алфавитная система. Например sda — первый диск, sdb — второй диск, sdc — третий и так далее. Дальше следует цифра — это номер раздела на диске — sda1, sda2.



