Как узнать pid процесса Linux
1. ps
Самый распространённый способ узнать PID Linux — использовать утилиту ps:
Кроме нужного нам процесса, утилита также выведет PID для grep, ведь процесс был запущен во время поиска. Чтобы его убрать, добавляем такой фильтр:
Например, узнаём PID всех процессов, имя которых содержит слово «Apache»:
2. pgrep
Если вам не нужно видеть подробную информацию о процессе, а достаточно только PID, то можно использовать утилиту pgrep:
По умолчанию утилита ищет по командной строке запуска процесса, если нужно искать только по имени процесса, то надо указать опцию -f:
3. pidof
Эта утилита ищет PID конкретного процесса по его имени. Никаких вхождений, имя процесса должно только совпадать с искомым:
С помощью опции -s можно попросить утилиту выводить только один PID:
4. pstree
Утилита pstree позволяет посмотреть список дочерних процессов для определённого процесса, также их pid-идентификаторы. Например, посмотрим дерево процессов Apache:
Идентификатор в банковской системе
Каждая банковская карта содержит 16 цифр на своей лицевой стороне, представляющие из себя идентификатор. Каждая карта имеет уникальный номер, так что вероятность появления ошибки в этой системе стремится к нулю.
Первые шесть цифр говорят основную информацию о карте. Первым определяется платежная система. Следующие три — код банка-производителя. Оставшиеся 5 и 6 определяют номер продукции. Оставшиеся цифры предназначены для уникального кода самой карты. По итогу, можно узнать достаточно информации о банке, просто посмотрев на цифры, расположенные на пластиковой карте.

В случае потери карты злоумышленник без проблем сможет с ее помощью что-то купить или выполнить перевод средств. Для контроля ситуации со своим счетом современные банки предлагают подключение СМС-подтверждений, чтобы избежать неприятных инцидентов.
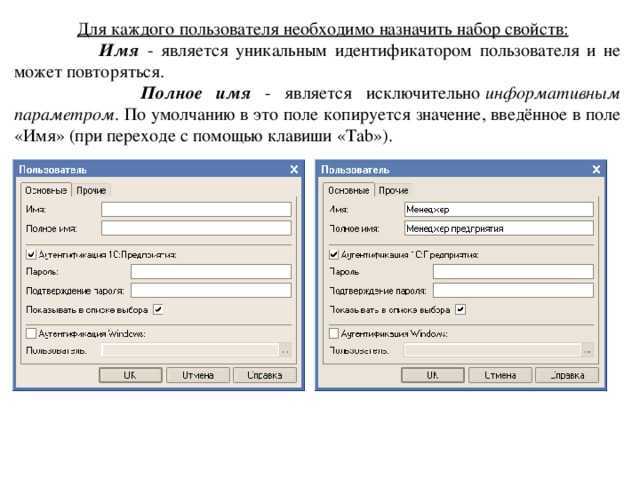
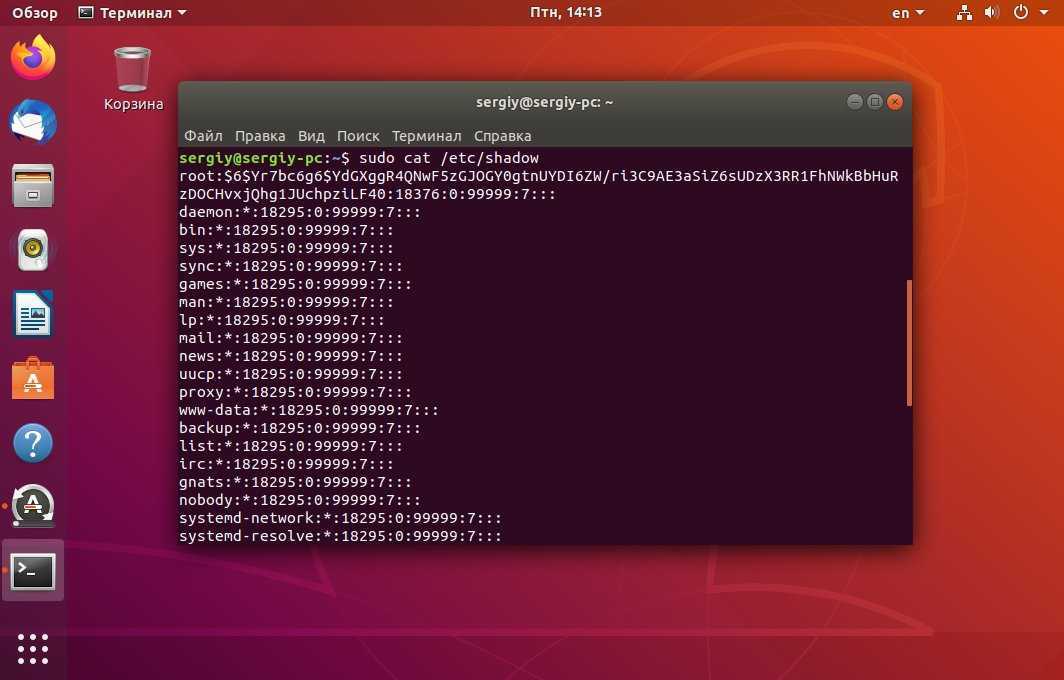
Идентификатор пользователя и группы
Еще один тип ИД, встречающийся в операционной системе «Линукс». С его помощью пользователь может получить полномочия для работы с файлом, который также ему принадлежит. К числу возможностей относится чтение, запись или выполнение. Этот способ помогает контролировать доступ к любому действию в рамках операционной системы, поскольку «Линукс» полностью состоит из файлов. Чтобы совместно работать над тем или иным объемом данных во время разработки самой системы была введена система групп, определяющая пользователей со схожими полномочиями.

Для каждого пользователя и группы определяется свой идентификатор. В этом примере он представляет собой список доступных прав к определенным файлам. Для пользователя, имеющего свою группу, есть не только юзер ИД, но и групповой ИД, которые могут быть объединены между собой в набор полномочий, доступных для этой учетной записи.
Удобство в выдаче уникального идентификатора для каждой группы состоит в том, что в процессе администрирования крайне удобно разделять их на определенные узконаправленные задачи. Чтобы повысить эффективность работы.
