
Происхождение непрерываемости
Но вдруг на сайте oldlinux.org в архивированном файле почтового ящика за 1993 я нашёл это:
Было просто невероятно прочитать о размышлениях 24-летней давности, ставших причиной этого изменения. Письмо подтвердило, что изменение в метрике должно было учитывать потребности и в других ресурсах системы, а не только процессора. Linux перешла от «средней нагрузки на процессор» к чему-то вроде «средней нагрузки на систему».
Упомянутый пример с диском с более медленной подкачкой не лишён смысла: снижая производительность системы, потребность в ресурсах (исполняемые и ждущие очереди процессы) должна расти. Однако средние значения нагрузки снижались, потому что они учитывали только состояния выполнения процессора (CPU running states), но не состояния подкачки (swapping states). Маттиас вполне справедливо считал это нелогичным, и потому исправил.
Три числа
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие скользящие суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
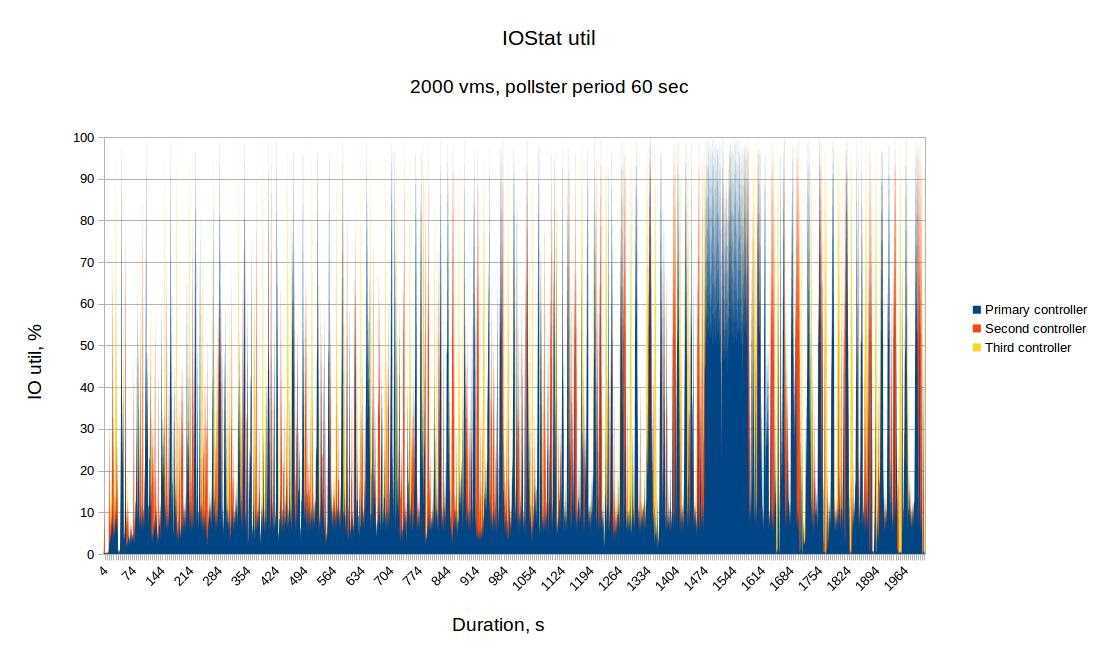
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:
Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Running iostat
The iostat tool is accessed via its command, iostat. Enter this command to see how it works:
Here is a sample output of the sort you will when you call the iostat command:
While this report may, at first glance, look complicated, understanding what the report shows is actually fairly straightforward. We will explain, section by section, what each aspect of the iostat report entails so that you can easily use the reporting for yourself:
Section 1: the CPU report
Within the first part of the report (the area with percentage values), you will find the CPU statistics that iostat has collected. Here we break down for you the statistics that you will find, and what they mean. For related statistics, we have added a helpful summary in bold so that you can see what is involves at an overview:
Concerning CPU usage at the user/application level with and without nice priority, and at the system/kernel level:
%user: This column displays the percentage of CPU utilization that has occured during execution at the user/application level.%nice: This column also displays the percentage of CPU utilization that occurs while executing at the user level, however this time with a nice priority. This means that only commands called with the Linux command nice, which lowers priority below the standard level, are shown in this statistic.%system: In this column, you can see the percentage of CPU utilization that occured while executing at the system (also known as kernel) level, as opposed to the above statistics.
