
Назначение
Во время чтения человек сравнивает буквенный текст со своим словарным запасом.
Подобным образом работают программы, осуществляющие Парсинг (Parsing, англ.).
Этим термином в информатике обозначается синтаксический анализ, для проведения которого на языке программирования создаётся математическая модель.
Тогда программа, запущенная компьютером, сравнивает набор конкретного текста со словами из интернета и выдаёт результат в каком-то удобном виде. Именно такие программы называют парсерами.
Отсюда понятен алгоритм его работы:
- Выход в интернет;
- Просмотр/обработка информации;
- Подведение/выдача итоговых данных.
Для получения результатов парсера его можно заказать или делать самостоятельно с использованием купленных или бесплатных приложений.
Для бесплатного (!) поиска и составления слов-ключей относительно своего веб-проекта удобно воспользоваться приложением «Словоёб» (хотелось бы посмотреть в глаза маньяку, давшему такое название).
Однако в любом случае для того чтобы приложение правильно работало — нужно всё верно настроить.
ВАЖНО. Бесплатный «Slovoeb» ограничивается Яндексом.
Создание семантического ядра интернет-магазина: инструменты
Каждый день мне приходится использовать множество программ, но именно для сбора я могу выделить три. Итак, встречайте, наши главные помощники в этом нелегком деле.
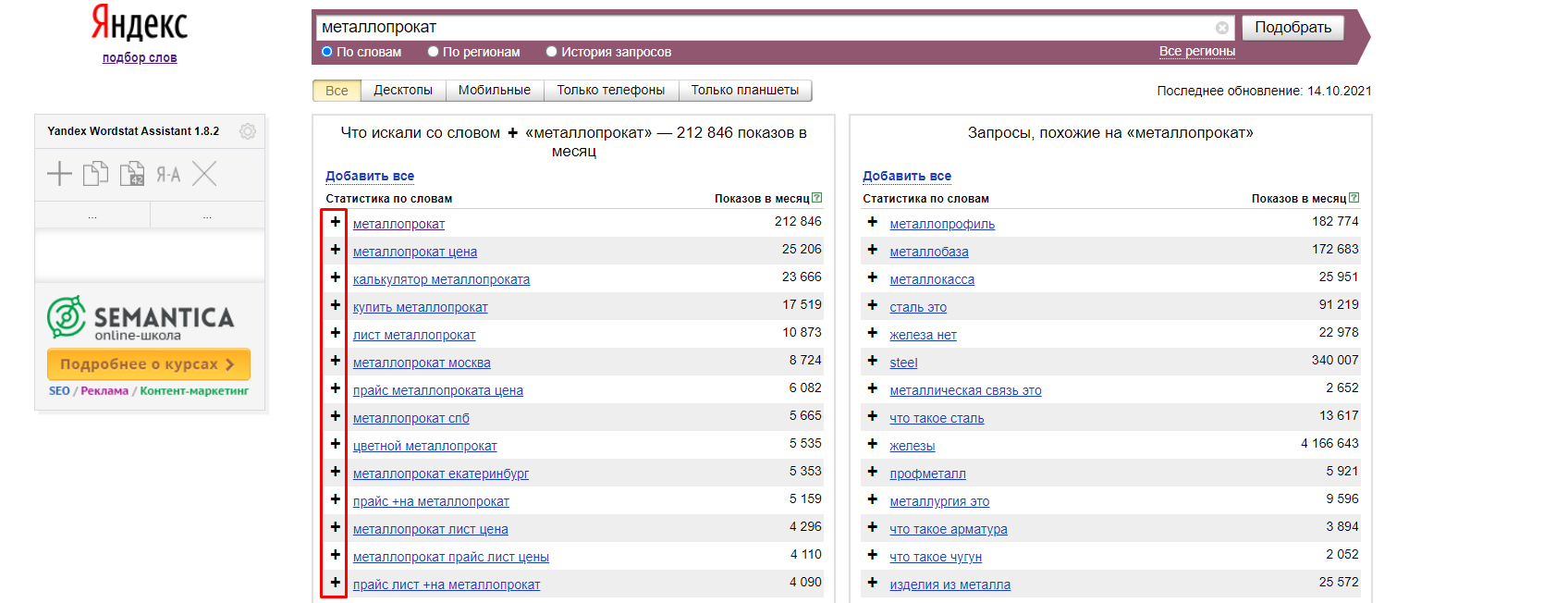
Wordstat.Yandex – мой любимый сервис. Здесь вы можете отфильтровать запросы по региону (1), оценить сезонность по истории (2), отследить частоту фразы, запрошенную с ПК или мобильного устройства (3), а также посмотреть подсказки в колонке справа (4).
Key.so – сервис для парсинга ключевиков у конкурентов. Здесь вы сможете не только собрать СЯ с конкурентных страниц, но и проанализировать целые сайты, оценить их структуру.
