Разработка
PostgreSQL развивается силами международной группы разработчиков (PGDG), в которую входят как непосредственно программисты, так и те, кто отвечают за продвижение PostgreSQL (Public Relation), за поддержание серверов и сервисов, написание и перевод документации, всего на 2005 год насчитывается около 200 человек. Другими словами, PGDG — это сложившийся коллектив, который полностью самодостаточен и устойчив. Проект развивается по общепринятой среди открытых проектов схеме, когда приоритеты определяются реальными нуждами и возможностями. При этом, практикуется публичное обсуждение всех вопросов в списке рассылке, что практически исключает возможность неправильных и несогласованных решений.
Это относится и к тем предложениям, которые уже имеют или рассчитывают на финансовую поддержку коммерческих компаний.
Цикл работой над новой версией обычно длится 10-12 месяцев (сейчас ведется дискуссия о более коротком цикле 2-3 месяца) и состоит из нескольких этапов.
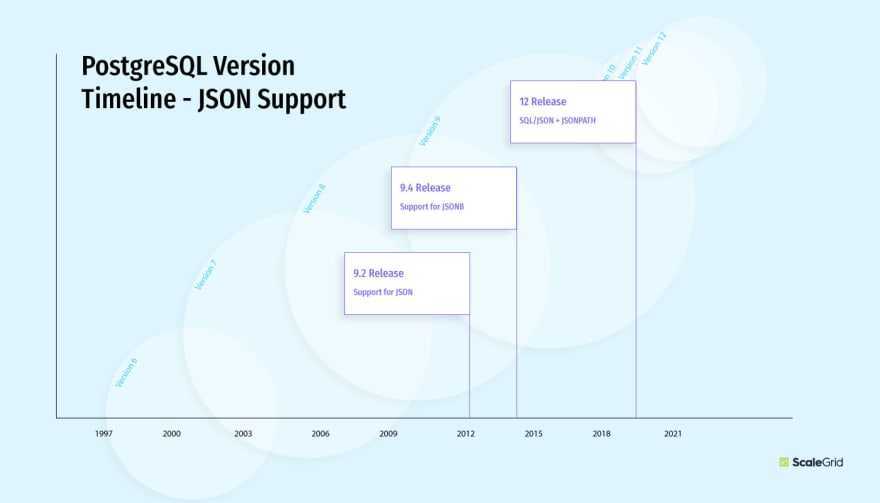
Применения PostgreSQL
PostgreSQL применяется в различных ситуациях. Основные области применения PostgreSQL можно отнести к двум категориям:
- обработка транзакций в реальном времени (OLTP): OLTP характеризуется большим количеством операций вставки, обновления и удаления, очень высокой скоростью работы и поддержанием целостности данных в многопользовательской среде. Производительность измеряется количеством транзакций в секунду;
- интерактивная аналитическая обработка (OLAP): OLAP характеризуется небольшим количеством сложных запросов, включающих агрегирование данных, получение гигантских объемов данных из разных источников в разных форматах, добычу данных и анализ исторических данных.
OLTP применяется для моделирования таких приложений, как управление взаимоотношениями с клиентами (CRM). Например, сайт торговли автомобилями из предыдущей статьи — пример OLTP-приложения. OLAP находит применение в задачах бизнес-аналитики, поддержки принятия решений, генерации отчетов и планирования. Размер базы данных для OLTP сравнительно невелик по сравнению с базой данных OLAP. При проектировании базы данных OLTP обычно придерживаются концепций реляционной модели, в т. ч. нормализации, тогда как базы данных OLAP меньше похожи на реляционные; схема часто имеет вид звезды или снежинки, а данные намеренно денормализованы.
В примере сайта торговли автомобилями можно было бы завести вторую базу для хранения исторических данных о продавцах и пользователях, чтобы анализировать предпочтения пользователей и активность продавцов. Это был бы пример OLAP-приложения.
В отличие от OLTP, основная операция OLAP — выборка и анализ данных. Данные для OLAP часто генерируются процессом извлечения, преобразования и очистки (ETL), который загружает данные в базу OLAP из разных источников в разных форматах. Для OLTP-приложений достаточно PostgreSQL в стандартной комплектации. А для поддержки OLAP имеется много расширений и инструментов, в т. ч. адаптеры внешних данных (foreign data wrappers — FDW), секционирование таблиц, а в последних версиях еще и параллельное выполнение запросов.
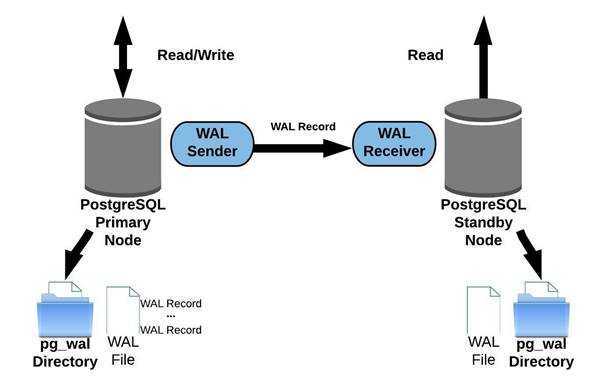
Всё работает? Всё работает!
Как узнать что все завелось и работает? Попробуем просто посмотреть в список процессов.
