
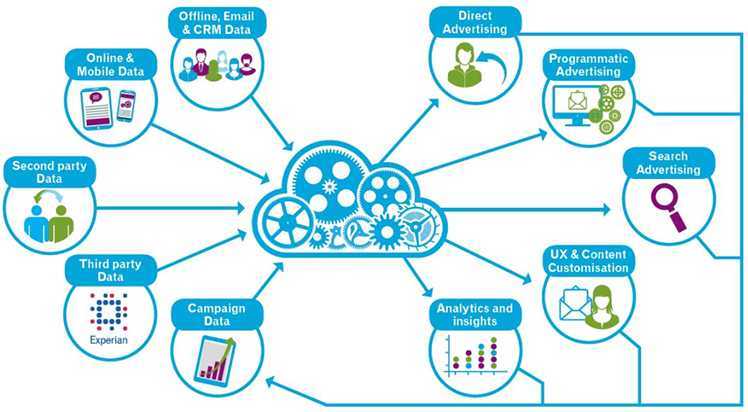
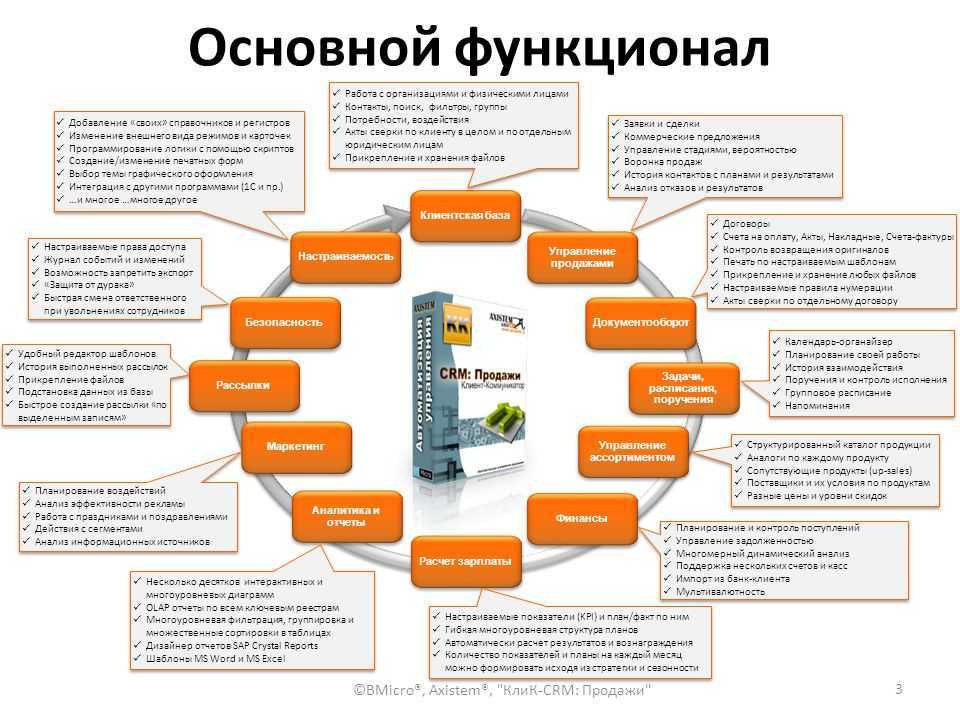
DMP (Data Management Platform)
DMP — платформы для сбора и управления клиентскими данными. Они умеют собирать информацию трёх уровней:
1) сведения, которые компания получает от клиента напрямую: история посещений сайта, количество регистраций и т. д.;
2) результаты рекламных кампаний, активность клиентов в соцсетях бренда;
Как работают
Сначала платформа собирает сырые данные о поведении клиентов в сети. Это обезличенная информация об интересах пользователя (сайтах, которые он посещает, вовлечённости, устройствах, с которых он выходит в сеть). Затем DMP сегментирует эти сведения, а такая информация помогает маркетологам создать усреднённый портрет пользователя. Такие сведения очень интересны любому бизнесу: DMP гарантирует, что вы точно будете знать, что делать, дабы наладить контакт со своей целевой аудиторией.
DMP также позволяют связывать несколько различных сервисов вместе. Объединив полученные сведения с данными о целевой аудитории, можно понять, какие методики являются эффективными, а какие не работают.
Сведения, полученные при помощи DMP, позволяют контролировать расходы бюджетов рекламных кампаний.
Зачем это бизнесу
-
Возможность работать и управлять Big Data.
-
Сегментировать целевую аудиторию и понимать её поведение в сети.
-
Повысить показатели конверсии, потребительскую вовлечённость и улучшить отношение к бренду.
-
Персонализировать ваши сообщения и контент для существующих и потенциальных клиентов через рекламу, ремаркетинг, рассылки и другие взаимодействия с брендом.