Key Collector – с помощью этого инструмента вы можете полностью автоматизировать процесс сбора, чистки, кластеризации СЯ. Главное – разобраться с настройками.
Теорию прошли, переходим к практике.
Анализ
Для начала стоит проанализировать проект заказчика его конкурентов, чтобы понимать, по каким направлениям нам предстоит собирать СЯ.
Про анализ сайта клиента, думаю, уточнять не нужно – вы просто составляете список всех имеющихся страниц. И всё. А вот о конкурентах поговорим подробнее. Идем в поисковик и вбиваем запросы, по которым мы планируем продвигаться. После того как вы нашли 5-10 конкурентных сайтов, которые находятся на первых 10 строчках поисковой выдачи, переходите на каждый из них и выписывайте заголовки H1 со всех страниц – не забывайте чистить дубли.
На выходе должен получиться большой список, который и станет нашей черновой структурой.
Собираем СЯ через Яндекс.Вордстат
Если вбить интересующие вас слова в строку поиска (не забывая указать регион продвижения, если он есть), мы получим список запросов, содержащих указанные вами словоформы, за последний месяц. С операторов «+» и «-» вы можете добавить или убрать ключи из выдачи. Например, для «арматуры» я вписала коммерческое «купить» и исключила фразы, содержащие аббревиатуру «ГОСТ»:
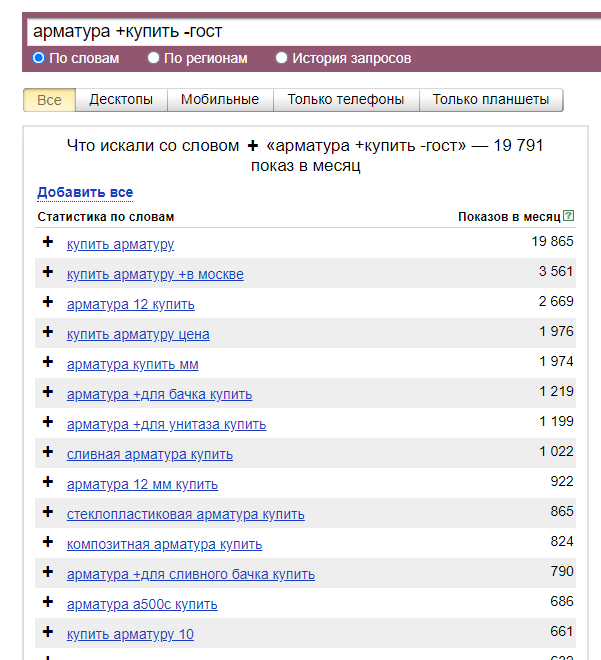
Это не единственные операторы, которые помогут упростить поиск ключей. Подробнее о работе с этим сервисом мы писали в статье Wordstat Yandex – рекомендую почитать.
Хочу уточнить, что такой способ сбора можно скорее назвать ручным, и подойдет он для формирования маленьких СЯ или поиска ключевиков для отдельных страниц. Если вам нужно составить объемное ядро, лучше использовать этот сервис как дополнение для расширения слов или проверки полноты вашей семантики.
Как облегчить работу через Яндекс.Вордстат
Чтобы сделать процесс проще, быстрее и эффективнее, я рекомендую вам установить расширение для браузера Yandex Wordstat Assistant. Благодаря своим функциям он гарантированно ускорит процесс сбора СЯ в несколько раз.
Основные преимущества:
Удобный способ добавления фразы с помощью оператора «+».
- Весь список можно скопировать одним нажатием клавиши.
Даже если вы случайно закрыли вкладку или браузер – все добавленное в «ассистента» сохраняется.

- Автоматически производится проверка на дубли, если вы добавляете в список запрос, слова в котором стоят в разном порядке, или фразы, найденные на другом сервисе.
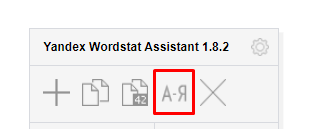
- Имеется несколько вариантов сортировки: по алфавиту, частотности и порядку добавления. Для переключения режима нужно нажать на кнопку, отмеченную на скриншоте ниже.
Вы не сможете добавить в список один и тот же ключевик, так как добавленные слова обесцвечиваются. Из-за этого вам не придется чистить дубли.





Сбор через Key.so
Чтобы собрать семантику конкурентов, вам необходимо скопировать URL конкурентного сайта и вставить его в поисковую строку. Для получения результата нажмите «анализировать».
