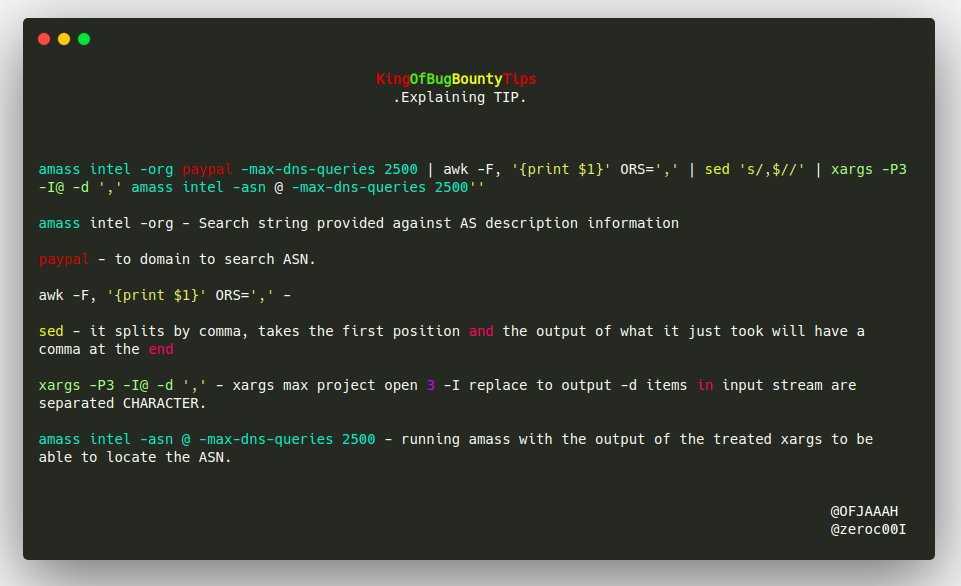
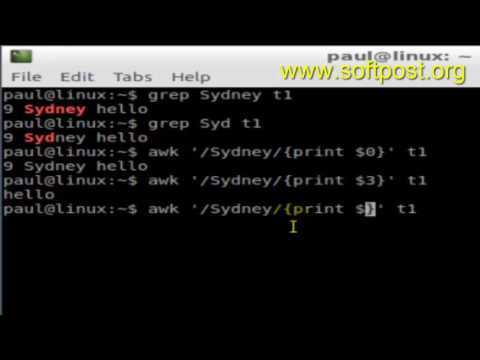
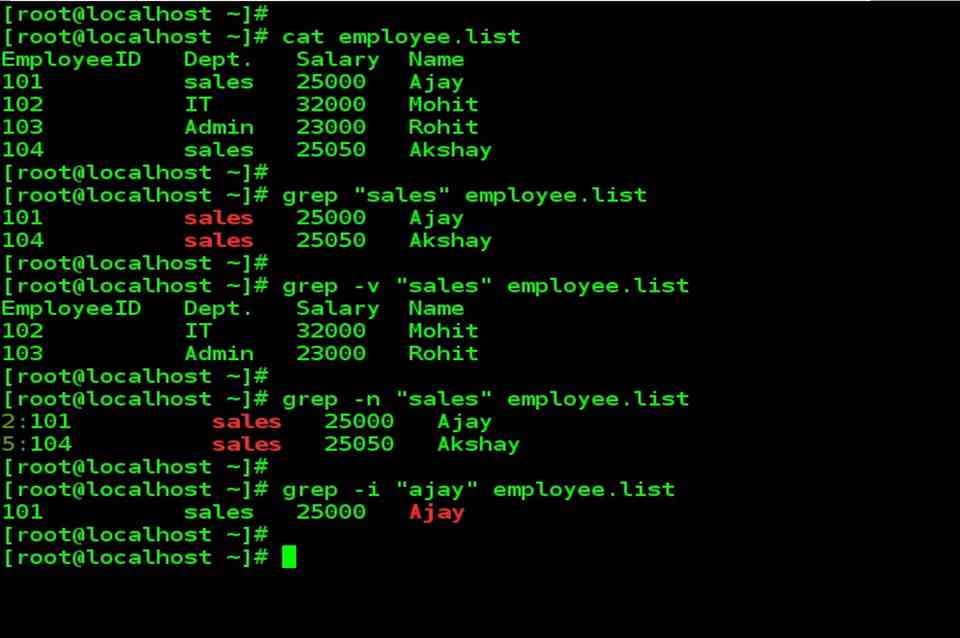
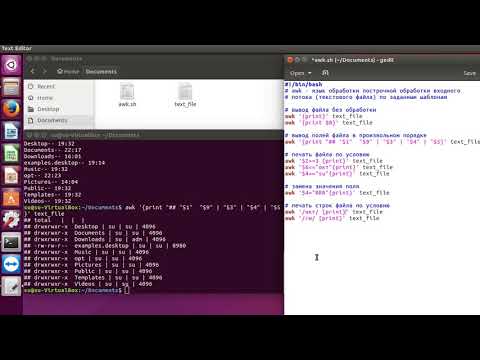
Printing Lines
In the previous example, you saw that input passed into without any operations would print the results directly to standard output.
