Предисловие
Об этом руководстве
Добро пожаловать в «Системное администрирование», последнюю из четырех частей руководства, предназначенного для подготовки к экзамену “101 Linux Professional Institute’s”. В этой части, вы познакомитесь с такими навыками администрирования Linux, как файловые системы, процесс загрузки, уровни запуска, файловые квоты, а также системные журналы (логи).
Это руководство является особенно полезным для тех, кто хочет впервые попробовать себя в качестве системного администратора, так как тут описано много основных вопросов, которые должны знать системные администраторы. Если вы новичок в Linux, мы рекомендуем вам начать изучение с части 1. Для некоторых, большая часть этого материала будет новой, но и более опытные пользователи Linux могут найти в этом руководстве новое для себя, что может быть отличным способом обновления своих знаний по системному администрированию Linux и подготовке к следующему уровню сертификации LPI.
К концу этой серии учебных пособий (всего их восемь для экзаменов LPI 101 и 102), вы будете иметь знания, необходимые, чтобы стать администратором систем Linux и будете готовы для достижения первого уровня LPIC сертификации от “Linux Professional Institute” если вы того пожелаете.
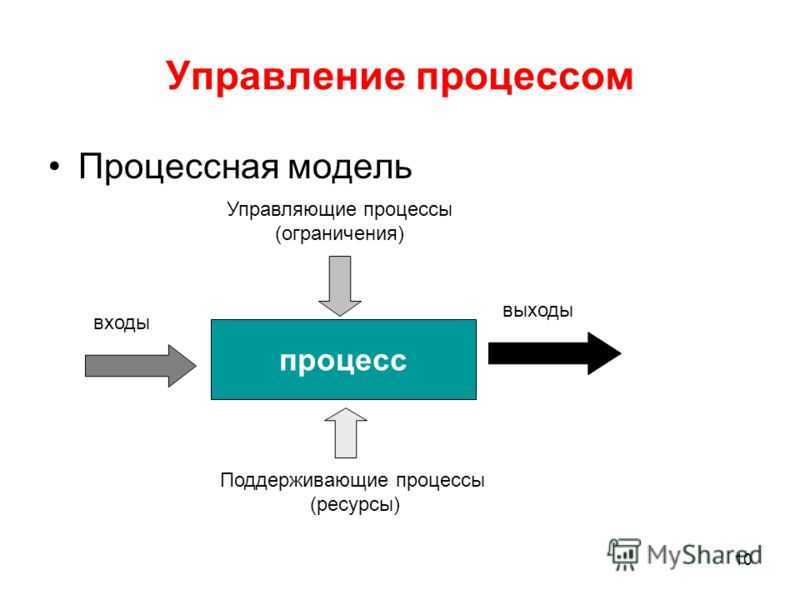
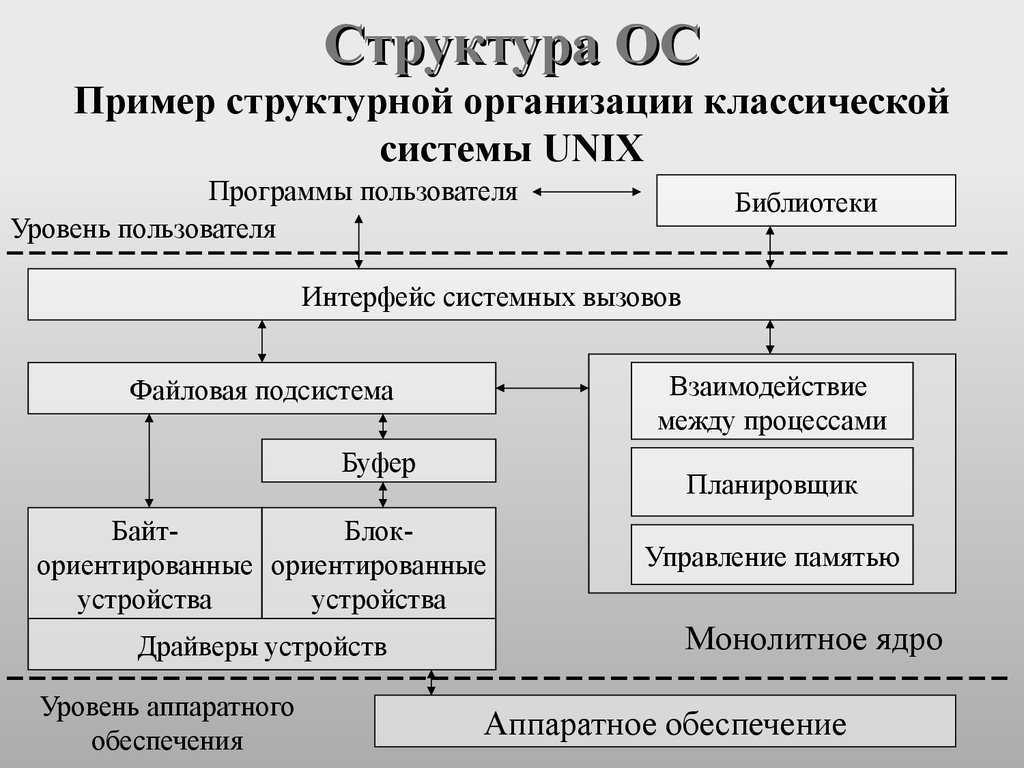
Слежение за VFS
Самый простой способ узнать как ядро управляет файлами в sysfs — это посмотреть на это всё в действии. А самый простой способ это сделать на ARM64 или x86_64 — это использование eBPF. eBPF (extended Berkeley Packet Filter) — состоит из виртуальной машины, работающей на уровне ядра, к которой привилегированные пользователи могут обращаться из командной строки. Исходный код ядра показывает читателю как ядро может что-то сделать. Инструменты eBPF показывают как на самом деле всё происходит.
К счастью, начать работу с eBPF довольно просто с помощью инструментов bcc, для которых доступны пакеты в множестве дистрибутивов. Инструменты bcc — это скрипты на Python с небольшими фрагментами кода на Си, а это значит, что любой кто знаком с этим языком может их модифицировать. На данный момент существует около 80 скриптов на Python в bcc, поэтому каждый найдёт то, что ему надо.
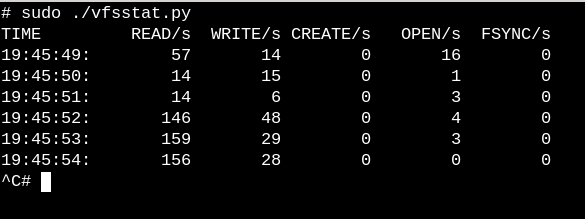
Чтобы получить общее представление о работе VFS в работающей системе используйте простые скрипты vfscount и vfsstat, которые покажут, что каждую секунду выполняются десятки вызовов vfs_open() и подобных функций:
В качестве менее общего примера, давайте посмотрим что происходит, когда к работающей системе подключается USB накопитель:
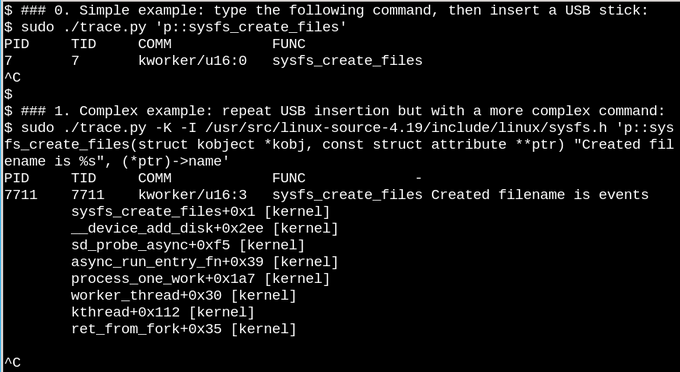
В первом примере на этом снимке скрипт trade.py выводит сообщение всякий раз, когда вызывается функция sysfs_create_files(). Вы можете видеть, что эта функция была вызвана процессом kworker после подключения USB, но какой файл был создан? Следующий пример иллюстрирует полную силу eBPF. Скрипт trade.py выводит трассировку вызовов ядра (опция -K), а также имя файла, созданного функцией sysfs_create_files(). Фрагмент в одинарных кавычках — это строка кода на Си, которую Python скрипт компилирует и выполняет внутри виртуальной машины в ядре. Полную сигнатуру функции sysfs_create_files () надо воспроизвести во втором примере чтобы можно было ссылаться на один из её параметров в функции вывода. Ошибки в этом коде вызовут ошибки компиляции.
Когда USB-накопитель вставлен, появляется трассировка вызовов ядра, показывающая что один из потоков kworker с PID 7711 создал файл с именем events в sysfs. При попытке отслеживать вызов sysfs_remove_files() вы увидите, что извлечение флешки приводит к удалению файла events в соответствии с идеей отслеживания ссылок. Отслеживание sysfs_create_link() во время подключения USB накопителя показывает что создается не менее 48 ссылок.
Зачем же нужен файл events? Используя инструмент cscope можно найти функцию __device_add_disk(), которая вызывает функцию disk_add_events(). А та в свою очередь может записать в файл «media_change» или «eject request». Здесь ядро сообщает в пользовательское пространство о появлении или исчезновении диска. Это намного информативнее, чем просто анализ исходников.
Монтирование
Файловая система proc поддерживает следующие параметры монтирования:
hidepid = n (начиная с Linux 3.3). Эта опция контролирует, кто может получить доступ к информации в каталогах / proc / . Аргумент n является одним из следующих значений:
-
- 0 Каждый может получить доступ ко всем каталогам . Это традиционное поведение и значение по умолчанию, если этот параметр монтирования не указан.
