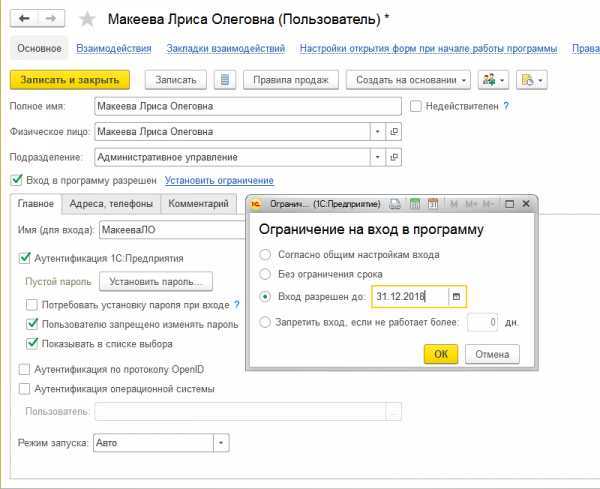
Начало работы с MySQL
Введение
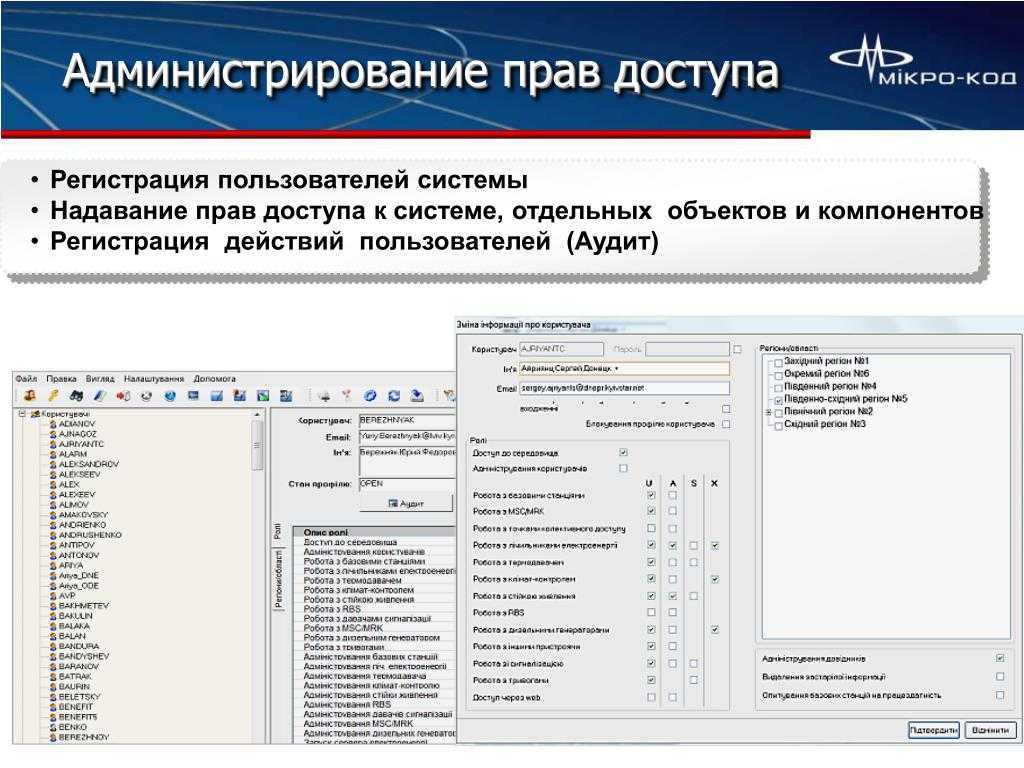
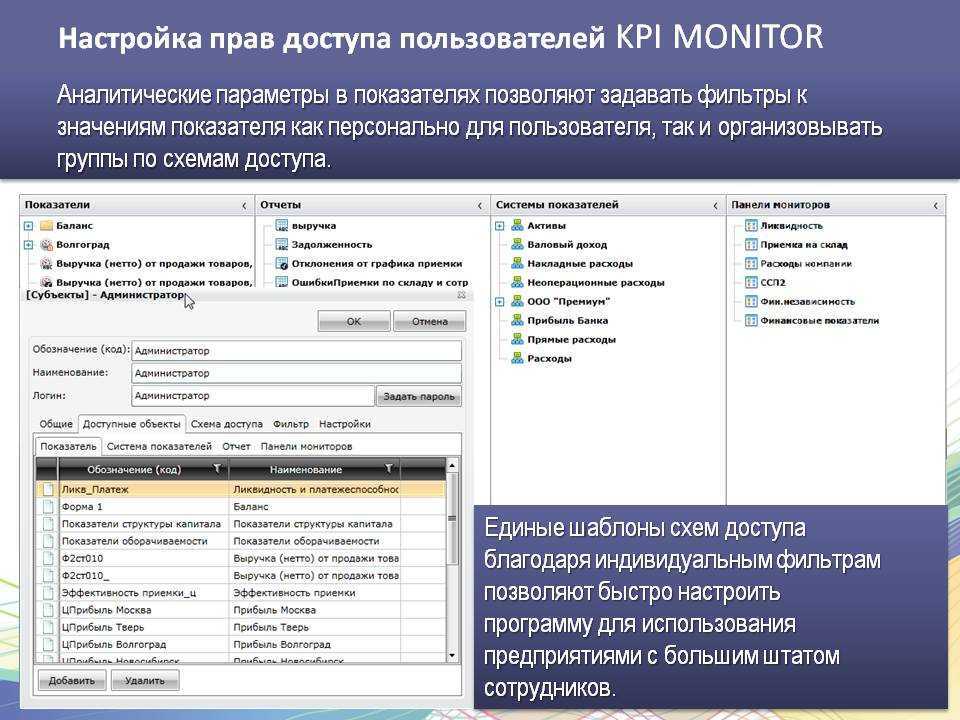
MySQL — это популярный сервер баз данных, используемый в разных приложениях. SQL означает язык структурированных запросов — (S)tructured (Q)uery (L)anguage, который MySQL использует для коммуникации с другими программами. Сверх того, MySQL имеет свои собственные расширенные функции SQL для того чтобы обеспечить пользователям дополнительный функционал. В этом документе мы рассмотрим как провести первоначальную установку MySQL, настроить базы данных и таблицы, и создать новых пользователей. Давайте начнем с установки.