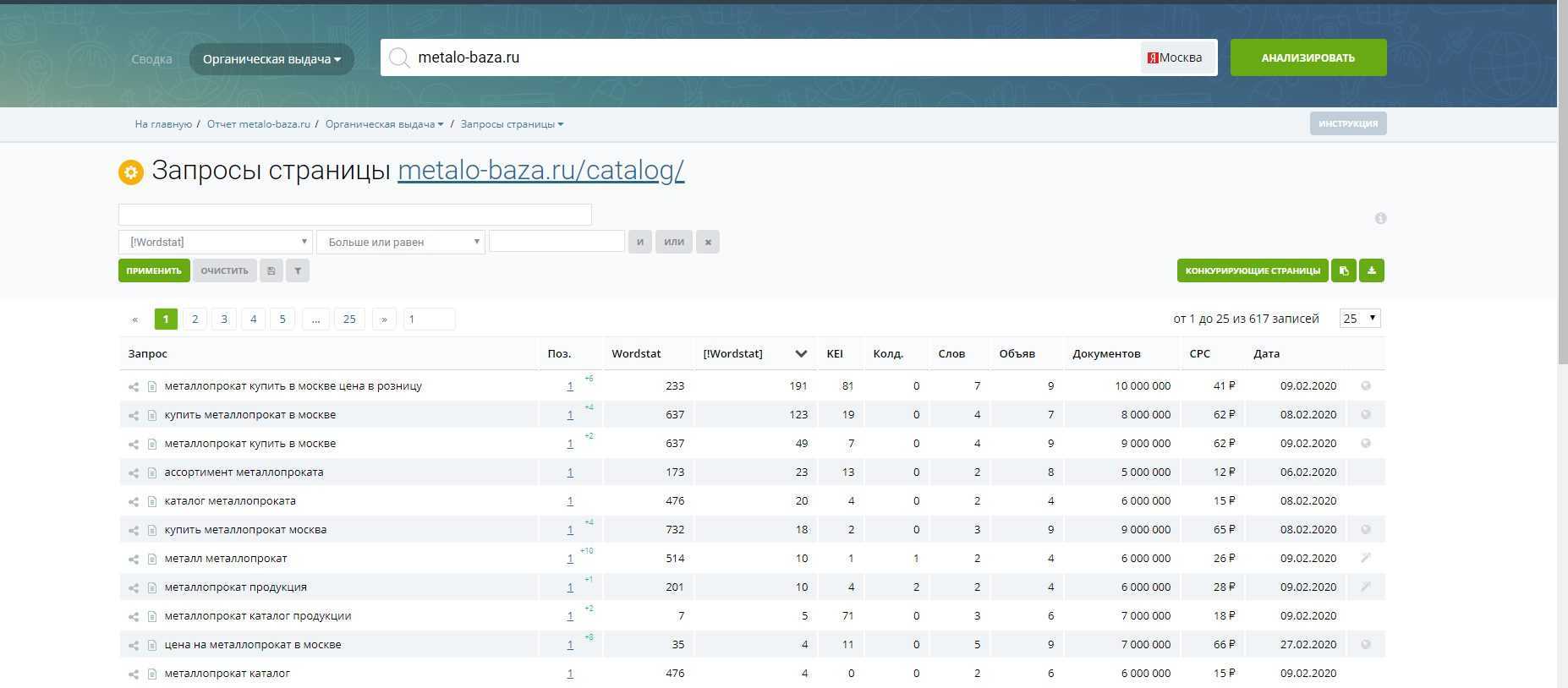
На скриншоте видно часть СЯ, фразы можно скопировать и добавить себе в Exel таблицу.
Конечно, количество сервисов не ограничивается теми тремя, которые мы рассмотрели с вами пару разделов назад. Для сбора СЯ вы также можете воспользоваться:
- Словоёбом. Инструмент помогает собирать ключевики, оценивать конкуренцию, изучать результаты и автоматизировать все эти процессы. У него похожий интерфейс с коллектором, поэтому разобраться с кнопками, если вы до этого работали и с ним, не составит труда.
- Магаданом. Позволяет собрать, обработать и проанализировать запросы Яндекс.Директа. Есть как бесплатная версия в формате LITE, так и PRO с оплатой в 1500 рублей.
Среди них можно выделить:
- Базу Пастухова. Здесь собраны ключевики из Яндекса и Google, список периодически обновляется. Комплект используется онлайн или скачивается в версии для ПК. Обе они обойдутся в 36000 рублей.
- A-parser. Парсер с огромным количеством функций и возможностей. Обладает большой скоростью обработки информации, удобными фильтрами, а также имеет живой форум, в котором можно задавать насущные вопросы. Стоит такое удовольствие от 14000 рублей за версию LITE.
Чистка семантического ядра
Мы спарсили подсказки и ключевые фразы конкурентов. Порой получается несколько десятков, а то и сотен запросов. Что со всем этим делать? Нам нужно оставить только релевантные, то есть соответствующие нашему сайту, запросы. Для этого нужно удалить все нерелевантные запросы, но делать это вручную очень долго. Рассмотрим сервисы, которые помогут почистить наше семантическое ядро.
