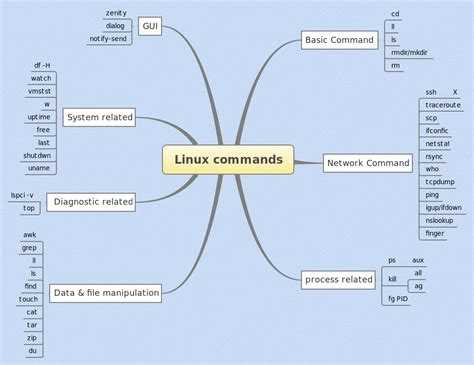
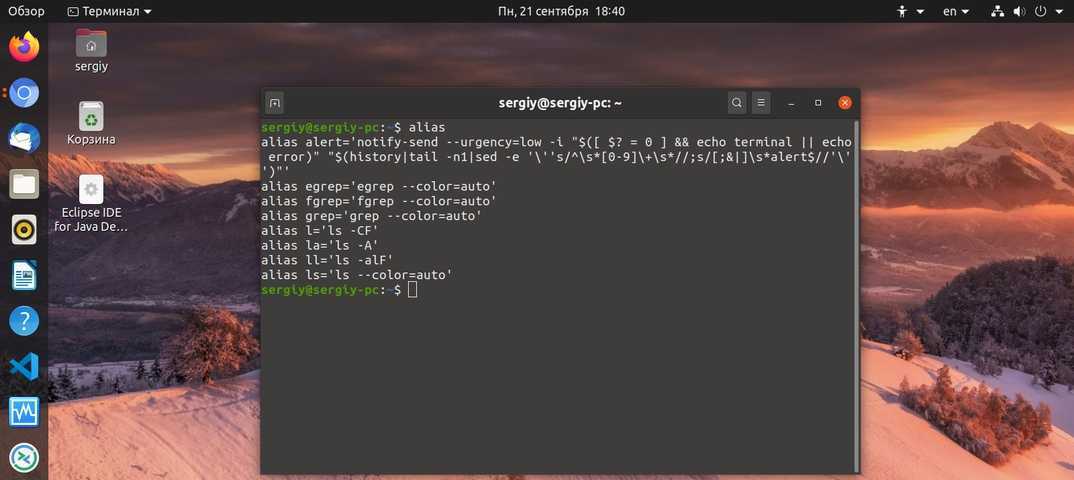
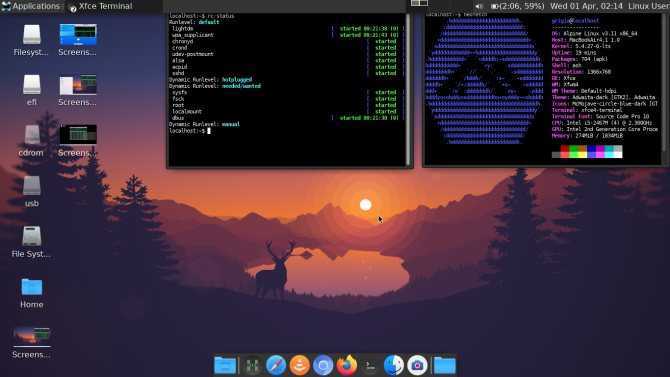
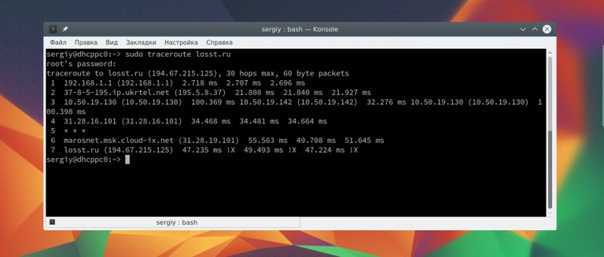
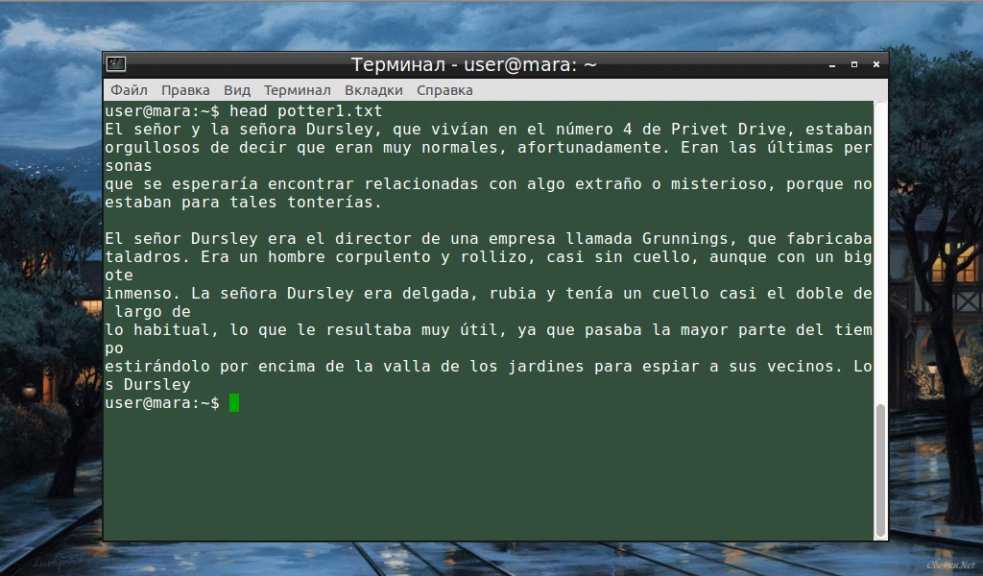
Как работает awk
Существует несколько различных реализаций awk. Мы будем использовать GNU-реализацию awk, которая называется gawk. В большинстве систем Linux интерпретатор — это просто символическая ссылка на .
Записи и поля
Awk может обрабатывать текстовые файлы данных и потоки. Входные данные разделены на записи и поля. Awk работает с одной записью за раз, пока не будет достигнут конец ввода. Записи разделяются символом, который называется разделителем записей. Разделителем записей по умолчанию является символ новой строки, что означает, что каждая строка в текстовых данных является записью. Новый разделитель записей может быть установлен с помощью переменной .
Записи состоят из полей, разделенных разделителем полей. По умолчанию поля разделяются пробелом, включая один или несколько символов табуляции, пробела и новой строки.
