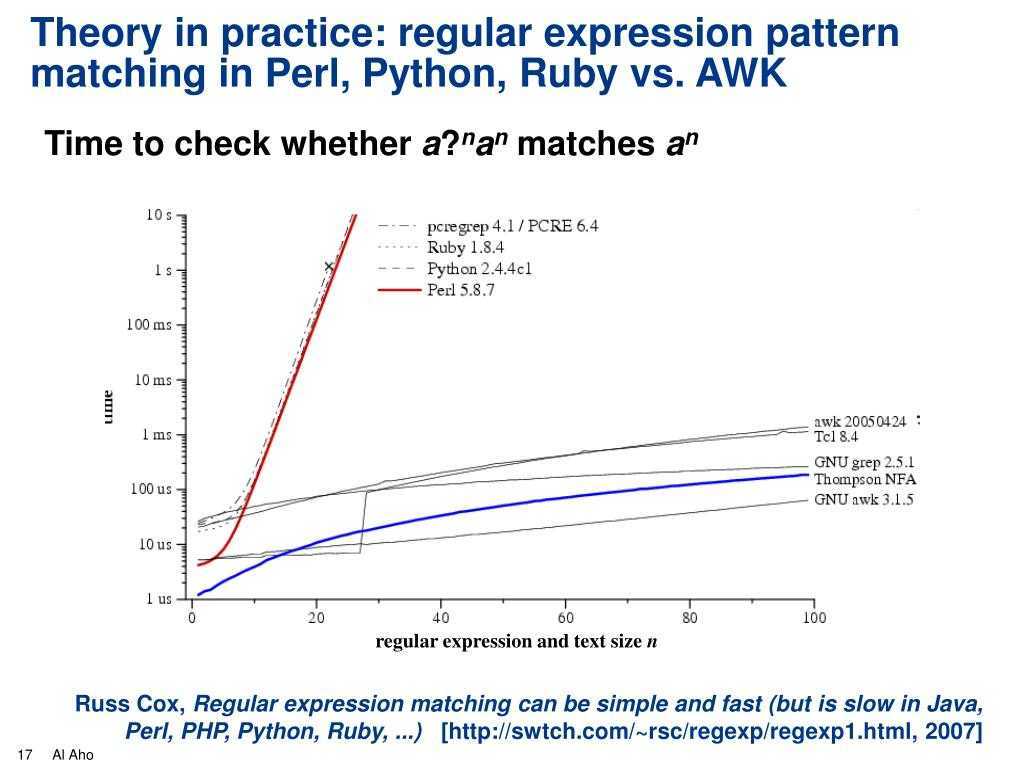
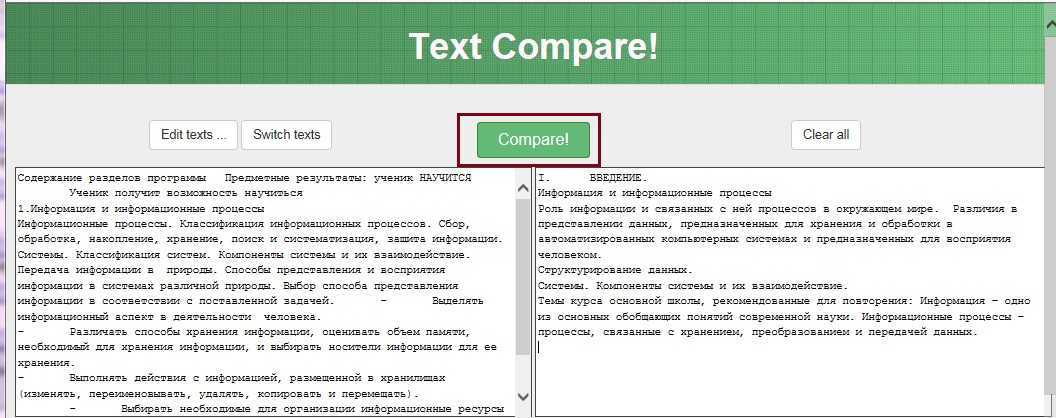
Сравните два файла / листа Excel и узнайте разницу с помощью VBA
Если вам нужно часто сравнивать файлы или листы Excel, рекомендуется иметь готовый код VBA макроса Excel и использовать его всякий раз, когда вам нужно проводить сравнение.
Вы также можете добавить макрос на панель быстрого доступа, чтобы получить доступ с помощью одной кнопки и мгновенно узнать, какие ячейки различаются в разных файлах / листах.
Предположим, у вас есть два листа Jan и Feb, и вы хотите сравнить и выделить различия в листе Jan, вы можете использовать приведенный ниже код VBA:
Sub CompareSheets()
Dim rngCell As Range
For Each rngCell In Worksheets("Jan").UsedRange
If Not rngCell = Worksheets("Feb").Cells(rngCell.Row, rngCell.Column) Then
rngCell.Interior.Color = vbYellow
End If
Next rngCell
End Sub
В приведенном выше коде цикл For Next используется для просмотра каждой ячейки на листе Jan (весь используемый диапазон) и сравнения его с соответствующей ячейкой на листе Feb. Если он обнаруживает разницу (которая проверяется с помощью оператора If-Then), он выделяет эти ячейки желтым цветом.
Вы можете использовать этот код в обычном модуле редактора VB.
И если вам нужно делать это часто, лучше сохранить этот код в книге личных макросов, а затем добавить его на панель быстрого доступа. Таким образом, вы сможете выполнить это сравнение одним нажатием кнопки.
Вот шаги, чтобы получить личную книгу макросов в Excel (она недоступна по умолчанию, поэтому вам необходимо включить ее).
Сравнение двух списков в Excel
Конечно, можно сравнивать два списка вручную. Но это займет много времени. Excel обладает собственным интеллектуальным инструментарием, который позволит сравнивать данные не только быстро, но и получать ту информацию, которую глазами и не получить так легко. Предположим, у нас есть два столбца с координатами A и B. Некоторые значения в них повторяются.
Постановка задачи
Итак, нам нужно сравнить эти столбцы. Методика сравнения двух документов следующая:
- Если уникальные ячейки каждого из этих списков совпадают, и общее количество уникальных ячеек совпадает, и ячейки те же самые, то можно считать эти списки одинаковыми. То, в каком порядке значения в этом перечне уложены, не имеет столь большого значения.
- О частичном совпадении перечней можно говорить, если сами уникальные значения те же самые, но отличается количество повторов. Следовательно, в таких списках может быть и разное количество элементов.
- О том, что два списка не совпадают, говорит разный набор уникальных значений.
Все эти три условия одновременно и являются условиями нашей задачи.
Решение задачи
Давайте сгенерируем два динамических диапазона, чтобы было более удобно сравнивать перечни. Каждый из них будет соответствовать каждому из перечней.
Чтобы сравнить два списка, надо выполнить следующие действия:
- В отдельной колонке создаем список уникальных значений, характерных для обоих списков. Для этого используем формулу: ЕСЛИОШИБКА(ЕСЛИОШИБКА( ИНДЕКС(Список1;ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$4:D4;Список1);0)); ИНДЕКС(Список2;ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$4:D4;Список2);0))); «»). Сама формула должна записываться, как формула массива.
- Определим, сколько раз каждое уникальное значение, встречается в массиве данных. Вот, какими формулами можно это сделать: =СЧЁТЕСЛИ(Список1;D5) и =СЧЁТЕСЛИ(Список2;D5).
- Если и число повторений, и количество уникальных значений одинаковое во всех перечнях, которые входят в эти диапазоны, то функция возвращает значение 0. Это говорит о том, что совпадение стопроцентное. В этом случае заголовки этих списков обретут зеленый фон.
- Если все уникальное содержимое есть в обоих списках, то возвращенное формулами =СЧЁТЕСЛИМН($D$5:$D$34;»*?»;E5:E34;0) и =СЧЁТЕСЛИМН($D$5:$D$34;»*?»;F5:F34;0) значение составит ноль. Если же E1 содержит не ноль, а такое значение содержится в ячейках E2 и F2, то в этом случае диапазоны будут признаны совпадающими, но только частично. В таком случае заголовки соответствующих списков станут оранжевыми.
- И в случае возвращения одной из формул, описанных выше, ненулевого значения перечни будут полностью не совпадающими.
Вот и ответ на вопрос, как проанализировать столбцы на предмет совпадений с помощью формул. Как видим, с применением функций можно реализовать почти любую задачу, которая на первый взгляд с математикой не связана.
Тестирование на примере
В нашем варианте таблицы есть три вида списков каждой описанной выше разновидности. В нем есть частично и полностью совпадающие, а также не совпадающие.
