
Введение
В своей инструкции по установке и настройке zabbix я вообще не затрагиваю вопрос базы данных mysql или производительности сервера в целом. Я просто беру дефолтные настройки mariadb, которые идут с установкой и использую их. Когда у вас не очень большая инфраструктура на мониторинге этого вполне достаточно, чтобы нормально пользоваться системой.
Если вы активно используете zabbix и внедряете его повсеместно во все используемые системы (а я рекомендую так делать), то вы рано или поздно столкнетесь с вопросом производительности системы мониторинга и размера базы данных zabbix.
Тема производительности zabbix очень индивидуальная. Она напрямую зависит от того, как вы его используете, а схемы мониторинга могут быть очень разные. Одно дело мониторить несколько серверов, а другое дело нагруженные свичи на 48 портов со съемом метрик с каждого порта раз в 30 секунд.
Чтобы помочь вам разобраться в этой теме и прикинуть, к чему готовиться, я поделюсь с вами своим опытом эксплуатации заббикса, его нагрузки, производительности и обслуживания базы данных mysql. Расскажу, как можно уменьшить размер базы.
Использование распространенных инструментов
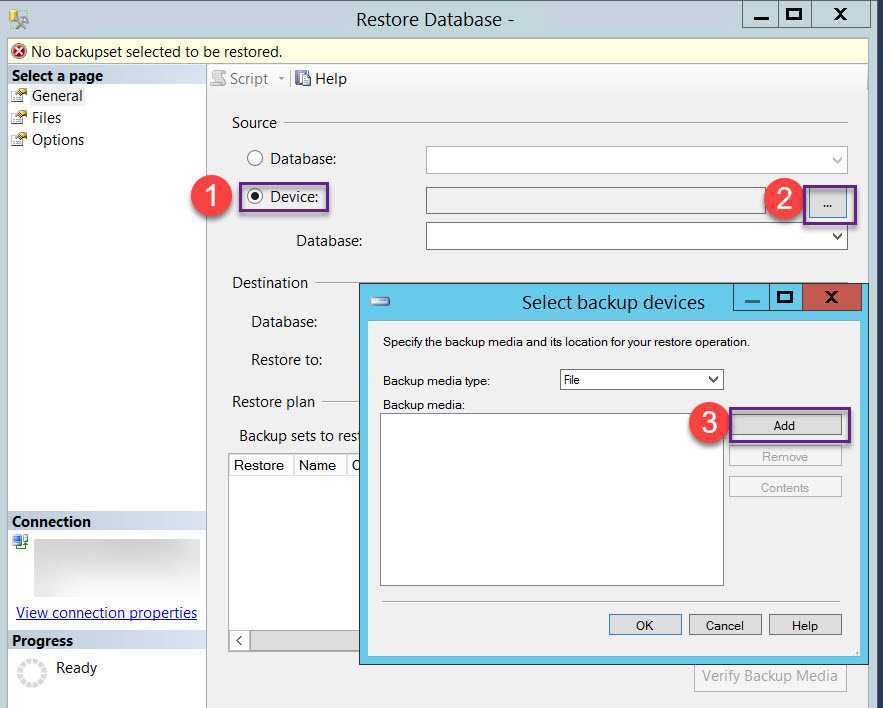
Используйте распространенные инструменты и служебные программы, такие как MySQL Workbench или mysqldump, для удаленного подключения и восстановления данных в Базу данных Azure для MariaDB. Используйте эти инструменты на своем клиентском компьютере, подключенном к Интернету, чтобы подключиться к Базе данных Azure для MariaDB. В целях безопасности рекомендуется использовать подключение с шифрованием SSL. Дополнительные сведения см. в статье Настройка SSL-подключения в Базе данных Azure для MariaDB. При переносе данных в Базу данных Azure для MariaDB не нужно перемещать файлы дампа в особое облачное расположение.
Саги
Cага (saga) по своему дизайну представляет собой алгоритм, который координирует многочисленные изменения в состоянии, но позволяет избегать необходимости запирания ресурсов на «замок» в течение длительного периода времени. Мы делаем это путем моделирования шагов, привлекаемых в качестве дискретных действий, которые исполняются независимо.
На рис. 7 изображен простой поток исполнения заказа. Здесь процесс исполнения заказа представлен как одна сага, причем каждый шаг в этом потоке представляет собой операцию, которая выполняется другой службой. В каждой службе любое изменение состояния регулируется в рамках локальной ACID-транзакции.
Рис. 7 — Пример потока исполнения заказа наряду со службами,
ответственными за проведение операции.
Когда сага разбивается на отдельные транзакции, нужно подумать о том, как восстанавливаться, когда происходит сбой.
Обратное восстановление предусматривает отмену сбоя с возвратом назад и последующую очистку — откат. Чтобы это работало как надо, необходимо определить компенсирующие действия, которые позволят отменять ранее совершенные транзакции. Прямое восстановление позволяет восстанавливаться из точки, где произошел сбой, и продолжать обработку. А для того чтобы и это работало как надо, необходимо, чтобы была возможность делать повторные попытки транзакций.
В зависимости от природы моделируемого бизнес-процесса вы можете предусмотреть, чтобы любой режим сбоя запускал обратное восстановление, прямое восстановление или, возможно, их смесь.
Откаты в саге. С сагой у нас вовлечены многочисленные транзакции, и некоторые из них, возможно, уже зафиксированы до того, как мы решим откатить всю операцию. Давайте вернемся к нашему примеру с обработкой заказа. Возьмем потенциальный режим сбоя. Мы дошли до попытки упаковать товарную позицию и обнаружили, что указанная товарная позиция на складе не найдена. Проблема в том, что мы уже приняли оплату и присудили за заказ баллы за лояльность. Вместо этого, если вы хотите реализовать откат, то вам нужно реализовать компенсирующую транзакцию. Компенсирующая транзакция — это операция, которая отменяет ранее зафиксированную транзакцию. Для отката процесса исполнения заказа запускаем компенсирующую транзакцию для каждого шага нашей саги, которая уже была зафиксирована.
Рис. 8 – Запуск отката всей саги.
Ротация логов MariaDB
Откроем необходимый файл и сделаем необходимые изменения:
vim /etc/logrotate.d/mysql
= часть вывода с необходимыми изменениями =
/var/lib/mysql/*log {
# create 600 mysql mysql
notifempty
daily
size 5M
rotate 7
missingok
compress
postrotate
# just if mysqld is really running
if test -x /usr/bin/mysqladmin && \
/usr/bin/mysqladmin ping &>/dev/null
then
/usr/bin/mysqladmin --local flush-error-log \
flush-engine-log flush-general-log flush-slow-log
fi
endscript
}
Мы указали что надо ротировать все логи и хранить 7 дней при условии что размер файла 5 Mегабайт.
Сохраним и применим изменения без перезагрузки:
logrotate /etc/logrotate.conf
Проверим правильность выполнив тестирование (опция -d):
logrotate -d /etc/logrotate.d/mysql = вывод команды = reading config file /etc/logrotate.d/mysql Allocating hash table for state file, size 15360 B Handling 1 logs rotating pattern: /var/lib/mysql/*log 5242880 bytes (7 rotations) empty log files are not rotated, old logs are removed considering log /var/lib/mysql/mysql_error.log log does not need rotating (log size is below the 'size' threshold) considering log /var/lib/mysql/slow_queries.log log does not need rotating (log size is below the 'size' threshold) considering log /var/lib/mysql/tc.log log does not need rotating (log size is below the 'size' threshold)
Все логи не имеют необходимого размера для выполнения ротации.