Муравейник Tools
Аналогов этого инструмента я не встречал. Чтобы почистить ядро с помощью Муравейник Tools, нужно зайти в «Анализ семантики», добавить задачу и загрузить ключи (до 10 000 запросов).
Затем скачиваем файл и сортируем сайты по схожести. Если в Яндексе и Гугле напротив запроса стоит 0, то такой запрос продвигать бесполезно.
Далее СЯ нужно проверить вручную. После чистки нужно будет пробежаться по ядру и вручную удалить неподходящие запросы.
Чистим ядро с помощью Key Collector
В Key Collector можно не только собирать, но и чистить запросы. Для этого во вкладке «Данные» нажимаем «Анализ групп». После этого программа группирует слова. Выбираем группировку по отдельным словам. Если слово явно не подходит для вашей тематики, ставим напротив него галочку. После простановки галочек возвращаемся к «Сбору данных» и нажимаем «Удалить фразы».
Экспортируем оставшиеся фразы и проверяем полученные данные.
Муравейник Tools и Key Collector можно использовать в паре. Это поможет сэкономить время.
Как парсить ключевые запросы в СловоЁБ
После того, как мы подобрали основные ключевые запросы, которые будем парсить (их можно сохранить для дальнейшей обработки в программе Excel, или подобной), переходим к работе с программой парсером.
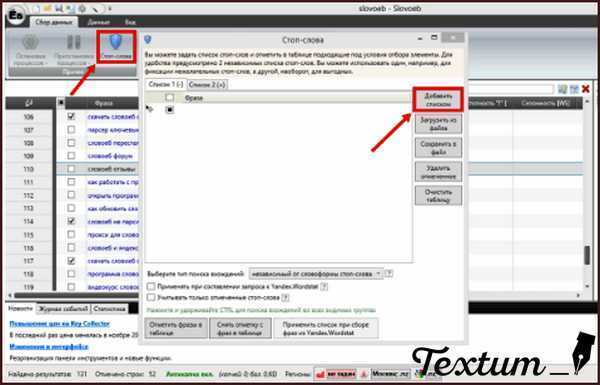
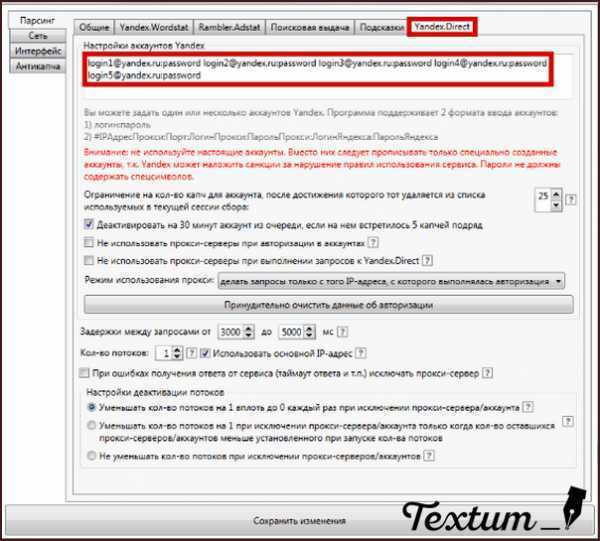
После первого запуска необходимо провести минимальные настройки для дальнейшей работы с программой. Первое, это ввести логин и пароль от имеющегося аккаунта Яндекс в формате «мойлогин:мойпароль». Я рекомендую для работы с Словоёбом использовать отдельно созданную учетную запись, чтоб не потярять наработки. если вдруг аккаунт будет по каким то причинам заблокирован. Для ввода логина и пароля жмем значок шестеренки в верхней пали программы и в открывшемся окне выбираем вкладку «Yandex.Direct»:
Далее переходим на вкладку «Yandex.Wordstat», и выставляем значение «глубина парсинга» равное двум.
После чего сохраняем настройки. Все программа готова к работе. Теперь создаем новый проект, нажав кнопку «Создать новый проект» и сохраняем его в удобном для нас месте.
В открывшемся окне проекта переименовываем название Группы по умолчанию в ключевое слово, которое собираемся парсить и жмем кнопку «Пакетный сбор слов из левой колонки….», для начала процедуры парсинга.
В следующем окне вводим ключевое слово, которое мы хотим найти в разных сочетаниях и жмем кнопку «Начать сбор».
Если появится окно с капчей, то вводим соответствующие символы и запускаем поиск.
Вот и все. Сбор слов начался. Вы можете ждать, пока программа соберет все вариации и остановится сама, или остановить поиск вручную, если данные в колонке «Частотность» напротив найденных слов будут составлять менее цифры 7.