Для сравнения данных мы используем диапазон A5:B19, в который мы попеременно вставляем эти пары списков. О том, какой будет итог сравнения, мы поймем по цвету исходных перечней. Если они абсолютно разные, то это будет красный фон. Если часть данных одинаковая, то желтый. В случае же полной идентичности соответствующие заголовки будут зелеными. Как же сделать цвет, зависящий от того, какой результат получился? Для этого нужно условное форматирование.
Быстрый способ сравнения двух столбцов или списков без формул.
Теперь, когда вы знаете, что предлагает Excel для сравнения и сопоставления столбцов, позвольте мне продемонстрировать вам альтернативное решение, которое может сравнить 2 списка с разным количеством столбцов на предмет дубликатов (совпадений) и уникальных значений (различий).
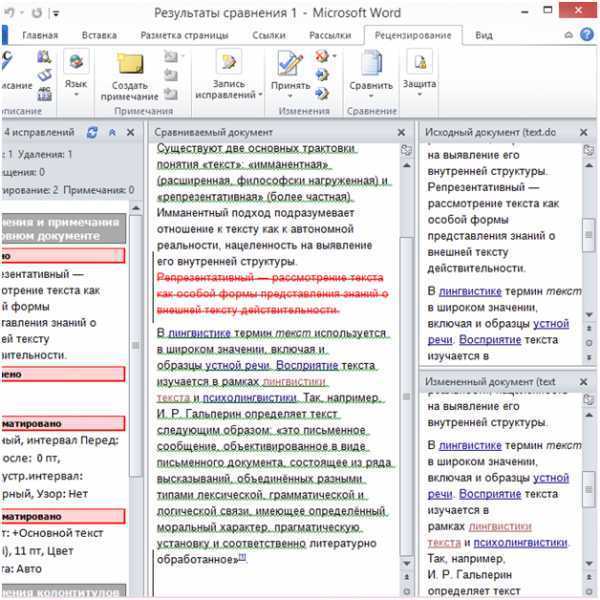
Надстройка Ultimate Suite умеет искать идентичные и уникальные записи в одной таблице, а также сравнивать две таблицы, находящиеся на одном листе или в двух разных листах или даже в разных книгах.
В рамках этой статьи мы сосредоточимся на функции под названием «Сравнить таблицы (Compare Tables) , которая специально разработана для сравнения двух списков по любым указанным вами столбцам. Сравнение двух наборов данных по нескольким столбцам является реальной проблемой как для формул Excel, так и для условного форматирования, но этот инструмент легко справляется с этим.
Для начала рассмотрим самый простой случай – сравним два столбца на совпадения и различия.
Предположим, у нас имеется два списка товаров. Нужно сравнить их между собой, как ранее мы делали при помощи формул.
Запускаем инструмент сравнения таблиц и выбираем первый столбец. При необходимости активируем создание резервной копии листа.
На втором шаге выбираем второй столбец для сравнения.
На третьем шаге нужно указать, что именно мы ищем – дубликаты либо уникальные значения.
Далее указываем столбцы для сравнения. Поскольку столбцов всего два, то здесь все достаточно просто:
На пятом шаге выберите, что нужно сделать с найденными значениями – удалить, выбрать, закрасить цветом, скопировать либо переместить. Можно добавить столбец статуса подобно тому, как мы это делали ранее при помощи функции ЕСЛИ. С использованием формул вы кроме того сможете разве что закрасить ячейки. Здесь же диапазон возможностей гораздо шире. Но мы выберем простой и наглядный вариант – заливку ячеек цветом.


Ячейки списка 1, дубликаты которых имеются в списке 2, будут закрашены цветом.
А теперь повторим все описанные выше шаги, только будем сравнивать список 2 с первым. И вот что мы в итоге получим:
Не закрашенные цветом ячейки содержат уникальные значения. Красиво и наглядно.
А теперь давайте попробуем сравнить сразу несколько столбцов. Допустим, у нас есть два экземпляра отчёта о продажах. Они расположены на разных листах нашей книги Excel. Список товаров совершенно одинаков, а вот сами цифры продаж отличаются кое-где.
Действуя совершенно аналогичным образом, как это было описано выше, выбираем эти две таблицы для сравнения. На третьем шаге выбираем поиск уникальных значений, чтобы можно было выбрать и выделить именно несовпадения в данных.
Устанавливаем соответствие столбцов, как это показано на рисунке ниже.
Для наглядности вновь выбираем заливку цветом для несовпадающих значений.
И вот результат. Несовпадающие строки закрашены цветом.
Если вы хотите попробовать этот инструмент, вы можете загрузить его как часть надстройки Ultimate Suite for Excel.
Вот какими способами вы можете сравнить столбцы в Excel на наличие дубликатов и уникальных значений.
Если у вас есть вопросы или что-то осталось неясным, напишите мне комментарий, и я с радостью уточню это подробнее. Спасибо за чтение!
Способ № 4: использовать Excel Power Query
Power Query — технология подключения к данным, которая помогает обнаруживать, подключать, объединять и уточнять данные из различных источников для анализа.
Чтобы начать с ней работать, необязательно заранее подготавливать файлы Excel, сохранять, копировать таблицы. Power Query позволяет загружать данные:
-
из интернета;
-
внешнего файла форматом Excel, CSV, XML;
-
баз данных SQL, Access, IBM DB2 и других;
-
Azure;
-
веб-служб Dynamics 365,
Самые продвинутые пользователи могут «Написать запрос с нуля».
В этой статье я подробно опишу только сопоставление двух таблиц. На первый взгляд, способ очень трудный и долгий, но если вы освоите его, то процесс будет занимать не больше 10 минут.
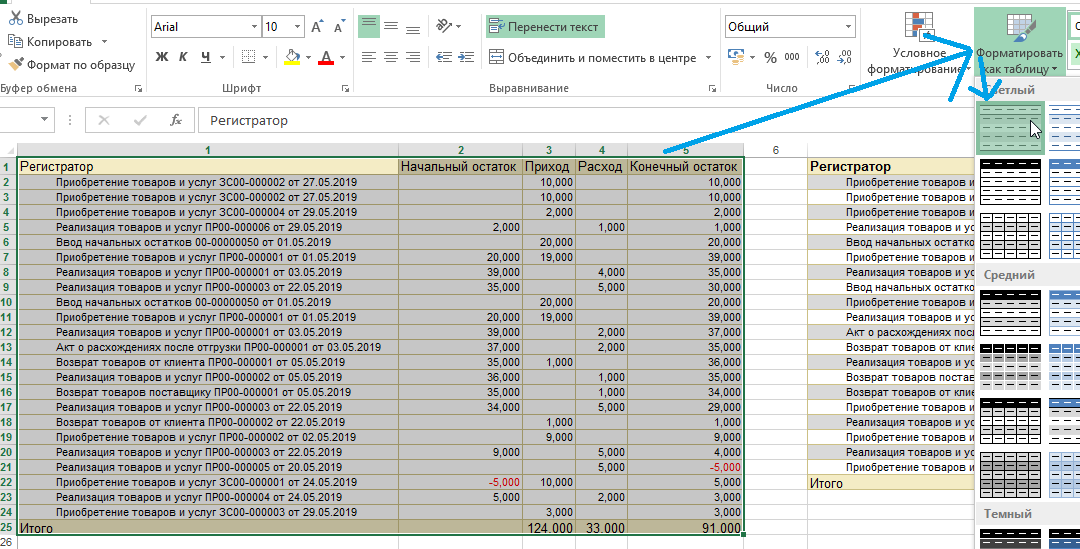
Перед вами две таблицы в Excel. Нужно преобразовать каждую в умную таблицу. Для этого выделите нужный диапазон, на вкладке «Главная» кликните на «Форматировать как таблицу» или на клавиатуре нажмите Ctrl+T.
Теперь с каждой таблицы необходимо создать отдельные запросы для сравнения. Выделите любую ячейку в первой таблице и перейдите на вкладку Power Query «Из таблицы или диапазона». Она откроется в «Редакторе Power Query». Рекомендую задать ей «Имя» в свойствах, чтобы в дальнейшем не путать файлы. При необходимости уберите лишние строки и столбцы.
