
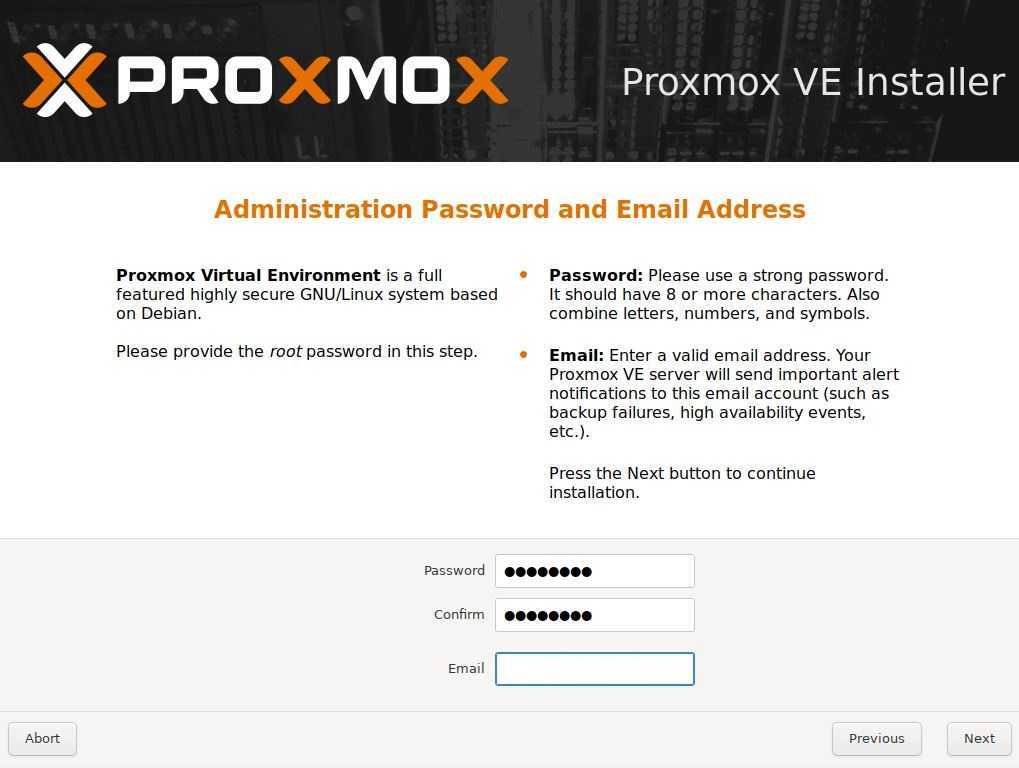
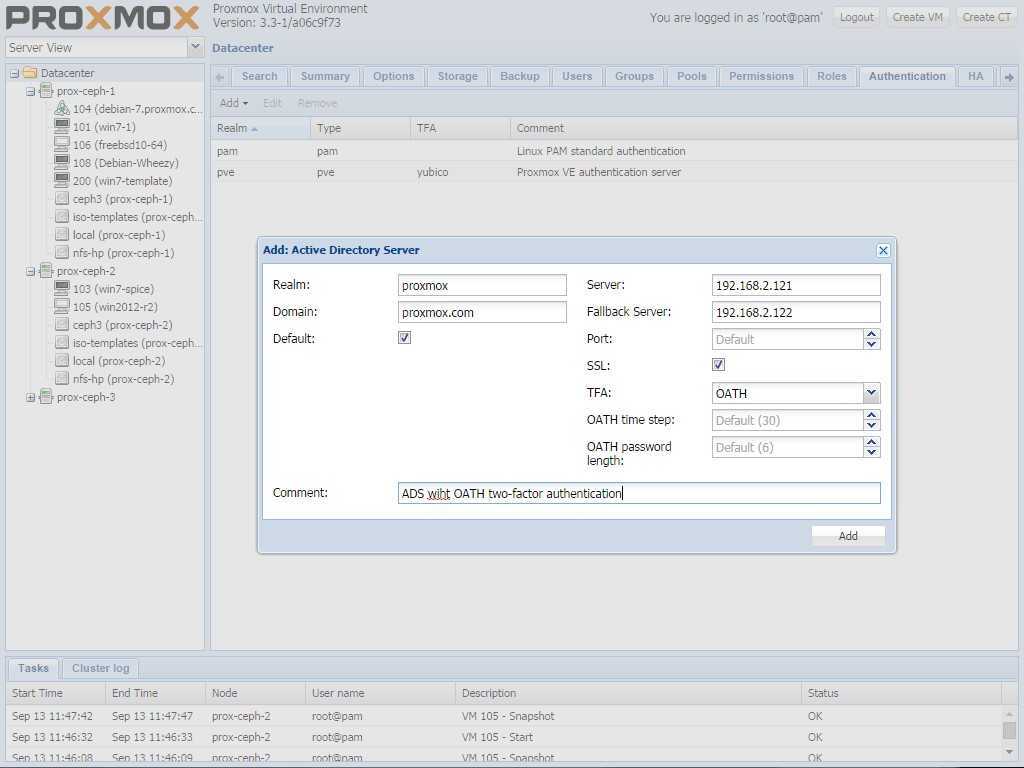
Thin provisioning
Note: When mounting a thin LV file system, always remember to use the option or to use fstrim regularly, to allow the thin LV to shrink as files are deleted.
From :
- Blocks in a standard Logical Volume (LV) are allocated when the LV is created, but blocks in a thin provisioned LV are allocated as they are written. Because of this, a thin provisioned LV is given a virtual size, and can then be much larger than physically available storage. The amount of physical storage provided for thin provisioned LVs can be increased later as the need arises.
Example: implementing virtual private servers
Here is the classic use case. Suppose you want to start your own VPS service, initially hosting about 100 VPSes on a single PC with a 930 GiB hard drive. Hardly any of the VPSes will actually use all of the storage they are allotted, so rather than allocate 9 GiB to each VPS, you could allow each VPS a maximum of 30 GiB and use thin provisioning to only allocate as much hard drive space to each VPS as they are actually using. Suppose the 930 GiB hard drive is . Here is the setup.
Prepare the volume group, .
# vgcreate MyVolGroup /dev/sdb
Create the thin pool LV, . This LV provides the blocks for storage.
# lvcreate --type thin-pool -n MyThinPool -l 95%FREE MyVolGroup
The thin pool is composed of two sub-volumes, the data LV and the metadata LV. This command creates both automatically. But the thin pool stops working if either fills completely, and LVM currently does not support the shrinking of either of these volumes. This is why the above command allows for 5% of extra space, in case you ever need to expand the data or metadata sub-volumes of the thin pool.
For each VPS, create a thin LV. This is the block device exposed to the user for their root partition.
# lvcreate -n SomeClientsRoot -V 30G --thinpool MyThinPool MyVolGroup
The block device may then be used by a VirtualBox instance as the root partition.
Use thin snapshots to save more space
Instead of installing Linux from scratch every time a VPS is created, it is more space-efficient to start with just one thin LV containing a basic installation of Linux:
# lvcreate -n GenericRoot -V 30G --thinpool MyThinPool MyVolGroup *** install Linux at /dev/MyVolGroup/GenericRoot ***
Then create snapshots of it for each VPS:
# lvcreate -s MyVolGroup/GenericRoot -n SomeClientsRoot
This way, in the thin pool there is only one copy the data common to all VPSes, at least initially. As an added bonus, the creation of a new VPS is instantaneous.
Since these are thin snapshots, a write operation to only causes one COW operation in total, instead of one COW operation per snapshot. This allows you to update more efficiently than if each VPS were a regular snapshot.
Example: zero-downtime storage upgrade
There are applications of thin provisioning outside of VPS hosting. Here is how you may use it to grow the effective capacity of an already-mounted file system without having to unmount it. Suppose, again, that the server has a single 930 GiB hard drive. The setup is the same as for VPS hosting, only there is only one thin LV and the LV’s size is far larger than the thin pool’s size.
# lvcreate -n MyThinLV -V 16T --thinpool MyThinPool MyVolGroup
This extra virtual space can be filled in with actual storage at a later time by extending the thin pool.
Suppose some time later, a storage upgrade is needed, and a new hard drive, , is plugged into the server. To upgrade the thin pool’s capacity, add the new hard drive to the VG:
# vgextend MyVolGroup /dev/sdc
Now, extend the thin pool:
# lvextend -l +95%FREE MyVolGroup/MyThinPool
Since this thin LV’s size is 16 TiB, you could add another 15.09 TiB of hard drive space before finally having to unmount and resize the file system.
Note: You will probably want to use or a disk quota to prevent applications from attempting to use more physical storage than there actually is.
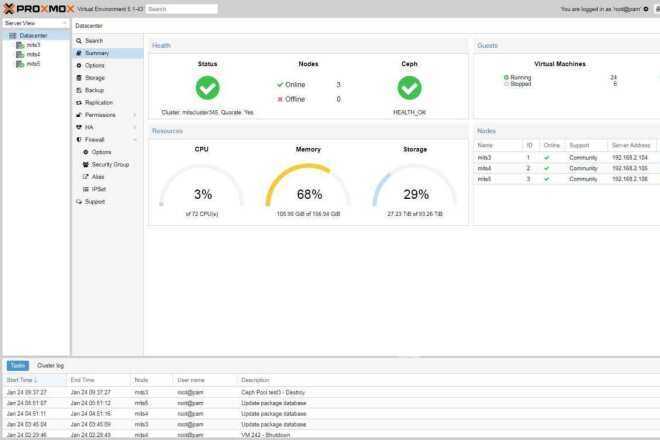
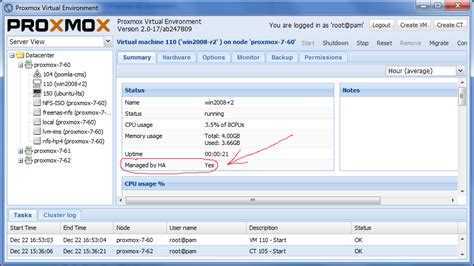
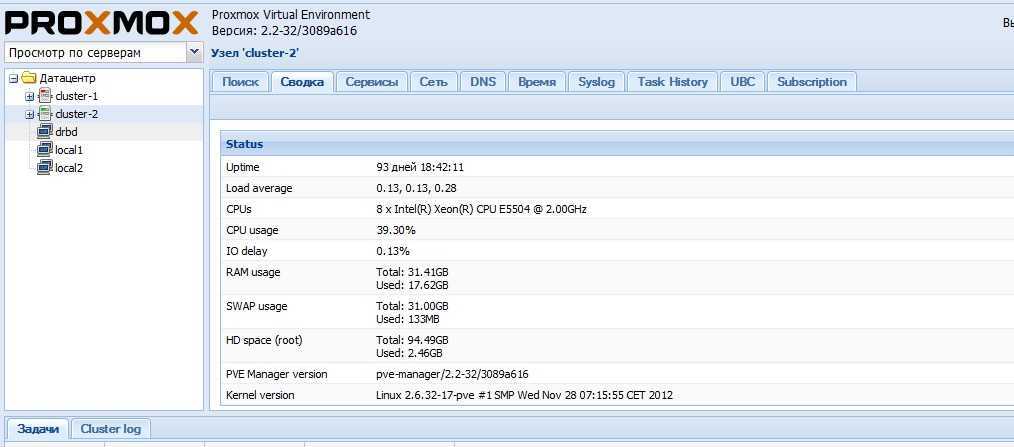
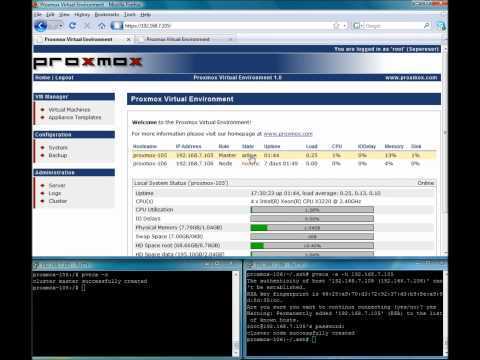
Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
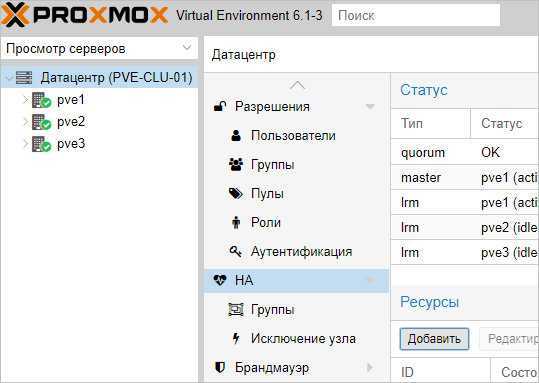
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
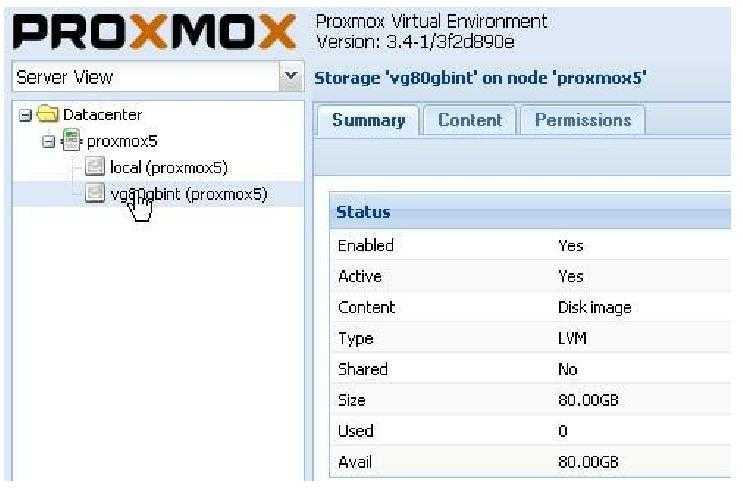
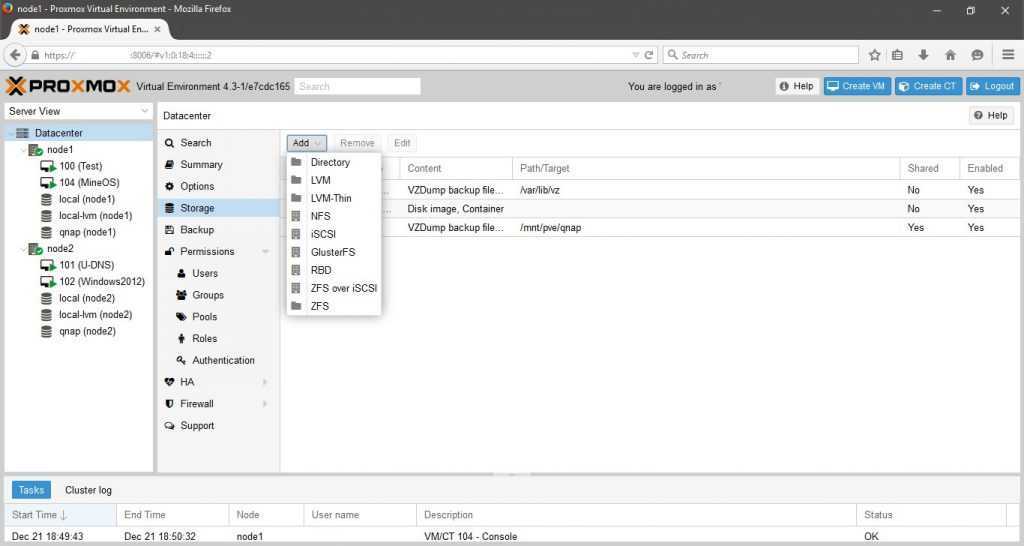
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
… IQN инициаторов. Пример ответа:
…
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
После настройки СХД, в панели управления Proxmox переходим в Датацентр — Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):
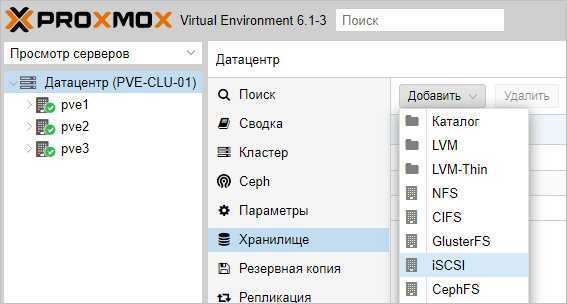
В открывшемся окне указываем настройки для подключения к хранилке:
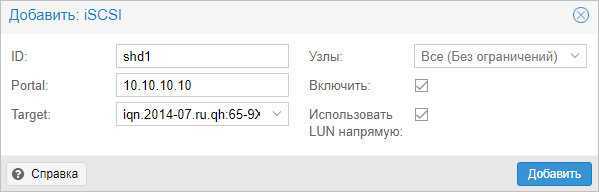
* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:
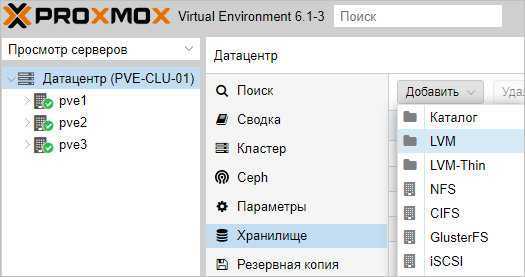
Задаем настройки для тома LVM:

* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
3. Настройка отказоустойчивости
Создание группы
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр — HA — Группы. Кликаем по кнопке Создать:
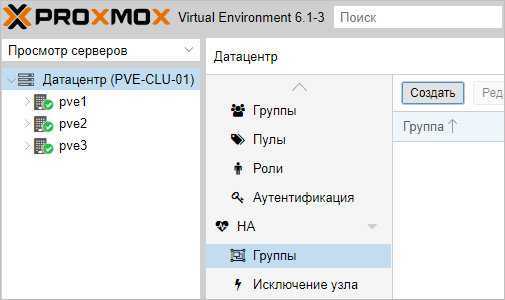
Вносим настройки для группы и выбираем галочками участников группы:

* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр — HA. Кликаем по кнопке Добавить:
В открывшемся окне выбираем виртуальную машину и группу:

… и нажимаем Добавить.
4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 — 2 минут.
Тюнинг сервера PVE
Внесем несколько изменений, которые сделают работу с Proxmox VE удобнее.
Отключение предупреждения об отсутствии подписки
Каждый раз при заходе в панель управления мы будем видеть такое предупреждение:
Оно говорит нам о том, что мы используем бесплатную версию программного продукта. Чтобы сообщение нас не беспокоило, выполним 2 действия:
- Отключим платный репозиторий для получения пакетов proxmox.
- Отредактируем файл js для отключения данного сообщения.
И так, в SSH открываем на редактирование репозиторий proxmox:
nano /etc/apt/sources.list.d/pve-enterprise.list
Приводим его к виду:
#deb https://enterprise.proxmox.com/debian/pve buster pve-enterprise
deb http://download.proxmox.com/debian/pve stretch pve-no-subscription
* мы закомментировали репозиторий pve-enterprise и добавили pve-no-subscription.
* при большом желании, можно удалить файл репозитория с именем pve-enterprise.list и создать новый — кому как будет удобнее.
После обновим список пакетов:
apt-get update
Последнее — редактируем файл /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js:
sed -i «s/getNoSubKeyHtml:/getNoSubKeyHtml_:/» /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js
* данной командой мы находим getNoSubKeyHtml в файле /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js и меняем на getNoSubKeyHtml_.
Закрываем окно браузера с Proxmox, если оно было открыто и запускаем его снова. Входим в систему — сообщение не должно появиться.
Сертификаты
Сервер PVE устанавливается с самоподписанным сертификатом. Это означает, что при подключении к панели управления мы будем видеть предупреждение от системы безопасности. Чтобы браузер принимал сертификат, он должен соответствовать следующим требованиям:
- Быть выдан доверенным центром сертификации или зарегистрированным в вашей локальной сети, например, локальный AD CS.
- Быть для доменного имени, по которому мы заходим в панель управления.
- Иметь актуальные даты начала действия и окончания.
При этом, мы не должны заходить в панель управления по IP-адресу — в противном случае, независимо от сертификата, мы все-равно, получим предупреждение.
И так, сам сертификат можно купить, запросить бесплатно у Let’s Encrypt или создать с использованием локального центра сертификации, например, по данной инструкции. Получив сертификат, открываем панель управления PVE и переходим к серверу — Система — Сертификаты — кликаем по Загрузить пользовательский сертификат:
В открывшемся окне заполняем поля для закрытого и открытого ключей:
… и нажимаем Загрузить. Система предупредит, что загрузится с новым сертификатом — необходимо закрыть вкладку в браузере и открыть консоль управления снова. Если сертификат загружен правильный, мы не увидим предупреждения.
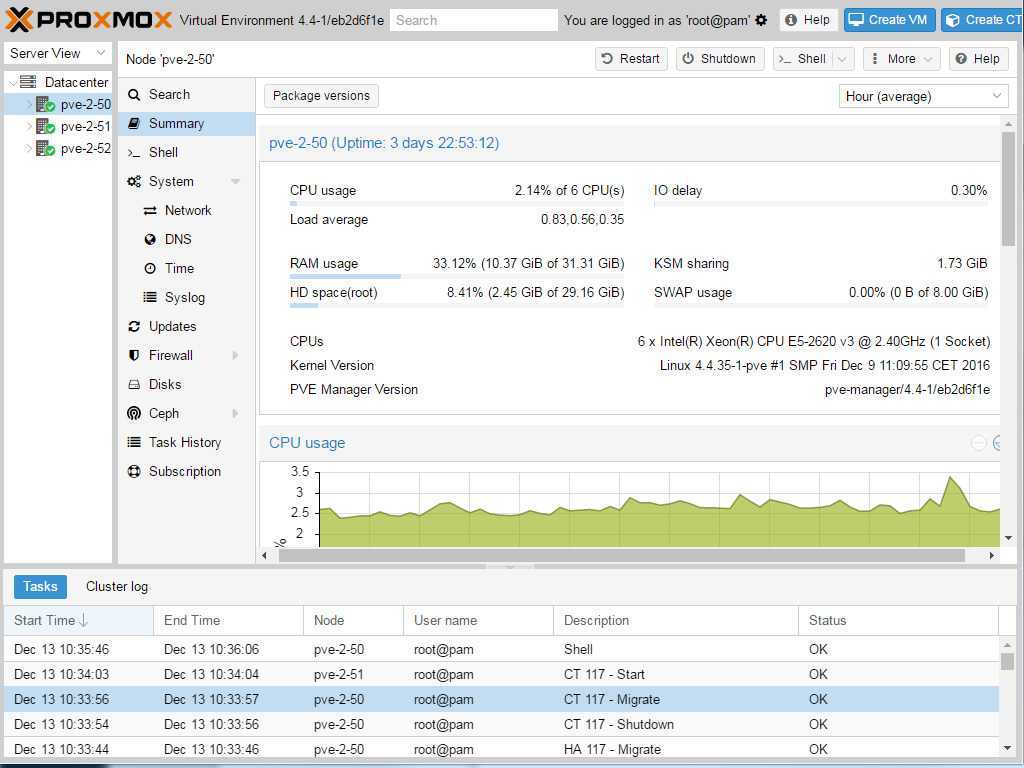
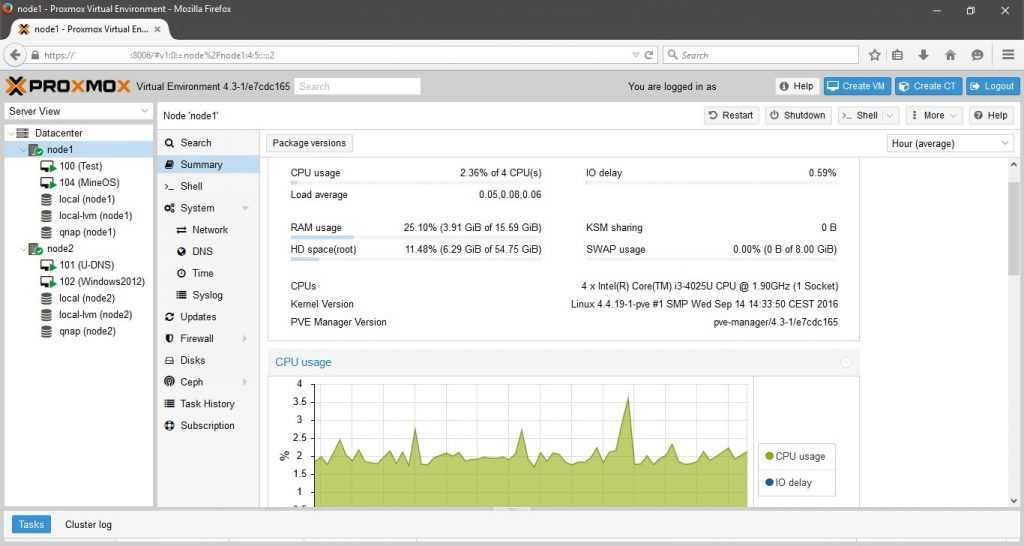
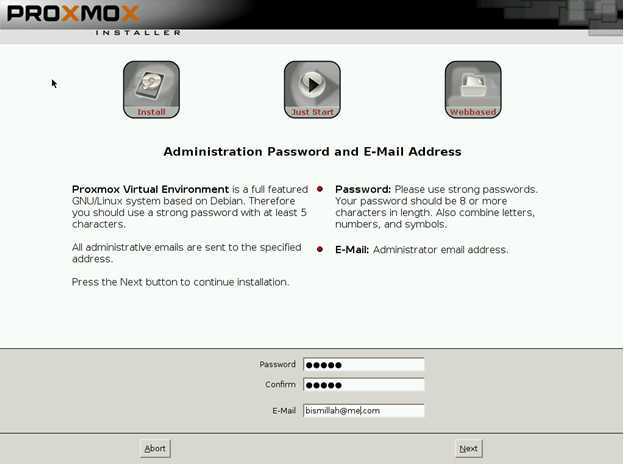
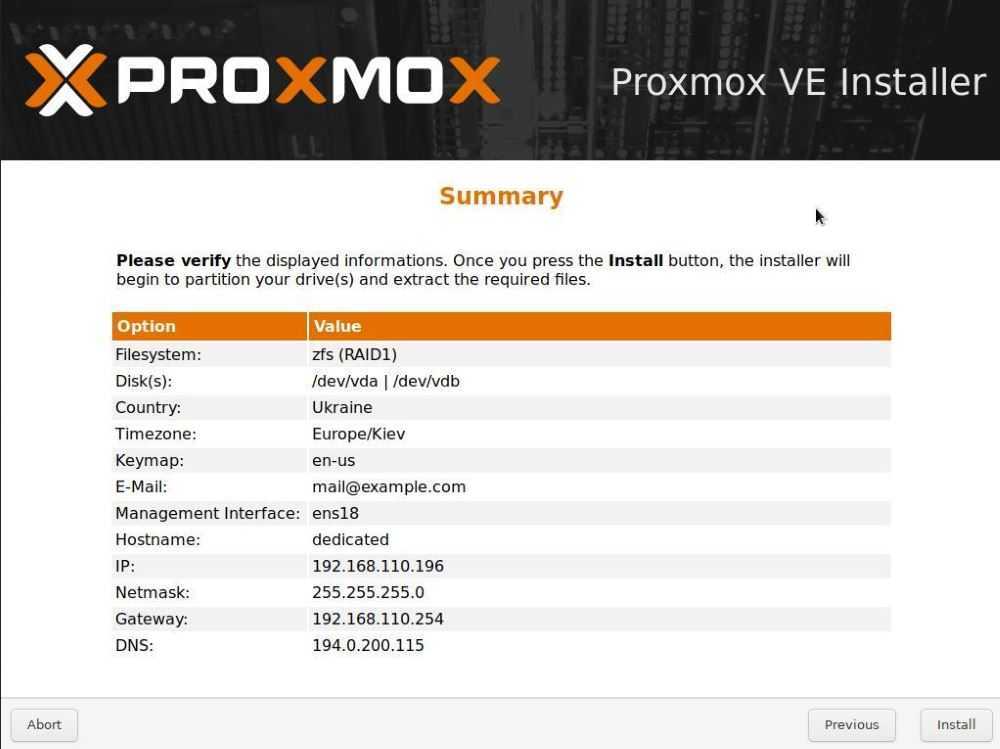
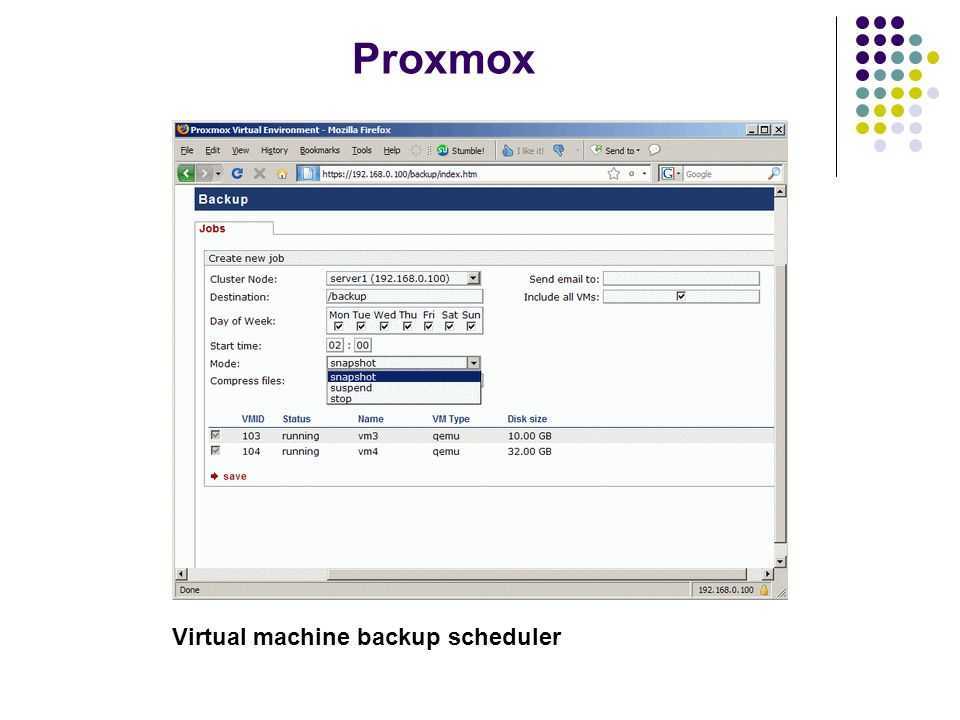
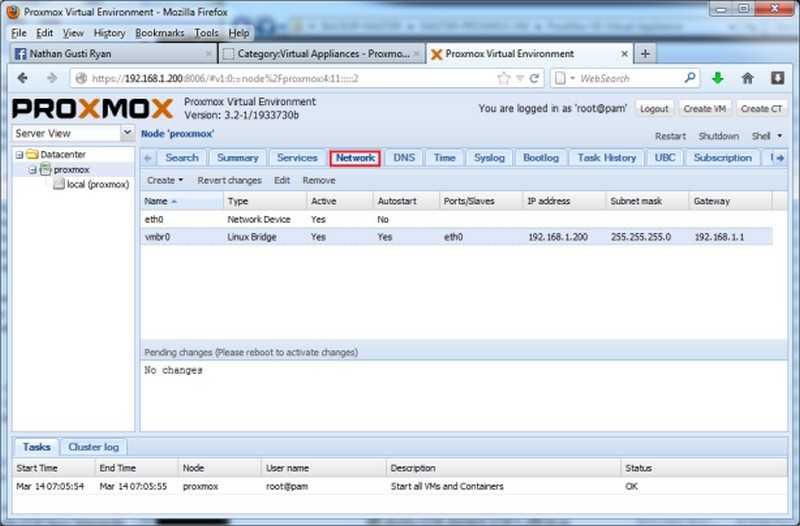
Настройка сети в Proxmox VE
После установки всех необходимых пакетов и перезагрузки ОС в WTB-интерфейсе Proxmox VE перейдите в раздел Датацентр, выберите имя гипервизора (на скриншоте PVE). В меню Система найдите раздел Сеть и нажмите кнопку Создать:
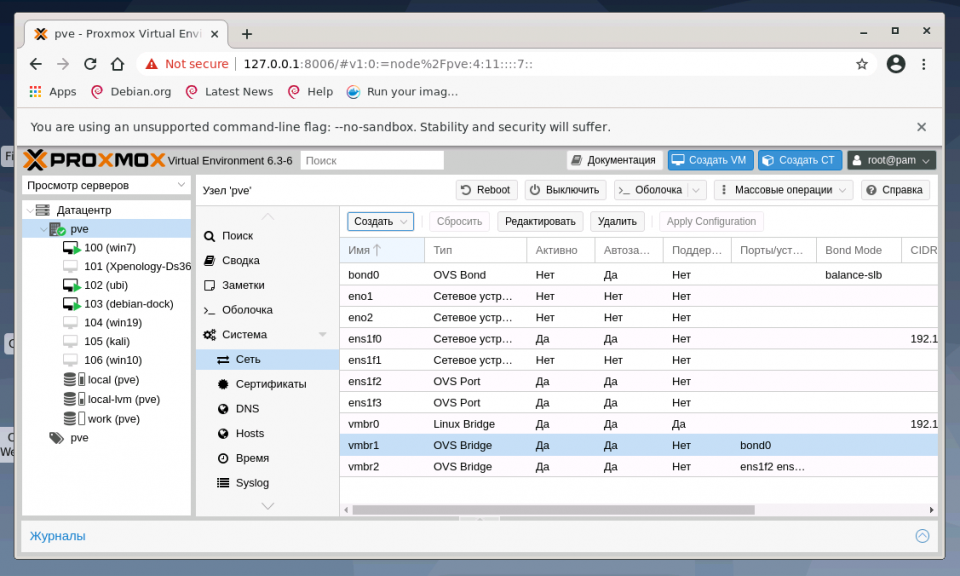
1. Настройка bridge
Создание интерфейса bridge для Open vSwitch и для ядра Linux практически ничем не отличаются, за исключением выбора способа создания и возможности указания для OVS Bridge дополнительных ключей Open vSwitch. Если планируется использовать VLAN для сетевого интерфейса, не забудьте указать чек-бокс возле пункта VLAN при создании bridge. Включение чек-бокса Автозапуск позволяет запускать выбранный сетевой интерфейс при загрузке гипервизора:
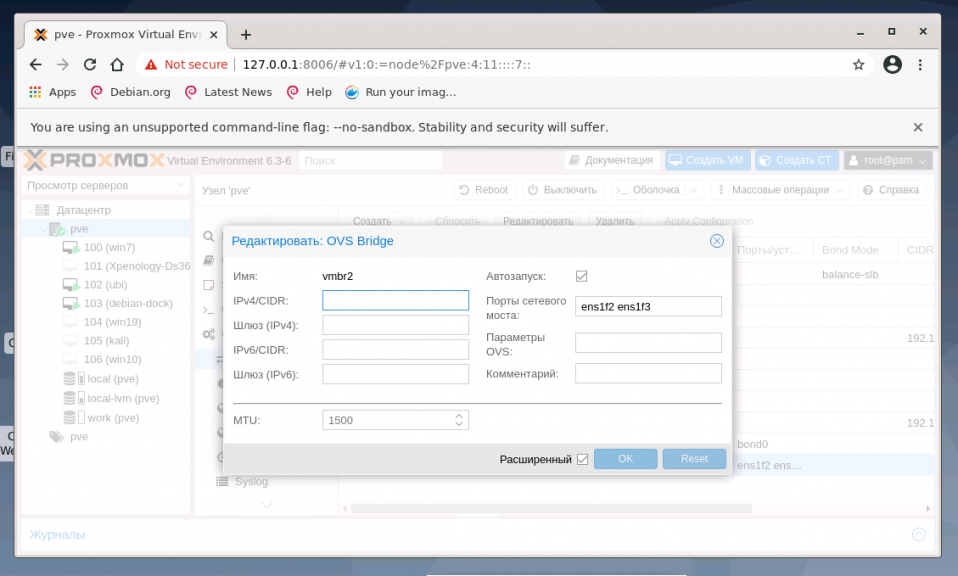
В общем случае, если сетевой интерфейс bridge создаётся единственный для гипервизора, то нет необходимости перечислять в пункте Порты сетевого моста все имеющиеся сетевые карты. Однако, если существует необходимость на уровне интерфейса разделить подключения к различным каналам связи или сегментам сети, то можно использовать различные комбинации сетевых устройств. На представленном хосте гипервизора их четыре, поэтому можно ввести два из них (перечислением через пробел) в bridge OVS:
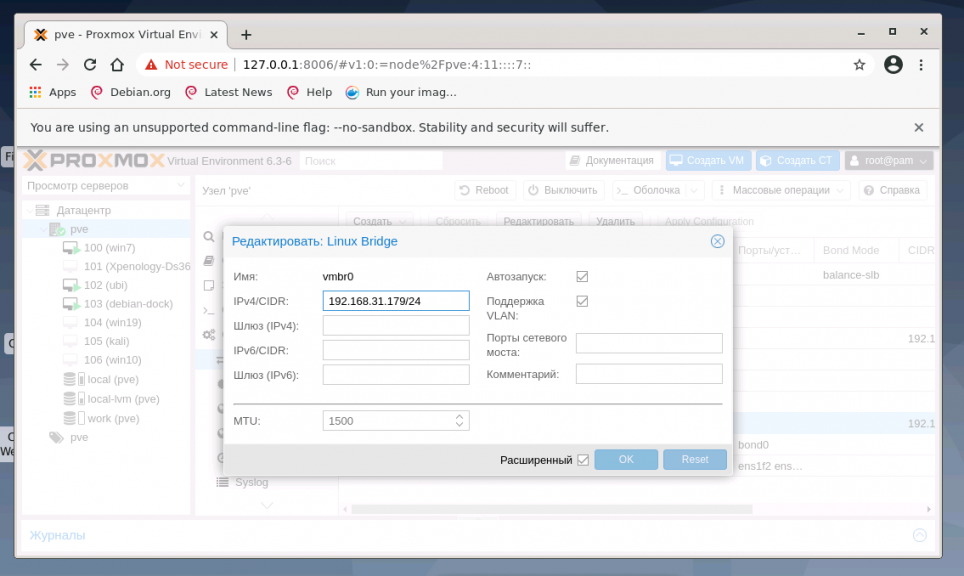
Адрес интерфейса можно не указывать, настроенные на подключение к интерфейсу виртуальные машины будут использовать его как обычный свитч. Если же указать адрес IPv4 и/или IPv6, то он будет доступен извне на всех сетевых интерфейсах или на интерфейсах, перечисленных в поле Порты сетевого моста:
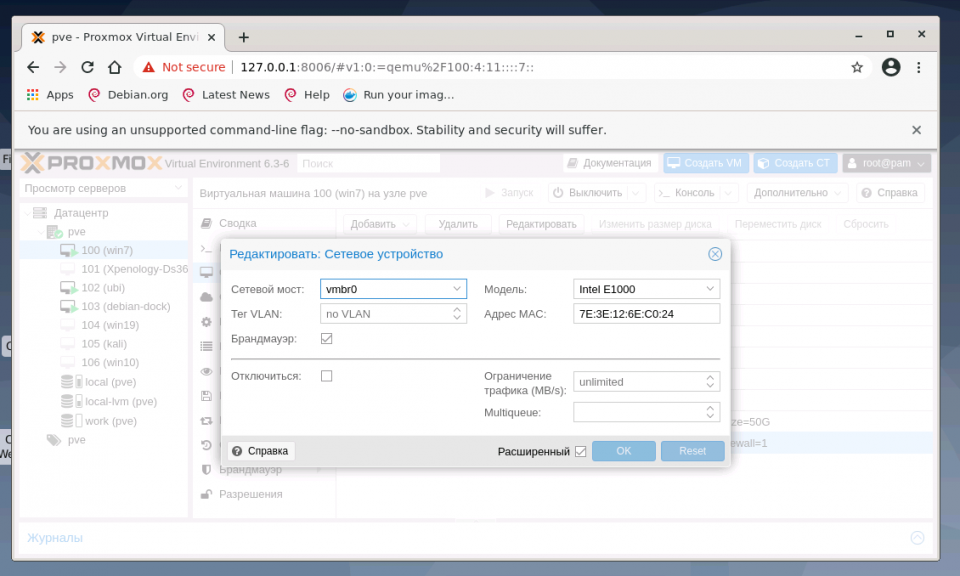
2. Настройка bond
Для балансировки нагрузки и объединения нескольких сетевых интерфейсов в один виртуальный, создайте OVS Bond. Это связано с тем, что его возможности шире, чем Linux Bond, а процесс создания практически идентичен. Для создания балансировщика нагрузки нажмите в меню Сеть кнопку Создать и выберите пункт OVS Bond:
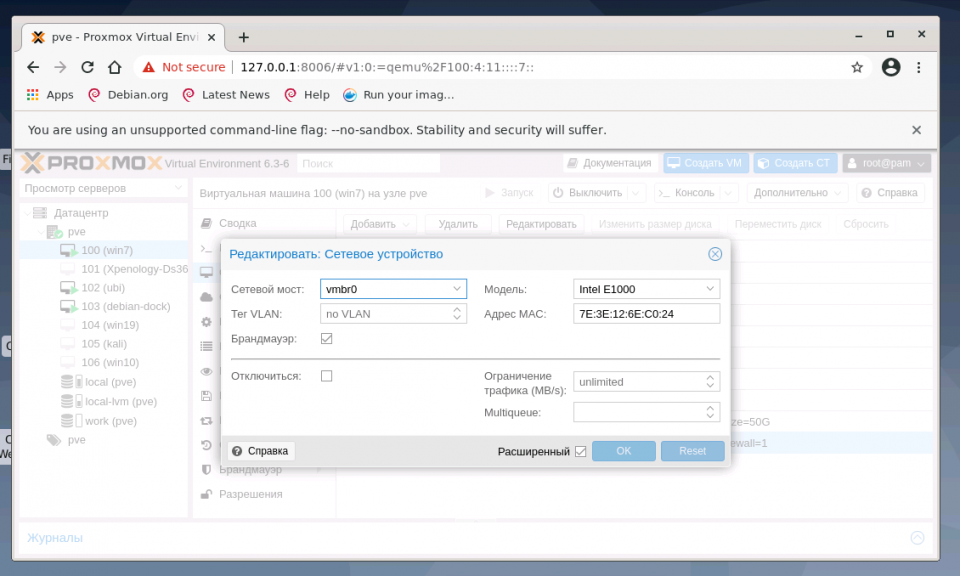
В отличие от создания OVS bridge, в параметрах vmbr1 OVS Bond указано в портах сетевого моста bond0 и в пункте OVS Options для тегирования VLAN можно использовать ключ tag=$VLAN, где $VLAN надо заменить на целое числовое значение, в примере это 50:
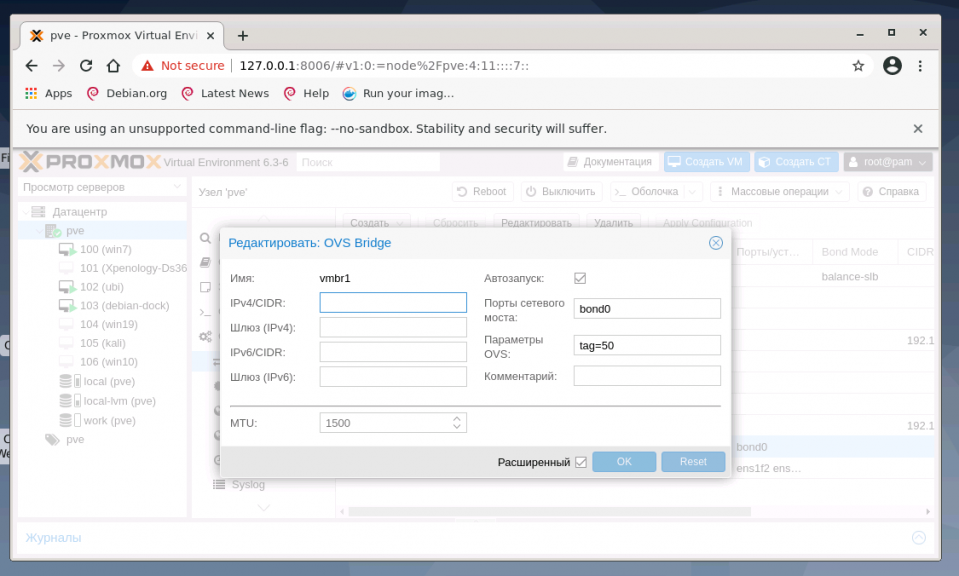
Режимы балансировки можно установить только при создании интерфейса bond, перечислим их основные характеристики.
