
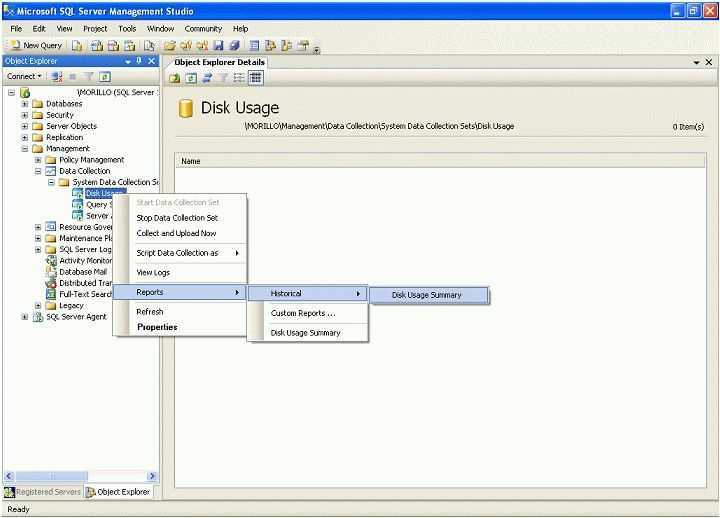
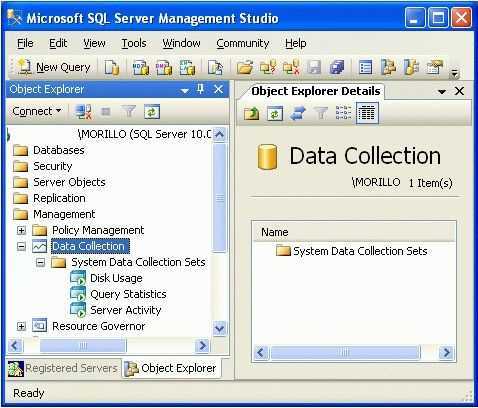
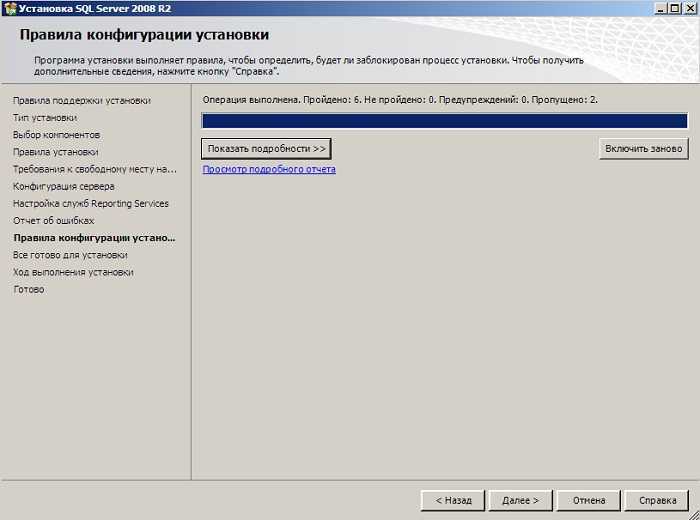
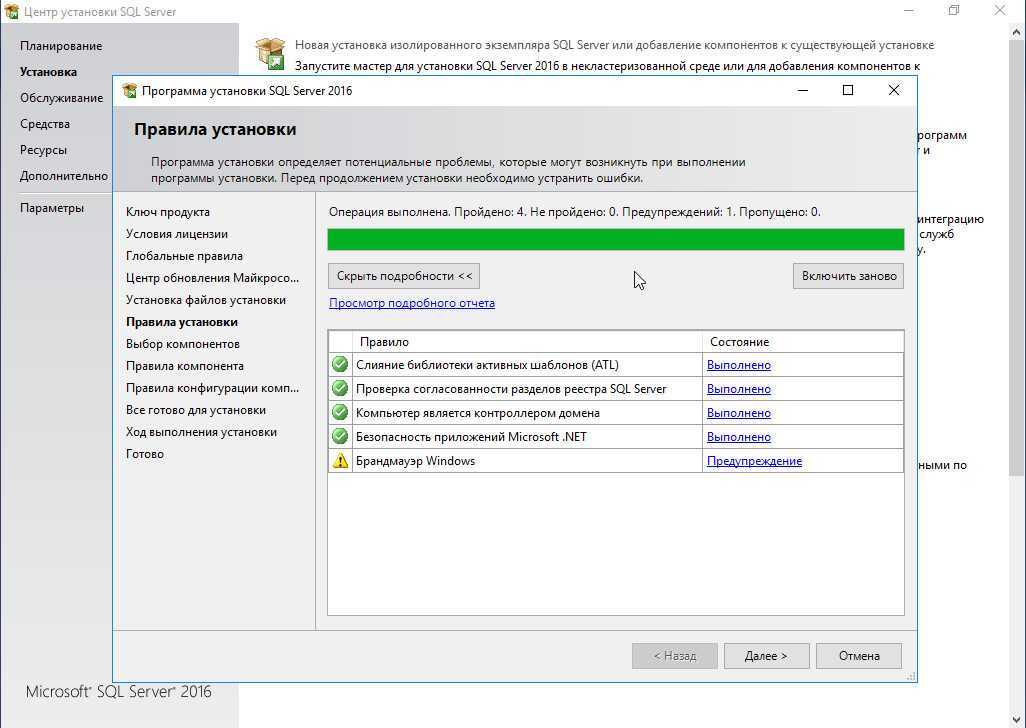
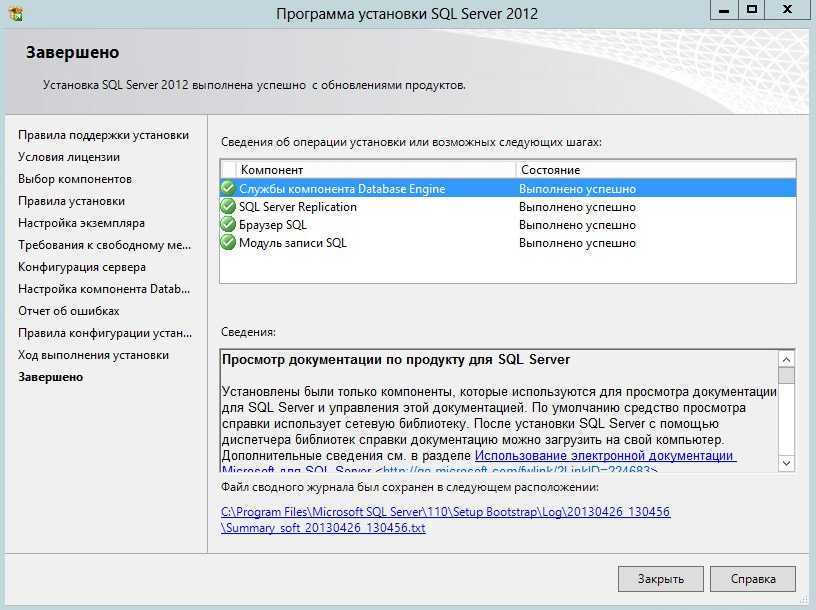
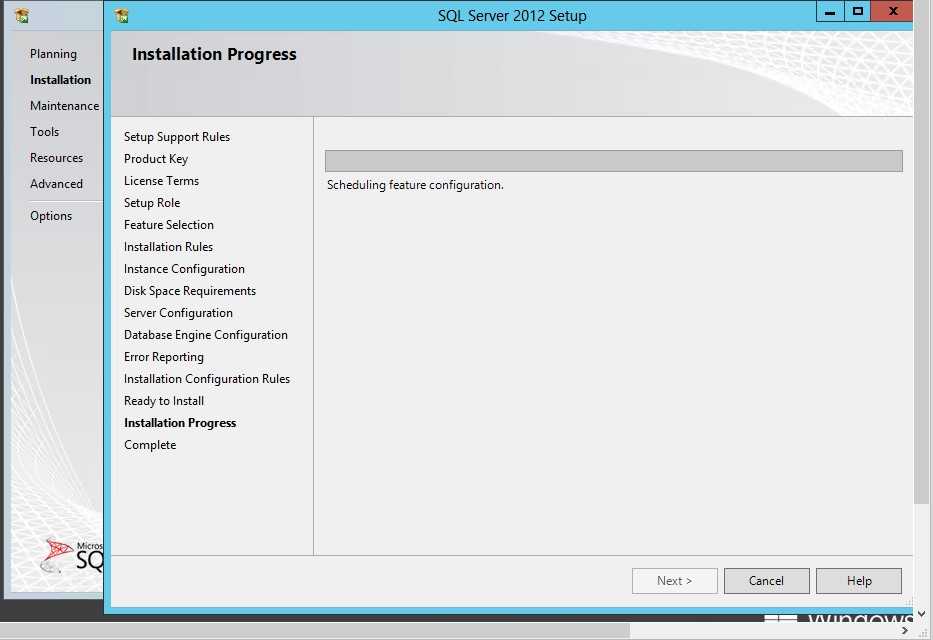
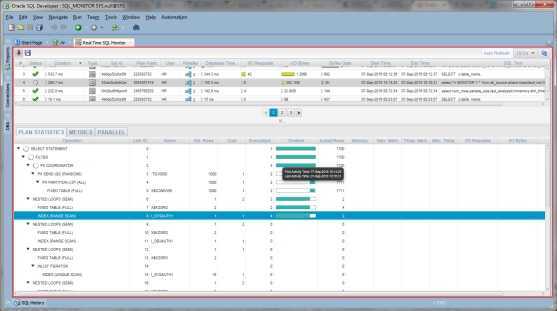
Изучение плана выполнения
После подтверждения существования правильных индексов и того, что никакие подсказки не ограничивают способность оптимизатора создавать эффективный план, можно изучить план выполнения запроса. Для просмотра плана выполнения запроса можно использовать любой из следующих методов:
-
SQL Profiler
Если вы захватили событие MISC: План выполнения в SQL Profiler, оно произойдет непосредственно перед событием StmtCompleted для запроса для ID системного процесса (SPID).
-
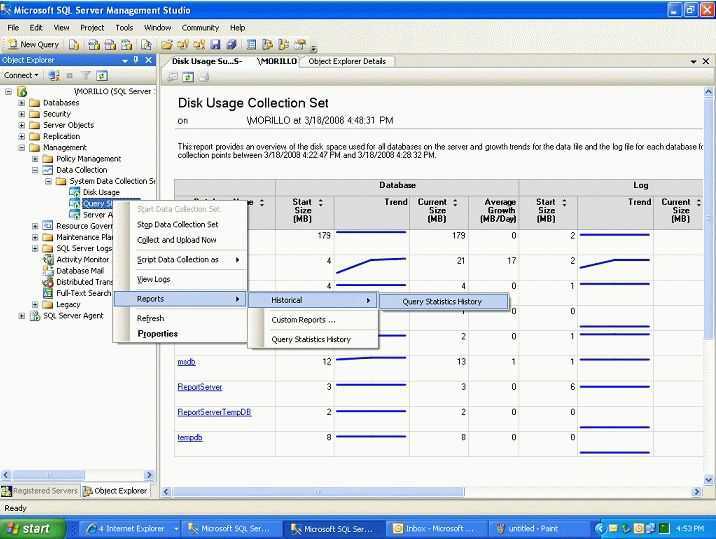
SQL Анализатор запросов: план графического показа
Чтобы запрос был выбран в окне запроса, щелкните меню запроса и нажмите кнопку Отображаемая оценка плана выполнения.
Примечание
Если хранимая процедура или пакет создает временные таблицы и ссылается на них, необходимо использовать заявление SET STATISTICS PROFILE ON или явно создать временные таблицы перед отображением плана выполнения.
-
и
