
Настройка swap
7.1. Создаем раздел ZFS
- -V 32G — Размер нашего SWAP, можно определить тот который требуется реально;
- -b $(getconf PAGESIZE) — размер блока (4K c ashift=12);
- compression=zle — выбираем минимальный по ресурсоёмкости алгоритм сжатия, по сути так как размер блока у нас 4К, то сжатия как таковое не даст утилизации по вводу-выводу, но при этом можно будет сэкономить на нулевых блоках;
- logbias=throughput — установка пропускной способности для оптимизации синхронных операций;
- sync=always — всегда синхронизировать запись. Это несколько снижает производительность, но полностью гарантирует достоверность данных;
- primarycache=metadata — кешировать только метаданные, так как из swap не будет производится множественное чтение одного и того же блока;
- secondarycache=none — вторичный кеш вообще отключить по причинам указанным выше;
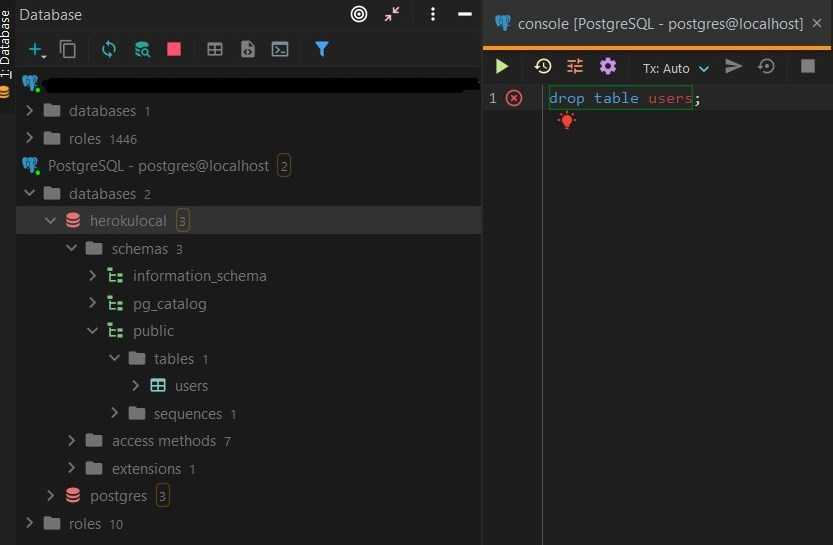
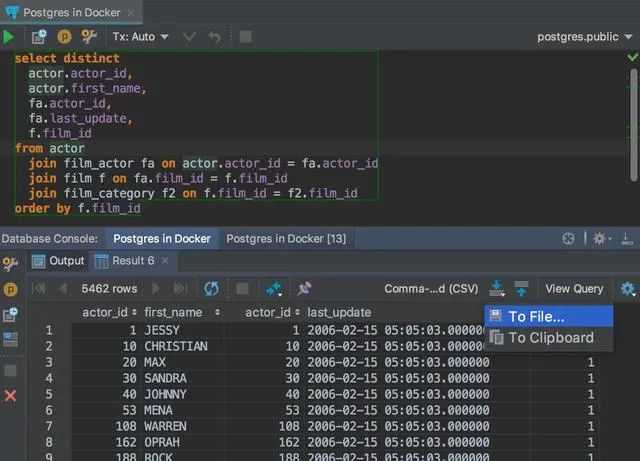
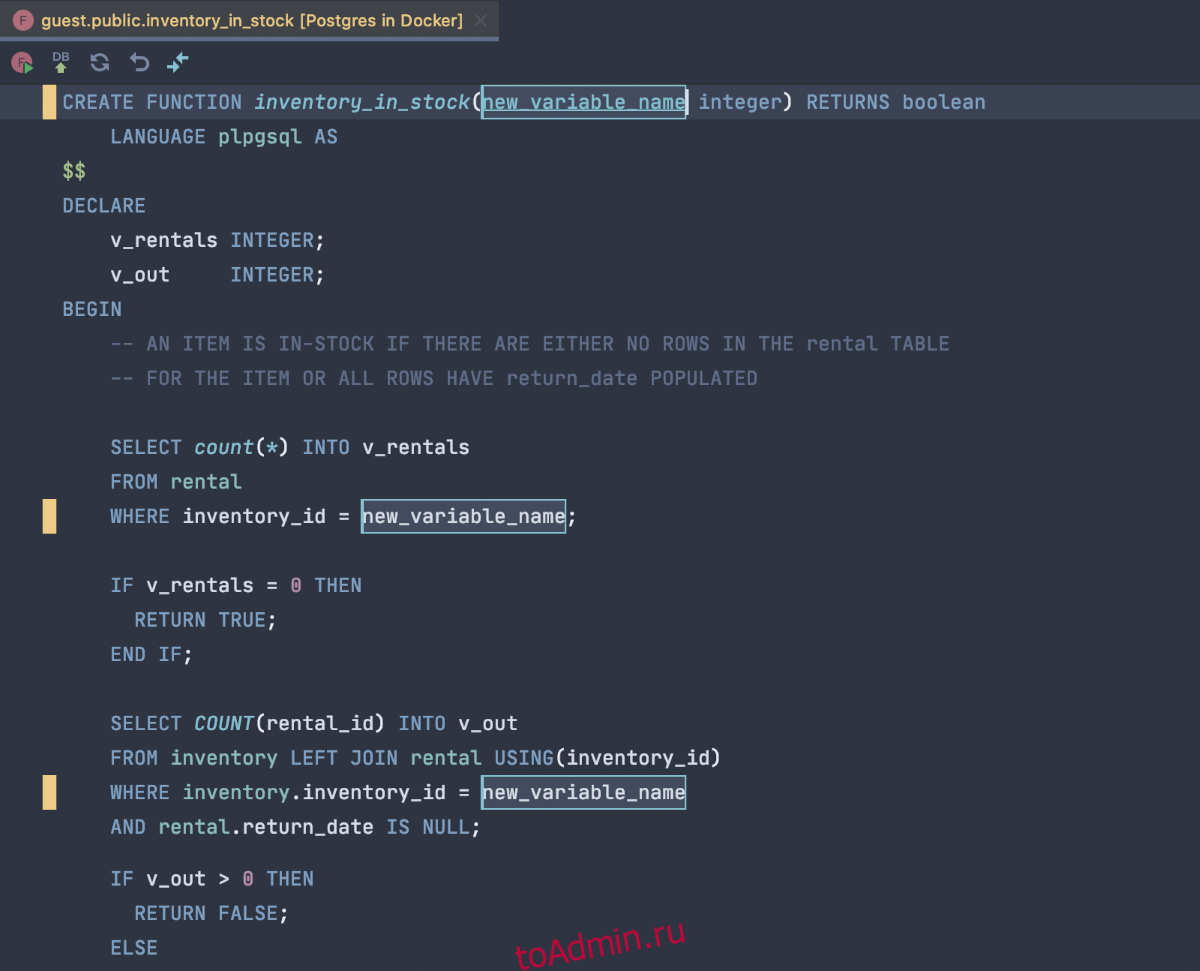
psql
На первом месте psql, и это неудивительно. Надежный как автомат калашникова, бесплатный, стоит из коробки, что еще надо для счастья? Для редактирования запросов используется редактор, указанный в переменной окружения EDITOR, обычно ставят vim, nano или что-то в этом духе. Ну и вообще, psql — это unix-way, т.е. можно его запускать со своим редактором, своим пейджером для отображения результатов, ему можно на вход подавать sql-запрос через пайп, и вывод направлять куда надо.
Из минусов можно отметить слабенький автокомплит, а также то, что приходится заучивать неинтуитивные команды из серии и т.д. (впрочем, все описания команд доступны через команду )
Ну, и работа в консоли и в виме — это не всех устраивает почему-то ![]()
На самом деле, иногда хочется иметь где-нибудь слева полный список таблиц/вьюх и иметь возможность щелкнуть мышкой по нужной, чтобы посмотреть, что там вообще. Т.е. хоть какой-то GUI. Работа в psql хоть и эффективна, но напоминает работу в темной комнате с маленьким фонариком, освещающим лишь только один объект за раз.
Дополнительные возможности
— список пакетов, которые запрещено обновлять подобным способом. Тут же нам в примере сразу предлагают это сделать для libc, а выше описан другой пример — с PostgreSQL. Но помните, что на другой чаше весов: откладывая критичные исправления, вы рискуете безопасностью.
— если последний процесс установки/обновления не смог завершиться по каким-либо причинам, вероятно, вам приходилось исправлять ситуацию вручную. То же самое делает и эта опция, т.е. вызывает
Обратите внимание, что здесь указана опция — она означает, что будут сохранены старые версии конфигов, если возникнут конфликты.
— выполнять обновления минимально возможными частями. Позволяет прервать обновление отправкой SIGUSR1 процессу unattended-upgrade
— устанавливать обновления перед выключением компьютера. Лично мне кажется плохой идеей, т.к. не хотелось бы получить труп после плановой перезагрузки сервера.
и — кому отправлять письма об обновлениях и/или проблемах с ними. Письма отправляются через стандартный MTA sendmail (используется переменная окружения ). К сожалению, только письма, а выполнять curl к какому-то API здесь нельзя.
— перезагружать автоматически после окончания установки, если есть файл . Сам файл появляется, например, после установки пакета ядра Linux, когда срабатывает правило . В общем, ещё одна опция из набора «грязного Гарри».
— если вы хотите сделать свои тёмные дела ночью, пока никто не видит… задаёт конкретное время автоматической перезагрузки.
— это уже из общего набора параметров apt. Ограничивает скорость загрузки обновлений, чтобы не забить канал.
Первый запуск DataGrip
При первом запуске, как и другие проекты от JetBrains программа предложит импортировать настройки. Если вы ею раньше не пользовались, этот шаг можно пропустить:
Затем надо будет активировать лицензию на программу. Вы можете войти в свой аккаунт, активировать лицензионный ключ или получить пробную бесплатную версию на 30 дней. Для получения пробной версии перейдите на вкладку Evaluate for free и кликните по кнопке Evaluate.

