
Введение
Дедупликация является актуальной технологией находящей всё большее применение в области резервного копирования и восстановления данных.
Сегодня большинство систем хранения корпоративного уровня поддерживают данную технологию. Среди компаний производителей таких систем лидеры мирового уровня в данной области EMC, IBM, NetApp, HP, Oracle, Quantum.
На сегодняшний день большинство существующих корпоративных систем резервного копирования/восстановления данных обладают собственной реализацией технологии дедупликации данных, ввиду наиболее эффективного применения данной технологии именно в области резервного копирования данных по причине наличия большой избыточности в наборах данных резервных копий.
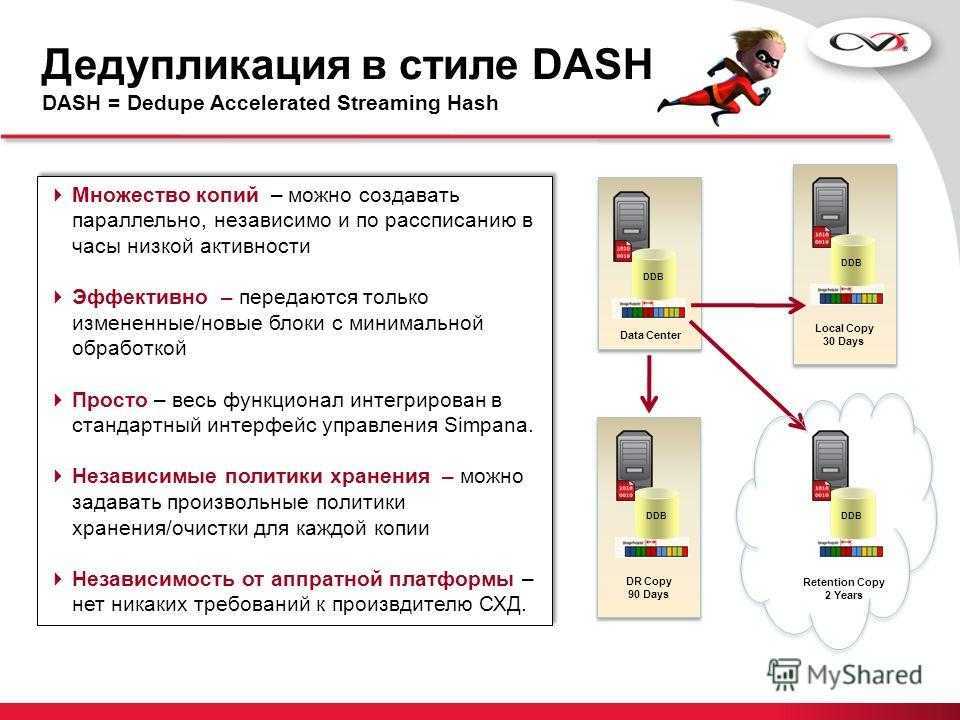
Следует отметить, что в крупных инфраструктурах, имеющих террабайты продуктивных данных, применение дедупликации в резервном копировании позволяет существенно сократить затраты на приобретение и поддержку информационных систем, за счет сокращения потребностей в пространстве для хранения резервных копий, так как все технические характеристики системы, а также стоимость внедрения и владения существенно зависят от применяемых технологий хранения и резервного копирования.
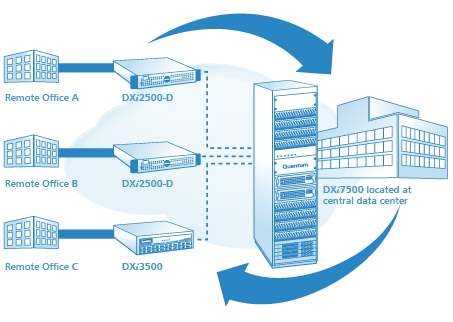
В случае наличия распределенной системы резервного копирования между различными площадками инфраструктуры соединенных через глобальную компьютерную сеть (WAN), обладающую ограниченной, как правило не достаточно высокой пропускной способностью, применение дедупликации позволяет сократить время передачи/репликации данных резервных копий между площадками, позволяя в определенных случаях осуществить размещение необходимых данных в территориально удаленном месте в отведенное под данную задачу время. На сегодняшний день подобная потребность растет с развитием и уменьшением стоимости сервиса типа «облачное хранилище данных» cloud storage, позволяющее защитить данные в случае физического уничтожения серверной в случае стихийных, технологических бедствий или изъятия оборудования и устройств хранения проверяющими органами.
Btrfs — ключ к блочной дедупликации
Если вы запишете на NAS в 10 папок 10 файлов windows.iso размером по 3 Гб, то вы займете 30 Гб свободного места. Обычная дедупликация способна выявить повторяющиеся файлы и показать вам, что их можно удалить, у Synology есть эта функция в пакете «анализатор хранения», но это — прошлый век. Блочная дедупликация сканирует каждый файл в поисках повторяющихся блоков (экстентов), и если находит в разных файлах идентичные блоки, то в одном из них она производит удаление дубля экстента, заменяя его ссылкой на такой же экстент в другом файле. Совсем грубо это выглядит так: допустим, есть 10 архивов, в каждом из которых лежит dx.dll, так вот из 9 архивов содержимое файла dx.dll будет удалено и заменено на ссылку, отправляющую к 10-му архиву, где этот файл сохранился. Конечно, на самом деле этот процесс куда более сложный, но смысл все равно остается тем же — ссылка на dx.dll, например, занимает 128 байт, а сам dx.dll — 300 мегабайт. Проведя дедупликацию, мы сэкономим 2700 мегабайт из 3000, и при этом все файлы останутся на месте, их можно копировать, открывать и удалять независимо друг от друга. При записи на другой носитель, например на компьютер, дедуплицированные данные снова займут 3000 мегабайт, так что экономим мы место только внутри NAS-а.
Современные NAS-ы Synology поддерживают файловую систему Btrfs, в которой вот такие «ссылки» на экстенты — есть основа всего, поэтому ядро операционной системы, умеющее работать с Btrfs поддерживает функцию дедупликации само по себе, без лишних инструментов. Но Btrfs сама не умеет проводить дедупликацию, как например ZFS, ни на лету, ни как-то иначе. Файловой системе нужно, чтобы кто-то просмотрел все файлы, нашел в них повторяющиеся блоки и указал, что их можно удалить, заменяя ссылками. Для этой цели существуют несколько программ, одна из которых — duperemove.
Поскольку поддержка Btrfs встроена в ядро операционных систем Synology DSM 6.x, то нам не важно, что в самой Synology DSM нет инструмента дедупликации, ведь все что нам нужно — это сообщить файловой системе, где лежат повторяющиеся блоки данных внутри файлов, а дальше Synology DSM все сделает сама
Как вы уже поняли, раздел данных на вашем NAS-е должен иметь файловую систему Btrfs, а не EXT4.
What’s Data Deduplication in Windows Server 2016?
Files, which are stored to a disk volume and left there for several days (to ensure it’s not fast-changing data), can be checked by a special process, splitting this data into small blocks, named chunks (32 KB – 128 KB) and then analyzed chunk by chunk. The system preserves unique blocks only, moving them into a chunk store and leaving references (reparse points) for those blocks that are used more than once. This allows you to have valuable storage savings if the said data is similar. The most important use cases include: Hyper-V VDI environment, backup storages and file servers. A Data Deduplication process runs one of four different task types: Optimization (splitting data into chunks and moving them into the chunk store), garbage collection (reclaiming space by removing obsolete chunks), integrity scrubbing (detecting corruption in the chunk store) or unoptimization (undoing optimization and disabling data deduplication on this volume).