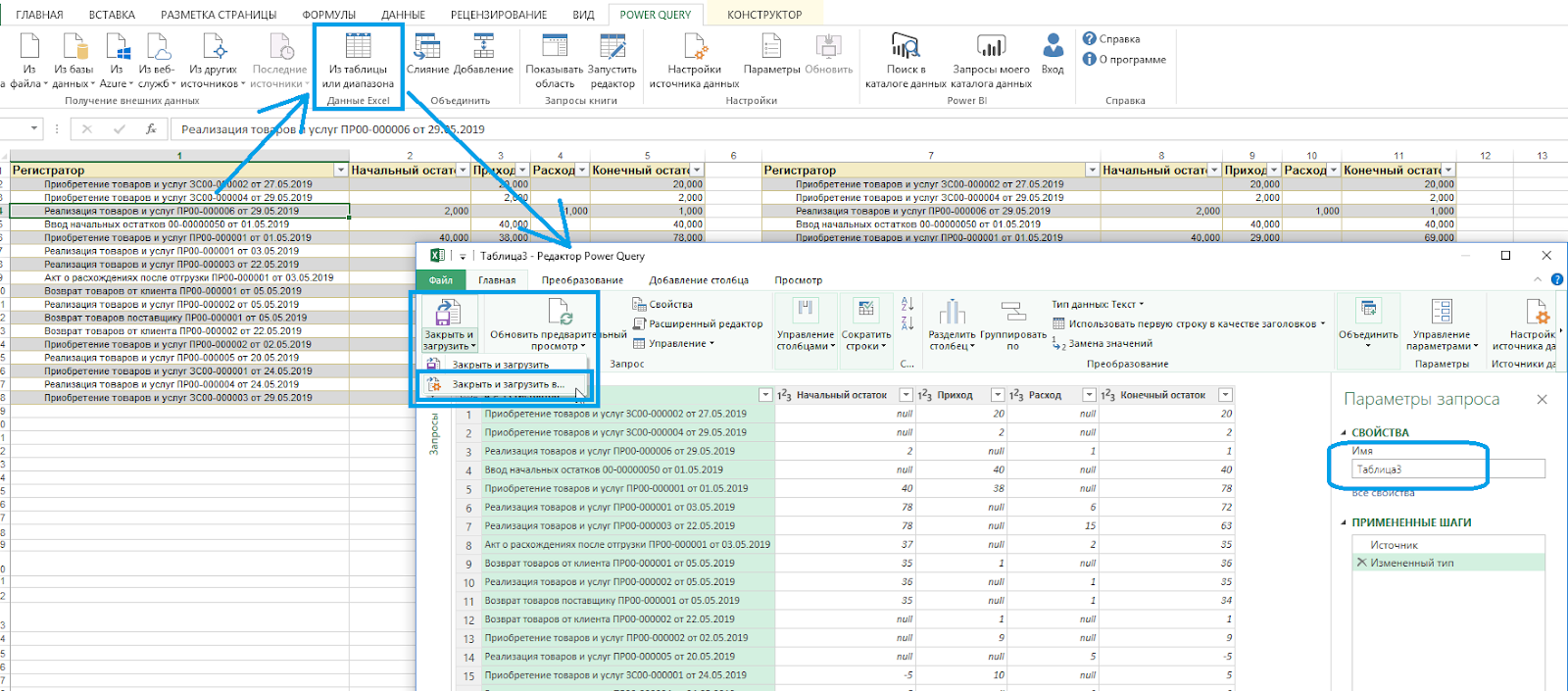
Нажмите «Закрыть и загрузить в …», выберите «Только создать подключение» и кликните на кнопку «Загрузить».
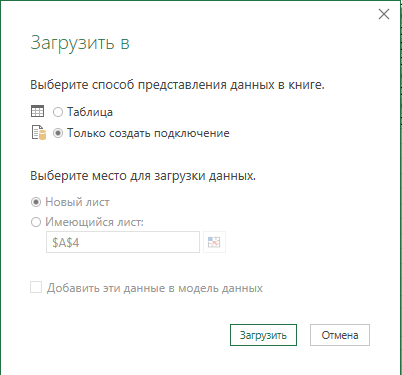
Повторите все шаги со вторым документом.
В правой части окна появились два запроса с указанными именами таблиц. На панели инструментов выберите команду «Слияние» и укажите поочередно созданные запросы. По одному разу в каждой части окна кликом выделите колонки, по которым нужно объединить файлы. Тип соединения «Полное внешнее (все строки из обеих таблиц)». Кликните на «ОК».
![7 способов сравнения файлов по содержимому в windows или linux [айти бубен]](https://smartshop124.ru/wp-content/uploads/5/3/c/53c64c6ada5cc5161e67e494921ea8bc.jpeg)

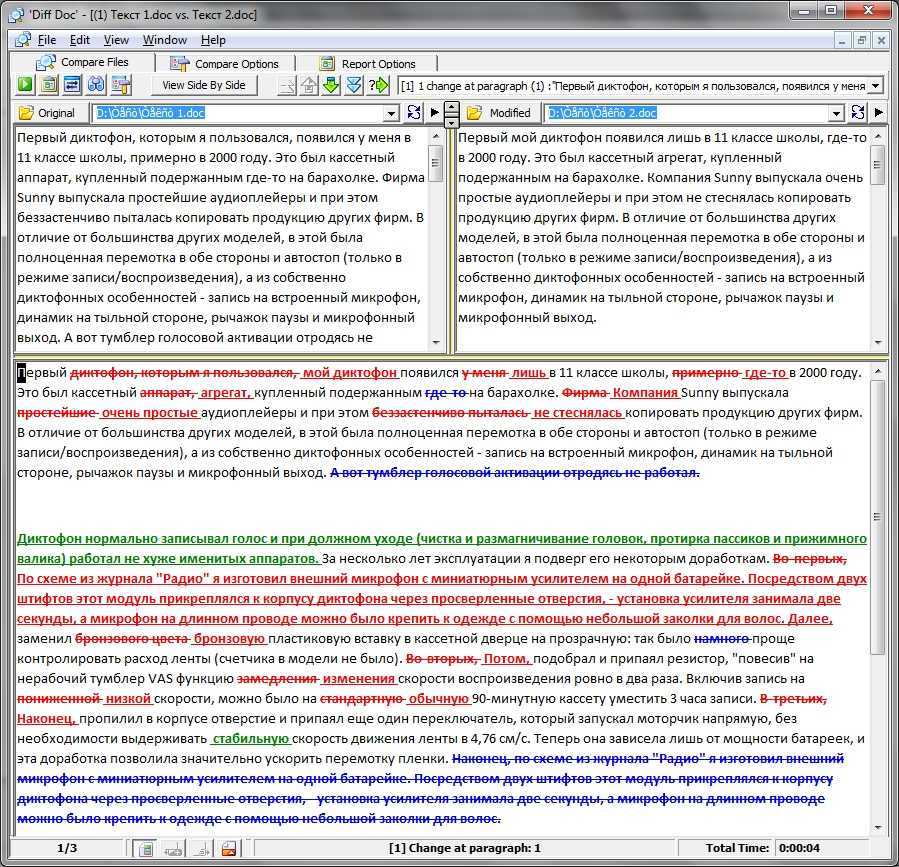
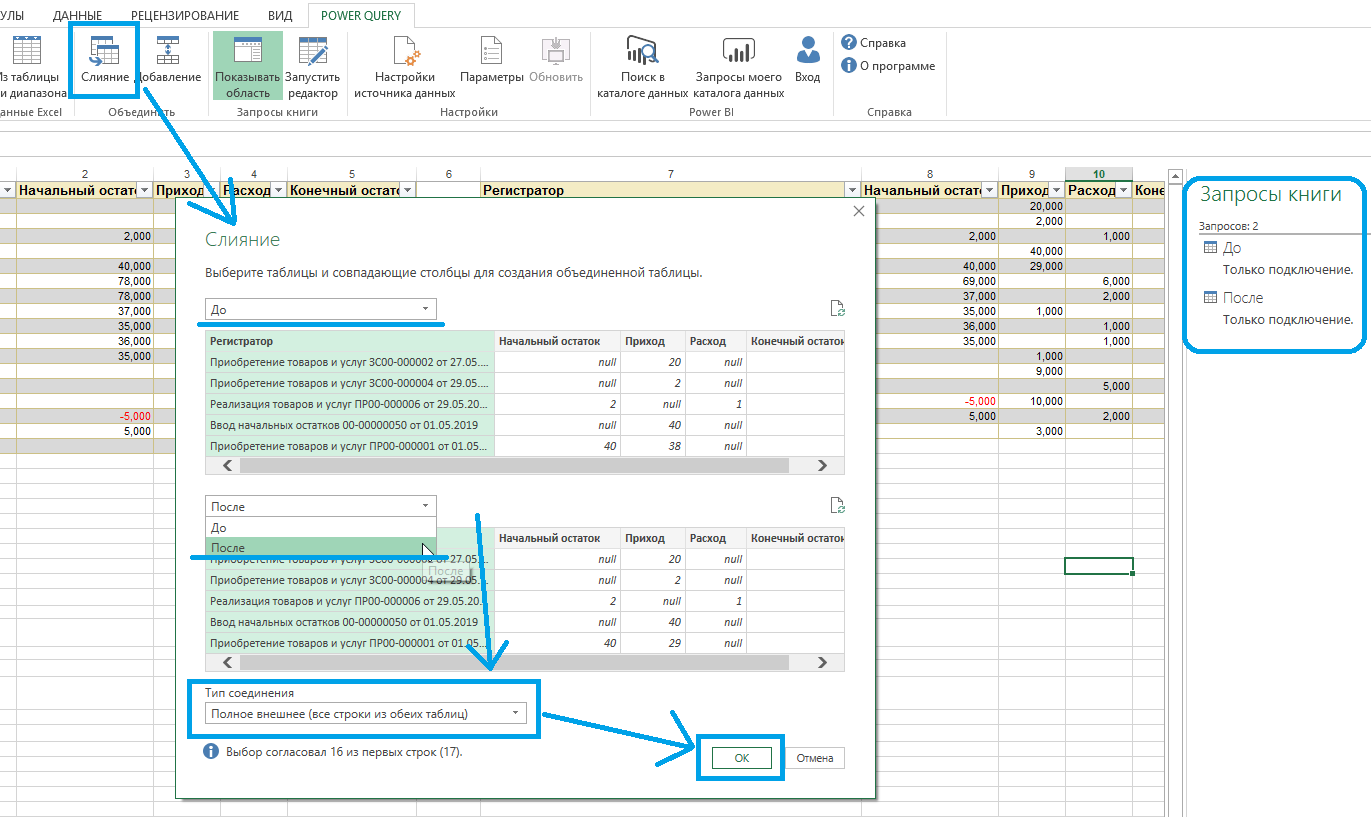
Вы снова попали в «Редактор Power Query». Здесь обе таблицы объединены в одну путем слияния указанных столбцов. В «Свойствах» задайте имя новому документу — раскройте крайнюю правую колонку, нажав на иконку .