Concerning CPU idle and wait times:
%iowait: This statistic is the percentage of the time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.%steal: The second to last column goes on to show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.%idle: The last column in this section shows the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O (input/output) request.
Section 2: the device utilization report
The second portion of the iostat report, which is oftentimes larger than the first section, lists all devices and displays statistics that concern their usage. This section is read horizontally, with each row displaying the statistics for its respective device:
Device: The very first column is the one that shows the device or partition name as listed in the /dev directory is shown.tps: This next column begins the statistics for the device, and displays the number of transfers per second (tps) that were issued to the device. A busier processor will have a higher number of these transfers.Blk_read/s: This statistic, blocks read per second, shows the amount of data read from the device, as expressed in a number of blocks (e.g. kilobytes, megabytes) per second.Blk_wrtn/s: Similarly, blocks written per second is shown with the amount of data written to the device also expressed in a number of blocks (e.g. kilobytes, megabytes) per second.Blk_read: The total number of blocks read for each device are displayed in the second-to-last column.Blk_wrtn: Likewise, the total number of blocks written is displayed, for each device, is in the last column.
Явное открытие файлов с помощью функции open()
Точно так же, как мы явно закрываем файл с помощью метода close(), мы можем явно открывать файл с помощью функции open(). Функция open() работает аналогично конструкторам класса файлового ввода/вывода: принимает имя файла и режим (необязательно), в котором нужно открыть файл, в качестве параметров. Например:
#include <fstream>
int main()
{
using namespace std;
ofstream outf(«SomeText.txt»);
outf << «See line #1!» << endl;
outf << «See line #2!» << endl;
outf.close(); // явно закрываем файл
// Упс, мы кое-что забыли сделать
outf.open(«SomeText.txt», ios::app);
outf << «See line #3!» << endl;
outf.close();
return 0;
// Когда outf выйдет из области видимости, то деструктор класса ofstream автоматически закроет наш файл
}
|
1 |
#include <fstream> intmain() { usingnamespacestd; ofstreamoutf(«SomeText.txt»); outf<<«See line #1!»<<endl; outf<<«See line #2!»<<endl; outf.close();// явно закрываем файл // Упс, мы кое-что забыли сделать outf.open(«SomeText.txt»,ios::app); outf<<«See line #3!»<<endl; outf.close(); return; // Когда outf выйдет из области видимости, то деструктор класса ofstream автоматически закроет наш файл } |
Результат:
На этом всё! На следующем уроке мы рассмотрим рандомный файловый ввод/вывод.
top
top — утилита, с помощью которой можно вывести список работающих в системе процессов и информацию о них. Данная утилита установлена в РЕД ОС по умолчанию.



Для запуска утилиты необходимо в терминале выполнить команду:
$ top
После запуска в терминале можно увидеть вывод, примерно следующего содержания:
Где первая строка:
— текущее время (15:53:43);
— время работы системы (up 9 min);
— количество открытых пользовательских сессий (1 users);
— среднюю загрузку системы (load average: 1.39, 0.71, 0.42).
Вторая строка:
— общее количество процессов в системе (157 total);
— количество работающих в данный момент процессов (2 running);
— количество ожидающих событий процессов (115 sleeping);
— количество остановленных процессов (0 stopped);
— количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie).
Третья строка выводит информацию о работе процессора:
— использование центрального процессора (в процентах) пользовательскими процессам (1.7 us);
— использование центрального процессора (в процентах) системными процессами (0.3 sy);
— использование центрального процессора (в процентах) процессами с приоритетом, повышенным при помощи вызова nice (0.0 ni);
— время (в процентах), когда центральный процессор не используется (97,7 id);
— использование центрального процессора (в процентах) процессами, ожидающими завершения операций ввода-вывода (0.3 wa);
— использование центрального процессора (в процентах) обработчиками аппаратных прерываний (0.0 hi — Hardware IRQ (аппаратные прерывания));
— использование центрального процессора (в процентах) обработчиками программных прерываний (0.0 si — Software Interrupts (программные прерывания));
— количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины), это значение будет равно нулю на настольных компьютерах и серверах, не использующих виртуальные машины (0.0 st — Steal Time (заимствованное время)).
Четвертая и пятая строка показывает информацию об использовании физической оперативной памяти и раздела подкачки (swap):
— общее количество памяти (в килобайтах);
— количество используемой памяти (в килобайтах);
— количество свободной памяти (в килобайтах);
— количество памяти в кэше буферов (в килобайтах).
