
7. Переустановка Windows и подключение массива к другим компьютерам
Дисковые пространства существуют и вне среды работающей Windows, ведь информация о конфигурациях массивов хранится на самих дисках. Вот только распознать массив — по сути, виртуальный тип устройства информации — сможет только совместимое с Windows 8/8.1/10, Server 2012/2012 R2/2016 программное обеспечение. Это установочные процессы этих версий, LiveDisk на базе WinPE 8-10, ну и, конечно же, сами ОС. Если мы установим, к примеру, Win7 или перенесём весь массив на другой компьютер с этой версией, она не будет видеть такой массив, увидит только отдельные носители как таковые, что «Вне сети». И не предложит ничего более, как удалить на них разделы.
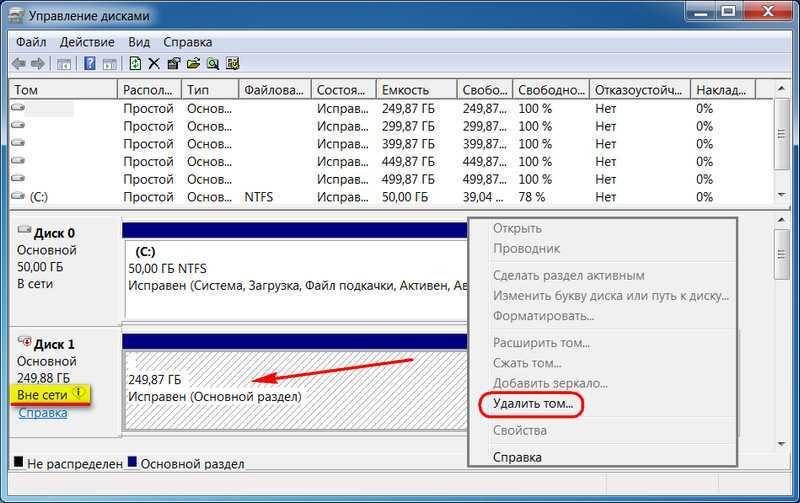
Поддерживающие же технологию версии Windows при переустановке или подключении массива к другому компьютеру обнаружат его автоматически, без нашего вмешательства. Непосредственно во время переустановки ОС мы будем видеть массив как единое устройство информации. Кстати, если переустанавливается EFI-система Windows, необходима внимательность, чтобы по ошибке не удалить или не отформатировать MSR-раздел дискового пространства, а не ОС.
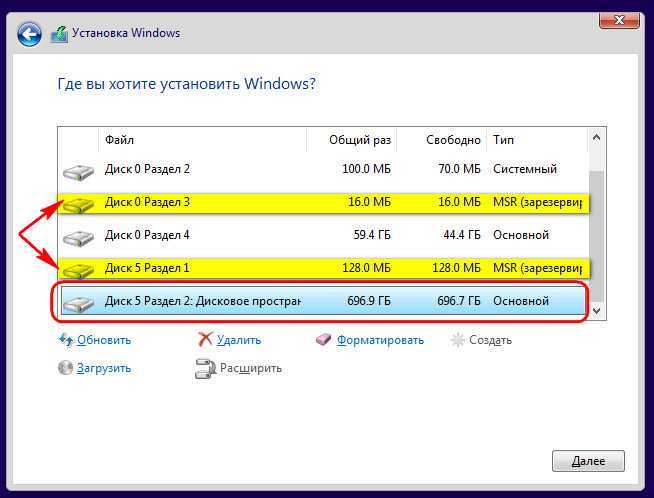
На дисковое пространство даже можно установить второю Windows. Вот только делать этого не стоит. Вторая ОС установится, но не сможет запускаться. Да и ещё и затрёт загрузчик первой ОС, и его придётся восстанавливать.
Переносим /home на RAID
Конечно, можно было монтировать raid в любое место и использовать, но для меня самым удобным было использовать его как /home. Процесс не представляет из себя ничего сложного.
Сначала убираем имеющиеся на raid данные в одну папку чтоб потом их растащить куда надо. Далее копируем данные из текущего /home на raid (который смонтирован, например, как /media/raid). В силу того, что я копировал home на свежей системе, то он был почти пустой и копировал я его без выкрутасов, как предлагается во многих рецептах.
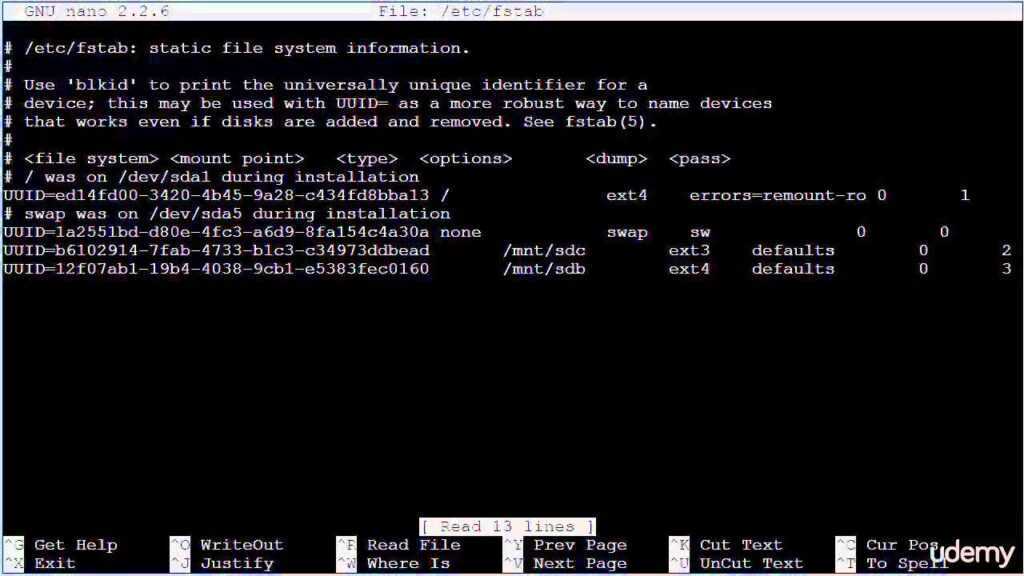
Далее вписываем в /etc/fstab новую точку монтирования для /home
UUID взят из вывода команды
не путать с выводом из mdadm —detail —scan, который дает другой UUID.
После изменения fstab перезагружаемся и смотрим на результат, и если в /home есть данные с raid (которые выше были убраны в одну папку), то все хорошо ![]()
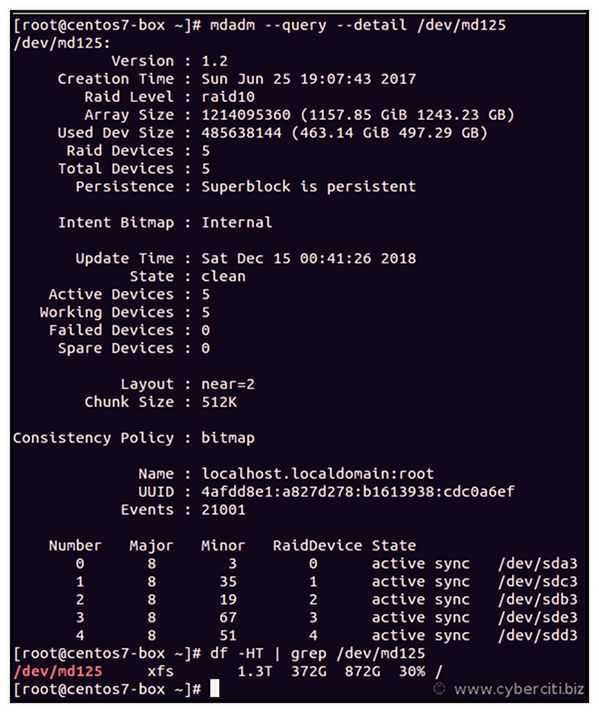
Восстановление RAID при сбое, замена диска
Если у вас вышел из строя или повредился один из дисков в RAID-массиве, его можно заменить другим. Для начала определим, поврежден ли диск и какой диск нам следует менять.
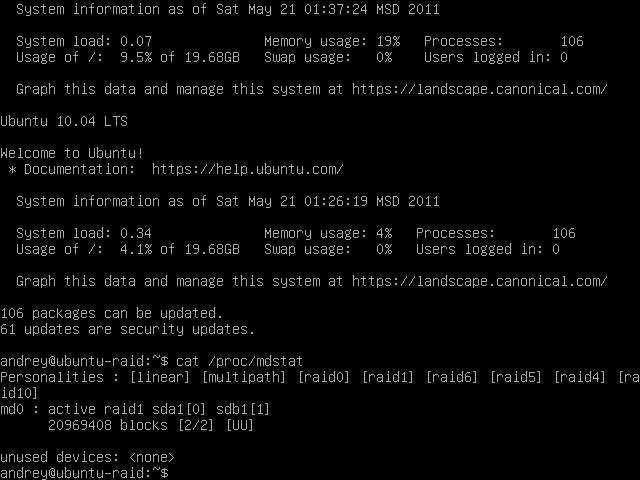
Personalities : md0 : active raid1 vdb 20954112 blocks super 1.2 [2/1]
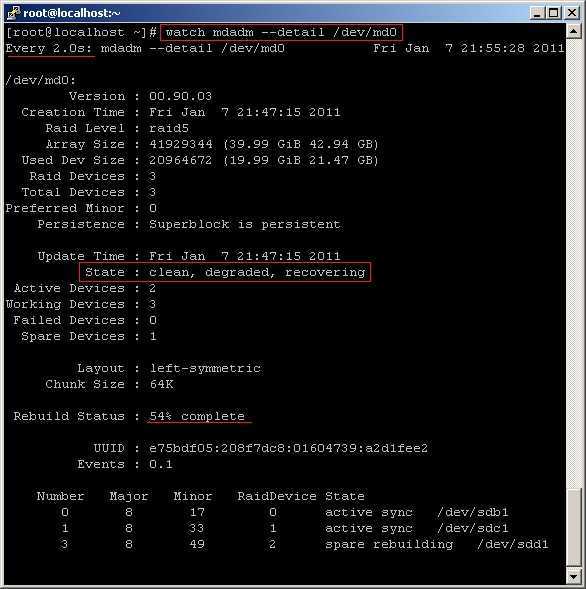
Из листинга команды, вы видим, что только один диск активен. Так же о проблеме говорит . Когда оба диска рабочие, вывод будет .