(на мастере):
root@master:/# ps wax|grep sender
Что выведет:
2741 ? Ss 0:00 postgres: 9.6/main: wal sender process replication
192.168.0.200(50696) streaming 0/14002500
(на слейве):
root@slave:/# ps wax|grep receiver
Что выведет:
1178 ? Ss 0:00 postgres: 9.6/main: wal receiver process streaming 0/14002538
Это значит что репликация как-то работает. Более точно помогут следующие команды:
(на мастере):
root@master:/# sudo -u postgres psql -c 'SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s;'
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state | byte_lag ------+----------+-------------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+-----------+---------------+----------------+----------------+-----------------+---------------+------------+---------- 2741 | 16406 | replication | walreceiver | 192.168.0.200 | | 50696 | 2016-11-27 20:17:59.464068+02 | | streaming | 0/1400A9B8 | 0/1400A9B8 | 0/1400A9B8 | 0/14007C38 | 0 | async | 11648
Что покажет не только список клиентов-слейвов, подключенных к мастеру, а и последняя колонка покажет отставание слейва от мастера в байтах (11648 байт в примере выше).
UPDATE:
Для PostgreSQL 10+ команда и её вывод будет немного другой
root@master:/# sudo -u postgres psql -c 'SELECT *,pg_wal_lsn_diff(s.sent_lsn,s.replay_lsn) AS byte_lag FROM pg_stat_replication s;'
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | byte_lag -------+----------+-------------+------------------+--------------+-----------------+-------------+------------------------------+--------------+-----------+-------------+-------------+-------------+-------------+-----------+-----------+------------+---------------+------------+---------- 15405 | 16387 | replication | walreceiver | 192.168.0.200| | 47052 | 2017-12-06 10:16:51.94418+02 | | streaming | 46/941D79C0 | 46/941D79C0 | 46/941D79C0 | 46/941D79C0 | | | | 0 | async | 11648
Также на слейве можно смотреть, как давно было последнее обновление данных с мастера:
root@slave:/# sudo -u postgres psql -c "SELECT now()-pg_last_xact_replay_timestamp();"
Что выведет:
?column?
-----------------
00:00:12.778029
Всё работает. Можете добавлять реплик столько, сколько захотите. Не забудьте только увеличить значение в конфиге мастера и перезапустить его.
При довольно нагруженной работе с БД может быть такой случай, что слейв будет быстро отставать от мастера. В таком случаи увеличьте значение до нужного значения. Не забывайте только что каждый сегмент занимает по 16 МБ.
Настройка master
Сперва нужно настроить ведущий сервер (master)
Расположение конфигурационного файла
postgresql.conf
можно получить выполнив
-bash-4.2$ su — postgres -c «psql -c ‘SHOW config_file;'»
Password:
config_file
————————————-
/var/lib/pgsql/data/postgresql.conf
(1 row)
vi /var/lib/pgsql/data/postgresql.conf
wal_level = hot_standby
max_wal_senders = 1
wal_keep_segments = 50
- 192.168.56.109 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
-
wal_level
указывает, сколько информации записывается в WAL (Write Ahead Log — журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Перезапустить postgresql от обычного пользователя
$ sudo systemctl restart postgresql
Снова залогиньтесь под postgres
sudo su — postgres
В файле
pg_hba.conf
добавьте
slave_ip
vi /var/lib/pgsql/data/pg_hba.conf
host replication postgres 192.168.56.110/32 trust
![Postgresql [айти бубен]](https://smartshop124.ru/wp-content/uploads/8/8/c/88c8204550faf8f31919013731185414.jpeg)




Теперь нужно сделать копию данных с мастера и отправить на слейв
Если вы вышли из пользователя postgres — залогиньтесь снова
su — postgres
Бэкап (я делаю с пустой базы, сразу после установки)
psql -c «SELECT pg_start_backup(‘replbackup’);»
pg_start_backup
——————
0/2000020
(1 row)
tar cfP /tmp/db_file_backup.tar /var/lib/pgsql/data
psql -c «SELECT pg_stop_backup();»
Скорее всего появится ошибка
NOTICE: WAL archiving is not enabled; you must ensure that all required WAL segments are copied through other means to complete the backup
pg_stop_backup
—————-
0/20000E0
(1 row)
Так как скопирована будет вся директория, можно сказать, что мы пользуемся other means
Отправьте на слейв
scp /tmp/db_file_backup.tar andrei@192.168.56.110:/tmp/
Тонкая настройка ежедневного резервного копирования базы данных 1С средствами SQL ver. 2014 (SP3) — 12.0.6024.0 (X64)
Хочу вам предложить небольшой пример, как можно реализовать резервное копирование 1С-ых баз данных средствами SQL. Данный материал не претендует на пулитцеровскую премию. Но возможно кому-то будет интересно узнать, что-то новенькое.
Данный материал для резервного копирования только одной базы данных. А именно, если у вас 20-ть баз, то вам придется создавать 20-ть планов обслуживания для каждой базы индивидуально.
(Слава разработчикам SQL, они разрешили копировать блоки из одного плана в другой, вам остается только произвести небольшую настройку для каждого скопированного блока — некоторые настройки блоков сбрасываются и выставляются значением по умолчанию и остаются неактивными)
18.6.3. Standby Servers
These settings control the behavior of a standby server that
is to receive replication data. Their values on the master
server are irrelevant.