Установка MySQL
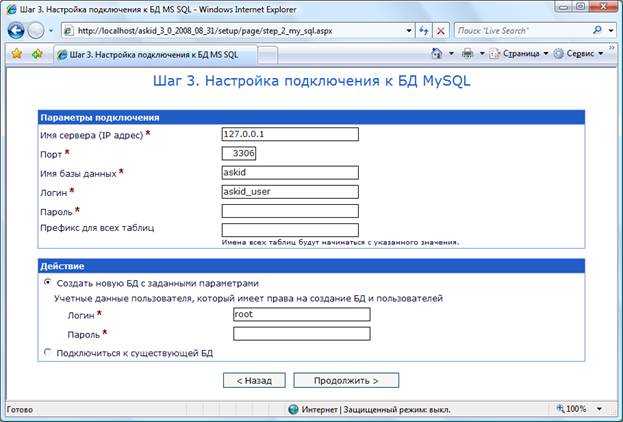
Сначала убедитесь что MySQL установлен на вашу систему. В случае если вам требуется определенная функциональность MySQL, убедитесь, что установлены необходимые USE-флаги, так как они помогут в тонкой настройке инсталляции.
По завершении установки, вы увидите следующее уведомление:
Код Сообщение einfo MySQL
You might want to run: "emerge --config =dev-db/mysql-" if this is a new install.
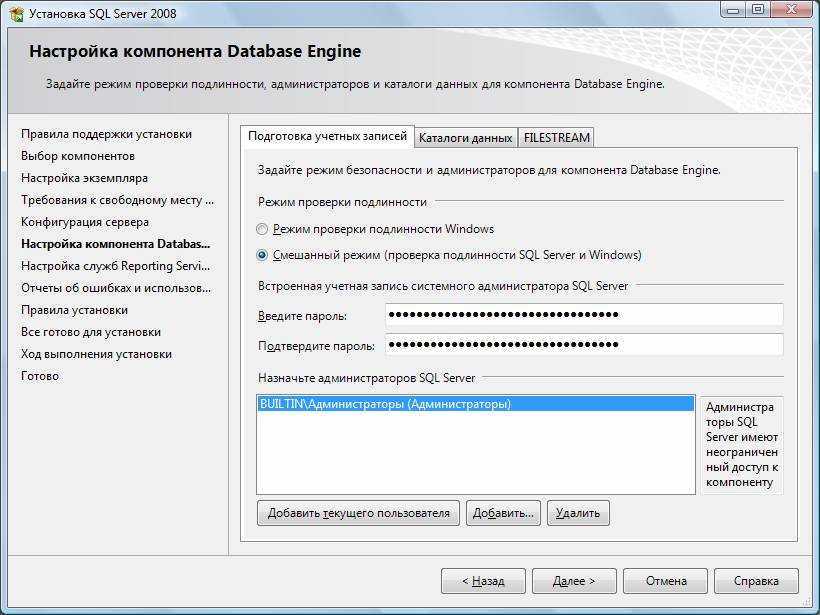
Так как это новая установка, мы запустим эту команду. Вам надо нажать по запросу во время конфигурации базы данных MySQL. В процессе конфигурации устанавливается основная база данных MySQL, которая содержит служебную информацию, такую как базы данных, таблицы, пользователи, разрешения и т.д. В процессе конфигурации рекомендуется чтобы вы изменили свой пароль root так быстро, как это возможно. Мы определенно это сделаем, иначе кто-нибудь сможет волей случая появиться и взломать сервер MySQL, настроенный по умолчанию.
* MySQL DATADIR is /var/lib/mysql * Press ENTER to create the mysql database and set proper * permissions on it, or Control-C to abort now... Preparing db table Preparing host table Preparing user table Preparing func table Preparing tables_priv table Preparing columns_priv table Installing all prepared tables To start mysqld at boot time you have to copy support-files/mysql.server to the right place for your system PLEASE REMEMBER TO SET A PASSWORD FOR THE MySQL root USER ! To do so, issue the following commands to start the server and change the applicable passwords: /etc/init.d/mysql start /usr/bin/mysqladmin -u root -h pegasos password 'new-password' /usr/bin/mysqladmin -u root password 'new-password' Depending on your configuration, a -p option may be needed in the last command. See the manual for more details.
ЗаметкаЕсли предыдущая команда не выполнится из-за того, что имя хоста установлено в localhost, измените его на другое имя, например gentoo. Обновите файл /etc/conf.d/hostname и перезапустите /etc/init.d/hostname.
Некоторая нехарактерная для ebuild-файлов информация MySQL удалена отсюда, чтобы содержать этот документ настолько последовательным, насколько возможно.
ВажноНачиная с mysql-4.0.24-r2, пароли вводятся во время этапа конфигурации, что делает пароль root более надежным.
Сценарий конфигурации уже вывел команды, которые нам нужно запустить, чтобы настроить наш пароль, поэтому нам сейчас надо их выполнить.
Если вы используете OpenRC, выполните данную команду:
* Re-caching dependency info (mtimes differ)... * Starting mysqld (/etc/mysql/my.cnf) ...
Если вы используете systemd, вместо этого используйте следующую команду:
После этого установите пароль root:
Теперь вы можете проверить, что пароль root был успешно настроен, попытавшись войти на MySQL-сервер:
Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 to server version: 4.0.25 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
Параметр указывает пользователя, который будет выполнять вход. Параметр указывает хост. Обычно это будет , если только вы не настраиваете удаленный сервер. И, наконец, сообщает клиенту mysql что вы будете вводить пароль для доступа к базе данных
Обратите внимание на приглашение. Это то место, где вы будете вводить все ваши команды
Теперь, когда мы в командной строке mysql в качестве пользователя root, мы можем начать настраивать нашу базу данных.
ВажноУстановка mysql по умолчанию приемлема для систем разработки. Для более безопасных значений по умолчанию можно запустить /usr/bin/mysql_secure_installation
Условия для выстраивания систем защиты
Уровни обеспечения безопасности баз данных MySQL могут быть различными.
