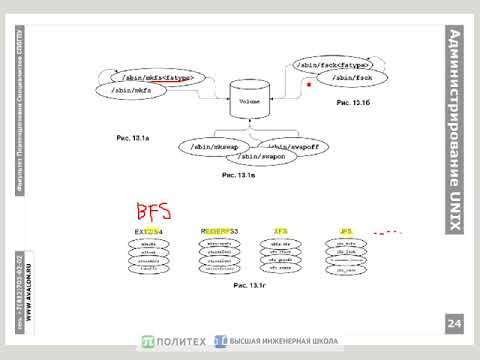
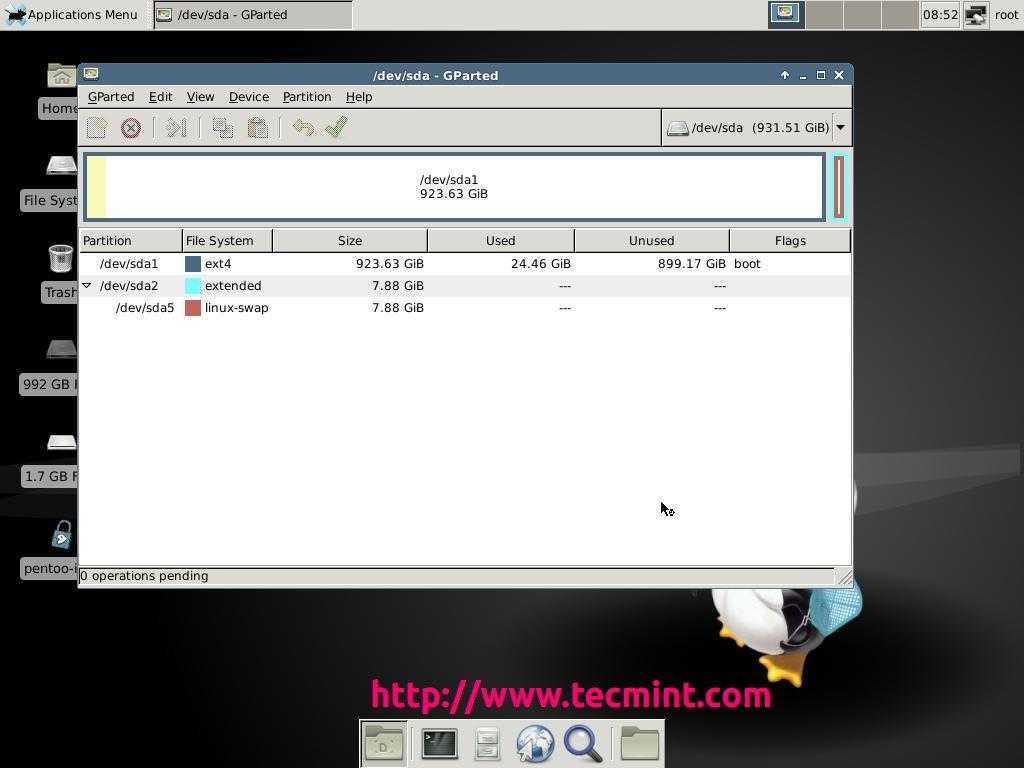
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки — спецсимвол «$»:
Найдём все строки, которые содержат цифры:
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
Рекурсивное использование grep
Если вам нужно провести поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах, например в файлах конфигурации Apache — /etc/apache2/, используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займётся поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Получим:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
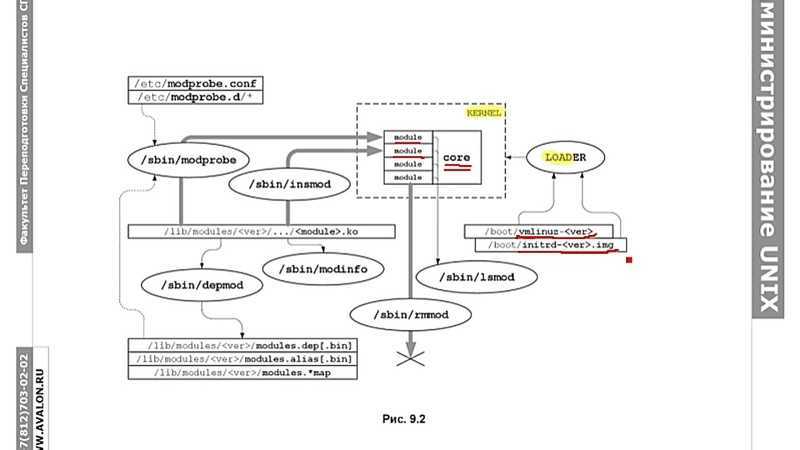
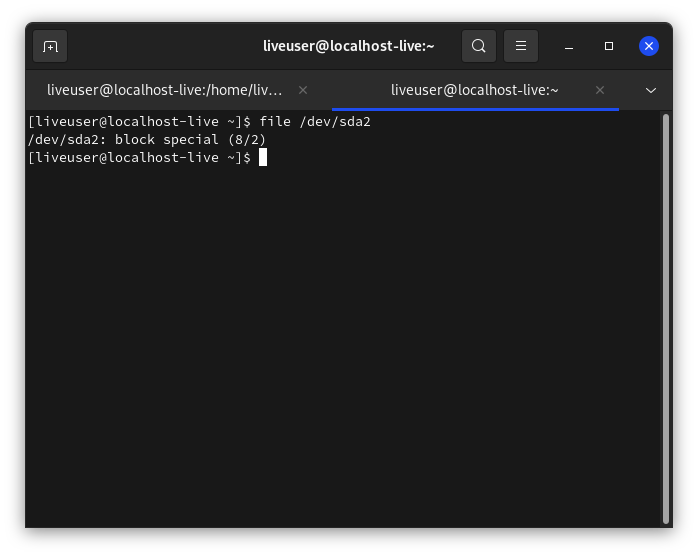
Создание устройств в Linux
В прошлом все устройства из каталога /dev создавались во время установки системы, а это означало, что каталог содержал все возможные поддерживаемые устройства, даже если они не использовались. Если вам нужно было создавать или переинициализировать файлы устройств, использовалась утилита mknod. Но для работы с ней вам нужно знать старший и младший номер устройства.
Сейчас ситуация изменилась и все файлы устройств linux создаются во время загрузки только для нужных устройств. Менеджер устройств следит за подключаемыми и отключаемыми устройствами и добавляет или удаляет соответствующие файлы. Вы можете убедиться, что устройства были созданы сейчас просмотрев дату создания в с помощью команды ls.
Команда mknod все еще есть, но уже существует более новая разработка — makedev. Она предоставляет очень простой интерфейс для создания устройств.