Подробная информация о RAID-массиве также показывает, что естт проблемы:
/dev/md0: Version : 1.2 Creation Time : Tue Oct 29 12:39:22 2019 Raid Level : raid1 Array Size : 20954112 (19.98 GiB 21.46 GB) Used Dev Size : 20954112 (19.98 GiB 21.46 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Tue Oct 29 14:41:13 2019 State : clean, degraded Active Devices : 1 Working Devices : 1 Failed Devices : 1
– данная строка указывает на то, что диск в raid-массиве поврежден.
В нашем случае нужно заменить неисправный диск /dev/vdc. Для восстановления массива, нужно удалить нерабочий диск и добавить новый.
Удаляем неиспраный диск:
Добавляем в массив новый диск :
Восстановление диска запустится автоматически после добавления нового диска:
/dev/md0: Version : 1.2 Creation Time : Tue Oct 29 12:39:22 2019 Raid Level : raid1 Array Size : 20954112 (19.98 GiB 21.46 GB) Used Dev Size : 20954112 (19.98 GiB 21.46 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Tue Oct 29 14:50:20 2019 State : clean, degraded, recovering Active Devices : 1 Working Devices : 2 Failed Devices : 0 Spare Devices : 1 Consistency Policy : resync Rebuild Status : 69% complete Name : server.vpn.ru:0 (local to host server.vpn.ru) UUID : 9d59b1fb:7b0a7b6d:15a75459:8b1637a2 Events : 42 Number Major Minor RaidDevice State 0 253 16 0 active sync /dev/vdb 2 253 48 1 spare rebuilding /dev/vdd
— показывает текущее состояние восстановления массива.
— показывает какой диск добавляется к массиву.
После восстановления массива, листинг по дискам выглядит так:
State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0
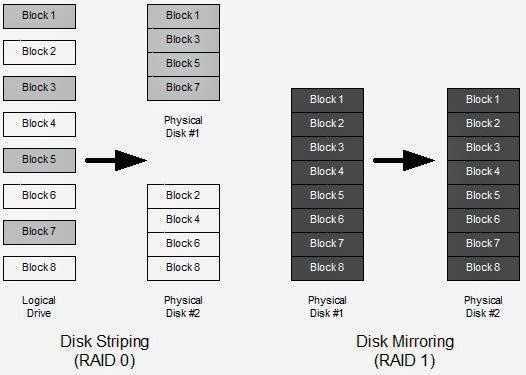
Raid Layout (расположение данных на дисках в RAID)
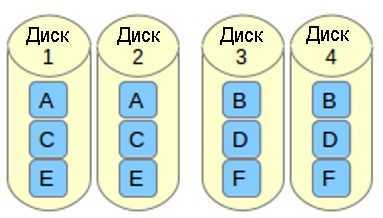
o означает offset copies (смещение копий). Вместо того, чтобы дублировать куски данных в полосе, дублируются целые полосы, но они на каждом устройстве сдвинуты, так что дублируемые блоки находятся на разных устройствах с разными смещениями. То есть следующая копия на следующем диске находится на один фрагмент данных дальше. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=o2 в команду, с помощью которой создается массив.
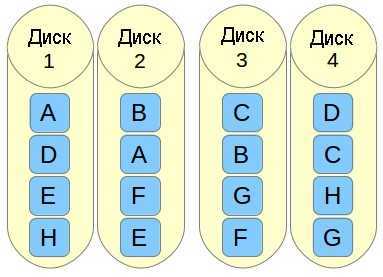
f означает far copies (копии с сильно различающимися смещениями). Такая компоновка обеспечивает более высокую производительность чтения, но худшую производительность записи. Таким образом, это лучший вариант для систем, в которых операции чтения должны выполняться гораздо чаще операций записи. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=f2 в команду, с помощью которой создается массив.
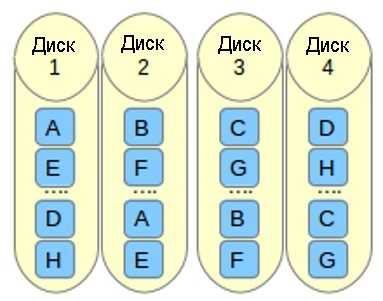
Число, которое расположено за n, f и o в параметре —layout, указывает, какое количество копий необходимо для каждого блока данных. Это значение по умолчанию равно 2, но оно может быть в диапазоне от 2 и до числа, равного количеству устройств в массиве. Указывая правильное количество копий, вы можете минимизировать влияние операций ввода/вывода на каждый отдельный диск.
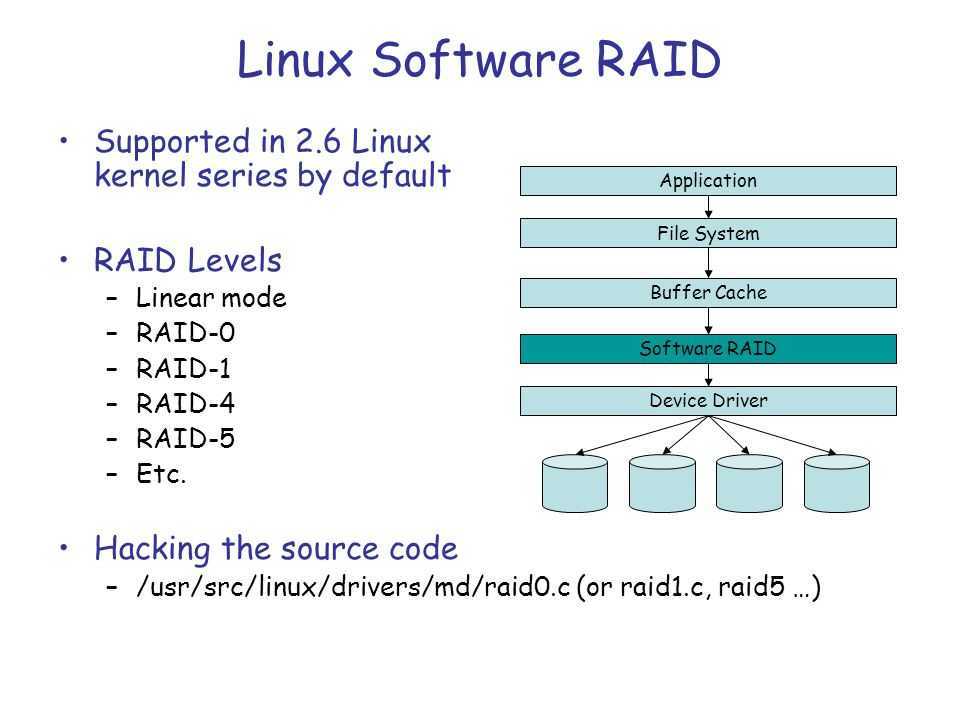
Implementation
The RAID devices can be managed in different ways:
- Software RAID
- This is the easiest implementation as it does not rely on obscure proprietary firmware and software to be used. The array is managed by the operating system either by:
- by an abstraction layer (e.g. );
Note: This is the method we will use later in this guide. - by a logical volume manager (e.g. );
- by a component of a file system (e.g. ZFS, ).
- by an abstraction layer (e.g. );
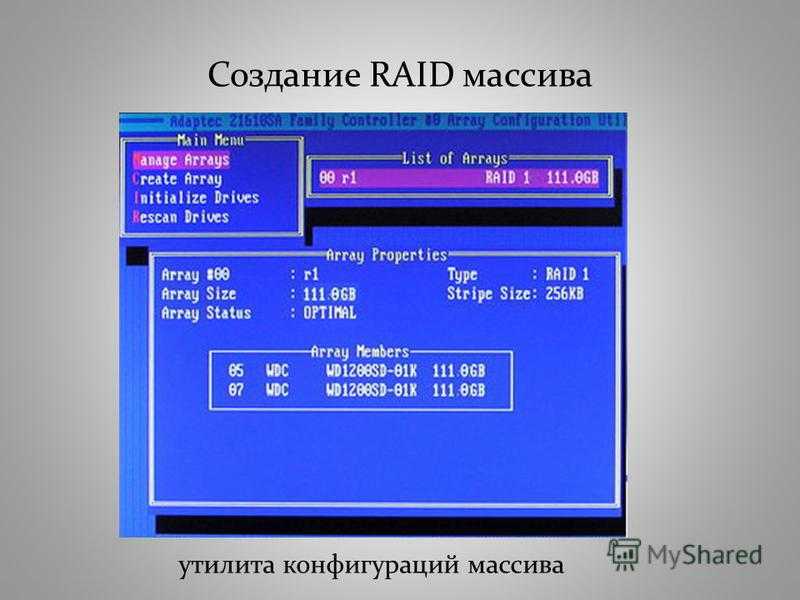
- Hardware RAID
- The array is directly managed by a dedicated hardware card installed in the PC to which the disks are directly connected. The RAID logic runs on an on-board processor independently of the host processor (CPU). Although this solution is independent of any operating system, the latter requires a driver in order to function properly with the hardware RAID controller. The RAID array can either be configured via an option rom interface or, depending on the manufacturer, with a dedicated application when the OS has been installed. The configuration is transparent for the Linux kernel: it does not see the disks separately.
- FakeRAID
Which type of RAID do I have?
Since software RAID is implemented by the user, the type of RAID is easily known to the user.
However, discerning between FakeRAID and true hardware RAID can be more difficult. As stated, manufacturers often incorrectly distinguish these two types of RAID and false advertising is always possible. The best solution in this instance is to run the command and looking through the output to find the RAID controller. Then do a search to see what information can be located about the RAID controller. Hardware RAID controllers appear in this list, but FakeRAID implementations do not. Also, true hardware RAID controller are often rather expensive, so if someone customized the system, then it is very likely that choosing a hardware RAID setup made a very noticeable change in the computer’s price.
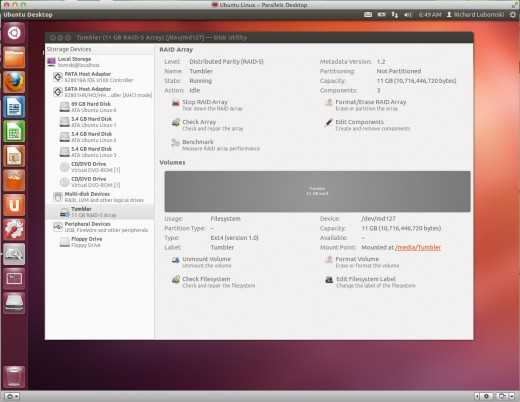
Что у нас в коробке?
IsoVibe
- Специализированная прошивка дисков, которая с помощью датчиков управляет сервоприводами и предиктивно снижает уровень вибраций.
- Вибрационно изолированные разъемы на задней панели сервера (рис. 1).
- Ну и, конечно, специальные крепления дисков, которые не требуют винтов.
