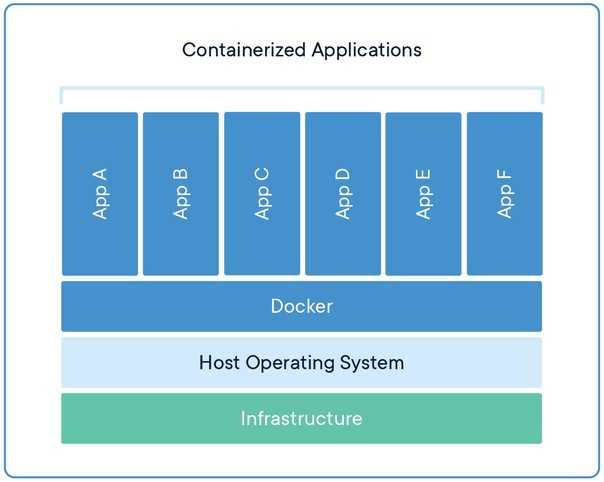
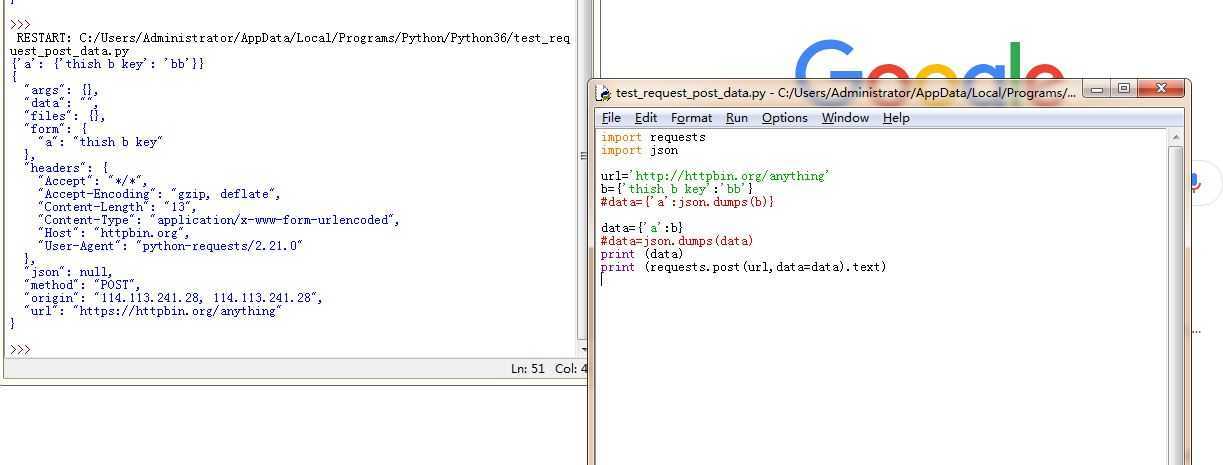
Установка Docker
Рассмотрим примеры установки на базе операционных систем Red Hat/CentOS и Debian/Ubuntu.
Red Hat/CentOS
Устанавливаем репозиторий — для этого загружаем файл с настройками репозитория:
wget https://download.docker.com/linux/centos/docker-ce.repo
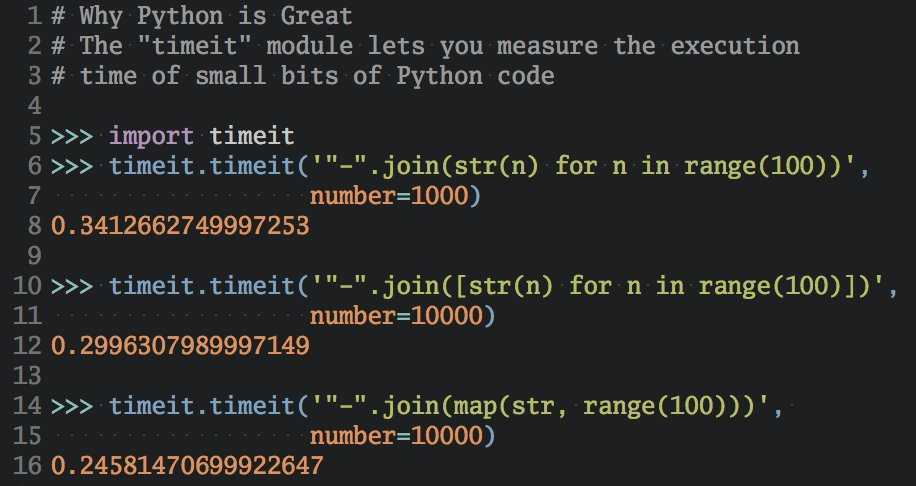
* если система вернет ошибку, устанавливаем wget командой yum install wget.
… и переносим его в каталог yum.repos.d:
mv docker-ce.repo /etc/yum.repos.d/
Устанавливаем docker:
yum install docker-ce docker-ce-cli containerd.io
Если система вернет ошибку Необходимо: container-selinux >= …, переходим на страницу пакетов CentOS, находим нужную версию container-selinux и копируем на него ссылку:
… с помощью данной ссылки выполняем установку:
yum install http://mirror.centos.org/centos/7/extras/x86_64/Packages/container-selinux-2.99-1.el7_6.noarch.rpm
После повторяем команду на установку докера:
yum install docker-ce docker-ce-cli containerd.io
В deb-системе ставится командой:
apt-get install docker docker.io
После установки
Разрешаем запуск сервиса docker:
systemctl enable docker
… и запускаем его:
systemctl start docker
После проверяем:
docker run hello-world
… мы должны увидеть:
…
Hello from Docker!
