
Стандартизация
Система DOI — это международный стандарт, разработанный Международной организацией по стандартизации в ее техническом комитете по идентификации и описанию, TC46 / SC9. Проект международного стандарта ISO / DIS 26324, Информация и документация — Система цифровой идентификации объектов соответствует требованиям ISO для утверждения. Соответствующая рабочая группа ISO позже представила отредактированную версию в ISO для распространения в качестве бюллетеня для голосования FDIS (окончательный проект международного стандарта), который был одобрен 100% голосовавших при закрытии бюллетеня 15 ноября 2010 года. Окончательный стандарт был опубликован 23 ноября. Апрель 2012 г.
DOI — это зарегистрированный URI в схеме информационного URI, указанной в IETF RFC . info: doi / — это пространство имен infoURI идентификаторов цифровых объектов.
Синтаксис DOI — это стандарт NISO , впервые стандартизованный в 2000 году, ANSI / NISO Z39.84-2005 Syntax for the Digital Object Identifier.
Сопровождающие систему DOI намеренно не зарегистрировали пространство имен DOI для URN , заявив, что:
Команда blkid
Программа blkid, используя библиотеку libblkid, умеет читать содержимое файлов блочных устройств типа /dev/hda2. Эти специальные файлы, находящиеся в директории /dev иначе называются нодами устройств, имеют весьма специфичную структуру, и не могут быть прочитаны обычными средствами (скажем, командой cat).
Однако программа blkid по умолчанию не считывает информацию о разделах непосредственно из соответствующих нод устройств, а считывает ее из файла /etc/blkid.tab. Этот файл зачем-то называется в мане команды blkid кэш файлом, а всем известно, что слово cache имеет множесто значений, а потому совершенно бессмысленно. Должен вас сразу предупредить, что в файле /etc/blkid.tab со временем накапливается устаревшая информация о давно несуществующих разделах, поэтому не думайте читать сам файл в поисках UUID’ов, можете жестоко обмишулиться. Пользуйтесь командой blkid с соответсвующими опциями.
Команда blkid без опций
Команда blkid без опций, запущенная с правами суперпользоателя, выведет на экран дисплея информацию, содержащуюся в файле /etc/blkid.tab:
Я предупреждал. Тут, конечно, можно разобраться при желании, но непонятно, откуда может взяться такое желание, когда можно поступить проще. А именно запустить команду blkid с опцией -c.
Команда blkid с опцией -c
Вообще-то опция -c заставляет blkid читать не из файла blkid.tab, а из любого указанного файла. Скажем, /dev/null. Не имея никакой информации из данного файла, команда вынуждена будет прочитать информацию из нод устройств, то есть выдать нам реальную картину на текущий момент:
Совсем другое дело, не правда ли?
Поэтому советую сохранить старые файлы blkid.tab и blkid.tab.old под другими именами, тогда при следующей загрузке будет создан новенький чистенький файлик blkid.tab, где все будет как в выводе команды blkid -c /dev/null. Стоит после этого проверить /etc/fstab и /boot/grub/menu.lst.
Остальные опции команды крайне невыразительны и бесполезны. Чем трудиться запоминать их, проще запустить команду вовсе без опций или с опцией -c /dev/null. Тем не менее:
Опция -t
Найдет все устройства, отвечающие заданному критерию, будь то TYPE, LABEL, или UUID. Можно сужать круг поиска, вводя в командную строку имена интересующих устройств:
Опция -o
Позволяет выбирать формат вывода из трех возможных: value (значение критерия), device (устройство), или full (полный). Например:
Опция -l
Применяется вместе с опцией поиска -t. Но из всего найденного выдаст сведения только об одном устройстве. Обычно это первое прочитанное в файле /etc/blkid.tab устройство.
Опция -w
Записывает данные в указанный вами файл, вместо файла /etc/blkid.tab.
По моему, проще переадресовать в файл “file” вывод команды.
Опция -v
Выводит версию программы.
Вот все, что касается команды blkid. Однако существуют и другие возможности узнать UUID раздела.