Let’s explore ’s explicit command, which you specify by using the character within single quotes.
Execute the following command:
You’ll see each line of the file printed twice:
automatically prints each line by default, and then you’ve told it to print lines explicitly with the “p” command, so you get each line printed twice.
If you examine the output closely, you’ll see that it has the first line twice, followed by the second line twice, etc, which tells you that operates on data line by line. It reads a line, operates on it, and outputs the resulting text before repeating the process on the next line.
You can clean up the results by passing the option to , which suppresses the automatic printing:
We now are back to printing each line once.
The examples so far can hardly be considered editing (unless you wanted to print each line twice…). Next you’ll explore how can modify the output by targeting specific sections of the text data.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
# sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.


Deleting Text
You can perform text deletion where you previously were specifying text printing by changing the command to the command.
In this case, you no longer need the command because will print everything that is not deleted. This will help you see what’s going on.
Modify the last command from the previous section to make it
delete every other line starting with the first:
The result is that you see every line you were not given last time:
It is important to note here that our source file is not being affected. It is still intact. The edits are output to our screen.
If we want to save our edits, we can redirect standard output to a file like so:
Now open the file with :
You see the same output that you saw onscreen previously:
The command does not edit the source file by default, but you can change this behavior by passing the option, which means “perform edits in-place.” This will alter the source file.
Warning: Using the switch will overwrite the original file, so you should use this with care. Perform the operations without the switch first and then run the command again with once you have what you want, create a backup of the original file, or redirect the output to a file. It’s very easy to accidentally alter the original file with the switch.
Let’s try it by editing the file you just created, in-place. Let’s further reduce the file by deleting every other line
again:
If you use to display the file with , you’ll see that the file has been edited.
The option can be dangerous. Thankfully, gives you the ability to create a backup file prior to editing.
To create a backup file prior to editing, add the backup extension directly after the “-i” option:
This creates a backup file with the extension, and then edits the original file in-place.
Next you’ll look at how to use to perform search and replace operations.
Basic Usage
operates on a stream of text that it reads from either a text file or from standard input (STDIN). This means that you can send the output of another command directly into sed for editing, or you can work on a file that you’ve already created.
You should also be aware that outputs everything to standard out (STDOUT) by default. That means that, unless redirected, will print its output to the screen instead of saving it in a file.
The basic usage is:
In this tutorial, you’ll use a copy of the BSD Software License to experiment with . On Ubuntu, execute the following commands to copy the BSD license file to your home directory so you can work with it:
If you don’t have a local copy of the BSD license, create one yourself with this command:
Let’s use to view the contents of the BSD license file. sends its results to the screen by default, which means you can use it as a file reader by passing it no editing commands. Try executing the following command:
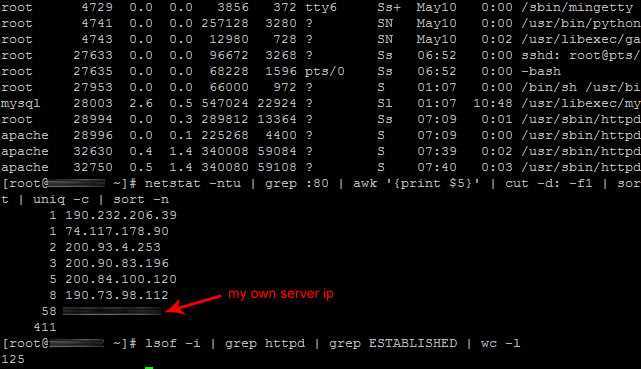
![Текстовые_редакторы_ed_sed_vi_vim [методические материалы лохтурова вячеслава]](https://smartshop124.ru/wp-content/uploads/f/d/9/fd968859be39ce8bb4b11f9aacc3b7b3.jpeg)
You’ll see the BSD license displayed to the screen:
The single quotes contain the editing commands you pass to . In this case, you passed it nothing, so printed each line it received to standard output.