This message shows that your installation appears to be working correctly.
…
Overlay: история неуспеха
Драйвер файловой системы — это сложное программное обеспечение, и оно требует огромного уровня надежности. Старички помнят, как Linux мигрировал с ext3 на ext4. Его не сразу написали, еще больше времени дебажили, и в конце концов ext4 стал основной файловой системой во всех популярных дистрибутивах.
Сделать новую файловую систему за 1 год — невыполнимая миссия. Это даже забавно, учитывая что задача легла не на кого-нибудь, а на Докер, с его послужным списком из нестабильностей и жутких поломманных обновлений — в точности того, чего не хочется видеть в файловой системе.
Короче. В этой истории всё пошло не так. Жуткие истории до сих пор населяют кэш Гугла.
Разработку Overlay бросили в течение года после первого релиза.
драматическая пауза
Время для Overlay2!
«Драйвер overlay2 призван решить ограничения overlay, но он совместим только с ядрами Linux 4.0 и старше, и docker 1.12» — статья «»
Сделать файлуху за год — всё еще невыполнимая миссия. Докер попытался и опростоволосился. Тем не менее, они продолжают пробовать! Посмотрим, как это обернется на дистанции в несколько лет.
Сейчас она не поддерживается ни на каких используемых нами системах. Не то что использовать, даже протестировать ее мы не можем.
Выводы: как мы видим на примере Overlay и Overlay2. Нет бэкпортов. Нет патчей. Нет совместимости со старыми версиями. Докер просто идет вперед и ломает вещи ![]() Если вы хотите использовать Докер, придется тоже двигаться вперед, успевая за релизами докера, ядра, дистрибутива, файловых систем, и некоторых зависимостей.
Если вы хотите использовать Докер, придется тоже двигаться вперед, успевая за релизами докера, ядра, дистрибутива, файловых систем, и некоторых зависимостей.
Бонус: всемирное падение Докера
2 июня 2016, примерно в 9 утра (по Лондонскому времени). Новые ключи пушатся в публичный репозиторий докера.
Прямым следствием этого является то, что любой (или аналог) на системе, в которую подключен сломанный репозиторий, падает с ошибкой «Error https://apt.dockerproject.org/ Hash Sum mismatch».




Это проблема случилась по всему миру. Она повлияла на ВСЕ системы на планете, к которым подключен репозиторий Докера. На всех версиях Debian и Ubuntu, вне запвисимости от версии операционной системы и докера.
Все пайплайны непрерывной интеграции в мире, основывающиеся на установке/обновлении докера или установке/обновлении системы — сломались. Невозможно запустить обновление или апгрейд существующей системы. Невозможно сделать новую систему, на которую устанавливался бы докер.
Через некоторое время. Новость от сотрудника докера: «Есть новости. Я поднял этот вопрос внутри компании, но люди, которые могут это починить, находятся в часовом поясе Сан Франциско (8 часов разницы с Лондоном — прим. автора), поэтому их еще нет на работе.»
Я лично рассказываю эту новость разработчикам внутри нашей компании. Сегодня не будет никакого CI на Докере, мы не сможем делать новые системы, или обновлять старые, у которых есть зависимость на Докер. Вся наша надежда — на чувака из Сан-Франциско, который сейчас спит.
Пауза, в ходе которой мы употребили всю наличную еду и выпивку.
Новость от чувака из Докера во Флориде, примерно 3 часа дня по Лондонскому времени. Он проснулся, обнаружил ошибку, и работает над фиксом.
Позже были переопубликованы ключи и пакеты.
Мы попробовали и подтвердили работоспособность фикса примерно в 5 дня (по Лондону).
По сути случилось 7 часовое общемировое падение систем, исключительно по причине поломки Докера. Всё что осталось от этого события — несколько сообщений на страничке бага на GitHub. Никакого постмортема. Немного (или вообще никаких?) технических новостей или освещения в прессе, несмотря на катастрофичность проблемы.
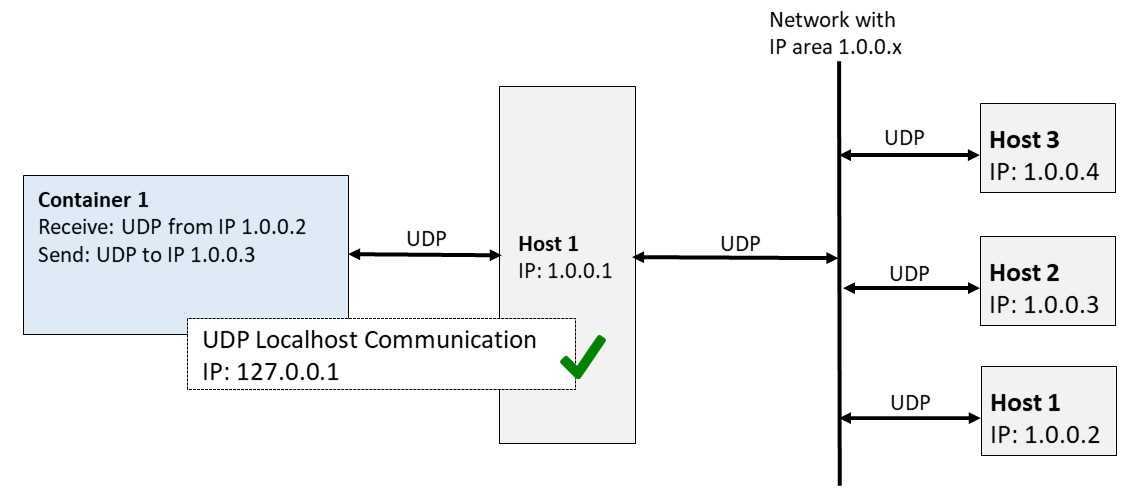
Docker Registry
Реестр хранит и обслуживает образы докера.
