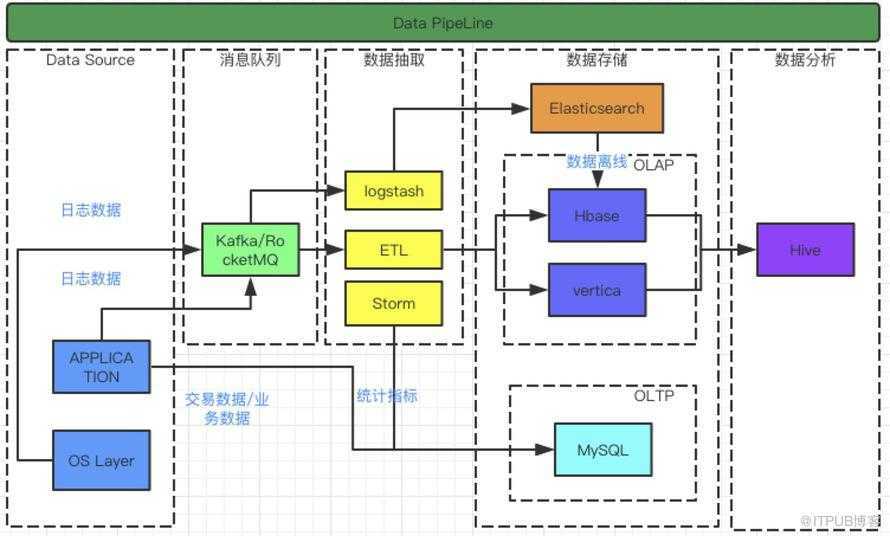
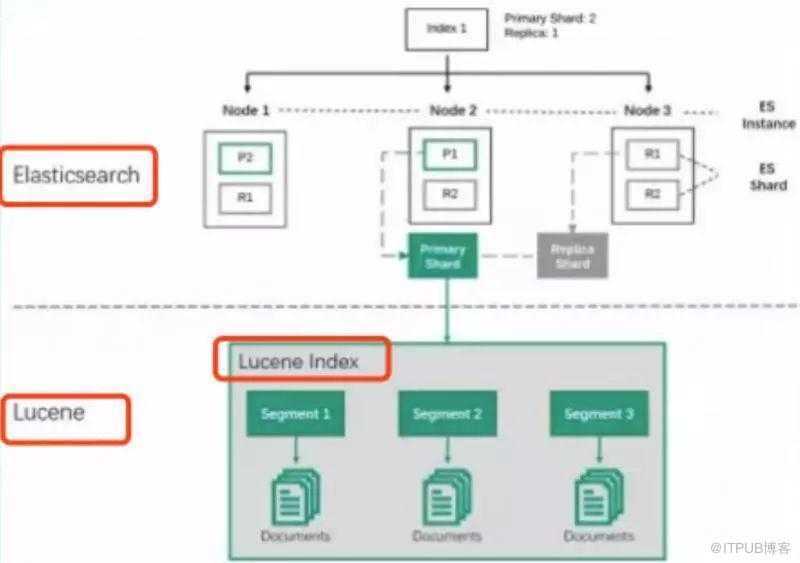
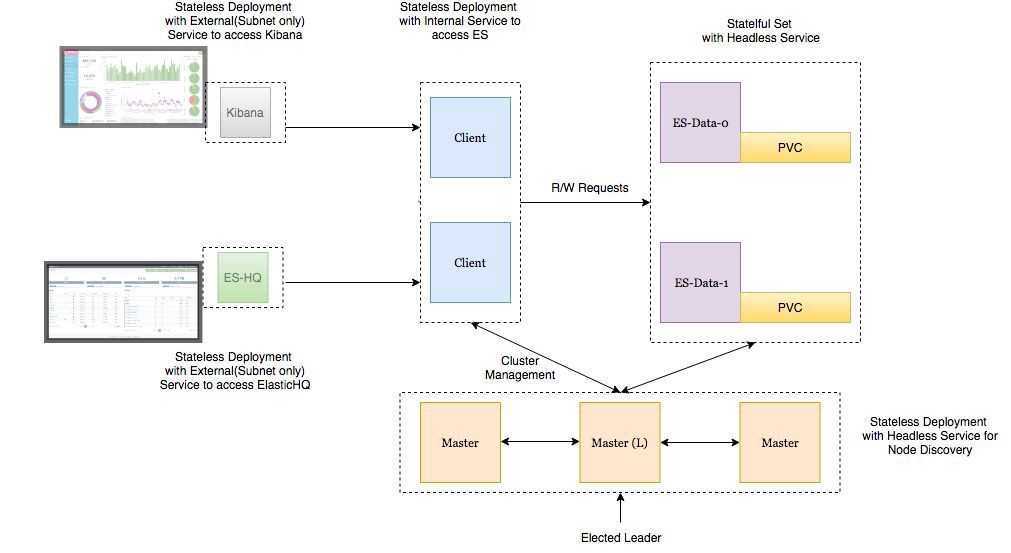
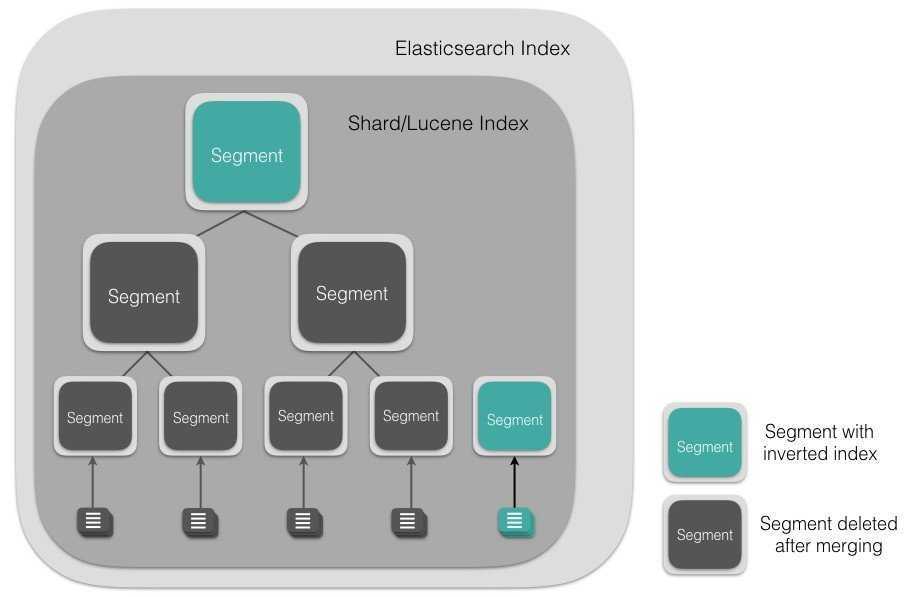
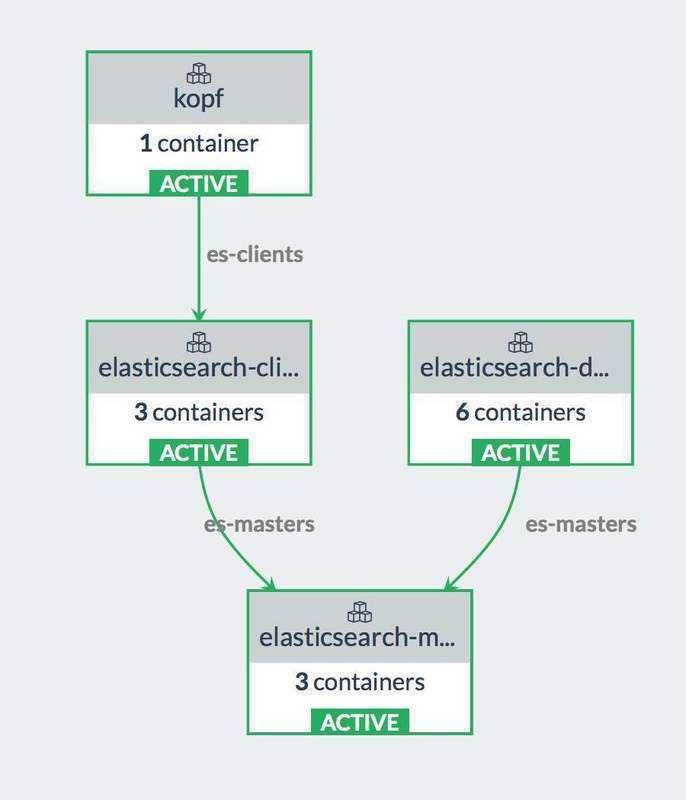
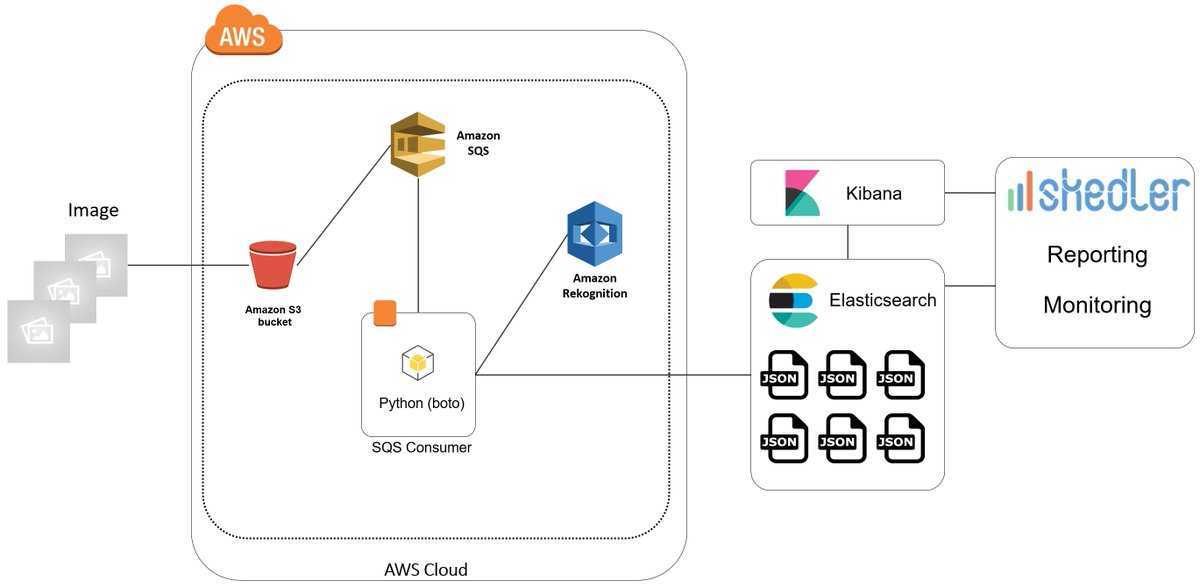
Clusters and nodes
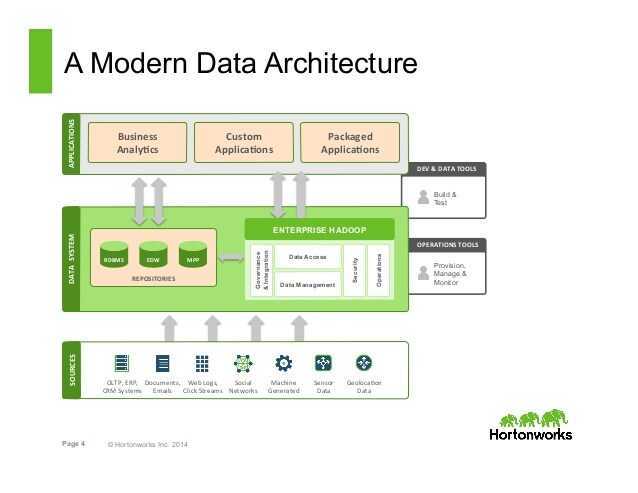
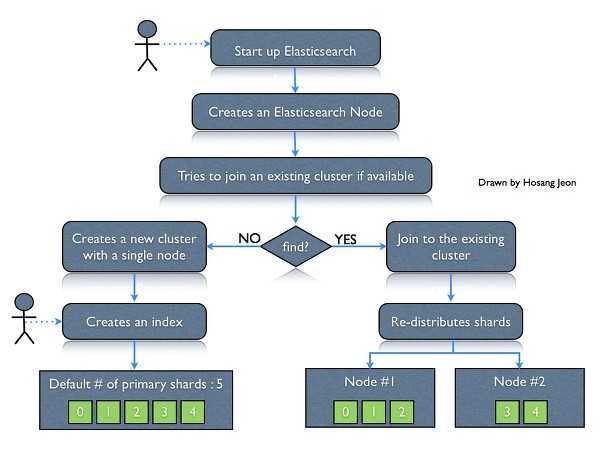
Its distributed design means that you interact with Elasticsearch clusters. Each cluster is a collection of one or more nodes, servers that store your data and process search requests.
You can run Elasticsearch locally on a laptop—its system requirements are minimal—but you can also scale a single cluster to hundreds of powerful machines in a data center.
In a single node cluster, such as a laptop, one machine has to do everything: manage the state of the cluster, index and search data, and perform any preprocessing of data prior to indexing it. As a cluster grows, however, you can subdivide responsibilities. Nodes with fast disks and plenty of RAM might be great at indexing and searching data, whereas a node with plenty of CPU power and a tiny disk could manage cluster state. For more information on setting node types, see Cluster Formation.
Создание индекса
Итак, мы получили нужные данные и должны их сохранить. Самое первое, что мы должны сделать, — это создать индекс. Давайте назовем эторецепты, Тип будет называтьсясалаты, Другая вещь, которую я собираюсь сделать, это создатьотображениенашей структуры документа.
Прежде чем мы перейдем к созданию индекса, мы должны подключить сервер ElasticSearch.