Чтобы получить текстовую версию предполагаемого плана выполнения, можно использовать параметры SET SHOWPLAN_ALL SET. Дополнительные сведения см. в SHOWPLAN_ALL (T-SQL) и set SHOWPLAN_TEXT (T-SQL) SQL Server Books Online.
Примечание
Если сохраненная процедура или пакет создает и ссылается на временные таблицы, необходимо использовать параметр SET STATISTICS PROFILE ON или явно создать временные таблицы перед отображением плана выполнения.
-
ПРОФИЛЬ СТАТИСТИКИ
При отображии предполагаемого плана выполнения графически или с помощью SHOWPLAN запрос не выполняется. Поэтому, если вы создаете временные таблицы в пакете или в сохраненной процедуре, вы не сможете отобразить предполагаемые планы выполнения, так как временные таблицы не будут существовать. ПРОФИЛЬ STATISTICS сначала выполняет запрос, а затем отображает фактический план выполнения. Дополнительные сведения см. в разделе SET STATISTICS PROFILE (T-SQL) SQL Server Books Online. При выполнении в SQL анализаторе запросов это отображается в графическом формате на вкладке План выполнения в области результатов.
Дополнительные сведения о том, как отобразить предполагаемый план выполнения, см. в разделе Display the Estimated Execution Plan in SQL Server Books Online.