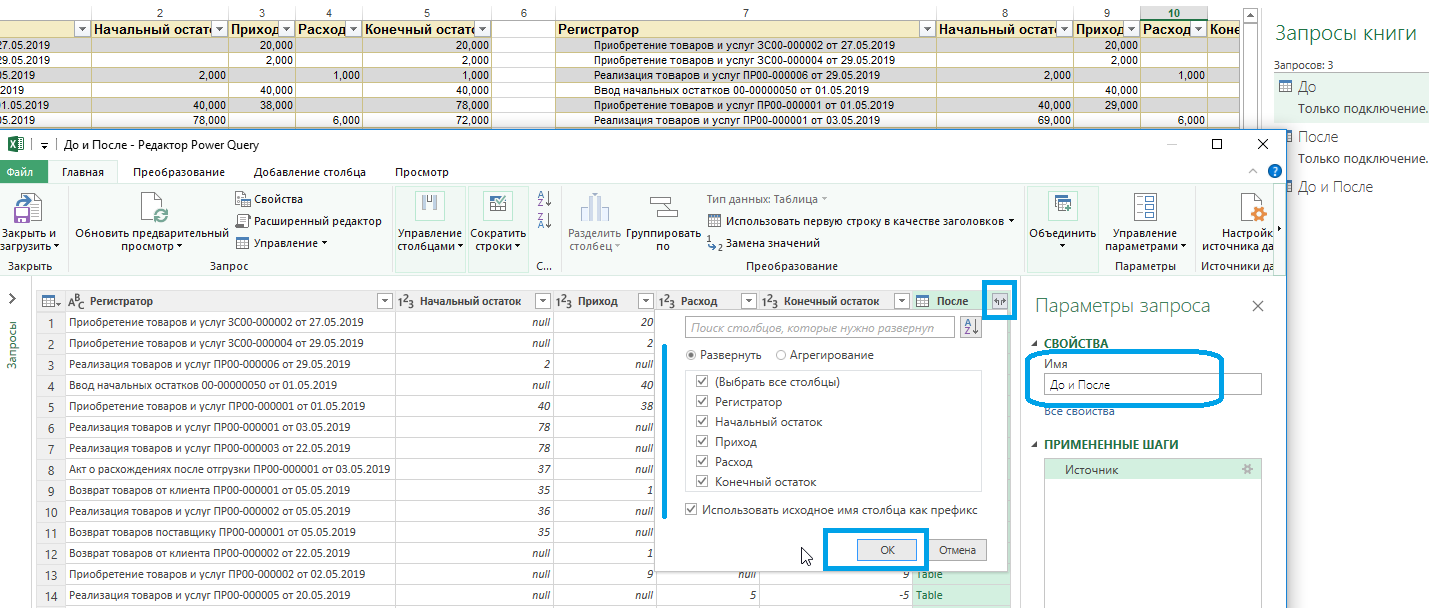
Следующий этап — вывести отличия таблиц в отдельную колонку. На вкладке «Добавление столбца» выберите «Условный столбец». В окне настройки задайте «Имя нового столбца» и проставьте условия сравнений колонок и какой вывод должен отразиться при их соблюдении. Правил можно задавать неограниченное количество с помощью команды «Добавить правило».
В примере задано:
1. Если в колонке «Регистратор» первой таблицы стоит значение null, а во второй таблице это значение заполнено, значит документ «Добавили».
2. Если в колонке «Регистратор1» второй таблицы стоит значение null, значит документ «Удалили».
3. Если значения колонок «Конечный остаток» и «Конечный остаток1» не равны, значит данные «Изменили».
Обратите внимание на третье условие. Чтобы в «Значении» выбрать нужную колонку, кликните на иконку , затем «Выберите столбец»
Только тогда появится выпадающий список допустимых колонок.
Обязательно заполните в левом нижнем углу значение «В противном случае» — оно будет исполняться, если ни одно из вышеприведенных условий не выполнено. Нажмите «ОК».
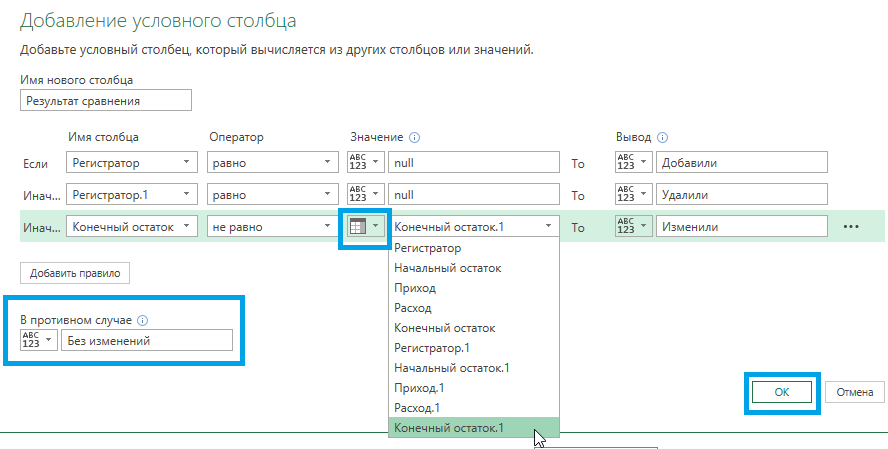
В «Редакторе» появилась крайняя правая колонка, в которой выведены результаты сравнения по каждой строке. С помощью удобного фильтра можно вывести только строки с интересующим итогом.
