
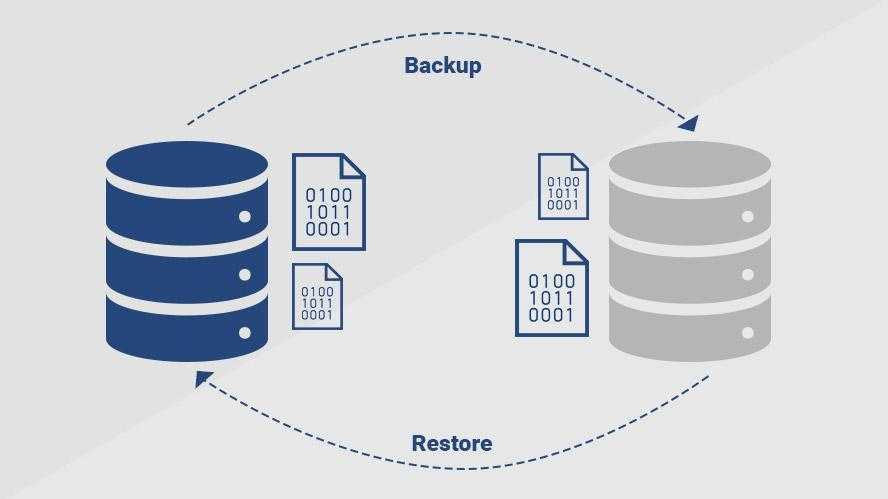
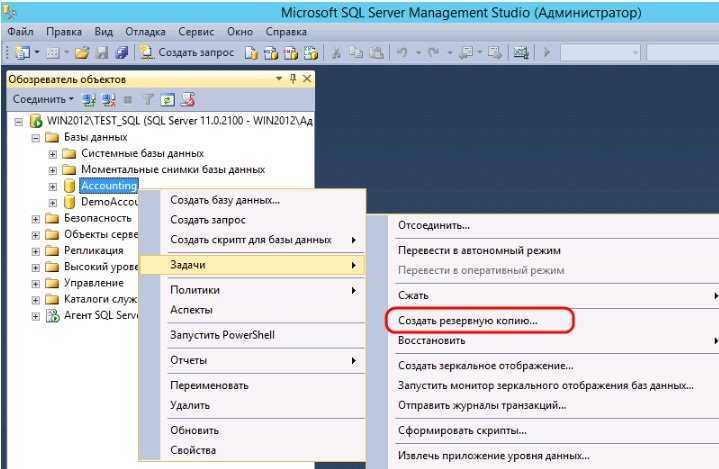
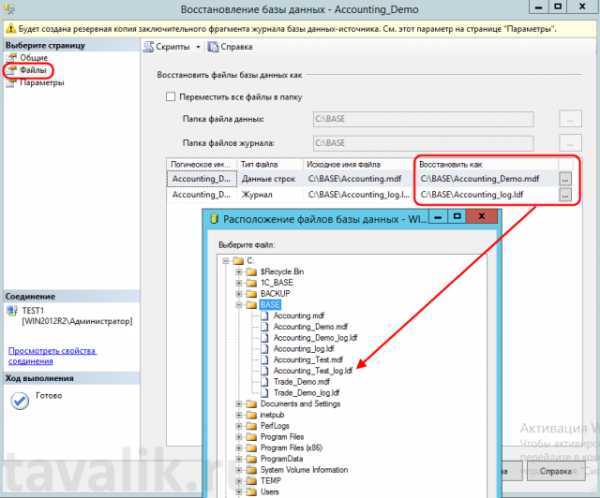
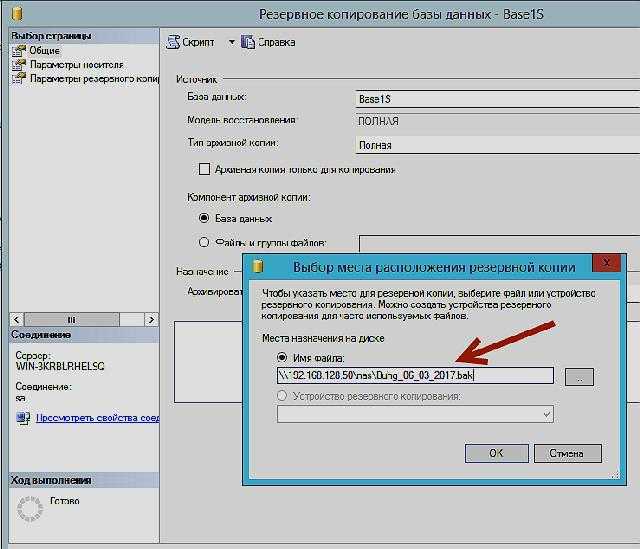
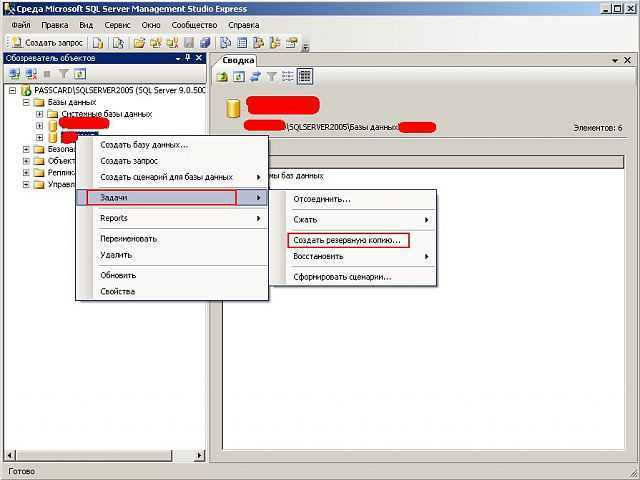
Потеря контроля над данными
Потеря цифровых данных часто рассматривается как потеря доступа к этой информации. Это может быть результат:
- физического повреждения носителя данных, препятствующее восстановлению даже через специализированные сервисы;
- случайное необратимое удаление данных с носителя;
- ошибки сетевых серверов в службе, которую мы используем для хранения данных.
В этих случаях безопасность можно обеспечить с помощью резервного копирования, а в случае данных, которые не создаются инкрементно, лучше всего сразу сохранять их в двух экземплярах. Предположим на минуту, что вторая копия не будет повреждена. Означает ли это, что все наши данные находятся в безопасности? Ответ зависит от того, что мы понимаем под термином «данные».
Данные – это не только наши фотографии с цифровой камеры, цифровые музыкальные файлы или цифровые заметки, которые мы храним в компьютере, а в последнее время всё чаще в мобильных устройствах. Данные – это также вся информация, которая будет нам полезна в работе и повседневной жизни. К этой категории относятся персональные данные, данные для доступа к цифровой версии услуг, в том числе банков. Ценными данными следует считать также все виды контента, анализ которого может стать для киберпреступников источником информации о нашей личности. Даже если они не столь важные, чтобы выполнять их резервное копирование.
Потеря данных – это любая ситуация, в которой мы не знаем, что происходит с нашими данными
В свете такого определения данных следует опасаться не только их потери, но, прежде всего, потери контроля над ними. Этим термином мы обозначаем совокупность действий враждебно к нам настроенных людей или организации, которые осуществляют захват наших данных (возможно, контроль над ними), часто без нашего ведома.
Давайте зададим себе вопрос ещё раз. Резервное копирование обеспечивает безопасность наших данных? Короткий ответ и, к сожалению, угрожающий – не обеспечивает. Позволяет их восстановить, но никоим образом не защищает от последствий использования спасенных данных.
Каким образом мы можем потерять контроль над данными?
- Данные могут быть украдены с незащищенного компьютера или через сервера злоумышленников;
- Доступ к данным может быть получен с помощью фишинга и социальной инженерии, либо в результате действия вредоносного программного обеспечения;
- Могут быть прямо опубликованы на незащищенной странице, с которой каждый может их прочитать;
- Они также могут быть потеряны пользователем в дороге.
Смартфон – это сегодня наш цифровой сейф. Его потеря – это для большинства людей риск огромных потерь.
Что ещё хуже, в ситуациях, когда мы слишком щедры в предоставлении персональных данных, даже человек, который не обладает большими навыками, может получить к ним доступ, испытав искушение в соответствии с правилом «возможность делает вора».
В дополнение, мы можем ощутить последствия потери данных, даже если сами не будем виноваты. Лучшим примером является похищение данных доступа к компьютеру одного из сотрудников компании, в которой мы заняты. Злоумышленники могут украсть наши данные, или, например, техническую документацию, используя слабое звено, которым является этот работник. Кража ценных данных компании, т.е. промышленный шпионаж, порождает экономические последствия для компании, и, в результате, может повлиять на наше профессиональное благополучие.
Converting data formats
If an input file uses a character set that is not the native character set of the host computer, the import operator must perform a conversion. For example, if ASCII is the native format for strings on your host computer, but the input data file represents strings using EBCDIC, you must convert EBCDIC to ASCII and vice versa.
a. Convert the data format of a file from EBCDIC to ASCII
If there’s an ebcdic file with you, mostly retrieved from mainframe systems, then, you would like to convert them to ASCII for making modifications using text editors on UNIX servers
# dd if=textfile.ebcdic of=textfile.ascii conv=ascii
The value parameter now is ascii because we convert from EBCDIC to ASCII
b. Convert the data format of a file from ASCII to EBCDIC
After modifying the ASCII version and once done, you may convert it back to EBCDIC to be used by your application.
# dd if=textfile.ascii of=textfile.ebcdic conv=ebcdic
The value parameter now is ebcdic because we convert from ASCII to EBCDIC. If you’re just replacing particular number of bytes with an equivalent number of bytes having different characters, the conversion would be smooth and application reading the file should not have any issues.
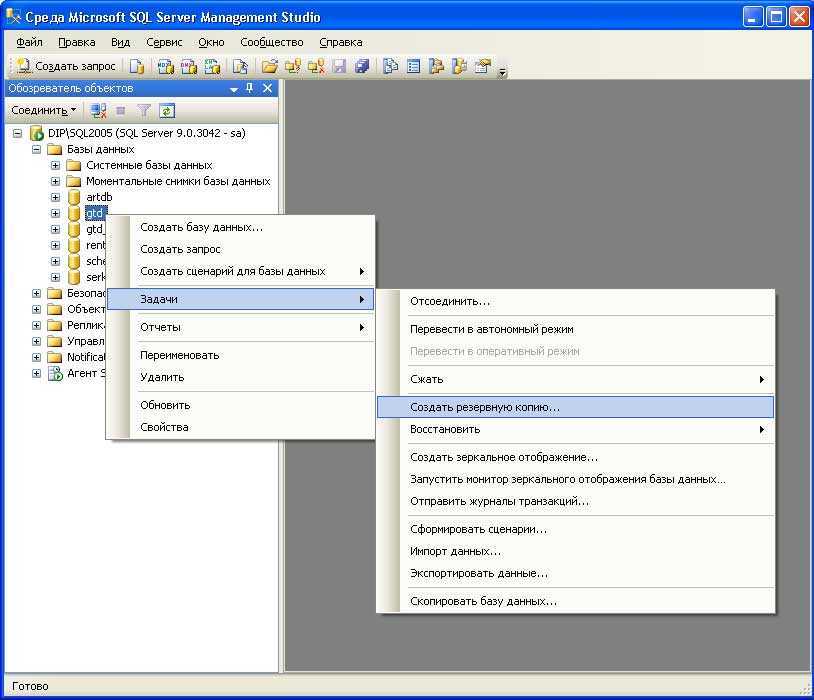
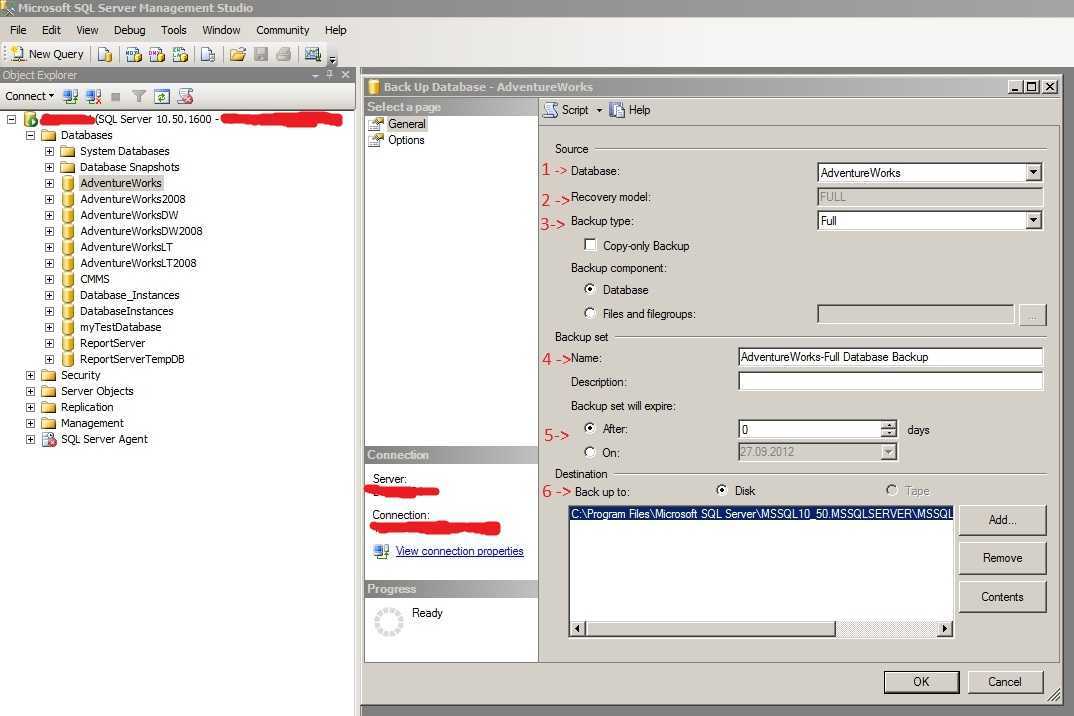
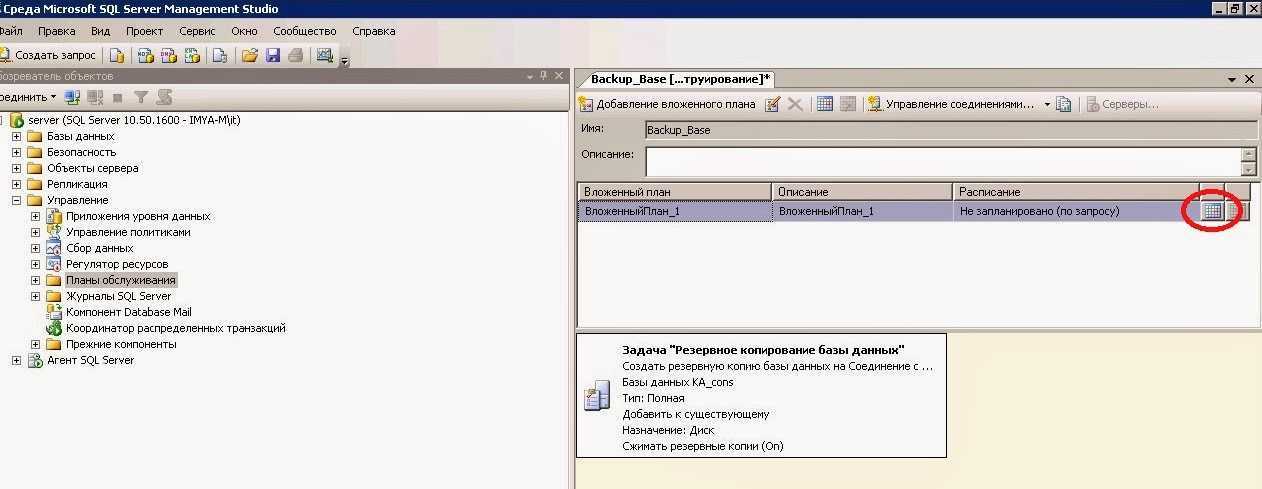
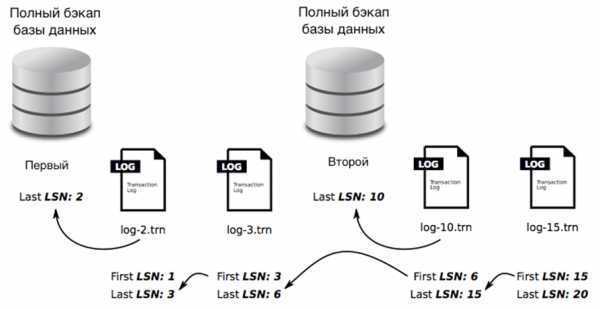
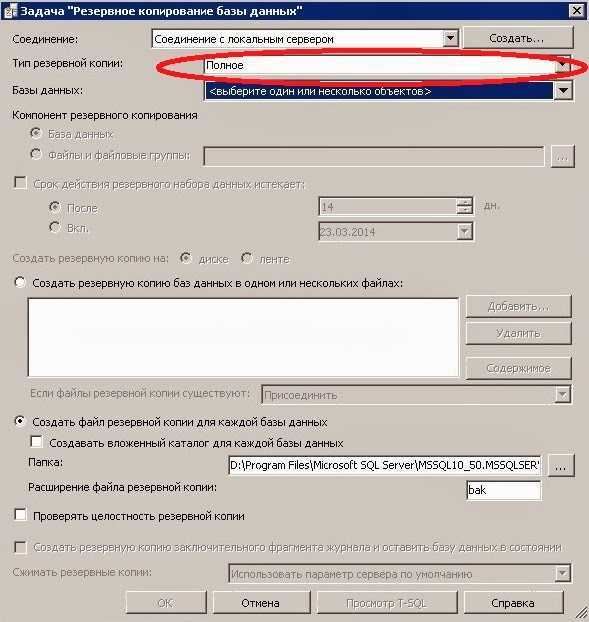
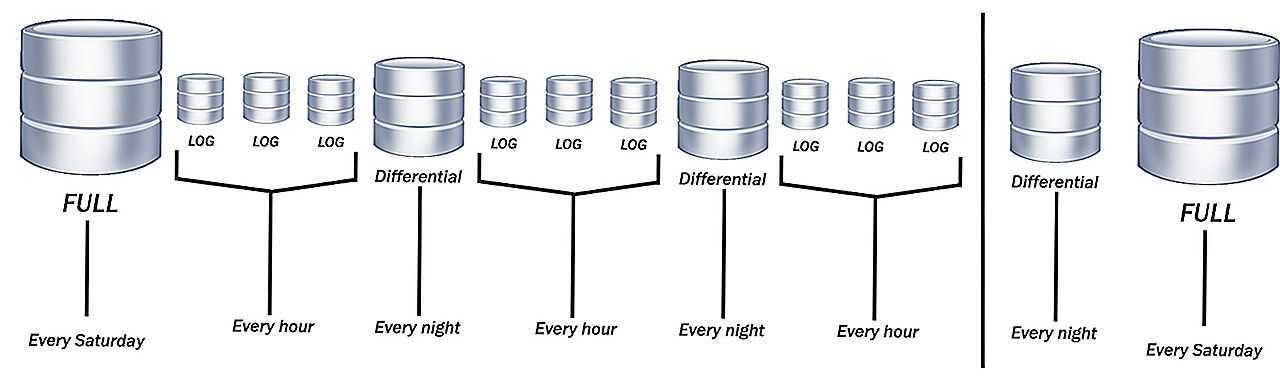
Три вида копий
Существует три основных типа бэкапа – всегда стоит подумать, какой из них лучше всего подходит для данных, которые нужно защитить:
- Полное – это база, включает все указанные файлы. Этот метод используется для создания точной копии данных, и доступ к ней аналогичен доступу к оригиналу.
- Дифференциальное – копируются файлы, измененные по сравнению с последней полной копией (разница между текущим состоянием данных и состоянием последней полной копии архивируется).
- Инкрементное – копируются файлы, добавленные из любой из самых последних резервных копий (копируются только те, которые были получены (увеличены) после бэкапа самой последней версии).

Изображение из открытого доступа
Выбор правильного метода зависит от объема данных, от того, как часто вы выполняете бэкап, как часто и как быстро меняются данные.