Для реализации максимально возможного уровня защиты конфигурация системы должна выглядеть следующим образом:
- база данных MySQL реализуется только в chrooted-среде, это значит, что исключено взаимодействие с программами в других корневых каталогах;
- все процессы базы данных выполняются с уникальными значениями UID (User identifier) и GID (Group identifier) – числовых идентификаторов пользователя и группы, которые не используются ни в каких других процессах и программах;
- доступ к базе может быть только локальный, удаленный по возможности необходимо исключить;
- чем более сложный пароль используется для основной учетной записи, тем лучше;
- изначально заданная в свободной лицензии учетная запись администратора требует переименования;
- анонимный доступ к базе данных MySQL с использованием идентификатора nobody должен быть исключен;
- стандартные форматы баз данных и таблиц придется удалить.
При выполнении этих условий защита станет эффективнее.
Базы данных часто страдают от действий инсайдеров: сотрудники после конфликта с руководством удаляют из БД критически важные данные, взламывают базу, чтобы украсть данные клиентов на продажу. Как защититься?
Как правильно устанавливать базу данных MySQL
Вопрос инсталляции программы является ключевым в обеспечении ее безопасности. При выполнении этого процесса потребуется создать уникальную учетную запись пользователя и собственный корневой каталог. Необходимые команды можно найти в руководстве пользователя программы, скрипты также размещены в тематических сообществах. Отличия при защищенной инсталляции возникнут при необходимости внесения дополнительных параметров в раздел, посвященный конфигурации системы. Предлагаемые значения снижают риск того, что проникновение в базу данных произойдет с использованием смежно протекающих процессов. При установке файл конфигурации копируется, возникает необходимость выбрать его подвариант, исходя из предполагаемых размеров БД – малая, средняя, большая, грандиозная.

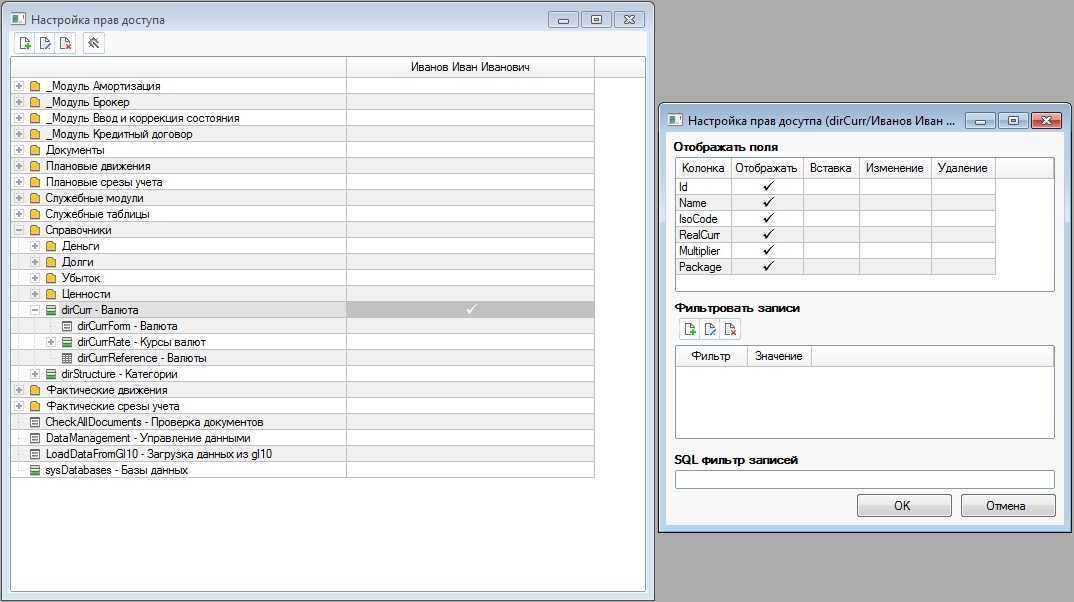
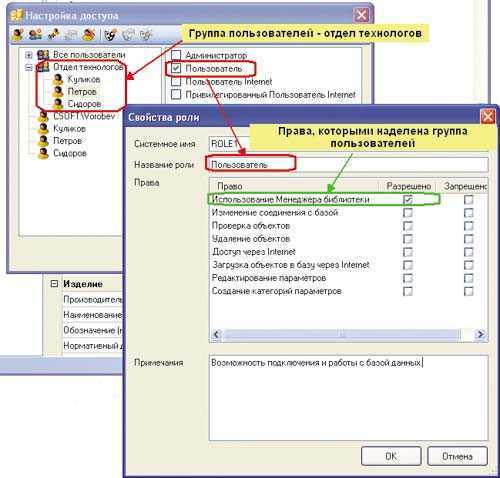
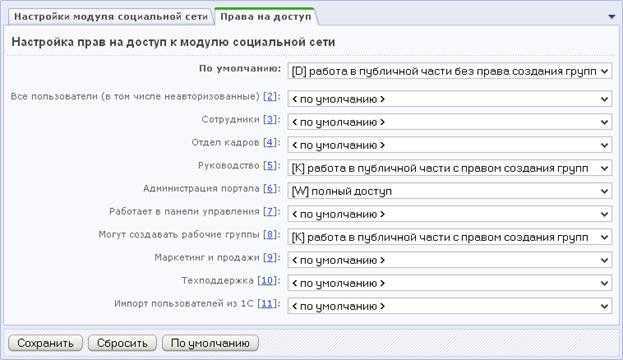
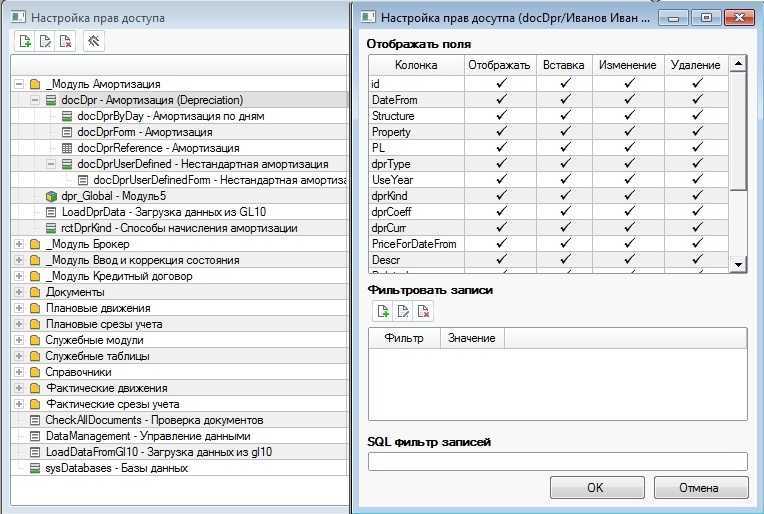
Далее запускается сервер и происходит проверка соединений с БД. После фиксации подключения работа базы данных MySQL останавливается и начинается решение задачи по обеспечению ее защиты. Если подключения не произошло, источник проблемы можно установить, изучив файл регистрации, который поможет ее устранить.