Затем можно скопировать найденные слова кликнув правой кнопкой мышки по колонке «Фраза» и выбрав в выпадающем меню пункт «Скопировать колонку в буфер обмена».
Далее найденные слова можно вставить в Excel файл и продолжить там работу по сортировке этих слов, очистки от не нужных приложений и не подходящих ключевых фраз.
Другие возможности
У Словоеба есть возможность задавать регион поиска, домен поисковой системы (Google.ru, google.com):







Также в программе можно проверять позиции вашего сайта по ключевым фразам и определять релевантные страницы.
Словоеб в колонках отображает и другую полезную информацию, которую стоит учитывать. Например, количество главных страниц сайтов в ТОП-10 по запросу или количество в ТОП-10 страниц, которые содержат ключевую фразу (проверяется в Яндекс и в Google).
Видно, что по запросу «Продвижение сайтов» в ТОП-10 Яндекса находится 10 сайтов с прямым вхождением в заголовке страницы, а в Google таких только 8. Зато количество главных страниц одинаково – по семь.
В целом, возможностей Словоеба вполне хватит большинству оптимизаторов. У платных программ функционал шире, но он нужен далеко не всем. Но даже не слишком богатый функционал Словоеба дает очень много пищи для размышлений и облегчает поисковое продвижение сайта. Эта программа относится к тем, которые однозначно можно рекомендовать использовать при составлении семантического ядра.
Обычные кейсы
Но руководство по запуску утилит само по себе мало что говорит о том, как именно их нужно применять в зависимости от ситуации. Приведём несколько примеров.
Пример 1. Максимально простой.
Дано:
- один процессор с 4 ядрами
- одна 1 Гбит/сек сетевая карта (eth0) с 4 combined очередями
- входящий объём трафика 600 Мбит/сек, исходящего нет.
- все очереди висят на CPU0, суммарно на нём ≈55000 прерываний и 350000 пакетов в секунду, из них около 200 пакетов/сек теряются сетевой картой. Остальные 3 ядра простаивают
Решение:
- распределяем очереди между ядрами командой
- увеличиваем ей буфер командой
Пример 2. Чуть сложнее.
Дано:
- два процессора с 8 ядрами
- две NUMA-ноды
- Две двухпортовые 10 Гбит/сек сетевые карты (eth0, eth1, eth2, eth3), у каждого порта 16 очередей, все привязаны к node0, входящий объём трафика: 3 Гбит/сек на каждую
- 1 х 1 Гбит/сек сетевая карта, 4 очереди, привязана к node0, исходящий объём трафика: 100 Мбит/сек.
Решение:
1 Переткнуть одну из 10 Гбит/сек сетевых карт в другой PCI-слот, привязанный к NUMA node1.
2 Уменьшить число combined очередей для 10гбитных портов до числа ядер одного физического процессора:
3 Распределить прерывания портов eth0, eth1 на ядра процессора, попадающие в NUMA node0, а портов eth2, eth3 на ядра процессора, попадающие в NUMA node1:
4 Увеличить eth0, eth1, eth2, eth3 RX-буферы:
Установка Slovoeb в Linux
Для запуска Словоеб Ubuntu, нам нужна 32-битная система Windows, так что если в вас 64 бит нужно экспортировать специальную переменную, чтобы создать префикс 32 бит. Заодно и создадим новый префикс:
$ export WINEARCH=win32
Теперь переходим к установке всех необходимых компонентов. Их довольно таки много.
Установим шрифты:
Установим компоненты среды выполнения Microsoft Visual Runtime:
Установим Flash плеер и ie8, браузер обязательно нужен чтобы выполнить запуск словоеб linux:
Начнем установку Microsoft Net Framework, нам нужна версия 4.0, но для ее установки необходимо будет установить и все предыдущие. Сначала выполните:
После завершения установки утилита откроет браузер и папку, скачайте установочный файл и скопируйте в открытую папку, затем еще раз выполните:
Теперь устанавливаем четвертую версию:
Дальше нам нужно установить пакет windowscodecs:
Но библиотека в 64-битной системе установится не полностью. Поэтому скачиваем библиотеку здесь и скидываем ее в папку ~/Slovoeb/drive_c/windows/system32/:
Теперь остался последний штрих. Скачиваем библиотеку msctf.dll для Windows XP и тоже скопируйте ее в ~/Slovoeb/drive_c/windows/system32/:
Дальше запускаем winecfg, переходим на вкладку библиотеки и нажимаем кнопку Добавить. Далее пишем *msctf и выбираем сторонняя (Windows).