Самая очевидная – заглянуть в директорию /dev:
Там четыре субдиректории, одна из которых by-uuid. Посмотрим:
Вот поди, догадайся, что к чему относится! Нет, это не метод.
Двусмысленность
Идентификаторы (ID) по сравнению с уникальными идентификаторами (UID)
Многие ресурсы могут иметь несколько идентификаторов. Типичные примеры:
- Один человек с несколькими именами, псевдонимами и формами обращения (титулы, приветствия)
- Один документ с несколькими версиями
- Одно вещество с несколькими названиями (например, названия индексов CAS по сравнению с названиями IUPAC ; названия INN непатентованных лекарств по сравнению с названиями генерических лекарств USAN по сравнению с названиями торговых марок)
Обратное также возможно, когда несколько ресурсов представлены с одним и тем же идентификатором (обсуждается ниже).
Неявные конфликты контекста и пространства имен
Многие коды и номенклатурные системы возникают в небольшом пространстве имен . С годами некоторые из них перетекают в более крупные пространства имен (поскольку люди взаимодействуют способами, которых раньше не было, например, приграничная торговля, научное сотрудничество, военный союз и общие культурные взаимосвязи или ассимиляция). Когда такое распространение происходит, ограничения первоначального соглашения об именах, которое раньше было скрытым и спорным, становятся болезненно очевидными, часто требуя ретронимии , синонимии , перевода / транскодирования и так далее. Такие ограничения обычно сопровождают отход от исходного контекста к более широкому. Обычно система демонстрирует неявный контекст (ранее предполагавшийся и узкий контекст), нехватку емкости (например, небольшое количество возможных идентификаторов, отражающих устаревший узкий контекст), отсутствие расширяемости (нет функций, определенных и зарезервированных для будущих потребностей) и отсутствие специфичности и возможности устранения неоднозначности (связано со сдвигом контекста, когда давняя уникальность встречается с новой неуникальностью). В информатике эта проблема называется конфликтом имен . История возникновения и расширения системы CODEN является хорошим примером в контексте технической номенклатуры последних десятилетий. Варианты использования заглавных букв, наблюдаемые с показывают пример этой проблемы, возникающей в естественных языках , где необходимо иметь дело с различием существительного собственного и существительного нарицательным (и его осложнениями). Вселенная, в которой каждый объект имеет UID, не будет нуждаться в каких-либо пространствах имен, то есть будет составлять одно гигантское пространство имен; но человеческий разум никогда не мог отследить или семантически связать такое количество UID.
Форматирование HDD через терминал на Ubuntu/Debian
Для форматирования разделов дисков в системе используем команду parted.
Для начала определяем с каким диском мы будем работать. Для этого набираем все ту же нами знакомую команду
После вывода информации определяем наш диск и набираем:
где sdb — это наш диск
Далее создаем новую таблицу разделов:
После можно создавать разделы. Если вам нужно создать один большой раздел, который будет занимать весь объем диска, то команда будет такой:
Если же вы хотите создать несколько разделов на диске, то последовательность команд будет следующей:
После данной команды у вас будут три раздела с соответствующими размерами в 5 Гб, 15 Гб, а третий займет все оставшееся пространство на данном диске.
Для вывода информации набираем:
Если вас все устраивает, то выходим из программы форматирования:
Давайте теперь отформатируем получившиеся разделы в файловую систему :
или в случае с несколькими разделами диска:
После данной процедуры разделы готовы к использованию. Только не забудьте предварительно примонтировать их к системе.










Перечисление UID
Утверждены следующие конструкции перечисления:
- UID Construct 1, состоящий из кода агентства-эмитента, идентификатора предприятия и серийного номера, уникального для предприятия.
- UID Construct 2, состоящий из кода агентства-эмитента, идентификатора предприятия, номера детали или кода партии / партии и серийного номера (уникального в пределах номера детали)
- Идентификационный номер автомобиля (VIN)
- Глобальный идентификатор возвращаемого актива (GRAI)
- Глобальный идентификатор индивидуального актива (GIAI)
- Электронный серийный номер (ESN), обычно присваиваемый сотовым телефонам.