Далее идет список процессов, отсортированных по величине использования центрального процессора:PID – идентификатор процесса;USER — имя пользователя, который является владельцем процесса;PR — приоритет процесса;NI — значение «NICE», влияющие на приоритет процесса;VIRT — объем виртуальной памяти, используемый процессом;RES — объем физической памяти, используемый процессом;SHR — объем разделяемой памяти процесса;S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс);%CPU — процент использования центрального процессора данным процессом;%MEM — процент использования оперативной памяти данным процессом;TIME+ — общее время активности процесса;COMMAND — имя процесса.
Далее приведено описание наиболее часто используемых интерактивных команд, которые вы можете выполнять во время работы программы:h — вывод справки по утилите;q (Ctrl+C) — выход из top;A — выбор цветовой схемы;d или s — изменить интервал обновления информации;H — выводить потоки процессов;k — послать сигнал завершения процессу;W — записать текущие настройки программы в конфигурационный файл;Y — посмотреть дополнительные сведения о процессе, открытые файлы, порты, логи и т д;Z — изменить цветовую схему;l — скрыть или вывести информацию о средней нагрузке на систему;m — выключить или переключить режим отображения информации о памяти;x — выделять жирным колонку, по которой выполняется сортировка;y — выделять жирным процессы, которые выполняются в данный момент;z — переключение между цветным и одноцветным режимами;c — переключение режима вывода команды, доступен полный путь и только команда;F — настройка полей с информацией о процессах;o — фильтрация процессов по произвольному условию;u — фильтрация процессов по имени пользователя;V — отображение процессов в виде дерева;i — переключение режима отображения процессов, которые сейчас не используют ресурсы процессора;n — максимальное количество процессов, для отображения в программе;L — поиск по слову;<> — перемещение поля сортировки вправо и влево.
Для получения более подробной справки необходимо нажать клавишу «h» во время работы утилиты.
Что такое «хорошие» или «плохие» средние нагрузки?
Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
FreeBSD
Во FreeBSD есть штатная утилита gstat, при запуске которой без параметров мы увидим текущую нагрузку на диски.
#gstat
dT: 1.043s w: 1.000s
L(q) ops/s r/s kBps ms/r w/s kBps ms/w %busy Name
1 248 81 5154 10.0 168 11719 7.1 93.5| ad4
0 0 0 0 0.0 0 0 0.0 0.0| md0
0 0 0 0 0.0 0 0 0.0 0.0| amrd0
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1a
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1b
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1d
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1e
0 0 0 0 0.0 0 0 0.0 0.0| amrd0s1f
Как видно из примера, очень большая нагрузка на диск ad4.
Так же можно смотреть и через iostat (пример из другой ОС):
#iostat -x 1
extended device statistics
device r/s w/s kr/s kw/s qlen svc_t %b
ada0 1.8 5.0 8.9 115.0 0 11.1 1
pass0 0.0 0.0 0.0 0.0 0 0.0 0
extended device statistics
device r/s w/s kr/s kw/s qlen svc_t %b
ada0 2.0 0.0 35.8 0.0 0 2.9 1
pass0 0.0 0.0 0.0 0.0 0 0.0 0
А ещё можно использовать команду systat -iostat:
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10
Load Average |||
/0% /10 /20 /30 /40 /50 /60 /70 /80 /90 /100
cpu user|XXXXXX
nice|
system|X
interrupt|
idle|XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
/0% /10 /20 /30 /40 /50 /60 /70 /80 /90 /100
ad8 MB/sXXXXXXXX
tps|XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX144.17
ad10 MB/s
tps|XXXXXXXXXX
А что-бы определить процесс, который нагружает диски, выполним такую команду:
Linux
Для Linux есть аналог утилиты gstat — iostat. В Debian/Ubuntu она находится в пакете sysstat.
#iostat -p 1
Linux 2.6.26-2-686 02/02/2012 _i686_
avg-cpu: %user %nice %system %iowait %steal %idle
5.55 0.10 0.28 5.09 0.00 88.98
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 21.11 169.01 847.22 581573217 2915262040
sda1 0.00 0.00 0.00 6198 5000
sda2 21.11 169.01 847.22 581566715 2915257040
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 0.00 8.90 0.00 91.10
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 0.00 0.00 0.00 0 0
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
Здесь мы поставили автообновление каждую секунду
Хочу обратить внимание на то, что первые пару выводов во внимание не брать, так как в первом выводе отображается информация из кеша, а не реальные показатели. Как видим, диски здесь не нагружены
Для определения процесса, который нагружает диски, есть утилита iotop, правда её нужно ставить отдельно.