import loggingdef connect_elasticsearch(): _es = None _es = Elasticsearch() if _es.ping(): print('Yay Connect') else: print('Awww it could not connect!') return _esif __name__ == '__main__': logging.basicConfig(level=logging.ERROR)
на самом деле пингует сервер и возвращаетесли подключится. Мне потребовалось некоторое время, чтобы понять, как отследить трассировку стека,t, что это было только зарегистрировано!
def create_index(es_object, index_name='recipes'): created = False # index settings settings = { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "members": { "dynamic": "strict", "properties": { "title": { "type": "text" }, "submitter": { "type": "text" }, "description": { "type": "text" }, "calories": { "type": "integer" }, } } } }try: if not es_object.indices.exists(index_name): # Ignore 400 means to ignore "Index Already Exist" error. es_object.indices.create(index=index_name, ignore=400, body=settings) print('Created Index') created = True except Exception as ex: print(str(ex)) finally: return created
Здесь много чего происходит. Сначала мы передали переменную конфигурации, которая содержит отображение всей структуры документа.картографированиеявляется терминологией Elastic для схемы. Так же, как мы устанавливаем определенный тип данных поля в таблицах, мы делаем нечто подобное здесь. Проверьте документы, это охватывает больше, чем это. Все поля имеют типнокоторый имеет тип
Затем я проверяю, что индекс вообще не существует, а затем создаю его. Параметрбольше не требуется после проверки, но в случае, если вы не проверяете существование, вы можете устранить ошибку и перезаписать существующий индекс. Это рискованно, хотя. Это как перезаписать БД.