Автоматическая сборка CI ===> (при удаче) заливка образа в ===> docker registry
Команда на разворачивание <=== залить образ из <=== docker registry
Существует публичный реестр, обслуживаемый докером. Как организация, у нас тоже есть наш внутренний реестр. Он является образом докера, запущенным внутри докера на докерном хосте (это прозвучало довольно метауровнево!). Образ реестра докера является наиболее часто используемым докерным образом.
Существует 3 версии реестра:
- Registry v1 — устаревший и заброшенный
- Registry v2 — полностью переписанный на Go, впервые релизнутый в апреле 2015
- Trusted Registry — (платный?) сервис, на который много раз ссылается документация, не уверен что понимаю — что это, просто пропускаем его.
Рост в вебе и микросервисах
Докер впервые появился через веб-приложение. В то время, это был простой путь разработчику запаковать и развернуть его. Они попробовали и быстро научились применять. Как только мы начали использовать микросервисную архитектуру, докер распространился и на микросервисы.
Веб-приложения и микросервисы — похожи. Они не имеют состояния, они могут быть запущены, остановлены, убиты, перезапущены, совершенно без раздумий. Вся тяжелая работа делегируется внешним системам (базам данных и бэкендам).
Применение докера началось с небольших новых сервисов. Вначале, всё нормально работало в деве, и в тестинге, и в продакшене. По мере докеризации всё большего количества веб-сервисов и веб-приложений, понемногу начали случаться паники ядра. Чем больше мы росли, тем большее явными и важными становились проблемы со стабильностью.
В течение года появилось несколько патчей и регрессий. С тех пор мы начали играться с поиском проблем Докера и методами их обхода. Это боль, но не похоже чтобы она оттолкнула людей от внедрения Докера. Внутри компании постоянно существует запрос на использование Докера, и на его поддержку.
Заметка: никакие из этих проблем не коснулись наших клиентов и их денег. Мы довольно успешно сдерживаем буйство Докера.
Частые команды при работе с Docker
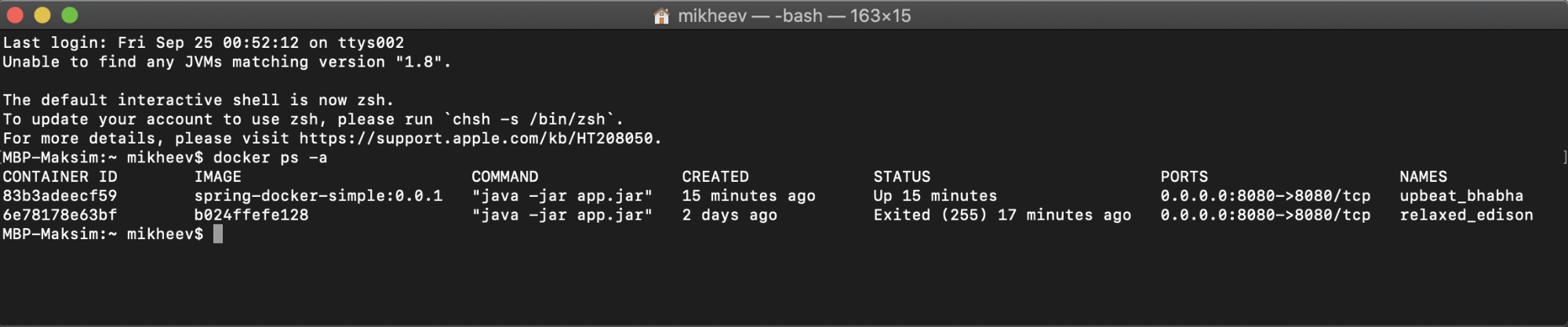
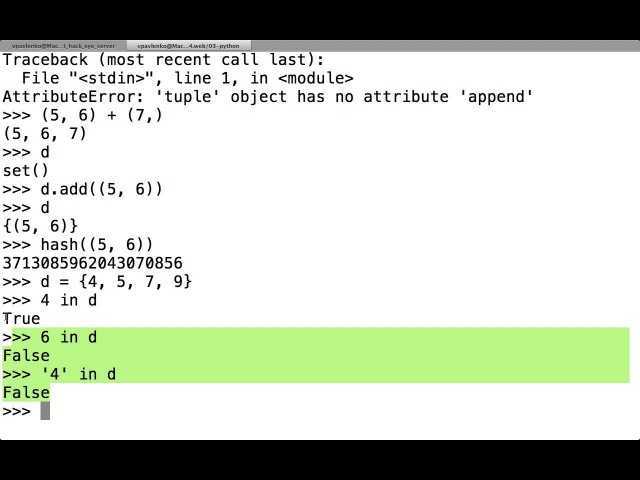
docker ps — выводит список запущенных контейнеров. Также ей можно передать параметр -a, чтобы вывести все контейнеры, а не только запущенные.
docker build — собирает образ Docker из Dockerfile и набора файлов, расположенных по определённому пути.
Параметр -t используется, чтобы задать имя образа, последний параметр. — наименование каталога (в нашем случае текущий каталог).
docker images — выводит список образов в вашей системе.