Рис. 1. Вибрационно изолированные разъемыArcticFlowРис. 2. Принцип работы ArcticFlowРис. 3. Температурная карта Ultrastar Data 102
- Полка в сборе весит 120 кг, а без дисков — 32 кг
- Глубокая стойка в данном случае начинается от 1200 мм
- Ну и добавляем кабели SAS и питания
Рис. 4. Ultrastar Data 102. Вид спередиРис. 5. Ultrastar Data 102Рис. 6. Ultrastar Data 102. Вид сверхуРис. 7. Ultrastar Data 102. Вид сверху без дисковРис. 8. Ultrastar Data 102. Вид сзади
Создание массива
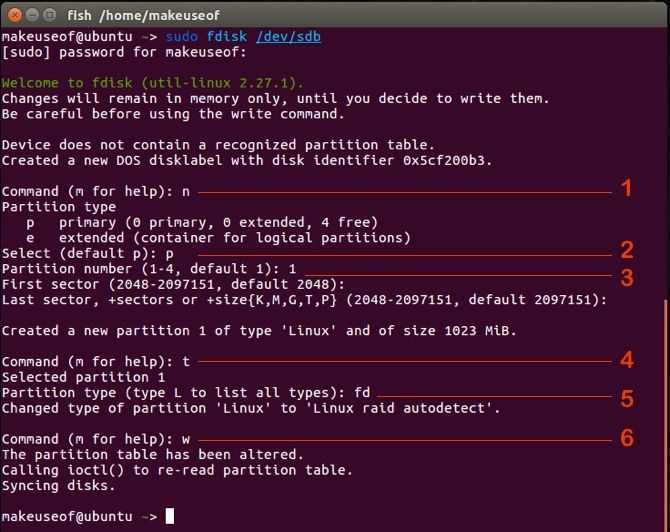
Перед созданием массива следует создать для него устройство-идентификатор (если оно отсутствует): mknod /dev/md1 b 9 1;
в данном случае создаётся идентификтор для массива с номером 1, что
указывается в имени устройства и его коде (9 — это код устройства всех
RAID-массивов, 1 — идентификатор).
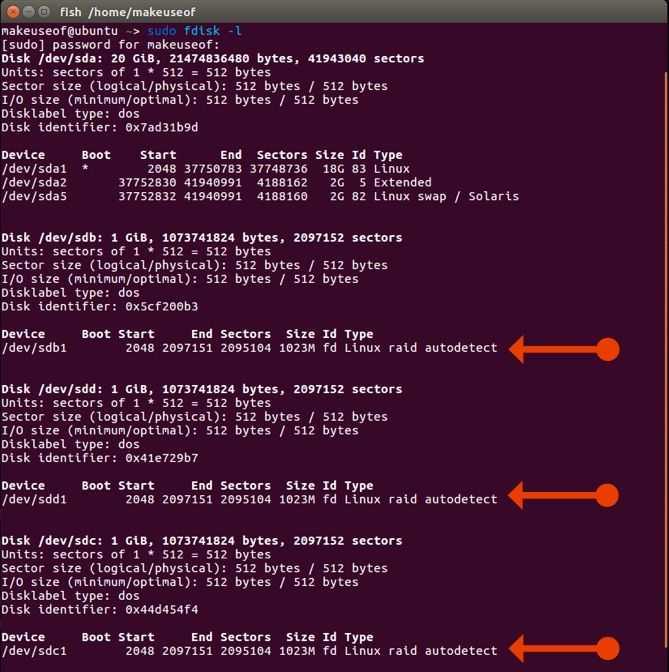
Желательно,
чтобы разделы, из которых создаётся массив, имели одинаковый размер
(хотя они могут располагаться на физических дисках разного размера и
даже разного типа). При создании этих разделов следует присвоить им тип
fd («Linux raid autodetect»). Не следует создавать массив из разделов,
размещающихся на одном физическом диске — хотя это и возможно, это
совершенно бессмысленно и приведет к существенному снижению
быстродействия дисковой подсистемы. Интересной идеей является создание
массива из USB-флеш дисков с целью повышения скорости, но из-за низкой надёжности USB портов система будет менее надёжна, чем массив из жёстких дисков.
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/hda3 /dev/hdc3
Этот
пример создаёт массив RAID 1 из двух разделов: один из hda и второй из
hdc. Несколько дисков можно указывать с помощью шаблона, например /dev/sd2 или /dev/sd1.
- --create (или сокращённо -С): команда создания
- /dev/md0: имя устройства создаваемого виртуального раздела
- --level=1 (или сокращённо -l 1): уровень RAID. См. справочник по использованию mdadm (используйте «man mdadm» в командной строке)
- --raid-devices=2 (или сокращённо -n 2): количество устройств
- /dev/hda3: первый диск в массиве
- /dev/hdc3: второй диск
Если на момент создания массива диска нет (например, при переходе на RAID) вместо имени диска просто напишите missing. Команда завершается сразу, обычно выдавая сообщение mdadm: array /dev/mdХ started. При этом уже сразу можно использовать массив. Фактически массив строится в фоновом режиме, прогресс можно посмотреть в файле /proc/mdstat; там же указывается предположительное время завершения построения массива.
После
создания RAID-раздела можно создать на нем файловую систему как на
обычном разделе диска. Созданный и отформатированный RAID-раздел можно
использовать как корень файловой системы (но для этого поддержка RAID должна быть встроена в ядро, а не как загружаемый модуль). Не следует создавать RAID-массив для своп-раздела — система сама обнаружит своп-разделы на разных дисках и будет использовать их по принципу RAID-массива. Не забудьтедобавить соответствующую строку в файл конфигурации /etc/fstab, чтобы RAID-раздел монтировался автоматически при загрузке системы.
Жесткий диск Toshiba 6 TB MG06ACA600E

Диски Toshiba из линейки Enterprise Capacity идеально подходят для корпоративных массивов хранения, для промышленных серверов и систем хранения данных. Их высокая емкость и современные технологии отвечают всем тем требованиям, которые предъявляются инфраструктурами центров обработки данных и облачных решений.
Жесткий диск корпоративного класса MG06ACA600E имеет емкость 6 ТБ, скорость вращения шпинделя 7200 об/мин и отличается надежной конструкцией. Рассчитан на критически важные для бизнеса рабочие нагрузки в полуоперативном режиме.
Чтобы достичь оптимальной емкости и надежности работы с данными, жесткий диск поколения MG06ACA имеет стандартный для отрасли формфактор 3.5 дюйма с толщиной корпуса 26.1 мм и использует расширенный формат секторов. Эти модели поддерживают технологию постоянного кеширования записи Toshiba Persistent Write Cache, позволяющую повысить производительность и обеспечить целостность записи в случае неожиданного отключения питания. Жесткий диск корпоративного класса MG06ACA с интерфейсом SATA с пропускной способностью 6 Гбит/с обеспечивает экономию места в стойках, уменьшение занимаемой площади и снижение эксплуатационных расходов для критически важных серверов и систем хранения данных предприятий.
В серии MG06ACA устойчивая скорость передачи данных увеличена до 230 МБ/с, а среднее время наработки на отказ на 25 % превышает аналогичный показатель у моделей предыдущей серии MG05ACA. Предлагаются модели с технологиями секторов «Расширенный формат» 4Kn и 512e. Модели с поддержкой формата 4Kn (MG06ACAxxxA) обеспечивают отличную производительность и совместимость с приложениями и операционными средами, использующими секторы размером 4 КБ. Модели с поддержкой формата 512e (MG06ACAxxxE) поддерживают устаревшие приложения и операционные среды, работающие с секторами размером 512 байт.
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
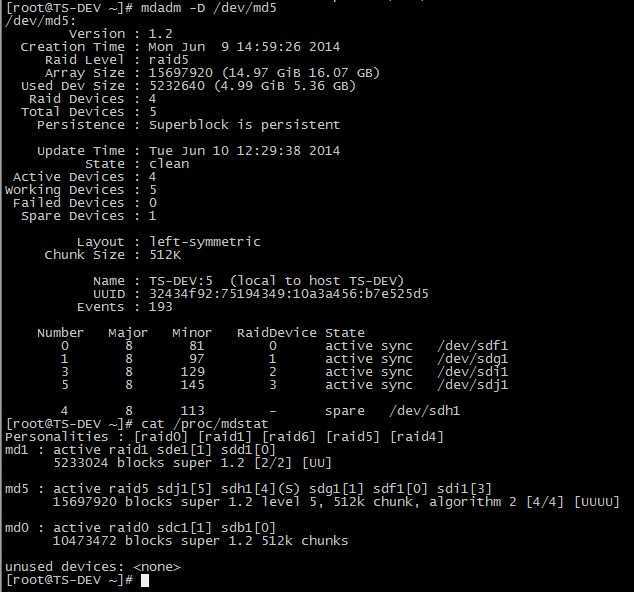
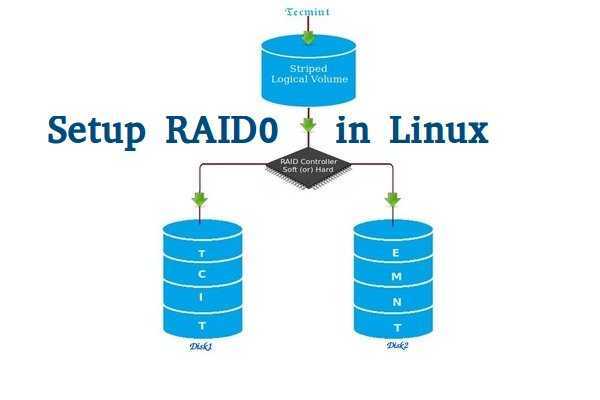
Собираем программный RAID в Linux
Так как я использую в качестве основной операционной системы Linux, то естественно, что и RAID будем собирать на работающем компьютере под управлением Linux
Собирать буду зеркальный RAID из двух дисков, но таким же способом можно собрать RAID с большим количеством дисков.
Перед сборкой массива, диски, в моем случае два диска по 1Tb, за ранее подключаем к компьютеру.
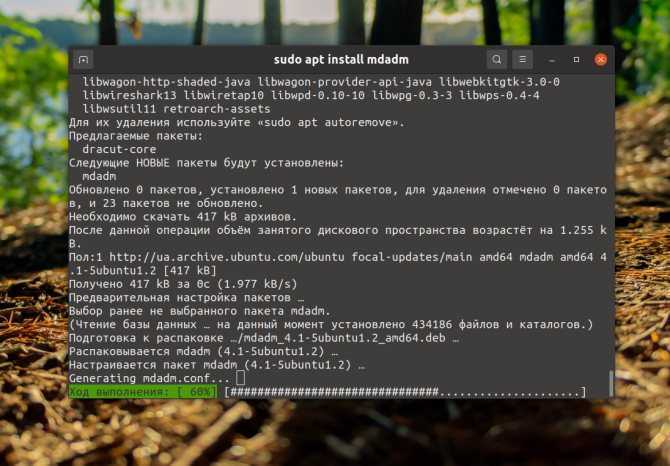
Для работы с массивами в Linux необходимо установить утилиту администрирования и контроля программного RAID — mdadm
Запускаем терминал.
