
Введение
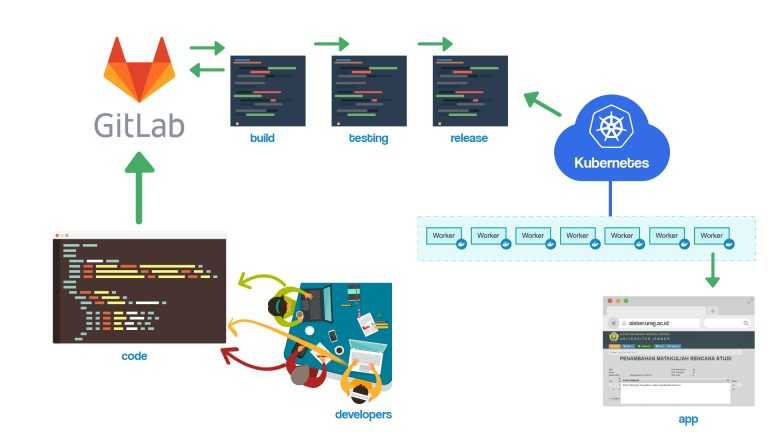
Для начала, что такое deploy для тех, кто будет читать статью для общего развития, не имея потребности в настройки описанных решений. В общем случае deploy — задача развертывания приложения. Разработчик или команда разработчиков что-то программируют у себя на компьютерах или в тестовых окружениях. В какой-то момент им нужно все то, что они напрограммировали, собрать и где-то развернуть для тестирования или эксплуатации. Можно по старинке все копировать руками на нужные сервера. Но сейчас все стараются как-то ускорить и автоматизировать этот процесс.
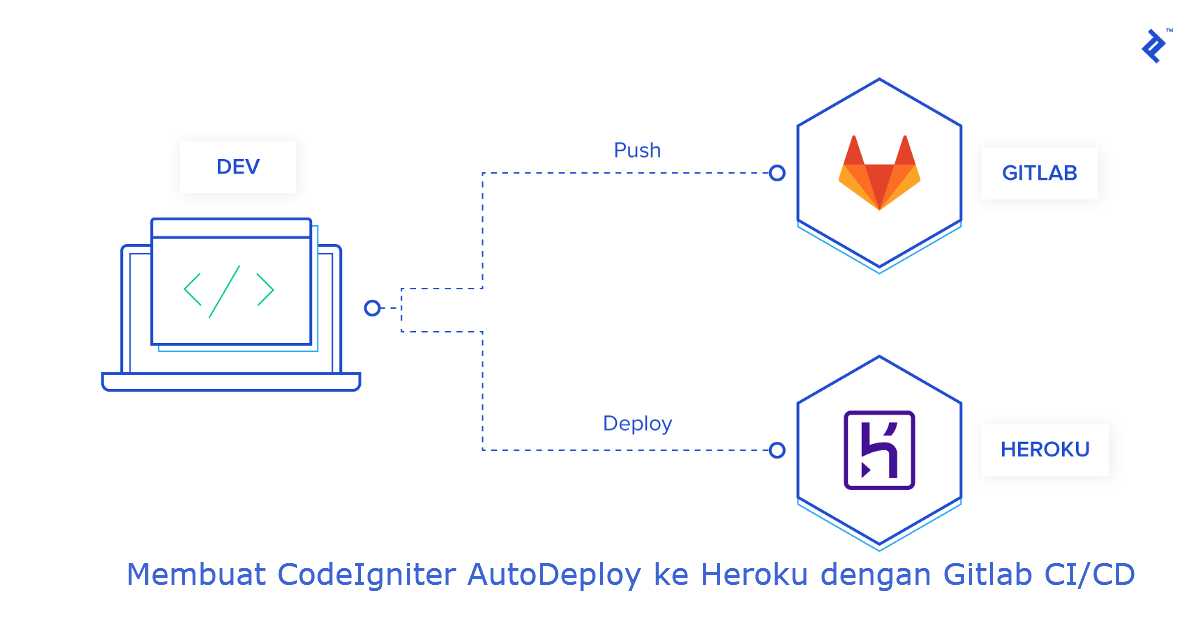
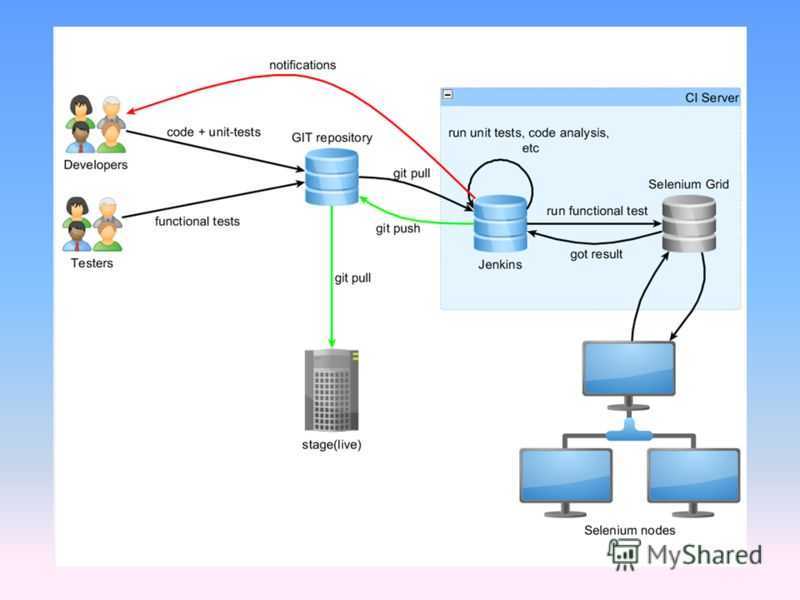
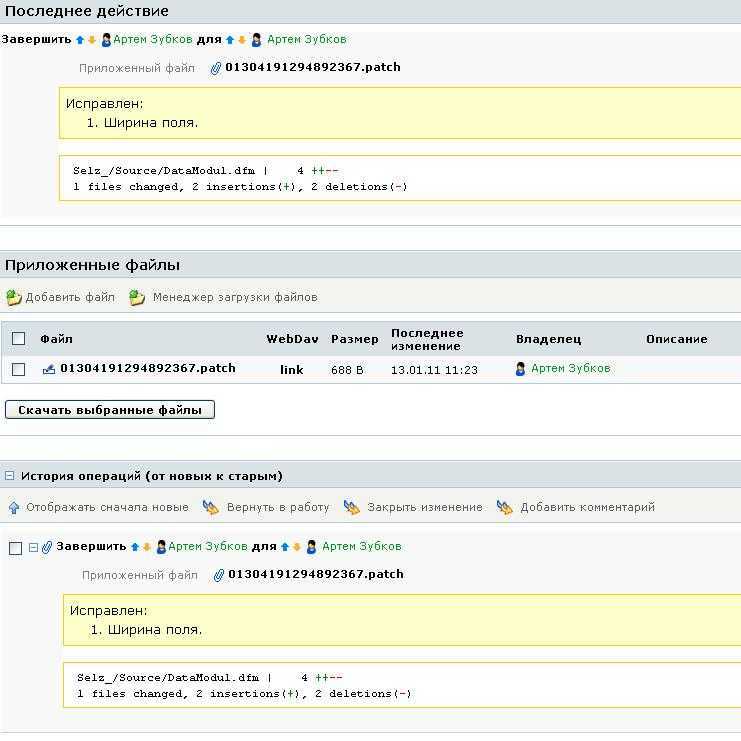
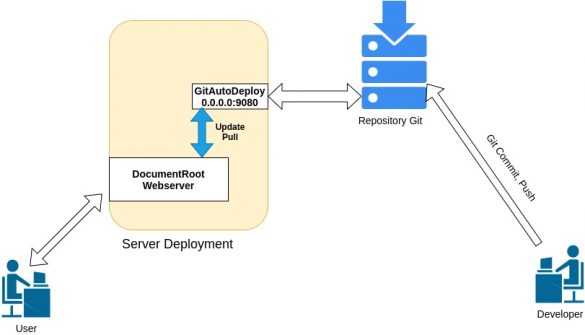
Конкретно в моем примере я расскажу, как автоматизировать процесс деплоя сайта на bitrix. После коммита разработчика в git репозиторий, будет запускаться webhook через штатный функционал gitlab. Этот вебхук будет дергать url на сервере. Авторизация через token в заголовке запроса. Запрос по этому url будет инициировать запуск bash скрипта, который делает git pull на сервере.
Как я уже сказал, автор данного решения мне не известен. Ему кто-то увидит свое решение тут и расстроится, что его просто скопировали и не указали авторство, то сообщите мне, я укажу вас.
Сразу добавлю, что способов похожего деплоя может быть много. В данном примере через вебхук, но можно и gitlab-runner использовать для этих целей.