Когда лицензия будет успешно активирована программа откроет окно, в котором будет предложено создать новый проект. Здесь же можно установить дополнительные плагины или настроить тему, но это уже не так актуального как для среды разработки:
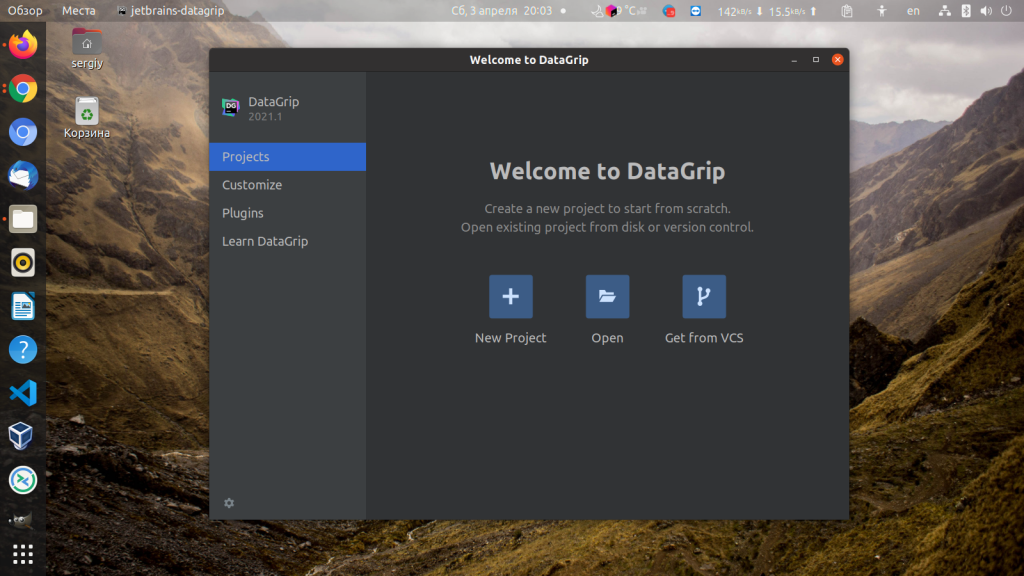
Для создания проекта кликните по пункту New Project и введите имя для нового проекта:
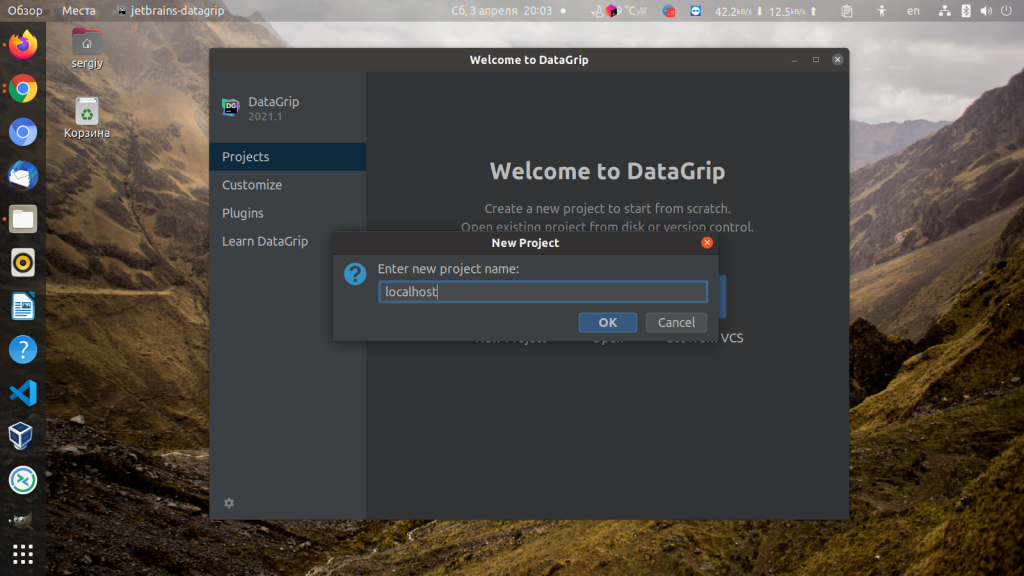
Теперь можно добавлять базы данных.
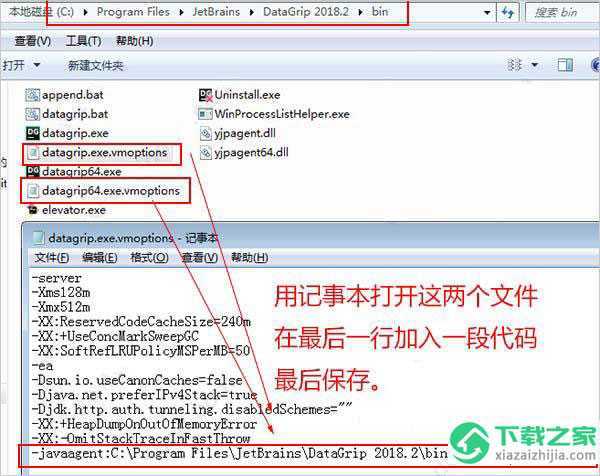
Silent installation on Windows
Silent installation is performed without any user interface. It can be used by network administrators to install DataGrip on a number of machines and avoid interrupting other users.
To perform silent install, run the installer with the following switches:
-
: Enable silent install
-
: Specify the path to the
-
: Specify the path to the installation directory
This parameter must be the last in the command line and it should not contain any quotes even if the path contains blank spaces.
For example:
datagrip.exe /S /CONFIG=d:\temp\silent.config /D=d:\IDE\DataGrip
To check for issues during the installation process, add the switch with the log file path and name between the and parameters. The installer will generate the specified log file. For example:
datagrip.exe /S /CONFIG=d:\temp\silent.config /LOG=d:\JetBrains\DataGrip\install.log /D=d:\IDE\DataGrip
О выборе NoSQL-баз данных
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
О выборе SQL-баз данных
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
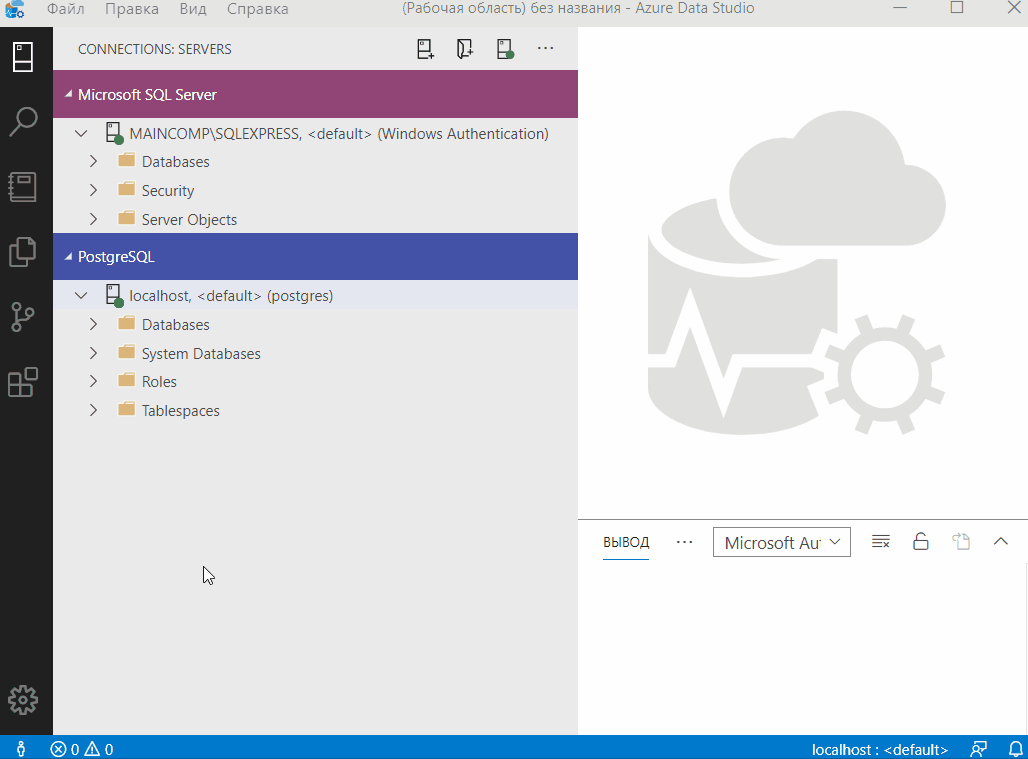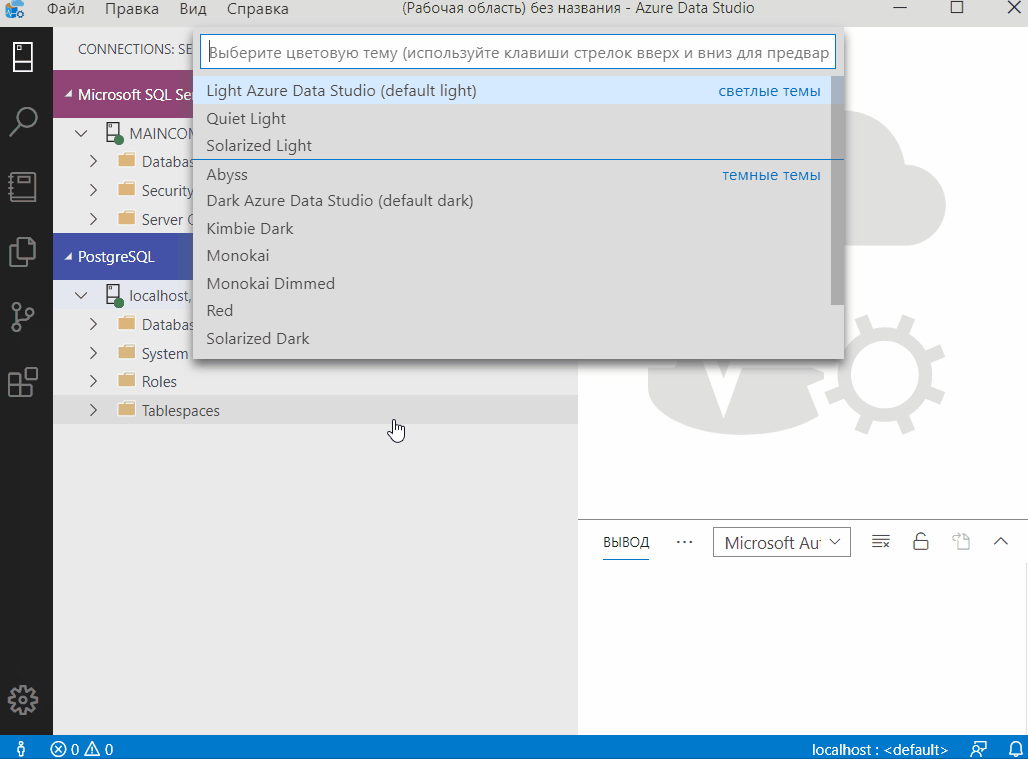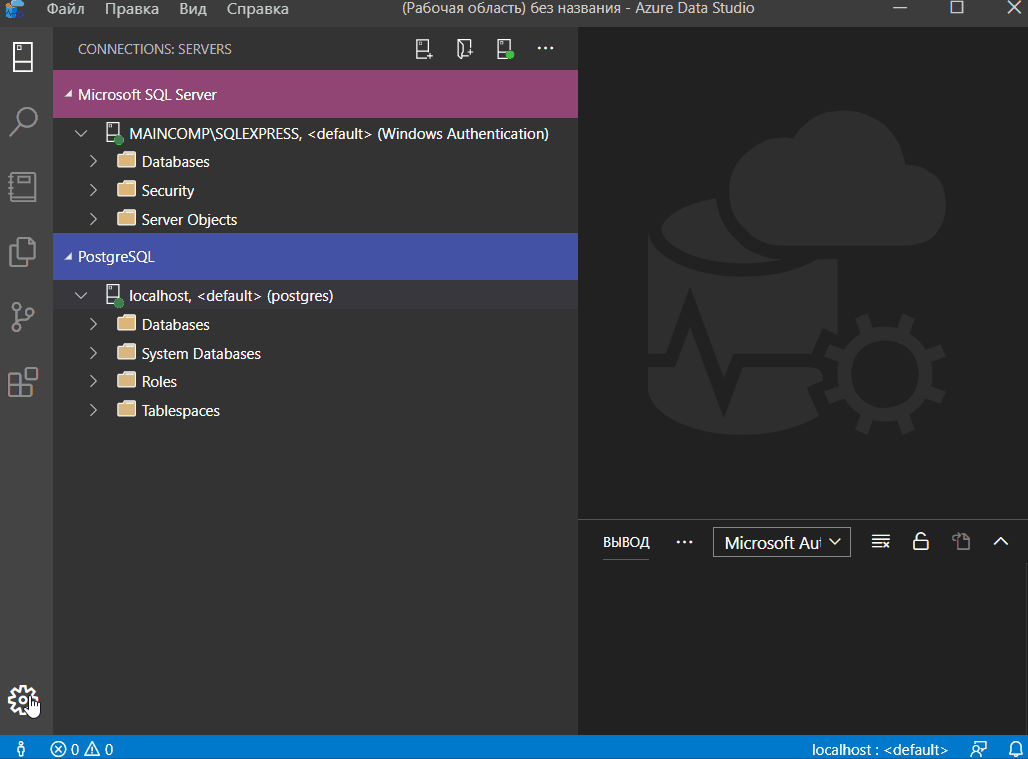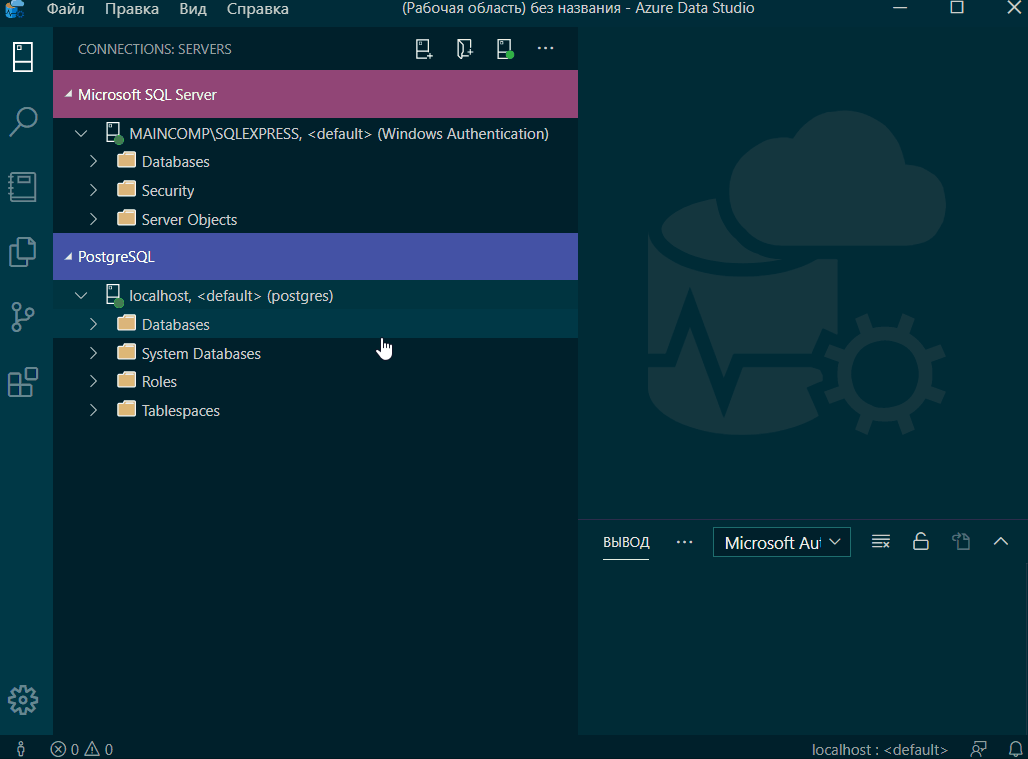
Azure Data Studio
Azure Data Studio – это бесплатный, кроссплатформенный инструмент с открытым исходным кодом для работы с базами данных Microsoft SQL Server.