В отличие от CRM, DMP-платформы умеют работать с новыми данными о потенциальных клиентов и их поведении. Такие решения помогают бизнесу привлекать новых целевых клиентов.
Ограничения
Данные подобных платформ используются для программатик рекламы, но не для работы с самими клиентами и улучшения клиентского сервиса. Использование 3d-party данных может приводить к неоднозначным выводам и нерабочим моделям. Ведь достоверность таких данных, покупаемых на стороне, часто оставляет желать лучшего.
Большинство отечественных маркетологов ещё не умеет работать с DMP-платформами.
Что учесть при выборе
Платформы используются преимущественно в рекламном бизнесе. Решение может понадобиться компании для понимания поведения своей аудитории в интернете, планирования рекламных кампаний (ведь с клиентами, уже совершившими покупку, надо работать иначе). Применение DMP экономит время, деньги и позволяет добиться максимального эффекта от рекламных кампаний. Перед выбором решений для DMP-платформы необходимо чётко понимать, для каких целей вы хотите использовать решение. На рынке есть несколько типов DMP-систем, каждый из которых подойдёт под определённые задачи.
Читайте обзор, как выбрать DMP-платформу.
Самые популярные языки программирования
Выбор языка зависит от направления разработки. После того как разобрались, какое программирование востребовано и подходит лично вам, нужно искать и изучать инструменты для работы.
Топ TIOBE основывается на количестве поисковых запросов, обучающих курсов и специалистов. Здесь лидеры выглядят так:
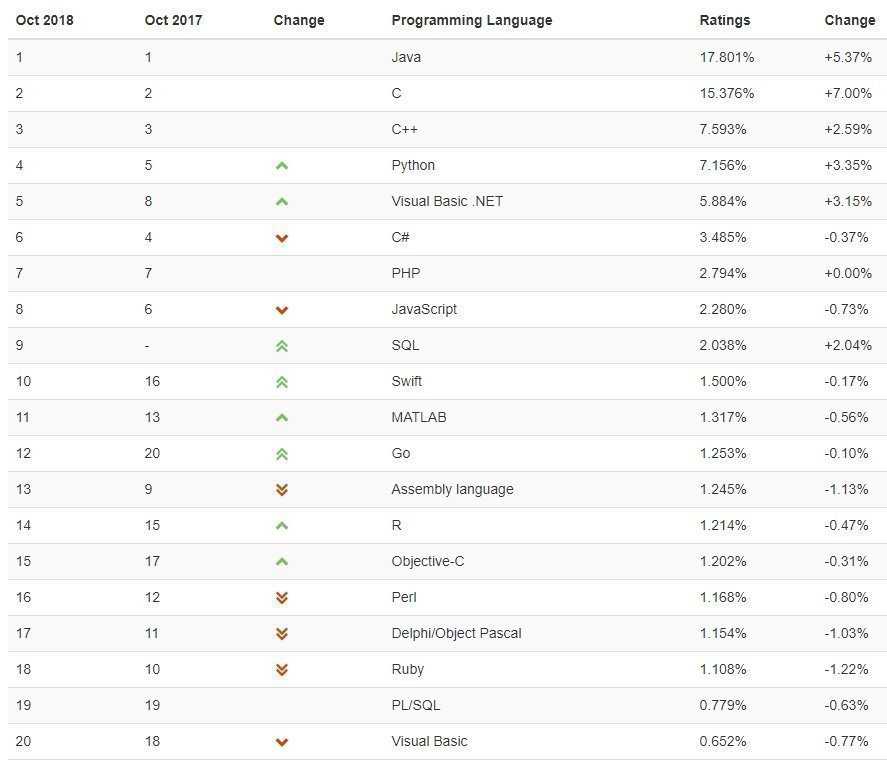
Рейтинг IEEE Spectrum анализирует частоту поисковых запросов, число проектов на GitHub, а также упоминания в Twitter и главных IT-порталах сети. Здесь в пятёрке лидеров — Python, C++, Java, C, C#.
Если ориентироваться на данные российского сайта HeadHunter, картина меняется. Наглядно она представлена таблицей из статьи в корпоративном блоге HeadHunter на «Хабре»:
Учтены упоминания языков в любом пункте вакансии.
Как добавить графики
Последний этап — добавление графиков в панели администрирования Grafana. Открываем через браузер утилиту и авторизуемся.
Важно! IP-адрес, логин и пароль указаны в разделе «Настройка Grafana». 1
Открываем верхнее меню Data Sources, пункт Add. В первом блоке поле name — придумываем произвольное наименование (в нашем примере используется имя My), а во втором поле указываем Graphite
1. Открываем верхнее меню Data Sources, пункт Add. В первом блоке поле name — придумываем произвольное наименование (в нашем примере используется имя My), а во втором поле указываем Graphite.
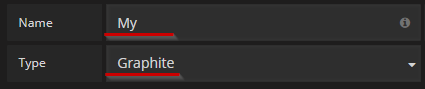
Скриншот №8. Раздел Add.