Поля в каждой записи обозначаются знаком доллара ( ), за которым следует номер поля, начинающийся с 1. Первое поле представлено с помощью , второе — с помощью и так далее. На последнее поле также можно ссылаться с помощью специальной переменной . На всю запись можно ссылаться с помощью .
Вот визуальное представление, показывающее, как ссылаться на записи и поля:
Программа awk
Чтобы обработать текст с помощью , вы пишете программу, которая сообщает команде, что делать. Программа состоит из ряда правил и пользовательских функций. Каждое правило содержит одну пару шаблон и действие. Правила разделяются новой строкой или точкой с запятой ( ). Обычно awk-программа выглядит так:
Когда обрабатывает данные, если шаблон соответствует записи, он выполняет указанное действие с этой записью. Если у правила нет шаблона, все записи (строки) совпадают.
Действие awk заключено в фигурные скобки ( ) и состоит из операторов. Каждый оператор определяет операцию, которую нужно выполнить. В действии может быть несколько операторов, разделенных новой строкой или точкой с запятой ( ). Если правило не имеет действия, по умолчанию выполняется печать всей записи.
Awk поддерживает различные типы операторов, включая выражения, условные операторы, операторы ввода, вывода и т. Д. Наиболее распространенные операторы awk:
- — останавливает выполнение всей программы и выходит.
- — останавливает обработку текущей записи и переходит к следующей записи во входных данных.
- — Печать записей, полей, переменных и настраиваемого текста.
- — дает вам больше контроля над форматом вывода, аналогично C и bash .
При написании программ awk все, что находится после решетки и до конца строки, считается комментарием. Длинные строки можно разбить на несколько строк с помощью символа продолжения, обратной косой черты ( ).
Выполнение программ awk
Программа awk может быть запущена несколькими способами. Если программа короткая и простая, ее можно передать непосредственно интерпретатору из командной строки:
При запуске программы в командной строке ее следует заключать в одинарные кавычки ( ), чтобы оболочка не интерпретировала программу.
Если программа большая и сложная, лучше всего поместить ее в файл и использовать параметр для передачи файла команде :
В приведенных ниже примерах мы будем использовать файл с именем «team.txt», который выглядит примерно так:
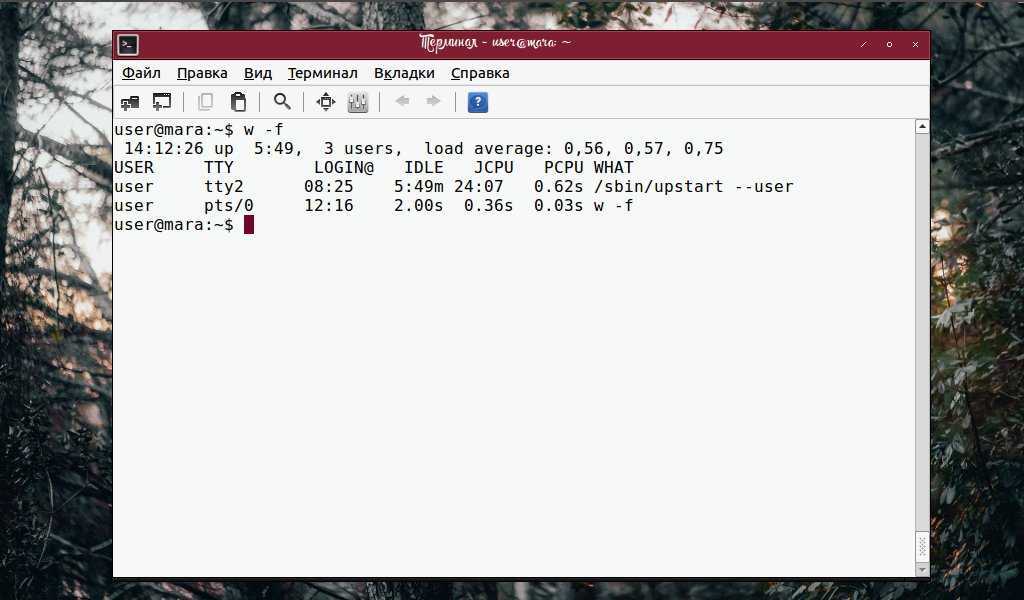
Команды для мониторинга и отладки:
top
— отобразить запущенные процессы, используемые ими ресурсы и другую полезную информацию (с автоматическим обновлением данных)
ps -eafw
— отобразить запущенные процессы, используемые ими ресурсы и другую полезную информацию (единожды)
ps -e -o pid,args --forest
— вывести PID’ы и процессы в виде дерева
pstree
— отобразить дерево процессов
kill -9 98989
— «убить» процесс с PID 98989 «на смерть» (без соблюдения целостности данных)
kill -TERM 98989
— Корректно завершить процесс с PID 98989
kill -1 98989
— заставить процесс с PID 98989 перепрочитать файл конфигурации
kill -HUP 98989
— заставить процесс с PID 98989 перепрочитать файл конфигурации
lsof -p 98989
— отобразить список файлов, открытых процессом с PID 98989
lsof /home/user1
— отобразить список открытых файлов из директории /home/user1
strace -c ls >/dev/null
— вывести список системных вызовов, созданных и полученных процессом ls
strace -f -e open ls >/dev/null
— вывести вызовы бибилотек
watch -n1 'cat /proc/interrupts'
— отображать прерывания в режиме реального времени
last reboot
— отобразить историю перезагрузок системы
last user1
— отобразить историю регистрации пользователя user1 в системе и время его нахождения в ней
lsmod
— вывести загруженные модули ядра
free -m
— показать состояние оперативной памяти в мегабайтах
smartctl -A /dev/hda
— контроль состояния жёсткого диска /dev/hda через SMART
smartctl -i /dev/hda
— проверить доступность SMART на жёстком диске /dev/hda
tail /var/log/dmesg
— вывести десять последних записей из журнала загрузки ядра
tail /var/log/messages
— вывести десять последних записей из системного журнала
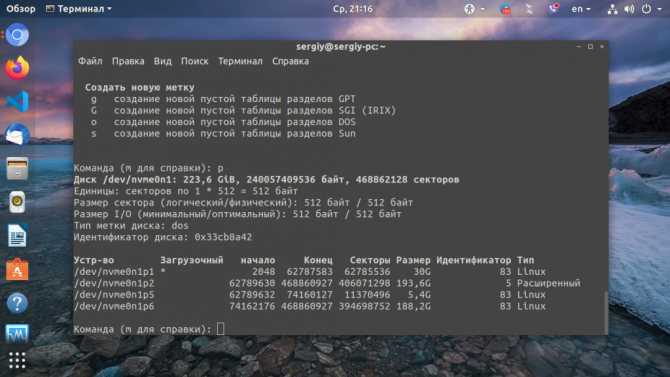
Системные команды Linux
Эти команды используются для просмотра информации и управления, связанной с системой Linux.