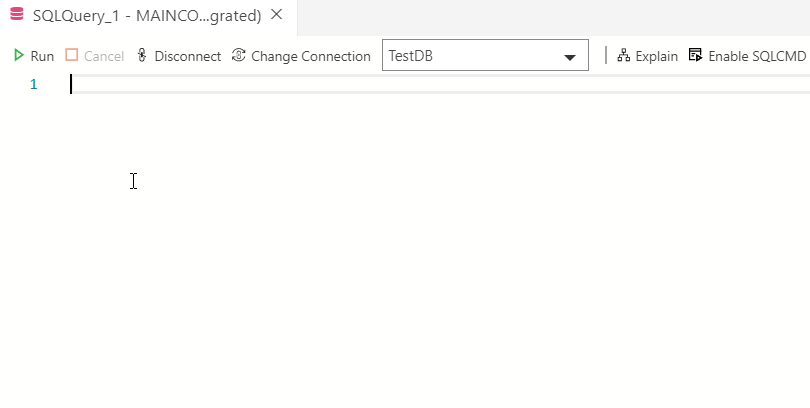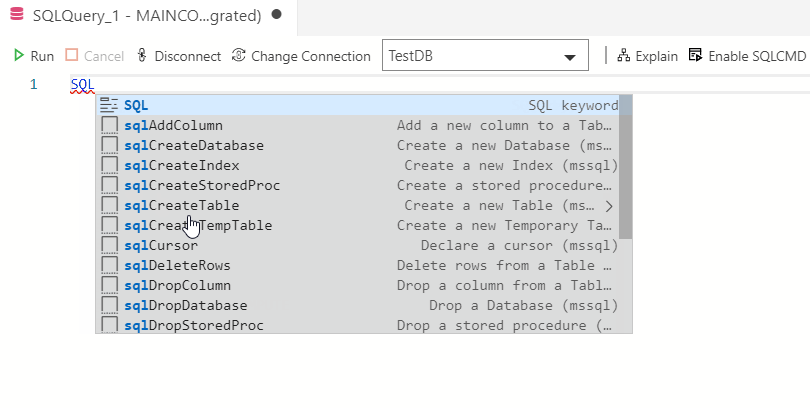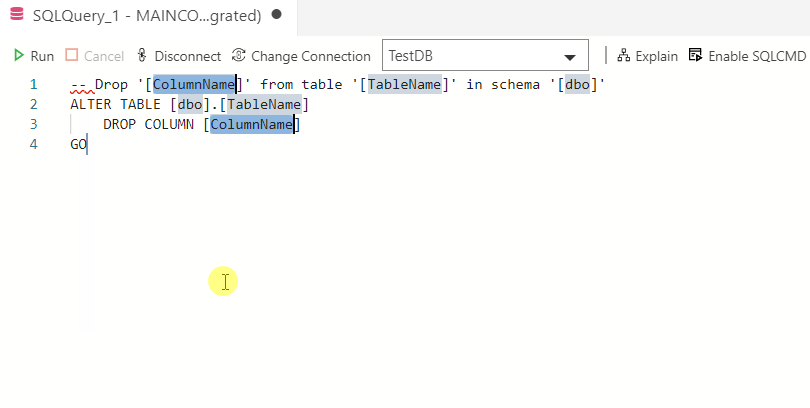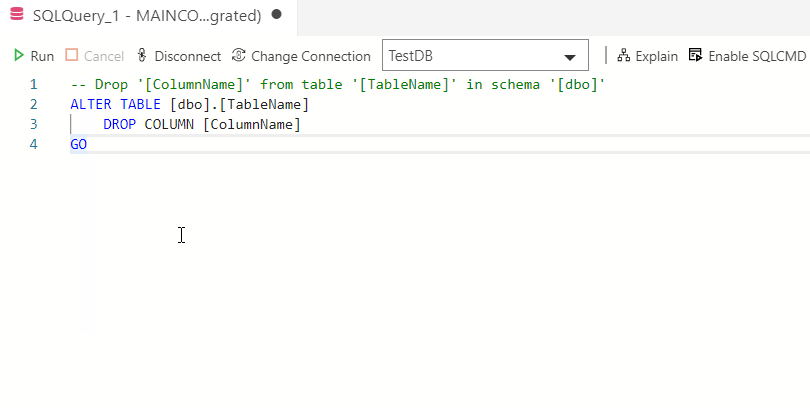
Azure Data Studio основана на Visual Studio Code и ориентирована на SQL разработчиков, так как основное назначение Azure Data Studio – это написание, редактирование и выполнение SQL запросов, иными словами, это редактор SQL кода.
Azure Data Studio позволяет работать с базами данных Microsoft SQL Server, SQL Azure, а также с другими СУБД, например, с PostgreSQL
Основные особенности
Инструмент бесплатный
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на SQL разработчиков
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Расширяемость (встроенная поддержка расширений)
Работа с другими СУБД
Встроенная возможность выгрузки данных в формат Excel, XML, JSON, CSV
Группировка подключений к серверам
Визуализация данных с помощью диаграмм и графиков
Поддержка нескольких цветовых тем
Встроенный терминал (Bash, PowerShell, sqlcmd)
Записные книжки
Недостатки
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Отсутствует функционал для большинства задач администрирования
Мне нравится4Не нравится
Установка DataGrip в Ubuntu 20.04
1. Центр приложений
Откройте центр приложений и наберите в строке поиска DataGrip:
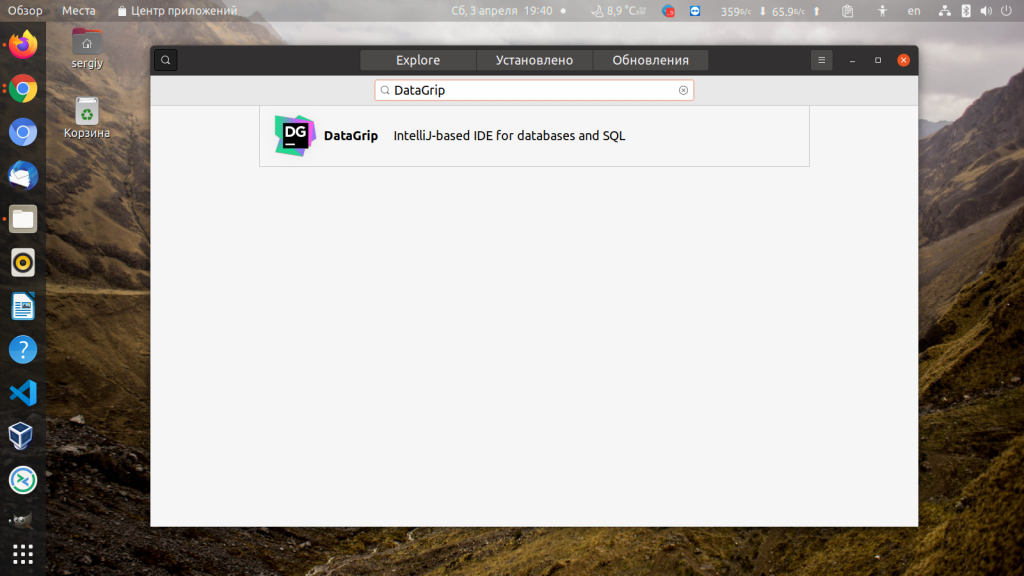
В списке будет только одна программа — DataGrip от JetBrains. Выберите её, а затем, в открывшемся окне нажмите кнопку Установить:
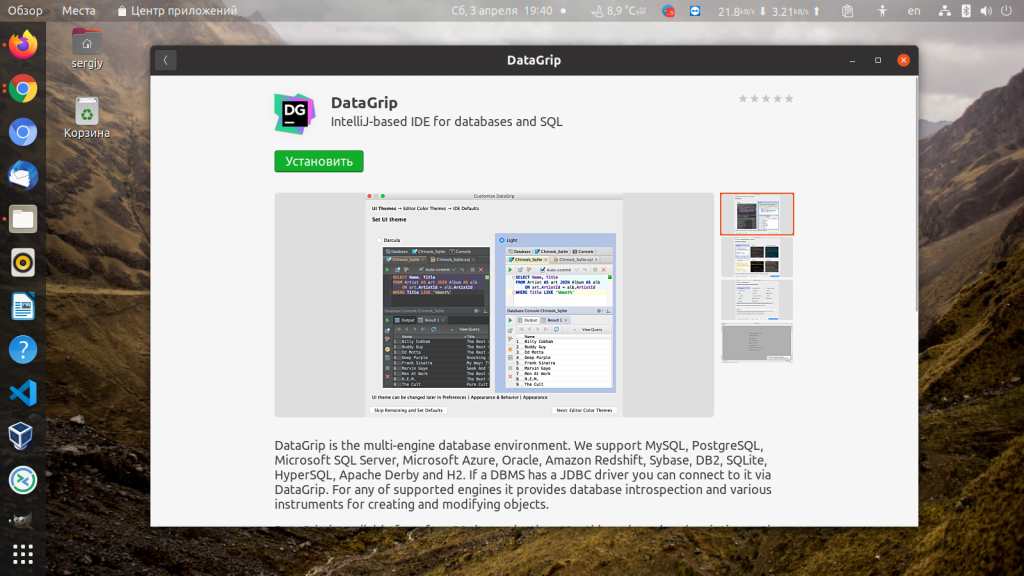
После завершения установки вы сможете найти программу в главном меню.
2. Пакет snap
Если вы не хотите использовать центр приложений, можно установить DataGrip с помощью менеджера пакетов snap. Фактически это одно и то же, потому что центр приложений тоже использует snap. Для этого выполните:
sudo snap install datagrip —classic
После завершения установки программа будет доступна в главном меню.
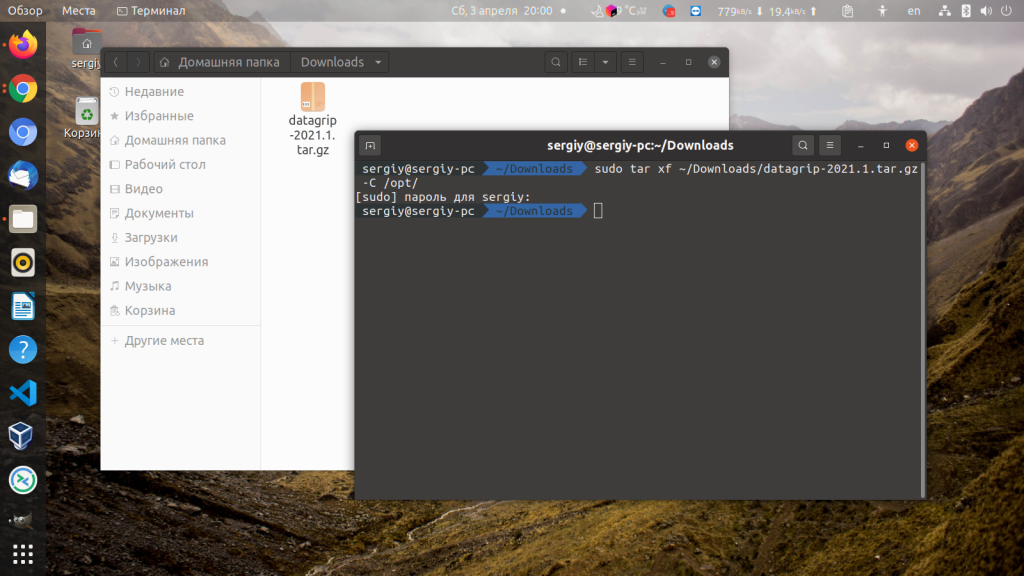
После завершения загрузки, полученный архив необходимо распаковать в папку /opt. Для этого можно использовать такую команду:
/Downloads/datagrip-2021.1.tar.gz -C /opt/
В имени файла есть версия, поэтому оно может не совпадать с загруженным вами файлом. Вам надо будет поправить версию на свою. После этого создайте символическую ссылку на исполняемый файл программы в каталог /bin:
sudo ln -s /opt//bin/datagrip.sh /usr/local/bin/datagrip
После этого можно запускать программу с помощью терминала:
Ярлык для главного меню можно создать уже в программе. Для этого откройте меню Tools и выберите Create desktop entry:

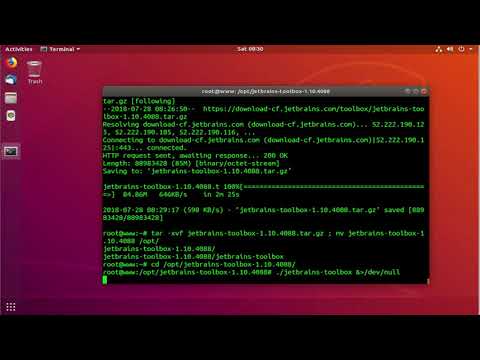
4. JetBrains Toolbox

Распакуйте её куда нибудь и запустите исполняемый файл из архива. Сначала надо принять лицензионное соглашение:
Затем выберите в списке программ нужную программу. В данном случае DataGrip и нажмите справа от неё кнопку Install:
После завершения установки программа будет доступна в главном меню. Также вы можете запускать её с помощью ToolBox, она появится в секции Installed в верху окна. Здесь же её можно удалить выбрав в настройках кнопку Uninstall.
Программа автоматически создаст ярлык в главном меню, так что после этого можно начинать ею пользоваться.
Общие инструкции для Linux
Если вы предпочитаете общую версию JetBrains DataGrip для Linux, вот как заставить ее работать. Сначала отправляйтесь в на сайте JetBrains. Оттуда нажмите синюю кнопку «Загрузить», чтобы загрузить последний архивный файл TarGZ.
Когда процесс загрузки завершится, используйте команду CD, чтобы перейти в каталог «Загрузки». После этого распакуйте файл DataGrip TarGZ с помощью команды tar.
cd ~/Downloads
tar xvf datagrip-*.tar.gz
После распаковки файла архива используйте команду CD для перехода в папку «DataGrip — * /». Затем снова вставьте компакт-диск в папку «bin», где находится файл «datagrip.sh».
cd DataGrip-*/
cd bin/
Выполните файл сценария «datagrip.sh» как программу с помощью команды sh. Не используйте команду sudo, если вы не знаете, что делаете с DataGrip.
sh datagrip.sh
После выполнения файла «datagrip.sh» JetBrains DataGrip установлен и готов к использованию. Наслаждаться!
Как пользоваться DataGrip
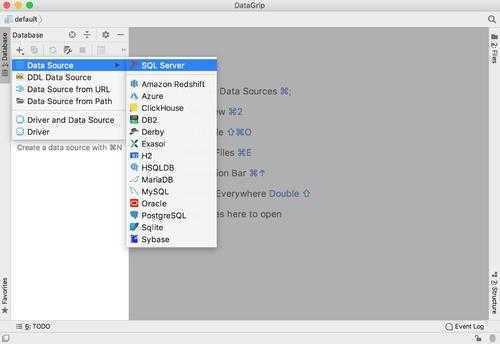
После первоначальной настройки и создания проекта вы можете добавлять в него базы данных. Для этого кликните по значку плюса на панели слева и в раскрывающемся списке Data Source выберите нужный движок баз данных, например MySQL:

Затем нужно ввести имя пользователя, пароль и хост базы данных. После этого нажмите кнопку Test connection чтобы проверить что подключение выполняется успешно. Подключится к только что установленной MySQL у вас, скорее всего, не получится, потому что от имени root можно подключатся только из терминала. Сначала надо создать пользователя. Об этом читайте здесь. Затем введите нужные данные:
Затем на панели слева, ниже плюса появится ваш сервер баз данных, а в рабочей области справа откроется консоль с помощью которой на этом сервере можно выполнять команды.

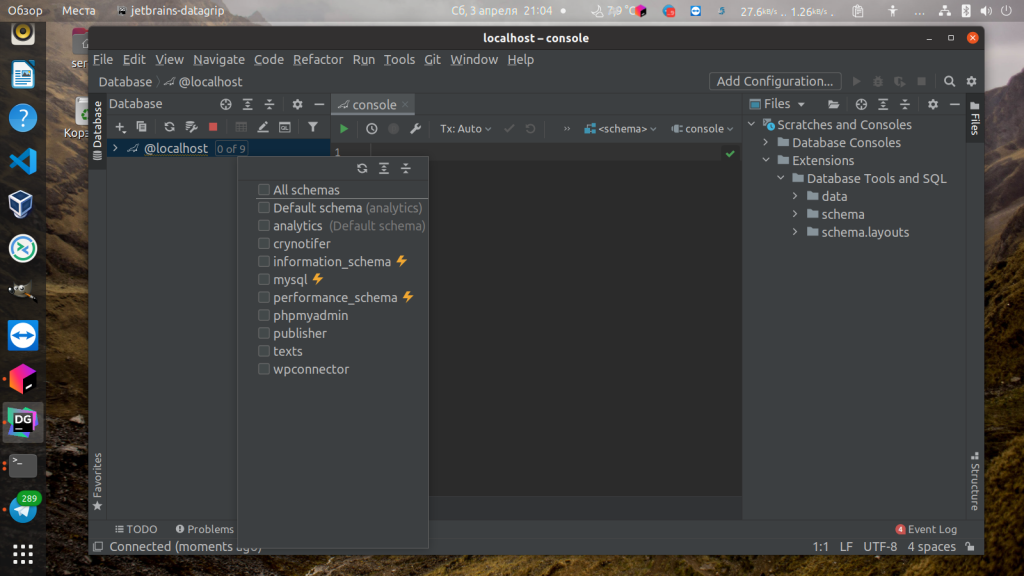
По умолчанию базы данных либо вообще выводится не будут, либо будут выведены не все. Чтобы выбрать базы данных для вывода кликните по надписи 1-9 слева от названия сервера. В открывшемся списке отметьте нужные базы данных:
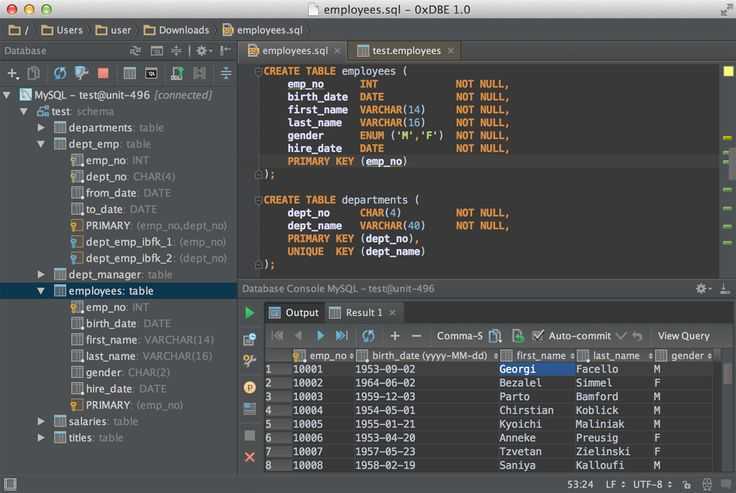

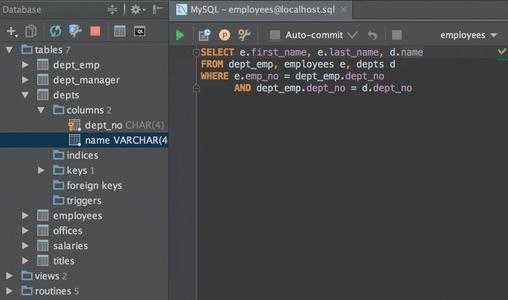
Затем вы сможете посмотреть таблицы базы данных, а также содержимое таблиц:
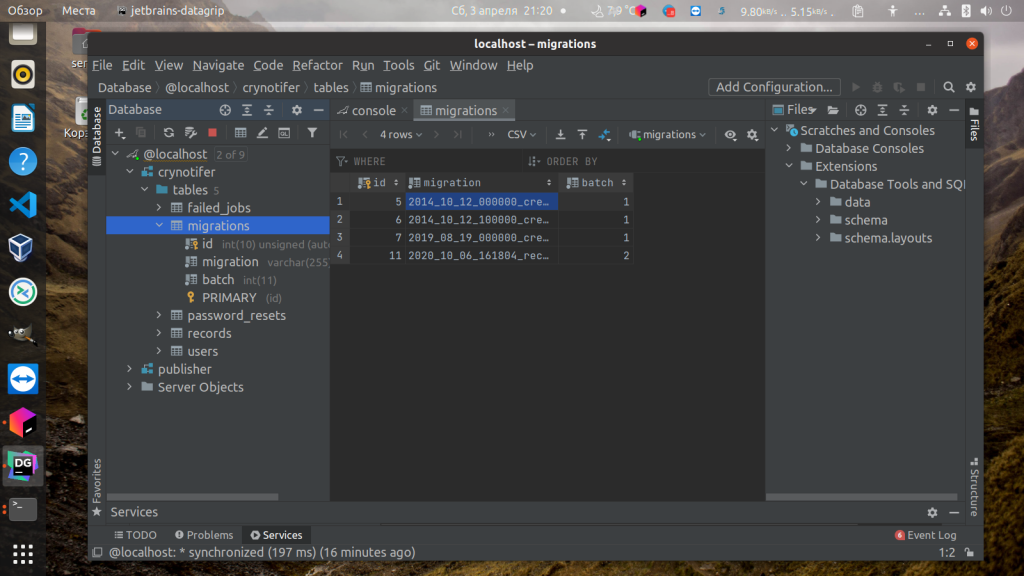
Если вам надо изменить значения полей или удалить их, то обратите внимание, что изменения не применяются автоматически. Для того чтобы их применить необходимо нажать Ctrl+Enter
EMS Studio
EMS Studio, похоже, работает только под Windows. Это его главный недостаток, потому что, как известно PostgreSQL очень редко используют под виндой.
До кучи там зачем-то сделан визуальный конструктор запросов. Где вместо того, чтобы текстом написать , надо нажать мышкой несколько кнопок и понавыбирать из выпадающего списка. Тем, кто знает SQL — это не нужно, тем кто не знает — это не поможет.
Фичи, которые называют как удобные: auto-complete с алиасами, экспорт результата выполнения запроса в SQL формате (insert), удобный GUI для экпорта базы, возможность выполнять только выделенную часть SQL.
Умеет дебаг pl/pgsql. В общем, много чего умеет, но какой-то выдающейся особенности, что отличало бы от других, я не могу назвать.
История
Логотип JetBrains использовался с 2000 по 2016 год.
JetBrains, первоначально называвшаяся IntelliJ Software, была основана в 2000 году в Праге тремя российскими разработчиками программного обеспечения: Сергеем Дмитриевым, Валентином Кипятковым и Евгением Беляевым. Первым продуктом компании был IntelliJ Renamer, инструмент для рефакторинга кода на Java.
В 2012 году генеральный директор Сергей Дмитриев покинул компанию к двум вновь назначенным генеральным директорам, Олегу Степанову и Максиму Шафирову, чтобы работать в области биоинформатики .
В 2021 году New York Times на основании неустановленных источников заявила, что неизвестные стороны могли встроить вредоносное ПО в программное обеспечение JetBrains, что привело к взлому SolarWinds и другим широко распространенным нарушениям безопасности. В JetBrains заявили, что с ними не связывалось ни одно правительство или агентство безопасности, и что они «никоим образом не участвовали и не участвовали в этой атаке».
NAVICAT
Navicat — это, наверное, самая богатая фичами программа. Она умеет всё, что умеют другие GUI для БД: дизайнер объектов, просмотрщик таблиц, автокомплит, инструменты проектирования базы, отладка pl/pgsql, импорт/экспорт и так далее.
Поистине всеобъемлющий софт, который работает практически на любой ОС. Навскидку, намного удобнее EMS Studio.
Киллер-фичей, на мой взгляд, является сравнение баз. Т.е. можно взять две базы, узнать, чем они отличаются по структуре и сформировать запросы для синхронизации.
Ценник, правда, что называется, «конский» — в два раза дороже, чем EMS. Но тут, похоже, это полностью оправдано.
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.

Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Применение для репозитория/PPA
- «Давайте проклянём на несколько часов одного из стажёров и пусть себе выкатывает!» — возможно, это и окажется полезным для стажёра, но только на этапе обучения работы с системой и при условии, что он совсем не умеет работать apt. Дальше это действительно превратится в проклятие. Вдобавок, получаемый результат будет больше зависим от человеческого фактора, чем хотелось бы.
- «Выкатить везде с Chef/Puppet/Ansible/…!» — отличная мысль, но не наш случай на тот момент и в той ситуации. Ради одного пакета пришлось бы победить дракона, т.е. завести множество машин в выбранную систему управления конфигурациями.
- Поскольку статья посвящена unattended upgrades, легко догадаться, что именно этот механизм и предлагает иной способ решить задачу, не потратив на неё множество человекочасов…
очень
- — «происхождение» репозитория, что может указывать на имя мейнтейнера или самого репозитория;
- — ветка дистрибутива; например, stable, testing для Debian или trusty, xenial для Ubuntu.
Примечание: Более подробную документацию по файлам Release/InRelease и используемым в них параметрах см. на .
обратные стороны
- Если установка пакета требует интерактивности, т.е. вмешательства пользователя (особенно актуально, если вы делаете масштабное обновление системы, поскольку уже давно этого не делали) — unattended upgrades просто ничего не будут делать.
- Пример с автоматическим обновлением nginx из PPA не стоит проверять в реальной жизни production, если только вы не хотите прослыть «грязным Гарри» обновления пакетов. Ещё раз вспомните название утилиты и запомните, что обновлять так можно только то, что действительно не требует никакого присмотра. Например, библиотеки (хотя даже тут бывают подводные камни, если вспомнить хотя бы недавние танцы Ubuntu с libc и сломанным DNS resolver) и софт, не требующий конфигурации и запускающийся по требованию (atop, htop и подобные).
рестарту
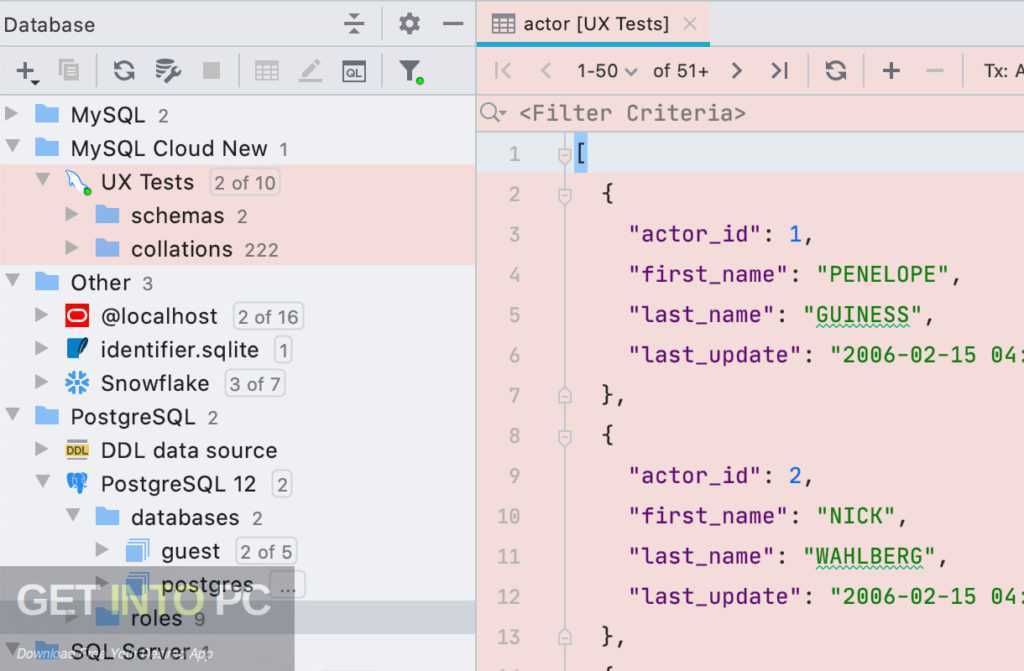
Подключение к базе данных:
В этом разделе я покажу вам, как подключиться к базе данных SQL с помощью DataGrip.
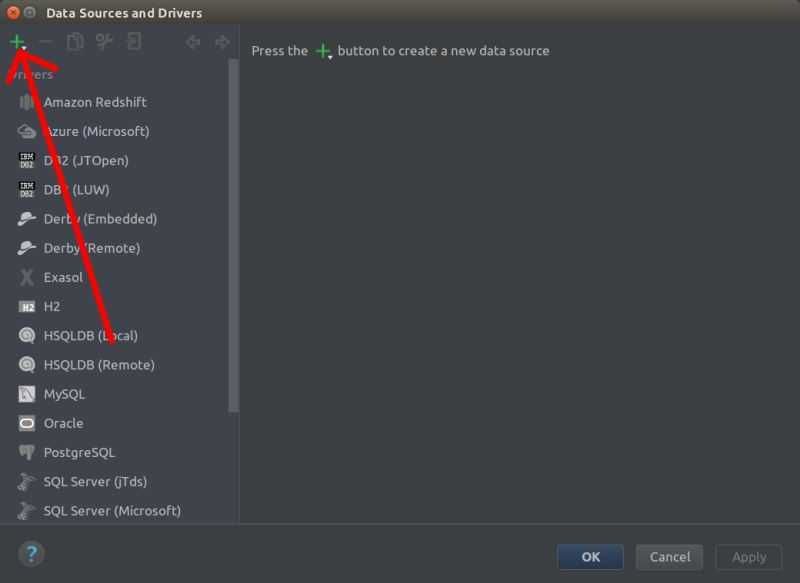
Сначала из База данных щелкните значок + , как отмечено на скриншоте ниже.
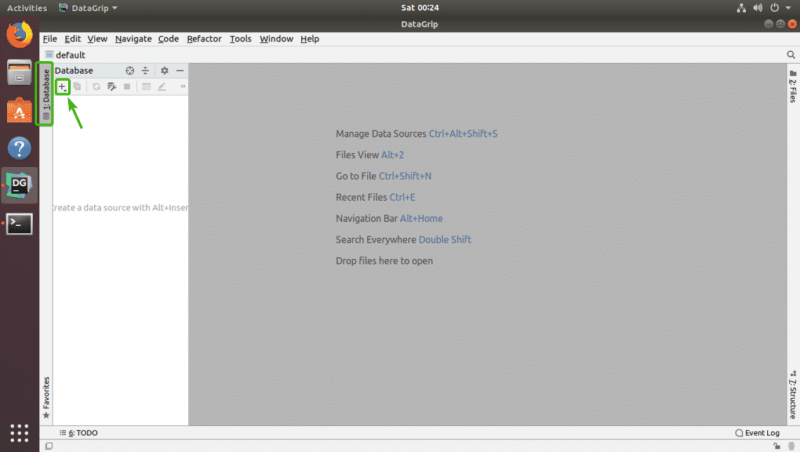
Теперь в Источник данных выберите база данных, к которой вы хотите подключиться. Я выберу MariaDB .
