
Начните с профиля вашей компании сегодня
Надеемся, что эти советы, шаблоны и образцы — именно то, что вам нужно, чтобы работать над профилем вашей компании. Просто не забывайте обновлять его с любыми дополнениями, изменениями или заслуживающими внимания элементами.
Написание профиля компании — не единственное место, где шаблоны пригодятся. Например, существует множество шаблонов и советов для проведения эффективных собраний , помогающих вам оставаться продуктивными и вывести свою компанию на новый уровень. Вы также можете использовать шаблоны, которые помогают хранить протоколы заседаний или шаблоны для написания документов бизнес-требований. документов
Изображение предоставлено: Raevsky Lab / Shutterstock
Извлекаем файлы из HTML методами String объекта
Одним из методов извлечения информации HTML файла могут быть string методы. Например, .find() для поиска через текст .
.fing() возвращает индекс первого входа нужного нам символа/тега. Покажем на примере «<title>» методом .find().
>>> title_index = html.find("<title>")
>>> title_index
14
Для того чтобы найти начало заголовка нам нужно к индексу добавить длину тега «<title>».
>>> start_index = title_index + len("<title>")
>>> start_index
21
Также можем найти место где заканчивается «<title>»:
>>> end_index = html.find("</title>")
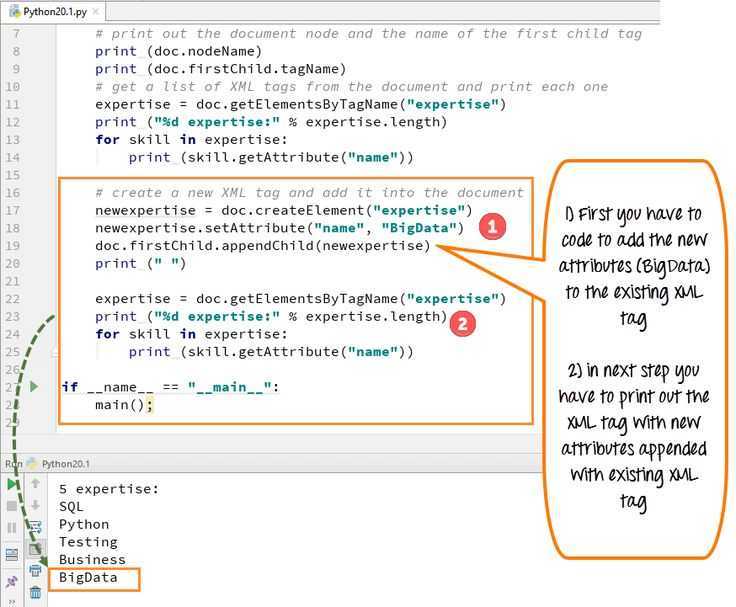
>>> end_index
39
Наконец, мы можем извлечь всё что находится в «<title>», зная первый и последний индекс:
>>> title = html >>> title 'Profile: Aphrodite'
На самом деле, HTML файл может быть намного менее предсказуемым, чем на Aphrodite странице. Поэтому далее мы вам покажем другой способ, который может решить эту задачу.
Регулярные выражения
Регулярные выражения — это паттерны, которые используются для поиска внутри текста типа string. Для этого нам нужна библиотека re.
Мы импортируем модуль re.
>>> import re
Регулярные выражения используют специальные метасимволы для определения разных паттернов. Например символ «*» разрешает вводить любые символы после себя.
Покажем на примере .findall() мы будем искать все совпадения с требуемым для нас выражением (первый элемент — то что мы ищем, второй — в каком тексте).
>>> re.findall("ab*c", "ac")
Используя параметр re.IGNORECASE позволяет методу не учитывать регистр.
>>> re.findall("ab*c", "ABC")
[]
>>> re.findall("ab*c", "ABC", re.IGNORECASE)
Метод .replace() — заменяет все символы в тексте на требуемые нам символы.
Метод .sub() — «<.*>» для замены всего что находится между < и >.
Давайте взглянем ближе на регулярные выражения:
- <title*?> — отмечает открытие тега «title»
- *? — отмечает весь текст после открытие тега «<title>»
- </title*?> — отмечает элемент, который закрывает тег.
Конструктор
Конструктор работает по простому принципу — методист формирует блоки курса, а темы для подробного обсуждения выбирают сами участники. Это своеобразная дженга, когда полностью убрать тот или иной уровень не получится, но в наших силах вытащить отдельные кубики и поэкспериментировать с ними.
Как и в случае с групповым проектом, этот формат позволяет ученикам влиять на программу, подбирать что-то полезное для себя и заодно погружаться в теорию, без которой выбрать практику невозможно.