-
hot_standby
(boolean) -
Specifies whether or not you can connect and run
queries during recovery, as described in Section 25.5. The default value is
off. This parameter can only be
set at server start. It only has effect during archive
recovery or in standby mode. - max_standby_archive_delay (integer)
-
When Hot Standby is active, this parameter determines
how long the standby server should wait before canceling
standby queries that conflict with about-to-be-applied
WAL entries, as described in . max_standby_archive_delay applies when WAL
data is being read from WAL archive (and is therefore not
current). The default is 30 seconds. Units are
milliseconds if not specified. A value of -1 allows the
standby to wait forever for conflicting queries to
complete. This parameter can only be set in the
postgresql.conf file or on the
server command line.Note that max_standby_archive_delay is not the same
as the maximum length of time a query can run before
cancellation; rather it is the maximum total time allowed
to apply any one WAL segment’s data. Thus, if one query
has resulted in significant delay earlier in the WAL
segment, subsequent conflicting queries will have much
less grace time. - max_standby_streaming_delay (integer)
-
When Hot Standby is active, this parameter determines
how long the standby server should wait before canceling
standby queries that conflict with about-to-be-applied
WAL entries, as described in . max_standby_streaming_delay applies when
WAL data is being received via streaming replication. The
default is 30 seconds. Units are milliseconds if not
specified. A value of -1 allows the standby to wait
forever for conflicting queries to complete. This
parameter can only be set in the postgresql.conf file or on the server
command line.Note that max_standby_streaming_delay is not the
same as the maximum length of time a query can run before
cancellation; rather it is the maximum total time allowed
to apply WAL data once it has been received from the
primary server. Thus, if one query has resulted in
significant delay, subsequent conflicting queries will
have much less grace time until the standby server has
caught up again. - wal_receiver_status_interval (integer)
-
Specifies the minimum frequency for the WAL receiver
process on the standby to send information about
replication progress to the primary or upstream standby,
where it can be seen using the view. The standby will
report the last transaction log position it has written,
the last position it has flushed to disk, and the last
position it has applied. This parameter’s value is the
maximum interval, in seconds, between reports. Updates
are sent each time the write or flush positions change,
or at least as often as specified by this parameter.
Thus, the apply position may lag slightly behind the true
position. Setting this parameter to zero disables status
updates completely. This parameter can only be set in the
postgresql.conf file or on the
server command line. The default value is 10 seconds.When is enabled on a sending server,
wal_receiver_status_interval
must be enabled, and its value must be less than the
value of replication_timeout. - hot_standby_feedback (boolean)
-
Specifies whether or not a hot standby will send
feedback to the primary or upstream standby about queries
currently executing on the standby. This parameter can be
used to eliminate query cancels caused by cleanup
records, but can cause database bloat on the primary for
some workloads. Feedback messages will not be sent more
frequently than once per wal_receiver_status_interval. The default
value is off. This parameter can
only be set in the postgresql.conf file or on the server
command line.If cascaded replication is in use the feedback is
passed upstream until it eventually reaches the primary.
Standbys make no other use of feedback they receive other
than to pass upstream. -






Архитектура
Логическая репликация начинается с копирования снимка данных в базе данных публикации. По завершении этой операции изменения на стороне публикации передаются подписчику в реальном времени, когда они происходят. Подписчик применяет изменения в том же порядке, в каком они вносятся на узле публикации, так что для публикаций в рамках одной подписки гарантируется транзакционная целостность.
Логическая репликация построена по схеме, подобной физической потоковой репликации. Она реализуется процессами «walsender» (передачи WAL) и «apply» (применения). Процесс walsender запускает логическое декодирование WAL и загружает стандартный модуль логического декодирования (pgoutput). Этот модуль преобразует изменения, считываемые из WAL, в протокол логической репликации и отфильтровывает данные согласно спецификации публикации. Затем данные последовательно передаются по протоколу логической репликации рабочему процессу применения изменений, который сопоставляет данные с логическими таблицами и применяет отдельные изменения по мере их поступления, сохраняя транзакционный порядок.
Процесс применения изменений в базе данных подписчика всегда выполняется со значением session_replication_role, равным replica, что влечёт соответствующие эффекты для триггеров и ограничений.
Процесс применения логической репликации в настоящее время вызывает только триггеры уровня строк, но не триггеры операторов. Однако начальная синхронизация таблицы реализована как команда COPY и поэтому вызывает триггеры для INSERT и уровня строк, и уровня оператора.
Начальный снимок
Начальные данные существующих таблиц в подписке помещаются в снимок и копируются в параллельном экземпляре процесса применения особого вида. Этот процесс создаёт собственный слот репликации и производит копирование существующих данных. Когда существующие данные будут скопированы, этот рабочий процесс переходит в режим синхронизации, в котором таблица приводится в синхронизированное состояние для основного процесса применения, то есть передаёт все изменения, произошедшие во время начального копирования данных, используя стандартную логическую репликацию. По завершении синхронизации управление репликацией этой таблицы возвращается главному процессу, который продолжает репликацию в обычном режиме.
Если упираемся в процессор
вот результаты всё тех же sysbench тестов
- MTS на слейве достигает 10-кратного увеличения производительности по сравнению с однопоточной репликацией
- использование уже приводит к росту пропускной способности слейва в более чем 3.5 раза
- производительность row-based репликации практически всегда выше, чем statement-based. Но MTS оказывает больший эффект на statement-based, что несколько уравнивает оба формата с точки зрения производительности на OLTP нагрузках.