docker logs — позволяет вывести на консоль логи указанного контейнера. Для этого необходимо указать имя или id контейнера. Можно использовать флаг —follow, чтобы следить за логами работающего контейнера: например, docker logs —follow c5ecc88de8f9.
docker run — запускает контейнер на основе указанного образа.
docker stop — останавливает контейнер. Можно передать опцию $(docker ps -a -q) для остановки всех запущенных контейнеров.

docker rm и docker rmi — команды, удаляющие контейнер и образ соответственно.
Удалить все контейнеры:
Установка WSL 2
Сначала включим компонент Windows Subsystem for Linux (WSL). Для этого запустим PowerShell с правами администратора и выполним первую команду
Выполним следующую команду
Чтобы завершить установку, перезагрузим компьютер
Установим пакет обновления ядра Linux
Выберем WSL 2 по умолчанию для новых дистрибутивов Linux
Для целей этой статьи это необязательно, но установим дистрибутив Linux через Microsoft Store, например, Ubuntu 20.04 LTS
При первом запуске установленного дистрибутива введем имя пользователя и пароль
Чтобы увидеть запущенные дистрибутивы Linux, выполним в PowerShell команду
Чтобы завершить работу дистрибутива Linux, выполним команду
Файловая система запущенного дистрибутива Linux будет смонтирована по этому пути
Докер: Нестабильные драйвера файловой системы
У докера есть куча драйверов для подсистемы хранения. Единственный (якобы) ревностно поддерживаемый — AUFS.




Драйвер AUFS нестабилен. Включая критические баги, приводящие к панике ядра и повреждениям данных.
Он сломан (как минимум) на всех ядрах linux-3.16.x. Лечения не существует.
Мы часто обновляемся вслед за Дебианом и ядром. Дебиан выложил специальные патчи вне обычного цикла. Был один большой багфикс AUFS где-то в марте 2016. Мы думали, что это ТОТ САМЫЙ ФИКС, но нет. После него паники начали случаться реже (каждую неделю вместо каждого дня), но баг никуда не исчез.
Однажды летом случилась реграессия прямо в мажорном обновлении, которая притащила с собой предыдущий критичный баг. Он начал убивать сервера CI один за другим, со средним перерывом в 2 часа между умерщвлениями.
В 2016 случилось множество фиксов AUFS. Некоторые критичные проблемы починилсь, но куча других всё еще существует. AUFS нестабилен как минимум на всех ядрах linux-3.16.x.
- Debian Stable сосет на 3.16. Нестабильно. Нельзя ничего сделать кроме как переключиться на Debian Testing (который использует четвертое ядро).
- Ubuntu LTS работает на 3.19. Нет никаких гарантий, что последнее обновление починило на нем проблему. Менять нашу основную операционную систему было бы огромной проблемой, но мы так отчаялись, что даже рассматривали этот вариант какое-то время.
- RHEL/CentOS-6 работает на ядре 2.x, RHEL/CentoS-7 — на ядре 3.10 (с кучей бэкпортов от рэдхата RedHat).
А куда сохраняются мои данные?
Базы данных – это в первую очередь история про персистентность. И,.. Хьюстон, кажется у нас проблема… К настоящему моменту мы никак не управляем долговременным хранением нашей базы данных. Эту задачу целиком на себя берёт Docker, автоматически создавая volume для контейнера с БД. Есть целый ворох причин, почему это плохо, начиная от банальной невозможности просматривать содержимое volume’ов в бесплатной версии Docker Desktop и заканчивая лимитами дискового пространства.
Разумеется, хорошей практикой является полностью ручное управление физическим размещением создаваемых баз данных. Для этого нам нужно подмонтировать соответствующий каталог (куда будут сохраняться данные) в контейнер и при необходимости переопределить переменную окружения PGDATA:
Вариант с макросом, использующий для инициализации БД скрипты из предыдущего раздела:
С однострочниками на этом закончим. Все дальнейшие шаги будем осуществлять только через compose-файл:
При запуске этого скрипта рядом с ним создастся директория pgdata, где будут располагаться файлы БД.
Часть 0.1 Сравнение с VM
- независимость — контейнер может быть перемещен на любую ОС с docker-службой на борту и контейнер будет работать. (Официально — да, по факту, не уверен что совместимость такая радужная, как пони, радуга и бабочки. Если у вас есть иной опыт — прошу поделиться)
- самодостаточность — контейнер будет выполнять свои функции в любом месте, где бы его не запустили.
- Внутри контейнера находится минимально необходимый набор софта, необходимый для работы вашего процесса. Это уже не полноценная ОС, которую надо мониторить, следить за остатком места итд итп.
- Используется другой подход к виртуализации. почитать об этом. Я имею ввиду сам прицип — там нет привычной хостовой ОС.
- Следует особо относиться к контейнеру и генерируемым им данным. Контейнер это инструмент обработки данных, но не инструмент их хранения. Как пример — контейнер — это гвоздезабивающая машина, подаваемые на вход данные — доска и гвоздь, результат работы — забить гвоздь в доску. При этом доска с гвоздем не остается частью той самой гвоздезабивающей машины, результат отдельно, инструмент отдельно. Выходные данные не должны сохраняться внутри контейнера (можно, но это не docker-way). Поэтому, контейнер это либо worker (отработал, отчитался в очередь), либо, если это, например, веб-сервер, то нужно использовать внешние тома. (все это очень просто, не стоит в этом моменте грустить).