А теперь всё вместе (All Together Now)
Надеюсь, вы найдёте этот трёх-окошечный метод разрешения конфликтов, таким же полезным каким нахожу его я. Но согласитесь что запускать новые вызовы meld вручную каждый раз при разрешении конфликтов, не очень то и удобно. Выход, это настроить git таким образом чтобы все три окна открывались автоматически при вызове команды git mergetool. Для этого можно создать выполняемый скрипт, который должен находится в переменной окружения PATH (например $HOME/bin/gitmerge), со следующим содержимым:
И добавьте следующее в ваш ~/.gitconfig файл:
Теперь, когда вы в следующий раз будете запускать команду git mergetool для разрешения конфликта, откроются все три окна:
После того как вы привыкните к такому разрешению конфликтов с использованием трёх вышеупомянутых окон, вы скорее всего обнаружите, что процесс стал более методичным и механическим. В большинстве случаев, вам даже не придётся читать и понимать куски кода из каждой ветки, для того чтобы понять какой же вариант применить для слияния. Вам больше не понадобится догадываться, потому что вы будете гораздо более уверенным в корректности вашего комита. Из-за этой уверенности, появится чувство что разрешение конфликтов превратилось в увлекательное занятие.
Бонус от переводчика
Для тех кто пользуется tmux и n?vim, предлагаю следующий скрипт gitmerge:
Примечание: если вы не используете в своем ~/.tmux.conf, то вам надо поменять в двух последних строках на
Соответственно добавьте следующее в ваш
Воркфлоу разрешения конфликта будет выглядеть так:
Пока игнорируем вопрос (Was the merge successful [y/n]?) и переключаемся в сессию под названием gitmerge (сочетание TMUXPREFIX + s):
Видим наше трёх-оконное представление на одном экране. Цифрами обозначены сплиты (panes) tmux’a, буквами соответствующие состояния. Делаем правки для разрешения конфликта, т.е. редактируем состояние (D) и сохраняем. После этого возвращаемся обратно в исходную сессию tmux’a и подтверждаем что слияние произошло успешно.
git rebase master
Лично я предпочитаю и считаю более правильным делать сначала rebase master в ветке beta, и только после этого переключаться в master и делать git merge beta. В принципе воркфлоу не сильно отличается, за исключением трёх-оконного вида.
Переключаемся в сессию gitmerge
Обратите внимание, что состояния (B) и поменялись местами:
Рекомендую всем поиграться с примером репозитария хотя бы один раз, сделать разрешение конфликта по вышеописанной схеме. Лично я больше не гадаю а что же выбрать «Accept theirs» или «Accept yours».
Как делить на коммиты
При делении своих изменений на коммиты не следует смешивать изменения разных типов. Но и делать слишком мелкие коммиты тоже не нужно. Постараюсь описать несколько ситуаций, из которых станет более понятна идея.
Ревью
Вы решили исправить баг, но внезапно оказалось, что ругается линтер из-за слишком длинной строчки. Вы решили переименовать переменную, так как её название было излишне длинным. Тут возникает соблазн сделать все одним коммитом. Но ревьюверам такой merge request с одним коммитом будет очень сложно смотреть, так как из сотен строк, которые просто переименовывают переменную, нужно будет отыскать пару-тройку строк, которые действительно исправляют логику. В идеале это надо оформить в виде двух коммитов — первый переименовывает, второй — исправляет баг. Но вообще удобнее, если баг чинится одним коммитом.
Перенос изменений
В процессе реализации новой фичи вы нашли серьезный баг в безопасности. Не дожидаясь конца отладки новой фичи вы исправили этот баг, после доделали фичу и сделали коммит. И вот так лучше не делать, так как правку серьезного бага скорее всего захотят влить и в старые ветки уже выпущенных релизов или побыстрее влить в мастер в случае облачного продукта. А с фичами спешки скорее всего нет. Если все сделать в одном коммите, то придется вместе с фиксом бага обязательно вливать новую фичу, которая потребует провести полный цикл тестирования.
Декомпозиция
Вам поручили сделать новую фичу, и пусть это даже новый небольшой микросервис в отдельном репозитории. Но все мы люди, и выдать за один раз кусок кода размером в 5000 строчек мало кому под силу. Так что несмотря на то, что с точки зрения менеджеров это одна задача, вам будет удобнее эту задачу декомпозировать:
-
Добавить шаблон микросервиса.
-
Добавить пару базовых методов и работу с базой.
-
Добавить взаимодействие с сервисом X.
-
Добавить еще методов.
-
Добавить обработку каких-то сложных случаев и дополнительных параметров в первые два метода.
-
…
-
Можно конечно все это сделать одним коммитом. Но скорее всего за один день это сделать не получится, так что встанет вопрос о сохранении промежуточной работы. Во-вторых, начальник захочет отслеживать ваш прогресс и если делаете отдельными коммитами — это будет гораздо проще. Да и самому удобно наметить какой-то план работы и на каждый пункт этого плана делать коммит.
Бывают ситуации, когда вы вошли в раж и починили три бага и реализовали пару фич и только потом вспомнили, что эти изменения надо еще и куда-то послать. В этом случае поможет интерактивный коммит. Подробно останавливаться на нем не буду, так как иначе статья получится слишком большая. Запускается командой:
Позволяет добавить в разные коммиты даже изменения в одном файле.
Абсолютное зло, которое ни в коем случае нельзя допускать
-
fix compilation
-
fix tests
-
fix linter
Это коммиты, которые чинят предыдущие коммиты в этой же серии. Никому не интересен тот факт, что вы при написании кода допустили ошибку и сразу же её исправили, интересен только конечный результат. Всё это лучше проверить и исправить до того, как будет сделан коммит. Если забыли и закоммитили а оказалось, что тесты не проходят, то от таких коммитов надо избавляться. Каким образом — в следующей главе.
Работа в большой команде
Со временем ваш сайт стал очень популярным, а ваша команда выросла с двух до восьми человек. Разработка происходит параллельно, и людям все чаще приходится ждать в очереди для превью на Staging. Подход “Проводите развертывание каждой ветки на Staging” больше не работает.

Пришло время вновь модифицировать рабочий процесс. Вы и ваша команда пришли к соглашению, что для выкатывания изменений на staging-сервер нужно сначала сделать мерж этих изменений в ветку “staging”.
Для добавления этой функциональности нужно внести лишь небольшие изменения в файл :
становится
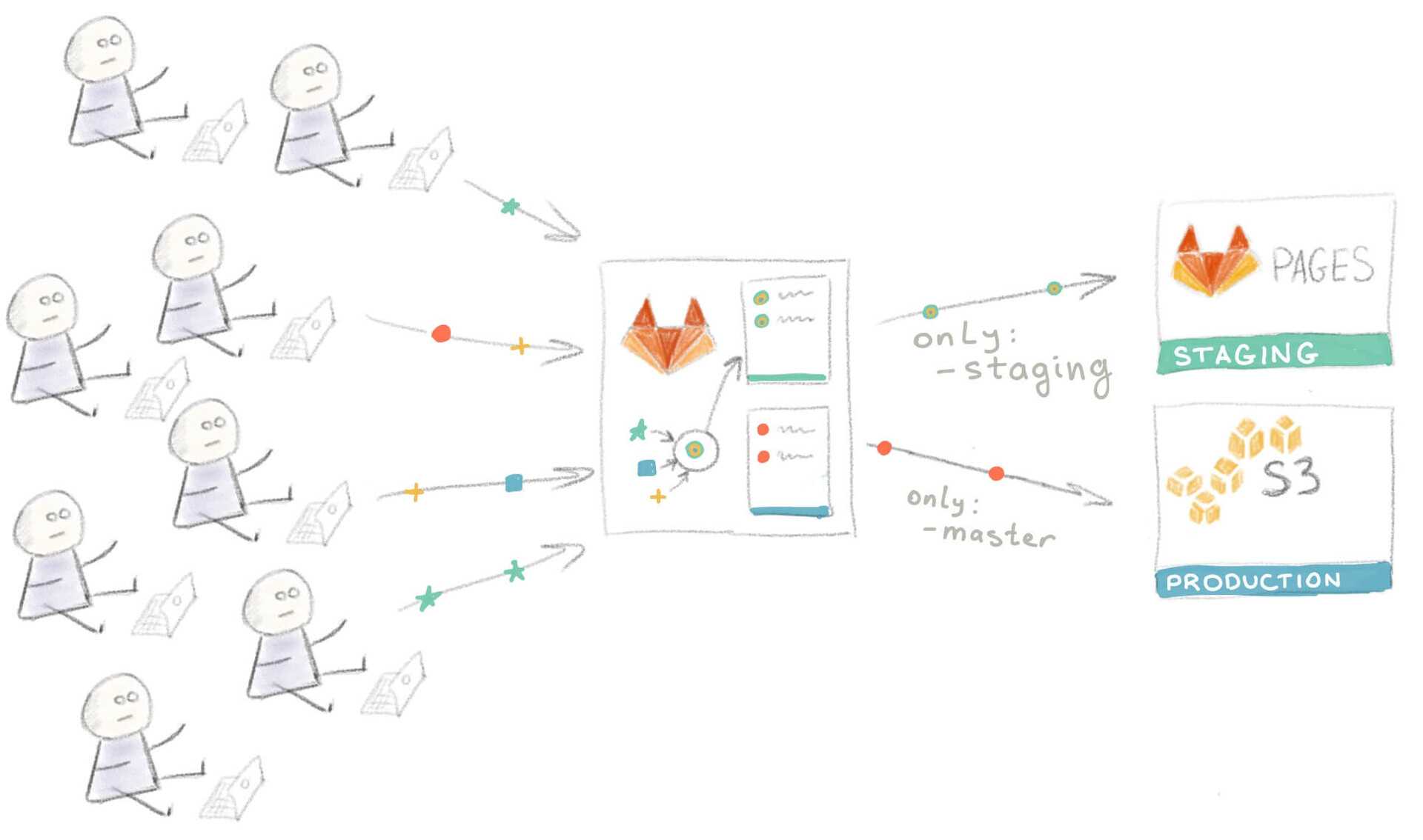 Разработчики проводят мерж своих feature-веток перед превью на Staging
Разработчики проводят мерж своих feature-веток перед превью на Staging
Само собой, при таком подходе на мерж тратятся дополнительное время и силы, но все в команде согласны, что это лучше, чем ждать в очереди.