Физическая репликация в PostgreSQL
документации по Hot Standby
- не поддерживаются, потому что для этого требуется модификация файлов данных
- 2PC команды не поддерживаются по тем же причинам
- явное указание «read write» состояние транзакций ( и т.д.), LISTEN, UNLISTEN, NOTIFY, обновления sequence не поддерживаются. Что в целом объяснимо, Но это значит, что какие-то приложения придётся переписывать при миграции на Hot Standby, даже если никаких данных они не модифицируют
- Даже read-only запросы могут вызывать конфликты с DDL и vacuum операциями на мастере (привет «агрессивным» настройкам vacuum!) В этом случае запросы могут либо задержать репликацию, либо быть принудительно прерваны и есть конфигурационные параметры, которые этим поведением управляют
- слейв можно настроить для предоставления «обратной связи» с мастером (параметр ). Что хорошо, но интересны накладные расходы этого механизма в нагруженных системах.
failoverОбновлено 28.09.2016:eng.uber.com/mysql-migrationОбновлено 30.10.2017:thebuild.com/blog/2017/10/27/streaming-replication-stopped-one-more-thing-to-checkтоже люди
Логическая репликация в PostgreSQL
что-то приунылкто сказал «разброд»?за них часто критикуют репликацию в MySQLкто сказал «форки»?быстро
- Это не репликация как таковая, а конструктор/фреймворк/API для создания сторонних решений для логической репликации
- Использование Logical Decoding требует записи дополнительной информации в WAL (требуется установить ). Привет критикам бинарного журнала в MySQL!
- Какие-то из сторонних решений уже переехали на Logical Decoding, а какие-то ещё нет.
- Из чтения документации у меня сложилось впечатление, что это аналог row-based репликации в MySQL, только с кучей ограничений: никакой параллельности в принципе, никаких GTID (как делают клонирование слейва и failover/switchover в сложных топологиях?), каскадная репликация не поддерживается.
- Если я правильно понял эти слайды SQL интерфейс в Logical Decoding использует Poll модель для распространения изменений, а протокол для репликации использует Push модель. Если это действительно так, что происходит при временном выпадении слейва из репликации в Push модели, например из-за проблем с сетью?
- Есть поддержка синхронной репликации, что хорошо. Как насчёт полусинхронной репликации, которая более актуальна в высоконагруженных кластерах?
- Можно выбирать избыточность информации с помощью опции для таблицы. Это некий аналог переменной в MySQL. Но переменная в MySQL динамическая, её можно устанавливать отдельно для сессии, или даже отдельно для каждого запроса. Можно ли так в PostgreSQL?
- Короче говоря, где можно посмотреть доклад «Асинхронная логическая репликация в PostgreSQL без цензуры»?. Я бы с удовольствием почитал и посмотрел.
разных докладах
Установка MS SQL и PostgreSQL
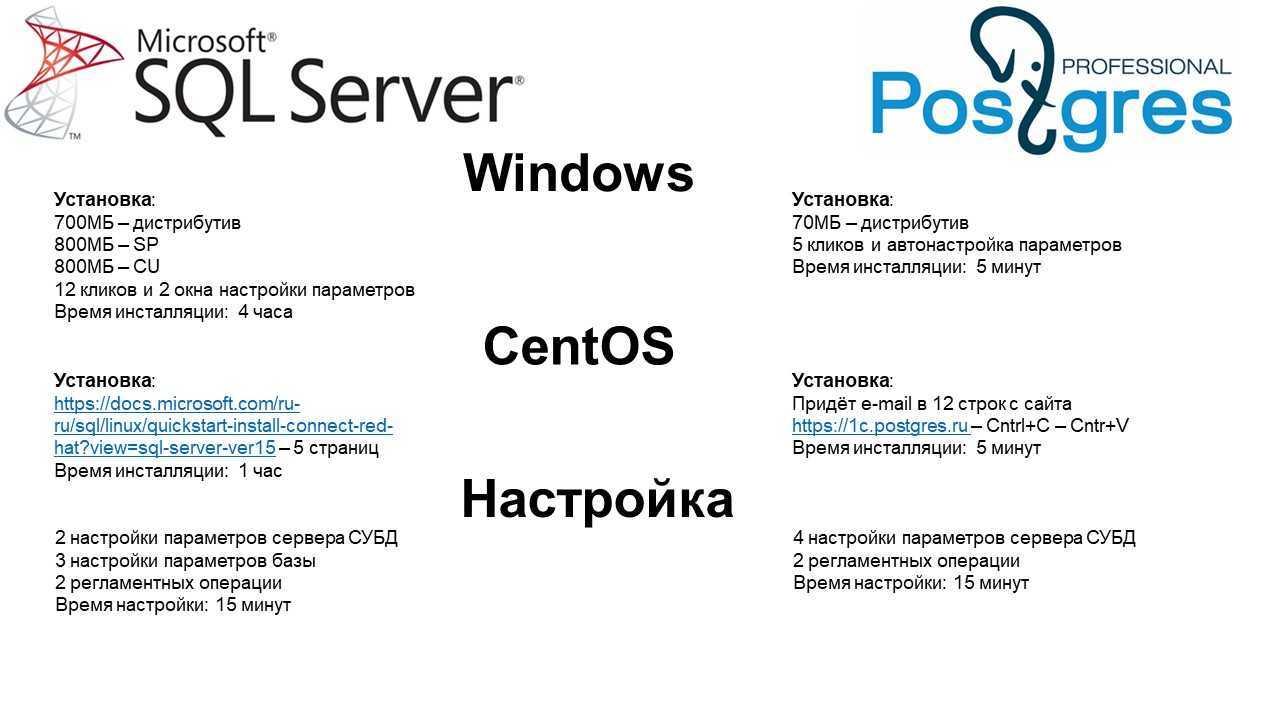
Давайте сравним установку PostgreSQL и MS SQL Server на Windows.