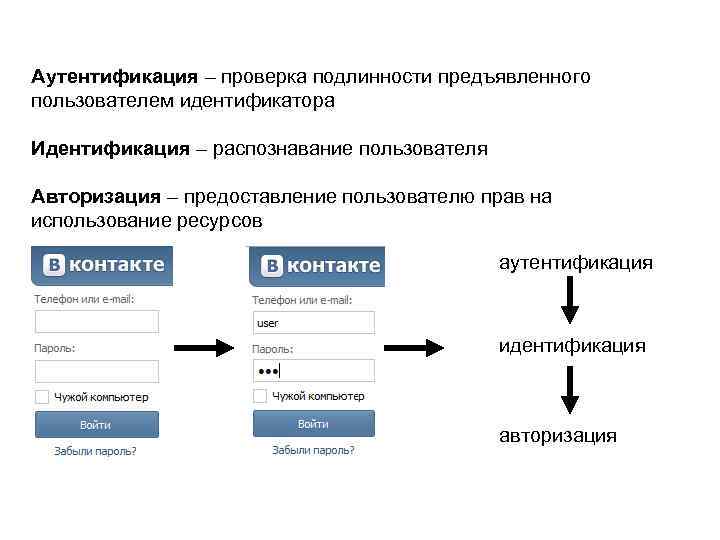
Определение
Идентификатором называется уникальный признак объекта. С помощью которого система можно произвести его опознание в системе. В его качестве может использоваться набор из символов, получаемый при регистрации в системе, или логин с паролем, введенные и сохраненные в базе данных при регистрации. Идентификатор пользователя в системе крайне важен для сохранения личных данных. Поскольку он известен только человеку, создавшему учетную запись. В этом случае шансы для постороннего получить возможность контроля над чужими данными крайне низкая.

К любому идентификатору система предъявляет определенные требования, которые разнятся у разных компаний. К примеру, одни могут затребовать использовать только одну раскладку клавиатуры, с использованием букв с верхним и нижним регистром, а также цифр. Другие же системы принимают лишь набор из букв и цифр, где все компоненты одинаково нужны.
Как управлять процессами из окна терминала
Команда ps – это традиционная команда Ubuntu Linux для отображения списка запущенных процессов.
ps -aux sudo ps -a
Идентификатор процесса (PID) необходим для завершения или управления процессом в Ubuntu. Например, рассмотрим следующий вывод:
root 42421 0.0 0.0 13160 8452 - S 22:18 0:00.03 firefox
Здесь:
- root – имя пользователя
- 42421 – PID (Ubuntu Linux process ID)
- 22:18 – время запуска процесса
- firefox – название процесса
Процессов может быть очень много, поэтому разумно использовать команду “/more” для отображения списка по одному экрану за раз. Для выхода нужно нажать q.
ps -aux | more ps -aux | less
Команды для поиска процессов
Для поиска процессов в Ubuntu используется команда “pgrep”. Синтаксис такой:
pgrep process sudo pgrep sshd pgrep vim
Если использовать опцию -l, то будет отображен вывод с названием процесса.
Команда “top” – это еще один удобный инструмент для просмотра использования ресурсов вашей ОС. Можно увидеть список топовых процессов, которые используют больше всего памяти, процессора или диска.


Команды завершения процессов
Для завершения процесса в Ubuntu используется команда “kill”. Синтаксис такой:
kill pid kill -signal pid
Чтобы завершить процесс, к команде kill нужно добавить идентификатор процесса. Узнать его можно с помощью команд “ps”, “pgrep” или “top”. Например вы хотите завершить процесс, идентификатор которого 25100. Для этого наберите:
kill 25100
Если по какой-то причине процесс не хочет завершаться, используйте принудительное завершение.
kill -9 25100 kill -KILL 25100
Завершить процесс можно и по имени. Для этого существуют команды “pkill” и “killall”.
pkill название процесса pkill nginx pkill -9 nginx pkill -KILL nginx
killall название процесса killall nginx killall -9 nginx killall -KILL nginx
Команды изменения приоритета процесса
Основная цель команды nice – запустить процесс/команду с более низким или более высоким приоритетом. Используйте команду renice, чтобы изменить значение nice одного или нескольких уже запущенных процессов Ubuntu. Значение nice может варьироваться от -20 до 19, причем 19 является самым низким приоритетом.
nice -n 15 команда для запуска
renice {приоритет} {ID процесса}
renice 10 69947
Учтите, что для “nice” нужно имя команды, а для “renice” нужен PID процесса.
Каким процессом занят файл Linux
Выше мы рассмотрели, как получить PID процесса Linux по имени, а теперь давайте узнаем PID по файлу, который использует процесс. Например, мы хотим удалить какой-либо файл, а система нам сообщает, что он используется другим процессом.
С помощью утилиты lsof можно посмотреть, какие процессы используют директорию или файл в данный момент. Например, откроем аудио-файл в плеере totem, а затем посмотрим, какой процесс использует её файл:
В начале строки мы видим название программы, а дальше идёт её PID. Есть ещё одна утилита, которая позволяет выполнить подобную задачу — это fuser:
Здесь будет выведен только файл и PID процесса. После PID идёт одна буква, которая указывает, что делает этот процесс с файлом или папкой:
- c — текущая директория;
- r — корневая директория;
- f — файл открыт для чтения или записи;
- e — файл выполняется как программа;
- m — файл подключен в качестве библиотеки.
User Namespaces
User namespace имеет собственную копию пользовательского и группового идентификаторов. Затем изолирование позволяет связать процесс с другим набором ID — в зависимости от user namespace, которому он принадлежит в данный момент. Например, процесс может выполняться от (UID 0) в user namespace P и внезапно продолжает выполняться от (UID 13) после переключения в другой user namespace Q.
User spaces могут быть вложенными! Это означает, что экземпляр пользовательского namespace (родительский) может иметь ноль и больше дочерних пространств имён, и каждое дочернее пространство имён может, в свою очередь, иметь свои собственные дочерние пространства имён и так далее… (до достижения предела в 32 уровня вложенности). Когда создаётся новый namespace C, Linux устанавливает текущий User namespace процесса P, создающего C, как родительский для C и это не может быть изменено впоследствии. В результате все user namespaces имеют ровно одного родителя, образуя древовидную структуру пространств имён. И, как и в случае с деревьями, исключение из этого правила находится наверху, где у нас есть корневой (или начальный, дефолтный) namespace. Это, если вы еще не делаете какую-то контейнерную магию, скорее всего user namespace, к которому принадлежат все ваши процессы, поскольку это единственный user namespace с момента запуска системы.
Написание UID Map файлов
Чтобы исправить наш вновь созданный user namespace C, нам просто нужно предоставить наши нужные маппинги, записав их содержимое в map-файлы для любого процесса, который принадлежит C (мы не можем обновить этот файл после записи в него). Запись в этот файл говорит Linux две вещи:
- Какие UID’ы доступны для процессов, которые относятся к целевому user namespace C.
- Какие UID’s в текущем user namespace соответствуют UID’ам в C.
Например, если мы из родительского user namespace P запишем следующее в map-файл для дочернего пространства имён C:
мы по существу говорим Linux, что:
- Что касается процессов в C, единственным UID’ами, которые существуют в системе, являются UID’ы и . Например, системный вызов всегда будет завершаться чем-то вроде недопустимого id пользователя.