Для чего подходит
Для преподавания очень объёмных, но непрофильных для конкретной целевой аудитории тем, которые нужно «вложить» в них за короткий срок. Например, курс права для студентов-экономистов (понятно, что за один семестр невозможно изучить всё то, что студенты-юристы проходят за четыре года, поэтому создаётся курс-ликбез по основам).
Конструктор можно использовать и в образовательных учреждениях, и в корпоративном обучении.
Как применяется
Подобный формат я делала несколько лет назад для студентов ИТМО, когда мне предложили прочитать им курс с ёмким названием «Психология». Задача была сложной, поскольку в техническом вузе знаний по психологии даётся минимум, и есть всего одна попытка, чтобы увлечь ребят предметом и не разочаровать их. При этом глубоко погрузиться в тему психологии за 5–6 занятий просто невозможно, поэтому и был задействован конструктор: на лекции я давала студентам теорию, а они на основании этого материала выбирали тему, которую хотели бы изучить подробнее, и предлагали обоснование своего выбора. Те, кто не посещал лекции, не могли повлиять на выбор практической темы — благодаря этому бонусу я получила лучшую посещаемость за все курсы, которые когда-либо вела.
Эта статья подготовлена на основе вебинара «Больше, чем лекция: 6 неклассических способов провести курс», который прошёл на онлайн-площадке «Ра-курс».
обложка: Оля Ежак для Skillbox
Пример HTML-кода страницы
В последующих примерах будет использован данный HTML-файл:
XHTML
<!DOCTYPE html>
<html>
<head>
<title>Header</title>
<meta charset=»utf-8″>
</head>
<body>
<h2>Operating systems</h2>
<ul id=»mylist» style=»width:150px»>
<li>Solaris</li>
<li>FreeBSD</li>
<li>Debian</li>
<li>NetBSD</li>
<li>Windows</li>
</ul>
<p>
FreeBSD is an advanced computer operating system used to
power modern servers, desktops, and embedded platforms.
</p>
<p>
Debian is a Unix-like computer operating system that is
composed entirely of free software.
</p>
</body>
</html>
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
<!DOCTYPE html> <head> <title>Header</title> <meta charset=»utf-8″> </head> <body> <h2>Operating systems</h2> <ul id=»mylist»style=»width:150px»> <li>Solaris</li> <li>FreeBSD</li> <li>Debian</li> <li>NetBSD</li> <li>Windows</li> </ul> <p> FreeBSD is an advanced computer operating system used to </p> <p> Debian is a Unix-like computer operating system that is </p> </body> </html> |
Создание парсера на Python:
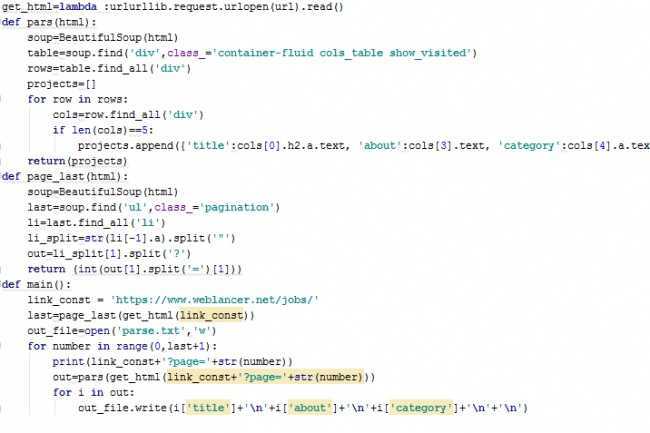
Теперь перейдём к разработки парсера, тут будет два примера, первый простой, просто получим страницу и запишем в файл, а второй уже сделаем список статей из сайта, в качестве примера будем использовать сайт stopgame.ru.
Первый пример:
Первый пример очень простой, и очень короткий, вот он:
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
importrequests# Импортируем библиотек Requests defmain() # URL страницы url=’https://stopgame.ru/’ # Получаем страницу r=requests.get(url) # Открываем файл withopen(‘test.html’,’w’,encoding=’utf-8′)asoutput_file # Выводим страницу в HTML файл output_file.write(r.text) if__name__==’__main__’ main() |
В этом файле мы первым делом подключили библиотеку Requests, потом создали функцию в которой будет вся логика программы.
Внутри функции мы создали переменную с адресом страницы и получили её, сделали это с помощью , которая соответственно получает данные страницы, там cookce и т.д, но нам нужен только текст.