Поиск планов запросов, вызывающих сканирование
CROSS APPLY
select qp.query_plan,qt.text from sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
query_planresult to grid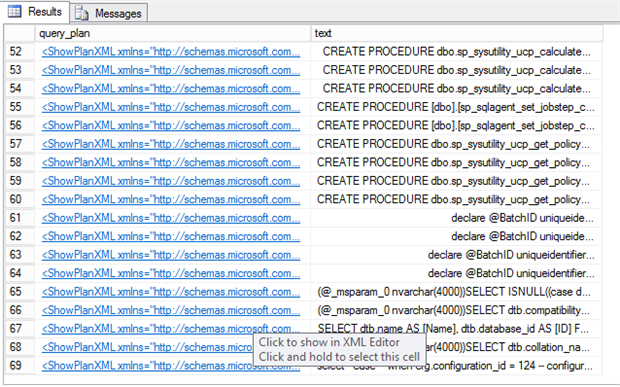 query_planRelOpLogicalOp
query_planRelOpLogicalOp
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp')=1
IndexScanIndexScanObjectIndexScanRelOp
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp/qplan:IndexScan/qplan:Object"]')=1
total_worker_time
select qp.query_plan,qt.text,total_worker_time from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp/qplan:IndexScan/qplan:Object"]')=1
order by total_worker_time desc


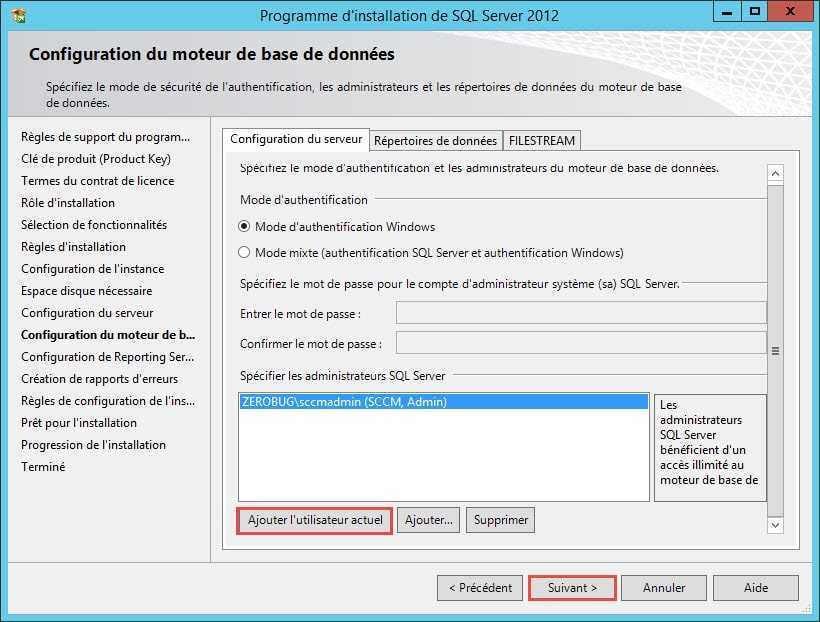
Проверка наличия правильных индексов
Одна из первых проверок, выполняемых при медленном выполнении запроса, — анализ индекса. Если вы изучаете один запрос, вы можете использовать анализ запроса в помощник по настройке ядра СУБД в SQL анализаторе запросов; Если у вас есть SQL профилировка большой рабочей нагрузки, вы можете использовать помощник по настройке ядра СУБД. Оба метода используют SQL Server оптимизатор запросов, чтобы определить, какие индексы будут полезны для указанных запросов. Это эффективный метод определения того, существуют ли правильные индексы в базе данных.
Сведения о том, как использовать помощник по настройке ядра СУБД, см. в разделе «Запуск и использование помощник по настройке ядра СУБД» в SQL Server Books Online.
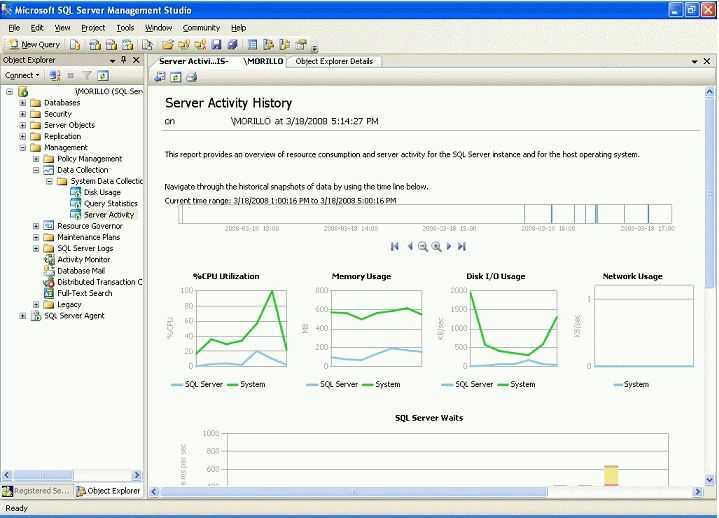
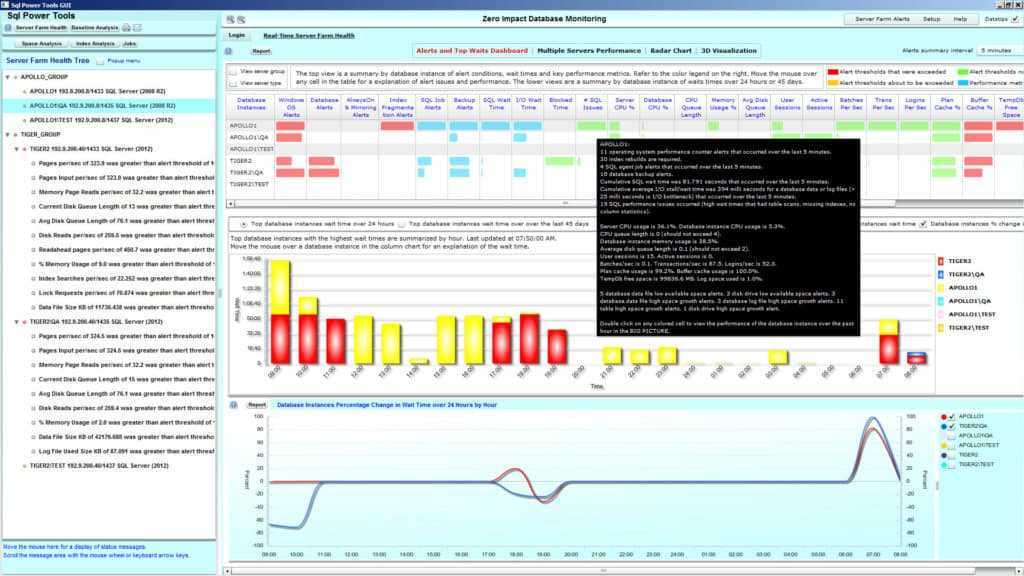

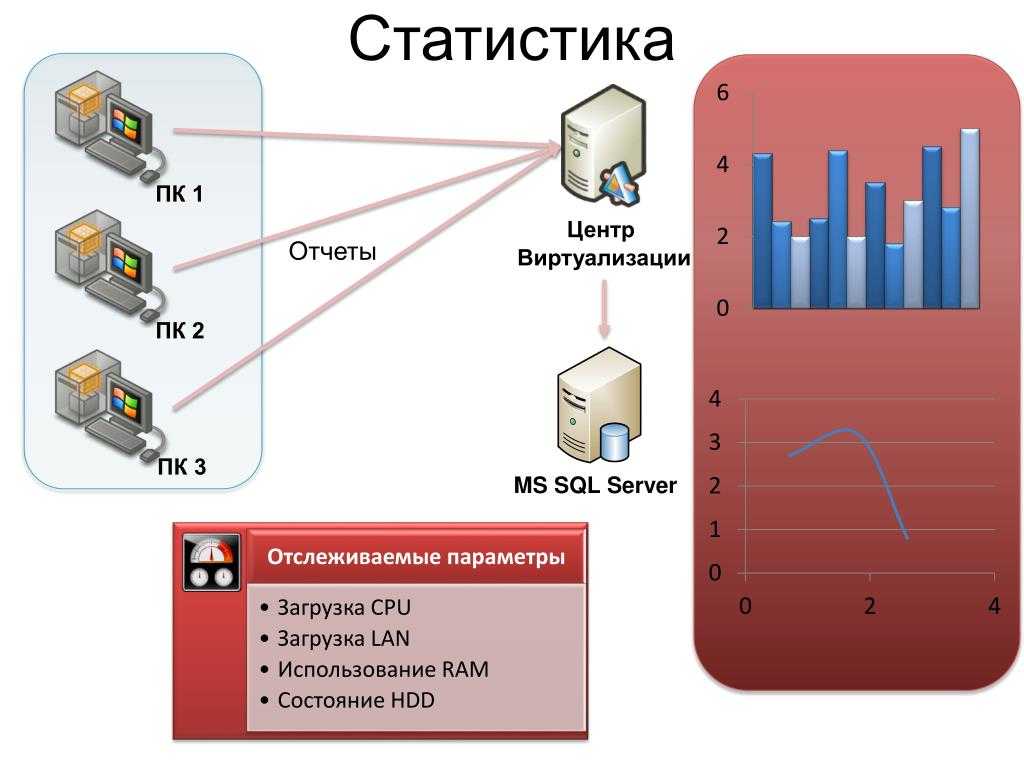
Если вы обновили приложение из предыдущей версии SQL Server, различные индексы могут быть более эффективными в новой сборке SQL Server из-за изменений оптимизатора и двигателя хранения. Этот помощник по настройке ядра СУБД позволяет определить, улучшит ли изменение стратегии индексирования производительность.