Непредвиденные обстоятельства
Невозможно все контролировать, и неприятности имеют свойство случаться. К примеру, кто-то неправильно смержил ветки и запушил результат прямо в production как раз когда ваш сайт находился в топе HackerNews. В результате тысячи человек увидели кривую версию сайта вместо вашей шикарной главной страницы.
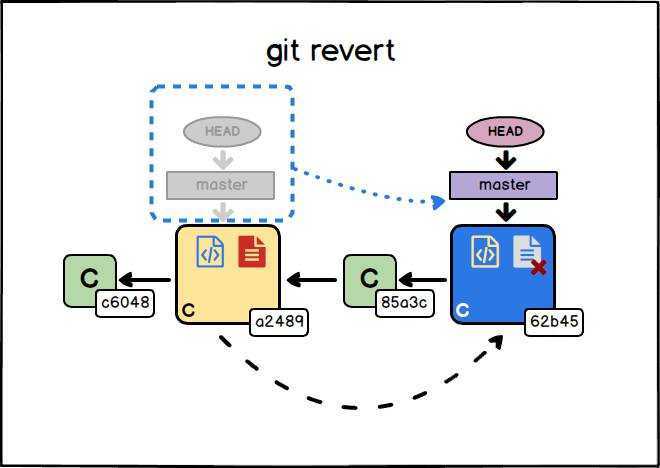
К счастью, нашелся человек, который знал про кнопку Rollback, так что уже через минуту после обнаружения проблемы сайт принял прежний вид.
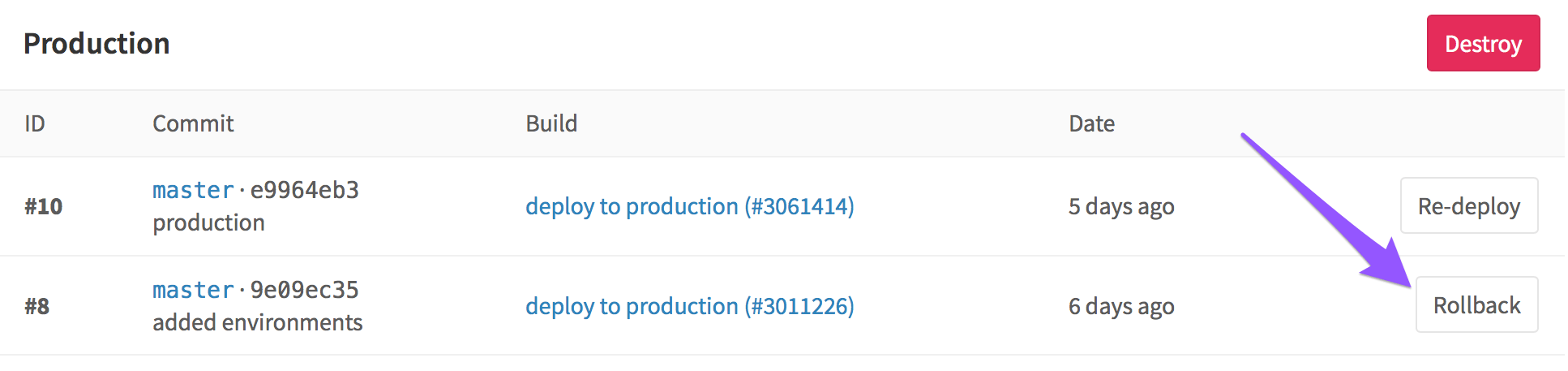 Rollback перезапускает более раннюю задачу, порожденную в прошлом каким-то другим коммитом
Rollback перезапускает более раннюю задачу, порожденную в прошлом каким-то другим коммитом
Чтобы избежать подобного в дальнейшем, вы решили отключить автоматическое развертывание в production и перейти на развертывание вручную. Для этого в задачу нужно добавить .
Для того, чтобы запустить развертывание вручную, перейдите на вкладку Pipelines > Builds и нажмите на вот эту кнопку:

И вот ваша компания превратилась в корпорацию. Над сайтом работают сотни человек, и некоторые из предыдущих рабочих практик уже не очень подходят к новым обстоятельствам.
Ревью приложений
Следующим логическим шагом является добавление возможности развертывания временного инстанса приложения каждой feature-ветки для ревью.
В нашем случае для этого надо настроить еще один бакет S3, с той лишь разницей, что в этом случае содержимое сайта копируется в “папку” с названием ветки. Поэтому URL выглядит следующим образом:
А так будет выглядеть код, замещающий задачу :
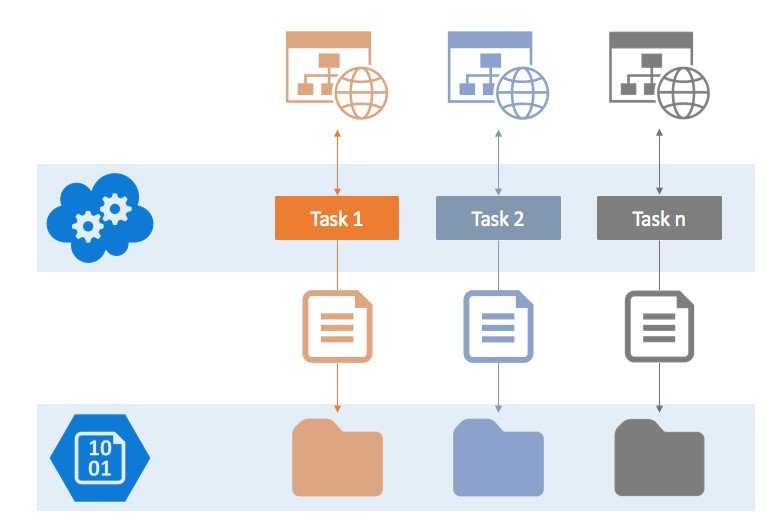
Стоит объяснить откуда у нас появилась переменная — из списка , которые вы можете использовать для любой своей задачи.