Полная копия будет работать в случае небольшого объема данных или когда она сделана на устройствах, которые обеспечивают очень быстрый бэкап, например, второй диск компьютера или внешний накопитель USB 3.0.
Converting case of a file
DD command can be also used for an amazing thing. It can convert all text (alphabets) in a file to upper or lower case and vice versa. For the example below, we will have a file for the tests.
# cat file10 test dd convert
a. Converting a file to uppercase
Because our text file example is on lowercase, we will convert it to uppercase
# dd if=~/file10 of=~/file20 conv=ucase
The command will create the new file indicated. See that now option takes ucase value. Let’s check the result
# cat file20 TEST DD CONVERT
b. Converting a file to lowercase
Now we will do the reverse operation which will convert to lowercase
# dd if=~/file20 of=~/file30 conv=lcase
See that we use lcase of option to convert from upper case to lower case.
# cat file30 test dd convert
dd command does not convert the file names, only its content.
Команда df linux
Утилита df поставляется по умолчанию во всех дистрибутивах Linux и имеет очень простой синтаксис. Фактически вы можете просто набрать df и уже получить результат, но чтобы сделать вывод более читаемым используются дополнительные опции. Вот основной синтаксис:
$ df опции устройство
Устройство указывать необязательно, но можно указать раздел диска, о котором мы хотим посмотреть информацию. А теперь рассмотрим основные опции утилиты:
- -a, —all — отобразить все файловые системы, в том числе виртуальные, псевдо и недоступные;
- -B — изменить размер одного блока перед выводом данных, например, можно использовать BM, чтобы вывести все данные в мегабайтах;
- -h — выводить размеры в читаемом виде, в мегабайтах или гигабайтах;
- -H — выводить все размеры в гигабайтах;
- -i — выводить информацию об inode;
- -k — выводить размеры в килобайтах;
- —output — использовать специальный формат вывода, если не задано, выводит все поля. Доступны такие варианты: ‘source’, ‘fstype’, ‘itotal’, ‘iused’, ‘iavail’, ‘ipcent’, ‘size’, ‘used’, ‘avail’, ‘pcent’, ‘file’ и ‘target’;
- -P — использовать формат вывода POSIX;
- —total — выводить всю информацию про использованное и доступное место;
- -t, —type — выводить информацию только про указанные файловые системы;
- -x — выводить информацию обо всех, кроме указанных файловых систем;
Теперь, после основных опций рассмотрим подробнее как примеры df linux.
Backing up and restoring an entire disk or a partition
It is possible to save all the data from an entire disk/partition to another disk/partition. Not a simple copy as cp command but a block size copy.
a. Backup entire disk to disk
You can copy all the data (entire disk) from the disk to . dd doesn’t know anything about the filesystem or partitions; it will just copy everything from to . You need to indicate the block size to be copied at time with option. So, this will clone the disk with the same data on the same partition.
# dd if=/dev/sda of=/dev/sdb bs=4096 conv=noerror,sync 97281+0 records in 97280+0 records out 99614720 bytes (100 MB) copied, 2.75838 s, 36.1 MB/s
This works only if the second device is as large as or larger than the first. Otherwise, you get truncated and worthless partitions on the second one. Here, if stands for input file , of stands for output file and bs stands for the block size (number of bytes to be read/write at a time). Make sure you use block sizes in multiples of 1024 bytes which is equal to 1KB. If you don’t specify block size, dd use a default block size of 512 bytes. The value parameter noerror allows the tool to continue to copy the data even though it encounters any errors. The sync option allows to use synchronized I/O.
b. Creating dd disk image (file image)
You can create an image of a disk or a file image. Backing up a disk to an image will be faster than copying the exact data. Also, disk image makes the restoration much easier.
# dd if=/dev/sda of=/tmp/sdadisk.img
You can store the output file where you want but you have to give a filename ending with extension as above. Instead of , you could store it for example at if you want.
c. Creating a compressed disk image
Because dd creates the exact content of an entire disk, it means that it takes too much size. You can decide to compress the disk image with the command below
# dd if=/dev/vda | gzip -c >/tmp/vdadisk.img.gz
The pipe | operator makes the output on the left command become the input on the right command. The option writes output on standard output and keeps original files unchanged.
d. Backup a partition or clone one partition to another
Instead of an entire disk, you can only backup a simple partition. You just need to indicate the partition name in input file as below
# dd if=/dev/sda1 of=/dev/sdb1 bs=4096 conv=noerror,sync
This will synchronize the partition to . You must verify that the size of should be larger than . Or you can create a partition image as below
# dd if=/dev/sda1 of=/tmp/sda1.img
e. Restoring a disk or a partition image
Save a disk or a partition helps to restore all the data, if there is any problem with our original drive. To restore, you need to inverse the input file with the output file indicated during backup operation as below.
# dd if=/tmp/sdadisk.img of=/dev/sda
You will retrieve data that were present before the backup operation and not after the operation
e. Restoring compressed image
You need to first indicate the compressed file and the output file which is the disk compressed before.
# gzip -dc /tmp/vdadisk.img.gz | dd of=/dev/vda
The -d option here is to uncompress. Note the output file. You can mount the restored disk to see the content. Note that you will data added after the last compression backup operation.
