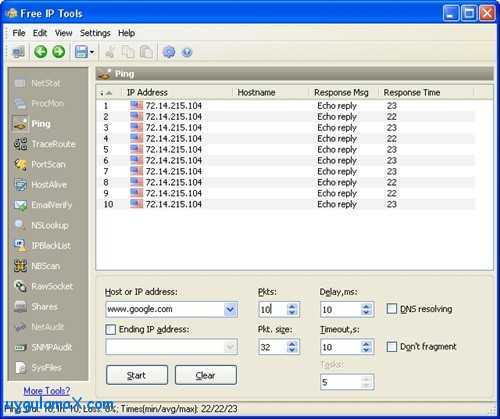
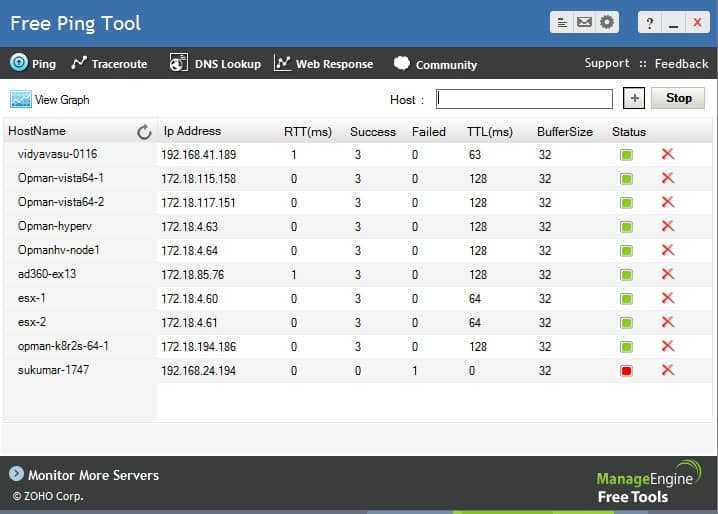
Основы мониторинга процессов Unix
Когда дело доходит до мониторинга процессов для систем Unix, у вас есть несколько вариантов.
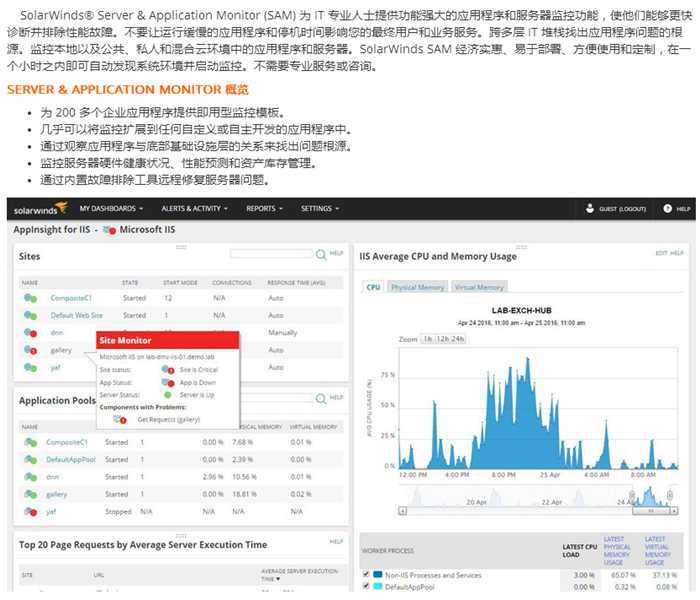
Самым популярным, наверное, является «top».
Top предоставляет полный обзор показателей производительности вашей системы, таких как текущее использование ЦП , текущее использование памяти, а также показатели для отдельных процессов.
Эта команда широко используется системными администраторами и, вероятно, является первой командой, запускаемой при обнаружении узкого места производительности в системе (если вы, конечно, можете получить к нему доступ!)
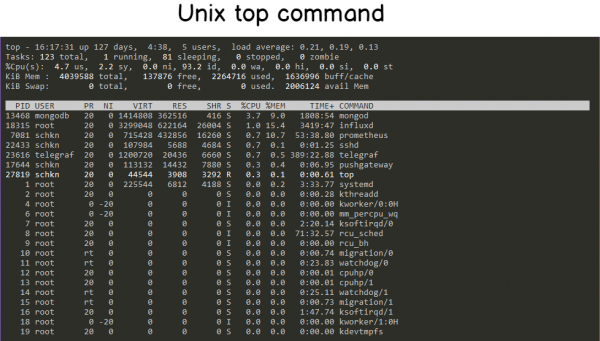
Команда top уже хорошо читается, но есть команда, которая делает все еще более читаемым, чем эта: htop .
Htop предоставляет тот же набор функций (процессор, память, время безотказной работы …), что и top, но в красочной и приятной форме.
Htop также предоставляет датчики , отражающие текущее использование системы.
Основная причина — доступность системы : в случае перегрузки системы у вас может не быть физического или удаленного доступа к вашему экземпляру.
Благодаря внешнему мониторингу процесса вы можете анализировать причину сбоя, не обращаясь к машине.
Другая причина в том, что процессы создаются и уничтожаются все время , часто самим ядром.
В этом случае выполнение команды top не даст вам никакой информации, так как вам будет слишком поздно понять, кто вызывает проблемы с производительностью в вашей системе.
Вам придется покопаться в журналах ядра, чтобы увидеть, что было убито.
С помощью панели мониторинга вы можете просто вернуться в прошлое и увидеть, какой процесс вызвал проблему.
Теперь, когда вы знаете, почему мы хотим создать эту панель управления, давайте посмотрим на архитектуру, созданную для ее создания.

Как получить информацию о файловой системе Linux
Что бы получить информацию о системных разделах используйте команду fdisk
Shell
fdisk -l
Disk /dev/sda: 1000 GB, 1000204887016 bytes
255 heads, 63 sectors/track, 121601 cylinders, total 1953525168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0xcee8ad92
Device Boot Start End Blocks Id System
/dev/sda1 1 1953425167 976762583+ ee GPT
Partition 1 does not start on physical sector boundary.
|
1 |
fdisk-l Disk/dev/sda1000GB,1000204887016bytes 255heads,63sectors/track,121601cylinders,total1953525168sectors Units=sectors of1*512=512bytes Sector size(logical/physical)512bytes/4096bytes I/Osize(minimum/optimal)4096bytes/4096bytes Disk identifier0xcee8ad92 Device Boot Start EndBlocks IdSystem /dev/sda111953425167976762583+ee GPT Partition1does notstart on physical sector boundary. |
Создание сценария bash для получения показателей
Ваша следующая задача — создать простой сценарий bash, который извлекает такие показатели, как использование ЦП и использование памяти для отдельных процессов.
Ваш скрипт можно определить как задачу cron, которая будет запускаться каждую секунду позже.
Для выполнения этой задачи у вас есть несколько кандидатов.
Вы можете запускать топ-команды каждую секунду, анализировать их с помощью sed и отправлять метрики в Pushgateway.
Сложность с top заключается в том, что он работает на нескольких итерациях, обеспечивая средние показатели с течением времени. Это не совсем то, что мы ищем.
Вместо этого мы собираемся использовать команду ps, а точнее команду ps aux .
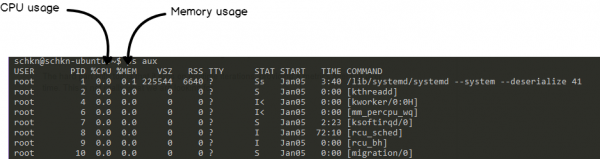
Эта команда раскрывает использование отдельных ЦП и памяти, а также точную команду, стоящую за ними.
Это именно то, что мы ищем.
Но прежде чем идти дальше, давайте посмотрим, что ожидает Pushgateway в качестве входных данных.
Pushgateway, как и Prometheus, работает с парами ключ-значение : ключ описывает отслеживаемую метрику, а значение не требует пояснений.