2. Переходим к блоку HTTP Settings. Добавляем в поле URL адрес http://localhost:8080:
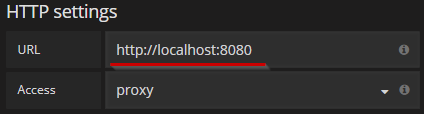
Скриншот №9. Раздел сетевых настроек.

3. Снова переходим к меню. Выбираем Dashboards, раздел New. Переключаем на режим Graph.
4. В пункте Metrics указываем источник, из которого берутся данные для построения графика и нажимаем ОК.
191028
Санкт-Петербург
Литейный пр., д. 26, Лит. А
+7 (812) 403-06-99
 700
700
300
ООО «ИТГЛОБАЛКОМ ЛАБС»
700
300
Community Plugins
In addition to the official plugins, many other community plugins are also avaialble:
- actuator
- apachelog
- appserver_certificates
- blockdevice_drivers
- bonding
- cadvisor
- certificate
- compute
- cvmfs
- elasticsearch
- elasticsearch_functional
- elasticsearch_kibana_functional
- elasticsearch_ownhome_functional
- eos
- filter
- flume
- haproxy
- heartbeat
- kafka
- kafka_consumer_group
- kafka_topic
- kafka_topics
- lb_status
- mdstat
- megaraidsas
- monit_alarm_handler
- nfsiostat
- processcount
- puppet
- sasarray
- sendmail
- session
- simplerabbitmq
- slurm
- smart_tests
- systemd
- tail
- tapequeue
- unmounted_filesystems
- vmstats
To start using any of these plugins:
- check if the plugin is already whitelisted, if not please open a SNOW ticket.
- check if your hostgroup is already whitelisted (must be included in some ‘selector’), if not please open a SNOW ticket.
- declare the plugin in your hostgroup, for example:
If you wish to add another plugin write the deployment and configuration of the plugin following the release process below.
Asana
-
Создать сколько угодно проектов с высоким уровнем декомпозиции на основе шаблонов.
-
Организовать работу над проектами: создать доски, поставить задачи, назначить исполнителей.
-
Классифицировать задачи при помощи тегов.
-
Начать общение в карточках задач и общей новостной ленте.
-
Настроить для себя личный планировщик: сортировать задачи по сроку их выполнения, делать приватные задачи.
За что точно придется платить:
-
Отчеты. Вы не сможете посмотреть отчет даже про проектам или исполнителям.
-
Контроль выполнения задач, просмотр незавершенных и просроченных. Придется верить людям на слово, что все задачи выполняются в срок.
-
Возможность следить за новыми задачами, обновлениями и статусами важных проектов.
-
Визуализация процессов и создание связей между задачами. «Timeline» недоступен.
-
Работа с задачами, которые вы создали и поручили коллегам. Их даже нельзя вывести отдельно.
-
Работа с формами.
Без отчетов, форм, визуализации процессов, чужих задач, списка обновлений и контроля сроков работать в системе управления практически невозможно. Asana хочет, чтобы вы стали платящим клиентом, и потому забирает у вас половину функций. Бесплатная версия нужна только для знакомства – «подглядеть», что происходит внутри.
Release Process
To add a new or existing plugin to monitor your service, please check this workflow:
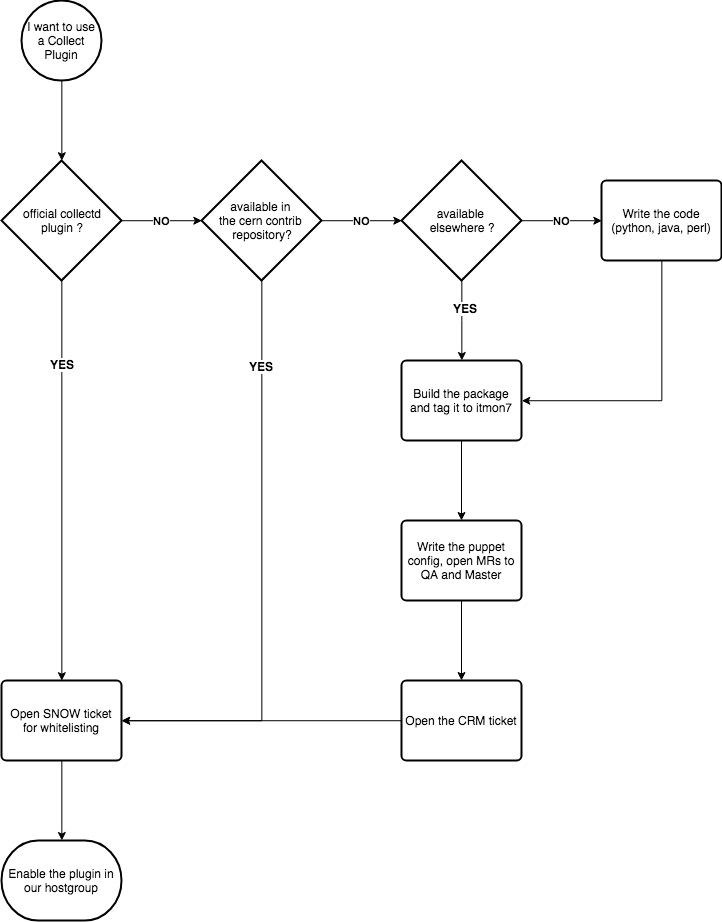
To add a new plugin in cerncollectd_contrib please follow these steps:
- complete the implementation of the puppet module for your plugin (please branch from QA).