Обратите внимание на то, что переменная определена внутри задачи — таким образом можно переписывать определения более высокого уровня. Визуальная интерпретация такой конфигурации:
Визуальная интерпретация такой конфигурации: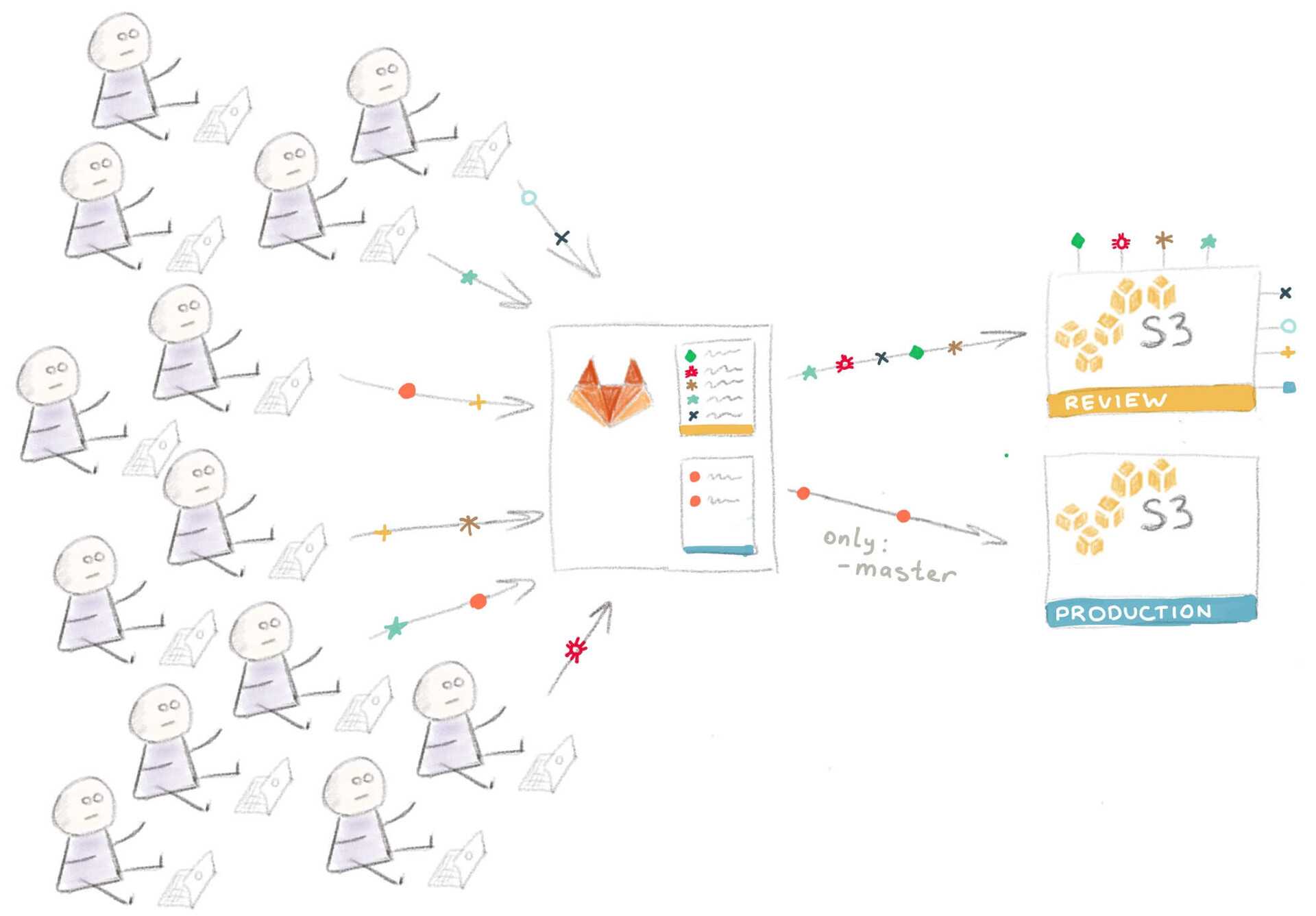
Технические детали реализации такого подхода сильно разнятся в зависимости от используемых в вашем стеке технологий и от того, как устроен ваш процесс развертывания, что выходит за рамки этой статьи.
Реальные проекты, как правило, значительно сложнее, чем наш пример с сайтом на статическом HTML. К примеру, поскольку инстансы временные, это сильно усложняет их автоматическую загрузку со всеми требуемыми сервисами и софтом “на лету”. Однако это выполнимо, особенно, если вы используете Docker или хотя бы Chef или Ansible.
Про развертывание при помощи Docker будет рассказано в другой статье. Честно говоря, я чувствую себя немного виноватым за то, что упростил процесс развартывания до простого копирования HTML-файлов, совершенно упуская более хардкорные сценарии. Если вам это интересно, рекомендую почитать статью «Building an Elixir Release into a Docker image using GitLab CI».
А пока что давайте обсудим еще одну, последнюю проблему.
Развертывание на различные платформы
В реальности мы не ограничены S3 и GitLab Pages; приложения разворачиваются на различные сервисы.
Более того, в какой-то момент вы можете решить переехать на другую платформу, а для этого вам нужно будет переписать все скрипты развертывания. В такой ситуации использование gem’а сильно упрощает жизнь.
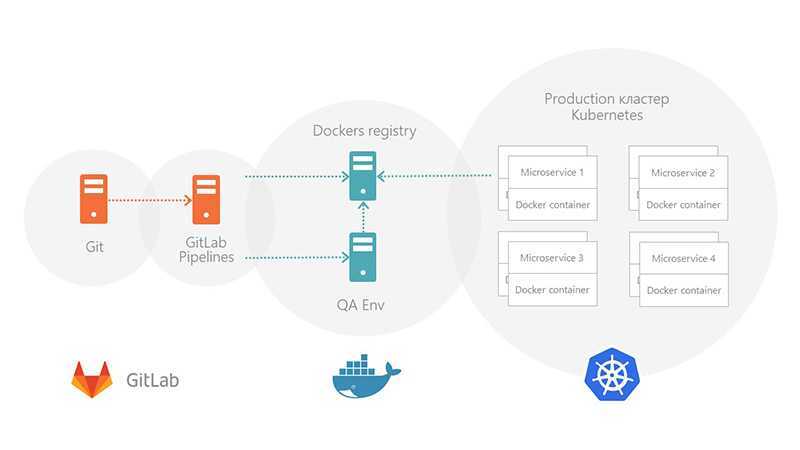
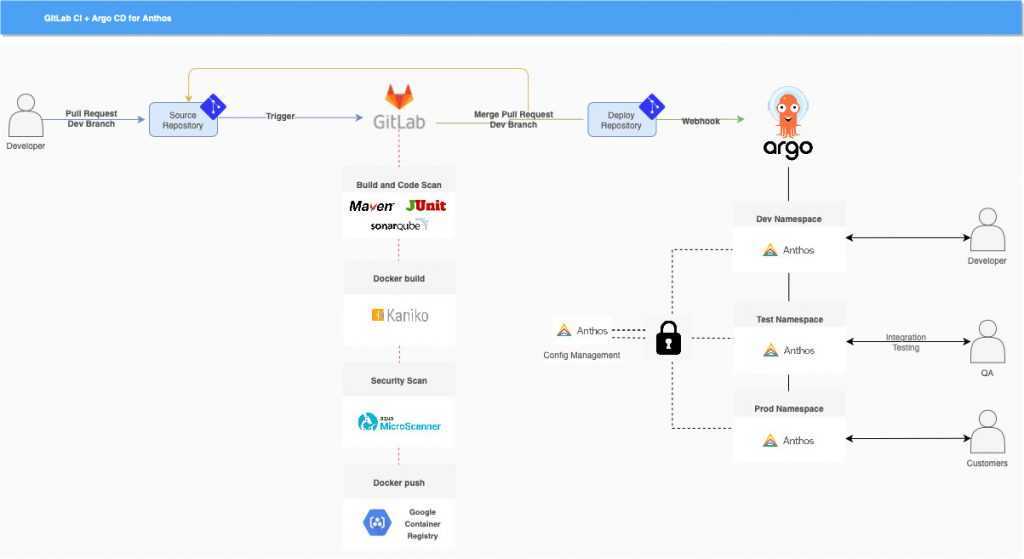
В приведенных в этой статье примерах мы использовали в качестве инструмента для доставки кода на сервис Amazon S3
На самом деле, неважно, какой инструмент вы используете и куда вы доставляете код — принцип остается тот же: запускается команда с определенными параметрами и в нее каким-то образом передается секретный ключ для идентификации
Инструмент для развертывания придерживается этого принципа и предоставляет унифицированный интерфейс для , предназначенных для развертывания вашего кода на разных хостинговых площадках.
Задача для развертывания в production с использованием dpl будет выглядеть вот так:
Так что если вы проводите развертывание на различные хостинговые площадки или часто меняете целевые платформы, подумайте над использованием в скриптах развертывания — это способствует их единообразию.
Редактирование коммитов
Предупреждение — редактировать коммиты можно только до тех пор, пока кто-то другой их себе не взял. Например, если вы сделали несколько коммитов, но не запушили это в общий репозиторий. Или уже запушили, но никто вашу ветку себе не брал и ничего не дорабатывал поверх.
В такой ситуации нельзя редактировать коммит B. Если вы уже делали для вашей ветки, то после редактирования коммитов надо делать с опцией —. Да, и категорически запрещено редактировать коммиты в мастере. Вернемся к самому редактированию.
Самый простой случай — вы нашли ошибку в последнем коммите. В этом случае после исправления нужно для каждого измененного и добавленного файла сделать и потом . Там же можно будет отредактировать commit message.
И немного более сложный случай — когда нужно внести правки в несколько коммитов. В этом случае нужно правки к каждому коммиту оформить в виде отдельного коммита и потом сделать . Там надо переместить коммиты-фиксы после коммитов, которые они исправляют и указать команду fixup:
Дальнейшие коммиты
Давайте изменим несколько файлов после того, как мы их закоммитили. После того, как мы их изменили, сообщит о том, что у нас есть измененные файлы.
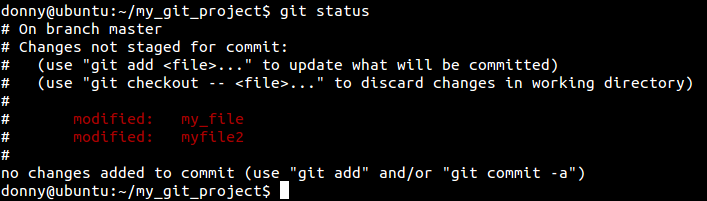
Можно посмотреть, что же изменилось в этих файлах с момента предыдущего коммита, с помощью команды . Если вы хотите просмотреть изменения для конкретного файла, можно использовать .