Что такое сжатие в Microsoft SQL Server?
Сжатие — это процесс удаления неиспользуемого пространства в файлах базы данных и журнала транзакций.
Физический размер файлов базы данных со временем растет, это связанно с добавлением данных, но при их удалении физический размер файлов остается неизменным, однако в данных файлах появляется логическое неиспользуемое пространство, которое и можно удалить.
Наибольший эффект от сжатия достигается тогда, когда операция сжатия выполняется после операции удаления таблиц из БД или удаления данных из таблиц.
Следует отличать процедуру сжатия журнала транзакций от процедуры усечения журнала транзакций. Сжатие — это уменьшение физического размера журнала за счет удаления неиспользуемого пространства, а усечение – это освобождение места в логическом журнале для повторного использования (т.е. образуется неиспользуемое пространство) журналом транзакций при этом размер физического файла не уменьшается.
Усечение журнала транзакций происходит автоматически:
- В простой модели восстановления — после достижения контрольной точки, которая может возникнуть, например, после создания BACKUP базы данных, при явном выполнении инструкции CHECKPOINT, или тогда когда размер логического журнала транзакций заполняется на 70 процентов, во всех этих случаях происходит автоматическая очистка неактивной части журнала, т.е. его усечение;
- В модели полного восстановления или в модели восстановления с неполным протоколированием — после создания резервной копии журнала при условии, что с момента создания последней резервной копии журнала была достигнута контрольная точка.
Если Вы используете модель полного восстановления или в модель восстановления с неполным протоколированием и у Вас файлы журнала транзакций слишком велики, то скорей всего Вы достаточно долго не делали BACKUP (резервную копию) журнала транзакций. В данном случае Вам необходимо сделать сначала BACKUP журнала транзакций, а затем выполнить сжатие журнала транзакций, которое мы как раз и рассмотрим чуть ниже.
