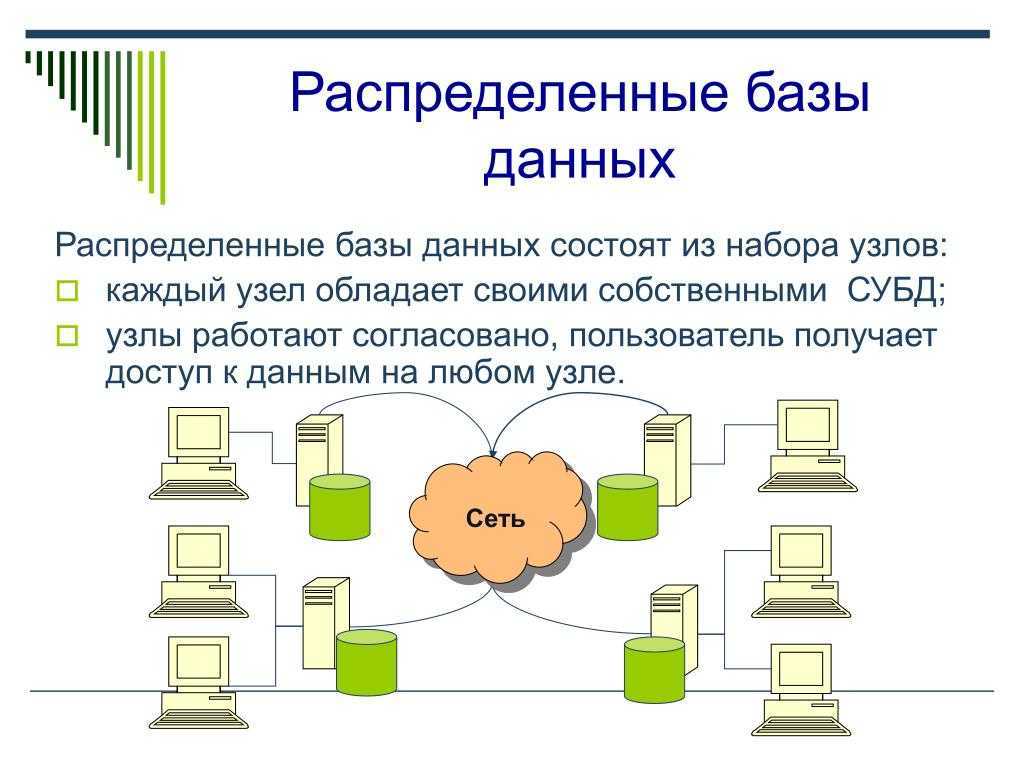
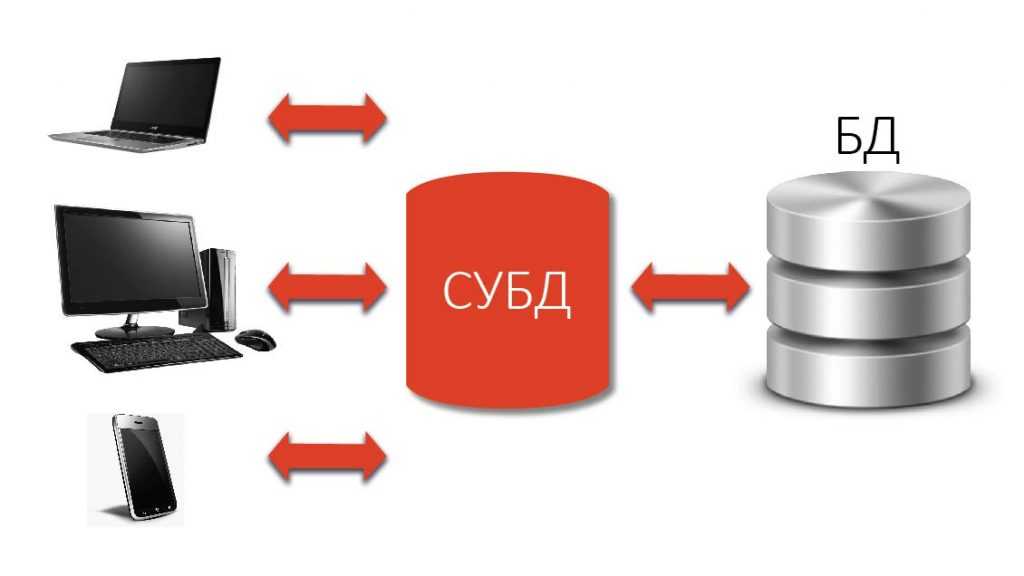
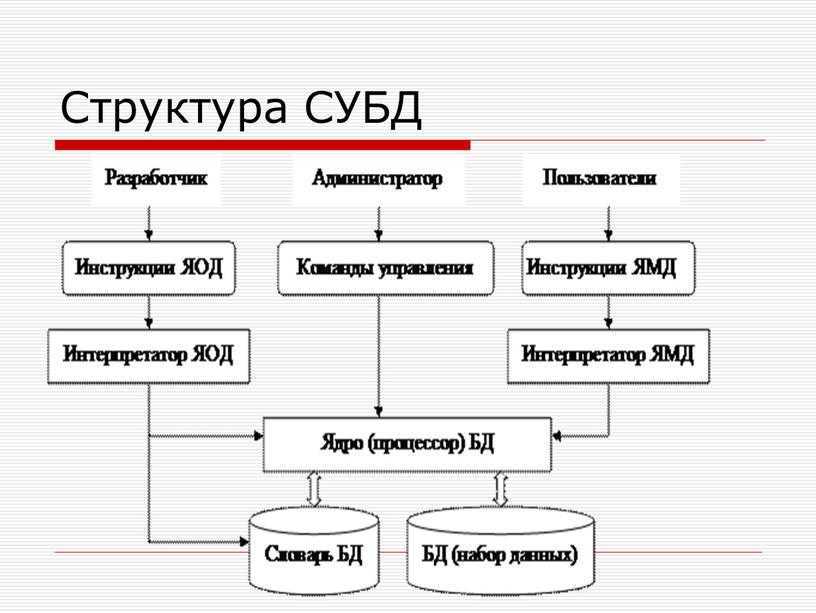
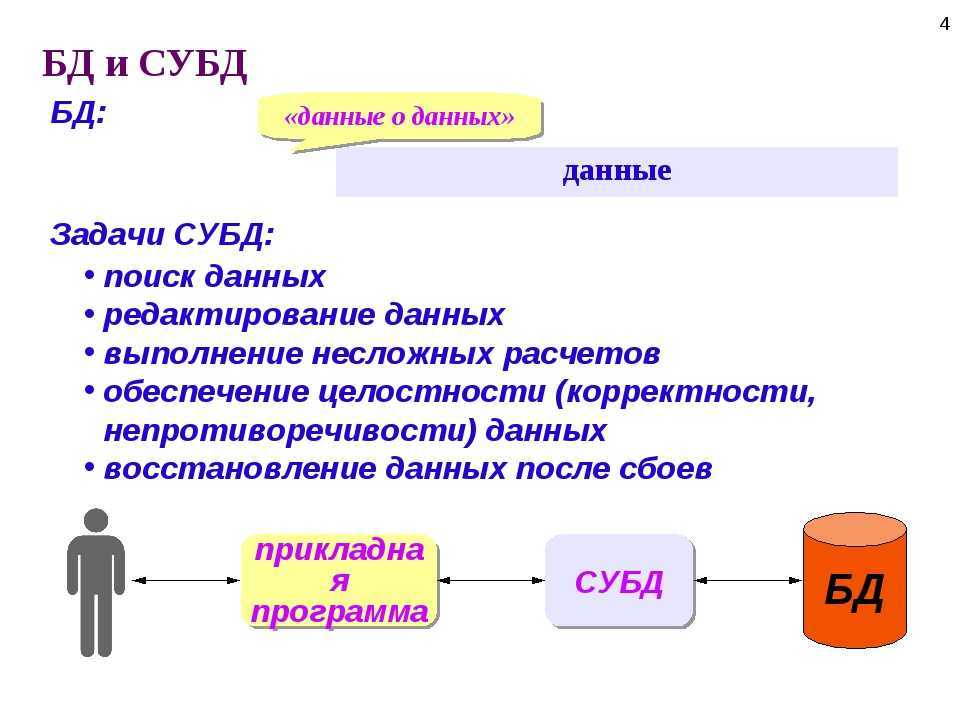
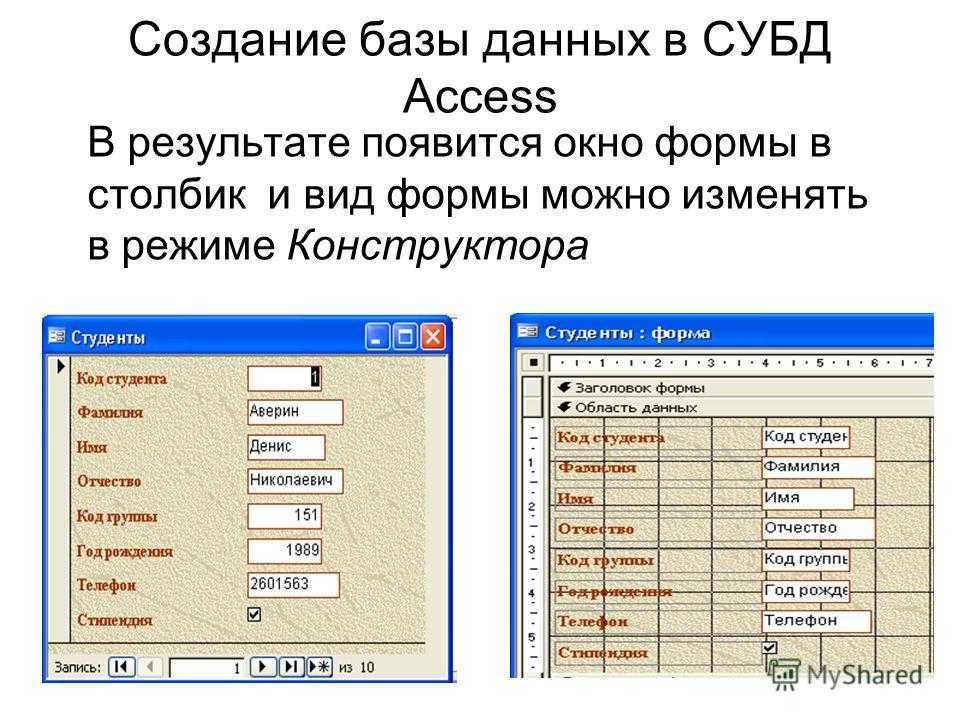
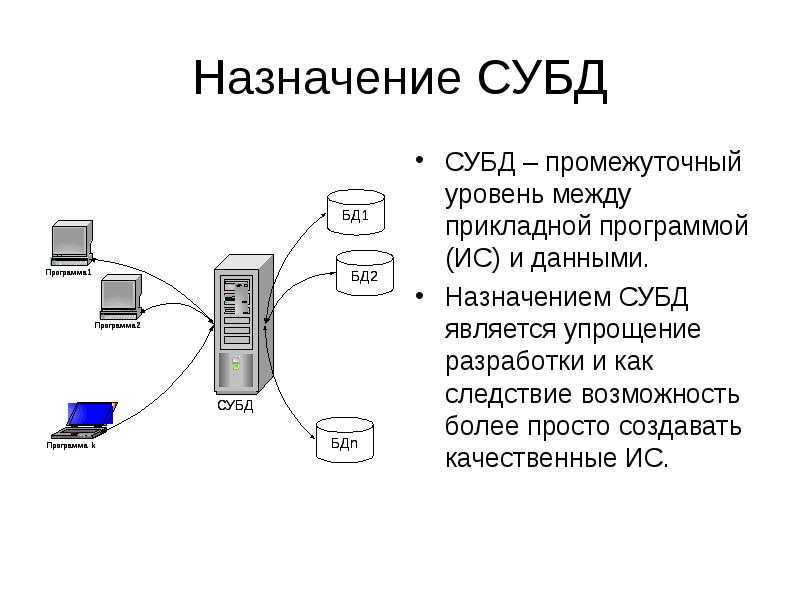
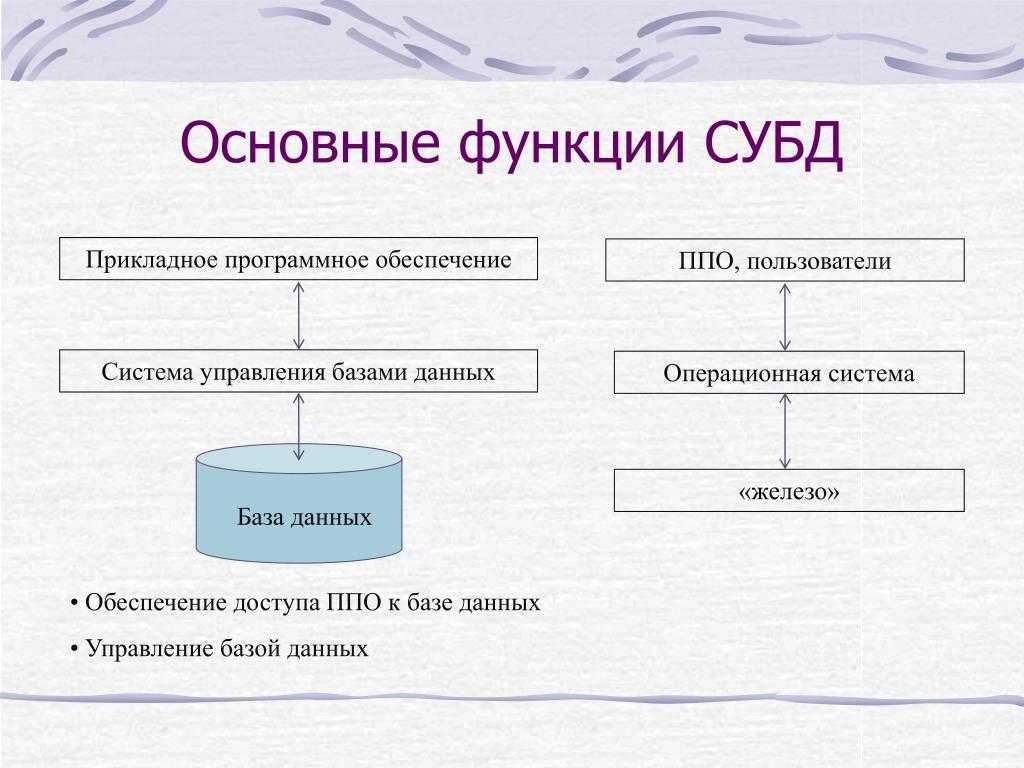
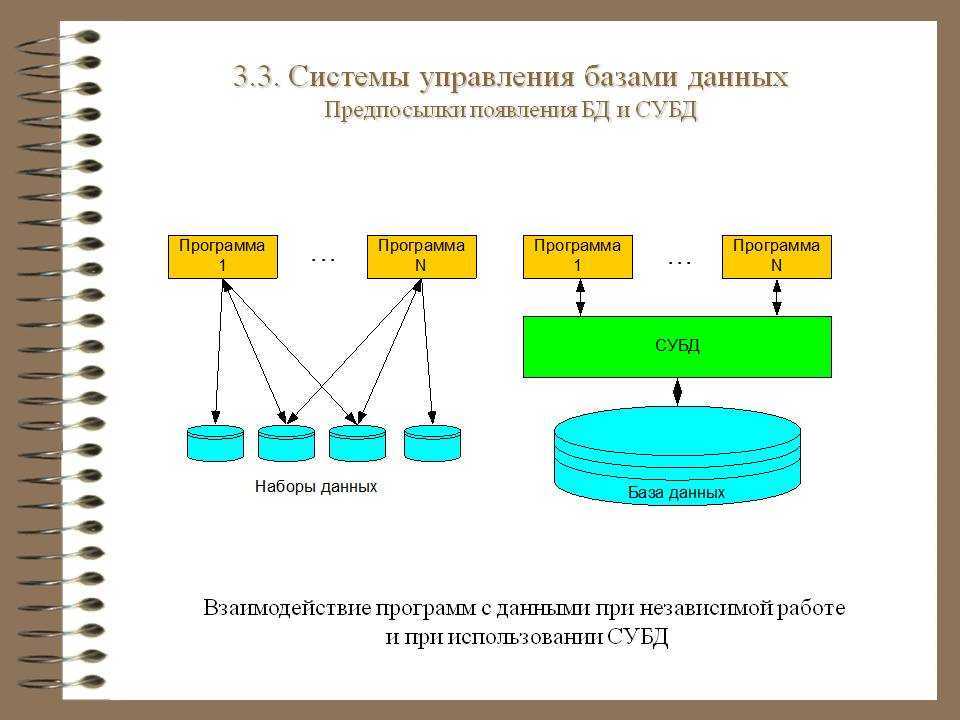
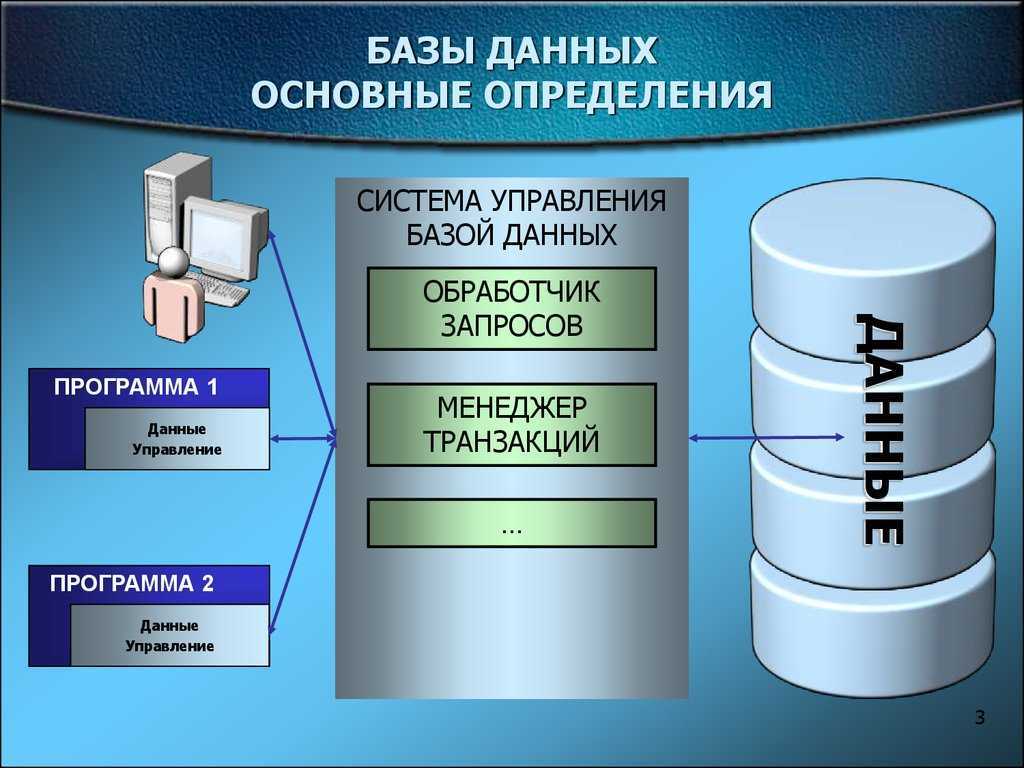
1С:Предприятие Бухгалтерия переход с редакции 2.0 на 3.0. Практика перевода информационной базы для работы в управляемом приложении. Промо
Из информационного выпуска 1С № 16872 от 08.07.2013г. стало известно об относительно скором необходимом переходе на редакцию 1С:Бухгалтерия 3.0. В данной публикации будут разобраны некоторые особенности перевода нетиповой конфигурации 1С:Бухгалтерия 2.0 на редакцию 3.0, которая работает в режиме «Управляемое приложение».