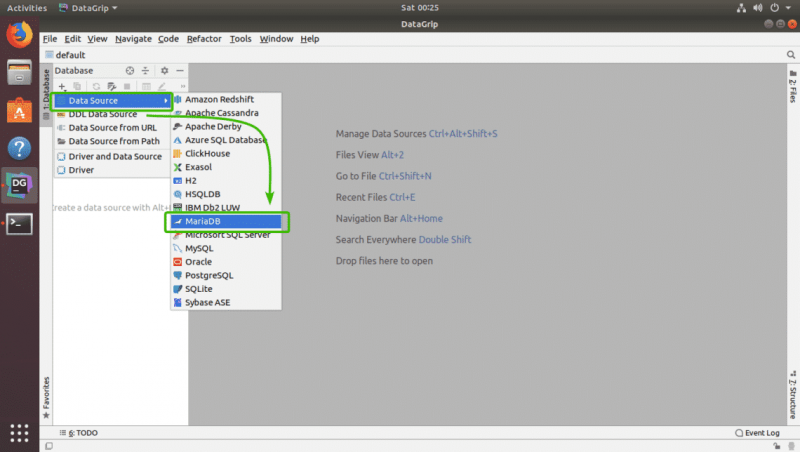
Поскольку вы впервые запускаете DataGrip для этой базы данных (MariaDB в моем случае), вам нужно будет загрузить драйвер базы данных. Вы можете нажать Загрузить , как отмечено на скриншоте ниже, чтобы загрузить драйвер базы данных.
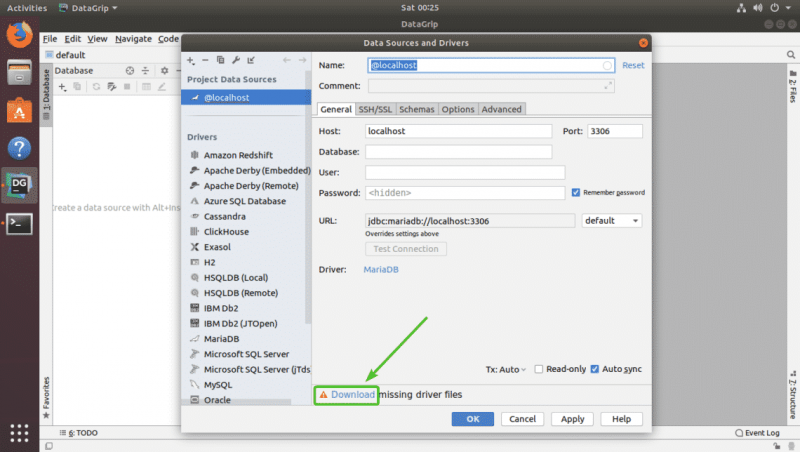
Как видите, необходимые файлы драйвера базы данных загружаются.
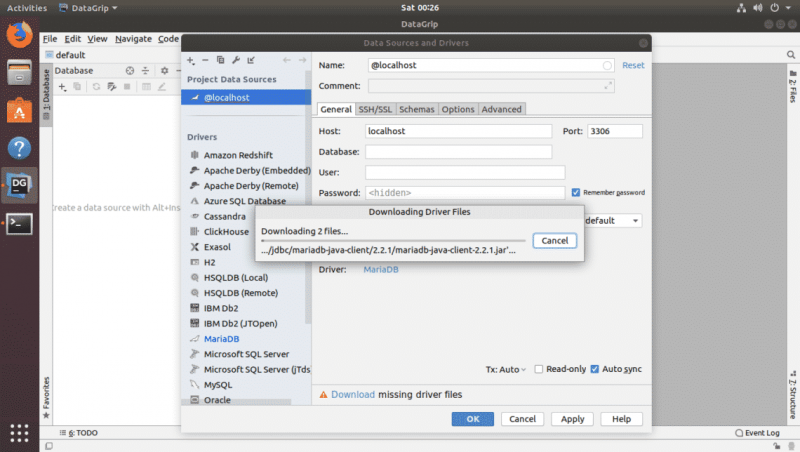
После загрузки драйвера введите все данные и нажмите Проверить соединение .
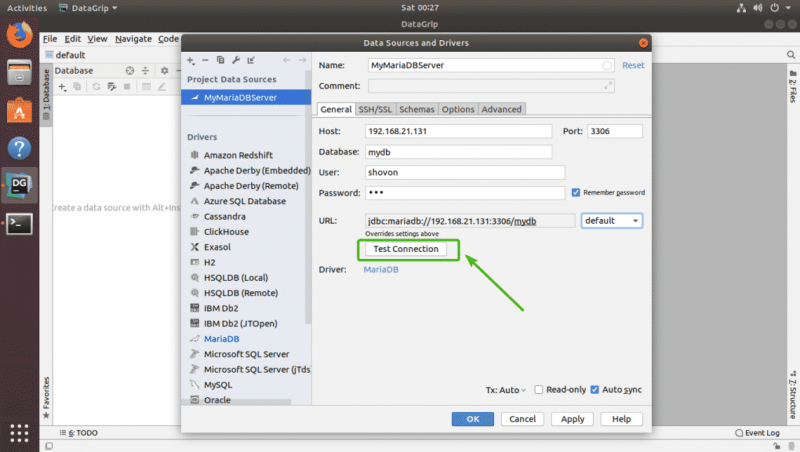
Если все в порядке, вы должны увидеть зеленый значок Успешно сообщение, как показано на скриншоте ниже.
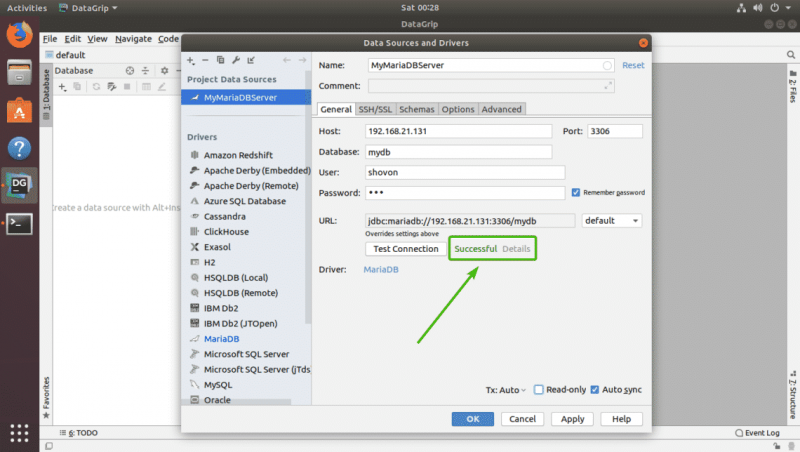
Наконец, нажмите OK .
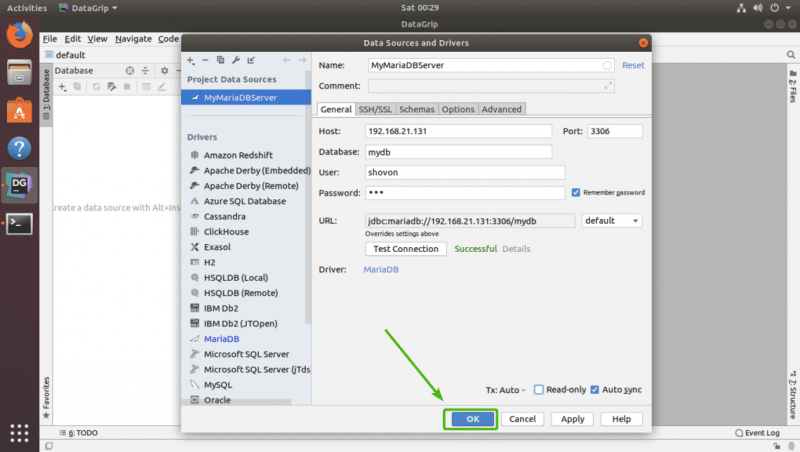
Вы должны быть подключены к желаемой базе данных.
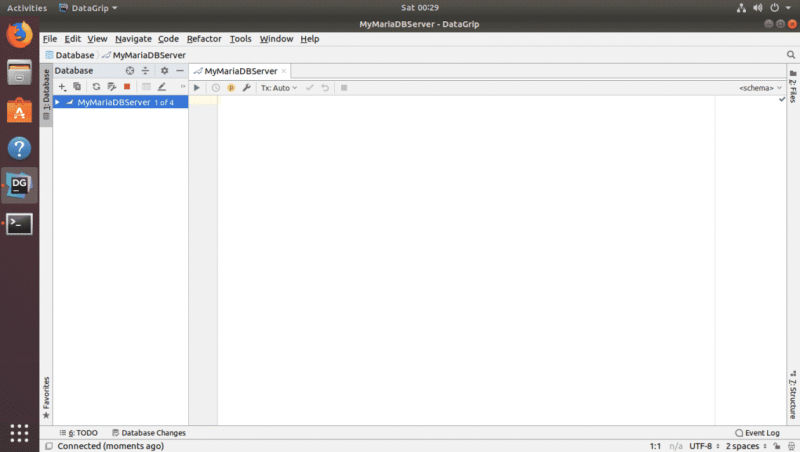
Создание таблиц с помощью DataGrip:
Вы можете создавать таблицы в своей базе данных графически, используя DataGrip. Сначала щелкните правой кнопкой мыши свою базу данных в списке и перейдите к New > Table , как отмечено на скриншоте ниже.

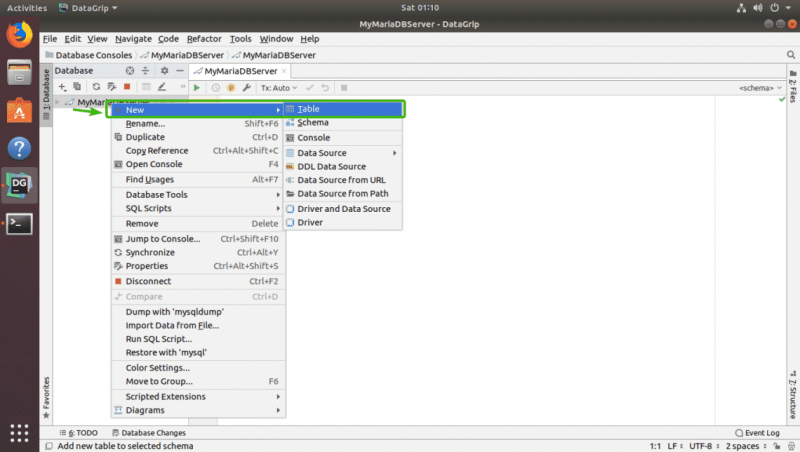
Теперь введите имя вашей таблицы. Чтобы добавить новые столбцы в таблицу, щелкните значок + , как отмечено на скриншоте ниже.
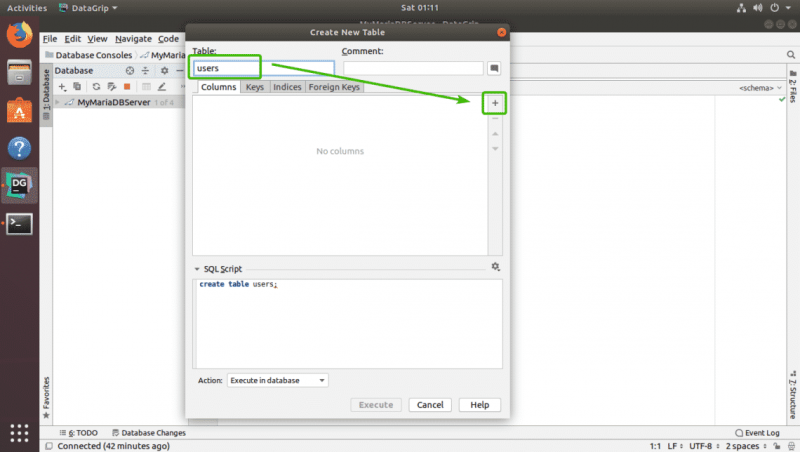
Теперь введите имя столбца, тип, значение по умолчанию, если оно есть в вашем дизайне, и проверьте атрибуты столбца, такие как Auto Increment, Not null, Уникальный первичный ключ в зависимости от ваших потребностей.