Для OVS Bridge:
- Режим Active-Backup использует один из перечисленных сетевых интерфейсов для работы, а остальные находятся в резерве в статусе down, на случай выхода из строя основного интерфейса
- Режимы Balance-slb, LACP (balance-slb), LACP (balance-tcp) подходят для случая, когда вам необходимо расширить полосу пропускания и отказоустойчивость канала, объединив в единый бонд несколько сетевых интерфейсов.
Для Linux Bond:
- Режим balance-rr ядра Linux скорее переназначен для исходящего траффика, чем для входящего. Пакеты отправляются последовательно, начиная с первого доступного интерфейса и заканчивая последним. Применяется для балансировки нагрузки и отказоустойчивости.
- Режим active-backup ничем не отличается от аналогичного режима в OVS. Передача распределяется между сетевыми картами используя формулу: . Получается одна и та же сетевая карта передаёт пакеты одним и тем же получателям. Режим XOR применяется для балансировки нагрузки и отказоустойчивости.
- Режим агрегирования каналов по стандарту IEEE 802.3ad. Создаются агрегированные группы сетевых карт с одинаковой скоростью и дуплексом. При таком объединении передача задействует все каналы в активной агрегации, согласно стандарту IEEE 802.3ad. Необходимо оборудование гипервизора и активной сетевой части с поддержкой стандарта.
- Режим адаптивной балансировки нагрузки передачи balance-tlb. Исходящий трафик распределяется в зависимости от загруженности каждой сетевой карты (определяется скоростью загрузки). Не требует дополнительной настройки на коммутаторе. Входящий трафик приходит на текущую сетевую карту. Если она выходит из строя, то другая сетевая карта берёт себе MAC адрес вышедшей из строя карты.
- Режим адаптивной балансировки нагрузки Balance-alb. Включает в себя политику balance-tlb, а также осуществляет балансировку входящего трафика. Не требует дополнительной настройки на коммутаторе.
3. Настройка VLAN
В меню Система найдите раздел Сеть и нажмите кнопку Создать и выберите OVS InPort:
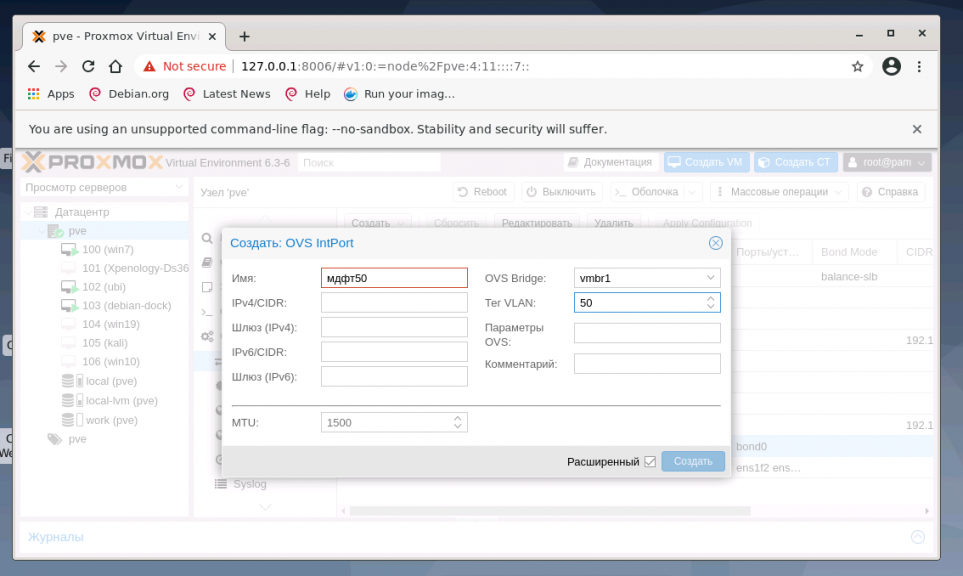
Задайте имя интерфейса vlan50 тег VLAN, равный 50, укажите OVS Bridge. VLAN 50 на указанном виртуальном интерфейсе OVS Bridge vmbr1 с тегом 50 создан и может быть использован, например для организации видеонаблюдения. Таким образом, предлагаю настроить дополнительно VLAN30 для IP телефонии и VLAN100 для локальной сети с виртуализированными рабочими местами. Для создания всех VLAN используйте интерфейс vmbr1.
Переход на Proxmox VE 4.х + Ceph
Было решено перейти на связку Proxmox VE 4.х + Ceph, что позволило бы создать масштабируемое и отказоустойчивое собственное «облако».
В отличие от таких распределённых файловых систем, как GFS, OCFS2 и GPFS, в Ceph обработка данных и метаданных разделена на различные группы узлов в кластере, примерно как это сделано в Lustre, с тем различием, что обработка производится на уровне пользователя, не требуя никакой особой поддержки от ядра операционных систем узлов. Ceph может работать поверх блочных устройств, внутри одного файла или используя существующую файловую систему узла (например, XFS).
В Proxmox VE 4.0 OpenVZ был заменен на LXC. При конвертации образов машин из OpenVZ в LXC наблюдали некоторые проблемы, например:
- Контейнер LXC работает в 2 — 3 раза медленнее OpenVZ;
- Контейнеры с Debian 6 и CentOS 5 не поддерживаются;
- В CentOS 6 не работала сеть из-за переименования сетевых интерфейсов с venet0 на eth0;
- Нельзя зайти в контейнер redhat based по ssh из за отсутствия tty;
В версии 4.3 все исправили.
На конец 2016 года идет создание тестового стенда для внедрения собственного «облака».