Публикация будет дополняться по мере подготовки нового материала. Публикация не является «универсальной инструкцией».
Update 3. Права доступа. 14.08.2013
Update 4. Добавлен раздел 0. Дополнен раздел 4. Добавлен раздел 7. Внесены поправки, актуализирована информация. 23.11.2013.
1 стартмани
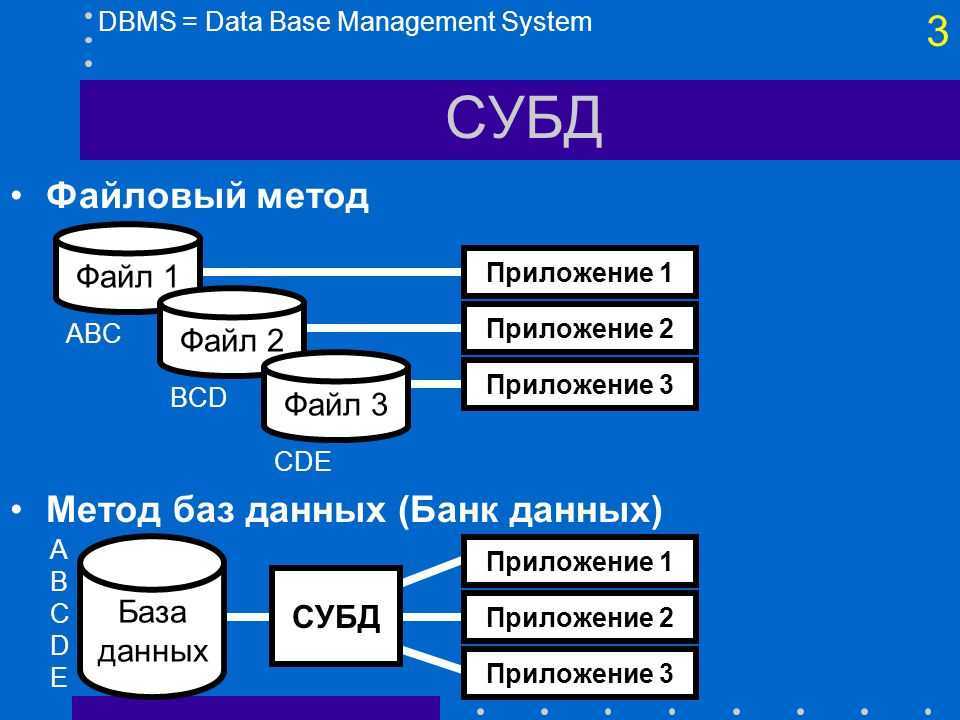
Шаг 1. Выбор источника для установки
PostgreSQL является очень популярным сервером баз данных, поэтому присутствует в официальных репозиториях Ubuntu. Однако в PPA разработчиков PostgreSQL можно найти самую свежую версию. Например, на момент написания данной инструкции в репозитории Ubuntu имеется PostgreSQL 9.5, а из PPA можно установить 9.6. Если у вас нет потребности в самых последних возможностях данной СУБД, то текущий шаг можно пропустить. Иначе добавьте репозиторий PostgreSQL в системный список источников:
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
и добавьте для него ключ
wget -q https://www.postgresql.org/media/keys/ACCC4CF8.asc -O - | sudo apt-key add -
Это позволит при обновлении пакетов получать наиболее свежие версии.
Три, psql
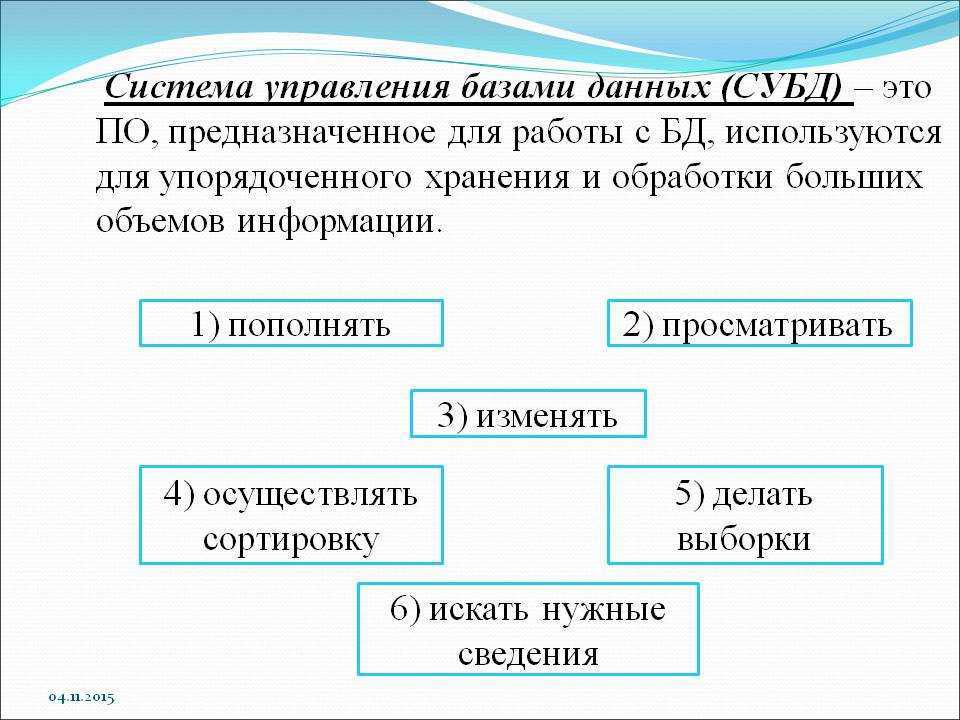
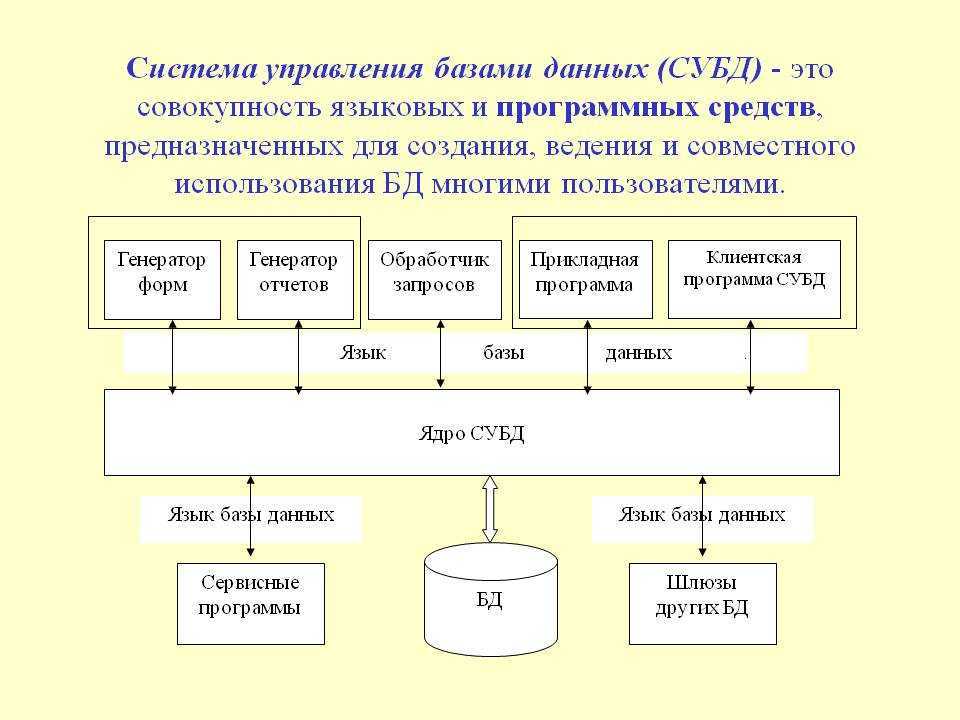
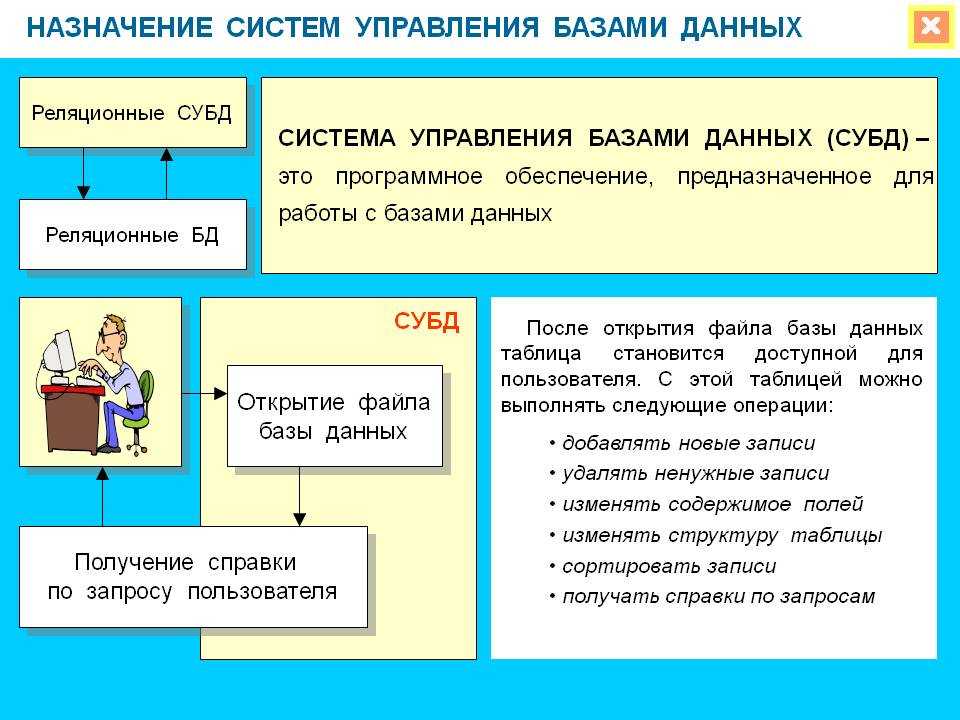
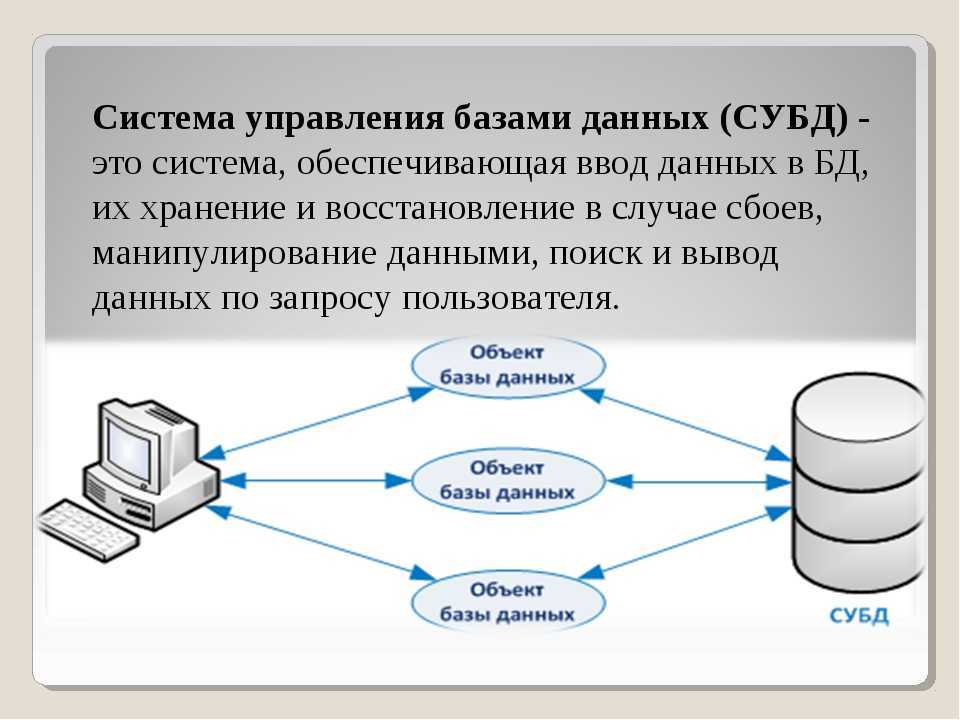
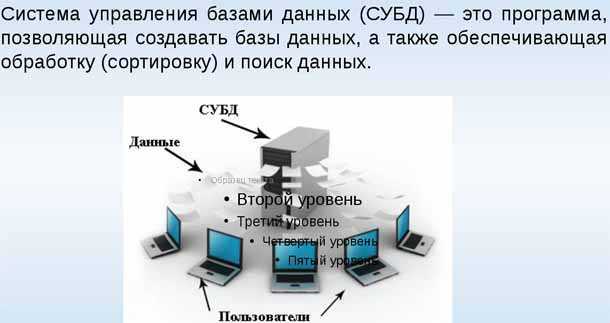
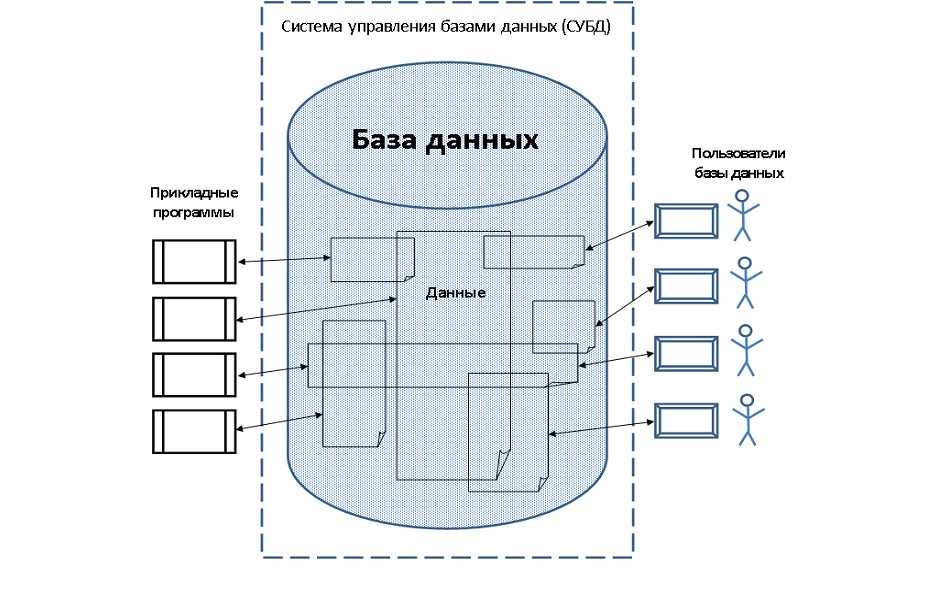
Каждая система управления базами данных предоставляет интерфейс управления командной строкой, например sqlplus Oracle, isql и osql SQL Server и т. Д. Все функции, которые могут быть реализованы с помощью графического интерфейса управления, в принципе могут быть реализованы с помощью команд интерфейса командной строки. У обоих есть свои преимущества и недостатки, и они используются в разных ситуациях. Конечно, графические интерфейсы управления обычно используются под Windows, потому что инструменты командной строки часто встраиваются в интерфейсы управления изображениями. В Unix и Linux, конечно, обычно используются инструменты командной строки, за исключением той причины, по которой мы в основном используем символьные интерфейсы. под Unix-подобным Кроме того, потому что в большинстве случаев мы можем только удаленно подключиться к серверу через telnet или инструмент ssh для работы, а в настоящее время мы можем использовать только командную строку.Откройте оболочку SQL (psql) из начального каталога и введите пароль, чтобы получить следующий интерфейс:
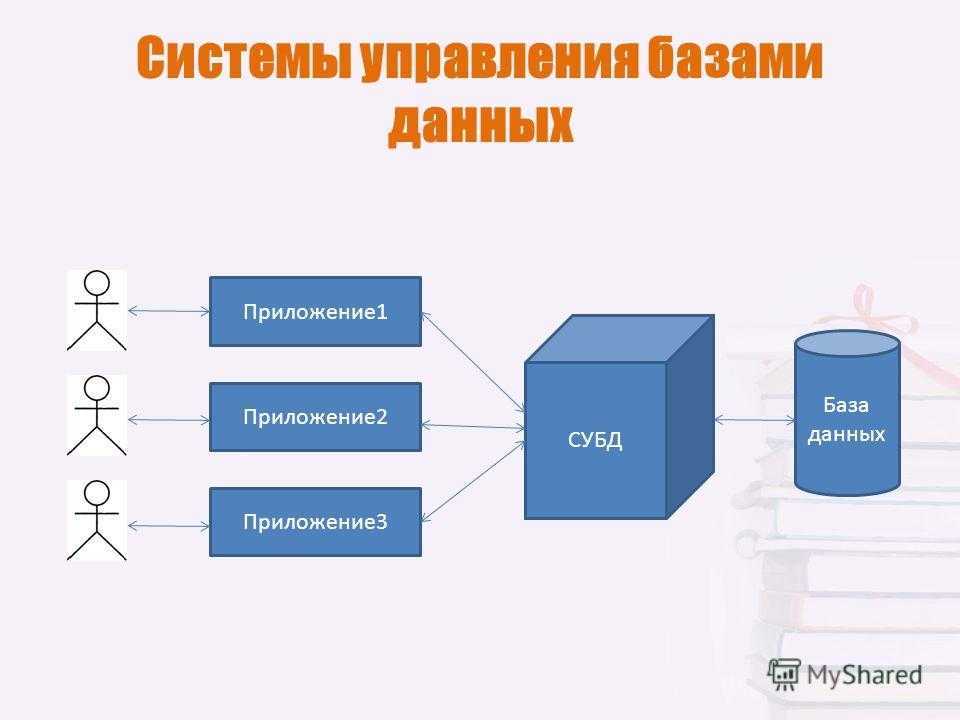
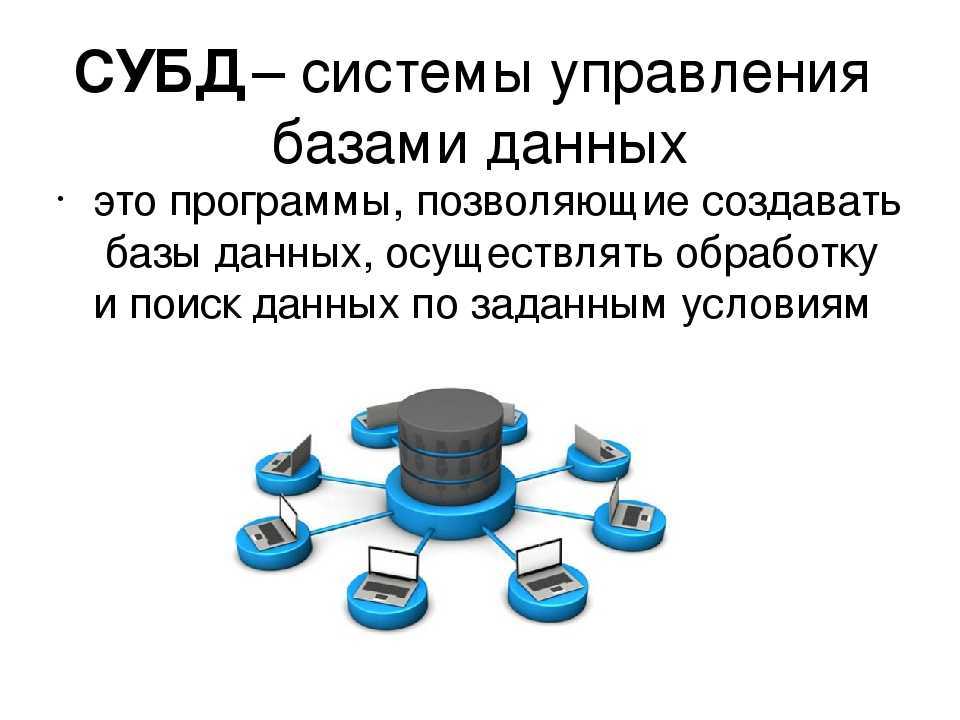
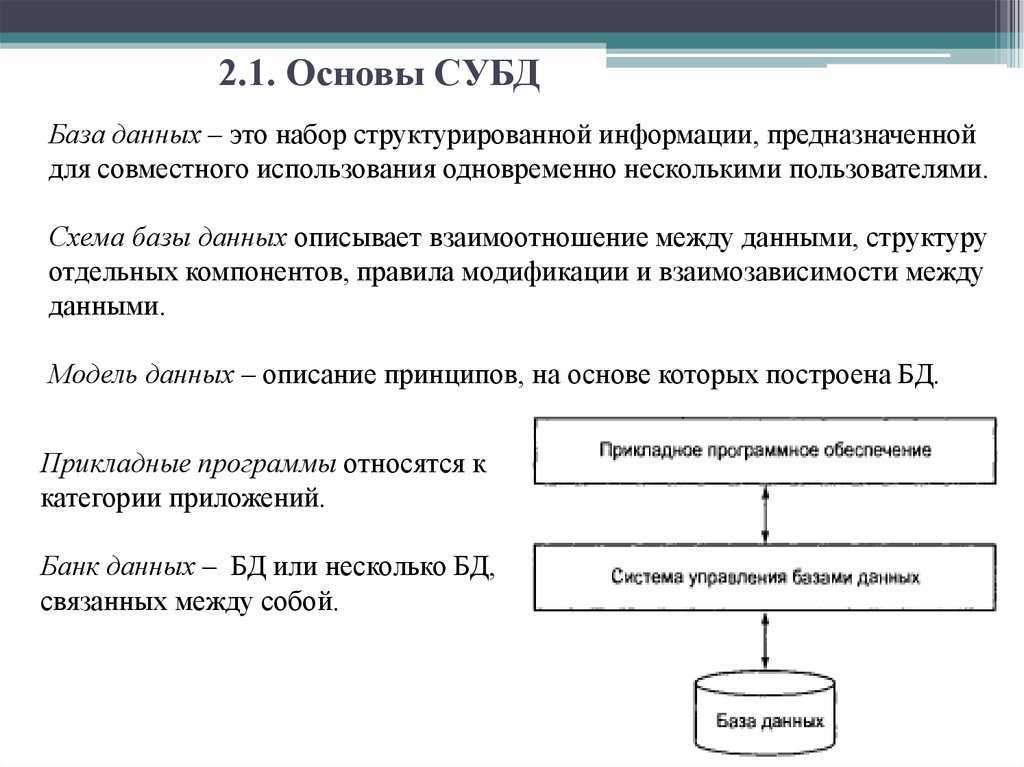
Реляционные СУБД
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа — Oracle, Microsoft SQL, PostgreSQL, MySQL.
Когда выбирать реляционную СУБД
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Когда не выбирать реляционную СУБД
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится «дорого» в реляционных СУБД, и нужно применять «продвинутую магию» что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
Что нового в PostgreSQL 10?
Начиная с PostgreSQL 10, меняется схема нумерации версий, это вызвано тем, что раньше выходило множество минорных версий (например, 9.x), многие из которых на самом деле вносили значительные изменения не соответствующие минорным, теперь мажорные версии будут нумероваться 10, 11, 12, а минорные 10.1, 10.2, 11.1 и так далее.
Основные нововведения:
- Логическая репликация с использованием публикации и подписки — теперь возможно осуществлять репликацию отдельных таблиц на другие базы, это реализовывается с помощью команд CREATE PUBLICATION и CREATE SUBSCRIPTION;
- Декларативное партиционирование таблиц – в PostgreSQL 10 добавился специальный синтаксис для партиционирования, который позволяет легко создавать и поддерживать таблицы с интервальной или списочной схемой партиционирования;
- Улучшенный параллелизм запросов – другими словами, появилась дополнительная оптимизация запроса, для того чтобы пользователь получал данные быстрей;
- Аутентификация пароля на основе SCRAM-SHA-256 – добавился новый метод аутентификации, который является более безопасным, чем метод с использованием MD5;
- Quorum Commit для синхронной репликации – теперь администратор может указать что, если какое-либо количество реплик подтвердило, что внесено изменение в базу данных, данное изменение можно считать надёжно зафиксированным;