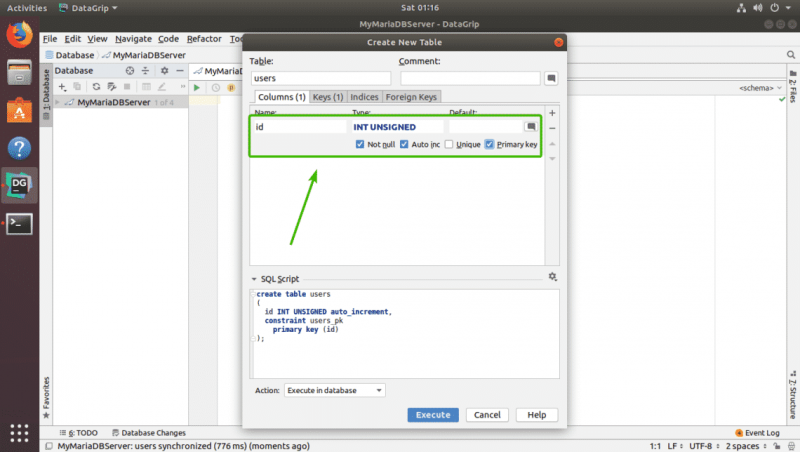
Если вы хотите создать еще один столбец, просто щелкните значок + еще раз. Как видите, я создал id , firstName , lastName , адрес , возраст , phone и country . Вы также можете использовать значок — для удаления столбца, значки со стрелками вверх и вниз для измените положение столбца. Когда вы будете удовлетворены своей таблицей, нажмите Выполнить .
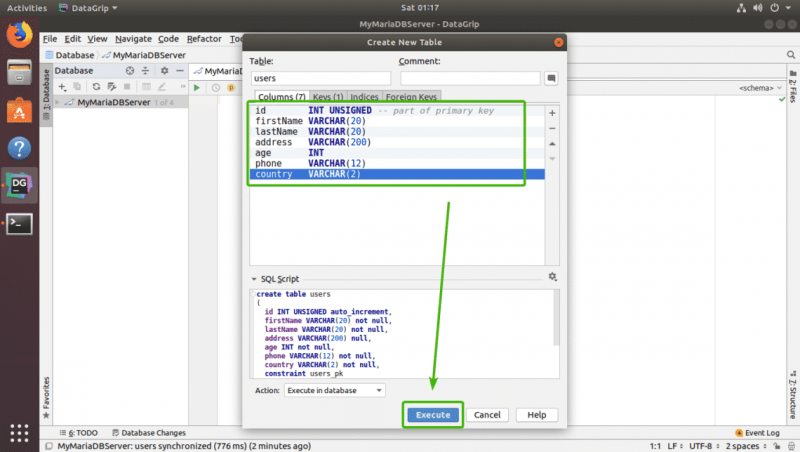
Ваша таблица должна быть создана.
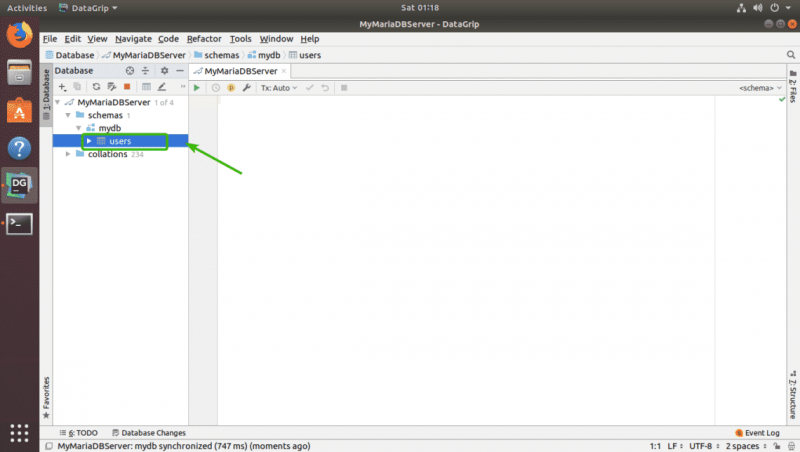
Вы можете дважды щелкнуть таблицу, чтобы открыть ее в графическом редакторе. Отсюда вы можете очень легко добавлять, изменять и удалять строки таблицы. Это тема следующего раздел этой статьи.
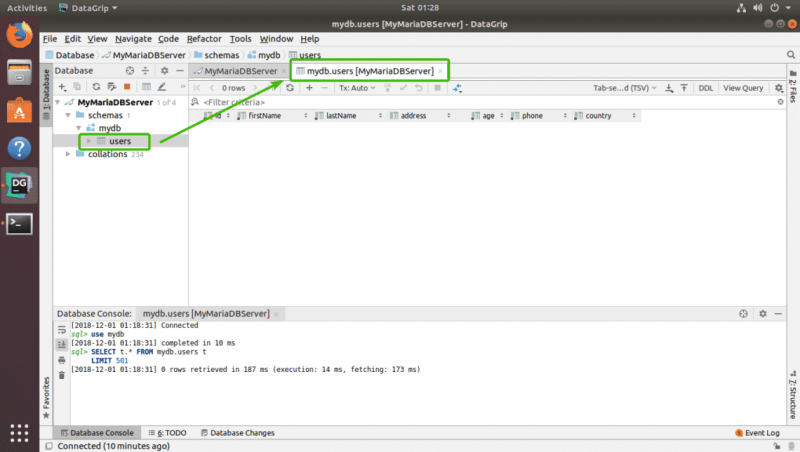
Работа с таблицами в DataGrip:
Чтобы добавить новую строку, от t В редакторе таблиц просто щелкните значок + , как отмечено на скриншоте ниже.
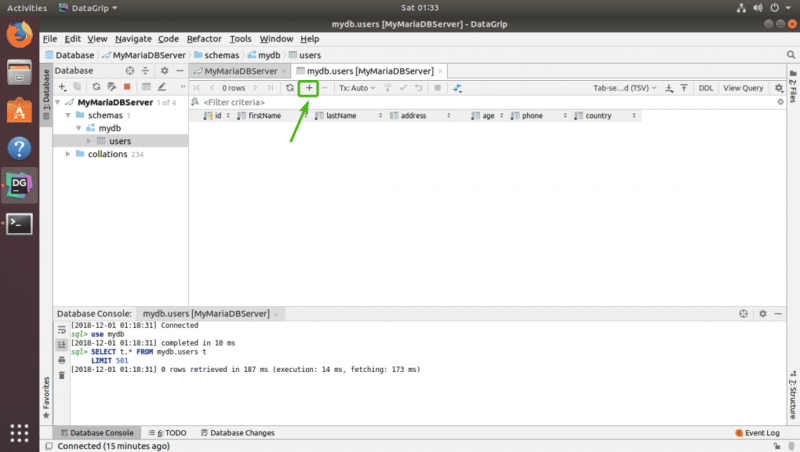
Должна появиться новая пустая строка.
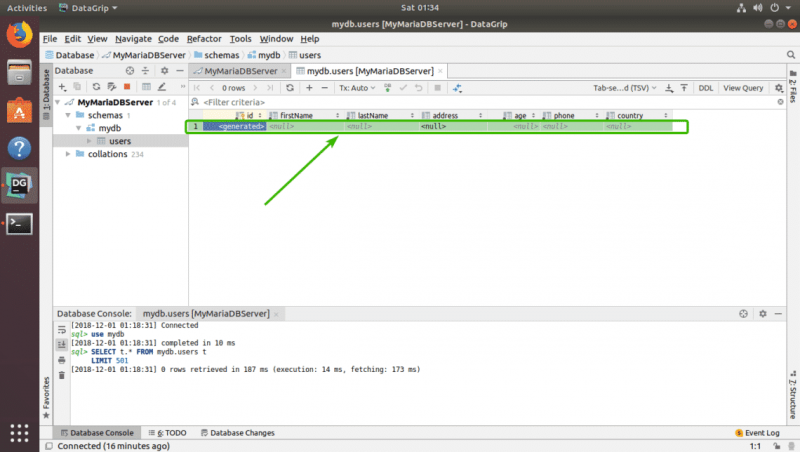
Теперь щелкните столбцы и введите значения, которые вы хотите использовать для новой строки. Когда вы закончите, щелкните значок загрузки БД, как показано на скриншоте ниже.
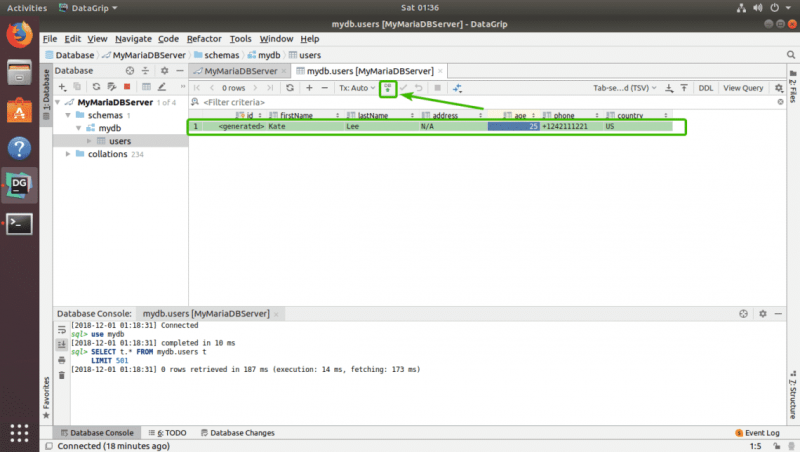
Как видите, изменения постоянно сохраняются в базе данных.
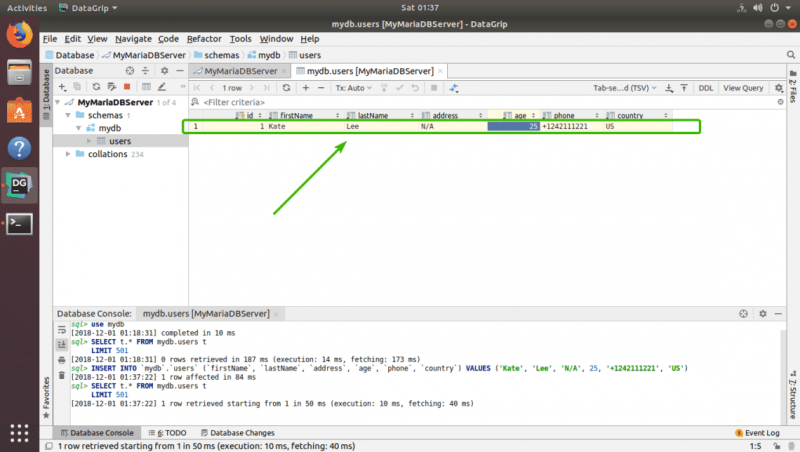
Я добавил еще одну строку фиктивных данных, чтобы продемонстрировать, как работает удаление и изменение.