Режимы архивирования
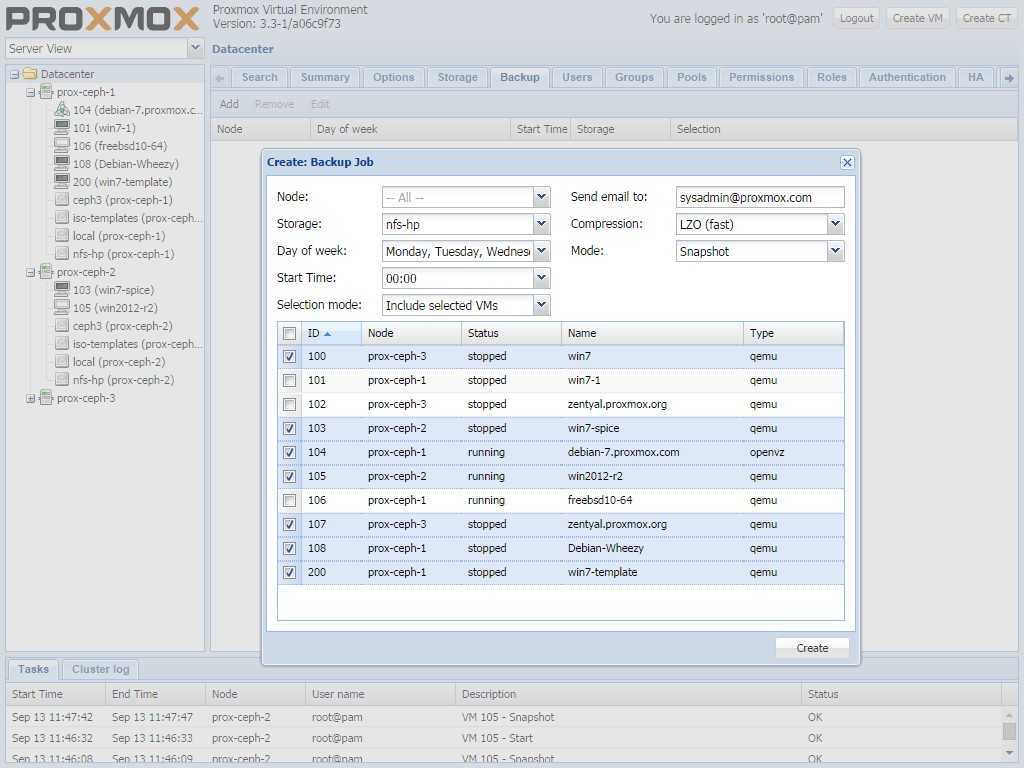
- Режим Snapshot (Снимок). Этот режим можно еще назвать как Live backup, поскольку для его использования не требуется останавливать работу виртуальной машины. Использование этого механизма не прерывает работу VM, но имеет два очень серьезных недостатка — могут возникать проблемы из-за блокировок файлов операционной системой и самая низкая скорость создания. Резервные копии, созданные этим методом, надо всегда проверять в тестовой среде. В противном случае есть риск, что при необходимости экстренного восстановления, они могут дать сбой.
- Режим Suspend (Приостановка). Виртуальная машина временно «замораживает» свое состояние, до окончания процесса резервного копирования. Содержимое оперативной памяти не стирается, что позволяет продолжить работу ровно с той точки, на которой работа была приостановлена. Разумеется, это вызывает простой сервера на время копирования информации, зато нет необходимости выключения/включения виртуальной машины, что достаточно критично для некоторых сервисов. Особенно, если запуск части сервисов не является автоматическим. Тем не менее такие резервные копии также следует разворачивать в тестовой среде для проверки.
- Режим Stop (Остановка). Самый надежный способ резервного копирования, но требующий полного выключения виртуальной машины. Отправляется команда на штатное выключение, после остановки выполняется резервное копирование и затем отдается команда на включение виртуальной машины. Количество ошибок при таком подходе минимально и чаще всего сводится к нулю. Резервные копии, созданные таким способом, практически всегда разворачиваются корректно.
Как увеличить диск LVM на ProxMox VE 5.4
Итак приступим. Сперва выключаем нашу виртуальную машину в программе VirtualBox и добавляем место на диске для нашей виртуальной машины.
Меняем размер на 70ГБ:
На картинке внизу мы видим что у нас получился новый размер диска:
Ниже видно что размер диска sda изменился и стал 70G. Но sda3 раздел диска остался старого размера.
1. Настройка размера раздела LVM через Gparted
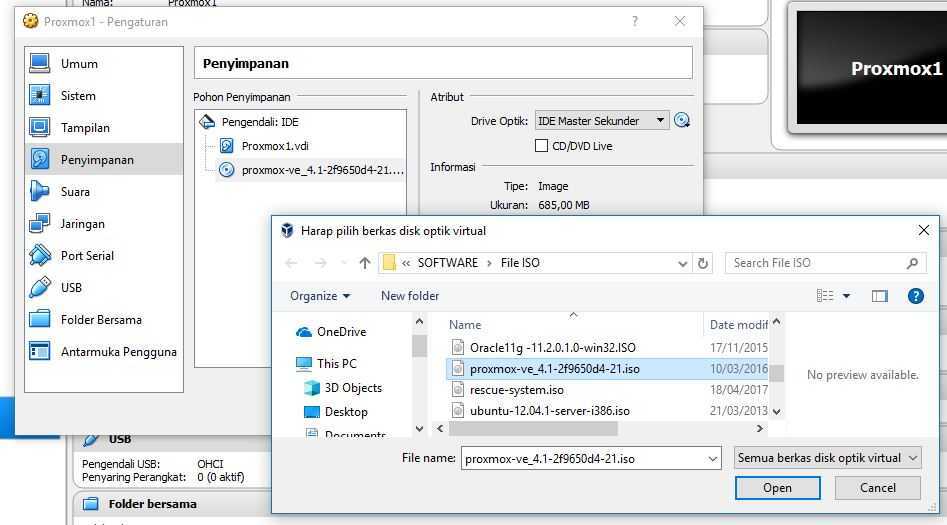
Вот так это будет смотреться если вы в VirtualBox на нашей виртуальной машине в оптический привод вставите iso образ LinuxMint, загрузитесь с него и посмотрите через программу Gparted. Видно что физический том LVM не изменился:
Сразу скажу если у вас есть возможность запустить GParted как показано выше, то вы можете и отсюда изменить размер sda3 без потерь следующим образом. Выбираете раздел -> sda3 и в меню, затем Edit ->Resize/Move см. ниже:
Смотрим ниже — тянем коричневую полосу до конца чтобы увеличить размер диска proxmox:
Жмем Resize:
Теперь чтоб применить все изменения нажимаем на галочку:
После выключаем виртуальную машину Proxmox, ставим первой загрузку с жесткого диска -> запускаем виртуальную машину и увидим что размер логической группы pve увеличился на 20G. И после в консоли можно добавить нужный нам размер, например, для логического тома data с помощью команды:
Мы добавили 10G для логического тома data.
2. Увеличение размера LVM Proxmox через треминал
Но бывает так что только через консоль есть возможность изменить размер, и желательно это сделать в самой вирт. машине. Давайте рассмотрим этот вариант. Вернемся к тому что мы добавили нашей виртуальной машине свободного места через VirtualBox, И все выглядит вот так:
Если с LiveCD смотреть то вот так это выглядит:
Итак мы загрузили нашу виртуальную машину Proxmox, зашли на нее по ssh, набрали lsblk, увидели новый размер sda = 70G. Теперь через консоль будем менять размер раздела sda3 а с ним и размер логического тома LMV c именем dаta:
Первое что нужно сделать это поставить программу parted, это консольная версия программы Gparted:
После успешной установки заходим в parted и выбираем наш диск /dev/sda. Прошу не путать именно /dev/sda:
Далее смотрим наши разделы с помощью команды print:
Cверху на картинке видим что размер нашего lvm диска 42.4 GB и его номер 3. Будем его изменять. Наберем команду resizepart 3 и жмем Enter:


Далее пишем 100%FREE это значит что увеличиваем диск до максимально возможного и жмем Enter:
После выполнения можно снова выполнить команду print и мы увидим новый размер нашего LVM тома который стал 74.6GB:
Далее выходим с помощью команды quit и жмем Enter:
Теперь проверим как все это выглядит с помощью команды:
Итак на картинке сверху мы видим что размер sda3 раздела стал 69.5G но при этом сам LVM том data мы увеличить не сможем, а будет выходить ошибка, давайте попробуем все таки увеличить логический том LVM, и проверим:
Мы видим что изменения не применялись т.к. недостаточно свободного места. Если мы загрузимся с LiveCD в нашу виртуальную машину и посмотрим через программу Gparted то увидим следующую картину:
Дело в том что раздел sda3 мы увеличили, но при этом сам LVM физический том остался прежним. Физический LVM том — как следствие и группа LVM занимают старый объем. Чтобы это изменить надо растянуть физический LVM том на все свободное место для этого мы применим команду pvresize /dev/sda3 и жмем Enter:
На нижней картинке размер физического тома изменился мы это видим в сообщении:
Так же мы это заметим если поочередно введем команды pvs (инф. о физических томах), vgs (инф. о группах LVM). А вот vgs (инф. о логических томах) показывает старый объем для data root и swap т. к. нам его еще предстоит изменить.
Вот так теперь отображается в программе Gparted если загрузиться с LiveCD:
Осталось только добавить свободный объем в логический раздел data. Набираем команду:
Наши 20G добавились:
Проверяем изменения вводим поочередно команды:
Видим что для pvs и vgs неизменны параметры, а команда lvs показывает что наш раздел data стал 38.87G мы видим что он увеличился на 20G. Если мы посмотрим предыдущий вывод команды lvs на снимке, то там видно, что логический том data занимает 18.87G:
В вэб интерфейсе нашей машины мы тоже видим изменения в логическом томе dаta:
Форматы виртуальных накопителей
-
RAW. Самый понятный и простой формат. Это файл с данными жесткого диска «байт в байт» без сжатия или оптимизации. Это очень удобный формат, поскольку его легко смонтировать стандартной командой mount в любой linux-системе. Более того это самый быстрый «тип» накопителя, так как гипервизору не нужно его никак обрабатывать.
Серьезным недостатком этого формата является то, что сколько Вы выделили места для виртуальной машины, ровно столько места на жестком диске и будет занимать файл в формате RAW (вне зависимости от реально занятого места внутри виртуальной машины). -
QEMU image format (qcow2). Пожалуй, самый универсальный формат для выполнения любых задач. Его преимущество в том, что файл с данными будет содержать только реально занятое место внутри виртуальной машины. Например, если было выделено 40 Гб места, а реально было занято только 2 Гб, то все остальное место будет доступно для других VM. Это очень актуально в условиях экономии дискового пространства.
Небольшим минусом работы с этим форматом является следующее: чтобы примонтировать такой образ в любой другой системе, потребуется вначале загрузить особый драйвер nbd, а также использовать утилиту qemu-nbd, которая позволит операционной системе обращаться к файлу как к обычному блочному устройству. После этого образ станет доступен для монтирования, разбиения на разделы, осуществления проверки файловой системы и прочих операций.
Следует помнить, что все операции ввода-вывода при использовании этого формата программно обрабатываются, что влечет за собой замедление при активной работе с дисковой подсистемой. Если стоит задача развернуть на сервере базу данных, то лучше выбрать формат RAW. -
VMware image format (vmdk). Этот формат является «родным» для гипервизора VMware vSphere и был включен в Proxmox для совместимости. Он позволяет выполнить миграцию виртуальной машины VMware в инфраструктуру Proxmox.
Использование vmdk на постоянной основе не рекомендуется, данный формат самый медленный в Proxmox, поэтому он годится лишь для выполнения миграции, не более. Вероятно в обозримом будущем этот недостаток будет устранен.
PVE scripts
- Configure forced command inside PVE «authorized_keys" file:
command="/opt/snap/snap-backup-restore" ssh-rsa AAAAB3NzaC1...
where AAAAB3Nza... is the public counterpart of the id_rsa_backup configured on virtual machines.
NOTE: Take care that /opt/snap/snap-backup-restore is the correct location of the snapshot master script.
You will need on PVE also a recent version of ntfs-3g (Debian Squeeze package is currently too old, Wheezy version is ok), and the attr package.
Utilities
- Copy in a directory of your choice (scripts are configured with C:\App\Scripts\bin\ by default) the executable SetACL.exe
It’s the Open Source tool that takes care of backup and iteractive restore of Windows ACL.
- Copy in a directory of your choice (scripts are configured with C:\App\Scripts\bin\ by default ) the executable sync.exe
N.B.: sync.exe is NOT Open Source software, and you need to execute it the first time from GUI for aknowledging the EULA;
Создание виртуальных машин
Обратите внимание, что веб интерфейс Proxmox VE позволяет создавать виртуальные машины двух типов:
- VM это полностью виртуализированная машина, созданная из ISO образа, который необходимо загрузить в хранилище Proxmox VE;
- CT – паравиртуализированная машина на ядре Linux, шаблоны которой необходимо сначала загрузить и установить в хранилище Proxmox VE.
Параллельно можно поставить загрузку дистрибутива debian10 netinstall ISO со своего рабочего компьютера в хранилище home. Для этого выберите в WEB-интерфейсе хранилище home, тип хранения выберите ISO Images и нажмите кнопку Загрузить, в появившемся окне выберите файл образа ISO со своего компьютера и нажмите ОК.