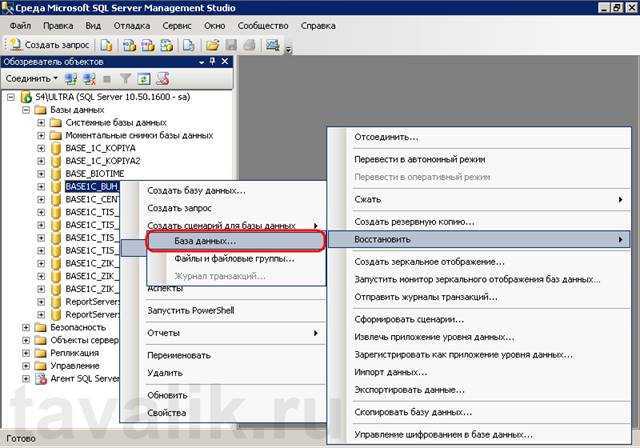
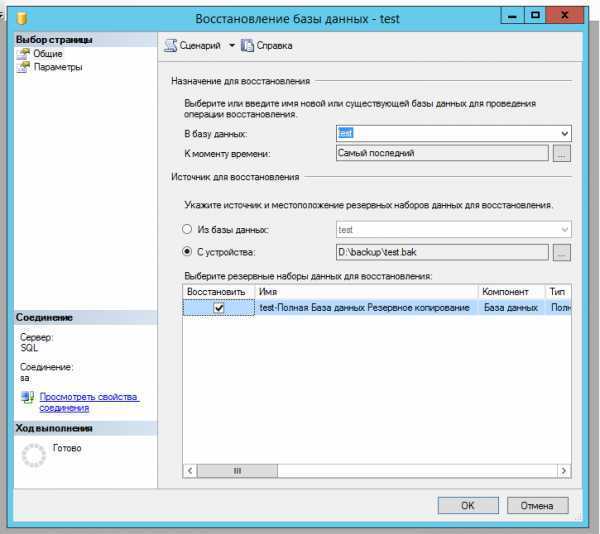
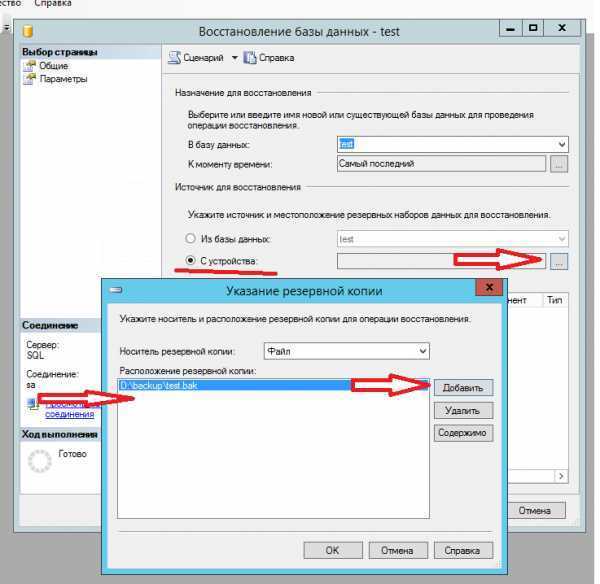
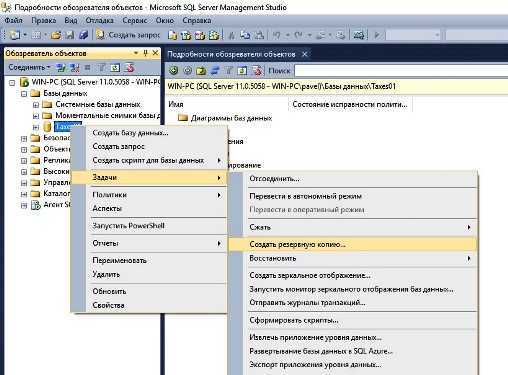
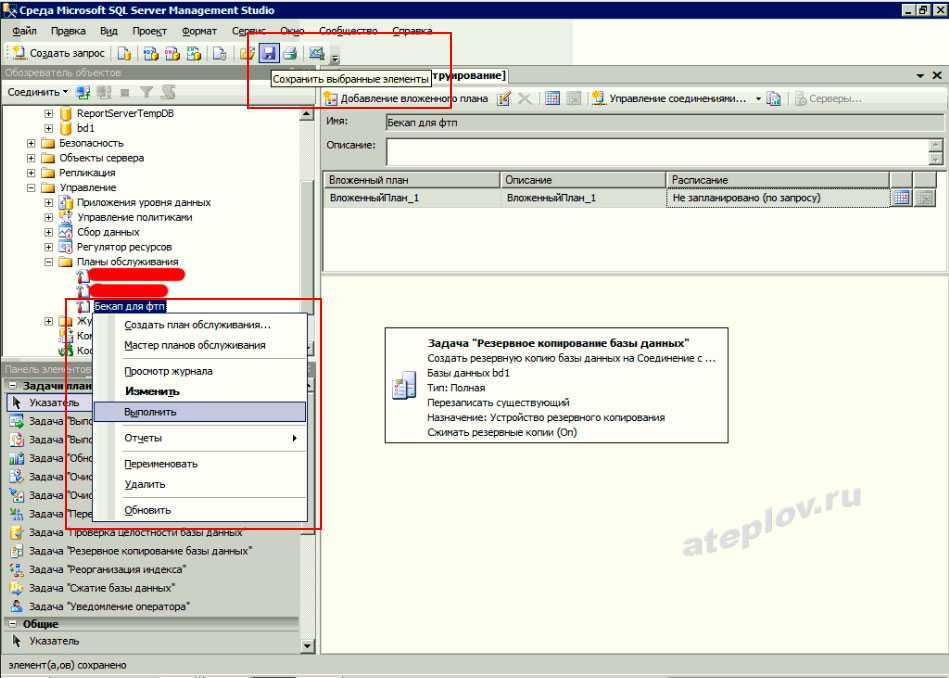
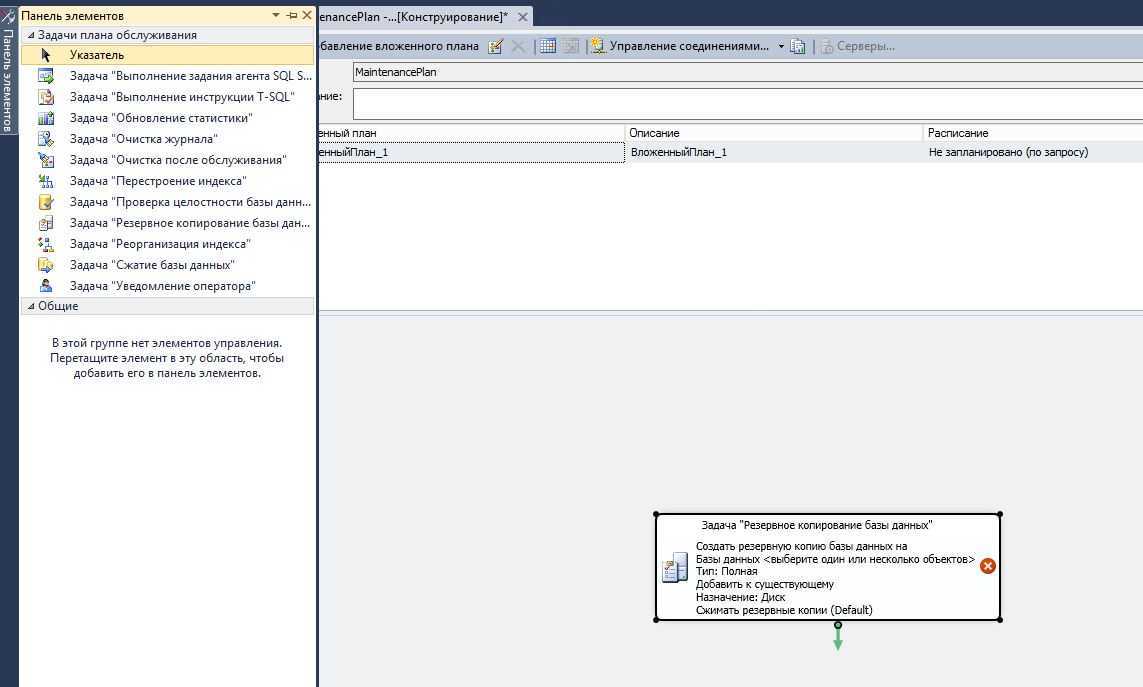
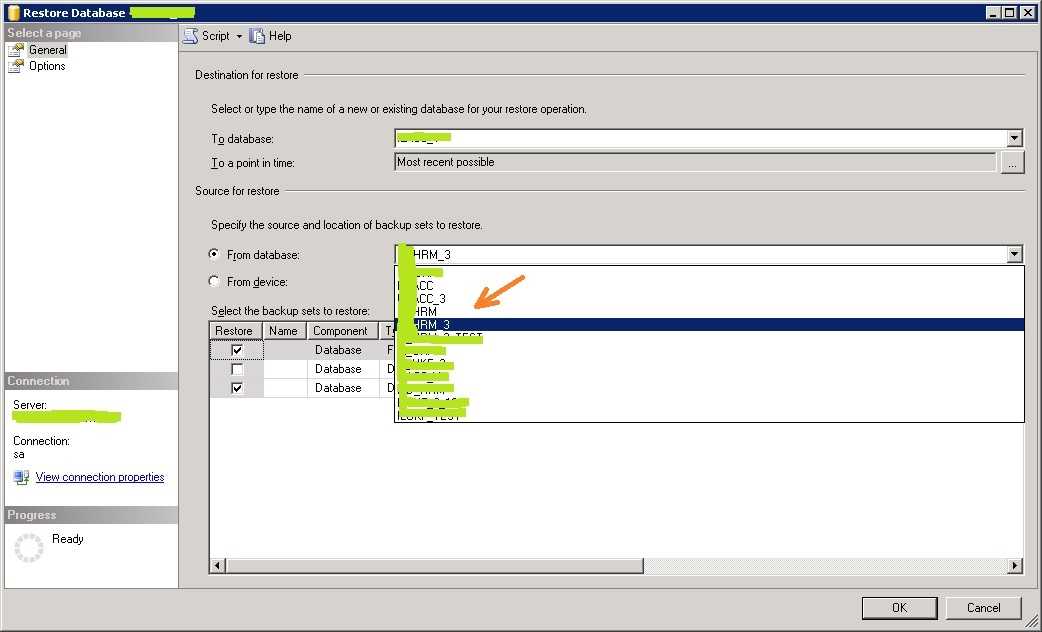
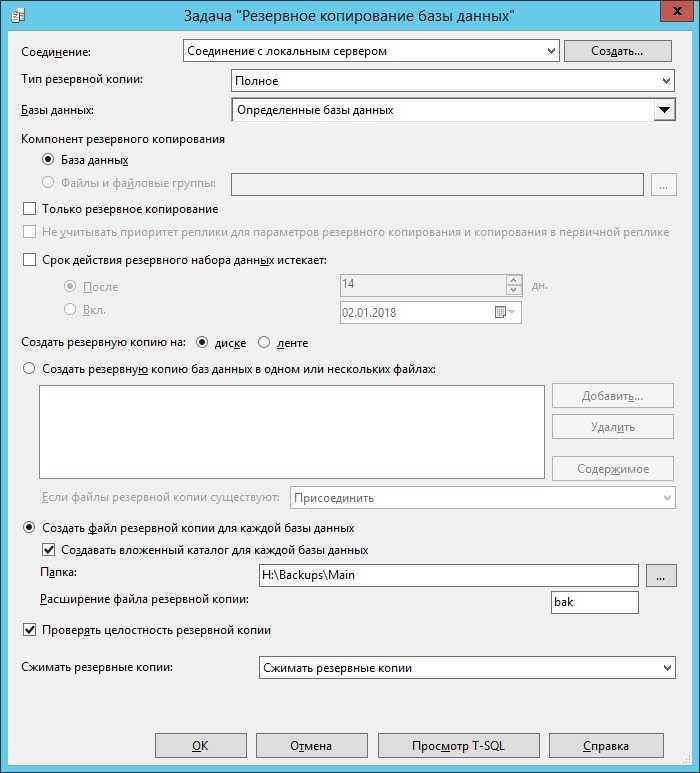
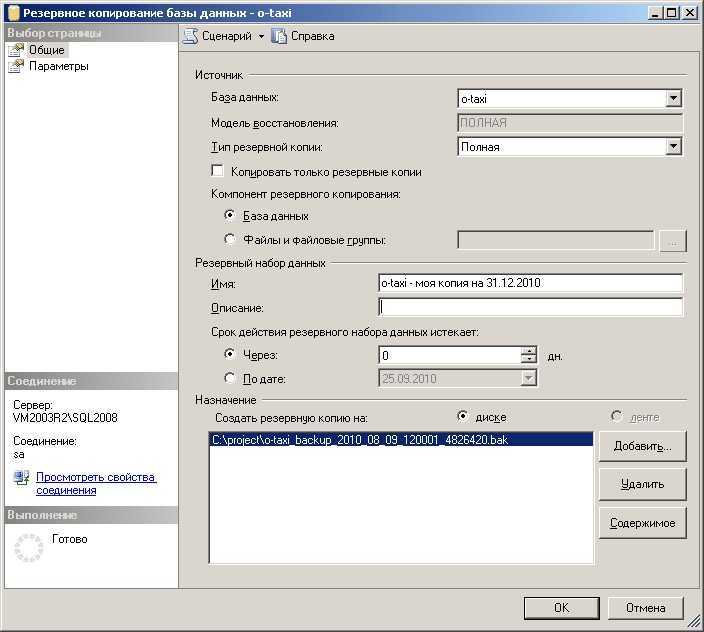
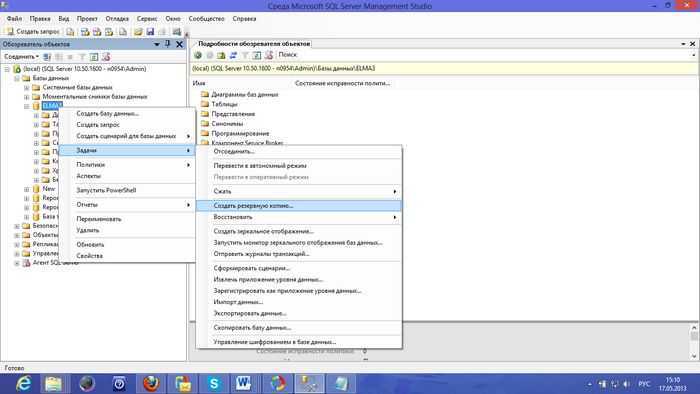
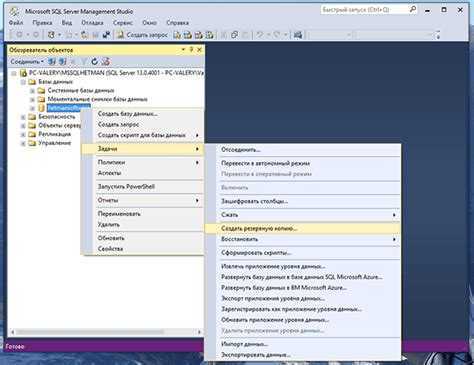
В каких случаях что-то может пропасть из базы «1С»? Есть несколько вариантов.
Человек ошибается или человеческий фактор: пользователь программы ошибочно удалил или изменил файлы.
Есть решение: ограничить права пользователей для внесения изменений. Поможет ограничить права в 1С
Техника ломается или поломка жесткого диска: вышел из строя или был отформатирован HDD
Какое решение: сохранение данных в облачных сервисах или на флешках.
Сбой windows, например после их знаменитых обновлений (как отключить обновления читай в нашей статье)
Решение: не хранить базы на системных дисках. В случае, если установлена ОС Windows 10, заранее подготавливаться к обновлению подредакций два раза в год.
Но совсем скоро Windows будет обновлять 1 раз в год.
Самое неприятное, это вирусы:Полное удаление или шифрования файлов вредоносными программами с последующим требованием выкупа. (Подробнее про шифровальщик)
Решение: Использование лицензионного и правильно настроенного антивируса, но взломщики не спят, они развиваются и их уже сложно остановить одним антивирусником, обязательно нужен BACKUP.
Файлы, которые не нужно копировать
Никогда не было оснований для резервного копирования каталога Windows или папки Program Files. Оставьте эти папки в покое.
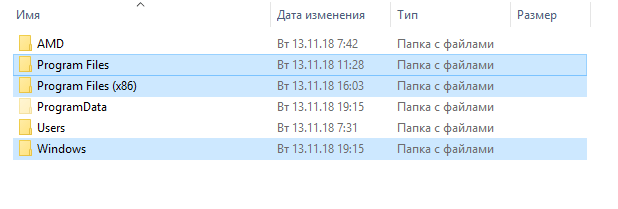
Каталог Windows содержит системные файлы Windows, и они не переносимы между различными аппаратными средствами ПК. Windows вновь создаст эти файлы, когда эти программы будут установлены на новом ПК, поэтому они Вам не нужны.
Папка Program Files содержит файлы для установленных приложений. Обычно вы не можете просто копировать эти папки. Вам придётся переустанавливать большинство приложений с нуля, поэтому обычно нет необходимости в резервном копировании этой папки.