1. uname
Команда Uname используется в Linux для поиска информации об операционных системах. В Uname существует много опций, которые могут указывать имя ядра, версию ядра, тип процессора и имя хоста.
Следующая команда uname с опцией отображает всю информацию об операционной системе.
2. uptime
Информация о том, как долго работает система Linux, отображается с помощью команды uptime. Информация о времени безотказной работы системы собирается из файла ‘/proc/uptime‘. Эта команда также отобразит среднюю нагрузку на систему.
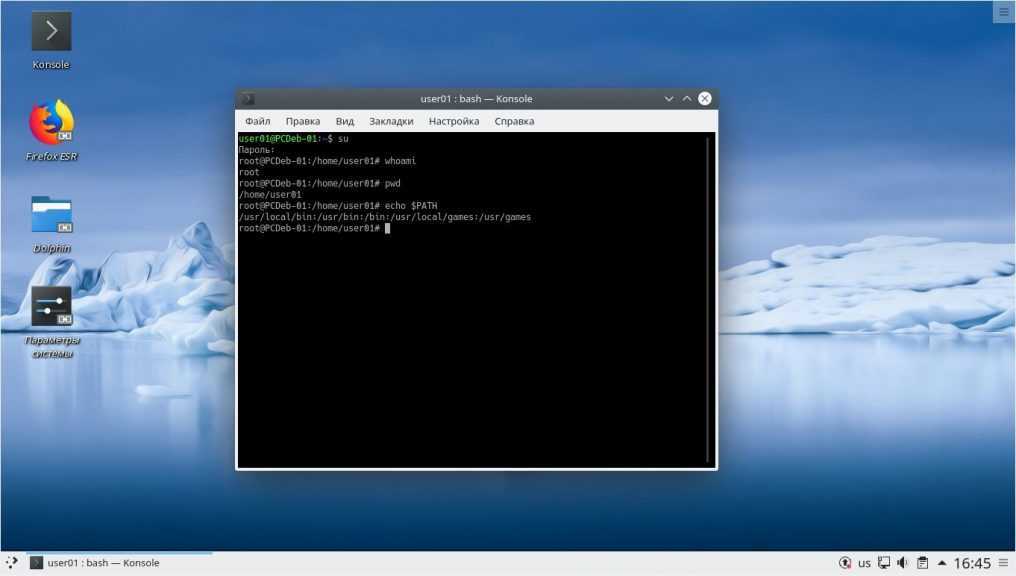
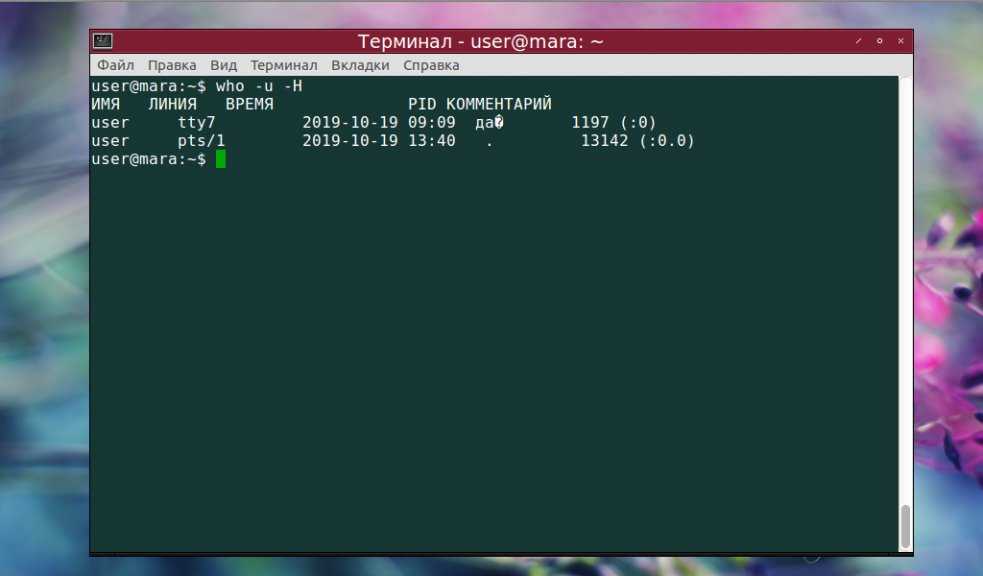
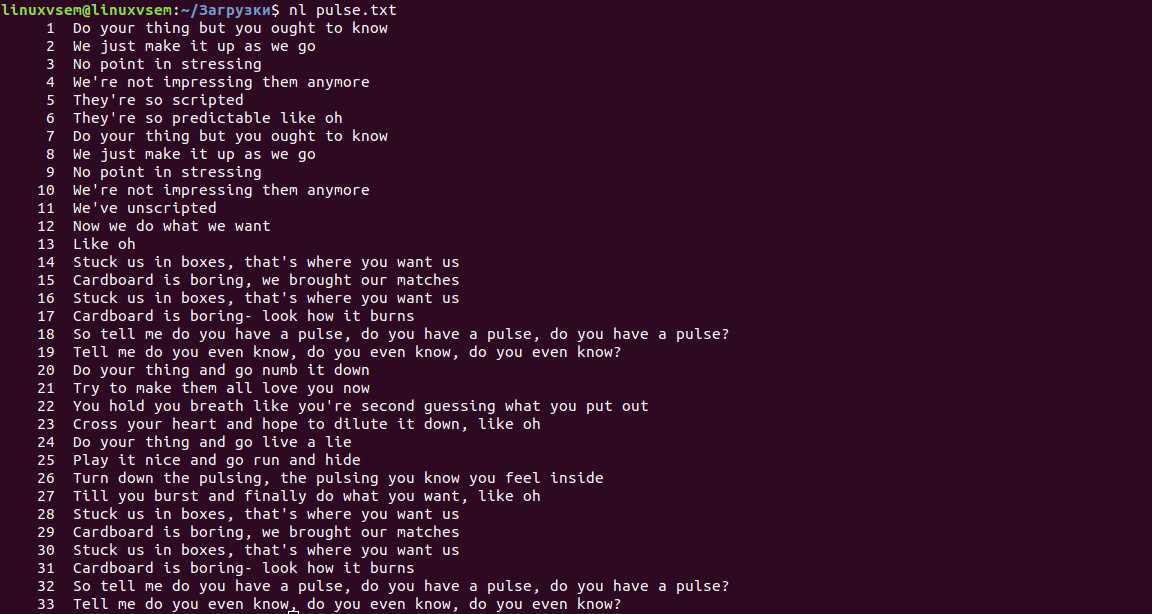
Из следующей команды мы можем понять, что система работает в течение последних 36 минут.