- if you are updating an existing plugin, open a CRM ticket and add «monit-support» in the watch list.
- open one Merge Request for your module into QA
- tag it with the CRM number » Descriptive message» or » Descriptive message»
- select «Squash commits» and «Remove source branch» in both cases.
- make sure the plugin package is available in Koji/Yum under Collectd7/Collectd8.
- the MONIT team will take care of reviewing the MR and move the changes to QA and Master
- once the MR is in production you can close the CRM ticket.
Уведомления на e-mail
В случаем выхода указанного параметра за рамки диапазона мы получим на почту письмо WARNING или FAILURE, и когда значение вернётся к нормальным значением получим письмо OKAY
Устанавливаем библиотеку для отпрaвки почты
aptitude install libesmtp5
Настраиваем параметры почтового соединения — добавляем в конец файла строки
Например, так:
nano /etc/collectd/collectd.conf
LoadPlugin notify_email
<Plugin notify_email>
SMTPServer "smtp.yandex.ru"
SMTPPort 25
SMTPUser "login"
SMTPPassword "password"
From "mailbox@yandex.ru"
# # <WARNING/FAILURE/OK> on <hostname>.
# # Beware! Do not use not more than two placeholders (%)!
Subject " %s on %s!"
Recipient "mailbox@yandex.ru"
</Plugin>
Добавляем простейшую новую реакцию на событие (триггер) — например, процессор загружен пользовательским процессом свыше 85 % — добавляем в конец файла строки.
nano /etc/collectd/thresholds.conf
<Threshold>
<Type "cpu">
Instance "user"
WarningMax 85
Hits 6
</Type>
</Threshold>
Перезапускаем collectd
/etc/init.d/collectd restart
Нагрузить процессор очень просто — ставим cpuburn:
aptitude install cpuburn
Грузим процессор
burnP6
И проверяем почту — письмо-уведомление должно быть.
Далее не забываем отключить нагрузку Ctrl+C
Или варианты оповещения посложнее — нигде в интернет подобных работоспособных примеров найдено не было, нащупал сам ![]()
Отсылаем письмо, если скорость передачи данных на сервер (rx) превысит 9 мегабит в секунду (грубо) или если температура процессора на материнке Sapphire IPC-?E350M1) превысит 50 градусов.
nano /etc/collectd/thresholds.conf
<Threshold>
<Host "gtx.home">
<Plugin "interface">
<Type "if_octets">
Instance "eth0"
DataSource "rx"
WarningMax 9000000
</Type>
</Plugin>
<Plugin "sensors">
instance "k10temp-pci-00c3"
<Type "temperature">
instance "temp1"
DataSource "value"
WarningMax 50
</Type>
</Plugin>
</Host>
</Threshold>
Проверенно рабочий конфиг для материнки Sapphire IPC-E350M1W:
/etc/collectd/thresholds.conf
<Threshold>
<Plugin "cpu">