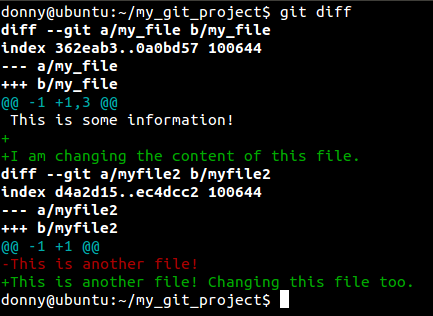
Необходимо проиндексировать изменения, и закоммитить их. Все измененные файлы проекта можно добавить на коммит следующей командой:
git add -u
Можно избежать использования этой команды, если добавить параметр к . Эта команда проиндексирует все измененные файлы, и закоммитит их. Но такой подход может быть довольно опасным, так по ошибке можно закоммитить то, что не хотелось. Например, скажем, что вы открыли файл, и случайно его изменили. При индексировании измененных файлов вы будете оповещены об изменениях в каждом файле. Но если вы отправите на коммит все измененные файлы не глядя с помощь. , то будут закоммичены все файлы, включая те, которые вы коммитить не хотели.
Как только вы проиндексировали файлы, можно приступать к коммиту. Как упоминалось ранее, к коммиту можно указать сообщение с помощью ключа . Но также можно указывать и многострочные комментарии с помощью команды , которая открывает консольный редактор для ввода комментария.
git commit
Упростите ваш рабочий процесс
Работа с GitLab Container Registry проста и безопасна. Вот несколько примеров того, как использование GitLab Container Registry может упростить процесс разработки и развертывания ПО:
- Проводите сборку образов Docker с помощью GitLab CI с последующим их хранением в GitLab Container Registry.
- Привязывайте образы к веткам, тегам исходного кода или используйте любой другой способ, подходящий для вашего процесса разработки. Созданные образы можно быстро и легко сохранить на GitLab.
- Используйте собственные образы сборок, хранящиеся в вашем реестре, для тестирования приложений.
- Пусть остальные участники команды также участвуют в разработке образов. Это не потребует от них дополнительных усилий, так как используется тот же рабочий процесс, к которому они привыкли. GitLab CI позволяет проводить автоматическую сборку образов, унаследованных от ваших, что в свою очередь позволяет с легкостью добавлять фиксы и новые фичи в базовый образ, используемый вашей командой.
- Настройте CaaS на использование образов напрямую из GitLab Container Registry, получив таким образом процесс непрерывного развертывания кода. Это позволит проводить автоматическое развертывание приложений в облако (Docker Cloud, Docker Swarm, Kubernetes и т. п.) каждый раз, когда вы собираете или тестируете образ.
Верификация коммитов GPG (CE, EES, EEP)
При коммите изменений в Git есть возможность указать их автора. Проверка при этом не производится, что допускает ситуацию, в которой автором можно указать другого человека.
Подпись коммитов GPG решает эту проблему, позволяя вам подписывать свои коммиты. Подпись однозначно указывает на автора, поскольку только у него есть приватный ключ, соответствующий публичному.
В GitLab 9.5 включена поддержка подписей коммитов GPG. Вы можете загрузить ваш публичный ключ в меню Settings → GPG Keys. Теперь подписанные коммиты будут отображаться в GitLab как «подтвержденные».
Спасибо Alexis Reigel за внедрение этой функциональности!
Больше информации о подписях коммитов GPG в нашей документации
Что такое генератор статического сайта? И почему был выбран именно MkDocs?
Генератор статического сайта это программа, собирающая полноценный сайт из одного или нескольких шаблонов, а также материалов для сайта.
Создание или редактирование статического сайта выполняется предельно просто:
-
Владелец создаёт новый файл или редактирует существующий в человекочитаемом формате (например, в markdown).
-
Далее запускается генератор статического сайта — и результатом работы он выдаёт сайт в виде набора html-страниц с уже применённой темой, форматированием, построенным оглавлением и пр.
-
Полученный сайт владелец уже может использовать локально. Ну или выложить на каком-либо хостинге — чтобы к нему могли получить доступ другие люди.
И важно отметить: для статических сайтов не требуется поддержка каких-либо серверных языков и/или баз данных — всё уже свёрстано и готово к использованию. Минусом же статических сайтов является то, что все пользователи будут видеть один и тот же контент (то есть сделать авторизацию, разделение на роли и прочее не получится)
Минусом же статических сайтов является то, что все пользователи будут видеть один и тот же контент (то есть сделать авторизацию, разделение на роли и прочее не получится).
Немного личных впечатлений
19 мая 2015 года Rich Lander сделал первый коммит в репозиторий с комментарием «Experimenting with docs». Похоже, что именно с этого коммита и началась история docs.microsoft.com — проекта, содержащего на текущий момент документацию по огромному количеству языков, технологий и продуктов Microsoft.
Впервые попав на этот сайт, я был поражён:
-
на сайте имелась «гибкая» вёрстка (было удобно смотреть сайт и с компьютеров, и с мобильных устройств),
-
присутствовала удобная навигация с фильтром: находясь в документации по .NET, можно было ввести название класса или метода и сразу перейти к нему.
Как выглядит docs.microsoft.com
В дальнейшем на сайте появился автоперевод статей на русский язык (а также возможность переключения и чтения статьи на языке оригинала).
Но самое главное, что меня зацепило — кто угодно (а не только сотрудник Microsoft) мог предложить правки, дополнения или перевод материалов. Ведь все материалы лежали в публичном репозитории github!
И эта идея хранения информации в стиле «предложить новое может каждый» так плотно засела у меня в голове, что, обретя возможность сделать документацию для одного из разрабатываемых приложений, я решил попробовать сделать маленький, но аналог.
На сегодняшний день список самых популярных систем, способных сгенерировать статические сайты, достаточно небольшой:
-
Jekyll. Написан на Ruby, его использует Github для Github Pages (вероятно потому, что один из создателей Jekyll — сооснователь github?).
-
Hugo. Написан на Go, позиционирует себя как самый быстрый генератор статических сайтов.
-
Sphinx. Написан на Python. Именно с его помощью сгенерирована документация к языку Python.
-
MkDocs. Также написан на Python.
MkDocs был выбран как самый популярный генератор на Github (на момент написания статьи у репозитория MkDocs было более 12 тыс. «звёздочек»). А больше всего приглянулся его форк с красивой (по моему мнению) встроенной темой, называемый Material for MkDocs. А всё потому, что сгенерированный с его помощью сайт из коробки предоставлял и гибкую вёрстку, и человекочитаемые url-ы, и встроенный быстрый поиск по всем статьям (который не требует какой-либо серверной реализации).
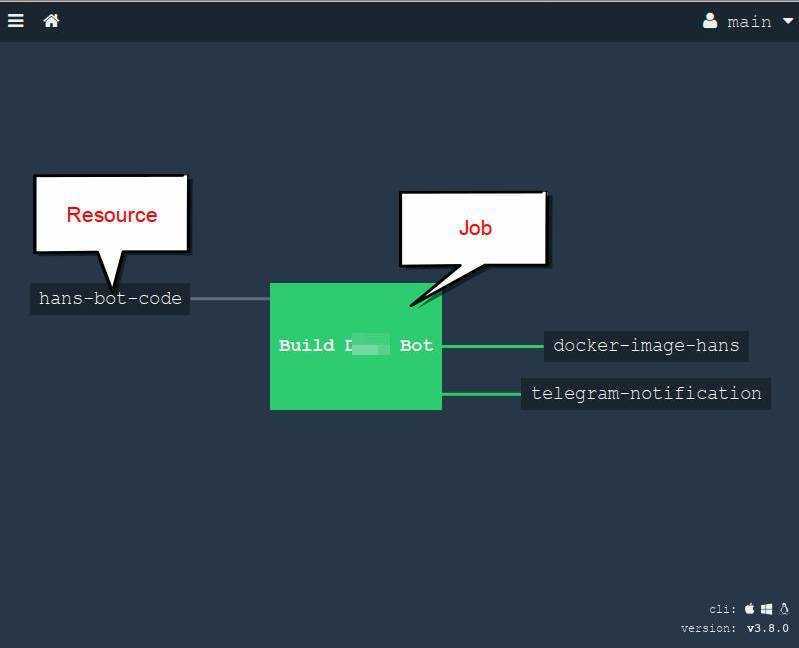
Бонус: уведомления о деплое в Telegram
Полезная фишка для уведомления менеджеров. После сборки в телеграм отправляется статус сборки, название проекта и ветка сборки.
В задачах деплоя последней командой пропишите:
Сам файл необходимо добавить в корень проекта, рядом с файлом .
Содержимое файла:
Скрипт отправляет запрос к API Telegram, через curl. Параметром скрипта передается emoji статуса билда.
Не забудьте добавить новые параметры в CI/CD:
- — токен бота в телеграмм. Получить его можно при создании своего бота.
- — идентификатор чата или беседы, в которую отправляется сообщение. Узнать идентификатор можно с помощью специального бота.
Необходимо создать задачи для уведомления о падении сборки.