Dstat инструмент для мониторинга в Linux
Dstat является универсальной заменой для Vmstat, IOSTAT, NetStat и ifstat. Dstat преодолевает некоторые из их ограничений и добавляет некоторые дополнительные возможности, больше счетчиков и гибкости. Dstat удобный для систем мониторинга во время настройки тестов и производительности или устранения неполадок.Dstat позволяет просматривать все ресурсы системы в режиме реального времени , вы можете , например, . сравнить использование дискового пространства в сочетании с прерываний от контроллера IDE или сравнить числа пропускной способности сети непосредственно с диска пропускной способности ( в том же интервале ) .Dstat дает вам подробную выборочную информацию в колонках. Меньше путаницы и меньше ошибок . И самое главное это то что очень легко писать плагины для сбора собственные счетчиков.


![Проверка состояния жестких дисков в linux [colobridge wiki]](https://smartshop124.ru/wp-content/uploads/4/c/c/4ccf7f7f7810a0073f783a238543353e.jpeg)
Особенности
- Объединяет вместе: Vmstat, IOSTAT, ifstat, NETSTAT;
- Показывает статистику в точно таком же сроки;
- Включает счетчики для устранения неисправностей
- Модульная конструкция;
- Написанная на питоне так легко расширяется для выполнения этой задачи;
- Легко расширяется, добавить свои собственные счетчики;
- Включает в себя множество внешних плагинов, чтобы показать, как легко можно добавить счетчики;
- Может подвести итог групповых блоков / сетевых устройств и дать общую численность;
- Может показывать прерываний в устройстве;
- Очень точные сроки, нет timeshifts когда система неустойчива;
- Показывает точные единицы и ограничивает ошибки преобразования;
- Можно указывать различные единицы с различными цветами;
- Может показывать промежуточные результаты, когда промедление> 1;
- Позволяет экспортировать выход CSV, который может быть импортирован в Gnumeric и Excel, чтобы сделать графики.
Мониторинг состояния системы с разбиением по процессам
Поиск проблемных мест стоит начать с использования команды top.
Данная утилита широко используется для анализа программ в режиме реального времени. Набрав в командной строке top, мы сразу же видим динамическую выдачу процессов, которые в данный момент выполняются, спят или ожидают своей очереди. Однако сейчас нас в большей степени интересует самый верх — шапка — вывода команды. Выглядит это следующим образом:
top - 19:18:29 up 12 days, 16:55, 8 users, load average: 1,80, 1,77, 1,98 Tasks: 289 total, 4 running, 284 sleeping, 0 stopped, 1 zombie %Cpu(s): 33,6 us, 2,7 sy, 0,0 ni, 63,7 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st KiB Mem: 12211328 total, 11368356 used, 842972 free, 172500 buffers KiB Swap: 6105648 total, 1405972 used, 4699676 free. 3704548 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28124 admin7 20 0 3065672 1,508g 242044 R 132,6 12,9 3084:46 mysqld 21572 admin7 20 0 3294116 1,518g 221012 S 8,0 13,0 1718:40 nginx
Показатели, на которые стоит обратить внимание, помечены красным цветом, их показатели — зелёным. В данном случае значения были выделены вручную для наглядности
Более яркий вывод может обеспечить использование htop — это аналог рассматриваемой нами системной утилиты top, но для начала разберёмся с тем, на что стоит обращать внимание в обоих случаях. Состоит из трёх чисел и демонстрирует усреднённую загрузку сервера за 1, 5 и 15 минут
Чем ниже значения, тем лучше
Состоит из трёх чисел и демонстрирует усреднённую загрузку сервера за 1, 5 и 15 минут. Чем ниже значения, тем лучше.
Простое правило: значения не должны быть больше количества процессоров.
2. %CPU
Какие процессы сколько процессорных ресурсов потребляют:
us
Загрузка пользовательскими процессами. Если ваш сервер постоянно не загружен ресурсоёмкими операциями типа конвертации видео, то этот показатель не должен превышать 10-20%.
id
Процент времени бездействия процессора должен быть высоким, в норме — от 80.
wa
Ожидание операций ввода/вывода, чем ниже, тем лучше (иначе процессор слишком долго ждёт ответы от диска или сети).