Обновляем информацию о пакетах
Устанавливаем утилиту
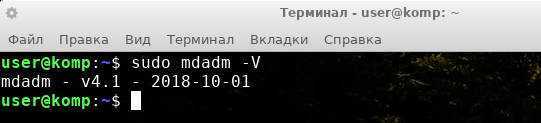
Проверяем установлена ли утилита
если утилита стоит вы увидите примерно такой текст
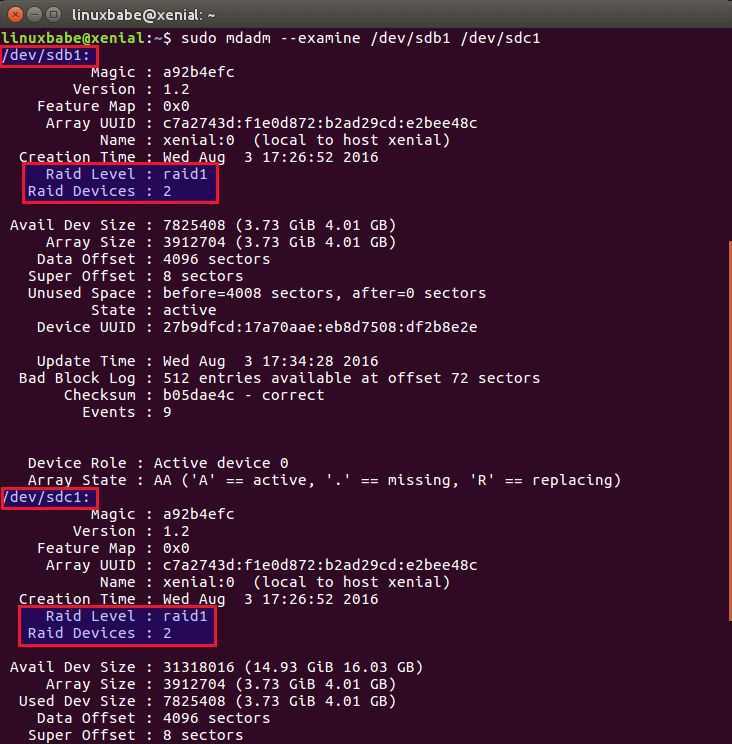
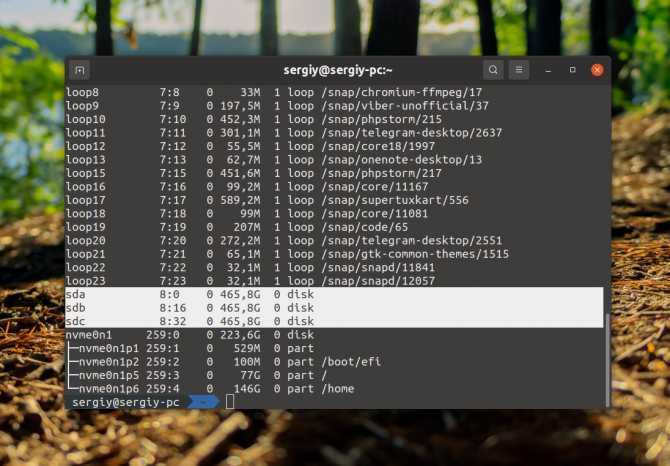
Узнаем информацию о подключенных дисках
Проверяем идентификаторы дисков которые будем использовать, их принадлежность
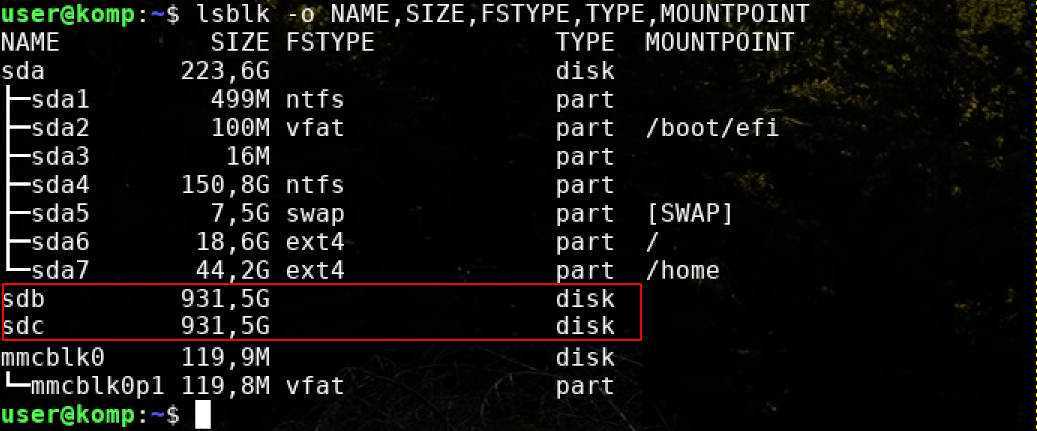
В данном случае, видим два диска sdb и sdc.
Их идентификаторы будут /dev/sdb и /dev/sdc, соответственно.
Из этих дисков и будем создавать массив Raid-1.
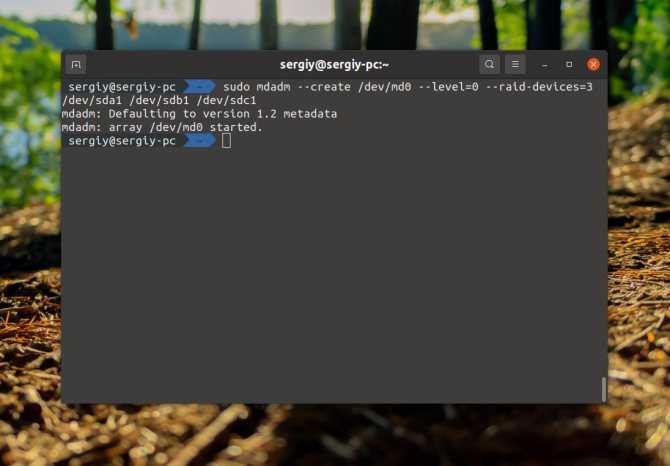
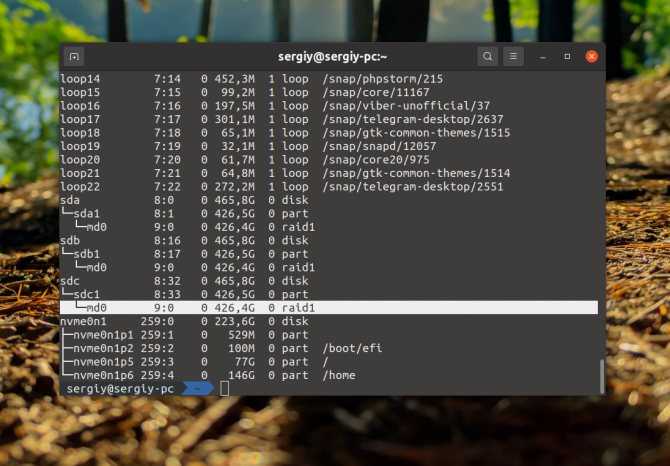
Создаем RAID массив
/dev/md0 — имя нашего будущего рейда
—livel=1 — уровень рейда, в нашем варианте собираем RAID1, если собираете RAID2 то ставим =2, ну и так далее
—raid-devices=2 — количество дисков используемых в рейде, ну и далее перечисляются их имена
После ввода команды будет вопрос
Continue creating array ? — соглашаемся, введя Y и нажимаем Enter
Если сделали все правильно, начнется процесс зеркалирования дисков.
Проверить статус можно командой
Мониторинг процесса удобно отслеживать с помощью команды
Так вы в реальном времени сможете наблюдать процесс и знать время его завершения.
Желательно дождаться окончания процесса.
Создаем и монтируем файловую систему в нашем RAID
Созданный массив должен иметь свою файловую систему, так как в данном случае linux, очевидно, что это будет ext4
Создаем ее командой
/dev/md0 — имя нашего созданного массива.
Создаем точку в которую будем монтировать наш массив
/mnt/md0 — точка куда будем монтировать наш массив
Теперь можно смонтировать массив /dev/md0 в нашу ранее созданную директорию /mnt/md0
Проверить доступно ли новое пространство можно командой
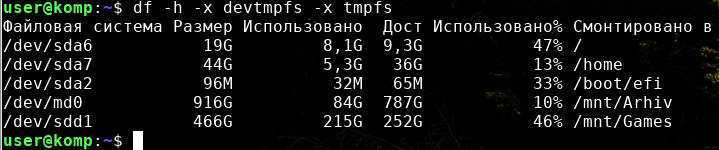 В моем случае массив md0 смонтирован в /mnt/Arhiv использовано 10%
В моем случае массив md0 смонтирован в /mnt/Arhiv использовано 10%
Сохраняем наш программный RAID
Если не сохранить все проделанное, после перезагрузки мы не увидим нашего рейда в наличии.
Настраиваем автоматическую сборку рейда при запуске системы.