Как работает репликация
Ни MySQL не знает о Tarantool, ни Tarantool не знает о MySQL. Репликатор вычитывает bin log’и с MySQL Master, и всё это записывается в Tarantool.
Что умеет делать репликатор?
При запуске репликатор полностью забирает данные с Master’а, основываясь на конфиге, в котором указано, какие базы/таблицы нужно реплицировать, т. е. для запуска достаточно просто взять тарантул с пустыми спейсами, что очень удобно.
Вы как системный администратор должны понимать, работает ли вообще репликация, какой bin log сейчас читает репликатор, какую его позицию, всё это, конечно же, есть. Есть отдельный Space, в котором всего три значения: имя bin log’а и считываемая в данный момент позиция, т. е. существует маленький аналог привычного всем Show slave status.
После внедрения репликатора мы развернули семь экземпляров Tarantool, которые работают только на двух серверах, потому что один инстанс Tarantool не может утилизировать все ядра машины. Немножко напомню архитектуру тарантула, один инстанс умеет потреблять от трёх ядер: одно ядро и более — сеть, строго одно ядро — транзакционная часть, строго одно ядро — работа с wal-файлами.
Мониторинг
После настройки репликации следует постоянно следить за несколькими параметрами на слейве:
# Запрос вернет статистику и настройки слейва
Стоит обратить внимание на такие показатели:
Slave_IO_State: Waiting for master to send event
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
Last_Errno: 0
Last_Error:
...
Seconds_Behind_Master: 0
...
# Статус работы реплики
Показатели и отражают нормальную работу реплики. Оба должны иметь значение Yes. Когда один из этих показателей равен No, в будет виден текст ошибки репликации.
Параметр отражает количество секунд, на которое слейв отстает от мастера. Этот показатель должен быть равен нулю (иногда может вырастать до нескольких секунд).
Что такое язык SQL
Чтобы работать с реляционной базой данных, нужно знать специальный язык запросов — SQL. Это расшифровывается как structured query language — язык структурированных запросов. «Структурированный» означает, что каждый запрос должен иметь определённую структуру, чтобы база поняла, как на него реагировать.
Сами запросы вводятся в специальном терминале, который отвечает за управление базой данных.
С помощью запросов можно делать что угодно:
- создавать и изменять таблицы,
- настраивать связи между ними,
- вносить и удалять данные,
- настраивать доступ для разных пользователей,
- а главное — искать то, что нужно, по любым параметрам.
Если вы знаете SQL, то можете работать с любой реляционной базой данных, которые его поддерживают.
Преимущества Tarantool
Что будет, если вытащить из сервера MySQL кабель питания, а потом запустить сервер опять? При старте начнётся процесс InnoDB Recovery, и в итоге база восстановится. Но у нас пару раз случалось, что в какой-то момент контроллер переставал писать на диск адекватную информацию, сервер падал в kernel panic по причине сбоя контроллера, процесс innodb recovery после ребута заканчивался Core Dump. В Tarantool настолько удачно продуман механизм write-ahead-log, что даже если по каким-то причинам контроллер записал в wal-файл какую-то ерунду, из-за чего Tarantool не поднимается, то вы просто сносите wal-файл. Или открываете файл и убиваете из него данные записи построчно до тех пор, пока Tarantool не запустится. Причём вы можете указывать желаемое количество транзакций, которые будут записываться в wal-файле, хоть по одной транзакции. Подчеркну, что пример с MySQL, который я привел выше, — это именно последствия аппаратного сбоя сервера, при нормальных условиях innodb recovery отработает как часы.
Snapshot’ы в Tarantool сделаны здорово. Этот механизм работает с безумной скоростью — 800 Мбит в секунду, может быть, даже 1 Гбит. Пишется последовательно в один файл. Тут не нужны какие-то супердиски, всё работает очень быстро и грамотно даже на самых дешёвых SATA. Поднятие snapshot’а 20-гигабайтной базы занимает не более пяти минут. Я проверял, и в MySQL у меня получалось гораздо медленнее.
Настройка репликации с mysqldump
При создании дампа БД мастер-сервера с использованием mysqldump, необходимые значения GTID для слейва уже будут содержаться в дампе. Это параметр gtid_purged, который является gtid_executed с мастера. После восстановления дампа на слейве, переменная gtid_executed будет равна gtid_purged.
При запуске репликации слейв отправит мастеру диапазон GTID, которые он выполнил у себя, а мастер отправит в ответ все отсутствующие транзакции, которых нет на слейве. Таким образом можно настраивать репликацию на работающей базе (снимать копию), не останавливая запись с помощью переменной read_only=1, но очень не желательно!
При необходимости снять дамп с работающей базы, нужно использовать ключ –single-transaction, который позволяет не блокировать таблицы на момент создания дампа, но при выполнении операторов вида ALTER TABLE, DROP и т.п., которые выполняют изменения, данные в дампе могут оказаться поврежденными.
Как правило, на небольших базах допустимо использовать –single-transaction при снятии дампа. А вот на более объемных, где часто совершается запись или изменения, рекомендуется сначала выполнить блокировку таблиц на запись с помощью set global read_only=1, а потом уже выполнять снятие дампа. Но такой вариант будет очень долгий, поэтому в следующем разделе будет рассказано про Percona XtraBackup.