Критически важная безопасность
SQL Server предоставляет архитектуру безопасности, которая позволяет администраторам и разработчикам баз данных создавать защищенные приложения баз данных и противостоять угрозам. Каждая версия SQL Server улучшала возможности предыдущих версий с помощью введения новых функций, и SQL Server 2019 (15.x) продолжил эту традицию.
| Новые функции или обновления | Сведения |
|---|---|
| Always Encrypted с безопасными анклавами. | К Always Encrypted добавляется функция шифрования на месте и полнофункциональные вычисления, что позволяет выполнять вычисления с данными в виде обычного текста внутри безопасного анклава на стороне сервера. Шифрование на месте повышает производительность и надежность криптографических операций (шифрования столбцов, смены ключей шифрования столбцов и т. д.), поскольку не требуется перемещать данные за пределы базы данных. Поддержка многофункциональных вычислений (сопоставления шаблонов и операций сравнения) дает возможность использовать Always Encrypted в более широком спектре сценариев и приложений, которые требуют защиты конфиденциальных данных, а также более широкой функциональности в запросах Transact-SQL. См. подробнее об использовании Always Encrypted с безопасными анклавами. |
| Управление сертификатами в диспетчере конфигурации SQL Server. | Теперь с помощью диспетчера конфигурации SQL Server можно выполнять задачи управления сертификатами, такие, как просмотр и развертывание сертификатов. См. статью Управление сертификатами (диспетчер конфигурации SQL Server). |
| Обнаружение и классификация данных | Обнаружение и классификация данных предоставляет возможности для классификации и создания меток столбцов в пользовательских таблицах. Классификация конфиденциальных данных (деловых, финансовых, персональных и т. д.) может играть ключевую роль в защите информации в организации. На основе этих процессов может формироваться инфраструктура для решения следующих задач:
|
| подсистема аудита SQL Server | Возможности аудита также расширены. Теперь в запись журнала аудита добавлено новое поле , в котором содержится классификация конфиденциальности (метки) фактических данных, возвращенных запросом. Дополнительные сведения и примеры см. |
Настройка производительности полнотекстовых индексов
Чтобы получить максимальную производительность полнотекстовых индексов, воспользуйтесь следующими рекомендациями.
-
Чтобы в максимальной степени задействовать все процессоры или ядра ЦП, присвойте параметру max full-text crawl range процедуры sp_configure значение, равное числу ЦП в системе. Сведения об этом параметре конфигурации см. в разделе Параметр конфигурации сервера max full-text crawl range.
-
Убедитесь, что для базовой таблицы установлен кластеризованный индекс. Первый столбец кластеризованного индекса должен иметь целочисленный тип данных. Старайтесь не использовать идентификатор GUID в качестве первого столбца кластеризованного индекса. Многодиапазонное заполнение кластеризованного индекса может обеспечить наивысшую скорость заполнения. Рекомендуется, чтобы столбец, служащий в качестве полнотекстового ключа, имел целочисленный тип данных.
-
Обновите статистику базовой таблицы с помощью инструкции UPDATE STATISTICS . Еще важнее обновить статистику кластеризованного индекса или полнотекстового ключа для полного заполнения. Это позволит при многодиапазонном заполнении сформировать для таблицы хорошие секции.
-
Перед выполнением полного заполнения на мощном многопроцессорном компьютере рекомендуется временно ограничить размер буферного пула, задав для параметра Макс. памяти сервера значение, оставляющее достаточно памяти для процесса fdhost.exe и для использования операционной системой. Дополнительные сведения см. в подразделе далее в этом разделе.
-
При использовании добавочного заполнения на основе значений столбца метки времени создайте вторичный индекс по столбцу timestamp, если нужно повысить производительность добавочного заполнения.
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани
Включение хранилища запросов
Хранилище запросов не включено по умолчанию для новых баз данных Azure Synapse Analytics и SQL Server, но включено по умолчанию для новых баз данных в службе «База данных SQL Azure».
Использование страницы «Хранилище запросов» в SQL Server Management Studio
-
В обозревателе объектов щелкните правой кнопкой мыши базу данных и выберите пункт Свойства.
Примечание
Требуется Среда Management Studio версии не ниже 16.
-
В диалоговом окне Свойства базы данных перейдите на страницу Хранилище запросов .
-
В поле Режим работы (запрошенный) выберите значение Чтение и запись.
Использование инструкций Transact-SQL
Используйте инструкцию , чтобы включить хранилище запросов для указанной базы данных. Пример:
В Azure Synapse Analytics включите Хранилище запросов без дополнительных параметров, например:
Другие параметры синтаксиса, связанные с хранилищем запросов, см. в статье Параметры ALTER DATABASE SET (Transact-SQL).
Примечание
Хранилище запросов не может быть включено для баз данных и .
Важно!
Дополнительные сведения о включении хранилища запросов и настройке в соответствии с требованиями рабочей нагрузки см. в .
Совет 2: Табличные переменные и объединения
Когда у вас есть сложные запросы, такие как получение заказов для клиентов, вместе с их именами и датами заказа, вам нужно нечто большее, чем простой оператор выбора. В этом случае мы получаем данные из таблиц клиентов и заказов. Вот где вступают в силу объединения .
Давайте посмотрим на пример соединения:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Табличные переменные — это локальные переменные, которые временно хранят данные и обладают всеми свойствами локальных переменных. Не используйте табличные переменные в объединениях, как SQL видит их как одну строку. Несмотря на то, что они быстрые, табличные переменные плохо работают в соединениях.
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани
И снова о скорости работы 1с 8.х + тест от Гилева (конфигурация TPС_1C_GILV_A) + как Выбрать сервер для 1С 8.х Промо
Предыстория:
Есть в конторе, где я работаю, пара практически ОДИНАКОВЫХ по железу сервера…
так вот заметили что на одном из них 1С 8.2 работает значительно быстрей что в Клиент-Серверном, что в файловом варианте…
и что именно удивило так это что медленней работал сервер с большим количеством Оперативной памяти + RAID10 на SSD.
