Управление данными в облачной среде
Функции облачной платформы управления данными в представлении Gartner: распределение ресурсов, автоматизация и оркестрация; управление запросами на обслуживание; управление высокого уровня и контроль соблюдения политик; мониторинг и измерение параметров; поддержка мультиоблачных сред; оптимизация и прозрачность затрат; оптимизация мощностей и ресурсов; миграция в облако и обеспечение катастрофоустойчивости (DR); управление уровнем обслуживания; безопасность и идентификация; автоматизация обновления конфигураций.Управление облачными данными (Cloud Data Management, CDM) – это платформа, которая используется для управления корпоративными данными в различных облачных средах с учетом частных, публичных, гибридных и мультиоблачных подходов.Управление облачными данными в Veeam считают неотъемлемой частью интеллектуального управления данными, обеспечивающего их доступность для бизнеса из любой точки. Veeam Cloud Data Management Platform — «современная платформа для управления данными, поддерживающая любое облако».маркетплейсе
Подключение
Итак, давайте начнём с подключения к MySQL при помощи команды:
mysql -u username -p
Вместо username введите имя существующего в вашей инсталляции MySQL пользователя.
Теперь, находясь в оболочке mysql-клиента, можно увидеть список доступных БД при помощи команды:
SHOW DATABASES;
Обратите на точку с запятой в конце. Она сообщает MySQL о том, что команда завершена. Если строку не завершить этим символом, то после нажатия Enter MySQL будет ожидать ввода продолжения команды в новой строке. Такое поведение MySQL часто оказывается полезным при вводе нескольких команд за один раз.
Также имейте ввиду, что MySQL хранит историю команд. Нажмите стрелку вверх и вы увидите введённую вами ранее команду.
В случае, если вам необходимо начать работу с какой-то конкретной базой данных, воспользуйтесь командой:
USE databasename;
заменив databasename на имя нужной вам базы данных. Нужной вам базы данных не существует и вам необходимо её создать? Нет проблем!
База данных (Database)
Сегодня этот термин обозначает как программное обеспечение, содержащее информацию, так и саму информацию, которая в нем хранится. Разработчики используют его в значении коллекции данных, поскольку ПО должно знать, что заказы хранятся на одной машине, а адреса — на другой. Пользователи, как правило, не знают, где находятся значения, а потому могут называть базой данных всю систему.
Для большинства корпоративных вычислений используются реляционные базы данных, обладающие следующими свойствами.
- Организуют информацию в столбцы и строки, составляющие таблицы, которые можно разделить на несколько подтаблиц.
- Иногда содержат индексы, упрощающие поиск.
- Могут использовать SQL-запросы и сложное планирование, чтобы быстро сокращать количество повторяющихся элементов и создавать краткие отчеты.
В последнее время также начали распространяться нереляционные типы баз данных или NoSQL, которые не хранят информацию в реляционных таблицах. Они дают разработчикам большую гибкость, например позволяют добавлять новые поля или элементы для отдельных записей.
Но в некоторых случаях баз данных бывает недостаточно.