История
В 1980-х годах Apollo Computer первоначально использовала UUID в сетевой вычислительной системе (NCS), а затем в распределенной вычислительной среде (DCE) Open Software Foundation (OSF ). Первоначальный дизайн DCE UUID был основан на NCS UUID, дизайн которого, в свою очередь, был вдохновлен ( 64-битными ) уникальными идентификаторами, определенными и широко используемыми в Domain / OS , операционной системе, разработанной Apollo Computer. Позже платформы Microsoft Windows приняли дизайн DCE как «глобальные уникальные идентификаторы» (GUID). RFC 4122 зарегистрировал пространство имен URN для UUID и резюмировал более ранние спецификации с тем же техническим содержанием. Когда в июле 2005 года RFC 4122 был опубликован в качестве предлагаемого стандарта IETF , ITU также стандартизировал UUID на основе предыдущих стандартов и ранних версий RFC 4122.
Стандартизация
Система DOI — это международный стандарт, разработанный Международной организацией по стандартизации в ее техническом комитете по идентификации и описанию, TC46 / SC9. Проект международного стандарта ISO / DIS 26324, Информация и документация — Система цифровой идентификации объектов соответствует требованиям ISO для утверждения. Соответствующая рабочая группа ISO позже представила отредактированную версию в ISO для распространения в качестве бюллетеня для голосования FDIS (окончательный проект международного стандарта), который был одобрен 100% голосовавших при закрытии бюллетеня 15 ноября 2010 года. Окончательный стандарт был опубликован 23 ноября. Апрель 2012 г.
DOI — это зарегистрированный URI в схеме информационного URI, указанной в IETF RFC . info: doi / — это пространство имен infoURI идентификаторов цифровых объектов.
Синтаксис DOI — это стандарт NISO , впервые стандартизованный в 2000 году, ANSI / NISO Z39.84-2005 Syntax for the Digital Object Identifier.
Сопровождающие систему DOI намеренно не зарегистрировали пространство имен DOI для URN , заявив, что:
Формат
В каноническом текстовом представлении 16 октетов UUID представлены в виде 32 шестнадцатеричных (base-16) цифр, отображаемых в пяти группах, разделенных дефисами, в форме 8-4-4-4-12, всего 36 символов. (32 шестнадцатеричных символа и 4 дефиса). Например:
Четырехбитовые поля M и 1-3-битные поля N кодируют формат самого UUID.
Четыре бита цифры — это версия UUID, а от 1 до 3 наиболее значимых битов цифрового кода — вариант UUID. (См. ) В этом примере M равно , а N равно (10xx 2 ), что означает, что это UUID версии 1, варианта 1; то есть основанный на времени UUID DCE / RFC 4122.
Строка канонического формата 8-4-4-4-12 основана на структуре записи для 16 байтов UUID:
| Имя | Длина (байты) | Длина (шестнадцатеричные цифры) | Длина (бит) | |
|---|---|---|---|---|
| time_low | 4 | 8 | 32 | целое число, дающее младшие 32 бита времени |
| time_mid | 2 | 4 | 16 | целое число, дающее средние 16 бит времени |
| time_hi_and_version | 2 | 4 | 16 | 4-битная «версия» в старших разрядах, за которыми следуют старшие 12 бит времени |
| clock_seq_hi_and_res clock_seq_low | 2 | 4 | 16 | 1–3-разрядный «вариант» в наиболее значимых битах, за которым следует 13–15-разрядная тактовая последовательность. |
| узел | 6 | 12 | 48 | 48-битный идентификатор узла |
Эти поля соответствуют UUID версии 1 и 2 (то есть UUID на основе времени), но одно и то же представление 8-4-4-4-12 используется для всех UUID, даже для UUID, построенных по-разному.
Идентификаторы GUID Microsoft иногда обозначаются фигурными скобками:
Этот формат не следует путать с « реестром Windows форматом», который относится к формату в фигурных скобках.