Проводили много тестов на работу дисковой системы + различные тесты SQL — ВЫВОД: ничего непонятно где тормоза.
И вот попала ко мне конфигурация 1С для оценки производительности 1С от Гилева http://infostart.ru/public/57204/
Подробности в Описании…
2 стартмани
Как работает SQL-инъекция
Типы атак, которые могут быть выполнены с использованием SQL-инъекции, различаются по типу поражаемых механизмов базы данных. Атака нацеливается на динамические операторы SQL. Динамический оператор — это оператор, который создается во время выполнения на основе параметров из веб-формы или строки запроса URI.
Рассмотрим простое веб-приложение с формой входа. Код HTML-формы приведен ниже:
<form action=‘index.php’ method="post"> <input type="email" name="email" required="required"/> <input type="password" name="password"/> <input type="checkbox" name="remember_me" value="Remember me"/> <input type="submit" value="Submit"/> </form>
Здесь:
- Форма принимает адрес электронной почты, а затем пароль отправляется в файл PHP с именем index.php;
- Сессия хранится в файле cookie. Эта возможность активируется при установке флажка remember_me. Для отправки данных используется метод post. Это означает, что значения не отображаются в URL-адресе.
Предположим, что запрос для проверки идентификатора пользователя на стороне сервера выглядит следующим образом:
SELECT * FROM users WHERE email = $_POST AND password = md5($_POST);
Здесь:
- Запрос использует значения массива $ _POST[] напрямую, не санируя его;
- Пароль шифруется с использованием алгоритма MD5.
Мы рассмотрим атаку с использованием SQL инъекции sqlfiddle. Откройте в браузере URL-адрес http://sqlfiddle.com/. На экране появится следующее окно.
Примечание: вам нужно будет написать инструкции SQL:
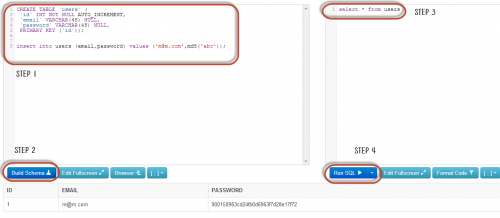
Шаг 1. Введите этот код в левую панель:
CREATE TABLE `users` (
`id` INT NOT NULL AUTO_INCREMENT,
`email` VARCHAR(45) NULL,
`password` VARCHAR(45) NULL,
PRIMARY KEY (`id`));
insert into users (email,password) values ('m@m.com',md5('abc'));
Шаг 2. Нажмите кнопку «Build Schema». Шаг 3. Введите приведенный ниже код в правой панели:
select * from users;
Шаг 4. Нажмите «Run SQL». Вы увидите следующий результат:

Предположим, что пользователь предоставляет адрес электронной почты admin@admin.sys и 1234 в качестве пароля. Запрос, который должен быть выполнен в базе данных, может выглядеть следующим образом:
SELECT * FROM users WHERE email = 'admin@admin.sys' AND password = md5('1234');
Приведенный выше код SQL инъекции примера может быть обойден путем выведения в комментарии части пароля и добавления условия, которое всегда будет истинным. Предположим, что злоумышленник подставляет следующие данные в поле адреса электронной почты:
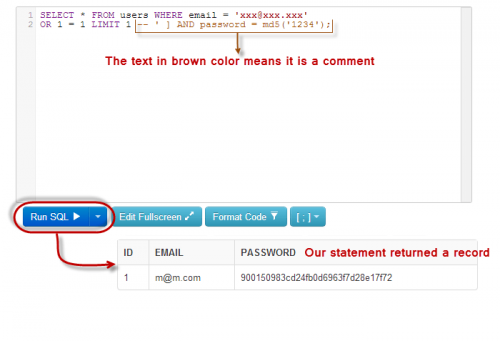
xxx@xxx.xxx' OR 1 = 1 LIMIT 1 -- ' ]
и xxx в поле пароля.
Сгенерированный динамический оператор будет выглядеть следующим образом:
SELECT * FROM users WHERE email = 'xxx@xxx.xxx' OR 1 = 1 LIMIT 1 -- ' ] AND password = md5('1234');
Здесь:
- xxx@xxx.xxx заканчивается одной кавычкой, которая завершает строку;
- OR 1 = 1 LIMIT 1 — это условие, которое всегда будет истинным, оно ограничивает возвращаемые результаты только одной записью.
0; ‘ AND … — это комментарий SQL, который исключает часть пароля.
Скопируйте приведенный выше запрос и вставьте его в текстовое поле SQL FiddleRun SQL, как показано ниже:
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
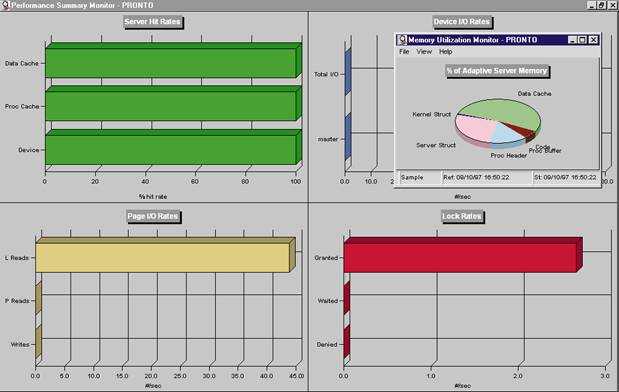
Потенциальные узкие места
Память
- Недостаток объема оперативной памяти, установленной на компьютере, оказывает негативное влияние на производительность всех компонент 1С:Предприятия 8 и Microsoft SQL Server.
- При увеличении количества пользователей и объема информационной базы требования к этому ресурсу со стороны сервера 1С:Предприятия 8 и Microsoft SQL Server возрастают.
- Нехватка памяти приводит к увеличению интенсивности страничного обмена между файлом подкачки и физической памятью, что существенно снижает производительность системы.
Процессоры
- Недостаточная производительность или количество процессоров может стать узким местом при увеличении нагрузки на систему, связанной с увеличением количества пользователей.
- Эффект от увеличения количества процессоров в многопользовательской системе, как правило, существенно выше, чем от увеличения их быстродействия.
Дисковые операции
- Производительность дисковой подсистемы является одним из решающих факторов, определяющих производительность Microsoft SQL Server.
- На производительность сервера 1С:Предприятия 8 влияния, как правило, не оказывает.
Конфликты блокировок Microsoft SQL Server
- Один из основных факторов снижения производительности в многопользовательском режиме
- Вероятность возникновения конфликтов блокировок можно снизить за счет доработки прикладного решения
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Дополнительные сведения
Важно!
Команда предназначена для диагностики служб поддержки клиентов Майкрософт. Формат выпуска и уровень детализации могут изменяться между пакетами служб и выпусками продуктов. Функции, которые предоставляет команда, могут быть заменены другим механизмом в более поздних версиях продукта. Поэтому в более поздних версиях продукта эта команда может больше не функционировать. Никаких дополнительных предупреждений не будет сделано до изменения или удаления этой команды. Поэтому приложения, которые используют эту команду, могут нарушаться без предупреждения.