- 1 Пользователи могут не иметь доступа к файлам и подкаталогам внутри каких-либо каталогов , но свои собственные (сами каталоги остаются видимыми). Чувствительные файлы, такие как и , теперь защищены от других пользователей. Это делает невозможным изучение того, запускает ли какой-либо пользователь определенную программу (при условии, что программа не раскрывает себя по своему поведению).
- 2 То же, что и 1, но кроме этого каталоги , принадлежащие другим пользователям, становятся невидимыми. Это означает, что записи больше не могут использоваться для обнаружения PID в системе. Это не скрывает того факта, что процесс с определенным значением PID существует (его можно узнать другими способами, например, «»), но он скрывает UID и GID процесса, которые в противном случае могли бы научиться применять stat (2) в каталоге / proc / . Это значительно усложняет задачу злоумышленника по сбору информации о запущенных процессах (например, обнаружение, работает ли какой-либо демон с повышенными привилегиями, выполняет ли какой-либо другой пользователь какую-либо чувствительную программу, запускают ли другие пользователи какую-либо программу вообще и т. д.).
- (начиная с Linux 3.3). Задает идентификатор группы, члены которой уполномочены изучать информацию о процессах, иначе запрещенную hidepid (т.е. пользователи в этой группе ведут себя так, как будто был смонтирован с ). Эта группа должна использоваться вместо подходов, таких как помещение нерутованных пользователей в файл sudoers (5).
Информация о видеокарте в /proc
Информация о PCI устройствах содержится в файле /proc/bus/pci/devices, а также в поддиректориях /proc/bus/pci. Как и с другими устройствами, здесь нет информации о производителе — только тип устройства и, видимо, используемое адресное пространство.
Больше информации вы сможете найти в папке /proc/driver, пример вывода данных о драйвере NVidia:
cat /proc/driver/nvidia/gpus/0000\:01\:00.0/information
Пример вывода:
Model: GeForce GTX 1050 Ti IRQ: 157 GPU UUID: GPU-e7cc6b38-164e-babb-d5e7-14b23d2e5e05 Video BIOS: 86.07.50.00.54 Bus Type: PCIe DMA Size: 47 bits DMA Mask: 0x7fffffffffff Bus Location: 0000:01:00.0 Device Minor: 0 Blacklisted: No
Здесь информация о модели, версии БИОСа, типе шине, находиться ли устройство в чёрном списке (для отключения) и некоторые другие данные.
Подробная информация о процессе
Для каждого процесса создается каталог по пути /proc/<PID>, в котором создаются папки и файлы с описанием процесса.
Примеры использования /proc/<PID>
Подробный вывод статуса:
cat /proc/<PID>/status
Адрес в ячейках оперативной памяти, которые занял процесс:
cat /proc/<PID>/syscall
Команда, которой был запущен процесс:
cat /proc/<PID>/cmdline
Символьная ссылка на рабочий каталог процесса:
ll /proc/<PID>/cwd
Символьная ссылка на исполняемый файл, запустивший процесс:
ll /proc/<PID>/exe
Увидеть ссылки на дескрипторы открытых файлов, которые затрагивает процесс:
ll /proc/<PID>/fd/
Подробное описание на сайте man7.org.


Колонка TYPE
В столбце TYPE может отображаться более 70 записей. Далее перечислены только некоторые из часто встречающихся записей:
- REG: Обычный файл файловой системы.
- DIR: Директория.
- FIFO: Специальный файл FIFO (First In First Out).
- CHR: Специальный символьный файл.
- BLK: Специальный блочный файл.
- INET: Интернет-сокет.
- unix: Доменный сокет UNIX.
- IPv4: IPv4 сокет.
- IPv6: Файлы IPv6 сети — даже если её адрес IPv4 преобразован в IPv6 адрес.
- sock: Сокет неизвестного домена.
- DEL: Указатель Linux для удалённого файла.
- LINK: Файл символьной ссылки.
- PIPE: Труба (pipe) — способ обмена данными между процессами.
удаленный;
— удаленные вызовы процедур (Remote Procedure Calls — RPC)
RPC — разновидность технологий, которая позволяет компьютерным программам вызывать функции или процедуры в другом адресном пространстве (как правило, на удалённых компьютерах). Обычно, реализация RPC технологии включает в себя два компонента: сетевой протокол (чаще TCP и UDP, реже HTTP) для обмена в режиме клиент-сервер и язык сериализации объектов (или структур, для необъектных RPC).
— сокеты Unix
Сокеты UNIX бывают 2х типов: локальные и сетевые. При использовании локального сокета, ему присваивается UNIX-адрес и просто будет создан специальный файл (файл сокета) по заданному пути, через который смогут сообщаться любые локальные процессы путём простого чтения/записи из него. Сокеты представляют собой виртуальный объект, который существует, пока на него ссылается хотя бы один из процессов. При использовании сетевого сокета, создается абстрактный объект привязанный к слушающему порту операционной системы и сетевому интерфейсу, ему присваивается INET-адрес, который имеет адрес интерфейса и слушающего порта.
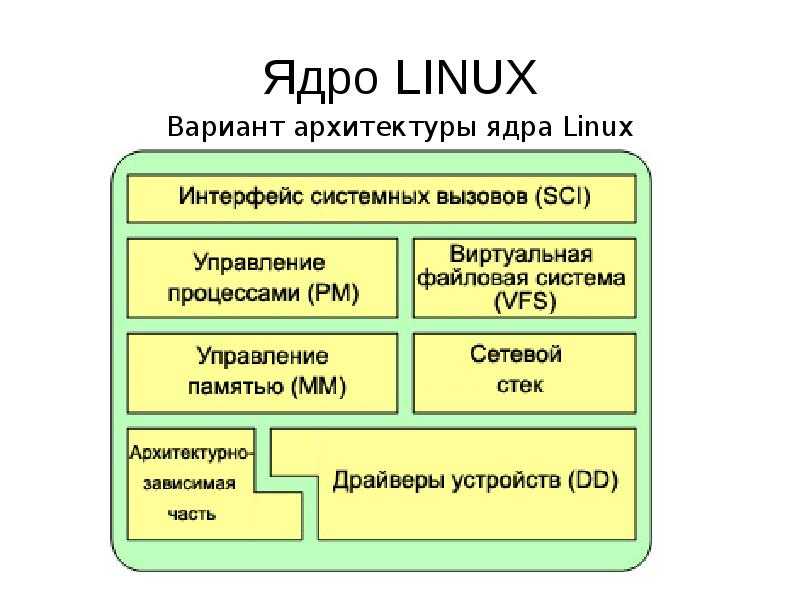
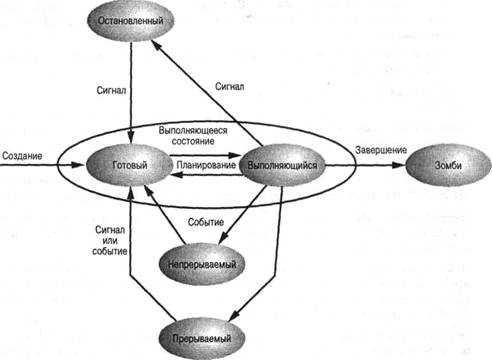
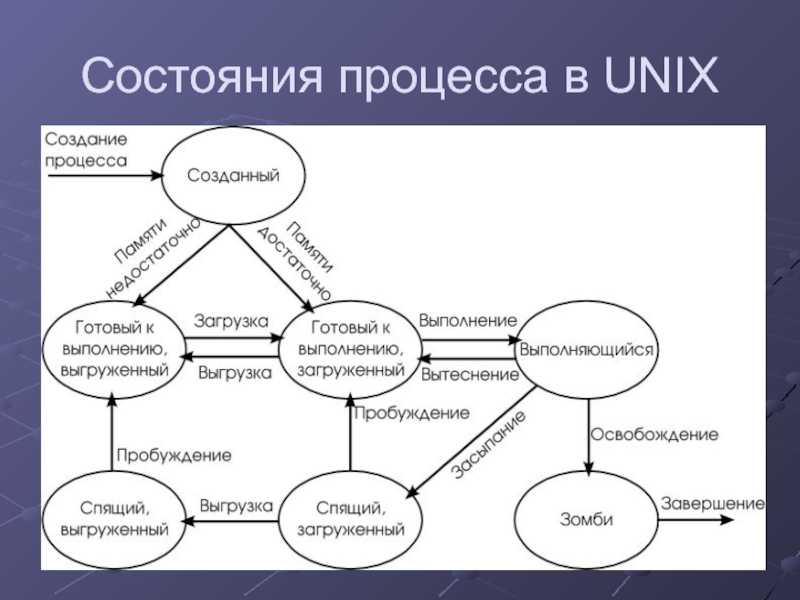
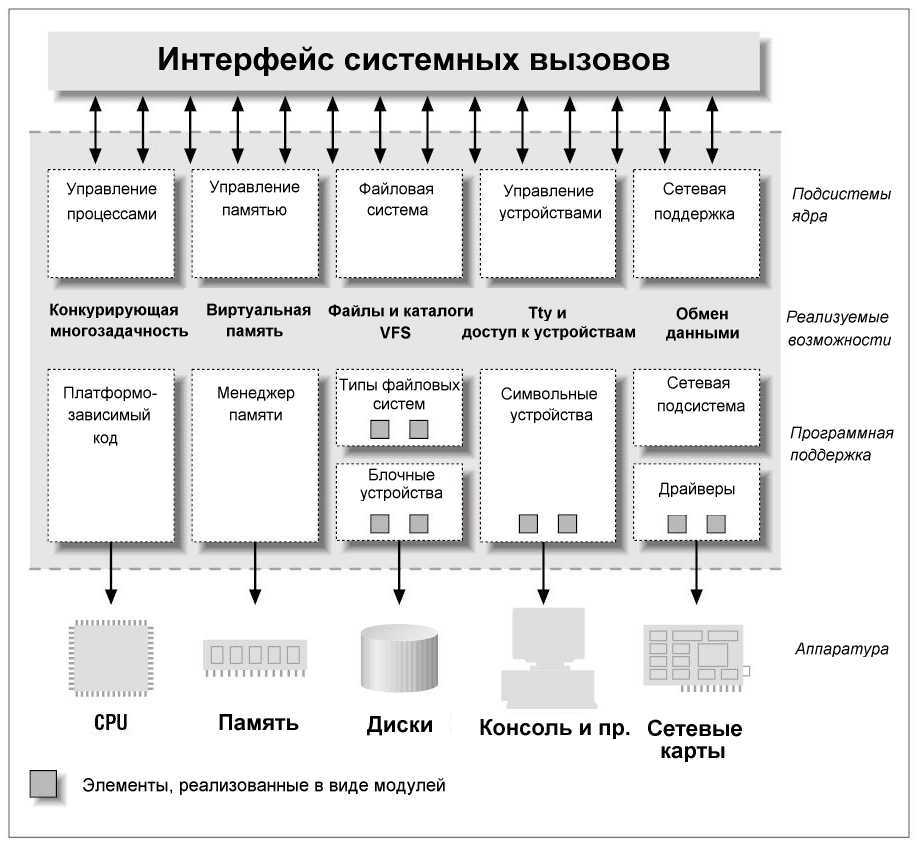
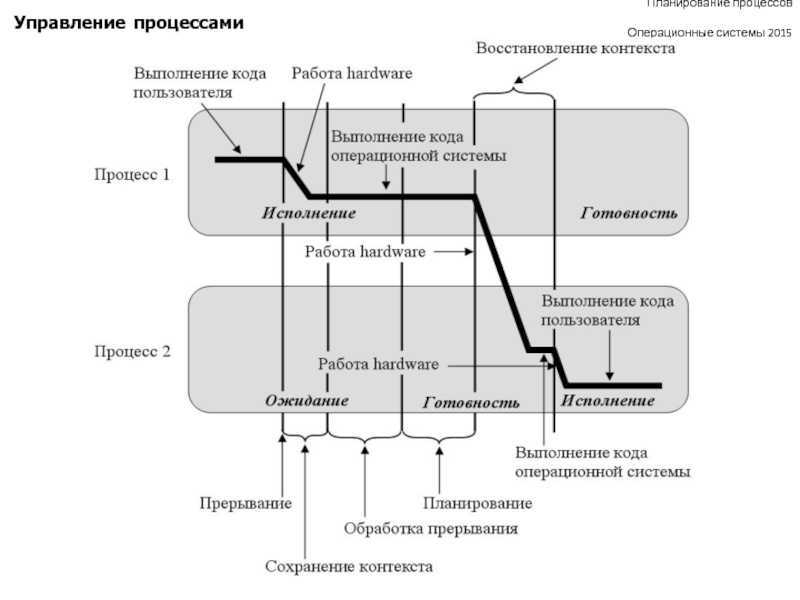
Управление процессами в Linux
Сердцем всех Linux и Unix-подобных операционных систем является ядро. Среди его многочисленных обязанностей — распределение системных ресурсов, таких как оперативная память и процессорное время. Они должны выполняться в режиме реального времени, чтобы все запущенные процессы получали свою справедливую долю в соответствии с приоритетом каждой задачи.