После получения дампа через mysqldump внутри него должно быть следующее:
У mysqldump есть важный параметр –set-gtid-purged, который позволяет управлять информацией глобальных идентификаторов транзакций (GTID), записанной в файл дампа, указывая, добавлять ли оператор SET @@ global.gtid_purged в вывод дампа. По умолчанию, значение этого флага auto, т.е. если GTID включен, то gtid_purged копируется, и наоборот.

Итого, чтобы правильно снять дамп через mysqldump с работающего мастера для настройки реплики необходимо:
- Перевести базу в read only – самый правильный вариант;
- Выполнить команду
После чего необходимо создать пользователя на мастере для выполнения репликация (лучше всего отдельного). С данным пользователем слейв будет подключаться к мастеру:
Важный момент! Необходимо убедиться, что слейв чистый, т.е. очищен от всех GTID. Для этого нужно на слейве выполнить следующее:
И запускать репликацию со слейва привычным способом, как и ранее с позицией бинлога, но позиция указывается автоматически:
Настройка репликации с Percona XtraBackup
При малых объемах БД и необходимости настройки реплики, легко и просто использовать mysqldump. Но когда объем БД за 10 Гб и более, то распаковка дампа может занять уже продолжительное время. Поэтому логичнее использовать инструмент XtraBackup от Percona. Он позволяет снимать копию с базы данных в момент её работы, используя возможности движка InnoDB.
Все транзакции, осуществленные в момент снятия копии, скапливаются в отдельном логе, который XtraBackup читает по ходу дела. После завершения бэкапа, XtraBackup применяет накопленные транзакции на снятую копию. Процесс выходит очень быстрым и позволяет переносить большие объемы данных.
Этот же инструмент можно использовать и при настройке репликации Master-Slave с GTID. XtraBackup поддерживает GTID с версии 2.1.0. Для работы с MySQL 5.7 необходима версия 2.4.
Процесс подготовки мастера и слейва ничем не отличается от ранее описанного при использовании XtraBackup. Необходимо также подготовить конфиг, указав использование GTID и ID сервера, а также создать пользователя для репликации, чтобы была возможность подключения со слейва.
При работе с XtraBackup, все значения для подключения к MySQL берутся из конфигов.
Для снятия полной копии всей БД и размещения её по пути /mnt/share необходимо выполнить следующую команду:
Подготовленную копию теперь необходимо восстановить на слейве. Для этого демон mysql слейва должен быть остановлен, а директория data_dir быть пуста:
До текущего момента процесс подготовки копии был стандартный. Копия снята, слейв запущен. Но теперь необходимо выполнить подготовку GTID для последующей настройки репликации. При снятии копии, на мастере создался файл xtrabackup_binlog_info, в котором указано значение GTID последней транзакции в данной копии. Это значение необходимо импортировать на слейв. Вывод будет следующий:
На слейве установить значение GTID из файла xtrabackup_binlog_info для переменной GTID_PURGED:
И далее выполнить стандартную настройку репликации, подключаясь к мастеру с использованием GTID:
В данном случае по сути было выполнено тоже самое, что и через mysqldump, но с помощью XtraBackup. А значение GTID_PURGED, которое хранится обычно в дампе, было создано вручную – это единственный нюанс, который нужно учесть.
Настройка UserParameter агента Zabbix
На slave сервере открываем настройки zabbix агента:
vi /etc/zabbix/zabbix_agentd.conf
Добавляем строку:
UserParameter=mysql_repl_mon,/etc/zabbix/zabbix_agentd.d/repl_mon.sh
* в данном случае, мы создаем в zabbix агенте пользовательский параметр с именем mysql_repl_mon — при его вызове будет запускаться скрипт /etc/zabbix/zabbix_agentd.d/repl_mon.sh, который мы ранее создали.
Перезапускаем агента:
systemctl restart zabbix-agent
Проверяем работу параметра. Для этого с сервера zabbix выполняем команду:
zabbix_get -s 192.168.0.15 -k mysql_repl_mon
* данной командой мы обращаемся к серверу 192.168.0.15 (это должен быть адрес сервера, на котором мы настроили агента и скрипт); mysql_repl_mon — параметр, который мы вызывает.
* если после запуска команды система вернет ошибку Can’t connect to local MySQL server through socket, необходимо проверить, не запущен ли SELinux — если запущен, необходимо его отключить или настроить.
… команда должна вернуть либо 0 (если есть проблемы с репликацией), либо 1.
Нагрузка
Запустили репликатор, и нагрузка на MySQL Slave’ах, на которых работал handler socket, резко провалилась — практически в ноль.
После этого я попробовал вместо текущих восьми MySQL slave серверов оставить только один, уже один сервер полностью держал нагрузку. Мы не отказались полностью от MySQL slave серверов, мы оставили на них те запросы, которые работают без handler socket, а значит, можно полностью перейти на 5.7. В результате мы сэкономили минимум семь серверов, накопители Enterprise SSD, которые работают в них, место в стойке, электричество, деньги.
Что можно сказать интересного про время ответа? В компании Мамба есть свой opensource-продукт BTP, вот его графики.
У handler socket очень необычный API. Надо сначала вызвать метод Connect, потом метод Open Index, потом метод Execute. Суммарное время всех трёх методов представлено на иллюстрации: длительность выполнения запроса на handler socket могла достигать 1 секунды.
А теперь всё то же самое, но уже с Tarantool’овскими серверами, куда реплицируется с Master та же самая база:
Причина очень проста: Tarantool — это In-Memory база данных, а MySQL работал на SSD, под buffer pool size было выделено памяти меньше, чем размер базы данных. Здесь же у нас полный In-Memory, причём даже во всех instance, выключены wal-файлы, т. е. нет работы с диском, только память, есть отдельные инстансы, на которые не идут боевые запросы, там wal-файлы включены и с них делаются snapshot’ы.
Master-slave репликация одной базы MySQL
Это простой пример master-slave репликации одной базы MySQL. Тем кто это делает впервые, следует начать с этого примера и в точности соблюдать инструкции.
Для начала, нужно прописать различные id для Master и Slave серверов. На Master-сервере нужно включить бинарный журнал (log-bin), указать БД для репликации и создать пользователя подчиненного сервера, через которого slave-сервер будет получать данные с master`а. На slave-сервере включается релейный лог (relay-log), указывается БД для репликации и запускается slave-репликация.