Выход команды изменился из более ранних выпусков SQL Server. Вывод содержит несколько разделов, недоступных в предыдущих версиях продукта.
Задание очистки
В данном разделе предоставляются сведения о функционировании задания очистки для отслеживания измененных данных.
Структура задания очистки
В системе отслеживания измененных данных для управления размером таблиц изменений используется стратегия очистки данных по истечении срока хранения. В SQL Server и Управляемом экземпляре Azure SQL механизм очистки состоит из задания Transact-SQL агента SQL Server, которое создается при включении первой таблицы базы данных. Одно задание очистки управляет очисткой всех таблиц изменений базы данных; оно применяет одно значение срока хранения ко всем определенным экземплярам системы отслеживания.
Задание очистки инициируется путем запуска хранимой процедуры без параметров . После запуска данная хранимая процедура получает значение срока хранения и пороговое значение, установленные для задания очистки из системной таблицы . Значение срока хранения используется для вычисления нижнего предела таблиц изменений. Указанное число минут вычисляется из максимального значения таблицы для получения нового значения нижнего предела в виде значения datetime. Затем таблица «CDC.lsn_time_mapping» используется для преобразования значения datetime в соответствующее значение . Если одно и то же время фиксации задано для нескольких значений в таблице, то номер , соответствующий записи с наименьшим номером выбирается в качестве нового значения нижнего предела. Значение номера передается в хранимую процедуру для удаления записей из таблиц изменений базы данных.
Примечание
Преимуществом использования времени фиксации недавней транзакции в качестве основы для вычисления нового значения нижнего предела является то, что это позволяет хранить сведения об изменениях в таблицах изменений в течение определенного времени. Это происходит, даже если процесс отслеживания запущен позже. Все изменения, имеющие то же время фиксации, что и значение нижнего предела, и далее представляются в таблицах изменений методом выбора наименьшего номера , имеющего то же время фиксации, что и реальное значение нижнего предела.
Если выполняется очистка, то значение нижнего предела всех экземпляров системы отслеживания изначально обновляется в одной транзакции. Затем производится попытка удаления устаревших записей из таблиц изменений и таблицы cdc.lsn_time_mapping. Настраиваемое пороговое значение ограничивает количество записей, удаляемое в любой одиночной инструкции. Неуспешное выполнение удаления в любой отдельной таблице не повлияет на выполнение операции в остальных таблицах.
Настройка задания очистки