Иногда задачи могут блокироваться, или зацикливаться, или перестать отвечать по другим причинам. Или они могут продолжать работать, но сожрать слишком много процессорного времени или оперативной памяти, или вести себя каким-то похожим антисоциальным образом. Иногда задачи должны быть убиты для сохранения стабильной работы системы. Разумеется, первых шаг заключается в идентификации проблемного процесса.
Но, возможно, у вас вообще нет проблем с задачами или производительностью. Возможно, вам просто любопытно, какие процессы выполняются на вашем компьютере, и вы хотели бы заглянуть под капот операционной системы Linux. Команда ps удовлетворяет обоим этим требованиям. Она даёт вам снимок того, что происходит внутри вашего компьютера «прямо сейчас».
ps достаточно гибка, чтобы предоставить вам именно ту информацию, которая вам нужна, именно в том формате, который вам нравится. На самом деле, у ps очень много опций. Опции, описанные здесь, будут соответствовать большинству обычных потребностей. Если вы хотите изучить команду ps ещё глубже, то знакомство с командой ps в этой статье и примеры использования ps облегчат вам восприятие справочной страницы.
Преимущества WSL 2.0
Переход от эмулятора к полноценному ядру Linux в WSL 2.0, по задумке Microsoft, должен обеспечить прирост производительности в Linux-приложениях, запущенных непосредственно под Windows 10. Также это прямым образом повлияет на оптимизацию использования оперативной памяти, уменьшит время загрузки самой подсистемы и приложений и ускорит работу ввода-вывода файловой системы. К преимуществам разработчики отнесли также возможность запуска Docker-контейнеров напрямую, то есть уже без использования виртуальной машины.
Что дает интеграция ИТ-систем и московских судов
ИТ в госсекторе
Между тем, реальный прирост производительности уже установлен. Внутренние тесты бета-версии WSL 2.0 в Microsoft показали 20-кратное увеличение скорости работы при распаковке архивов tarball и 5-кратный рост производительности при использовании git clone, npm install и cmake.
Просмотр файлов /proc
С помощью файлов в /proc Вы можете получить информацию о состоянии ядра,
процессов, параметрах компьютера и т.д. Большинство файлов в /proc содержат
самую свежую информацию о системном оборудовании. Несмотря на то, что эти
файлы виртуальные — их можно просмотреть любым текстовым редактором или
с помощью команд «more», «less» или «cat».
При попытке открытия виртуального файла текстовым редактором — этот
файл создается на лету на основе информации, содержащейся в ядре. Приведу
здесь некоторые интересные цифры о моей системе:
$ ls -l /proc/cpuinfo -r--r--r-- 1 root root 0 Dec 25 11:01 /proc/cpuinfo $ file /proc/cpuinfo /proc/cpuinfo: empty $ cat /proc/cpuinfo processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 8 model name : Pentium III (Coppermine) stepping : 6 cpu MHz : 1000.119 cache size : 256 KB fdiv_bug : no hlt_bug : no sep_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 2 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 mmx fxsr xmm bogomips : 1998.85 processor : 3 vendor_id : GenuineIntel cpu family : 6 model : 8 model name : Pentium III (Coppermine) stepping : 6 cpu MHz : 1000.119 cache size : 256 KB fdiv_bug : no hlt_bug : no sep_bug : no f00f_bug : no coma_bug : no fpu : yes fpu_exception : yes cpuid level : 2 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 mmx fxsr xmm bogomips : 1992.29
Ограничение процессов
Управление процессами в Linux позволяет контролировать практически все. Вы уже видели что можно сделать, но можно еще больше. С помощью команды ulimit и конфигурационного файла /etc/security/limits.conf вы можете ограничить процессам доступ к системным ресурсам, таким как память, файлы и процессор. Например, вы можете ограничить память процесса Linux, количество файлов и т д.
Запись в файле имеет следующий вид:
<домен> <тип> <элемент> <значение>
- домен — имя пользователя, группы или UID
- тип — вид ограничений — soft или hard
- элемент — ресурс который будет ограничен
- значение — необходимый предел
Жесткие ограничения устанавливаются суперпользователем и не могут быть изменены обычными пользователями. Мягкие, soft ограничения могут меняться пользователями с помощью команды ulimit.
Рассмотрим основные ограничения, которые можно применить к процессам:
- nofile — максимальное количество открытых файлов
- as — максимальное количество оперативной памяти
- stack — максимальный размер стека
- cpu — максимальное процессорное время
- nproc — максимальное количество ядер процессора
- locks — количество заблокированных файлов
- nice — максимальный приоритет процесса
Например, ограничим процессорное время для процессов пользователя sergiy:
Посмотреть ограничения для определенного процесса вы можете в папке proc:
Ограничения, измененные, таким образом вступят в силу после перезагрузки. Но мы можем и устанавливать ограничения для текущего командного интерпретатора и создаваемых им процессов с помощью команды ulimit.


Вот опции команды:
- -S — мягкое ограничение
- -H — жесткое ограничение
- -a — вывести всю информацию
- -f — максимальный размер создаваемых файлов
- -n — максимальное количество открытых файлов
- -s — максимальный размер стека
- -t — максимальное количество процессорного времени
- -u — максимальное количество запущенных процессов
- -v — максимальный объем виртуальной памяти
Например, мы можем установить новое ограничение для количества открываемых файлов:
Теперь смотрим:
Установим лимит оперативной памяти:
Напоминаю, что это ограничение будет актуально для всех программ, выполняемых в этом терминале.
