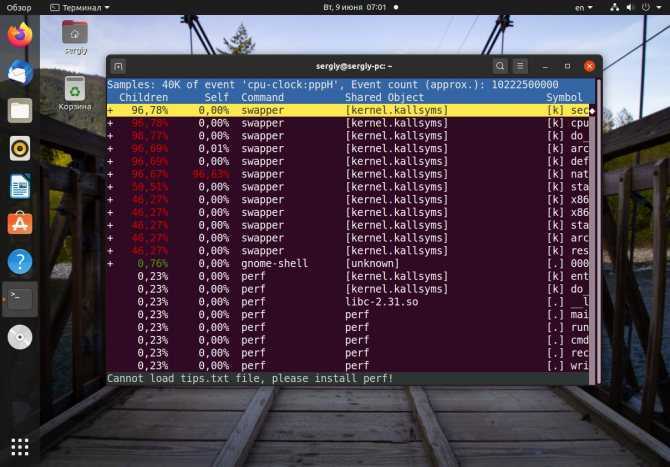
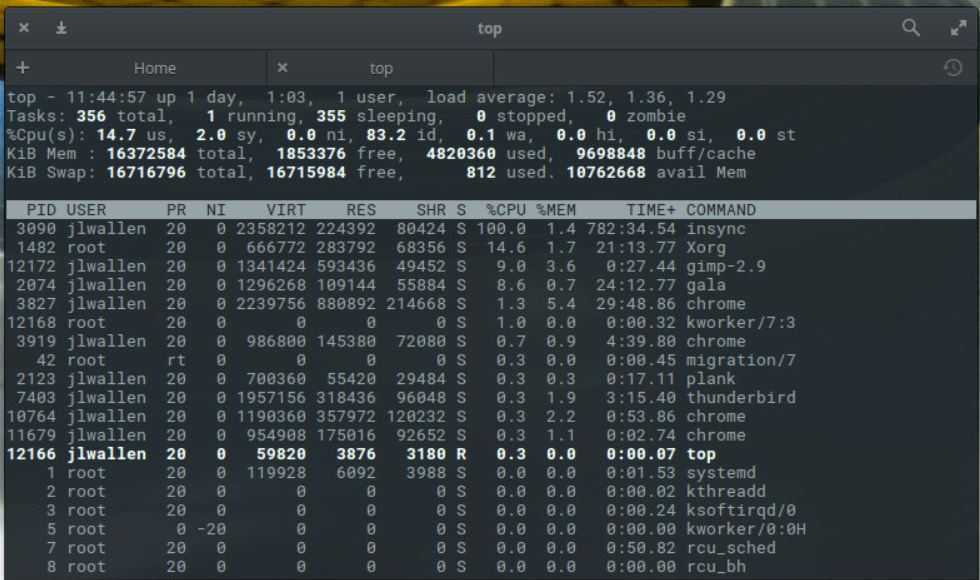
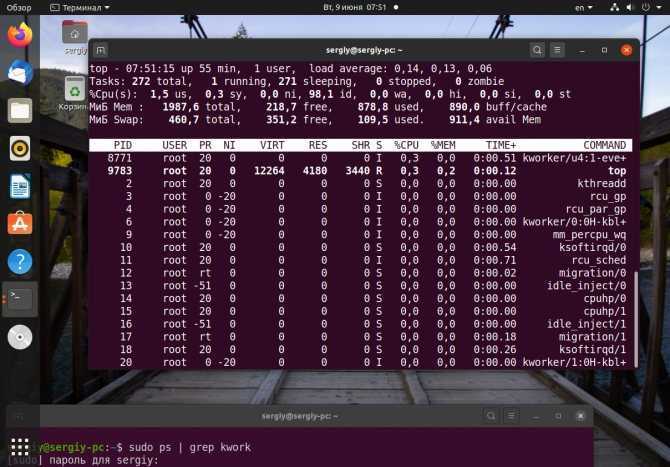
[kworker] Одно ядро на 90-97% загружено процессом kworker
Всем пинг! Относительно давно поставил htop для того, чтобы поглядывать на загруженность системы. Но поскольку я его очень редко использовал я почти не замечал ничего. И вот некоторое время спустя я поставил себе Conky и после настройки я увидел полную загруженность одного ядра.
Я просматривал все процессы и не мог найти в чем проблема. Очень долго сидел в гугле и искал решение данного вопроса, но все время упирался вразные решения, которые не давали требуемого результата. Я понимал логику как решить проблему, но не сразу нашел как эту логику реализовать.
Суть проблемы: существут некий процесс под названием kworker , который после запуска системы отжирает одно ядро полность. Быстрый гуглеж дал мне понять, что это не критично и связано с прерываниями (сильно глубоко не было желания разбираться в проблеме).
Решалось это все довольно примитивно. Для начала находим (от рута) виновника вот такой командой:
Там увидим примерно следующее:
Вот на последней строке у меня и есть виновник. У вас вполне вероятно могут быть другие цифры после gpe
Лечить его можно вот такой командой (важно — ОТ РУТА):
После этого вы можете проверить через тот же htop и увидите, съеденное ядро вернулось обратно. Это конечно приятно и не может не радовать, но тут есть один маленький минус — после перезагрузки все снова будет как и раньше и процедуру придется повторять.
Меня это через пару дней выбесило и был реализован простой способ решения данного косяка в автоматическом режиме. Написан скрипт-однострочник:
Недавно я обновился до Kubuntu Natty Beta 1, и у меня было много проблем с процессом kworker . Порой он использует почти половину моего процессора. Кроме того, как ни странно, это влияет на мои USB-порты; всякий раз, когда я подключаю USB-накопитель, процесс kworker переходит в hyperdrive, оставляя меня неспособным работать.
Я думал о регистрации ошибки, но так как я даже не нашел разумного объяснения того, что kworker , я решил, что сначала должен узнать.
Более подходящие метрики
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
- использование каждого процессора (per-CPU utilization): например, используя .
- использование процессора для каждого процесса (per-process CPU utilization): например, и так далее.
- задержка очереди выполнения (диспетчера) для каждого потока (per-thread run queue (scheduler) latency): например, в /proc/PID/schedstats, delaystats, perf sched
- задержка очереди выполнения процессора (CPU run queue latency): например, в , , моём инструменте runqlat bcc.
- длина очереди выполнения процессора (CPU run queue length): например, используя vmstat 1 и колонку ‘r’, или мой инструмент .
Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция () стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация
Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим
Три числа
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие скользящие суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:
Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Отслеживание активных процессов
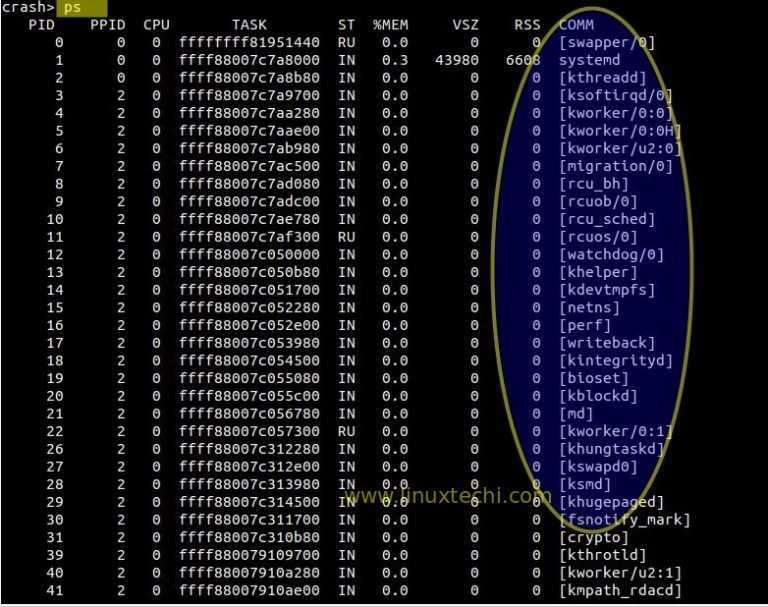
Существует несколько различных инструментов для просмотра/перечисления запущенных в системе процессов. Двумя традиционными и хорошо известными из них являются команды ps и top:
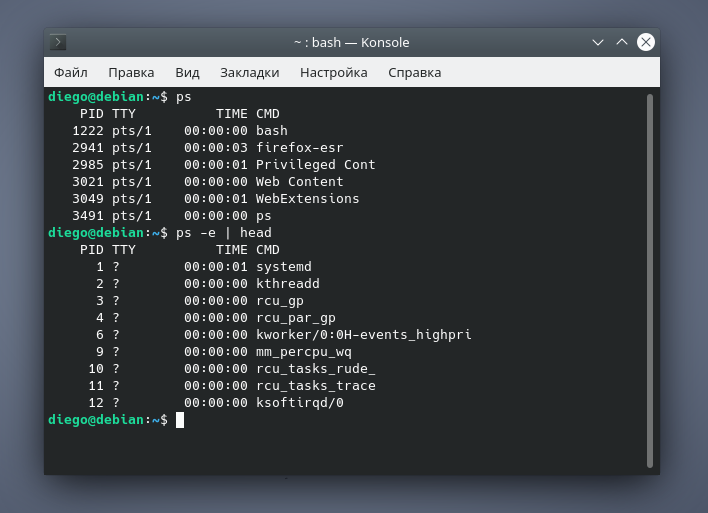
Команда ps
Отображает информацию об активных процессах в системе, как показано на следующем скриншоте:
Для получения дополнительной информации о процессах, запущенных текущим пользователем, применяется опция :
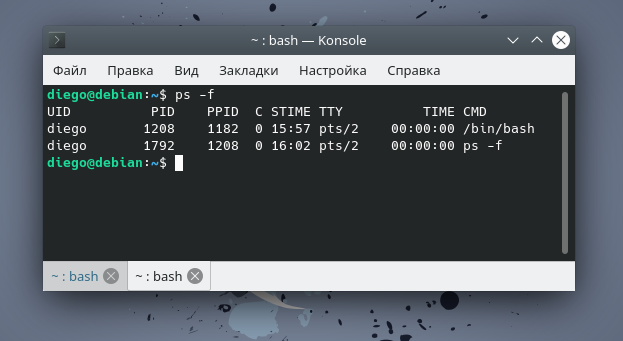
Столбцы, присутствующие в выводе команды , имеют следующие значения:
UID — идентификатор пользователя, которому принадлежит процесс (тот, от чьего имени происходит выполнение).
PID — идентификатор процесса.
PPID — идентификатор родительского процесса.
C — загрузка CPU процессом.
STIME — время начала выполнения процесса.
TTY — тип терминала, связанного с процессом.
TIME — количество процессорного времени, потраченного на выполнение процесса.
CMD — команда, запустившая этот процесс.
Также можно отобразить информацию по конкретному процессу, используя команду , например:
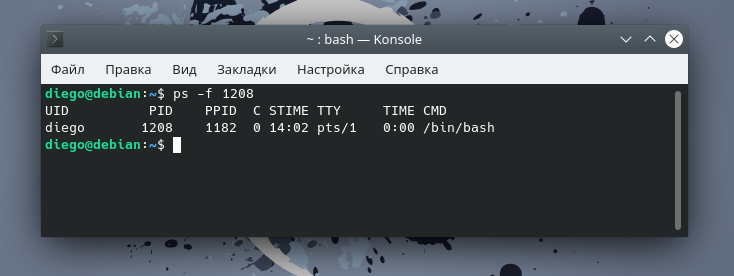
Есть и другие опции, которые можно использовать вместе с командой :
— показывает информацию о процессах по всем пользователям;
— показывает информацию о процессах без терминалов;
— показывает дополнительную информацию о процессе по заданному UID или имени пользователя;
— отображение расширенной информации.