Также возможно размер файлов журнала транзакций слишком большой (как при простой, так и при полной модели восстановления) за счет задержки процедуры усечения, т.е. размер журнала, состоит в основном из активной части журнала, а активную часть усечь нельзя, поэтому физический размер журнала растет. На задержку процедуры усечения влияют такие факторы как: активные длительные транзакции, некоторые сценарии отображения зеркальных баз данных и журнала транзакций, некоторые сценарии при репликации транзакций и журнала транзакций, а также усечение журнала невозможно во время операций резервного копирования и восстановления данных. В данном случае Вам нужно устранить причины задержки, затем сделать усечение (т.е. например, для полной модели восстановления BACKUP журнала), а затем сжатие до приемлемых размеров.
Обычно если на постоянной основе с определенной периодичностью создаются резервные копии журнала транзакций или базы данных (при простой модели восстановления), файлы журнала транзакций не растут, и не возникает переполнение журнала транзакций.
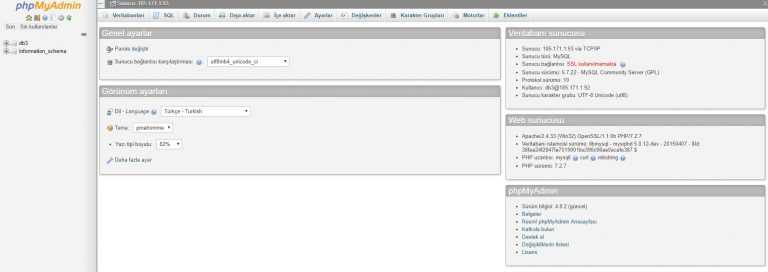
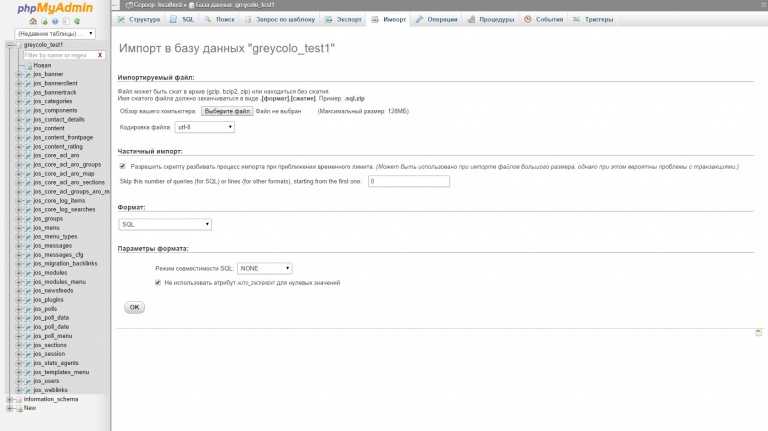
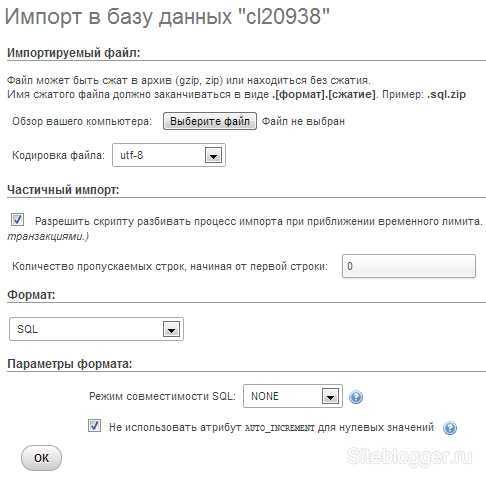
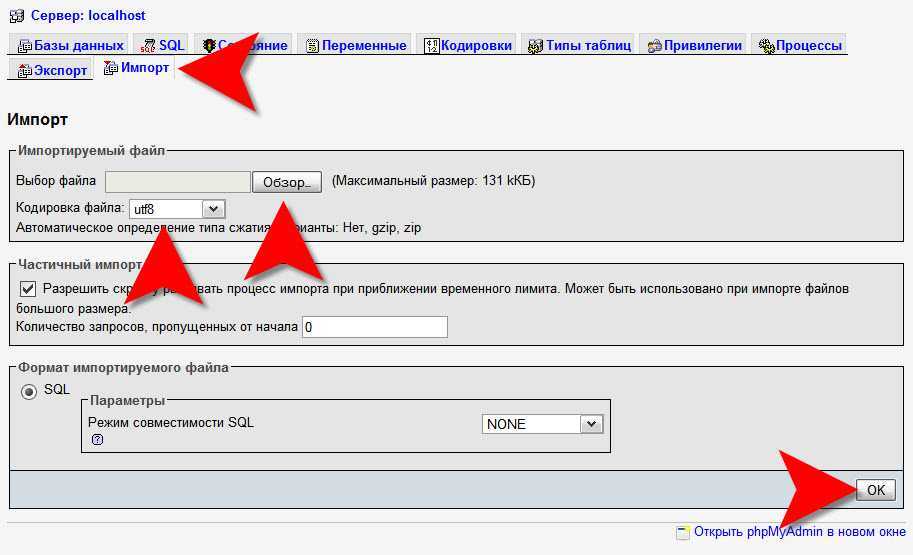
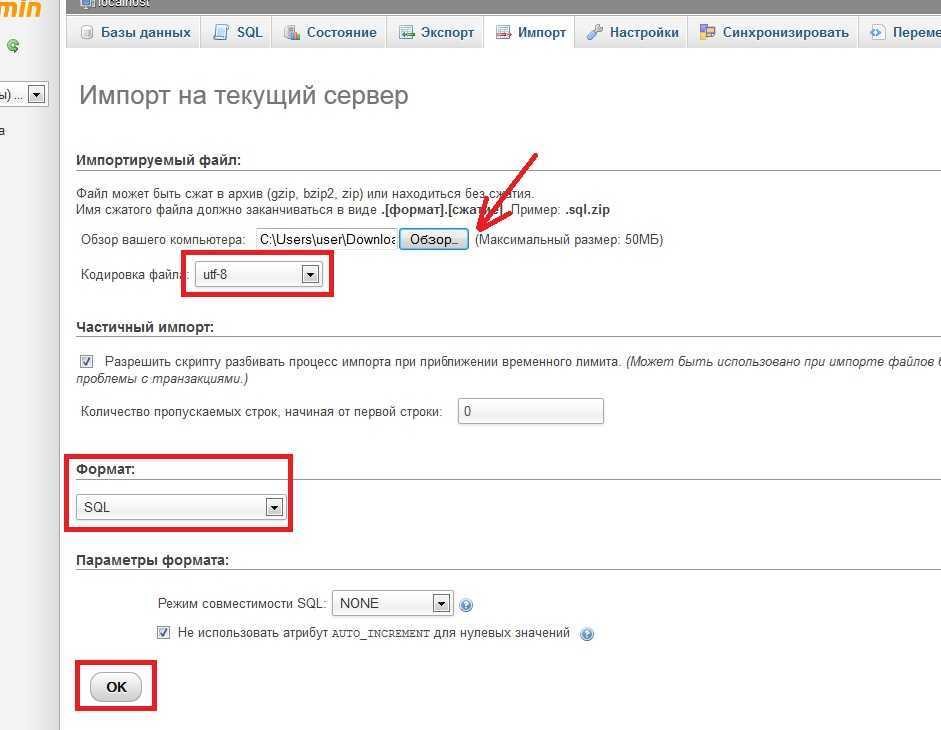
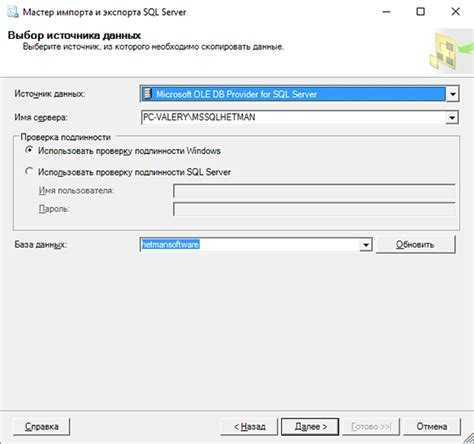
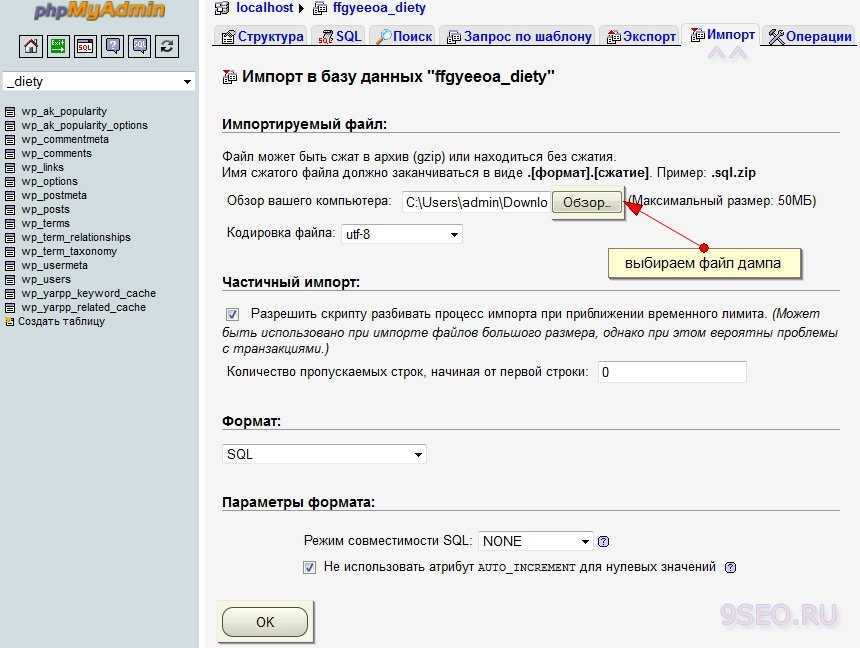
Импорт базы данных с помощью phpMyAdmin
Процесс импорта аналогичен процессу экспорта. Выполните следующие действия:
- Откройте phpMyAdmin.
- На странице настройки phpMyAdmin выберите Добавить, чтобы добавить Базу данных Azure для сервера MariaDB.
- Укажите сведения о подключении и учетные данные.
- Создайте базу данных, присвоив ей соответствующее имя. Затем выберите эту базу данных на левой панели. Чтобы перезаписать существующую базу данных, щелкните имя базы данных, установите все флажки рядом с именами таблиц, а затем выберите Удалить, чтобы удалить существующие таблицы.
- Щелкните ссылку SQL, чтобы отобразилась страница, на которой можно ввести команды SQL или передать файл SQL.
- Нажмите кнопку обзора, чтобы найти файл базы данных.
- Нажмите кнопку Перейти, чтобы экспортировать резервную копию, выполнить команды SQL и повторно создать базу данных.