Микросервисы
Будем рассматривать все на примере вышеупомянутого блога. Безусловно, это задача ради задачи, но хочется отметить что даже в таком варианте, это работать будет и будет работать неплохо (быстро и без проблем).
Суть микросервисов легко понять в сравнении с монолитной архитектурой. Как у нас выглядит обычный движок для блога? Грубо говоря это просто одно приложение. Работа с статьями, комментариями, страницами, пользователями и прочими функциональными единицами заключена в едином пакете исходного кода, который не делится никак.
Где все связи между компонентами — это вызовы внутри кода, какие-то отношения между классами, паттерны и т.п. или даже просто говнокод, если нельзя отделить одно от другого.
Как будет выглядеть наш блог? Да примерно также, если честно.
Единственное отличие, что квадратики с компонентами — это больше не компоненты заключенные в код одного приложения, а стрелочки — это больше не системные вызовы классов внутри этого кода. Теперь — это отдельные компоненты, а стрелочки — обычные запросы по http.
Зачем это нужно? Сразу определимся, что наверное, это нужно не всем. Это должно быть очень удобно, если вы — достаточно крупная компания, способная выделить по команде разработки на каждый сервис. Думаю, даже средним компаниям, если выделить по человеку на каждый сервис будет тоже неплохо. Впрочем, даже если ты один на всю компанию, ты сможешь найти в микросервисах что-то интересное.
Насколько большим должен быть сервис? Границы провести сложно, ошибка будет стоить вам дорого, но, если вкратце, то сервис это некая единица вашей системы, которую вы можете полностью переписать за короткое время. Эмпирически пусть за неделю вы или ваша команда должны справится с сервисом. Основная идея тут — сервисы должны быть небольшие. Они не должны превращаться в кучу монолитов.
Итак, позитивные вещи, которые я смог выделить для себя, в целом все они проходят под одним трендом: Невероятное удобство для разработки:
- Отказоустойчивость. Так как связи между сервисами больше не жесткие, сервис может умереть по чьей-то глупости (например сервис комментариев), но в целом на блоге это не скажется никак, кроме того что пропадут комментарии.
- Язык. Вы можете разработывать новый сервис на чем угодно. В общем выбор языка перестает напоминать поиск серебряной пули, для каждого компонента системы вы можете выбрать тот инструмент, который ей подходит больше всего в текущий момент времени. Почему? Потому что это больше не дорого для компании (сервис маленький), вы всегда можете выкатить старый сервис назад, вы даже можете использовать одновременно одинаковые сервисы написанные на разных языках, чтобы понять, что лучше. Цена ошибки неизмеримо меньше.
- Маштабируемость. Приложение тормозит и не справляется? Нужен новый огромный сервер для всего приложения, а лучше 10? Забудьте. Теперь вы можете масштабировать сервисы. Просто добавьте побольше сервисов

- В целом высокая скорость работы, как результат всего что выше.
Что должно уметь наше приложение? Так то не очень много.
Четыре страницы:
- Список постов
- Открытый пост с комментариями
- Добавление поста
- Авторизация
Функционал простой:
- Авторизованный пользователь может добавить пост
- Кто угодно может его комментировать.
Auth Server
Обязанности по авторизации полностью вынесены в отдельное приложение, которое выдает OAuth2 токены для доступа к ресурсам бэкенда. Auth server используется как для авторизации пользователей, так и для защищенного общения сервис-сервис внутри периметра.
На самом деле, здесь описан только один из возможных подходов. Spring Cloud и Spring Security позволяют достаточно гибко настраивать конфигурацию под ваши нужды (например, имеет смысл проводить авторизацию на стороне API Gateway, а внутрь инфраструктуры передавать запрос с уже заполненными данными пользователя).
В этом проекте я использую grant type для авторизации пользователей и grant type — для авторизации между сервисами.
Spring Cloud Security предоставляет удобные аннотации и автоконфигурацию, что позволяет достаточно просто реализовать описанный функционал как со стороны клиента, так и со стороны авторизационного сервера.
Со стороны клиента это ничем не отличается от традиционной авторизации с помощью сессий. Из запроса можно получить объект , проверить роли и другие параметры с использованием аннотации .
Кроме того, каждое OAuth2-приложение имеет : для бэкенд-сервисов — , для браузера — . Так мы можем ограничить доступ к некоторым эндпоинтам извне:
Реестр: Забросить и Сломать
Реестр v2 — это полностью переписанный софт. Реестр v1 был отправлен на пенсию сразу же после выпуска v2.
Мы обязаны установить новую штуку (снова!) просто чтобы докер продолжал работать. Они поменяли конфигурацию, урлы, пути, ендпоинты.
Переход к v2 был не бесшовным. Нам пришлось починить нашу установку, билды, скрипты развертывания.
Выводы: не доверяй никакому инструменту или API из докера. Они постоянно забрасываются и ломаются.
Одна из целей реестра v2 была в создании более качественного API. Это задокументировано здесь, 9 месяцев назад существовала документация, о которой мы уже и не помним.
Лучшие практики разработки Dockerfile
Базовый образ
Первая инструкция из Dockerfile определяет базовый образ, поверх которого мы добавляем новые слои для приложения. Выбор базового слоя весьма важен, поскольку поставляемые им возможности могут влиять на качество надстроенных слоёв.
По возможности старайтесь работать с официальными образами, которые, как правило, часто обновляются и имеют меньше проблем с безопасностью.