Please refer to the Microsoft knowledge base for more details about Data Deduplication basics.
Вопросы эффективности
Для того, чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
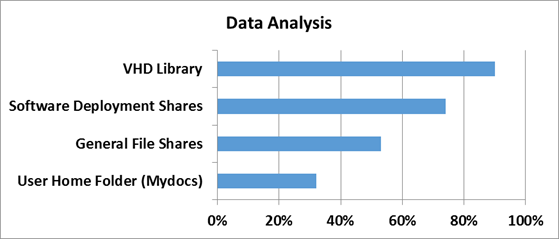
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.
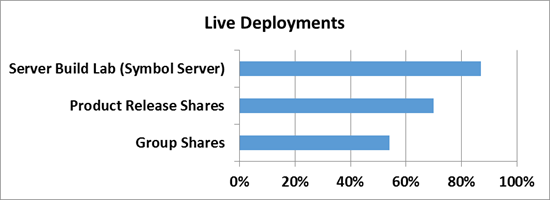
А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.
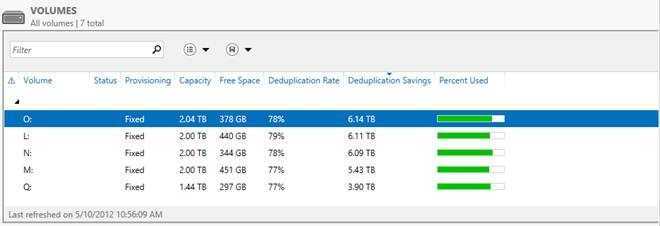
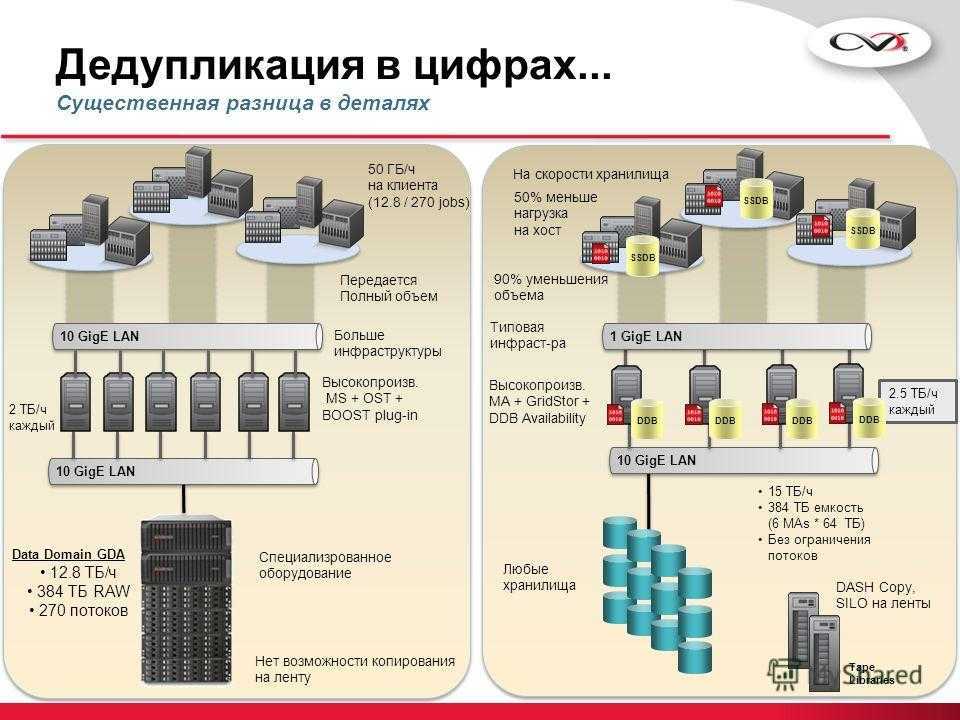
Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Является ли дедупликация общераспространенной технологией?
Дедупликация окончательно перешла из категории экспериментальных в категорию общераспространенных технологий. По словам аналитиков, сегодня на западе более 30% ИТ-подразделений применяют ее, по край-ней мере, к части своих данных. Сейчас на рынке предлагаются продукты и решения, имеющие за собой уже пару поколений, которые уже оптимизированы для упрощенной установки, без нарушения работы других приложений.
Тем не менее, это не означает, что все решения у различных производителей одинаковы. Большинство по-ставщиков технологий дедупликации проходят этап накопления технического опыта, поэтому желательно при оценке решений узнавать уровень квалификации компании, требовать рекомендации и узнавать о тех-нической поддержке.
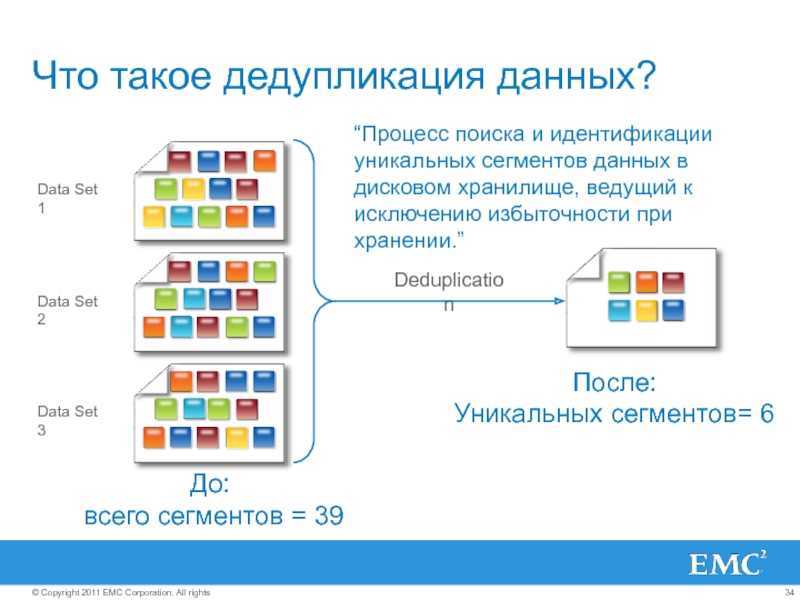
Что такое дедупликация данных?