RFC 4122 определяет пространство имен Uniform Resource Name (URN) для UUID. UUID, представленный как URN, выглядит следующим образом:
История и стандартизация
Первоначальная (версия 1) схема генерации UUID заключалась в объединении версии UUID с MAC-адресом компьютера, генерирующего UUID, и количеством 100 наносекундных интервалов с начала григорианского календаря . На практике реальный алгоритм более сложен. Эта схема подверглась критике, потому что она раскрывает как личность генерирующего компьютера, так и время генерации.
Несколько других алгоритмов генерации были разработаны и включены в стандарт, такие как схема, основанная только на случайных числах (версия 4 UUID) и схемы, в которых UUID состоит из любой строки (например, запись DNS , URL , ISO OID , « Отличительные имена X.500 », но также и любая другая семантика, при условии, что для нее определен базовый UUID) выводится через значения хеш-функции MD5 — (UUID версии 3) или SHA-1 — (UUID версии 5) .
Вариант: Microsoft GUID
Microsoft также использует UUID в своей компонентной объектной модели, также называемой здесь GUID . Однако некоторые из этих идентификаторов соответствуют их собственным спецификациям. Описанные здесь UUID можно распознать по двум верхним битам поля . Они всегда имеют значение 10 ; В шестнадцатеричной системе счисления первая шестнадцатеричная цифра четвертого числа всегда находится между 8 шестнадцатеричным и шестнадцатеричным числом B , например Например: 5945c961-e74d-478f- 8 afe-da53cf4189e3. Исторические UUID , используемые Microsoft имеют значение 110 в верхних трех битов этого поля , так что в шестнадцатеричном представлении первое шестнадцатеричное число четвертого числа обозначает либо С шестигранной или D. гекс . Пример: GUID интерфейса в COM имеет UUID 00000000-0000-0000- C 000-000000000046.
Особенности и преимущества
IDF разработала систему DOI, чтобы обеспечить форму постоянной идентификации , в которой каждое имя DOI постоянно и однозначно идентифицирует объект, с которым оно связано (хотя, когда издатель журнала меняется, иногда все DOI меняются с старые DOI больше не работают). Он также связывает метаданные с объектами, позволяя предоставлять пользователям соответствующую информацию об объектах и их отношениях. В состав этих метаданных включены сетевые действия, которые позволяют разрешать имена DOI в веб-расположения, где можно найти объекты, которые они описывают. Для достижения своих целей система DOI объединяет систему обработки и модель контента indecs с социальной инфраструктурой.
Система обработки гарантирует, что имя DOI для объекта не основано на каких-либо изменяемых атрибутах объекта, таких как его физическое местоположение или владение, что атрибуты объекта закодированы в его метаданных, а не в его имени DOI, и что нет двум объектам присваивается одно и то же имя DOI. Поскольку имена DOI представляют собой короткие символьные строки, они удобочитаемы, могут быть скопированы и вставлены как текст и вписываются в спецификацию URI . Механизм разрешения имен DOI действует за кулисами, так что пользователи общаются с ним так же, как с любой другой веб-службой; он построен на открытых архитектурах , включает механизмы доверия и спроектирован для надежной и гибкой работы, чтобы его можно было адаптировать к меняющимся требованиям и новым приложениям системы DOI. Разрешение имен DOI может использоваться с OpenURL для выбора наиболее подходящего из множества местоположений для данного объекта в соответствии с местоположением пользователя, выполняющего запрос. Однако, несмотря на эту возможность, система DOI вызвала критику со стороны библиотекарей за направление пользователей к платным копиям документов, которые можно было бы получить без дополнительной платы из других мест.






INDECS Модель содержимого , используемая в метаданных системы DOI ассоциированных с объектами. Небольшое ядро общих метаданных используется всеми именами DOI и может быть дополнено другими соответствующими данными, которые могут быть общедоступными или ограниченными. Регистранты могут обновлять метаданные для своих имен DOI в любое время, например, при изменении информации публикации или при перемещении объекта на другой URL-адрес.