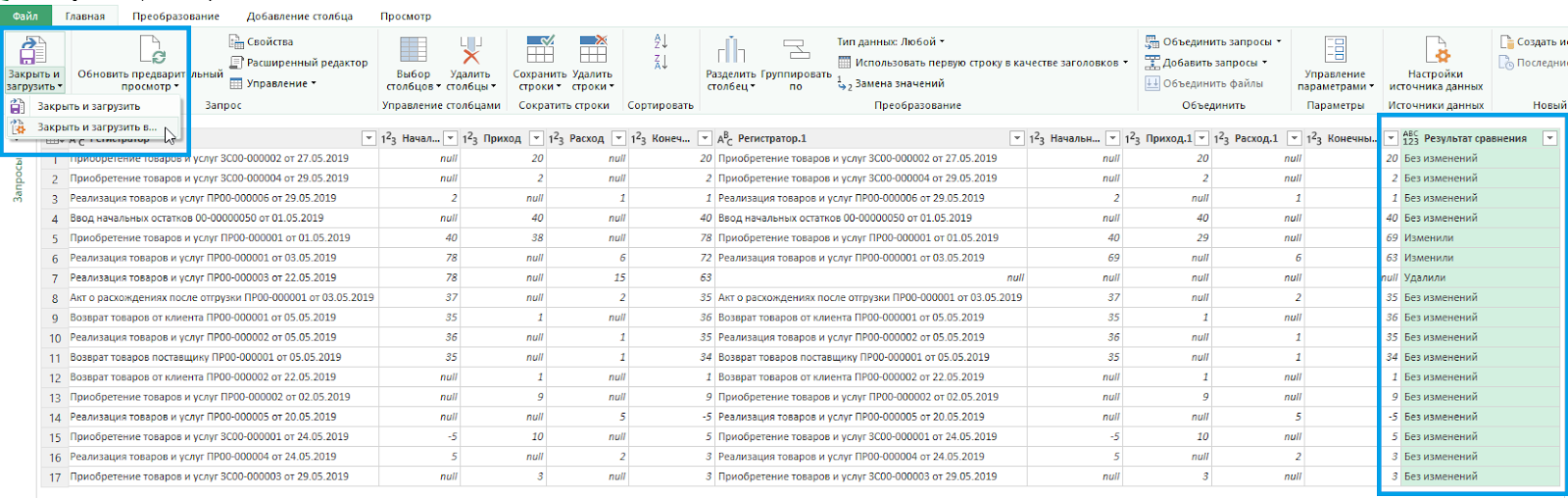
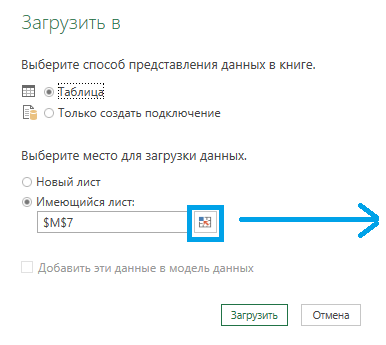
Сохраните документ с помощью команды на «Главной» вкладке: «Закрыть и загрузить в … — Таблица — Имеющийся лист — — укажите ячейку, с которой должна начаться новая таблица — ОК — Загрузить».
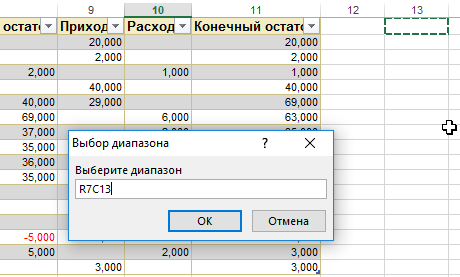
Итог: таблицы до сравнения и объединенная сводка с готовыми результатами для анализа.

Плюсы:
-
исключены ошибки по невнимательности, вам нужно только указать, что с чем сравнивать и что вывести в вывод;
-
надстройка работает со множеством форматов и различными источниками данных.
Как сравнить 2 столбца по строкам
Когда мы сравниваем две колонки, нам нередко приходится сопоставлять информацию, которая находится в разных рядах. Чтобы сделать это, нам поможет оператор ЕСЛИ. Давайте разберем принцип ее работы на практике. Для этого приведем несколько наглядных ситуаций.
Пример. Как сравнить 2 столбца на совпадения и различия в одной строке
Чтобы проанализировать, являются ли значения, находящиеся в том же самом ряду, но разных колонках, одинаковыми, запишем функцию ЕСЛИ. Формула вставляется в каждый ряд, размещенный во вспомогательном столбце, куда будут выводиться результаты обработки данных. Но вовсе не обязательно прописывать ее в каждый ряд, достаточно просто скопировать ее в оставшиеся ячейки этой колонки или же воспользоваться маркером автозаполнения.
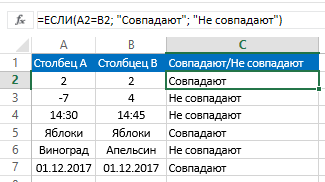
Нам следует записать такую формулу, чтобы понять, совпадают ли значения в обеих колонках или нет: =ЕСЛИ(A2=B2; “Совпадают”; “”). Логика работы этой функции очень проста: она сопоставляет значения в ячейках A2 и B2, и если они одинаковые, выводит значение «Совпадают». Если же данные отличаются, то не возвращает никакого значения. Можно также проверить ячейки на предмет отсутствия между ними совпадения. В этом случае используемая формула следующая: =ЕСЛИ(A2<>B2; “Не совпадают”; “”). Принцип тот же самый, сначала осуществляется проверка. Если оказывается, что ячейки удовлетворяют критерию, то выводится значение «Не совпадают».
Также возможно применение следующей формулы в поле формулы, чтобы выводить и «Совпадают» если значения одинаковые, и «Не совпадают», если они отличаются: =ЕСЛИ(A2=B2; “Совпадают”; “Не совпадают”). Также вместо оператора равенства можно использовать оператор неравенства. Только порядок значений, которые будут выводиться в этом случае будет несколько другим: =ЕСЛИ(A2<>B2; “Не совпадают”; “Совпадают”). После использования первого варианта формулы результат получится следующим.
Этот вариант формулы не учитывает регистр значений. Поэтому если значения в одной колонке отличаются от других только тем, что они написаны большими буквами, то этой разницы программа не заметит. Чтобы при сравнении учитывался регистр, нужно в критерии использовать функцию СОВПАД. Остальные аргументы оставляем без изменений: =ЕСЛИ(СОВПАД(A2,B2); “Совпадает”; “Уникальное”).
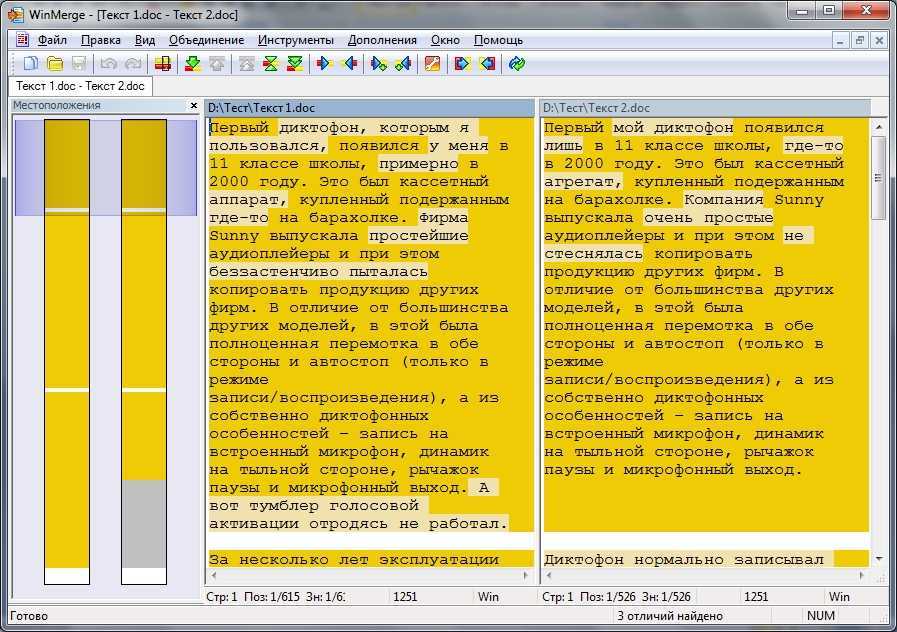
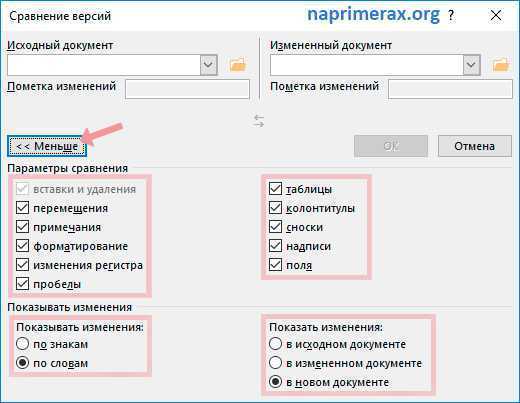
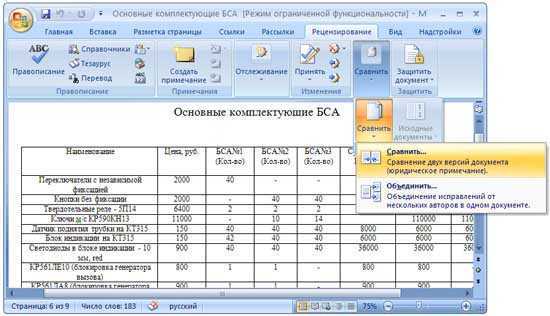
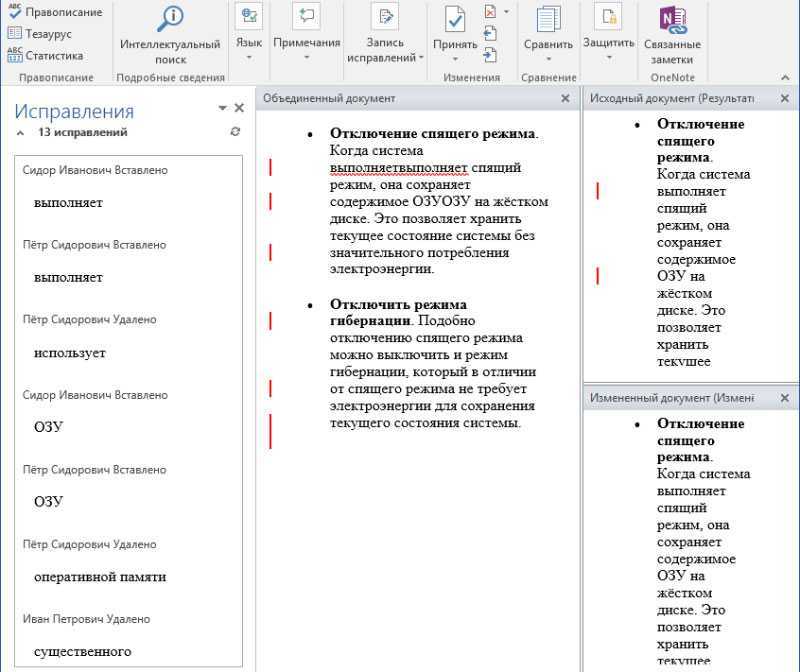
Сравните два листа и выделите различия (с использованием условного форматирования)
Хотя вы можете использовать описанный выше метод для выравнивания книг вместе и вручную просматривать данные построчно, это не лучший способ, если у вас много данных.
