Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.
При помощи формулы массива
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите .
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
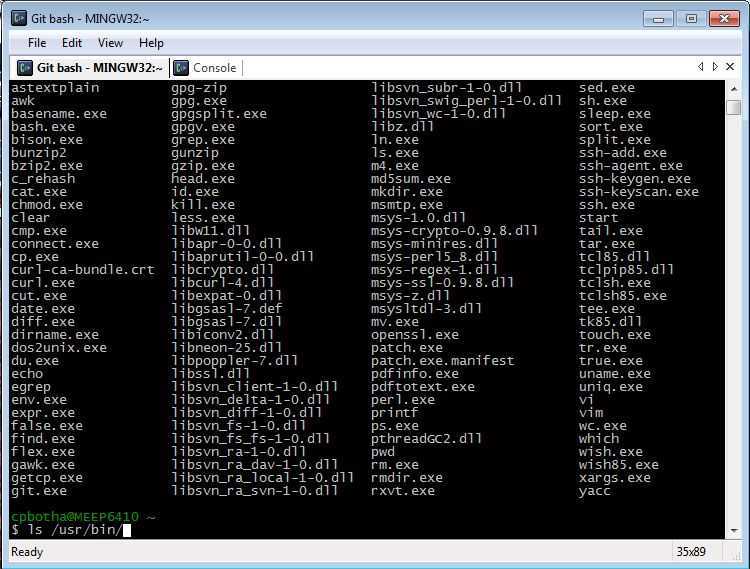
Частичное использование команды Linux uniq
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>style=»clear:both;»>
uniq Команда uniq может удалить повторяющиеся строки в отсортированном файле, поэтому uniq часто используется с sort. То есть, чтобы Uniq работал, все повторяющиеся строки должны быть смежными.
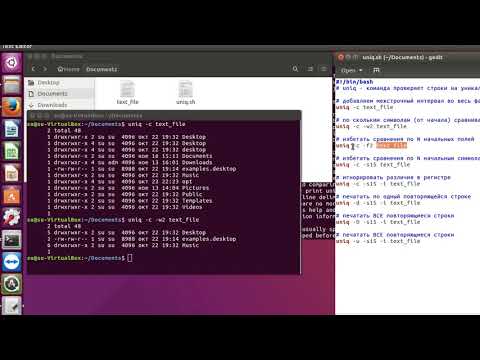
команда uniq Команда uniq используется для сообщения или игнорирования повторяющихся строк в файле и обычно используется вместе с командой sort. -c или —count: отображает количество повторений этой строки рядом с каждым столбцом; -d или -repeated: отображаются только повторяющиеся строки и столбцы; -f <field> или -skip-fields = <field>: игнорировать указанное поле для сравнения; -s <позиция символа> или -skip-chars = <позиция символа>: игнорировать сравнение указанных символов; -u или —unique: строки и столбцы отображаются только один раз; -w <позиция символа> или –check-chars = <позиция символа>: укажите символы для сравнения.
Содержание testfile выглядит следующим образом: #cat testfile hello world friend hello world hello
Интеллектуальная рекомендация
…
1. Определите класс узла: 2. Класс реализации алгоритма: 3. Просмотрите двоичное дерево на следующем рисунке….
Последовательность развития 1. Создать сущность для реализации хозяйствующего субъекта. 2. Создайте IDAL для реализации интерфейса. 3. Создайте DAL для реализации методов в интерфейсе. 4. Увеличьте ин…
pinyin4j действительно сложно, вот простое приложение …
Создать проект взломанная версия pycharm -> новый проект -> django. Project Interpreter использует среду New Virtualenv по умолчанию. settings.py Часовой пояс и язык Статические файлы Зарегистри…
Вам также может понравиться
1. Загрузите исходный код https://github.com/tzutalin/labelImg, После скачивания разархивируйте его. 2. Установите Python3.5. Не используйте 3.6! Не используйте 3.6! Не используйте 3.6! Пока что при в…
Я столкнулся с бизнес-сценарием в недавнем проекте: Перенесите таблицы из текущей базы данных в другую базу данных. Для обеспечения эффективности миграции требуется одновременная миграция данных. Для …
…
С развитием технологии виртуализации все больше и больше веб-проектов используют докер для развертывания и обслуживания. Мы попытались использовать docker-compose для организации веб-проекта, основанн…
После того, как язык задан, режим интерпретатора может определять представление его грамматики и одновременно предоставлять переводчика. Клиент может использовать этот интерпретатор для интерпретации …
Предложение FROM
В предложении перечисляются имена таблиц, которые содержат столбцы, указанные после слова .