Несколько программ можно просто перемещать между ПК. Например, вы можете создавать резервные копии своих каталогов Steam или Battle.net и копировать их на новый компьютер, сохранив файлы игр. Однако, даже эти папки не имеют решающего значения для резервного копирования. Они могут ускорить настройку нового ПК и сэкономить время загрузки, но они не заполнены критическими файлами, которые вы никогда не сможете вернуть. Вы всегда можете просто переустановить свои программы, поэтому они не являются приоритетом, если вы ограничены в пространстве.
Backing up and restoring MBR
The GRUB bootloader is most commonly stored in the MBR of the bootable drive. The MBR makes up the first 512 bytes of the disk, allowing up to 466 bytes of storage for the bootloader. The additional space will be used to store the partition table for that drive. If MBR gets corrupted, we will not be able to boot into Linux.
a. Backing up MBR
Because the MBR makes up the first 512 bytes of the disk, we just need to copy that block size
# dd if=/dev/sda of=/tmp/sdambr.img bs=512 count=1
With the and , only 512 bytes will be copied which correspond to the size of our MBR.
You can display the saved MBR with the od command which dump files in octal and other formats as below
# od -xa /tmp/sdambr.img
0000000 bf52 81f4 8b66 832d 087d 0f00 e284 8000
R ? t soh f vt - etx } bs nul si eot b nul nul
0000020 ff7c 7400 6646 1d8b 8b66 044d 3166 b0c0
| del nul t F f vt gs f vt M eot f 1 @ 0
option selects named characters and selects hexadecimal 2-byte units
b. Backing up the boot data of MBR excluding the partition table
The MBR 512 bytes data is located at the first sector of the hard disk. It consists of 446 bytes bootstrap, 64 bytes partition table and 2 bytes signature. It means that we can exclude the partition table and bytes signature while backing up the MBR with conserving only a block size equal to the bootstrap size.
# dd if=/dev/sda of=/tmp/sdambr2.img bs=446 count=1
Использование cd в linux
Я не буду здесь описывать какими бывают пути в Linux. Мы рассматривали эту тему в отдельной статье. По умолчанию, в качестве рабочего каталога используется домашняя папка пользователя. Давайте сначала перейдем в одну из подпапок домашней папки:
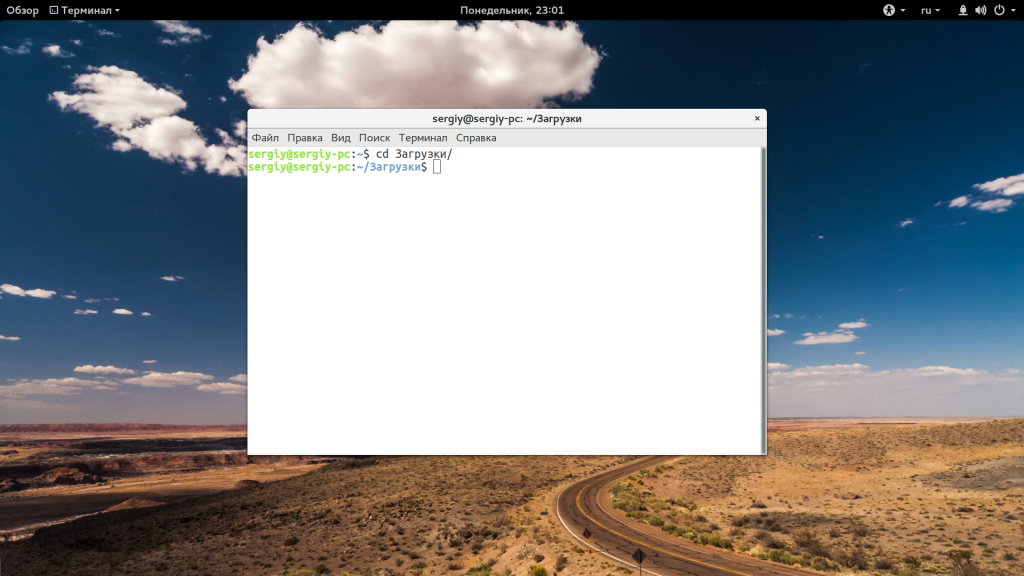
Домашняя папка обозначается как ~/. Поэтому следующая команда выполнит аналогичное действие:
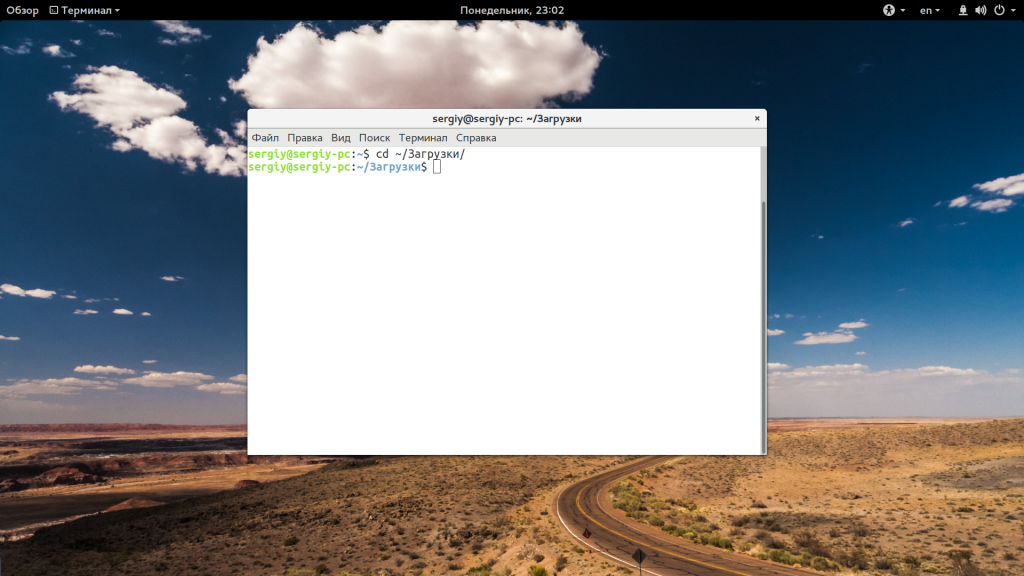
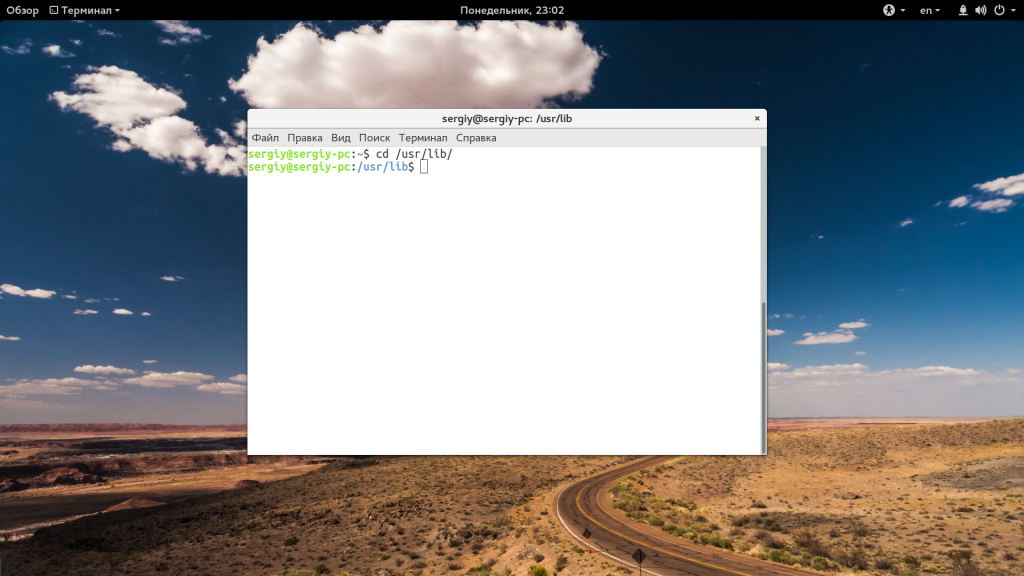
Правда, здесь есть преимущество. В первой команде используется относительный путь, тогда как вторая правильно выполнится из любой папки. Теперь переместимся в папку /usr/lib относительно корня:
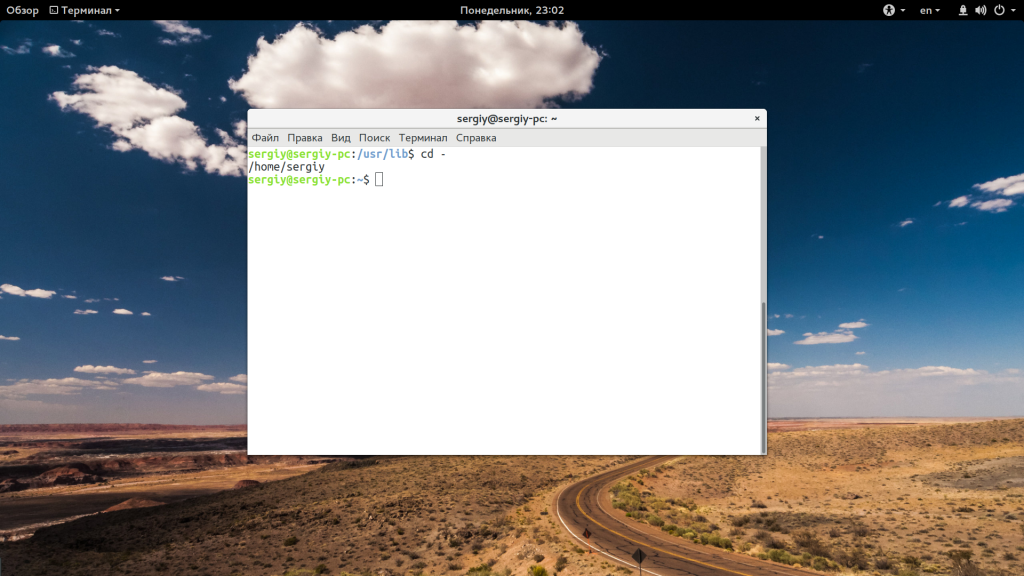
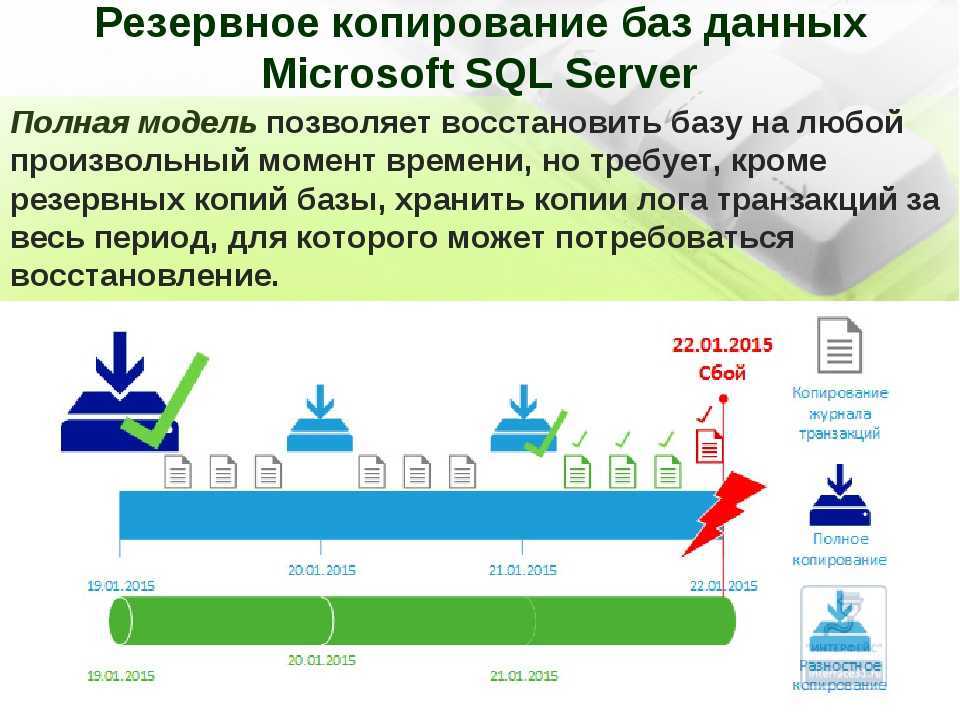
С помощью символа черты «-» вы можете вернуться в предыдущую папку:
Используя двойную точку «..» можно перейти в родительский каталог:
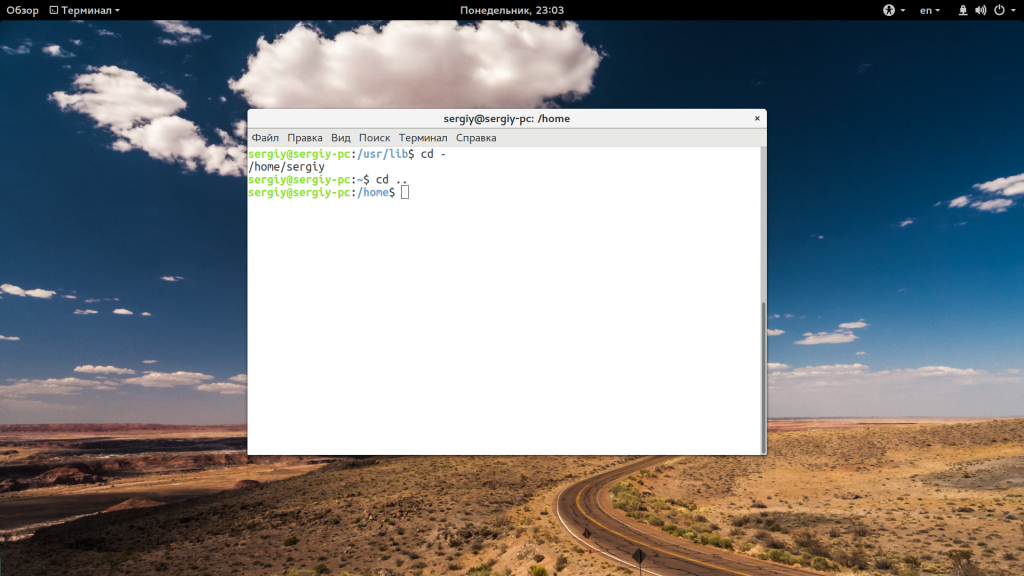
Вы можете использовать несколько блоков с точками для перемещения на несколько уровней вверх:
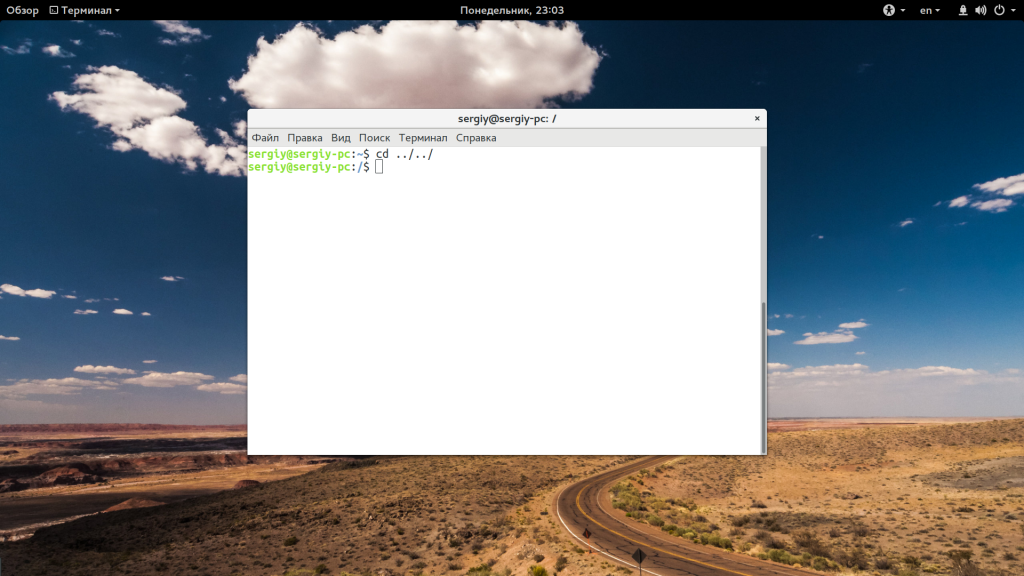
Как уже говорилось, если не передать папку, в которую нужно перейти, будет открыта домашняя папка:
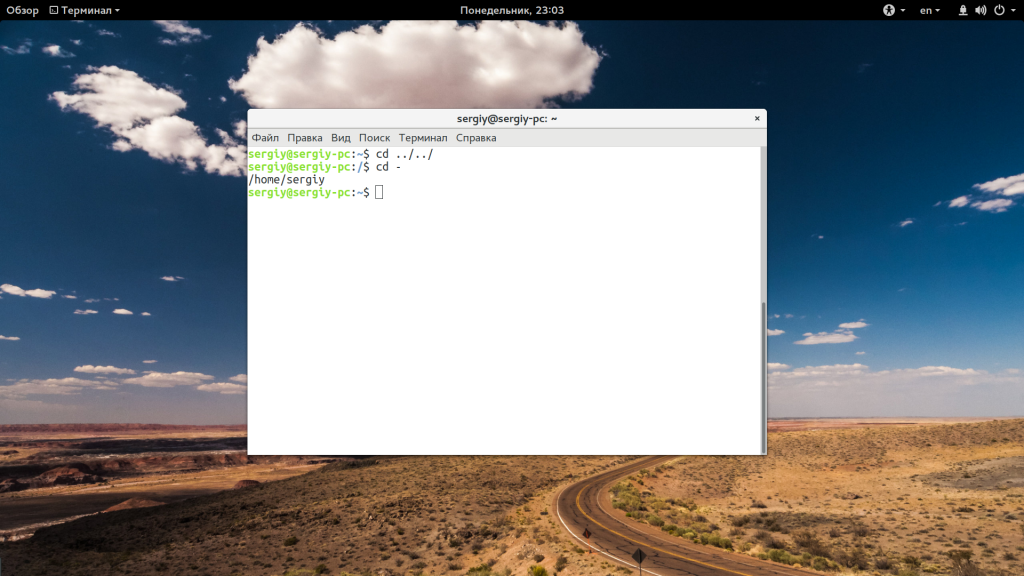
Аналогичный результат выдаст команда:
Для упрощения перехода по папкам можно использовать символ звездочки. Правда, автодополнение сработает только если на указанные символы будет начинаться только одна папка.