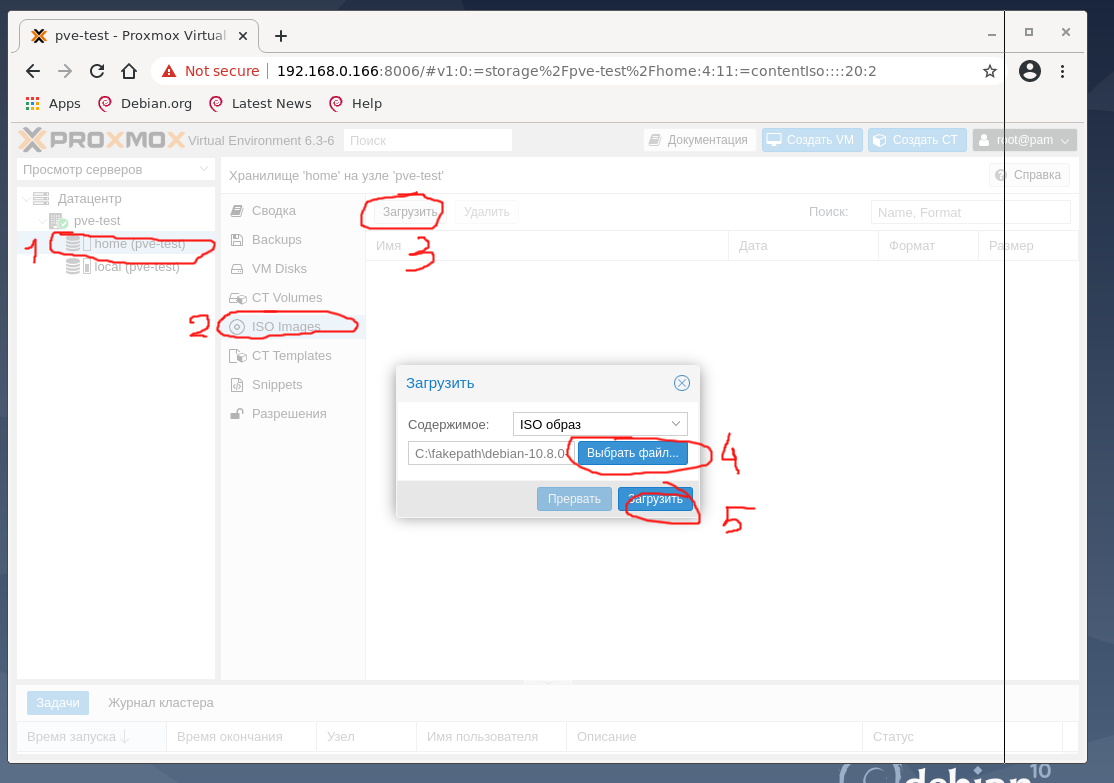
Так же информацию можно загрузить с usb-хранилища, с CD-Диска (на тестовой машине он подключён), передать по сети с помощью FTP, Samba, http. Для этого можно использовать из консоли соответствующие утилиты wget, curl, ftp или файловый менеджер Midnight Commander:
Шаблоны и загрузки расположены по путям хранилищ local: /var/lib/vz или home: /home/pmx. Вы можете напрямую копировать в соответствующий раздел файлы. Логическая структура размещения информации на скриншоте:

Для создания виртуальных машин необходимо создать Пул ресурсов. Для этого кликните в дереве на вкладку Датацентр, справа выберите пункт Пулы, нажмите Создать, на тестовой машине задано имя пула home, по окончании нажмите ОК:
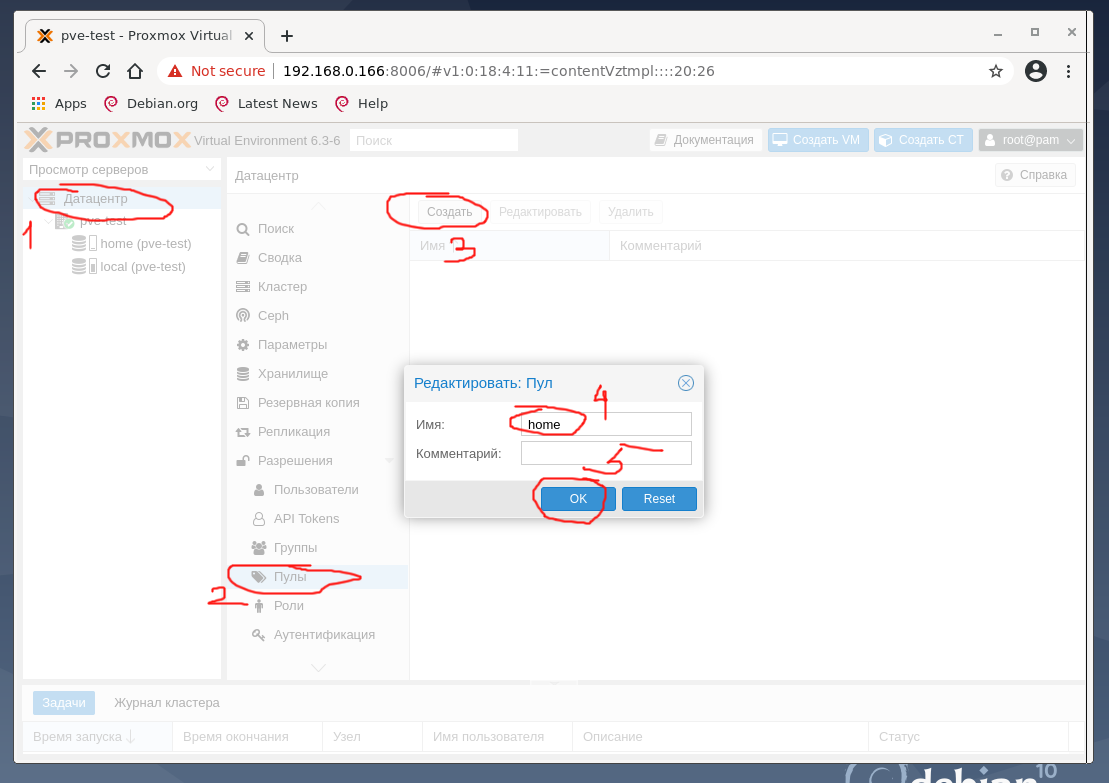
Создание виртуального контейнера CT
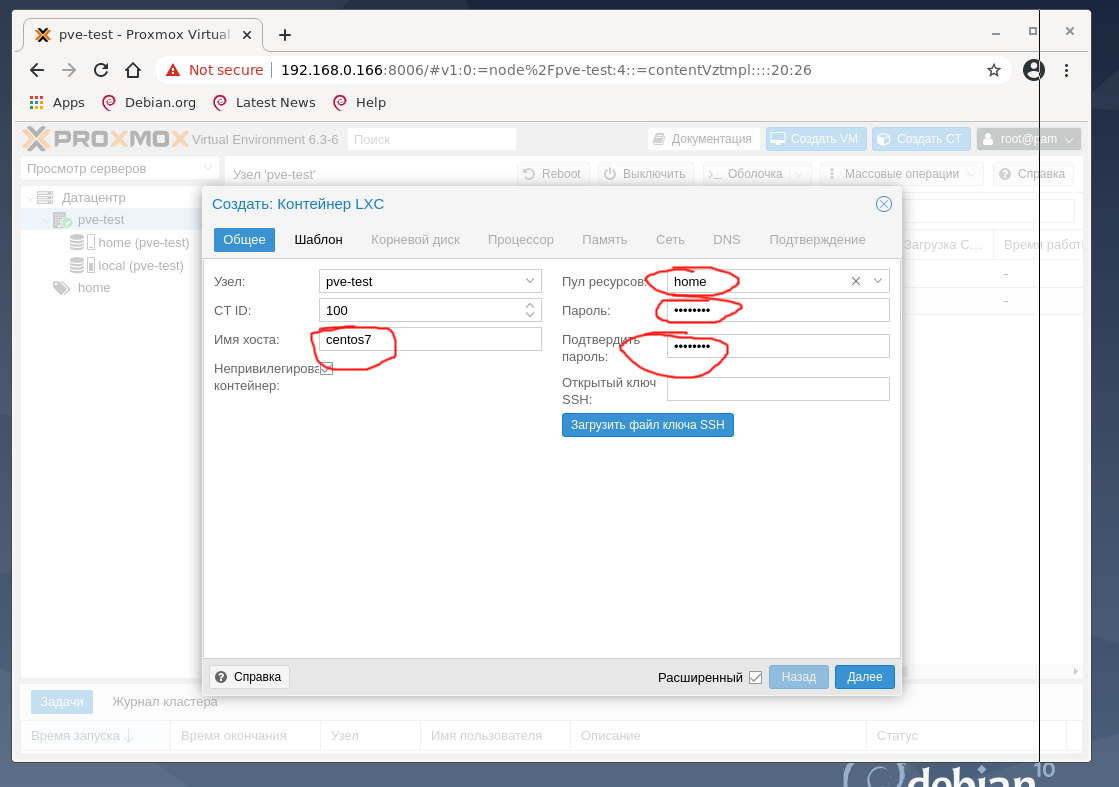
Сначала создайте CT виртуальную машину из скачанного шаблона CentOS 7. Для этого нажмите кнопку Создать CT, заполните поля и нажмите ОК.
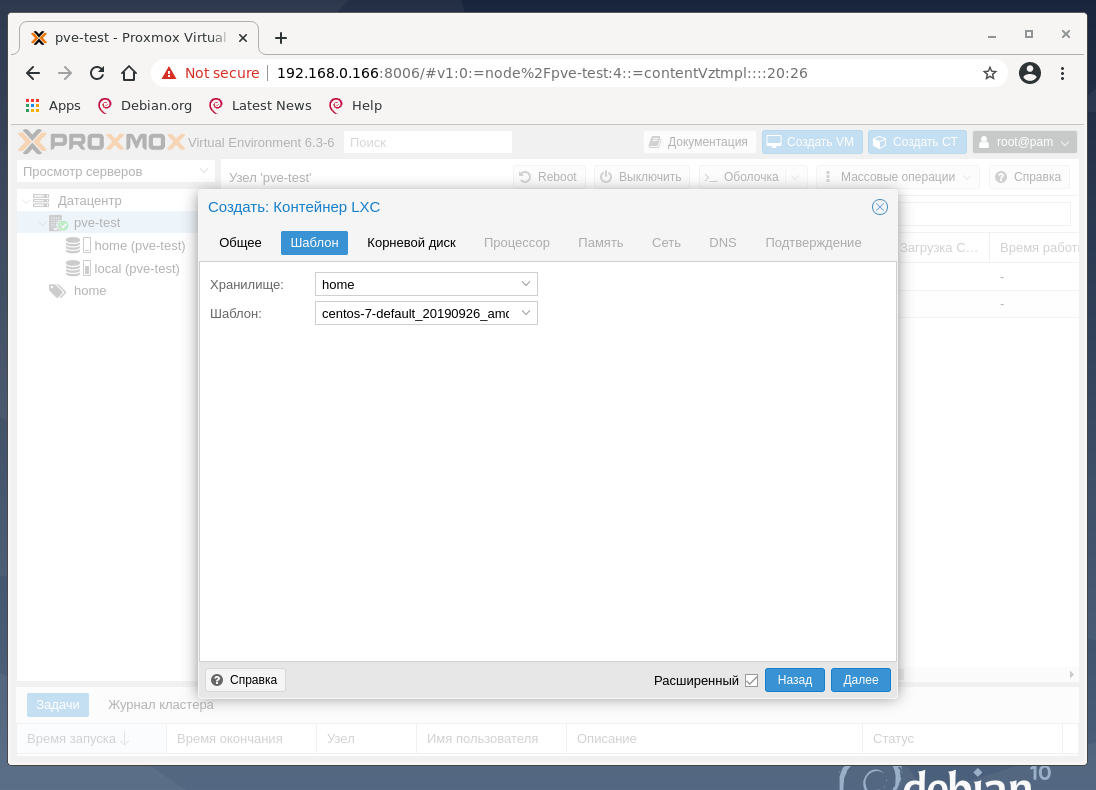
На следующей вкладке выберите хранилище home и ранее закачанный шаблон CentOS 7.
Настройки корневого диска, процессора и памяти на тестовой машине оставим как предложено гипервизором
Обратите внимание на раздел сеть:
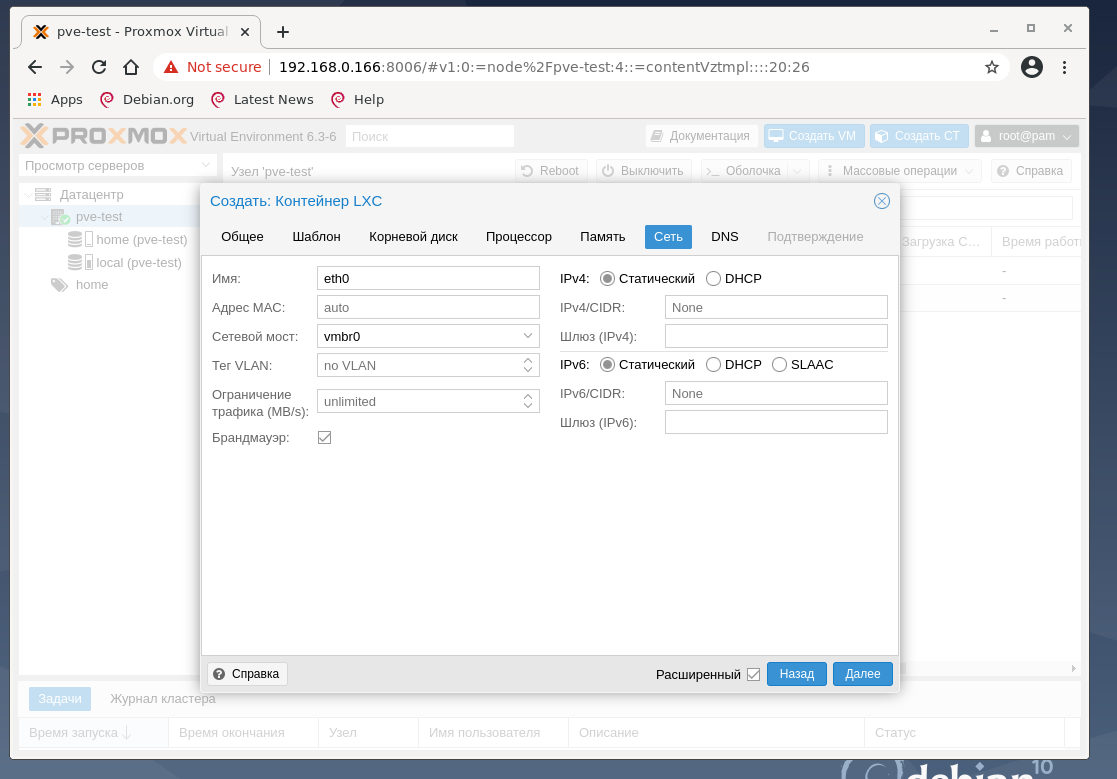
Итак, созданный нами ранее сетевой мост vmbr0 используется в виртуальных машинах Proxmox VE для создания виртуальных сетевых интерфейсов для них. Через vmbr0 интерфейс будет подключён к роутеру сети, к которому подключена сетевая карта, на которой работает vmbr0.