Если вы хотите вывести вообще всю информацию по всем процессам системы, то используйте команду :
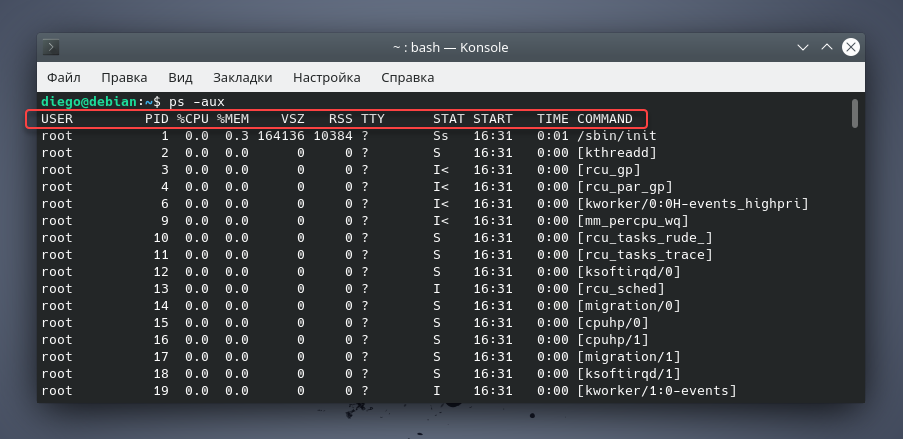
Обратите внимание на выделенный заголовок. Команда поддерживает функцию сортировки процессов по соответствующим столбцам
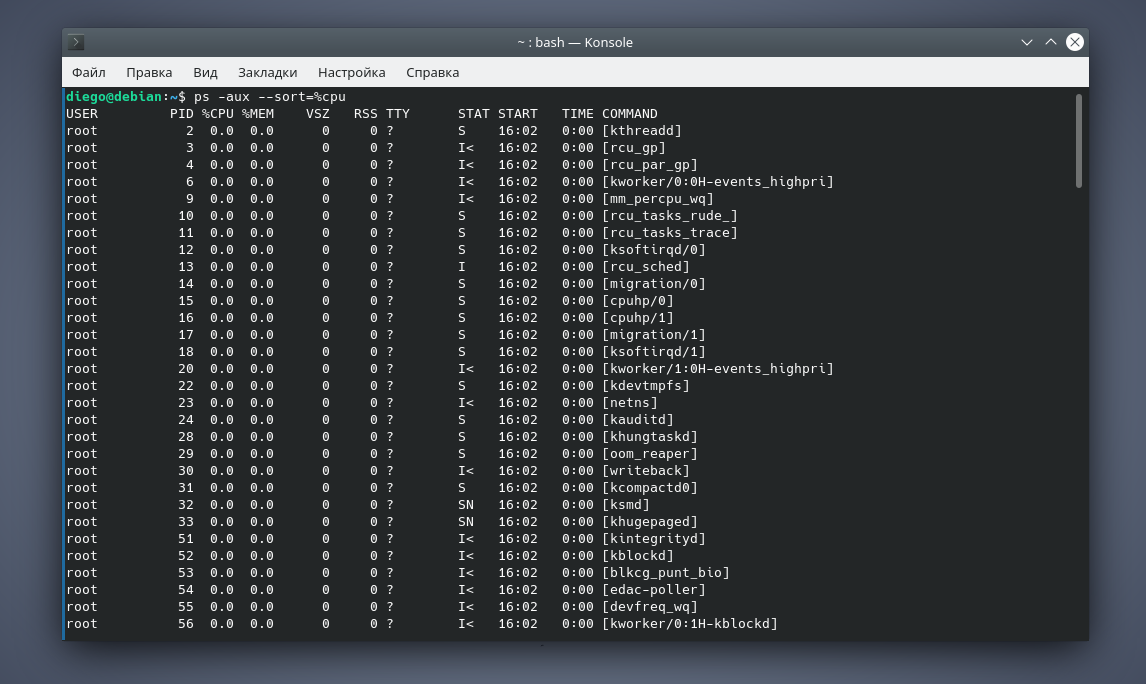
Например, чтобы отсортировать список процессов по потреблению ресурсов процессора (в порядке возрастания), введите команду:
Результат:
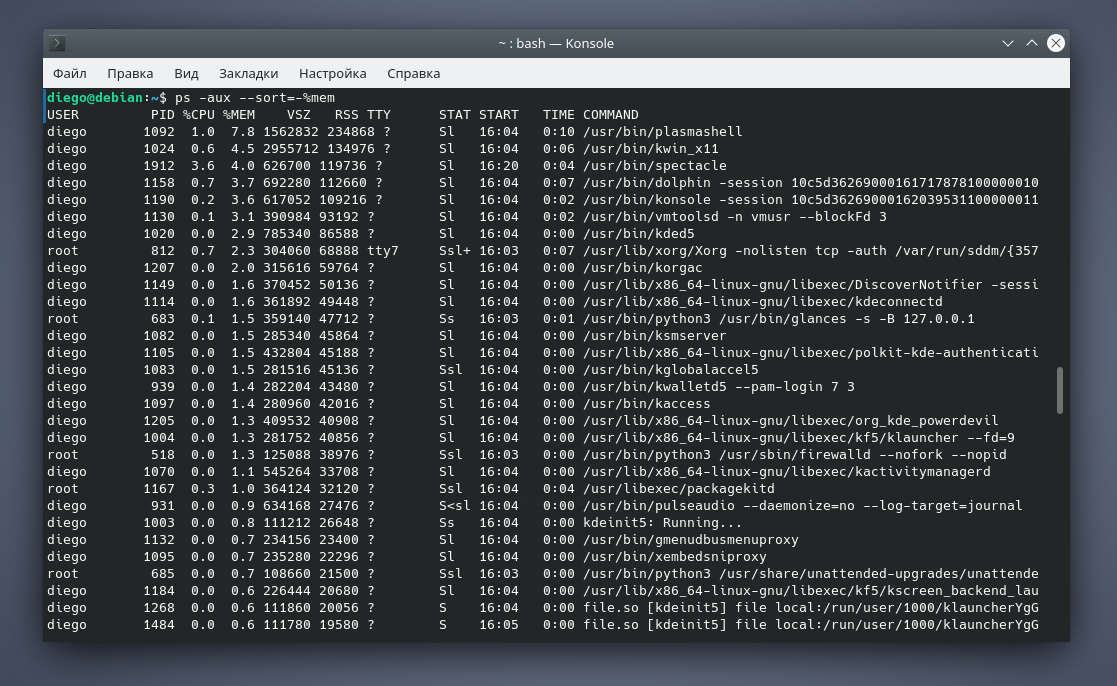
Если вы ходите выполнить сортировку по потреблению памяти (в порядке убывания), то добавьте к имени интересующего столбца знак минуса:
Результат:
Еще один очень популярный пример использования команды — это объединение её и для поиска заданного процесса по его имени:
Результат:
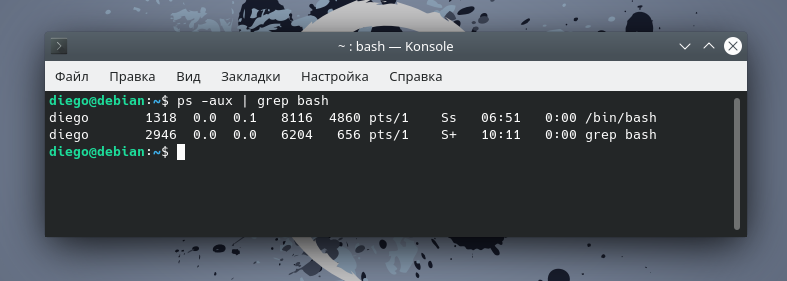
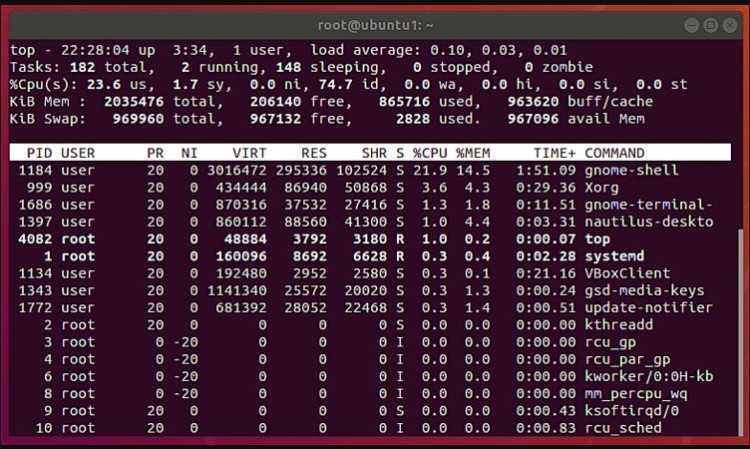
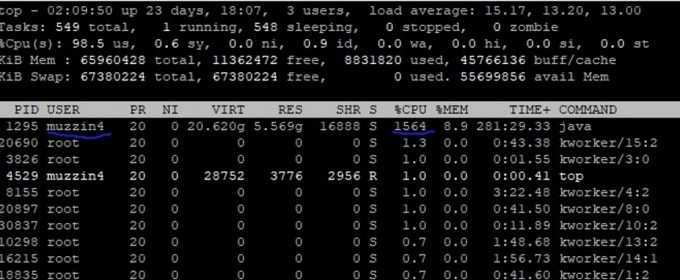
Команда top
Команда top отображает информацию о запущенных процессах в режиме реального времени:
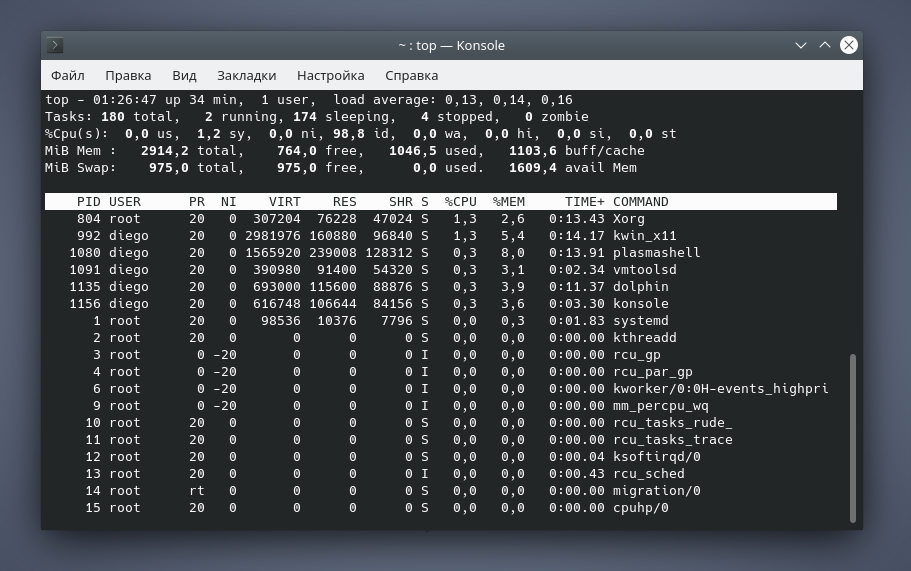
Рассмотрим детально:
PID — идентификатор процесса.
USER — пользователь, которому принадлежит процесс.
PR — приоритет процесса на уровне ядра.
NI — приоритет выполнения процесса от до .
VIRT — общий объем (в килобайтах) виртуальной памяти (физическая память самого процесса; загруженные с диска файлы библиотек; память, совместно используемая с другими процессами и т.п.), используемой задачей в данный момент.



RES — текущий объем (в килобайтах) физической памяти процесса.
SHR — объем совместно используемой с другими процессами памяти.
S (сокр. от «STATUS») — состояние процесса:
S (сокр. от «Sleeping») — прерываемое ожидание. Процесс ждет наступления события.
I (сокр. от «Idle») — процесс бездействует.
R (сокр. от «Running») — процесс выполняется (или поставлен в очередь на выполнение).