-
Чтобы поставить MS SQL-сервер, надо скачать 2,5 Гб с интернета.
-
При этом дистрибутив Postgres для Windows – 70 Мб.
-
В процессе инсталляции для MS SQL Server, нам надо сделать 12 кликов и пройти два окна настройки параметров, где мы сразу можем настроить: количество и расположение файлов для tempDB, а также расположение базы данных и лога транзакций. Время инсталляции SQL-сервера с учетом скачивания дистрибутивов – 4 часа.
-
«Виндовый» Postgres настраивается в 5 кликов (там всего одно окно настройки), почти все параметры проходят автонастройку, опираясь на параметры вашего компьютера. Я сейчас говорю про дистрибутив от компании Postgres Pro (и платный, и бесплатный настраиваются одинаково). Время инсталляции – 5 минут. Если надо разнести файлы базы, WAL и временных файлов то тогда ещё три строчки в конфигурационном файле.
Дальше давайте теперь сравним установку на Linux. В данном случае будут рассматривать CentOS.
-
Установка MS SQL-сервера на CentOS представляет собой 5 страниц инструкций с сайта Microsoft. Время инсталляции – час. В этот час будет скачиваться неслабый дистрибутив, и потом его нужно будет установить и настроить в командной строке. Время настройки – 15 минут.
-
Для самого MS SQL Server в CentOS нужно будет настроить хотя бы два параметра: это параллелизм и количество потребляемой оперативной памяти.
-
Нужно будет настроить хотя бы три параметра самой базы: как у вас база будет прирастать, какой у вас будет изначальный объем файлов базы данных и журналов транзакций, установить уровень журналирования.
-
Плюс к этому нужно будет настроить минимум две регламентных операций ухаживания за базой – реиндексация и апдейт статистики.
-
-
Устанавливая на CentOS Postgres вам придет письмо с кодом в 12 строчек. Копируете, вставляете, и через 5 минут у вас есть запущенный и готовый Postgres. Для настройки Postgres в Windows и в CentOS вам нужно провести всего четыре настройки параметров сервера СУБД и задать две регламентные операции в cron. На это уйдет максимум 15 минут.
-




Все эти цифры по поводу настройки и установки пока не в пользу MS SQL.
Я свято уверен, что после настройки и установки в СУБД потом постоянно что-то крутить в настройках СУБД не нужно. Анализ проблем лучше делать в технологическом журнале 1С. Техжурнал 1С покажет более полную комплексную информацию, которая будет содержать не только «тормоза» СУБД, но и «тормоза» самого движка платформы, что часто занимает гораздо более длительное время в исполнении запросов чем время, которое тратит на этот запрос СУБД. И только когда вы нашли проблему, код 1С кажется идеальным а СУБД ведёт себя странно, вот тогда уже нужно идти и смотреть планы запросов, делать выводы и может быть менять настройки, хотя лучше всё таки поменять код 1С, так как улучшив одну операцию изменением настроек СУБД можно очень легко “положить” всю систему.
Ограничения
Логическая репликация в настоящее время имеет ограничения и недостатки, описанные ниже. Они могут быть устранены в будущих выпусках.
- Схема базы данных и команды DDL не реплицируются. Изначальную схему можно скопировать, воспользовавшись командой pg_dump —schema-only. Последующие изменения схемы необходимо будет синхронизировать вручную. (Заметьте, однако, что схемы не обязательно должны быть абсолютно идентичными на обеих сторонах репликации.) Если определения схемы в исходной базе данных меняются, логическая репликация работает надёжно — когда данные после изменения схемы прибывают на сторону подписчика, но не вписываются в схему его таблиц, выдаётся ошибка, требующая обновления схемы. Во многих случаях возникновение таких ошибок можно предупредить, сначала применяя дополняющие изменения на подписчике.
- Данные последовательностей не реплицируются. Данные в столбцах serial или столбцах идентификации, выдаваемые последовательностями, конечно, будут реплицированы в составе таблицы, но сама последовательность на подписчике будет сохранять стартовое значение. Если подписчик используется в качестве базы только для чтения, обычно это не является проблемой. Если же, однако, предусматривается возможность переключения на базу подписчика некоторым образом, текущие значения в этих последовательностях нужно будет обновить, либо скопировав текущие данные из базы публикации (вероятно, с применением pg_dump), либо выбрав достаточно большие значения из самих таблиц.
- Команды TRUNCATE не реплицируются. Разумеется, это можно обойти, выполняя вместо них команды DELETE. Чтобы предотвратить случайное выполнение TRUNCATE, вы можете отозвать право TRUNCATE для реплицируемых таблиц.
- Большие объекты не реплицируются. Это ограничение нельзя обойти никак, кроме как хранить данные в обычных таблицах.
- Реплицировать данные возможно только из базовых таблиц в базовые таблицы. То есть таблицы на стороне публикации и на стороне подписки должны быть обычными, а не представлениями, мат. представлениями, секционированными или сторонними таблицами. Это означает, что вы можете реплицировать секции одну в одну, но реплицировать данные в таблицы, секционированные по-другому, нельзя. При попытке реплицировать таблицы, отличные от базовых, будет выдана ошибка.
Резервные копии (экспорт и импорт дампа)
При установке PostgreSQL на сервер устанавливаются утилиты и , с помощью которых вы сможете из консоли Linux создавать резервные копии базы данных (pg_dump) и восстанавливать данные из них ().