Если индекс успешно создан, вы можете проверить его, посетивHttp: // Localhost: 9200 / рецепты / _mappingsи он напечатает что-то вроде ниже:
{ "recipes": { "mappings": { "salads": { "dynamic": "strict", "properties": { "calories": { "type": "integer" }, "description": { "type": "text" }, "submitter": { "type": "text" }, "title": { "type": "text" } } } } }}
Мимоходоммы заставляем Elasticsearch проводить строгую проверку любого входящего документа. Вот,на самом деле тип документа.на самом деле ответ Elasticsearch RDBMSтаблицы,
Редактирование документа
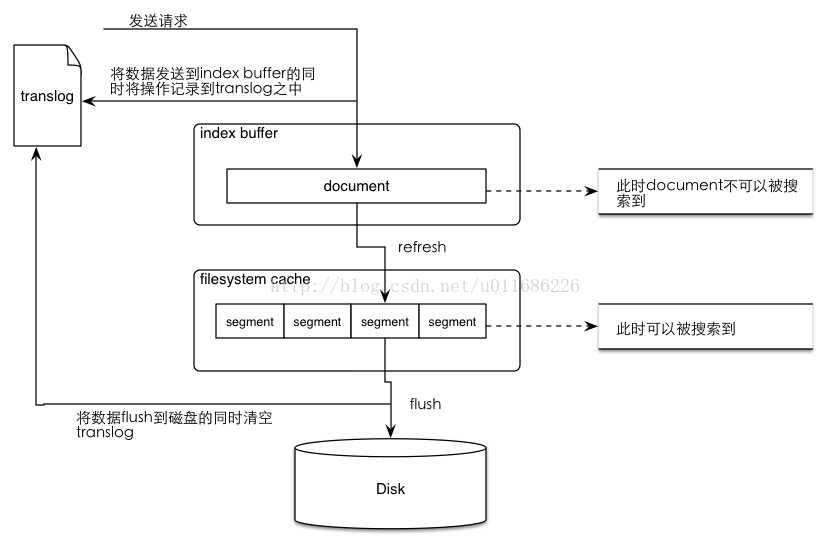
Для обновления данных в документе нам необходимо сначала его извлечь. Для этого указываем , и документа в методе . Текущие данные можно найти в сегменте . Для обновления данных, просто обращаемся к полям и задаём новые значения. Для сохранения результатов следует вызвать метод update.
$params = array();
$params = 'pokemon';
$params = 'pokemon_trainer';
$params = '1A-001';
$result = $client->get($params);
$result = 21; //задаём полю новое значение
//добавляем новое поле
$result = array(
'Onix' => array(
'type' => 'rock',
'moves' => array(
'Rock Slide' => array(
'power' => 100,
'pp' => 40
),
'Earthquake' => array(
'power' => 200,
'pp' => 100
)
)
)
);
$params = $result;
$result = $client->update($params);
Результат:
Array
(
=> pokemon
=> pokemon_trainer
=> 1A-001
=> 2
)
Значение поля будет увеличиваться каждый раз при вызове метода (в том случае, если хоть одно поле было изменено).
Вы можете подумать, что Elasticsearch сохраняет предыдущие версии документа, но это не так. Данный счётчик просто показывает количество обновлений документа.
Индексирование записей
Следующим шагом является сохранение фактических данных или документа.
def store_record(elastic_object, index_name, record): try: outcome = elastic_object.index(index=index_name, doc_type='salads', body=record) except Exception as ex: print('Error in indexing data') print(str(ex))
Запустите его, и вас встретят:
Error in indexing dataTransportError(400, 'strict_dynamic_mapping_exception', 'mapping set to strict, dynamic introduction of within is not allowed')
Можете ли вы догадаться, почему это происходит? Так как мы не ставилив нашем отображении ES не позволил нам сохранить документ, который содержитполе. Теперь вы знаете преимущество назначения картографии на первом месте. Делая это, вы можете избежать повреждения ваших данных. Теперь давайте немного изменим отображение, и теперь оно будет выглядеть так:
"mappings": { "salads": { "dynamic": "strict", "properties": { "title": { "type": "text" }, "submitter": { "type": "text" }, "description": { "type": "text" }, "calories": { "type": "integer" }, "ingredients": { "type": "nested", "properties": { "step": {"type": "text"} } }, } } }
Мы добавилитипаа затем присваивается тип данных внутреннего поля. В нашем случае это
вложенныйТип данных позволяет вам установить тип вложенных объектов JSON. Запустите его снова, и вы увидите следующее:
{ '_index': 'recipes', '_type': 'salads', '_id': 'OvL7s2MBaBpTDjqIPY4m', '_version': 1, 'result': 'created', '_shards': { 'total': 1, 'successful': 1, 'failed': 0 }, '_seq_no': 0, '_primary_term': 1}
Так как вы не прошливообще, сама ES назначала динамический идентификатор хранимому документу. Я использую Chrome, я использую ES Data Viewer с помощью инструмента под названиемElasticSearch Toolboxпросмотреть данные.
Прежде чем мы продолжим, давайте отправим строку вполе и посмотрим, как оно идет. Помните, что мы установили его как, При индексации выдает следующую ошибку:
Итак, теперь вы знаете преимущества назначения сопоставления для ваших документов. Если вы этого не сделаете, он все равно будет работать, поскольку Elasticsearch назначит свое собственное отображение во время выполнения.