Типы файлов
Есть 3 типа файлов:
- Обыкновенные, которые используются для хранения информации
- Специальные (для туннелей и устройств)
- Директории (их ещё называют папками или каталогами)
С обычными файлами пользователь работает чаще всего. Это документы, текстовые файлы, музыка, видео и пр.
Для того, чтобы просмотреть эти файлы, выполнить:
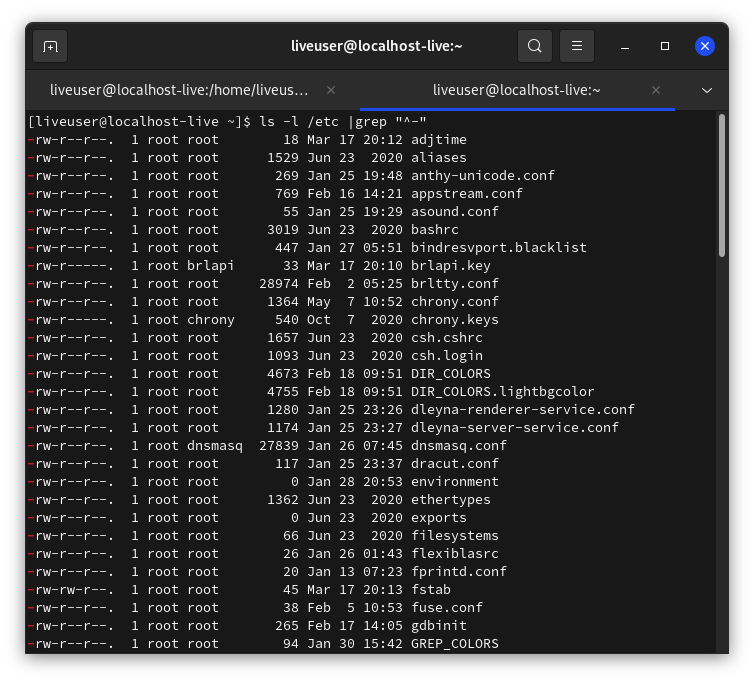
Объяснение команды
- просматривает каталог, а ключ добавляет отображение прав на файл. замените на нужную директорию
- — так как “обычные” файлы обозначаются чертой (в первой колонке вывода , где отображаются права на файл), то эта команда выведет только эти файлы по маске .
По поводу специальных файлов. Они обеспечивают обмен информации с ядром, работу с устр-вами и пр. Собственно, делятся ещё на несколько видов:
- Символьные файлы — любые специальные системные, например , или периферийные устр-ва (последовательные/параллельные порты). Такие файлы идентифицированы символом .
- Блочные — периферийные устр-ва, но в отличии от предыдущего типа, содержание блочных файлов буферизируется. Эти файлы идентифицированы символом .
-
Символические ссылки (симлинки) — указывают на другие файлы по их имени, указывают и на другие файлы, в т.ч. каталоги. Обозначены символом . В выводе команды можно увидеть, на какой файл ссылаются симлинки — в последней колонке название имеет следующий вид:
-> -
Туннели (каналы/именованные каналы) — очень похожи на туннели из , но разница в том, что именованные каналы имеют название. Они очень редки. Обозначены символом .
-


Основные характеристики ОС Linux
Несмотря на свою непопулярность среди рядовых пользователей, ОС Linux доказала свою жизнеспособность. О ней написано множество статей, обзоров и учебных пособий. В списке возможностей Limux есть как присущие другим реализация семейства UNIX, так и абсолютно уникальные.
- Многозадачность. У ядра Linux есть функция разделения времени центрального процессора. Суть функции заключается в том, что ядро по очереди выделяет отрезок времени для выполнения каждой задачи. Таким образом, все процессы происходят независимо и не мешают друг другу.
- Многопользовательский доступ. OC Linux поддерживает одновременную работу нескольких пользователей, обеспечивая им все системные ресурсы с помощью различных удаленных терминалов. Точно так же, как и в других ОС, пользователей можно делить на группы и ограничивать их возможности чтения, записи и запуска на исполнение.
- Страничная организация памяти. Организация системной памяти Linux выполнена в виде страниц объемом 4K. В случае, если оперативная память закончится, система начнет поиск неиспользуемых страниц для того, чтобы переместить их на жесткий диск, откуда впоследствии их можно будет восстановить.
- Загрузка выполняемых модулей «по требованию». Ядро Linux работает так, что в оперативной памяти находится только нужная часть кода программа, которая используется, а остальные части остаются на диске.
- Динамическое кэширование диска. Память, приготовленная для кэша, уменьшается, если компьютеру или пользователю необходимо больше места.
- Запуск программ для других ОС. Для того, чтобы запуск программ, разработанных для других ОС, был возможен на ПК с Linux, там установлены эмуляторы DOS, Windows 3.1 и Windows 95.
- Сетевые возможности. Интеграция Linux возможна в любую локальную сеть. Поддерживаются все службы Unix, в том числе Networked File System (NFS), удаленный доступ (telnet, rlogin), работа в TCP/IP сетях, NFS, и dial-up-доступ по протоколам SLIP и PPP.
- Соответствие стандарту POSIX 1003.1. Частичная поддержка возможностей System V и BSD.
- Поддержка ряда популярных файловых систем (MINIX, Xenix, System V). Также у Linux есть своя файловая система объемом до 4 Терабайт и с именами файлов до 255 знаков.
- Прозрачный доступ к разделам DOS (или OS/2 FAT): раздел DOS выглядит как часть файловой системы Linux; поддержка VFAT.
- Специальная файловая система UMSDOS, которая позволяет устанавливать Linux в файловую систему DOS.
Как получить информацию об инодах в Linux?
Вы можете легко вывести список номеров инодов с помощью следующей команды:
На следующем скриншоте показан мой корневой каталог с соответствующими номерами инодов:
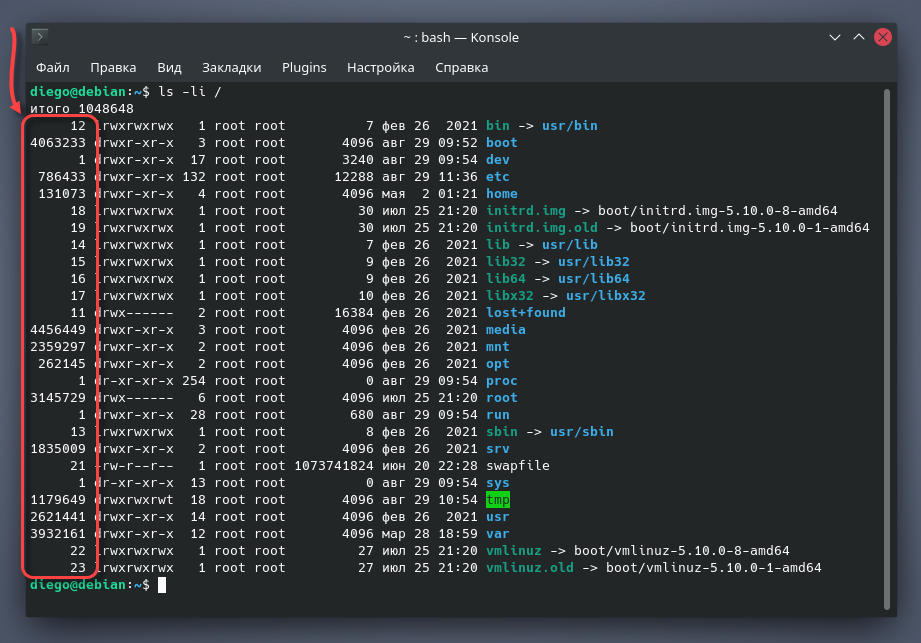
Количество инодов в каждой файловой системе задается на этапе её создания, и, как правило, для большинства пользователей их количества более чем достаточно.