Пример 1.Вывести список наименований деталей из таблицы D (“Детали”).





Пример 2.Получить всю информацию из таблицы D (“Детали”).
Получить результат можно двумя способами:
Явным указанием всех столбцов таблицы.
Полный список столбцов таблицы заменяет символ *.
В результате и первого и второго запроса получаем новую таблицу, представляющую собой полную копию таблицы D (“Детали”).
Можно осуществить выбор отдельных столбцов и их перестановку.
Пример 3.Получить информацию о наименовании и номере поставщика.
Пример 4.Определить номера поставщиков, которые поставляют детали в настоящее время (то есть номера тех поставщиков, которые присутствуют в таблице PD (“Поставки”)).
Результат:
| pnum |
|---|
| 1 |
| 1 |
| 1 |
| 2 |
| 2 |
| 3 |
Что такое команда uniq?
Команда uniq в Linux используется для отображения идентичных строк в текстовом файле. Эта команда может быть полезна, если вы хотите удалить повторяющиеся слова или строки из текстового файла. Поскольку команда uniq сопоставляет соседние строки для поиска избыточных копий, она работает только с отсортированными текстовыми файлами.
К счастью, вы можете передать команду сортировки по конвейеру с помощью uniq, чтобы организовать текстовый файл таким образом, чтобы это было совместимо с командой. Помимо отображения повторяющихся строк, команда uniq также может подсчитывать появление повторяющихся строк в текстовом файле.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