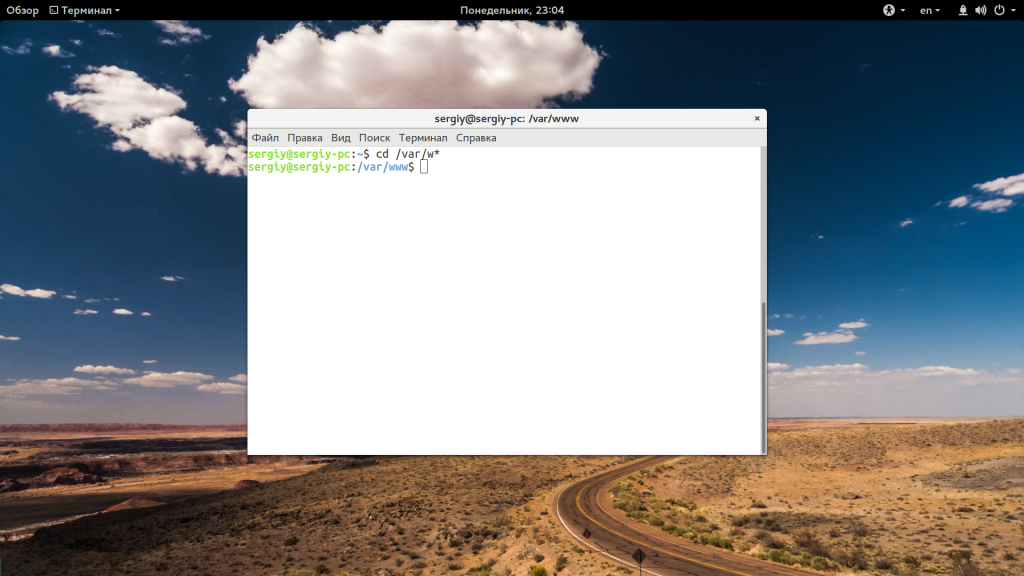
Кроме cd, есть еще две дополнительные команды, это pushd и popd. Можно сказать, что простая реализация стека для рабочих каталогов. Когда вы выполняете pushd, текущий рабочий каталог сохраняется в памяти, а на его место устанавливается указанный:
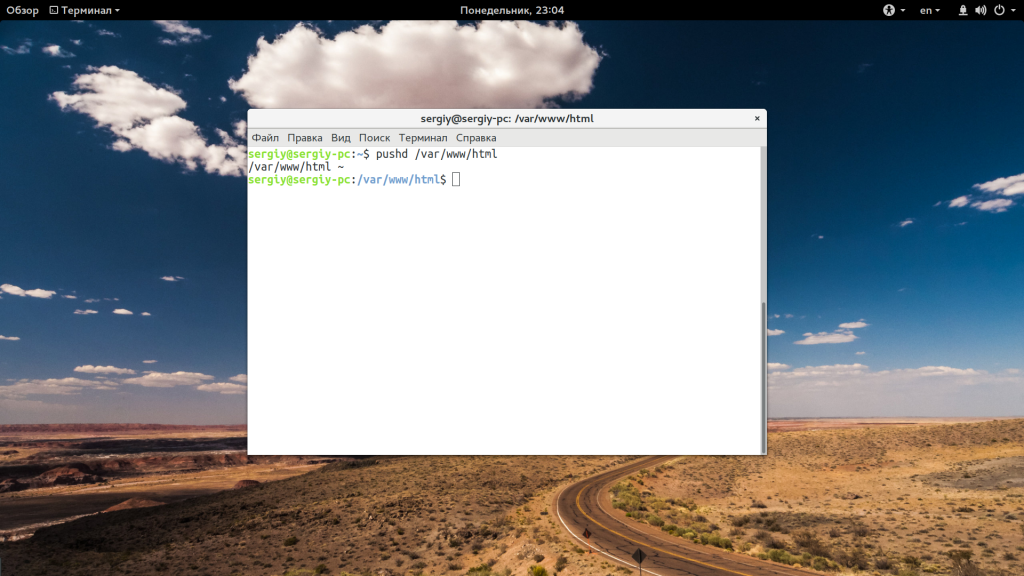 Теперь наберите popd, чтобы вернуться в предыдущий каталог:
Теперь наберите popd, чтобы вернуться в предыдущий каталог:
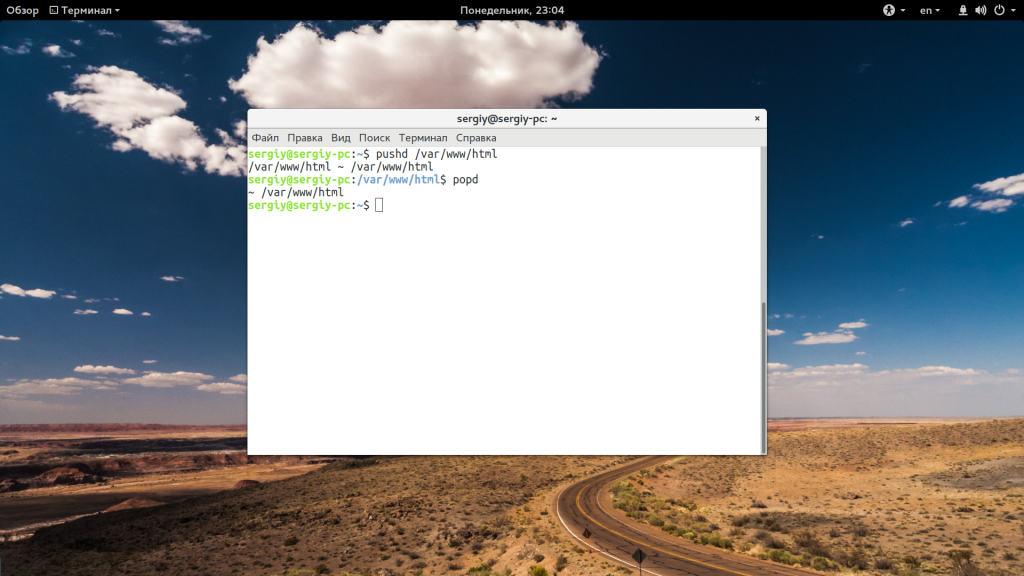
Это реализация стека, поэтому количество каталогов в памяти не ограничено двумя. Вы можете перемещаться по такому количеству папок, как вам нужно.
Наконец, еще один момент, если вам нужно перейти в каталог, в имени которого есть пробелы, используйте символ экранирования обратный слэш «\» или просто возьмите его имя в скобки:
Создать образ клонированного диска
Теперь у вас есть почти вся информация о диске «/ dev / sda». Нажмите «q», чтобы выйти из командной темы. Теперь вы готовы создать образ диска с помощью команды DD. Итак, дайте себе понять, что команде DD всегда требуются привилегии sudo для выполнения. Как мы уже знаем из изображения выше, «/ dev / sda» имеет три раздела, и мы создадим образ одного из них. Итак, мы выбрали «sda1» для создания его клона. Вы должны выполнить приведенную ниже команду «DD», за которой следует путь «если» и путь «из». Путь «if» относится к входному диску, который предназначен для клонирования, а путь «of» — к диску устройства вывода, куда он будет скопирован как образ. Итак, из этого вы можете понять, что «sda1.img» — это клонированный файл для диска, а sda1 — это фактический диск. Мы указали количество байтов в секунду для копирования из одного места в другое. Мы присвоили ему значение 1000. Команда выглядит следующим образом:
Выходные данные показывают количество записей, введенных и выведенных из двух мест, например, из источника и назначения. Он также показывает количество байтов с указанием времени в секундах, скопированных в место назначения в МБ. Это означает, что клон был успешно выполнен.

Давайте проверим файл образа назначения, чтобы убедиться, что все данные с исходного диска были клонированы в него должным образом или нет. Используйте команду списка ниже вместе с путем к файлу образа диска как:
Вывод показывает права, назначенные этому файлу изображения, его размер и расположение. Вы можете сказать, что он имеет такие же права и размер, что и исходный диск.

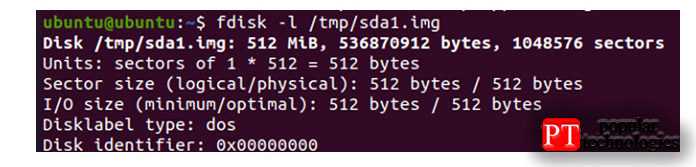
Чтобы увидеть дополнительную информацию о файле образа диска, вы должны попробовать следующую команду «fdisk». За которой следует флаг «-l», как показано ниже.
Вывод показывает ту же информацию об этом файле образа. Которую мы видели для исходного диска перед созданием этого файла образа. Он показывает размер диска образа, его общее количество байтов и общее количество секторов.
curl
Утилита curl извлекает информацию и файлы с url-страниц.
Будет полезна тем, кто часто загружает:
- Скрипты.
- Исполняемые файлы программ.
- Архивы.
С помощью команды curl это можно делать не через браузер, а прямо из терминала, что дает возможность автоматизировать процесс.
На самом деле curl является не просто утилитой, а целым набором библиотек, способными реализовать все основные возможности по работе c передачей файлов и url-страницами.
Curl поддерживает работу с протоколами:
- FTP
- FTPS
- HTTP
- HTTPS
- TFTP
- SCP
- SFTP
- Telnet
- DICT
- LDAP
- POP3
- IMAP
- SMTP
Загрузка файлов с помощью curl
Самая распространенная задача для утилиты curl – это загрузка файлов. Чтобы скачать файл достаточно передать утилите имя файла или адрес страницы, например:
Таким образом содержимое файла будет отправлено на стандартный вывод. Для записи его в файл (для примера ex.txt) нужно ввести:
Чтобы скачанный файл назывался так же, как и на сервере необходимо использовать опцию -O:
Стоит отметить, что не во всех дистрибутивах Linux утилита предустановлена по умолчанию.
использование
Командной строки Синтаксис дд отличается от многих других программ Unix. Он использует синтаксис option = value для своих параметров командной строки, а не более стандартные форматы — option value или — option = value . По умолчанию dd читает из stdin и записывает в stdout , но это можно изменить с помощью параметров if (входной файл) и of (выходной файл).