Существует целый набор консольных утилит для измерения и анализа производительности системы — sysstat:
- iostat — показывает статистику использования процессора и потоков ввода/вывода для дисков;
- mpstat — выводит информацию об отдельных параметрах и общей статистике по процессору;
- isag — построение графика активности системы в интерактивном режиме;
- pidstat — мониторинг отдельных задач, управление которыми осуществляется ядром Linux.
Последнюю утилиту стоит рассмотреть подробнее. Для её использования мы сможем применить информацию, полученную с помощью предыдущей программы — top.
Pidstat — это утилита, которая предназначена для сбора и вывода статистики использования ресурсов процессами.
Команда сообщает об использовании процессорного времени. Мы используем её с флагом -р (что означает, сейчас мы будет указывать PID):
pidstat -p 611,1102 10 1
PID необходимого процесса вы можете посмотреть в результатах вывода той же команды top: первый столбец сообщается process id (мы указали PID 611 и 1102).
Таким образом мы узнаём количество выделяемых ресурсов процессам с определённым идентификационным номером в системе.
После необходимо указать время в секундах, в течение которого будет осуществляться проверка (в данном случае это 10 секунд). Вы можете задавать время на своё усмотрение в зависимости от задач, которые предстоит решить.





В завершение указываем число отчётов, которые желаем видеть по итогу.
При помощи флага -d можно получить статистику ввода/ вывода (остальные показатели остались неизменными):
pidstat -p 1102 -d 10 1
При помощи флага -r можно получить статистику использования оперативной памяти:
pidstat -p 1102 -r 10 1
Using iostat command to generate report and statistics
To generate report and statistics with the iostat command use :
iostat
Output :
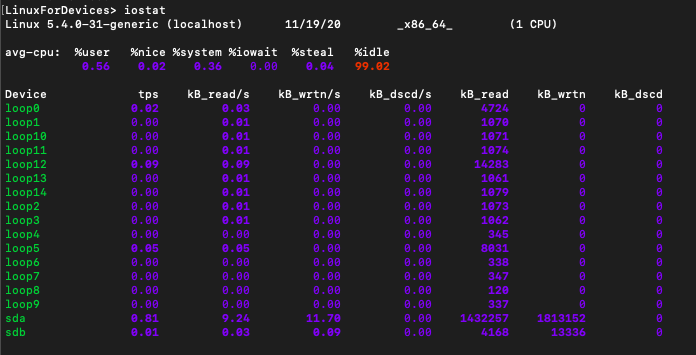 Iostat Output
Iostat Output
In the output there are two types of reports. The first one is the CPU utilization report. The second one is the Device utilization report.
Let’s try and understand the different fields in the output.
1. CPU Utilization Report
The CPU Utilization report has the following fields :
- %user : Displays the percentage of CPU utilization that occurred while executing at the user level.
- %nice : Displays the percentage of CPU utilization that occurred while executing at the user level with a nice priority.
- %system : Displays the percentage of CPU utilization that occurred while executing at the system (kernel) level.
- %iowait : Displays the percentage of the time that the CPU(s) was(were) idle during which the system had an outstanding disk I/O request.
- %steal : Displays the percentage of time being spent in involuntary wait by the virtual CPU(s) while the hypervisor was servicing another virtual processor.
- %idle : Displays the percentage of time that the CPU(s) were idle and the system did not have an outstanding disk I/O request.
2. Device Utilization Report
The Device Utilization report has the following fields :
- Device : Displays the device/partition name as listed in /dev directory.
- tps : Displays the number of transfers per second that were issued to the device. A transfer is an I/O request to the device.
- Blk_read/s : Displays the amount of data read from the device expressed in a number of blocks (kilobytes, megabytes) per second. This is the rate at which data is being read.
- Blk_wrtn/s : Amount of data written to the device expressed in a number of blocks (kilobytes, megabytes) per second. This is the rate at which data is being written.
- Blk_dscd/s : Data discarded for the device expressed in a number of blocks (kilobytes, megabytes) per second. This is the rate at which data is being discarded.
- Blk_read : Total number of blocks read.
- Blk_wrtn : Total number of blocks written.
- Blk_dscd : Displays the total number of blocks discarded.
You can also generate the two reports individually. Let’s learn how to do that.