can use standard input rather than a file. Pipe the output of the command into to produce the same result:
You’ll see the output of the file:
As you can see, you can operate on files or streams of text, like the ones produced when piping output with the pipe character, just as easily.
Создать функцию
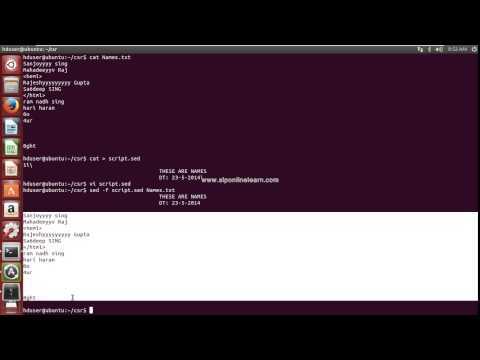
Чтобы каждый раз не вспоминать команды sed можно создать функцию
Возьмём команду, которая удаляет комментарии и пустые строки из предыдущего примера и
запишем как функцию clean_file.
Первым делом в коносли нужно написать в терминале function clean_file {
и нажать Enter
Затем ввести выражение sed -i ‘/^#/d ; /^$/d’ $1
$1 означает, что функция будет принимать один аргумент. Это, конечно, будет название файла.
Затем нужно снова нажать Enter и в новой строке написать } и нажать Enter ещё раз
$ function clean_file {
> sed -i ‘/^#/d;/^$/d’ $1
> }
Убедитесь, что файл содержит комментарии и пустые строки. Если нет — создайте для чистоты эксперимента.
cat websites
# Travel
https://www.heihei.ru
# Bicycles
https://www.topbicycle.ru
# IT
https://www.urn.su
clean_file websites
cat websites
https://www.heihei.ru
https://www.topbicycle.ru
https://www.urn.su
Примеры
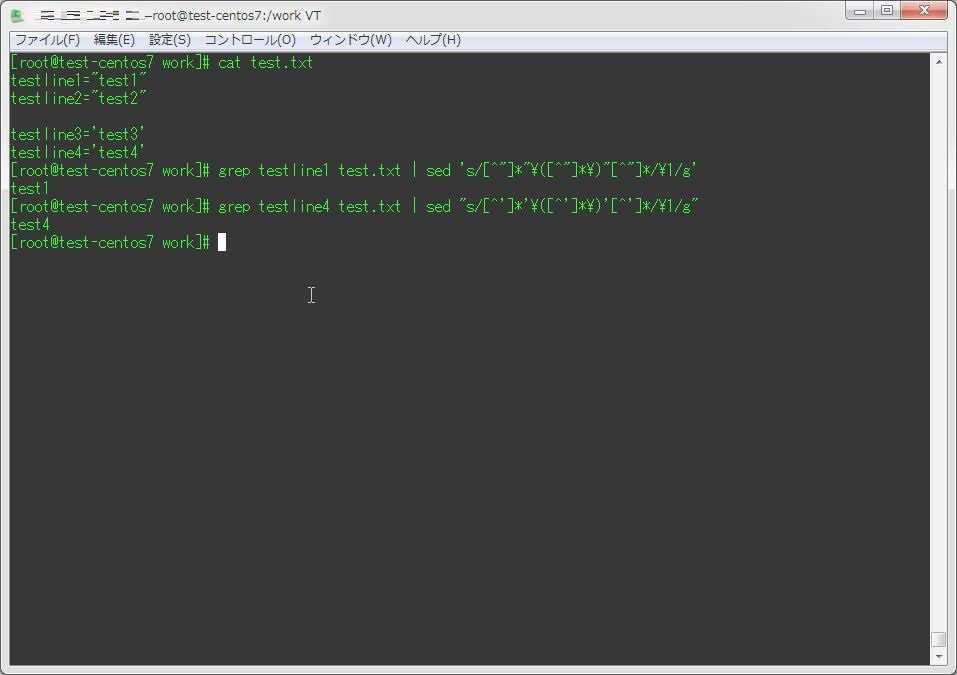
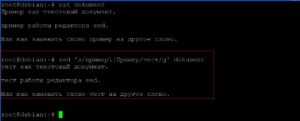
Для первого примера, заменим каждое вхождение «пример» на «тест» в файле «dokument».
