
Во-вторых, ограничения ресурсов Linux
1. Ограничения пользовательских ресурсов
В Bash есть команда ulimit, которая обеспечивает управление доступными ресурсами оболочки и процессами, запускаемыми оболочкой. В основном это количество открытых файловых дескрипторов, максимальное количество процессов пользователя, размер файла coredump и т. Д.
Конфигурацию ограничений ресурсов можно настроить в файле подконфигурации в /etc/security/limits.conf или /etc/security/limits.d/. Система сначала загружает limits.conf, а затем загружает каталог limits.d в алфавитном порядке. После загрузки файла конфигурации он перезапишет предыдущую конфигурацию. Формат конфигурации следующий:
soft — значение предупреждения, hard — максимальное значение, * означает соответствие всем пользователям
Просмотр ограничений пользовательских ресурсов для входа в текущую оболочку
2. ограничение ресурса обслуживания
Мы всегда упоминали оболочку выше, поэтому для тех пользователей, которые не вошли в систему через аутентификацию PAM, таких как mysql, nginx и т. Д., Вышеуказанная конфигурация не эффективна;
Поскольку в системе CentOS 7 / RHEL 7 вместо предыдущего SysV используется Systemd, область конфигурации файла /etc/security/limits.conf сокращается. Конфигурация в limits.conf применима только для аутентификации PAM. Ограничение ресурсов вошедшего в систему пользователя, оно не влияет на ограничение ресурсов службы systemd.
Его нужно настроить с помощью файлов /etc/systemd/system.conf и /etc/systemd/user.conf. Точно так же все файлы .conf в двух соответствующих каталогах /etc/systemd/system.conf.d/* .conf и /etc/systemd/user.conf.d/*.conf.
Среди них system.conf используется экземплярами системы, а user.conf — экземплярами пользователей. Для общих служб используйте конфигурацию в system.conf. Конфигурация в system.conf.d / *. Conf переопределит system.conf.
Формат конфигурации следующий:
= Тип ресурса слева, размер справа
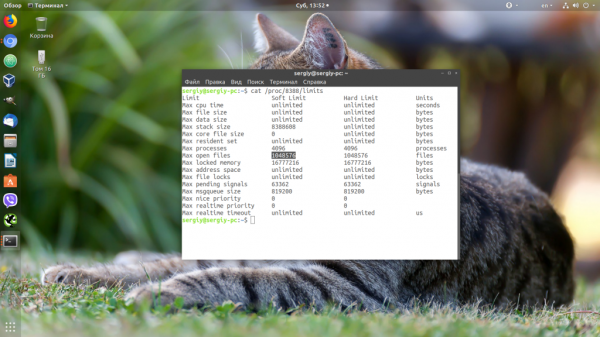
Просмотр лимита ресурсов службы
cat /proc/YOUR-PID/limits
Например, проверьте влияние конфигурации службы nginx:
3. Лимит системных ресурсов
Для пользователя и службы ранее были выделены ресурсы, но каково общее количество ресурсов в системе? Сюда входят параметры ядра. Существует много параметров ядра. Нам нужно только знать, как изменить наиболее часто используемые, такие как количество процессов и количество дескрипторов.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
Ошибка too many open files Linux
Дословно эта ошибка означает, что программа открыла слишком много файлов и больше ей открывать нельзя. В Linux установлены жёсткие ограничения на количество открываемых файлов для каждого процесса и пользователя.
Посмотреть, сколько файлов можно открыть в вашей файловой системе, можно, выполнив команду:

Посмотреть текущие ограничения количества открытых файлов для пользователя можно командой:
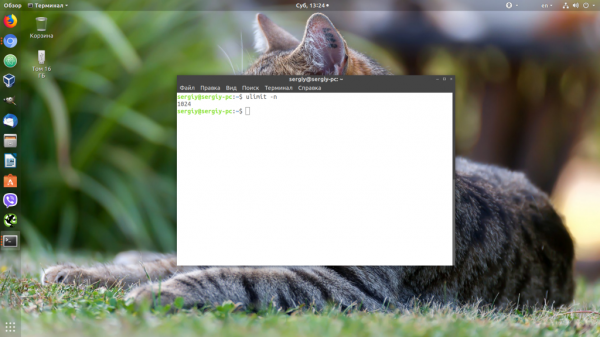
Утилита ulimit возвращает два вида ограничений — hard и soft. Ограничение soft вы можете менять в любую сторону, пока оно не превышает hard. Ограничение hard можно менять только в меньшую сторону от имени обычного пользователя. От имени суперпользователя можно менять оба вида ограничений так, как нужно. По умолчанию отображаются soft-ограничения:
Чтобы вывести hard, используйте опцию -H:
Вы можете изменить ограничение, просто передав в ulimit новое значение:

Но поскольку hard-ограничение составляет 4000, то установить лимит больше этого значения вы не сможете. Чтобы изменить настройки ограничений для пользователя на постоянной основе, нужно настроить файл /etc/security/limits.conf. Синтаксис у него такой:
имя_пользователя тип_ограничения название_ограничения значение
Вместо имени пользователя можно использовать звездочку, чтобы изменения применялись ко всем пользователям в системе. Тип ограничения может быть soft или hard. Название — в нашем случае нужно nofile. И последний пункт — нужное значение. Установим максимум — 1617596.