Вот некоторые примеры:
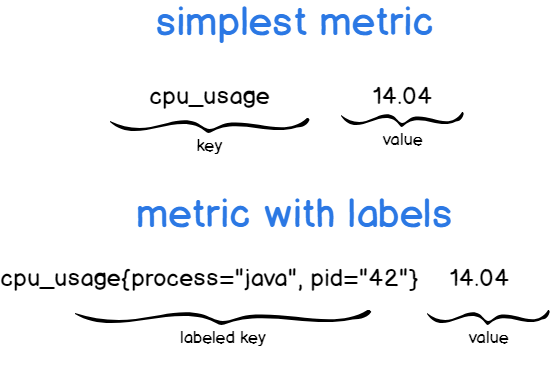
Как вы можете заметить, первая форма просто описывает использование ЦП, а вторая описывает использование ЦП для процесса java.
Добавление ярлыков — это способ более точно указать, что описывает ваша метрика.
Теперь, когда у нас есть эта информация, мы можем создать наш окончательный сценарий.
Напоминаем, что наш скрипт выполнит команду ps aux, проанализирует результат, преобразует его и отправит в Pushgateway с помощью синтаксиса, который мы описали ранее.
Создайте файл сценария, дайте ему права и перейдите к нему.
> touch better-top > chmod u+x better-top > vi better-top
Вот сценарий:
#!/bin/bash
z=$(ps aux)
while read -r z
do
var=$var$(awk '{print "cpu_usage{process=\""$11"\", pid=\""$2"\"}", $3z}');
done <<< "$z"
curl -X POST -H "Content-Type: text/plain" --data "$var
" http://localhost:9091/metrics/job/top/instance/machine
Если вам нужен тот же сценарий для использования памяти, просто измените метку cpu_usage на memory_usage и $ 3z на $ 4z
Итак, что делает этот сценарий?
Во-первых, он выполняет команду ps aux, которую мы описали ранее.
Затем он выполняет итерацию по различным строкам и форматирует их в соответствии с форматом пары значений с меткой ключа, который мы описали ранее.
Наконец, все объединяется и отправляется в Pushgateway с помощью простой команды curl.
Как видите, этот скрипт собирает все метрики для наших процессов, но выполняет только одну итерацию.
На данный момент мы просто собираемся выполнять его каждую секунду с помощью команды сна.
Позже вы можете создать службу, которая будет запускать ее каждую секунду с помощью таймера (по крайней мере, с помощью systemd).
> while sleep 1; do ./better-top; done;
Теперь, когда наши метрики отправлены в Pushgateway, давайте посмотрим, сможем ли мы изучить их в веб-консоли Prometheus.
Перейдите по адресу http: // localhost: 9090. В поле «Выражение» просто введите cpu_usage . Теперь вы должны увидеть все показатели в своем браузере.
Поздравляю! Ваши показатели ЦП теперь хранятся в Prometheus TSDB.
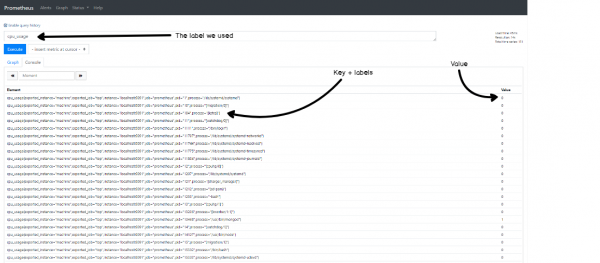

Бонус: исследуйте данные с помощью специальных фильтров
Данные в реальном времени интересно видеть, но настоящая ценность приходит тогда, когда вы можете исследовать свои данные.
В этом бонусном разделе мы не будем использовать функцию «Исследовать» (может быть, в другой статье?), Мы будем использовать специальные фильтры.
С Grafana вы можете определять переменные, связанные с графиком . У вас есть много разных вариантов переменных: вы можете, например, определить переменную для вашего источника данных, которая позволит динамически переключать источник данных в запросе.
В нашем случае мы собираемся использовать простые специальные фильтры для исследования наших данных.
Оттуда просто нажмите «Переменные» в левом меню, затем нажмите «Создать».
Взгляните на верхний левый угол приборной панели.
Фильтры!
Теперь предположим, что вам нужна производительность определенного процесса в вашей системе: возьмем, к примеру, сам Прометей.
Просто перейдите к фильтрам и посмотрите, как обновляется панель управления.
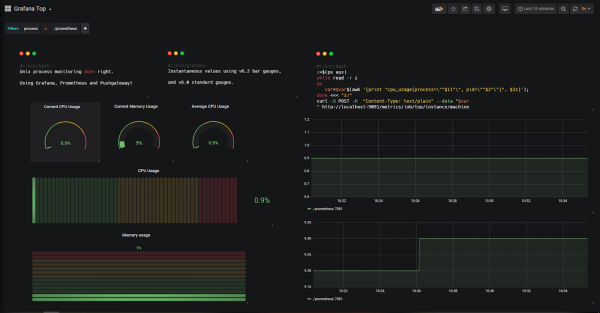
Теперь у вас есть прямой взгляд на то, как Prometheus ведет себя в вашем экземпляре.
Вы даже можете вернуться в прошлое и посмотреть, как ведет себя процесс, независимо от его pid!

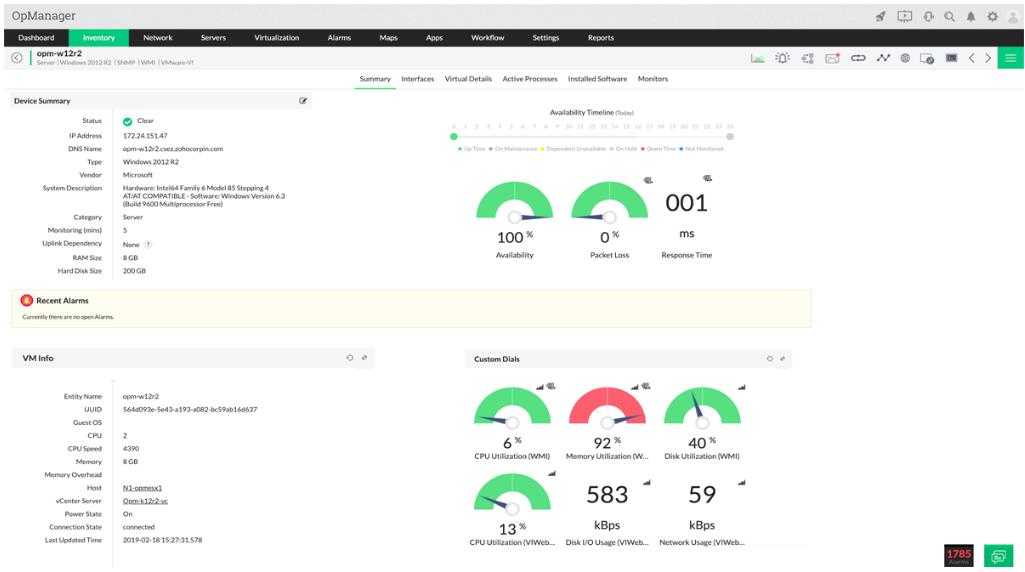
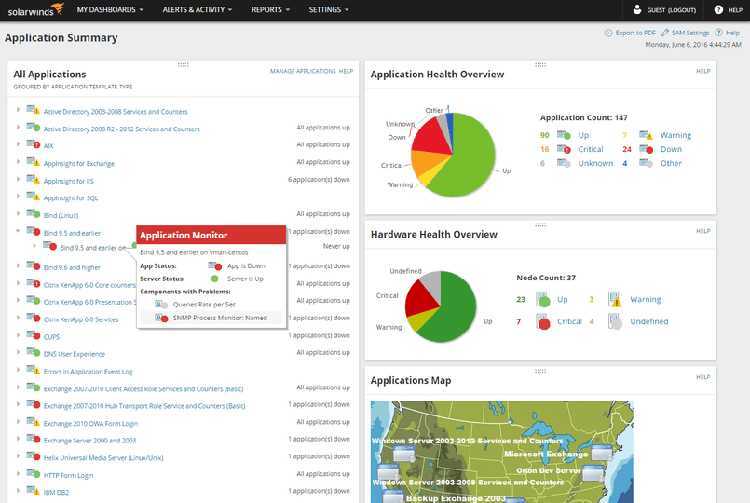
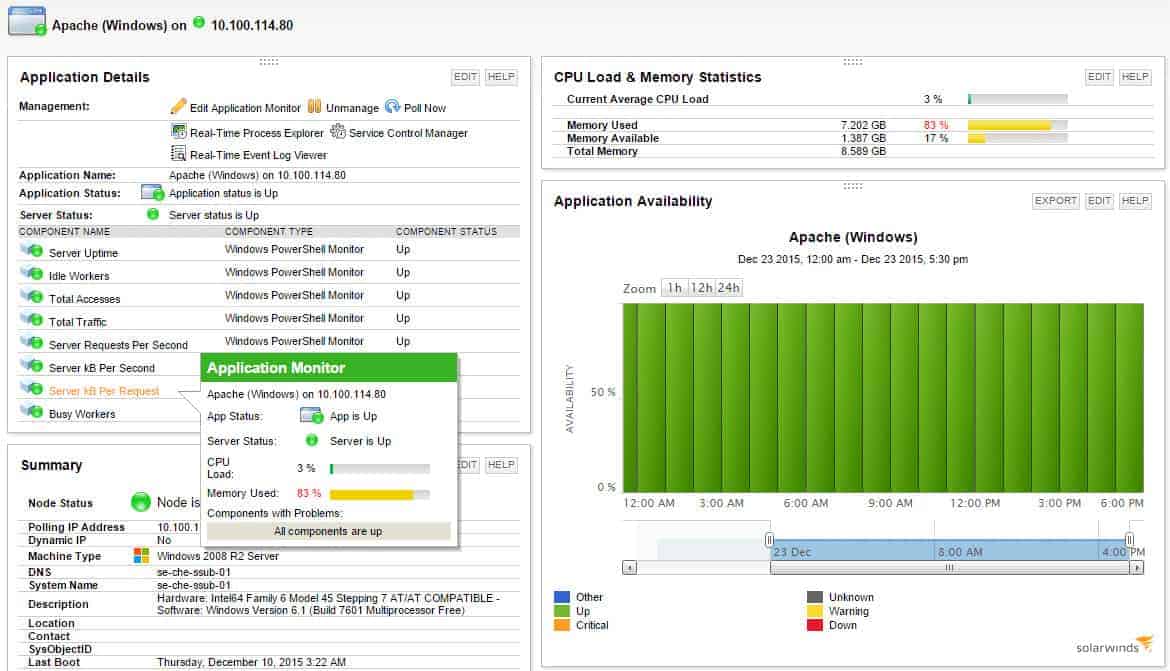
Инструменты мониторинга с графическим пользовательским интерфейсом
Большинство инструментов мониторинга серверов Linux с графическим пользовательским интерфейсом основаны на сборе информации по протоколу SNMP для последующего «рисования» графиков, которые очень легко интерпретировать. Поэтому мы собираемся найти большое количество инструментов, которые выполнят эту задачу.