Параметры
|
-c |
Отобразите отчет об использовании ЦП. |
|
-d |
Отобразите отчет об использовании устройства. |
|
-гимя группы ВСЕ |
Отображение статистики для группы устройств. В iostat команда сообщает статистику для каждого устройства в списке, затем строка глобальной статистики для группы отображается как имя группы состоит из всех устройств в списке. В ВСЕ ключевое слово означает, что все блочные устройства, определенные системой, должны быть включены в группу. |
|
-час |
Сделайте отчет об использовании устройства более удобным для чтения человеком. (Это ты!) |
|
-k |
Отображать статистику в килобайтах в секунду. |
|
-м |
Отображать статистику в мегабайтах в секунду. |
|
-N |
Отображение зарегистрированных имен сопоставителей устройств для любых устройств сопоставления устройств. Полезно для просмотра статистики LVM2. |
|
-п [ устройство ] |
В -п опция отображает статистику по блочным устройствам и всем их разделам, которые используются системой. Если имя устройства введено в командной строке, то отображается статистика для него и всех его разделов. В ВСЕ ключевое слово указывает, что статистика должна отображаться для всех блочных устройств и разделов, определенных системой, включая те, которые никогда не использовались. |
|
-T |
Эта опция должна использоваться с опцией -г и указывает, что должна отображаться только глобальная статистика для группы, а не статистика для отдельных устройств в группе. |
|
-t |
Распечатайте время для каждого отображаемого отчета. Формат метки времени может зависеть от значения параметра S_TIME_FORMAT переменная окружения (см. ниже). |
|
-V |
Распечатать номер версии и выйти. |
|
-Икс |
Показать расширенную статистику. |
|
-z |
Расскажи iostat исключить вывод для любых устройств, для которых не было активности в течение периода выборки. |








![Проверка состояния жестких дисков в linux [colobridge wiki]](https://smartshop124.ru/wp-content/uploads/2/7/5/2753f60d0691b5d303a718c57aa02e52.jpeg)
Iotop и iostat для проверки статистики ввода-вывода
