
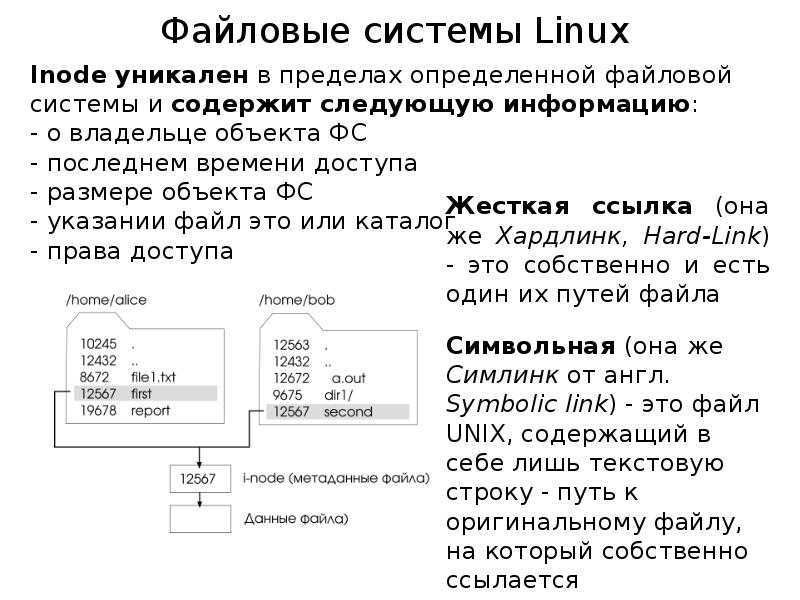
Альтернативные файловые системы
Существует несколько альтернативных файловых систем, поддерживаемых ядром Linux.
XFS
XFS — это 64-разрядная файловая система, которая впервые была представлена в 1994 году и встроена в ядро Linux с 2001 года. XFS поддерживает максимальный размер файла в 8 эксбибайт и ограничивает длину имени файла 255 байтами. Она поддерживает ведение логов и, как и ext4, сохраняет изменения в лог-файле до того, как они будут зафиксированы в основной файловой системе. Это снижает вероятность повреждения файлов.
Данные структурированы в виде B+-деревьев, что обеспечивает эффективное распределение пространства и, следовательно, повышение производительности.
Основным недостатком этой системы является сложный процесс изменения размера существующей файловой системы XFS.
OpenZFS
OpenZFS — это платформа, которая объединяет функционал традиционных файловых систем и диспетчера томов. Впервые была представлена в 2013 году. OpenZFS поддерживает максимальный размер файла в 16 эксбибайт и ограничивает максимальную длину имени файла 255 символами. В качестве особенностей данной системы можно выделить защиту от повреждения данных, шифрование данных, поддержку накопителей увеличенного объема, копирование при записи и RAID-Z.
Основным недостатком OpenZFS является юридическая несовместимость между лицензиями CDDL (OpenZFS) и GPL (ядро Linux). Эта проблема решается путем компиляции и загрузки кода ZFS в ядро Linux.
Btrfs
Btrfs (сокр. от англ. «B–tree file system») — это файловая система, которая была разработана компанией Oracle и выпущена вместе с ядром Linux 2.6.29 в 2009 году. Btrfs поддерживает максимальный размер файла в 16 эксбибайт и ограничивает максимальную длину имени файла 255 символами.
Некоторые особенности Btrfs включают в себя:
онлайн-дефрагментацию;
добавление и удаление блочных устройств в режиме онлайн;
поддержка RAID;
настраиваемое для каждого файла или тома сжатие;
клонирование файлов;
контрольные суммы и возможность создания файлов подкачки и разделов подкачки.
JFS
JFS (сокр. от англ. «Journaled File System») — это файловая система, которая была разработана компанией IBM для AIX Unix в 1990 году. Она является альтернативой файловой системе ext. Она также может быть использована вместо ext4 там, где требуется стабильность при небольшом количестве затрачиваемых ресурсов.
ReiserFS
ReiserFS — это альтернатива файловой системе ext3, которая обладает улучшенной производительностью и расширенным функционалом. Ранее, ReiserFS использовалась в качестве файловой системы по умолчанию в SUSE Linux. ReiserFS поддерживает динамическое изменение размеров файловой системы. К недостаткам можно отнести относительно низкую производительность.