Mrtg
Это приложение, хотя и устарело, продолжает собирать данные о соединениях по протоколу SNMP и рисует графики, которые очень легко интерпретировать. Чтобы установить этот инструмент, мы должны выполнить следующую команду в терминале:
Чтобы запустить этот инструмент, нам нужно будет выполнить команду «ipband» с правами суперпользователя, и он покажет нам справку и все, что мы можем сделать с помощью этой бесплатной программы.
Собран
Один из самых полных инструментов для мониторинга сети из Linux. Он позволяет отслеживать многие аспекты сети, а также расширять ее функции с помощью плагинов. Он имеет функцию клиент / сервер, позволяющую отслеживать и анализировать одноранговые сети. Эта программа отвечает за периодический сбор показателей производительности системы и приложения, сохраняя всю информацию в файлах RRD для последующей интерпретации.
Collectd может собирать различные метрики из различных источников, таких как операционная система, приложения, файлы журналов, внешние устройства и т. Д., Чтобы впоследствии проанализировать их и даже спрогнозировать будущую нагрузку на операционную систему. Если вам нужна достаточно интуитивно понятная и хорошо сделанная графика, эта программа также подойдет вам.
Графит
Он позволяет рисовать любой тип трафика из любого аспекта системы. Необходимые данные будут переданы ему через скрипт с программой мониторинга, поскольку по умолчанию Graphite не контролирует сеть самостоятельно, то есть показывает только информацию, собранную другим программным обеспечением для мониторинга.
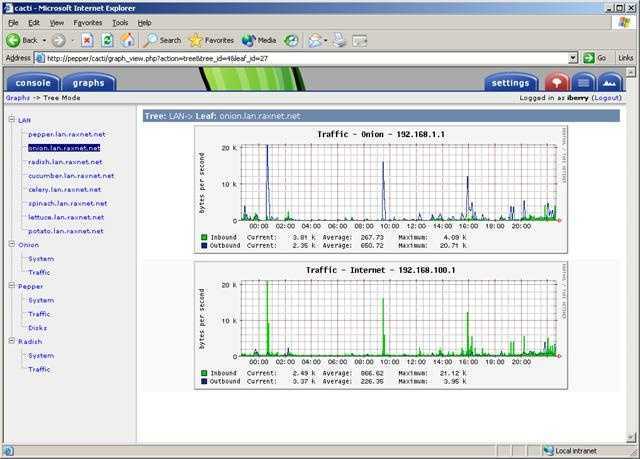
Кактусы
Cacti — это полноценный инструмент, который позволяет нам рисовать графики на основе информации RRD, хранящейся в операционной системе. Cacti — это очень полный графический интерфейс для RRDtool, который хранит всю необходимую информацию для последующего создания графиков и дополнения их информацией из базы данных MySQL. Графический интерфейс всех Cacti разработан на PHP, кроме того, он также имеет поддержку SNMP для пользователей, которым нравится создавать графики с помощью популярной программы MRTG, которую мы видели ранее.
Munin
Munin — это полная система сетевого мониторинга для операционных систем Linux, этот инструмент не только отвечает за отображение всей информации RRDtool, но также отвечает за сбор всей информации. Что нам больше всего нравится в Munin, так это большое количество плагинов, которые у нас есть для мониторинга различных аспектов операционных систем, кроме того, у него есть функция клиент / сервер для мониторинга и анализа сетей точка-точка.
Графический пользовательский интерфейс Munin действительно чистый и интуитивно понятный, он идеально подходит для того, чтобы показывать нам только то, что нас интересует, и ничего больше, кроме того, мы можем фильтровать и сортировать информацию по часам, дням, неделям, месяцам и годам.
Пропускная способность
Bandwidthd — очень простой инструмент, который позволит нам рисовать большое количество графиков, но, тем не менее, у него не так много параметров конфигурации, что может быть неудобством для тех пользователей, которым требуются дополнительные функции. Графики, которые он нам покажет, также очень просты, но если нам понадобится эта «простота», инструмент отлично послужит нам, поскольку потребляет очень мало ресурсов.
Как вы видели, у нас есть большое количество альтернатив для мониторинга сети в нашей операционной системе на базе Linux, как через консоль, так и через графический пользовательский интерфейс, где мы можем видеть действительно интуитивно понятные и хорошо продуманные графики.