Чтобы подробно проверить статистику ввода-вывода, пользователи могут использовать команды iotop и iostat. Эти команды используются для выявления проблем с производительностью запоминающих устройств.включая локальные диски или сетевую файловую систему.
Что такое iotop?
Эта утилита Она похожа на команду top, но показывает активность диска в реальном времени.. Эта утилита просматривает информацию об использовании ввода-вывода ядра и отображает таблицу текущего использования ввода-вывода процессами или потоками в системе. Он также показывает полосу пропускания и время чтения и записи ввода-вывода каждого процесса или потока.
Установить Iotop
Эту утилиту мы можем легко установить с помощью менеджера пакетов apt. Для систем Debian / Ubuntu нам нужно будет только открыть терминал (Ctrl + Alt + T) и выполнить команду:
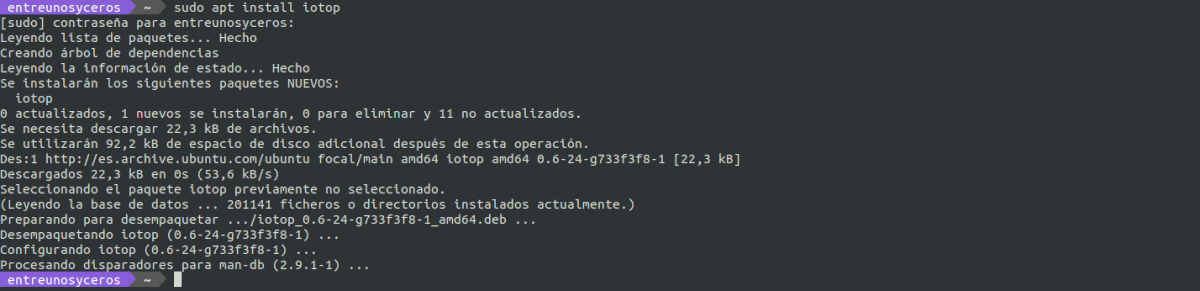
sudo apt install iotop
Отслеживайте активность дискового ввода-вывода с помощью iotop
В команде iotop доступно множество параметров для проверки различной статистики дискового ввода-вывода. Нам нужно будет только выполнить команду iotop без аргументов, даже если нам нужно будет запустить его с привилегиями суперпользователя, чтобы увидеть каждый процесс или поток о текущем использовании ввода-вывода:

sudo iotop
к проверить, какие процессы фактически используют дисковый ввод-вывод, нам нужно будет добавить к команде iotop -oo –only option:
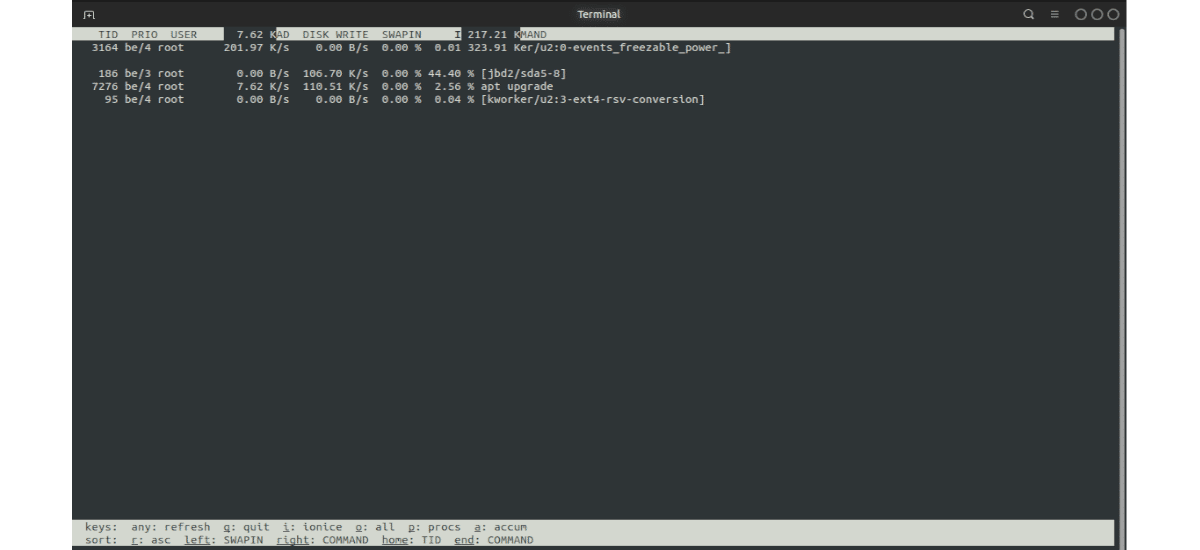
sudo iotop --only
к увидеть больше параметров, применимых к iotop, в терминале мы можем проконсультироваться с вашей помощью с помощью команды:
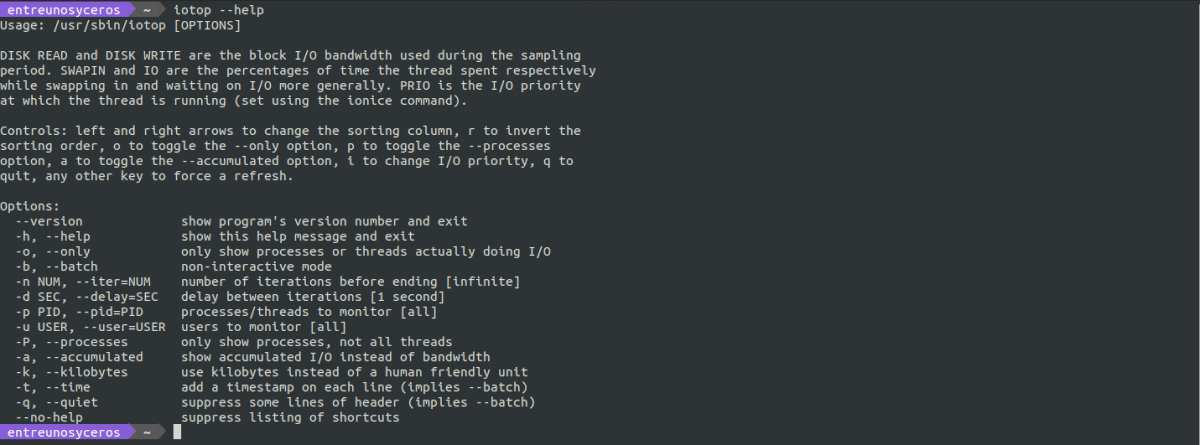
iotop --help
деинсталляция
к удалите iotop из нашей команды, в терминале (Ctrl + Alt + T) нам нужно будет только выполнить:

sudo apt remove iotop
Что такое iostat?
Команда iostat используется для контроля загрузки системного устройства ввода / вывода., глядя на то, как долго устройства активны по отношению к их средней скорости передачи данных. Его также можно использовать для сравнения активности между дисками.