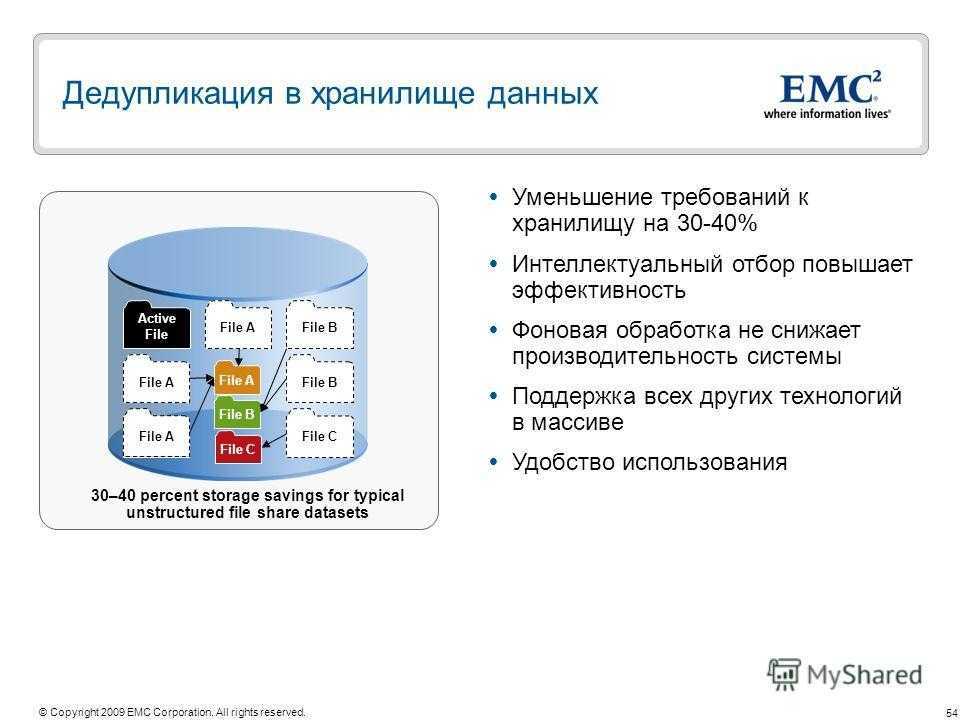
Дедупликация – это технология поиска повторяющихся данных на уровне файла, и замена их соответст-вующим указателем. Его можно использовать для уменьшения дискового пространства, а также полосы про-пускания, необходимой для передачи данных.
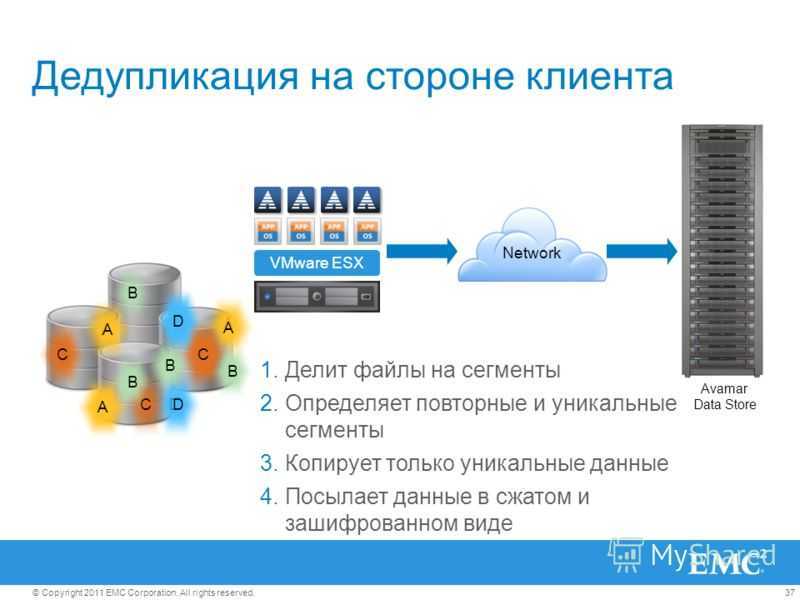
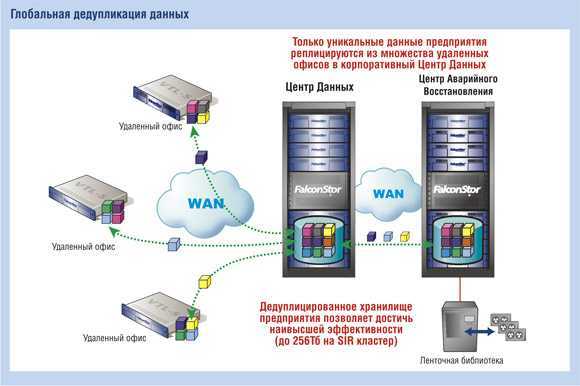
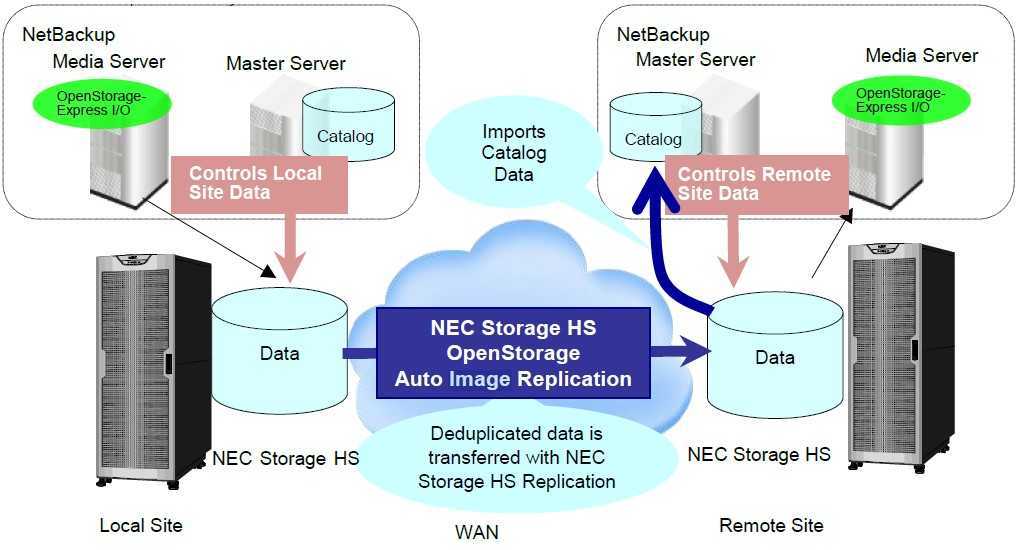

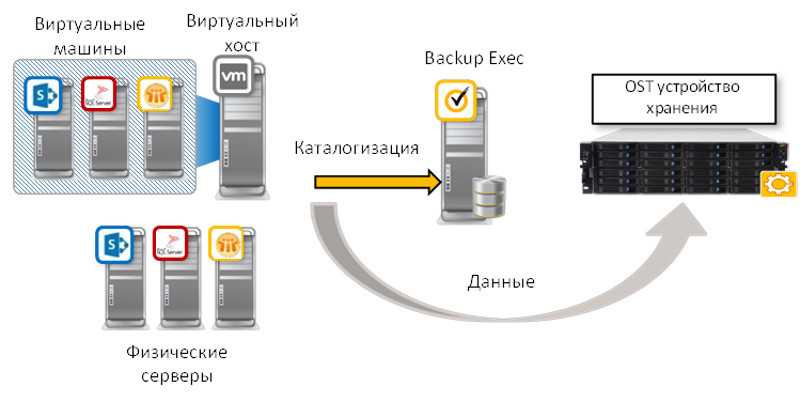

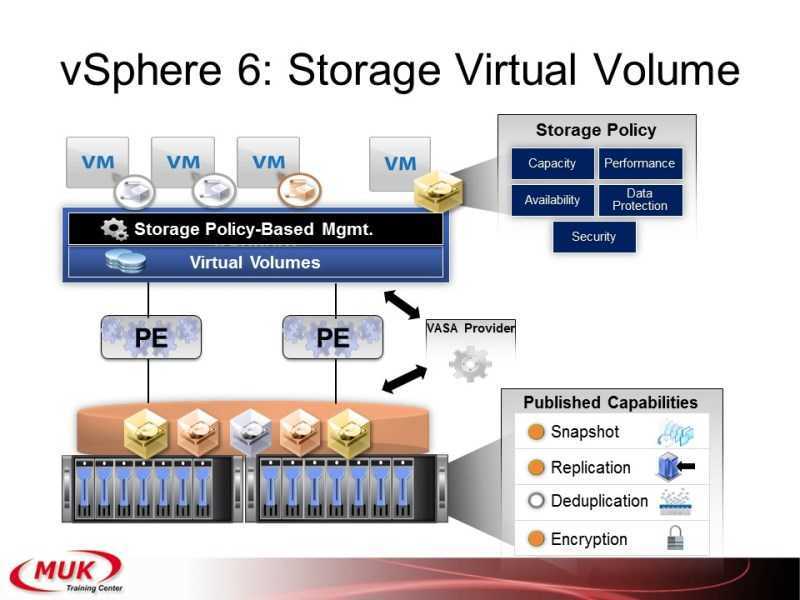
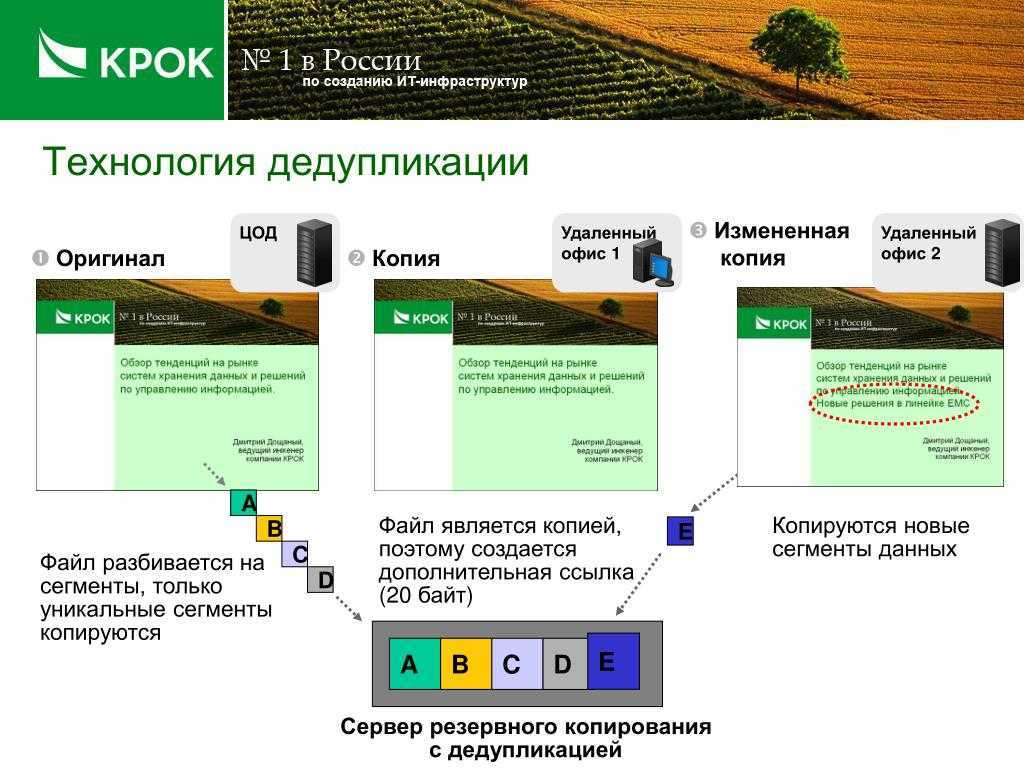
Существует несколько различных и приемлемых методов выполнения дедупликации — и хотя она, в боль-шинстве случаев, выполняется на уровне блоков данных, некоторые решения в состоянии обнаруживать различия между файлами на уровне даже одного байта. Разные методы могут иметь ограничения по произ-водительности, размеру оперативной памяти, поддержке программного обеспечения (ПО), а также простоте настройки репликации.
Результаты тестирования
Мы записали в тестовую папку 397 Гб образов виртуальных машин, создав 6 копий одинаковых данных и положили туда же обычную папку с инсталляционными файлами различных программ и игр. До начала дедупликации на томе было 1.69 Гб свободных данных и 397 Гб тестовых образов (на скриншоте ниже видно, что файлы занимают 381 Гб, так как используется сжатие на уровне файловой системы Btrfs).
Файловая дедупликация обрадовала своей скоростью — уже через 5 часов на диске было 1.9 Тб свободного места, а занятое пространство сократилось до 175 Гб.