- Значительные общие улучшения производительности;
- Улучшенный мониторинг и контроль.
Более детально обо всех нововведениях можете почитать на официальном сайте – PostgreSQL 10.
Информация о текущих настройках сервера
В PostgreSQL есть 2 представления через которые можно посмотреть текущие настройки сервера:
- pg_file_settings – какие параметры записаны в файлах postgresql.conf и postgresql.auto.conf;
- pg_settings – текущие параметры, с которыми работает сервер.
Например посмотрим значение параметра config_file из представления pg_settings, который покажет конфигурационный файл текущего кластера:
postgres@postgres=# SELECT setting FROM pg_settings WHERE name = 'config_file';
setting
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 1,844 ms
Внесём изменения в параметр work_mem в postgresql.conf и postgresql.auto.conf. Затем посмотрим на все не закомментированные параметры в этих файлах:
postgres@postgres=# \! echo 'work_mem = 8MB' >> $PGDATA/postgresql.conf
postgres@postgres=# ALTER SYSTEM SET work_mem TO '10MB';
ALTER SYSTEM
Time: 0,728 ms
postgres@postgres=# SELECT sourceline, name, setting, applied FROM pg_file_settings;
sourceline | name | setting | applied
------------+----------------------------+--------------------+---------
63 | port | 5433 | f
64 | max_connections | 100 | t
121 | shared_buffers | 128MB | t
142 | dynamic_shared_memory_type | posix | t
228 | max_wal_size | 1GB | t
229 | min_wal_size | 80MB | t
563 | log_timezone | Europe/Moscow | t
678 | datestyle | iso, dmy | t
680 | timezone | Europe/Moscow | t
694 | lc_messages | ru_RU.UTF-8 | t
696 | lc_monetary | ru_RU.UTF-8 | t
697 | lc_numeric | ru_RU.UTF-8 | t
698 | lc_time | ru_RU.UTF-8 | t
701 | default_text_search_config | pg_catalog.russian | t
780 | work_mem | 8MB | f
3 | work_mem | 10MB | t
(16 rows)
Time: 0,650 ms
Как можно заметить в примере выше, у меня 2 одинаковых параметра work_mem. Колонка applied показывает, может ли быть применён параметр. Первый work_mem не может быть применен, так как второй его перезапишет. При этом реальное значение с которым работает сервер отличается, так как сервер не перечитал конфигурацию.