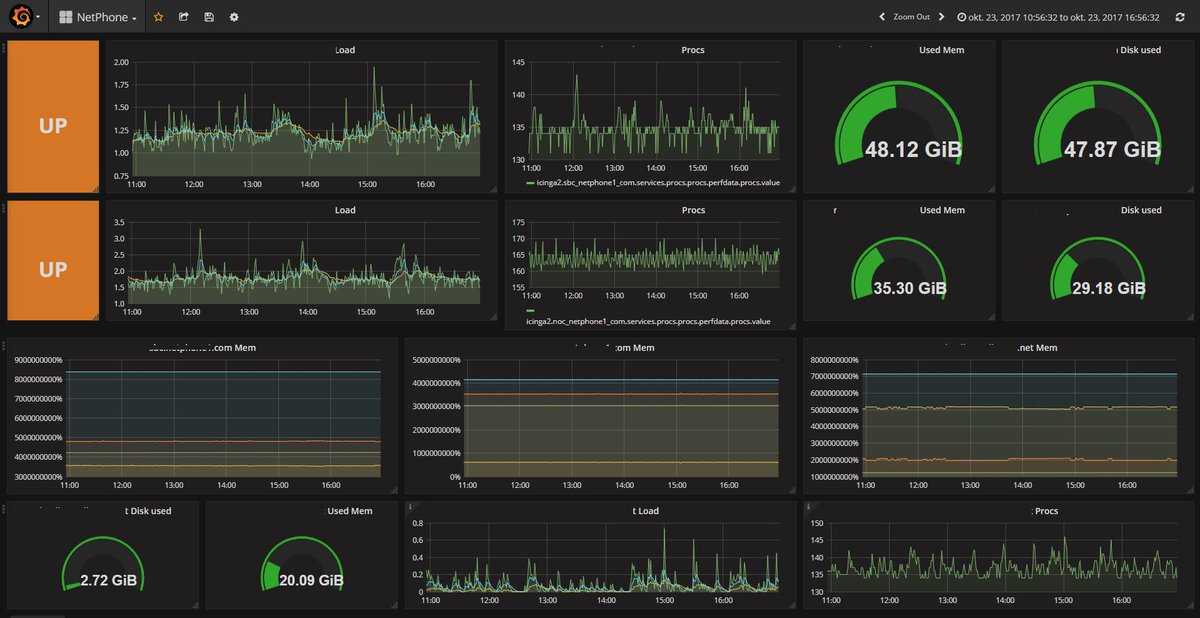
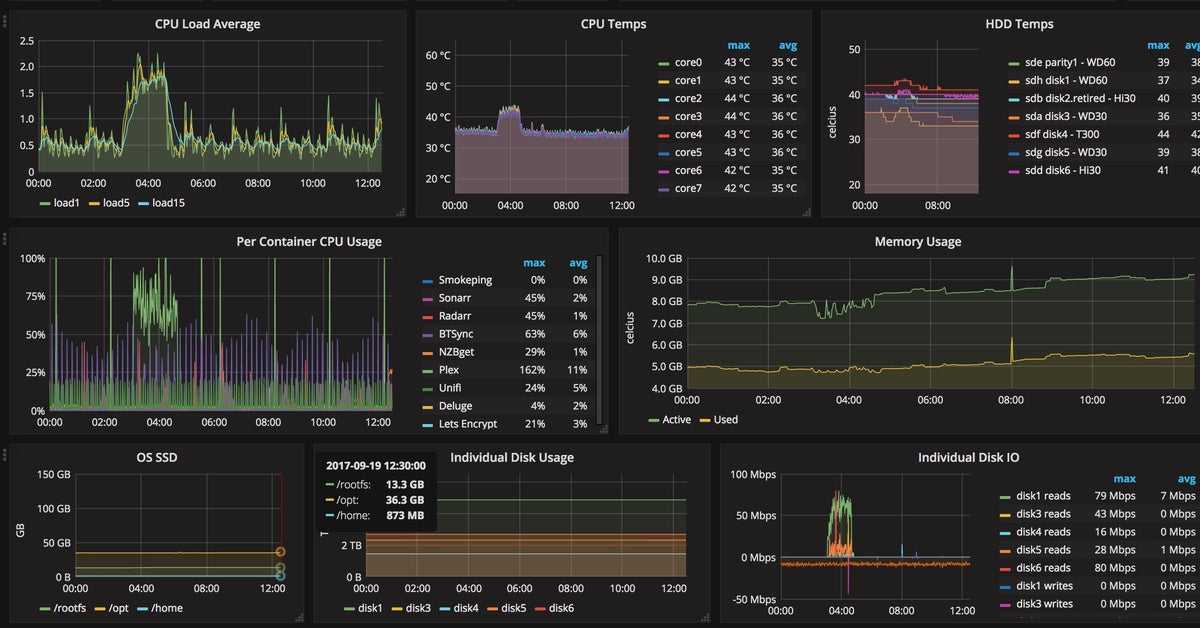
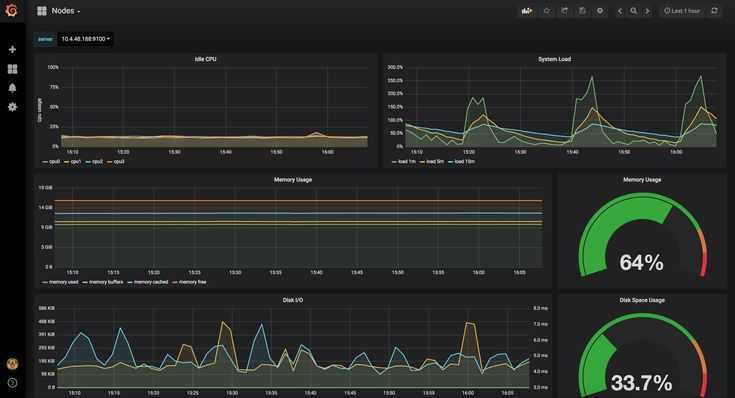
Создание отличной приборной панели с Grafana
Теперь, когда наши метрики хранятся в Prometheus, нам просто нужно создать панель управления Grafana , чтобы визуализировать их.
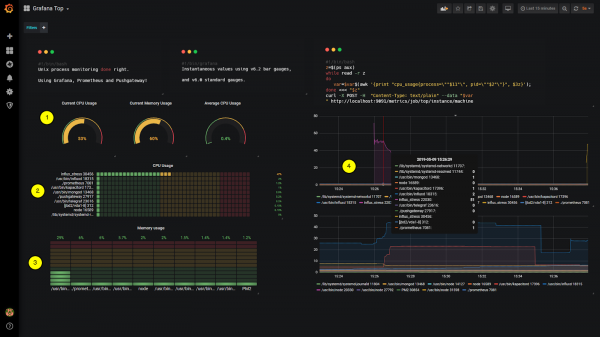
Мы будем использовать новейшие панели, доступные в Grafana v6.2: вертикальные и горизонтальные шкалы , закругленные шкалы и классические линейные диаграммы.
Для вашего удобства я снабдил последнюю сводку цифрами от 1 до 4.
Они будут соответствовать различным подразделам этой главы. Если вас интересует только определенная панель, перейдите непосредственно к соответствующему подразделу.
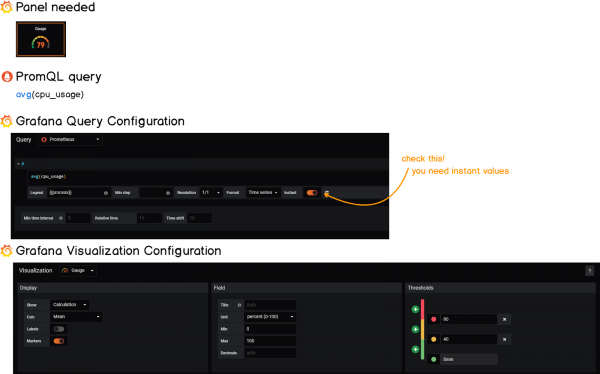
1 — Строительство круглых датчиков
Вот более подробное представление о том, какие округлые шкалы на нашей панели.
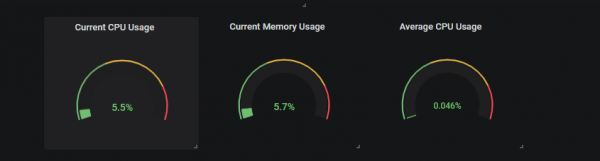
А пока мы собираемся сосредоточиться на использовании ЦП нашими процессами, поскольку его можно легко отразить для использования памяти.
С помощью этих панелей мы собираемся отслеживать два показателя: текущее использование ЦП всеми нашими процессами и среднее использование ЦП.
Чтобы получить эти метрики, мы собираемся выполнять запросы PromQL в нашем экземпляре Prometheus?
PromQL — это язык запросов, разработанный для Prometheus .
Аналогично тому, что вы нашли в экземплярах InfluxDB с InfluxQL (или IFQL), запросы PromQL могут агрегировать данные с использованием таких функций, как сумма, среднее значение и стандартное отклонение.
Синтаксис очень прост в использовании, поскольку мы собираемся продемонстрировать его на наших панелях.