Блочную дедупликацию на том же объеме провести не удалось — за сутки работы программы из 785 000 экстентов обработаны было всего 1200, расчеты на коленках показали, что тест на таком объеме будет идти два года, и возможно более быстрый процессор решил бы нашу задачу. На тестовом объеме в 1 Гб, удалось добиться той же точной дедупликации, что и в файловом методе. Естественно, в реальной жизни эффективность может быть другой, как выше, так и ниже. Что неприятно, так это невозможность прервать работу Duperemove; какие-то экстенты она отрабатывает за считанные секунды, а на какие-то тратит часы. И пока программа обрабатывает экстент, остановить или перезапустить контейнер не получится. В нашей тестовой машине использовался 2-ядерный процессор Celeron J3355, и возможно на топовых NAS-ах Synology с Xeon-ами, блочная дедупликация больших объемов данных будет проходить за считанные дни или часы.
Дедупликация и компрессия
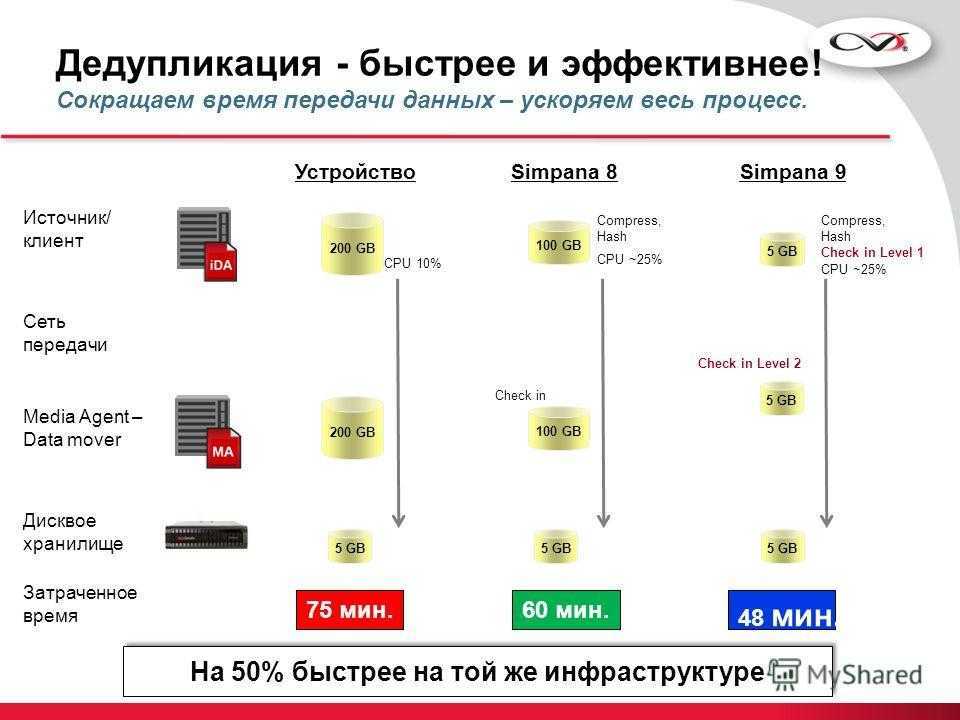
Дедупликация позволяет сократить время выполнения сжатия данных используя последовательную обработку данных дедупликацией, сокращая количество избыточных данных, и производя компрессию над уже дедуплицированными данными. При компрессии в общем виде представляет из себя изменение кодирования внутри блоков данных определенной длины. При сокращении количества блоков (в случае первоначальной обработки данных дедупликацией) время потраченное на компрессию будет меньше на время обработки для сокращенных блоков, а общий коэффициент сокращения объема данных будет так же меньше, чем при использовании одной компрессии, за счет сокращения количества сжатых объектов на выходе. Оценить параметры по времени можно зная среднюю скорость работы системы компрессии с определенным алгоритмом на целевой системе, среднюю скорость дедупликации данных, оценочный коэффициент дедупликации используемого для сокращения набора данных.