Международный фонд DOI Foundation (IDF) наблюдает за интеграцией этих технологий и работой системы через техническую и социальную инфраструктуру. Социальная инфраструктура федерации независимых регистрационных агентств, предлагающих услуги DOI, была смоделирована на основе существующих успешных федеративных развертываний идентификаторов, таких как GS1 и ISBN .
История [ править ]
В 1980-х годах Apollo Computer первоначально использовала UUID в сетевой вычислительной системе (NCS), а затем в распределенной вычислительной среде (DCE) Open Software Foundation (OSF ). Первоначальный дизайн DCE UUID был основан на NCS UUID , дизайн которого, в свою очередь, был вдохновлен ( 64-битными ) уникальными идентификаторами, определенными и широко используемыми в Domain / OS , операционной системе, разработанной Apollo Computer. Позже, платформы Microsoft Windows приняли дизайн DCE как «глобальные уникальные идентификаторы» (GUID). RFC 4122 зарегистрировал URNпространство имен для UUID и резюмирует более ранние спецификации с тем же техническим содержанием. [ необходима цитата ]
Когда в июле 2005 года RFC 4122 был опубликован в качестве предлагаемого стандарта IETF , ITU также стандартизировал UUID на основе предыдущих стандартов и ранних версий RFC 4122. [ необходима ссылка ]
Загрузчик grub2
Для большинства современных систем характерно использование grub2. Его мы и будем рассматривать. Но если в вашем случае используется сервер с grub первой версии, то мы можем обратиться к инструкции How to Migrate the Root Filesystem to a New Disk.
Открываем файл:
vi /etc/default/grub
Мы можем увидеть разные варианты строки, указывающей на загрузку системы.
а) В некоторых случаях это будет универсальная строка, которую не нужно менять, например:
GRUB_CMDLINE_LINUX=»crashkernel=auto spectre_v2=retpoline rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet»
* в данной строке мы видим, что загрузчик будет искать том LVM centos/root. Так как после клонирования он не поменяется, то нам ничего не нужно редактировать.
б) В некоторых случаях строка может быть пустой:
GRUB_CMDLINE_LINUX=»»
* в данном примере также от нас не потребуется никаких действий.
в) В некоторых случаях указатель может вести на конкретные диски:
GRUB_CMDLINE_LINUX=»root=/dev/disk/by-id/<partition/disk name> resume=/dev/disk/by-id/<partition/disk name> splash=silent quiet showopts»
Тогда нам понадобиться изменить строки, чтобы диск соответствовал новому.
Также стоит иметь ввиду, что если после копирования мы собираемся извлечь диск из компьютера, порядок дисков и имя могут поменяться, что приведет к неработоспособности загрузки.
Стоит сделать тестовое отключение с целью проверки, какое имя станет у диска.
Классификация
Существует несколько основных типов уникальных идентификаторов, каждый из которых соответствует своей стратегии генерации :
- серийные номера, назначаемые постепенно или последовательно, центральным органом или принятой ссылкой.
- случайные числа, выбранные из числа, намного превышающего максимальное (или ожидаемое) число объектов, подлежащих идентификации. Хотя не совсем уникальные, некоторые идентификаторы этого типа могут подходить для идентификации объектов во многих практических приложениях и при неформальном использовании языка все еще называются «уникальными»
- Хеш-функциями : на основе содержимое идентифицированного объекта, гарантируя, что эквивалентные объекты используют один и тот же UID.
- Генератор случайных чисел : на основе случайного процесса.
- имена или коды, выделенные по выбору, которые принудительно быть уникальным, сохраняя центральный реестр, такой как EPC Information Services.