Общее
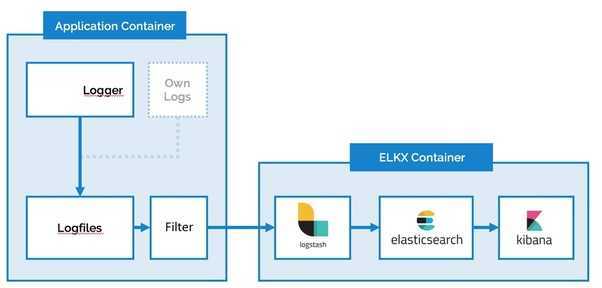
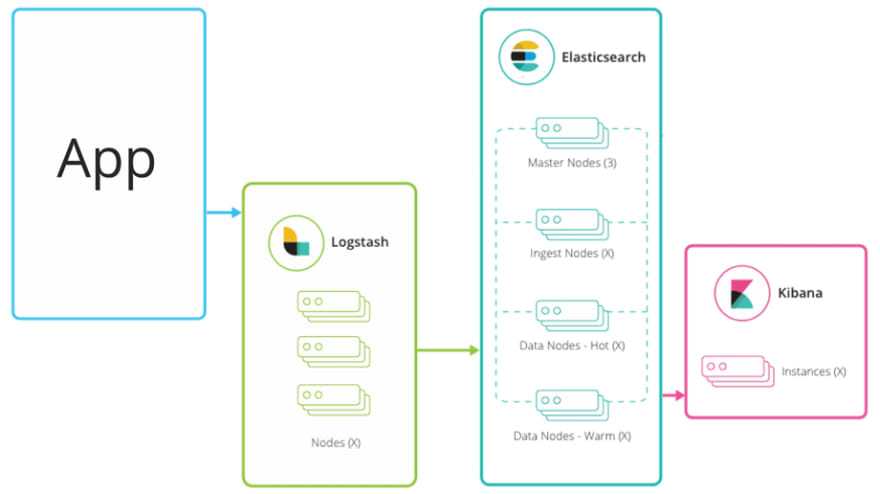
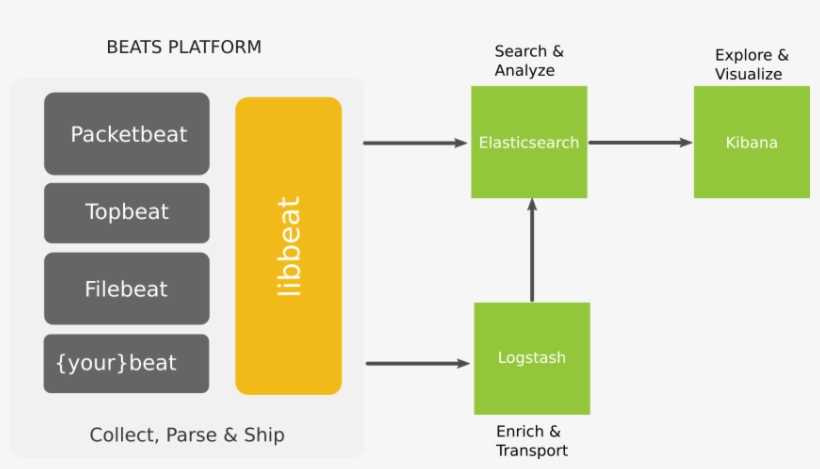
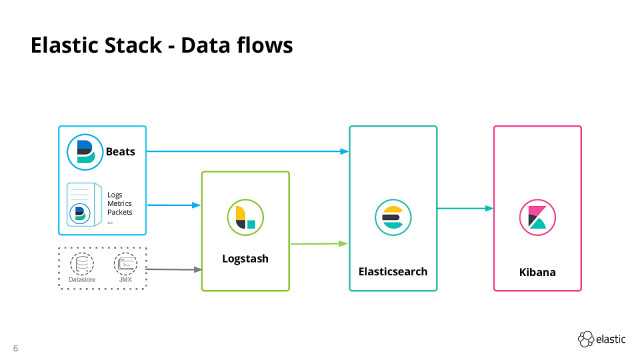
Elastic стек (ELK стек) — это инфраструктурная программа, состоящая из нескольких компонентов, разработанных компанией Elastic.
Компоненты включают:
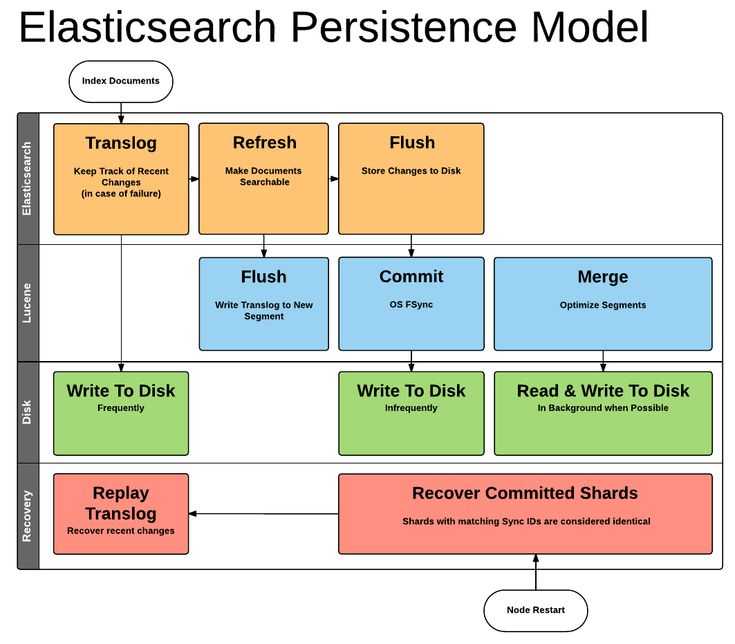
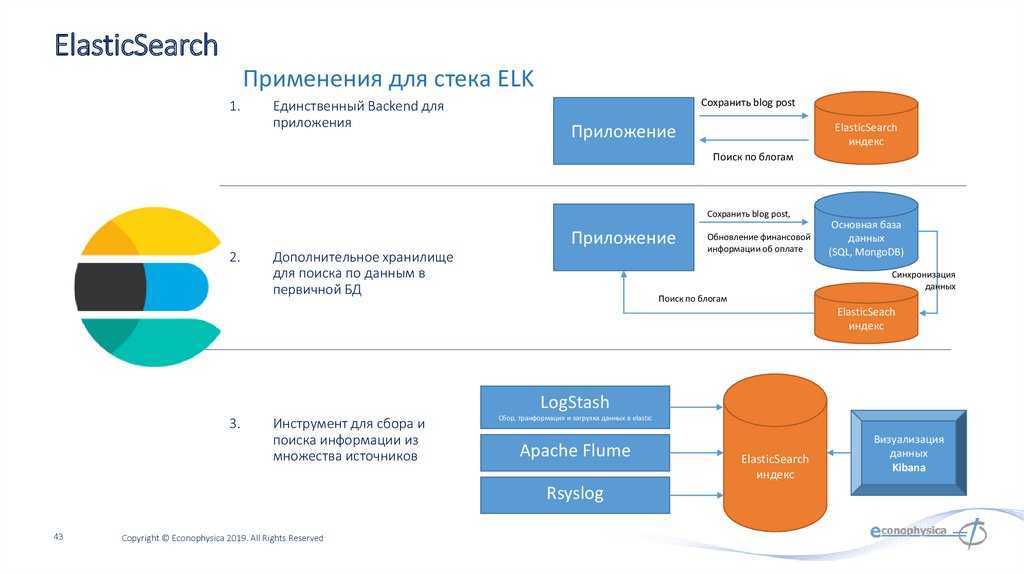
- Elasticsearch — высокомасштабируемая поисковая система полнотекстового поиска и аналитики данных с открытым исходным кодом. Данная утилита позволяет быстро (а главное, — режиме реального времени) хранить, искать и анализировать большие объемы данных. Обычно он используется в качестве базового механизма / технологии, которая обеспечивает помощь приложениям со сложными функциями поиска.
- Logstash — механизм сбора событий, который обеспечивает конвейер в реальном времени. Он может принимать данные из нескольких источников и преобразовывать их в документы JSON.
- Kibana — утилита с открытым исходным кодом которая визуализирует работу Elasticsearch. Он используется для взаимодействия с данными, хранящимися в индексах Elasticsearch. Kibana имеет веб-интерфейс, который позволяет быстро создавать и обмениваться динамическими панелями мониторинга, отображающими изменения в запросах Elasticsearch в реальном времени.