Применение последовательности из дедупликации и сжатия данных реализовано по умолчанию в продуктах Quantum DXI, В качестве примера на рисунке приведено изображение из управляющего интерфейса продукта Quantum DXiV1000 использующегося в качестве системы хранения резервных данных 4 баз данных MS SQL и дифференциальных резервных копий 4 однородных систем на платформе Microsoft Windows Server 2008R2 и одной системы на платформе Linux (дистрибутив openSuse 12.3).

Как видно из информации из управляющего интерфейса, общее сокращение объема после обработки сокращено в 12 раз (Total Reduction Ratio в блоке Data Reduction Statistics), при этом сокращение объема более чем в 5 раз приходится именно на обработку дедупликацией (Deduplication Ratio в блоке Data Reduction Statistics), с последующем сокращением дедуплицированных данных алгоритмом компрессии в более 2 раз(Compression Ratio) в блоке Data Reduction Statistics. Помимо самих данных требуется хранить метаданные, обеспечивая целостность данных, которые на данном наборе хранения занимают 11,8 ГБ (System Metadata в блоке Disk Usage), большей частью которых являются метаданные используемые при дедупликации данных.
Суммируя объем обработанных данных с объемом метаданных общий объем необходимый для хранения резервных копий данных сокращается в 10 раз, что является наглядным показателем эффективности применения технологии дедупликации данных.
Стоит ли вообще отказываться от использования накопителей на магнитных лентах
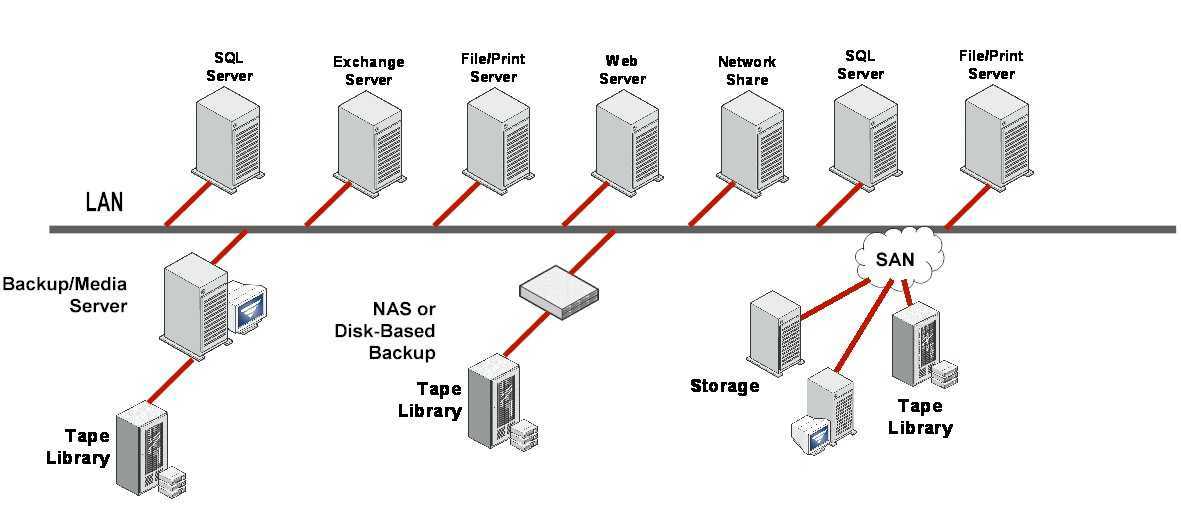
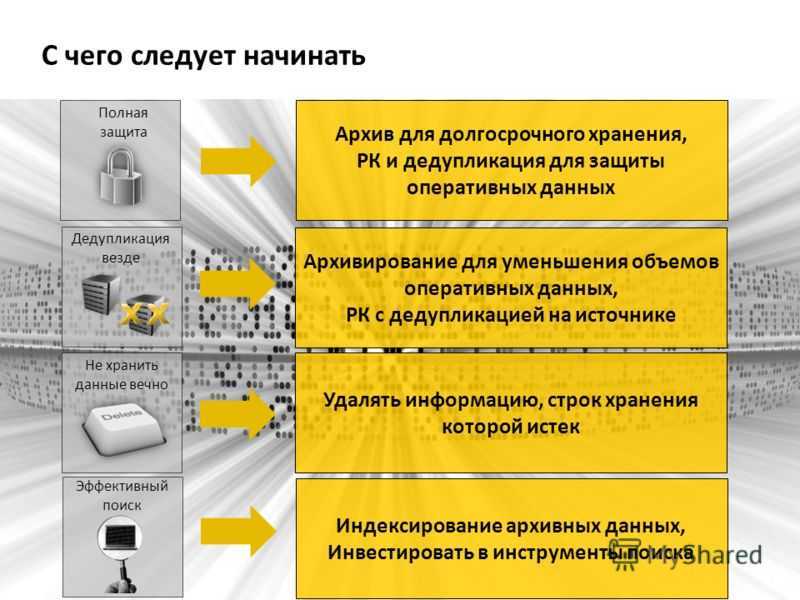
Хотя большинство конечных пользователей, которые применяют технологии дедупликации, уменьшают коэффициент использования своих съемных носителей, очень немногие из них отказываются от них полно-стью. И для этого есть вполне серьезная причина. Обычно, потребности пользователей в резервном копиро-вании можно разделить на три уровня: ежедневное резервное копирование и восстановление, краткосрочная защита от потери данных на случай аварий или стихийных бедствий, и долгосрочное хранение данных. Имеет смысл использовать разные технологии на каждом уровне.
Ежедневное резервное копирование и восстановление: у многих пользователей профили чтения и записи дисков позволяют им выполнять ежедневное резервное копирование и восстановление. Технология дедупликации позволяет им дольше хранить данные на диске, тем самым давая возможность несколько раз использовать эти профили для восстановления данных.
Краткосрочная защита от потери данных на случай аварий или стихийных бедствий: функции репликации, включаемая в технологию дедупликации, позволяет пользователям, имеющим несколько площадок, заменять съемные носители технологией удаленной репликации на случай аварий или стихийных бедствий. В результате, они получают больше точек восстановления, уменьшают затраты, и автоматизируют опера-ции, которые большинство вынуждено делать вручную.
Долгосрочное хранение данных: съемные носители продолжают оставаться экономически выгодным и без-опасным решением. Они потребляют меньше электрической энергии, занимают меньше места, и требуют меньше охлаждения в любой СХД, что делает их предпочтительным средством долгосрочного хранения данных. Новые технологии с использованием накопителей на магнитных лентах (НМЛ), в том числе шиф-рование и анализ целостности информации, сделали их более безопасными и надежными.
Какой самый простой способ внедрения дедупликации?
Большинство ИТ-подразделений стоят перед выбором – либо устанавливать специализированные устройст-ва дедупликации, либо выполнять дедупликацию с помощью программного обеспечения для резервного копирования. На вопрос о том, какой подход проще нет однозначного ответа. Тем не менее, можно дать не-сколько рекомендаций.
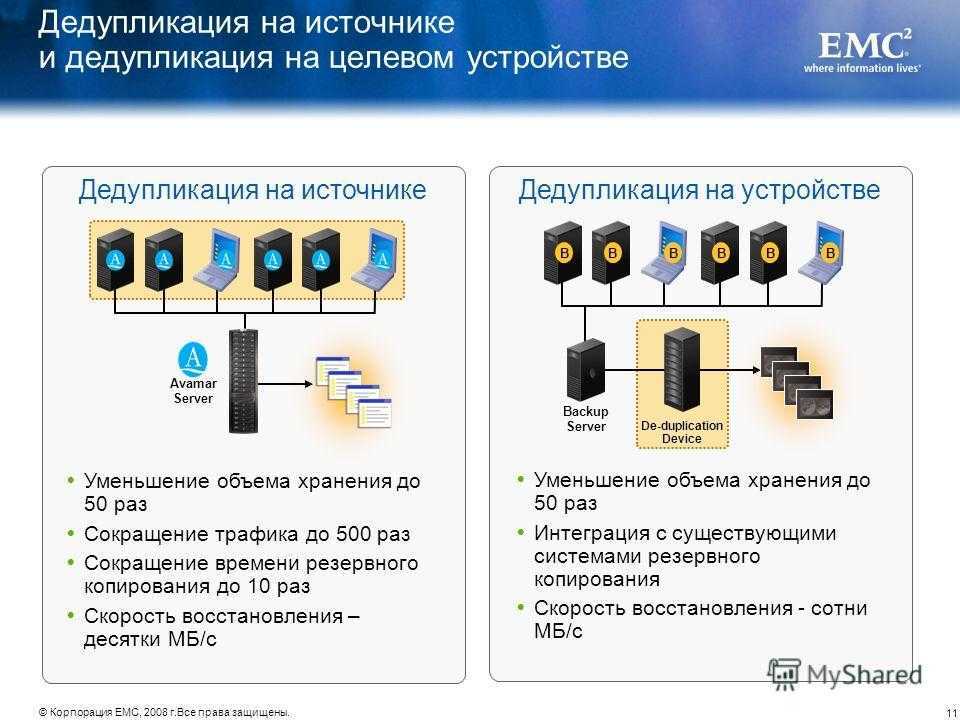
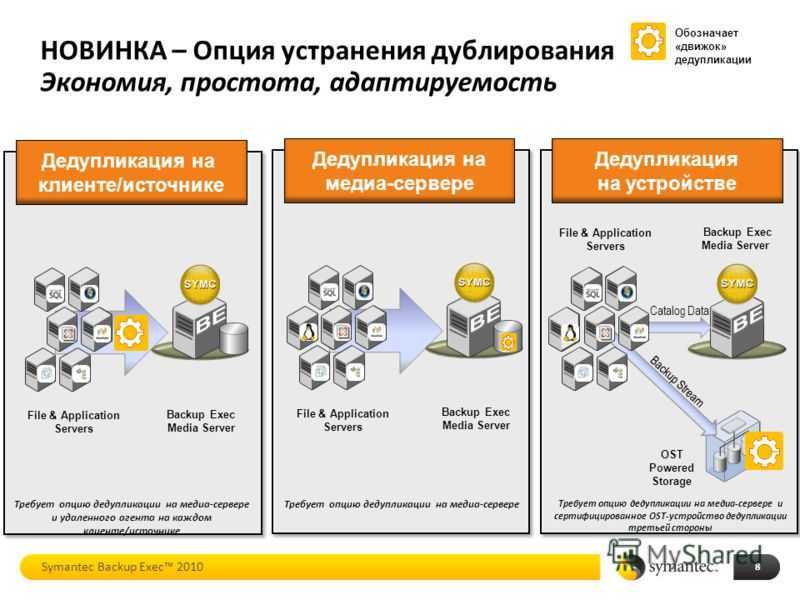
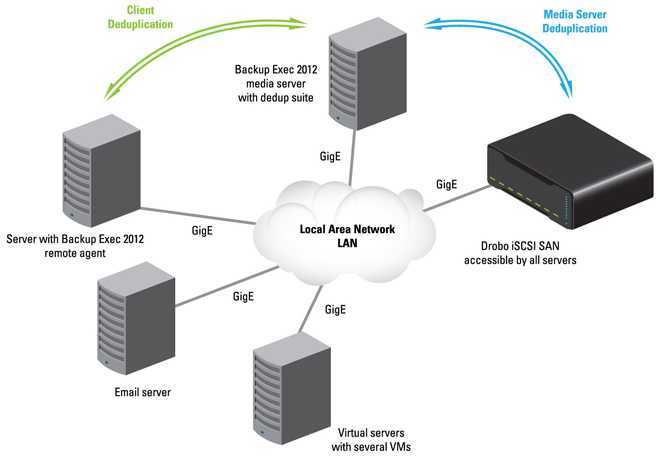
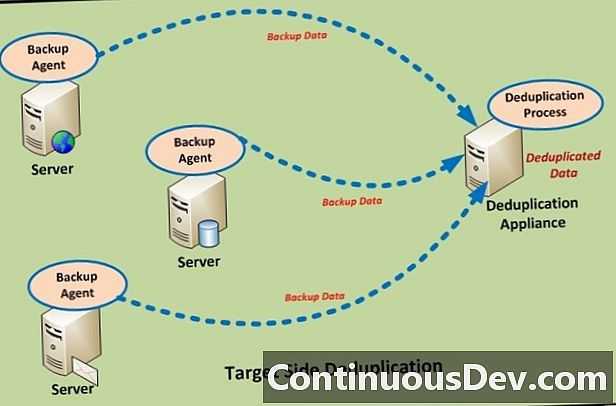
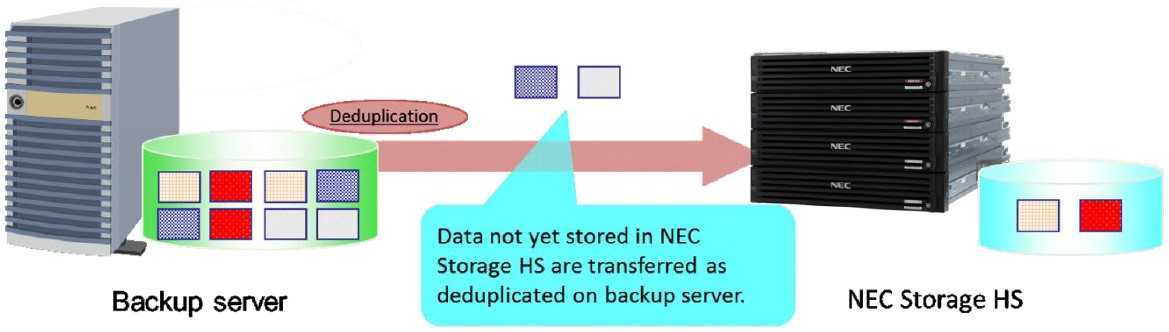
При использовании специализированных устройств дедупликации, сейчас это наиболее распространенный метод дедупликации, все резервные копии данных отправляются специализированный сервер, и там выпол-няется дедупликация. В этом случае, пользователи могут заменять или дополнять установленные целевые системы резервного копирования с минимальными изменениями общей методологии резервного копирова-ния. Поскольку дедупликация выполняется на специализированном устройстве, она не приводит к увеличе-нию нагрузки на клиенты резервного копирования или медиа серверы, и это упрощает выполнение таких операций как репликация. Этот метод является не только самым распространенным, но и самым разрабо-танным. Его использование подразумевает более быструю установку и меньшие требования к сервисному обслуживанию.