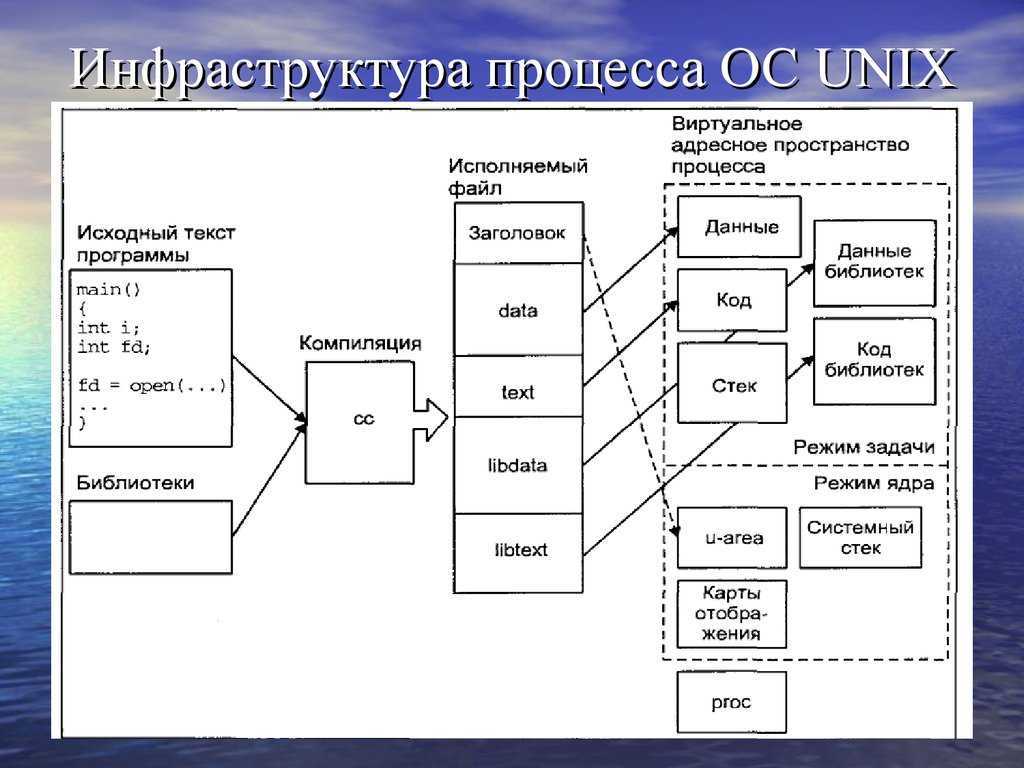
Разделение адресного пространства виртуальной памяти в ОС
Существуют несколько принципиально разных концепций разделения адресного пространства виртуальной памяти ОС.
Системы UNIX
В таких системах пространство ядра («Kernel space») отделяется от пользовательского и отводится для обеспечения работы ядра операционной системы ,его расширений и подсистем. Данное разделение служит для обеспечения безопасности памяти и аппаратных средств от вмешательства пользователя или некорректного поведения программного обеспечения.
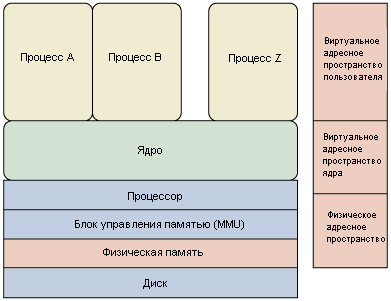
Организация взаимодействия адресных пространств в системе Linux
В большинстве Unix-образных операционных системах каждый процесс в пользовательском пространстве обычно выполняется в собственной области виртуальной памяти, и при отсутствии явной необходимости, не может получить доступа к памяти, используемой другими процессами. Такой подход является основным для обеспечения защиты памяти большинства современных операционных систем и фундаментом для обеспечения права доступа.
В зависимости от привилегий процесс может запросить ядро отобразить часть адресного пространства другого процесса на своё, как, например, это делают отладчики. Программы также могут запрашивать для себя область разделяемой памяти совместно с другими процессами.
Пользовательские приложения так же не могут напрямую взаимодействовать с оборудованием, осуществлено это, опять же, по соображениям безопасности. Пространство ядра может быть доступно процессам пользователя только с помощью системных вызовов («System calls«).То есть, системные вызовы — это точки входа в ядро, так что ядро может выполнять работу от имени приложения. Доступ пользователя к оборудованию так же может осуществляться посредством использования драйверов.
Регистр имен
Также стоит отметить чувствительность файловой системы Linux к регистру. Файлы Temp.txt и temp.txt будут интерпретироваться как разные файлы и могут находиться в одной директории, в отличие от ОС Windows, который не различает регистр имен. То же правило действует и на каталоги — имена в разных регистрах указывают на разные каталоги.
Назначение каждой директории регламентирует «Стандарт иерархии файловой системы» FHS (Filesystem Hierarchy Standard). Ниже опишем основные директории согласно стандарту FHS:
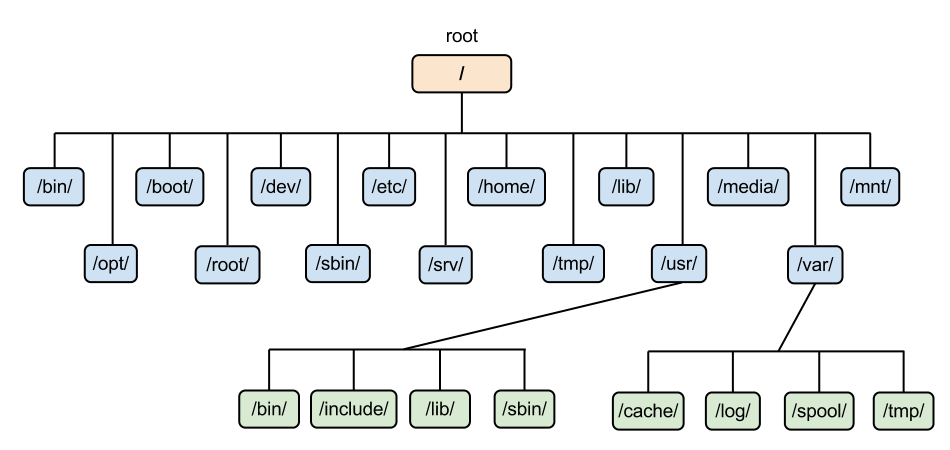
Стандарт иерархии файловой системы
- / — root каталог. Содержит в себе всю иерархию системы;
- /bin — здесь находятся двоичные исполняемые файлы. Основные общие команды, хранящиеся отдельно от других программ в системе (прим.: pwd, ls, cat, ps);
- /boot — тут расположены файлы, используемые для загрузки системы (образ initrd, ядро vmlinuz);
- /dev — в данной директории располагаются файлы устройств (драйверов). С помощью этих файлов можно взаимодействовать с устройствами. К примеру, если это жесткий диск, можно подключить его к файловой системе. В файл принтера же можно написать напрямую и отправить задание на печать;
- /etc — в этой директории находятся файлы конфигураций программ. Эти файлы позволяют настраивать системы, сервисы, скрипты системных демонов;
- /home — каталог, аналогичный каталогу Users в Windows. Содержит домашние каталоги учетных записей пользователей (кроме root). При создании нового пользователя здесь создается одноименный каталог с аналогичным именем и хранит личные файлы этого пользователя;
- /lib — содержит системные библиотеки, с которыми работают программы и модули ядра;
- /lost+found — содержит файлы, восстановленные после сбоя работы системы. Система проведет проверку после сбоя и найденные файлы можно будет посмотреть в данном каталоге;
- /media — точка монтирования внешних носителей. Например, когда вы вставляете диск в дисковод, он будет автоматически смонтирован в директорию /media/cdrom;
- /mnt — точка временного монтирования. Файловые системы подключаемых устройств обычно монтируются в этот каталог для временного использования;
- /opt — тут расположены дополнительные (необязательные) приложения. Такие программы обычно не подчиняются принятой иерархии и хранят свои файлы в одном подкаталоге (бинарные, библиотеки, конфигурации);
- /proc — содержит файлы, хранящие информацию о запущенных процессах и о состоянии ядра ОС;
- /root — директория, которая содержит файлы и личные настройки суперпользователя;
- /run — содержит файлы состояния приложений. Например, PID-файлы или UNIX-сокеты;
- /sbin — аналогично /bin содержит бинарные файлы. Утилиты нужны для настройки и администрирования системы суперпользователем;
- /srv — содержит файлы сервисов, предоставляемых сервером (прим. FTP или Apache HTTP);
- /sys — содержит данные непосредственно о системе. Тут можно узнать информацию о ядре, драйверах и устройствах;
- /tmp — содержит временные файлы. Данные файлы доступны всем пользователям на чтение и запись. Стоит отметить, что данный каталог очищается при перезагрузке;
- /usr — содержит пользовательские приложения и утилиты второго уровня, используемые пользователями, а не системой. Содержимое доступно только для чтения (кроме root). Каталог имеет вторичную иерархию и похож на корневой;
- /var — содержит переменные файлы. Имеет подкаталоги, отвечающие за отдельные переменные. Например, логи будут храниться в /var/log, кэш в /var/cache, очереди заданий в /var/spool/ и так далее.