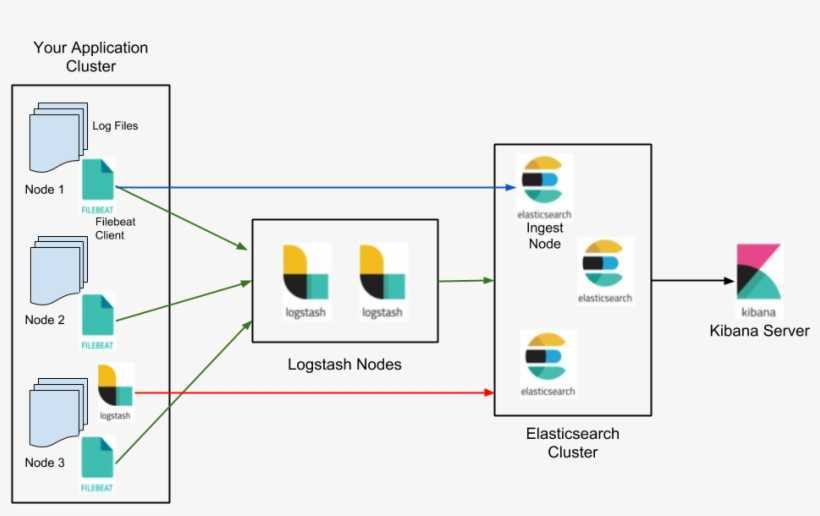
- FileBeat — утилита с открытым исходным кодом, которая работает в качестве агентов на серверах, для отправки различных типов оперативных данных в Elasticsearch.
В основе ELK лежит построенный на базе библиотеки Apache Lucene поисковый движок Elasticsearch для индексирования и поиска информации в любом типе документов. Для сбора журналов из многочисленных источников и централизованного хранения используется Logstash, который поддерживает множество входных типов данных — это могут быть журналы, метрики разных сервисов и служб. При получении он их структурирует, фильтрует, анализирует, идентифицирует информацию (например, геокоординаты IP-адреса), упрощая тем самым последующий анализ. Kibana — это веб-интерфейс для вывода индексированных Elasticsearch логов. Результатом может быть не только текстовая информация, но и, что удобно, диаграммы и графики. Он может визуализировать геоданные, строить отчеты и тд. Здесь уже каждый подстраивает интерфейс под свои задачи. Все продукты выпускаются одной компанией, поэтому их развертывание и совместная работа не представляет проблем, нужно только все правильно соединить.
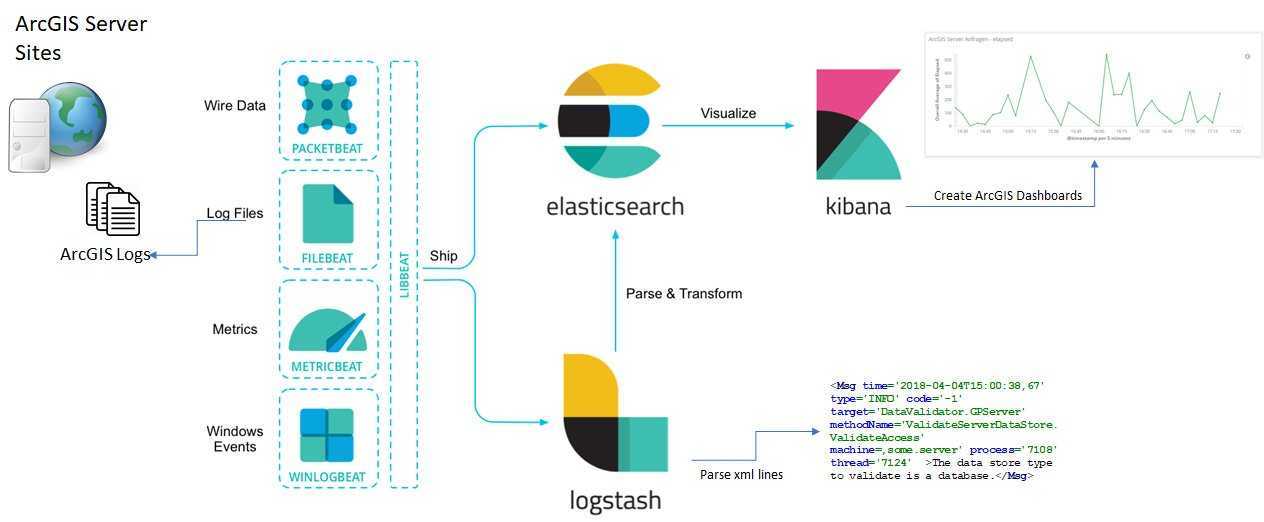
В зависимости от инфраструктуры в ELK могут участвовать и другие приложения. Так, для передачи логов приложений с серверов на Logstash можно использовать Filebeat. Кроме этого, также доступны Winlogbeat (события Windows Event Logs), Metricbeat (метрики), Packetbeat (сетевая информация) и Heartbeat (uptime).
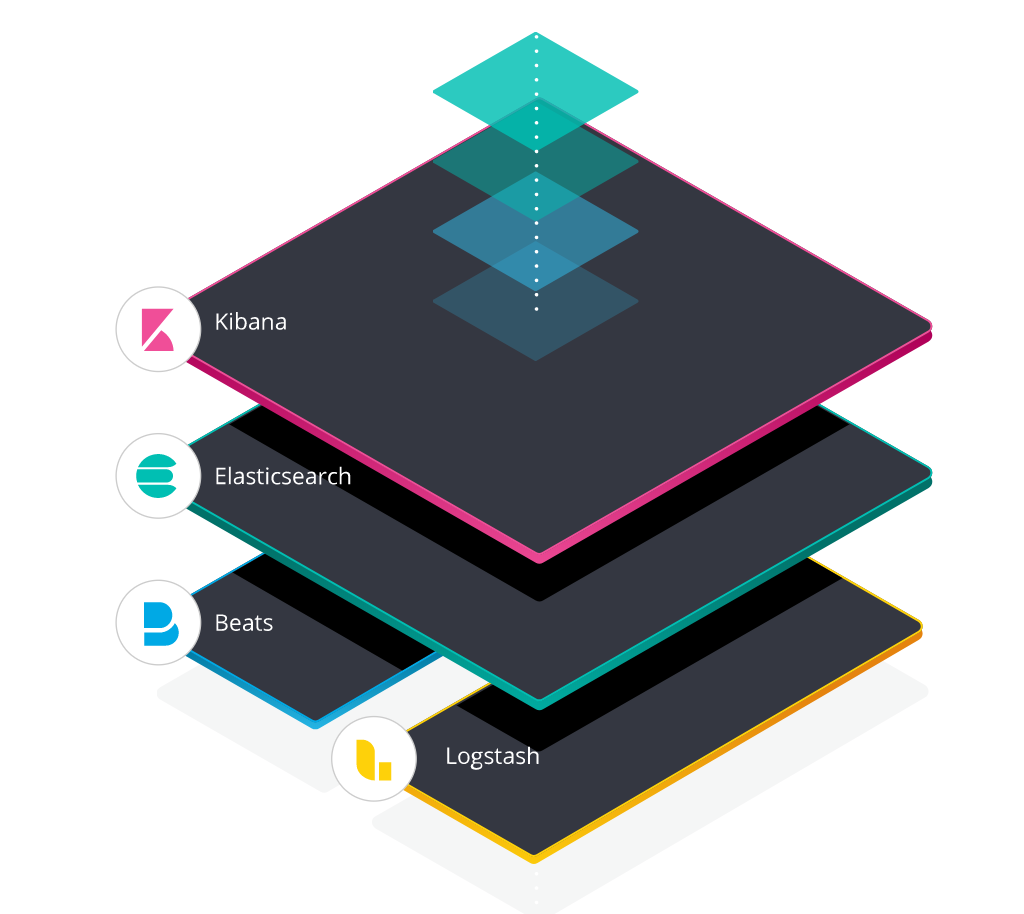
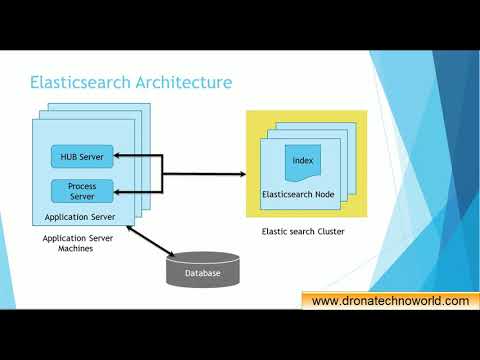
Архитектура стека ELK
Установка Elastic Logstash на Ubuntu 18.04
Установка Java
Так как Logstash не поддерживает Java 9, установим Java 8.