<Type "cpu">
Instance "user"
WarningMax 85
# 10 hits - 2 min
Hits 50
</Type>
</Plugin>
<Plugin "df">
<Type "df">
instance "mnt-data"
#Если занято свыше 400ГБ
WarningMax 429496729600
#Percetage false
</Type>
<Type "df">
instance "mnt-cache"
# Если занято свыше 500ГБ
WarningMax 536870912000
#Percentage false
</Type>
<Type "df">
instance "root"
# Если занято свыше 80%
WarningMax 80
Percentage true
</Type>
</Plugin>
<Plugin "sensors">
instance "k10temp-pci-00c3"
<Type "temperature">
instance "temp1"
DataSource "value"
# Если температура процессора свыше 75 градусов по Цельсию
WarningMax 75
</Type>
instance "f71808e-isa-0290"
<Type "temperature">
instance "temp1"
DataSource "value"
WarningMax 65
</Type>
<Type "temperature">
instance "temp2"
DataSource "value"
WarningMax 55
</Type>
<Type "voltage">
instance "in0"
DataSource "value"
WarningMax 3.4
WarningMin 3.2
</Type>
<Type "voltage">
instance "in1"
DataSource "value"
WarningMax 1.35
WarningMin 0.55
</Type>
<Type "voltage">
instance "in3"
DataSource "value"
WarningMax 1.65
WarningMin 1.55
</Type>
<Type "voltage">
instance "in4"
DataSource "value"
WarningMax 1.15
WarningMin 1.05
</Type>
<Type "voltage">
instance "in5"
DataSource "value"
WarningMax 1.85
WarningMin 1.75
</Type>
<Type "voltage">
instance "in7"
DataSource "value"
WarningMax 3.45
WarningMin 3.25
</Type>
<Type "voltage">
instance "in8"
DataSource "value"
WarningMax 3.25
WarningMin 3.05
</Type>
</Plugin>
<Plugin "exec">
# Температура жёских дисков по Цельсию
instance "smart"
<Type "temperature">
instance "sda"
DataSource "value"
WarningMax 50
</Type>
<Type "temperature">
instance "sdb"
DataSource "value"
WarningMax 43
</Type>
<Type "temperature">
instance "sdc"
DataSource "value"
WarningMax 43
</Type>
</Plugin>
<Plugin "memory">
<Type "memory">
Instance "used"
# Если занято свыше 1ГБ
WarningMax 1073741824
</Type>
</Plugin>
</Threshold>
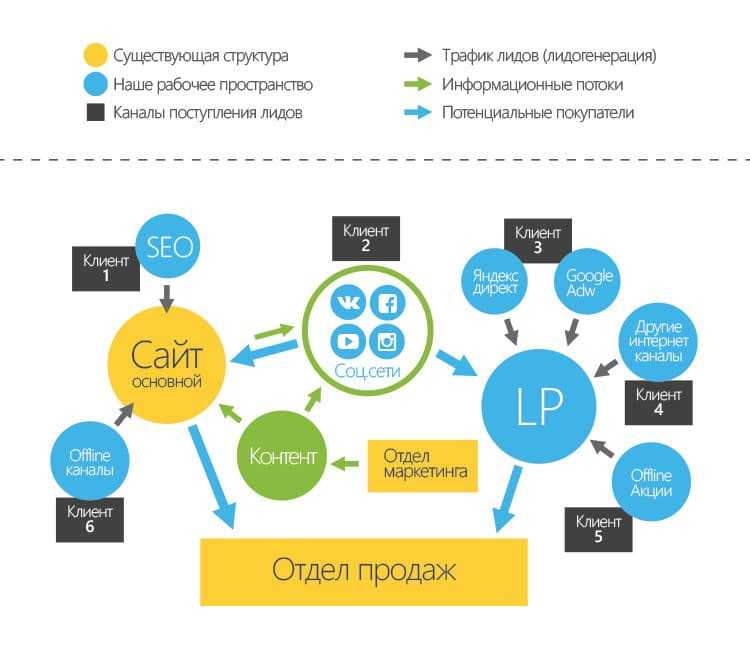
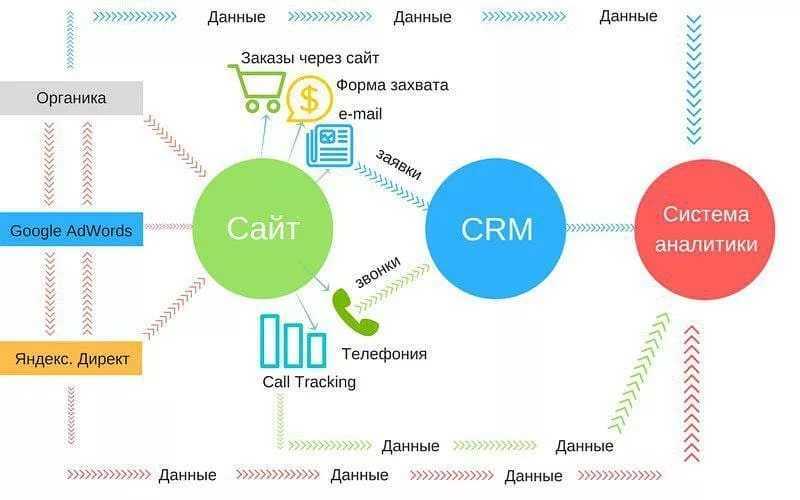
Платформы для омниканального обслуживания
Ещё один инструмент для клиентского обслуживания и управления маршрутом покупателя — омниканальные платформы.
Платформы для омниканального обслуживания позволяют сохранять данные о взаимодействии клиента с компанией и обогащать уже имеющиеся. Среди наиболее заметных на российском рынке вендоров такие, как LiveTex, Genesys, Oktell Omnichannel, Naumen Оmni-Сhannel. Такие решения отличаются по стоимости и возможностям, но даже малый и средний бизнес сейчас может выбрать и настроить подходящую платформу под себя.