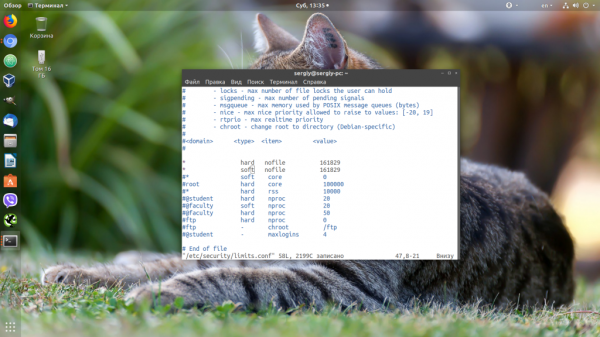
Нужно установить значение для soft и hard параметра, если вы хотите, чтобы изменения вступили в силу. Также убедитесь, что в файле /etc/pam.d/common-session есть такая строчка:
Если её нет, добавьте в конец. Она нужна, чтобы ваши ограничения загружались при авторизации пользователя.
Если вам нужно настроить ограничения только для определенного сервиса, например Apache или Elasticsearch, то для этого не обязательно менять все настройки в системе. Вы можете сделать это с помощью systemctl. Просто выполните:
И добавьте в открывшейся файл такие строки:

Здесь мы устанавливаем максимально возможное ограничение как для hard- так и для soft-параметра. Дальше нужно закрыть этот файл и обновить конфигурацию сервисов:
Затем перезагрузить нужный сервис:
Убедится, что для вашего сервиса применились нужные ограничения, можно, открыв файл по пути /proc/pid_сервиса/limits. Сначала смотрим PID нужного нам сервиса:
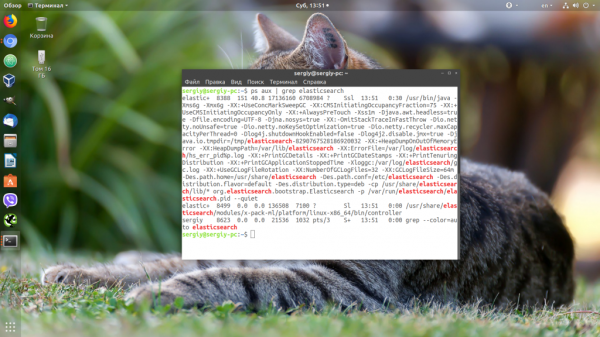
Затем смотрим информацию:
Поиск открытых файлов с помощью отладчика ядра.
Хотя для поиска дескрипторов открытых файлов можно воспользоваться такими средствами, как Process Explorer, Handle и OpenFiles.exe, они недоступны при просмотре аварийного дампа или удаленном анализе системы.
Вместо них для поиска дескрипторов, отрытых для файлов на том или ином томе, можно воспользоваться командой !devhandles.