MASTER: действия, выполняемые на Master-сервере MySQL.
Отредактировать my.cnf — конфигурационный файл MySQL. Его месторасположение зависит от операционной системы и настроек самой MySQL. В my.cnf, в секции добавляются такие параметры:
# Идентификатор Master сервера (число от 1 до 4294967295)
server-id=1# Путь к бинарному логу.# Записывается название файла, без расширения, так как расширение все равно будет установлено # MySQL-сервером автоматически (.000001, .000002 и т.д.)# Располагать mysql-bin желательно в корне директории, где хранятся все БД,# во избежание проблем с правами доступа.
log-bin=/varlibmysqlmysql-bin# Название БД MySQL, которая будет реплицироваться
replicate-do-db=»dbreplica»
После модификации my.cnf следует перезапустить MySQL. В директории для хранения журнала бинарных логов (log-bin) должен появиться один или несколько файлов mysql-bin.000001, mysql-bin.000002, … .
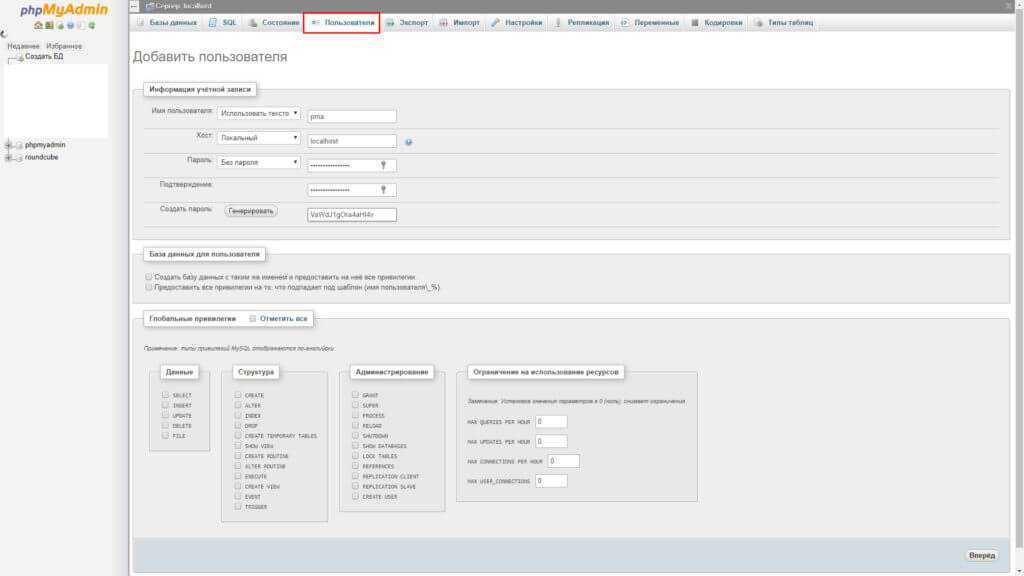
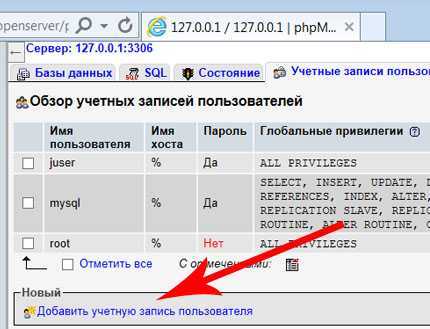
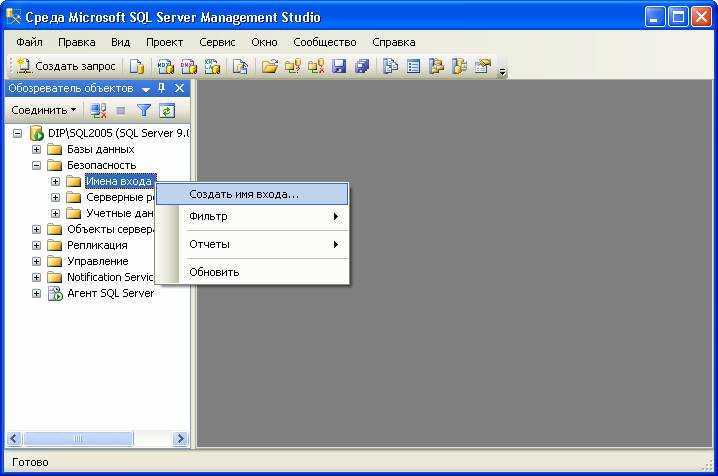
Теперь нужно подключиться к MySQL как пользователь с максимальными правами и создать пользователя (rpluser_s500) с паролем (заменить PASSW), через которого Slave-сервер будет получать данные об обновлениях БД:
mysql> GRANT replication slave ON *.* TO «rpluser_s500″@»%» IDENTIFIED BY «PASSW»;
mysql> FLUSH PRIVILEGES;
Далее создается полная копия главной БД, путем запуска mysqldump с параметром —master-data, который запишет в дамп информацию, необходимую для корректной работы slave-сервера:
$ mysqldump —master-data -hHOST -uUSER -p dbreplica > dbreplica.sql
Дамп можно снимать с БД под нагрузкой, но следует учесть, что если БД большая, то на время записи дампа БД будет не доступна на запись.
SALVE: действия, выполняемые на Slave-сервере MySQL.
Первым делом нужно провести правки my.cnf в секции :
# Идентификатор Master сервера (число от 1 до 4294967295)
server-id=500
# Путь к релей-логу, в котором хранятся данные, полученные от Master-сервера # Требования такие же, как и к бинарному логу.
relay-log=/varlibmysqlmysql-relay-bin
relay-log-index=/varlibmysqlmysql-relay-bin.index
# Имя базы, в которую будут записываться все изменения, # происходящие в БД с тем же именем на Master-сервере
replicate-do-db=»dbreplica»
После модификации my.cnf — перезапустить MySQL.