Некоторые функции dd будут зависеть от возможностей компьютерной системы, например, от способности dd реализовать возможность прямого доступа к памяти. Отправка сигнала SIGINFO (или сигнала USR1 в Linux) запущенному процессу dd заставляет его один раз распечатать статистику ввода-вывода со стандартной ошибкой, а затем продолжить копирование. dd может читать стандартный ввод с клавиатуры. Когда будет достигнут конец файла (EOF), dd выйдет. Сигналы и EOF определяются программным обеспечением. Например, инструменты Unix, перенесенные в Windows, различаются по EOF: Cygwin использует Ctrl+ D(обычный EOF для Unix), а MKS Toolkit использует Ctrl+ Z(обычный EOF для Windows).
Нестандартизированные части вызова dd различаются в зависимости от реализации.
Выходные сообщения
По завершении dd выводит в поток статистику передачи данных. Формат стандартизирован в POSIX. Страница руководства для GNU dd не описывает этот формат, но руководства BSD описывают его.
Каждая из строк «Входящие записи» и «Выходные записи» показывают количество переданных полных блоков + количество частичных блоков, например, потому что физический носитель закончился до того, как был прочитан полный блок, или физическая ошибка помешала чтению всего блока.
Как пользоваться df
Чтобы посмотреть доступное пространство на всех примонтированных разделах и информацию о них достаточно набрать:
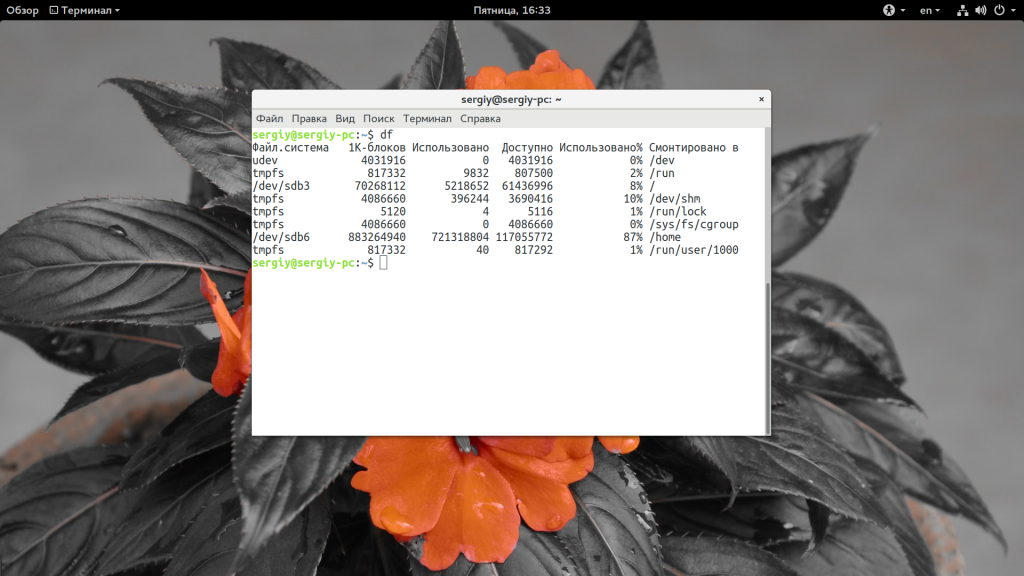
Утилита отображает стандартный набор колонок, но понять в ее выводе что-то с первого раза сложно. Все данные выводятся в килобайтах. Теперь давайте попросим утилиту выводить данные в более читаемом формате:
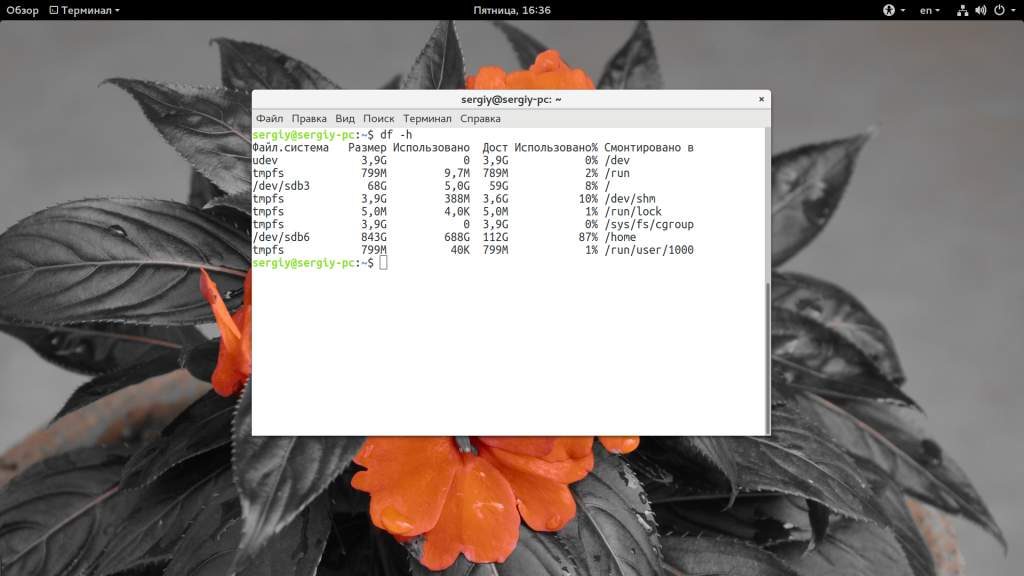
Это самое популярное сочетание опций, потому что оно дает максимально понятную информацию и уже можно судить о том, что происходит на диске. Например, мы видим, что в домашней папке уже занято 87% места и, возможно, пора что-то удалить. Если задать опцию -a, вы можете получить информацию обо всех файловых системах известных ядру, которые были смонтированы:
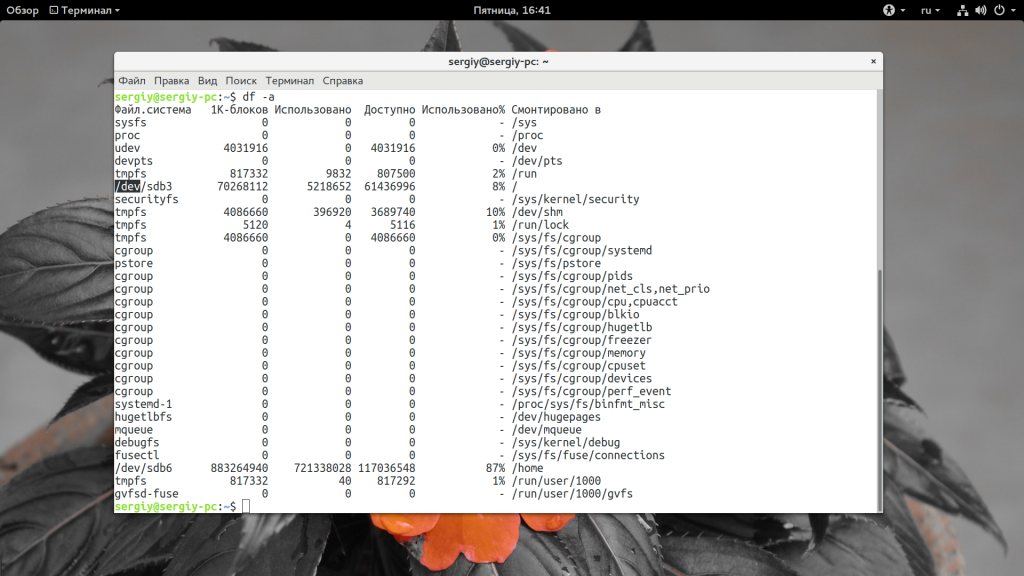
Здесь отображается огромное количество виртуальных файловых систем ядра. Если вы хотите вывести только информацию про реальные файловые системы на жестком диске можно использовать опцию -x чтобы отфильтровать все tmpfs:
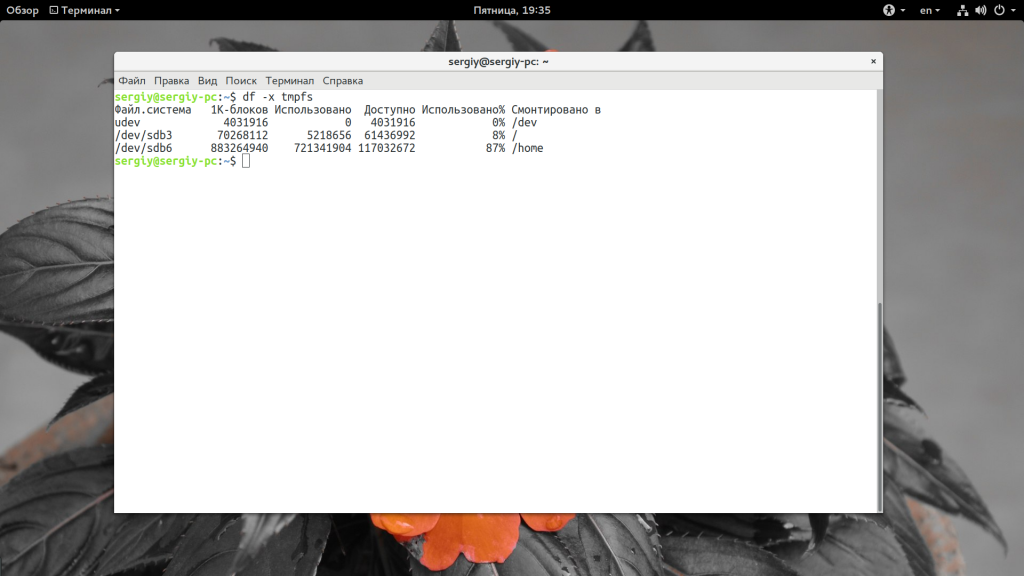
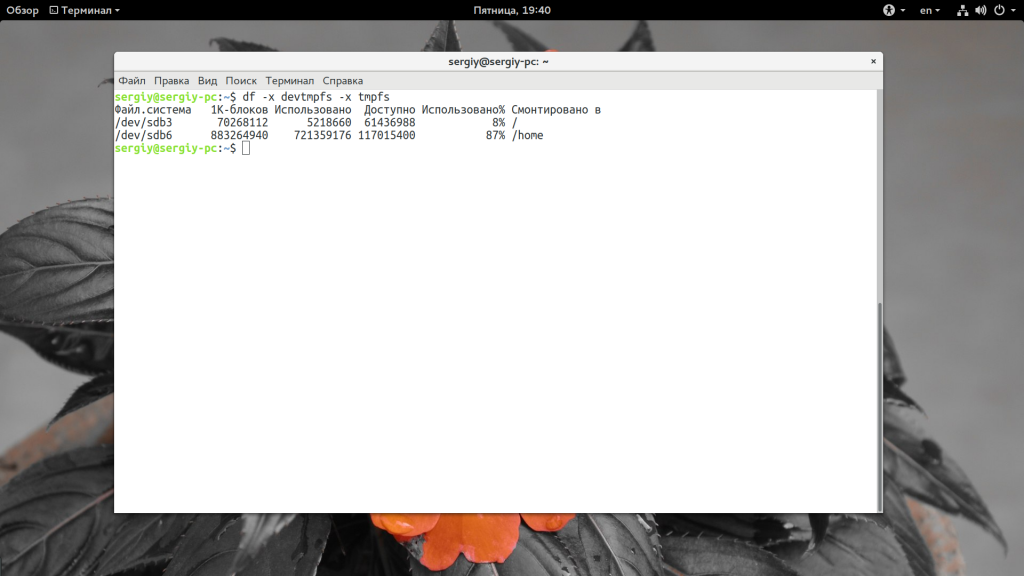
Или же указать файловую систему, которую нужно отображать:
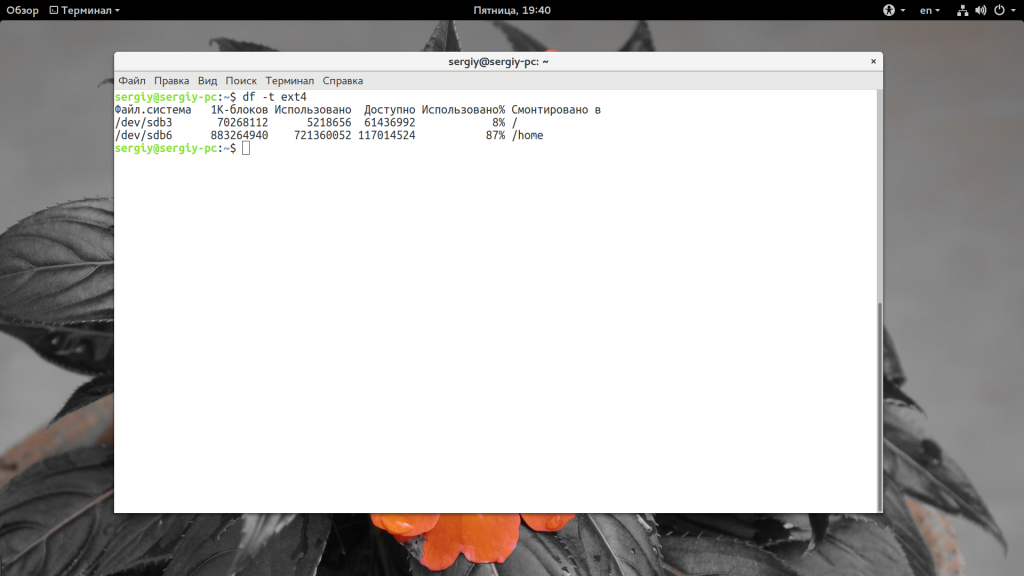
Также можно указать интересующий вас раздел, как вы видели в синтаксисе команды:
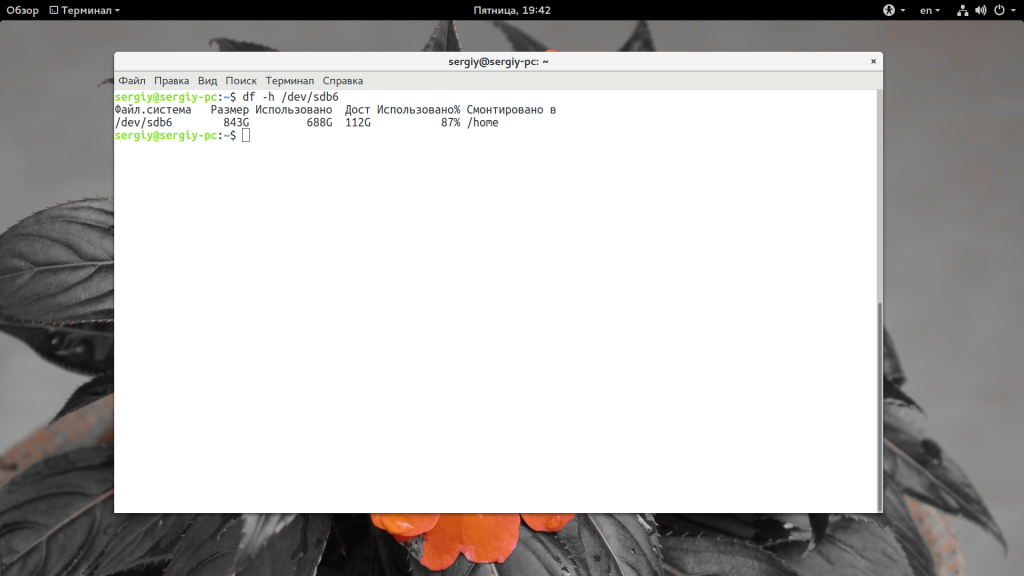
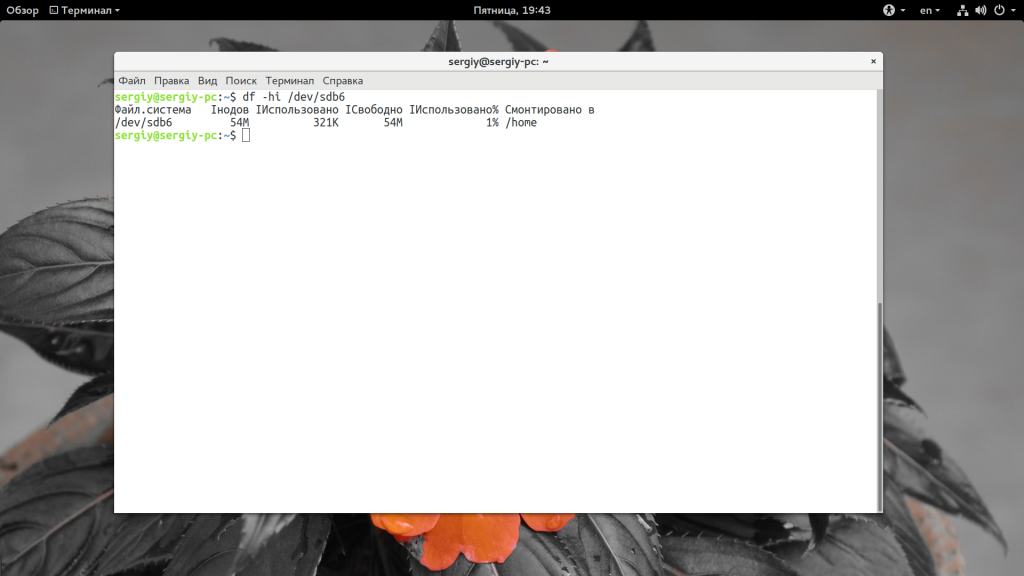
С помощью опции -i вы можете посмотреть информацию про состояние inode в вашей файловой системе:
Видео, о том, как пользоваться утилитой df:
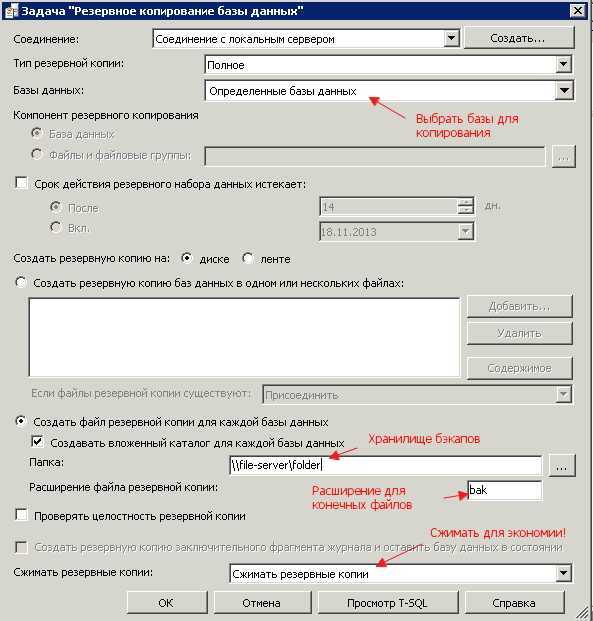
Клонирование диска
Первым делом мы создаем полную копию нашего диска. Это единственный этап, который может быть выполнен без нюансов на любой из систем, так как он выполняется с помощью утилиты dd.
Смотрим состояние дисков и разделов на текущий момент:
lsblk
Определяемся, с какого диска на какой мы будем выполнять копию
Это может прозвучать банально, но тут важно не перепутать источник диска, с которого клонируется информация и целевой носитель
Выполняем команду:
dd if=/dev/sdx1 of=/dev/sdy1 bs=64K conv=noerror,sync
* Команда выполняет блочное копирование и запускается со следующими параметрами:
- if — источник данных.
- of — куда копировать данные.
- bs — объем блока, который будет читаться и копироваться за раз.
- conv — дополнительные опции. В данном примере noerror — продолжать операцию в случае ошибки чтения данных; sync — копировать все, в том числе и нулевые данные.
* Таким образом, мы клонируем диск или раздел с /dev/sdx1 в /dev/sdy1 (не путаем источник и назначение).
Команда будет выполняться некоторое время. После ее завершения можно снова посмотреть состояние дисков и разделов:
lsblk
При клонировании диска мы должны увидеть, что целевой носитель приобрел такую же разметку.
Следующим шагом настроим загрузчик.
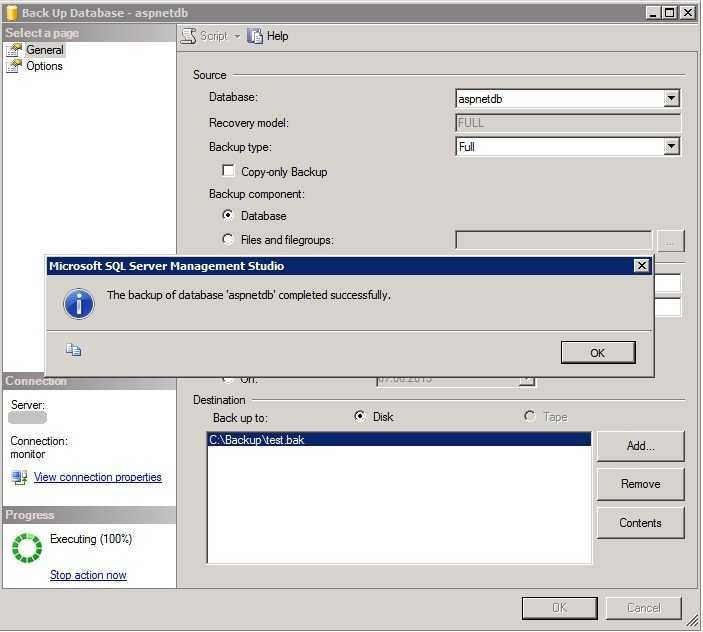
Как пользоваться dd?
Обычные пользователи используют команду dd чаще всего для создания образов дисков DVD или CD. Например, чтобы сохранить образ диска в файл можно использовать такую команду:
sudo dd if=/dev/sr0 of=
/CD.iso bs=2048 conv=noerror
Фильтр noerror позволяет отключить реагирование на ошибки. Дальше, вы можете создать образ жесткого диска или раздела на нем и сохранить этот образ на диск. Только смотрите не сохраните на тот же жесткий диск или раздел, чтобы не вызвать рекурсию:
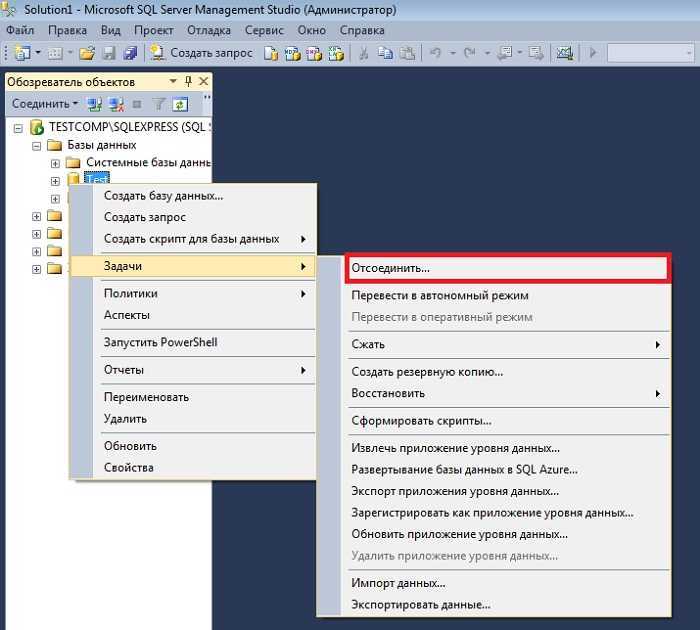
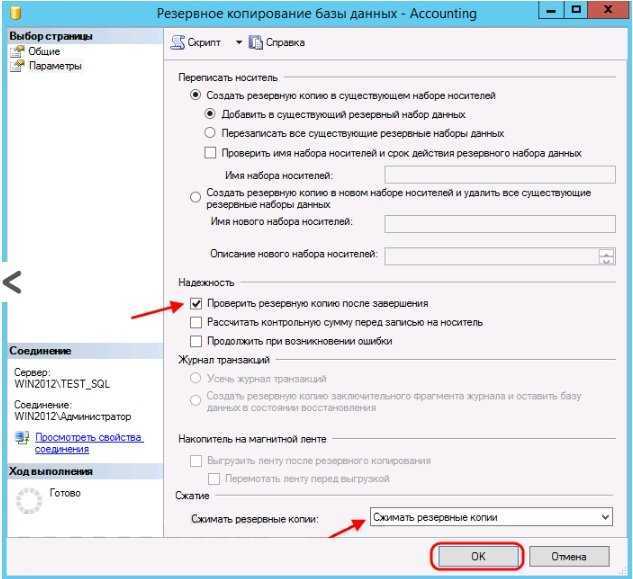
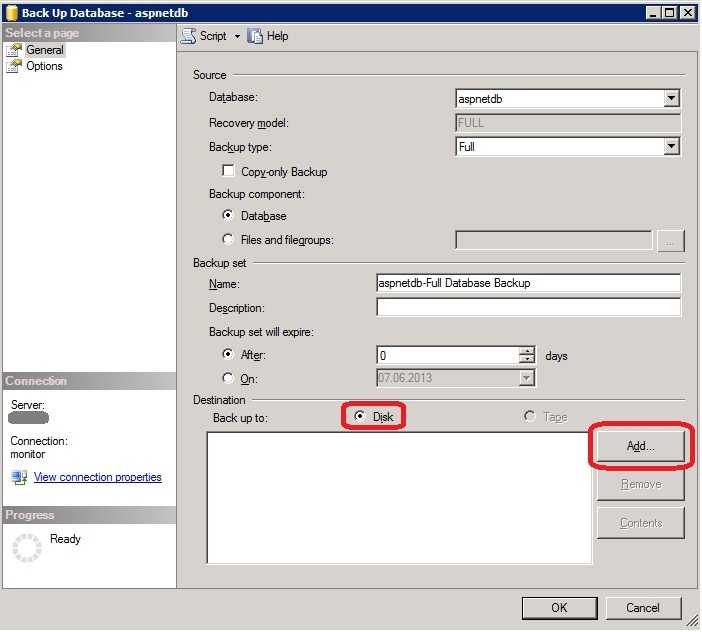
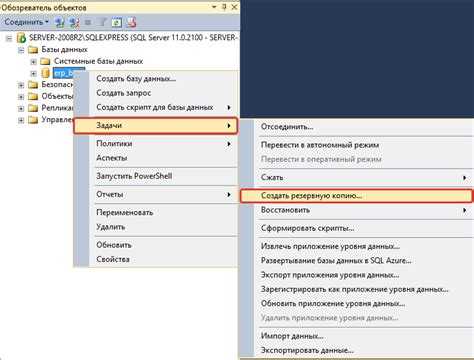
В вашей домашней папке будет создан файл с именем disk1.img, который в будущем можно будет развернуть и восстановить испорченную систему. Чтобы записать образ на жесткий диск или раздел достаточно поменять местами адреса устройств:
Очень важная и полезная опция — это bs. Она позволяет очень сильно влиять на скорость работы утилиты. Этот параметр позволяет установить размер одного блока при передаче данных. Здесь нужно задать цифровое значение с одним из таких модификаторов формата:
- с — один символ;
- b — 512 байт;
- kB — 1000 байт;
- K — 1024 байт;
- MB — 1000 килобайт;
- M — 1024 килобайт;
- GB — 1000 мегабайт;
- G — 1024 мегабайт.