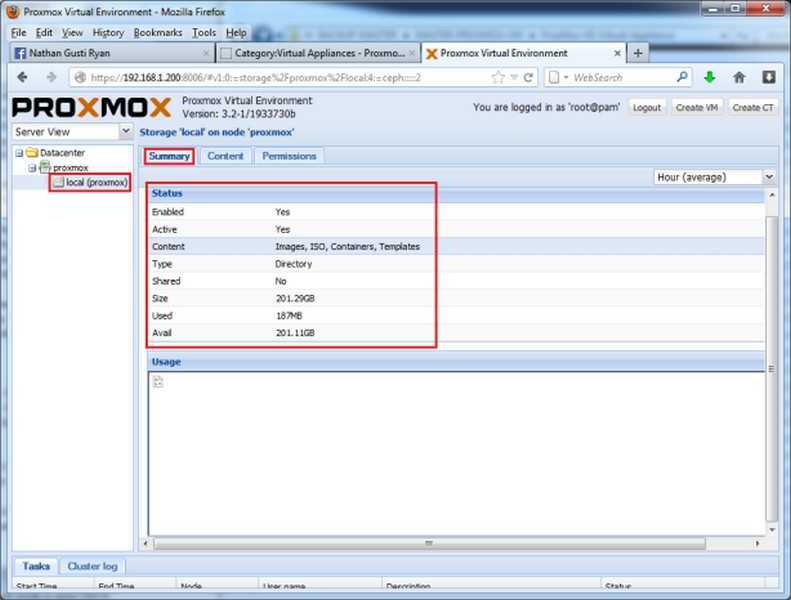
В результате наших действий начинает разворачиваться контейнер, содержащий CentOS 7 и настраиваться виртуальная машина.
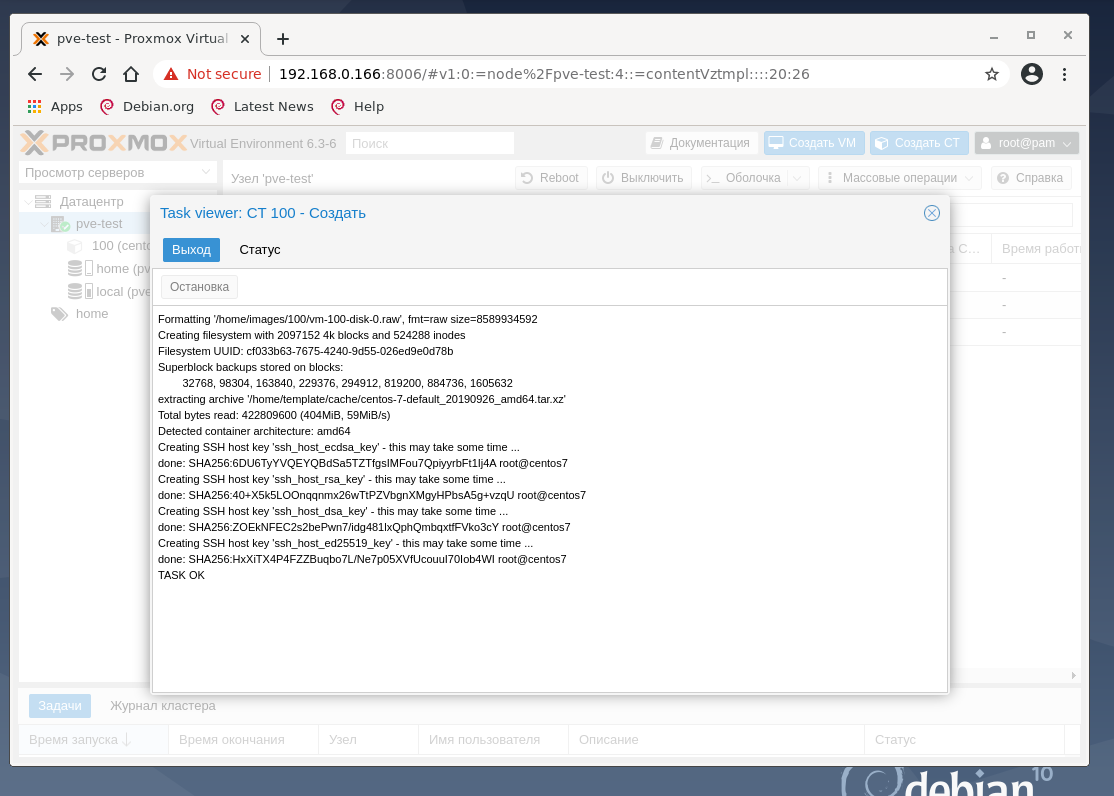
Вернитесь в pve-test, найдите вновь созданный контейнер c ID 100 и названием centos7 и нажмите Запуск, а затем Консоль. Откроется окно браузера, в котором видно запущенный CentOS:
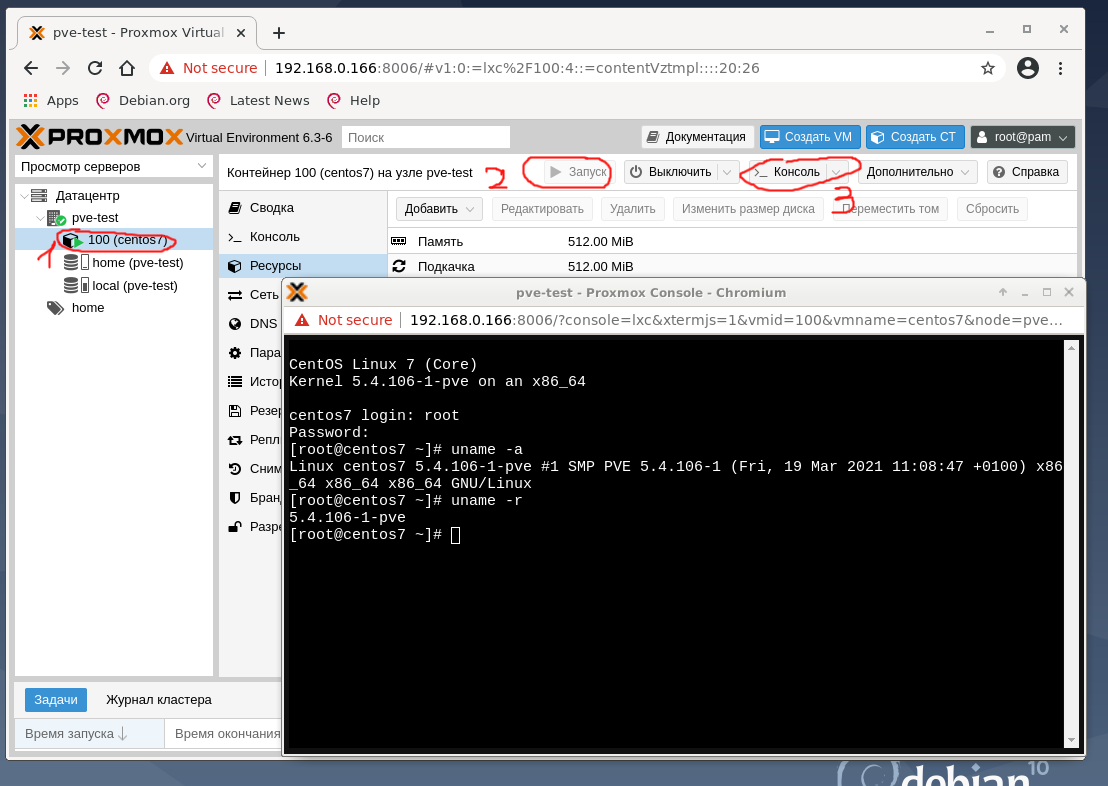
Укажите имя пользователя root и пароль, который ввели при создании контейнера CT и, если все сделано верно, можно управлять виртуальной машиной. Узнайте её IP-адрес, так как роутер, подключённый к тестовому хосту, должен был его выдать:
В результате получилось запустить полноценную виртуальную машину с Linux.
Создание виртуального контейнера VM
Для создания виртуальной машины VM с любой ОС нажмите кнопку Создать VM, укажите имя создаваемой VM, выберите пул ресурсов, нажмите Далее:
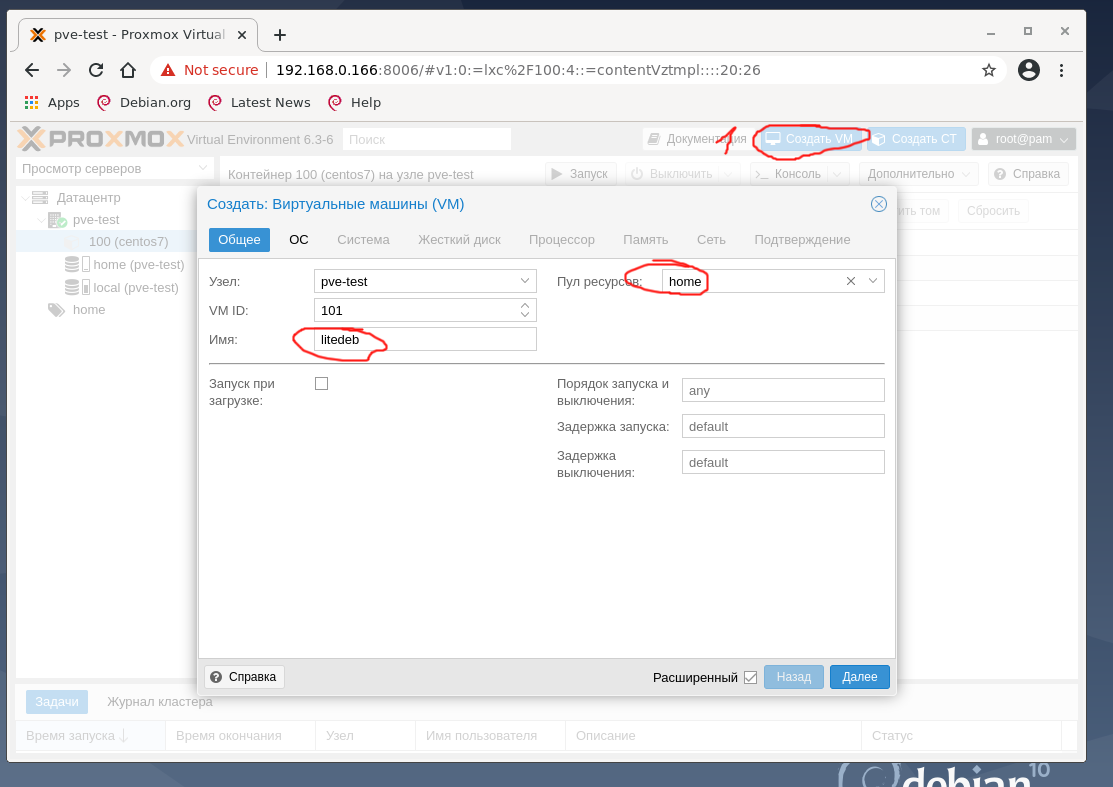
На втором окне предлагается выбрать загрузочный образ виртуального CD-диска, указать тип гостевой ОС:
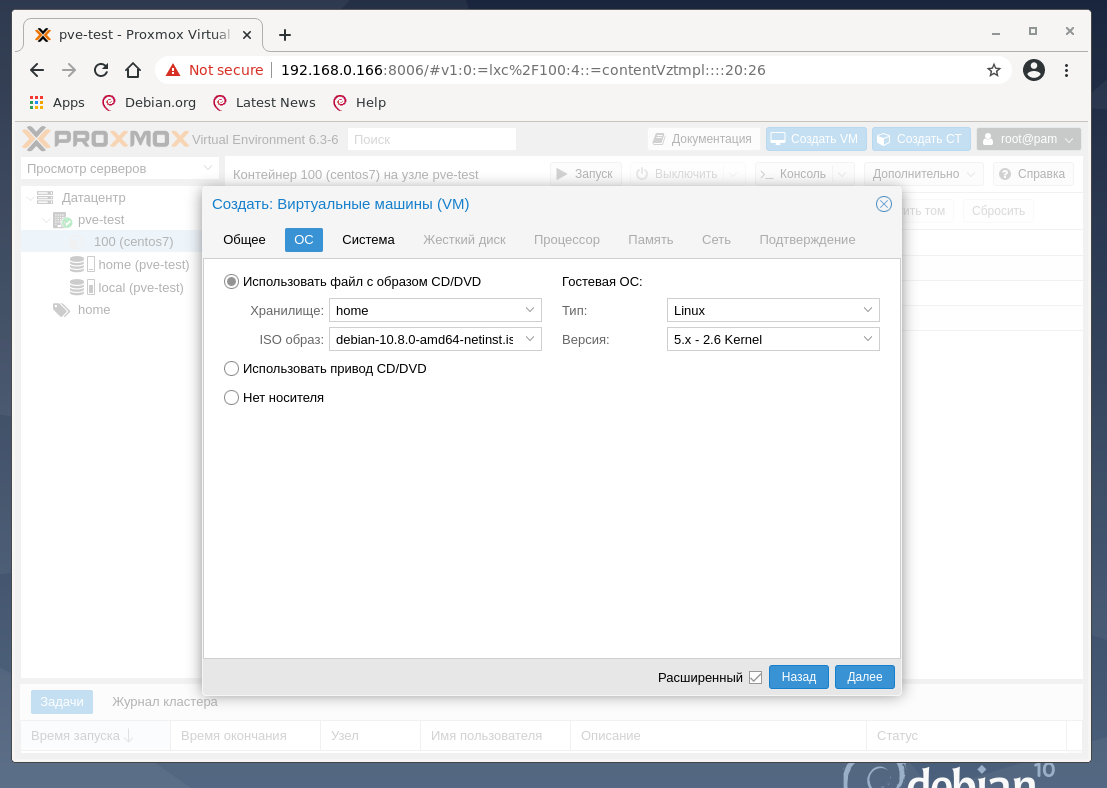
Если все сделано правильно, то загруженный ISO образ должен быть доступен по клику по обведённому красным полю. Этот параметр может быть настроен позже из интерфейса управления виртуальной машиной VM.