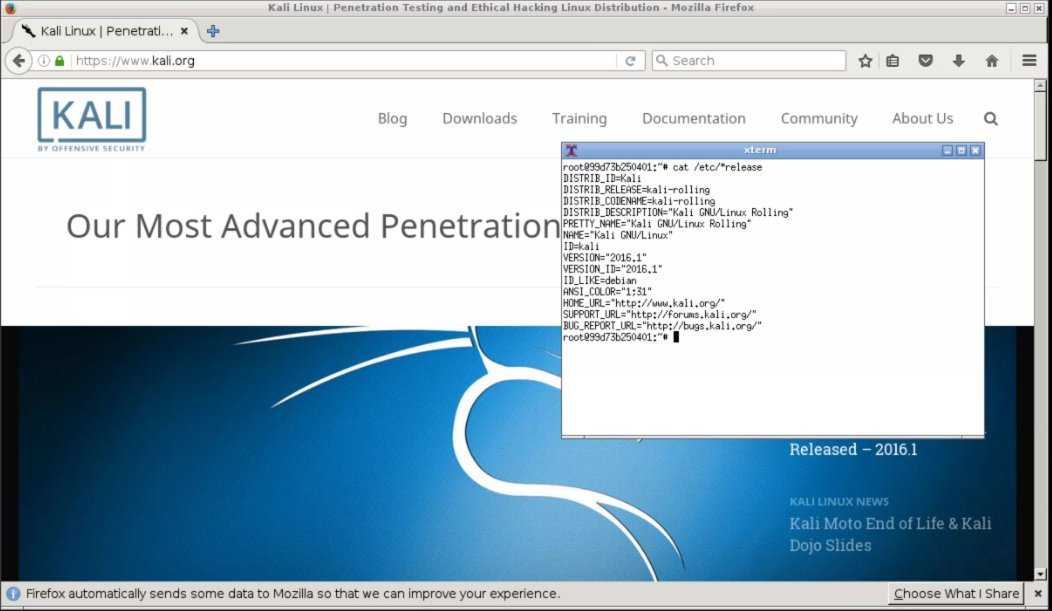
5. Debian
Debian — свободная операционная система, и здесь нет коммерческой поддержки. Но вы можете воспользоваться поддержкой сертифицированных центров Debian, которые есть по всему миру. Проект Debian возник в 1993 году и сейчас на нем основано большое количество дистрибутивов, самые известные из которых: Ubuntu и Linux Mint.
Debian остается отличным вариантом, для тех, кто ценит стабильность взамен на отказ от последних технологий. Такая стабильность достигается тщательным тестированием программного обеспечения и редкими релизами новых версий.
Новые версии Debian выходят примерно раз в 2-4 года, точного расписания у них нет, но в последнее время они стали выходить немного чаще. Debian уже использует systemd вместо старой системы инициализации SysV init, а также nftables вместо iptables.
Собирают ли о нас информацию в интернете?
Информация – оружие XXI века. Крупные компании научились собирать и обрабатывать данные миллионов людей, использовать их в маркетинговых целях, для формирования статистики. Часть конфиденциальной информации интернет-пользователи предоставляют добровольно: банкам, платёжным системам, социальным сетям, транспортным службам, но гораздо большие объёмы собираются «тайно». Почему, например, корпорация Google так сильно разрекламировал свой браузер Chrome?
Почти всё, известное о вас благодаря интернету, предоставляется через браузер: история поиска, навигации по сети и поведение на сайтах, cookies, банковские транзакции, геометки, IP-адреса, масса различной информации о компьютере. И в большинстве случаев пользователей к этому принуждают. Без галочки под условиями использования интернет-сервиса или приложения вы не сможете работать с ним или останетесь без части функций.

На мобильном устройстве слежка реализуется еще проще: достаточно установить и запустить приложение, требующее доступа к камере, микрофону, списку контактов, местоположению и т.д. И смартфон превращается в шпиона, особенно при включённом интернете.