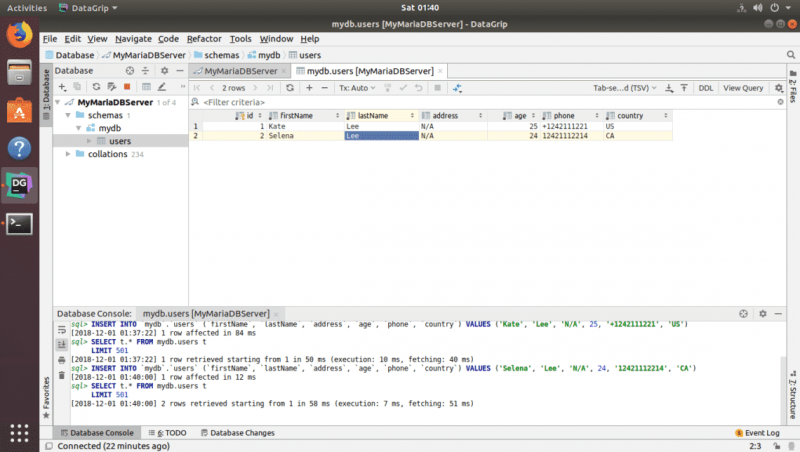
Чтобы удалить строку, выберите любой столбец строки, которую вы хотите удалить, и щелкните значок — , отмеченный на снимке экрана ниже. .


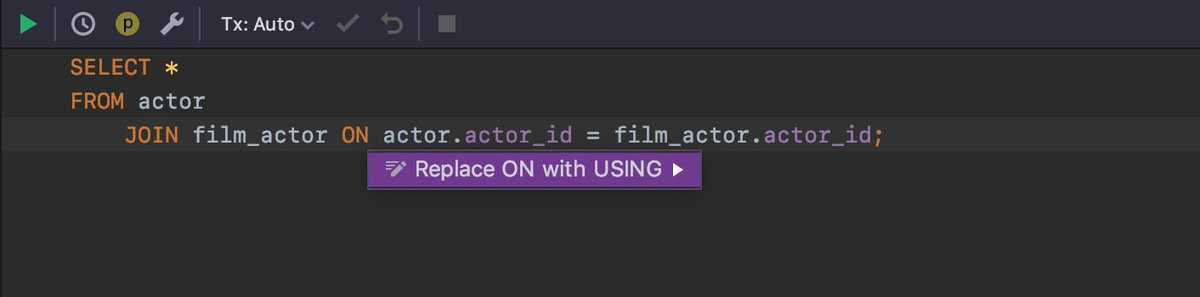


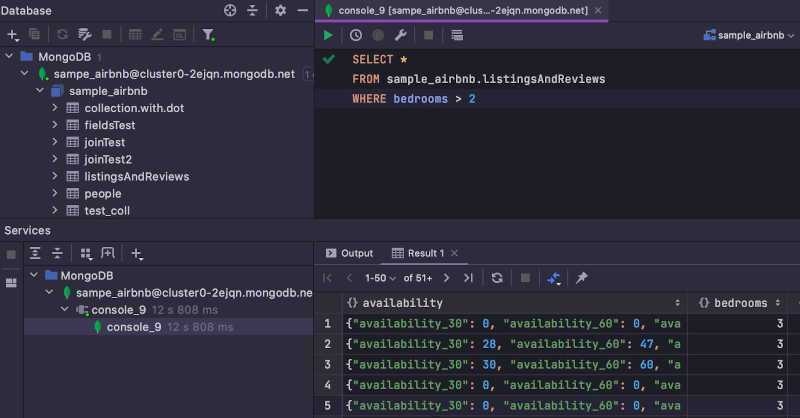
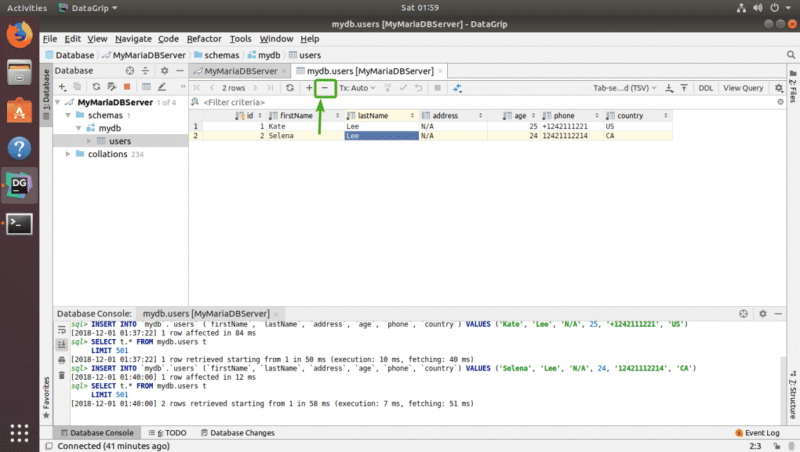
Как видите, строка не в серый цвет. Чтобы сохранить изменения, щелкните значок загрузки БД, как показано на снимке экрана ниже.
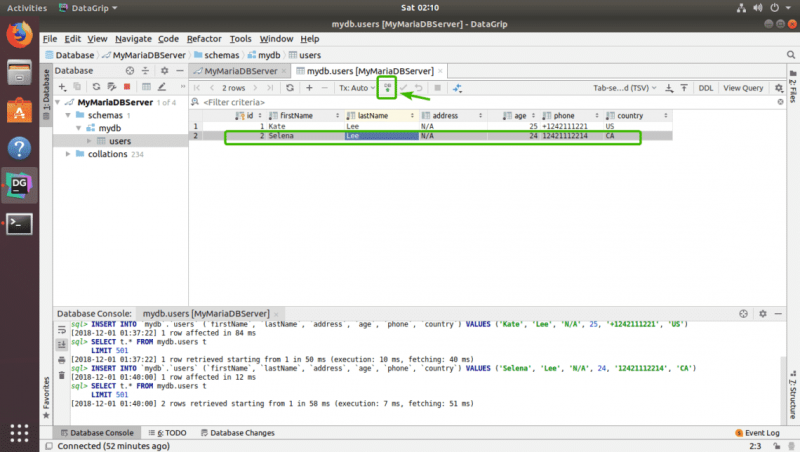
Как видите, таблица исчезла.
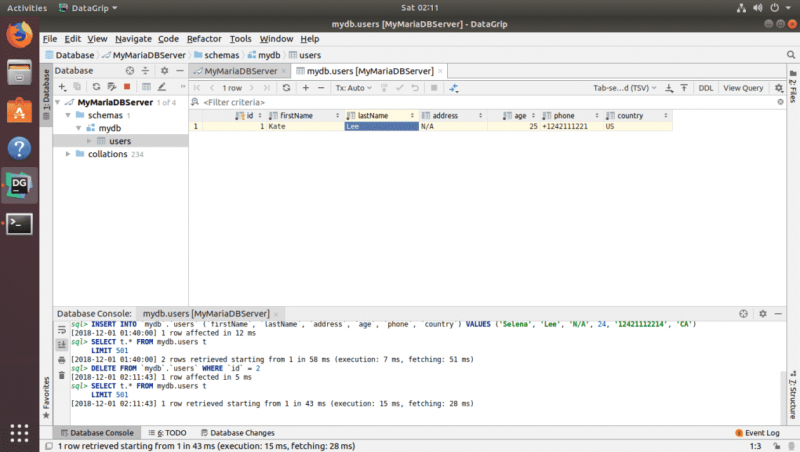
Чтобы изменить любую строку, просто дважды щелкните столбец строки, которую вы хотите изменить, и введите новое значение.
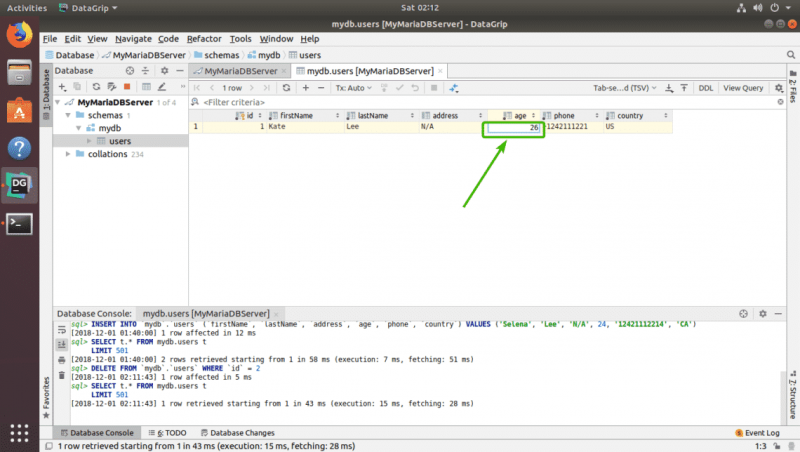
Наконец, щелкните в другом месте, а затем щелкните значок загрузки БД, чтобы изменения были сохранены.
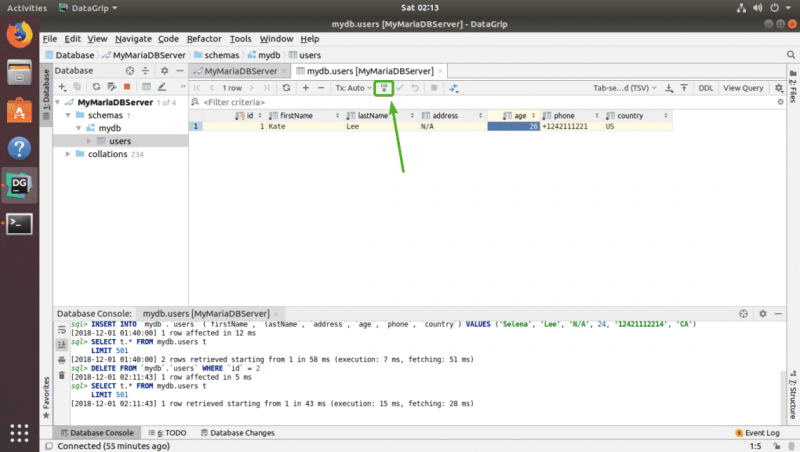
Выполнение операторов SQL в DataGrip:
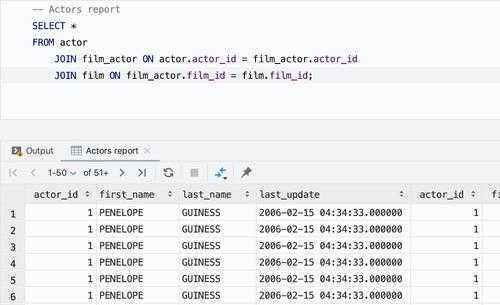
Для выполнения операторов SQL просто введите оператор SQL, переместите курсор в конец оператора SQL и нажмите + . Он будет выполнен, и результат будет отображаться, как вы можете видеть на скриншоте ниже..
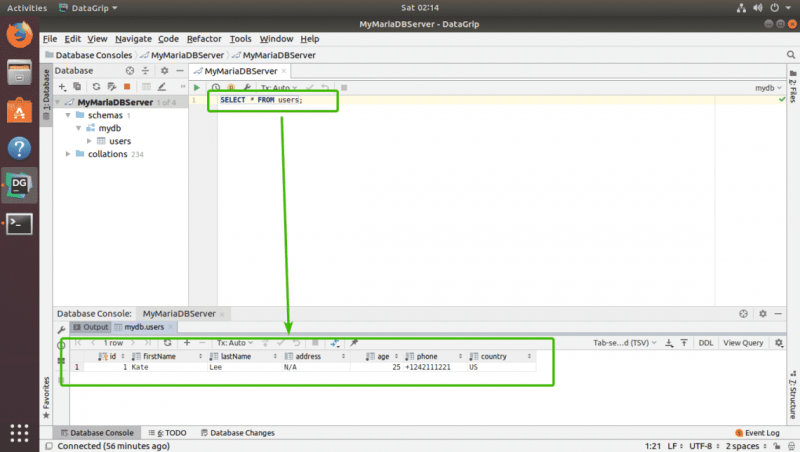
Итак, вот как вы устанавливаете и используете DataGrip в Ubuntu . Спасибо, что прочитали эту статью.