По умолчанию параметры файловой системы таковы, что создается 1 инод на 2 КБ пространства диска. Такого количества инодов достаточно для большинства систем. Скорее место на вашем жестком диске исчерпается раньше, чем закончатся все иноды. При необходимости, во время определения первоначальных параметров файловой системы, вы можете указать, сколько инодов требуется создать.
Если у вас всё-таки закончатся иноды, то ни вы, ни ваша система больше не сможете создавать новые файлы. Это довольно редкая ситуация, но все же она может возникнуть. Например, в старые времена некоторые почтовые серверы, которые хранили сообщения электронной почты в виде отдельных файлов (что быстро приводило к созданию больших коллекций маленьких файлов размером менее 2 килобайт), довольно часто сталкивались с данной проблемой. Однако, когда они перешли на использование баз данных, проблема решилась.
В некоторых файловых системах, таких как , , , реализованы динамические иноды. При необходимости такие файловые системы могут увеличить количество доступных инодов.
Работа с устройствами в Linux
Давайте проведем несколько экспериментов, которые помогут вам понять как работают устройства Linux и как ими управлять в этой операционной системе. Большинство дистрибутивов Linux имеют несколько виртуальных консолей, обычно от 1 до 7, которые могут использоваться для входа в сеанс командной оболочки. К этим виртуальным консолям можно получить доступ с помощью сочетаний клавиш Ctrl+Alt+Fn, например, Ctrl+Alt+F1 для первой консоли, Ctrl+Alt+F2 для второй и так далее.
Сейчас нажмите Ctrl+Alt+F2 для перехода во вторую консоль, в некоторых дистрибутивах, кроме запроса логина и пароля, будет выведена информация про активную TTY связанную с этой консолью. Но этой информации может и не быть. В данном случае консоль будет связана с устройством tty2.
Войдите от имени обычного пользователя, затем наберите такую команду, чтобы посмотреть номер устройства tty:
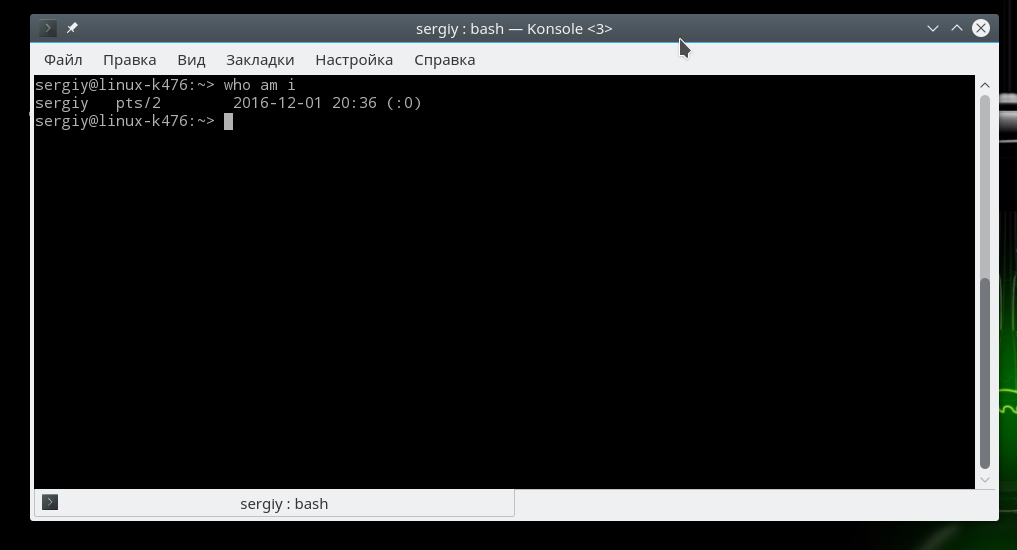
У меня вы видите устройство /dev/pts/0, это виртуальное устройство эмулятора терминала, но если вы будете выполнять задачу в tty2, то отобразиться именно она. Теперь давайте посмотрим список tty устройств с помощью команды ls:
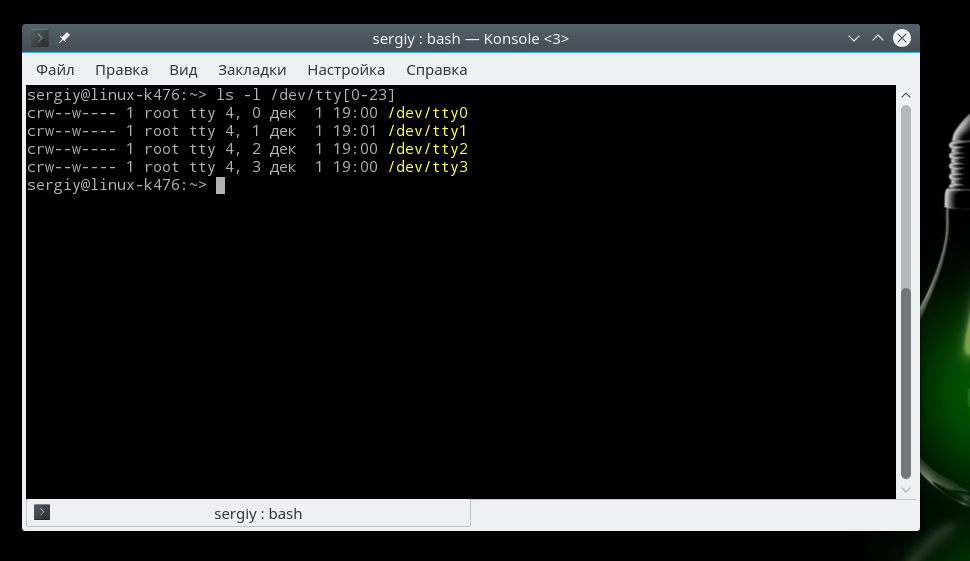
Нас будут интересовать не все устройства, а только первые три. В этих устройствах нет ничего особенного, это обычные устройства символьного типа. Устройство tty2 подключено к консоли 2, устройство tty3 подключено к консоли 3.