Теперь посмотрим на реальное, текущее значение этого параметра:
postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'\gx ----+--------- name | work_mem setting | 4096 unit | kB boot_val | 4096 reset_val | 4096 source | default sourcefile | sourceline | pending_restart | f context | user Time: 0,854 ms
В примере выше мы использовали расширенный режим (в конце запроса \gx), поэтому табличка перевёрнута. Разберём колонки:
- name – имя параметра;
- setting – текущее значение;
- unit – единица измерения;
- boot_val – значение по умолчанию (жёстко задано в коде postgresql);
- reset_val – если перечитаем конфигурацию, то применится это значение;
- source – источник, это значение по умолчанию;
- sourcefile – если бы источником был конфигурационный файл, то тут был бы указан этот файл;
- sourceline – номер строки в этом файле;
- pending_restart – параметр изменили в конфигурационном файле и требуется перезапуск сервера. У нас требуется всего лишь перечитать конфигурацию;
-
context – действия, необходимые для применения параметра, может быть таким:
- internal – изменить нельзя, задано при установке;
- postmaster – требуется перезапуск сервера;
- sighup – требуется перечитать файлы конфигурации;
- superuser – суперпользователь может изменить для своего сеанса;
- user – любой пользователь может изменить для своего сеанса на лету.
Перечитаем конфигурацию сервера:
postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 3,178 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'\gx ----+------------------------------------------- name | work_mem setting | 10240 unit | kB boot_val | 4096 reset_val | 10240 source | configuration file sourcefile | /usr/local/pgsql/data/postgresql.auto.conf sourceline | 3 pending_restart | f context | user Time: 1,210 ms
Как видим, параметр изменился. Он был взят из postgresql.auto.conf и теперь равняется 10 MB.
Step 1 – Downloading the installer for Windows
As mentioned earlier, PostgreSQL is implemented for many platforms, but since we will be installing PostgreSQL on Windows, we need a Windows installer accordingly. You can of course download this distribution from the official PostgreSQL website, here is the download page – https://www.postgresql.org/download/windows/.
After going to the page you need to click on the link “Download the installer”, as a result you will be taken to the site of EnterpriseDB, which prepares graphical distributions of PostgreSQL for many platforms, including Windows, so you can immediately go to this site, here is the link to the download page https://www.enterprisedb.com/downloads/postgres-postgresql-downloads.

Here you need to select the PostgreSQL version and platform, in our case choose PostgreSQL 12 and Windows x86-64.
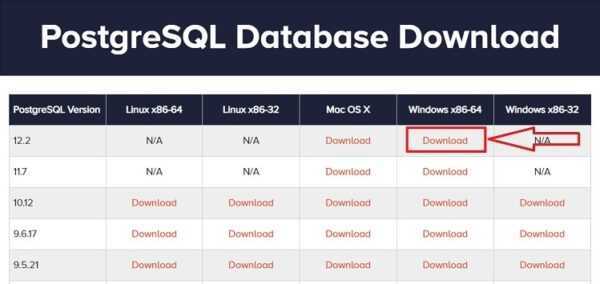
As a result, you should download the file postgresql-12.2-2-windows-x64.exe with the size of about 191 Mbytes (version 12.2-2 is available at the time of writing).
Конфигурационный файл postgresql.conf
Главный конфигурационный файл для кластера PostgreSQL – это postgresql.conf, в разных системах он может находится в разных местах. Так как мы собирали сервер из исходников и не меняли путь хранения этого файла, то по умолчанию он будет находится в каталоге PGDATA:
postgres@s-pg13:~$ echo $PGDATA /usr/local/pgsql/data postgres@s-pg13:~$ ls -l $PGDATA/postgresql.conf -rw------- 1 postgres postgres 28023 июн 21 15:15 /usr/local/pgsql/data/postgresql.conf
Этот конфигурационный файл читается один раз при запуске сервера. Если параметр указан несколько раз, то применяется последний.
Самый точный способ узнать расположение этого файла, посмотреть из терминала psql:
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SHOW config_file;
config_file
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 0,391 ms
postgres@postgres=# \q postgres@s-pg13:~$ pg_ctl reload server signaled
Второй способ – из терминала psql:
postgres@s-pg13:~$ psql Timing is on. psql (13.3) Type "help" for help. postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 0,555 ms
Но есть некоторые параметры, для изменения которых потребуется перезапуск сервера.
Участники опроса
Как и следовало ожидать, исходя, например, из анализа материалов конференции INFOSTART EVENT 2018, более 51% опрошенных работают в коммерческих компаниях не ИТ-специализации. Это само по себе делает результаты опроса интересными, поскольку они в существенной степени отражают ситуацию с тем, кто и как использует СУБД для 1С в реальных условиях бизнеса.
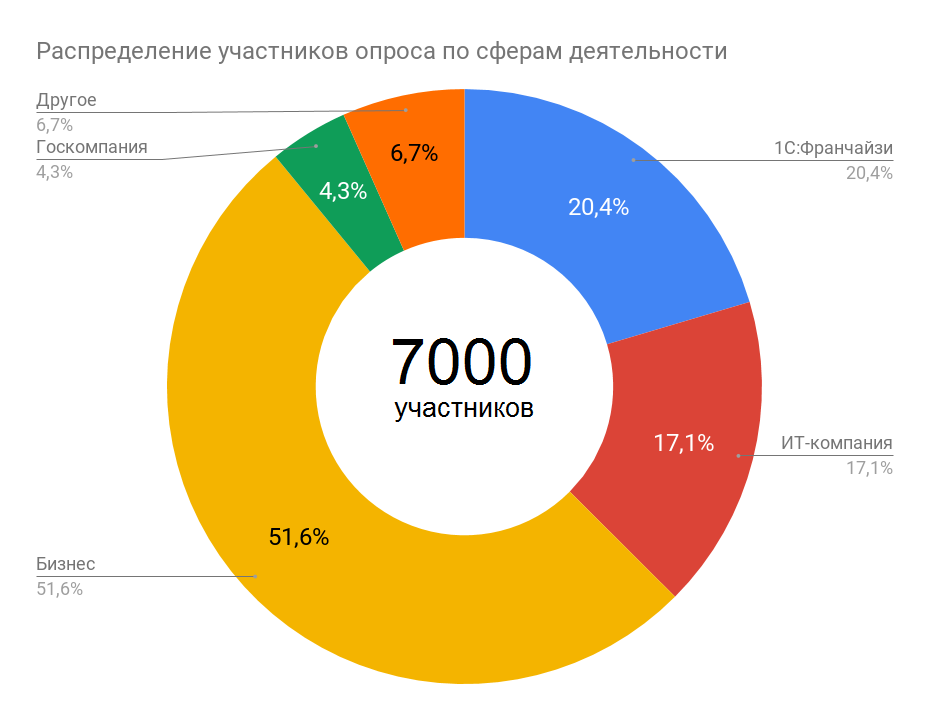
1С:Франчайзи – примерно пятая часть респондентов, чуть меньше доля среди опрошенных у ИТ-компаний (не франчайзи 1С) – около 17%. Работники государственных предприятий составили лишь порядка 4%, что можно объяснить не только строгой конфиденциальностью, но и отсутствием желания свидетельствовать, что госструктуры все еще сильно зависят от зарубежных ИТ.
Масштабы нагрузки на систему
Вместе с тем, мы полагаем, что таких параметров, как объем основной БД и число одновременно работающих с ней пользователей, достаточно для общего понимания того, с какими задачами сталкиваются владельцы и администраторы СУБД.