Выбор базового образа также влияет на размер итогового. Если для вас размер имеет первостепенное значение, то можно выбрать какой-нибудь очень маленький нетребовательный к ресурсам образ. Такие образы обычно основываются на дистрибутиве Alpine и имеют соответствующий тег. Тем не менее для приложений Python в большинстве случаев отлично подходит slim-вариант официального Python-образа Docker (например, )
Порядок инструкций влияет на использование кэша сборки
При частой сборке образа мы определённо будем использовать механизм кэширования для ускорения. Как я упоминала ранее, инструкции выполняются в заданном порядке. Для каждой инструкции сборщик сначала проверяет свой кэш на наличие образа для повторного использования. При обнаружении изменения в слое этот и все последующие слои пересобираются. Чтобы кэширование было эффективным, нужно поместить инструкции часто изменяемых слоёв после тех, которые меняются редко.
Посмотрим на пример Dockerfile, чтобы понять, как порядок инструкций влияет на кэширование. Ниже я привела интересующие нас строки:
В процессе разработки зависимости нашего приложения изменяются не так часто, как Python-код. В связи с этим мы устанавливаем их в слое, предшествующем слою кода. То есть мы копируем файл зависимостей, устанавливаем их, а затем копируем исходный код. Это главная причина изолирования исходного кода в отдельную директорию, о котором было сказано в начале статьи.
Многоэтапные сборки
Хотя это может и не быть существенным в разработке, мы кратко расскажем о подобных сборках, поскольку они интересны в плане итоговой отправки контейнеризованного приложения уже по её завершении.
Многоэтапные сборки используются для очистки итогового образа от ненужных файлов и пакетов ПО, чтобы отправлять только необходимые для выполнения кода файлы. Вот небольшой пример многоэтапного Dockerfile:
Обратите внимание, что здесь мы используем двухэтапную сборку, где только первый этап называем builder — сборщик. Название этапу мы задаём, добавляя к инструкции и используем это название в инструкции , где хотим скопировать в итоговый образ только необходимые файлы
Результат — облегчённый образ:
В этом примере мы установили зависимости в локальную директорию user и скопировали эту директорию в итоговый образ с помощью опции pip . Однако для выполнения этих действий есть и другие решения вроде или сборки в виде пакетов с последующим их копированием и установкой в итоговый образ.






Запуск контейнера
После написания Dockerfile и сборки образа, мы запускаем контейнер с нашим сервисом:
Мы и поместили в контейнер сервер и теперь можем запросить порт, сопоставленный с localhost:
Что дальше?
Мы показали, как помещать в контейнер сервер на Python для облегчения разработки. Контейнеризация позволяет не только добиваться одинаковых результатов на разных платформах, но также избегать конфликтов зависимостей и поддерживать в чистоте стандартную среду разработки. Контейнеризованная среда легко управляется и удобна при совместной работе с другими разработчиками: они смогут без проблем развёртывать её в своих стандартных средах, не внося изменений.
В следующей статье вы узнаете, как настроить основанный на контейнерах многосервисный проект, где Python-компонент соединён с внешними компонентами, а также научитесь управлять жизненным циклом всех компонентов проекта при помощи Docker Compose.
- Пять действительно крутых пакетов Python
- Встроенная база данных Python
- Пространства имен и области видимости в Python
Читайте нас в Telegram, VK и
Перевод статьи ANCA IORDACHEContainerized Python Development — Part 1
Service discovery
Еще один широко известный паттерн для распределенных систем. Service discovery позволяет автоматически определять сетевые адреса для доступных инстансов приложений, которые могут динамически изменяться по причинам масштабирования, падений и обновлений.
Ключевым звеном здесь является Registry service. В этом проекте я использую Netflix Eureka (но есть еще Consul, Zookeeper, Etcd и другие). Eureka — пример client-side discovery паттерна, что означает клиент должен запросить адреса доступных инстансов и осуществлять балансировку между ними самостоятельно.
Чтобы превратить Spring Boot приложение в Registry server, достаточно добавить зависимость на и аннотацию . На стороне клиентов — зависимость , аннотацию и имя приложения (serviceId) в :
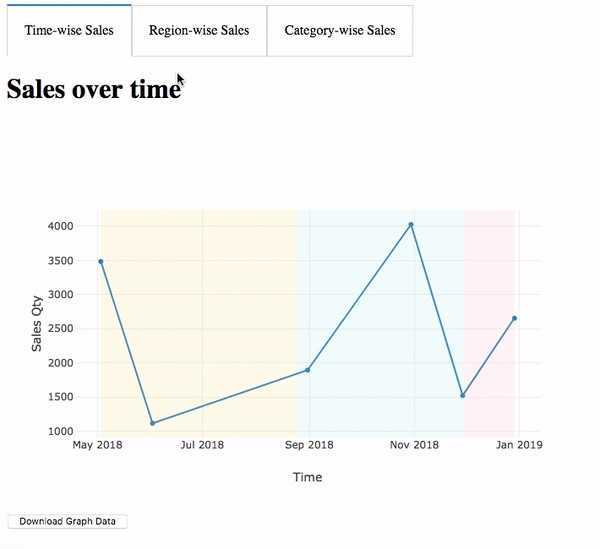
Теперь инстанс приложения при старте будет регистрироваться в Eureka, предоставляя мета-данные (такие как хост, порт и прочее). Eureka будет принимать хартбит-сообщения, и если их нет в течении сконфигурированного времени — инстанс будет удален из реестра. Кроме того, Eureka предоставляет дашборд, на котором видны зарегистрированные приложения с количеством инстансов и другая техническая информация:
Это не может быть так просто…
Эта картинка из Nigel Poulton очень хорошо обобщает различия между старым Swarm и новым Swarm.
Перевод картинки:
Старый путь (много шагов и команд не показано)
- Создать ключи
- Перезапустить демоны manager1 и node1 с TLS-флагами на 2376
- Запустить распределенный сервис Consul (контейнер)
- Запустить клиент Consul на node1 (не показано, но он успешно присоединился к серверу Consul)
- Начать управление Swarm (контейнер) на 2376 и карты 3376:2376
5.1. Скопировать ключи в контейнер Swarm менеджера с помощью объема и специальных ключей и порт для менеджера команд Swarm
5.2. Успешно получить роль лидера - Начать присоединять к Swarm контейнер на node1
6.1. Не монтируйте ключи внутрь контейнера и задайте команду присоединения как неподдерживаемую опцию - Сконфигурируйте клиент при помощи DOCKER_HOST (указывающий на Swarm)
7.1. …
Новый путь
С Docker 1.12 вы также как и раньше можете инсталлировать внешние распределенные службы (consul, etcd, zookeeper), или отдельную службу планирования. Настройка TLS сквозная из коробки, нет “незащищенного режима”. У меня не существует никаких сомнений, что новый Docker Swarm является самым быстрым путем для получения запущенного и работающего docker-native кластера, готового быть развернутым в продакшн.
А что насчет большого масштабирования? Спасибо усилиям “капитана” Docker’a Chanwit Kaewkasi и DockerSwarm2000, они показали нам, что вы можете создать кластер из 2384 узлов и 96287 контейнеров.
Разворачивание контейнера с PGAdmin
Чтобы быстро развернуть PGAdmin, клонируем репозиторий https://github.com/khezen/compose-postgres.
Внесем изменения в файл docker-compose.yml.
-
Секция postgres нам здесь не нужна, мы ее отсюда удаляем.
-
Порты закомментируем,
-
Вставим настройки для Traefik.
-
Имя внешней сети у меня называется proxy.
Больше ничего менять не будем.
Теперь поднимаю контейнер по команде:
Логи от каждого контейнера можно посмотреть по команде:
Переходим по адресу pgadmin.demoncat.ru – открывается PGAdmin.
Таким образом работает Docker и его взаимосвязь между различными сервисами.
Этих сервисов очень много. Вы можете зайти на https://hub.docker.com/ и здесь есть огромное количество образов на все случаи жизни, которые вы можете посмотреть, скопировать и переделать под себя.
Google Cloud: Google Container Engine
Как мы говорили раньше, не существует никакой известной стабильной комбинации: операционная система + дистрибутив + версия докера, поэтому не существует стабильной экосистемы для запуска на ней Kubernetes. Это — проблема.
Но существует потенциальный вокрэраунд: Google Container Engine. Он хостится на Kubernetes (и Docker) как сервис, часть Google Cloud.
Google должен был решить проблемы Докера, чтобы предлагать то, что они предлагают, других вариантов нет. Внезапно, они могут оказаться единственными людьми, разобравшимися как найти стабильную экосистему для Докера, починить баги, и продать это готовое решение как облачный сервис. Получается, однажды у нас были общие цели.
Они уже предлагают этот серивис, что означает — они придумали обходные пути для починки проблем Докера. Поэтому самым простым способом иметь контейнеры, которые будут работать в продакшене (ну, или будут работать вообще), может оказаться использование Google Container Engine.
Цель: перейти на Google Cloud, начиная с филиалов, не привязанных к AWS. Игнорирвать оставшуюся часть перечисленных здесь задач, т.к. они становятся нерелевантными.
Google Container Engine: еще одна причина, почему Google Cloud — это будущее, и AWS — это прошлое (в т.ч. на 33% более дешевые инстансы со в 3 раза большей скоростью и IOPS в среднем).
Disclaimer (прочитайте, прежде чем комментировать!)
Небольшой кусочек контекста потерялся где-то между строк. Мы — небольшая контора с несколькими сотнями серверов. По сути, мы делаем финансовую систему, которая перемещает миллионы долларов в день (или миллиарды — в год).



Честно сказать, у нас были ожидания выше среднего, и мы воспринимаем проблемы с продакшеном довольно (слишком?) серьезно.
В общем, это «нормально», что у вас никогда не было этих проблем, если вы не используете докер на больших масштабах в продакшене, или не использовали его достаточно долго.
Хочется отдельнро отметить, что все эти проблемы и обходные пути были пройдены за период более года, а сконцентрированы в заметке, которую вы успели прочитать отсилы за 10 минут. Это сильно нагнетает градус драматизма, и боль от прочитанного.
В любом случае, чтобы ни случилось в прошлом — прошлое уже в прошлом. Наиболее важная часть — план на будущее. Это то, что вам точно нужно знать, если собираетесь внедрять Докер (или использовать Амазон вместо этого).
Резервное копирование и восстановление контейнера
Созданный нами контейнер можно сохранить в виде архива и, при необходимости, перенести на другой сервер или оставить как бэкап.
Создание резерва
И так, для создания резервной копии контейнера, смотрим их список:
docker ps -a
… и для нужного выполняем команду:
docker save -o /backup/docker/container.tar <container image>
* в данном примере мы создаем архив контейнера <container image> в файл /backup/docker/container.tar.
Чтобы уменьшить размер, занимаемый созданным файлом, раархивиркем его командой:
gzip /backup/docker/container.tar
* в итоге, мы получим файл container.tar.gz.