Нажмите сочетание клавиш Ctrl+Alt+F3, чтобы переключиться в третью консоль, затем выполните команду:
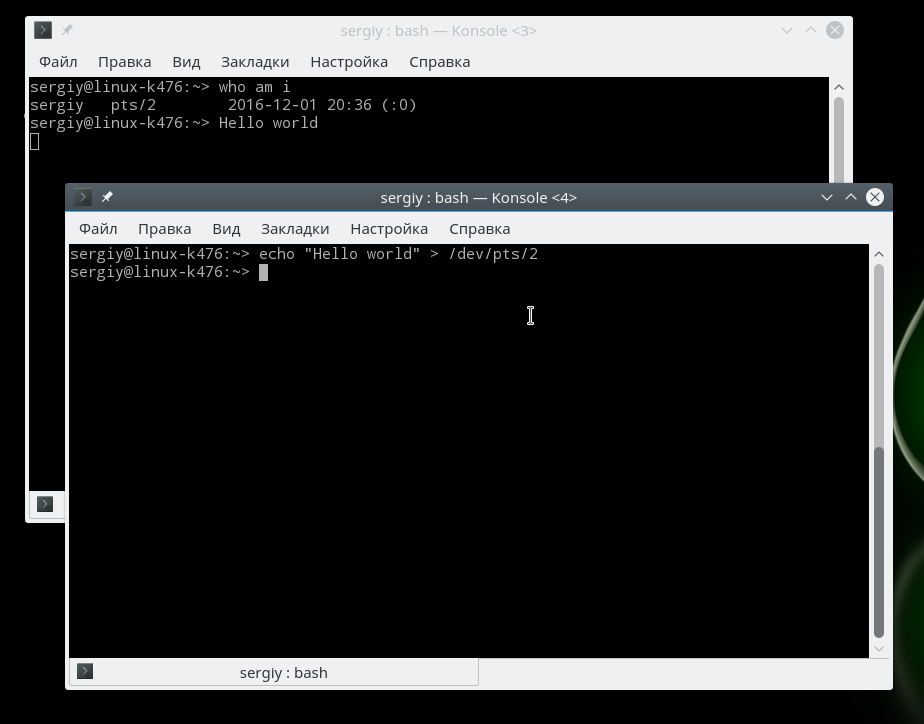
Затем вернитесь во вторую консоль. Здесь вы увидите отправленную строку, Hello World. Все это можно повторить с помощью эмуляторов терминала в графическом интерфейсе, только здесь будут использоваться псевдо-терминальные устройства /dev/pts/*. Теперь попробуем отобразить содержимое файла fstab с помощью cat в другом терминале:
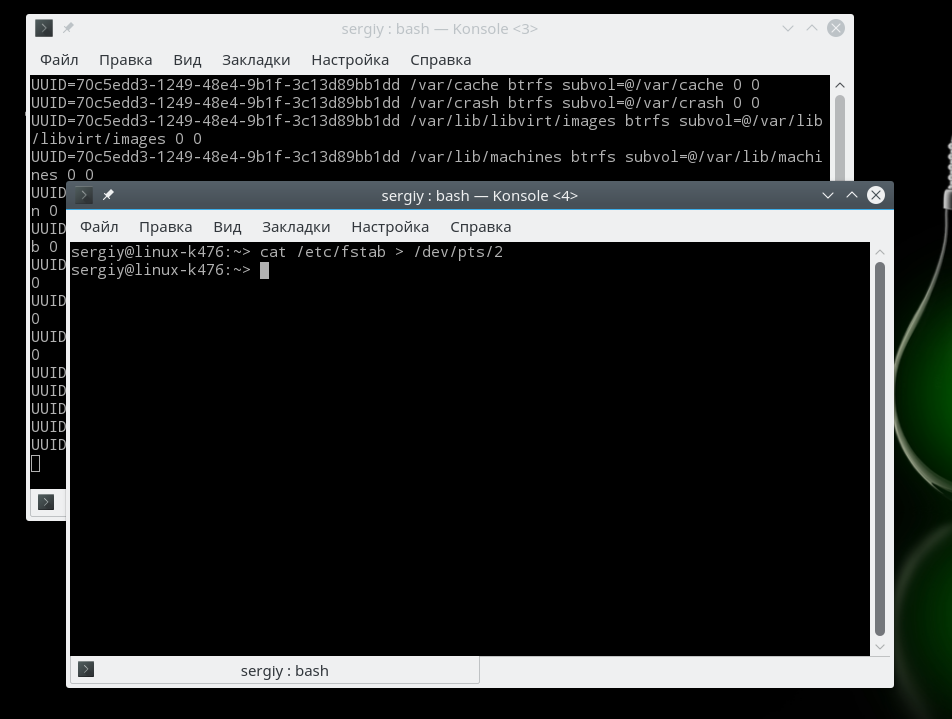
С помощью cat вы можете отправить файл непосредственно на принтер. Например, если устройство принтера /dev/usb/lp0, то для печати файла будет достаточно выполнить:
Каталог /dev/ содержит много интересных файлов устройств. Это интерфейсы доступа к аппаратному обеспечению и вам не нужно думать, что это, жесткий диск или экран. Например, вся оперативная память компьютера доступна в виде устройства /dev/mem. С помощью него вы можете иметь прямой доступ к памяти. Мы можем вывести содержимое памяти в терминал:
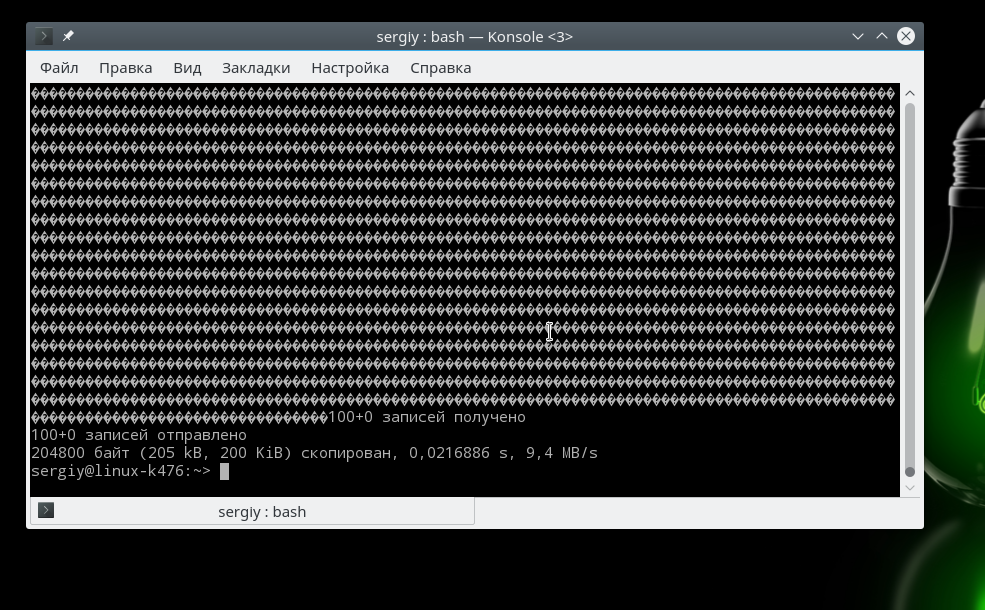
Утилита dd, в отличие от cat дает больше контроля над процессом и позволяет указать сколько данных нужно прочитать. Но не ко всей памяти вы можете получить доступ. В ядре встроена защита, поэтому обычно, вы можете читать память, только для своего процесса.