В задании очистки присутствует возможность настройки стратегии, определяющей, какие из записей таблиц изменений подлежат удалению. В передаваемом задании очистки поддерживается только основанная на времени стратегия. В данной ситуации новое значение нижнего предела вычисляется методом вычитания допустимого срока хранения из времени фиксации последней обработанной транзакции. Поскольку лежащие в основе процедуры очистки используют вместо времени номера , для определения наименьшего сохраняемого в таблицах изменений номера может использоваться любое число стратегий. Только часть из этих стратегий являются полностью основанными на времени. Сведения о клиентах, например, могут быть использованы для обеспечения предохранительных мер на тот случай, если не удастся запустить последующие процессы, которым необходим доступ к таблицам изменений. Хотя в стратегии по умолчанию для очистки таблиц изменений всех баз данных используется один и тот же номер , для выполнения очистки на уровне экземпляра системы отслеживания также можно вызвать процедуру очистки на уровне экземпляра отслеживания.
Примечание
В Базах данных SQL Azure планировщик отслеживания измененных данных периодически вызывает хранимую процедуру для записи и очистки таблиц изменений. Таким образом, настройка процесса записи и очистки в Базе данных SQL Azure в настоящее время невозможна. Хотя планировщик запускает хранимые процедуры автоматически, их также можно запустить вручную.
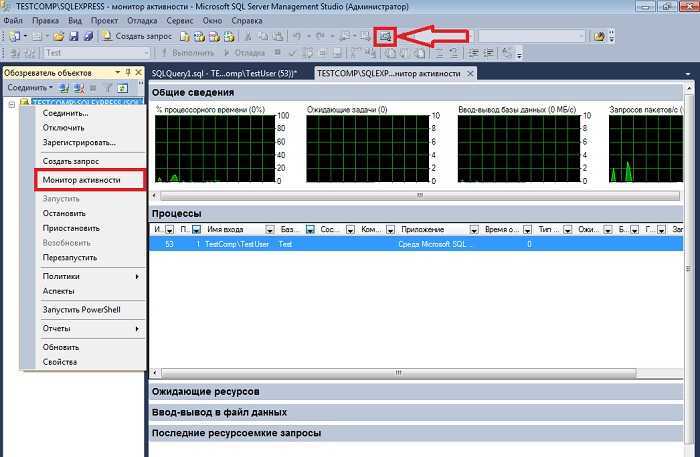
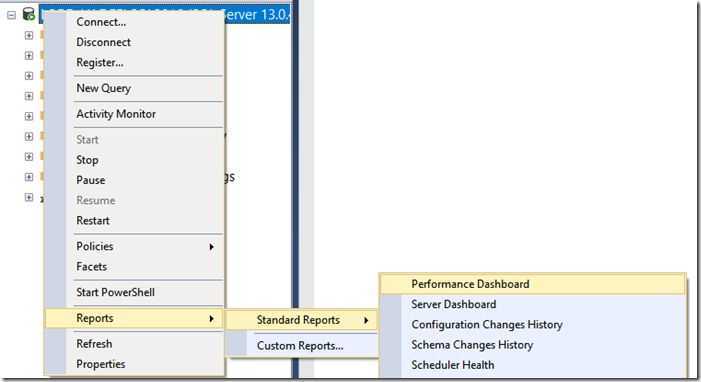
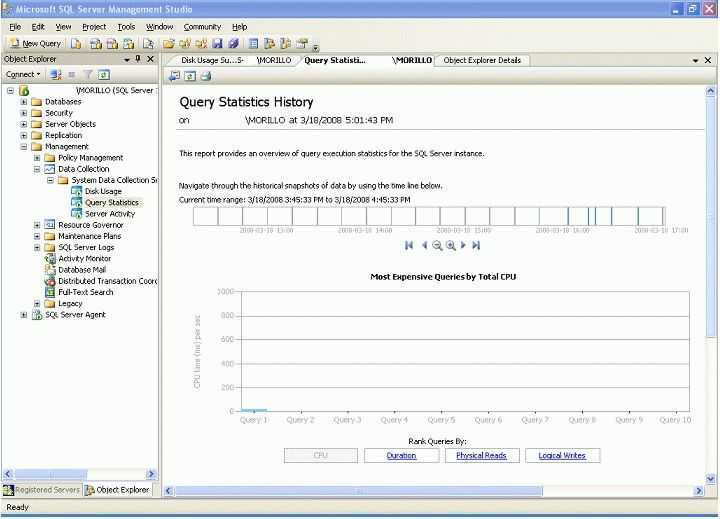
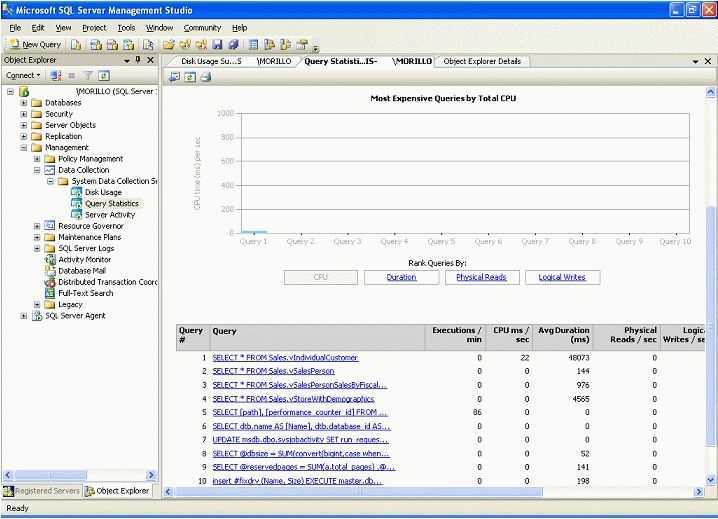
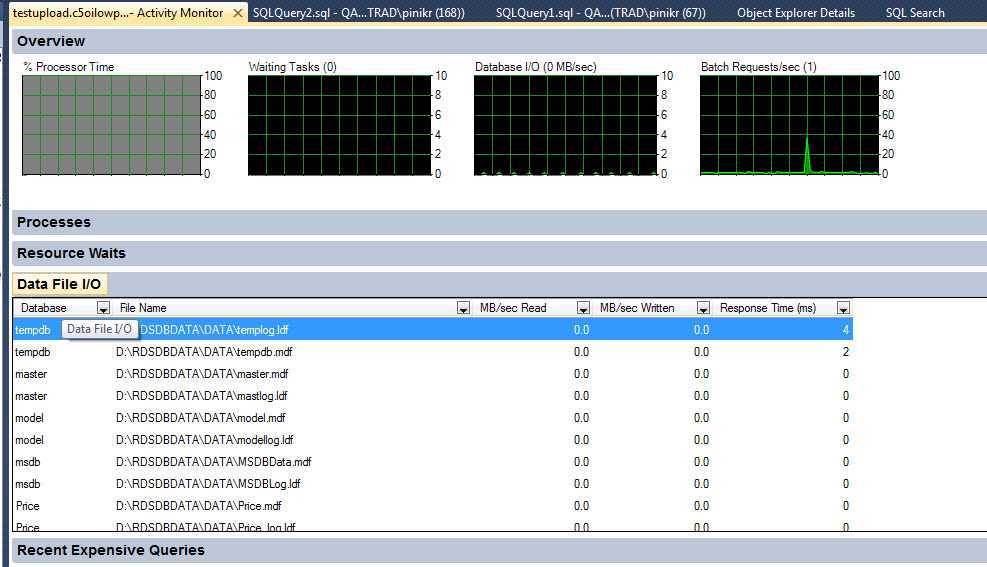
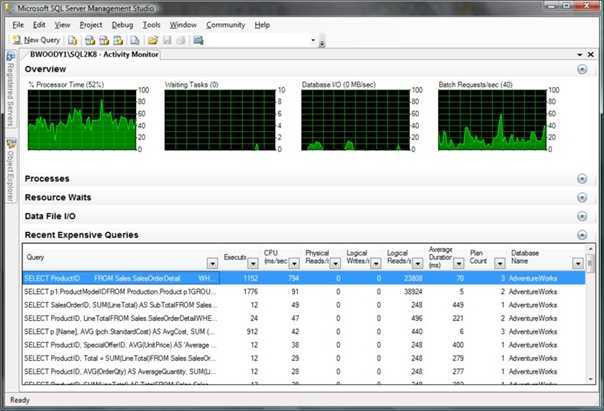
Что такое SQL Profiler и зачем оно вообще нужно
SQLProfilerэто программа поставляемая вместе с MS SQL Server и предназначена она для и просмотра всех событий, которые происходят в SQL сервер или говоря другими словами для записи трассировки. Зачем SQLProfiler может понадобиться программисту 1С? Хотя бы для того, что бы получить текст запроса на языке SQL и посмотреть его план. Конечно, это можно сделать и с помощью технологического журнала, но это требует некоторых навыков, да и план в ТЖ получается не такой красивый и удобочитаемый. В профайлере можно посмотреть не только текстовый, но и графический план выполнения запроса, что на мой взгляд, гораздо удобнее. Так же с помощью профайлера можно определить: запросы длиннее определенного времени запросы к определенной таблице ожидания на блокировках таймауты взаимоблокировки и многое другое…
Расположение файлов журнала
На серверах Windows журналы расположены в каталоге установки, по умолчанию в C:\Program Files\Microsoft SQL Server\MSSQLnn.InstanceName\MSSQL\Log\Polybase.
На серверах Linux журналы по умолчанию расположены в папке var/opt/mssql/log/polybase.
Файлы журналов перемещения данных PolyBase:
- <INSTANCENAME>_<SERVERNAME>_Dms_errors.log
- <INSTANCENAME>_<SERVERNAME>_Dms_movement.log
Файлы журналов службы ядра PolyBase:
- <INSTANCENAME>_<SERVERNAME>_DWEngine_errors.log
- <INSTANCENAME>_<SERVERNAME>_DWEngine_movement.log
- <INSTANCENAME>_<SERVERNAME>_DWEngine_server.log
Файлы журналов Java для PolyBase (в Windows):
- <SERVERNAME> Dms polybase.log
- <SERVERNAME>_DWEngine_polybase.log
Файлы журналов Java для PolyBase (в Linux):
- /var/opt/mssql-extensibility/hdfs_bridge/log/hdfs_bridge_pdw.log
- /var/opt/mssql-extensibility/hdfs_bridge/log/hdfs_bridge_dms.log
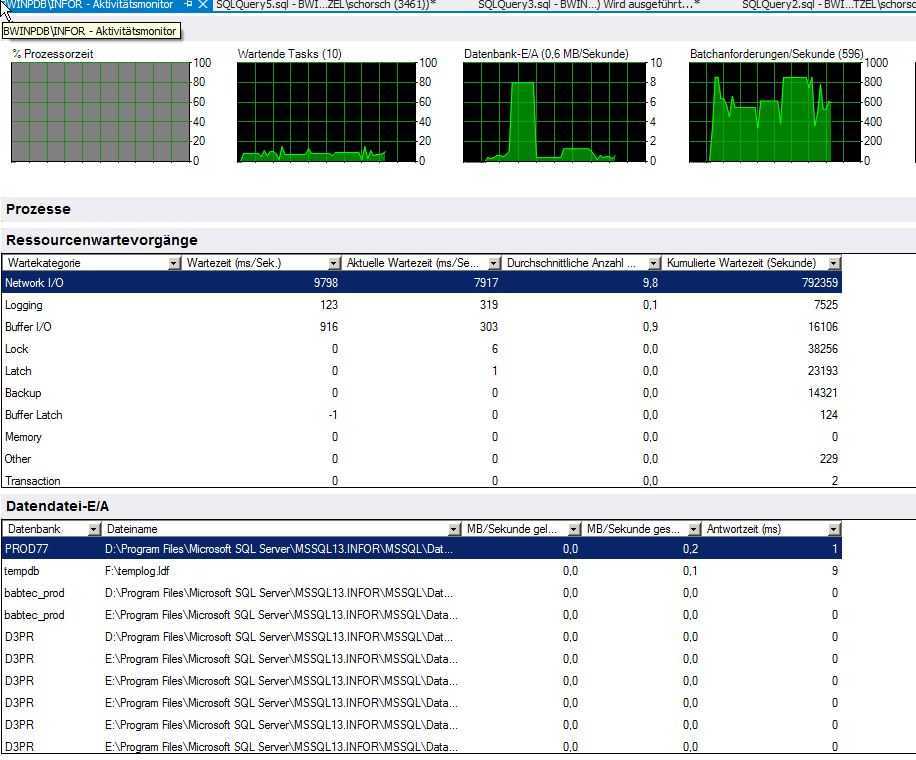
Идентификация узких мест
В таблице приведен перечень основных объектов и счетчиков, используемых при анализе проблем с производительностью.