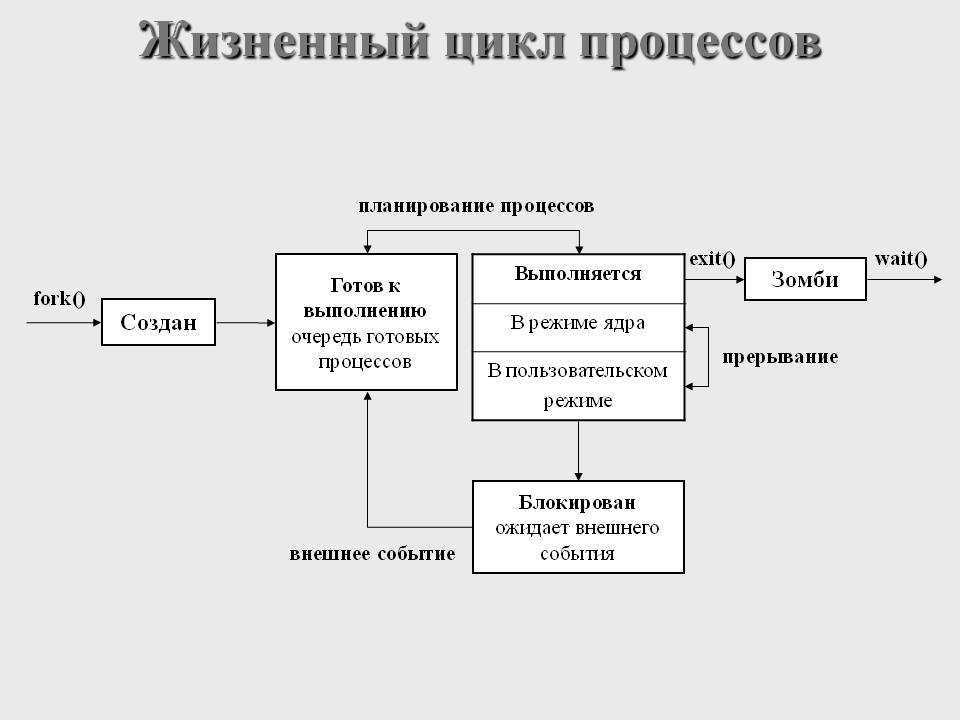
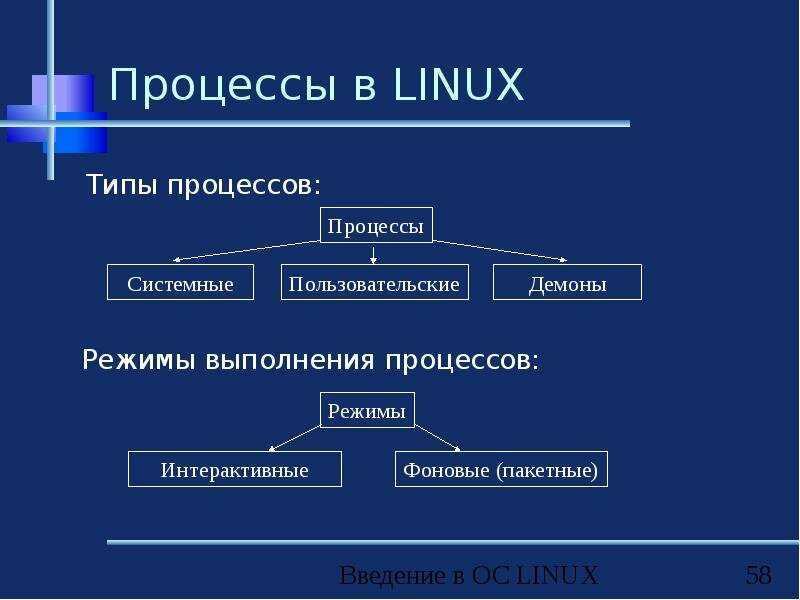
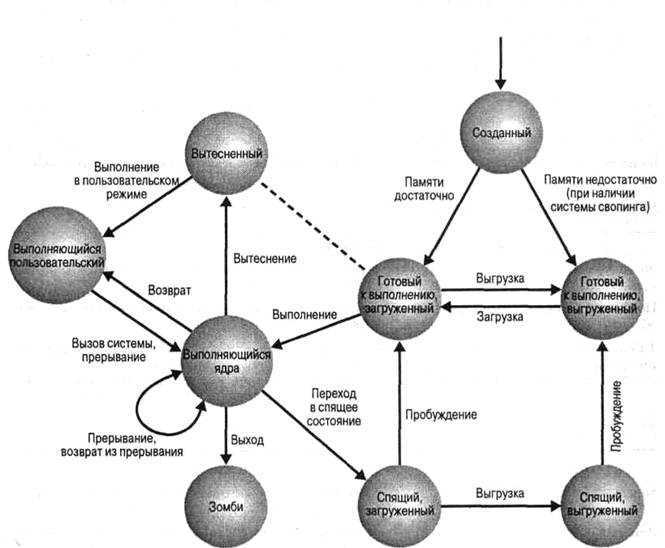
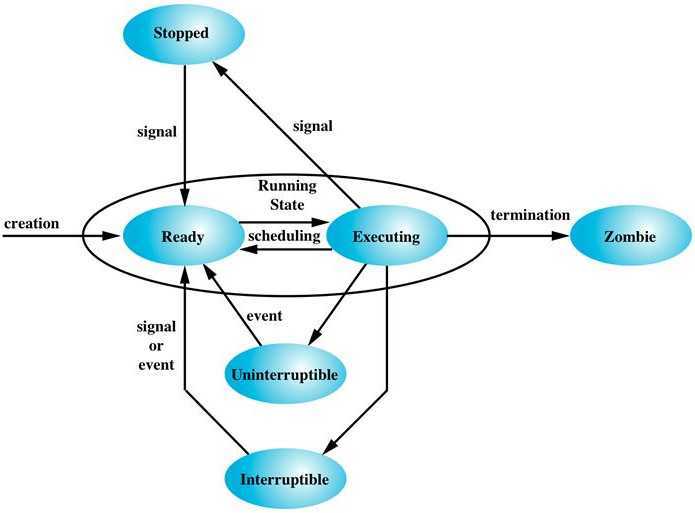
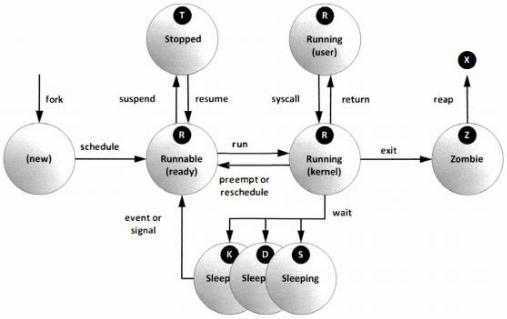
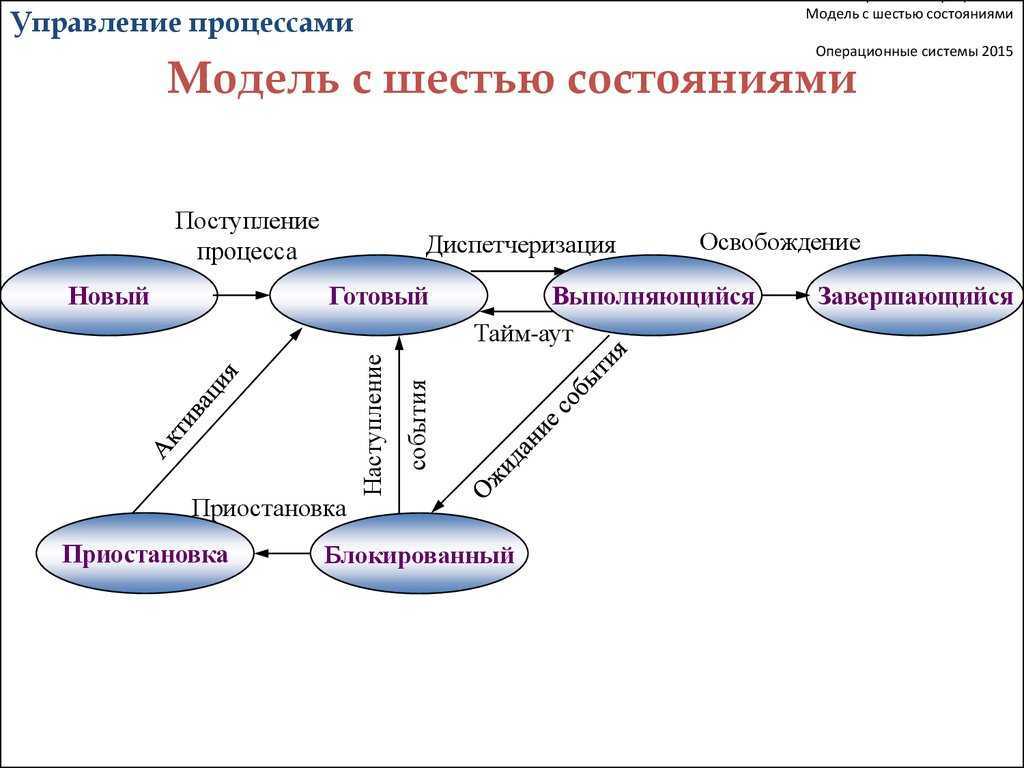
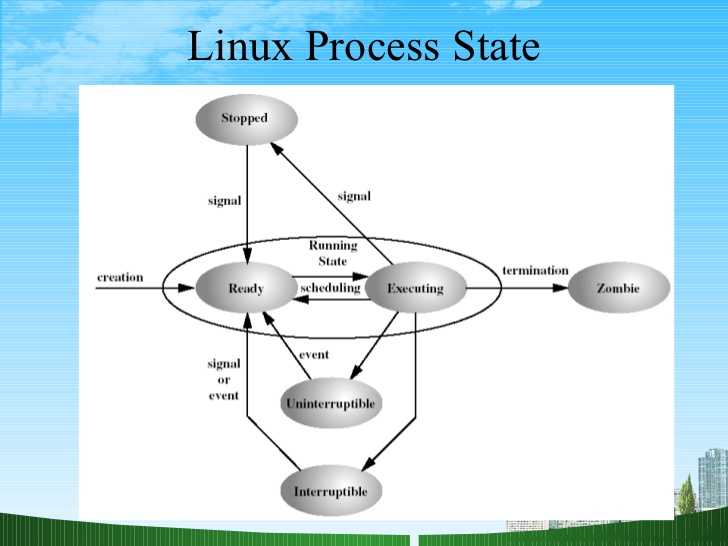
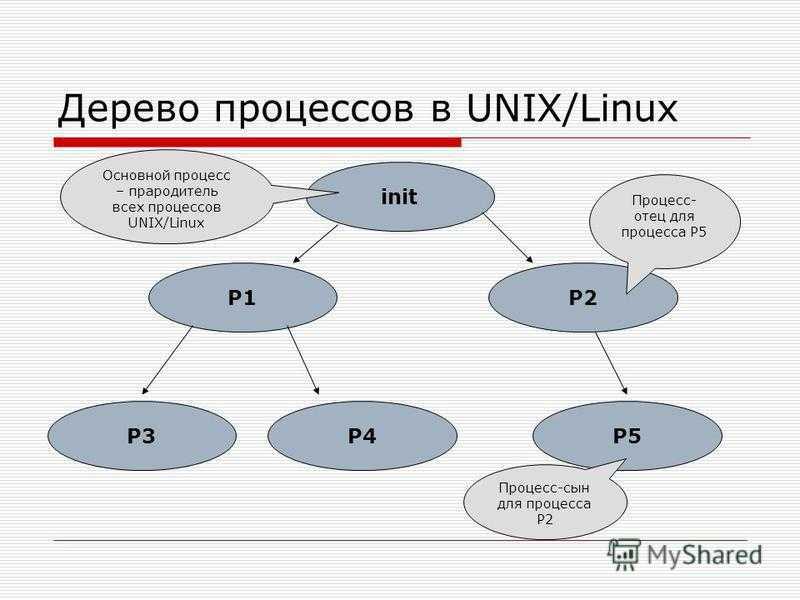
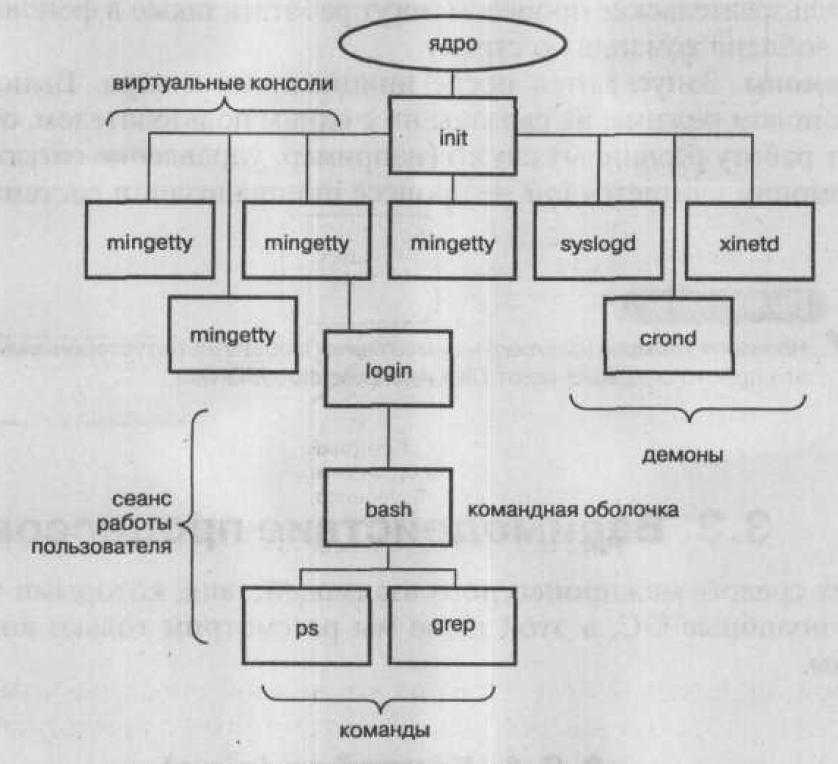
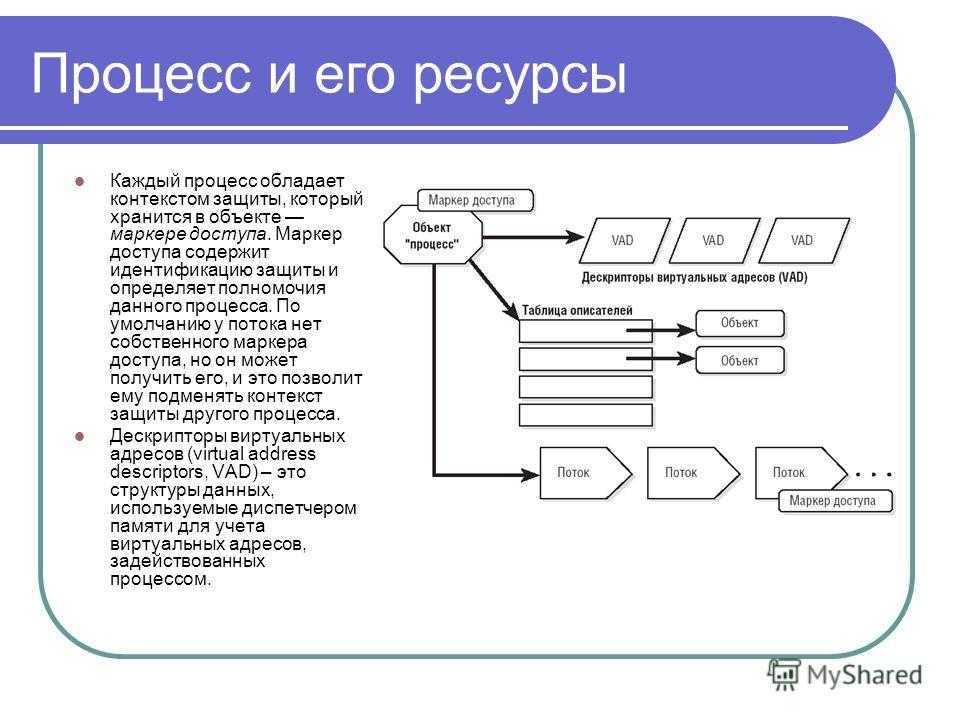
Что такое процесс?
Начнем с того, что разберемся в терминах. По сути, процесс — это каждая программа. Как я уже говорил для каждой запускаемой программы создается отдельный процесс. В рамках процесса программе выделяется процессорное время, оперативная память и другие системные ресурсы. У каждого процесса есть свой идентификатор, Proccess ID или просто PID, по ним, чаще всего и определяются процессы Linux. PID определяется неслучайно, как я уже говорил, программа инициализации получает PID 1, а каждая следующая запущенная программа — на единицу больше. Таким образом PID пользовательских программ доходит уже до нескольких тысяч.
На самом деле, процессы Linux не настолько абстрактны, какими они вам сейчас кажутся. Их вполне можно попытаться пощупать. Откройте ваш файловый менеджер, перейдите в корневой каталог, затем откройте папку /proc. Видите здесь кучу номеров? Так вот это все — PID всех запущенных процессов. В каждой из этих папок находится вся информация о процессе.
Например, посмотрим папку процесса 1. В папке есть другие под каталоги и много файлов. Файл cmdline содержит информацию о команде запуска процесса:
Поскольку у меня используется система инициализации Systemd, то и первый процесс запускается для нее. С помощью каталога /proc можно сделать все. Но это очень неудобно, особенно учитывая количество запущенных процессов в системе. Поэтому для реализации нужных задач существуют специальные утилиты. Перейдем к рассмотрению утилит, которые позволяют реализовать управление процессами в Linux.
Pivot root
Имея наш новый mount namespace и копию системных файлов, мы хотели бы смонтировать эти файлы в корневом каталоге нового mount namespace не выбивая землю из под наших ног. Linux предлагает нам системный вызов pivot_root (есть соответствующая команда), который позволяет нам контролировать то, что именно процессы видят как корневую файловую систему.
Команда принимает два аргумента: , где — это путь к файловой системе, будущей вскоре корневой файловой системой, а — путь к каталогу. Это работает так:
- Монтирование корневой файловой системы вызывающего процесса в .
- Монтирование в качестве корневой файловой системы в .
Давайте посмотрим на это в действии. В нашем новом mount namespace мы начинаем с создания файловой системы из наших файлов alpine:
Затем мы делаем pivot root:
Наконец, мы размонтируем старую файловую систему из , так что вложенный шелл не сможет получить к ней доступ.
При этом мы можем запускать любую команду в нашем шелле, и она будут работать с использованием нашей специфичной корневой файловой системы alpine, пребывая в неведении об инструментарии, что привел к её запуску. И наши драгоценные файлы в старой файловой системе находятся вне пределов досягаемости.