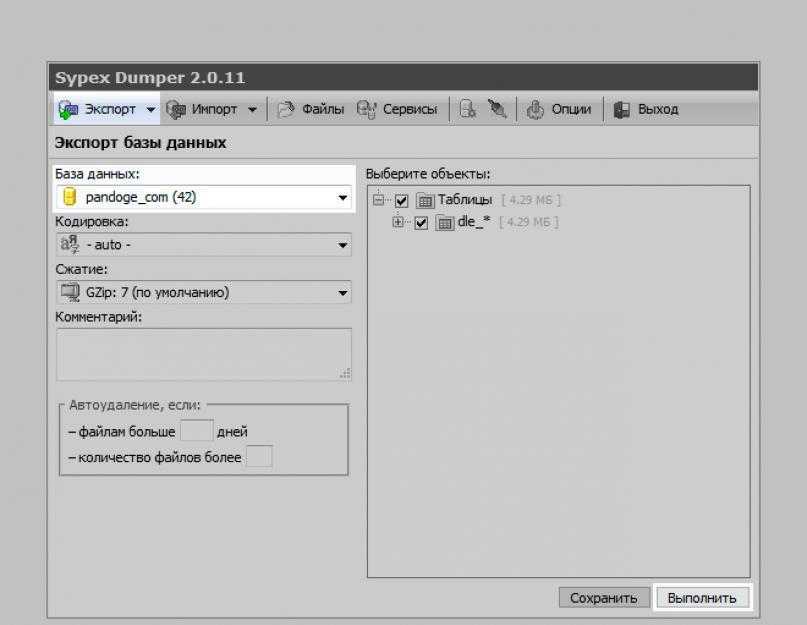
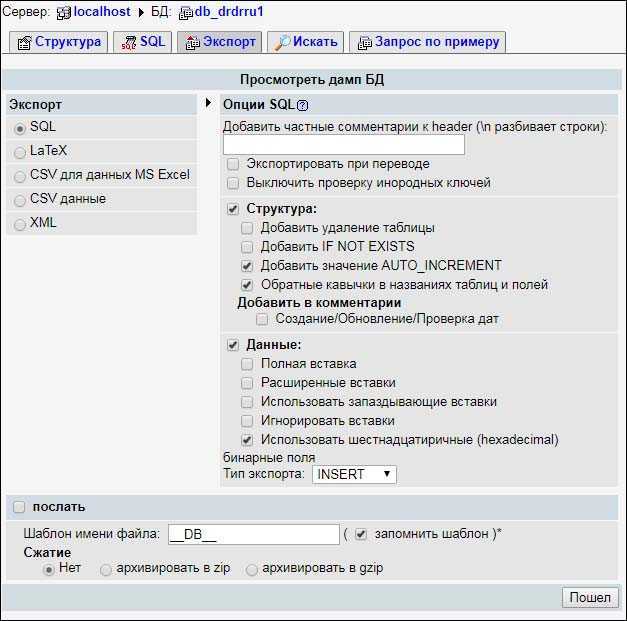
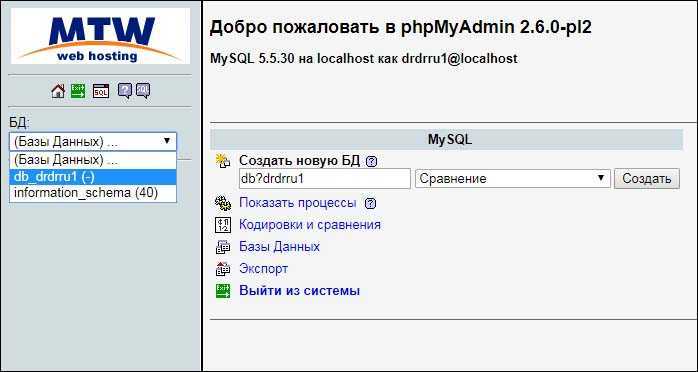
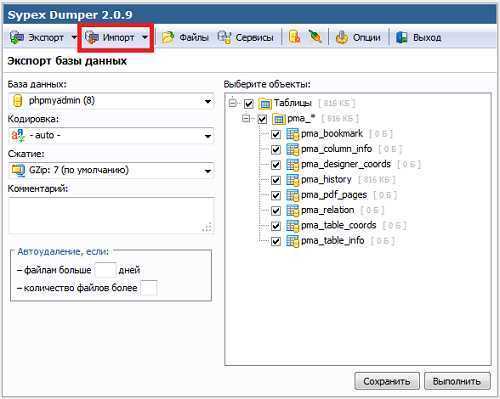
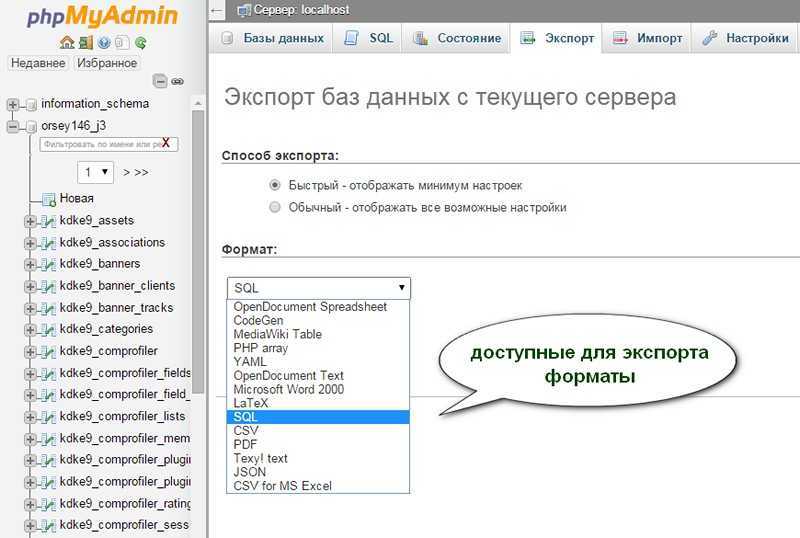
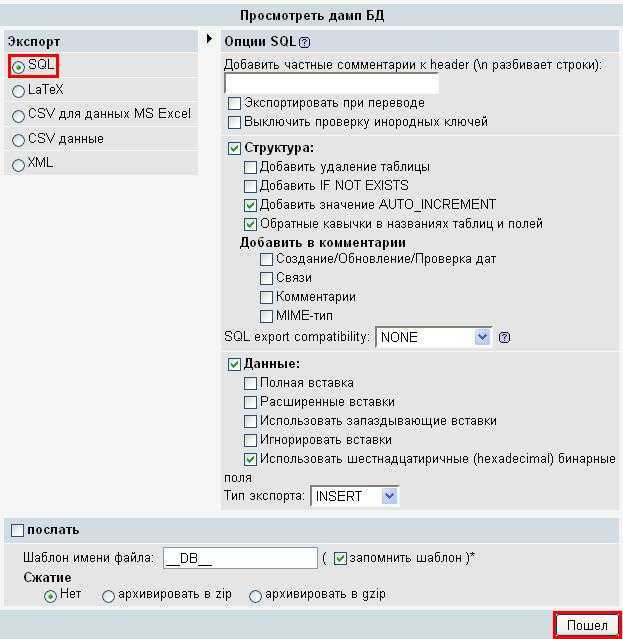
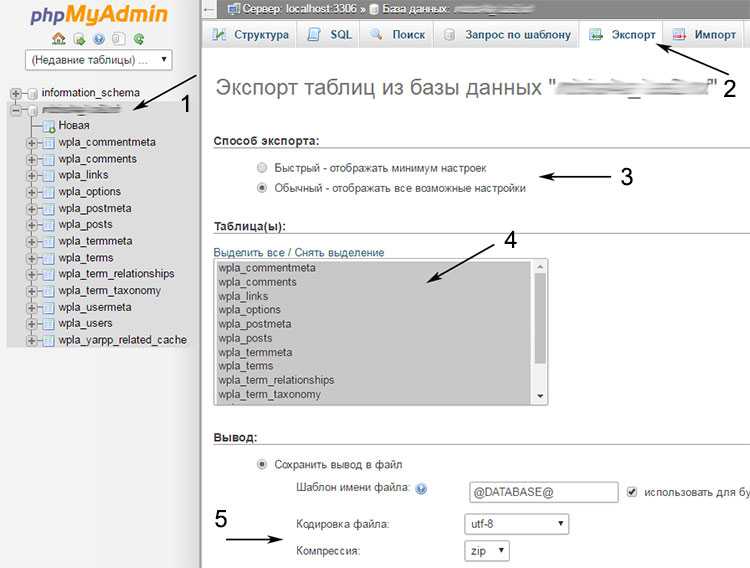
Используем phpMyAdmin
Экспорт и импорт баз данных можно также делать через phpMyAdmin. В общем и целом, пожалуй, это даже более простой путь, чем использование консоли.