Полное руководство команды Uptime
3. hostname
Вы можете отобразить имя хоста вашей машины, введя в своем терминале. С помощью опции вы можете просмотреть ip-адрес компьютера. А с помощью параметра вы можете просмотреть доменное имя.
4. last
Команда last в Linux используется для определения того, кто последним вошел в систему на вашем сервере. Эта команда отображает список всех пользователей, вошедших (и вышедших) из «/var/log/wtmp » с момента создания файла.
Вам просто нужно ввести «last» в своем терминале.
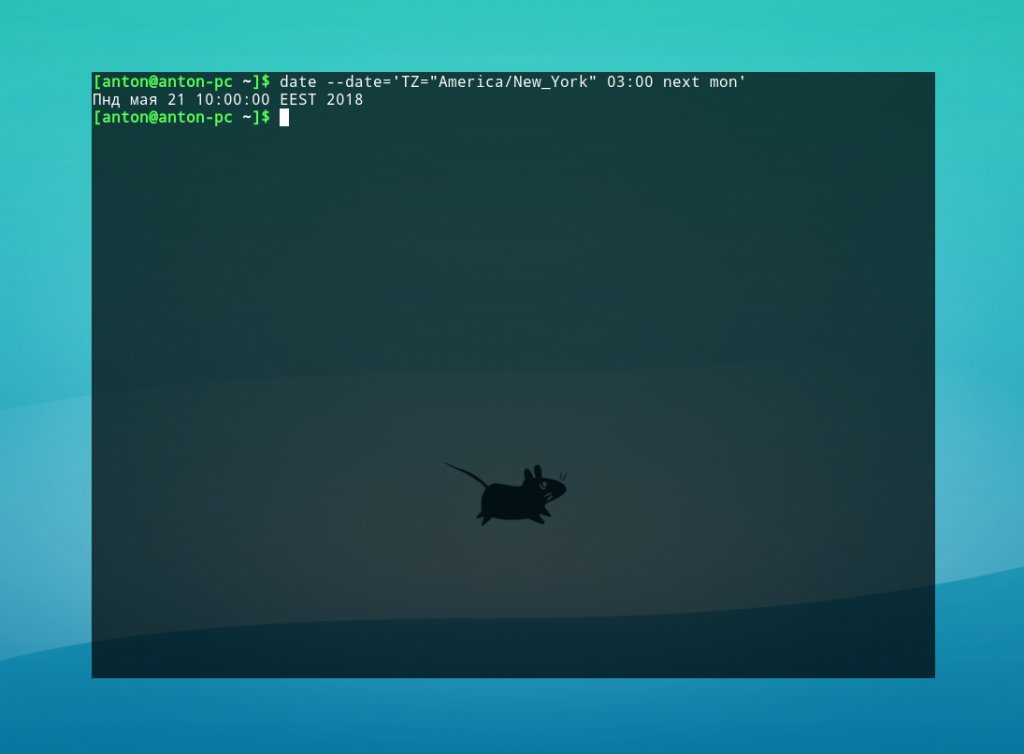
5. date
В Linux команда date используется для проверки текущей даты и времени системы. Эта команда позволяет задать пользовательские форматы для дат.
Рекомендуем статью Команда Date (Дата) в Linux с примерами использования
Например, используя «date +%D«, вы можете просмотреть дату в формате «ММ/ДД/ГГ«.
6. cal
По умолчанию команда cal отображает календарь текущего месяца. С помощью опции вы можете просмотреть календарь на весь год.
9. reboot
Команда reboot используется для перезагрузки системы Linux. Вы должны запустить эту команду из терминала с правами суперпользователя sudo.
10. shutdown
Команда shutdown используется для выключения или перезагрузки системы Linux. Эта команда позволяет планировать завершение работы и уведомлять пользователей сообщениями о выключении и перезагрузке.
По умолчанию компьютер (сервер) выключится через 1 минуту. Вы можете отменить расписание, выполнив команду:
Немедленное отключение тоже возможно, для этого используется опция «now»
Своя сортирующая функция
Язык Python позволяет
создавать свои сортирующие функции для более точной настройки алгоритма
сортировки. Давайте для начала рассмотрим такой пример. Пусть у нас имеется вот
такой список:
a=1,4,3,6,5,2
и мы хотим,
чтобы вначале стояли четные элементы, а в конце – нечетные. Для этого создадим
такую вспомогательную функцию:
def funcSort(x): return x%2
И укажем ее при
сортировке:
print( sorted(a, key=funcSort) )
Мы здесь
используем именованный параметр key, который принимает ссылку на
сортирующую функцию. Запускаем программу и видим следующий результат:
Разберемся,
почему так произошло. Смотрите, функция funcSort возвращает вот
такие значения для каждого элемента списка a:
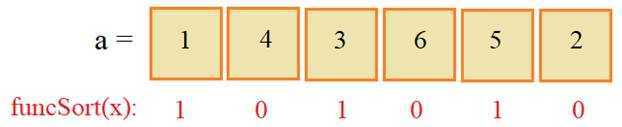
И, далее, в sorted уже
используются именно эти значения для сортировки элементов по возрастанию. То
есть, сначала, по порядку берется элемент со значением 4, затем, 6 и потом 2.
После этого следуют нечетные значения в порядке их следования: 1, 3, 5. В
результате мы получаем список:
А теперь,
давайте модифицируем нашу функцию, чтобы выполнялась сортировка и самих
значений:
def funcSort(x): if x%2 == : return x else: return x+100
Здесь четные
значения возвращаются такими как они есть, а к нечетным прибавляем 100. В
результате получим:

Здесь элементам
нашего списка ставятся в соответствие указанные числа, и по этим числам
выполняется их сортировка. То есть, эти числа можно воспринимать как некие
ключи, по которым и происходит сортировка элементов списка. Поэтому в Python
такую
сортировку называют сортировкой по ключам.