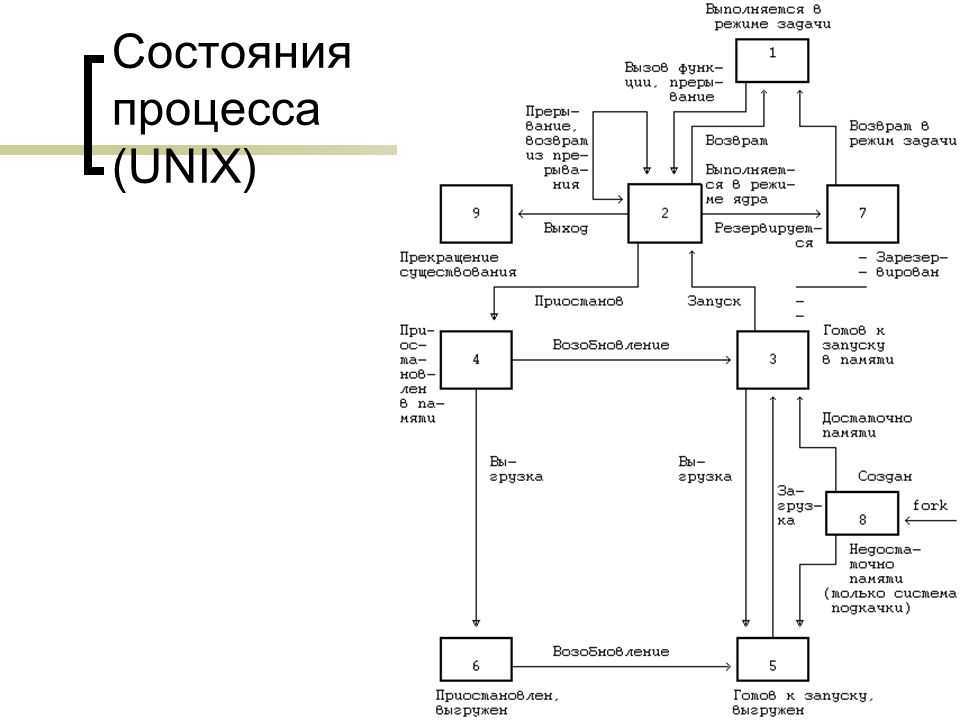
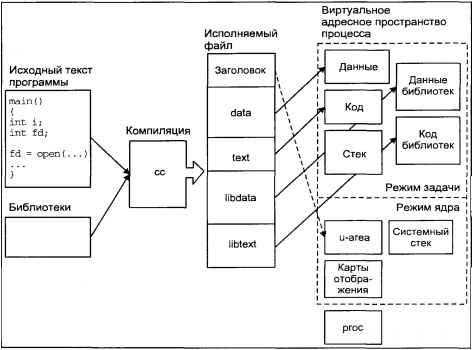
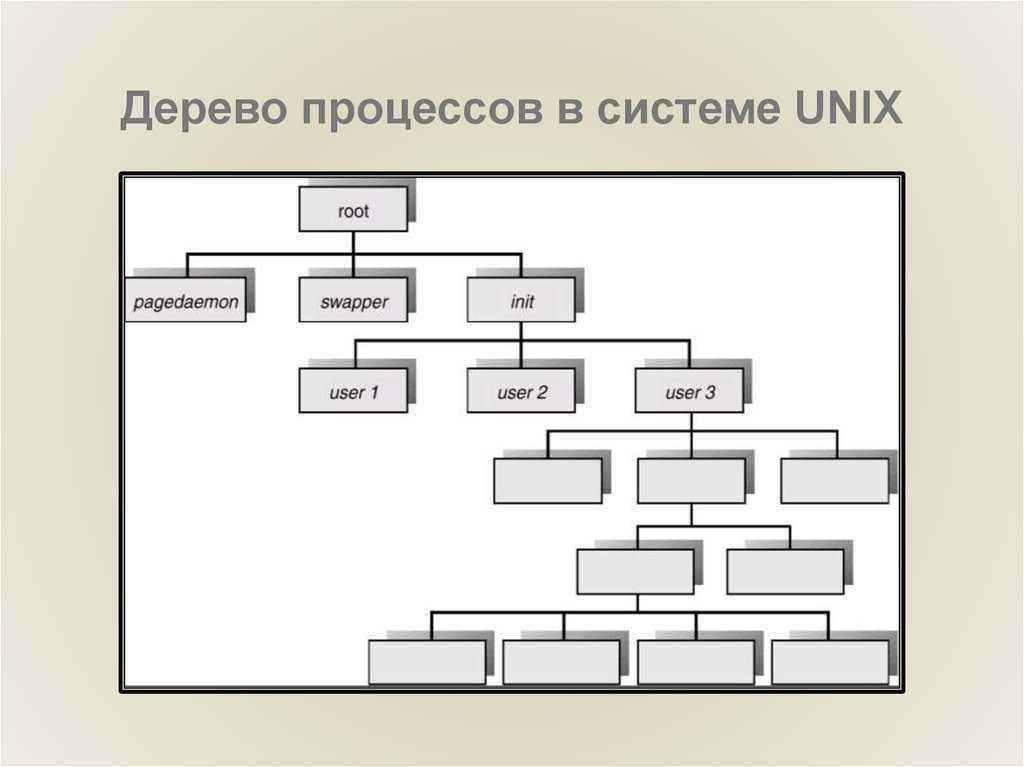

Что такое файловая система простыми словами
Термин «файловая система» можно понимать двояко. С одной стороны — это архитектура хранения битов на жестком диске, с другой — это организация каталогов в соответствии с идеологией Unix. В этой статье мы более подробно обсудим первую сторону.
Файловая система (сокращенно ФС, англ. «file system») — это архитектура хранения данных в системе, хранение данных в оперативной памяти и доступа к конфигурации ядра. ФС устанавливает физическую и логическую структуру файлов, правила их создания и управления ими.
В физическом смысле файловая система Linux/UNIX представляет собой пространство раздела диска разбитое на блоки фиксированного размера. Их размер кратен размеру сектора: 1024, 2048, 4096 или 8120 байт. Размер блока известен заранее.
Как происходит обмен данными между ядром, приложениями и жестким диском? Для этого существуют 2 технологии:
- Виртуальная файловая система (VFS). Некий интерфейс, между ядром и файловой системой (ext2, ext4 и т.д.). Это позволяет взаимодействовать ядру и приложениям без особенностей работы конкретного типа ФС. Иногда VFS называют «виртуальным коммутатором файловых систем».
- Драйверы файловых систем. Специальные программы, которые устанавливают «мост» (интерфейс) взаимодействия между аппаратурой и программой.
Список поддерживаемых ядром файловых систем находится в файле :
andrey@andrey-VirtualBox:~$ cat /proc/filesystems nodev sysfs nodev rootfs nodev ramfs nodev bdev nodev proc nodev cpuset nodev cgroup nodev cgroup2 nodev tmpfs nodev devtmpfs nodev debugfs nodev tracefs nodev securityfs nodev sockfs nodev bpf nodev pipefs nodev hugetlbfs nodev devpts ext3 ext2 ext4 squashfs vfat nodev ecryptfs fuseblk nodev fuse nodev fusectl nodev pstore nodev mqueue nodev autofs
Иерархия файловой системы
Как мы уже сказали выше, есть вторая сторона ФС, которая состоит в определении ее с точки зрения организации расположения файлов в Linux. В этом случае можно сказать, что: файловая система — это иерархическая структура, которая начинается с корневого каталога «/» (корневой каталог) и дальше ветвится в соответствие с работой системы.
В этой статье мы будем говорить подробнее про типы файловых систем. Про организацию и структуру каталогов в Linux можно отдельно прочитать в статье:
Каталоги Linux — организация файловой системы
Где в Linux диски C, D, E?
Если задаться вопросов, где диск C в Linux, то его можно обнаружить сразу в двух местах. Во-первых, поскольку в Linux все физические устройства являются файлами, то диск C будет представлен файлом, например, с именем /dev/sda. Первая часть в этом имени — /dev/ — это директория, в которой расположены файлы, обозначающие устройства (о всех директориях будет рассказано далее). А sda — это уже непосредственно имя диска. Если однотипных дисков несколько, то последующим присваиваются другие буквы: /dev/sdb, /dev/sdc и т. д. Имя диска указывает на вид носителя. Например, буквы sd означают Solid Drive, то есть твердотельный диск. Если имя /dev/hda, то буквы hd означают Hard Drive (жёсткий диск).
Допустим имя диска /dev/hdc, что можно сказать о нём? Можно утверждать, что это жёсткий диск и он третий в системе.
Диски могут иметь и другие имена, например, у меня системный диск называется /dev/nvme0n1 — я погуглил, оказывается это новый вид твердотельных дисков NVM Express (NVMe).
Итак, мы уже нашли диск C? Не совсем. Имя /dev/sda это всего лишь обозначение устройства, которое предполагает использование имени для управления самим устройством. Например, если мы хотим создать новый раздел на диске или изменить размеры существующих, то мы откроем соответствующую программу, и в качестве параметра передадим ей имя диска, с которым хотим работать. Мы не можем открывать файлы обращаясь к диску по имени вида /dev/*
Как видеть процессы, которые открыли файл
Чтобы увидеть процессы, открывшие определённый файл, укажите имя файла в качестве параметра для lsof. Например, чтобы увидеть процессы, которые открыли файл /dev/sda, используйте эту команду:
lsof /dev/sda
Пример вывода:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME doublecmd 1982 mial cwd DIR 8,0 4096 32768001 /mnt/disk_d/Share

Как вы можете знать (а если не знаете, то смотрите статью «Структура директорий Linux. Важные файлы Linux»), файл /dev/sda является жёстким диском. Приведённая выше команда поможет найти процесс, который не даёт отмонтировать (отсоединить) диск.
Можно проверить, какой командой открыты обычные файлы, например:
lsof 'Documents/Linux.odt'
Вывод:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME soffice.b 3686 mial 92uW REG 259,2 19826 5390035 Documents/Linux.odt
Видно, что файл открыт пользователем mial, это обычный файл (REG) и что он открыт приложением soffice.b (на самом деле приложение soffice.bin, но его имя здесь не целиком).