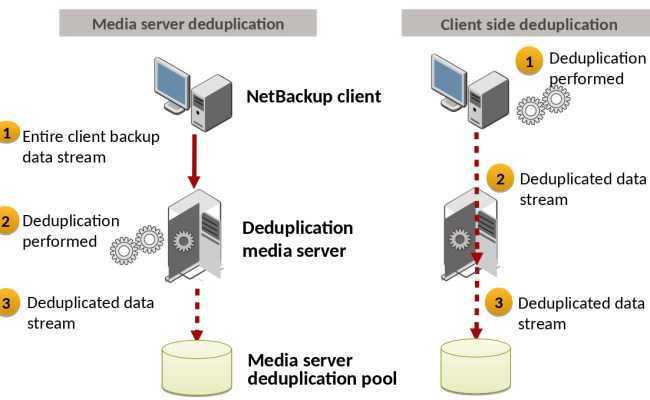
При использовании программ, система резервного копирования включает дедупликацию в список других задач, которые выполняются либо на клиентах резервного копирования, либо на медиа серверах. Выполне-ние дедупликации данных перед их отправкой на целевую систему позволяет уменьшать объем данных, ко-торые необходимо передавать по сети. Эта идея аналогична выполнению сжатия данных в программе, и, между прочим, дедупликация данных почти всегда включает сжатие данных. Поскольку дедупликация яв-ляется относительно ресурсоемкой операцией, есть вероятность замедления операций резервного копирова-ния, поэтому может потребоваться добавление новых серверов или специализированных СХД. Это может увеличивать стоимость системы и сложность интеграции.
В определенных обстоятельствах может подходить любой из описанных выше подходов. Для того чтобы решить, какой из них лучше подходит в вашей ситуации, определите критические элементы своей системы, коэффициент использования своих медиа серверов, а также уровень интеграции, который будет оправдан в данной ситуации.

Установка Docker и образа Debian
Убедившись, что у вас на NAS-е файловая система Btrfs, открываем «Пуск — центр пакетов», листаем вниз и инсталлируем Docker.
Запускаем Docker и во вкладке «Реестр» выбираем образ debian:latest. Мы будем использовать именно этот образ, хотя точно так же должно работать и в Ubuntu и в Centos.
Переходим на вкладку «Образ», жмем «Запустить» — наш контейнер запущен. Останавливаем его, кликая на выключатель справа.
Выделив контейнер Debian1, жмем кнопку «Настройки». Нам надо предоставить контейнеру полный доступ к DSM, поэтому выбираем эту галочку, после чего настраиваем ограничение ресурсов. По умолчанию duperemove использует все ядра процессоров и может скушать всю память, доступную в системе. Сам процесс дедупликации очень ресурсоемкий и долгий, поэтому лучше ограничить ресурсы контейнеру, выделив не более половины ядер CPU и около половины используемого объема ОЗУ. Когда дедупликация закончится, все лишние данные из памяти будут удалены. Это вам не ZFS, тут хранить таблицы экстентов в памяти не нужно.
По умолчанию наш контейнер не видит файлы и директории, которые хранятся на NAS-е, и надо «пробросить» физические каталоги в его виртуальную среду. Жмем кнопку «дополнительные настройки», переходим в закладку «Том» и жмем кнопку «Добавить папку». Выбираем нужную нам папку, это может быть как корневая, так и любая вложенная, жмем «OK» и вводим путь внутри контейнера, куда будет смонтирована папка NAS-а, пусть это будет /tmp/hwp_vmware. Если нужно добавить несколько папок NAS-а, повторяем этот шаг несколько раз.
Вообще, как я говорил, дедупликация в Btrfs- очень тяжелый для системы процесс, поэтому имеет смысл проводить её выборочно, например только для папки с образами виртуальных машин или другими дублирующимися данными. Причем, лучше сделать несколько копий контейнера для разных папок и запускать, например, каждый из них отдельно по расписанию (как настроить запуск контейнеров по расписанию — ищите в гугле), а мы идем дальше.
Запускаем наш контейнер, нажав на выключатель справа. Нажимаем кнопку «Сведения», открывается новое окно. Нажимаем «Терминал», и чуть подождав, попадаем в интерфейс командной строки. У нас совершенно «голый» debian, в котором нет даже доступа по SSH, поэтому лучше и быстрее один раз ввести длинный URL с клавиатуры, чем пробрасывать порты внутрь контейнера и заходить из терминальной программы.
Заходим в папку, /tmp
Включаем права root и устанавливаем wget
Update: программа Duperemove была включена в тестовый репозиторий buster, поэтому подключаем его.
добавляем в конец
deb http://deb.debian.org/debian buster main
Все, теперь все что нужно — у нас есть, пришло время запустить дедупликацию!
, где
- -r — ходить по каталогам внутри (рекурсивно)
- -d — произвести дедупликацию
- -h — вывести отчет на человеческом языке
- —hashfile=hwp_hash — файл в котором будут храниться хэши на время дедупликации. Если его не указать, все хэши будут храниться в ОЗУ и это может привести к переполнению памяти и ошибке программы. По окончанию процесса, этот файл автоматически будет удален. На время процедуры он лежит в папке /tmp
- ./hwp_vmware — путь к смонтированному каталогу внутри контейнера, который ведет в каталог на NAS-е
Процесс дедупликации очень долгий — на процессорах серии Celeron он может занимать несколько дней или даже недель для папки объемом в 1 Тб. Сначала программа создаст набор хэшей для экстентов каждого файла внутри смонтированного каталога, а потом начнет удалять их из самих файлов. Если процесс прервать, придется начинать с самого начала. В случае если во время дедупликции сервер будет выключен (пропадет электричество или все повиснет) — после перезагрузки ничего не должно сломаться. Мы проверяли это 3 раза во время тестирования — данные были целы.