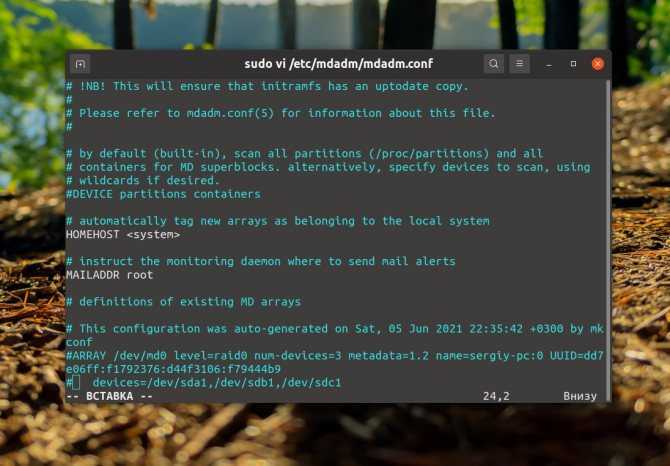
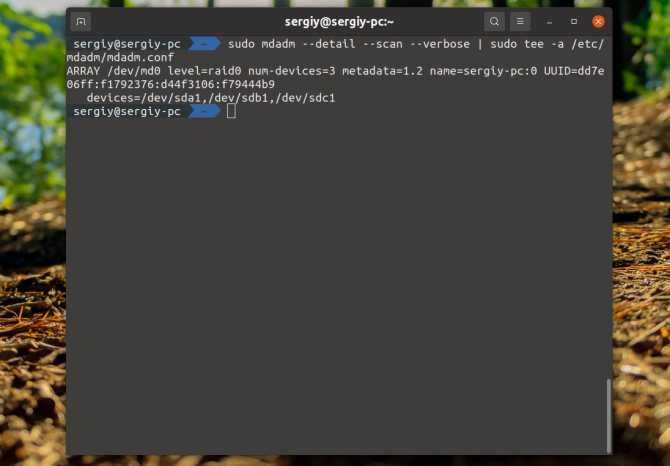
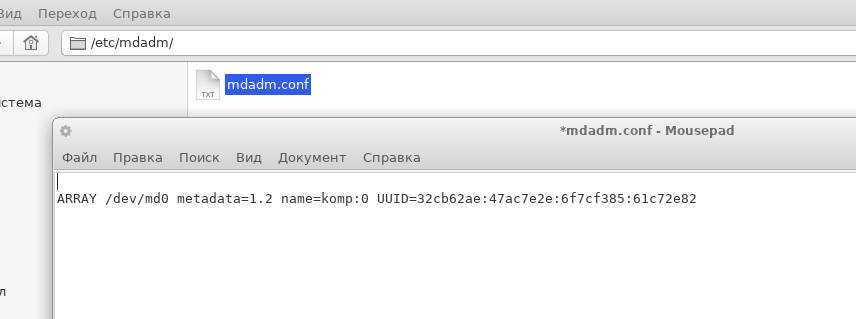
Информацию, о нашем созданном рейде, необходимо записать в файл /etc/mdadm/mdadm.conf
Выполним команду которая сделает это автоматически
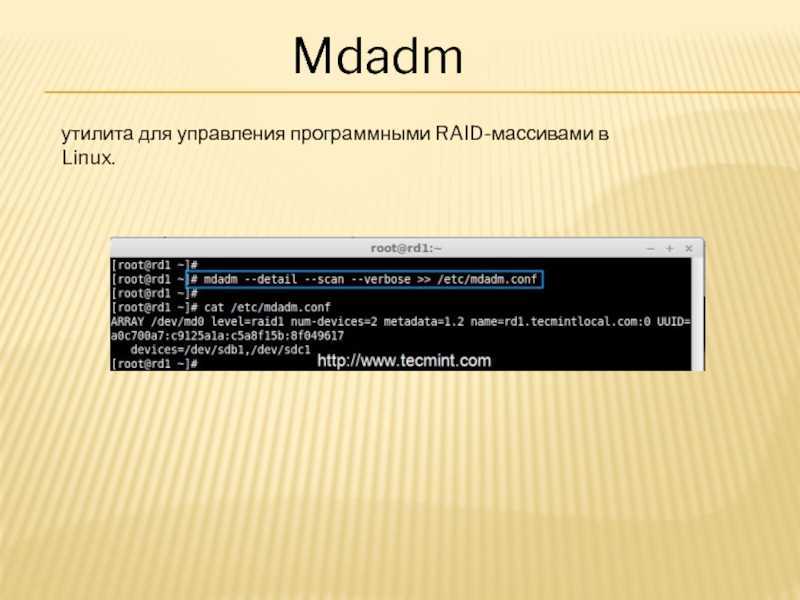
В результате в файл mdadm.conf будет сделана запись о сформированном RAID. Если открыть этот файл в блокноте то выглядеть это будет примерно так
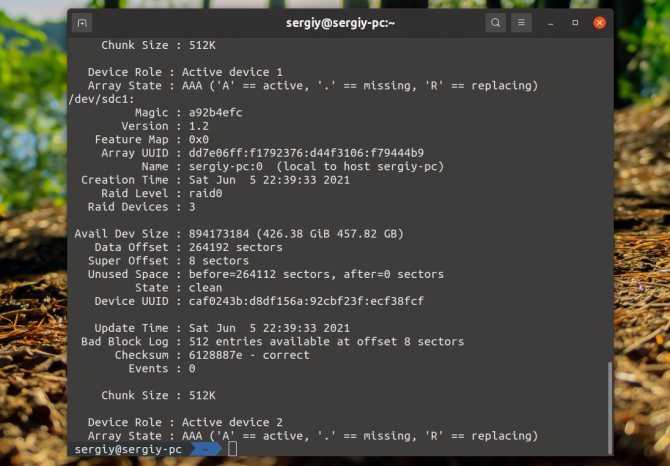
![Как удалить raid-массив linux software raid (mdraid) [вики it-kb]](https://smartshop124.ru/wp-content/uploads/e/7/b/e7b4ece38e74958e85333f5c3813512e.jpeg)
Теперь необходимо обновить информацию о наших файловых системах для их автоматического распознования при запуске системы
Для автоматического монтирования нашего диска /dev/md0 в нашу ранее созданную директорию /mnt/md0, нам необходимо так же зделать запись в файл /etc/fstab
В результате будет сделана запись в файл fstab. Если открыть этот файл в блокноте то выглядеть это будет примерно так
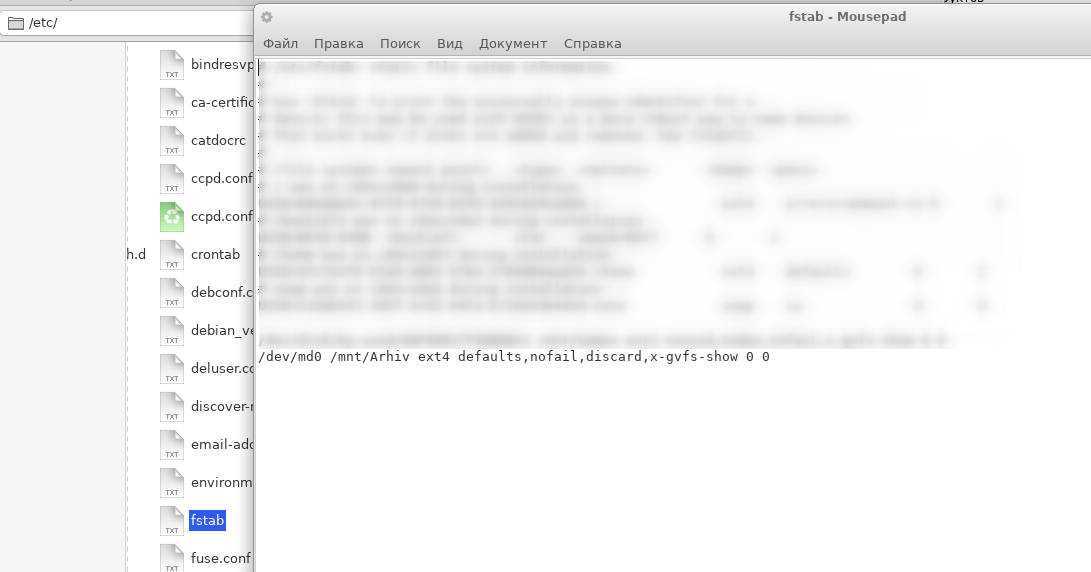
Теперь можете перезагружать систему. После перезагрузки ваш RAID массив должен быть там куда вы его смонтировали.
Всем Удачи!
Установка утилиты управления программным RAID — mdadm
Чтобы установить утилиту mdadm, запустите команду установки:
- Для Centos/Red Hat используется yum/dnf:
- Для Ubuntu/Debian:
В резульатте в системе будет установлена сама утилита mdadm и необходимые библиотеки:
Running transaction Installing : libreport-filesystem-2.1.11-43.el7.centos.x86_64 1/2 Installing : mdadm-4.1-1.el7.x86_64 2/2 Verifying : mdadm-4.1-1.el7.x86_64 1/2 Verifying : libreport-filesystem-2.1.11-43.el7.centos.x86_64 2/2 Installed: mdadm.x86_64 0:4.1-1.el7 Dependency Installed: libreport-filesystem.x86_64 0:2.1.11-43.el7.centos Complete!
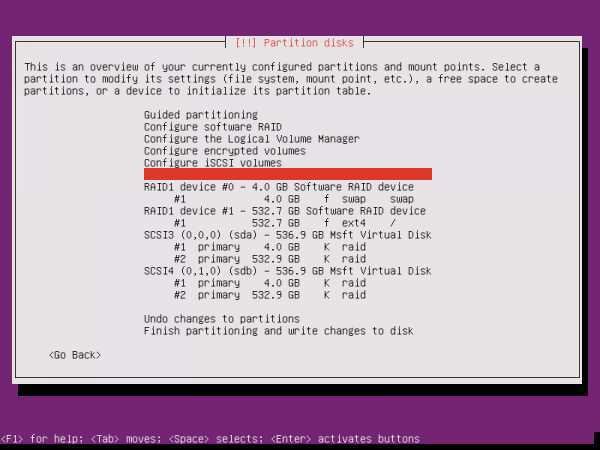
Creating a RAID 6 Array
The RAID 6 array type is implemented by striping data across the available devices. Two components of each stripe are calculated parity blocks. If one or two devices fail, the parity blocks and the remaining blocks can be used to calculate the missing data. The devices that receive the parity blocks are rotated so that each device has a balanced amount of parity information. This is similar to a RAID 5 array, but allows for the failure of two drives.
- Requirements: minimum of 4 storage devices
- Primary benefit: Double redundancy with more usable capacity.
- Things to keep in mind: While the parity information is distributed, two disk’s worth of capacity will be used for parity. RAID 6 can suffer from very poor performance when in a degraded state.
Identify the Component Devices
To get started, find the identifiers for the raw disks that you will be using:
As you can see above, we have four disks without a filesystem, each 100G in size. In this example, these devices have been given the , , , and identifiers for this session. These will be the raw components we will use to build the array.
Create the Array
To create a RAID 6 array with these components, pass them in to the command. You will have to specify the device name you wish to create ( in our case), the RAID level, and the number of devices:
The tool will start to configure the array (it actually uses the recovery process to build the array for performance reasons). This can take some time to complete, but the array can be used during this time. You can monitor the progress of the mirroring by checking the file:
As you can see in the first highlighted line, the device has been created in the RAID 6 configuration using the , , and devices. The second highlighted line shows the progress on the build. You can continue the guide while this process completes.
Create and Mount the Filesystem
Next, create a filesystem on the array:
Create a mount point to attach the new filesystem:
You can mount the filesystem by typing:
Check whether the new space is available by typing:
The new filesystem is mounted and accessible.