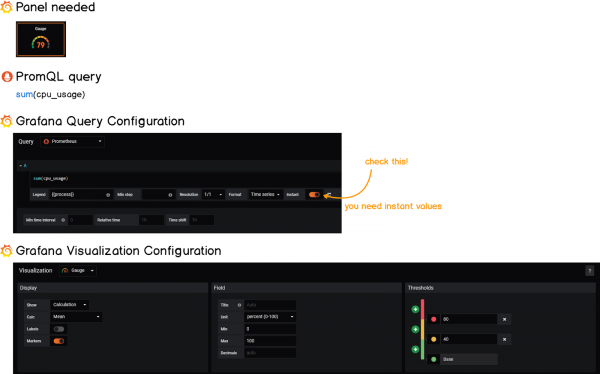
a — Получение текущего общего использования ЦП
Чтобы получить текущее общее использование ЦП, мы собираемся использовать функцию суммы PromQL.
В данный момент общее использование ЦП — это просто сумма отдельных использований.
Вот шпаргалка:
b — Получение средней загрузки ЦП
Не так много работы для среднего использования ЦП, вы просто собираетесь использовать функцию avg в PromQL . Вы можете найти шпаргалку ниже.
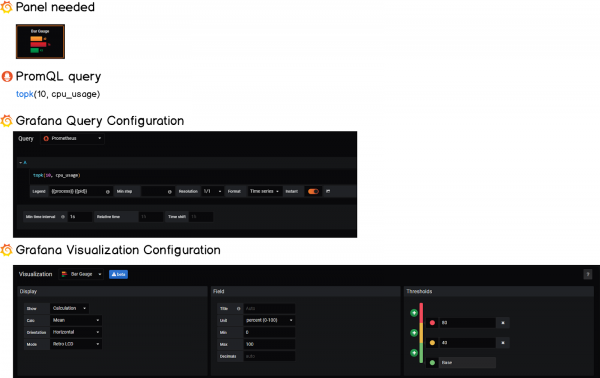
2 — Построение горизонтальных манометров
Горизонтальные датчики — одно из последних дополнений Grafana v6.2.
Наша цель с этой панелью — выявить 10 самых ресурсоемких процессов нашей системы.
Для этого мы собираемся использовать функцию topk, которая извлекает верхние k элементов для метрики.
Подобно тому, что мы делали раньше, мы собираемся определить пороги, чтобы получать информацию, когда процесс потребляет слишком много ресурсов.
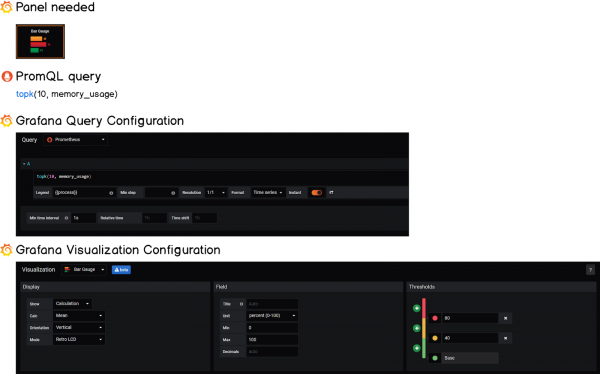
3 — Строительство вертикальных датчиков
Вертикальные датчики очень похожи на горизонтальные, нам нужно только настроить параметр ориентации на панели визуализации Grafana.
Кроме того, мы собираемся отслеживать использование памяти с помощью этой панели, поэтому запрос будет немного другим.
Вот шпаргалка
Потрясающе ! Пока мы добились большого прогресса, осталось провести одну панель.
4 — Построение линейных графиков
Линейные графики используются в Grafana в течение долгого времени, и это панель, которую мы собираемся использовать, чтобы получить историческое представление о том, как наши процессы развивались с течением времени.
Этот график может быть особенно полезен, когда:
- В прошлом у вас был сбой, и вы хотите выяснить, какие процессы были активны в то время.
- Определенный процесс умер, но вы хотите увидеть его поведение прямо перед тем, как это произошло.
Когда дело доходит до исследования по устранению неполадок, честно говоря, потребуется целая статья (особенно с недавним добавлением Grafana Loki).
Хорошо, вот последняя шпаргалка !

Оттуда у нас есть все панели, которые нам нужны для нашей окончательной панели инструментов.
Вы можете расположить их так, как хотите, или просто вдохновиться тем, что мы создали.
Шаг 1 — Установка Checkmk на Ubuntu
Вначале обновим список пакетов, чтобы получить последнюю версию списка репозитория:
Для просмотра пакетов можно перейти на сайт списка пакетов. Среди прочих можно выбрать Ubuntu 18.04 в меню страницы.
Теперь загрузите пакет:
Затем установите только что загруженный пакет:
Эта команда установит пакет Checkmk со всеми необходимыми зависимостями, включая веб-сервер Apache, который используется для веб-доступа к интерфейсу мониторинга.
По завершении установки теперь можно получить доступ к команде . Попробуйте сделать следующее:
Эта команда выведет следующее:
Команда может управлять всеми экземплярами Checkmk на нашем сервере. Она может запускать и останавливать все службы мониторинга одновременно, и мы можем использовать ее для создания нашего экземпляра Checkmk. Однако сначала нам нужно обновить настройки брандмауэра, чтобы разрешить внешний доступ к веб-портам по умолчанию.
Prometheus
Prometheus не устанавливается из репозитория и имеет, относительно, сложный процесс установки. Необходимо скачать исходник, создать пользователя, вручную скопировать нужные файлы, назначить права и создать юнит для автозапуска.
Загрузка
Переходим на официальную страницу загрузки и копируем ссылку на пакет для Linux:
и используем ее для загрузки пакета на Linux:
wget https://github.com/prometheus/prometheus/releases/download/v2.17.2/prometheus-2.17.2.linux-amd64.tar.gz
* если система вернет ошибку, необходимо установить пакет wget.
Установка (копирование файлов)
После того, как мы скачали архив prometheus, необходимо его распаковать и скопировать содержимое по разным каталогам.
Для начала создаем каталоги, в которые скопируем файлы для prometheus:
mkdir /etc/prometheus
mkdir /var/lib/prometheus
Распакуем наш архив:
tar zxvf prometheus-*.linux-amd64.tar.gz
… и перейдем в каталог с распакованными файлами:
cd prometheus-*.linux-amd64
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
Назначение прав
Создаем пользователя, от которого будем запускать систему мониторинга:
useradd —no-create-home —shell /bin/false prometheus
* мы создали пользователя prometheus без домашней директории и без возможности входа в консоль сервера.
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
Задаем владельца для скопированных файлов:
chown prometheus:prometheus /usr/local/bin/{prometheus,promtool}
Запуск и проверка
Запускаем prometheus командой:
/usr/local/bin/prometheus —config.file /etc/prometheus/prometheus.yml —storage.tsdb.path /var/lib/prometheus/ —web.console.templates=/etc/prometheus/consoles —web.console.libraries=/etc/prometheus/console_libraries
… мы увидим лог запуска — в конце «Server is ready to receive web requests»:
level=info ts=2019-08-07T07:39:06.849Z caller=main.go:621 msg=»Server is ready to receive web requests.»
Открываем веб-браузер и переходим по адресу http://<IP-адрес сервера>:9090 — загрузится консоль Prometheus:
Установка завершена.
Автозапуск
Мы установили наш сервер мониторинга, но его необходимо запускать вручную, что совсем не подходит для серверных задач. Для настройки автоматического старта Prometheus мы создадим новый юнит в systemd.
Возвращаемся к консоли сервера и прерываем работу Prometheus с помощью комбинации Ctrl + C. Создаем файл prometheus.service:
vi /etc/systemd/system/prometheus.service
Description=Prometheus Service
After=network.target
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
—config.file /etc/prometheus/prometheus.yml \
—storage.tsdb.path /var/lib/prometheus/ \
—web.console.templates=/etc/prometheus/consoles \
—web.console.libraries=/etc/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
systemctl daemon-reload
Разрешаем автозапуск:
systemctl enable prometheus
После ручного запуска мониторинга, который мы делали для проверки, могли сбиться права на папку библиотек — снова зададим ей владельца:
chown -R prometheus:prometheus /var/lib/prometheus
Запускаем службу:
systemctl start prometheus
… и проверяем, что она запустилась корректно:
systemctl status prometheus
Что вы узнаете
Прежде чем перейти прямо к этому техническому пути, давайте кратко рассмотрим все, что вы собираетесь узнать, прочитав эту статью:
- Понимание современных способов мониторинга производительности процессов в системах Unix;
- Узнайте, как установить последние версии Prometheus v2.9.2 , Pushgateway v0.8.0 и Grafana v6.2 ;
- Создайте простой сценарий bash, который экспортирует метрики в Pushgateway;
- Создайте полную приборную панель Grafana, включая новейшие доступные панели, такие как «Датчик» и «Барный датчик»;
- Бонус: реализация специальных фильтров для отслеживания отдельных процессов или экземпляров.