Далее создать БД, с таким же именем, как и на Master-сервере:
mysql> CREATE DATABASE dbreplica
Теперь в неё нужно залить дамп:
$ mysql -uROOT -p dbreplica < dbreplica.sql
Далее настраиваем подключение к Master-серверу, где MASTER_HOSTNAME_OR_IP заменяется на адрес или ip MySQL master сервера, а MASTER_USER и PASSWORD — учетные данные пользователя, созданного на Master-сервере для подключения со Slave:
mysql> CHANGE MASTER TO MASTER_HOST = «MASTER_HOSTNAME_OR_IP», MASTER_USER = «rpluser_s500», PASSWORD = «PASSW»;
После запуска этого запроса, в директории, где хранятся БД, создается файл master.info, куда записываются данные о подключении к Master.

Теперь, для начала репликации осталось отправить запрос к MySQL:
mysql> START SLAVE;
После этого, если все прошло успешно, можно наблюдать, как все изменения в БД на Master-сервере, появляются в БД на Slave.
А что такое SQL?
Эта аббревиатура расшифровывается как Structured Query Language, что в переводе означает «язык структурированных запросов».
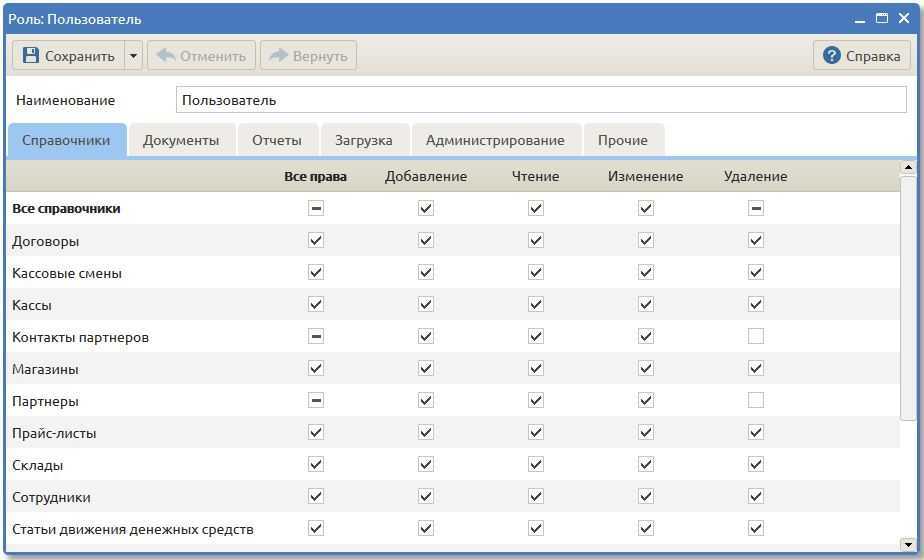
SQL – это стандартизированный язык, использующийся для взаимодействия с базой данных. С помощью него, собственно, и получают доступ к информации, хранящейся в таблицах MySQL. Язык делится на три части:
- Синтаксис, помогающий решать семантические вопросы языка. То есть идентифицировать отдельные компоненты базы данных.
- Синтаксис для управления данными в базе, который помогает обновлять и искать информацию.
- Синтаксис, позволяющий выдавать пользователям права на отдельные единицы данных в базе.
Основные задачи, выполняемые SQL
Structured Query Language появился в 1970 году и быстро заменил собой аналогичные, но устаревшие VISAM и ISAM. Они были нужны для управления данными.
В их «обязанности» входило:
- Извлечение запрашиваемой информации из ячеек базы данных по запросу клиента.
- Разного рода манипуляции с данными, включая добавление новых элементов в таблицу, удаление, изменение существующей в базе информации и ее сортировку. Сюда же относят и некоторые другие редко используемые операции.
- Идентификация данных из базы. Я уже упомянул это выше. Речь идет об определении отдельных компонентов. К примеру, идентификации чисел в тексте как целых чисел для соответствующей их обработки. Также процесс идентификации необходим реляционной сущности MySQL для определения взаимоотношений между разными слоями таблиц в базе данных.
- Управление данными.
- Защита и шифрования информации в таблицах.
SQL закрывает все 5 аспектов.
Отключение sync_binlog
Параметр определяет логику синхронизации данных из бинлога с диском. Если значение равно , запись на диск будет происходить после каждой транзакции. Это делает хранилище очень надежным, но крайне сильно нагружает дисковую подсистему на мастере.
Значение отключит синхронизацию из Mysql, и база данных будет полагаться на ОС в вопросе записи лога на диск. Такое значение может увеличить производительность мастера в несколько раз.
Проверить текущее значение можно так:
mysql -e "show variables like 'sync_binlog'"
# Проверка режима синхронизации бинлога
+---------------+-------+ | Variable_name | Value | +---------------+-------+ | sync_binlog | 1 | +---------------+-------+
# Синхронизацию лучше отключить
Отключить синхронизацию можно без перезагрузки сервера, для этого достаточно выполнить:
Однако не забудьте исправить этот параметр и в my.cnf, чтобы он сохранился после перезагрузки:
... sync_binlog = 0 ...
В-третьих, репликация mysql для решения стратегии давления на запись
Для mysql есть только один способ решить проблему давления записи, то есть база данных и таблица
Есть 2 способа разделить,
Вертикальная перегородка
Этот метод соответствует таблицам, которые не имеют отношения к бизнесу, и нет отношения подключения, а таблицы базы данных в разных компаниях разделены на разных машинах.
Горизонтальное шардирование
Если есть бизнес-соединение, таблица и таблица имеют отношение соединения, вы можете разделить таблицу на несколько частей по горизонтали, например, чтобы разделить таблицу по идентификатору и разместить от 1 до 5 миллионов строк на одном компьютере, 5 миллионов После того, как линия будет размещена на другом компьютере, в дополнение к нечетному и четному номеру идентификатора или в соответствии с областью и уровнем пользователя, таблица может быть разделена
Планировщик сегментирования
Поскольку таблицы находятся на разных машинах, мы полагаемся на планировщик для планирования запросов доступа. В планировщике есть индекс таблицы, и вы можете запросить, на каком компьютере находится запись, в соответствии с индексом.
Четыре, принцип репликации mysql
Введение:
Когда основные данные обновляются, обновленные данные будут записаны в двоичный журнал, и на главном устройстве будет фиктивный поток для отправки обновленных данных на подчиненное устройство.