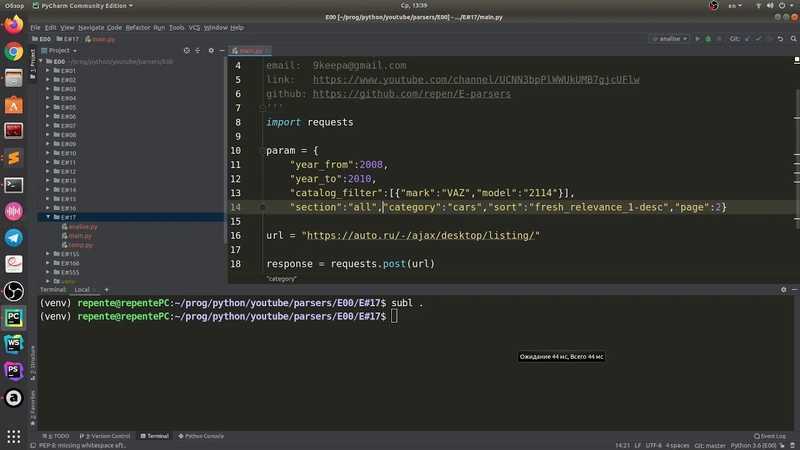




Последнее мы открываем файл «text.html», и записываем в него весь HTML который получили, запускаем программы, открываем файл и вот что получается:
Вот такой на Python парсер страниц получился, как видите мы получили весь документ, единственное мы не получили стили, поэтому всё так выглядит, их надо отдельно парсить.
Второй пример:
Второй пример уже не много более сложный и там мы уже будем использовать библиотеку Beautiful Soup, вот код:
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
importrequests# Импорт библиотеки Requests frombs4 importBeautifulSoup# Импорт библиотеки Beautiful Soup defmain() # URL страницы url=’https://stopgame.ru/news/all/p1′ # Получаем страницу r=requests.get(url) # Открываем файл withopen(‘test.html’,’w’,encoding=’utf-8′)asoutput_file # Добавляем страницу для парсинга soup=BeautifulSoup(r.text,’html.parser’) # Получаем все по селектору элементы и проходима по ним циклам foriinsoup.select(«.items > .article-summary > .article-description») # Получаем заголовок title=i.select(«.caption > a») # Добавляем заголовок во файл output_file.writelines(«<h2>»+title.text+»</h2>») if__name__==’__main__’ main() |
Тут в начале всё точно также как и в первом пример, только добавляем Beautiful Soup, потом до открытия файла опять же делаем всё как в первом примере.
Когда открыли файл, начинаем парсить страницу с помощью Beautiful Soup, и создаём цикл, где по селектору выбираем нужные элементы страницы, это делается благодаря методу и проходимся по ним циклам.
Внутри цикла же опять по селектору выбираем заголовок и добавляем его в качестве строки в файл, запускаем программу и смотрим файл.

Как видите парсер на Python с нуля работает, для этого вам нужно знать только метод , для библиотеки Beautiful Soup, ну и селекторы CSS, вот и всё.
Также для более качественного вывода в HTML, например виде таблицы, рекомендую использовать библиотеку LXML.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Scrapy сделает для вас все!
Из этого руководства вы узнали о Scrapy, о его отличиях от BeautifulSoup, о Scrapy Shell и о создании собственных проектов. Scrapy перебирает на себя весь процесс написания кода: от создания файлов проекта и папок до обработки дублирующихся URL. Весь процесс парсинга занимает минуты, а Scrapy предоставляет поддержку всех распространенных форматов данных, которые могут быть использованы в других программах.
Теперь вы должны лучше понимать, как работает Scrapy, и как использовать его в собственных целях. Чтобы овладеть Scrapy на высоком уровне, нужно разобраться со всеми его функциями, но вы уже как минимум знаете, как эффективно парсить группы веб-страниц.
BeautifulSoup метод replace_with() замена текста в теге
Метод заменяет содержимое выбранного элемента.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
tag = soup.find(text=»Windows»)
tag.replace_with(«OpenBSD»)
print(soup.ul.prettify())
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) tag=soup.find(text=»Windows») tag.replace_with(«OpenBSD») print(soup.ul.prettify()) |
В примере показано, как при помощи метода найти определенный элемент, а затем, используя метод , заменить его содержимое.
Получение значения соответствующих атрибутов
Итак, теперь наша задача — получить значение внутри атрибута с помощью нашего Python XML Parser.
Его позиция от корневого узла — , поэтому нам нужно перебрать все совпадения на этом уровне дерева.
Мы можем сделать это с помощью , где level — это желаемая позиция (в нашем случае ).
for tag in root_node.find_all(level):
value = tag.get(attribute)
if value is not None: print(value)
получит значение нашего на уровнях, на которых мы ищем. Итак, нам просто нужно сделать это в и получить значения атрибутов и . Это оно!