По сложившейся традиции у нас отдельная задача для прод-среды. Благодаря параметру задача отрабатывает только, когда одна из предыдущих завершилась неудачно.
Удобно, что теперь и код и сборка находятся в одном месте. Несмотря на недостатки GitLab CI, пользоваться им в целом удобно.
Как обновлять из mainstream
Часто работа над какой-то фичей ведется долгое время и вам может, например, понадобиться функция, которую добавили в проект уже после того, как вы начали работу над вашей фичей. В этом случае нужно подтянуть свежие изменения в свою ветку.
Пожалуйста, не пользуйтесь для этого IDE и командой git pull! Никто не понимает, что при этом происходит и постоянно делают что-то не то.
Вообще есть 2 способа добавить свежие изменения из mainstream в вашу ветку:
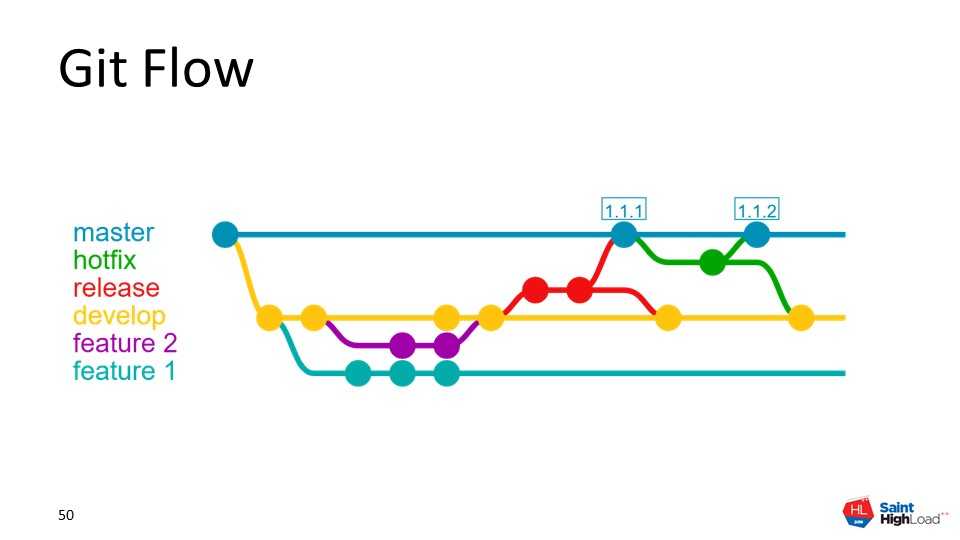
Rebase — переносит ваши изменения поверх mainstream. История получается максимально чистая, но коммиты меняются, то есть если кто-то воспользовался вашей веткой, а вы ее поребейсили — у вашего товарища могут возникнуть проблемы.
Merge — выбирая путь merge приходится отказаться от редактирования коммитов и считать, что как только вы набрали — коммит высечен в камне, и рано или поздно окажется в мастере.
Тема выбора merge или rebase очень холиварная. По опыту очень мало людей могут правильно использовать merge. Начинающие пользователи git вообще не понимают, что это такое, и часто пишут код и чинят баги внутри merge-коммитов, а на ежедневных совещаниях (стендапах) можно услышать «я вчера мержил весь день ветки».
Если совсем кратко: при использовании rebase будет чистая история, но нельзя организовать работу нескольких человек над фичей в отдельной ветке. При merge наоборот: любой коммит, косой-кривой, с ошибками и ломающий все на свете навсегда впечатывается в историю но зато несколько человек могут работать над фичей в отдельной ветке.
Правильное использование rebase:
Правильное использование merge:
На мой взгляд, более выгодно привыкнуть делать rebase, так как его вам никто не запретит. А вот merge-коммиты вы как минимум не сможете послать в проекты, которые принимают изменения через список рассылки.
GitLab CI Bootstrap
GitLab CI Bootstrap — это микрофреймворк для разработки GitLab CI. Его основные цели:
-
Разделить описание пайплайна (файл ) и его скрипты (bash или shell), чтобы оставить YAML более декларативным.
-
Дать возможность разбивать большие скрипты на более мелкие и подключать одни скрипты к другим, чтобы улучшить структурирование кода и упростить его поддержку.
-
Дать возможность выносить скрипты и джобы (со скриптами) в отдельные репозитории, чтобы повторно использовать их в разных проектах.
GitLab CI Bootstrap состоит из одного единственного файла bootstrap.gitlab-ci.yml, который необходимо подключить в файле при помощи . Сделать это можно несколькими способами. Проще всего скопировать файл в свой проект и подключить его через :


В этом файле находится один единственный скрытый джоб , который имеет следующий вид:
Другие джобы могут расширять джоб , используя :
В таких джобах будет включаться механизм загрузки скриптов (который описан ниже), который позволяет загружать скрипты из текущего репозитория или из любого другого репозитория внутри того же экземпляра GitLab.
При этом для загрузки скриптов не нужны специальные токены доступа. Загружать скрипты можно даже из внутреннего или приватного репозиториев. Главное, чтобы у разработчика, запустившего пайплайн был доступ на чтение к этим репозиториям.
Единственным требованием для загрузчика является наличие bash или shell. Также желательно наличие git, однако при его отсутствии он будет установлен автоматически. Благодаря этому джоб можно использовать практически с любыми официальными docker-образами и он будет там корректно работать.
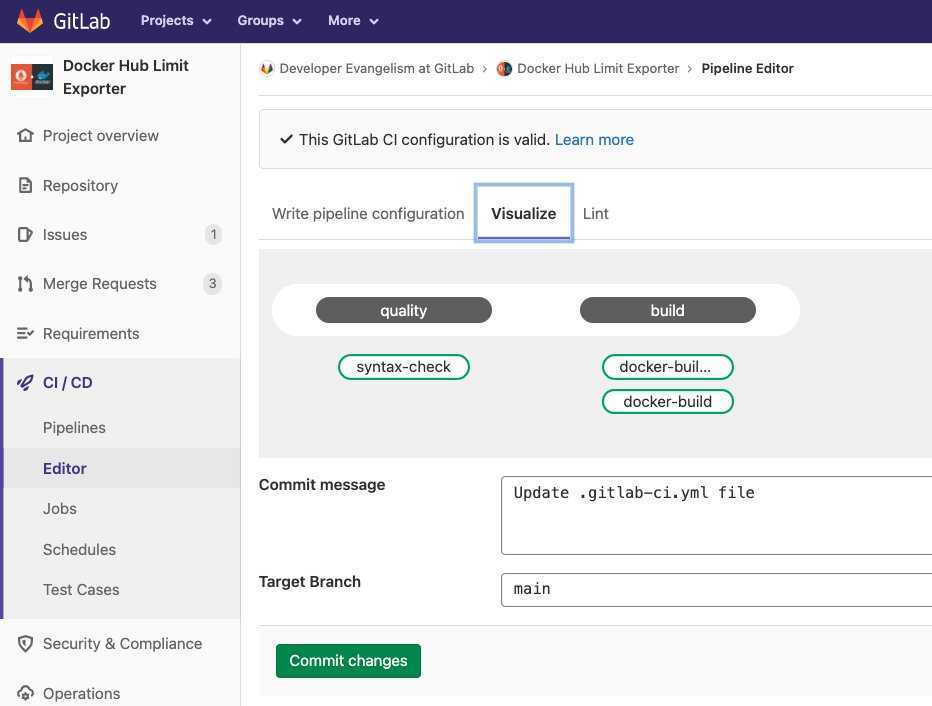
Итак, давайте посмотрим, как это поможет нам упростить наш пайплайн для сборки docker-образов.
Шаг 2: Выносим все скрипты в отдельный файл
Все джобы, использующие джоб автоматически проверяют наличие в репозитории специального файла . При его наличии этот файл автоматически загружается и все переменные и функции, которые в нём определены становятся доступными на этапе выполнения скриптов джоба.
Поэтому мы можем вынести все скрипты в этот файл и разбить их на функции, чтобы избежать дублирования, а затем вызвать эти функции из файла :
Файл :
Файл :
Ссылки на проект:
-
Репозиторий (ветка step2): https://gitlab.com/chakrygin/dockerfiles-example/-/tree/step2
-
Пайплайн: https://gitlab.com/chakrygin/dockerfiles-example/-/pipelines/303676828
Теперь все скрипты у нас вынесены в отдельный файл и разбиты на функции, которые вызываются из файла . Функции и заполняют переменную , которая позже используется функцией для сборки докерфайлов.