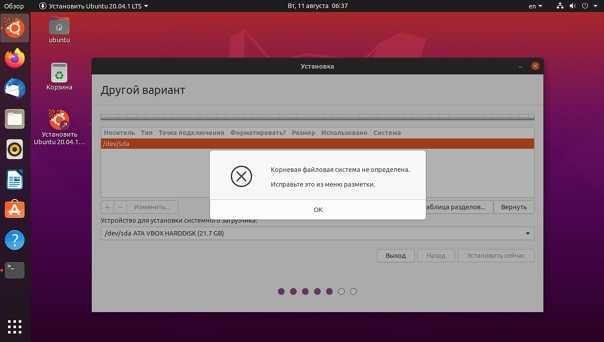
Примечание: Такие файловые системы, как NTFS, FAT и HFS могут использоваться в Linux, но корневая файловая система Linux на них не устанавливается, поскольку они для этого не предназначены. Swap — это файл подкачки, служащий источником дополнительной памяти в тех случаях, когда для выполнения программы требуется больше оперативной памяти, чем имеется в компьютере, — он не является отдельной файловой системой.
Создание файловой системы XFS
Чтобы создать файловую систему XFS, используйте команду <mkfs.xfs/Dev/device>. Все параметры по умолчанию являются оптимальными для общего пользования.
При использовании <mkfs.xfs> на блочном устройстве, содержащем существующую файловую систему, используйте опцию <-f>, чтобы принудительно перезаписать файловую систему.После того, как создана файловая система XFS, её размер уже не может быть уменьшен. Тем не менее, он может быть увеличен с помощью команды xfs_growfs
Пример 6.1. <mkfs.xfs> команда вывода
Ниже приведен пример команды <mkfs.xfs>:
<meta-data = /dev/device isize=256 agcount=4, agsize=3277258 blks sectsz=512 attr=2 data = bsize=4096 blocks=13109032, imaxpct=25 sunit=0 swidth=0 blks naming = version 2 bsize=4096 ascii-ci=0 log = internal log bsize=4096 blocks=6400, version=2 sectsz=512 sunit=0 blks, lazy-count=1 realtime = none extsz=4096 blocks=0, rtextents=0>
Повреждение данных
В случае повреждения данных по какой-либо причине придётся восстанавливать файловую систему вручную.
Восстановление файловой системы XFS
Сначала размонтируйте файловую систему XFS.
# umount /dev/sda3
После размонтирования запустите утилиту .
# xfs_repair -v /dev/sda3
Проверка метаданных «на лету» (scrub)
Важно: Эта программа является экспериментальной, соответственно, её поведение и интерфейс могут измениться в любое время, см. .. запрашивает ядро очистить (англ
scrub) все объекты метаданных в XFS.Записи метаданных сканируются на очевидно ошибочные значения, после чего перекрёстно ссылаются на остальные метаданные. Это делается для того, чтобы иметь достаточно уверенности в целостности всей файловой системы, анализируя отдельные записи метаданных на фоне остальных метаданных в файловой системе. Повреждённые метаданные можно восстановить из других метаданных при наличии неповреждённых избыточных структур данных.
запрашивает ядро очистить (англ. scrub) все объекты метаданных в XFS.Записи метаданных сканируются на очевидно ошибочные значения, после чего перекрёстно ссылаются на остальные метаданные. Это делается для того, чтобы иметь достаточно уверенности в целостности всей файловой системы, анализируя отдельные записи метаданных на фоне остальных метаданных в файловой системе. Повреждённые метаданные можно восстановить из других метаданных при наличии неповреждённых избыточных структур данных.
Включите и запустите для периодической проверки метаданных всех файловых систем XFS «на лету».
Примечание: Для удобства, можно : таймер выполняется каждое воскресенье в 3:10 и , если последний запуск был пропущен (например, так как система была выключена).
Настройка квоты XFS
Файловая система XFS поддерживает настройку квот дискового пространства для каждого пользователя, папки, группы или проекта. Рассмотрим как настроить дисковую квоту для определенной папки. Для начала необходимо, чтобы файловая система была смонтирована с поддержкой коты. Дальше создадим тестовую папку в нашей файловой системе:
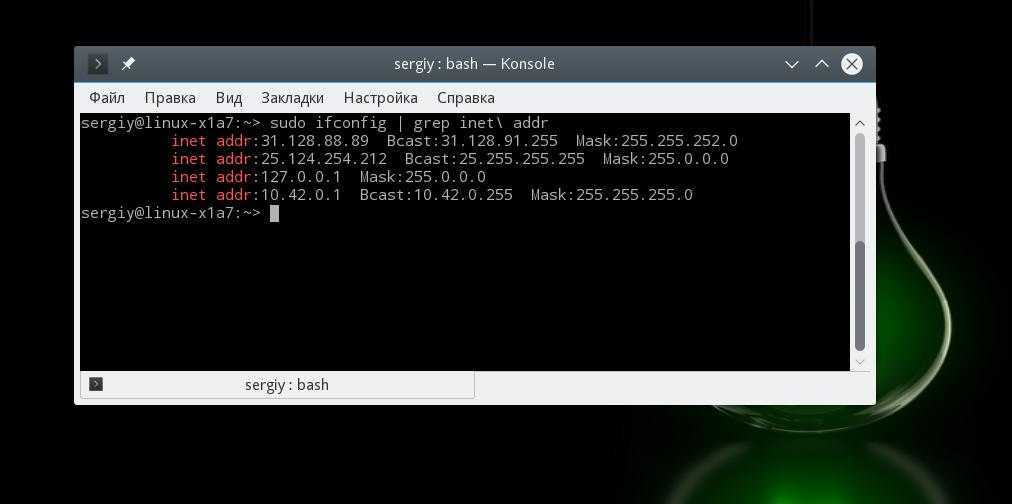
Управление квотами выполняется с помощью утилиты xfs_quota, но сначала нам необходимо, чтобы файловая система была смонтирована с поддержкой настройки квот. Для этого перемонтируем ее:
Дальше эти же опции желательно добавить в /etc/fstab для этой файловой системы. Теперь рассмотрим как настроить XFS квоту. Сначала запустите утилиту xfs_quota для каталога, куда смонтирована XFS:
Вы можете посмотреть состояние с помощью команды:
Затем, чтобы задать ограничение на использование пространства в этой файловой системе для пользователя sergiy используйте команду limit:
Мы задали ограничение 5 гигабайт и жестко — 6 Гб. Вы можете снова посмотреть report чтобы убедиться в правильности изменений:
Недостатки
- Операции с метаданными в XFS были медленнее по сравнению с журнальными файловыми системами, реализованными позже и предназначенными для работы с гораздо большими журналами, что, например, приводило к снижению производительности таких операций, как удаление большого количества файлов. Однако новая функция XFS, реализованная Джоном Нельсоном и называемая отложенным ведением журнала , доступная с версии 2.6.39 основной ветки ядра Linux, как говорят, решает эту проблему; тесты производительности, проведенные разработчиком в 2010 году, показали, что уровни производительности аналогичны ext4 при небольшом количестве потоков и превосходят их при большом числе потоков.
- Ведение журнала нельзя отключить. Это может привести к сокращению срока службы твердотельных накопителей .
Отложенное журналирование
Проблема заключается в журнале ввода/вывода: XFS генерировала очень большое количество трафика для изменения метаданных. В худших случаях практически весь трафик ввода/вывода представлял собой данные для журнала, а не данные, которые пользователь пытался записать на диск
Попытки решения данной задачи в течение многих лет включали одно важное изменение алгоритма записи и множество других важных оптимизаций и настроек. Единственное, что не требовалось — любое изменение формата данных на диске, хотя оно может быть востребовано в будущем.Нагрузки, связанные с изменением большого количества метаданных, могут в конечном итоге привести к тому, что один и тот же блок директории будет изменен много раз за короткий период времени, а каждое из этих изменений генерирует запись, которая должна быть сохранена в журнале
Это и есть источник огромного журнального трафика. Концепция решения этой проблемы очень проста: отложить обновление журнала и объединять изменения одного и того же блока в одной записи. На самом деле, для претворения в жизнь этой идеи в масштабируемой реализации потребовалось несколько лет тяжелой работы, но сейчас она уже работает. Отложенное журналирование для файловой системы XFS поддерживается в ядре версии 3.3.Фактически технология отложенного журналирования была позаимствована у файловой системы ext3, поэтому алгоритм ее работы известен и требуется намного меньше времени для ее внедрения в XFS, чем если бы она разрабатывалась с нуля. Вместе с преимуществами в быстродействии это также значит значительное уменьшение объема кода. Если вы хотите более детально изучить, как работает эта технология, подробности можно найти в файле filesystems/xfs-delayed-logging.txt в дереве документации ядра.Отложенное журналирование — это большое изменение, но не единственное. Быстрый способ резервирования места в журнале остается горячей темой в XFS. Сегодня он не требует блокировки, в то время как медленный способ все еще требует глобальной блокировки этой точки. Код асинхронной записи метаданных приводил к сильной фрагментации ввода/вывода, значительно уменьшая производительность. Теперь запись метаданных откладывается, а перед записью они сортируются. Это значит, что, по словам Дэйва, файловая система выполняет функции планировщика ввода/вывода. Но планировщик ввода/вывода работает с очередью запросов, которая, как правило, ограничивается 128 записями, в то время как очередь отложенных метаданных XFS может содержать многие тысячи записей, так что имеет смысл производить сортировку в файловой системе, до передачи метаданных системе ввода/вывода. «Активные элементы журнала (Active log items)» — это механизм, который повышает производительность при работе с большими сортированными списками элементов журнала путем накапливания изменений и применения их в пакетном режиме. Кроме того, кэшированные метаданные были удалены со страницы подкачки, так их наличие приводило к запросам на загрузку страниц в неподходящее время.
Рынок высокопроизводительных серверов
SGI продолжала расширять линейку серверов (включая некоторые суперкомпьютеры ) на основе архитектуры SN . SN (Scalable Node) — это технология, разработанная SGI в середине 1990-х годов, которая использует (cc-NUMA). В системе SN процессоры, память, а также контроллер шины и памяти объединены в объект, называемый узлом, обычно на одной печатной плате . Узлы соединены высокоскоростным межсоединением под названием NUMAlink (первоначально продаваемым как CrayLink ). Там нет внутренней шины , а вместо этого доступа между процессорами, памятью и I / O устройств осуществляется через переключился ткань ссылок и маршрутизаторов .
Благодаря согласованности кеш-памяти распределенной разделяемой памяти системы SN масштабируются сразу по нескольким осям: по мере увеличения количества ЦП увеличивается объем памяти, объем ввода-вывода и пропускная способность системы . Это позволяет получить доступ к объединенной памяти всех узлов из одного образа ОС с использованием стандартных методов синхронизации с общей памятью . Это значительно упрощает программирование системы SN и позволяет достичь более высокой максимальной производительности, чем системы, не связанные с кешем, такие как обычные кластеры или массивно-параллельные компьютеры, которые требуют написания (или переписывания) кода приложений для явного выполнения передачи сообщений связи между их узлами.
Первая система SN, известная как SN-0, была выпущена в 1996 году под названием Origin 2000 . Основанный на процессоре MIPS R10000 , он масштабируется от 2 до 128 процессоров, а меньшая версия Origin 200 (SN-00) масштабируется от 1 до 4. Более поздние улучшения позволили использовать системы с 512 процессорами.
Система второго поколения, первоначально называвшаяся SN-1, но позже SN-MIPS, была выпущена в июле 2000 года под названием Origin 3000 . Он масштабировался от 4 до 512 процессоров, а конфигурации с 1024 процессорами были доставлены некоторым клиентам по специальному заказу. Затем последовала меньшая, менее масштабируемая реализация под названием Origin 300.
В ноябре 2002 года SGI объявила о переупаковке своей системы SN под названием Origin 3900. Она в четыре раза увеличила плотность процессорной площади системы SN-MIPS с 32 до 128 процессоров на стойку при переходе к топологии межсоединений « толстого дерева ». .
В январе 2003 года SGI анонсировала вариант платформы SN под названием Altix 3000 (внутреннее название — SN-IA). Он использовал процессоры Intel Itanium 2 и работал под управлением ядра операционной системы Linux. На момент выпуска это был самый масштабируемый компьютер на базе Linux в мире, поддерживающий до 64 процессоров в одном системном узле. Узлы могут быть соединены с использованием той же технологии NUMAlink для формирования того, что SGI предсказуемо назвал «суперкластерами».
В феврале 2004 года SGI объявила об общей поддержке 128 процессорных узлов, за которыми в этом году последуют версии с 256 и 512 процессорами.
В апреле 2004 года SGI объявила о продаже своего программного обеспечения Alias примерно за 57 миллионов долларов.
В октябре 2004 года SGI построила суперкомпьютер Columbia , побивший мировой рекорд скорости компьютеров, для исследовательского центра NASA Ames Research Center. Это был кластер из 20 суперкомпьютеров Altix, каждый с 512 процессорами Intel Itanium 2 под управлением Linux, и достиг стабильной скорости 42,7 триллиона операций с плавающей точкой в секунду ( терафлопс ), что легко превзошло рекорд знаменитого японского Earth Simulator в 35,86 терафлопс. (Неделю спустя обновленный IBM Blue Gene / L показал тактовую частоту 70,7 терафлопс.)
В июле 2006 года SGI анонсировала систему SGI Altix 4700 с 1024 процессорами и 4 ТБ памяти, на которой работает один образ системы Linux.
Типы файловых систем Linux — описание и обзор
Файловые системы условно делятся на два типа
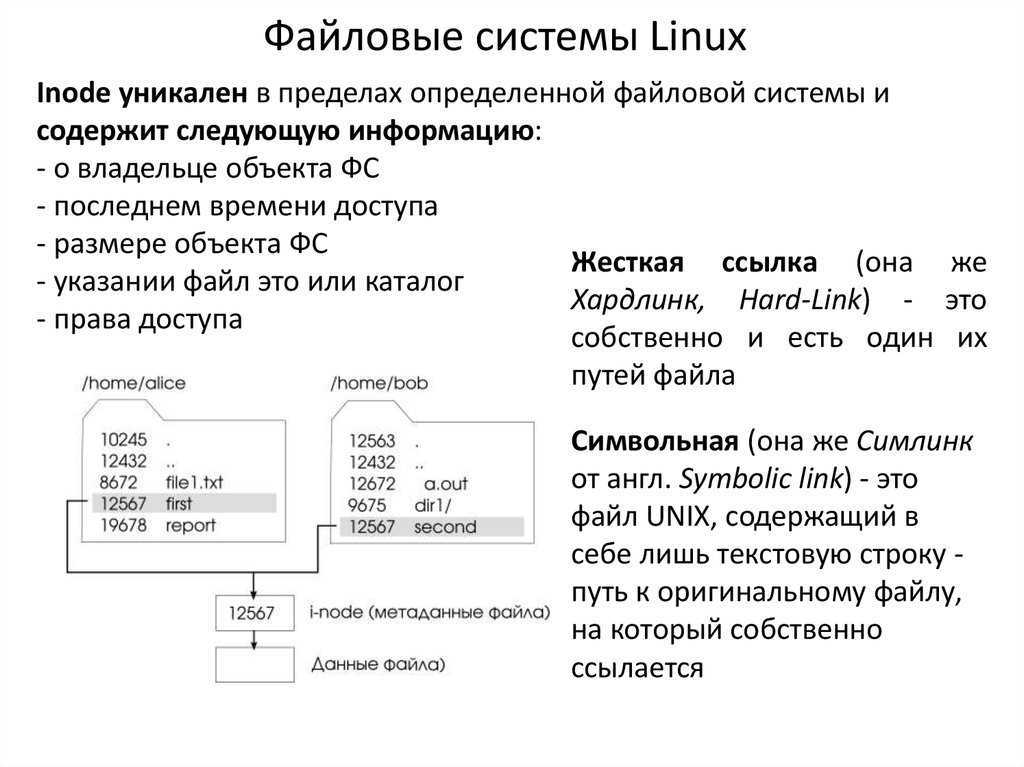
- Журналируемые. Имеют в своем арсенале специальный файл, который хранит историю действий (лог) и план дальнейшей проверки. Характерной особенностью является устойчивость к сбоям и большая гарантия на сохранение целостности данных.
- Не журналируемые. Отсутствует файла с логом. Работают более быстро. Не гарантируют целостность и сохранность данных. Особенно это проблема встает в случае сбоев, когда некоторые действия могли редактировать файл и прервать изменения в неправильном месте.
Узнать файловую систему в ОС Linux
file -s
Самые популярными типами ФС в Linux являются:
- Ext4 (считается стандартом для Linux)
- Ext2
- ReiserFS
- XFS
- SWAP
В Windows поддерживаются свои ФС: NTFS, FAT32. Линукс также их поддерживает, а вот Windows не поддерживает линуксовые системы.
1 Extfs (Extended File System). Дата появления на свет апреле 1992 года. Самая первая файловая система разработанная специально для ОС на ядре Linux. Наибольший возможный размер раздела файла — 2 Гб. Максимальная длина имени файла — 255 символов. Является прародителем популярных ФС Ext2, Ext3.
2 Ext2 (second extended file system). Дата создания 1993 год. Является не журналируемой файловой системой. Была популярна до 2000-х. Имеет ряд ограничений на работу с большими файлами, зато является и самой быстрой, поэтому её часто используют в различных сравнительных тестах как эталонную.
3 Ext3 (third extended filesystem). Дата выхода 2001 год. Считается революционной, поскольку относится к поколению журналируемых систем. В настоящее время файловая система Ext3 поддерживает файлы размером до 1 ТБайт. Используется в некоторых случаях до сих пор. Разделы Ext3 могут читать Windows-программы (например, Total Commander). Разработчик Стивен Твид.
4 Ext4 (дата выхода 2006 год). Является стандартом во всех современных Linux (а сейчас 2019 год). Хорошо защищена от проблем фрагментации и оптимизирована для работы с большими файлами. Максимальный размер файловой системы не может превышать 16 ТБайт.





5 ReiserFS (или Reiser3). Создана уже после ext3 в качестве ее альтернативы. Журналируемая система. Поддерживает большую производительность. Позволяет изменять размеры разделов во время работы.
Считается самой экономичной, поскольку позволяет хранить несколько файлов в одном блоке, что позволяет использовать каждый байт жесткого диска. Обычные файловые системы могут хранить в одном блоке один файл или одну его часть.
6 Reiser4 (дата создания 2004 году). Система включает себя такие передовые технологии как транзакции, задержка выделения пространства, а так же встроенная возможность кодирования и сжатия данных.
7 XFS (журналируемая файловая система). Это производительная файловая система, разработанная в Silicon Graphics для свой операционной системы еще в 2001 году. Позволяла использовать диски 2 ТБайт. Существует возможность потери данных во время записи при сбое питания, так как большое количество буферов хранится в памяти.
8 Btrfs или B-Tree File System. Журналируемая файловая система. Совершенно новоиспеченная файловая система, которая сосредоточена на отказоустойчивости, свободности администрирования и восстановления данных. К её особенностям относятся хранение индекса файлов в так называемых «B-деревьях» – иерархических структурах, которые максимально оптимально используют ресурсы оперативной памяти за счёт небольшой глубины вложения данных.
9 SWAP – особый вид не журналируемой файловой системы, которая реализует структуру хранения данных, аналогичную структуре оперативной памяти. Используется для реализации файла подкачки в Linux.
Сравнение файловых систем
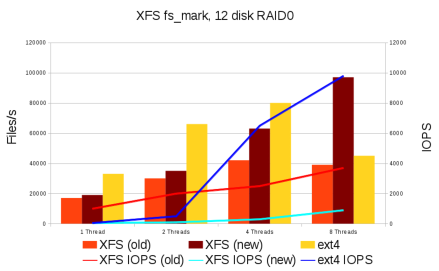
Как же XFS масштабируется после всех изменений? При работе с одним или двумя потоками она все еще немного медленнее, чем ext4, но с увеличением числа потоков до восьми ее производительность линейно возрастает, в то время как у ext4 ухудшается, а у btrfs ухудшается еще больше. На сегодняшний день масштабируемость XFS ограничивается блокировкой слоя ядра, работающего с виртуальными файловыми системами, а не кодом, связанным непосредственно с файловой системой. Обход директорий теперь работает быстрее даже с одним потоком, и еще быстрее при использовании восьми потоков.
Масштабируемость выделения дискового пространства в настоящее время на несколько порядков быстрее, чем в ext4. Это положение немного изменится после введения в релизе 3.2 функции «bigalloc», которая повышает масштабируемость выделения дискового пространства в ext4 на два порядка, если используется достаточно большой размер блока. К сожалению, при этом пропорционально увеличивается место, занимаемое на диске файлами малых размеров. Например, для размещения исходного кода ядра Linux в этом случае потребуется 160 Гб дискового пространства. Bigalloc не очень хорошо совместим с некоторыми другими функциями ext4 и требует сложной настройки. По словам Дэйва ext4 страдает от архитектурных недостатков — такие вещи, как использование битовых карт для отслеживания дискового пространства, были типичны для восьмидесятых годов. Она просто не может масштабироваться на действительно большие файловые системы.
Выделение дискового пространства в Btrfs происходит еще медленнее, чем в ext4. По словам Дэйва, проблема в основном заключается в перемещении кэша свободного дискового пространства, на которое затрачивается слишком много ресурсов процессора. Однако это не архитектурная ошибка, поэтому она может быть достаточно легко исправлена.