От количества информации у компании зависит объём данных для анализа. Чем её больше, тем мощнее алгоритмы обработки, следственно – выше доход от рекламы. Кроме того информация покупается и продаётся. Даже Facebook уличили в торговле данными пользователей c такими IT-гигантами как Netflix, Apple, Microsoft.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
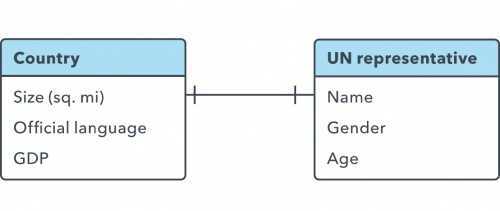
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
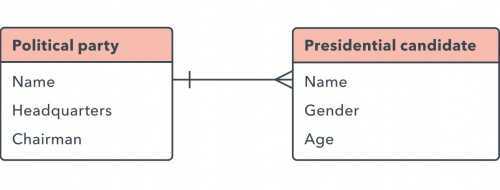
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
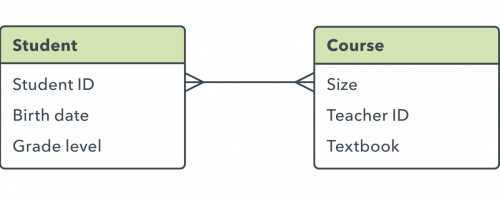
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
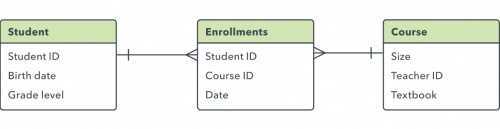
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:




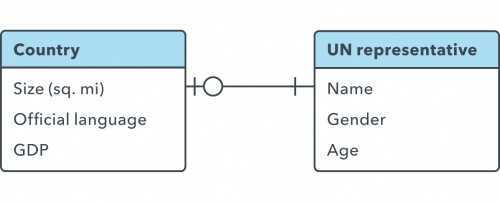
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Платформы управления данными (DPM) в рекламе и маркетинге
По прогнозу Market Research Future (MRFR), мировой рынок платформ управления данными (DMP) может достичь к концу 2023 года 3 млрд. долларов при среднегодовом росте 15%, а в 2025 году его объем превысит 3,5 млрд. долларов.
- Дает возможность собирать и структурировать все типы аудиторных данных; анализировать имеющиеся данные; передавать данные в любое медийное пространство для размещения таргетированной рекламы.
- Помогает собирать, организовывать и активировать данные из различных источников и переводить их в полезную форму.
- Организует все данные в категории на основе бизнес-целей и маркетинговых моделей. Система анализирует данные и генерирует сегменты аудитории, которые точно представляют клиентскую базу в широком диапазоне каналов, основанных на различных общих характеристиках.
- Позволяет повысить точность таргетинга рекламы в онлайне и выстроить персонализированные коммуникации с релевантной аудиторией. На базе DMP также можно настроить цепочки взаимодействия с каждым целевым сегментом, чтобы пользователи получали актуальные сообщения в нужное время и в нужном месте.
Электронные носители личной информации
Хранение персональных данных на электронных носителях предполагает использование автоматизированных баз данных и защищенных информационных систем. Обработка конфиденциальных данных на электронных носителях имеет ряд преимуществ, однако в таком способе есть и недостатки.
Хранение ПДн на электронных носителях
| Преимущества | Недостатки |
| Снижение расходов на приобретение дополнительных ресурсов для хранения данных. | Необходимость создавать резервные копии баз данных. |
| Отсутствие необходимости в специальных помещениях для хранения. | Высокая стоимость оборудования и программ, обеспечивающих безопасность персональных данных, которые хранятся на электронном носителе. |
| Высокая скорость поиска, обработки и использования данных. | Необходимость в обучении персонала навыкам администрирования для пользования электронными данными. |
| Защищенность конфиденциальных данных от несанкционированного доступа. | Сотрудники, получившие доступ к данным, должны уметь работать с электронными носителями информации. |
| Неограниченный срок хранения данных (в отличие от бумажных носителей). | |
| Автоматическая архивация данных. |
Для защиты электронных баз данных и хранящейся на них личной информации:
- внедряют уровни доступа сотрудников к данным хранилищам;
- ограничивают свободный вход работников без специального допуска в помещения, где установлено оборудование для обработки данной информации;
- четко регламентируют хранение, обработку и учет данной информации и электронных носителей.
Создание и настройка пользователя
Прежде, чем начать, вы должны знать пароль пользователя root в вашей инсталляции MySQL. Это не тот же самый root, который присутствует в вашей операционной системе. Чтобы не использовать учётную запись root для работы со всеми БД в вашей системе, вы можете создать отдельного пользователя. Например, чтобы работать с БД моего WordPress, я использую отдельного пользователя, наделённого не столь высокими привилегиями, как пользователь root.
Создать пользователя очень просто. Войдите в оболочку MySQL и дайте команду:
CREATE USER 'bob'@'localhost' IDENTIFIED BY 'password';
заменив bob на имя нужного вам пользователя, а password на пароль пользователя.