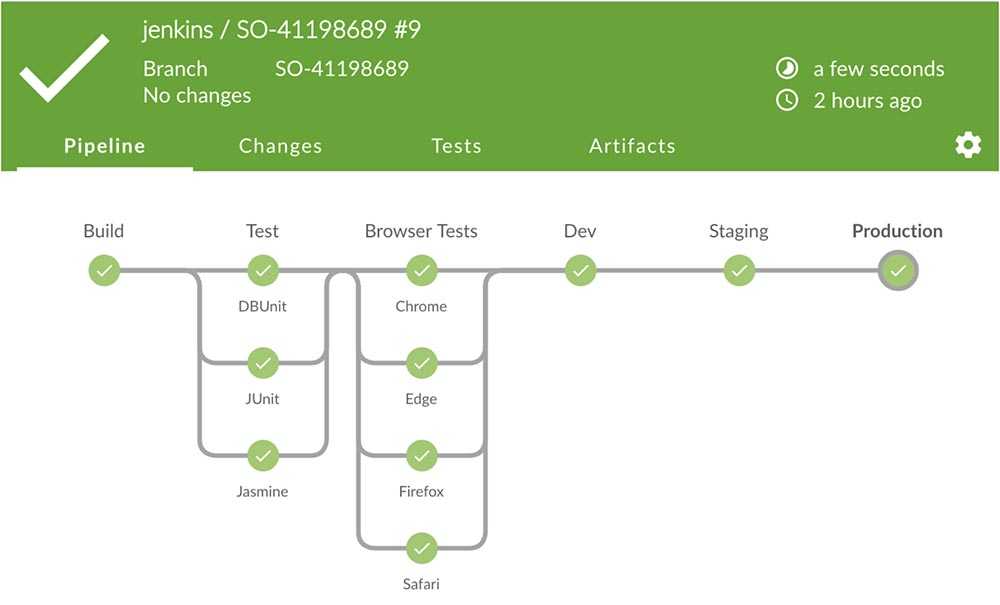
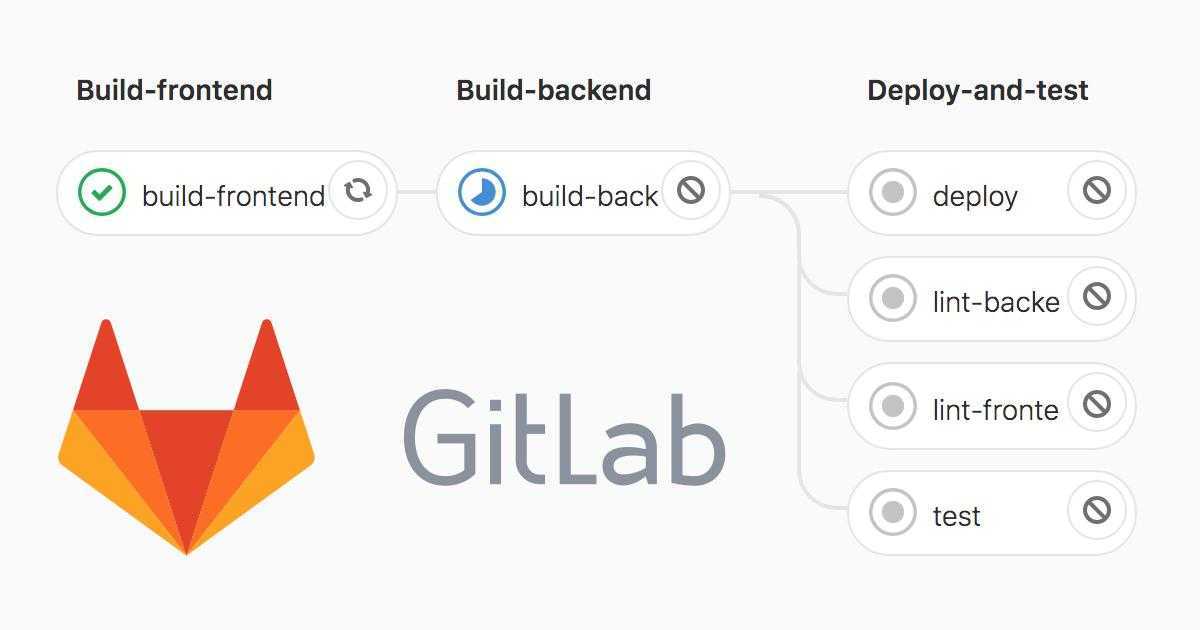
Коротко о Gitlab Pipline
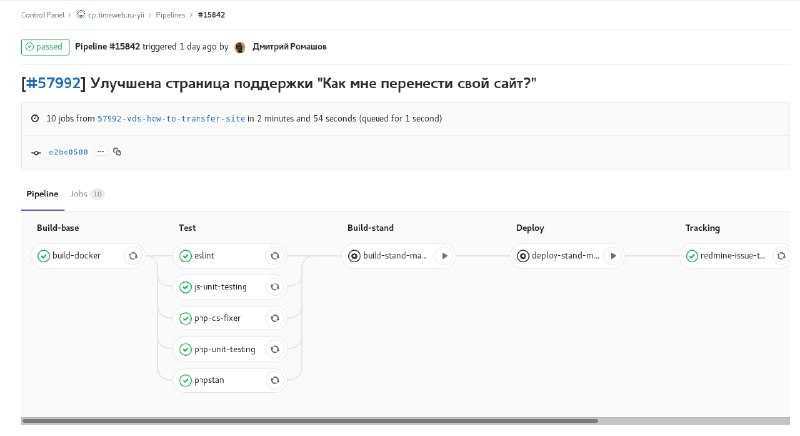
Если говорить простыми словами: сборка делится на задачи. Какие-то задачи выполняются последовательно и передают результаты следующим задачам, какие-то задачи распаралеливаются: например можно одновременно деплоить на сервер и в nexus.
Не обязательно один раннер отвечает за все задачи в сборке. Если на проекте два раннера, то первую задачу может взять один ранер, после ее выполнения вторую задачу возьмет другой раннер.
Раннеры бывают разных типов. Мы рассмотрим executor docker. Для каждой задачи создается новый чистый контейнер. Но между контейнерами можно передавать промежуточные результаты — это называется кэширование.
Кэширование и его особенности
Механизм кэширования разрабатывал какой-то одаренный человек. Поэтому сразу разобраться, как оно работает, будет не просто. В отдельной статье можно прочитать о кэшировании подробнее.
Каждый раннер хранит кэш в папке . Для каждого проекта в этой папке создается еще папка. Сам кэш хранится в виде zip архива.
Из-за наличия у каждого раннера своей папки для кэша, возникает проблема. Если один раннер кэшировал папку в первой задаче, а второй раннер взялся за выполнение второй задачи, то у него не окажется кэша из первой задачи. Чуть далее рассмотрим как это исправить.
Можно определить только один набор папок для кэша. Также только для всего набора можно выбрать политику кэширования. Например если вы уверены, что задача не изменит кэш, то можно его не загружать. Но нельзя запретить загружать например две папки из четырех.
Нет возможности установить глобальный кэш и добавить к нему дополнительные папки для конкретных задач.
Так же стоит знать, что кэш не удаляется после окончания сборки. При следующей такой же сборке старый кэш будет доступен.
Эти особенности усложняют создание инструкций для CI CD.
Артефакты
Помимо кэша между сборками можно передавать артефакты.
Артефакт — это файлы, которые считаются законченным продуктом сборки. Например .jar файлы приложения.
В отличие от кэша, артефакт передается между раннерами. Из-за этого многие злоупотребляют использованием артефактов там, где стоит использовать кэш.
Следуйте следующим правилам:
- Если текущее задание может выполняться самостоятельно, но в присутствии контента работа будет идти быстрее, используйте кэш.
- Если текущее задание зависит от результатов предыдущего, то есть не может выполняться само по себе, используйте артефакты и зависимости.