Кроме того, выполнение этого уровня сравнения вручную может привести к множеству ошибок.
Поэтому вместо того, чтобы делать это вручную, вы можете использовать возможности условного форматирования, чтобы быстро выделить любые различия на двух листах Excel.
Этот метод действительно полезен, если у вас есть две версии на двух разных листах и вы хотите быстро проверить, что изменилось.
Поскольку условное форматирование не может ссылаться на внешний файл Excel, сравниваемые листы должны находиться в одной книге Excel. Если это не так, вы можете скопировать лист из другого файла в активную книгу, а затем провести это сравнение.
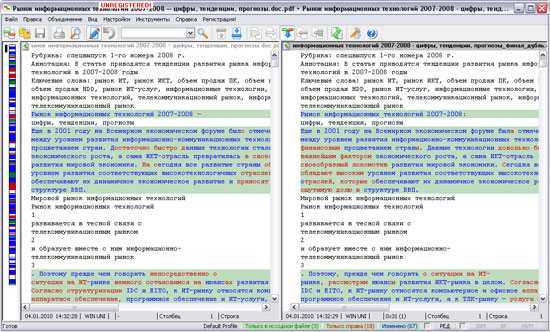
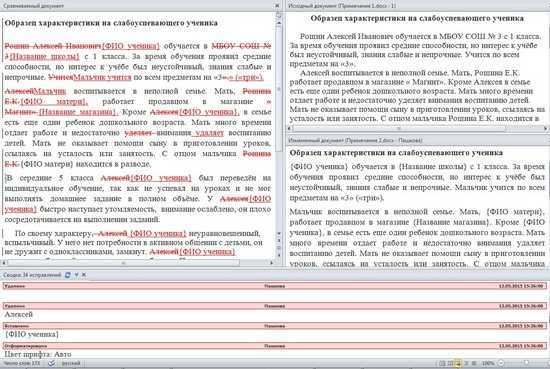
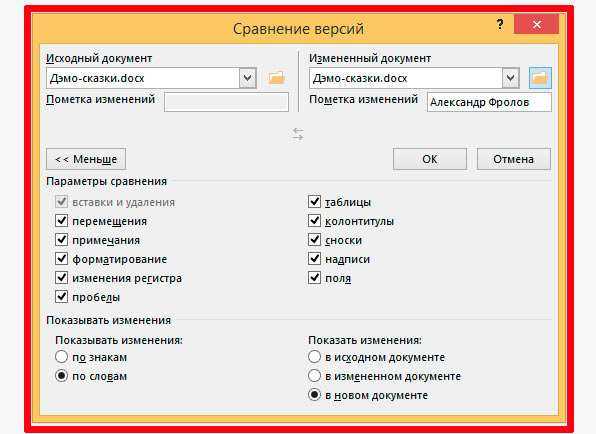
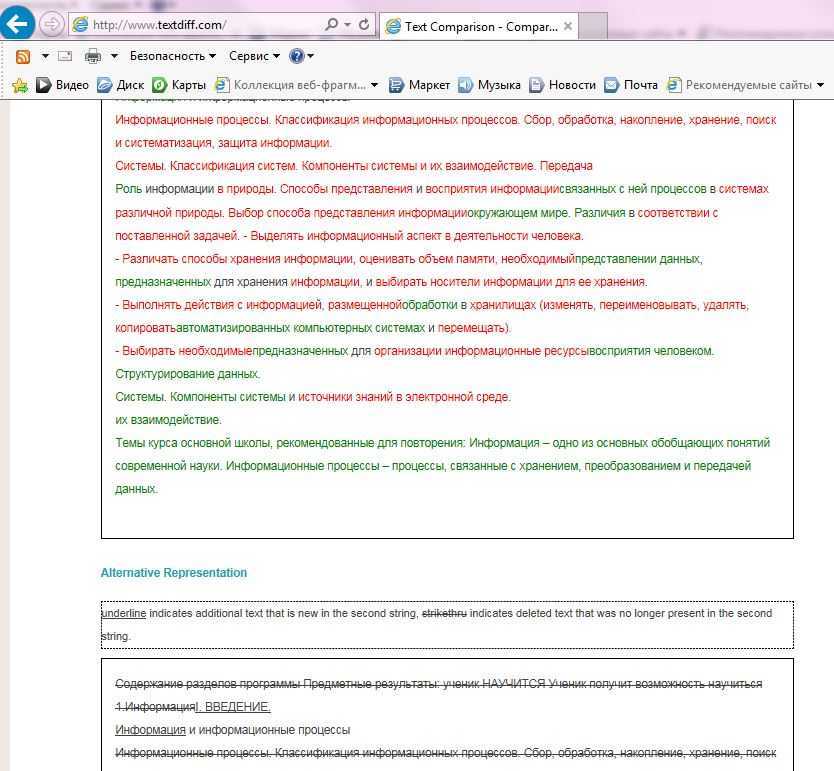
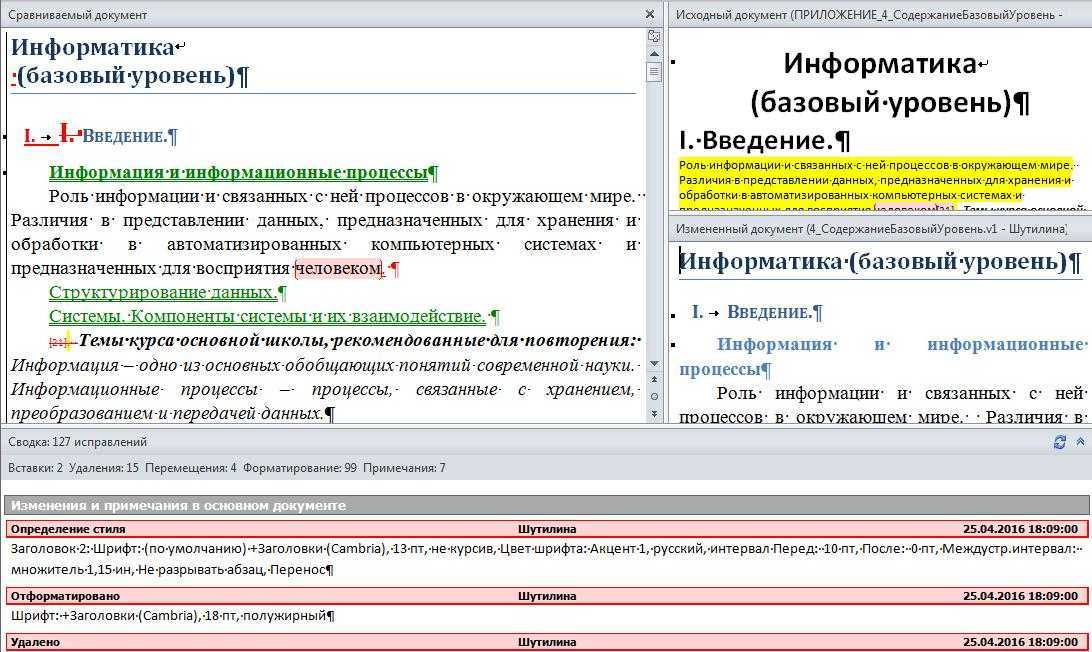
В этом примере предположим, что у вас есть набор данных, показанный ниже, за два месяца (январь и февраль) на двух разных листах, и вы хотите быстро сравнить данные на этих двух листах и проверить, изменились ли цены на эти товары или нет.