Будем использовать установку Oracle Java сторонним скриптом от проекта webupd8.org (JRE и JDK).
В связи с тем, что Oracle изменила условия распространения своей реализации Java, в репозитории Ubuntu не содержатся компоненты Oracle Java.
Существует PPA организованный сайтом webupd8.org содержащий в себе программу, которая будет автоматически проверять версию Java на сайте Oracle и сравнивать её с версией установленной на вашем компьютере. Это позволяет обойти ограничения наложенные на распространение Oracle Java.
Проверяем наличие java:
java -version javac -version
Чтобы добавить данный репозиторий и использовать последнюю версию Java с сайта Oracle, выполните в терминале следующие действия:
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installer
Кроме того, данный репозиторий изменяет зависимости пакетов, использующих Java, так, что становится возможным безболезненное удаление OpenJDK из системы.
Шаг 3
Проверьте установленную версию:
java -version javac -version
Инсталятор требует подтвердить принятие лицензии, если вы хотите принять лицензию автоматически, то выполните команду:
echo oracle-java8-installer shared/accepted-oracle-license-v1-1 select true | sudo /usr/bin/debconf-set-selections
Шаг 5
Для автоматической установки переменных среды вы можете выполнить команду:
sudo apt-get install oracle-java8-set-default
Установка ElasticSearch
Для функционирования ElasticLogstash необходимо будет установить ElasticSeacrh.
Шаг 3
Перейти в эту папку, перейти в папку bin и установить elasticsearch из исходников.
./elasticserach
Шаг 3
Перейти в эту папку, и создать там конфигурационный файл logsatsh.conf
Со следующими параметрами:
input { stdin { } }
output {
elasticsearch { hosts => "localhost:9200" }
stdout { codec => rubydebug }}
Запустим logsatsh
bin/logstash -f logstash.conf
Шаг 5
Проверяем, что Logstash запущен:
netstat -nat |grep 9200
Если порт 9200 присутствует, значит Logstash готов принимать логи.
Примечание
Если вы разворачиваете ELK на VirtualBox/VMware или на любом другом продукте виртуализации ОС, у вас может возникнуть ошибка hs_err_pid3889.
Это связано с тем,что :
- Cистема находится вне физической памяти;
- В 32-битном режиме был достигнут предел размера процесса.
Возможные решения:
- Уменьшить нагрузку на память в системе;
- Увеличить физическую память;
- Использовать 64-разрядную Java на 64-битной ОС;
- Уменьшить размер «кучи» Java (-Xmx / -Xms);
- Уменьшить размеры стека потоков Java (-Xss).
Индексирование
Задача сервиса — непрерывно извлекать новые объекты из очереди и индексировать соответствующие документы. В этом процессе мы используем не объектную модель NEST, а низкоуровневую библиотеку ElasticsearchNet. Она предоставляет интерфейс взаимодействия с базой данных через JSON. Объекты формируем динамически обходом в глубину иерархической структуры документа. Для этого используется всем известная библиотека NewtonsoftJson.
Индексирование реализовано многопоточно с параллельной обработкой каждого документа. Процесс формирования JSON занимает на порядок больше времени, чем его индексирование. Поэтому используется API для индексирования отдельных документов, а не Bulk API, при котором за один вызов в ES загружается массив документов. В таком случае индексирование бы происходило со скоростью формирования JSON для самого большого документа.
Индексирование файлов
Файлы индексируются вместе с остальными данными как часть JSON-объекта. Всё, что для это нужно — преобразовать поток байтов в Base64 строку. Это делается средствами стандартной библиотеки. Кроме того, необходимо, чтобы файлы попали под определение процессора. Иначе магии не произойдет, и они так и останутся обычной Base64 строкой. Чтобы при индексировании использовать конвейер, изменим вызов метода.
Создаем пользователей и роли
Ранее мы активировали встроенные учетные записи и сгенерировали для них пароли, но использовать пользователя elastic (superuser) не лучшая практика, поэтому рассмотрим, как создавать пользователей и роли к ним.
Для примера создадим администратора Kibana. Открываем Menu > Management > Stack Management, выбираем Users и нажимаем Create user. Заполняем все поля и жмем Create User.
Создание пользователя в Kibana
Или же можно воспользоваться API. Делать запросы к кластеру можно через консоль Dev Tools инструмента Kibana. Для этого перейдите Menu > Management > Dev Tools. В открывшейся консоли можно писать запросы к Elasticsearch.
Создание пользователя kibana_admin через API
После создания пользователя, можно его использовать.
Далее создадим роль для работы с данными в ранее созданном индексом logstash-logs*. Открываем Menu > Management > Stack Management. Слева выбираем Roles и нажимаем Create role. Настраиваем привилегии, указав в качестве индекса logstash-logs*:
|
Index privileges |
read |
Read only права на индекс |
Предоставляем пользователю доступ к Kibana, для этого ниже наживаем Add Kibana privilege и выбираем требуемые привилегии:
Чтобы создать роль с привилегиями в Elasticsearch и Kibana через API, делаем запрос к Kibana:
Создаем пользователя logstash_reader и связываем его с созданной ролью (это мы уже научились делать) и заходим данным пользователем в Kibana.
Главная страница Kibana для пользователя logstash_reader
Как видно, у данного пользователя не так много прав. Он может просматривать индексы logstash-logs*, строить графики, создавать панели и делать GET запросы к этому индексам через Dev Tools.
Дополнение 2
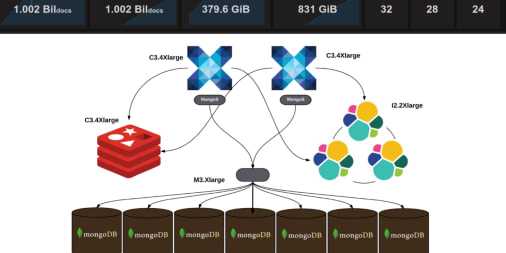
Индексация — 30664 док/сек (правда, асинхронно)
|
Запрос |
QPS |
avg |
50%% |
90%% |
99%% |
100%% |
|---|---|---|---|---|---|---|
|
1 слово |
59.08 |
16.93 ms |
14.04 ms |
31.24 ms |
63.49 ms |
246.68 ms |
|
3 слова |
41.74 |
23.96 ms |
21.51 ms |
38.55 ms |
73.75 ms |
152.33 ms |
Документация выстроена неочевидно для человека со стороны и сильно «заточена» под использование как библиотеки для golang. Также в процессе «поймал» баг, когда невалидный utf-8 на входе прекрасно индексируется, но валится при поиске.
Также, это in-memory storage, т.е. объем данный жестко ограничен размером памяти (на моем тесте процесс потреблял около 9 Гб).