Конечно, здесь
вместо определения своей функции можно также записывать анонимные функции,
например:
print( sorted(a, key=lambda x: x%2) )
Получим ранее
рассмотренный результат:
Или, то же самое
можно делать и со строками:
lst = "Москва", "Тверь", "Смоленск", "Псков", "Рязань"
Отсортируем их
по длине строки:
print( sorted(lst, key=len) )
получим
результат:
Или по
последнему символу, используя лексикографический порядок:
print( sorted(lst, key=lambda x: x-1) )
Или, по первому
символу:
print( sorted(lst, key=lambda x: x) )
И так далее. Этот
подход часто используют при сортировке сложных структур данных. Допустим, у нас
имеется вот такой список из книг:
books = {
("Евгений Онегин", "Пушкин А.С.", 200),
("Муму", "Тургенев И.С.", 250),
("Мастер и Маргарита", "Булгаков М.А.", 500),
("Мертвые души", "Гоголь Н.В.", 190)
}
И нам нужно его
отсортировать по возрастанию цены (последнее значение). Это можно сделать так:
print( sorted(books, key=lambda x: x2) )
На выходе
получим список:
Вот так можно
выполнять сортировку данных в Python.
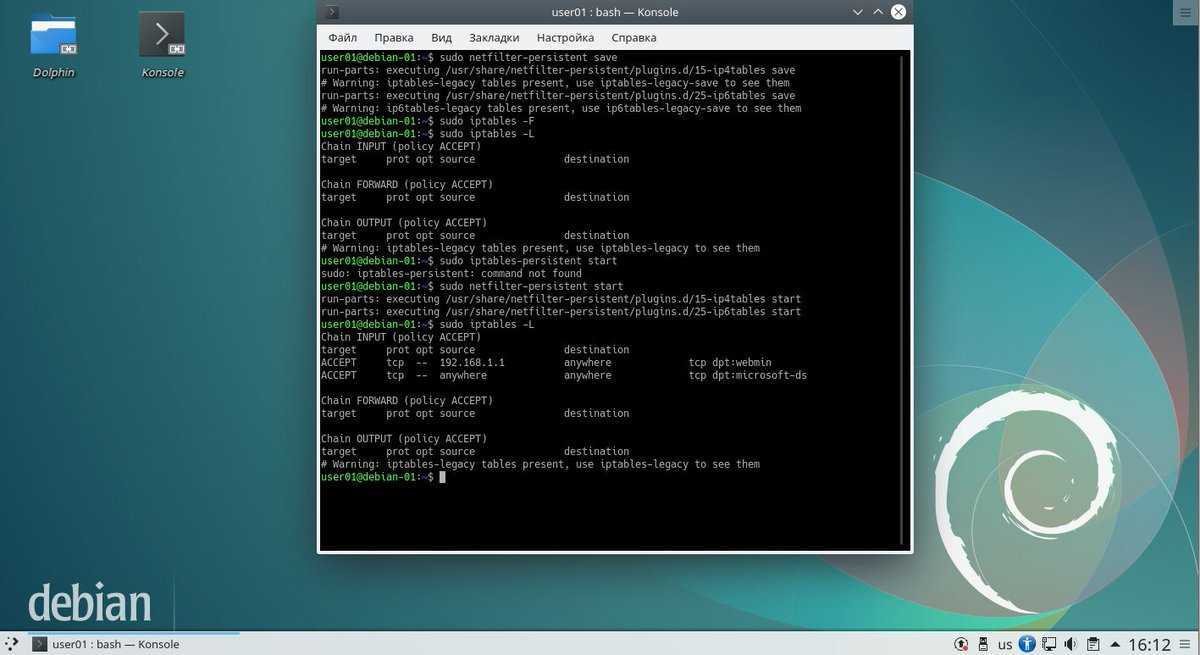
IPTABLES (firewall)
-
отобразить все цепочки правил
-
отобразить все цепочки правил в NAT-таблице
-
очистить все цепочки правил в filter-таблице
-
очистить все цепочки правил в NAT-таблице
-
удалить все пользовательские цепочки правил в filter-таблице
-
позволить входящее подключение telnet’ом
-
блокировать исходящие HTTP-соединения
-
позволить «прокидывать» (forward) POP3-соединения
-
включить журналирование ядром пакетов, проходящих через цепочку INPUT, и добавлением к сообщению префикса «DROP INPUT»
-
включить NAT (Network Address Translate) исходящих пакетов на интерфейс eth0. Допустимо при использовании с динамически выделяемыми ip-адресами
-
перенаправление пакетов, адресованных одному хосту, на другой хост
Examples
Let’s say you have a file, data.txt, which contains the following ASCII text:
apples oranges pears kiwis bananas
To sort the lines in this file alphabetically, use the following command:
sort data.txt
…which will produce the following output:
apples bananas kiwis oranges pears
Note that this command does not actually change the input file, data.txt. If you want to write the output to a new file, output.txt, redirect the output like this:
sort data.txt > output.txt
…which will not display any output, but will create the file output.txt with the same sorted data from the previous command. To check the output, use the cat command:
cat output.txt
…which displays the sorted data:
apples bananas kiwis oranges pears
You can also use the built-in sort option -o, which allows you to specify an output file:
sort -o output.txt data.txt
Using the -o option is functionally the same as redirecting the output to a file; neither one has an advantage over the other.
Примеры использования find
Поиск файла по имени
1. Простой поиск по имени:
find / -name «file.txt»
* в данном примере будет выполнен поиск файла с именем file.txt по всей файловой системе, начинающейся с корня .
2. Поиск файла по части имени:
find / -name «*.tmp»
* данной командой будет выполнен поиск всех папок или файлов в корневой директории /, заканчивающихся на .tmp
3. Несколько условий.
а) Логическое И. Например, файлы, которые начинаются на sess_ и заканчиваются на cd:
find . -name «sess_*» -a -name «*cd»
б) Логическое ИЛИ. Например, файлы, которые начинаются на sess_ или заканчиваются на cd:
find . -name «sess_*» -o -name «*cd»
в) Более компактный вид имеют регулярные выражения, например:
find . -regex ‘.*/\(sess_.*cd\)’
find . -regex ‘.*/\(sess_.*\|.*cd\)’
* где в первом поиске применяется выражение, аналогичное примеру а), а во втором — б).
4. Найти все файлы, кроме .log:
find . ! -name «*.log»
* в данном примере мы воспользовались логическим оператором !.
Поиск по дате
1. Поиск файлов, которые менялись определенное количество дней назад:
find . -type f -mtime +60
* данная команда найдет файлы, которые менялись более 60 дней назад.
2. Поиск файлов с помощью newer. Данная опция доступна с версии 4.3.3 (посмотреть можно командой find —version).