Во вкладках Система, Жёсткий диск, Процессор, Память, Сеть оставлены все значения так, как предложил гипервизор. В последней вкладке Подтверждение кликем Готово и перейдите в настройки виртуальной машины ID 101 с именем litedeb, во вкладку Оборудование:
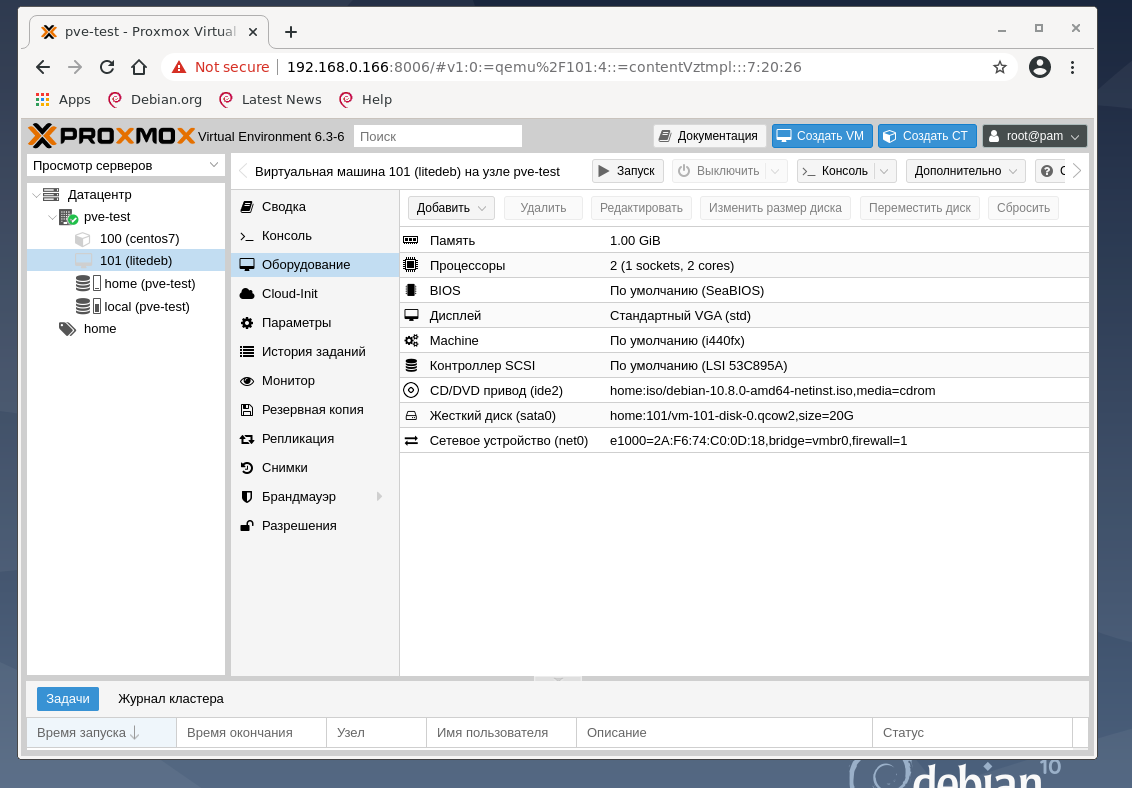
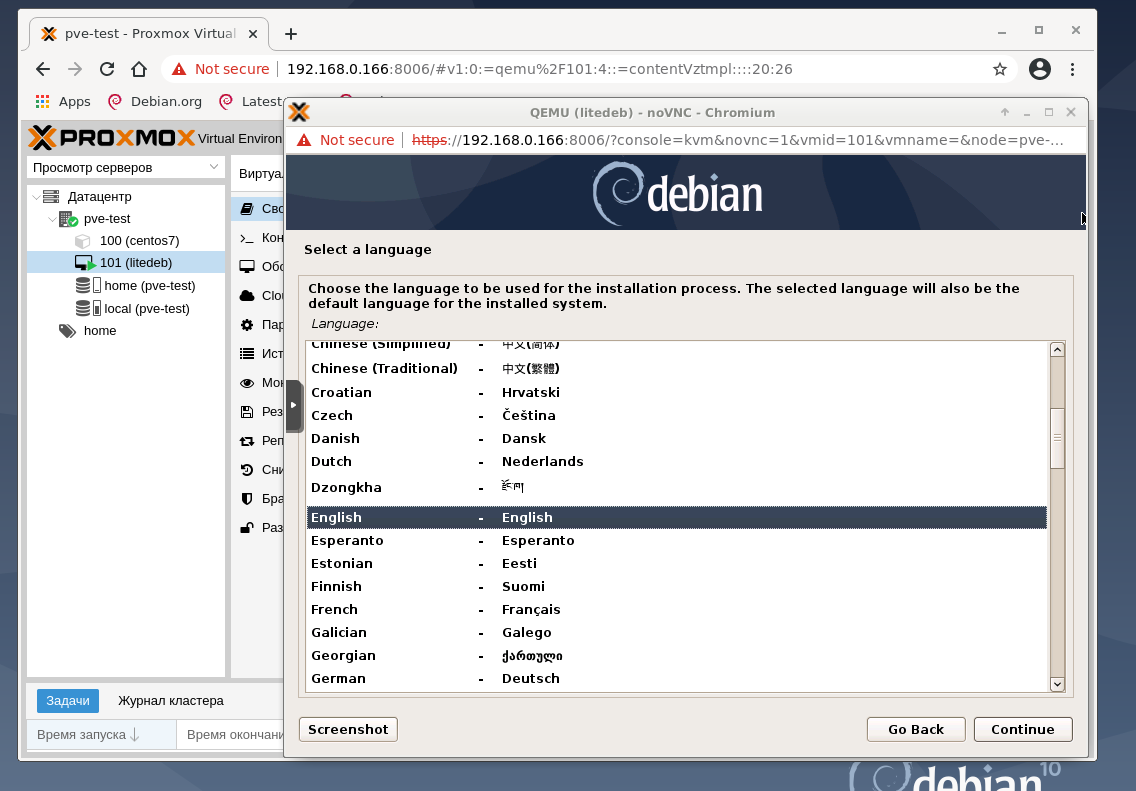
Если все нас устраивает и ничего менять не надо, нажмите кнопку Запуск и откройте Консоль. На тестовом хосте выяснилось, что лучше эксперимент проводить на дистрибутиве Debian 10 netinstall, и поменять тип жёсткого диска со SCSI на SATA, а также увеличить размер оперативной памяти виртуальной машины. И результат работы после нажатия кнопки Запуск и подключению к Консоли:
Конвертация виртуальной машины Windows.
Создадим на хосте Proxmox виртуальную машину с необходимыми настройками и ресурсами. Создайте два жестких диска, один IDE для системного диска, второй SCSI или Virtio, в зависимости от того, какой тип планируете использовать. Диск IDE должен присутствовать обязательно, иначе виртуальная машина не загрузится. Вот такая конфигурация получилась у меня:

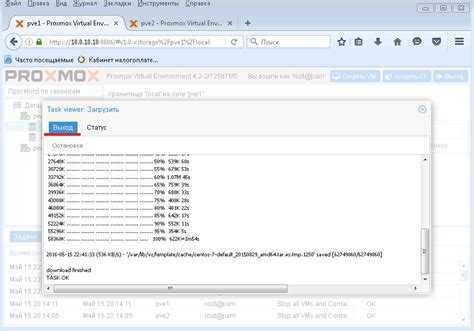
Теперь переходим непосредственно к конвертации. В консоли хоста Proxmox выполним команду:
Shell
qemu-img convert -f vmdk </path/to/disk.vmdk> -O raw /mnt/pve/hdd1/images/101/disk0.raw -p
| 1 | qemu-img convert-fvmdk<pathtodisk.vmdk>-Orawmntpvehdd1images101disk0.raw-p |
В команде, естественно, укажите свои параметры.
Запустится процесс конвертации диска.
![]()
После завершения конвертации нужно изменить конфиг виртуальной машины. Для этого открываем в редакторе файл конфигурации ВМ(в нашем случае ВМ имеет ID 101):
Shell
nano /etc/pve/qemu-server/101.conf
| 1 | nanoetcpveqemu-server101.conf |
Если узел Proxmox находится в кластере, путь до файла конфигурации будет выглядеть так:
Shell
nano /etc/pve/nodes/<node-name>/qemu-server/101.conf
| 1 | nanoetcpvenodes<node-name>qemu-server101.conf |

В строке ide0 укажем наш сконвертированный диск:
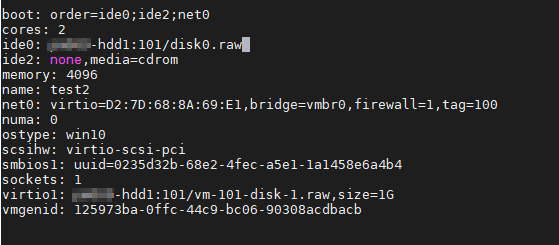
Сохраните изменения. Теперь можно запустить виртуальную машину.
Настройка ВМ после конвертации.
После конвертации необходимо проделать следующие действия: удалить VMtools(если они установлены) и установить необходимые драйвера.
Удаление VMtools производится через стандартную оснастку «Программы и компоненты».

Перезагрузку после удаления можно отложить.
Для установки драйверов потребуется скачать и подключить к ВМ образ с драйверами. Скачать его можно из официального источника..
После подключения образа с драйверами, перейдите в него и запустите мастер установки драйверов, выбрав нужную разрядность:

Это самый простой способ установить необходимые драйвера. Также, не лишним будет установить гостевой агент из папки guest-agent.
Теперь нам нужно переключить системный диск с устаревшего контроллера IDE на Virtio. Для этого выключаем виртуальную машину и вносим изменения в конфиг файл, который мы уже редактировали. Приведем его к следующему виду:
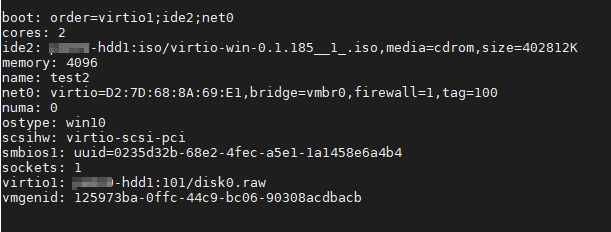
Обратите внимание, что нужно указать первым загрузочным устройством наш системный диск. (Думаю, что загрузочный диск, всё же, лучше разместить на шине 0, поэтому нужно заменить в файле конфигурации virtio1 на virtio0)
Диски, созданные при создании ВМ, теперь можно удалить.
После этого можно включать виртуальную машину и использовать по назначению.