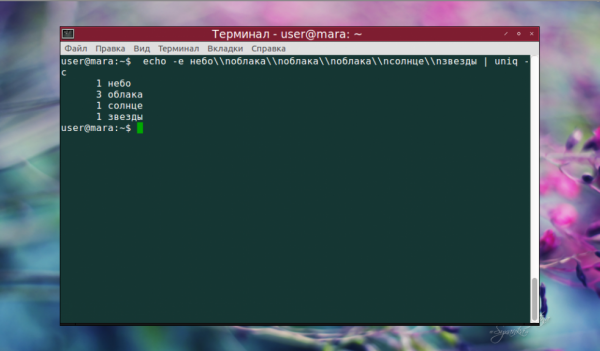
После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
Теперь применим команду к тексту, который находится в файле.
Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.
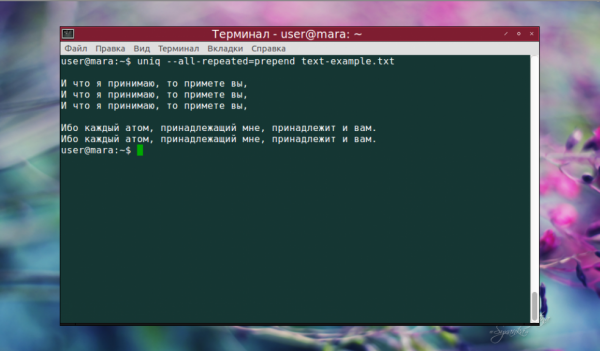
Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
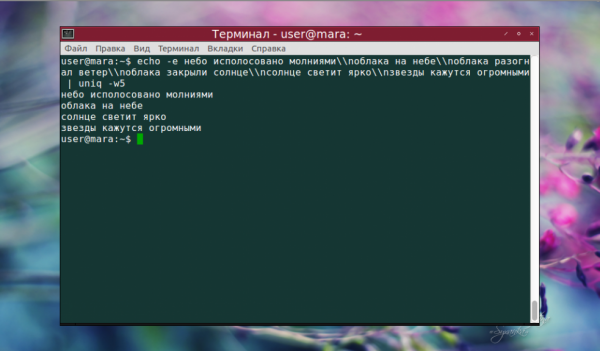
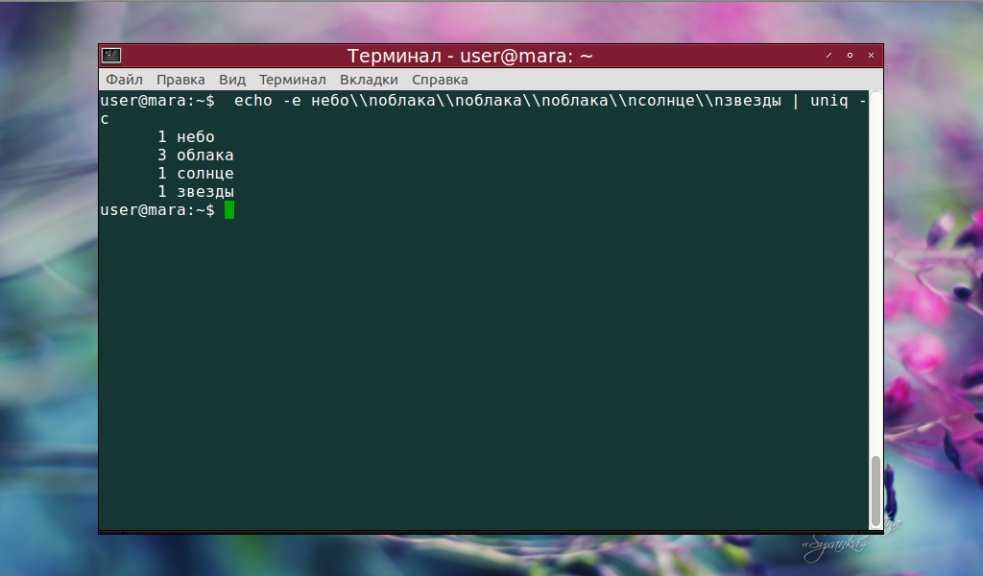
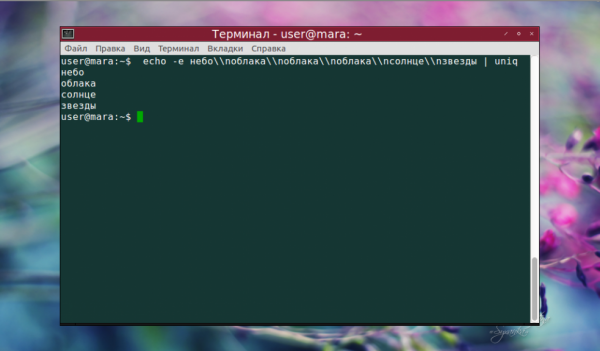
Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
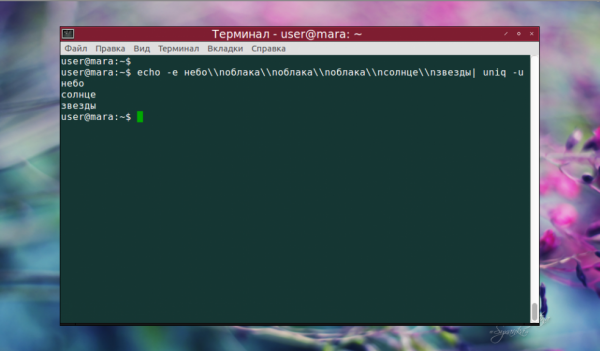
Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
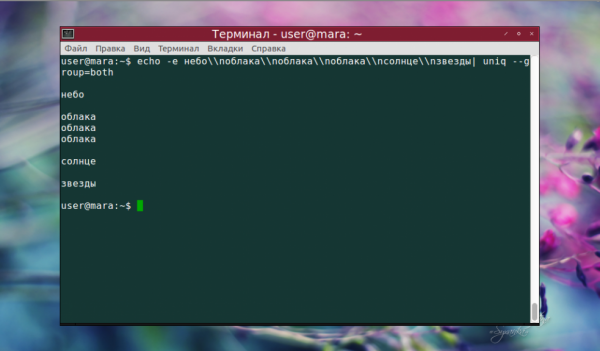
А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
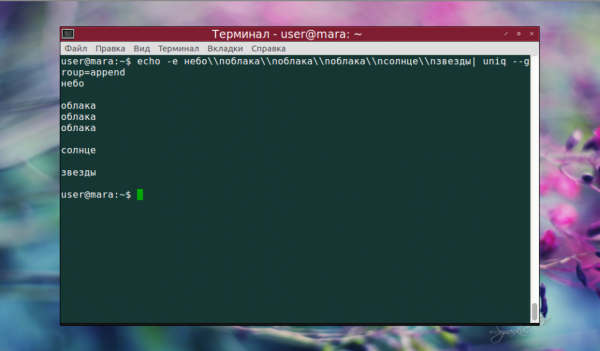
Тогда как append не добавило пустую строку перед текстом:
Синтаксис функции UNIQUE
Синтаксис функции UNIQUE следующий:
UNIQUE(range, filter_by_column, exactly_once)
Здесь,
- range — это данные, из которых мы хотим извлечь уникальные записи
- filter_by_column — необязательный параметр. Он указывает, нужно ли фильтровать данные по строке или столбцу. Значение FALSE означает, что мы хотим, чтобы он был отфильтрован по строке, а значение TRUE означает, что мы хотим, чтобы он был отфильтрован по столбцу. По умолчанию это значение FALSE.