- UID’ы и в P соответствуют UID’ам и в C. Например, если процесс, работающий с UID в P, переключится в C, он обнаружит, что после переключения его UID стал .
Реализация
Как вы можете видеть, есть много сложностей, связанных с управлением user namespaces, но реализация довольно проста. Всё, что нам нужно сделать, это написать кучу строк в файл — муторно было узнать, что и где писать. Без дальнейших церемоний, вот наши цели:
- Клонировать командного процесса в его собственном user namespace.
- Написать в UID и GID map-файлы командного процесса.
- Сбросить все привилегии суперпользователя перед выполнением команды.
достигается простым добавлением флага в наш системный вызов .
Для мы добавляем функцию , которая осторожно представляет одного обычного пользователя в качестве. И вызовем его из основного процесса в родительском user namespace прямо перед тем, как мы подадим сигнал командному процессу
И вызовем его из основного процесса в родительском user namespace прямо перед тем, как мы подадим сигнал командному процессу.
Для шага мы обновляем функцию , чтобы убедиться, что команда выполняется от обычного непривилегированного пользователя , которого мы предоставили в маппинге (помните, что root пользователь в user namespace командного процесса — это пользователь ):
И это всё! теперь запускает процесс в изолированном user namespace.
В этом посте было довольно много подробностей о том, как работают User namespaces, но в конце концов настройка экземпляра была относительно безболезненной. В следующем посте мы рассмотрим возможность запуска команды в своём собственном Mount namespace с помощью (раскрывая тайну, стоящую за из ). Там нам потребуется немного больше помочь Linux, чтобы правильно настроить инстанс.

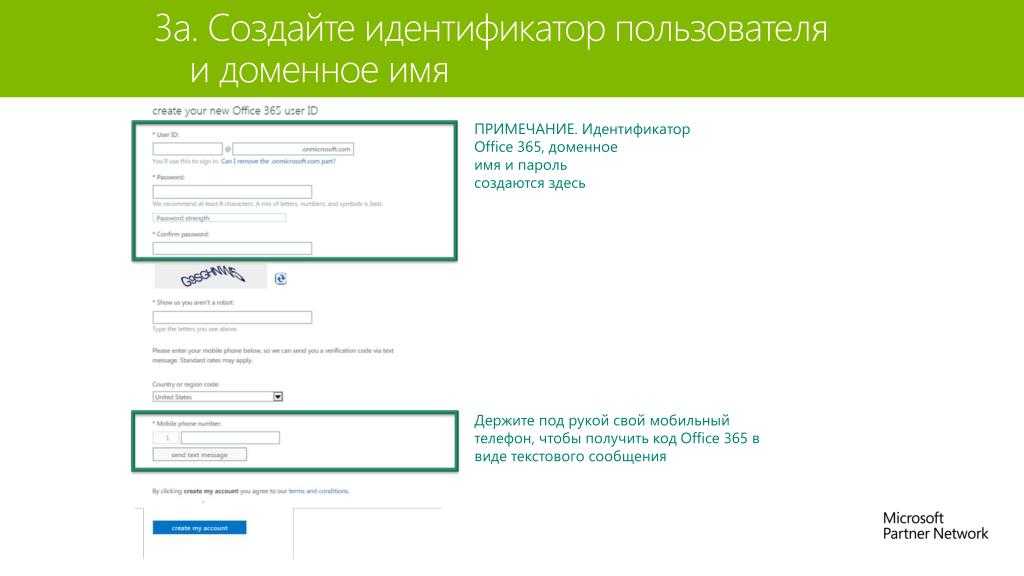




Идентификаторы для автономных программ
К числу данного софта принадлежит большое количество приложений, направленных на выполнение чего-либо. Объединение нескольких автономных программ называется прикладным программным обеспечением. Во время работы с ними также применяются идентификаторы пользователя. Однако отличительная черта состоит в том, что это уникальный признак одной из большого множества ячеек. Для каждой ячейки сопоставляется свой ИД, что в итоге помогает не допустить ошибки в случае выявления места, информация в котором должна быть обновлена или исправлена для поддержания корректного функционирования.
Map-файлы
Map-файлы — особенные файлы в системе. Чем особенные? Ну, тем, что возвращают разное содержимое всякий раз, когда вы читаете из них, в зависимости от того, какой ваш процесс читает. Например, map-файл возвращает маппинг от UID’ов из user namespace, которому принадлежит процесс , UID’ам в user namespace читающего процесса. И, как следствие, содержимое, возвращаемое в процесс X, может отличаться от того, что вернулось в процесс Y, даже если они читают один и тот же map файл одновременно.
В частности, процесс X, считывающий UID map-файл , получает набор строк. Каждая строка отображает непрерывный диапазон UID’ов в user namespace C процесса , соответствующий диапазону UID в другом namespace.
Каждая строка имеет формат , где:
- является стартовым UID диапазона для user namespace процесса
- — это длина диапазона.
- Трансляция зависит от читающего процесса X. Если X принадлежит другому user namespace U, то — это стартовый UID диапазона в U, который мапится с . В противном случае — это стартовый UID диапазона в P — родительского user namespace процесса C.
Например, если процесс читает файл и среди полученных строк видно , то UID’ы с 15 по 19 в user namespace процесса маппятся в UID’ы 22-26 отдельного user namespace читающего процесса.
С другой стороны, если процесс читает из файла (или map-файла любого процесса, принадлежащего тому же user namespace, что и читающий процесс) и получает , то UID’ы c 15 по 19 в user namespace C маппятся в UID’ы c 22 по 26 родительского для C user namespace.
Давайте это попробуем:
Хорошо, это было не очень захватывающе, так как это были два крайних случая, но это говорит там о нескольких вещах:
- Вновь созданный user namespace будет фактически иметь пустые map-файлы.
- UID 4294967295 не маппится и непригоден для использования даже в user namespace. Linux использует этот UID специально, чтобы показать отсутствие user ID.
Кто использовал файл в Linux
Узнать процесс, который сейчас занимает файл, достаточно просто. Но как узнать, какой процесс обращается к файлу не надолго, например, выполняет его как программу или читает оттуда данные? Эта задача уже труднее, но вполне решаема с помощью подсистемы ядра auditd. В CentOS набор программ для работы с этой подсистемой поставляется по умолчанию, в Ubuntu же его придётся установить командой:
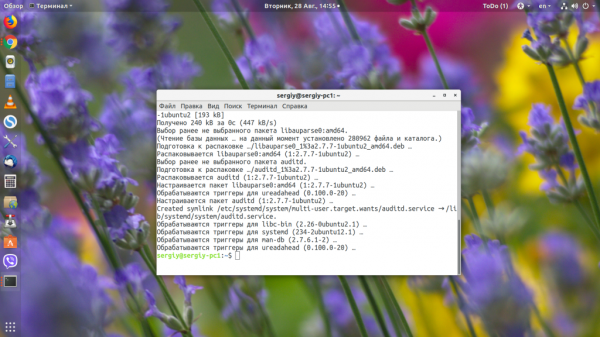
Теперь создаём правило для мониторинга. Например, отследим, кто запускает утилиту who:
Здесь -w — адрес файла, который мы будем отслеживать, -p — действие, которое нужно отслеживать, -k — произвольное имя для правила. В качестве действия могут использоваться такие варианты:
- x — выполнение;
- w — запись;
- r — чтение;
- a — изменение атрибутов.