Создание резервной копии
Чтобы создать резервную копию базы и сохранить ее на сервере, необходимо выполнить команду:
pg_dump -h хост -U имя_роли -F формат_дампа -f путь_к_дампу имя_базы
Параметры:
- — сервер, на котором располагается база; может быть указан localhost, IP-адрес или домен;
- — имя пользователя PostgreSQL, под которым вы подключаетесь к базе;
- — формат, в котором будет сохранен дамп; указывается буквами c, t или p: ‘с’ (custom — архив .tar.gz), ‘t’ (tar — архив .tar), ‘p’ (plain — текстовый файл без сжатия, как правило, .sql);
- — путь сохранения для файла дампа и имя файла;
- — имя базы данных, для которой создается резервная копия.
Например:
pg_dump -h localhost -U tmweb -F c -f /home/user/backups/dump.tar.gz tmweb
После выполнения команды будет запрошен пароль пользователя Postgres, указанного в команде (в примере — tmweb).
Восстановление из дампа
Импорт дампов, сохраненных в форматах .tar.gz и .tar, выполняется с помощью :
pg_restore -h хост -U имя_роли -F формат_дампа -d имя_базы путь_к_дампу
Параметры:
- — сервер, на котором располагается база; может быть указан localhost, IP-адрес или домен;
- — имя пользователя PostgreSQL, под которым вы подключаетесь к базе;
- — формат, в котором был сохранен дамп; необходимо указать ‘с’ для архива .tar.gz и ‘t’ для архива .tar;
- — имя базы данных, в которую импортируется дамп;
- — путь к файлу дампа и имя файла.
Например:
pg_restore -h localhost -U tmweb -F c -d new_db /home/user/backups/dump.tar.gz
Для импорта дампов в формате .sql используется cat:
cat путь_к_дампу | psql -h хост -U имя_роли имя_базы
Параметры:
- — путь к файлу дампа и имя файла;
- — сервер, на котором располагается база; может быть указан localhost, IP-адрес или домен;
- — имя пользователя PostgreSQL, под которым вы подключаетесь к базе;
- — имя базы данных, в которую импортируется дамп.
Например:
cat /home/user/backups/dump.sql | psql -h localhost -U tmweb new_db
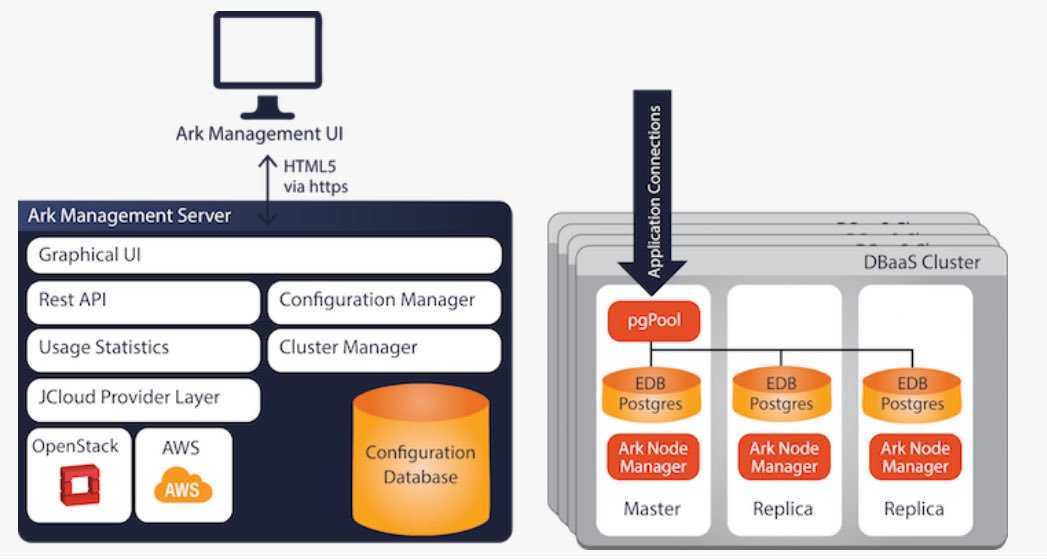
ПРЕИМУЩЕСТВА РЕПЛИКАЦИИ
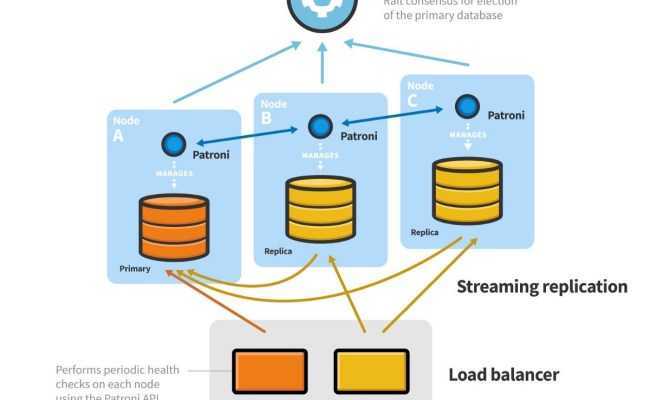
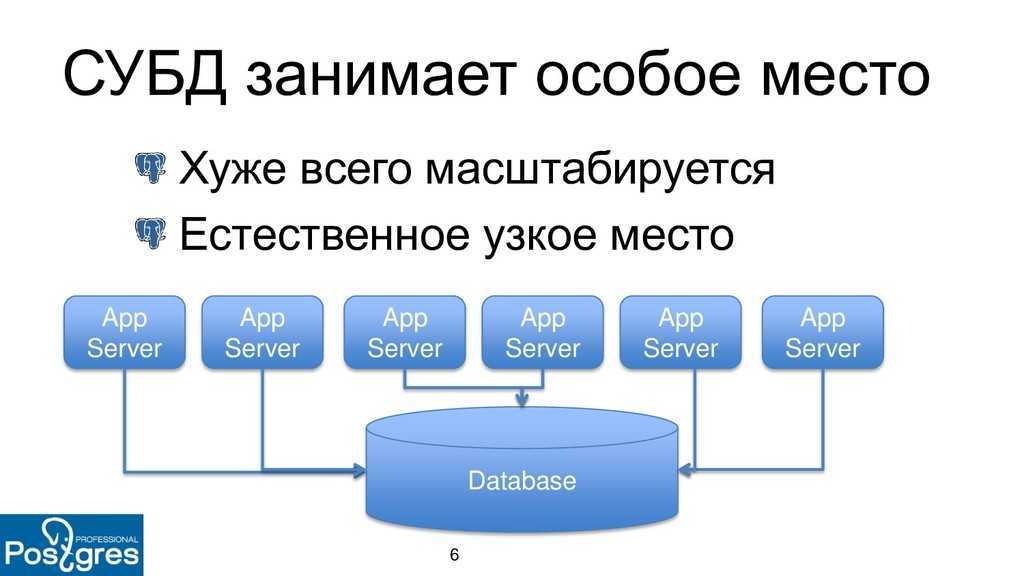
Основное преимущество — распределение базы данных между несколькими машинами. Если с основным сервером что-то происходит и он перестает работать, то данные все еще доступны на резервном сервере и могут быть без труда получены или восстановлены. Работа проекта продолжится без каких-либо трудностей.
В PostgreSQL доступно несколько способов репликации базы данных в зависимости от цели репликации. Можно настраивать репликацию только для резервного копирования или для организации отказоустойчивого сервера баз данных. Мы будем использовать репликацию типа Master-Salve. Она более подходит для резервного копирования. Для реализации будет использоваться модуль standby.
Основные операции с БД