- exactly_once также является необязательным параметром. Он указывает, нужны ли нам только записи без дубликатов. Значение FALSE означает, что мы хотим включить записи, которые имеют дубликаты ровно один раз, в то время как значение TRUE означает, что мы хотим полностью исключить любую запись, которая имеет дубликаты.
Параметр диапазона может включать в себя либо диапазон имен столбцов, либо диапазон ссылок на ячейки. Функция покажет результат, начиная с ячейки, в которую вы ввели формулу.








Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи — куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
Программа Faster 9.4 позволяет ускорить процесс работы программиста
(работает в любом текстовом редакторе).
Подсказка при вводе текста на основе ранее введенного текста и настроенных шаблонов.
Программа Faster позволяет делится кодом с другими программистами в два клика или передать ссылку через QR Код.
Исправление введенных фраз двойным Shift (с помощью speller.yandex). Переводчик текста. Переворачивает текст случайно набранный на другой раскладке.
Полезная утилита для тех, кто печатает много однотипного текста, кодирует в среде Windows на разных языках программирования.
Через некоторое время работы с программой у вас соберется своя база часто используемых словосочетаний и кусков кода.
Настройка любых шорткатов под себя с помощью скриптов.
Никаких установок и лицензий, все бесплатно.
1 стартмани
Как извлечь значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, формула, которую мы только что обсудили, вернет ноль для каждой пустой строки, что может быть проблемой. Это вы и наблюдаете на скриншоте чуть выше. Чтобы исправить это, сделаем несколько небольших корректировок.
Формула массива для извлечения различных значений, исключая пустые ячейки:
Аналогичным образом вы можете получить список различных значений, исключая пустые ячейки и ячейки с числами:
Напоминаем, что в приведенных выше формулах A2: A13 – это исходный список, а B1 – ячейка прямо над первой позицией формируемого списка.
На этом скриншоте показан результат отбора:
Быть может, кому-то будет полезна еще одна формула –
Она работает с числами и текстом, игнорирует пустые ячейки.
Фильтры в Linux
Фильтры — это способ получения необработанных данных, созданных другой программой или сохраненных в файле.
Эти фильтры имеют различные параметры командной строки, которые изменяют их поведение. В результате, всегда полезно проверить страницу руководства для фильтра.
В приведенных ниже примерах мы будем предоставлять данные для этих программ с помощью файла.
Для каждой из демонстраций ниже будет использоваться следующий файл в качестве примера. Этот файл примера содержит список содержимого, чтобы немного облегчить понимание примеров. Кроме того, файл фактически указан как путь, и поэтому вы можете использовать абсолютные и относительные пути, а также подстановочные знаки.
СКРИН
head
Head — это программа, которая печатает первые строки ввода. По умолчанию он напечатает первые 10 строк, но мы можем изменить это с помощью аргумента командной строки.
head
tail
Данная команда противоположна head. Tail — это команда, которая печатает последние строки ввода. По умолчанию он напечатает последние 10 строк, но мы можем изменить это с помощью аргумента командной строки.
tail
Выше было поведение tail по умолчанию. А ниже указывается заданное количество строк.
sort
Сортировка — это красиво и просто. По умолчанию сортировка выполняется в алфавитном порядке. Между тем, существует множество параметров, позволяющих изменить механизм сортировки. Кроме того, не забудьте проверить справочную страницу, чтобы увидеть все, что он может сделать.
sort
nl
Обозначение чисел в Linux реализуется за счет команды nl.
nl
Вот еще несколько полезных опций командной строки.
В приведенном выше примере мы использовали 2 параметра командной строки. Первый -s указывает, что следует печатать после числа. С другой стороны, второй -w указывает, сколько отступов ставить перед числами. Для первого нам нужно было включить пробел как часть того, что было напечатано.










Поскольку пробелы обычно используются в качестве символов-разделителей в командной строке, нам нужен был способ указать, что пробел является частью нашего аргумента, а не просто между аргументами. Мы сделали это, включив аргумент в кавычки.
wc
wc обозначает количество слов, а также символы и строки. По умолчанию он подсчитывает все вышеперечисленное. Между тем, используя параметры командной строки, мы можем ограничить его только тем, что нам нужно.
wc
Иногда вам просто нужно одно из этих значений. -l даст нам только строки, -w даст нам слова, а -m даст нам символы.
Кроме того, Вы можете комбинировать аргументы командной строки.
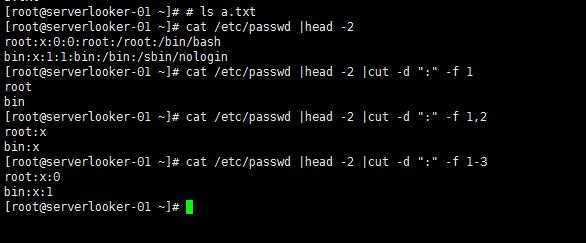
cut
Cut — это хорошая команда, которую можно использовать, если ваш контент разделен на столбцы и вам нужны только определенные поля.
вырезать
В нашем примере файла у нас есть данные в 3 столбцах. Допустим, мы хотели только первый столбец.
По умолчанию cut использует символ TAB в качестве разделителя для идентификации полей. Опция -f позволяет нам указать, какое поле мы бы хотели. Если нам нужно 2 или более полей, мы разделяем их запятой, как показано ниже.
sed
Sed расшифровывается как Stream Editor и позволяет эффективно выполнять поиск и замену наших данных. Это довольно мощная команда, но мы будем использовать ее здесь в ее базовом формате.
sed <выражение>
Инициал s обозначает замену и определяет действие, которое нужно выполнить. Между первой и второй косой чертой (/) мы размещаем то, что ищем. Затем между вторым и третьим слэшем, чем мы хотим его заменить.
uniq
Uniq означает уникальный, и его работа заключается в удалении повторяющихся строк из данных. Однако одно ограничение заключается в том, что эти линии должны быть смежными.
uniq
tac
Ребята из Linux известны своим забавным чувством юмора. Программа TAC на самом деле является CAT наоборот. Это было названо так, как это делает противоположность CAT. Получив данные, он напечатает последнюю строку первой, вплоть до первой строки.
TAC
С помощью счетчика
В этом методе мы будем использовать функцию счетчика из библиотеки коллекций. В этом случае мы будем создавать словарь с помощью функции counter (). Ключи будут уникальными элементами, а значения-числом этого уникального элемента. Взяв ключи из словаря, мы создадим список и напечатаем длину списка.
#import Counter from collections
from collections import Counter
#input of list
lst =
print("Input list : ",lst)
lst1 = Counter(lst).keys()
print("output list : ",lst1)
print("No of unique elements in the list are:", len(lst1))
Выход:
Input list : output list : dict_keys() No of unique elements in the list are: 6
Объяснение:
Здесь, во-первых, мы импортировали функцию Counter() из библиотеки коллекций. Во-вторых, мы взяли входной список и напечатали входной список. В-третьих, мы применили счетчик(), неупорядоченную коллекцию, где элементы хранятся как ключи словаря, а их подсчеты хранятся как значения словаря. Из входного списка мы создали новый список, в котором хранятся только те элементы, ключевые значения которых присутствуют один раз. Все эти элементы различны в списке. Наконец, мы напечатали пустой список, который теперь содержит уникальные значения и количество списка. Таким образом, мы можем видеть все уникальные элементы в списке.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.