Теперь выполним один раз who и посмотрим, что происходит в логе с помощью команды ausearch:
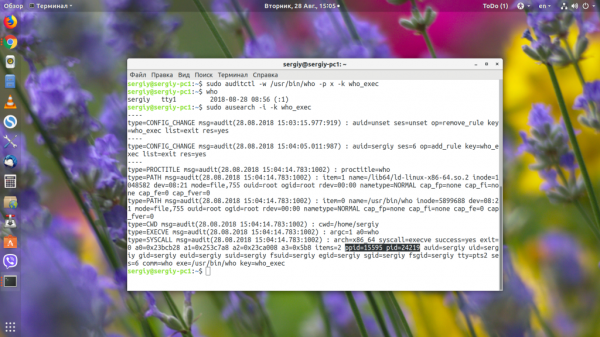
Здесь в секции SYSCALL есть PID процесса, под которым была запущена программа, а также PPID — программа, которая запустила нашу who. Копируем этот PID и смотрим информацию о нём с помощью ps:
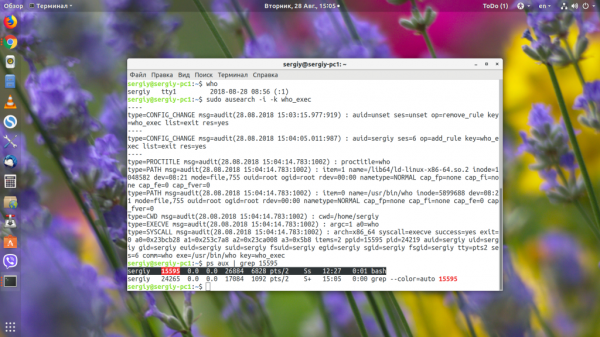
Становиться понятно, что это bash.
Как использовать ps команду
Общий синтаксис команды выглядит следующим образом:
По историческим причинам и из соображений совместимости команда принимает несколько различных типов параметров:
- Опции стиля UNIX, перед которыми стоит одна черточка.
- Варианты стиля BSD, используемые без тире.
- Длинные опции GNU, начинающиеся с двух тире.
Различные типы опций могут быть смешаны, но в некоторых конкретных случаях могут возникать конфликты, поэтому лучше придерживаться одного типа опций.
Опции BSD и UNIX могут быть сгруппированы.
В простейшем виде, при использовании без какой-либо опции, напечатает четыре столбца информации для минимум двух процессов, запущенных в текущей оболочке, самой оболочки и процессов, которые запускаются в оболочке при вызове команды.
Вывод включает в себя информацию о shell ( ) и процессе, запущенном в этой оболочке ( введенная вами команда):
Четыре колонки помечены , , , и .
— Идентификатор процесса
Обычно при запуске команды наиболее важной информацией, которую ищет пользователь, является идентификатор процесса. Знание PID позволяет убить сбойный процесс .
— Название управляющего терминала для процесса.
— Совокупное время ЦП процесса, показанное в минутах и секундах.
— Имя команды, которая использовалась для запуска процесса.
Вывод выше не очень полезен, так как он не содержит много информации. Настоящая сила команды появляется при запуске с дополнительными опциями.





Команда принимает огромное количество опций, которые можно использовать для отображения определенной группы процессов и различной информации о процессе, но для повседневного использования требуется лишь несколько из них.
чаще всего используется со следующей комбинацией параметров:
Форма BSD :
- Опция указывает отображать процессы всех пользователей. Только процессы, не связанные с терминалом, и процессы руководителей групп не отображаются.
- — обозначает пользовательский формат, который предоставляет подробную информацию о процессах.
- Инструктирует перечислить процессы без управляющего терминала. В основном это процессы, которые запускаются во время загрузки и работают в фоновом режиме .
Команда отображает информацию в одиннадцати столбцах , , , , , , , , , , и .
Мы уже объяснили , , и . Вот объяснение других меток:
- — Пользователь, который запускает процесс.
- — The CPU использование процесса.
- — Процент резидентного установленного размера процесса к физической памяти на машине.
- — Размер виртуальной памяти процесса в КиБ.
- — Размер физической памяти , используемой процессом.
- — Код состояния процесса, такой как (зомби), (спящий) и (работает).
- — время, когда команда началась.
Опция указывает , чтобы отобразить в виде дерева родителя к ребенку процессов:
Команда также позволяет вам сортировать вывод. Например, чтобы отсортировать вывод на основе использования памяти, вы должны использовать:
UNIX форма :
- Параметр предписывает , чтобы отобразить все процессы.
- На стендах полноформатный листинг, в котором представлена подробная информация о процессах.
Команда отображает информацию в восьми столбцах , , , , , , и .
Метки, которые еще не объяснены, имеют следующее значение:
- — То же , что и пользователь, который запускает процесс.
- — Идентификатор родительского процесса.
- — То же , что и загрузка ЦП процесса.
- — То же , что и время начала команды.
Чтобы просмотреть только процессы, запущенные от имени определенного пользователя, введите следующую команду, где указано имя пользователя:
Кто использовал файл в Linux
Узнать процесс, который сейчас занимает файл, достаточно просто. Но как узнать, какой процесс обращается к файлу не надолго, например, выполняет его как программу или читает оттуда данные? Эта задача уже труднее, но вполне решаема с помощью подсистемы ядра auditd. В CentOS набор программ для работы с этой подсистемой поставляется по умолчанию, в Ubuntu же его придётся установить командой:
Теперь создаём правило для мониторинга. Например, отследим, кто запускает утилиту who:
Здесь -w — адрес файла, который мы будем отслеживать, —p — действие, которое нужно отслеживать, —k — произвольное имя для правила. В качестве действия могут использоваться такие варианты:
- x — выполнение;
- w — запись;
- r — чтение;
- a — изменение атрибутов.
Теперь выполним один раз who и посмотрим, что происходит в логе с помощью команды ausearch:
Здесь в секции SYSCALL есть PID процесса, под которым была запущена программа, а также PPID — программа, которая запустила нашу who. Копируем этот PID и смотрим информацию о нём с помощью ps:
Становиться понятно, что это bash.