а) дате изменения:
find . -type f -newermt «2019-11-02 00:00»
* покажет все файлы, которые менялись, начиная с 02.11.2019 00:00.
find . -type f -newermt 2019-10-31 ! -newermt 2019-11-02
* найдет все файлы, которые менялись в промежутке между 31.10.2019 и 01.11.2019 (включительно).
б) дате обращения:
find . -type f -newerat 2019-10-08
* все файлы, к которым обращались с 08.10.2019.
find . -type f -newerat 2019-10-01 ! -newerat 2019-11-01
* все файлы, к которым обращались в октябре.
в) дате создания:
find . -type f -newerct 2019-09-07
* все файлы, созданные с 07 сентября 2019 года.
find . -type f -newerct 2019-09-07 ! -newerct «2019-09-09 07:50:00»
* файлы, созданные с 07.09.2019 00:00:00 по 09.09.2019 07:50

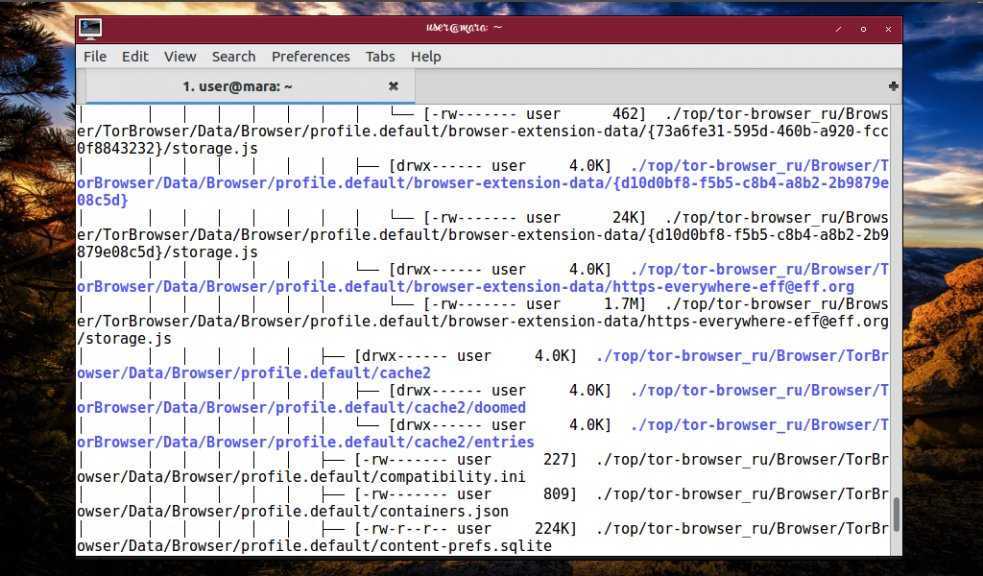
Искать в текущей директории и всех ее подпапках только файлы:
find . -type f
* f — искать только файлы.
Поиск по правам доступа
1. Ищем все справами на чтение и запись:
find / -perm 0666
2. Находим файлы, доступ к которым имеет только владелец:
find / -perm 0600
Поиск файла по содержимому
find / -type f -exec grep -i -H «content» {} \;
* в данном примере выполнен рекурсивный поиск всех файлов в директории и выведен список тех, в которых содержится строка content.
С сортировкой по дате модификации
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r
* команда найдет все файлы в каталоге /data, добавит к имени дату модификации и отсортирует данные по имени. В итоге получаем, что файлы будут идти в порядке их изменения.
Лимит на количество выводимых результатов
Самый распространенный пример — вывести один файл, который последний раз был модифицирован. Берем пример с сортировкой и добавляем следующее:
find /data -type f -printf ‘%TY-%Tm-%Td %TT %p\n’ | sort -r | head -n 1
Поиск с действием (exec)
1. Найти только файлы, которые начинаются на sess_ и удалить их:
find . -name «sess_*» -type f -print -exec rm {} \;
* -print использовать не обязательно, но он покажет все, что будет удаляться, поэтому данную опцию удобно использовать, когда команда выполняется вручную.
2. Переименовать найденные файлы:
find . -name «sess_*» -type f -exec mv {} new_name \;
или:
find . -name «sess_*» -type f | xargs -I ‘{}’ mv {} new_name
3. Вывести на экран количество найденных файлов и папок, которые заканчиваются на .tmp:
find . -name «*.tmp» | wc -l
4. Изменить права:
find /home/user/* -type d -exec chmod 2700 {} \;
* в данном примере мы ищем все каталоги (type d) в директории /home/user и ставим для них права 2700.
5. Передать найденные файлы конвееру (pipe):
find /etc -name ‘*.conf’ -follow -type f -exec cat {} \; | grep ‘test’
* в данном примере мы использовали find для поиска строки test в файлах, которые находятся в каталоге /etc, и название которых заканчивается на .conf. Для этого мы передали список найденных файлов команде grep, которая уже и выполнила поиск по содержимому данных файлов.
6. Произвести замену в файлах с помощью команды sed:
find /opt/project -type f -exec sed -i -e «s/test/production/g» {} \;
* находим все файлы в каталоге /opt/project и меняем их содержимое с test на production.
CDROM
<box 100% round left |>
cdrecord -v gracetime=2 dev=/dev/cdrom -eject blank=fast -force — clean a rewritable cdrommkisofs /dev/cdrom > cd.iso — create an iso image of cdrom on diskmkisofs /dev/cdrom | gzip > cd_iso.gz — create a compressed iso image of cdrom on diskmkisofs -J -allow-leading-dots -R -V «Label CD» -iso-level 4 -o ./cd.iso data_cd — create an iso image of a directorycdrecord -v dev=/dev/cdrom cd.iso — burn an ISO imagegzip -dc cd_iso.gz | cdrecord dev=/dev/cdrom — burn a compressed ISO imagemount -o loop cd.iso /mnt/iso — mount an ISO imagecd-paranoia -B — rip audio tracks from a CD to wav filescd-paranoia – «-3» — rip first three audio tracks from a CD to wav filescdrecord –scanbus — scan bus to identify the channel scsi
</box>
IPTABLES (firewall)
<box 100% round left |>
iptables -t filter -nLiptables -nL — отобразить все цепочки правил iptables -t nat -L — отобразить все цепочки правил в NAT-таблицеiptables -t filter -F или iptables -F — очистить все цепочки правил в filter-таблицеiptables -t nat -F — очистить все цепочки правил в NAT-таблицеiptables -t filter -X — удалить все пользовательские цепочки правил в filter-таблицеiptables -t filter -A INPUT -p tcp –dport telnet -j ACCEPT — позволить входящее подключение telnet’омiptables -t filter -A OUTPUT -p tcp –dport http -j DROP — блокировать исходящие HTTP-соединенияiptables -t filter -A FORWARD -p tcp –dport pop3 -j ACCEPT — позволить «прокидывать» (forward) POP3-соединенияiptables -t filter -A INPUT -j LOG –log-prefix «DROP INPUT» — включить журналирование ядром пакетов, проходящих через цепочку INPUT, и добавлением к сообщению префикса «DROP INPUT»iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE — включить NAT (Network Address Translate) исходящих пакетов на интерфейс eth0. Допустимо при использовании с динамически выделяемыми ip-адресами.iptables -t nat -A PREROUTING -d 192.168.0.1 -p tcp -m tcp –dport 22 -j DNAT –to-destination 10.0.0.2:22 — перенаправление пакетов, адресованных одному хосту, на другой хост
</box>
Оператор точка с запятой (;)
Оператор точка с запятой выполняет несколько команд одновременно последовательно, как упоминалось, и обеспечивает вывод без зависимости от успеха и отказа других команд, таких как && и OR (||).