- Сначала нужно выбрать букву диска, представляющего интерес, и получить указатель на его объект Device. Для этого, как показано ниже, можно воспользоваться командой !object:
1: kd> !object \Global??\C:
Object: fffff8a00016ea40 Type: (fffffa8000c38bb0) SymbolicLink
ObjectHeader: fffff8a00016ea10 (new version)
HandleCount: 0 PointerCount: 1
Directory Object: fffff8a000008060 Name: C:
Target String is ‘\Device\HarddiskVolume1’
Drive Letter Index is 3 (C:)
- Затем нужно воспользоваться командой !object, чтобы получить объект
Device для нужного имени тома:
1: kd> !object \Device\HarddiskVolume1
Object: fffffa8001bd3cd0 Type: (fffffa8000ca0750) Device
- Теперь можно воспользоваться указателем на объект Device, вставив его в команду !devhandles. Каждый показанный объект указывает на файл:
!devhandles fffffa8001bd3cd0
Checking handle table for process 0xfffffa8000c819e0
Kernel handle table at fffff8a000001830 with 434 entries in use
PROCESS fffffa8000c819e0
SessionId: none Cid: 0004 Peb: 00000000 ParentCid: 0000
DirBase: 00187000 ObjectTable: fffff8a000001830 HandleCount: 434.
Image: System
0048: Object: fffffa8001d4f2a0 GrantedAccess: 0013008b Entry: fffff8a000003120
Object: fffffa8001d4f2a0 Type: (fffffa8000ca0360) File
ObjectHeader: fffffa8001d4f270 (new version)
HandleCount: 1 PointerCount: 19
Directory Object: 00000000 Name: \Windows\System32\LogFiles\WMI\
RtBackup\EtwRTEventLog-Application.etl {HarddiskVolume1}.






MapReduce
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Неблокирующий режим (O_NONBLOCK)
Файловый дескриптор помещают в “неблокирующий” режим, добавляя флаг к существующему набору флагов дескриптора с помощью :
С момента установки флага дескриптор становится неблокирующим. Любые системные вызовы для ввода-вывода, такие как и , в случае неготовности данных в момент вызова ранее могли бы вызвать блокировку, а теперь будут возвращать и глобальную переменную устанавливать в , Это интересное изменение поведения, но само по себе мало полезное: оно лишь является базовым примитивом для построения эффективной системы ввода-вывода для множества файловых дескрипторов.
Допустим, требуется параллельно прочитать целиком данные из двух файловых дескрипторов. Это может быть достигнуто с помощью цикла, который проверяет наличие данных в каждом дескрипторе, а затем засыпает ненадолго перед новой проверкой:
Такой подход работает, но имеет свои минусы:
- Если данные приходят очень медленно, программа будет постоянно просыпаться и тратить впустую процессорное время
- Когда данные приходят, программа, возможно, не прочитает их сразу, т.к. выполнение приостановлено из-за
- Увеличение интервала сна уменьшит бесполезные траты процессорного времени, но увеличит задержку обработки данных
- Увеличение числа файловых дескрипторов с таким же подходом к их обработке увеличит долю расходов на проверки наличия данных
Для решения этих проблем операционная система предоставляет мультиплексирование ввода-вывода.
Что такое файловая система
Обычно вся информация записывается, хранится и обрабатывается на различных цифровых носителях в виде файлов. Далее, в зависимости от типа файла, кодируется в виде знакомых расширений – *exe, *doc, *pdf и т.д., происходит их открытие и обработка в соответствующем программном обеспечении. Мало кто задумывается, каким образом происходит хранение и обработка цифрового массива в целом на соответствующем носителе.
Операционная система воспринимает физический диск хранения информации как набор кластеров размером 512 байт и больше. Драйверы файловой системы организуют кластеры в файлы и каталоги, которые также являются файлами, содержащими список других файлов в этом каталоге. Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные.
Запись файлов большого объема приводит к необходимости фрагментации, когда файлы не сохраняются как целые единицы, а делятся на фрагменты. Каждый фрагмент записывается в отдельные кластеры, состоящие из ячеек (размер ячейки составляет один байт). Информация о всех фрагментах, как части одного файла, хранится в файловой системе.
Файловая система связывает носитель информации (хранилище) с прикладным программным обеспечением, организуя доступ к конкретным файлам при помощи функционала взаимодействия программ API. Программа, при обращении к файлу, располагает данными только о его имени, размере и атрибутах. Всю остальную информацию, касающуюся типа носителя, на котором записан файл, и структуры хранения данных, она получает от драйвера файловой системы.
На физическом уровне драйверы ФС оптимизируют запись и считывание отдельных частей файлов для ускоренной обработки запросов, фрагментации и «склеивания» хранящейся в ячейках информации. Данный алгоритм получил распространение в большинстве популярных файловых систем на концептуальном уровне в виде иерархической структуры представления метаданных (B-trees). Технология снижает количество самых длительных дисковых операций – позиционирования головок при чтении произвольных блоков. Это позволяет не только ускорить обработку запросов, но и продлить срок службы HDD. В случае с твердотельными накопителями, где принцип записи, хранения и считывания информации отличается от применяемого в жестких дисках, ситуация с выбором оптимальной файловой системы имеет свои нюансы.