Теперь, когда у нас есть обзор всего, что мы собираемся изучить, и, без дальнейших подробностей, давайте познакомимся с тем, что в настоящее время существует для систем Unix.
Уязвимости
Одним из самых распространённых методов проникновения в систему — использование уязвимостей. Отсутствие процедур управления и отслеживания уязвимостей, не говоря уже об отсутствии выстроенных процессов установки исправлений, может привести к тому, что системы окажутся беззащитными после обнаружения очередной уязвимости и публикации эксплойта для неё. Часто эксплойт публикуют уже через несколько часов после её обнаружения. Для Linux эта проблема более критична, поскольку открытый исходный код позволяет быстро найти проблемную функцию и написать код для эксплуатации ошибки.

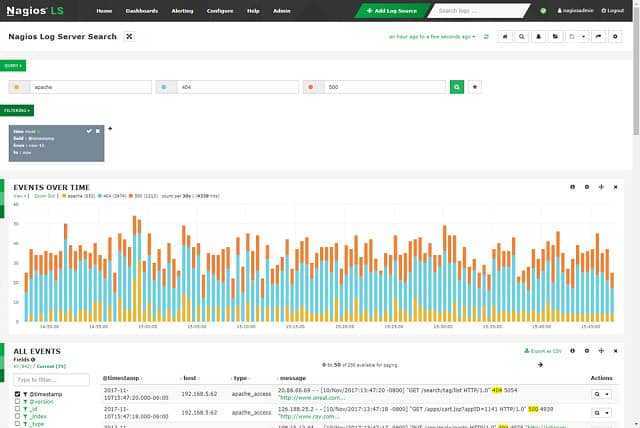

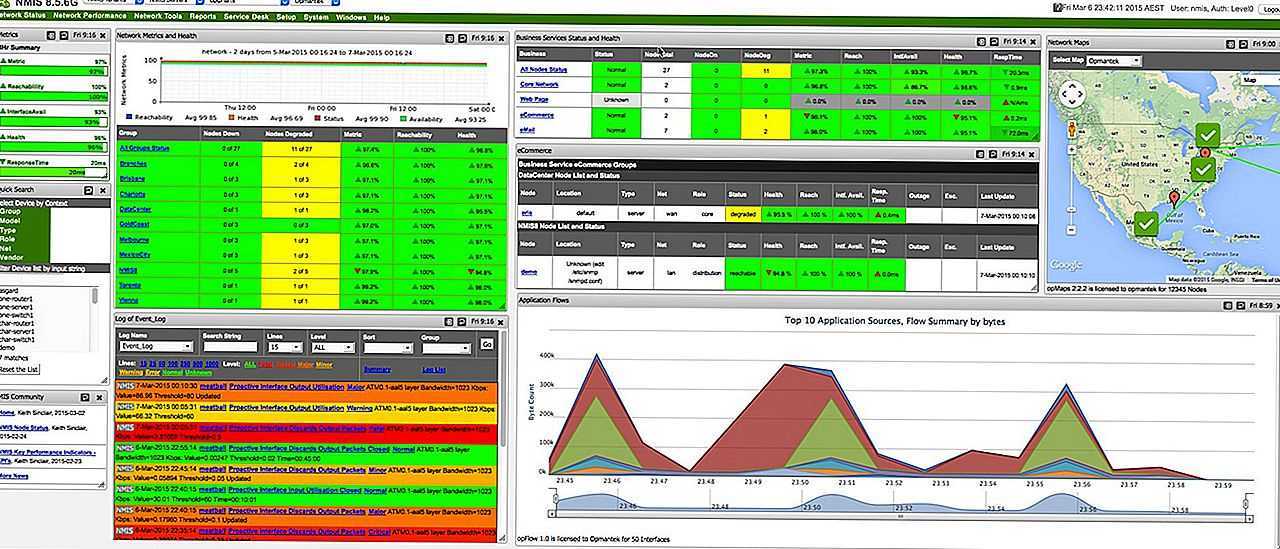
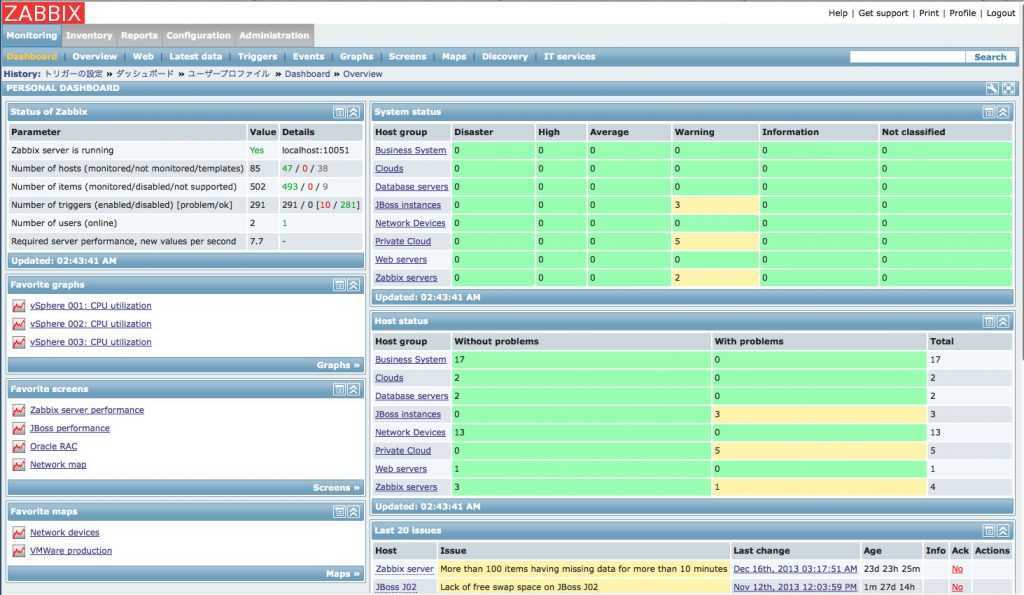
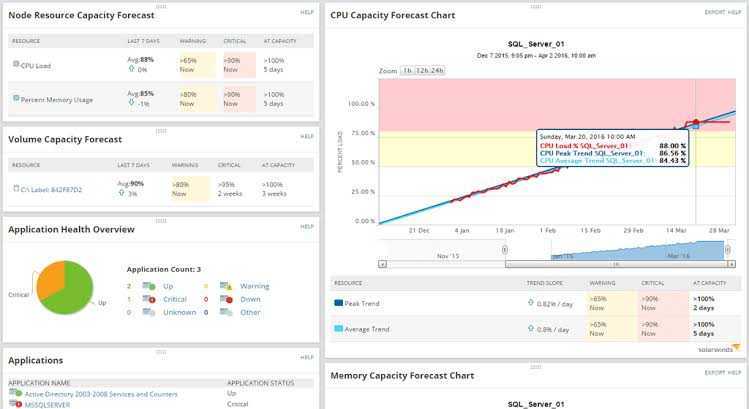
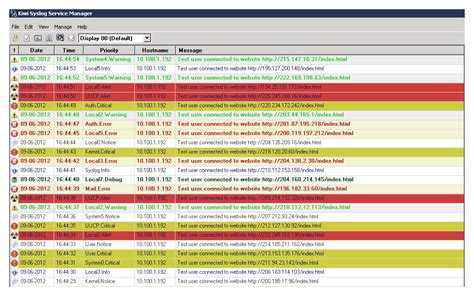
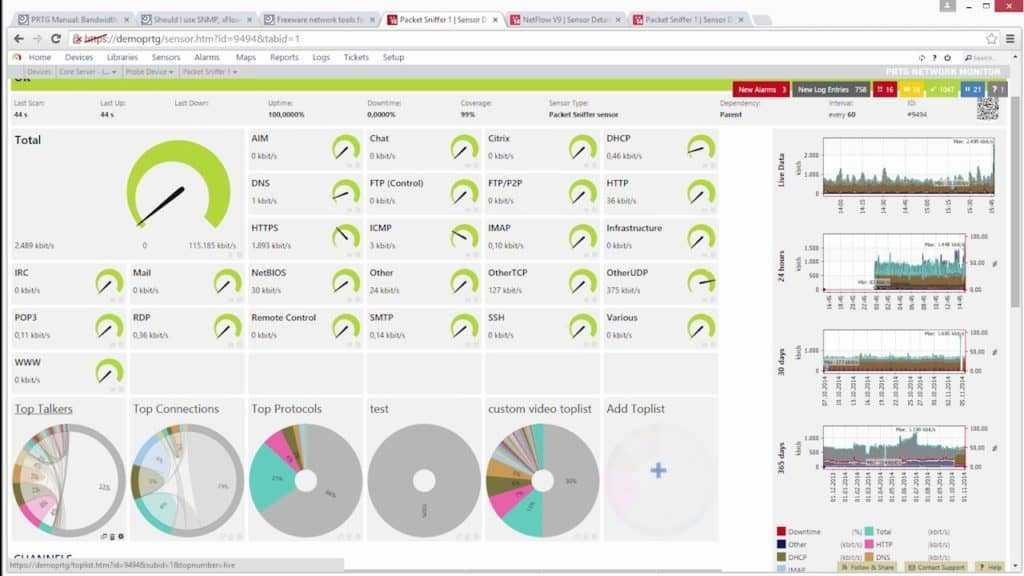
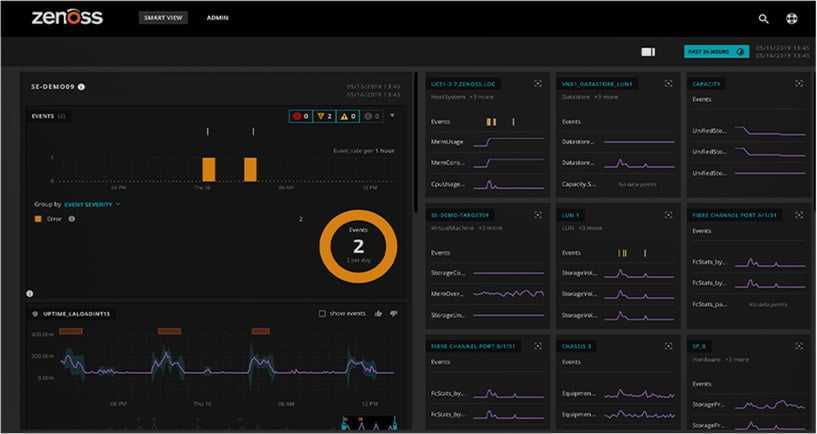
Важно отметить, что значительное количество уязвимостей в сервисе или платформе не обязательно означает, что эти уязвимости обязательно несут существенный риск. Каждый производитель дистрибутива Linux выполняет свою процедуру обработки уязвимостей
В то время как исправления от вендоров приходят в разное время, заплатки upstream, будь то оригинальный пакет или исходный код утилиты, появляются первыми. Вендоры Linux отвечают за исправление уязвимостей в таких компонентах, как ядро, утилиты и пакеты. В 2019 году Red Hat исправил более 1000 CVE в своём дистрибутиве Red Hat Enterprise Linux (RHEL), согласно их отчёту Product Security Risk Report. Это более 70% от общего числа уязвимостей, исправленных во всех продуктах
Каждый производитель дистрибутива Linux выполняет свою процедуру обработки уязвимостей. В то время как исправления от вендоров приходят в разное время, заплатки upstream, будь то оригинальный пакет или исходный код утилиты, появляются первыми. Вендоры Linux отвечают за исправление уязвимостей в таких компонентах, как ядро, утилиты и пакеты. В 2019 году Red Hat исправил более 1000 CVE в своём дистрибутиве Red Hat Enterprise Linux (RHEL), согласно их отчёту Product Security Risk Report. Это более 70% от общего числа уязвимостей, исправленных во всех продуктах.