| Объект | Основные счетчики | Описание | Основные признаки наличия проблемы | Варианты решения проблемы |
| Память | Memory\Pages/sec | Характеризует интенсивность обмена между дисковой подсистемой и оперативной памятью. Обращение к дисковой системе происходит из-за того, что запрашиваемые страницы отсутствуют в оперативной памяти. | Нормальное значение этого счетчика должно быть близко к нулю. Увеличение показания этого счетчика свыше 20 страниц в секунду говорит о необходимости увеличения объема оперативной памяти. |
Увеличение объема оперативной памяти, установленной на компьютере. Перенос приложений, интенсивно использующих оперативную память, на отдельный компьютер.Например, установка сервера 1С:Предприятия 8.0 и Microsoft SQL Server на разных компьютерах. |
| Процессор | Processor \ %Processor Time | Время, которое процессор тратит на выполнение полезной работы, в процентах от общего системного времени. | Если среднее значение величины утилизации процессора превышает 85%, значит, процессор – узкое место в системе. |
Замена процессоров на более быстродействующие. Увеличение количества процессоров. Перенос приложений, интенсивно использующих процессор на отдельный компьютер. Например, установка сервера 1С:Предприятия 8.0 и Microsoft SQL Server на разных компьютерах. |
| System \ Processor Queue Length | Длина очереди к процессору. | Если в течение длительного времени средняя длина очереди превышает значение 2, то это говорит о том, что процессор является узким местом. | ||
| Дисковая система | Physical Disk \ %Disk Time | Процент времени, которое диск был занят, обслуживая запросы чтения или записи. | Снижение утилизации процессоров сервера |
Установка более быстрых дисков. Использование дисков с интерфейсом SCSI. Использование аппаратного RAID — контроллера. Увеличение количества дисков в RAID — массиве. |
| Physical Disk\Avg. Disk Queue Length | Показывает эффективность работы дисковой подсистемы. Представляет собой среднюю длину очереди запросов к диску. | Увеличение очереди запросов к дисковой подсистеме | ||
| Сетевой интерфейс | Network Interface\ Bytes Total/sec | Скорость, с которой происходит получение или посылка байт через сетевой интерфейс | Значение этого счётчика не должно превышать 65% величины пропускной способности сетевого адаптера. |
Установка сетевого адаптера с более высокой пропускной способностью (если позволяют параметры сети). Установка дополнительного сетевого адаптера. |
| Блокировки | SQL Server: Locks \ Lock Wait Time (ms) | Показывает общее время ожидания (в миллисекундах) выполнения запросов на блокировку за последнюю секунду | Среднее значение общего времени ожидания не должно превышать заданного времени отклика системы умноженного на количество активных пользователей |
Сокращение времени выполнения транзакции. Обеспечение единого порядка доступа ко всем ресурсам. Оптимизация запросов в прикладном решении. Правильная установка признаков индексирования у реквизитов объектов конфигурации позволяет существенно сократить диапазон блокировок. Поддержание актуальности индексов и статистики Microsoft SQL Server. Использование в запросах оператора «ДЛЯ ИЗМЕНЕНИЯ». |
| SQL Server: Locks\ Average Wait Time (ms) | Показывает среднее время ожидания (в миллисекундах) выполнения каждого запроса на блокировку | Не должно превышать заданного времени отклика системы | ||
| Взаимные блокировки | SQL Server: Locks \ Number of Deadlocks/sec | Показывает количество запросов на блокировку в секунду, которые закончились взаимной блокировкой | Ненулевое значение счетчика |

Мониторинг узлов в группе PolyBase
После настройки нескольких компьютеров в рамках масштабируемой группы PolyBase можно отслеживать состояние компьютеров. Дополнительные сведения о создании масштабируемой группы см. в разделе Масштабируемые группы PolyBase.
-
Подключитесь к SQL Server на головном узле группы.
-
Запустите sys.dm_exec_compute_nodes (Transact-SQL) динамического административного представления, чтобы просмотреть все узлы в группе PolyBase.
-
Запустите sys.dm_exec_compute_node_status (Transact-SQL) динамического административного представления, чтобы просмотреть состояние всех узлов в группе PolyBase.
Наблюдение за памятью операционной системы
Для отслеживания нехватки памяти используйте приведенные ниже счетчики Windows. Значения многих счетчиков памяти операционной системы можно запрашивать с помощью динамических административных представлений sys.dm_os_process_memory и sys.dm_os_sys_memory.
-
Память: доступно байтов
Этот счетчик указывает на то, сколько байт памяти доступно на данный момент для использования процессами. Низкие значения счетчика Доступно байтов могут указывать на общую нехватку памяти операционной системы. Это значение можно запросить с помощью T-SQL из sys.dm_os_sys_memory.available_physical_memory_kb. -
-
Память: страниц/с
Этот счетчик показывает число страниц, которые были или получены с диска из-за ошибок страниц физической памяти, или записаны на диск для освобождения пространства в рабочем множестве из-за ошибок страниц. Большое значение счетчика Страниц/с может означать излишнюю подкачку. -
Память: ошибок страницы/с Этот счетчик показывает частоту ошибок страниц для всех процессов, включая системные. Низкий, но не нулевой уровень выгрузки на диск (и вызванные ею ошибки страниц) является нормальным, даже если у компьютера достаточно большое количество доступной памяти. Диспетчер виртуальной памяти (VMM) Microsoft Windows берет страницы из SQL Server и других процессов по мере того, как он урезает размеры рабочих множеств этих процессов. Деятельность VMM может привести к ошибкам страниц.
-
Процесс: ошибок страницы/с Этот счетчик показывает частоту ошибок страниц для определенного пользовательского процесса. С помощью счетчика Процесс: ошибок страниц/с можно определить, вызвана ли повышенная активность диска подкачкой, выполняемой сервером SQL Server. Чтобы определить, является ли SQL Server или другой процесс причиной излишней подкачки, наблюдайте за счетчиком Процесс: ошибок страниц/с для экземпляра процесса SQL Server.

Дополнительные сведения об устранении проблемы излишней подкачки см. в документации по операционной системе.



![Сервис_prometheus [методические материалы лохтурова вячеслава]](http://smartshop124.ru/wp-content/uploads/1/f/8/1f806d1969da0e4af99d57839b388d6f.jpeg)