Индексация — 4481 док/сек
|
Запрос |
QPS |
avg |
50%% |
90%% |
99%% |
100%% |
|---|---|---|---|---|---|---|
|
1 слово |
128.41 |
7.79 ms |
6.52 ms |
10.12 ms |
23.86 ms |
334.15 ms |
|
3 слова И |
313.55 |
3.19 ms |
2.76 ms |
3.76 ms |
8.36 ms |
84.96 ms |
|
3 слова ИЛИ |
73.05 |
13.69 ms |
9.94 ms |
17.78 ms |
106.00 ms |
274.99 ms |
|
Точная фраза |
318.31 |
3.14 ms |
2.48 ms |
3.25 ms |
7.15 ms |
90.85 ms |
Неплохие показатели по поиску, но скорость индексации оставляет желать лучшего.
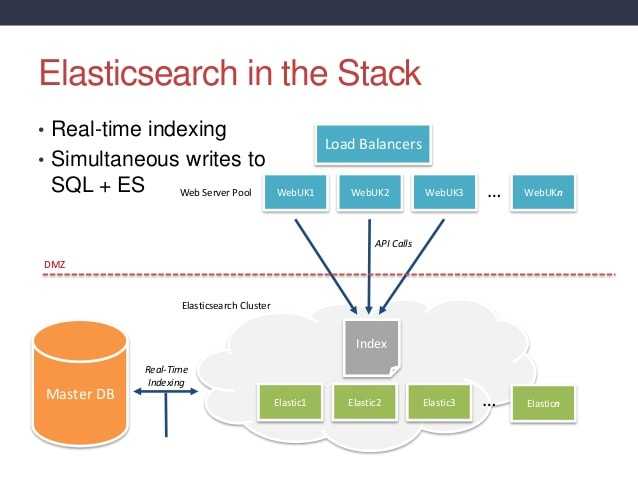
Установка Elasticsearch
Для установки Elasticsearch нам потребуется Java. По умолчанию в Ubuntu её нет, так что сначала добавляем репозиторий.
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update
Теперь приступаем непосредственно к установке Java.
sudo apt-get install oracle-java8-installer
Далее скачиваем Elasticsearch, используя .
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.5.2.tar.gz
На данный момент версия 1.5.2 является самой стабильной, поэтому мы будем использовать именно её. Если вам нужна какая-то другая версия, то архив релизов можно найти тут.
Затем распаковываем и запускаем установку.
mkdir es tar -xf elasticsearch-1.5.2.tar.gz -C es cd es ./bin/elasticsearch
Теперь после обращения к адресу в адресной строке браузера, вы должны увидеть следующее:
{
"status" : 200,
"name" : "Rumiko Fujikawa",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.5.2",
"build_hash" : "62ff9868b4c8a0c45860bebb259e21980778ab1c",
"build_timestamp" : "2015-04-27T09:21:06Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
Поиск по документам
Для поиска следует использовать метод или : в случа, если вы знаете ID документа. Так же следует отметить, что данный метод возвращает только один документ. Для поиска набора результатов по различным критериям (по полям) следует использовать метод .
Get
Давайте начнём с метода . Точно так же как метод он принимает массив аргументов. В массиве должны быть ключи , и документа, который вы хотите найти.
$params = array(); $params = 'pokemon'; $params = 'pokemon_trainer'; $params = '1A-001'; $result = $client->get($params);
Результат поиска:
Array
(
=> pokemon
=> pokemon_trainer
=> 1A-001
=> 1
=> 1
=> Array
(
=> Brock
=> 15
=> 0
)
)
Поиск по определённым полям
В массиве аргументов для метода следует указать ключи , и . В ключе указываем критерии запроса. Вот как можно вернуть все документы, где возраст равен .
$params = 'pokemon'; $params = 'pokemon_trainer'; $params = 15; $result = $client->search($params);
Результат:
Array
(
=> 177
=>
=> Array
(
=> 5
=> 5
=> 0
)
=> Array
(
=> 1
=> 1
=> Array
(
=> Array
(
=> pokemon
=> pokemon_trainer
=> 1A-001
=> 1
=> Array
(
=> Brock
=> 15
=> 0
)
)
)
)
)
Давайте разберём результат:
- – время выполнения запроса.
- – возвращает если время выполнения запроса прошло.
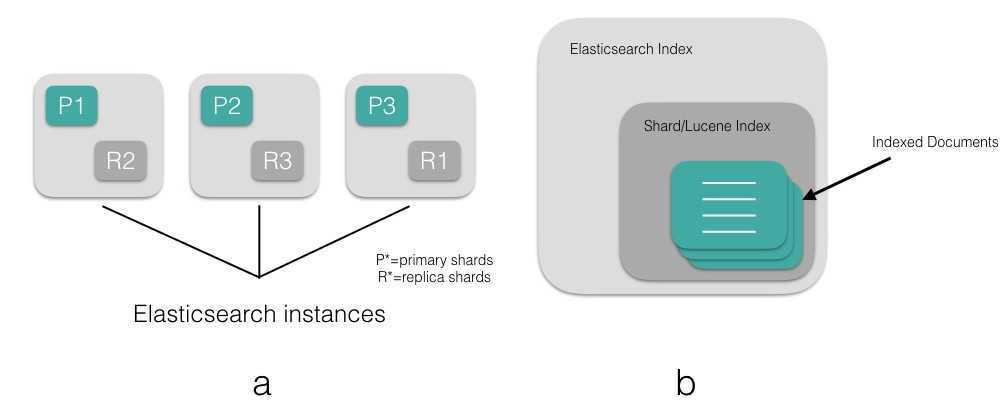
- – по умолчанию, Elasticsearch размещает данные по 5 шардам (сегментам). Если значение 5 будет в и то каждый шард работает корректно.
- содержит результат поиска.
Метод который мы продемонстрировали, позволяет осуществить поиск по глубине равной единице. Если мы хотим искать глубже, то нам следует воспользоваться запросами. Для этого указываем ключ в . Теперь в поиске будут задействованы все поля, разделяя их знаком .
$params = 'pokemon'; $params = 'pokemon_trainer'; $params[] = 'water'; $result = $client->search($params);
Поиск массивами
Так же мы можем осуществлять запросы, используя массивы, указав ключ , а затем , . В качестве значения указываем массив значений, который должен быть задействован в поиске. В данном примере ищем документы, где поле равняется 10 и 15.
$params = 'pokemon'; $params = 'pokemon_trainer'; $params = array(10, 15);
В данном способе можно применять только линейные массивы.
Поиск по фильтрам
Теперь давайте посмотрим как можно осуществить поиск с применением фильтров. Для фильтрации нужно указать ключ , а в качестве значения начальное и конечно число диапазона искомых значений. В данном случае мы будем искать по полю , где значение больше или равно (gte) 11 и меньше или равно (lte) 20.
$params = 'pokemon'; $params = 'pokemon_trainer'; $params = 11; $params = 20; $result = $client->search($params);
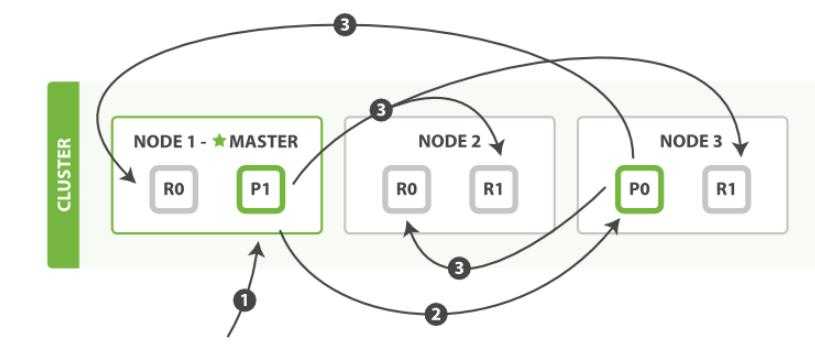
Кластеры и управление ими
Чтобы получать информацию из распределенной системы, масштаб которой со временем изменяется, нужно определять, когда и к каким сегментам следует обращаться. Поэтому узлы данных объединяются в кластеры, где существуют также координирующие узлы, которые выполняют именно эту функцию.