Ниже приведены шаги для этого:
- Выберите данные на листе, где вы хотите выделить изменения. Поскольку я хочу проверить, как изменились цены с января по февраль, я выбрал данные в таблице за февраль.
- Перейдите на вкладку «Главная»
- В группе «Стили» нажмите «Условное форматирование».
- В появившихся опциях нажмите «Новое правило».
- В диалоговом окне «Новое правило форматирования» нажмите «Использовать формулу, чтобы определить, какие ячейки нужно форматировать».
- В поле формулы введите следующую формулу: =B2<>Jan!B2
- Нажмите кнопку «Формат».
- В появившемся диалоговом окне «Формат ячеек» щелкните вкладку «Заливка» и выберите цвет, которым вы хотите выделить несоответствующие данные.
- Нажмите ОК.
- Нажмите ОК.
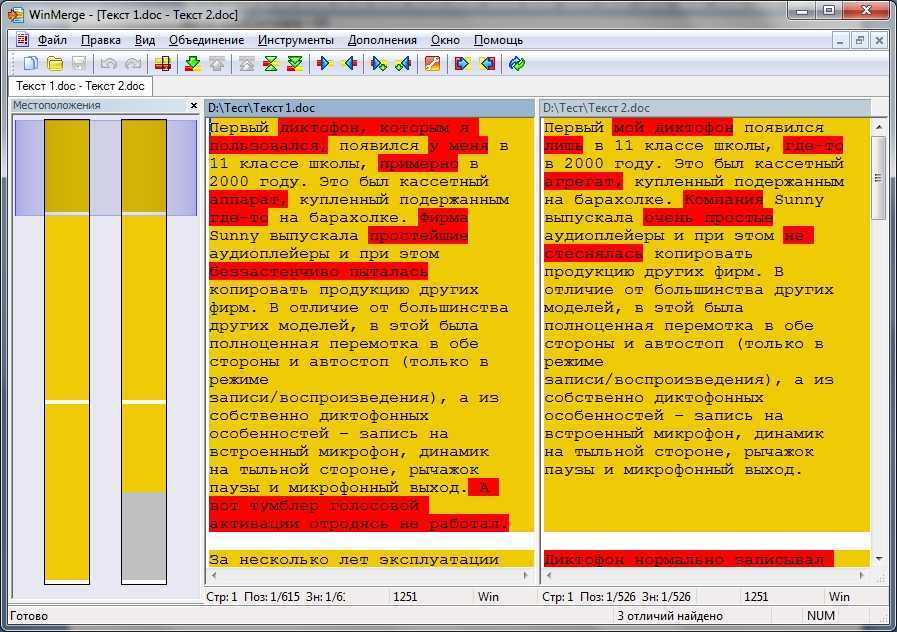
Вышеупомянутые шаги мгновенно подчеркнут любые изменения в наборе данных на обоих листах.
Как это работает?
Условное форматирование выделяет ячейку, когда заданная формула для этой ячейки возвращает ИСТИНА. В этом примере мы сравниваем каждую ячейку на одном листе с соответствующей ячейкой на другом листе (выполняется с помощью оператора «не равно» <> в формуле).
Когда условное форматирование обнаруживает какие-либо различия в данных, оно выделяет это на листе Jan (тот, в котором мы применили условное форматирование.
Обратите внимание, что в этом примере я использовал относительную ссылку (A1 and not $A$1 or $A1 or A$1). При использовании этого метода для сравнения двух листов в Excel помните следующее;
При использовании этого метода для сравнения двух листов в Excel помните следующее;
- Этот метод хорош для быстрого выявления различий, но вы не можете использовать его постоянно. Например, если я введу новую строку в любой из наборов данных (или удалю строку), это даст мне неверные результаты. Как только я вставляю / удаляю строку, все последующие строки считаются разными и соответственно выделяются.
- Вы можете сравнивать только два листа в одном файле Excel.
- Вы можете только сравнить значение (а не разницу в формуле или форматировании).
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили
CentOS Linux
и хотите посмотреть все установленные пакеты в названии которых есть слово
kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel
: нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
grep ‘\bkernel\b’ huge_file
Где huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово
kernel
в середине, а только те, которые начинаются с
kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
grep -E ‘ion$’ huge_file
compensation
generation
Допустим вы знаете только начало и конец слова
grep -E ‘^to..le$’ huge_file
topbicycle
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘{5}’ /usr/share/dict/words
cadiueio
Chaouia
cooeeing
euouae
Guauaenok
miaoued
miaouing
Pauiie
queueing
Поиск отличий в двух списках
Типовая задача, возникающая периодически перед каждым пользователем Excel – сравнить между собой два диапазона с данными и найти различия между ними. Способ решения, в данном случае, определяется типом исходных данных.

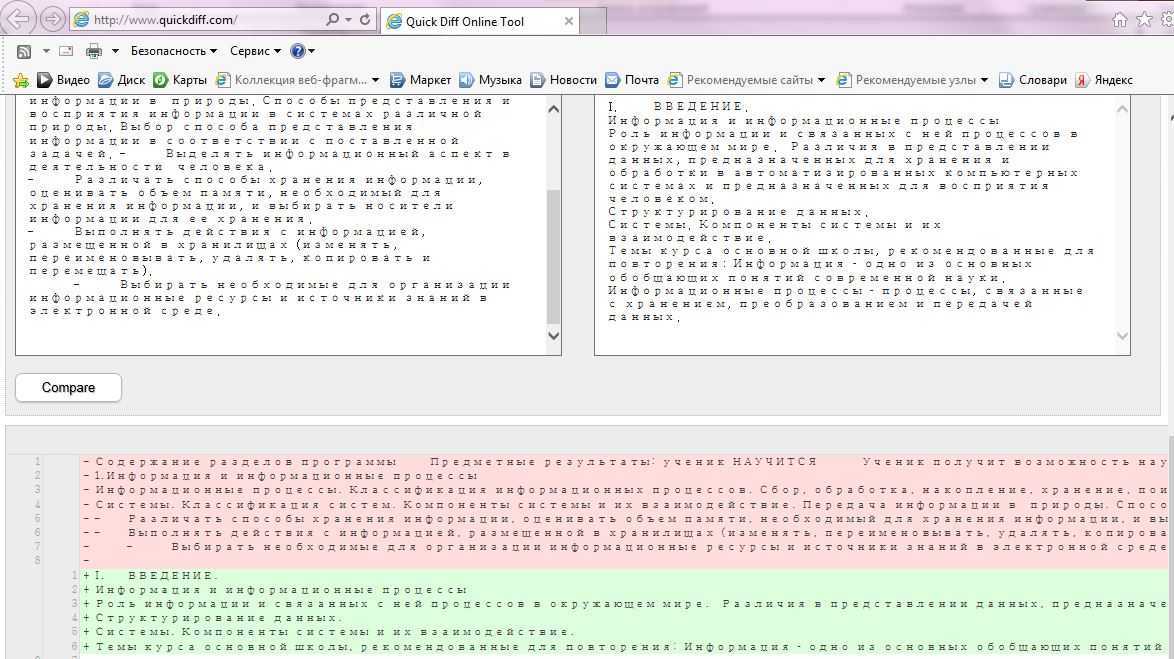



Вариант 1. Синхронные списки
Если списки синхронизированы (отсортированы), то все делается весьма несложно, т.к. надо, по сути, сравнить значения в соседних ячейках каждой строки. Как самый простой вариант – используем формулу для сравнения значений, выдающую на выходе логические значения ИСТИНА (TRUE) или ЛОЖЬ (FALSE) :
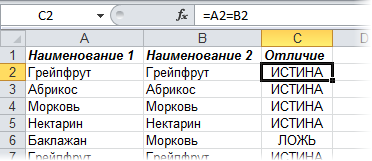
Число несовпадений можно посчитать формулой:
или в английском варианте =SUMPRODUCT(–(A2:A20B2:B20))
Если в результате получаем ноль – списки идентичны. В противном случае – в них есть различия. Формулу надо вводить как формулу массива, т.е. после ввода формулы в ячейку жать не на Enter, а на Ctrl+Shift+Enter.