Z (сокр. от «Zombie») — зомби-процесс.
%CPU — процент используемых ресурсов процессора.
%MEM — процент используемой памяти.
TIME+ — количество процессорного времени, потраченного на выполнение процесса.
COMMAND — имя процесса (команды).
Также в сочетании с основными символами состояния процесса (S от «STATUS») вы можете встретить и дополнительные:
— процесс с высоким приоритетом;
— процесс с низким приоритетом;
— многопоточный процесс;
— фоновый процесс;
— лидер сессии.
Примечание: Все процессы объединены в сессии. Процессы, принадлежащие к одной сессии, определяются общим идентификатором сессии — идентификатором процесса, который создал эту сессию. Лидер сессии — это процесс, идентификатор сессии которого совпадает с его идентификаторами процесса и группы процессов.
Команда glances
Команда glances — это относительно новый инструмент мониторинга системы с расширенными функциями:
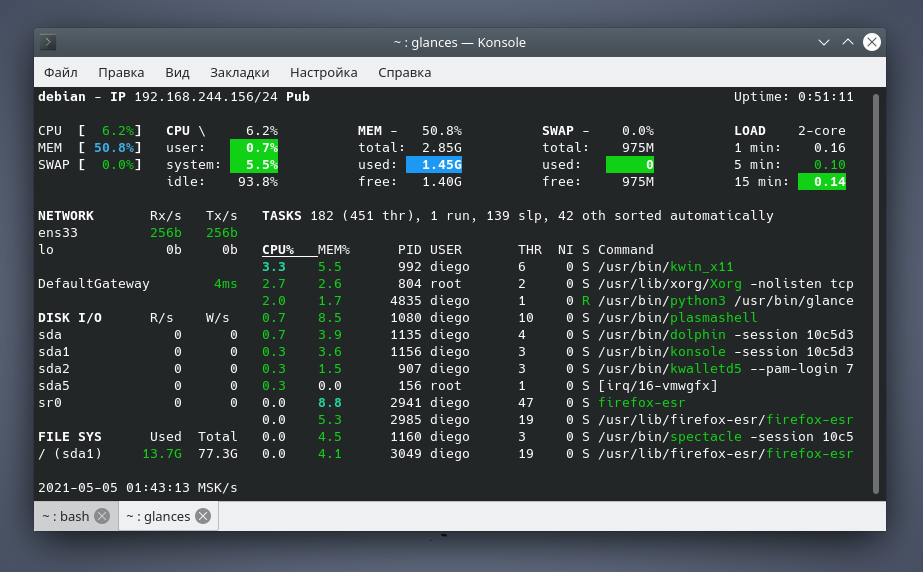
Примечание: Если в вашей системе отсутствует данная утилита, то установить её можно с помощью следующих команд:
RHEL/CentOS/Fedora
Debian/Ubuntu/Linux Mint
Непрерываемость сегодня
Но разве средние значения нагрузки в Linux иногда не поднимаются слишком высоко, что уже нельзя объяснить дисковым вводом/выводом? Да, это так, хотя я предполагаю, что это следствие новой ветви кода, использующей TASK_UNINTERRUPTIBLE, не существовавшего в 1993-м. В Linux 0.99.14 было 13 ветвей кода, которые напрямую использовали TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние подкачки позднее убрали из Linux). Сегодня в Linux 4.12 почти 400 ветвей, использующих TASK_UNINTERRUPTIBLE, включая некоторые примитивы блокировки. Вероятно, что одна из этих ветвей не должна учитываться в среднем значении нагрузки. Я проверю, так ли это, когда снова увижу, что значение слишком высокое, и посмотрю, можно ли это исправить.