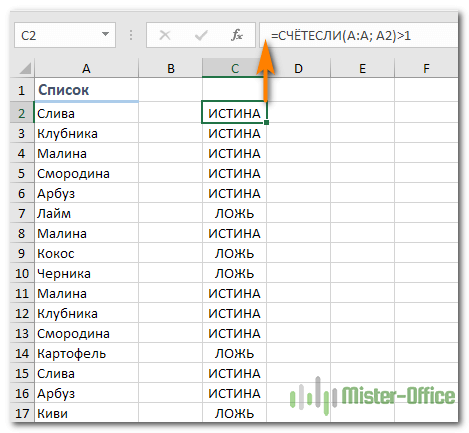
Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте









Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):
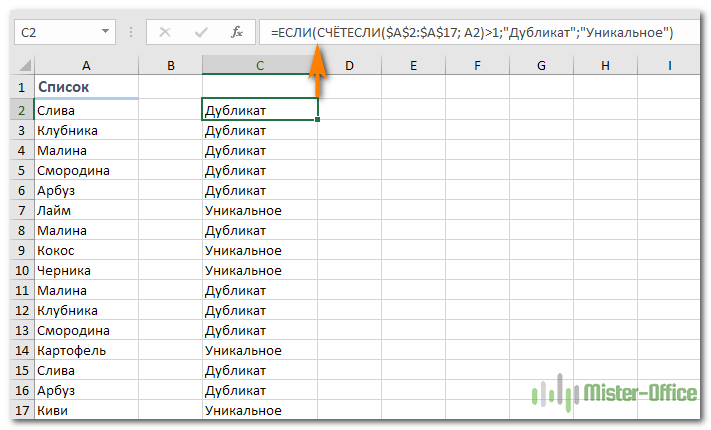
В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
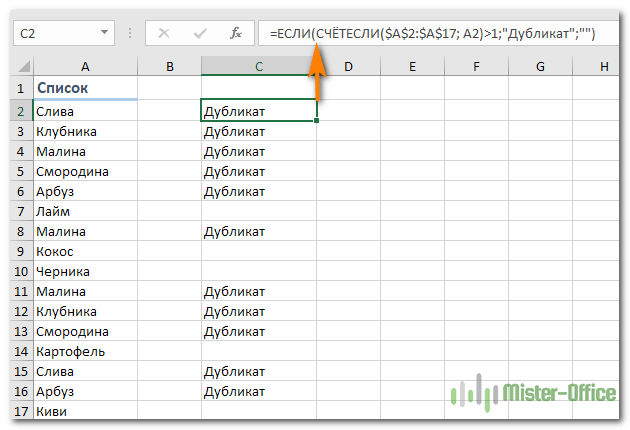
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми
То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
На скриншоте ниже вы видите эту формулу в деле.