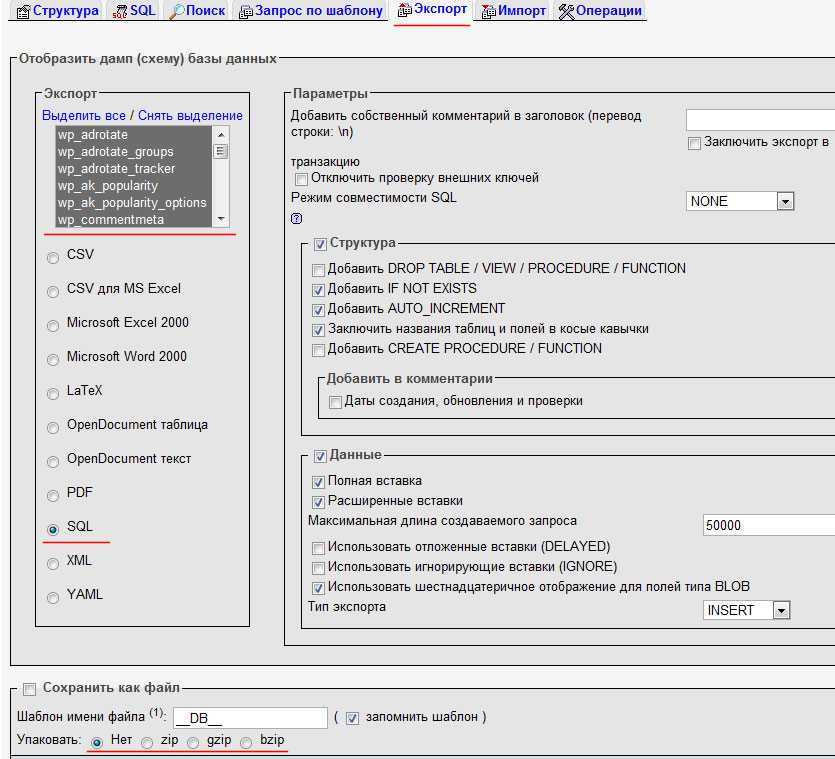
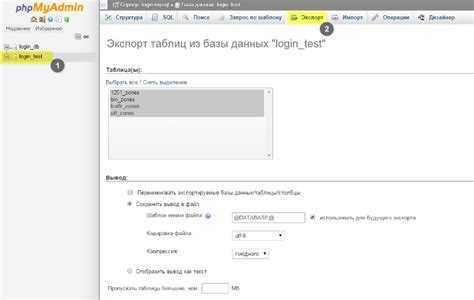
Экспорт
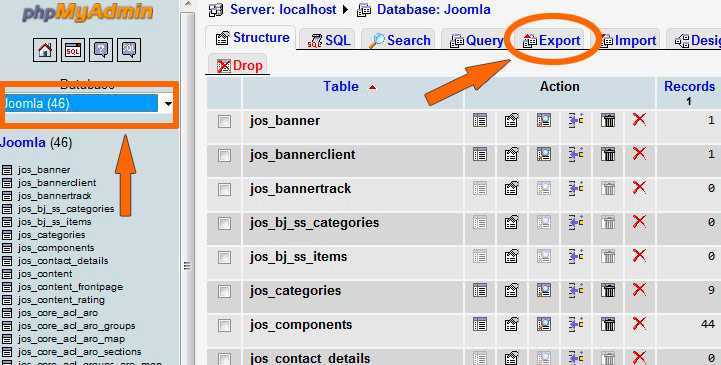
Зайдите в phpMyAdmin и выберите базу данных, с которых вы хотите работать.
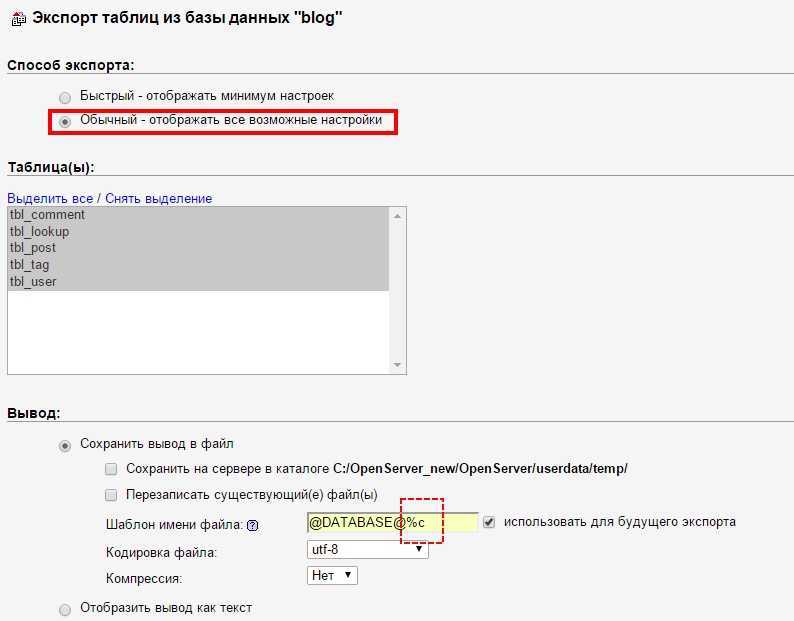
Далее выберите вкладку «Экспорт» и, в зависимости от своих предпочтений, быстрый или обычный метод экспорта. Второй подойдет для тех, кто хочет самостоятельно выставить все настройки.
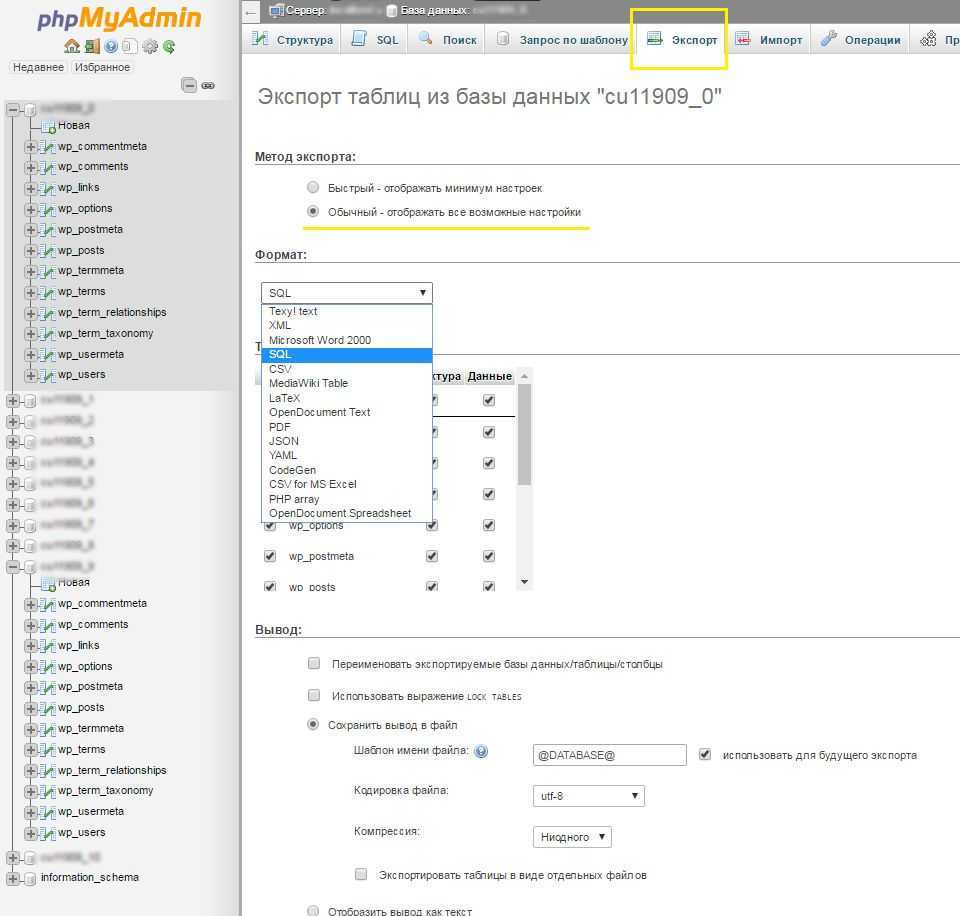 После внесения нужных изменений нажмите «Вперед» и выберите, куда хотите поместить созданный файл. Все, экспорт базы данных был успешно выполнен.
После внесения нужных изменений нажмите «Вперед» и выберите, куда хотите поместить созданный файл. Все, экспорт базы данных был успешно выполнен.
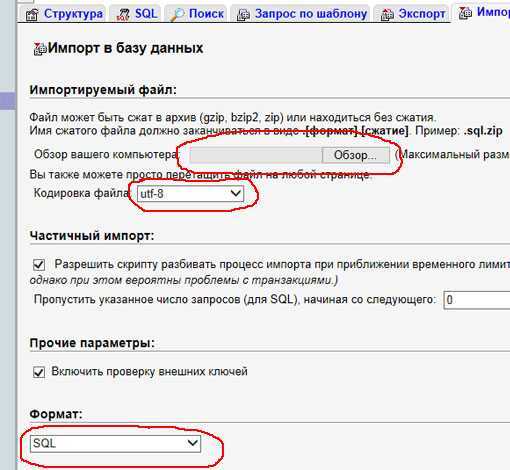
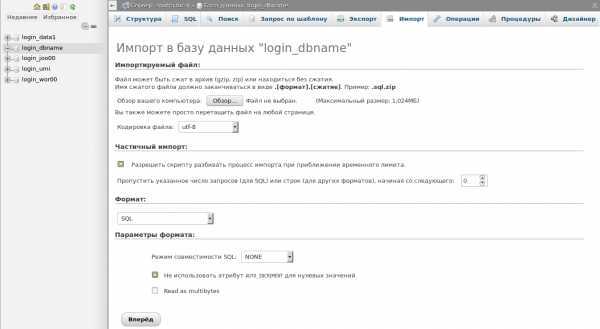
Импорт
Выполнить импорт базы данных тоже совсем несложно. Как и в предыдущем случае, в списке слева выберите нужную вам базу данных, а затем перейдите во вкладку «Импорт».
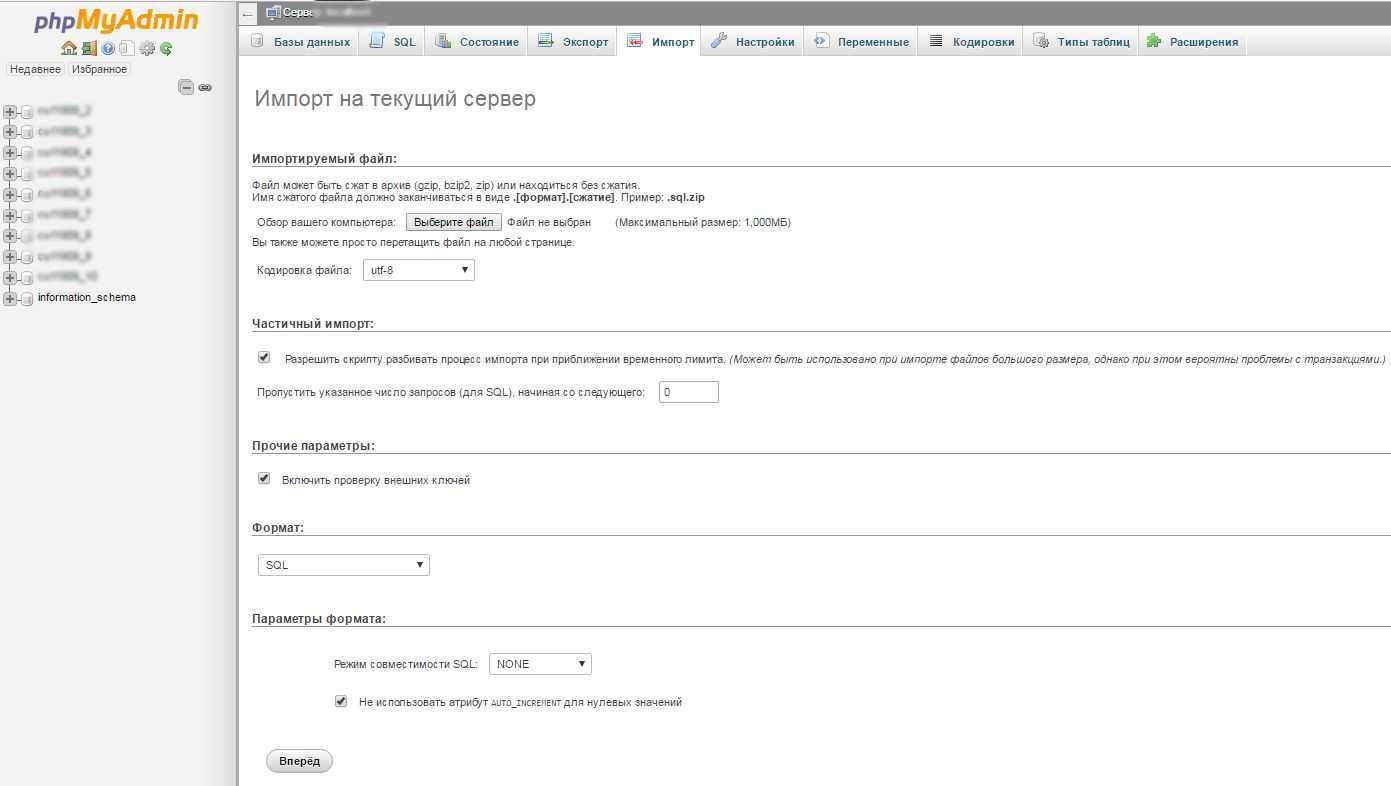
Выберите файл для импорта на вашем компьютере и проверьте настройки. Скорее всего, они подойдут для импортирования вашего файла, но при желании их можно изменить. Нажмите кнопку «Вперед» — и будет выполнен импорт файла. Вы увидите надпись вроде такой:
Импорт успешно завершён, выполнено 32 запроса.
Ниже в красной рамке могут идти сообщения о возникших ошибках (например, о дублировании).
В списке слева вы можете выбрать базу данных, с которой работали, и посмотреть имеющиеся файлы, а также их содержимое (и изменить их).
Факты о MySQL для начинающих
MySQL написан на языках программирования C и C++ и может использоваться более чем на 20 платформах, включая Mac, Windows, Linux и Unix.
MYSQL поддерживает большие базы данных с миллионами записей и целыми числами со знаком или без знака длиной 1, 2, 3, 4 и 8 байтов; Такие как FLOAT, DOUBLE, CHAR, VARCHAR, BINARY, VARBINARY, TEXT (STRING), BLOB, DATE, TIME, DATETIME, TIMESTAMP, YEAR, ENUM и пространственные типы OpenGIS. Также поддерживаются типы массивов фиксированной и переменной длины.
Кроме того, благодаря структуре реляционной базы данных он позволяет легко получать доступ к различным таблицам и подключаться к ним. Таким образом, модель базы данных, которую вы настроите, будет работать с высокой производительностью.
MySQL использует систему доступа, которая обеспечивает аутентификацию через хостинг-провайдера, и систему зашифрованных паролей для безопасности. Клиенты MySQL могут подключаться к серверу MySQL, используя различные протоколы, включая порты TCP/IP на любой платформе. MySQL также поддерживает несколько клиентов и утилит, программы командной строки и административные инструменты, такие как MySQL Workbench.
Расширения MySQL, также известные как разные версии, включают:
- Drizzle – это облегченная система управления базами данных с открытым исходным кодом, которая разрабатывается на основе MySQL 6.0; Однако он больше не используется.
- MariaDB – это популярная замена MySQL, разработанная сообществом с использованием API и команд MySQL. Percona Server с XtraDB – это расширенная версия MySQL, известная своей функцией горизонтальной масштабируемости.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Шаблон: «Монолит как слой доступа к данным»
Вместо прямого доступа к данным из монолита мы можем просто перейти к модели, в которой создаем API в самом монолите. «Счет-фактура» требуется информация о сотрудниках, которая хранится в БД монолита, поэтому мы создаем API «Сотрудники», позволяющий службе «Счет-фактура» к ним обращаться.
Одна из причин, почему указанный шаблон не применяется шире, вероятно, кроется в том, что у людей как бы застряла в голове мысль о том, что монолит мертв и бесполезен. Но плюсы здесь очевидны: пока не нужно заниматься декомпозицией данных, а необходимо заняться сокрытием информации, облегчая изолирование нашей новой службы от монолита. Этот шаблон хорошо работает, в особенности если новая служба практически не будет иметь состояния.
На этот шаблон можно смотреть как на способ выявления других потенциальных служб. Развивая эту идею, мы могли увидеть, что API «Сотрудники» выделяется из монолита, становясь микрослужбой самой по себе, как показано на рис. 2.
Рис. 2 — Использование API «Сотрудники» для выявления контура службы «Сотрудники», которая должна быть выделена из монолита.
Указанный шаблон лучше всего работает, когда код, управляющий данными, по-прежнему находится в монолите, то есть переход данных из одного состояния в другое обеспечивается именно монолитом. Поэтому из этого следует, что микрослужба, которая хочет обратиться к этому состоянию (или изменить его), должна обращаться к монолиту. Если данные, к которым пытаетесь обратиться, в БД монолита, но на самом деле должны быть «во владении» микрослужбы, то лучше пропустить этот шаблон и вместо него выделить данные.
Преимущества MariaDB перед MySQL
В MariaDB добавлены оптимизации, которые повышают производительность СУБД по сравнению с оригинальным MySQL.
Представления
В части производительности представлений в MariaDB проделана существенная оптимизация. «Представления» — это, по сути, виртуальные таблицы базы данных, к которым можно обращаться, как к обычным таблицам базы данных. В MySQL при запросе к представлению запрашиваются все таблицы, связанные с этим представлением, независимо от того, что для запроса могут не потребоваться некоторые представления. В отличие от MySQL, в MariaDB, запрашиваются только те таблицы, которые необходимы для запроса.
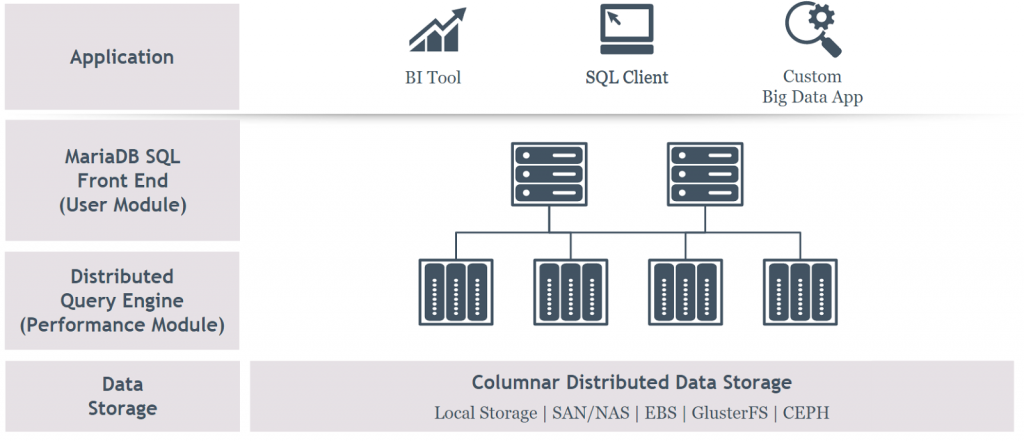
Колоночное хранилище
MariaDB предоставляет еще одно мощное улучшение производительности, достигаемое с помощью нового типа таблиц, представленных не в форме построчного хранилища, а в форме колоночного хранилища. Колоночные хранилища часто используются в аналитике больших данных. MariaDB позволяет масштабировать хранилище данных до петабайтного размера, обспечивая линейное повышение производительности запросов к хранимых данным при добавлении новых серверов.
Более высокая производительность на SSD
MariaDB предоставляет механизм хранения MyRocks, который позволяет хранить данные в RocksDB. RocksDB — это встраиваемая база данных, которая была разработана для повышения производительности обработки данных, хранимых на SSD-накопителях.
Сегментированный кеш ключей
MariaDB представляет еще одно улучшение производительности — сегментированный кеш ключей. В типичном кеше различные потоки конкурируют за блокировку кэшированной записи. Когда несколько потоков конкурируют за мьютекс, только один из них может получить его, в то время как другим приходится ждать освобождения блокировки перед выполнением операции. Это приводит к задержкам выполнения в этих потоках, замедляя производительность базы данных. В случае сегментированного кэша ключей потоку не нужно блокировать всю страницу, но он может блокировать только тот сегмент, к которому относится страница. Это помогает нескольким потокам работать параллельно, увеличивая параллелизм в приложении, что приводит к повышению производительности базы данных.
Виртуальные столбцы таблицы
Интересная функция, которую поддерживает MariaDB — это виртуальные столбцы. Эти столбцы способны выполнять вычисления на уровне базы данных. Это позволяет перенести типовые вычисления с приложений в сервер СУБД. Эта функция не доступна в MySQL.
Параллельное выполнение запросов
Одна из последних версий MariaDB — 10.0 допускает параллельное выполнение нескольких запросов. Идея состоит в том, что некоторые запросы от Master могут быть переданы на выполнение на ведомые серверы (slave). Этот параллелизм в выполнении запросов, безусловно, обеспечивает MariaDB преимущество над MySQL.
Пул потоков
MariaDB также представляет новую концепцию под названием «Thread Pooling». Ранее, когда требовалось несколько соединений с базой данных, для каждого соединения открывался поток, что приводило к архитектуре «один поток на соединение». С использованием «Thread Pooling» исспользуется пул потоков, которые могут повторно использоваться. Таким образом, новый поток не нужно открывать для каждого нового запроса на подключение, что приводит к более быстрым результатам запроса. Эта функция доступна в коммерческой версии MySQL, но, к сожалению, недоступна в версии для сообщества.