Я написал Маттиасу и спросил, что он думает 24 года спустя о своём изменении среднего значения нагрузки. Он ответил через час:
Так что Маттиас до сих пор уверен в правильности этого шага, как минимум относительно того, для чего предназначался TASK_UNINTERRUPTIBLE.
Но сегодня TASK_UNINTERRUPTIBLE соответствует большему количеству вещей. Нужно ли нам менять средние значения нагрузки, чтобы они отражали потребности в ресурсах только процессора и диска? Peter Zijstra уже прислал мне хорошую идею: учитывать в средней нагрузке вместо TASK_UNINTERRUPTIBLE, потому что это точнее соответствует вводу/выводу диска. Однако это поднимает другой вопрос: чего мы хотим на самом деле? Хотим ли мы измерять потребности в системных ресурсах в виде потоков выполнения, или нам нужны физические ресурсы? Если первое, то нужно учитывать непрерываемые блокировки, потому что эти потоки потребляют ресурсы системы. Они не находятся в состоянии простоя. Так что среднее значение нагрузки в Linux, вероятно, уже работает как нужно.
Чтобы лучше разобраться с непрерываемыми ветвями кода, я хотел бы измерить их в действии. Потом можно оценить разные примеры, измерить затраченное время и понять, есть ли в этом смысл.
Находим PID зависшего процесса
Каждый процесс в Linux имеет свой идентификатор, называемый PID. Перед тем, как выполнить остановку процесса, нужно определить его PID. Для этого воспользуемся командами ps и grep. Команда ps предназначена для вывода списка активных процессов в системе и информации о них. Команда grep запускается одновременно с ps (в канале) и будет выполнять поиск по результатам команды ps. Вывести список всех процессов можно, выполнив в командной строке:
Но, как правило, список очень большой и найти процесс, который мы хотим «убить», бывает не так просто. Здесь на помощь приходит команда grep. Например, чтобы найти информацию о процессе с именем gcalctool выполните команду:
Команда grep выполнит поиск по результатам команды ps и на экран будут выведены только те строки, которые содержат строку (слово) gcalctool. Здесь есть одна интересная деталь, например, если у вас не запущено приложение gcalctool, то после выполнения ps axu | grep gcalctool вы получите:
То есть мы получили сам процесс grep, так как в качестве параметра команде мы указали слово gcalctool, и grep нашел сам себя в выводе команды ps.
Если процесс gcalctool запущен, то мы получим:
Здесь нас интересует строка: «yuriy 25609 7.6 0.4 500840 17964 ? Sl 10:20 0:00 gcalctool». Число 25609 и есть идентификатор (PID) процесса gcalctool.








Есть еще один более простой способ узнать PID процесса — это команда pidof, которая принимает в качестве параметра название процесса и выводит его PID. Пример выполнения команды pidof:
Что такое «хорошие» или «плохие» средние нагрузки?
Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
Управление процессами в Linux
Сердцем всех Linux и Unix-подобных операционных систем является ядро. Среди его многочисленных обязанностей — распределение системных ресурсов, таких как оперативная память и процессорное время. Они должны выполняться в режиме реального времени, чтобы все запущенные процессы получали свою справедливую долю в соответствии с приоритетом каждой задачи.
Иногда задачи могут быть заблокированы, или зациклены, или перестать отвечать по другим причинам. Или они могут продолжать работать, но сожрать слишком много процессорного времени или оперативной памяти, или вести себя таким же антисоциальным образом. Иногда задачи должны быть убиты в качестве милости для всех участников. Первый шаг. Разумеется, стоит идентифицировать рассматриваемый процесс.
Но, возможно, у вас нет никаких задач или проблем с производительностью вообще. Возможно, вам просто любопытно, какие процессы выполняются внутри вашего компьютера, и вы хотели бы заглянуть под капот. Команда удовлетворяет обеим этим требованиям. Это дает вам снимок того, что происходит внутри вашего компьютера «прямо сейчас».
достаточно гибок, чтобы дать вам именно ту информацию, которая вам нужна, именно в том формате, который вам нравится. На самом деле, у очень много вариантов. Опции, описанные здесь, будут соответствовать большинству обычных потребностей. Если вам нужно углубиться в чем мы это рассмотрели в этой статье, вы обнаружите, что наше введение облегчает восприятие справочной страницы.
Уничтожение процессов по идентификатору процесса
Мы рассмотрели ряд способов идентификации процессов, включая имя, команду, пользователя и терминал. Мы также рассмотрели способы идентификации процессов по их динамическим атрибутам, таким как использование процессора и память.
Итак, так или иначе, мы можем определить процессы, которые работают. Зная их идентификатор процесса, мы можем (если нужно) уничтожить любой из этих процессов с помощью команды . Если бы мы хотели убить процесс 898, мы бы использовали этот формат:
sudo kill 898

Если все идет хорошо, процесс молча завершается.

СВЯЗАННЫЕ: Как убить процессы с терминала Linux
6 ответов
«kworker» – это процесс-заполнитель для рабочих потоков ядра, которые выполняют большую часть фактической обработки ядра, особенно в случаях, когда есть прерывания, таймеры, ввод-вывод и т. д. Они обычно соответствуют подавляющему большинству любое выделенное «системное» время для запуска процессов. Это не то, что можно безопасно удалить из системы и полностью не связано с nepomuk или KDE (за исключением того, что эти программы могут выполнять системные вызовы, которые могут потребовать от ядра делать что-то).
Были сообщения о чрезмерной активности kworker относительно начиная с разработки 2.6.36 ( примера обсуждения ) и широких сообщений о путанице и проблемах с 2.6 .38 (хотя многие из этих отчетов включают слово «Natty», поэтому я предполагаю, что эти люди не использовали какое-либо ядро между 2.6.35 (распространено в Ubuntu 10.10) и 2.6.38 (распространено в Ubuntu 11.04).
Я нашел много сообщений о том, что «исправлено» для того или иного пользователя. Большинство «исправлений», похоже, связаны с обновлениями ядра различного рода. Если обновление можно отследить по конкретной проблеме, часто кажется, что некоторые драйверы или службы ядра были исправлены, чтобы не ошибиться: у меня сложилось впечатление, что в ядре очень много вещей, которые могут вызвать поведение который наблюдается как чрезмерное использование kworker.