Также тут есть файлы, которые несвязанны ни с какими реальными устройствами, это null, zero, random и urandom. Устройство /dev/null может использоваться для перенаправления вывода команд, чтобы данные никуда не выводились. Устройство /dev/zero используется для получения строки, заполненной нулями.
Вы можете использовать ту же команду dd, чтобы попытаться вывести ряд символов с устройства /dev/null:
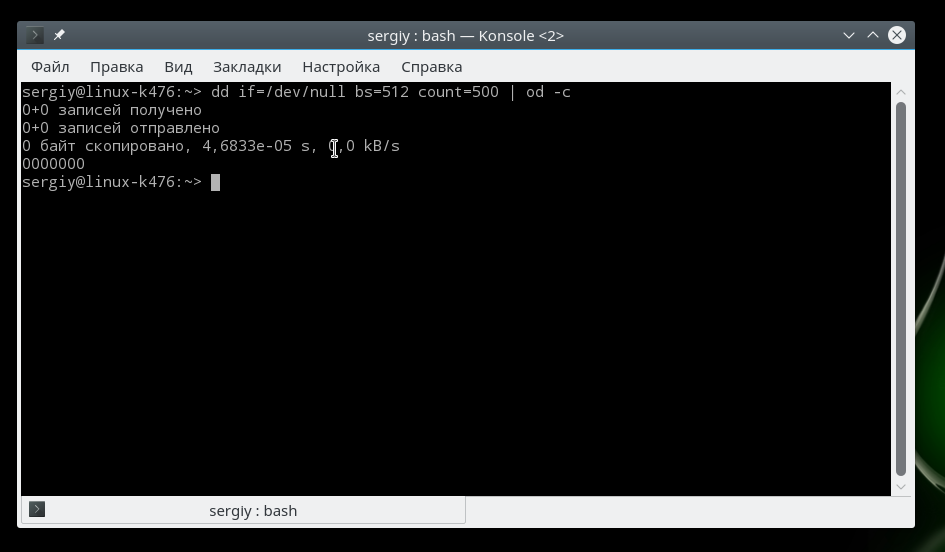
Обратите внимание, что ничего выведено не будет, потому что это устройство пусто, оно только принимает данные и никуда их не сохраняет. Устройства /dev/random и /dev/urandom позволяют получить случайные комбинации чисел или байт
Вы можете использовать такую команду, чтобы получить случайные байты информации:
Устройства /dev/random и /dev/urandom позволяют получить случайные комбинации чисел или байт. Вы можете использовать такую команду, чтобы получить случайные байты информации:
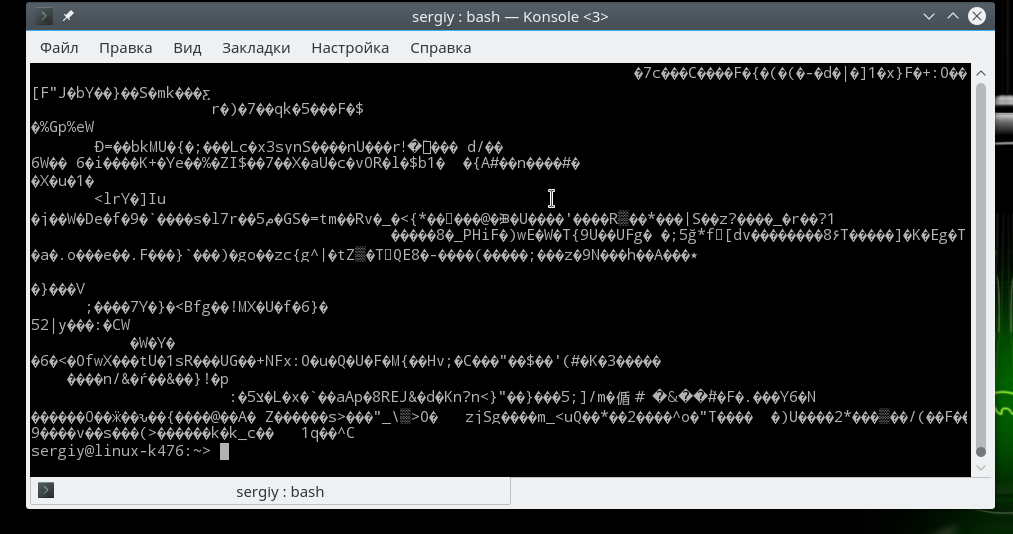
Для остановки нажмите Ctrl+C. Устройство urandom позволяет генерировать случайные последовательности независимые от предыдущего числа, в качестве источника энтропии используется нажатия клавиш и движения мыши.