Как разрешаются ID
Мы только что увидели процесс, запущенный от обычного пользователя внезапно переключился на . Не волнуйтесь, никакой эскалации привилегий не было. Помните, что это просто маппинг ID: пока наш процесс думает, что он является пользователем в системе, Linux знает, что — в его случае — означает обычный UID (благодаря нашему маппингу). Так что в то время, когда пространства имён, принадлежащие его новому user namespace (подобно network namespace в C), признают его права в качестве , другие (как например, network namespace в P) — нет. Поэтому процесс не может делать ничего, что пользователь не смог бы.
Всякий раз, когда процесс во вложенном user namespace выполняет операцию, требующую проверки разрешений — например, создание файла — его UID в этом user namespace сравнивается с эквивалентным ID пользователя в корневом user namespace путём обхода маппингов в дереве пространств имён до корня. В обратном направлении происходит движение, например, когда он читает ID пользователей, как мы это делаем с помощью . UID владельца маппится из корневого user namespace до текущего и окончательный соответствующий ID (или nobody, если маппинг отсутствовал где-либо вдоль всего дерева) отдаётся читающему процессу.
Владелец пространств имён и привилегии
В предыдущем посте мы упомянули, что при создании новых пространств имён требуется доступ с уровнем суперпользователя. User namespaces не налагают этого требования. На самом деле, еще одной их особенностью является то, что они могут владеть другими пространствами имён.
Всякий раз, когда создаётся не user namespace N, Linux назначает текущий user namespace P процесса, создающего N, владельцем namespace N. Если P создан наряду с другими пространствами имён в одном и том же системном вызове , Linux гарантирует, что P будет создан первым и назначен владельцем других пространств имён.