Если с отличающимися ячейками надо что сделать, то подойдет другой быстрый способ: выделите оба столбца и нажмите клавишу F5, затем в открывшемся окне кнопку Выделить (Special) – Отличия по строкам (Row differences) . В последних версиях Excel 2007/2010 можно также воспользоваться кнопкой Найти и выделить (Find & Select) – Выделение группы ячеек (Go to Special) на вкладке Главная (Home)
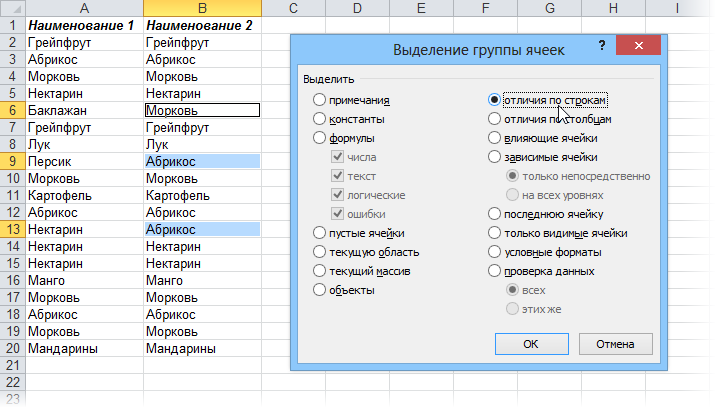
Excel выделит ячейки, отличающиеся содержанием (по строкам). Затем их можно обработать, например:
- залить цветом или как-то еще визуально отформатировать
- очистить клавишей Delete
- заполнить сразу все одинаковым значением, введя его и нажав Ctrl+Enter
- удалить все строки с выделенными ячейками, используя команду Главная – Удалить – Удалить строки с листа (Home – Delete – Delete Rows)
- и т.д.
Вариант 2. Перемешанные списки
Если списки разного размера и не отсортированы (элементы идут в разном порядке), то придется идти другим путем.
Самое простое и быстрое решение: включить цветовое выделение отличий, используя условное форматирование. Выделите оба диапазона с данными и выберите на вкладке Главная – Условное форматирование – Правила выделения ячеек – Повторяющиеся значения (Home – Conditional formatting – Highlight cell rules – Duplicate Values):
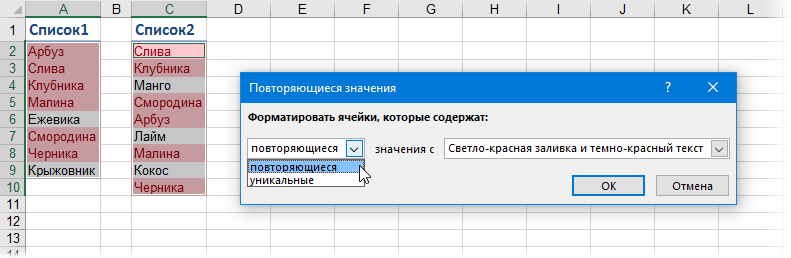
Если выбрать опцию Повторяющиеся, то Excel выделит цветом совпадения в наших списках, если опцию Уникальные – различия.
Цветовое выделение, однако, не всегда удобно, особенно для больших таблиц. Также, если внутри самих списков элементы могут повторяться, то этот способ не подойдет.
В качестве альтернативы можно использовать функцию СЧЁТЕСЛИ (COUNTIF) из категории Статистические, которая подсчитывает сколько раз каждый элемент из второго списка встречался в первом:
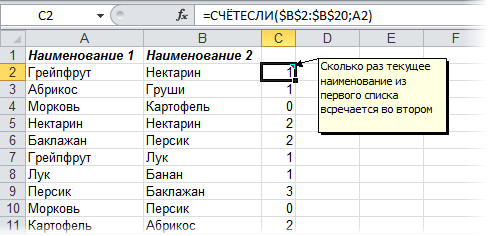
Полученный в результате ноль и говорит об отличиях.
И, наконец, “высший пилотаж” – можно вывести отличия отдельным списком. Для этого придется использовать формулу массива:
![]()
Выглядит страшновато, но свою работу выполняет отлично
Формат контекста
Когда используется формат вывода контекста, команда отображает несколько строк контекста вокруг строк, которые различаются между файлами.
Параметр указывает выводить вывод в контекстном формате:
Вывод начинается с имен и меток времени сравниваемых файлов, а также с одного или нескольких разделов, описывающих различия. Каждый раздел выглядит так:
- и — Номера строк или разделенный запятыми диапазон строк в первом и втором файле, соответственно.
- и — Строки, которые различаются, и строки контекста:
- Строки, начинающиеся с двух пробелов, являются строками контекста, одинаковыми в обоих файлах.
- Строки, начинающиеся со знака минуса ( ), — это строки, которые ничего не соответствуют во втором файле. Во втором файле отсутствуют строки.
- Строки, начинающиеся с символа плюса ( ), — это строки, которые ничего не соответствуют в первом файле. В первом файле отсутствуют строки.
- Строки, начинающиеся с восклицательного знака ( ), — это строки, которые меняются между двумя файлами. Каждая группа строк, начинающаяся с из первого файла имеет соответствующее совпадение во втором файле.
Давайте объясним наиболее важные части вывода:
- В этом примере у нас есть только один раздел, описывающий различия.
- и сообщает нам диапазон строк из первого и второго файлов, которые включены в этот раздел.
- Строки , , и последняя пустая строка в обоих файлах одинаковы. Эти строки начинаются с двойного пробела.
- Строка из первого файла ничего не соответствует во втором файле. Хотя эта строка также существует во втором файле, позиции другие.
- Строка из второго файла ничего не соответствует в первом файле.
- Линия из первого файла и строк и из второго файла меняются между файлами.
По умолчанию количество контекстных строк по умолчанию равно трем. Чтобы указать другой номер, используйте параметр ( ):
Способ 1. Meld
Meld — графический инструмент для получения различий и слияния двух файлов, двух каталогов. Meld — визуальный инструмент сравнения и объединения файлов и каталогов для Linux. Meld ориентирован, в первую очередь, для разработчиков. Однако он может оказаться полезным любому пользователю, нуждающемуся в хорошем инструменте для сравнения файлов и директорий.
В Meld вы можете сравнивать два или три файла, либо два или три каталога. Вы можете просматривать рабочую копию из популярных систем контроля версий, таких, таких как CVS, Subversion, Bazaar-NG и Mercurial. Meld представлен для большинства linux дистрибутивов (Ubuntu, Suse, Fedora и др.), и присутствует в их основных репозиториях.
# apt install meld
Meld существует и под Windows, но я не рекомендую его использовать в этой операционной системе.
Описание функционала отраслевой конфигурации 1С: Управление ветеринарными сертификатами
Данная статья представляет краткое описание функционала конфигурации 1С: Управление ветеринарными сертификатами. Судьба свела меня с данным программным продуктом не так давно, поэтому опыт общения с ним не сильно богатый. Но, с одной стороны, какие-то «шишки» я в этом вопросе уже «набил», а с другой — внятной документации или описания на данное творение, как говорится, «днем с огнем». Самое полезное, что я смог найти — это серия видеороликов от самих «АСБК Софт» (https://www.asbc.ru/catalog/vsd3428new/). В совокупности эти 2 обстоятельства наталкивают меня на мысль о том, что можно написать некоторое подобие общего описания программы. Искренне надеюсь, что кому-то мои творческие потуги принесут пользу.
Как посмотреть количество файлов в папке Linux
Самый простой способ решить эту задачу — использовать утилиту ls вместе с утилитой wc. Они покажут сколько файлов находится в текущей папке:
В моем случае утилита выдала результат 21, но поскольку ls выводит размер всех файлов в папке строкой total, то у нас файлов на один меньше. Нужно учесть, что тут отображаются еще и директории. Каждая директория начинается с символа «d», а каждый файл с «-«. Для символических ссылок используется «l». Посмотрите внимательно на вывод ls:




Чтобы их отсеять используйте grep:
Эта конструкция выберет только те строки, которые начинаются на дефис. Если вас интересуют не только обычные файлы, но и скрытые, то можно использовать опцию -a:
Так можно подсчитать количество папок:
А так символических ссылок:
Если вам нужно подсчитать количество файлов во всех подпапках, то можно использовать опцию -R:
С фильтром только файлы нам уже не страшно, что команда будет выводить служебную информацию. Если вы не хотите использовать ls, можно воспользоваться утилитой find:
Если нужно смотреть не только количество файлов в папке, но и подпапок, просто не нужно использовать -type f:
Только папки отдельно:
А в случае, когда необходимо перебрать все файлы во всех подпапках, не устанавливайте параметр -maxdepth:
Все эти команды это очень хорошо, но есть еще одно, более удобное средство посчитать количество файлов linux, это утилита tree.