Если вы обнаружите, что система недоступна из-за чрезмерной активности kworker, я бы рекомендовал попробовать сделать меньше. Если вы считаете, что ничего не делаете, попробуйте отключить долговременные службы или таймеры (RSS-ридеры, почтовые программы, файловые индексы, отслеживания активности и т. Д.). Если это не работает, попробуйте перезапустить. Если ваша система позволяет включать или отключать оборудование в среде предварительной загрузки, попробуйте отключить оборудование, которое вы не используете. Если это произойдет при каждом перезапуске, прежде чем что-либо сделать, вы можете попробовать удалить все, но в этот момент вы захотите использовать инструменты профилирования syscall для отслеживания определенных приложений, которые, как представляется, вызывают эту перегрузку.
Следует надеяться, что ваша конкретная система перестанет выражать это поведение с будущим обновлением ядра (и многие из наиболее распространенных причин этого были решены).
Что такое kworker? kworker означает, что процесс ядра Linux выполняет «работу» (обработка системных вызовов). У вас может быть несколько из них в вашем списке процессов: kworker/0:1 – это тот, который находится на вашем первом ядре процессора, kworker/1:1 на втором и т. Д.
Почему kworker запускает ваш процессор? . Чтобы узнать, почему kworker тратит впустую ваш процессор, вы можете создавать обратные трассировки процессора: следить за загрузкой процессора ( top или чем-то еще) и в моменты высокая загрузка через kworker , выполните echo l > /proc/sysrq-trigger , чтобы создать обратную трассировку. (На Ubuntu вам нужно войти в систему с sudo -s ). Сделайте это несколько раз, затем посмотрите обратные трассы в конце dmesg . Посмотрите, что часто происходит в обратном следе CPU, надеюсь, укажет на источник вашей проблемы.
Пример: e1000e. В моем случае я нашел такую обратную линию почти каждый раз:
Он намекнул мне на проблему в модуле карты e1000e Ethernet, и действительно, sudo rmmod e1000e сильно снизили загрузку процессора .
Почему kworker запускает ваш процессор (продолжение)? В качестве альтернативы мой другой ответ здесь , Perf – это более профессиональный способ проанализировать, какие задачи ядра вызывают зависание вашего процессора:
(Второй пакет должен соответствовать вашей версии ядра. Сначала вы можете установить только linux-tools-common и вызвать perf , чтобы сообщить, какой пакет ему нужен.)
Запишите около 10 секунд обратных отображений на всех ваших процессорах:
Проанализируйте свою запись:
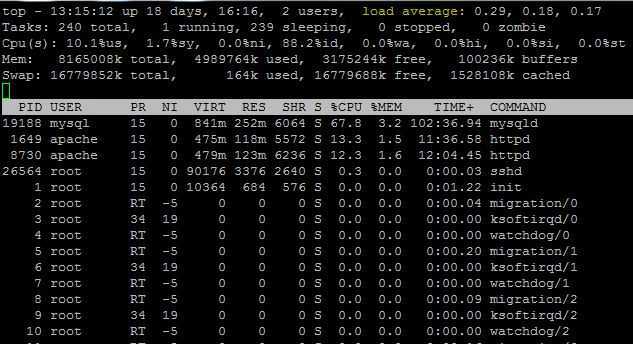
Загрузка системы
Загрузка системы
top - 10:12:16 up 1 day, 57 min, 3 users, load average: 0.48, 0.94, 1.19
- текущее время;
- up time — время работы системы после включения питания;
- user — количество пользователей, которые в данный момент работают в системе;
-
load average — общая средняя загрузка системы (измеряется каждые 1, 5 и 15 минут). Общей средней загрузкой системы называется среднее число процессов, находящихся в состоянии выполнения (R) или в состоянии ожидания (D), эту информацию можно увидеть в колонке S вывода команды top, она может принимать 5 значений:
'D' = uninterruptible sleep (состояние ожидания) 'R' = running (состояние выполнения) 'S' = sleeping 'T' = traced or stopped 'Z' = zombie
5 ответов
Что такое kworker? kworker означает, что процесс ядра Linux выполняет «работу» (обработка системных вызовов). У вас может быть несколько из них в списке процессов: kworker/0:1 — тот, что на вашем первом ядре процессора, kworker/1:1 тот, что на вашем втором и т. Д.
Что такое kworker? Чтобы узнать, почему kworker тратит впустую ваш процессор, вы можете создавать обратные трассировки процессора: смотрите загрузку процессора (с помощью top или что-то в этом роде) и в моменты высокой нагрузки через kworker выполните echo l > /proc/sysrq-trigger, чтобы создать обратную трассировку , (На Ubuntu вам нужно войти в систему с помощью sudo -s). Делайте это несколько раз, затем смотрите обратные трассы в конце выхода dmesg. Посмотрите, что часто случается в перепадах CPU, надеюсь, укажет на источник вашей проблемы.
Пример: e1000e. В моем случае я нашел такую обратную линию почти каждый раз:
Он намекнул мне на проблему в модуле карты Ethernet e1000e, и действительно sudo rmmod e1000e сделал высокую загрузку процессора немедленно уйдите .
ответ дан
25 May 2018 в 22:15
Почему kworker запускает ваш процессор (продолжение)? В качестве альтернативы моему другому ответу здесь Perf — это более профессиональный способ проанализировать, какие задачи ядра забивают ваш процессор:
Установить perf:
(Второй пакет должен соответствовать вашей версии ядра. Вы можете сначала установить только linux-tools-common и вызвать perf, чтобы он сообщил вам, какой пакет ему нужен.) Запишите около 10 секунд обратных отображений на всех ваших CPU:







Проанализируйте свою запись:
Просто чтобы все знали. Я столкнулся с этой проблемой, установил perf (это отличный инструмент), он указал на блокировку спина и XFS. Это указывало на NFS. Тогда я понял, что один из моих монстров был вне космоса. Освобождение пространства привело к тому, что CPU kworker упал до 0.
Таким образом, очевидно, что это может быть признаком нехватки места на занятом сервере NFS!
ответ дан
25 May 2018 в 22:15
Недавно я установил Ubuntu Natty на внешний диск usb wd. Когда я начинаю на своем рабочем столе, которому около двух лет, все работает как шарм. Когда я запускаю свой новый ноутбук (MSI gt680r system), он замедляется после того, как я просыпаю компьютер из сна, или если я подключаю другой USB-диск.
Процессы Kworker принимают все больше CPU, а время от времени зависает.
Я прочитал несколько решений на разных форумах, которые не работали.
Я вошел в BIOS моего ноутбука, где был:
Я изменил для:
, и с тех пор он не работает «Заморозите больше на natty на моем ноутбуке.
Я бы включил функцию обратной связи, если и когда проблема будет исправлена.
ответ дан
25 May 2018 в 22:15
Я думаю, что отключение Nepomuk может вам помочь:
http://www.freetechie.com/blog/disable-nepomuk-desktop-search-on-kde-4-4-2-kubuntu- осознанный-10-04 /
ответ дан
25 May 2018 в 22:15
5 ответов
Что такое kworker? kworker означает, что процесс ядра Linux выполняет «работу» (обработка системных вызовов). У вас может быть несколько из них в списке процессов: kworker/0:1 — тот, что на вашем первом ядре процессора, kworker/1:1 тот, что на вашем втором и т. Д.
Что такое kworker? Чтобы узнать, почему kworker тратит впустую ваш процессор, вы можете создавать обратные трассировки процессора: смотрите загрузку процессора (с помощью top или что-то в этом роде) и в моменты высокой нагрузки через kworker выполните echo l > /proc/sysrq-trigger, чтобы создать обратную трассировку , (На Ubuntu вам нужно войти в систему с помощью sudo -s). Делайте это несколько раз, затем смотрите обратные трассы в конце выхода dmesg. Посмотрите, что часто случается в перепадах CPU, надеюсь, укажет на источник вашей проблемы.
Пример: e1000e. В моем случае я нашел такую обратную линию почти каждый раз:
Он намекнул мне на проблему в модуле карты Ethernet e1000e, и действительно sudo rmmod e1000e сделал высокую загрузку процессора немедленно уйдите .
Установка различных инструментов
Теперь, когда вы лучше понимаете, что происходит в нашем приложении, давайте установим различные необходимые инструменты.
а — Установка Pushgateway
Чтобы установить Pushgateway , запустите простую команду wget, чтобы получить последние доступные двоичные файлы.
wget https://github.com/prometheus/pushgateway/releases/download/v0.8.0/pushgateway-0.8.0.linux-amd64.tar.gz
Теперь, когда у вас есть архив, извлеките его и запустите исполняемый файл, доступный в папке pushgateway.
> tar xvzf pushgateway-0.8.0.linux-amd64.tar.gz > cd pushgateway-0.8.0.linux-amd64 / > ./pushgateway &
В результате ваш Pushgateway должен запуститься в фоновом режиме .
me@schkn-ubuntu:~/softs/pushgateway/pushgateway-0.8.0.linux-amd64$ ./pushgateway & 22806 me@schkn-ubuntu:~/softs/pushgateway/pushgateway-0.8.0.linux-amd64$ INFO Starting pushgateway (version=0.8.0, branch=HEAD, revision=d90bf3239c5ca08d72ccc9e2e2ff3a62b99a122e) source="main.go:65"INFO Build context (go=go1.11.8, user=root@00855c3ed64f, date=20190413-11:29:19) source="main.go:66"INFO Listening on :9091. source="main.go:108"
Оттуда Pushgateway прослушивает входящие метрики на порт 9091 .
б — Установка Prometheus
Как описано в разделе «Начало работы» на веб-сайте Prometheus, перейдите по адресу https://prometheus.io/download/ и выполните простую команду wget, чтобы получить архив Prometheus для вашей ОС.
wget https://github.com/prometheus/prometheus/releases/download/v2.9.2/prometheus-2.9.2.linux -amd64.tar.gz
Теперь, когда у вас есть архив, распакуйте его и перейдите в основную папку:
> tar xvzf prometheus-2.9.2.linux-amd64.tar.gz > cd prometheus-2.9.2.linux-amd64 /
Как указывалось ранее, Prometheus периодически сбрасывает «цели», чтобы собрать с них метрики. Цели (в нашем случае Pushgateway) необходимо настроить с помощью файла конфигурации Prometheus.
> vi prometheus.yml
В разделе «global» измените значение свойства scrape_interval до одной секунды.
global: scrape_interval: 1s # Установить интервал очистки каждую 1 секунду.
В разделе scrape_configs добавьте запись в свойство target в разделе static_configs.
static_configs: - targets:
Выйдите из vi и запустите исполняемый файл prometheus в папке.
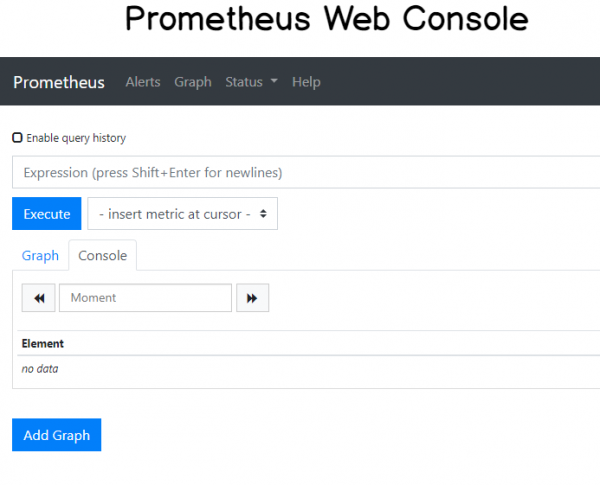
Prometheus должен запуститься при запуске последней команды Prometheus. Чтобы убедиться, что все прошло правильно, вы можете перейти на http: // localhost: 9090 / graph.
Если у вас есть доступ к веб-консоли Prometheus, значит, все прошло нормально.
Вы также можете убедиться, что Pushgateway правильно настроен как цель в «Статус»> «Цели» в веб-интерфейсе.
c — Установка Grafana
И последнее, но не менее важное: мы собираемся установить Grafana v6.2. Перейдите на https://grafana.com/grafana/download/beta
Как и раньше, запустите простую команду wget, чтобы получить ее.
> wget https://dl.grafana.com/oss/release/grafana_6.2.0-beta1_amd64.deb> sudo dpkg -i grafana_6.2.0-beta1_amd64.deb
Теперь, когда вы извлекли файл deb, grafana должна работать как служба на вашем экземпляре.
Вы можете проверить это, выполнив следующую команду:
> sudo systemctl status grafana-server ● grafana-server.service - Grafana instance Loaded: loaded (/usr/lib/systemd/system/grafana-server.service; disabled; vendor preset: enabled) Active: active (running) since Thu 2019-05-09 10:44:49 UTC; 5 days ago Docs: http://docs.grafana.org
Вы также можете проверить http: // localhost: 3000, который является адресом по умолчанию для веб-интерфейса Grafana.
Теперь, когда у вас есть Grafana в вашем экземпляре, нам нужно настроить Prometheus в качестве источника данных .