Владелец пространств имён важен потому, что процесс, запрашивающий выполнения привилегированного действия над ресурсом, задействованным не user namespace, будет иметь свои UID привилегии, проверенные в отношении владельца этого user namespace, а не корневого user namespace. Например, скажем, что P является родительским user namespace дочернего C, а P и C владеют собственными network namespace M и N соответственно. Процесс может не иметь привилегий для создания сетевых устройств, включенных в M, но может быть в состоянии это делать для N.
Следствием наличия владельца пространств имён для нас является то, что мы можем отбросить требование при выполнении команд с помощью или , если если мы запрашиваем также создание и user namespace. Например, потребует , но — уже нет:
Как узнать pid процесса Linux
1. ps
Самый распространённый способ узнать PID Linux — использовать утилиту ps:
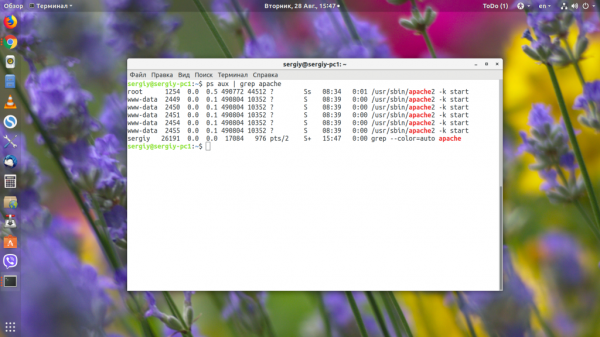
Кроме нужного нам процесса, утилита также выведет PID для grep, ведь процесс был запущен во время поиска. Чтобы его убрать, добавляем такой фильтр:
Например, узнаём PID всех процессов, имя которых содержит слово «Apache»:
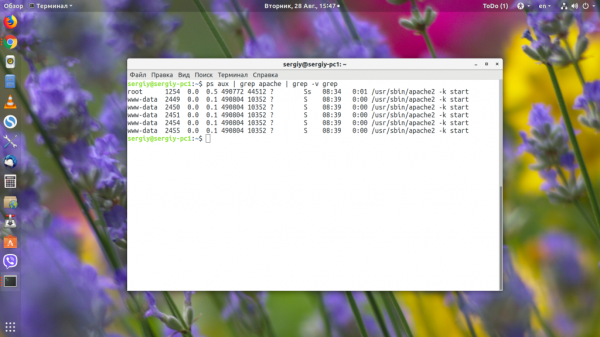
2. pgrep
Если вам не нужно видеть подробную информацию о процессе, а достаточно только PID, то можно использовать утилиту pgrep:
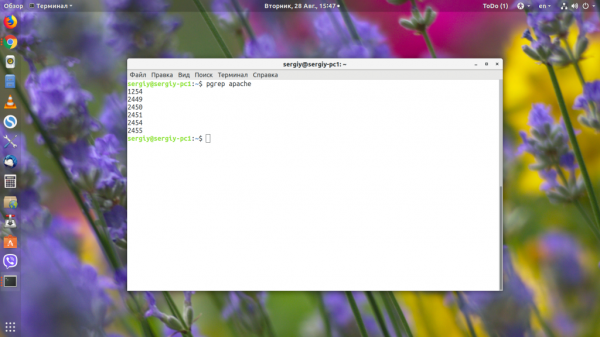
По умолчанию утилита ищет по командной строке запуска процесса, если нужно искать только по имени процесса, то надо указать опцию -f:
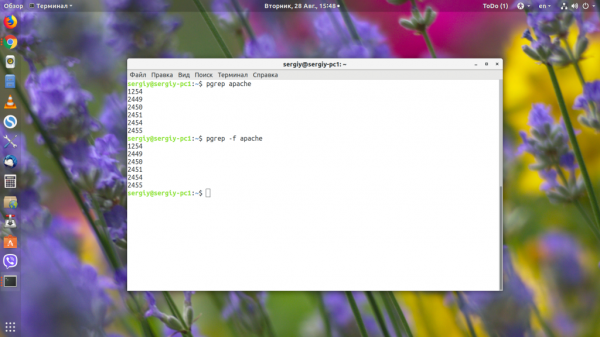
3. pidof