Чтобы выполнять базовые действия в СУБД, нужно знать язык запросов к базе данных SQL.
Создание базы данных
Для создания базы данных используется команда:
create database
В приведенном ниже примере создается база данных с именем proglib_db.
 Рисунок 3 — Создание базы данных с именем proglib_db
Рисунок 3 — Создание базы данных с именем proglib_db
Если забыть точку с запятой в конце запроса, знак «=» в приглашении postgres заменяется на «-». Это зачастую указывает на то, что необходимо завершить (дописать) запрос.
 Рисунок 4 — вывод ошибки при создании базы данных
Рисунок 4 — вывод ошибки при создании базы данных
На рисунке 4 видно сообщение об ошибке из-за того, что в нашем случае база уже создана.
Создание нового юзера
Для создания пользователя существует команда:
create user
В приведенном ниже примере создается пользователь с именем author.
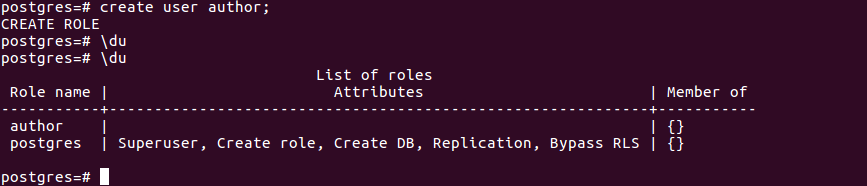 Рисунок 5 — Создание пользователя с именем author
Рисунок 5 — Создание пользователя с именем author
При создании пользователя отобразится сообщение CREATE ROLE. Каждый пользователь имеет свои права (доступ к базам, редактирование, создание БД / пользователей и т. д.). Вы могли заметить, что столбец Attributes для пользователя author пуст. Это означает, что пользователь author не имеет прав администратора. Он может только читать данные и не может создать другого пользователя или базу.




![Postgresql [айти бубен]](https://smartshop124.ru/wp-content/uploads/c/8/4/c840b1a08a87381ecf520c7befcfa548.jpeg)

Можно установить пароль для существующего пользователя.
С этой задачей справится команда :
postgres=#\password author
Чтобы задать пароль при создании пользователя, можно использовать следующую команду:
postgres=#create user author with login password 'qwerty';
Удаление базы или пользователя
Для этой операции используется команда : она умеет удалять как пользователя, так и БД.
drop database <database_name> drop user <user_name>
Данную команду нужно использовать очень осторожно, иначе удаленные данные будут потеряны, а восстановить их можно только из бэкапа (если он был).
Если вы укажете psql postgres (без имени пользователя), то postgreSQL пустит вас под стандартным суперюзером (postgres). Чтобы войти в базу данных под определенным пользователем, можно использовать следующую команду:
psql
Войдем в базу proglib_db под пользователем author. Выполним команду , чтобы выйти из текущей БД, а затем выполните следующую команду:
 Рисунок 6 — Вход в базу данных proglib_db
Рисунок 6 — Вход в базу данных proglib_db
Особенности физической репликации:
- проще в конфигурации и использовании: Сама по себе задача побайтового зеркалирования одного сервера на другой гораздо проще логической репликации с её многочисленными сценариями использования и топологиями. Отсюда знаменитое «настроил и забыл» во всех холиворах «MySQL против PostgreSQL».