Восстановление
Сначала распаковываем архив:
gunzip container.tar.gz
После восстанавливаем контейнер:
docker load -i container.tar
Смотрим, что нужный нам контейнер появился:
docker images
NGINX + PHP + PHP-FPM
Рекомендуется каждый микросервис помещать в свой отдельный контейнер, но мы (для отдельного примера) веб-сервер с интерпретатором PHP поместим в один и тот же имидж, на основе которого будут создаваться контейнеры.
Создание образа
Создадим каталог, в котором будут находиться файлы для сборки образа веб-сервера:
mkdir -p /opt/docker/web-server
Переходим в созданный каталог:
cd /opt/docker/web-server/
Создаем докер-файл:
vi Dockerfile
- FROM centos:8
- MAINTAINER Dmitriy Mosk <master@dmosk.ru>
- ENV TZ=Europe/Moscow
- RUN dnf update -y
- RUN dnf install -y nginx php php-fpm php-mysqli
- RUN dnf clean all
- RUN echo «daemon off;» >> /etc/nginx/nginx.conf
- RUN mkdir /run/php-fpm
- COPY ./html/ /usr/share/nginx/html/
- CMD php-fpm -D ; nginx
- EXPOSE 80
* где:
1) указываем, какой берем базовый образ. В нашем случае, CentOS 8.
3) задаем для информации того, кто создал образ. Указываем свое имя и адрес электронной почты.
5) создаем переменную окружения TZ с указанием временной зоны (в нашем примере, московское время).
7) запускаем обновление системы.
![]() устанавливаем пакеты: веб-сервер nginx, интерпретатор php, сервис php-fpm для обработки скриптов, модуль php-mysqli для работы php с СУБД MySQL/MariaDB.
устанавливаем пакеты: веб-сервер nginx, интерпретатор php, сервис php-fpm для обработки скриптов, модуль php-mysqli для работы php с СУБД MySQL/MariaDB.
9) удаляем скачанные пакеты и временные файлы, образовавшиеся во время установки.
10) добавляем в конфигурационный файл nginx строку daemon off, которая запретит веб-серверу автоматически запуститься в качестве демона.
11) создаем каталог /run/php-fpm — без него не сможет запуститься php-fpm.
13) копируем содержимое каталога html, который находится в том же каталоге, что и dockerfile, в каталог /usr/share/nginx/html/ внутри контейнера. В данной папке должен быть наше веб-приложение.
15) запускаем php-fpm и nginx. Команда CMD в dockerfile может быть только одна.
17) открываем порт 80 для работы веб-сервера.
В рабочем каталоге создаем папку html:
mkdir html
… а в ней — файл index.php:
vi html/index.php
<?php
phpinfo();
?>
* мы создали скрипт, который будет выводить информацию о php в браузере для примера. По идее, в данную папку мы должны положить сайт (веб-приложение).
Создаем первый билд для нашего образа:
docker build -t dmosk/webapp:v1 .
Новый образ должен появиться в системе:
docker images
При желании, его можно отправить на Docker Hub следующими командами:
docker login —username dmosk
docker tag dmosk/webapp:v1 dmosk/web:nginx_php7
docker push dmosk/web:nginx_php7
* первой командой мы прошли аутентификацию на портале докер-хаба (в качестве id/login мы используем dmosk — это учетная запись, которую мы зарегистрировали в Docker Hub). Вторая команда создает тег для нашего образа, где dmosk — учетная запись на dockerhub; web — имя репозитория; nginx_php7 — сам тег. Последняя команда заливает образ в репозиторий.
* подробнее про докера.


Запуск контейнера и проверка работы
Запускаем веб-сервер из созданного образа:
docker run —name web_server -d -p 80:80 dmosk/webapp:v1
Открываем браузер и переходим по адресу http://<IP-адрес сервера с docker> — откроется страница phpinfo:
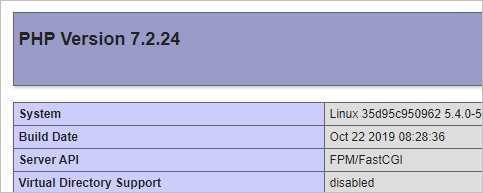
Наш веб-сервер из Docker работает.
Вывод
Я считаю что docker очень мощный и гибкий инструмент, в этом его недостаток (звучит странно, да). На него легко «подсаживаются» компаниии, используют где нужно и не нужно. Разработчики запускают свои контейнеры, какое то свое окружение, потом это все плавно перетекает в CI, продакшн. DevOps команда пишет какие то велосипеды чтобы запустить эти контейнеры.
Используйте docker только на самом последнем этапе в вашем рабочем процессе, не тащите его в проект в начале. Он не решит ваших бизнес проблем. Он только сдвинет проблемы на ДРУГОЙ уровень и будет предлагать свои варианты решения, вы будете делать двойную работу.
Когда docker нужен: пришел к мысли что docker очень хорош в оптимизации поставленного процесса но не в построении базового функционала
Если вы все-таки решили использовать docker, то:
- будьте предельно осторожны
- не навязывайте использование docker разработчикам
- локализуйте его использование в одном месте, не размазывайте по всем репозиториям Dockefile и docker-compose
PS:
- Недавно наткнулся на packer и говорят он очень хорошо работает с Ansible и позволяет унифицировать процесс построения образов (в т.ч. docker image)
- тоже про docker, интересная статья
Спасибо, что дочитали, желаю вам прозрачных решений в ваших делах и продуктивных рабочих дней!