Эта утилита ищет PID конкретного процесса по его имени. Никаких вхождений, имя процесса должно только совпадать с искомым:
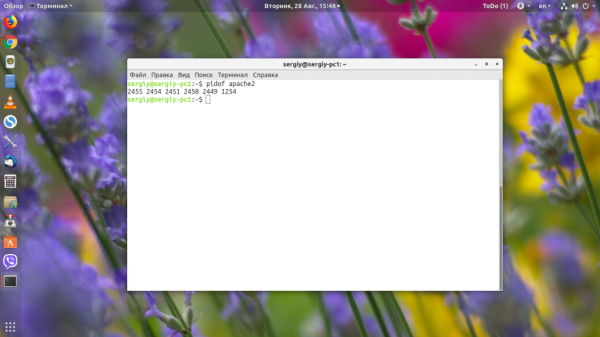
С помощью опции -s можно попросить утилиту выводить только один PID:
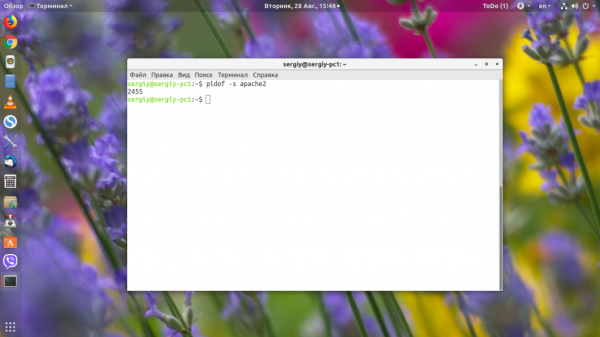
4. pstree
Утилита pstree позволяет посмотреть список дочерних процессов для определённого процесса, также их pid-идентификаторы. Например, посмотрим дерево процессов Apache:
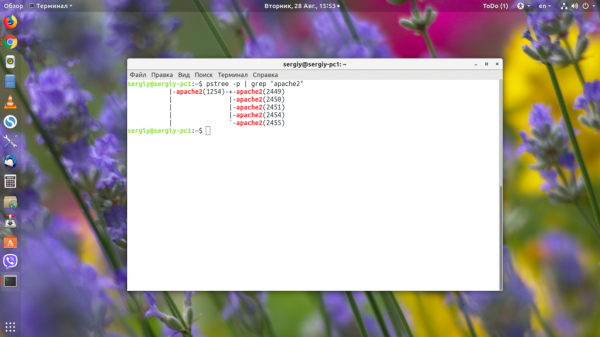
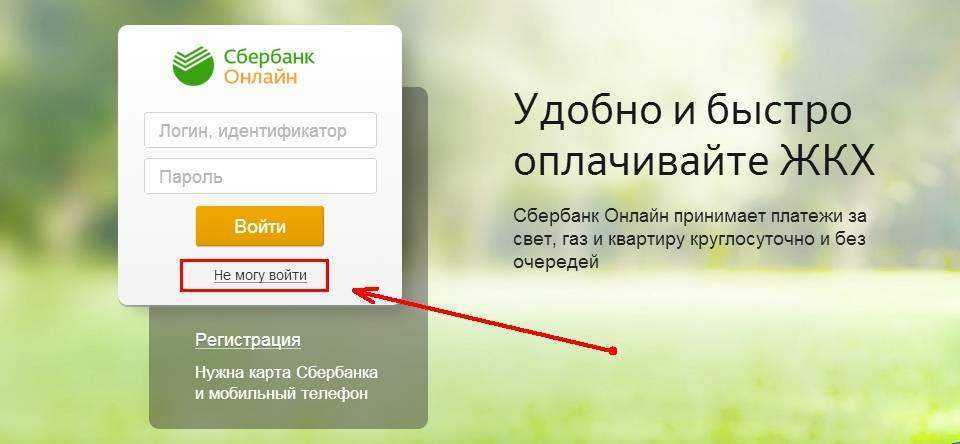
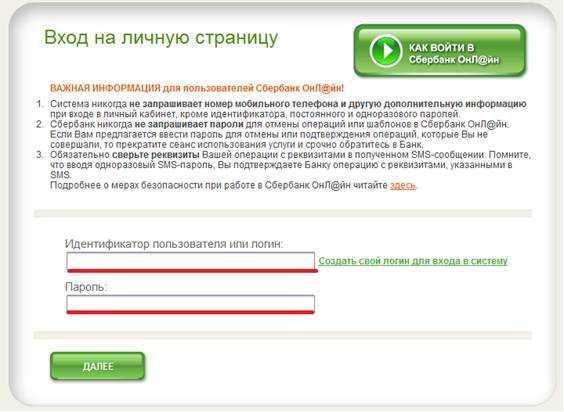
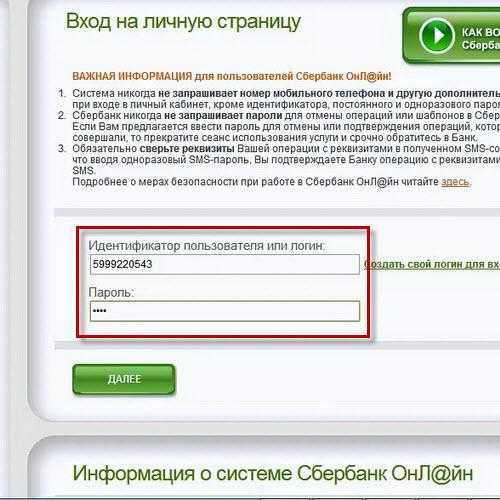
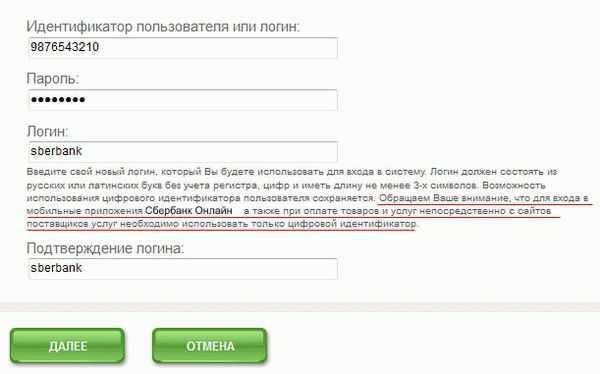
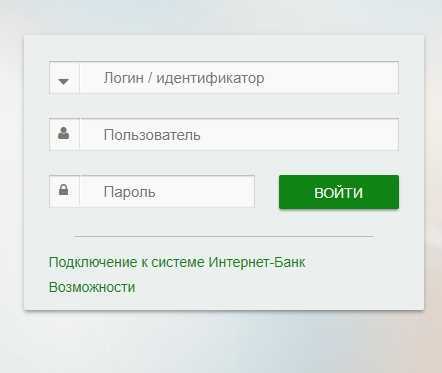
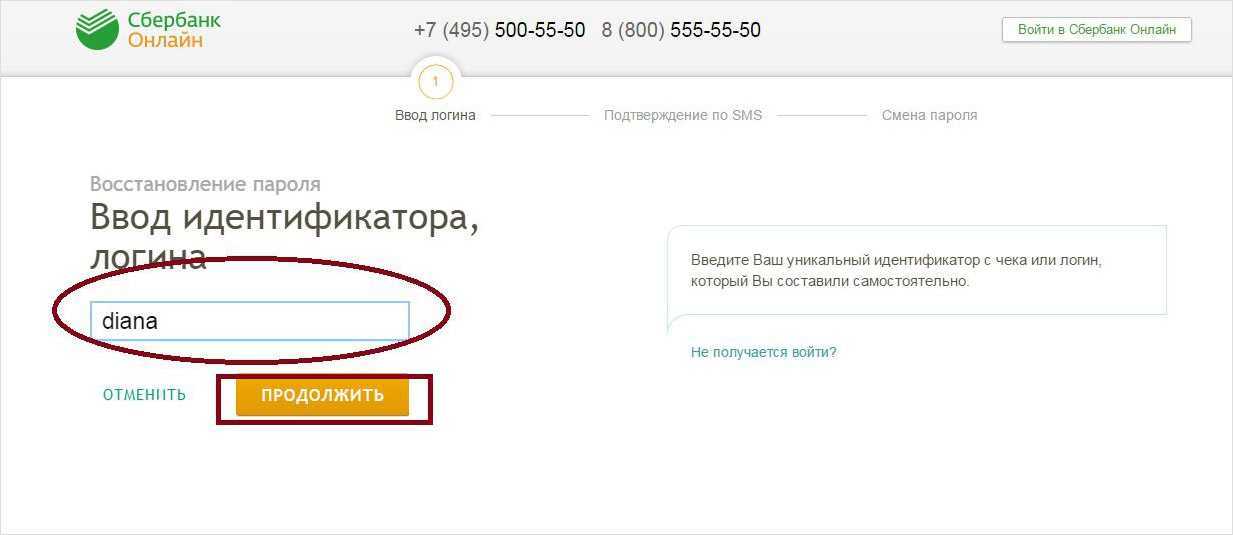
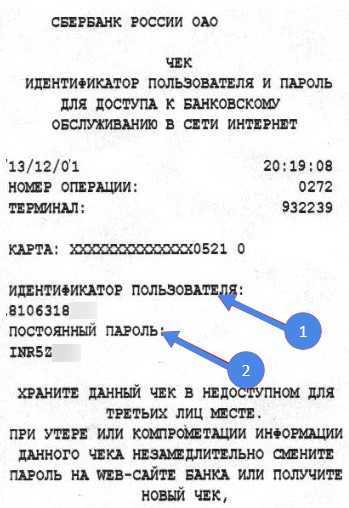
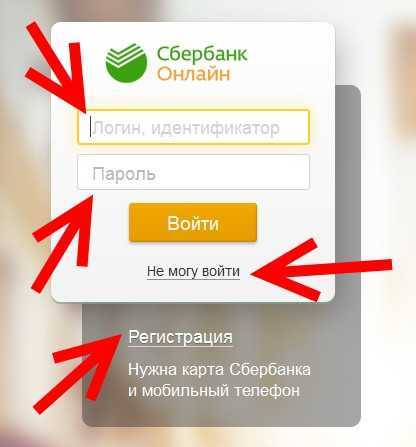
Идентификатор пользователя Сбербанк онлайн
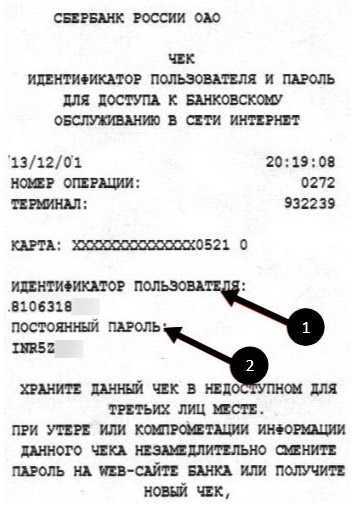
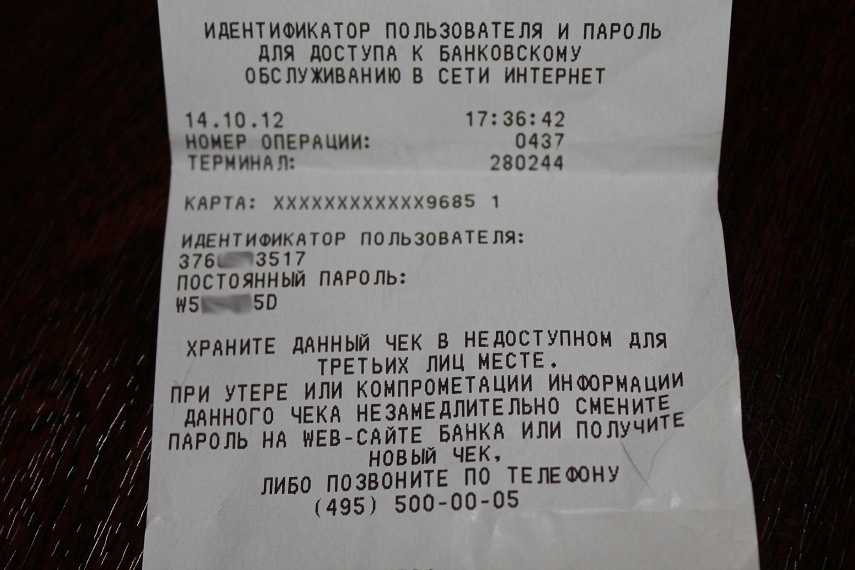
Этот ресурс известен большинству российских держателей карт, поскольку с его помощью можно проводить операции по работе со средствами на карте. Во время регистрации и получения карты каждому пользователю выдается чек с логином и паролем, чтобы иметь возможность войти в систему. В дальнейшем пользователю придется сохранить эти данные, чтобы не потерять возможность входа, так как восстановление пароля или логина достаточно трудозатратное дело.

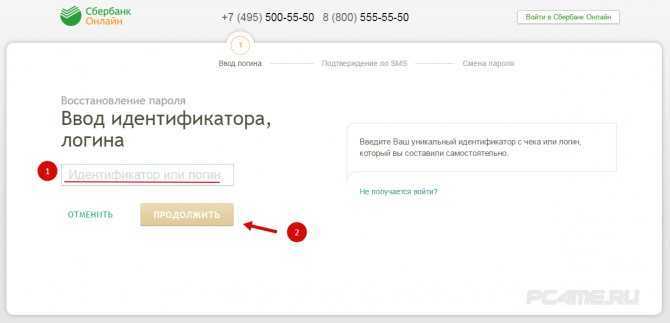

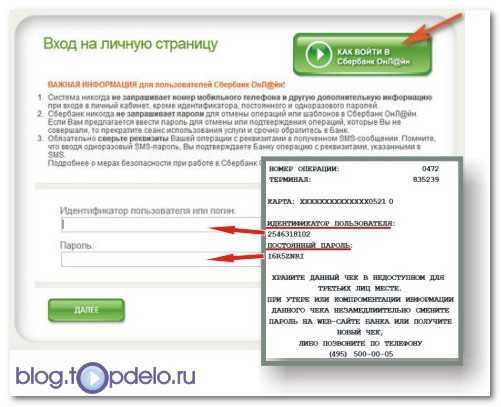

Приведенные выше способы использования ИД, и непосредственно его значение, помогают лучше понять необходимость в использовании этого способа защиты данных. К примеру, идентификатор пользователя Сбербанка онлайн способствует защите личных данных и денежных средств человека.