Бэкенды хранения данных
MariaDB предоставляет несколько мощных механизмов хранения, которые не доступны в MySQL. Например, XtraDB, Aria и т. д. Чтобы настроить эти механизмы хранения для MySQL, вам необходимо установить их вручную.
Совместимость
Команда MariaDB гарантирует, что MariaDB сможет заменить MySQL в существующих приложениях. Фактически для каждой версии MySQL они выпускают тот же номер версии MariaDB, чтобы указать, что MariaDB обычно совместима с соответствующей версией MySQL. Это открывает возможность беспрепятственного перехода на MariaDB без каких-либо изменений в кодовой базе приложения.
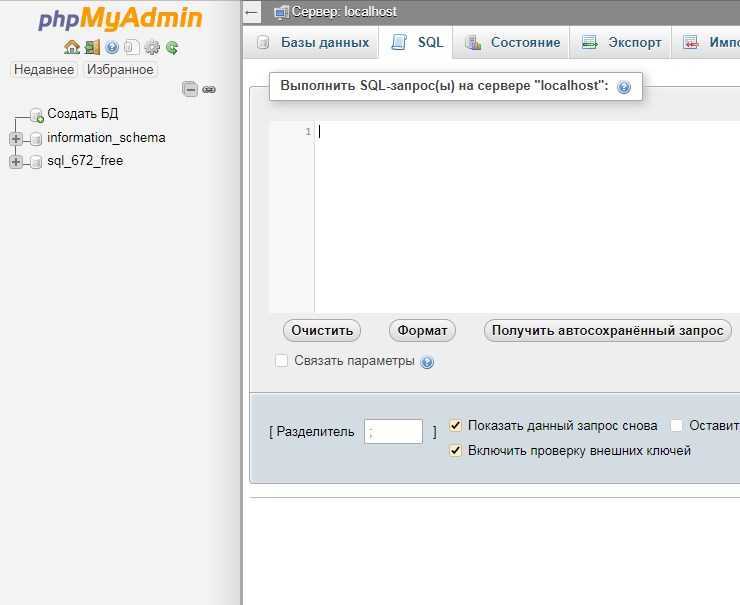
Используем консоль
Экспорт
Для того, чтобы произвести экспорт, мы будем использовать утилиту mysqldump. При помощи нее осуществляется работа с текстовыми файлами базы данных. Итак, вы должны знать название базы данных, а также иметь доступ (логин и пароль) к аккаунту, который имеет, по крайней мере, доступ read only (только для чтения).
Для экспорта базы данных введите вот такую команду:
mysqldump -u имя_пользователя -p название_БД > data-dump.sql
в которой нужно ввести имя пользователя с необходимым доступом, название нужной вам базы данных, а также data-dump.sql – файл в текущей директории, куда будут сохранены данные.
После ввода этой команды вы не увидите никакого вывода на экране, однако вы можете проверить содержимое файла data-dump.sql для того, чтобы убедиться, что теперь он является резервной копией вашей базы данных.
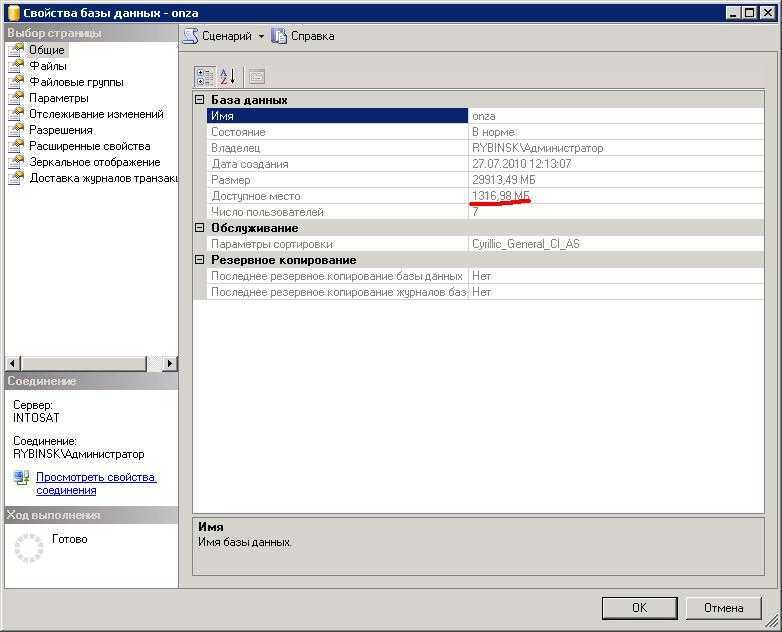
Содержимое файла должно выглядеть примерно так, как показано ниже. В документе будет указано название базы данных (в данном случае MySQL), ее название и другие данные.
-- MySQL dump 10.13 Distrib 5.7.16, for Linux (x86_64) -- -- Host: localhost Database: database_name -- ------------------------------------------------------ -- Server version 5.7.16-0ubuntu0.16.04.1
Если во время процесса экспорта будут какие-нибудь ошибки, утилита mysqldump выведет на экран сообщение о них.
Импорт
Для того, чтобы импортировать существующий файл в MySQL или MariaDB, вам нужно начать с создания новой базы данных. Именно в нее вы затем загрузите содержимое резервной копии.
Сначала подключитесь к базе данных в качестве root-пользователя (либо другого пользователя, который сможет создать новую базу данных):
$ mysql -u root –p
После того, как вы подключились к консоли MySQL, создайте новую базу данных (в данном случае new_database):
mysql> CREATE DATABASE new_database;
После этого на экране появился следующий вывод:
Output Query OK, 1 row affected (0.00 sec)
Теперь для выхода из консоли MySQL нажмите CTRL+D. Далее переходите к самому импорту. Сделать это можно, введя вот такую команду:
$ mysql -u имя_пользователя -p new_database < data-dump.sql
Команда очень похожа на команду экспорта, вам нужно ввести имя пользователя, название новой базы данных, куда вы будете импортировать данные (в качестве примера new_database), и название самого файла, который вы собираетесь импортировать (data-dump.sql).
Если команда выполнена корректно, то никакого вывода на экране вы не увидите; на экране могут отобразиться только сообщения о каких-то ошибках. Как и в случае с экспортом, проверить, точно ли все прошло успешно, вы можете путем подключения к MySQL и просмотра данных. Сделать это можно, к примеру, используя команды USE и SHOW. Команда use определяет, какая база данных будет использоваться в дальнейших запросах. Введите:
mysql> use new_database
И тогда при всех последующих запросах в данном сеансе автоматически будет использоваться эта база данных. Данную установку можно изменить, использовав команду use с названием другой базы данных.
Что касается команды show, то она используется для того, чтобы посмотреть информацию о самих базах данных, о таблицах, столбцах, которые они содержат, а также о состоянии сервера.
Допустим, нам нужно посмотреть, список таблиц в базе. Для этого вводим:
mysql> SHOW TABLES;
Хотите увидеть список столбцов в какой-то определенной таблице? Используйте команду SHOW COLUMNS FROM и название нужно вам таблицы:
SHOW COLUMNS FROM название_таблицы
Статистику по работе сервера можно получить в ответ на команду:
mysql> SHOW GLOBAL STATUS;
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани



