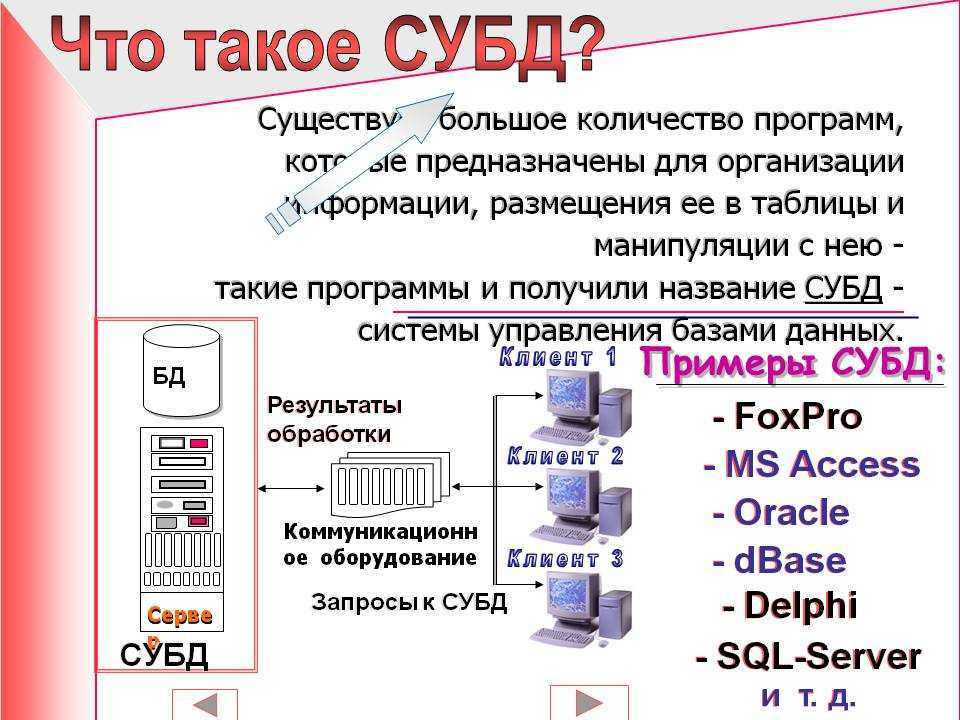
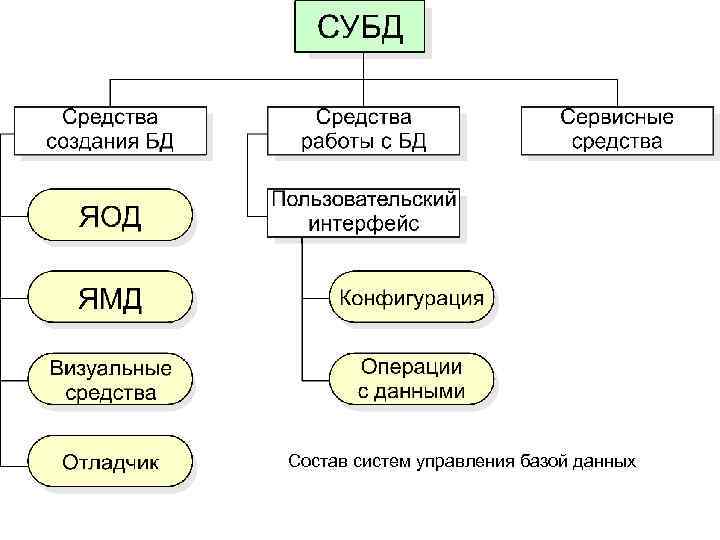
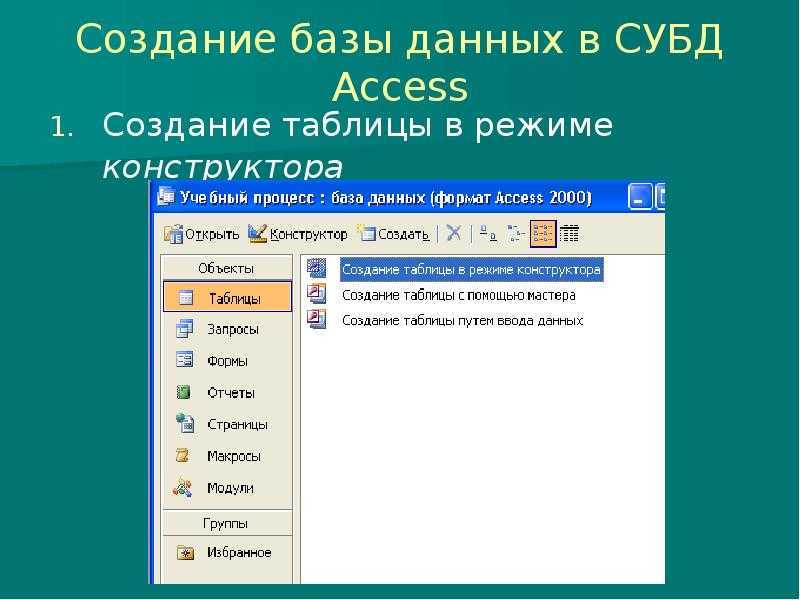
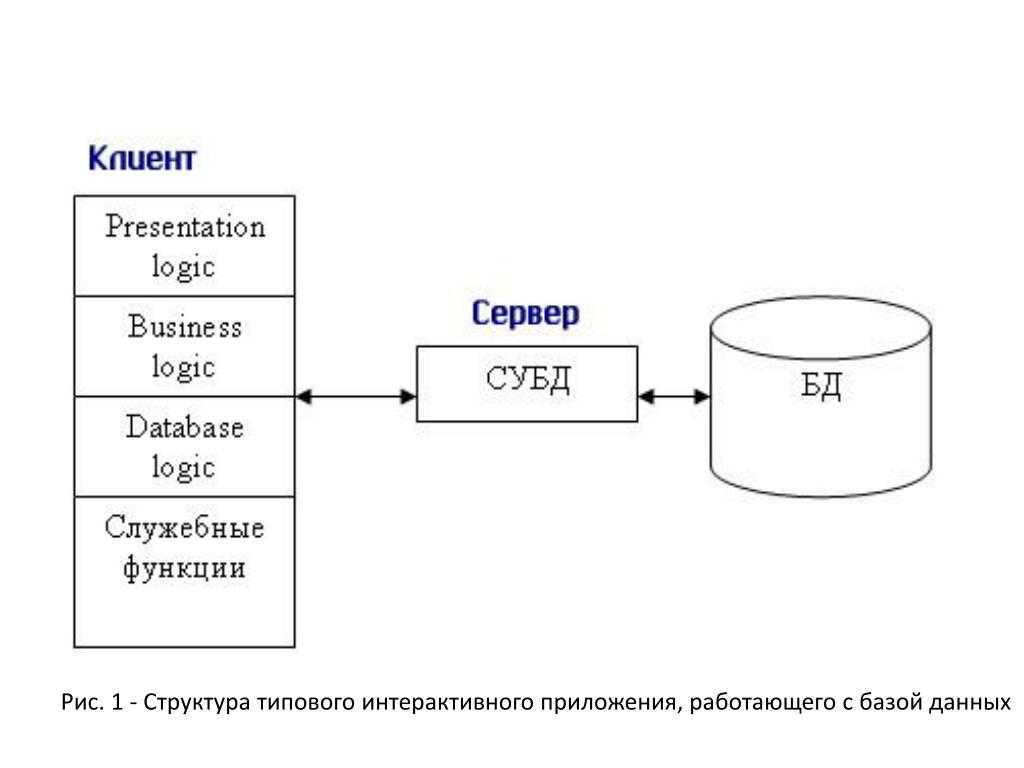
Увеличение максимального количества системных дескрипторов для увеличения степени параллелизма
MySQL — база данных с высокой степенью параллелизма. Количество параллельных дескрипторов по умолчанию для Linux — 1024. Однако их не всегда достаточно. Выполните следующие шаги, чтобы увеличить максимальное количество параллельных дескрипторов системы для поддержки высокой степени параллелизма MySQL.
Шаг 1. Изменение файла limits.conf
Добавьте следующие четыре строки в файл /etc/security/limits.conf, чтобы увеличить максимально допустимое количество параллельных дескрипторов
Обратите внимание, что максимальное количество, поддерживаемое системой, — 65536
Copy
Выполните следующие команды:
Copy
Шаг 3. Обеспечение обновления ограничений при загрузке
Вставьте следующие команды, выполняемые при запуске, в файл /etc/rc.local, чтобы они выполнялись при каждой загрузке.
Copy
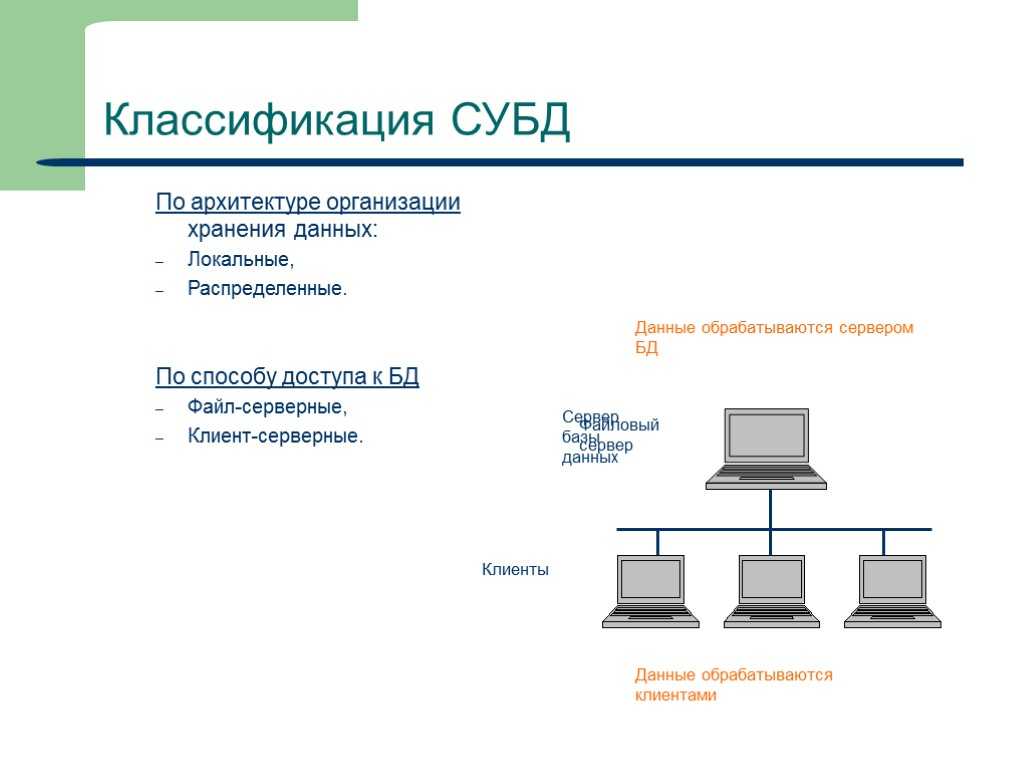
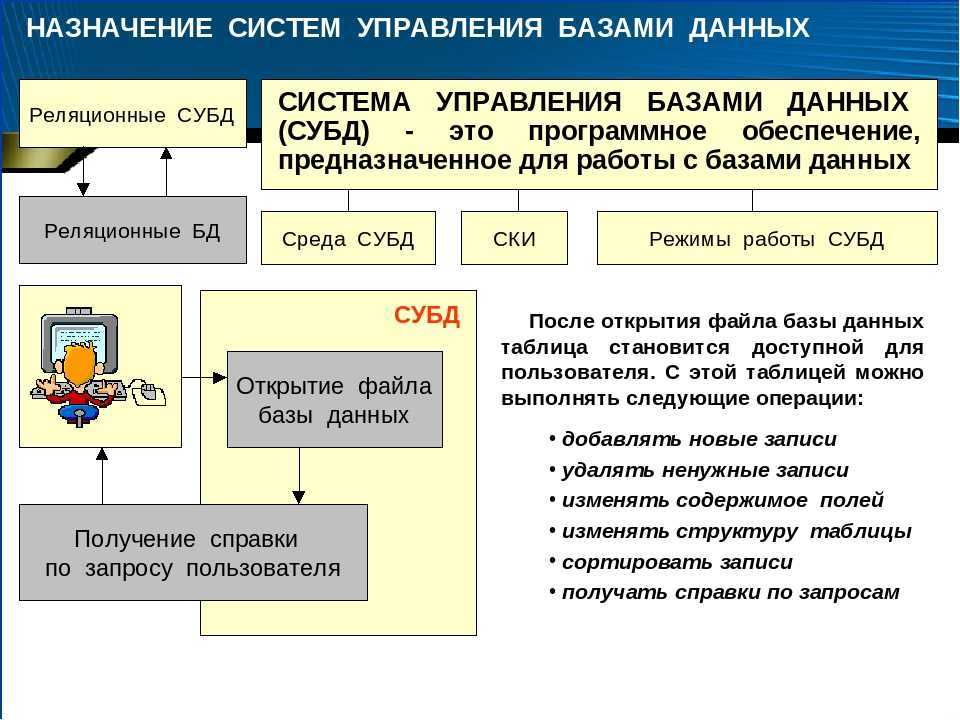
работа таблицы данных
База данных, как шкаф, в то время как небольшое отделение в шкафу, как пустой лист данных, задействуя разные типы одежды в каждом маленьком купе, так же, как мы добавляем данные в техпаспорте. Далее, давайте узнаем, как использовать таблицу данных.
Теперь мы используемСоздание таблицы данных в базе данных.
Формат синтаксиса для создания листа данных состоит в следующем.
Например, мы создаем имяБаза данных, мы создали в этой базе данныхТаблица данных, таблица включает в себя идентификатор студента, имя студента, пол информацию.
Дисплей показывает успех создания, как показано ниже.
Затем создайте имя с именемВ таблице, таблица содержит идентификатор студента, названия курса и оценки, для того, чтобы сделать код будет выглядеть более чистой и красивой, вы можете ввести свой филиал, как показано на рисунке ниже.
После создания листа данных, использованиеДля проверки, мы можем увидеть имена двух паспортов вы только что создали.
использовать Для просмотра полной информации о создании листа данных.
Например, давайте проверим данные листаПолная информация.
Из приведенной выше картинке мы видим три названия полей только что создали, Int и полукокс типы двух данных из MySQL, с большим количеством типов данных MySQL, незнакомых одноклассники, вы посмотрите на тип данных MySQL может.
Null все на рисунке ДА, то есть, потому что мы не указываем, что имя столбца не пусто. Если указать имяНЕТ будет отображаться, как показано ниже.
На данный момент, мы установили два листа данных в базе данных. Затем нам нужно добавить данные в таблицу. Добавление данных в таблицу, с участием Два пути.
- Можно добавить несколько данных, вы можете загрузить данные в текстовый файл в таблицу данных.
- Дополнительные новые данные.
использовать Загрузка данных, формат утверждение:
использовать Заявление вставляется в таблицу, формат утверждение:
Например, мы используемЗаявление с участием Добавление данных в таблицу.
существовать Информационные данные четыре полных студента вставляется в таблицу, как показано ниже.
Стоит отметить, что, когда данные, которые мы Вкладыш неполно, имя столбца соответствует NULL. Мы стараемся не оставить со значениями нуля в форме, потому что значения нулевых уменьшить производительность запроса. Мы можем использовать цифровые 0 вместо NULL, и обработка значений нуля будет разъяснены в последующих экспериментах.
После ввода данных, мы используемЗаявление приходит, чтобы просмотреть полную информацию в таблице. Грамматический формат:。
Опять такиВставка данных в таблицу, как показано ниже.
Из кода мы можем знать, как имяТип данных, мы должны использовать кавычки, чтобы изменить. В дополнение к типам полукокса, есть,,,,Тип данных также изменяется в одинарные кавычки.

Используйте ЗЕЬЕСТ, чтобы увидеть, если данные успешно добавлены в таблицу данных.
Совет по оптимизации MySQL № 6: не уделяйте слишком много внимания настройке
Администраторы баз данных, как правило, тратят огромное количество времени на настройки конфигураций. Результат, как правило, не является большим улучшением и иногда может быть даже очень опасным. Я видел много «оптимизированных» серверов, которые постоянно терпели крах, закончились нехваткой памяти и плохо работали, когда рабочая нагрузка стала немного более интенсивной.
Настройки по умолчанию в конфигурационных файлах MySQL, идут по принципу «одна общая конфигурация подходит для всех задач», и хоть такой подход достаточно устарели, но вам не нужно настраивать все подряд. Лучше правильно настроить базовые параметры и изменять другие настройки только в случае необходимости. В большинстве случаев вы можете получить 95% максимальной производительности сервера, установив примерно 10 параметров. Несколько ситуаций, когда это не применяется, — это крайностные случаи, уникальные для ваших конкретных обстоятельств.
В большинстве случаев серверные инструменты настройки (например, MySqlTuner) не рекомендуется использовать, поскольку они, как правило, дают рекомендации не имеющие смысла для конкретных случаев. У некоторых даже есть опасные, неточные рекомендации, закодированные в них, такие как отношение кэш-памяти и формулы потребления памяти. Они никогда не были правы, и с течением времени они стали еще менее эффективными.
Помните, что установочный дистрибутив базы данных MySQL и MariaDb идет с комплектом предустановленных конфигурационных файлов: my-small.cnf, my-medium.cnf, my-large.cnf и my-huge.cnf в зависимости от предполагаемых рабочих нагрузок и имеющихся аппаратных мощностей вашего сервера. Соответственно, для малых, средних, больших и очень больших систем. Выберете один из вариантов в соответствии с Вашими задачами и возможностями. Это дефолтные настройки перекроют от 80 до 95% максимально возможных результатов по оптимизации и настройки производительности.
Особенности нереляционных баз данных
NoSQL – аналог реляционной базы данных, в которой информация хранится без строгой структуры и явной связи между другими сведениями. Данные здесь могут храниться не только в табличной, но и текстовой, в графической, аудио-, видео- и любой другой форме. На практике широкое применение такие БД получили в компьютерных приложениях, мобильных софтах. Они используются тогда, когда в приоритете не четкое структурирование данных, а гибкая, масштабируемая база с высоким уровнем производительности. Здесь нет никаких ограничений ни при хранении, ни при использовании данных.
Нереляционные БД наделены рядом весомых преимуществ:
- Высокая гибкость. Это свойство положительным образом сказалось на оперативности разработок. Работы можно разбивать на отдельные этапы, привлекая к их выполнению нескольких специалистов. Также высокая гибкость позволяет работать как с неструктурированными, так и со структурированными данными. Можно создавать документы, заранее не устанавливая их структуру. К тому же она может быть своя для каждого файла. Может отличаться и синтаксис, а новые поля можно будет добавлять даже в рабочем процессе.
- Отличная эффективность. Базу, созданную на основе нереляционной системы можно легко оптимизировать под хранение определенных данных или готовых шаблонов. Такое решение позволяет существенно повысить производительность в сравнении с реляционными аналогами.·
- Хорошая масштабируемость. В NOSQL базах данных предусмотрена горизонтальная масштабируемость. Предусмотрено несколько кластеров, которые применяются для разделения информации и добавления любого количества серверов: как квартал, который можно расширять, достраивая новые здания. Чтобы сохранить на максимально высоком уровне управляемость, операции по созданию облачных решений можно выполнять в фоновом режиме. Благодаря масштабируемости нереляционная база данных стала оптимальным вариантом для часто меняющихся масштабных хранилищ.
Руководство
-
Большинство современных систем поддержки Войти электронной почты, номер мобильного телефона для входа в систему двумя способами, то, как обеспечить лучшую индексацию на производительность почтового ящика или номер телефона растяните его?
-
Сегодня article’re собирается исследовать, как добавить индекс строки для достижения максимальной производительности в Mysql.
-
Эта статья была впервые опубликована в авторской номер общественного микро-канал , Как друг, спасибо! Действительно Действительно
-
Чен будет отЧто такое индекс префикс、Сравните индекс префикс и общий индекс、Лучшие показатели индекса приставки Он Цзяньл、Влияние на индекс приставку покрывается индексомЭти пункты термины.
Когда выбрать SQL, а когда NOSQL?
SQL будет оптимальной при обработке большого числа сложных запросов, кропотливого, рутинного анализа информации. Если нужна надежная, стабильная и продуктивная обработка транзакций с сохранением ссылочной ценности, стоит отдать предпочтения SQL.
Нереляционная база данных – это выбор тех, кто будет работать с большими объемами различных данных. Здесь нет четких структурированных механизмов, благодаря чему процесс загрузки и обработки проходит максимально быстро. К тому же такие БД намного сложнее взломать: доступ к ним ограничен. Если вам необходимо хранить информацию в объектах JSON, если требуется горизонтальное масштабирование, если сведения находятся в коллекциях с разными атрибутами и полями, стоит сделать выбор в пользу NoSQL.
Более подробную информацию о том, что такое реляционные и нереляционные базы данных, сферах и особенностях их применения предоставят специалисты компании «Xelent». Большой опыт позволяет им находить решения, которые будут оптимальны именно для вашего бизнеса по надежности, продуктивности работы и стоимости. Для связи воспользуйтесь телефоном или онлайн-формой.
Популярные услуги
Облачные технологии в логистике
Облачные технологии в логистике применяются последние 5 лет. Они упрощают взаимодействие поставщиков, перевозчиков, потребителей между собой, упрощают рабочий процесс.Одним из направлений работы нашей компании является предоставление логистическим предприятиям в аренду облачных серверов, программного обеспечения (SaaS), ИТ-инфраструктуры с соблюдением требований к персональной защите информации.
Платформа облачных сервисов Cloud.Xelent
Оптимальные тарифы для облачных решений!
Полный аналог «железного» сервера в виртуальной среде.
Реализовано на VMware.
Удаленные рабочие места (VDI)
Переведите офис на удаленную работу в течение 1 дня. Облако VMware с площадками в Санкт-Петербурге, Москве, Алма-Ате и Минске.
Программное обеспечение для работы с базой данных MariaDB
Созданная разработчиками MySQL, MariaDB используется такими техническими гигантами, как Wikipedia, и даже . MariaDB – это сервер базы данных, который предлагает встраиваемую замену функционала MySQL. Безопасность является главным принципом и приоритетом разработчиков СУБД. В каждом релизе они добавляют все патчи безопасности MySQL и при необходимости улучшают их.
Достоинства
- Масштабируемость с простой интеграцией;
- Доступ в режиме реального времени;
- Основные функции MySQL (MariaDB является альтернативой MySQL);
- Альтернативные механизмы хранения, оптимизация серверов и патчи;
- Обширная база знаний по разработке баз данных SQL, накопленная в течение 20 лет работы MariaDB.
Недостатки
- Отсутствует плагин проверки сложности пароля;
- Отсутствует memcached интерфейс (распределённая система кэширования в оперативной памяти);
- Нет трассировки оптимизатора.
Оптимизация производительности MySQL сервера

От скорости работы баз данных (БД) зависит быстрота отклика сайта. Ведь замедленная обработка запросов влияет на PHP, следовательно — накапливается огромное количество операций, с которыми сервер может не справиться.
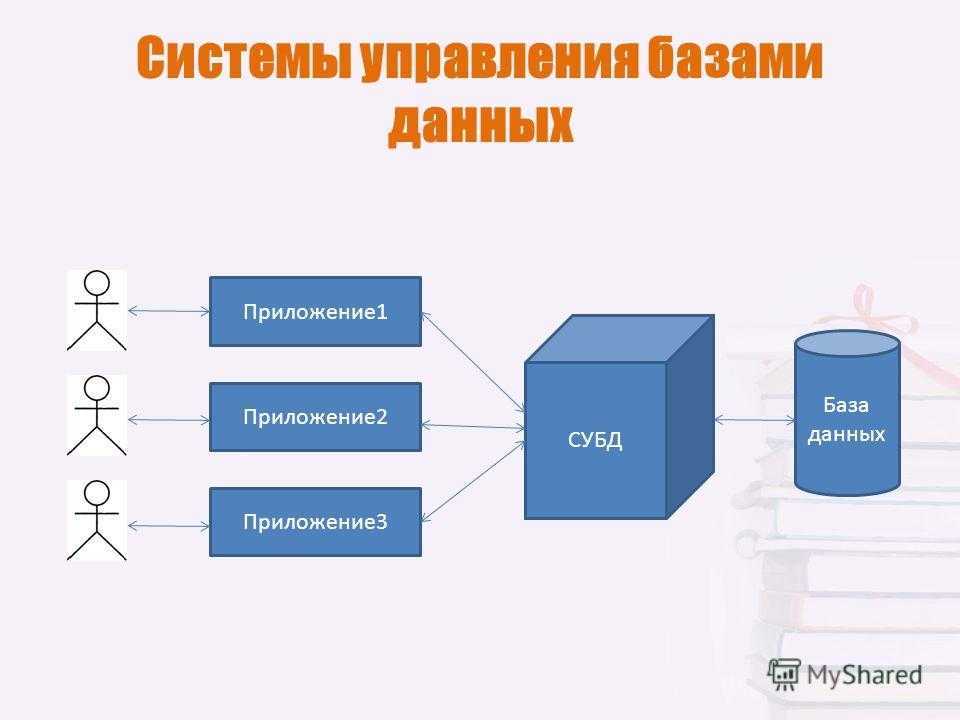
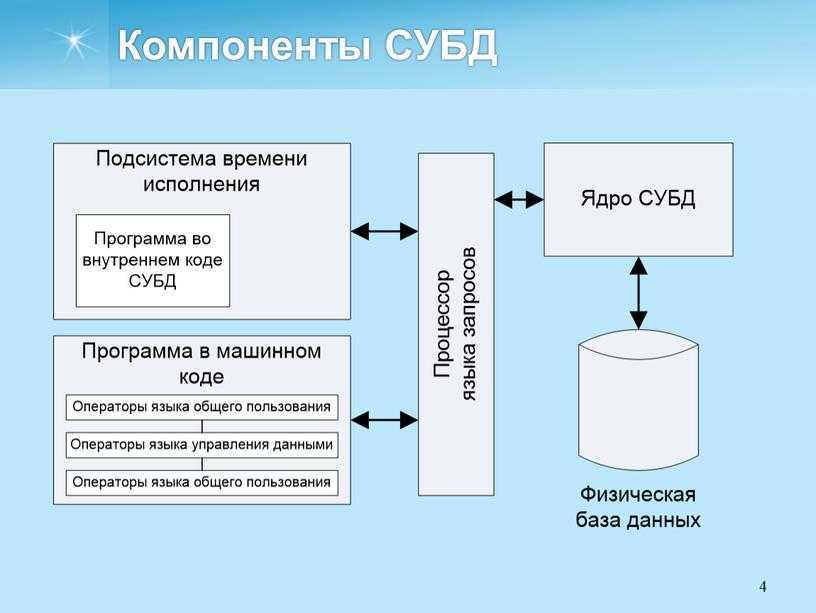
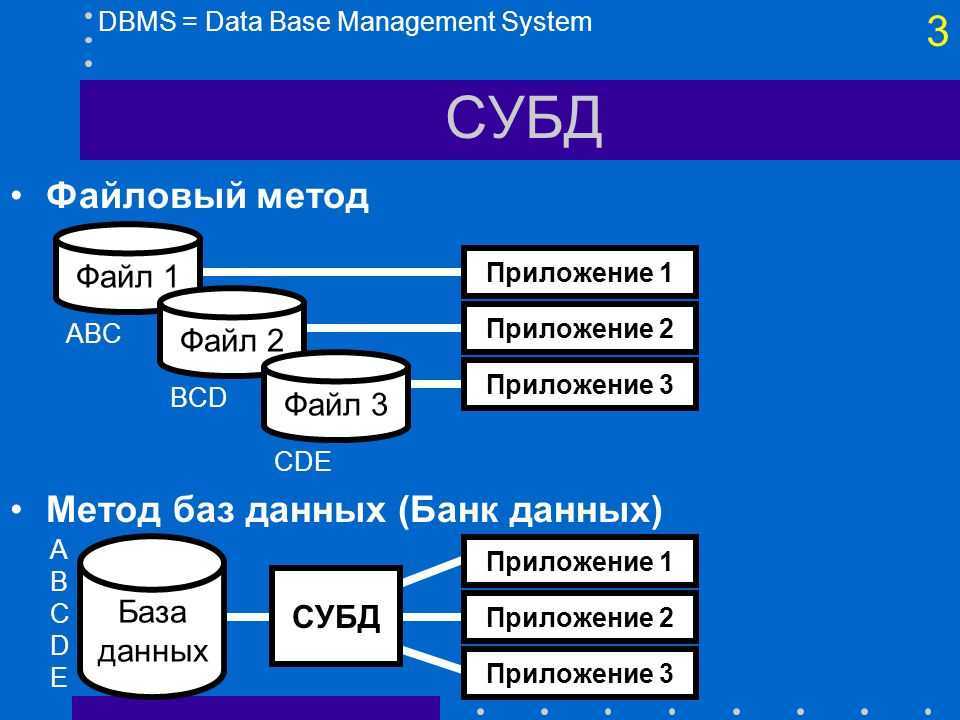
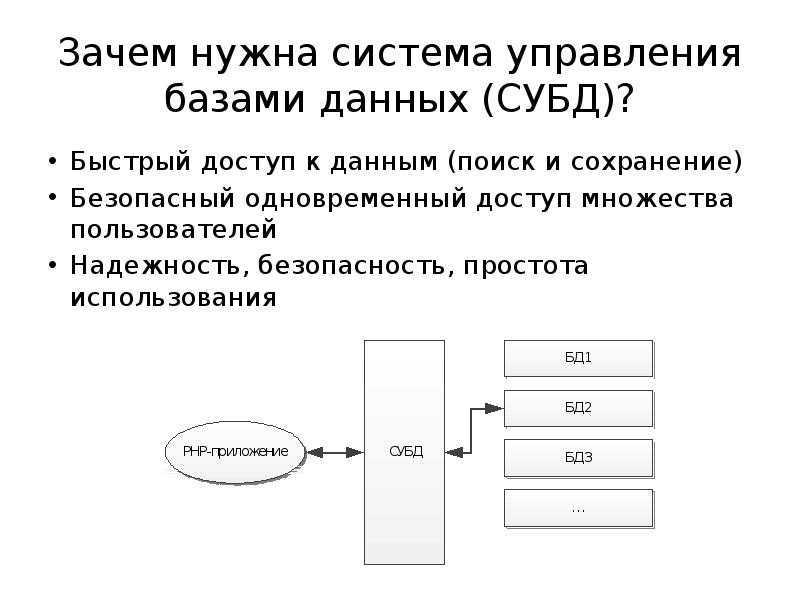
Управлять данным процессом позволяет использование систем управления базами данных или СУБД. Одной из самых широко применяемых СУБД является MySQL — ПО с открытым исходным кодом, созданное компанией MySQL AB (Oracle) ещё в 1995 году. Оптимизация MySQL позволяет избежать проблем с производительностью сервера и значительно ускорить интернет-ресурс.
В статье представлены варианты повышения производительности баз данных MySQL с помощью специального скрипта, а также указаны параметры настройки, на которые необходимо обратить внимание
Совет 7. Узнайте, как полностью защитить свой код
Базы данных хранят всевозможную информацию, что делает их основными целями атак. Распространенные атаки включают SQL-инъекции, когда пользователь вводит инструкцию SQL вместо имени пользователя и извлекает или изменяет вашу базу данных. Примеры SQL-инъекций:
textuserID = getRequestString("userID");
textSQL = "SELECT * FROM Users WHERE userID = " + textuserID;
Допустим, у вас есть это, вы textuserIDполучите ввод от пользователя. Вот как это может пойти не так:
SELECT * FROM Users WHERE userID = 890 OR 1=1;
Поскольку всегда верно, он будет извлекать все данные из таблицы Users.
Вы можете защитить свою базу данных от SQL-инъекций, используя параметризованные операторы, проверки ввода, очистку ввода и т. Д. Как вы защищаете свою базу данных, зависит от СУБД. Вам нужно будет разобраться в своей СУБД и ее проблемах безопасности, чтобы вы могли писать безопасный код.
Три, оптимизация индекса
Как выбрать правильный столбец для индексации
- Столбцы, которые появляются в предложении where, группировке по предложению, порядке по предложению и предложении on
- Чем меньше поле индекса, тем лучше
- Столбцы с большим разбросом ставятся перед объединенным индексом. О дисперсии можно судить по количеству (отдельное имя поля)
Обслуживание и оптимизация индексов — повторяющиеся и избыточные индексы
Повторяющийся индекс : Относится к одному и тому же столбцу в том же порядке для создания индекса одного типа, индексы в столбцах первичного ключа и идентификатора в следующей таблице являются повторяющимися индексами.
Резервный индекс: Относится к нескольким индексам с одним и тем же префиксом или к индексу, который содержит первичный ключ в объединенном индексе. В следующем примере ключ (имя, идентификатор) является избыточным индексом.




использоватьpt-duplication-key-checkerИнструменты могут проверять повторяющиеся и повторяющиеся индексы
Обслуживание и оптимизация индексов — удаление неиспользуемых индексов
Только через медленный журнал запросов в mysqlpt-index-usageИнструменты для анализа использования индекса
Использование RAID в виртуальной машине Azure
Хранилище — ключевой фактор, влияющий на производительность базы данных в облачных средах. По сравнению с одним диском, RAID может обеспечить более быстрый доступ за счет параллелизма. Дополнительные сведения см. в статье о стандартных уровнях RAID.
С помощью RAID можно существенно увеличить пропускную способность ввода-вывода диска и улучшить время ответа операций ввода-вывода в Azure. Наши лабораторные тесты показали, что при удвоении количества дисков RAID (с 2 до 4, с 4 до 8 и т. д.) удваивается пропускная способность ввода-вывода дисков, а время ответа операций ввода-вывода уменьшается в среднем в два раза. Дополнительные сведения см. в .
Помимо дисковых операций ввода-вывода производительность MySQL увеличивается при увеличении уровня RAID. Дополнительные сведения см. в .
Кроме того, вы можете обратить внимание на размер блоков. В целом чем больше размер блока, тем ниже нагрузка, особенно для объемных операций записи
Тем не менее, если размер блока слишком большой, это может привести к дополнительной нагрузке, и вы не сможете воспользоваться преимуществами RAID. Текущий размер блоков по умолчанию — 512 КБ. Он является оптимальным для большинства рабочих сред. Дополнительные сведения см. в .
Обратите внимание, что для виртуальных машин разных типов существуют ограничения на количество дисков, которые можно добавить. Эти ограничения описаны в статье Размеры виртуальных машин и облачных служб для Azure
Чтобы выполнить пример RAID в этой статье, вам понадобится 4 подключенных диска данных, хотя вы можете настроить RAID и с меньшим количеством дисков.
В этой статье предполагается, что вы уже создали виртуальную машину Linux, а также установили и настроили MySQL. Дополнительную информацию о начале работы см. в статье «Как установить MySQL в Azure».
Настройка RAID в Azure
Ниже объясняется, как создать RAID в Azure с помощью классического портала Azure. RAID также можно настроить с помощью сценариев Windows PowerShell. В этом примере мы настроим RAID 0 с 4 дисками.
Шаг 1. Добавление диска данных в виртуальную машину
На странице «Виртуальные машины» классического портала Azure щелкните виртуальную машину, в которую требуется добавить диск данных. В этом примере виртуальная машина — mysqlnode1.
На странице виртуальной машины щелкните Панель мониторинга.
На панели задач щелкните Подключить.
Затем щелкните Присоединить пустой диск.
Для дисков данных для параметра Настройки кэша узла необходимо задать значение Нет.
Это позволит добавить один пустой диск в виртуальную машину. Повторите этот шаг еще три раза, чтобы настроить 4 диска данных для RAID.
Добавленные диски можно просмотреть в виртуальной машине, открыв журнал сообщений ядра. Например, чтобы просмотреть этот журнал в Ubuntu, используйте следующую команду:
Copy
Шаг 2. Создание RAID с дополнительными дисками
Чтобы просмотреть подробные шаги по настройке RAID, перейдите к этой статье:
Примечание
Если вы используете файловую систему XFS, после создания RAID выполните следующие действия.
Чтобы установить файловую систему XFS в ОС Debian, Ubuntu или Linux Mint, используйте следующую команду:
Copy
Чтобы установить файловую систему XFS в ОС Fedora, CentOS или RHEL, используйте следующую команду:
Copy
Copy
Copy
Copy
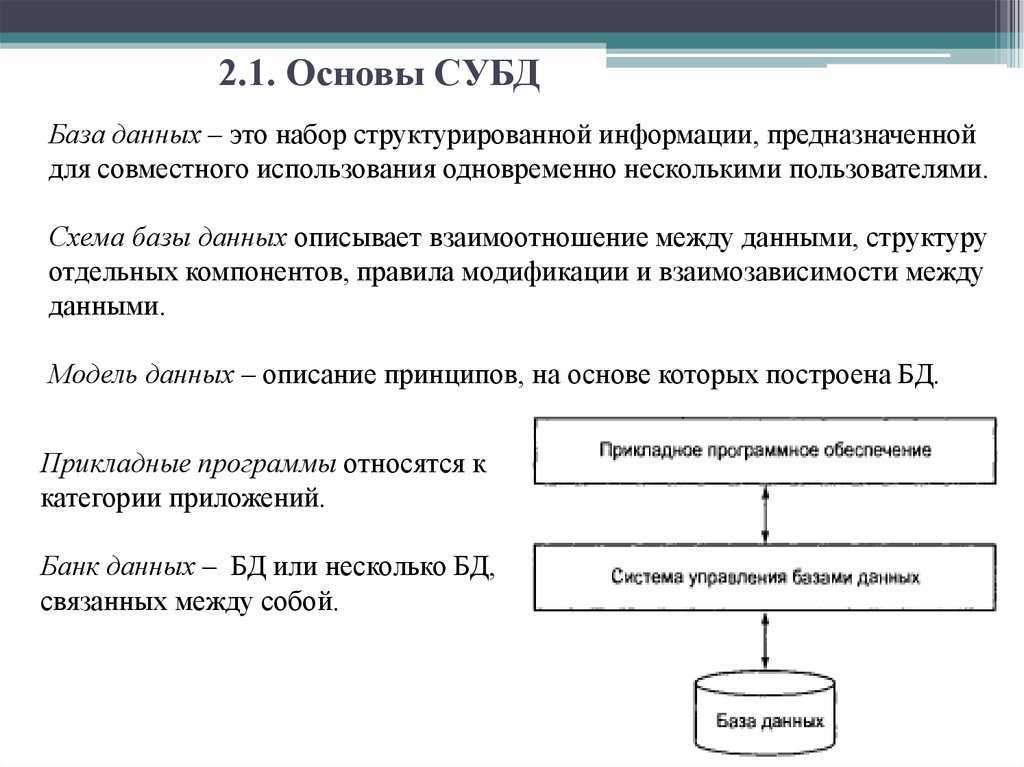
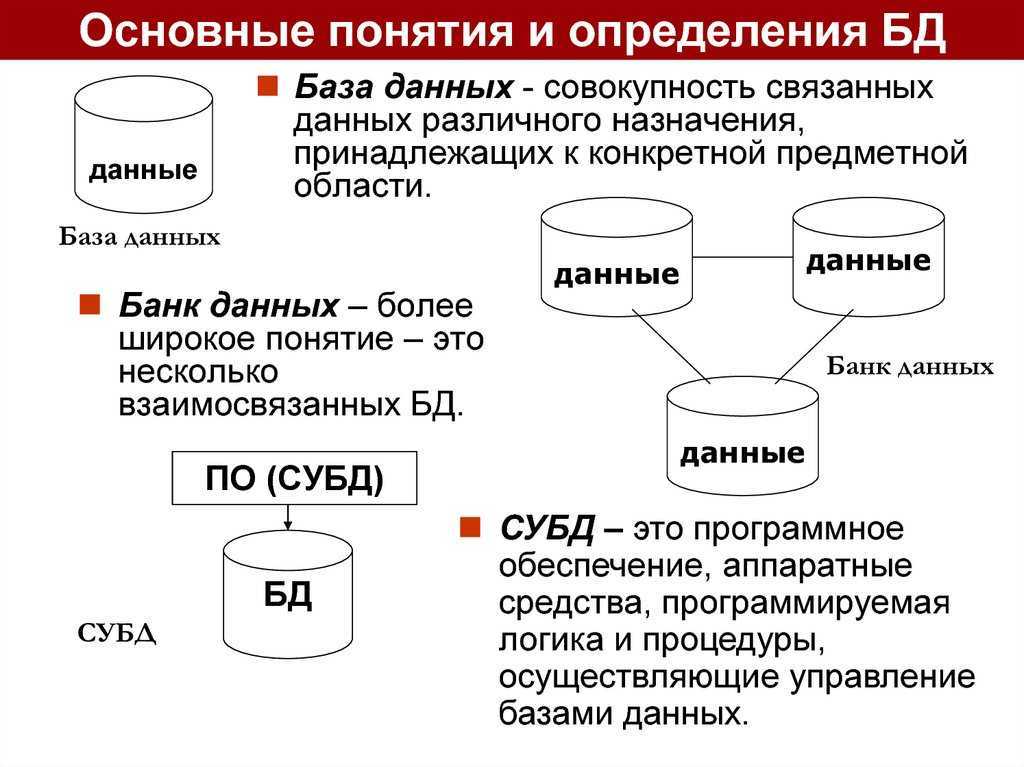
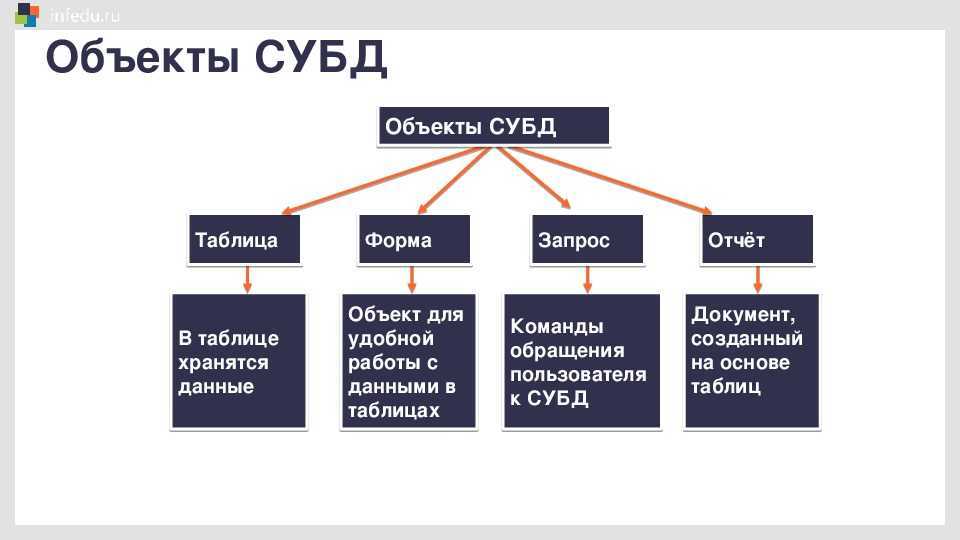
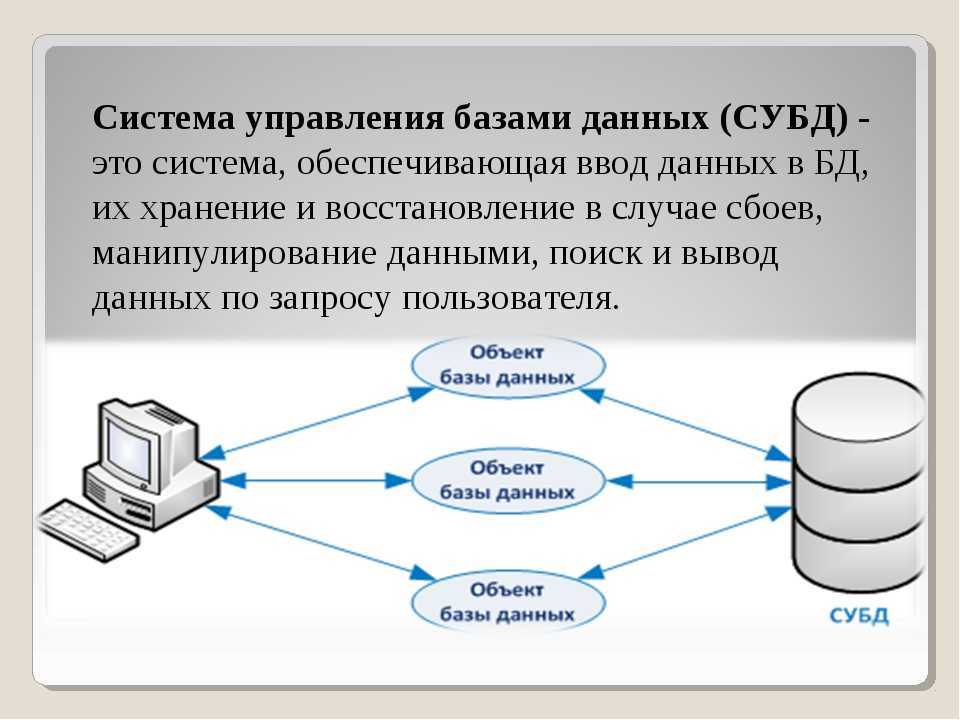
Что такое база данных?
В нашем случае данные — это файлы, а база — место, где они хранятся. Данные могут принимать любой облик.
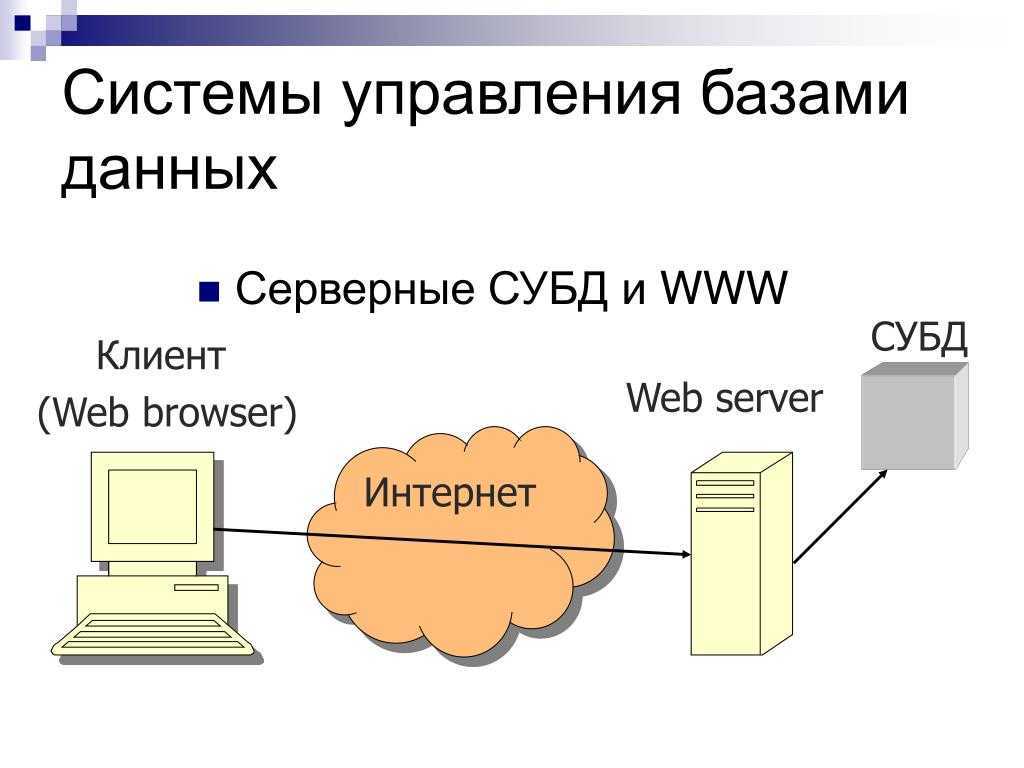




Представьте, что вы сделали плейлист в Spotify и добавили туда новый трек. Плейлист будет базой, а добавленная песня — данными. Каждая композиция, появившаяся в уже готовом плейлисте, станет частью существующей базы данных. Так она будет пополняться.
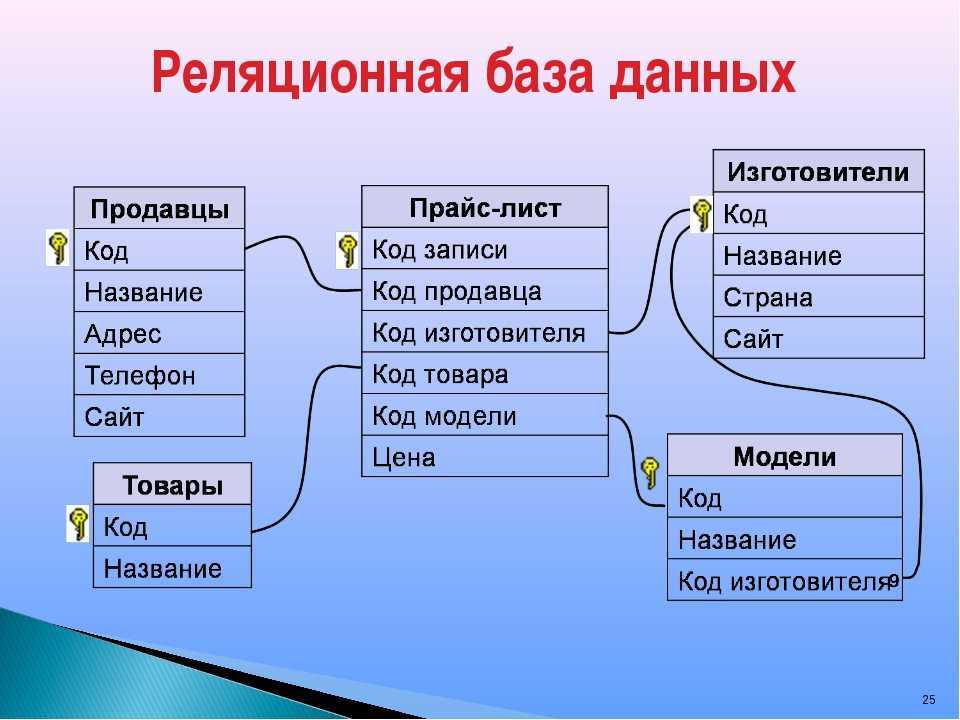
Получается, что базы могут быть многоуровневыми и делиться на различные категории (разделы каталога в случае с магазином). Так формируются взаимосвязи между разными элементами базы данных, появляется структура. Отсюда и термин «реляционная» – он намекает на зависимость элементов друг от друга.
Так что база данных — это набор структурированных данных с выстроенными между ними «взаимоотношениями» (делением на категории, к примеру).
Визуально она представляет собой таблицу с тысячами элементов (ссылками, файлами, отрывками текста и т.п.). Чтобы этим добром управлять, необходимо как-то обозначить таблицы и научиться ими управлять. Тут и пригодится SQL.
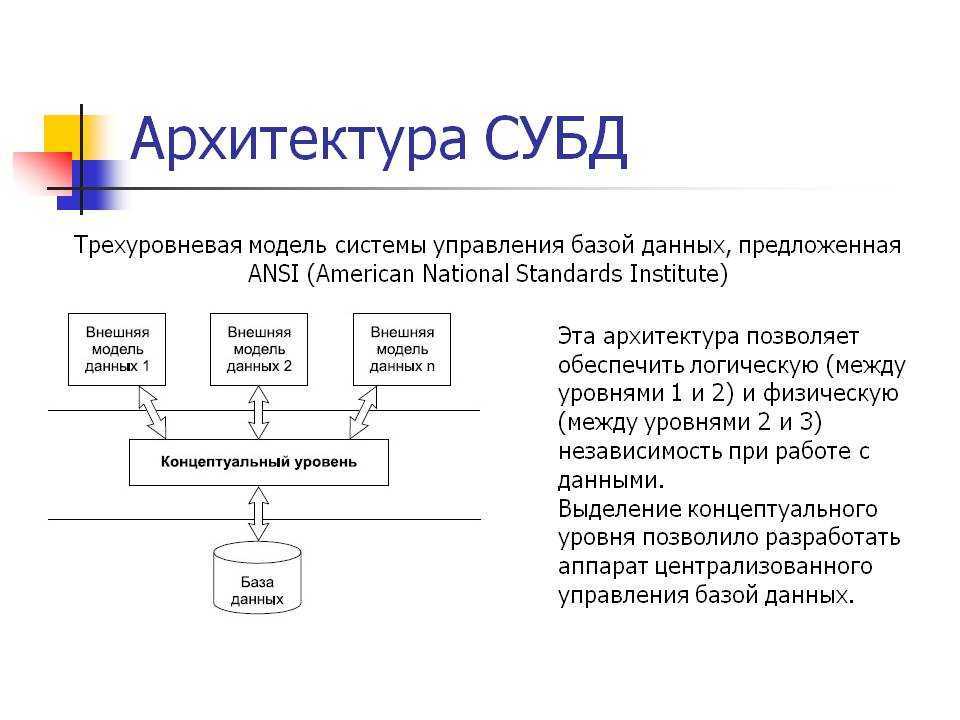
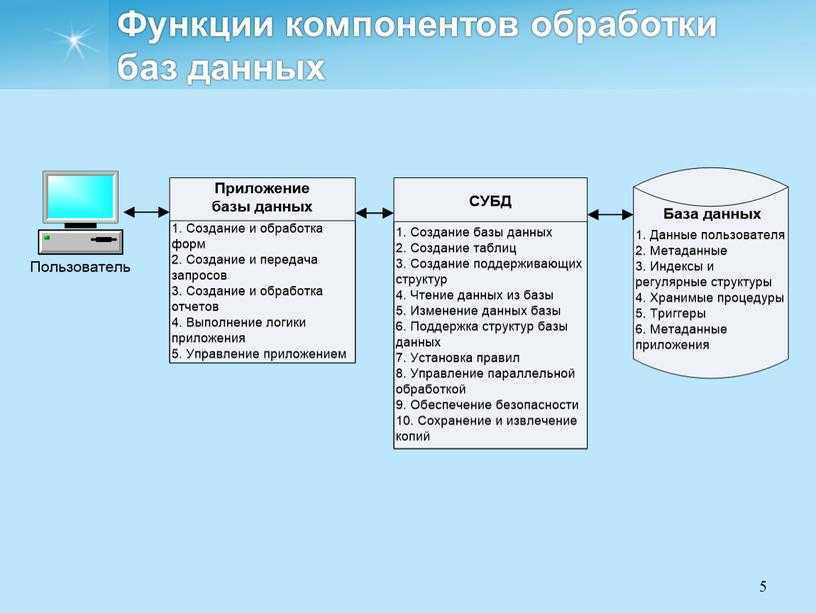
Реляционная модель базы данных
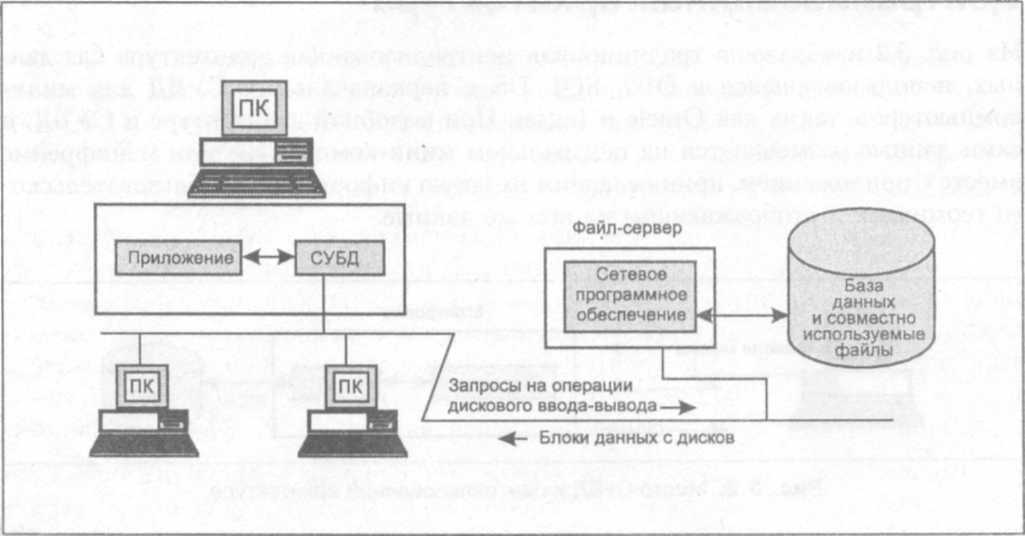
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
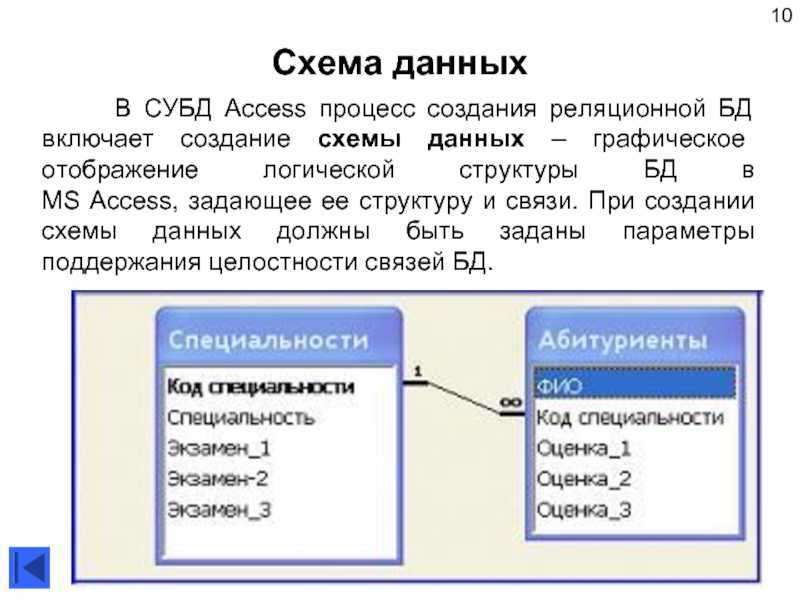
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
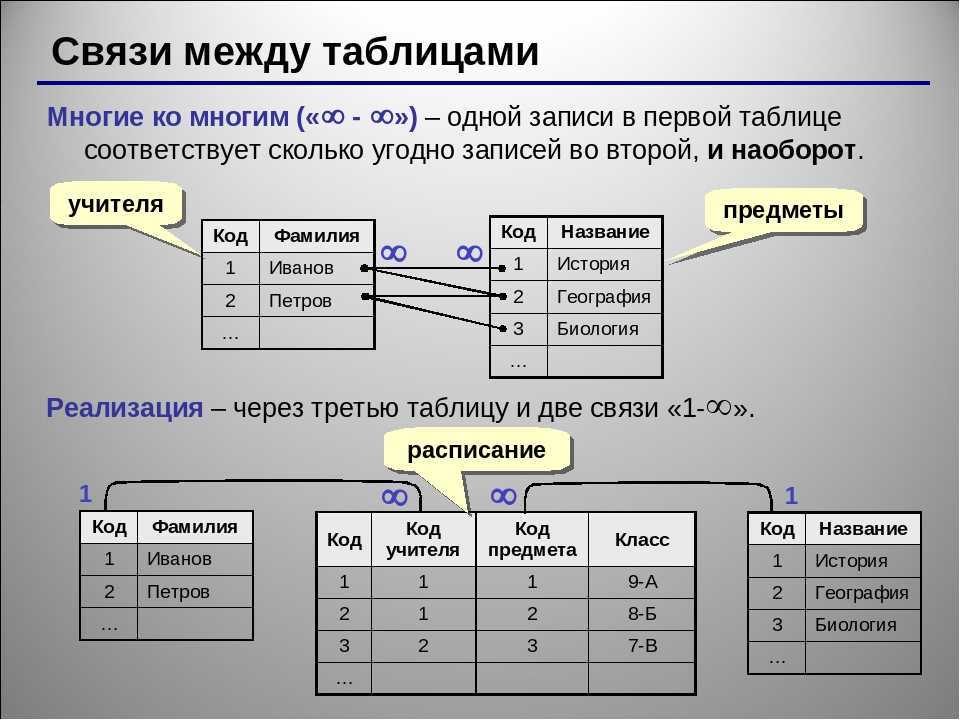
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Скорость работы MySQL
Оптимизация без аналитики бессмысленна. Перед тем как переходить к оптимизации давайте посмотрим как работает база данных сейчас, есть ли запросы, которые выполняются очень медленно. Все настройки вашего сервиса mysql находятся в файле /etc/my.cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию :
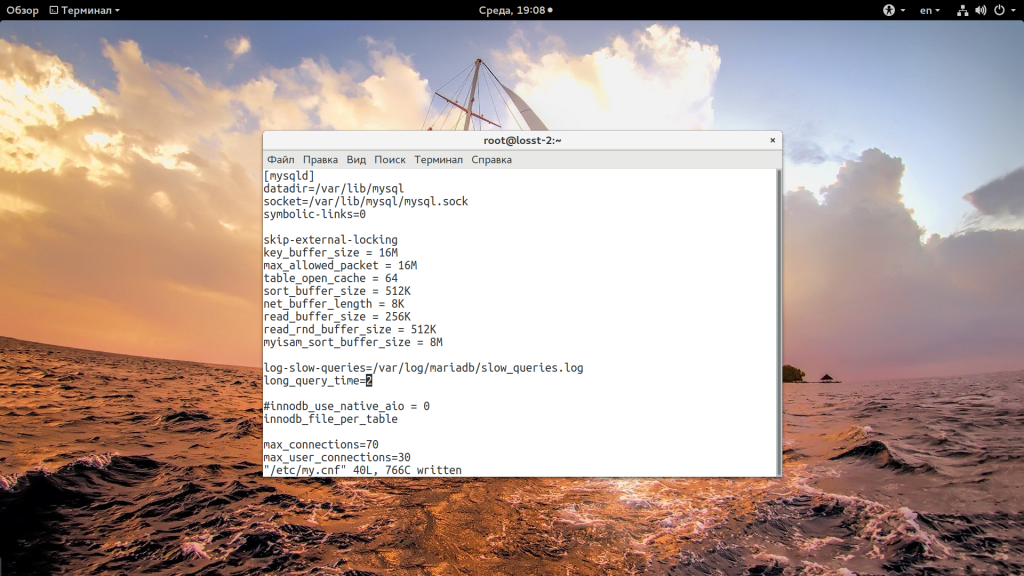
Здесь первая строка включает запись лога медленных запросов, вторая указывает, что минимальное время запроса для внесения его в этот лог — две секунды. Еще можно включить в лог запросы, которые не используют индексы:
Но это уже необязательно для проверки скорости и используется больше для отладки кода и правильности создания таблиц. Дальше перезапустите сервер баз данных и посмотрите лог:
systemctl restart mariadb
tail -f /var/log/mariadb/slow-queries.log
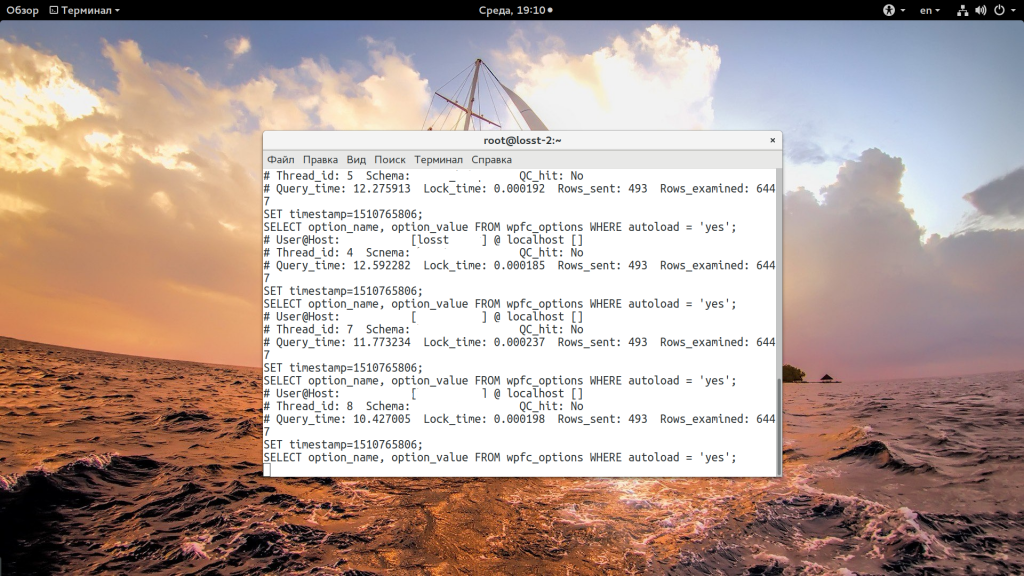
Мы можем видеть, что есть запросы, которые выполняются больше, чем 10 секунд. Это, например, запрос
SELECT option_name, option_value FROM wp_options WHERE autoload = ‘yes’;
Можно его выполнить отдельно, в консоли mysql:
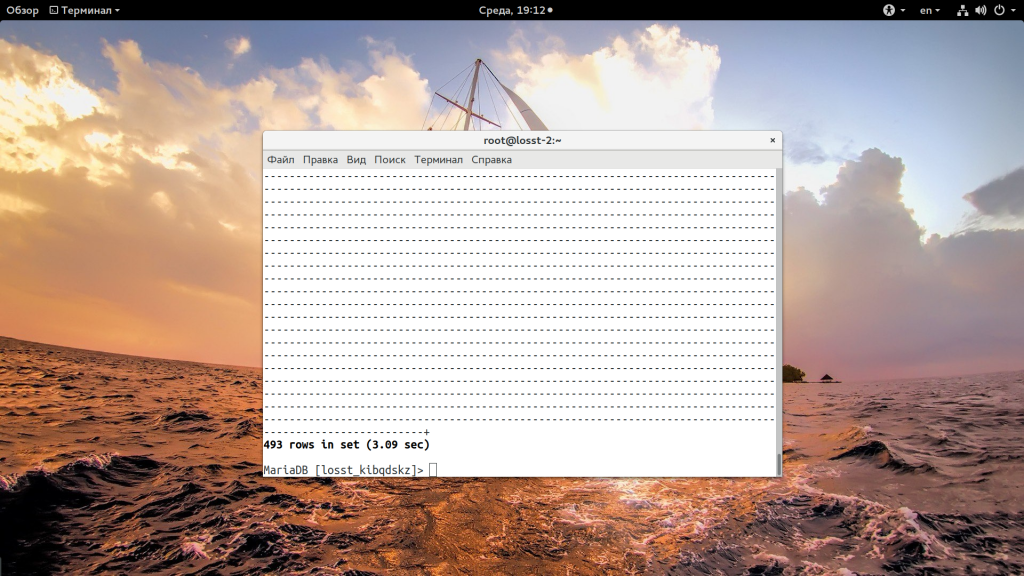
Здесь тоже измеряется время, и мы видим результат — три секунды. Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями — оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Совет по настройке производительности MySQL № 8: неистово накапливайте статистику, но не увлекайтесь чрезмерными оповещениями
Мониторинг и оповещение необходимы, но что происходит с типичной системой мониторинга? Он начинает отправлять ложные срабатывания, а системные администраторы настраивают правила фильтрации электронной почты, чтобы остановить весь этот спам. Вскоре ваша система мониторинга станет совершенно бесполезной.
Мы предлагаем воспринимать мониторинг в двух разрезах. Во-первых, как можно подробнее фиксировать показатели и оповещения
Очень важно фиксировать и сохранять все показатели, которые позволяет сделать сервер. Когда-нибудь возникнет странная проблема, и вам несомненно потребуется возможность проанализировать статистику и график изменения рабочей нагрузки сервера
Во-вторых, есть тенденция настраивать систему мониторинга на слишком много сигналов оповещения. Мы настоятельно предлагаем этого не делать. Системы мониторинга часто предупреждают о таких вещах, как коэффициент попадания в буфер или количество временных таблиц, созданных за секунду. Проблема в том, что для такого отношения нет хорошего порога чувствительности. Правильный порог отличается не только от сервера к серверу, но и от часа к часу с изменением рабочей нагрузки.
В результате, необходимо осторожно реагировать на статистику мониторинга и только на условиях, которые указывают на определенную, действующую проблему. Низкий коэффициент попадания в буфер не подлежит действию и не указывает на реальную проблему, но сервер, который не отвечает на попытку подключения, является реальной проблемой, которая должна быть решена
Сравните индекс префикс и общий индекс
alter table user add index index1(email); alter table user add index index2(email(7));
-
Предположим, чтоНесколько таких данных таблицы (идентификатор, имя, адрес электронной почты):、、、。
-
Index2 и index1 соответствующего дерева индекса ниже два фиг:
Если выполнить следующий запрос, Mysql, как использовать индекс для запроса это?
select * from user where email="";
выполнение регулярного индекса
-
Для первичного ключа первичный ключ найденСтрока, значение, которое определяется по электронной почте, сравнивает добавленный результирующий набор строк;
Этот процесс, нужно только принять его обратно к основным данным первичных индексов, так что рассматриваемая системаСканирование только одну строку。
Процесс реализации Индекс префикса
-
Найдено встретиться значение индекса из дерева индекс index2Запись, первый найденный идентификатор = 1;
-
Index2 взять на следующую запись только что нашел место и нашел ещеУдалить ID = 2, то округление индекс строки ID затем определяется, это значение, добавление этих строк результирующего набора;
-
Повторите предыдущий шаг, пока значение не будет не принимать idxe2Когда цикл заканчивается.
В этом процессе, возвращаясь к ключевому данным первичному индексу выборка в четыре раза,4 сканируется линия.
-
Сравнивая выше запрос, легко найти,После использования индекса префикса, может привести к запрашивать количество считанных данных становится большим.
-
Но для этого запроса, длина индекса префикса 13, если он установлен? Так встречаютсяЗапись только один, так что вы можете найти непосредственно на, На этот раз не только уменьшает пространство, количество линий сканирования также уменьшается.
-
Потом пришли к выводу:Используйте индекс префикса, если определение длины хорошо, это может быть сделано не только сэкономить пространство, это не добавляет много дополнительных затрат запросов.
-
Так как установить правильный индекс префикса для достижения максимальной производительности? Читать дальше …………….
-


Недостатки RDBMS
Стоимость
Одним из недостатков RDBMS является дорогостоящая настройка и поддержка системы баз данных. Чтобы создать реляционную базу данных, необходимо приобрести специальное программное обеспечение. Требуется время для ввода всей информации и настройки программы. Если компания большая, необходимо нанять программиста для создания реляционной базы данных с использованием Structured Query Language (SQL) и администратора базы данных для поддержки базы данных после ее создания. Независимо от того, какие данные используются, придется либо импортировать их из других данных, таких как текстовые файлы или электронные таблицы Excel, либо ввести данные на клавиатуре. Независимо от размера вашей компании придется защищать свои данные от несанкционированного доступа, чтобы соответствовать нормативным стандартам.
Изобилие информации
Успехи в сложности информации вызывают еще один недостаток RDBMS. Реляционные базы данных предназначены для организации данных по общим характеристикам. Сложные изображения, цифры, рисунки и мультимедийные продукты не поддаются простой классификации, что ведет к созданию нового типа базы данных, называемого объектно-реляционными системами управления базами данных ORDBMS. Эти системы предназначены для работы с более сложными приложениями и могут быть масштабируемыми.
Ограниченные пределы
Некоторые реляционные базы данных имеют ограничения на длину поля. При создании базы данных, необходимо указать количество данных, которое можно поместить в поле. Некоторые имена или поисковые запросы короче фактических, и это может привести к потере данных.
Изолированные базы данных
Сложные системы реляционных баз данных могут привести к тому, что эти базы данных станут «островами информации», где информация не может быть легко передана из одной большой системы в другую. Часто, в крупных фирмах или учреждениях, реляционные базы данных растут в разных подразделениях по-разному. Приведение этих баз данных к единой структуре может быть сложной и дорогостоящей процедурой.
SQLite
Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Совет по настройке производительности MySQL № 2: Понимание четырех основных ресурсов для оптимизации
Для работы серверу баз данных необходимы четыре основных ресурса: процессор, память, диск и сеть. Если какой-либо из них слабый, неустойчивый или перегруженный, то сервер базы данных, скорее всего, будет работать плохо.
Понимание основных ресурсов важно в двух конкретных областях: выбор оборудования и устранение неполадок. Выбирая аппаратные средства для MySQL сервера, обеспечьте наличие хороших компонентов
Так же важно, сбалансировать их достаточно хорошо друг с другом. Часто организации выбирают серверы с быстрыми процессорами и дисками, но с маленьким объемом памяти. В некоторых случаях добавление памяти является дешевым способом увеличения производительности на порядки, особенно при нагрузках, связанных с диском. Это может показаться противоречивым, но во многих случаях диски перенапряжены, потому что недостаточно памяти для хранения рабочего набора данных сервера, в следствие чего происходить кеширование данных на диски
Выбирая аппаратные средства для MySQL сервера, обеспечьте наличие хороших компонентов
Так же важно, сбалансировать их достаточно хорошо друг с другом. Часто организации выбирают серверы с быстрыми процессорами и дисками, но с маленьким объемом памяти
В некоторых случаях добавление памяти является дешевым способом увеличения производительности на порядки, особенно при нагрузках, связанных с диском. Это может показаться противоречивым, но во многих случаях диски перенапряжены, потому что недостаточно памяти для хранения рабочего набора данных сервера, в следствие чего происходить кеширование данных на диски.
Еще один хороший пример этого баланса относится к процессорам. В большинстве случаев MySQL будет хорошо работать с быстрыми процессорами, потому что каждый запрос работает в одном потоке и не может быть распараллелен между процессорами
Много ядер и много потоков в процессоре — это очень хорошо, но еще лучше, когда каждое конкретное ядро было бы быстрым! Важно не ошибиться при выборе процессора. Купить многоядерный, но с медленными потоками или 1-2 ядерный, но с высокой тактовой частотой каждого ядра? Это определяется конкретными Ваши задачами, которые будут выполнятся на сервере
Совет по оптимизации №1 MySQL вам в помощь, как говорится (проанализируйте Ваши приложения и задачи перед покупкой).
Когда дело доходит до устранения неполадок, проверьте производительность и использование всех четырех ресурсов, тщательно следя за тем, чтобы определить, работают ли все эти компоненты плохо или просто просят делают слишком много работы (аппаратная часть перегружена и требует модернизации). Эти знания помогут быстро решить Ваши проблемы. Вы удивитесь, как часто «бутылочное горлышко» находится именно в несбалансированной конфигурации аппаратной части сервера!
Заключение
Выбор реляционной СУБД является важным для тех, кто только начинает разработку приложения
Люди, которые выбрали одну систему, редко позже переключаются на другую, а это означает, что важно сразу взвесить разные предложения и выбрать лучшее для вас
В этом руководстве мы обсудили две наиболее распространенные реляционные СУБД – MySQL и Microsoft SQL сервер. Мы рассмотрели несколько ключевых различий между MySQL и SQL сервером, даже одного из которых может быть достаточно, чтобы сделать выбор.
В конечном счёте, выбор за вами. Как правило, если вы разрабатываете приложения среднего и малого размера и преимущественно используете PHP, переходите к MySQL
Принимая во внимание, что если вы заинтересованы в создании крупномасштабных, безопасных, устойчивых корпоративных приложений, SQL сервер может вам подойти куда больше
Заключение
По состоянию на 2017 год многие из широко используемых баз данных основаны на модели реляционной базы данных.
Практически все разработчики современных приложений, предусматривающих связь с системами баз данных, ориентируются на реляционные СУБД. По данным аналитиков на 2010 год, реляционные СУБД используются в абсолютном большинстве крупных проектов по разработке информационных систем. По результатам исследований компании IDC 2009 года всего около 7% составляют проекты, в которых используются СУБД нереляционного типа.




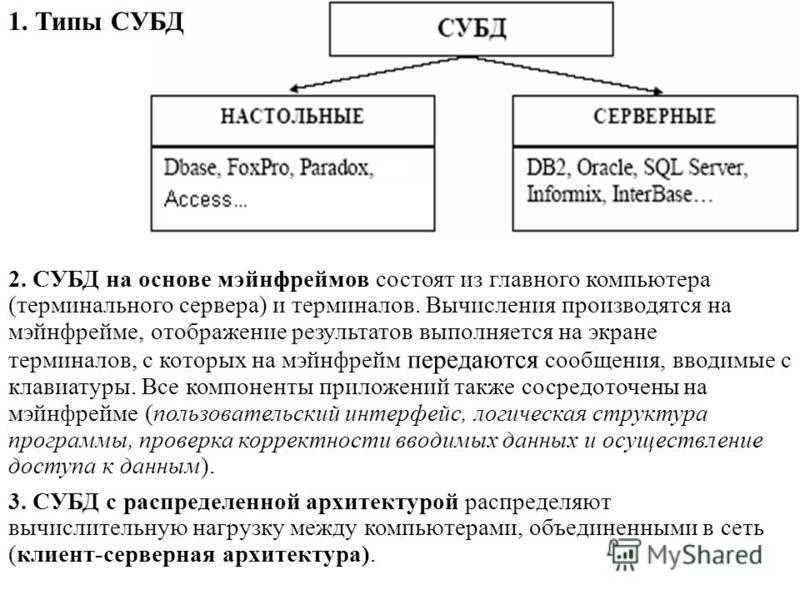
По оценке Gartner в 2013 году рынок реляционных СУБД составлял 26 млрд долларов с годовым приростом около 9 процентов, а к 2018 году рынок реляционных СУБД достигнет 40 млрд долларов. В настоящее время абсолютными лидерами рынка СУБД являются компании Oracle, IBM и Microsoft, с общей совокупной долей рынка около 90%, поставляя такие системы как Oracle Database, IBM DB2 и Microsoft SQL Server.
Единственной коммерчески успешной СУБД российского производства является реляционная СУБД Линтер.
Подводим итоги: сравниваем реляционную и нереляционную БД
 Чтобы понять, какой вид технологии предоставляет больше возможностей для бизнеса, выполним некоторое сравнение баз данных на основе реляционных и нереляционных систем:
Чтобы понять, какой вид технологии предоставляет больше возможностей для бизнеса, выполним некоторое сравнение баз данных на основе реляционных и нереляционных систем:
- Структура и тип данных. SQL требует жесткой структуризации на основании шаблонов. В NoSQL по отношению к структуре не предъявляется никаких требований.
- Масштабируемость. В SQL предусмотрено вертикальное масштабирование. В NoSQL можно использовать и вертикальное, и горизонтальное. Но второй вариант более простой и практичный.
- Запросы. В реляционных системах получить данные можно при помощи языка SQL. А вот в каждой NoSQL-базе предусмотрен свой алгоритм работы.
- Надежность. SQL более простые и удобные в последующей работе благодаря своей структуризации. NoSQL имеет высокую защиту от хакерских атак.
- Работа с данными сложных структур. Здесь первенство у реляционных БД, что также связано с наличием строгой структуры.
- Поддержка. БД SQL существуют намного дольше нереляционных аналогов, пользуются повышенной популярностью. То есть получить их поддержку достаточно просто. А вот NoSQL пока не в таком почете, особенно работают в сложных структурах.