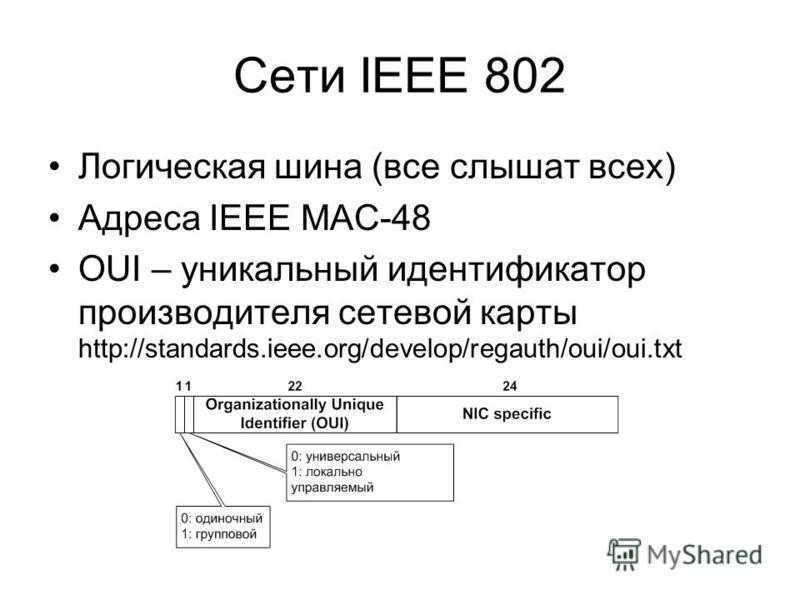
- имена или коды, выделенные с использованием режима, включающего несколько (одновременных) эмитентов уникальных идентификаторов каждому из которых назначены взаимоисключающие разделы глобального адресного пространства, так что уникальные идентификаторы, назначенные каждым издателем в каждом разделе эксклюзивного адресного пространства, гарантированно являются уникальными в глобальном масштабе. Примеры включают (1) адрес управления доступом к среде передачи MAC-адрес, однозначно назначенный каждому отдельному устройству сетевого интерфейса аппаратного обеспечения, произведенному производителем устройств, (2) штрих-коды потребительских товаров, назначенные продуктам с использованием идентификаторов, присвоенных производителями. которые участвуют в GS1 стандартах идентификации, и (3) уникальный и постоянный идентификатор юридического лица, присвоенный юридическому лицу одним из регистраторов LEI в Глобальной системе идентификации юридических лиц (GLEIS) под управлением Global LEI Foundation (GLEIF).
Вышеупомянутые методы можно комбинировать, иерархически или по отдельности, для создания других схем генерации, которые гарантируют уникальность. Во многих случаях один объект может иметь более одного уникального идентификатора, каждый из которых идентифицирует его для разных целей.



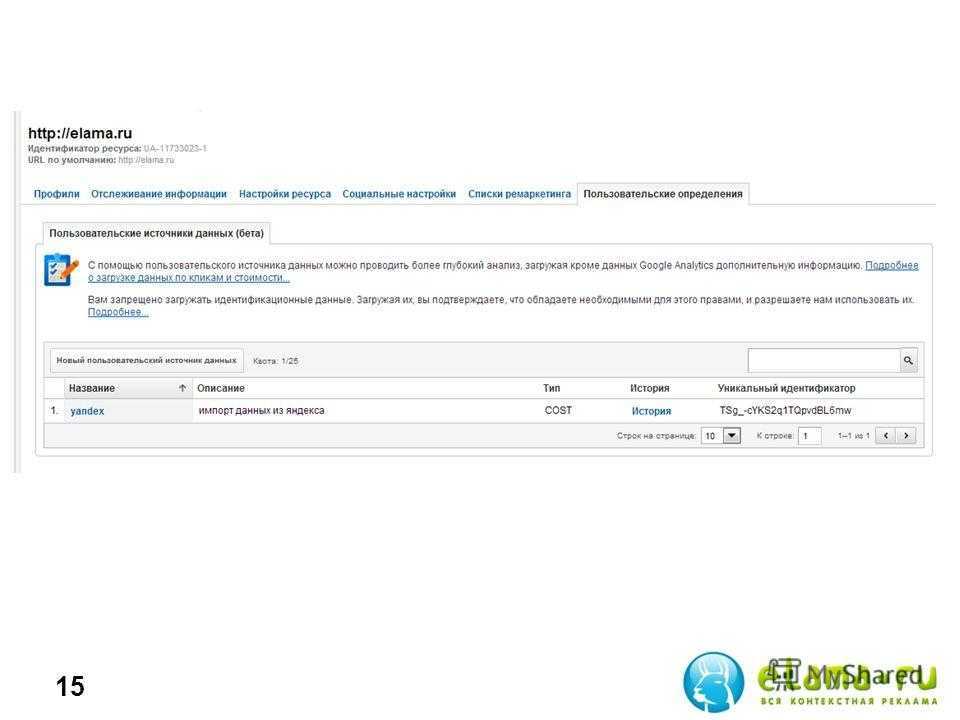


Предисловие
В новых дистрибутивах Линукс стало модным называть разделы не по «именам», скажем, /dev/hda2, а используя UUID’ы — Уникальные Идентификаторы. Выглядят они как абсолютно нечитаемые для человека многозначные номера, да еще и шестнадцатеричные, например: UUID=»5a179614-0415-48c6-a9ad-3f6ad9596619″.