На подчиненном устройстве будет поток io Thread для получения данных, отправленных матерью, и записи их в журнал реле (журнал реле), а затем поток потока SQL отвечает за чтение журнала в журнале реле и обновление его в базе данных
Поток репликации главный-подчиненный:
Главный узел:
dump Thread: запускает поток дампа для каждого ведомого потока ввода-вывода, Отправлять события двоичного журнала
Ведомый узел:
Поток ввода-вывода: запрашивать события двоичного журнала от мастера и сохранять их в журнале реле. SQL Thread: чтение событий журнала из журнала реле и локальное завершение воспроизведения
Файлы, связанные с функцией копирования: (генерируются при смене мастера на)
master.info:
Используется для сохранения соответствующей информации, когда ведомое устройство подключается к ведущему, например номер учетной записи, пароль, адрес сервера и т. д.

relay-log.info:
Соответствующие отношения между текущим двоичным журналом, скопированным на текущий подчиненный узел, и локальным журналом журнала воспроизведения.
Установка Percona Mysql Server
Установить percona mysql server не представляет никакой сложности, так как есть репозиторий с готовыми пакетами под все популярные системы, в том числе под centos. Подключаем этот репозиторий. Действия выполняем одновременно на обоих серверах.
Отключаем стандартный модуль mysql и активируем репозиторий перконы.
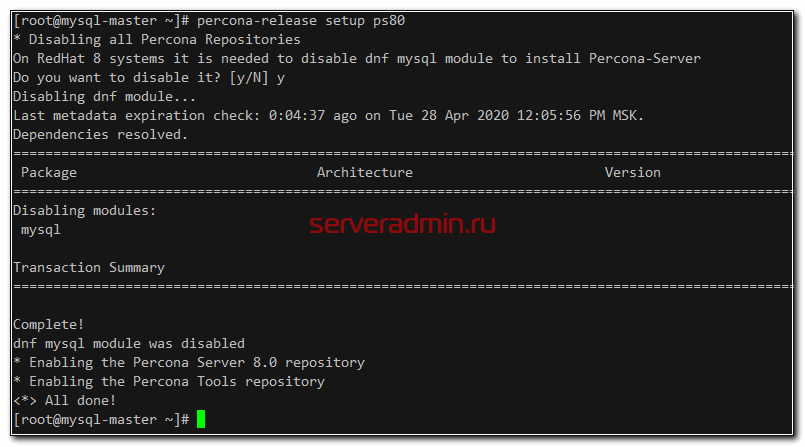
Устанавливаем Percona Mysql Server на Centos 8. Заодно поставим xstrabackup и другие утилиты, которые нам могут понадобиться в процессе эксплуатации.
После установки запускаем mysql сервер и добавляем в автозагрузку.
Во время установки был автоматически сгенерирован временный пароль root. Посмотреть его можно в логе /var/log/mysqld.log.
Используя этот пароль, выполним начальную настройку сервера, удалив все лишнее и указав свой пароль. Имейте ввиду, что по умолчанию установлен Password Validation Plugin, который не позволит вам создать простой пароль. Он должен удовлетворять следующим требованиям:
- Длина от 8-ми символов;
- Минимум 1 цифра;
- Минимум 1 спецсимвол.
Убедитесь, что вы запомнили свой новый пароль и можете подключаться, используя его.
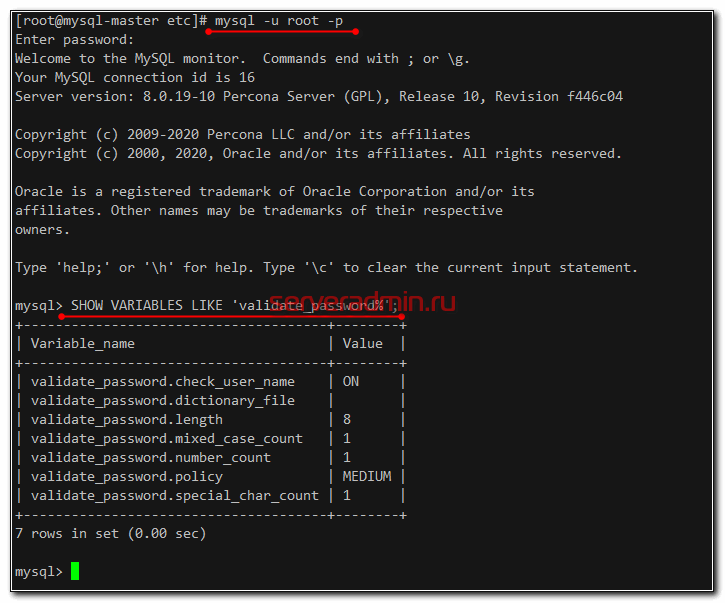
Серверы Mysql установили на обоих виртуальных машинах. Двигаемся дальше.
Заключение
Вот так относительно просто настраивается обычная master — slave репликация mysql. Подобным же образом настраивается и master-master репликация, но на практике она очень нестабильно работает. Я пробовал в свое время, но в итоге отказался, так как надоело ее чинить и исправлять ошибки. Для полноценного кластера с мультизаписью лучше использовать какие-то специализированные решения типа Percona XtraDB Cluster.
Кстати, он же может заменить и текущую конфигурацию, если сделать его из двух нод и писать только в одну. Разрешив ему работать при выходе из строя реплики, получится примерно то же самое, что и в статье. Но смысла в этом особо нет, так как предложенная мной конфигурация настраивается проще и быстрее. Плюс, это типовое решение для любого mysql сервера.
Онлайн курсы по Mikrotik
Если у вас есть желание научиться работать с роутерами микротик и стать специалистом в этой области, рекомендую пройти курсы по программе, основанной на информации из официального курса MikroTik Certified Network Associate. Помимо официальной программы, в курсах будут лабораторные работы, в которых вы на практике сможете проверить и закрепить полученные знания. Все подробности на сайте .
Стоимость обучения весьма демократична, хорошая возможность получить новые знания в актуальной на сегодняшний день предметной области. Особенности курсов:
- Знания, ориентированные на практику;
- Реальные ситуации и задачи;
- Лучшее из международных программ.