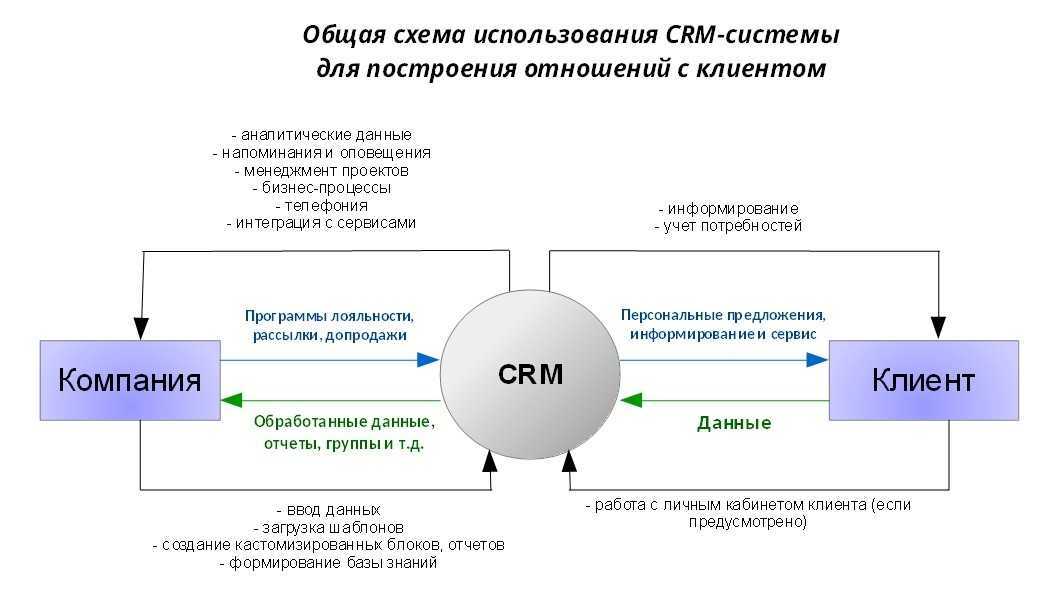
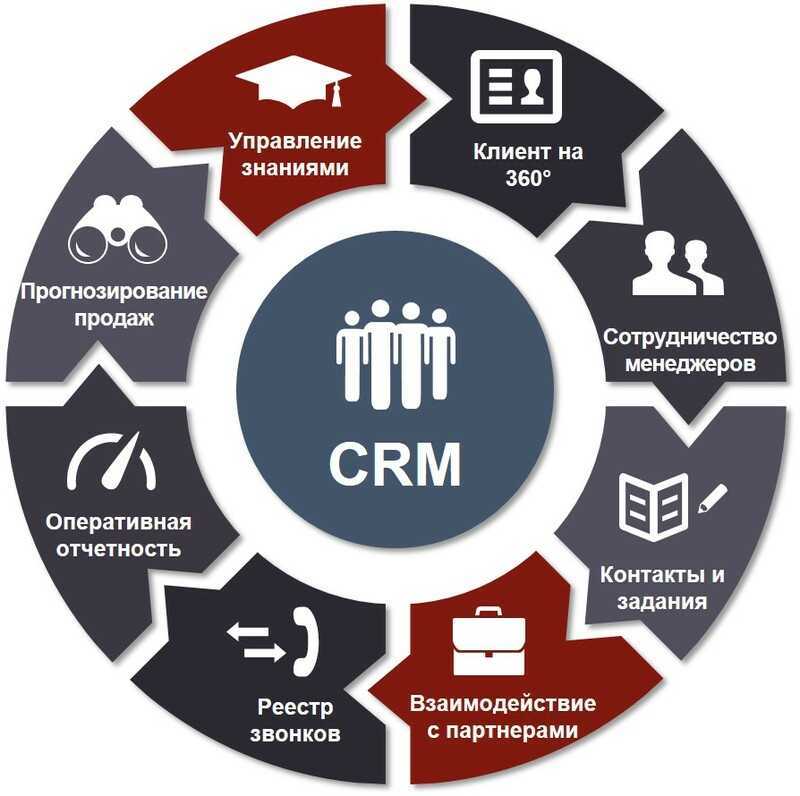
Как это работает
Вот как выглядит интерфейс, в котором собраны обращения клиентов из разных цифровых каналов.