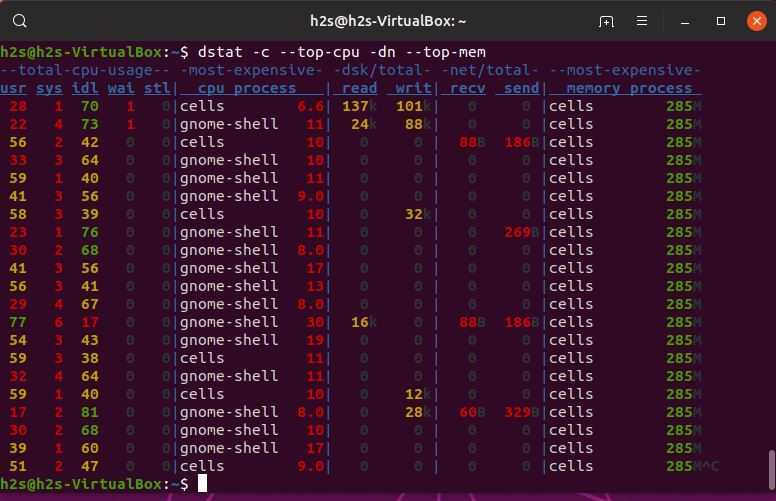




Эта команда генерирует отчеты, которые можно использовать для изменения конфигурации системы, чтобы лучше сбалансировать нагрузку ввода / вывода между физическими дисками. Команда iostat формирует два типа отчетов; Загрузка ЦП y использование устройства.
В многопроцессорных системах статистика ЦП рассчитывается по системе как среднее значение по всем процессорам.
Установить iostat
Инструмент iostat является частью пакета sysstat, который можно установить из официального репозитория. Нам нужно будет только открыть терминал (Ctrl + Alt + T) и выполнить в нем команду:

sudo apt install sysstat
Измерение производительности дискового ввода-вывода с помощью команды iostat
В команде iostat доступно множество опций для проверки различной статистики ввода-вывода процессора и диска. Если мы выполним команду iostat без аргументов, мы сможем просмотреть полную системную статистику:
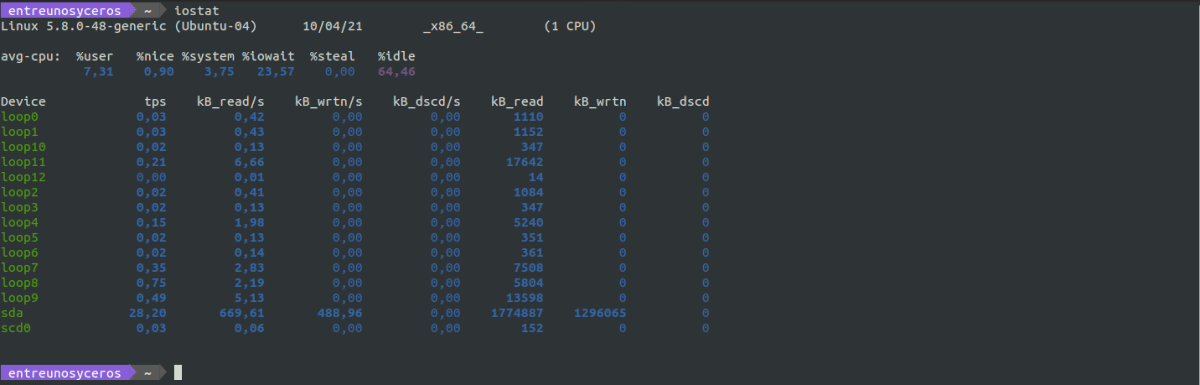
iostat
Если мы добавим -d опция команде iostat, мы можем просматривать статистику ввода / вывода для всех устройств:
iostat -d
С другой стороны, если мы добавим -p опция команде iostat, мы будем показать статистику ввода-вывода всех устройств и их разделов.
iostat -p
Если нас интересует просматривать подробную статистику ввода / вывода для всех устройств, нам нужно будет только добавить -x опция команде iostat:
iostat -x
Если нам интересно знать статистику ввода-вывода блочных устройств и всех их разделов, используемых системой, нам просто нужно добавить параметр -p, за которым следует имя устройства:

iostat -p sda
деинсталляция
к удалить iostat из нашей команды, нам просто нужно открыть терминал (Ctrl + Alt + T) и выполнить в нем:

sudo apt remove sysstat
Мы только что познакомились с еще двумя инструментами, которые могут помочь системному администратору обнаруживать проблемы с производительностью диска с помощью команд iotop e IOSTAT. Для получения дополнительной информации желающий пользователь может обратиться к источник этой статьи.