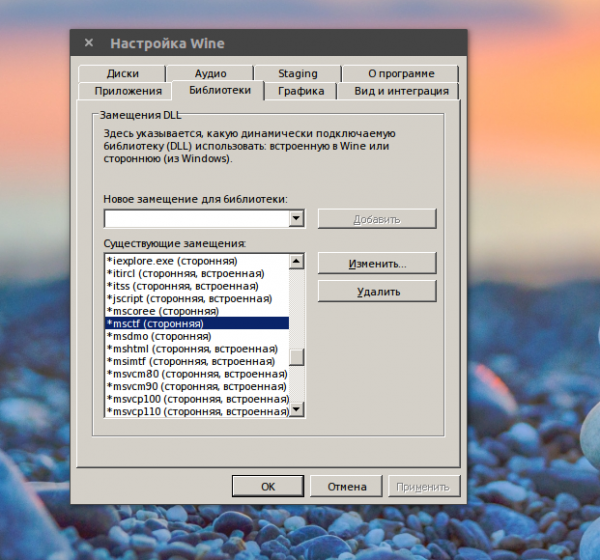
Нажимаем Ok и выполняем команду, чтобы зарегистрировать библиотеку в системе:
Наконец загружаем самую последнюю версию Словоеб с официального сайта. Распаковываем в папку с загрузками:
 И осталось запустить:
И осталось запустить:
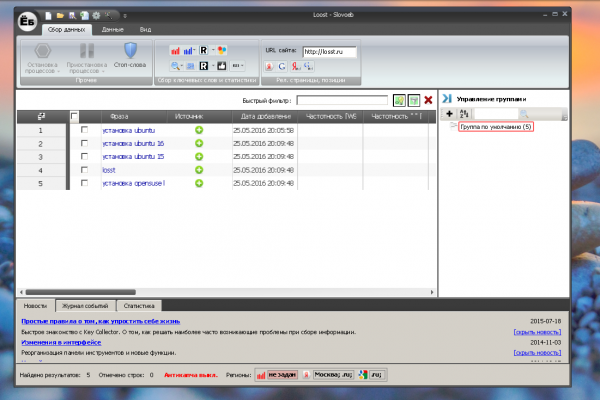
Все работает. Можете протестировать проверку позиций или сбор подсказок. Slovoeb Ubuntu отлично работает, точно так же как в в Windows. Если остались вопросы, пишите комментарии.





Обновление. Slovoeb прекрасно устанавливается и работает в 2019 по этой инструкции с wine 3.0. А вот KeyCollector запускается, но пока проект открыть невозможно. Видимо поддержка Microsoft NET 4.0 содержит еще много недоработок.
Как работают игры?
Ситуация с играми, в целом, схожая — то есть, что-то работает, что-то нет. Подробную информацию можно найти все в том же AppDB .
Здесь, правда, есть еще два важных момента.
Начнем с того, что в очень многих играх вы сможете использовать только DirectX 9. Работа над поддержкой 10-й и 11-й версий идет полным ходом, но работают они пока не во всех играх, местами некорректно, местами — медленнее, чем DX9. Однако, тот факт, что на момент написания статьи, в декабре 2015-го года, под DX10 и 11 не работало вообще ничего, а на момент внесения этой правки в марте 2018-го работает уже многое — внушает оптимизм.
Вторым краеугольным камнем является производительность. Проведенные мной тесты (этот, вот этот ну и вообще — следите за разделом про Wine) показали, что игры, использующие OpenGL, в производительности практически не теряют (если сравнивать с Windows), а вот с DirectX все не так радужно, и по сравнению с окошками она падает — на примере использованного мной в тестах бенчмарка Unigine Valley 2013 — более чем на 10% в DirectX 9.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
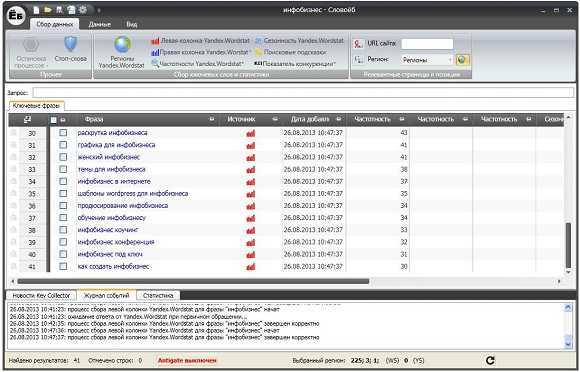
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
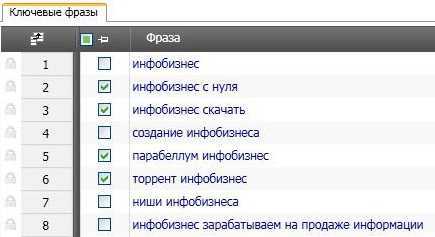
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
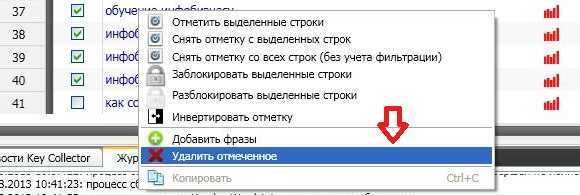
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Wordstat Яндекса и расширения для браузера
Wordstat — это бесплатный сервис поисковой статистики и подбора слов от Яндекса. Именно здесь можно посмотреть статистику запросов по любой поисковой фразе в зависимости от региона поиска.