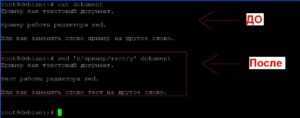
Дополним команду таким образом, чтобы менялось не только слово «пример», но и это же слово написанное с большой буквы. Для этого будем использовать специальные символы «\|».
Заменим два фрагмента текста: «документ» на «файл»; «как» на «не». Так как у нас несколько фрагментов текстов, будем использовать ключ «-е».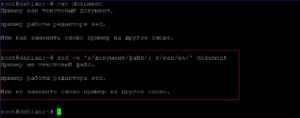
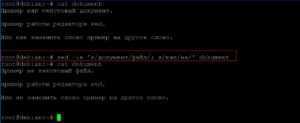
Теперь сохраним все изменения в файл. Для это будем использовать ключ «-i» редактирования файла на месте.
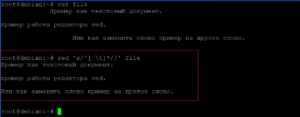
Удалим все пробелы в начале каждой строки слева.
Теперь удалим все пропуски в конце строки.
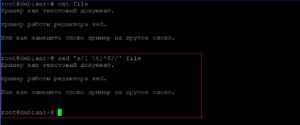
Удаление последней строки.
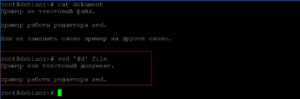
Добавление восьми пробелов в новый файл слева от текстовой информации. Будем использовать перенаправление вывода «>»
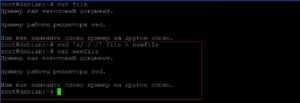
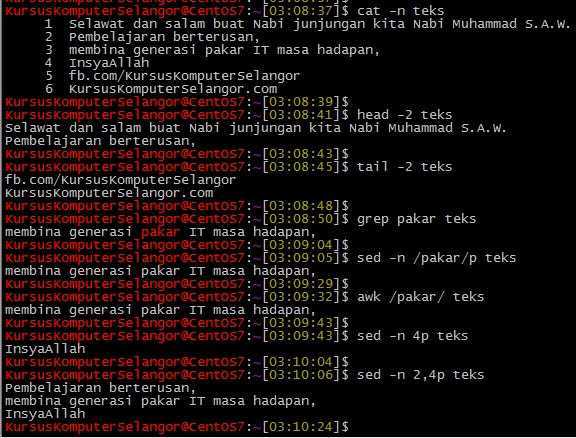
Выведение строк c 3 по 5 файла «newfile».
Выведение всего файла «newfile», кроме строк 3-5.
Удалим все пустые строки и сохраним эти изменения в файле.
Утилита «sed» является весьма гибким и максимально удобным инструментом, позволяющим сделать с текстом многие вещи. Такая команда отличается сложностью в усвоении, но дает решить множество задач.

Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
tr "SET1" "SET2"
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
-> восмеричные (OCT) символы NNN (1 до 3 цифр)
-> обратный слеш (экранированный)
-> новая строка (new line)
-> перенос строки (return)
-> табуляция (horizontal tab)
-> все буквы и цифры
-> все буквы
-> все пробелы
-> все управляющие символы (control)
-> все цифры
-> все буквы в нижнем регистре (строчные)
-> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
echo "something to translate" | tr "SET1" "SET2"
tr "SET1" "SET2" < file-to-translate
tr "SET1" "SET2" < file-to-translate > file-output
Вот некоторые опции:
, , -> удалить все символы, кроме тех, что в первом наборе, -> удалить символы из первого набора, -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы или для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
$ echo "hello linux world" | tr HELLO LINUX WORLD
А сейчас сделаем замену из файла input.txt
$ cat input.txt hi this is text $ tr "a-z" "A-Z" < input.txt HI THIS IS TEXT $ cat input.txt hi this is text
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
$ tr "a-z" "A-Z" < input.txt > output.txt $ cat output.txt HI THIS IS TEXT
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
Удалить строку со словом
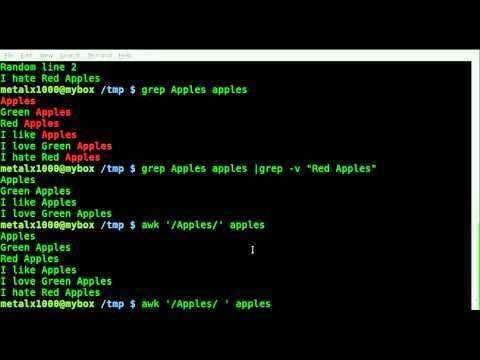
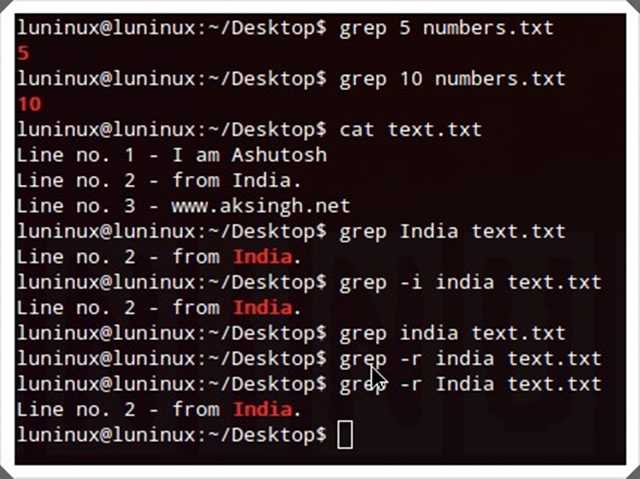
Удалить все строки где встречается слово Apple в файле
input.txt
Сделать это можно с помощью опции d
sed ‘/Apple/d‘ input.txt > output.txt
Результат:
Теперь сделаем более сложное условие — удалим все строки где есть слово Pineapple и слово Integer
sed ‘/Pineapple\|Integer/d’ input.txt > output.txt
| выступает в роли логического ИЛИ
\ нужна чтобы экранировать |
Результат:
Получить диапазон строк
В случае, когда Вы работаете с большими файлами, например с логами, часто бывает нужно
получить только определённые строки, например, в момент появления бага.
Копировать из UI командной строки не всегда удобно, но если Вы примерно представляете
диапазон нужных строк — можно скопировать только их и записать в отдельный файл.
Например, Вам нужны строки с 9570 по 9721
sed -n ‘9570,9721p;9722q’ project-2019-10-03.log > bugFound.txt
Using Address Ranges
Addresses let you target specific parts of a text stream. You can specify a specific line or even a range of lines.
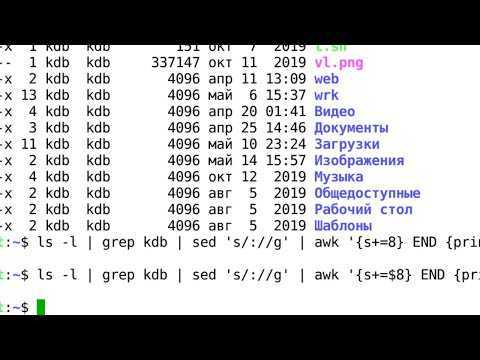
Let’s have print the first line of the file. Execute the following command:
The first line prints to the screen:
By placing the number before the print command, you told the line number to operate on. You can just as easily print five lines (don’t forget the “-n”):
You’ll see this output:
You’ve just given an address range to . If you give an address, it will only perform the commands that follow on those lines. In this example, you’ve told sed to print line 1 through line 5. You could have specified this in a different way by giving the first address and then using an offset to tell sed how many additional lines to travel, like this:
This will result in the same output, because you told to start at line 1 and then operate on the next 4 lines as well.
If you want to print every other line, specify the interval after the character. The following command prints every other line in the file, starting with line 1:
Here’s the output you’ll see:
You can use to delete text from the output as well.