Устройство /dev/zero позволяет получить строку, заполненную нулями. Для проверки используйте такую команду:
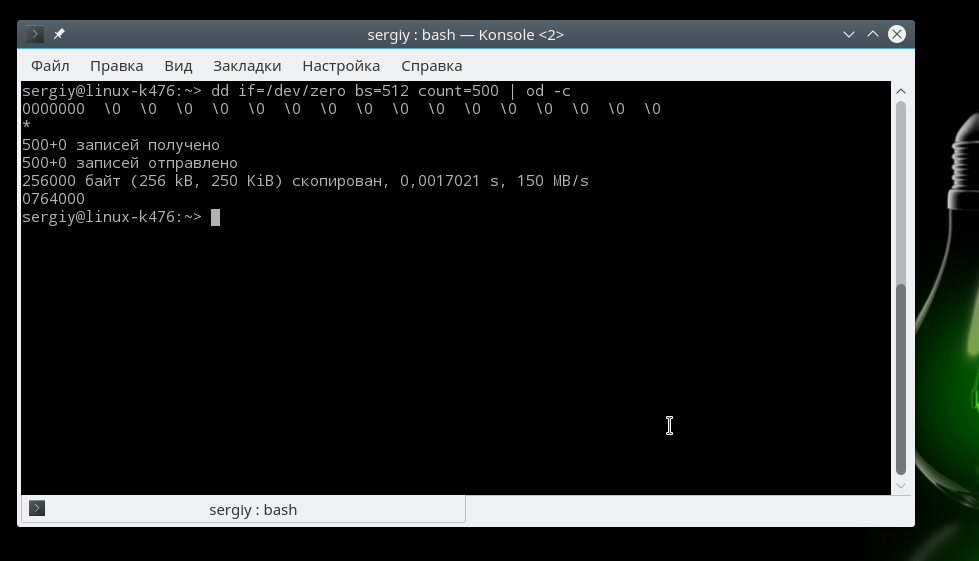
Обратите внимание, что восьмеричные нули и нули ASCII это не одно и то же
Лучшие условно-бесплатные IDE
Microsoft Visual Studio
Платформы: Windows/macOS (для Linux есть только редактор кода)
Поддерживаемые языки: Ajax, ASP.NET, DHTML, ASP.NET, JavaScript, Visual Basic, Visual C#, Visual C++, Visual F#, XAML и другие.

Стоимость: от 45$ в месяц. Есть бесплатная версия (Community) для частного использования, студентов и создателей опенсорсовых проектов.
Microsoft Visual Studio – это премиум IDE, стоимость которой зависит от редакции и типа подписки. Она позволяет создавать самые разные проекты, начиная с мобильных и веб-приложений и заканчивая видеоиграми. Microsoft Visual Studio включает в себя множество инструментов для тестирования совместимости – вы сможете проверить свое приложение на более чем 300 устройствах и браузерах. Благодаря своей гибкости, эта IDE отлично подойдет как для студентов, так и для профессионалов.
Особенности:
- Огромная коллекция всевозможных расширений, которая постоянно пополняется.
- Технология автодополнения IntelliSense.
- Возможность кастомизировать рабочую панель.
- Поддержка разделенного экрана (split screen).
Из недостатков можно выделить тяжеловесность этой IDE. Для выполнения даже небольших правок могут потребоваться значительные ресурсы, поэтому если нужно выполнить какую-то простую и быструю задачу, удобнее использовать более легкий редактор.
PyCharm
Платформы: Windows/Linux/macOS
Поддерживаемые языки: Python, Jython, Cython, IronPython, PyPy, AngularJS, Coffee Script, HTML/CSS, Django/Jinja2 templates, Gql, LESS/SASS/SCSS/HAML, Mako, Puppet, RegExp, Rest, SQL, XML, YAML и т.д.
Стоимость: от 199$ в год. Есть бесплатная версия, но она работает только с Python.
Это интегрированная среда разработки на языке Python, которая была разработана международной компанией JetBrains (да, и снова эти ребята). Эта IDE распространяется под несколькими лицензиями, в том числе как Community Edition, где чуть урезан функционал. Сами разработчики характеризуют свой продукт как «самую интеллектуальную Python IDE с полным набором средств для эффективной разработки на языке Python».
Преимущества
- Поддержка Google App Engine; IronPython, Jython, Cython, PyPy wxPython, PyQt, PyGTK и др.
- Поддержка Flask-фреймворка и языков Mako и Jinja2.
- Редактор Javascript, Coffescript, HTML/CSS, SASS, LESS, HAML.
- Интеграция с системами контроля версий (VCS).
- UML диаграммы классов, диаграммы моделей Django и Google App Engine.
Недостатки
Иногда встречаются баги, которые, как правило, не вызывают сильных неудобств.
IntelliJ IDEA
Платформы: Windows/Linux/macOS
Поддерживаемые языки: Java, AngularJS, Scala, Groovy, AspectJ, CoffeeScript, HTML, Kotlin, JavaScript, LESS, Node JS, PHP, Python, Ruby, Sass,TypeScript, SQL и другие.
Стоимость: от 499$ в год. Бесплатная версия работает только с Java и Android.
Еще одна IDE, разработанная компанией Jet Brains. Здесь тоже есть возможность использовать бесплатную версию Community Edition, а у платной версии есть тестовый 30-дневный период. Изначально IntelliJ IDEA создавалась как среда разработки для Java, но сейчас разработчики определяют эту IDE как «самую умную и удобную среду разработки для Java, включающую поддержку всех последних технологий и фреймворков». Используя плагины, эту IDE можно использовать для работы с другими языками.
Преимущества
- Инструменты для анализа качества кода, удобная навигация, расширенные рефакторинги и форматирование для Java, Groovy, Scala, HTML, CSS, JavaScript, CoffeeScript, ActionScript, LESS, XML и многих других языков.
- Интеграция с серверами приложений, включая Tomcat, TomEE, GlassFish, JBoss, WebLogic, WebSphere, Geronimo, Resin, Jetty и Virgo.
- Инструменты для работы с базами данных и SQL файлами.
- Интеграция с коммерческими системами управления версиями Perforce, Team Foundation Server, ClearCase, Visual SourceSafe.
- Инструменты для запуска тестов и анализа покрытия кода, включая поддержку всех популярных фреймворков для тестирования.
Недостатки
Придется потратить время для того, чтобы разобраться в этой IDE, поэтому начинающим программистам она может показаться сложноватой.
Как все это связано с шаблонами проектирования
Каждая книга, имеющая в заголовке слово «шаблоны», так или иначе связана с классической книгой Паттерны проектирования: Приемы объектно-ориентированного проектирования, написанной Эрихом Гаммой, Ричардом Хелмом, Ральфом Джонсоном и Джоном Вличидесом (их еще часто называют «Банда четырех»).
Называя свою книгу Шаблоны игрового программирования, я вовсе не имею в виду, что книга банды четырех неприменима в играх. Совсем наоборот: вторая часть этой книги как раз обозревает многие из шаблонов, впервые описанных в Паттернах проектирования, но с той точки зрения как они могут быть применены в программировании игр.
Более того, я считаю что эта книга будет полезна и для тех, кто не занимается разработкой игр. Использование описанных шаблонов будет уместным во многих не игровых приложениях. Я вообще мог бы назвать книгу Еще больше шаблонов проектирования, но на мой взгляд игровые примеры выглядят выразительнее. Или вам интереснее в очередной раз читать книгу о списках сотрудников и банковских счетах (прим.: часто в качестве примеров применения шаблонов проектирования используют банки, клиентов, счета и пр.)?
Их книга была посвящена архитектуре (в духе настоящей архитектуры, которая помогает строить дома, стены и т.д.), но они надеялись что и другие смогут использовать подобную структуру для описания решений в других областях. Паттерны проектирования банды четырех стараются применить тот же подход в программировании.