Посмотрите пример ниже:
$ ping -c 5 localhost ; ifconfig ens33 ; df -h PING localhost (127.0.0.1) 56(84) bytes of data. 64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.063 ms 64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.091 ms 64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.085 ms 64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=0.086 ms 64 bytes from localhost (127.0.0.1): icmp_seq=5 ttl=64 time=0.086 ms --- localhost ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4091ms rtt min/avg/max/mdev = 0.063/0.082/0.091/0.011 ms ens33 Link encap:Ethernet HWaddr 00:0c:29:ff:cd:2e inet addr:192.168.43.185 Bcast:192.168.43.255 Mask:255.255.255.0 inet6 addr: 2405:204:f017:75dd:65af:f027:85c2:88eb/64 Scope:Global inet6 addr: 2405:204:f017:75dd:f076:72b8:fd36:757f/64 Scope:Global inet6 addr: fe80::b396:d285:b5b3:81c3/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:146608 errors:0 dropped:0 overruns:0 frame:0 TX packets:78275 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:188124508 (188.1 MB) TX bytes:6912561 (6.9 MB) Filesystem Size Used Avail Use% Mounted on udev 966M 0 966M 0% /dev tmpfs 199M 12M 187M 6% /run /dev/sda1 18G 5.3G 12G 32% / tmpfs 992M 212K 992M 1% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 992M 0 992M 0% /sys/fs/cgroup tmpfs 199M 60K 199M 1% /run/user/1000
6. Амперсанд Оператор (&)
Оператор Амперсанда – это своего рода оператор, который выполняет заданные команды в фоновом режиме.
Вы можете использовать этот оператор для одновременного выполнения нескольких команд.
$ ping -c 50 localhost &
Вы также можете выполнять несколько команд с помощью оператора Ampersand. См. Команду ниже.
![Команды linux: расширенный cправочник команд unix [rtfm.wiki]](https://smartshop124.ru/wp-content/uploads/7/4/1/74182d1cc81f466cd39e5a029ba52ebc.jpeg)
$ ping -c 5 localhost & df -h & 25962 25963 $ PING localhost (127.0.0.1) 56(84) bytes of data. 64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.052 ms Filesystem Size Used Avail Use% Mounted on udev 966M 0 966M 0% /dev tmpfs 199M 12M 187M 6% /run /dev/sda1 18G 5.3G 12G 32% / tmpfs 992M 212K 992M 1% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 992M 0 992M 0% /sys/fs/cgroup tmpfs 199M 56K 199M 1% /run/user/1000 64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.091 ms 64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.070 ms 64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=0.091 ms 64 bytes from localhost (127.0.0.1): icmp_seq=5 ttl=64 time=0.117 ms --- localhost ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4072ms rtt min/avg/max/mdev = 0.052/0.084/0.117/0.022 ms
Linux Type Command
26 Апреля 2020
|
Терминал
В этой статье мы объясним, как использовать команду Linux type .

Команда используется для отображения информации о типе команды. Он покажет вам, как данная команда будет интерпретироваться при вводе в командной строке.
Как использовать команду
это оболочка, встроенная в Bash и другие оболочки, такие как Zsh и Ksh. Его поведение может немного отличаться от оболочки к оболочке. Мы рассмотрим встроенную версию Bash .
Синтаксис команды следующий:
Например, чтобы найти тип команды , вы должны ввести следующее:
Вывод будет примерно таким:
Вы также можете указать несколько аргументов команды:
Вывод будет включать информацию о как и команде:
Типы команд
Опция указывает печатать одно слово, описывающее тип команды, которое может быть одним из следующих:
- псевдоним (псевдоним оболочки)
- функция (функция оболочки)
- встроенный (встроенный в оболочку)
- файл (файл на диске)
- ключевое слово (зарезервированное слово оболочки)
Вот несколько примеров:
-
кличка
В моей системе есть псевдоним :
-
функция
это инструмент (функция) для установки, управления и работы с несколькими средами Ruby :
-
Builtin
это оболочка, встроенная в Bash и другие оболочки, такие как Zsh и Ksh:
-
файл
это исполняемый файл:
-
Ключевое слово
это зарезервированное слово в Bash:
Показать все места, которые содержат команду
Чтобы напечатать все совпадения, используйте опцию:
Вывод покажет вам, что это встроенная оболочка, но она также доступна как отдельный исполняемый файл:
Когда опция используется, команда type будет включать псевдонимы и функции, только если опция не используется.
Другие параметры команды типа
Опция заставит вернуть путь к команде только если команда является исполняемым файлом на диске:
Например, следующая команда не будет отображать никаких выходных данных, поскольку эта команда является встроенной оболочкой.
В отличие от этого , опция в верхнем регистре указывает искать исполняемый файл на диске, даже если команда не является файлом.
Когда опция используется, не будет искать функции оболочки, как с помощью встроенной команды.
Команда покажет вам, как будет интерпретироваться определенная команда, если она используется в командной строке.