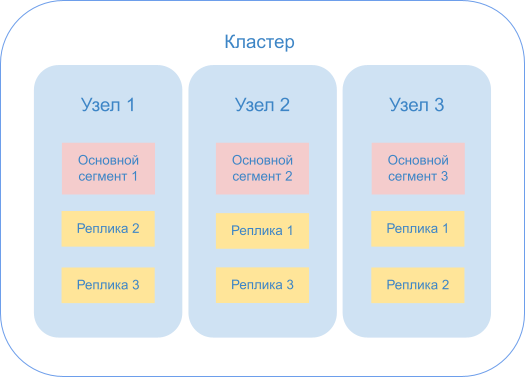
Кластер
Кластер — это группа узлов с одним и тем же значением атрибута . Если запущен один экземпляр Elasticsearch, то кластер состоит из единственного узла. Все первичные узлы находятся на нем, и он готов к использованию. Но создать на нем реплицированные сегменты невозможно, поэтому в случае сбоя могут быть потеряны данные.
Добавление узлов в кластер повышает его емкость и надежность. Когда в кластер добавляется узел, реплицированные сегменты выделяются автоматически, и его отказоустойчивость повышается.
По умолчанию добавляемый узел может быть как узлом данных, так и master-узлом, который управляет кластером. Рекомендуем помещать в кластер небольшое фиксированное количество узлов, которые могут быть выбраны основными (). Такие узлы отвечают, например, за создание или удаление индекса, отслеживание узлов, которые входят в кластер, и принятие решений о распределении сегментов между узлами. Добавлять же в кластер лучше те узлы данных, которые не могут быть выбраны основными.
Основные узлы обеспечивают управление кластером и позволяют избежать конфликтов между координирующими узлами, например, в случае перемещения сегментов с узла на узел. Поскольку у них есть вся информация о состоянии кластера, таким узлам требуется повышенный объем ресурсов и стабильное оборудование.
Напоследок о мониторинге
Чтобы всё это работало так, как задумывалось, мы мониторим следующее:
- Каждая дата-нода сообщает в наше облако, что она есть, и на ней находятся такие-то шарды. Когда мы где-то что-то тушим, кластер через 2-3 секунды рапортует, что в центре А мы потушили ноду 2, 3, и 4 — это означает, что в других дата-центрах мы ни в коем случае не можем тушить те ноды, на которых остались шарды в единственном экземпляре.
- Зная характер поведения мастера, мы очень внимательно смотрим на количество pending-задач. Потому что даже одна зависшая задача, если вовремя не оттаймаутится, теоретически в какой-то экстренной ситуации способна стать той причиной, по которой у нас не отработает, допустим, промоушен replica-шарда в primary, из-за чего встанет индексация.
- Также мы очень пристально смотрим на задержки garbage collector, потому что у нас с этим уже были большие сложности при оптимизации.
- Реджекты по тредам, чтобы понимать заранее, где находится «бутылочное горло».
- Ну и стандартные метрики, типа heap, RAM и I/O.
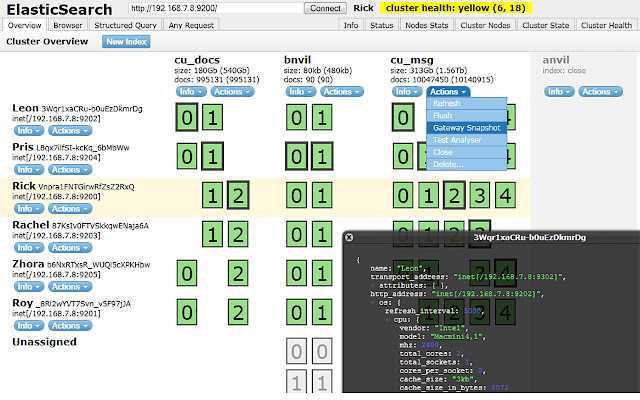
При построении мониторинга обязательно надо учитывать особенности Thread Pool в Elasticsearch. Документация Elasticsearch описывает возможности настройки и дефолтные значения для поиска, индексации, но полностью умалчивает о thread_pool.management.Эти треды обрабатывают, в частности, запросы типа _cat/shards и другие аналогичные, которые удобно использовать при написании мониторинга. Чем больше кластер, тем больше таких запросов выполняется в единицу времени, а вышеупомянутый thread_pool.management мало того, что не представлен в официальной документации, так ещё и лимитирован по дефолту 5 тредами, что очень быстро утилизируется, после чего мониторинг перестаёт работать корректно.
Что хочется сказать в заключение: у нас получилось! Мы сумели дать нашим программистам и разработчикам инструмент, который практически в любой ситуации способен быстро и достоверно предоставить информацию о происходящем на продакшене.
Да, это получилось довольно-таки сложно, но, тем не менее, наши хотелки удалось уложить в уже существующие продукты, которые при этом не пришлось патчить и переписывать под себя.
Дополнение: результаты Meilisearch и Typesense
Джейсон Боско из Typesense обратился к нам по поводу странных медленных выбросов с запросами из 3 слов и рекомендовал повторно запустить этот тест с параметром drop_tokens_threshold = 1, но мы получили в этом режиме похожие результаты (200+ мс). Мы также попробовали drop_tokens_threshold = 0 (по сути, превратив запрос в «ИЛИ»), это дало более высокую производительность.
То есть, по-видимому, замедление вызвано тем, что мы выбираем 3 случайных английских слова для запроса, и при отсутствии в индексе документов, содержащих все три слова Typesense начинает отбрасывать слова, пока не получает результат, и этот процесс не очень быстр.
Джейсон также отметил, что кажущаяся быстрая индексация Meilisearch на самом деле была вызвана асинхронностью запросов индексации. Мы обновили тест, чтобы он дожидался завершения индексирования каждой порции, но в таком режиме индексация занимает как-то невероятно много времени, так что, видимо, нам нужно повнимательнее изучить, как Meilisearch работает под капотом.
Выводы
Elasticsearch по-прежнему остается королем поиска, он выдает стабильную производительность и для индексирования, и для всех типов запросов.
RediSearch имеет посредственную производительность индексации; также RedisLabs изо всех сил стараются продать свое облачное решение, поэтому документация не на высоте. Но эта система показывает минимальную задержку (менее миллисекунды) для некоторых типов запросов.
PostgreSQL показал странную «яму» производительности для простых запросов из одного слова, и интерфейс поиска довольно сложен. Хотя, если у вас уже есть база данных Postgres, встроенный поиск может быть неплохим решением для простых случаев.
У TypeSense неплохой набор функций, и производительность в целом тоже на высоте, за исключением странного провала при запросах из нескольких слов.
Кажущаяся высокая производительность MeiliSearch была вызвана ориентацией теста только на время ответа при индексировании, но Meili больше других полагается на асинхронную обработку. Мы не смогли провести тест с ожиданием индексации каждой порции данных, т.к. в таком режиме система оказалась мучительно медленной.