Чтобы собрать семантическое ядро, используя исключительно Wordstat Яндекса, нужно копировать каждую страницу с результатами, переносить ее в Excel, а затем отсеивать нерелевантные запросы и только после этого добавлять в рекламные кампании.
Сократить процесс в несколько раз поможет расширение для браузера WordStater. После его установки Wordstat выглядит так:
![]()
Расширение позволяет одновременно собирать поисковые фразы, их частотность и минус-слова. При добавлении они будут подсвечены красным на всех страницах.
![]()
Далеко не всегда суть поискового запроса можно понять сразу же, иногда приходится копировать и искать его в новой вкладке. Разработчики расширения продумали этот момент — создали переход по нужному ключевому слову прямо из интерфейса при помощи одного клика. Это удобно и значительно экономит время.
Другие расширения с подобными возможностями:
- Yandex Wordstat Helper
- Yandex Wordstat Assistant
- Yandex Wordstat Keywords Add
Обзор других функций программы
Помимо парсинга Вордстата, у Словоеба есть и другие функции.
Парсинг подсказок в Словоебе
Для начала нужно проверить настройки подсказок и задать их под себя. Находятся они в разделе «Парсинг» во вкладке «Подсказки».
Настройки:
- Глубину парсинга лучше оставить 0 – при большем значении найденные подсказки будут парситься по второму кругу. Соберется много мусора.
- Чекбокс в пункте «Собирать только ТОП подсказок без перебора пробела после фразы» лучше оставить пустым. И выбрать все возможные символы для перебора, как на скриншоте ниже. Так, к заданной фразе соберуться все возможные подсказки.
- Если отметить «Выполнять подстановку выбранных групп перед заданной фразой», процесс затянется, а в итоге получится много мусора. Поэтому пользуйтесь функцией только тогда, когда без нее не обойтись.
- Остальные настройки можно оставить как есть, если не требуются подсказки из региональной выдачи.
Чтобы спарсить подсказки в программе, нажмите на соответствующий значок в панели инструментов и добавьте в открывшееся окно маркеры для парсинга.
Выберите, из каких поисковых систем нужны подсказки. Поставьте галочку, чтобы не добавлялись фразы, которые уже есть в других группах.
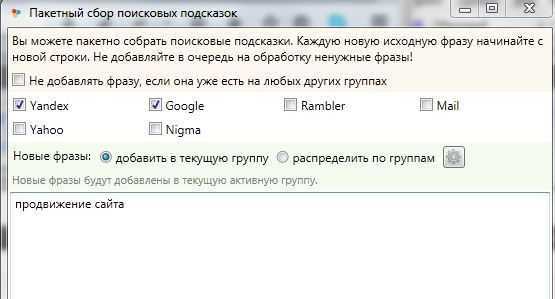







Теперь можно приступать к сбору подсказок.
Похожие фразы из Вордстата
В большинстве случаев нет смысла использовать эту функцию – для семантического ядра она может дать только мусор.
Но инструмент будет полезен, если нужны идеи первоначальных фраз для маркеров, которые в дальнейшем будут парситься.
Сезонность
Программа может проверить, является ли запрос сезонным. Словоеб анализирует историю запросов в Вордстате и выдает значение: да или нет.
Корректность словоформы
Функция проверяет, является ли словоформа корректной на основании поисковой выдачи.
Она пригодится, если в Словоеб добавлены ключевые слова из разных баз или выгрузки по конкурентам. С ее помощью можно избавиться от неправильных словоформ автоматически.
Опция для оценки конкурентности фразы в поисковых системах Яндекса и Гугла.
Позиции в Словоебе
Словоеб умеет определять, насколько страницы сайта релевантны запросам. За основу берутся данные поисковых систем Яндекса и Гугла. А также позиции сайта по этим ключам. Для проверки добавьте УРЛ сайта в строку меню.
«Господи, я не хочу в этом разбираться!»
И не нужно. Я уже разобрался и, чтобы не тратить время на то, чтобы объяснять это коллегам, написал набор утилит — netutils-linux. Написаны на Python, проверены на версиях 2.6, 2.7, 3.4, 3.6.
network-top
Эта утилита нужна для оценки применённых настроек и отображает равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора) на ресурсы сервера, всевозможные ошибки обработки пакетов. Значения, превышающие пороговые подсвечиваются.
rss-ladder
Эта утилита распределяет прерывания сетевой карты на ядра выбранного физического процессора (по умолчанию на нулевой).
autorps
Эта утилита позволяет настроить распределение обработки пакетов между ядрами выбранного физического процессора (по умолчанию на нулевой). Если вы используете RSS, скорее всего вам эта утилита не потребуется. Типичный сценарий использования — многоядерный процессор и сетевые карты с одной очередью.
server-info
Данная утилита позволяет сделать две вещи:
- : посмотреть, что за железо вообще установлено на сервере. В целом похоже на велосипед, повторяющий , но с акцентом на интересующие нас параметры.