Уязвимости приложений, работающих под управлением Linux, были причиной нескольких серьёзных инцидентов. Например, нашумевшая утечка данных в Equifax произошла в результате эксплуатации уязвимости CVE-2017-5638 в Apache Struts. Тогда хакеры проникли в корпоративную сеть бюро кредитных историй Equifax 13 мая 2017 года, но подозрительную активность служба безопасности заметила только в конце июля. Киберпреступники провели внутри сети 76 дней, успев за это время скачать из 51 базы данных личную информацию 148 млн американцев — это 56% взрослого населения США. Помимо американских граждан в утечку попали сведения 15 млн клиентов Equifax в Великобритании и около 20 тыс. граждан Канады. Общие расходы Equifax в результате этого инцидента за два следующих года составили более 1,35 млрд долларов США и включают расходы на укрепление систем безопасности, поддержку клиентов, оплату юридических услуг, а также выплаты по судебным искам.
Уязвимости публичных приложений входят в состав фреймворка MITRE ATT&CK (ID T1190), а также перечислены в топ-10 уязвимостей OWASP и являются наиболее популярными векторами проникновения в Linux-системы.
Почему мониторинг системы
Узнать, есть ли у компьютера проблемы, довольно просто, когда компьютер находится прямо перед вами. (Зная, в чем причина проблемы? Это сложнее.)
Но сам по себе компьютер не так полезен, как мог бы. Даже в самой маленькой сети для небольших офисов и домашних офисов есть несколько узлов: ноутбуки, настольные компьютеры, планшеты, точки доступа WiFi, интернет-шлюз, смартфоны, файловые серверы и / или медиа-серверы, принтеры и так далее. Это означает, что вы отвечаете за «инфраструктуру», а не за «оборудование». Любой компонент может начать плохо себя вести и может вызвать проблемы для других.
Скорее всего, вы также полагаетесь на сторонние серверы и сервисы. Даже на личном веб-сайте возникает неприятный вопрос: «Мой сайт все еще работает?» И когда у вашего интернет-провайдера возникают проблемы, полезность вашей локальной сети страдает. Вам нужен монитор активности. Организации все больше полагаются на серверы и службы, размещенные в облаке: приложения SaaS (электронная почта, офисные приложения, бизнес-пакеты и т. Д.); файловое хранилище; облачный хостинг для ваших собственных баз данных и приложений; и так далее. Это требует сложного решения для мониторинга, которое может обрабатывать гибридные среды.
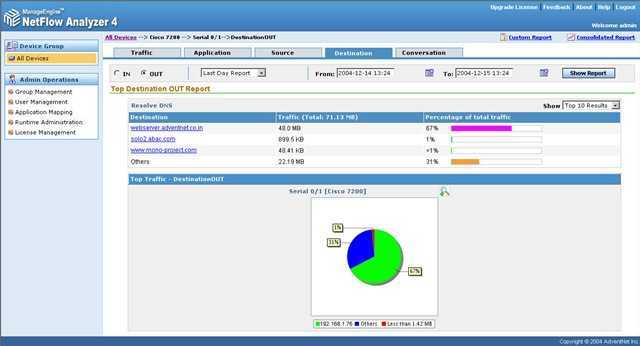
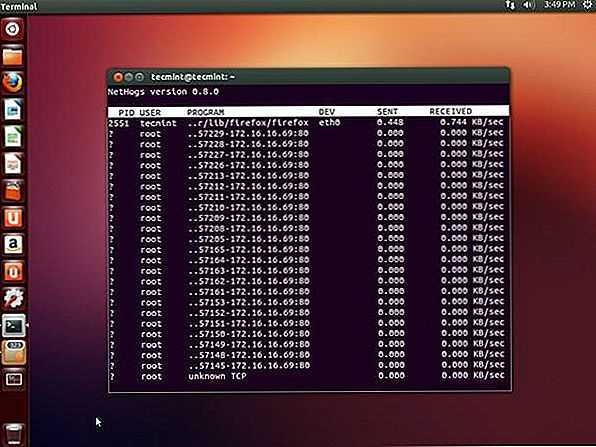
Инструменты мониторинга пропускной способности и анализаторы трафика на основе NetFlow и sFlow помогут вам всегда быть в курсе активности, емкости и работоспособности вашей сети. Они позволяют вам наблюдать за трафиком, который проходит через маршрутизаторы и коммутаторы, или достигает и покидает хосты..