Начало работы над задачей
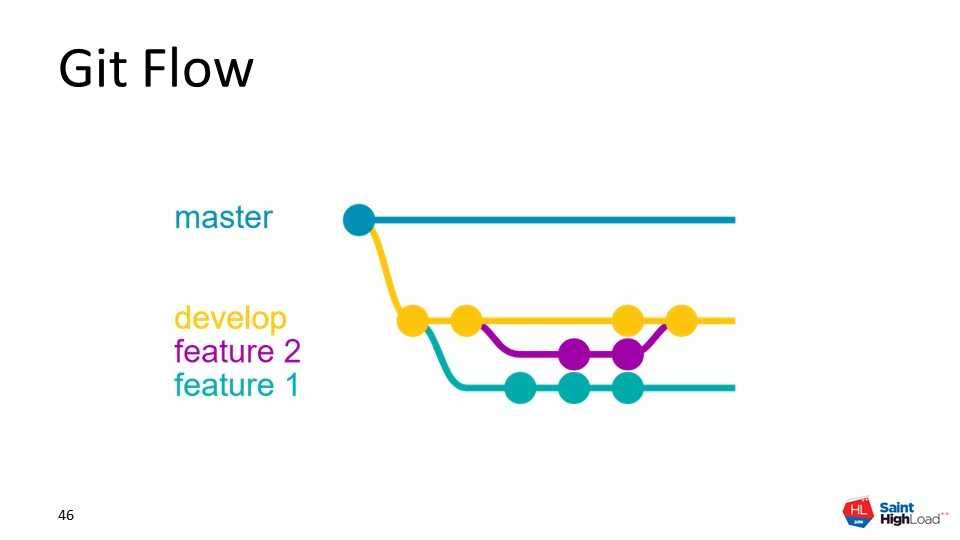
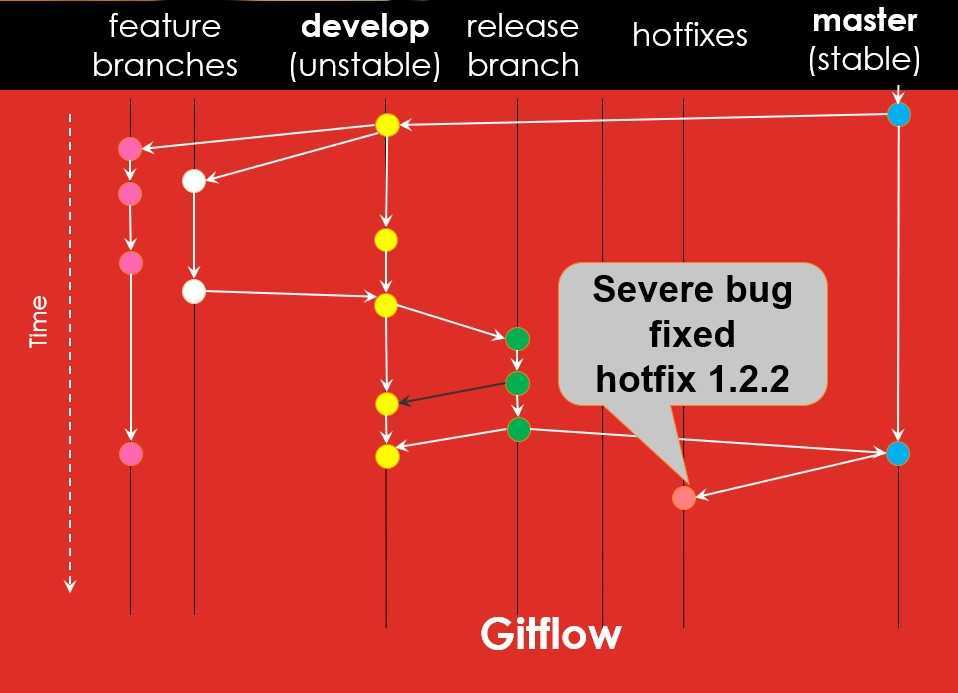
Работу по каждой задаче следует выполнять в отдельных ветках, называемых «фича». По соглашению в команде, имя фичи содержит, как правило, номер задачи из трекера. Например, у нас принят шаблон: feature9999. Фича начинается в основном стволе разработки (обычно это ветка develop) и сливается в него по окончании разработки.
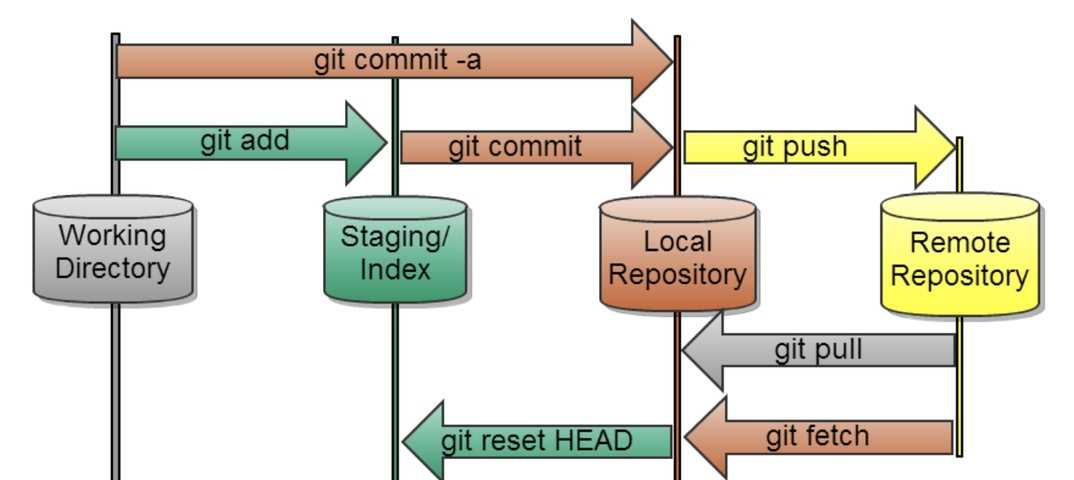
Прежде чем начать работу над задачей, актуализируем состояние своего локального репозитория, ведь с тех пор, как мы делали это последний раз, могли появиться новые коммиты наших коллег. Для этого сделаем текущей ветку develop, перейдя на неё, и выполним получение изменений.
Переход на ветку develop и получение изменений
При необходимости взять в работу еще одну фичу, приостановив работу над предыдущей, следует проделать эту последовательность еще раз. Но перед этим сделайте коммит в первой фиче (хотя, Git и так вас предупредит, если обнаружит не зафиксированные изменения). Таким образом, у разработчика может быть несколько незакрытых фич, между которыми он переключается в процессе работы, переходя с одной ветки на другую (точно так же, как мы в начале делали активной ветку develop).
Более того, разработчик может в рамках своей фичи создавать собственные суб-ветки и целые деревья, если это необходимо, чтобы, например, реализовать параллельно несколько идей в решаемой задаче или решить ее несколькими способами и сравнить результат. Главное, чтобы в конечном итоге на слияние в develop был отправлен тот единственный рабочий вариант, который должен уйти в рабочую версию.
Шаг 3: Переносим пайплайн в отдельный репозиторий
Мы сделали работающий пайплайн и вынесли его скрипты в отдельный файл, но пока этот пайплайн находится в том же репозитории, что и докерфайлы. Это означает, что если другая команда захочет использовать его для сборки своих докерфайлов, им придётся скопировать все скрипты. А это в свою очередь означает, что если нам необходимо будет внести в пайплайн какие-нибудь изменения, то потом их нужно будет внести и всем командам, которые скопировали себе пайплайн.
Вместо этого мы можем вынести пайплайн в отельный репозиторий и предложить нескольким командам подключить его через .
Однако для этого придётся внести в пайплайн небольшое изменение. Дело в том, что поскольку скрипты теперь будут фактически расположены не в том же репозитории, где запускается пайплайн, джоб должен как-то это понять и определить, откуда загрузить скрипты. Это делается при помощи специальных переменных, которые добавляются в пайплайн.
Если в джобе, использующей джоб определена переменная , то этот джоб проверит наличие трёх переменных: , и , где — это нормализованное значение переменной (приведённое в верхнему регистру с заменой дефисов на подчёркивания).
Если все три переменные существуют, джоб перед загрузкой скриптов из файла сначала загрузит файл, указанный в этих переменных.
Наш репозиторий с докерфайлами теперь будет выглядеть так:
Файл :
Сам пайплайн в отдельном репозитории будет выглядеть следующим образом:
Файл (сюда перенесён код из ):
Файл (сюда перенесён код из ):
Ссылки на проект:
-
Репозиторий с докерфайлами (ветка step3): https://gitlab.com/chakrygin/dockerfiles-example/-/tree/step3
-
Репозиторий с пайплайном (ветка step3): https://gitlab.com/chakrygin/dockerfiles-example-ci/-/tree/step3
-
Пайплайн: https://gitlab.com/chakrygin/dockerfiles-example/-/pipelines/303702906
Оба наших джоба и содержат переменную со значением . Поэтому загрузчик при старте джоба также проверит наличие трёх переменых: , и , которые также определены в пайплайне.
Благодаря этим переменным загрузчик понимает, что должен загрузить скрипты из файла , который находится в репозитории , в ветке .
Кроме того, мы убрали из скриптов функцию . Явная установка git больше не нужна, т.к. загрузчик сам по себе требует git для загрузки скриптов из другого репозитория и поэтому устанавливает git самостоятельно.
Заключение
Надеюсь, получилась полезная история на тему деплоя bitrix. С ним очень много нюансов и тонкостей. Программисты, которые первый раз его видят, не понимают, как с ним в принципе работать. Как организовать dev и stage окружение? У битрикса же лицензия на копию сайта. Она иногда слетает, если сайт скопировать и не выполнить некоторые действия с копией.
Так же проблемы возникают при разворачивании сайта для разработки на поддомене. Это не всегда возможно, так как есть шаблоны, в которых зашиты редиректы на основной домен. В итоге поддомен постоянно перекидывает на основной сайт. Ну и много остальных нюансов, описывать которые надо отдельно, не в рамках этой статьи.
У меня есть на примете черновики различных деплоев с помощью gitlab и teamcity, но оформлять их в полноценные статьи не хватает времени. Тема узкая, не очень читаемая. Писать долго, а выхлоп небольшой. Возможно в будущем напишу что-то еще по этой теме.
Рекомендую так же мою статью на тему оптимизации сервера под bitrix
Если ищите инструмент для обновления базы данных при деплое, обратите внимание на это решение — bitrix-reduce-migrations
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .