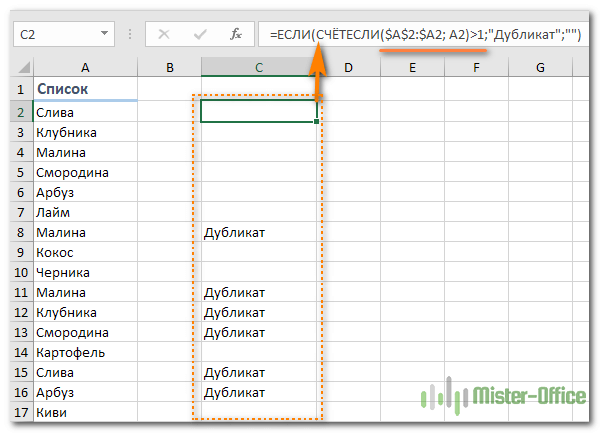
Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально
Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:
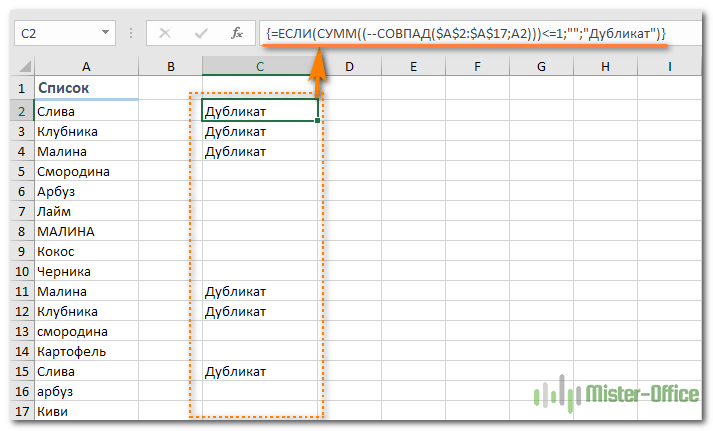
Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:
Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):
Дайте названия столбцам, например, «Name» и «Duplicate?» Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):
После этого нажмите меленькую серую стрелку рядом с «Duplicate?«, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate, и нажмите ОК.
Вот и всё, теперь Вы видите только те элементы столбца А, которые дублируются в столбце В. В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.
Чтобы снова отобразить все строки столбца А, кликните символ фильтра в столбце В, который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:
Изменение цвета или выделение найденных дубликатов
Если пометки «Duplicate» не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1, чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.









Теперь Вы точно не пропустите ни одной ячейки с дубликатами:
Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах, то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):
Нажмите ОК, когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:
Если 2 столбца расположены на одном листе, вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А, сделайте следующее:
- Отфильтруйте таблицу так, чтобы отображались только дублирующиеся значения, и выделите эти ячейки. Кликните по ним правой кнопкой мыши и в контекстном меню выберите Clear contents (Очистить содержимое).
- Очистите фильтр.
- Выделите все ячейки в столбце А, начиная с ячейки А1 вплоть до самой нижней, содержащей данные.
- Откройте вкладку Data (Данные) и нажмите Sort A to Z (Сортировка от А до Я). В открывшемся диалоговом окне выберите пункт Continue with the current selection (Сортировать в пределах указанного выделения) и нажмите кнопку Sort (Сортировка):
- Удалите столбец с формулой, он Вам больше не понадобится, с этого момента у Вас остались только уникальные значения.
- Вот и всё, теперь столбец А содержит только уникальные данные, которых нет в столбце В:
Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
Теперь применим команду к тексту, который находится в файле.
Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.
Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
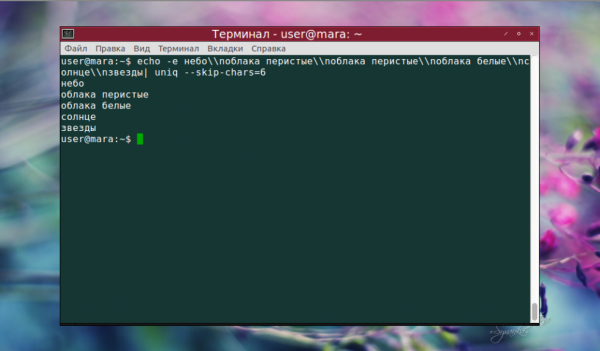
Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
Тогда как append не добавило пустую строку перед текстом:
Использование фрейма данных pandas.
В этом методе мы будем импортировать панд в качестве псевдонима pd. мы будем принимать входные данные в кадре данных панд.
import pandas as pd
df = pd.DataFrame({
'Marks' : },
Names = )
n = len(pd.unique(df))
print("No.of.unique values :",n)
Выход:
No.of.unique values : 5
Объяснение:
Здесь, во-первых, мы импортировали модуль панд с псевдонимом pd. Во – вторых, мы создали фрейм данных с вводом меток и имен. В-третьих, мы создали переменную n, в которой будем хранить значение. Мы применили уникальную функцию в метках в панд, а затем вычислили ее длину с помощью функции длины и сохранили ее в переменной n. Наконец-то мы напечатали результат.