Однако, созданный пользователь не сможет делать ничего полезного до тех пор, пока ему не предоставить необходимые привилегии в базам данных. Например, если вы хотите дать пользователю bob полный доступ к базе данных wordpress_db, достаточно дать команду:
GRANT ALL PRIVILEGES ON wordpress_db.* to 'bob'@'localhost';
Вы можете ограничить перечень операций, которые будет разрешено выполнять указанному пользователю. Например, вы можете разрешить лишь операции SELECT, INSERT и DELETE. Подробнее узнать об этом вы можете в соответствующем разделе руководства MySQL.
Firebird
Этот конструктор баз данных использовался в производственных системах (под разными названиями) с 1981 года и реализует многие стандарты ANSI SQL. Firebird может работать на Linux, Windows и различных Unix-платформах.
Достоинства
API трассировки для мониторинга в реальном времени;
Аутентификация с проверкой подлинности Windows;
Четыре поддерживаемые архитектуры: SuperClassic, Classic, SuperServer и Embedded;
Разнообразные средства разработки: коммерческие инструменты – FIBPlus и IBObjects;
Возможность автоматического развертывания для очистки базы данных;
Уведомления о событиях из триггеров базы данных и хранимых процедур;
Бесплатная поддержка глобального сообщества Firebird
Что важно при разработке требований к базам данных.. Недостатки
Недостатки
- Интегрированная поддержка репликации не включена и доступна только в качестве дополнения;
- Нехватка временных таблиц и интеграции с другими системами управления базами данных;
- Аутентификация с проверкой подлинности Windows недостаточна по сравнению с решениями, доступными в других операционных системах.
Оптимизация MySQL
Конфигурация MySQL достаточно сложная, но, к счастью, вам не нужно в нее сильно углубляться. Есть специальный скрипт под названием MySQLTunner, который анализирует работу MySQL и дает советы какие параметры нужно изменить и какие значения для них установить. Скрипт поддерживает большинство версий MariaDB, MySQL и Percona XtraDB. Нам понадобится загрузить три файла с помощью wget:




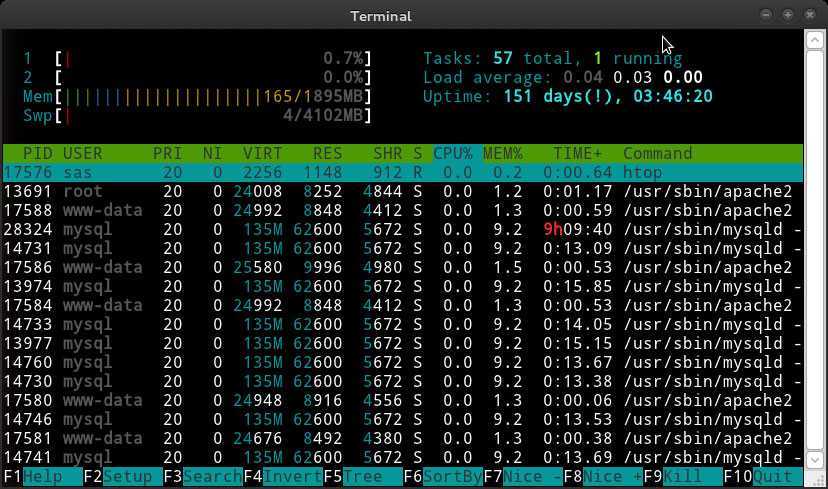





Первый из них — это сам скрипт, написанный на Perl, второй и третий — база данных простых паролей и уязвимостей. Они позволяют обнаружить проблемы с безопасностью. Дальше можно переходить к тестированию. Я использую сервер с настройками mysql по умолчанию, установленными панелью управления VestaCP.
Буквально за несколько минут скрипт выдаст полную статистику по работе MySQL. Количеству запросов, занимаемому объему памяти и эффективности работы буферов. Вы можете ознакомиться со всем этим, чтобы лучше понять в чем причина проблем. Проблемные места обозначены красными восклицательными знаками. Например, здесь мы видим, что размер буфера движка таблиц InnoDB (InnoDB buffer pool) намного меньше, чем должен быть для оптимальной работы:
Кроме того, в самом конце вывода утилита предоставит список рекомендаций как исправить ситуацию. Мы рассмотрим все сообщения утилиты из этого примера и почему нужно использовать именно их, а не другие.