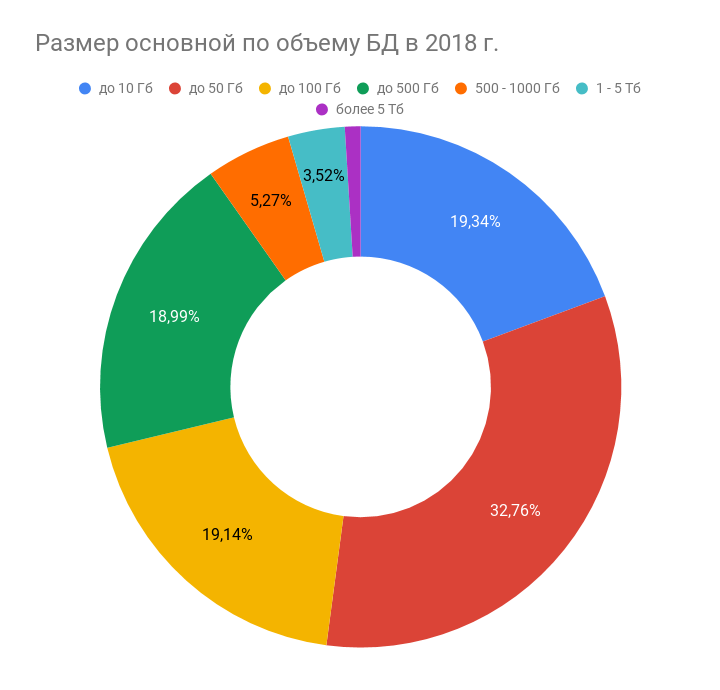
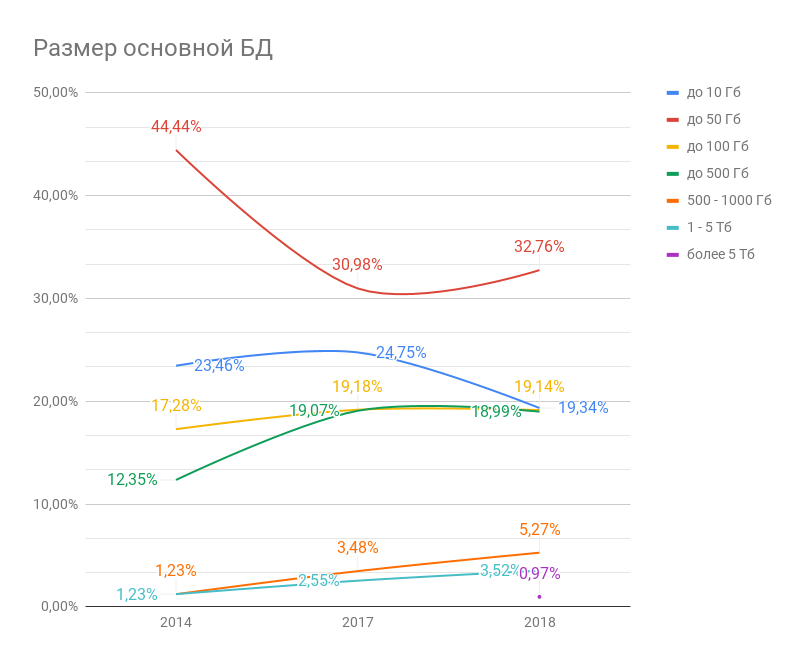
Чаще всего размер основной базы данных не превышает 50 Гб, причем это утверждение справедливо для всех трех опросов. Если говорить о тенденциях, то за прошедший год сократилось число компаний с небольшими БД до 10 Гб и стало больше тех, кто использует тяжеловесные базы, от 500 Гб. Так, в 2014 году крупными БД пользовались, согласно опросу, всего несколько человек, а спустя 4 года их стало 640, или 10% опрошенных. Поэтому сегодня основная база данных для 1С объемом от 1 Тб – уже не редкость.
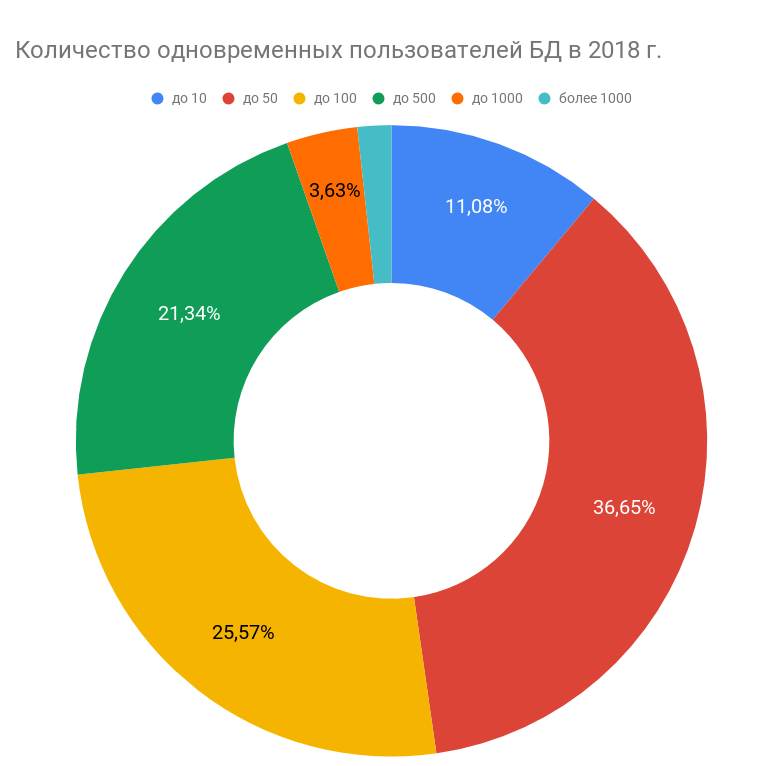
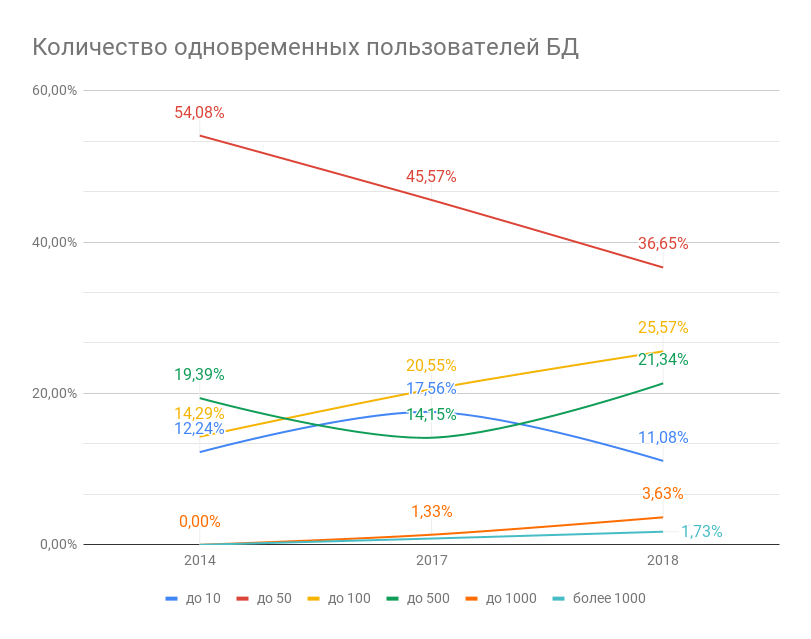
Аналогичная тенденция наблюдается и с числом одновременно работающих с базой пользователей. Количество систем с нагрузкой от 50 пользователей и выше растет и уже составляет более 52%, в то время как систем с низкой нагрузкой становится заметно меньше. При этом, как демонстрирует опрос 2018 года, чем больше объем базы, тем, как правило, выше число одновременных ее пользователей на пике активности. Тем не менее, пока наиболее типичный порядок нагрузки на СУБД – от 10 до 50 параллельных пользователей.
Мета-команды PostgreSQL
Теперь, когда ты все настроил и готов приступить к работе с базой данных, осталось разобрать несколько мета-команд.
Это не SQL запросы, а команды специфичные для PostgreSQL.
В других системах управления базами данных есть их аналоги, но их синтаксис немного отличается.
Всем мета-командам предшествует обратная косая черта , за которой следует фактическая команда.
Список всех баз данных
Чтобы получить список всех баз данных на сервере, ты можешь использовать команду .
Ввод этой мета-команды в оболочке Postgres выведет:
Это список всех имеющихся баз данных и служебная информация, такая как владелец базы данных, кодировка и права доступа.
На данный момент мы пока ничего не создали, а базы данных которые ты видишь на экране — создаются по умолчанию при установке Postgres.
- postgres — это просто пустая база данных.
- «template0» и «template1» — это служебные базы данных, которые служат шаблоном для создания новых баз.
Тебе пока не стоит беспокоиться о них. Если хочешь изучить все детали, то проверь официальную документацию.
Подключаемся к базе данных PostgreSQL
Некоторые команды SQL требуют, чтобы ты сначала вошел в базу данных (например, для создания новой таблицы).
Ты можешь выбрать, в какую базу данных входить, при запуске SQL Shell.




Когда ты находишься внутри оболочки (shell), то можешь использовать команду (или ), за которой следует имя
базы данных. Если бы у тебя была другая база данных под названием , то подключиться к ней можно было бы так:
Полностью в терминале у тебя получится что-то такое:
Обрати внимание, что приглашение оболочки изменилось с на. Это значит, что теперь ты
подключен к базе данных , а не
Получить список всех таблиц в базе данных
Как и в случае со списком существующих баз данных, ты можешь получить список таблиц внутри конкретной базы данных
с помощью команды .
Перед выполнением этой команды вам необходимо войти в базу данных.
Предположим, ты уже находишься внутри базы , и в ней есть таблица с именем. Набрав , ты
получишь следующее:
Ты можешь увидеть имя таблицы и некоторую другую информацию, такую как схема (мы обсудим схемы в более сложных
руководствах) и владельца.
Владелец (owner) — это пользователь, который создал таблицу.
Если ты создаешь других пользователей и используешь их для создания таблиц, то в последнем столбце будут именно они.
Список пользователей и ролей
Как ты уже знаешь, при установке Postgres создается суперпользователь с именем .
Список всех пользователей базы данных можно вывести на экран используя команду .
Обрати внимание, что первый столбец называется — роль (role name).
И весь вывод на экран называется “список ролей” (List of roles), а не список пользователей. В PostgreSQL пользователи и роли практически
одинаковы
В PostgreSQL пользователи и роли практически
одинаковы.
У ролей есть атрибуты, которые определяют их разрешения, такие как создание баз данных или даже создание
других новых ролей.
Любая роль с атрибутом LOGIN может рассматриваться, как пользователь.