import xml.etree.ElementTree as ET
# We're at the root node (<page>)
root_node = ET.parse('sample.xml').getroot()
# We need to go one level below to get <header>
# and then one more level from that to go to <type>
for tag in root_node.findall('header/type'):
# Get the value of the heading attribute
h_value = tag.get('heading')
if h_value is not None:
print(h_value)
# Get the value of the text attribute
t_value = tag.get('text')
if t_value is not None:
print(t_value)
Выход
XML Parsing in Python Hello from AskPython. We'll be parsing XML
Мы получили все значения на этом уровне нашего дерева синтаксического анализа XML! Мы успешно проанализировали наш XML-файл.
Возьмем другой пример, чтобы все прояснить.
Теперь предположим, что XML-файл выглядит так:
<data>
<items>
<item name="item1">10</item>
<item name="item2">20</item>
<item name="item3">30</item>
<item name="item4">40</item>
</items>
</data>
Здесь мы должны не только получить значения атрибутов , но также получить текстовые значения 10, 20, 30 и 40 для каждого элемента на этом уровне.
Чтобы получить значение атрибута , мы можем сделать то же самое, что и раньше. Мы также можем использовать чтобы получить значение. Это то же самое, что и , за исключением того, что он использует поиск по словарю.
attr_value = tag.get(attr_name) # Both methods are the same. You can # choose any approach attr_value = tag.attrib
Получить текстовое значение просто. Просто используйте:
tag.text
Итак, наша полная программа для этого парсера будет:
import xml.etree.ElementTree as ET
# We're at the root node (<page>)
root_node = ET.parse('sample.xml').getroot()
# We need to go one level below to get <items>
# and then one more level from that to go to <item>
for tag in root_node.findall('items/item'):
# Get the value from the attribute 'name'
value = tag.attrib
print(value)
# Get the text of that tag
print(tag.text)
Выход
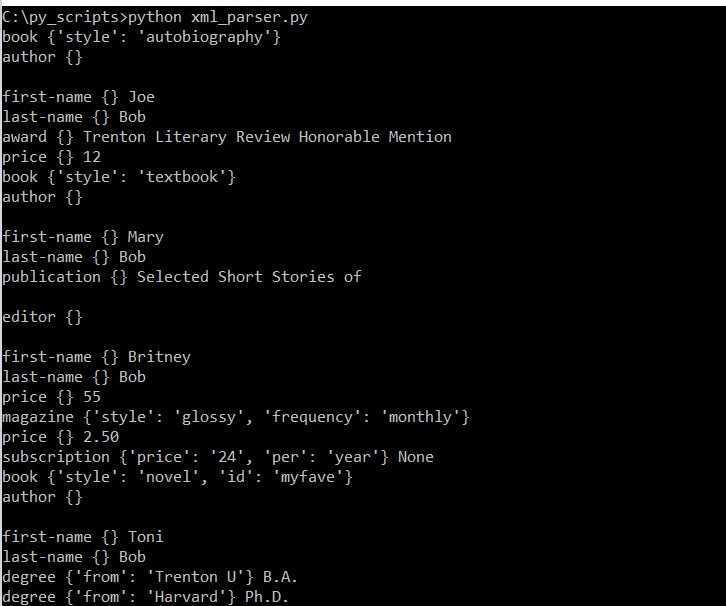
item1 10 item2 20 item3 30 item4 40
Вы можете расширить эту логику на любое количество уровней и для файлов XML произвольной длины! Вы также можете записать новое дерево синтаксического анализа в другой файл XML.
BeautifulSoap перебираем HTML теги
Метод позволяет перебрать содержимое HTML-документа.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
for child in soup.recursiveChildGenerator():
if child.name:
print(child.name)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) forchild insoup.recursiveChildGenerator() ifchild.name print(child.name) |
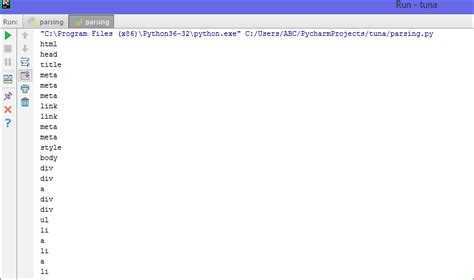
Данный пример позволяет перебрать содержимое HTML-документа и вывести названия всех его тегов.
Shell
$ ./traverse_tree.py
html
head
title
meta
body
h2
ul
li
li
li
li
li
p
p
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$.traverse_tree.py html |
Данные теги являются частью рассматриваемого HTML-документа.
Делайте обновления API удобными для пользователей
Если вы документируете API, для которых часто отправляются пользователям обновления, актуализация документации может предоставить сложности. Но обновление API тоже может быть сложным для пользователей. Ваша стратегия продукта — решение компании, но в целом сохранение обратной совместимости — весьма желательно. Если вы вынуждены отказаться от старой версии API, отправьте пользователям всю необходимую информацию.
Эджайл-методология также предоставляет хорошие процессы для уверенности в том, что документация актуальна. Если разработана новая функция, ваш процесс должен препятствовать отметке о том, что функция готова, до тех пор, пока не будет документации. Убедитесь, что основная документация имеет понятные контрольные точки для разработки и улучшений.
Изучите сайт перед тем, как начать писать код
Прежде чем начать писать программу, нужно понять содержание и структуру страницы. Это можно сделать довольно просто при помощи браузера. Мы будем использовать DevTools Chrome, но в других браузерах есть аналогичные инструменты.
Например, мы можем открыть любую страницу продукта на Amazon. Беглый просмотр покажет нам название продукта, цену, доступность и многие другие поля. Перед копированием всех этих селекторов мы рекомендуем потратить пару минут на поиск скрытых входных данных, метаданных и сетевых запросов.
Пользуясь Chrome DevTools или аналогичными инструментами, проявляйте осторожность. Контент, который вы увидите, возможно, был изменен в результате работы JavaScript и сетевых запросов
Да, это утомительно, но иногда нужно исследовать исходный HTML, чтобы избежать запуска JavaScript.
Дисклеймер: мы не будем включать URL-запрос в фрагменты кода для каждого примера. Все они похожи на первый. И помните: сохраняйте HTML-файл локально, если собираетесь протестировать его несколько раз.
Скрытые инпуты
Скрытые инпуты позволяют разработчикам включать поля ввода, которые конечные пользователи не могут видеть или изменять. Многие формы используют их для включения внутренних идентификаторов или токенов безопасности.
В продуктах Amazon мы видим, что их довольно много. Некоторые из них будут доступны в других местах или форматах, но иногда они уникальны. В любом случае имена скрытых инпутов обычно более стабильны, чем имена классов.
Метаданные
Хотя некоторый контент отображается через пользовательский интерфейс, его может быть проще извлечь с помощью метаданных. Например, можно получить количество просмотров в числовом формате и дату публикации в формате ГГГГ-ММ-ДД для видео на YouTube. Да, эти данные можно увидеть на сайте, но их можно получить и с помощью всего пары строк кода. Несколько минут на написание кода точно окупятся.
interactionCount = soup.find('meta', itemprop="interactionCount")
print(interactionCount) # 8566042
datePublished = soup.find('meta', itemprop="datePublished")
print(datePublished) # 2014-01-09
XHR-запросы
Некоторые сайты загружают пустой шаблон и вставляют в него все данные через XHR-запросы. В таких случаях проверки исходного HTML будет недостаточно. Нам нужно исследовать сеть, в частности XHR-запросы.
Возьмем, к примеру, Auction. Заполните форму с любым городом и выполните поиск. Вы будете перенаправлены на страницу результатов, которая, пока выполняются запросы для введенного вами города, представляет собой страницу-каркас.
Это вынуждает нас использовать headless-браузер, который может выполнять JavaScript и перехватывать сетевые запросы. Иногда вы можете вызвать конечную точку XHR напрямую, но обычно для этого требуются файлы cookie или другие методы аутентификации. Или вас могут немедленно забанить, поскольку это не обычный путь пользователя. Будьте осторожны.





Мы наткнулись на золотую жилу! Взгляните еще раз на изображение.
Все возможные данные, уже очищенные и отформатированные, готовы к извлечению. А также геолокация, внутренние идентификаторы, цена в числовом виде без форматирования, год постройки и т. д.
Устанавливаем библиотеку Beautiful Soup (Linux)
Прекрасным преимуществом этой библиотеки является наличие персонального алгоритма структурирования HTML-кода. А это уже позволяет сэкономить разработчику время, что не может не радовать. Итак, устанавливаем:
$ apt-get install python-bs4 $ apt-get install python-lxml $ apt-get install python-html5lib
Установив нужные модули, можем парсить сайт. В результате мы получим его структурированный код:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib2 import urlopen
html_doc = urlopen('http://otus.ru').read()
soup = BeautifulSoup(html_doc)
print soup
Чтобы выполнить поиск по ссылкам:
for link in soup.find_all('a'):
print link.get('href')
# Содержимое ссылок
for link in soup.find_all('a'):
print link.contents
А вот так работает парсер DIV-блоков:
# Содержимое из <div class="content"> ... </div>
print soup.find('div', 'content')
# Блок: <div id="top_menu"> ... </div>
print soup.find('div', id='top_menu')
Если хотим получить ссылки на изображения:
for img in soup.find_all('img'):
print img.get('src')
Как видим, ничего сложного нет. Но если хотите узнать больше, вы всегда можете записаться на курс «Разработчик Python» в OTUS!
Технологии ближайшего будущего
15. Плазменное силовое поле, защищающее автомобили от несчастных случаев и столкновений
Компания Boeing запатентовали метод создания плазменного поля, быстро нагревая воздух, чтобы быстро поглощать ударные волны.
Силовое поле можно будет генерировать с помощью лазеров или микроволнового излучения. Созданная плазма представляет собой воздух, нагретый до более высокой температуры, чем окружающий воздух, с другой плотностью и составом. Компания считает, что оно сможет отражать и поглощать энергию, генерируемую взрывом, защищая тех, кто находится внутри поля.
Если технологию удастся воплотить в жизнь, это станет революционным развитием в военной области.
16. Плавучие города
Плавающий экополоис, названный Lilypad, был предложен архитектором Винсентом Каллеба (Vincent Callebaut) для будущих климатических беженцев в качестве долговременного решения проблемы повышения уровня моря. Город может вместить 50 000 людей, используя возобновляемые источники энергии.
Плавающая структура состоит из трех «лепестков» и трех гор, которые окружают искусственную лагуну в центре, собирающую и очищающую воду.
Она использует энергию ветра, Солнца, приливных сил и других альтернативных источников энергии и даже собирает дождевую воду.
17. 3D печать органов для операций по пересадке
Ученые работают над технологией распечатывания жизнеспособных органов, которые можно будет использовать в качестве донорских при операциях.
Технология 3D печати уже претерпела большие изменения. Она использует картриджи, заполненные суспензией из живых клеток, и умным гелем, который придает структуру и создает биологическую ткань. При распечатывании гель охлаждают и вымывают, оставляя только клетки.
Ученые работают над решением сложностей, связанных с созданием органов, которые могли бы имитировать функции нормально выращенных органов в теле человека. Как только эти трудности будут преодолены, людям уже не придется беспокоиться об ожидании доноров.
18. Бионические насекомые
Ученые разрабатывают бионические средства для насекомых, благодаря которым ими можно будет управлять и направлять в труднодоступные места, чтобы найти людей, ставших жертвами землетрясений и других стихийных бедствий.
Например, усики тараканов присоединяют к небольшим радиоприемникам, прикрепленным на спине. Насекомые используют усики, как слепые люди используют трость, чтобы нащупать, что находится перед ними.
Исследователи контролируют движения насекомых, отправляя небольшие электрические импульсы к усикам и направляя их.
19. Вы сможете записывать свои сны
Ученым удалось преобразовать видеоролики YouTube, сканируя визуальные центры мозга человека, который их смотрит. В будущем технология будет достаточно продвинутой, чтобы записывать сны.
Мозг трех членов команды, участвовавших в проекте, сканировали с помощью функциональной магнитно-резонансной томографии, когда они смотрели видеоклипы на YouTube. Затем исследователи интерпретировали данные с помощью математической модели, которая служила своего рода словарем мозга. Словарь позже воссоздавал то, что видели участники, сканируя случайные клипы и подбирая те, которые соответствовали активизации мозговой активности.
Хотя результат оказался не таким четким, в будущем ученые надеются улучшить технологию.
20. Поиск внеземной жизни в космосе
В Китае завершается строительство самого крупного в мире радиотелескопа «FAST» с рефлектором площадью в 30 футбольных полей, состоящим из 4450 панелей для наблюдения за внеземной жизнью.
Специалисты собирают гигантский телескоп в провинции Гуйчжоу в Китае, который превосходит обсерваторию Аресибо Пуэрто-Рико диаметром 300 метров. У китайского телескопа диаметр — 500 метров и периметр — 1,6 километров, и требуется 40 минут, чтобы обойти его.
Согласно исследователям такой телескоп улучшит наши возможности наблюдения за космосом.
Бонус: Жизнь до 1000 лет
Кембриджский геронтолог Обри де Грей (Aubrey de Grey) считает, что если технологии продолжат развиваться с такой же скоростью, вполне возможно, что уже появился человек, который доживет до 1000 лет.
Исследователь работает над терапией, которая будет убивать клетки, потерявшие способность делиться, позволяя здоровым клеткам размножаться и восстанавливаться. Терапия позволит 60-летним оставаться такими еще 30 лет, пока им не исполнится 90 лет. Процесс будут повторять до 120 или 150 лет и так далее.




Согласно М-ру Грею этот метод может стать жизнеспособным уже в течение 6-8 лет. Так что вполне возможно, что в будущем человек все-таки найдет эликсир вечной молодости.
BeautifulSoup простой пример парсинга HTML
В первом примере будет использован BeautifulSoup модуль для получения трех тегов.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
print(soup.h2)
print(soup.head)
print(soup.li)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) print(soup.h2) print(soup.head) print(soup.li) |
Код в данном примере позволяет вывести HTML-код трех тегов.
Python
from bs4 import BeautifulSoup
| 1 | frombs4 importBeautifulSoup |
Здесь производится импорт класса из модуля . Таким образом, BeautifulSoup является главным рабочим классом.
Python
with open(«index.html», «r») as f:
contents = f.read()
|
1 2 3 |
withopen(«index.html»,»r»)asf contents=f.read() |
Открывается файл и производится чтение его содержимого при помощи метода .
Python
soup = BeautifulSoup(contents, ‘lxml’)
| 1 | soup=BeautifulSoup(contents,’lxml’) |
Создается объект . Данные передаются конструктору. Вторая опция уточняет объект парсинга.
Python
print(soup.h2)
print(soup.head)
|
1 2 |
print(soup.h2) print(soup.head) |
Далее выводится HTML-код следующих двух тегов: и .
Python
print(soup.li)
| 1 | print(soup.li) |
В примере много раз используются элементы , однако выводится только первый из них.
Shell
$ ./simple.py
<h2>Operating systems</h2>
<head>
<title>Header</title>
<meta charset=»utf-8″/>
</head>
<li>Solaris</li>
|
1 2 3 4 5 6 7 |
$.simple.py <h2>Operating systems<h2> <head> <title>Header<title> <meta charset=»utf-8″> <head> <li>Solaris<li> |
Это результат вывода.
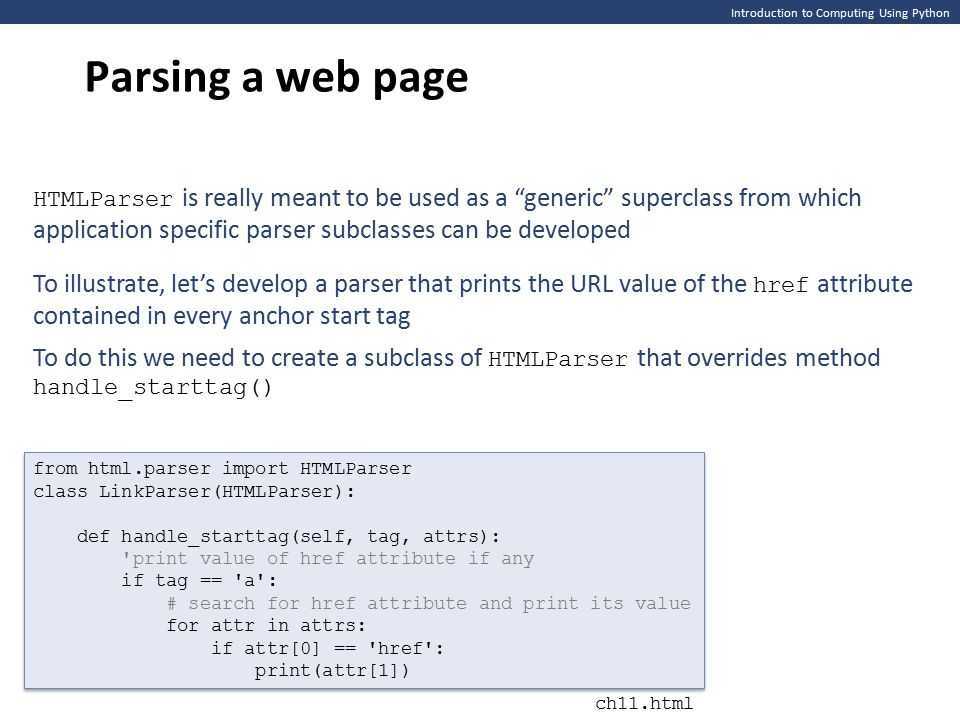
HTML парсер на Python
Ладно, хватит играться и развлекаться пора использовать серьёзные вещи для парсинг. К нашему счастью, в библиотеках Python есть множество инструментов, которые созданы для разных задач. Для парсинга нам подойдет Beautiful soup.
Воспользуемся терминалом:
$ python3 -m pip install beautifulsoup4
Теперь, вернёмся в едитор.
Создание объекта типа BeautifulSoup
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
Наша программа совершит 3 действия:
- Откроет URL
- Прочитает элементы и переведёт их в String
- Присвоит это объекту типа BeautifulSoup
При создании переменной «soup» мы передаём два аргумента, первый это сайт, который мы парсим, второй — какой парсер использовать.
BeautifulSoup теги, атрибуты name и text
Атрибут указывает на название тега, а атрибут указывает на его содержимое.
Python
#!/usr/bin/python3
from bs4 import BeautifulSoup
with open(«index.html», «r») as f:
contents = f.read()
soup = BeautifulSoup(contents, ‘lxml’)
print(«HTML: {0}, name: {1}, text: {2}».format(soup.h2,
soup.h2.name, soup.h2.text))
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#!/usr/bin/python3 frombs4 importBeautifulSoup withopen(«index.html»,»r»)asf contents=f.read() soup=BeautifulSoup(contents,’lxml’) print(«HTML: {0}, name: {1}, text: {2}».format(soup.h2, soup.h2.name,soup.h2.text)) |
Код в примере позволяет вывести HTML-код, название и текст тега.
Shell
$ ./tags_names.py
HTML: <h2>Operating systems</h2>, name: h2, text: Operating systems




|
1 2 |
$.tags_names.py HTML<h2>Operating systems<h2>,nameh2,textOperating systems |
Это результат вывода.
Новые технологии будущего
1. Биохолодильники
Российский дизайнер предложил концепцию холодильника, названного «Bio Robot Refrigerator», который охлаждает еду с помощью биополимерного геля. В нем нет полок, отделений и дверей – вы просто вставляете еду в гель.
Идея была предложена Юрием Дмитриевым для конкурса Electrolux Design Lab. Холодильник использует всего 8 процентов энергии дома для контрольной панели и не нуждается в энергии для фактического охлаждения.
Биополимерный гель холодильника использует свет, генерируемый при холодной температуре, чтобы сохранять продукты. Сам гель не имеет запаха и не липкий, а холодильник можно установить на стене или на потолке.
2. Сверхбыстрый 5G Интернет от беспилотников с солнечными панелями
Компания Google работает над дронами на солнечных панелях, раздающими сверхскоростной Интернет в проекте, названном Project Skybender. Теоретически беспилотники будут предоставлять Интернет услуги в 40 раз быстрее, чем в сетях 4G, позволяя передавать гигабайт данных в секунду.
Проект предусматривает использование миллиметровых волн для предоставления сервиса, так как существующий спектр для передачи мобильной связи слишком заполнен.
Однако эти волны имеют более короткий диапазон, чем мобильный сигнал 4G. Компания Google работает над этой проблемой, и если удастся решить все технические проблемы, вскоре может появится Интернет небывалой скорости.
3. 5D диски для вечного хранения терабайтов данных
Исследователи создали 5D диск, который записывает данные в 5 измерениях, сохраняющиеся миллиарды лет. Он может хранить 360 терабайт данных и выдержать температуру до 1000 градусов.
Файлы на диске сделаны из трех слоев наноточек. Пять измерений диска относятся к размеру и ориентации точек, а также их положению в пределах трех измерений. Когда свет проходит через диск, точки меняют поляризацию света, которая считывается микроскопом и поляризатором.
Команда из Саутгемптона, которая разрабатывает диск, смогла записать на диск Всеобщую декларацию прав человека, Оптику Ньютона, Магна Карту и Библию. Через несколько лет такой диск уже не будет экспериментом, а станет нормой хранения данных.
4. Инъекции частиц кислорода
Ученые из Бостонской детской больницы разработали микрочастицы, наполненные кислородом, которые можно вводить в кровоток, позволяя вам жить, даже если вы не сможете дышать.
Микрочастицы состоят из одного слоя капсул липидов, которые окружают небольшой пузырь кислорода. Капсулы размером 2-4 микрометра подвешены в жидкости, которая контролирует их размер, так как пузыри большего размера могут быть опасны.
При введении, капсулы, сталкиваясь с красными кровяными клетками, передают кислород. Благодаря этому методу удалось ввести в кровь 70 процентов кислорода.
5. Подводные транспортные туннели
В Норвегии планируют построить первые в мире подводные плавающие мосты на глубине 30 метров под водой с помощью больших труб, достаточно широких для двух полос.
Учитывая сложности перемещения по местности, в Норвегии решили работать над созданием подводных мостов. Ожидается, что проект, на который уже затрачено 25 миллиардов долларов, будет закончен в 2035 году.
Предстоит еще учесть и другие факторы, например, влияние ветра, волн и сильных течений на мост.
6. Биолюминесцентные деревья
Группа разработчиков решила создать биолюминесцентные деревья с помощью фермента, встречающегося у некоторых медуз и светлячков.
Такие деревья смогут освещать улицы и помогут прохожим лучше видеть ночью. Была уже разработана небольшая версия проекта в форме растения, светящегося в темноте. Следующим шагом станут деревья, освещающие улицы.
7. Сворачивающиеся в рулон телевизоры
Компания LG разработала прототип телевизора, который можно свернуть как рулон бумаги.
Телевизор использует технологию светодиодов на основе полимерной органики, чтобы уменьшить толщину экрана.
Кроме LG, другие крупные производители электроники, такие как Samsung, Sony и Mitsubishi работают над тем, чтобы сделать экраны более гибкими и портативными.