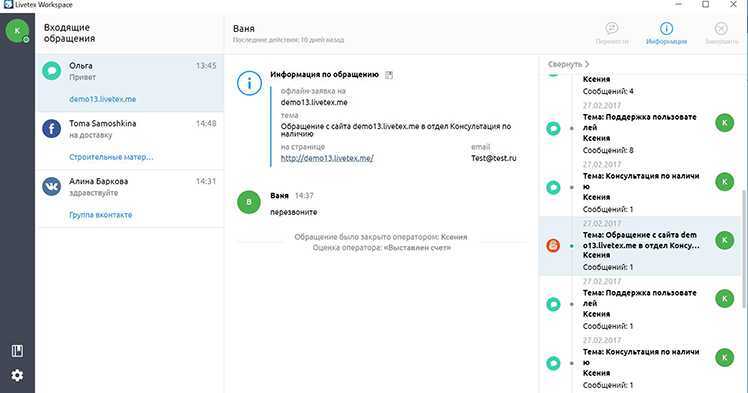
При интеграции с CRM омниканальная платформа будет автоматически сохранять и обогащать контактные данные клиента, поэтому человеческий фактор сводится к минимуму. Дополнительное удобство омниканальных решений — большинство вендоров предоставляет встроенные инструменты для аналитики качества клиентского сервиса, статистику по обращениям и многое другое. Это позволяет сотрудникам находиться в контексте обращения, не открывая дополнительно CRM для поиска нужной информации. В целом же достигается эффект синергии, повышается эффективность отдела продаж и растёт успешность различных программ лояльности.
Зачем это бизнесу
Возможность оказывать качественный клиентский сервис сразу во всех цифровых каналах. Омниканальные решения повышают эффективность работы службы клиентской поддержки или отделов продаж, сокращают затраты на работу контакт-центров.
Что учесть при выборе
-
Максимальное количество каналов повышает эффективность от совместной работы с ними.
-
Расширенные опции аналитики помогут контролировать работу отдела продаж или сотрудников контакт-центра.
-
Интеграция с системами аналитики поможет отслеживать, насколько эффективно платформа привлекает и конвертирует дополнительные лиды.
-
Наличие современных протоколов безопасности. Омниканальная платформа работает с клиентскими данными, убедиться лишний раз в их безопасности не помешает.
Для особо продвинутых пользователей можно рекомендовать к связке «CRM ― омниканальная платформа» добавить интеграцию с тикет-системой. Это поможет управлять заявками клиентов непосредственно в CRM-системе, что позволит получить полную картину о качестве работы клиентской службы.
Data Access
Grafana
Since the data is stored in InfluxDB it can be easily visualised with Grafana, the only thing you will need to do depending on which organisation you are working
will be add the datasource or ask for it to be added (playground).
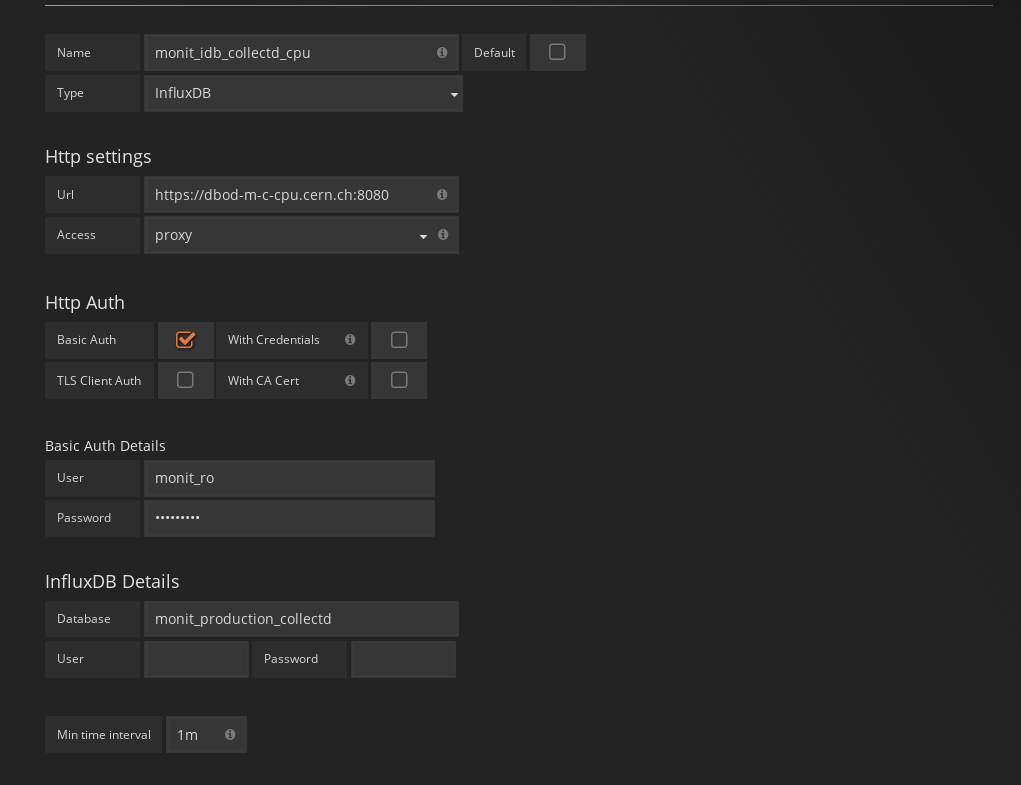
Adding the datasource
In order to add a datasource to Grafana you need to have admin rights on the organisation or ask someone that is. The procedure is easy, just press in the Grafana
logo in the top left corner and then click in «datasources», finally «add datasource».