Здесь мы видим только одну роль, суперпользователя по умолчанию.
В реальном мире все будет иначе, потому что использовать только суперпользователя все время опасно.
Вместо этого создают другие роли с меньшими привилегиями.
Это гарантирует, что никто не совершит нежелательных действий по ошибке.
Если у одной из ролей есть доступ только на чтение данных, то с помощью этой роли будет невозможно удалить таблицу или поле.
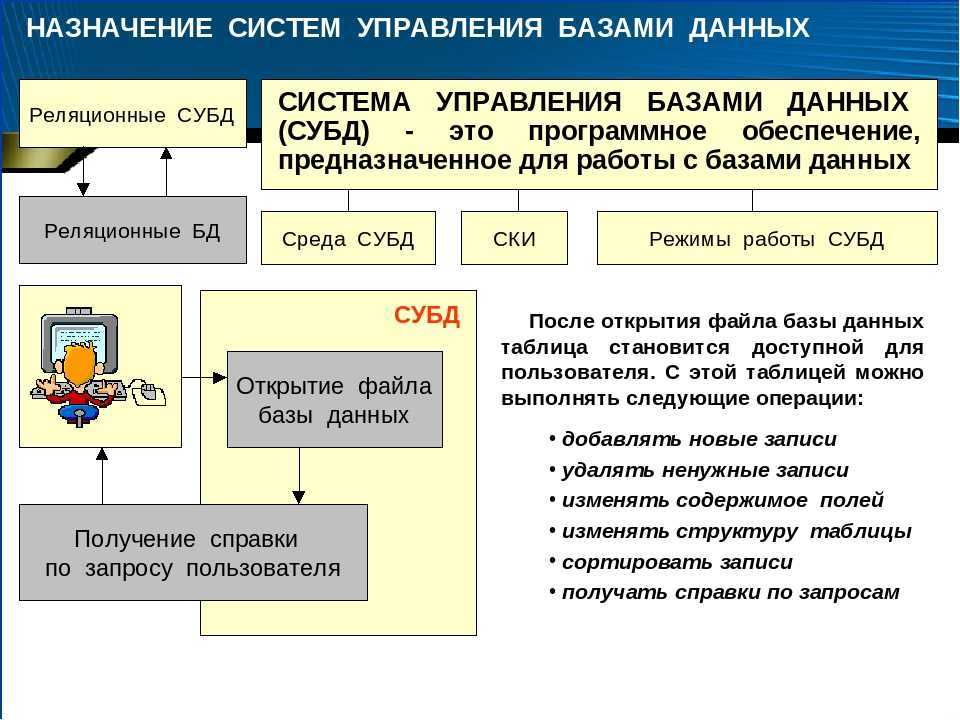
Подключение к СУБД
В процессе инсталляции, программа автоматически создает пользователя базы данных с правами администратора – postgres. Войти в СУБД на данный момент можно только через эту учетную запись. Следует добавить созданного пользователя в группу sudo:
usermod -a -G sudo postgres
Установить для него пароль:
passwd postgres
Выполнить запуск оболочки программы, можно переключившись на сессию учетной записи. Для этого используется команда:
sudo su - postgres psql
Ее можно также запустить, не переключая сессию от имени postgres:
sudo -u postgres psql
Для выхода из командной строки нужно ввести команду:
q
Запустите установку
Когда программа попросит выбрать один из вариантов, сделайте следующее:
- Когда вас попросят выбрать локаль, выберите UTF-8. Если варианта UTF-8 в списке нет, выберите вариант UTF-8 в списке локалей для языка. Например, en_US.UTF-8 для английского языка США;
- Если программа попросит установить StackBuilder – он инсталлирует некоторые дополнительные инструменты Web, репликации и ODBC, которые не требуются для CollectionSpace. Но может потребоваться инсталляция некоторых модулей PostgreSQL, таких как PostGIS.
Обратите внимание, что некоторые из перечисленных выше параметров могут не отображаться в зависимости от версии PostgreSQL и операционной системы
Проверка репликации
Посмотреть статус
Статус работы репликации можно посмотреть следующими командами.
На мастере:
=# select * from pg_stat_replication;
На слейве:
=# select * from pg_stat_wal_receiver;
Создать тестовую базу
На мастере заходим в командную оболочку Postgre:
su — postgres -c «psql»
Создаем новую базу данных:
=# CREATE DATABASE repltest ENCODING=’UTF8′;
Теперь на вторичном сервере смотрим список баз:
su — postgres -c «psql»
=# \l
Мы должны увидеть среди баз ту, которую создали на первичном сервере:
Name | Owner | Encoding | Collate | Ctype | Access
————+———-+———-+————-+————-+——————
…
repltest | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
…




Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Входим в систему под пользователем postgres:
su — postgres
Создаем нового пользователя для репликации:
createuser —replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
exit
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su — postgres -c «psql -c ‘SHOW config_file;'»
В моем случае система вернула строку:
/etc/postgresql/9.6/main/postgresql.conf
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
vi /etc/postgresql/9.6/main/postgresql.conf
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.10’
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
* где
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
vi /etc/postgresql/9.6/main/pg_hba.conf
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться
Шаг 4. Создание новой роли
Если вы производили установку по инструкции, то к этому моменту в вашей СУБД есть только одна роль — postgres. Рекомендуется не использовать данную роль для работы со своими базами данных, а создавать для каждой базы новую роль (или несколько при необходимости). Для создания новой роли предусмотрены два стандартных способа:


- интерактивный режим, в котором достаточно ответить на несколько простых вопросов;
- команда для создания роли через командную строку СУБД.
Мы не будем подробно останавливаться на интерактивном режиме, так как создать роль, которая полностью удовлетворяет требованиям в большинстве случаев, мы можем всего одной простой командой (перед этим нужно находиться в режиме командной строки как было описано на Шаге 3). Не забудьте заменить username на желаемое имя пользователя, а password — на пароль для этого пользователя:
create user username with password 'password';
Имя указывается без кавычек, а пароль — в одинарных кавычках.
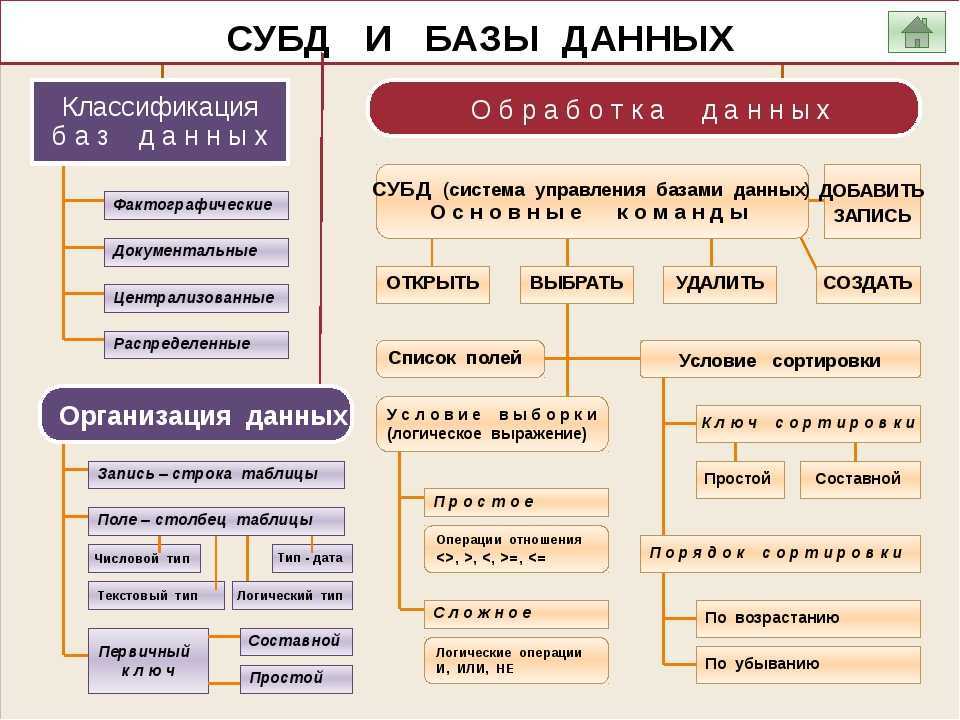
Итоги
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД
Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро. В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей
В данной статье я намеренно не делаю акцент на выбор между облачными и on-premise решениями — эта тема одной из следующих статей.
Итак, в таблице представленной ниже, кратко собрано то, что описано выше в статье.
|
Тип СУБД |
Когда выбирать |
Примеры популярных СУБД |
|
Реляционные |
Нужна транзакционность; высокая нормализация; большая доля операций на вставку |
Oracle, MySQL, Microsoft SQL Server, PostgreSQL |
|
Ключ-значение |
Задачи кэширования и брокеры сообщений |
Redis, Memcached |
|
Документные |
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON |
CouchDB, MongoDB, Amazon DocumentDB |
|
Графовые |
Задачи подобные социальным сетям; системы оценок и рекомендаций |
Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid |
|
Колоночные |
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов |
Vertica, ClickHouse, Google BigTable, Sybase \ SAP IQ, InfoBright, Cassandra |
Надеюсь данная статья оказалась полезной.
В следующих статьях посмотрим на выбор между облачными и on-premise СУБД, платными и бесплатными, и многое другое.