Команды для манипуляции с текстом:
cat file_originale | > result.txt
— общий синтаксис выполнения действий по обработке содержимого файла и вывода результата в новый
cat file_originale | >> result.txt
— общий синтаксис выполнения действий по обработке содержимого файла и вывода результата в существующий файл. Если файл не существует, он будет создан
grep Aug /var/log/messages
— из файла ‘/var/log/messages’ отобрать и вывести на стандартное устройство вывода строки, содержащие «Aug»
grep ^Aug /var/log/messages
— из файла ‘/var/log/messages’ отобрать и вывести на стандартное устройство вывода строки, начинающиеся на «Aug»
grep /var/log/messages
— из файла ‘/var/log/messages’ отобрать и вывести на стандартное устройство вывода строки, содержащие цифры
grep Aug -R /var/log/*
— отобрать и вывести на стандартное устройство вывода строки, содержащие «Aug», во всех файлах, находящихся в директории /var/log и ниже
sed 's/stringa1/stringa2/g' example.txt
— в файле example.txt заменить «string1» на «string2», результат вывести на стандартное устройство вывода.
sed '/^$/d' example.txt
— удалить пустые строки из файла example.txt
sed '/ *#/d; /^$/d' example.txt
— удалить пустые строки и комментарии из файла example.txt
echo 'esempio' | tr '' ''
— преобразовать символы из нижнего регистра в верхний
sed -e '1d' result.txt
— удалить первую строку из файла example.txt
sed -n '/string1/p'
— отобразить только строки содержавшие «string1»
sed -e 's/ *$//' example.txt
— удалить пустые символы в в конце каждой строки
sed -e 's/string1//g' example.txt
— удалить строку «string1» из текста не изменяя всего остального
sed -n '1,8p;5q' example.txt
— взять из файла с первой по восьмую строки и из них вывести первые пять
sed -n '5p;5q' example.txt
— вывести пятую строку
sed -e 's/0*/0/g' example.txt
— заменить последовательность из любого количества нулей одним нулём
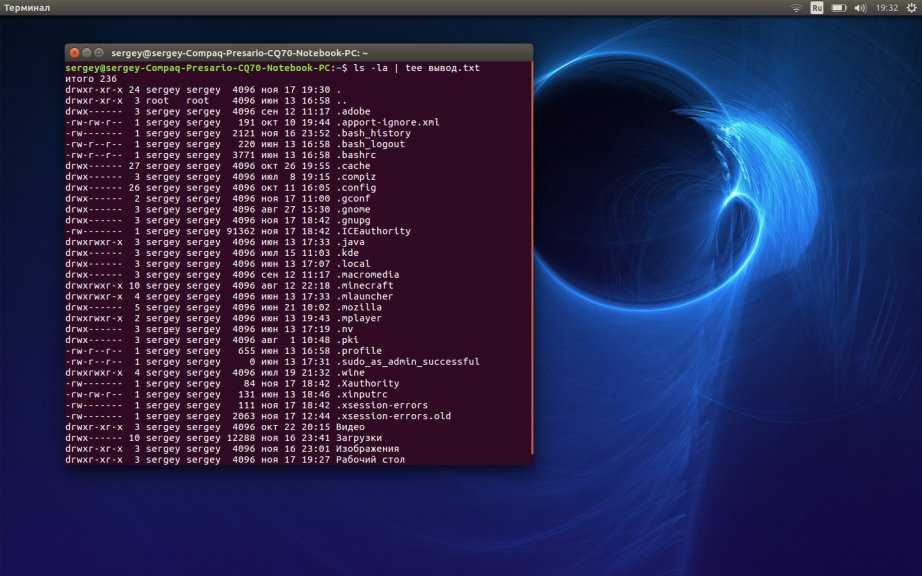
cat -n file1
— пронумеровать строки при выводе содержимого файла
cat example.txt | awk 'NR%2==1'
— при выводе содержимого файла, не выводить чётные строки файла
echo a b c | awk '{print $1}'
— вывести первую колонку. Разделение, по-умолчанию, по проблелу/пробелам или символу/символам табуляции
echo a b c | awk '{print $1,$3}'
— вывести первую и треью колонки. Разделение, по-умолчанию, по проблелу/пробелам или символу/символам табуляции
paste file1 file2
— объединить содержимое file1 и file2 в виде таблицы: строка 1 из file1 = строка 1 колонка 1-n, строка 1 из file2 = строка 1 колонка n+1-m
paste -d '+' file1 file2
— объединить содержимое file1 и file2 в виде таблицы с разделителем «+»
sort file1 file2
— отсортировать содержимое двух файлов
sort file1 file2 | uniq
— отсортировать содержимое двух файлов, не отображая повторов
sort file1 file2 | uniq -u
— отсортировать содержимое двух файлов, отображая только уникальные строки (строки, встречающиеся в обоих файлах, не выводятся на стандартное устройство вывода)
sort file1 file2 | uniq -d
— отсортировать содержимое двух файлов, отображая только повторяющиеся строки
comm -1 file1 file2
— сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file1’
comm -2 file1 file2
— сравнить содержимое двух файлов, не отображая строки принадлежащие файлу ‘file2’
comm -3 file1 file2
— сравнить содержимое двух файлов, удаляя строки встречающиеся в обоих файлах
Using sort And join Together
sort can be especially useful when used in conjunction with the join command. Normally join will join the lines of any two files whose first field match. Let’s say you have two files, file1.txt and file2.txt. file1.txt contains the following text:
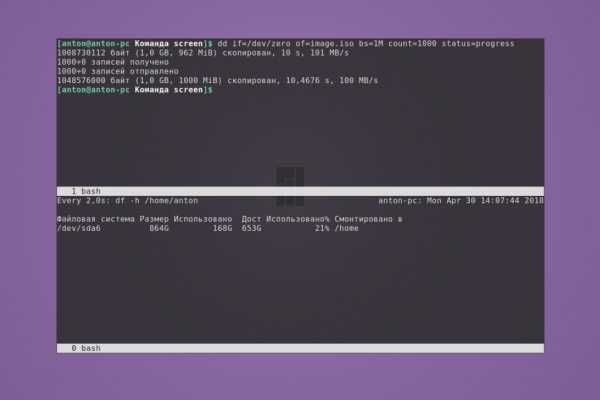
3 tomato 1 onion 4 beet 2 pepper
…and file2.txt contains the following:
4 orange 3 apple 1 mango 2 grapefruit
If you’d like sort these two files and join them, you can do so all in one command if you’re using the bash command shell, like this:
join <(sort file1.txt) <(sort file2.txt)
Here, the sort commands in parentheses are each executed, and their output is redirected to join, which takes their output as standard input for its first and second arguments; it is joining the sorted contents of both files and gives results similar to the below results.
1 onion mango 2 pepper grapefruit 3 tomato apple 4 beet orange