Удобство понимания и заполнения таких конфигурационных файлов как, скажем, /etc/fstab «значительно повысилось». Стало невозможным понять о каком разделе идет речь. Хорошо если у вас всего пять-шесть разделов, еще можно помнить, на каком своп, а на каком корень. А если разделов в три раза больше? Да если еще и постоянно удаляешь одни, и создаешь другие? Мода требует жертв.
Кому же нужны UUID’ы и для кого они действительно удобны? Сисадминам больших серверов, у которых одновременно присутствуют носители всевозможных типов, да еще и объединенные во всякие RAID’ы и прочие сиадминские заморочки. Для них, когда возникает необходимость перенести содержимое с одного носителя на другой, потом встает большая проблема правильно внести изменения в ту же /etc/fstab вручную. С UUID’ами же ядро, при помощи специальных программ, автоматически находит и размечает разделы по соответствующим носителям. Это им экономит много сил и времени.
Простым же смертным, имеющим два компьютера с тремя винчестерами на обоих, эти UUID’ы нужны как зайцу стоп-сигнал. Я лично первым делом безжалостно удаляю все эти номера из файлов /etc/fstab и /boot/grub/menu.lst. Это позволяет мне избежать головной боли при клонировании разделов, когда возникают два раздела с одинаковыми «Уникальными номерами».
Но многим почему-то нравятся UUID’ы, и они озабочены, если какой-нибудь раздел, например подкачки, вдруг прописан по «имени-отчеству». В Сети иногда встречаются такие вопли о помощи: «Мой раздел своппига не имеет UUID’а. Как мне узнать его и вписать в /etc/fstab?». Для вас, любители UUID’ов, эта статья.
Политика
Инструкция Министерства обороны США (DoDI) 8320.04 предписывает, чтобы следующие материальные предметы были помечены уникальным идентификатором предмета:
- Все доставленные товары, стоимость приобретения единицы которых для правительства составляет 5000 долларов США или более
- Предметы, стоимость приобретения единицы которых для правительства составляет менее 5 000 долларов, если требующаяся деятельность определяется как серийно управляемые, необходимые для выполнения миссии или контролируемые запасы;
- Последовательно управляемый — когда DoD выбирает серийное управление элементом, он становится «DoD серийно управляемым». Это означает, что это материальный объект, используемый DoD, который определен DoD или менеджером по предметам обслуживания для уникального отслеживания, контроля или управления при обслуживании, ремонте и / или поставке посредством его серийного номера.
- Важная миссия — мера военной ценности предмета с точки зрения того, как его отказ (если замена не доступна немедленно) повлияет на способность системы оружия, конечного предмета или организации выполнять свои намеченные функции. (DoD 4140.1-R)
- Контролируемая инвентаризация — те предметы, которые определены как имеющие характеристики, требующие, чтобы они были идентифицированы, учтены, отделены или обработаны особым образом для обеспечения их сохранности и целостности. Включает засекреченные предметы (требующие защиты в интересах национальной безопасности), чувствительные предметы (требующие высокой степени защиты и контроля в соответствии с законодательными требованиями или постановлениями, такие как драгоценные металлы; предметы высокой стоимости, высокотехнологичного или опасного характера; и стрелковое оружие) и предметы, которые могут быть украдены (предметы, имеющие готовую стоимость при перепродаже или предназначенные для личного владения, которые особенно подвержены краже) (DoD 4140.1-R); и предметы, контролируемые безопасностью.