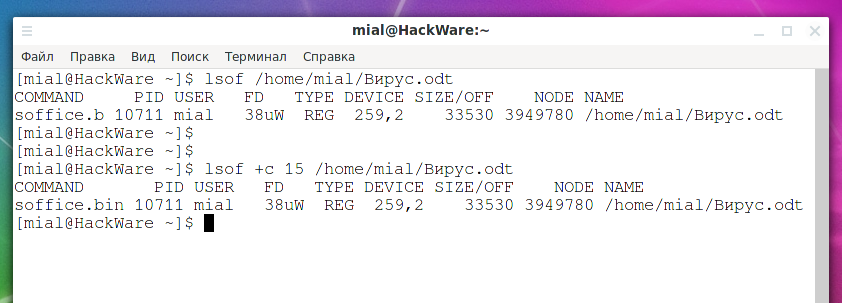
Чтобы вывести полное имя, используйте опцию +c, например:
lsof +c 15 /home/mial/Вирус.odt
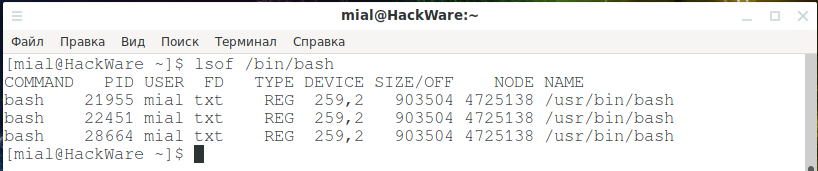
Аналогично можно проверить, открыты (запущены) ли исполнимые файлы, например, для проверки, запущен ли файл /bin/bash:
sudo lsof /bin/bash
Больше столбцов в выводе ps
Чтобы добавить дополнительные столбцы к выводу, используйте параметр -f (полный формат).
ps -ef | less
Дополнительный набор столбцов включён в вывод ps.
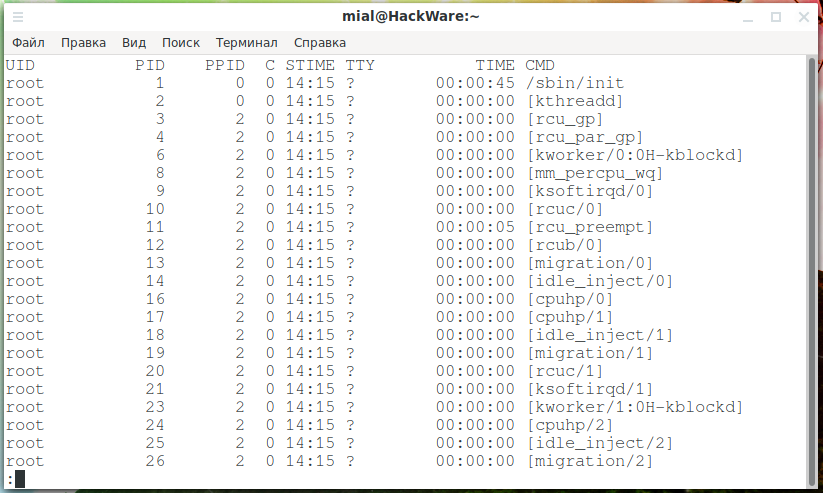
Добавлены следующие новые столбцы:
- UID: идентификатор пользователя владельца этого процесса.
- PPID: идентификатор родительского процесса.
- C: Количество детей, которые есть у процесса.
- STIME: Время начала. Время, когда процесс был запущен.
Используя опцию -F (дополнительный полный формат), мы можем получить ещё больше столбцов:
ps -eF | less
Если у вас маленькое окно терминала, то столбцы, которые мы получаем в этот раз, требуют прокрутки экрана в сторону, чтобы показать их все. Нажатие клавиши «Стрелка вправо» смещает дисплей влево.
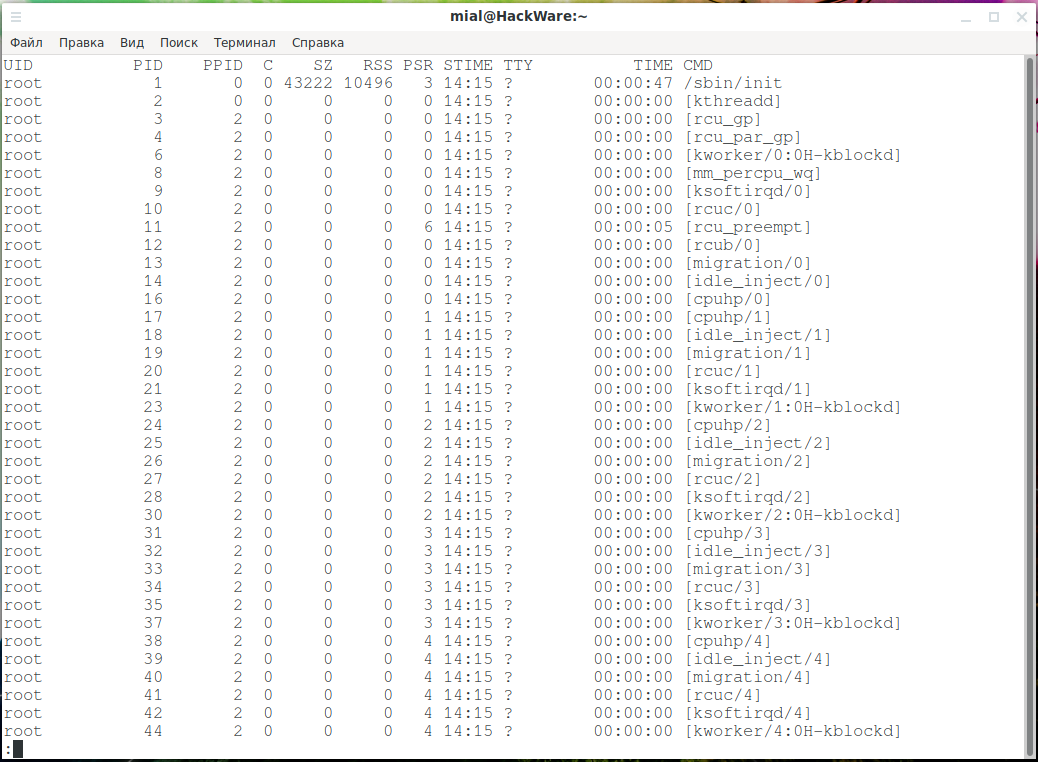
Теперь добавились следующие столбцы:
- SZ: размер страниц ОЗУ образа процесса.
- RSS: резидентный размер набора. Это не подкачанная физическая память, используемая процессом.
- PSR: процессор, которому назначен процесс.
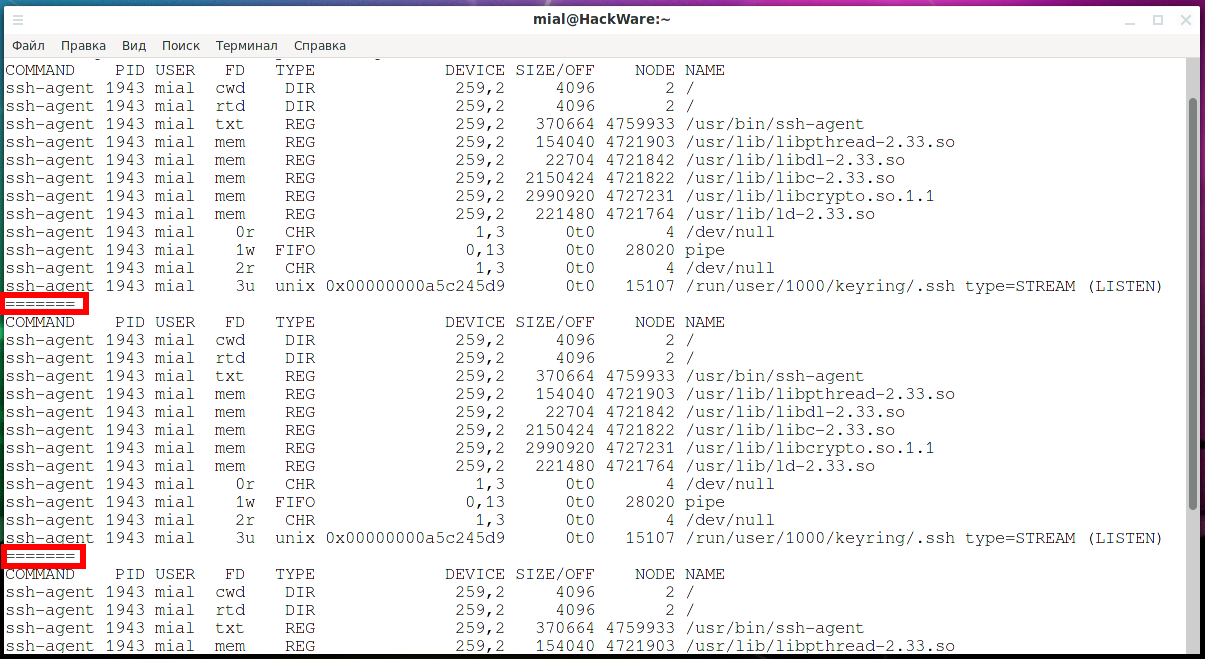
Автоматическое обновление выводимой информации lsof
Чтобы перевести lsof в режим повтора, мы можем использовать опцию +r СЕКУНДЫ или её вариант -r СЕКУНДЫ. Опцию повторения можно применить двумя способами: +r или -r. Мы также должны добавить количество секунд, которое мы хотим, чтобы lsof ожидал перед обновлением дисплея.
Использование опции повтора в любом формате заставляет lsof отображать результаты как обычно, но добавляет пунктирную линию внизу экрана. Программа ожидает количество секунд, указанное в командной строке, а затем обновляет дисплей новым набором результатов.
С опцией -r это будет продолжаться пока вы не нажмете Ctrl+c. В формате +r программа будет продолжаться до тех пор, пока не будет получен пустой результат, или пока вы не нажмете Ctrl+c.
sudo lsof -u mial -c ssh -a -r5
Обратите внимание на пунктирную линию (=======) внизу списка. Она отделяет каждое новое отображение данных при обновлении вывода.