Что можно делать с файловыми дескрипторами
Файловые дескрипторы можно использовать для исправления ошибок. Например, если на диске нет свободного места, но вы не видите файлы, которые занимают пространство, то можно посмотреть открытые дескрипторы. Это поможет понять, какое приложение заняло весь доступный объем.
Важно понимать, что если мы один раз открыли файл, и он получил файловый дескриптор, то мы можем взаимодействовать с ним дальше. Не имеет значения, что с этим файлом происходит
Его могут переименовать, удалить, могут изменить его владельца, отобрать права на запись и чтение. Если вы уже начали работать с файлом и знаете его дескриптор, то можете продолжать с ним работать.
Три, количество процессов ограничено
1. Ограничьте количество пользовательских процессов.
По умолчанию в /etc/security/limits.d/ есть файл подконфигурации 20-nproc.conf, который используется для установки максимального количества процессов для каждого пользователя.
Проверка /etc/security/limits.d/20-nproc.conf обнаружит, что пользователь root по умолчанию не ограничен, а максимальное количество обычных пользовательских процессов составляет 4096
Фактически, root и обычные пользователи по умолчанию используют значение # cat / proc / sys / kernel / threads-max / 2, что составляет половину количества системных потоков.
Установите максимальное количество процессов на пользователя
Примечание. Изменение файла конфигурации не повлияет на ограничение процесса для текущего пользователя, вошедшего в систему.




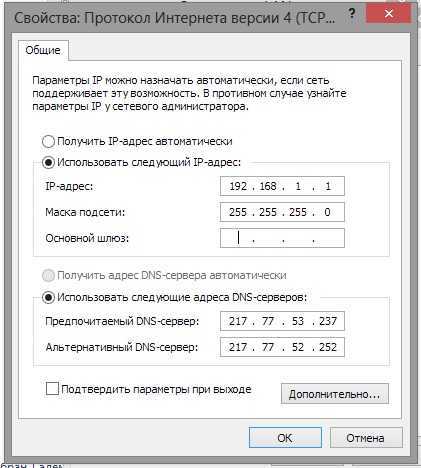


2. Лимит процесса обслуживания
Примечание: изменение файла конфигурации не изменит ограничение на количество процессов запущенной в данный момент службы, и ее необходимо перезапустить.
3. Общее количество процессов в системе.
Выше мы установили максимальное количество процессов, которые может открыть каждый пользователь, но это не контролирует общее количество процессов в системе (kernel.pid_max). Предполагая, что kernel.pid_max = 1000, максимальное количество пользовательских процессов пользователя, независимо от того, насколько велико заданное значение, Максимальное количество процессов, которые можно открыть, по-прежнему составляет 1000
Просмотрите глобальный метод pid_max:
метод первый:
Метод второй:
Временно измените этот метод значения:
Следовательно, после завершения вышеуказанных операций значение максимального числа пользовательских процессов изменяется правильно.
Вышеуказанное действует только временно, оно будет недействительным после перезапуска машины, постоянный эффективный метод:
Добавьте kernel.pid_max = 65535 в /etc/sysctl.conf
или же:
Затем перезапустите машину.
Практический пример использования файловых систем
Владельцы мобильных гаджетов для хранения большого объема информации используют дополнительные твердотельные накопители microSD (HC), по умолчанию отформатированные в стандарте FAT32. Это является основным препятствием для установки на них приложений и переноса данных из внутренней памяти. Чтобы решить эту проблему, необходимо создать на карточке раздел с ext3 или ext4. На него можно перенести все файловые атрибуты (включая владельца и права доступа), чтобы любое приложение могло работать так, словно запустилось из внутренней памяти.
Операционная система Windows не умеет делать на флешках больше одного раздела. С этой задачей легко справится Linux, который можно запустить, например, в виртуальной среде. Второй вариант — использование специальной утилиты для работы с логической разметкой, такой как MiniTool Partition Wizard Free. Обнаружив на карточке дополнительный первичный раздел с ext3/ext4, приложение Андроид Link2SD и аналогичные ему предложат куда больше вариантов.
Флешки и карты памяти быстро умирают как раз из-за того, что любое изменение в FAT32 вызывает перезапись одних и тех же секторов. Гораздо лучше использовать на флеш-картах NTFS с ее устойчивой к сбоям таблицей $MFT. Небольшие файлы могут храниться прямо в главной файловой таблице, а расширения и копии записываются в разные области флеш-памяти. Благодаря индексации на NTFS поиск выполняется быстрее. Аналогичных примеров оптимизации работы с различными накопителями за счет правильного использования возможностей файловых систем существует множество.
Надеюсь, краткий обзор основных ФС поможет решить практические задачи в части правильного выбора и настройки ваших компьютерных устройств в повседневной практике.
Разница между файловым дескриптором и файловым указателем
Преобразование между указателями файлов и дескрипторами файлов на языке C может быть достигнуто с помощью двух функций: fdopen и fileno. Все они включены в заголовочный файл stdio.h. Прототип fdopen:
Первый параметр filedes — это дескриптор открытого файла, а opentype — это строка, представляющая метод открытия, которая имеет то же значение, что и функция fopen, например «w» или «w +». Но вы должны убедиться, что описание строки соответствует фактическому методу открытия файла. Функция fopen () возвращает указатель на открытие файла; если операция не удалась, она возвращает нулевой указатель null.
Преобразуйте указатель файлового потока в файловый дескриптор с помощью функции fileno, Его прототип:
Он возвращает дескриптор файла, соответствующий потоку файлового потока. В случае неудачи верните -1; Когда программа выполняется, уже открыто три стандартных файловых потока: (стандартный ввод) stdin, (стандартный вывод) stdout, (стандартный вывод ошибок) stderr и потоковая передача В соответствии с файлом, есть также три предварительно занятых файловых дескриптора (это:0 ((стандартный ввод) stdin), 1 ((стандартный вывод) stdout), 2 ((стандартный ввод ошибок) stderr));
Термины: неблокирующий, асинхронный, событийный
- “Асинхронный” буквально означает “не синхронный”. Например, отправка email асинхронная, потому что отправитель не ожидает получить ответ сразу же. В программировании “асинхронным” называют код, в котором компоненты посылают друг другу сообщения, не ожидая немедленного ответа.
- “Неблокирующий” — термин, чаще всего касающийся ввода-вывода. Он означает, что при вызове “неблокирующего” системного API управление сразу же будет возвращено программе, и она продолжит использовать свой квант процессорного времени. Обычные, простые в использовании системные вызовы блокирующие: они усыпляют вызывающий поток до тех пор, пока данные для ответа не будут готовы.
- “Событийный” означает, что компонент программы обрабатывает очередь событий с помощью цикла, а тем временем кто-либо добавляет события в очередь, формируя входные данные компонента, и забирает у него выходные данные.
Термины часто пересекаются. Например, протокол HTTP сам по себе синхронный (пакеты отправляются синхронно), но при наличии неблокирующего ввода-вывода программа, работающая с HTTP, может оставаться асинхронной, то есть успевать совершить какую-либо полезную работу между отправкой HTTP-запроса и получением ответа на него.
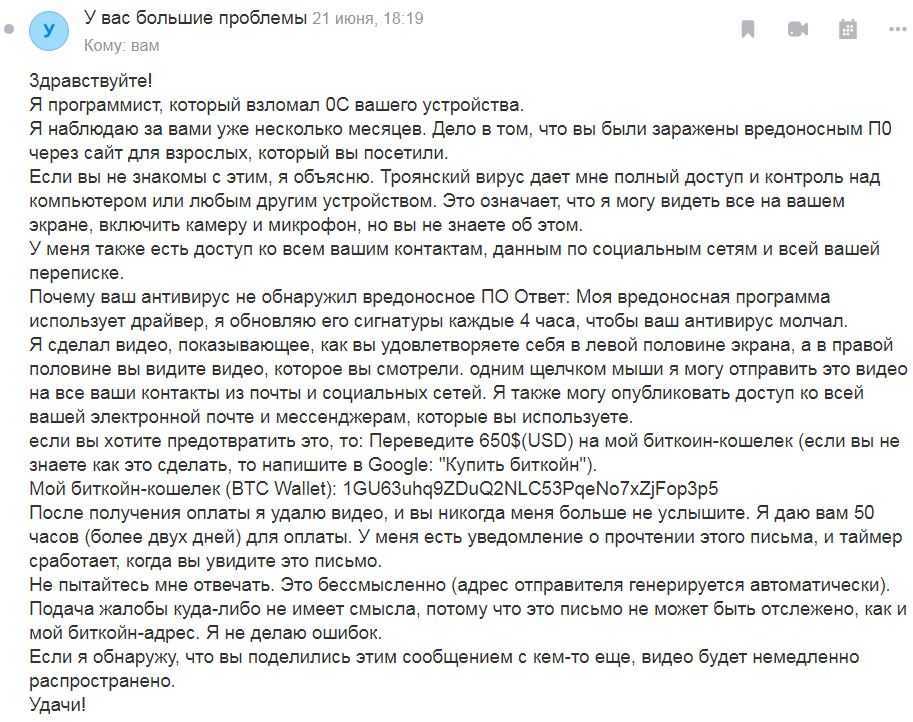
‘Too Many Open Files’ error & Open File Limits in Linux
Now we know that these titles mean that a process has opened too many files (file descriptors) and cannot open new ones. In Linux, the maximum open file limits are set by default for each process or user and the values are rather small.
We, at Bobcares have monitored this closely and have come up with a few solutions:
Increase the Max Open File Limit in Linux
A large number of files can be opened if we change the limits in our Linux OS. In order to make new settings permanent and prevent their reset after a server or session restart, make changes to /etc/security/limits.conf. by adding these lines:
- hard nofile 97816
- soft nofile 97816
If it is using Ubuntu, add this line as well:
session required pam_limits.so
These parameters allow to set open file limits after user authentication.
After making the changes, reload the terminal and check the max_open_files value:
# ulimit -n 97816
Increase the Open File Descriptor Limit per service
A change in the limit of open file descriptors for a specific service, rather than for an entire operating system is possible.
For example, if we take Apache, to change the limits, open the service settings using systemctl:
systemctl edit httpd.service
Once the service settings is open, add the limits required. For example;
LimitNOFILE=16000 LimitNOFILESoft=16000
After making the changes, update the service configuration and restart it:
# systemctl daemon-reload # systemctl restart httpd.service
To ensure the values have changed, get the service PID:
# systemctl status httpd.service
For example, if the service PID is 3724:
# cat /proc/3724/limits | grep “Max open files”
Thus, we can change the values for the maximum number of open files for a specific service.
Set Max Open Files Limit for Nginx & Apache
In addition to changing the limit on the number of open files to a web server, we should change the service configuration file.
For example, specify/change the following directive value in the Nginx configuration file /etc/nginx/nginx.conf:
worker_rlimit_nofile 16000
While configuring Nginx on a highly loaded 8-core server with worker_connections 8192, we need to specify
8192*2*8 (vCPU) = 131072 in worker_rlimit_nofile
Then restart Nginx.
For apache, create a directory:
# mkdir /lib/systemd/system/httpd.service.d/




Then create the limit_nofile.conf file:
# nano /lib/systemd/system/httpd.service.d/limit_nofile.conf
Add to it:
LimitNOFILE=16000
Do not forget to restart httpd.
Alter the Open File Limit for Current Session
To begin with, run the command:
# ulimit -n 3000
Once the terminal is closed and a new session is created, the limits will get back to the original values specified in /etc/security/limits.conf.
To change the general value for the system /proc/sys/fs/file-max, change the fs.file-max value in /etc/sysctl.conf:
fs.file-max = 100000
Finally, apply:
Conclusion
To conclude, today, we figured how our Support Engineers solve the error, ‘Too Many Open Files’ and discussed options to change the default limits set by Linux.
We saw that the default value of open file descriptor limit in Linux is too small, and discussed a few options for changing these limits of the server.
Конвейерная обработка
Как можно догадаться из названия, в этом подходе запросы обрабатываются по конвейеру. Обрабатывающий процесс состоит из нескольких потоков ОС, выстроенных в цепочку. Каждый поток — это звено цепочки, он выполняет определенное подмножество операций, необходимых для обработки запроса. Каждый запрос последовательно проходит через все звенья цепочки, а разные звенья в каждый момент времени обрабатывают разные запросы.
Плюсы:
- Этот подход хорошо масштабируется по rps. Чем больше звеньев цепочки, тем болшее количество запросов обрабатывается в секунду.
- Использование нескольких потоков позволяет хорошо масштабироваться по ядрам CPU.
Минусы:
- Не для всех категорий запросов подойдет этот подход. Например, организовать long polling с помощью этого подхода будет сложно и неудобно.
- Сложность реализации и отладки. Разбить последовательную обработку на стадии так, чтобы производительность была высокой, может быть непросто. Отлаживать программу, в которой каждый запрос поочередно обрабатывается в нескольких параллельно работающих потоках сложнее, чем последовательную обработку.
Примеры:
- Интересный пример конвейерной обработки был описан в докладе highload 2018 Эволюция архитектуры торгово-клиринговой системы Московской биржи
Конвейерная обработка широко используется, однако чаще всего звеньями являются отдельные компоненты в независимых процессах, которые обмениваются сообщениями, например, через очередь сообщений или БД.
Как файлы получают дескрипторы
Обычно файловые дескрипторы выделяются последовательно. Есть пул свободных номеров. Когда вы создаете новый файл или открываете существующий, ему присваивается номер. Следующий файл получает очередной номер — например, 101, 102, 103 и так далее.

Дескриптор для каждого процесса является уникальным. Но есть три жестко закрепленных индекса — это первые три номера (0, 1, 2).
- 0 — стандартный ввод (stdin), место, из которого программа получает интерактивный ввод.
- 1 — стандартный вывод (stdout), на который направлена большая часть вывода программы.
- 2 — стандартный поток ошибок (stderror), в который направляются сообщения об ошибках.
Когда вы завершаете работу с файлом, присвоенный ему дескриптор освобождается и возвращается в пул свободных номеров. Он снова доступен для выделения под новый файл.
В Unix-подобных системах файловые дескрипторы могут относиться к любому типу файлов Unix: обычным файлам, каталогам, блочным и символьным устройствам, сокетам домена, именованным каналам. Дескрипторы также могут относиться к объектам, которые не существуют в файловой системе: анонимным каналам и сетевым сокетам.
Понятием «файловый дескриптор» оперируют и в языках программирования. Например, в Python функция os.open(path, flags, mode=0o777, *, dir_fd=None) открывает путь к файлу path, добавляет флаги и режим, а также возвращает дескриптор для вновь открытого файла. Начиная с версии 3.4 файловые дескрипторы в дочернем процессе Python не наследуются. В Unix они закрываются в дочерних процессах при выполнении новой программы.
Основные функции файловых систем
Файловая система отвечает за оптимальное логическое распределение информационных данных на конкретном физическом носителе. Драйвер ФС организует взаимодействие между хранилищем, операционной системой и прикладным программным обеспечением. Правильный выбор файловой системы для конкретных пользовательских задач влияет на скорость обработки данных, принципы распределения и другие функциональные возможности, необходимые для стабильной работы любых компьютерных систем. Иными словами, это совокупность условий и правил, определяющих способ организации файлов на носителях информации.
Основными функциями файловой системы являются:
- размещение и упорядочивание на носителе данных в виде файлов;
- определение максимально поддерживаемого объема данных на носителе информации;
- создание, чтение и удаление файлов;
- назначение и изменение атрибутов файлов (размер, время создания и изменения, владелец и создатель файла, доступен только для чтения, скрытый файл, временный файл, архивный, исполняемый, максимальная длина имени файла и т.п.);
- определение структуры файла;
- поиск файлов;
- организация каталогов для логической организации файлов;
- защита файлов при системном сбое;
- защита файлов от несанкционированного доступа и изменения их содержимого.
Увеличиваем лимит на открытые файлы всей системы.
1. Получим значение количества файлов, которые можно открыть в нашей файловой системе:
| 1 | cat /proc/sys/fs/file-max |
Скорее всего, здесь мы увидим числа порядка: 97822; 65208 и т.д.




Такие пределы нас вполне устраивают.
Данное значение используем в дальнейшей настройке.
Но, если понадобится их увеличить – добавим строку настроек в конфигурационный файл /etc/sysctl.conf любым удобным способом:
| 1 | echo «fs.file-max = 65000» >>/etc/sysctl.conf |
2. Перечитаем параметры:
| 1 | sysctl –p |
где 6500 – это то число файлов, которое нам необходимо иметь возможность открывать в нашей файловой системе.



![Как исправить ошибку «заголовок запроса или файл cookie слишком велик» [новости minitool]](http://smartshop124.ru/wp-content/uploads/b/0/f/b0f2a13651b5b1883ba60cd46254c74f.jpeg)