-
Вместо того чтобы попытаться низвергнуть Паттерны проектирования, я рассматриваю свою книгу как их расширение. Пускай многие представленные здесь шаблоны будут полезны и в других типах программного обеспечения, я считаю что лучше всего они применимы именно к игровым задачам.
-
Время и последовательность действий зачастую являются ключевыми частями игровой архитектуры. События должны происходить в правильной последовательности и в нужное время.
-
Цикл разработки предельно сжат и множеству разработчиков необходимо иметь возможность быстро внедрять и итерационно менять широкий набор поведения, не наступая друг другу на ноги и не оставляя после себя следов по всей кодовой базе.
-
После того как поведение определено, начинается взаимодействие. Монстры кусают героя, зелья смешиваются, а бомбы взрывают врагов и друзей. Все эти взаимодействия должны реализовываться без превращения кодовой базы в спутанный клубок шерсти.
-
И наконец, для игр критична производительность. Игровые разработчики постоянно участвуют в гонке за первенство по максимально эффективному использования своей платформы. Небольшой трюк по сбережению нескольких тактов может отделять игру с наивысшим рейтингом и миллионными продажами от проблем с падением (кадров в секунду) и злыми рецензиями.
Отслеживание активных процессов
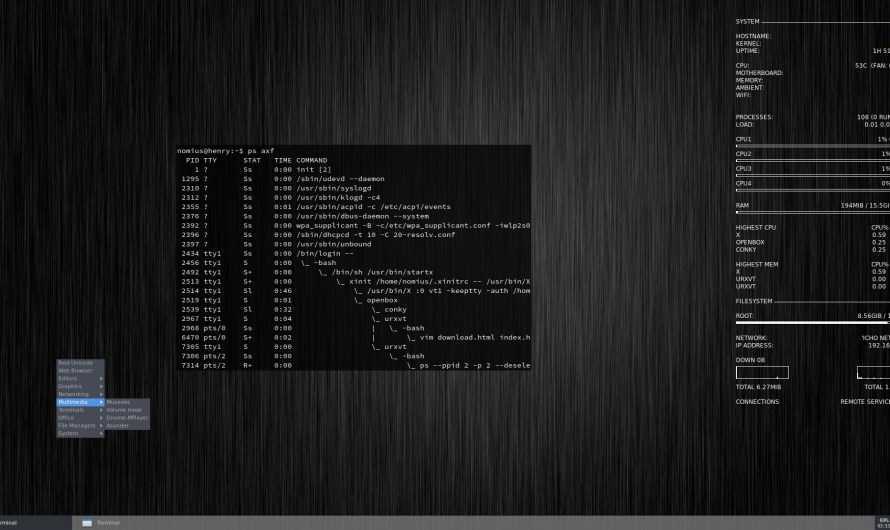
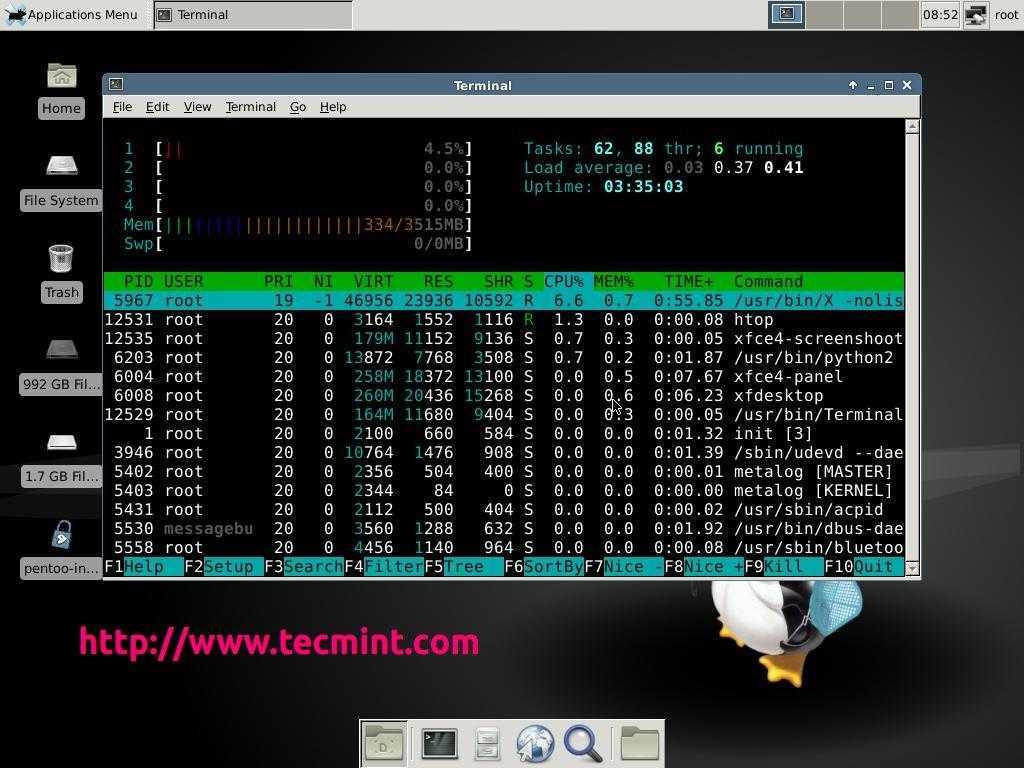
Существует несколько различных инструментов для просмотра/перечисления запущенных в системе процессов. Двумя традиционными и хорошо известными из них являются команды ps и top:
Команда ps
Отображает информацию об активных процессах в системе, как показано на следующем скриншоте:
Для получения дополнительной информации о процессах, запущенных текущим пользователем, применяется опция :
Столбцы, присутствующие в выводе команды , имеют следующие значения:
UID — идентификатор пользователя, которому принадлежит процесс (тот, от чьего имени происходит выполнение).
PID — идентификатор процесса.
PPID — идентификатор родительского процесса.
C — загрузка CPU процессом.
STIME — время начала выполнения процесса.
TTY — тип терминала, связанного с процессом.
TIME — количество процессорного времени, потраченного на выполнение процесса.
CMD — команда, запустившая этот процесс.
Также можно отобразить информацию по конкретному процессу, используя команду , например:
Есть и другие опции, которые можно использовать вместе с командой :
— показывает информацию о процессах по всем пользователям;
— показывает информацию о процессах без терминалов;
— показывает дополнительную информацию о процессе по заданному UID или имени пользователя;
— отображение расширенной информации.