- низкое потребление ресурсов: Логическое репликация требует дополнительных ресурсов, потому что логическое описание изменений ещё нужно «перевести» в физическое, т.е. понять что конкретно и куда записывать на диск
- требование 100% идентичности узлов: физическая репликация возможна только между абсолютно одинаковыми серверами, вплоть до архитектуры процессора, путей к tablespace файлам, и т.д. Это часто может стать проблемой для масштабных кластеров репликации, т.к. изменение этих факторов влечёт полную остановку кластера.
- никакой записи на слейве: вытекает из предыдущего пункта. Даже временную таблицу создать нельзя.
- чтение со слейва проблематично: чтение со слейва возможно, но не без проблем. См. «Физическая репликация в PostgreSQL» ниже
- ограниченность топологий: никакие multi-source и multi-master невозможны. В лучшем случае каскадная репликация.
- нет частичной репликации: вытекает всё из того же требования 100% идентичности файлов данных
- большие накладные расходы: нужно передавать все изменения в файлах данных (операция с индексами, vacuum и прочую внутреннюю бухгалтерию). А значит нагрузка на сеть выше, чем при логической репликации. Но всё как обычно зависит от количества/типа индексов, нагрузки и прочих факторов.
Логическая репликация в MySQL
zabivatorстатьипервой части памятки евангелистапо возможности избегайте этогопришлось бы подождатьвсех мастейпубликацияUnder the Hood
Ответвления
Ответвлением называется независимый программный проект, основанный на каком-то другом проекте. От PostgreSQL существует более 20 ответвлений; расширяемый API этому весьма способствует. На протяжении многих лет различные группы создавали ответвления и затем включали результаты своей работы в PostgreSQL.
- HadoopDB — гибрид PostgreSQL с технологиями MapReduce, ориентированный на аналитику. Ниже перечислены наиболее популярные ответвления от PostgreSQL:
- в Greenplum используется архитектура без разделения ресурсов с массово параллельной обработкой (MPP). Применяется для создания хранилищ данных и аналитики. Greenplum начиналась как коммерческий проект, но в 2015 году ее код был раскрыт;
- EnterpriseDB Advanced Server — коммерческая СУБД, дополняющая PostgreSQL средствами Oracle;
- Postgres-XC (eXtensible Cluster) — кластер на основе PostgreSQL с несколькими ведущими узлами, построенный на базе архитектуры без разделения ресурсов. Упор сделан на масштабируемость записи, приложениям предоставляется тот же API, что и в PostgreSQL;
- Vertica — столбцовая база данных, разработка которой была начата Майклом Стоунбрейкером в 2005 году. В 2011 году проект был приобретен компанией HP. Vertica заимствовала у PostgreSQL синтаксический анализатор SQL, семантический анализатор и стандартные методы переписывания SQL-запросов;
- Netezza — популярное хранилище данных, начавшее жизнь как ответвление от PostgreSQL;
- Amazon Redshift — популярное хранилище данных, основанное на Post- greSQL 8.0.2. Предназначено в основном для приложений OLAP.
Настройка сервера Zabbix
На сервере Zabbix создаем новый шаблон для выполнения запроса к агенту и привязываем его ко всем мастер-хостам СУБД PostgreSQL.
Создание шаблона
Для удобства скачиваем уже готовый шаблон pg_repl_template.xml. Заходим на страницу управления сервером Zabbix и переходим в раздел Настройка — Шаблоны:

Сверху справа кликаем по Импорт:
![]()
В открывшемся окне выбираем скачанный шаблон и нажимаем по Импорт:
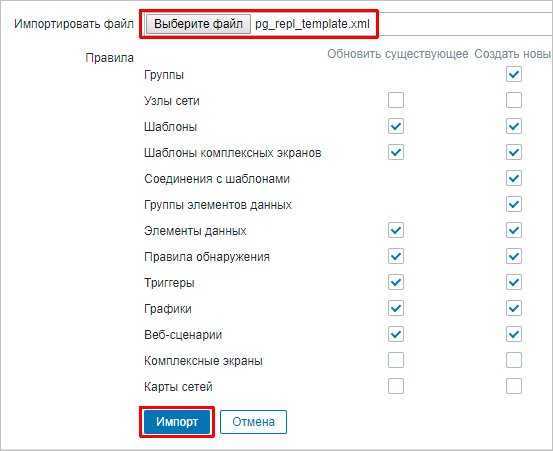
В шаблонах должен появиться новый с названием «Template PostgreSQL Replication».
Настройка хоста
Переходим в раздел Настройка — Узлы сети:

Находим среди узлов наш сервер PostgreSQL, который будем мониторить и переходим в его настройки.
На вкладке Шаблоны выбираем наш шаблон, который мы загрузили, добавляем его и обновляем настройки хоста:
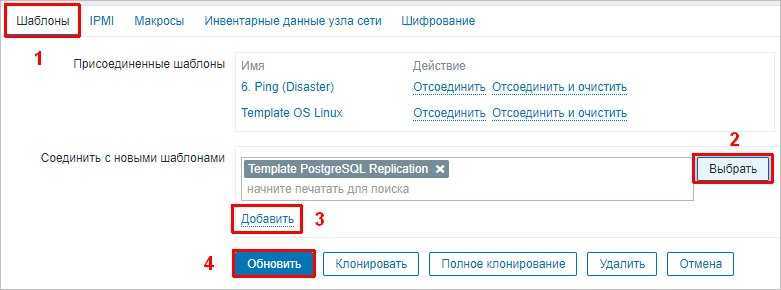
Готово. При возникновении проблем репликации мы увидим предупреждение «PostgreSQL: Replication Error».