- Предметы, стоимость приобретения единицы которых для правительства составляет менее 5000 долларов, когда требующаяся деятельность определяет, что требуется постоянная идентификация; и
- Независимо от стоимости —
- Любой серийно управляемый DoD узел, компонент или деталь, встроенные в доставленный элемент; и
- Родительский элемент (как определено в 252.211-7003 (a)), который содержит встроенный узел, компонент или деталь.
Ответственность. Часто вопрос об ответственности за IUID возникает, когда несколько организаций участвуют в производстве и / или закупке товаров. Согласно руководству, IUID требуется на уровне компонентов на основе определения менеджера программы. Под менеджерами программ следует понимать любого участника деятельности, который отвечает за выполнение требований по закупке товара. Сюда может входить такой персонал, как менеджеры групп интегрированной поддержки, менеджеры систем или менеджеры элементов .
Генеральный подрядчик несет ответственность за обеспечение уникальности. Главный подрядчик может дать указание своим поставщикам использовать EID основного подрядчика. Однако с точки зрения производственного процесса это может быть не самый эффективный способ маркировать детали для их поставщиков. Если предмет еще не имеет уникальной идентификации и соответствует критериям IUID, предприятие, поставляющее предмет государству, должно предоставить уникальную идентификационную маркировку предмета как часть закупочной цены. В ситуациях, когда субподрядчики поставляют предметы главному подрядчику, главный подрядчик несет ответственность за то, чтобы предметы были маркированы в соответствии с требованиями IUID до их поставки Правительству, либо путем перетекания требований к субподрядчик или маркируя товар сами. Прайм-агент также будет нести дополнительную ответственность за обеспечение уникальности серийного номера субподрядчика в пределах предприятия первичного лица (конструкция № 1) или серийного номера субподрядчика в номере детали субподрядчика в пределах предприятия первичного лица (конструкция № 2).
Восстановление RAID
Рассмотрим два варианта восстановлении массива.
Замена диска
В случае выхода из строя одного из дисков массива, команда cat /proc/mdstat покажет следующее:
cat /proc/mdstat
Personalities :
md0 : active raid1 sdb
1046528 blocks super 1.2 [2/1]
* о наличии проблемы нам говорит нижнее подчеркивание вместо U — вместо .
Или:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:20:40 2019
State : clean, degraded
…
* статус degraded говорит о проблемах с RAID.
Для восстановления, сначала удалим сбойный диск, например:
mdadm /dev/md0 —remove /dev/sdc
Теперь добавим новый:
mdadm /dev/md0 —add /dev/sde
Смотрим состояние массива:
mdadm -D /dev/md0
…
Update Time : Thu Mar 7 20:57:13 2019
State : clean, degraded, recovering
…
Rebuild Status : 40% complete
…


* recovering говорит, что RAID восстанавливается; Rebuild Status — текущее состояние восстановления массива (в данном примере он восстановлен на 40%).
Если синхронизация выполняется слишком медленно, можно увеличить ее скорость. Для изменения скорости синхронизации вводим:
echo ‘10000’ > /proc/sys/dev/raid/speed_limit_min
* по умолчанию скорость speed_limit_min = 1000 Кб, speed_limit_max — 200000 Кб. Для изменения скорости, можно поменять только минимальную.
Пересборка массива
Если нам нужно вернуть ранее разобранный или развалившийся массив из дисков, которые уже входили в состав RAID, вводим:
mdadm —assemble —scan
* данная команда сама найдет необходимую конфигурацию и восстановит RAID.
Также, мы можем указать, из каких дисков пересобрать массив:
mdadm —assemble /dev/md0 /dev/sdb /dev/sdc