- : найти узкие места в аппаратном обеспечении сервера. В целом похоже на индекс производительности Windows, но опять же с акцентом на интересующие нас параметры. Оценка производится по шкале от 1 до 10.
Прочие утилиты
- автоматически увеличивает буфер выбранной сетевой карты до оптимального значения.
- отключает плавающую частоту процессора. Энергопотребление будет повышенным, но это не ноутбук без зарядного устройства, а сервер, который обрабатывает гигабиты трафика.
Основные функции программы Словоеб
Словоеб (Slovoeb) – уникальная seo-программа, предназначенная для быстрого подбора и анализа ключевых запросов. Как я уже говорил ранее, это программа совершенно бесплатна. Она включает в себя базовый набор парсинга.
Парсинг – это процесс подбора поисковых ключевых запросов из разных источников (веб-статистика от поисковых систем, анализ сайтов конкурентов, а также сбор данных из веб аналитики и другие). Словоеб применяет для парсинга слов статистику поисковой системы Яндекс – WordStat, а также LiveInternet.
В свое время он задумался над поиском эффективного метода обработки и последующего анализа поисковых запросов. Естественно изначально вся работа в этом направлении велась с целью создания платной небезызвестной программы Key Collector. Однако стоит заметить, что основные функции для эффективного подбора ключевиков отлично представлены в бесплатной программе, о которой и пойдет речь в этой статье.
Включили в список только высокочастотные запросы
По низкочастотными запросами достаточно легко попасть на первые позиции. Также посетители, которые пришли по низкочастотному запросу, скорее сконвертируются в клиентов.
Плюсы низкочастотных запросов:
- ниже конкуренция и легче вывести в топ. Обычно по высокочастотным запросам все первые места прочно заняты гигантами отрасли и лидерами тематики, которых объективно потеснить будет практически невозможно. По узкоспециализированным запросам конкуренция меньше;
- для коммерческого проекта, велика вероятность, что посетитель, который пришел по низкочастотному запросу сконвертируется в клиента. Низкочастотные запросы — достаточно конкретные узконаправленные запросы, которые задает человек, которые знает, что хочет.
Следует ориентироваться и на тематику: частота, которую можно считать низкой в нише женской одежды, не будет таковой в тематике «охотничьи прицелы». Возьмем, например, проектирование домов. Для основного запроса «проект дома» высокочастотными будут считаться следующие запросы:
|
проекты домов |
16 229 |
|
проекты домов фото |
1 664 |
|
проекты одноэтажных домов |
1 610 |
|
проект дома цена |
1 368 |
Среднечастотные запросы:
|
проекты домов +до 100 м |
213 |
|
проекты домов +до 100 кв м |
212 |
|
проекты домов +до 150 |
209 |
|
проекты деревянных домов |
208 |
Низкочастотные запросы:
|
проекты цокольных домов +с мансардой |
47 |
|
проекты домов +из сип панелей +до 100 |
45 |
|
проекты домов +из профилированного бруса |
39 |
Под каждый отдельный вариант запроса должна быть создана отдельная страница. При ее грамотной оптимизации и наполнении качественным контентом можно легко получить хорошие результаты.










Подробно о том, как еще использовать низкочастотные запросы при продвижении, читайте в статье о креативном SEO.
Составили маленькое семантическое ядро
Семантическое ядро должно охватывать как можно больше ключевых запросов. Количество запросов может очень различаться от проекта к проекту — для низкочастотной тематики это может быть несколько сотен запросов, а для высокочастотной — десятки тысяч. Конечно, все ключевые слова должны соответствовать тематике сайта. Чтобы не пропустить нужные, используйте знакомые многим сервисы:
- Яндекс.Вордстат показывает, какие запросы с определенным ключевым словом вводили за выбранный период. Для каждого ключевого слова показывается частотность;
- Упрощает работу плагин wordstat helper — он позволяет выбирать и копировать нужные ключи с частотностью или без неё;
- Keyword Planner от Google позволяет собирать ключевые слова из поиска;
- Serpstat — многофункциональная платформа: собирает ключевые запросы из поисковых систем, анализирует семантику конкурентов, а также предоставляет базу похожих слов для расширения семантики.
Подробно о том, как расширить семантическое ядро, читайте в статье.