Команда dd linux использует именно такую систему, она сложная, но от этого никуда не деться. Ее придется понять и запомнить. Например, 2b — это 1 килобайт, и 1k, это тоже 1 килобайт, 1М — 1 мегабайт. По умолчанию утилита использует размер блока — 512 байт. Например, чтобы ускорить копирование диска можно брать блоки размером по 5 мегабайт. Для этого применяется такая команда:
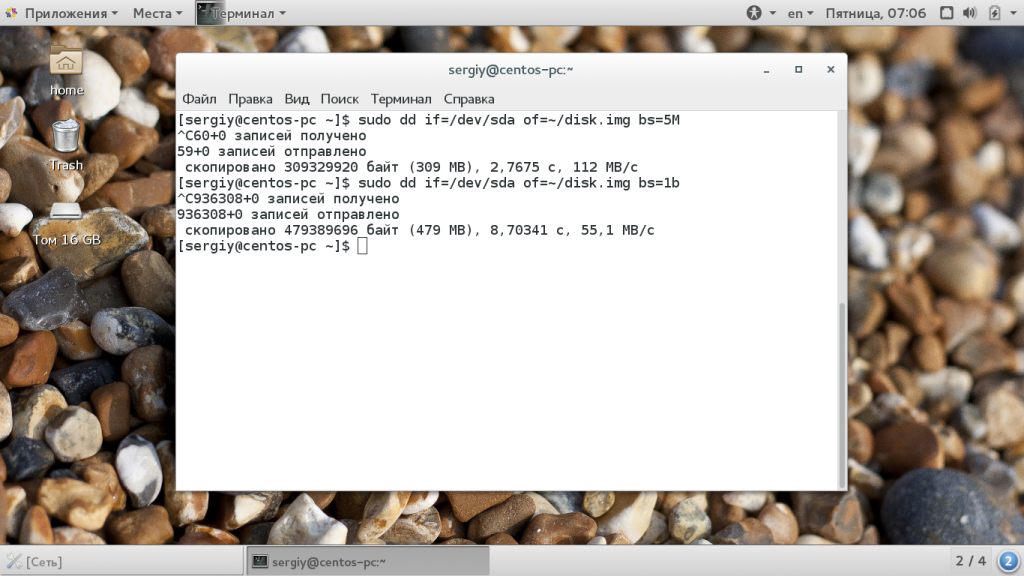
Следующий параметр — это count. С помощью него можно указать сколько блоков необходимо скопировать. Например, мы можем создать файл размером 512 мегабайт, заполнив его нулями из /dev/zero или случайными цифрами из /dev/random:
sudo dd if=/dev/zero of=file.img bs=1M count=512
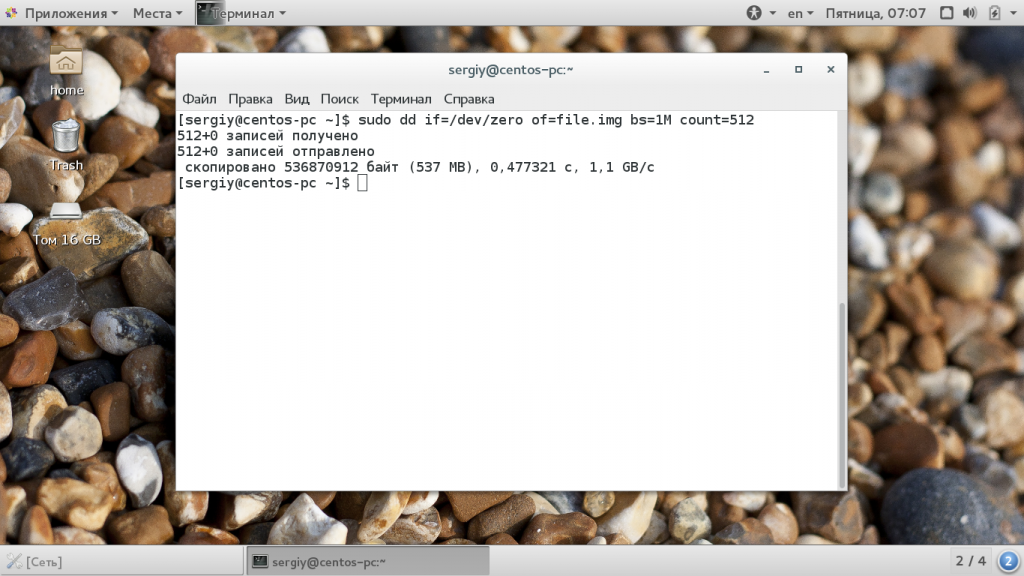
Обратите внимание, что этот параметр указывает не размер в мегабайтах, а всего лишь количество блоков. Поэтому, если вы укажите размер блока 1b, то для создания файла размером 1Кб нужно взять только два блока
С помощью этого параметра также можно сделать резервную копию таблицы разделов MBR. Для этого скопируем в файл первые 512 байт жесткого диска:
sudo dd if=/dev/sda of=mbr.img bs=1b count=1
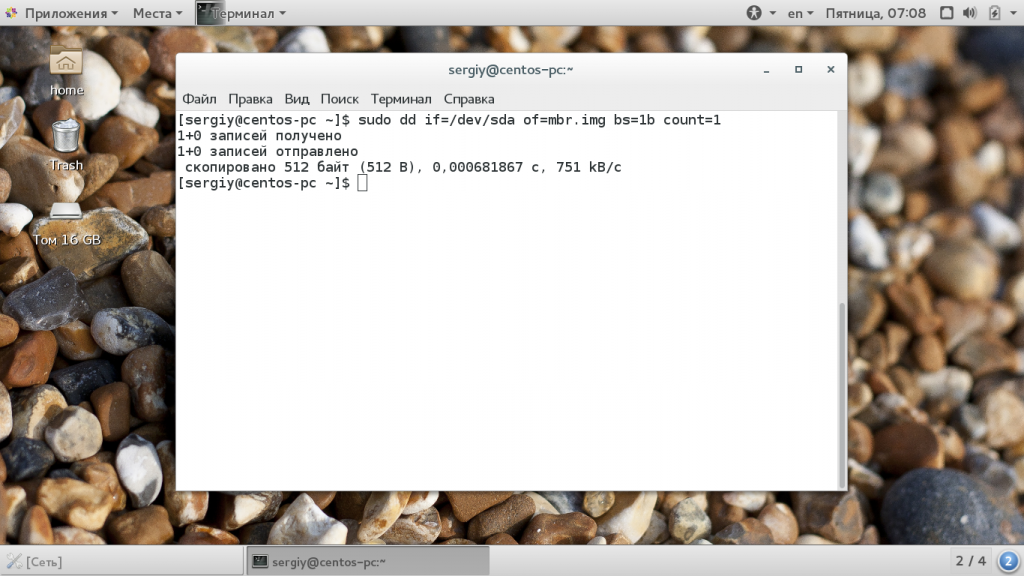
Для восстановления используйте обычную команду развертывания образа на диск.
Если образ диска слишком большой, можно перенаправить весь вывод нестандартный поток вывода утилиты gzip:
dd if =/dev/sda2 | bzip2 disk.img.bz2
Также можно использовать утилиту dd linux для копирования файлов, хотя это и не является ее прямым предназначением:
dd if=/home/sergiy/test.txt of=/home/sergiy/test1.txt
Как вы знаете, команда dd linux пишет данные на диск непосредственно в двоичном виде, это значит, что записываются нули и единицы. Они переопределяют то, что было раньше размещено на устройстве для записи. Поэтому чтобы стереть диск вы можете просто забить его нулями из /dev/zero.
sudo dd if=/dev/zero of=/dev/sdb
Такое использование dd приводит к тому что весь диск будет полностью стерт.
Файлы, которые следует добавить в резервные копии
Самое главное – создать резервную копию ваших личных файлов. На современном ПК с ОС Windows 10 вы обычно найдете их по адресу , где USER – имя ваше учетной записи пользователя.

По умолчанию этот каталог содержит папки данных вашей учетной записи пользователя. К ним относятся папка «Документы», в которой по умолчанию сохраняются ваши документы, папка «Изображения», которая, вероятно, содержит семейные фотографии, папка «Загрузки», в которую попадают загруженные файлы, папка «Музыка», в которой хранятся ваши музыкальные файлы, и папка «Видео», где сохраняются видео. В этот набор также следует включить папку «Рабочий стол», где многие люди хранят файлы.
Этот раздел также включает в себя другие важные папки, такие как OneDrive, Dropbox и Google Диск, где хранятся автономные копии ваших облачных файлов, если вы используете эти службы.
Здесь также скрыта папка AppData, но вы не увидите её, если не включите отображение скрытых файлов и папок. Здесь программы сохраняют настройки и данные, специфичные для вашей учетной записи пользователя. Вы можете использовать эти данные для восстановления настроек отдельной программы, если вам когда-нибудь понадобится восстановить резервную копию.

Имея это в виду, мы рекомендуем вам создать резервную копию всей вашей учетной записи пользователя, включая скрытую папку AppData. Это гарантирует, что у вас будет копия всех ваших личных файлов и настроек, и вам не нужно будет тратить много времени на размышления об этом. Если несколько человек используют один и тот же компьютер и имеют свои собственные файлы, создайте резервную копию папки каждой учетной записи пользователя.
Вы можете исключить определенные папки из резервной копии, если вы не хотите, чтобы они присутствовали. Например, если вы храните кучу загруженных видео в папке «Видео», и вы не планируете использовать их в будущем, тогда исключите эти файлы из резервной копии.
Возможно, Вы заметили, что мы используем много слов типа «по умолчанию», «вероятно» и «возможно», когда говорим о том, где хранятся ваши файлы. Это потому, что Windows позволяет хранить ваши файлы в любом месте, которое вам нравится. Если вы переместили свои файлы, то только вы знаете, где хранятся все ваши файлы.
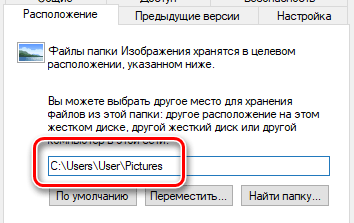
Например, Вы легко можете переместить папку Музыка, Видео, Загрузки, Картинки или Документы в другое место на вашем ПК. Например, эти файлы могут храниться на другом диске. Если вы храните файлы в нестандартных местах, то следует определить папки, содержащие важные файлы, и добавить их в резервную копию.
Закладки вашего браузера и другие настройки расположены где-то в папке AppData, поэтому резервное копирование всей папки пользователя также сохранит эти файлы. Однако, вы можете использовать функцию синхронизации своего браузера и синхронизировать свои настройки с учетной записью Google, Firefox или Microsoft. Это избавит вас от необходимости копаться в папке AppData.
Если вы используете настольный почтовый клиент, вы также можете создать резервную копию своих электронных писем. Это не обязательно, если вы используете современный протокол IMAP для своей электронной почты, поскольку основные копии ваших писем по-прежнему хранятся на удаленном сервере
Однако, если вы загружаете электронные письма через протокол POP3, важно, чтобы вы делали резервные копии своих электронных писем, так как они могут храниться только на вашем ПК
Хорошей новостью является то, что ваши письма, скорее всего, хранятся в папке AppData вашей учетной записи пользователя, поэтому будут автоматически созданы резервные копии, если вы создадите резервную копию всей папки пользователя. Тем не менее, вы все равно должны проверить расположение файлов электронной почты.
Любые другие персональные данные и настройки, которые не находятся в папке учетной записи пользователя, должны быть скопированы, если они Вам нужны. Например, вы можете создать резервные копии настроек приложения, которые находятся в папке C:\ProgramData для некоторых приложений.
В частности, файлы компьютерных игры можно найти повсюду. Многие игры синхронизируют свои файлы с онлайн-сервисами, поэтому им не нужны резервные копии. Многие хранят свои сейвы в папках «Документы» или «AppData», а другие сбрасывают сохранения игр в C:\ProgramData или в другое место, например, в папку Steam.
Убедитесь, что любые данные, о которых вы заботитесь – будь то ваши семейные фотографии, настройки для критически важного приложения или сохраненные игры, в которую вы играли больше 100 часов, будут скопированы
Принцип работы dd Linux
Изначально требуется понять, что представляет собой эта утилита и как она работает. Иными словами, dd Linux – это утилита для копирования данных СР. Нужно заметить, что она используется только для блочного типа информации. Команда способна перенести в пределах одного блока данные, имеющие предварительно выбранный размер, а также информацию из одного места в иное. В ОС Linux устройства являются файлами. У пользователя имеется возможность перенаправлять устройства в файлы, а также совершать операции в обратном порядке.
Утилита имеет большое количество параметров, способных повлиять на размер используемого блока. Такая особенность сильно влияет на скорость работы самой программы. Приложение dd Linux отличается хорошей функциональностью.
Синтаксис
У данной утилиты странный и слегка сложный синтаксис. Несмотря на это, он весьма прост. Пользоваться программой легко, вы быстро запомните алгоритм и привыкнете к нему.
С использованием параметра «if» потребуется прописать что копировать (источник). В «of» можно написать файл или устройство, например флешку или HDD диск.
Основные параметры:
- «bs» — количество байт, которые будут читаться и записываться за один раз.
- «cbs» — число байт, записываемых за один раз.
- «count» — число скопированных блоков. Размер блока прописывается в опции «bs».
- «ibs» — чтение определенного числа байт за 1 раз.
- «obs» — записывание определенного числа байт за 1 раз.
- «seek» — пропуск определенного числа байт в самом начале устройства во время чтения.
- «skip» — пропуск определенного числа байт в самом начале при выводе.
- «status» — подробность вывода.
- «iflag», «oflag» — создание дополнительных флагов, которые нужны для ввода или вывода.
- —help — показывает справку.
- —version — показывает информацию о версии утилиты.
Выше описаны наиболее популярные функции, которые могут потребоваться вам при использовании программы dd Linux.
Примеры
Утилита чаще всего применяется для формирования образов DVD- и CD-дисков. Для их сохранения в виде образа iso существуют определенные команды. Чтобы программа не реагировала на ошибки, можно запустить фильтр noerror. Далее создается образ, который в последующем сохраняется на диск.
Чтобы сделать образ, узнаем разметку диска, с помощью dh.

Сделаем образ раздела /home, файловая разметка /dev/sda6 в каталог /root/home.iso. В качестве аргумента укажем «noerror» — не выдавать ошибки. Также ограничим максимальный размер файла на 4096 байт.
![]()
Таким образом делаются образы жестких дисков, флешек, оптических приводов.
![]()
Как видно из примера выше, в каталоге /root появился файл home.iso. В дальнейшем его можно развернуть. Он позволит восстановить испорченную в ходе использования систему, в нашем случае файлы каталога home.
Весьма полезный параметр – «bs». Он в значительной мере влияет на скорость работы самой программы. Этот аргумент дает возможность установить размер блока во время передачи информации. Предварительно задается цифровое значение, где указывается один из модификаторов.

Как было сказано выше, dd Linux позволяет записать информацию на диск или в определенный раздел именно в двоичном виде. В этом случае записываются как нули, так и единицы. Для очистки диска достаточно наполнить его нулями.
Создадим образ диска. Пусть /dev/cdrom1 это наш оптический привод, cdrom.
Программа является практически незаменимым инструментом для эффективной работы системного администратора. С использованием данной программы можно создавать копию всей системы. Команда весьма полезна, имеет множество сфер применения.