Но что из хостов в вашей сети, их оборудования, а также сервисов и приложений, работающих там? Мониторинг активности, емкости и работоспособности хостов и приложений находится в центре внимания системного мониторинга..
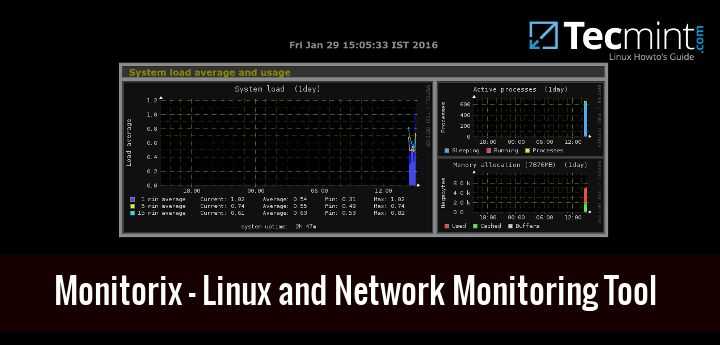
Dstat
Несколько менее известный монитор, чем предыдущие, но тоже очень полезный. Этот инструмент используется для генерации статистики использования операционной системы как на уровне ЦП, диска, ОЗУ, так и в локальной сети. Фактически, мы можем включать или отключать статус сети и даже выбирать интерфейсы. Чтобы установить этот инструмент, мы должны выполнить следующую команду в терминале:
Чтобы запустить этот инструмент, нам нужно будет запустить команду «dstat» с правами суперпользователя.
Что касается параметров конфигурации, если мы выполним команду «dstat -h», мы сможем получить доступ ко всем доступным параметрам.
Как вы видели, мы можем легко и быстро увидеть состояние различных частей нашей операционной системы, а не только сети.
Bwm-ng
Этот инструмент очень прост, мы можем получать информацию со всех сетевых интерфейсов в интерактивном режиме, и мы даже можем экспортировать ее в определенный формат, чтобы впоследствии было легче обращаться к ней на другом устройстве. Чтобы установить этот инструмент, мы должны выполнить следующую команду в терминале:
Чтобы запустить этот инструмент, нам нужно будет запустить команду «bwm-ng» с правами суперпользователя.
Если мы нажмем кнопку «h», появится справка, и мы сможем легко и быстро настроить различные параметры.
Как вы видели, это гораздо более простой инструмент, чем iptraf, но он также весьма полезен.
TCPtrack
Хотя это довольно неизвестное приложение, оно показывает нам все данные о потреблении нашего соединения. Чтобы установить этот инструмент, мы должны выполнить следующую команду в терминале:
Чтобы запустить этот инструмент, нам нужно будет запустить команду «tcptrack» с правами суперпользователя.
В этом случае нам нужно будет выполнить команду вместе с отслеживаемым интерфейсом, например, «tcptrack -i ens33».
Спидометр
Программа для мониторинга сети и пакетов, которые отправляются и принимаются, которая также позволяет проводить тесты скорости Интернета. Чтобы установить этот инструмент, мы должны выполнить следующую команду в терминале:
Чтобы запустить этот инструмент, нам нужно будет запустить команду «спидометр» с правами суперпользователя.
Мониторинг
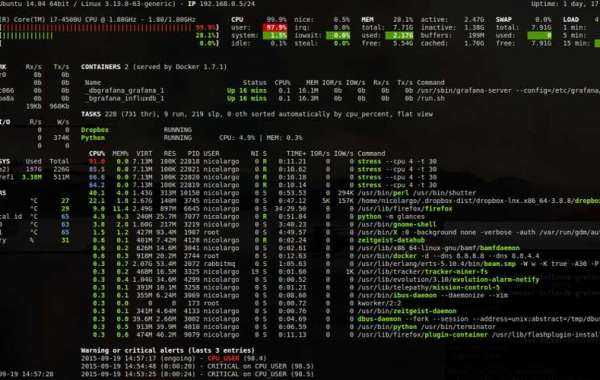
Системные ресурсы
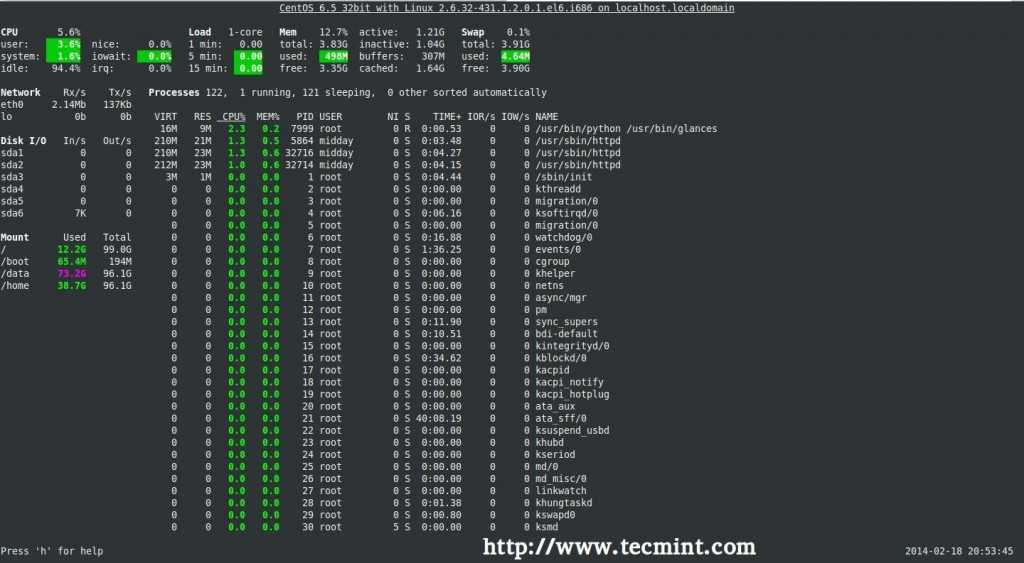
Мониторить ресурсы сервера можно консольной утилитой или ее более красочной версией . Установим и запустим ее
$ sudo apt install htop $ htop
Периодически контролируйте использование оперативной памяти. Если часто наблюдается загруженность около 100%, настройте файл подкачки.
$ sudo dd if=/dev/zero of=/swapfile bs=1M count=1024 $ sudo chmod 600 /swapfile && sudo mkswap /swapfile $ sudo swapoff -a $ sudo swapon /swapfile $ echo "/swapfile swap swap defaults 0 0"| sudo tee -a /etc/fstab
Здесь — размер файла подкачки в мегабайтах.
Дисковое пространство
Для мониторинга файловой системы удобно пользоваться файловым менеджером Midnight Commander. Если Вы застали времена MS DOS и Notron Commander, то объяснять ничего не нужно.
Устанавливаем и запускаем
$ sudo apt install mc $ mc
Так удобно наблюдать за файловым хранилищем, карантином, свободным дисковым пространством.
Короткое слово в заключение
Из этого урока вы лучше понимаете, что могут предложить Prometheus и Grafana .
Вы знаете, что у вас есть полная панель мониторинга для одного экземпляра, но на самом деле есть небольшой шаг, чтобы заставить ее масштабироваться и контролировать весь кластер экземпляров Unix.
DevOps-мониторинг — определенно интересная тема, но если вы сделаете это неправильно, он может превратиться в кошмар.
Именно поэтому мы пишем эти статьи и создаем эти информационные панели: чтобы помочь вам достичь максимальной эффективности того, что могут предложить эти инструменты.
Мы считаем, что отличные технологии можно улучшить с помощью полезных демонстраций.
А Ты?
Если вы согласны, присоединяйтесь к растущему списку DevOps, выбравших этот путь.