Intro
The amount of data we use grows every day. Everyone can notice this trend with the ever-expanding range of devices, all of which are collecting and storing data 24/7. In the IT world, these devices make up the Internet of Things (IOT). Microsoft says that by 2020, the amount of created information per person (sic!) will be just above 5 TB. With that said, everyone is participating in this trend but only a few must deal with it in their everyday work. It’s no secret that data management is an important part of a system administrator’s agenda. We are constantly looking to implement technologies and services that allow us to manage information flow better and let us store data efficiently without eating up our budget. There are many ways to achieve that but today I wanted to talk about one special example — Data Deduplication technology (often referred as “Dedup”), developed by the Microsoft Windows Server team. While the technology itself is interesting, it’s much more interesting to me if I can leverage it to save some space for my Veeam backup repository. So, this article should be useful for people who are considering data deduplication technology and would like to know its benefits as well as practical savings with specific Veeam scenarios.
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
How to run Data Deduplication
Enabling Dedup is as easy as adding a new server feature via Server Manager (Figure 1). As an alternative, you are able to install Windows Server Data Deduplication by running a simple PowerShell cmdlet:
Now, you can go to the list of disk volumes in Server Manager and enable Data Deduplication on NTFS volumes (ReFS is not supported yet), which are not system volumes (Figure 1) or again use PowerShell:
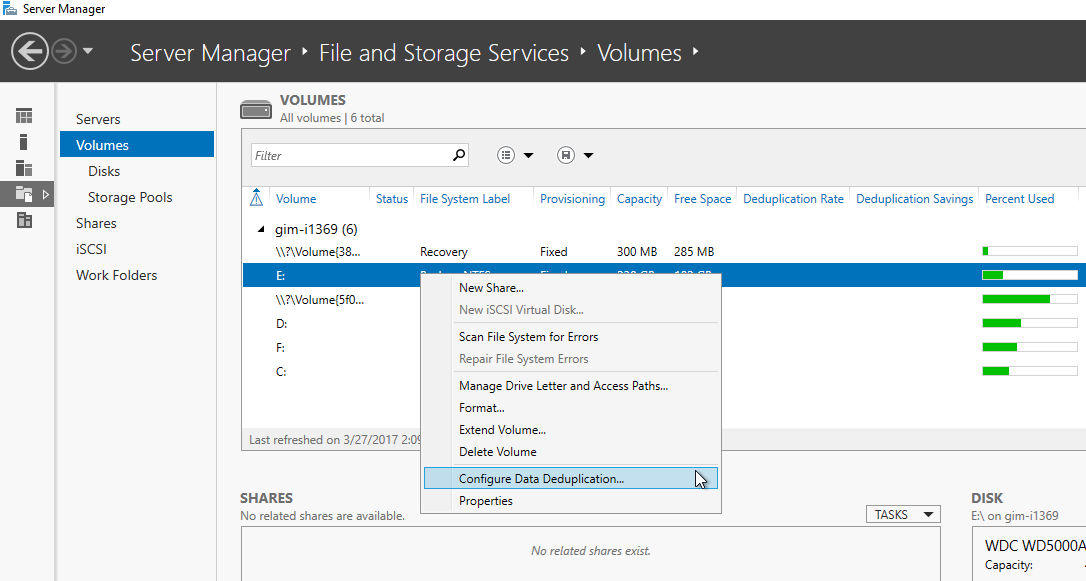 Figure 1. Enabling Dedup on disk volume
Figure 1. Enabling Dedup on disk volume
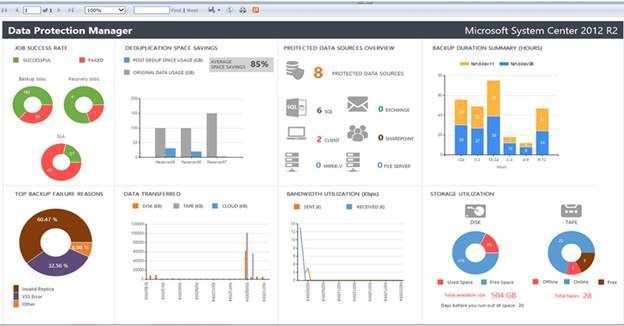
Then, you will need to select the schedule for the data deduplication job and adjust the default settings if required. Now, the feature is running and you should be getting your results as scheduled. It’s helpful to use PowerShell cmdlets to get more insight on the process. Get-DedupSchedule lists information about all deduplication tasks are that are configured on a system. Get-DedupJob shows the running Dedup job and its progress. Get-DedupStatus allows to see the details of the task: Amount of saved space and number of processed files on a volume. (Figure 2)
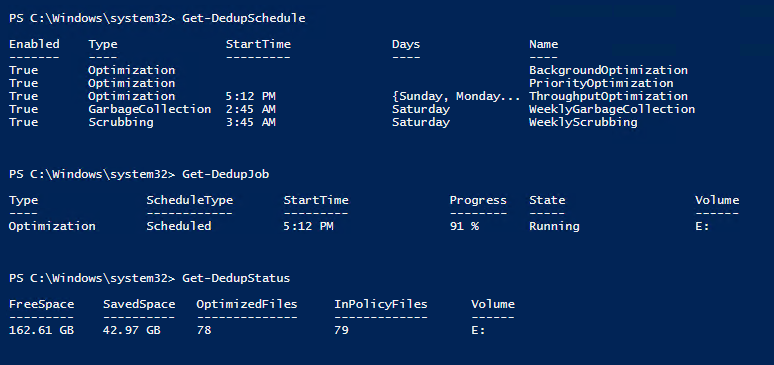
Figure 2. Useful PowerShell cmdlets for Dedup
Файловая дедупликация
Один из более быстрых вариантов — файловая дедупликация. В отличии от блочной, она работает целиком с файлами, и если находит два одинаковых — один как бы удаляет, указывая файловой системе, что его содержимое можно взять по другому адресу. Для пользователя этот процесс никак не заметен — у вас по-прежнему будут доступны все одинаковые файлы, только места они будут занимать как один оригинал. Это гораздо менее ресурсоемкий процесс, но и не такой эффективный, как блочная дедупликация, но при наличии первой, вторая не требуется. Давайте вернемся в наш контейнер и запустим файловую дедупликацию. Открываем контейнер и заходим в терминал, как показано ранее.
Устанавливаем программу fdupes, которая составляет список дублирующихся файлов
Теперь запускаем поиск и дедупликацию в нашей папке, как в примере выше
Аналогично, программа пройдет по всем файлам указанного каталога, создаст для них хэши и попросит программу duperemove сообщить файловой системе о наличии дубликатов и провести очистку.
Ну что, давайте протестируем как оно работает?
Типы дедупликации и их применение
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!



3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскрою свои таланты.
Заключение
Если вы знакомы с контейнерами, то сможете настроить автоматический запуск дедупликации по расписанию, не дожидаясь, пока Synology введет поддержку этой функции в DSM. Как уже было сказано выше, имеет смысл сделать отдельные контейнеры для отдельных папок и запускать их по очереди. Я тестировал работу блочной дедупликации на чистом Linux-е без контейнеров, и там этот процесс занимал на точно таком же процессоре всего несколько часов. Видимо, Docker является слишком толстой прослойкой, поглощающей ресурсы CPU.
Дедупликация не работает на зашифрованных папках.
Да, конечно Btrfs — это не ZFS, где дедупликация происходит на лету во время записи данных на диск. Но если достичь в DSM той же производительности, что на Debian 9, то можно проводить этот процесс еженедельно или по ночам, получая тот же эффект экономии, который дает ZFS.
Михаил Дегтярёв (aka LIKE OFF)
14/06.2018