6.5. Проверка файловой системы
Команда позволяет задействовать утилиту-обертку, используемую для вызова утилит, осуществляющих проверку файловых систем.
# ls /sbin/*fsck* /sbin/dosfsck /sbin/fsck /sbin/fsck.ext2 /sbin/fsck.msdos /sbin/e2fsck /sbin/fsck.cramfs /sbin/fsck.ext3 /sbin/fsck.vfat #
Значение из последнего столбца файла используется в качестве флага проверки файловой системы в процессе загрузки операционной системы.
$ grep ext /etc/fstab /dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 $
Проверка смонтированной файловой системы в ручном режиме приведет к выводу предупреждения и завершению работы утилиты fsck.
# fsck /boot fsck из util-linux 2.25.2 e2fsck 1.42.11 (09-Jul-2014) /dev/sda1 is mounted. e2fsck: Cannot continue, aborting.
Но после размонтирования файловой системы ext2 утилиты fsck и могут успешно использоваться для ее проверки.
# fsck /boot fsck из util-linux 2.25.2 e2fsck 1.42.11 (09-Jul-2014) /boot: clean, 44/26104 files, 17598/104388 blocks # fsck -p /boot fsck из util-linux 2.25.2 /boot: clean, 44/26104 files, 17598/104388 blocks # e2fsck -p /dev/sda1 /boot: clean, 44/26104 files, 17598/104388 blocks
Заключение и выводы
| Показатель | Ext4 | XFS | Btrfs |
| Дата выхода | 1992 | 2002 | 2006 |
| Максимальный размер раздела | 50-100 Тб | 8 Эб | 16 Эб |
| Максимальный размер файла | 16 Тб | 8 Эб | 16 Эб |
| Максимальное количество файлов | 2 в 32 степени | 2 в 64 степени | 2 в 64 степени |
| Максимальная длина имени | 255 | 255 | 255 |
| Прозрачное шифрование | Да | Нет | Нет |
| Прозрачное сжатие | Нет | Нет | Да |
| Управление томами | Нет | Нет | Да |
| Дедупликация | Нет | Нет | Да |
| Уменьшение размера раздела | Да | Нет | Да |
| Создание снапшотов | Нет | Нет | Да |
| Copy-on-write | Нет | Да | Да |
Так что же лучше использовать? До сих пор Ext4 была победителем, несмотря на идентичную производительность. Но почему? Ответ — удобство и популярность. Ext4 — по-прежнему отличная файловая система для рабочих станций и настольных компьютеров. Она поставляется по умолчанию, а потому пользователь получит её просто установив ОС. Кроме того, Ext4 поддерживает разделы до 100 терабайт и файлы до 16 терабайт, а это по-прежнему очень много. Обычным пользователям столько точно не надо.


Btrfs предлагает большие объемы до 16 экзабайт как для разделов так и для файлов, а также повышение отказоустойчивости и много дополнительных и очень интересных возможностей. Она уже интегрирована в ядро, однако её ещё многие боятся, потому что файловая система относительно новая и пока не совсем понятно чего от неё ждать.
Даже если скорость передачи данных не очень важна, есть такая характеристика, как скорость работы с файлами. В Btrfs есть много полезных функций: копирование при записи, контрольные сумы, снимки, очистка, самовосстановление данных, дедупликация, а также другие интересные улучшения, которые обеспечивают сохранность данных. В ней только недостает функции ZFS — Z-RAID, так что RAID пока находиться на экспериментальной стадии. Для обычного хранения данных Btrfs лучше подходит чем Ext4, но как будет на самом деле покажет время. Что использовать Btrfs или Ext4 — это только дело вашего вкуса.
На данный момент Ext4 — лучший выбор для обычных пользователей, так как она распространяется как файловая система по умолчанию, а также она быстрее Btrfs при передаче файлов. Btrfs, безусловно, стоит попробовать, но полностью заменять ext4 еще рано, это можно будет сделать лишь через несколько лет. Забавно, то же самое, говорили и несколько лет назад, с тех пор много чего поменялось, но Btrfs все еще не считается стабильной. Если у вас есть другое мнение по этому поводу, оставляйте комментарии!
Кстати, если вы используете Windows и Linux на одной машине, вам может быть интересна моя статья: Подключение ext4 в Windows