Вы можете настроить свой источник данных следующим образом:
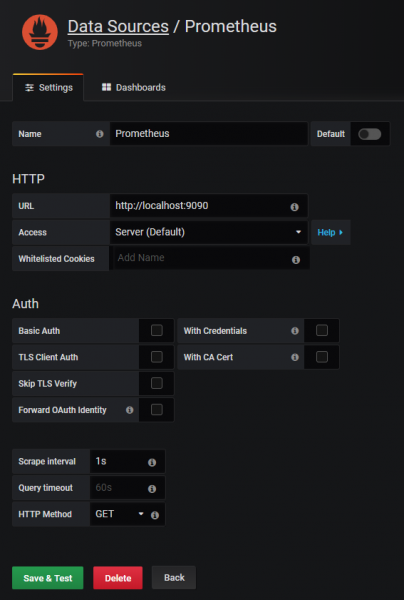
Вот и все!
Нажмите «Сохранить и проверить» и убедитесь, что ваш источник данных работает правильно.

Сортировка вывода по столбцам
Вы можете отсортировать вывод, используя опцию . Давайте отсортируем вывод по столбцу CPU:
ps -e -o pcpu, args --sort -pcpu | Меньше

Дефис « » в параметре сортировки дает нисходящий порядок сортировки.
Чтобы увидеть десять самых ресурсоемких процессов, передайте вывод через команду :
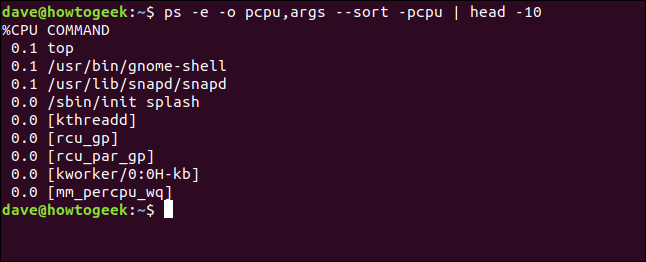
ps -e -o pcpu, args --sort -pcpu | голова -10

Мы получаем отсортированный, усеченный список.
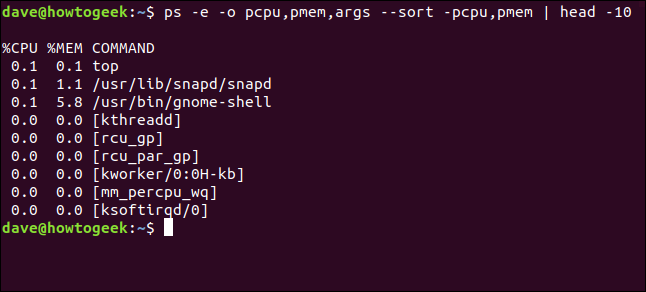
Если мы добавим больше столбцов на наш дисплей, мы сможем отсортировать по большему количеству столбцов. Давайте добавим столбец . Это процент памяти компьютера, который используется процессом. Без дефиса или со знаком « » порядок сортировки возрастает.

![Top, htop, atop интерактивные просмоторщики процессов [айти бубен]](https://smartshop124.ru/wp-content/uploads/6/c/e/6ce9d79132901c75ad61a533ef595afb.jpeg)
![Top, htop, atop интерактивные просмоторщики процессов [айти бубен]](https://smartshop124.ru/wp-content/uploads/1/a/d/1ad02470574dd55d1c0902ab4c2b6a5f.jpeg)


ps -e -o pcpu, pmem, args --sort -pcpu, pmem | голова -10

Мы получаем наш дополнительный столбец, и новый столбец включается в сортировку. Первый столбец сортируется перед вторым столбцом, а второй столбец сортируется в порядке возрастания, потому что мы не ставили дефис в .
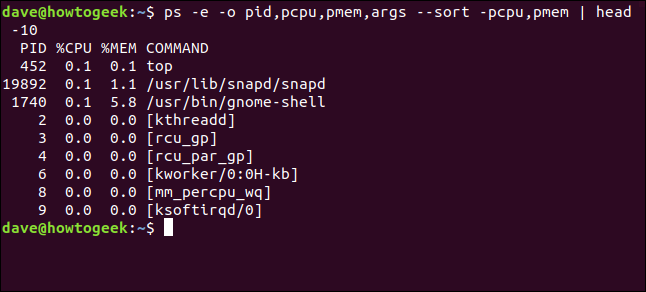
Давайте сделаем его немного более полезным и добавим столбец идентификатора процесса ( ), чтобы мы могли видеть номер процесса каждого процесса в нашем листинге.
ps -e -o pid, pcpu, pmem, args --sort -pcpu, pmem | голова -10

Теперь мы можем определить процессы.
Заключение
В 1993 году Linux-инженер обнаружил нелогичную работу средних значений нагрузки, и с помощью трёхстрочного патча навсегда изменил их с «со средних нагрузок на процессор» на «средние нагрузки на систему». С тех пор учитываются задачи в непрерываемом состоянии, так что средние нагрузки отражают потребность не только в процессорных, но и в дисковых ресурсах. Обновлённые метрики подсчитывают количество работающих и ожидающих работы процессов (ожидающих освобождения процессора, дисков и снятия непрерываемых блокировок). Они выводятся в виде трёх экспоненциально затухающих скользящих сумм, в уравнениях которых используются константы в 1, 5 и 15 минут. Эти три значения позволяют видеть динамику нагрузки, а самое большое из них может использоваться для относительного сравнения с ними самими.
С тех пор в ядре Linux всё активнее использовалось непрерываемое состояние, и сегодня оно включает в себя примитивы непрерываемой блокировки. Если считать среднее значение нагрузки мерой потребности в ресурсах в виде выполняемых и ожидающих потоков (а не просто потоков, которым нужны аппаратные ресурсы), то эта метрика уже работает так, как нам нужно.
Я откопал патч, с которым было внесено это изменение в Linux в 1993-м — его было на удивление трудно найти, — содержащий исходное объяснение его автора. Также с помощью bcc/eBPF я замерил на современной Linux-системе трейсы стеков и длительность нахождения в непрерываемом состоянии, и отобразил это на внепроцессорном флем-графике. На нём отражено много примеров состояний непрерываемого сна, такой график можно генерировать, когда нужно объяснить необычно высокие средние значения нагрузки. Также я предложил вместо них использовать другие метрики, позволяющие глубже понять работу системы.
В заключение процитирую комментарий из топа kernel/sched/loadavg.c исходного кода Linux:
Заключение
Сегодняшнее обсуждение вращалось вокруг различных методов, с помощью которых вы можете проверить запущенные процессы в Linux Mint 20. Эти методы могут использоваться в зависимости от того, какой вывод вы хотите получить. Первый метод просто перечисляет все запущенные процессы сразу, тогда как второй метод представляет их в красивой древовидной структуре, которую легче читать и обрабатывать. Третий метод следует табличной структуре для отображения запущенных процессов вместе с некоторой дополнительной информацией о них, тогда как четвертый более или менее отображает ту же информацию, но с относительно более приятным интерфейсом. Я надеюсь, что после ознакомления с этим руководством вы сможете легко проверить все запущенные процессы в операционной системе Linux Mint 20.