Все параметры нужно добавлять в /etc/my.cnf. Еще раз замечу, что вы не копируете статью, а смотрите что вам выдала утилита. Начнем с query-cache.
Скрипт рекомендует отключить кэш запросов. Query Cache — это кэш вызовов SELECT. Когда базе данных отправляется запрос, она выполняет его и сохраняет сам запрос и результат в этом кэше. И все бы ничего, но при использовании его вместе с InnoDB при любом изменении совпадающих данных кэш будет перестраиваться, что влечет за собой потерю производительности. И чем больше объем кэша, тем больше потери. Кроме того при обновлении кэша могут возникать блокировки запросов. Таким образом, если данные часто пишутся в базу данных — его надежнее отключить.
Оба параметра устанавливают размер памяти, которая используется для внутренних временных таблиц MySQL. Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64
Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное
Этот параметр отвечает за количество потоков, которые будут закэшированны. После того, как работа с подключением будет завершена, база данных не разорвет его, а закэширует, если количество кэшированных потоков не превышает ограничение. Утилита рекомендует больше четырех, например, 16.
Указывает, что не нужно пытаться определить доменное имя для подключений извне. Ускоряет работу, так как не тратится время на DNS запросы.
Этот параметр определяет размер буфера InnoDB в оперативной памяти, от этого размера очень сильно зависит скорость выполнения запросов. Значение зависит от размера ваших таблиц и количества данных в них. Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.
Размер файла лога innodb должен составлять 25% от размера буфера. В случае 800 мегабайт это будет 200М. Но тут есть одна проблема. Чтобы изменить размер лога нужно выполнить несколько действий. Поскольку мы изменили все нужные параметры перейдем к перезагрузке сервера. Для нашего лога нужно остановить сервис:
Затем переместите файлы лога в /tmp:
И запустите сервис:
Когда размер лога меняется сервис видит поврежденный лог, выдает ошибку и не запускается. Поэтому сначала нужно удалить старый. После этого смотрите есть ли сообщения об ошибках:
MySQL
Разработка базы данных MySQL началась в 1995 году, за это время над ней работали несколько компаний, и сейчас она принадлежит Oracle. Кроме версии с открытым исходным кодом, существует несколько коммерческих версий, в которых реализованы дополнительные возможности, такие как кластер гео-репликации и автоматическое масштабирование.
MySQL относиться к типичным реляционным базам данных, все данные хранятся в таблицах и приложения могут очень быстро получить к ним доступ. Для запросов используется стандартный язык SQL, поддерживается большинство возможностей языка, определенных стандартом. При всем этом, она легка в использовании и развертывании.
За время своего развития MySQL получила поддержку различных типов таблиц, интеграцию во многие программы и языки программирования, а также имеет веб и графические интерфейсы для настройки.
1. Ubuntu
На первом месте нашего списка Ubuntu. Это очень популярный дистрибутив Linux, основанный на Debian и разрабатываемый компанией Canonical. Кроме версии для рабочего стола, есть версия для сервера.








Ubuntu имеет несложный установщик, проста в использовании и настройке, а также имеет коммерческую поддержку мирового уровня от компании Canonical. Сейчас Ubuntu чаще всего используется для обеспечения работы веб-серверов среди всех других дистрибутивов.
Однако при выборе версии дистрибутива стоит обратить внимание на срок поддержки. У Ubuntu есть два вида релизов — с длинным сроком поддержки (LTS) и с коротким сроком поддержки
Первые активно получают обновления на протяжении двух лет с момента выпуска и ещё некоторое время поддерживаются, вторые же поддерживаются только девять месяцев до следующего релиза.
Нет никакого смысла ставить на сервер релиз с коротким сроком поддержки, он может быть нестабильным и к тому же его придется в скором времени обновлять до новой версии. Хотя LTS версию тоже довольно скоро придется обновлять.