Если вы хотите вывести вообще всю информацию по всем процессам системы, то используйте команду :
Обратите внимание на выделенный заголовок. Команда поддерживает функцию сортировки процессов по соответствующим столбцам
Например, чтобы отсортировать список процессов по потреблению ресурсов процессора (в порядке возрастания), введите команду:
Результат:
Если вы ходите выполнить сортировку по потреблению памяти (в порядке убывания), то добавьте к имени интересующего столбца знак минуса:
Результат:
Еще один очень популярный пример использования команды — это объединение её и для поиска заданного процесса по его имени:
Результат:
Команда top
Команда top отображает информацию о запущенных процессах в режиме реального времени:
Рассмотрим детально:
PID — идентификатор процесса.
USER — пользователь, которому принадлежит процесс.
PR — приоритет процесса на уровне ядра.
NI — приоритет выполнения процесса от до .
VIRT — общий объем (в килобайтах) виртуальной памяти (физическая память самого процесса; загруженные с диска файлы библиотек; память, совместно используемая с другими процессами и т.п.), используемой задачей в данный момент.
RES — текущий объем (в килобайтах) физической памяти процесса.
SHR — объем совместно используемой с другими процессами памяти.
S (сокр. от «STATUS») — состояние процесса:
S (сокр. от «Sleeping») — прерываемое ожидание. Процесс ждет наступления события.
I (сокр. от «Idle») — процесс бездействует.
R (сокр. от «Running») — процесс выполняется (или поставлен в очередь на выполнение).
Z (сокр. от «Zombie») — зомби-процесс.
%CPU — процент используемых ресурсов процессора.
%MEM — процент используемой памяти.
TIME+ — количество процессорного времени, потраченного на выполнение процесса.
COMMAND — имя процесса (команды).
Также в сочетании с основными символами состояния процесса (S от «STATUS») вы можете встретить и дополнительные:
— процесс с высоким приоритетом;
— процесс с низким приоритетом;
— многопоточный процесс;
— фоновый процесс;
— лидер сессии.
Примечание: Все процессы объединены в сессии. Процессы, принадлежащие к одной сессии, определяются общим идентификатором сессии — идентификатором процесса, который создал эту сессию. Лидер сессии — это процесс, идентификатор сессии которого совпадает с его идентификаторами процесса и группы процессов.
Команда glances
Команда glances — это относительно новый инструмент мониторинга системы с расширенными функциями:
Примечание: Если в вашей системе отсутствует данная утилита, то установить её можно с помощью следующих команд:
RHEL/CentOS/Fedora
Debian/Ubuntu/Linux Mint
Примеры использования file
Если вам нужно всего лишь посмотреть тип файла, использовать опции не обязательно. Достаточно прописать имя команды, а также название файла и путь к нему, при условии, что он находится не в корневой папке:
Случается, что нужно проверить не один, а несколько файлов. Чтобы не выполнять команду много раз подряд, перечисляйте названия всех файлов через пробел:
Как видно на примере, картинки с расширениями gif и tiff в действительности оказались текстовыми документами, а архив с расширением zip — PDF документом. Кстати, команда file даёт возможность не только проверить, является ли архив архивом, но и заглянуть внутрь, чтобы узнать, что в нём содержится. Для этой цели используется опция -z:
Как вы успели заметить, команда, возвращая ответ, постоянно выводит названия файлов, что в некоторых случаях бывает удобно, но зачастую только усложняет чтение результатов. Отключить эту функцию легко — воспользуйтесь опцией -b:
Иногда нужно узнать не просто тип файла, а его MIME-тип. В таком случае на помощь приходит опция -i:
Нередко по каким-либо причинам утилита не может найти указанный файл: например, вы ошиблись буквой в его названии или неверно указали папку, в которой он находится. Тогда вывод информации об этом файле предваряет фраза cannot open. Впрочем, есть возможность видоизменить результат, добавив в него сообщение об ошибке. Для этого используйте опцию -E.
Сравните вывод команды с опцией -E и без неё:
Еще один способ работы с утилитой file — запись названий и адресов документов в простой текстовый файл. Применяя этот способ на практике, не забывайте добавлять к команде опцию —files-from, после которой указывайте имя файла, содержащего список документов, и путь к нему.
Интерфейс
Итак, у нас есть некое устройство с трубкой, микрофоном, динамиком и средством набора номера. Но если вы вспомните рассказы мамы, бабушки и подруги, то обнаружите вот что:
- в микрофон говорят, чтобы собеседник мог вас услышать;
- чтобы слышать самому, ухо прикладывают к динамику;
- чтобы набрать номер, нужно с помощью номеронабирателя вызвать нужную последовательность цифр;
- когда идёт вызов, слышны гудки в динамике.
Всё это — интерфейсы. Они позволяют работать с объектом, не вникая в то, как он устроен внутри. Если вы умеете работать с интерфейсом номеронабирателя, то вам всё равно, нужно ли крутить диск, нажимать физические кнопки на радиотрубке или давить пальцем на сенсорный экран.
Такой интерфейс как бы говорит нам — я передам в телефон любые цифры, какие захочешь
Как я это сделаю внутри и как они будут обработаны — неважно, просто набери номер, а дальше телефон сам разберётся
Интерфейсы — это действия над объектом, доступные другим объектам (поэтому они называются публичными).
Есть ещё инкапсулированные, то есть внутренние методы. Например, у микрофона есть публичный метод «Слушать голос», и есть внутренний метод «Преобразовать голос в электрические сигналы». С его помощью он взаимодействует с другими частями нашего абстрактного телефона. Про инкапсуляцию будет отдельный материал, потому что тема большая.
Сложная терминология
Строго говоря, интерфейсы — это не действия, а методы. Сейчас объясним.
В программировании есть операции — это простейшие действия, например, скопировать значение из одной переменной в другую.
Из простых действий составляются функции — это когда несколько операций «склеиваются» в нечто единое. Мы даём этой склейке название и получаем функцию. Например, может быть функция «проверить правильность электронного адреса», которая состоит из нескольких десятков простых операций.
На языке ООП функции, привязанные к объектам, называются методами. Просто такой термин. По сути это функции, то есть склеенные вместе операции.
Итого: метод — это набор простых действий, которые склеили в единое целое и засунули в объект.
Парадигмы программирования и их виды
Парадигма разработки – это набор правил и критериев, соблюдаемых разработчиками, чтобы выдержать конкретную стилистику и модель написания кода.
Единая парадигма помогает избегать ошибок, упрощает работу в команде и ускоряет разработку. Ориентируясь на одну парадигму, можно корректно структурировать код приложения, зная четкие правила, выбранные командой, которая работает над конкретным проектом.
Существуют различные типы парадигм, например процедурный, ориентированный на работу с функциями, или логический, подразумевающий решение базовых логических задач в духе «если А = true, то и B = true». Но есть и более интересный подход к решению задач разработки, и это ООП-парадигма.