Save the Array Layout
To make sure that the array is reassembled automatically at boot, we will have to adjust the file. We can automatically scan the active array and append the file by typing:
Afterwards, you can update the initramfs, or initial RAM file system, so that the array will be available during the early boot process:
Add the new filesystem mount options to the file for automatic mounting at boot:
Your RAID 6 array should now automatically be assembled and mounted each boot.
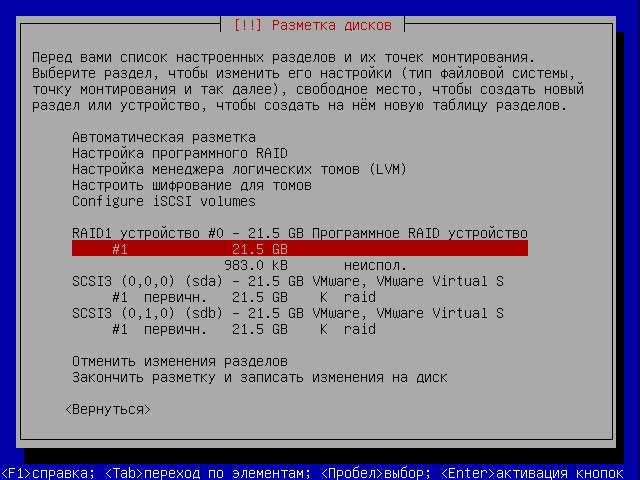
Создание и сборка массива
Весь этот процесс состоит из нескольких этапов:
- делаем разметку двух дисков sdb и sdc одинакового объёма, задаём тип разделов Linux RAID
- собираем зеркало из разделов
- форматируем массивы
- монтируем и проверяем работу
- подключаем в автозагрузку — прописываем в /etc/fstab
В первую очередь необходимо установить mdadm.
В Gentoo:
# emerge sys-fs/mdadm
В CentOS Stream:
# yum install mdadm
В Debian:
# apt install mdadm
В Ubuntu Server 20.10 уже есть, здесь ничего дополнительно устанавливать не нужно.
Теперь переходим к разметке диска sdb:
# cfdisk /dev/sdb
Зададим таблицу разделов GPT, создаём 2 раздела sdb1 и sdb2 и тип этих разделов Linux RAID
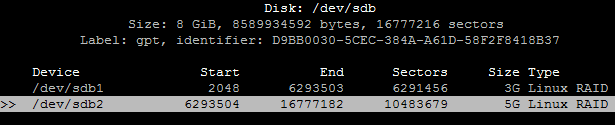
Теперь копируем структуру диска sdb на диск sdc утилитой sfdisk:
# sfdisk -d /dev/sdb | sfdisk /dev/sdc
Проверяем:
# fdisk -l /dev/sdb # fdisk -l /dev/sdc
Затем создаём массивы md1 и md2 с первым и вторым разделами каждого диска соответственно:
# mdadm --create --verbose /dev/md1 -l 1 -n 2 /dev/sdb1 /dev/sdc1 # mdadm --create --verbose /dev/md2 -l 1 -n 2 /dev/sdb2 /dev/sdc2
- l — уровень RAID (для зеркала нам нужен RAID 1, соответственно наше значение будет 1)
- n — количество дисков (так как у нас 2 диска, значит наше значение будет 2)
Теперь необходимо подождать, когда закончится синхронизация. Промониторить это можно командой
# cat /proc/mdstat
После окончания синхронизации запишем конфиг массивов.
Для Gentoo и CentOS:
# mdadm --detail --scan > /etc/mdadm.conf
а для Debian и Ubuntu Server:
# mdadm --detail --scan > /etc/mdadm/mdadm.conf
После этого отформатируем созданные массивы в ext4:
# mkfs.ext4 /dev/md1 # mkfs.ext4 /dev/md2
Теперь создадим каталоги /mnt/data, /mnt/data/part1 и /mnt/data/part2
# mkdir /mnt/data /mnt/data/part{1,2}
примонтируем массивы: /dev/md1 — в /mnt/data/part1, а /dev/md2 -в /mnt/data/part2
# mount /dev/md1 /mnt/data/part1 # mount /dev/md2 /mnt/data/part2
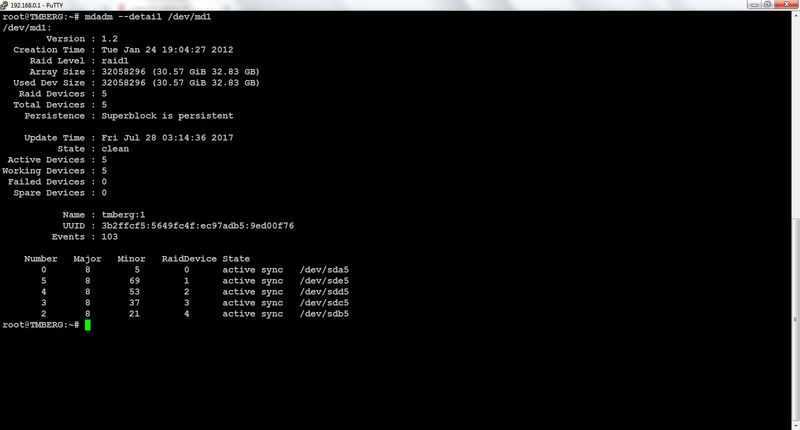
Получить подробную информацию по массиву можно с помощью команды:
# mdadm --detail /dev/md1 # mdadm --detail /dev/md2
Размонтировать массивы можно командой:
# umount /mnt/data/part{1,2}
Для того, чтобы массивы автоматически монтировались при загрузке системы, пропишем их в файл /etc/fstab:
# nano /etc/fstab
/dev/md1 /mnt/data/part1 ext4 noatime 1 0 /dev/md2 /mnt/data/part2 ext4 noatime 1 0
Замена диска в массиве
# mdadm /dev/md1 --fail /dev/sdc1 # mdadm /dev/md1 --remove /dev/sdc1 # mdadm /dev/md1 --add /dev/sdd1
Износ SSD и PostgreSQL
На самом деле я хотел посмотреть скорость износа ssd при различных нагрузках на запись в Postgres, но как правило на нагруженных базах ssd используются очень аккуратно и массивная запись идет на HDD. Пока искал подходящий кейс, наткнулся на один очень интересный сервер:
Износ двух ssd в raid-1 за 3 месяца составил 4%, но судя по скорости записи WAL данный постгрес пишет меньше 100 Kb/s:
Оказалось, что постгрес активно использует временные файлы, работа с которыми и создает постоянный поток записи на диск:
Так как в postgresql с диагностикой достаточно неплохо, мы можем с точностью до запроса узнать, что именно нам нужно чинить:
Как вы видите тут, это какой-то конкретный SELECT порождает кучу временных файлов. А вообще в постгресе SELECT’ы иногда порождают запись и без всяких временных файлов — вот тут мы уже про это рассказывали.
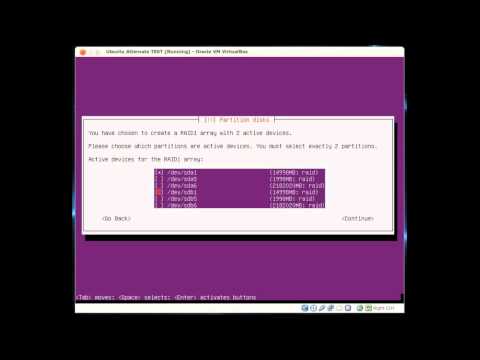
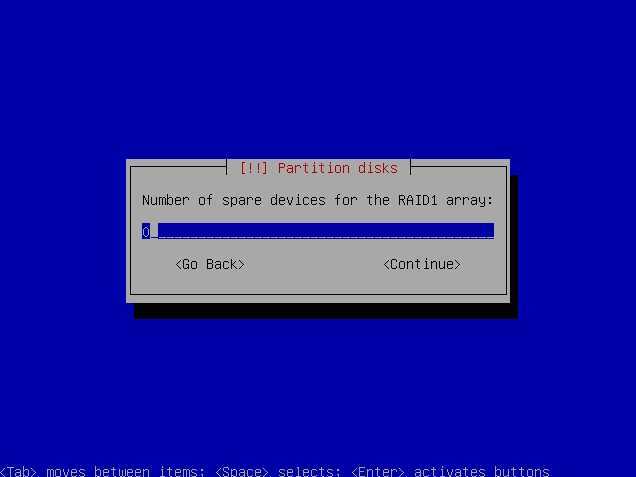
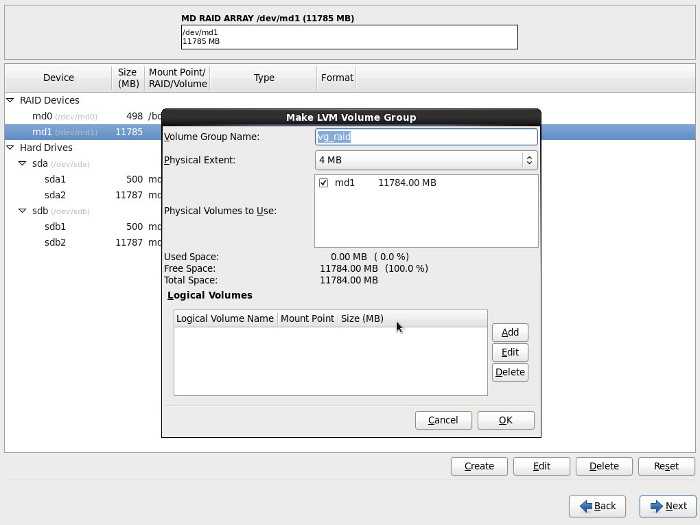

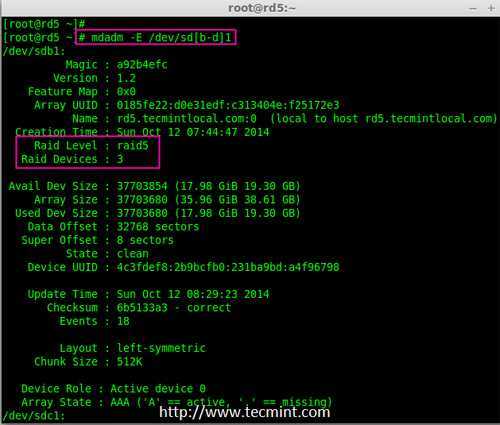
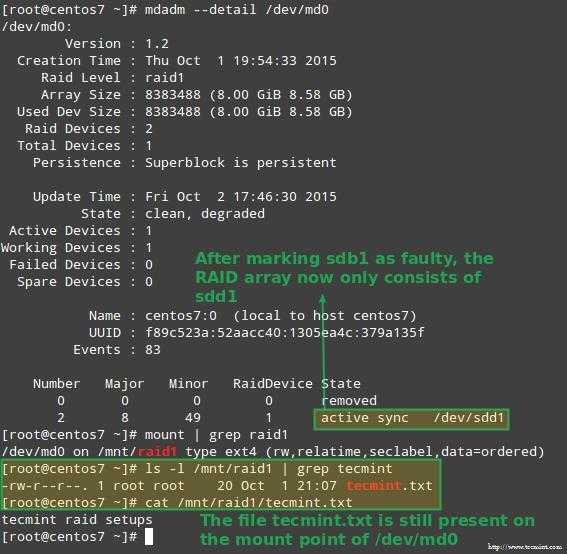
Действия при выходе одного жёсткого диска из строя[править]
Если один жёсткий диск вышел из строя, то загрузите операционную систему (она будет работать и на одном диске), зайдите под пользователем root и проделайте следующее:
1. Посмотрите, что сломалось:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sda2
4723008 blocks [2/1]
md0 : active (auto-read-only) raid1 sda1
513984 blocks [2/1]
Из вывода видно, что диск sdb недоступен: U_ показывает отсутствие второго раздела под RAID.