2. Кэси
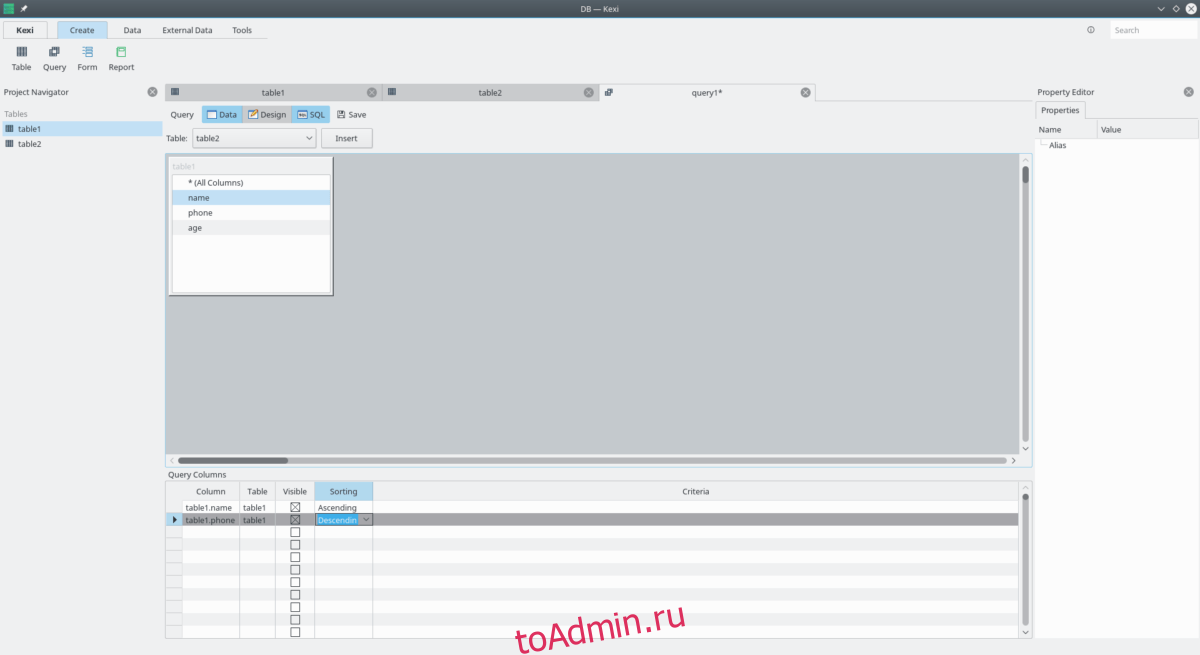
Kexi — это компонент базы данных в пакете Calligra Office с открытым исходным кодом. Как и большинство приложений баз данных, он предназначен для работы с различными базами данных (финансовыми, с информацией о студентах и т. Д.). Разработчики заявляют, что это отличная альтернатива Microsoft Access и, благодаря своей открытой природе, полезный набор функций (большинство из которые сравнимы с MS Access,) и способность обрабатывать несколько типов файлов баз данных из множества программ баз данных.
Kexi — не единственное приложение в этом списке, которое претендует на то, чтобы заменить Microsoft Access. Однако следует отметить, что разработчики Kexi очень много работают, чтобы сделать его конкурентоспособным. По этой причине стоит проверить, нужен ли вам хороший инструмент базы данных с графическим интерфейсом для Linux.
Примечательные особенности
Позволяет пользователям выбирать из нескольких механизмов баз данных для использования в проектах, включая MySQL, Microsoft SQL Server, MariaDB и многие другие.Информация базы данных хранится в одном файле, что упрощает обмен с коллегами.«Формы» Kexi означают, что базы данных не ограничиваются только текстом. Вместо этого приложение побуждает пользователей добавлять графические элементы для более удобного использования.Хорошо интегрируется с остальной частью Calligra Office Suite и имеет простой в навигации пользовательский интерфейс, который хорошо выглядит в большинстве операционных систем.