Маппинги User ID
User namespace, по сути, содержит набор идентификаторов и некоторую информацию, связывающую эти ID с набором ID других user namespace — этот дуэт определяет полное представление о ID процессов, доступных в системе. Давайте посмотрим, как это может выглядеть:
В другом окне терминала давайте запустим шелл с помощью (флаг создаёт процесс в новом user namespace):
Погодите, кто? Теперь, когда мы находимся во вложенном шелле в C, текущий пользователь становится nobody? Мы могли бы догадаться, что поскольку C является новым user namespace, процесс может иметь иной вид ID. Поэтому мы, возможно, и не ждали, что он останется , но — это не смешно. С другой стороны, это здорово, потому что мы получили изолирование, которое и хотели. Наш процесс теперь имеет другую (хоть и поломанную) подстановку ID в системе — в настоящее время он видит всех, как и каждую группу как .
Информация, связывающая UID из одного user namespace с другим, называется маппингом user ID. Он представляет из себя таблицы поиска соответствия ID в текущем user namespace для ID в других namespace и каждый user namespace связан ровно одним маппингом UID (в дополнение еще к одному маппингу GID для group ID).
Этот маппинг и есть то, что сломано в нашем шелле. Оказывается, что новые user namespaces начинаются с пустого маппинга, и в результате Linux по умолчанию использует ужасного пользователя . Нам нужно исправить это, прежде чем мы сможем сделать какую-либо полезную работу в нашем новом пространстве имён. Например, в настоящее время системные вызовы (например, ), которые пытаются работать с UID, потерпят неудачу. Но не бойтесь! Верный традиции всё-есть-файл, Linux представляет этот маппинг с помощью файловой системы в (в для GID), где — ID процесса. Мы будем называть эти два файла map-файлами
Как быстро выяснить какой процесс в Linux использует пространство подкачки (swap)
Заметка очень короткая и призвана администраторам помочь быстро найти процессы которые максимально используют пространство swap. Что делать с этими процессами — это уже отдельная тема, главное найти кто потребляет swap.
Подробности ниже…
Исходные данные: ОС Oracle Linux 7;Задач: Найти потребителя SWAP
Типичная ситуация на сервере с системой мониторинга — это аларм вида: prod-srv-01 Low free swap space (free: 0.15 %, threshold: 10%, alert started: 8.79 %)
Вначале немного теории, о том как получить информацию о распределении памяти процессами в Linux.
/proc/meminfo — псевдо-файл который сообщает статистику об использовании памяти в системе. Вы также можете использовать утилиты free, vmstat и другие инструменты, чтобы узнать ту же информацию;
/proc/${PID}/smaps, /proc/${PID}/status и /proc/${PID}/stat — используйте эти псевдо-файлы для поиска информации о потреблении памяти каждым процессом (${PID} замените на номер процесса);
— утилита (скрипт python), которая поможет вывести информацию в более удобном виде;
Теперь идем на сервер и смотрим:
~]# free -h
total used free shared buff/cache available
Mem: 15G 2.9G 168M 5.6G 12G 6.8G
Swap: 5.0G 5.0G 0B
~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 5242876 177632 5664 12976844 0 0 1102 189 0 0 21 2 70 7 0
Мы видим, что swap заполнен на 100% — это плохо.
Попробуем быстро выяснить кто основной потребитель, для этого обратимся к /proc/*/status Ниже простой сценарий на bash который выдаст нам список потребителей swap:
for file in /proc/*/status ; do awk '/VmSwap|Name/{printf $2 " " $3}END{ print ""}' $file; done | sort -k 2 -n -r | less
Результат будет длинным, я покажу только TOP потребителей:
top swap usage
Мы видим, что основной потребитель — это процесс ora_j001_bs. На сервере установлен Oracle и один из процессов потребляет swap. На втором месте мы видим процесс rsyslogd — думаю он в представлении не нуждается.
Если на потребителя №1 мы не можем повлиять быстро, то на потребителя №2 (rsyslogd) можем — это попытаться его перазапустить.
Выполняем перезапуск rsyslogd:
systemctl restart rsyslog
И смотрим состояние swap:
~]# free -h
total used free shared buff/cache available
Mem: 15G 2.8G 301M 5.6G 12G 6.9G
Swap: 5.0G 3.4G 1.6G
Мы видим, что стало доступно 1.6 GB, а это уже более 30% от размера swap, что вполне нас должно устроить на первое время.
На этом все, до скорых встреч. Если у Вас возникли вопросы или Вы хотите чтобы я помог Вам, то Вы всегда можете связаться со мной разными доступными способами.
Каким процессом занят файл Linux
Выше мы рассмотрели, как получить PID процесса Linux по имени, а теперь давайте узнаем PID по файлу, который использует процесс. Например, мы хотим удалить какой-либо файл, а система нам сообщает, что он используется другим процессом.
С помощью утилиты lsof можно посмотреть, какие процессы используют директорию или файл в данный момент. Например, откроем аудио-файл в плеере totem, а затем посмотрим, какой процесс использует её файл:
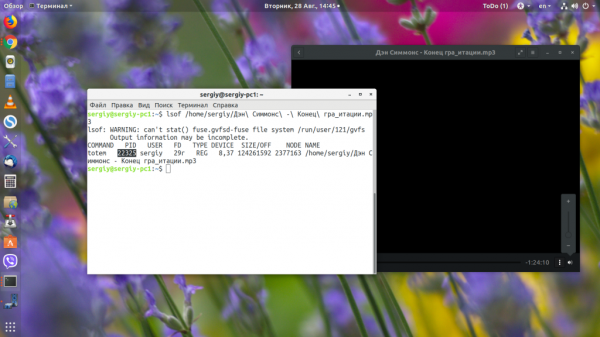
В начале строки мы видим название программы, а дальше идёт её PID. Есть ещё одна утилита, которая позволяет выполнить подобную задачу — это fuser:
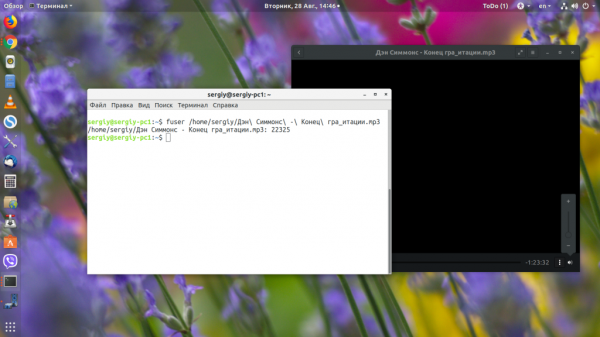
Здесь будет выведен только файл и PID процесса. После PID идёт одна буква, которая указывает, что делает этот процесс с файлом или папкой:
- c — текущая директория;
- r — корневая директория;
- f — файл открыт для чтения или записи;
- e — файл выполняется как программа;
- m — файл подключен в качестве библиотеки.