2. Подключаем диск и копируем таблицу разделов с диска sda на диск sdb. Также перечитаем скопированную таблицу разделов для ядра. Пример для таблицы разделов MBR:
# dd if=/dev/sda of=/dev/sdb bs=512 count=1 1+0 records in 1+0 records out 512 bytes (512 B) copied, 0.00682677 s, 75.0 kB/s # hdparm -z /dev/sdb /dev/sdb: re-reading partition table
Вместо hdparm можно использовать команду partprobe без параметров.
В случае GPT нужно копировать 2048 байт в начале диска (bs=2048), следом нужно запустить parted и подтвердить «починку» второй копии GPT, и уже тогда перечитывать ядром таблицу томов.
3. Добавляем разделы со второго диска к RAID-массиву:
# mdadm /dev/md0 -a /dev/sdb1 mdadm: added /dev/sdb1 # mdadm /dev/md1 -a /dev/sdb2 mdadm: added /dev/sdb2
4. Смотрим, что получилось:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sdb2 sda2
4723008 blocks [2/1]
recovery = 0.6% (32064/4723008) finish=9.7min speed=8016K/sec
md0 : active raid1 sdb1 sda1
513984 blocks [2/2]
unused devices: <none>
Всё нормально: md0 уже засинхронизировался, md1 в процессе синхронизации.
5. Через некоторое время (точнее — 10 минут, смотрите значение finish на этапе 4) смотрим ещё раз:
# cat /proc/mdstat
Personalities :
md1 : active raid1 sdb2 sda2
4723008 blocks [2/2]
md0 : active raid1 sdb1 sda1
513984 blocks [2/2]
unused devices: <none>
Теперь RAID полностью восстановлен.
6. Обязательно восстанавливаем загрузчик, для lilo:
# lilo Added ALTLinux * Added failsafe The Master boot record of /dev/sda has been updated. Warning: /dev/sdb is not on the first disk The Master boot record of /dev/sdb has been updated. One warning was issued.
или для grub2:
# grub-autoupdate Updating grub on /dev/sdb Installation finished. No error reported. Updating grub on /dev/sda Installation finished. No error reported.
и или для grub2:
# grub-install /dev/sda Установка завершена. Ошибок нет. # grub-install /dev/sdb Установка завершена. Ошибок нет. # update-grub
Отладка
Если вы получаете сообщение об ошибке, когда перезагружаетесь из-за «недопустимой магии суперблока raid», и у вас есть дополнительные жесткие диски, отличные от тех, на которые вы установили, убедитесь, что порядок этих дисков правильный. Во время установки RAID-устройства могут быть hdd, hde и hdf, но во время загрузки — hda, hdb и hdc. Отрегулируйте строку ядра соответственно.
Error: «kernel: ataX.00: revalidation failed»
Если у вас внезапно появляются сообщения об ошибках типа:
Feb 9 08:15:46 hostserver kernel: ata8.00: revalidation failed (errno=-5)
Это не обязательно означает, что диск сломан. Возможно, вы просто изменили настройки APIC или ACPI в параметрах BIOS или ядра. Поменяйте их обратно, и все будет хорошо. Обычно должно помочь отключение ACPI и / или ACPI.
Запуск массивов только для чтения
Когда запускается массив md, суперблок будет записан, и может начаться повторная синхронизация. Для запуска только для чтения установите в модуле ядра параметр md_mod start_ro. После этого новые массивы получают режим ‘auto-ro’, который отключает все внутренние операции ввода-вывода (обновления суперблока, повторную синхронизацию, восстановление) и автоматически переключается на ‘rw’, когда поступает первый запрос на запись.
Примечание: массив может быть переведен в режим ‘только чтение’ с использованием mdadm —readonly перед первым запросом на запись. Повторная синхронизация может быть запущена без записи с использованием mdadm —readwrite.
Для установки параметра при загрузке добавьте md_mod.start_ro=1 к строке ядра.
Или установите его во время загрузки модуля из файла /etc/modprobe.d/ или непосредственно из /sys/:
echo 1 > /sys/module/md_mod/parameters/start_ro
Восстановление из сломанного или пропавшего диска в RAID
Вы можете получить вышеупомянутую ошибку, когда один из дисков ломается. В этом случае вам придется заставить raid по-прежнему включаться даже без одного диска. Введите:
mdadm --manage /dev/md0 --run
Теперь вы сможете смонтировать его снова примерно так:
mount /dev/md0
Теперь рейд должен снова работать и быть доступным для использования, однако без одного диска! Добавьте один раздел диска. Как только это будет сделано, вы можете добавить новый диск в рейд, выполнив:
mdadm --manage --add /dev/md0 /dev/sdd1
Если вы пропишете:
cat < /proc/mdstat
Вы, вероятно, видите, что рейд сейчас активен и восстанавливается.
Вы также можете обновить свою конфигурацию.
Эталонное тестирование (Benchmarking)
Существует несколько инструментов для бенчмаркинга RAID. Самое заметное улучшение — это увеличение скорости при чтении нескольких потоков с одного тома RAID.
tiobench оценивает эти улучшения при помощи измерения полнопроточного ввода-вывода на диске.
bonnie++ проверяет модель базы данных, пробуя доступ к одному или нескольким файлам, а также создавая, читая и удаляя небольшие файлы, которые могут имитировать использование таких программ, как Squid, INN или директорию почтового ящика в формате электронной почты. Прилагаемая программа ZCAV проверяет производительность различных зон жесткого диска без записи данных.
hdparm не следует использовать для тестирования RAID, поскольку он дает противоречивые результаты.
И напоследок, несколько полезных ссылок:
Linux Software RAID (thomas-krenn.com)
- Linux RAID wiki entry on The Linux Kernel Archives
- How Bitmaps Work
- Chapter 15: Redundant Array of Independent Disks (RAID) of Red Hat Enterprise Linux 6 Documentation
- Linux-RAID FAQ on the Linux Documentation Project
- Dell.com Raid Tutorial — Interactive Walkthrough of Raid
- BAARF including Why should I not use RAID 5? by Art S. Kagel
- Introduction to RAID, Nested-RAID: RAID-5 and RAID-6 Based Configurations, Intro to Nested-RAID: RAID-01 and RAID-10, and Nested-RAID: The Triple Lindy in Linux Magazine
- HowTo: Speed Up Linux Software Raid Building And Re-syncing
- RAID5-Server to hold all your data
- Wikipedia:Non-RAID drive architectures
mdadm
- Debian mdadm FAQ
- mdadm source code
- Software RAID on Linux with mdadm in Linux Magazine
- Wikipedia — mdadm
Forum threads
- Raid Performance Improvements with bitmaps
- GRUB and GRUB2
- Can’t install grub2 on software RAID
- Use RAID metadata 1.2 in boot and root partition
RAID with encryption
Linux/Fedora: Encrypt /home and swap over RAID with dm-crypt by Justin Wells
1. О технологии
Итак, в версиях Windows 8.1 и 10 реализована технология по типу программного RAID, называется «Дисковые пространства». Реализована в панели управления.
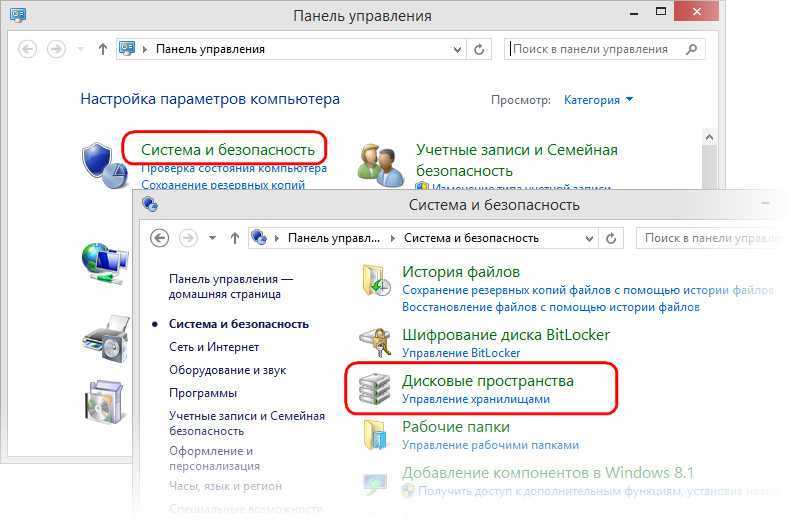
Предназначается для создания производительных и отказоустойчивых дисковых массивов. С помощью этой технологии можем два и более жёстких диска объединить в одно дисковое пространство, по сути, в единый пользовательский (несистемный) раздел
И хранить на этом разделе что-то не особо важное в случае конфигурации без отказоустойчивости или, наоборот, что-то важное, обеспечив этим данным двух- или трёхсторонние зеркала. Дисковые пространства могут быть сформированы из разного типа устройств информации – внутренних SATA, SAS и внешних USB-HDD
Чем эта технология отличается от динамических дисков? Дисковые пространства:
• В большей степени эмулируют аппаратный RAID;
• Лишены многих недостатков динамических дисков;
• При зеркалировании позволяют задействовать относительно современную наработку Microsoft — отказоустойчивую файловую систему ReFS;
• Не предусматривают, как динамические диски, возможность зеркалирования самой Windows (очевидно, как лишней функции в свете иных возможностей восстановления работоспособности ОС).