Скачать — Kexi
Kexi поставляется с пакетом Caligra Office для Linux. Хотя он не так популярен, как Libre Office, некоторые дистрибутивы Linux на основе KDE часто включают его по умолчанию.
Каллигра еще не настроена по умолчанию? Узнайте, как установить весь пакет, следуя этому руководству здесь.
Falkon
Это еще один браузер, изначально разрабатывавшийся для оболочки KDE, только в отличие от Konqueror его не собирались делать монструозным гигантом, делающим все и сразу. Наоборот, ставка делалась на легкость и аскетизм.
Разработчики так и говорили: Falkon – это легковесный браузер, адаптированный под все ключевые операционные системы. Изначально его создавали под нужды учебных заведений, но позже количество функций стало расти, и браузер стал неплохой альтернативой существующим решениям.
Минимализм прослеживается не только в дизайне продукта, но и в его возможностях. Тут нет функций, за которые можно было бы зацепиться в обзоре. Просто окно в интернет со встроенным блокировщиком рекламы (AdBlock, кстати). Так можно описать Falkon.
Рекомендую тем, кто хочет предельно простое и безопасное средство для выхода в интернет (ну и пользуется при этом рабочим столом KDE, конечно).
Chromium
Теперь поговорим о более классических браузерах для Linux. Вернее об одной из их вариаций. Я намеренно не беру привычный Google Chrome, потому что в Linux-среде предпочитают его «открытую» версию, не привязанную так жестко к сервисам корпорации добра.




При этом визуально и функционально Chromium практически не отличается от Chrome. Тот же интерфейс, аналогичное меню управления закладками, те же опции для работы с вкладками.
- Chromium поддерживает расширения из Chrome Web Store и оставляет возможность ставить плагины из сторонних источников.
- Не собирает данные о пользователе. Игнорирует даже отчеты об ошибках.
- Не поддерживает фирменную систему обновления программного обеспечения Google. Для обновления придется воспользоваться встроенным в дистрибутив пакетным менеджером или вручную скачать новую версию браузера с официального сайта.
- Не работает с проприетарными кодеками в духе AAC, H.264 или MP3.
- Chromium не содержит в себе инструментов сбора «статистики» и прочих рекламных трекеров. Можно считать его более безопасным браузером, уважающим конфиденциальность пользователя.
Рекомендую тем, кто не в силах отказаться от Chrome, но не хочет обогащать Google за счет личной информации.
CUBRID

Бесплатная программа для создания базы данных с открытым исходным кодом, оптимизированная специально для веб-приложений. Данный сервис предназначен для обработки больших объемов данных и генерации многочисленных параллельных запросов. Это решение реализовано на языке программирования C.
Достоинства
- Множественная степень дробления блокировок;
- Создание резервных копий онлайн;
- Инструменты GUI и драйверы для JDBC, PHP, Python, Perl и Ruby;
- Поддержка встроенного сегментирования базы данных для масштабирования;
- В крупных системах данные разделяются по нескольким экземплярам базы данных;
- Репликация полнотекстовых баз данных и согласованность транзакций.
Недостатки
- Не работает в системах Apple;
- Нет отладчика сценариев;
- Руководство доступно только на английском и корейском языках;
- Обсуждения на официальном форуме, как правило, устаревшие (большинству из них несколько лет).
Разработка
Оба проекта имеют открытый исходный код, но развиваются по-разному. Развитие MySQL нравится далеко не всем. И в этом сравнение mysql и postgresql дает много отличий.
MySQL
База данных MySQL разрабатывается компанией Oracle и ходят слухи, что компания намерено тормозит развитие движка. Было создано очень много форков проекта, в том числе форк MariaDB от разработчика оригинальной MySQL. Но все же развитие остается медленным.
Postgresql
Как было сказано в начале статьи разработка началась в университете Беркли. Затем перешла в коммерческую компанию. Сейчас программа разрабатывается независимой группой программистов и советом нескольких компаний. Новые версии выпускаются достаточно активно и получают все новые и новые функции.