Дисковое пространство – это территория с нуля, при её создании жёсткие диски форматируются, их структура и содержимое теряются. Тогда как при работе с динамическими дисками мы к любому существующему разделу без потери данных можем добавить его раздел-зеркало.
Как и динамические диски, современная технология программного RAID позволяет создавать массивы из разных жёстких дисков, в том числе и по объёму. Но последняя, в отличие от первой, не оставляет незанятое массивом место на одном из носителей меньшего объёма. Чтобы это незанятое место можно было присоединить к другим разделам или создать отдельный раздел. Наоборот, при создании дисковых пространств мы не ограничены объёмом одного из жёстких. Мы можем изначально указать любой виртуальный размер, а впоследствии обеспечить его реальными ресурсами устройств информации, добавив их к массиву — так называемому пулу носителей. Реализация последнего позволяет нам действовать несколько гибче, чем при оперировании динамическими дисками.
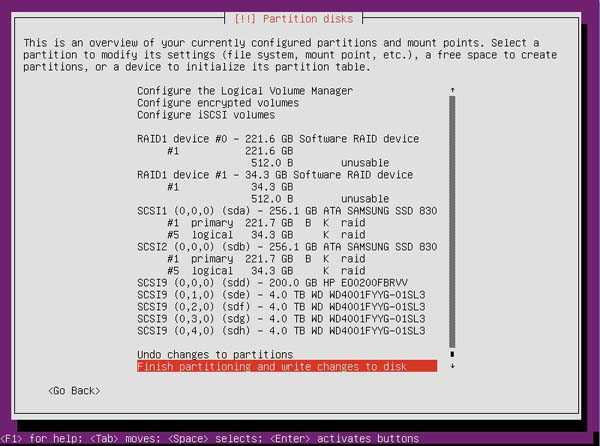
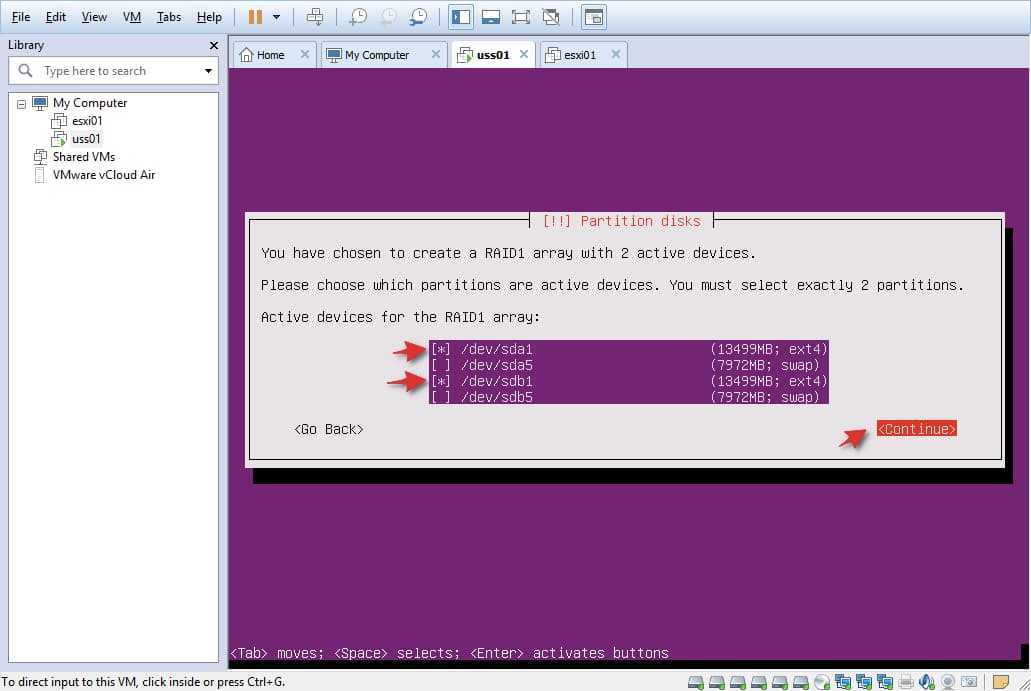
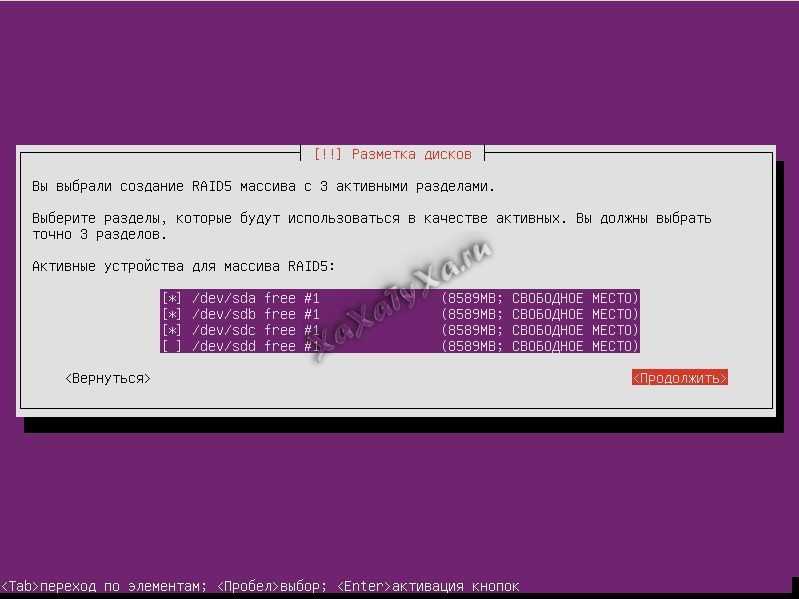
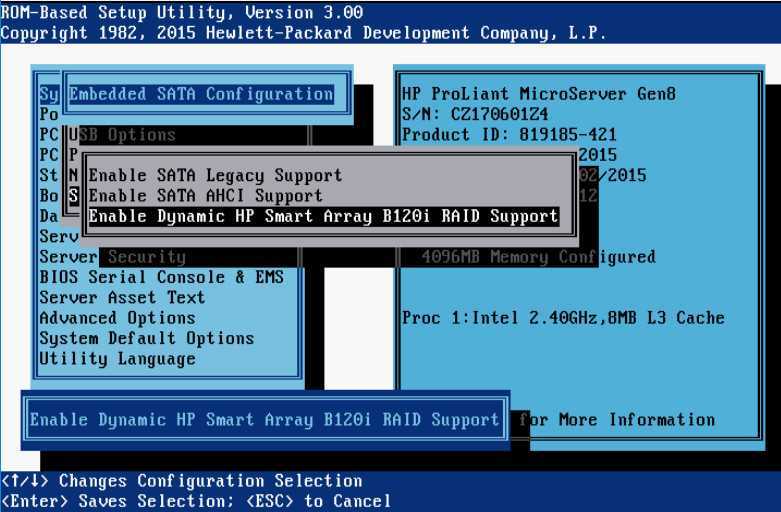
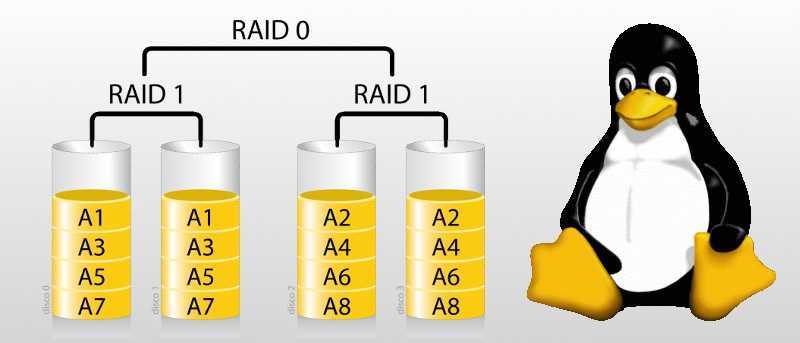
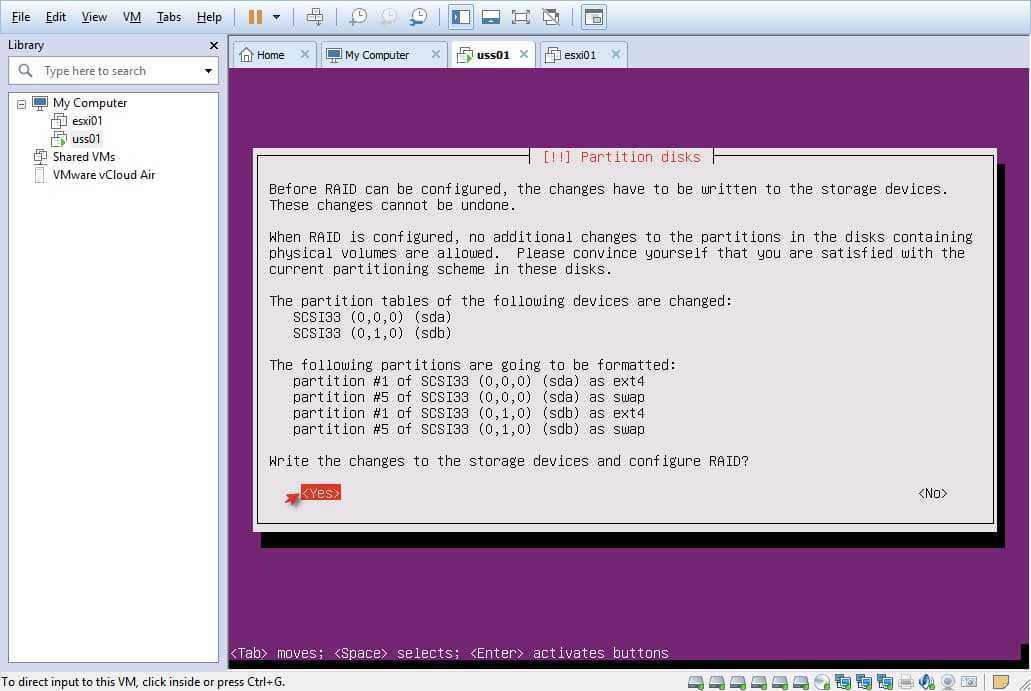
![Как удалить raid-массив linux software raid (mdraid) [вики it-kb]](https://smartshop124.ru/wp-content/uploads/a/6/4/a64d6dad014d4d2cde65e83daa0d7cd0.jpeg)


![Installation of clearos [clearos documentation]](http://smartshop124.ru/wp-content/uploads/9/8/d/98d2934d2092f6a91bb623e7c5fbf29a.jpeg)