Exploring your data
In grafana, data exploration is not so trivial, even with the autocompletion you need to more or less know before hand what you are looking for.
To facilitate this task we are providing a Grafana dashboard with some predefined templates variables. You can find the dashboard here
it is in the playground organisation, so it’s limited to the playground datasources, but it can be moved easily to your own organisation by exporting and importing it again in the right place.
Collectdctl
Collectdctl is the command line tool used to access your Collectd metrics locally, it comes installed by default as part of the Collectd deployment and already configured so you can use it right away.
As part of the CERN deployment of Collectd we have added some arguments to the tools that aren’t yet in sync with the upstream version, so here is the documentation for them.
- collectdctl listval state=: Will output the list of metrics on a given state.
- collectdctl flushstate : Puts the state of a metric back to the initial «UNKNOWN» state.
- collectdctl evalstate : Forces the threshold plugin to regenerate the state of a metric based on the last value sampled by Collectd.
Настройка collectd
Откройте конфигурационный файл collectd:
Сначала нужно установить имя хоста.
Примечание: Collectd может отправлять данные на удалённый сервер Graphite, но в данном руководстве программы находятся на одном сервере.
Выберите любое имя:
Если у вас есть домен, можете пропустить этот параметр и указать свой домен в FQDNLookup.
Параметр Interval устанавливает, как часто collectd будет запрашивать данные хоста. По умолчанию этот интервал составляет 10 секунд. Однако Graphite отслеживает статистику системы чаще. Чтобы Graphite и collectd могли продуктивно взаимодействовать, значение этого параметра в конфигурационных файлах программ должно совпадать
Теперь нужно задать сервисы, данные о которых будет собирать collectd. Для этого collectd применяет плагины. Большинство плагинов используется для считывания данных системы, но некоторые плагины также позволяют указать, куда нужно передать информацию. Одним из таких плагинов является Graphite.
В данном руководстве используется следующий список плагинов:
Вы можете расширить этот список.
Далее в конфигурационном файле находятся настройки каждого плагина, разделённые на блоки. Большинство плагинов может использовать параметры по умолчанию, но некоторые нуждаются в дополнительной настройке.
Во-первых, нужно настроить плагин Apache. Добавьте в его настройки:
В среде производства статистику сервера рекомендуется защитить при помощи аутентификации. Для этого ознакомьтесь с закомментированным кодом в этом разделе файла.
Добавьте настройки для инструмента df, который проверяет свободное пространство диска.
Устройство нужно направить на имя диска. Чтобы узнать имя диска, введите в терминал команду:
Выберите сетевой интерфейс, который нужно отслеживать:
Теперь нужно настроить плагин Graphite. Этот блок подключит collectd к Graphite. Настройки должны выглядеть примерно так:





Теперь программа знает, как создать подключение и передать собранные данные.
Чтобы защитить передаваемые данные, используется протокол TCP. Он будет регистрировать ошибки и устанавливать префиксы для данных. Поскольку строка Prefix заканчивается точкой, все статистические данные хоста будут сохраняться в каталог collectd.
Сохраните и закройте файл.
Настройки модулей
Правим основной файл конфигурации
nano /etc/collectd/collectd.conf
Подробно о плагинах смотрим на официальном сайте
Для очистки всех графиков можно сделать так:
/etc/init.d/collectd stop rm -fr /var/lib/collectd/rrd /etc/init.d/collectd start
Проверенно рабочий конфиг для материнки Sapphire IPC-E350M1W:
/etc/collectd/collectd.conf
Примечание — у меня сбоили показания через hddtemp, пришлось организовыывать сбор данных о температуре через плагин exec и утилитку smartctl
FQDNLookup true
LoadPlugin syslog
<Plugin syslog>
LogLevel info
</Plugin>
LoadPlugin cpu
LoadPlugin cpufreq
LoadPlugin df
LoadPlugin disk
LoadPlugin dns
LoadPlugin exec
LoadPlugin filecount
LoadPlugin interface
LoadPlugin load
LoadPlugin memory
LoadPlugin rrdtool
LoadPlugin sensors
LoadPlugin uptime
LoadPlugin notify_email
<Plugin notify_email>
SMTPServer "smtp.yandex.ru"
SMTPPort 25
SMTPUser "user@yandex.ru"
SMTPPassword "password"
From "ot-kogo-posilaem@yandex.ru"
Subject " %s on %s!"
Recipient "tot-komu-posilaem@yandex.ru"
</Plugin>
<Plugin df>
Device "/dev/mapper/sda2_crypt"
Device "/dev/mapper/data"
Device "/dev/mapper/cache"
</Plugin>
<Plugin disk>
Disk "sda"
Disk "sdb"
Disk "sdc"
</Plugin>
<Plugin dns>
Interface "eth0"
</Plugin>
<Plugin exec>
Exec smart "/usr/local/bin/collsmart.sh"
</Plugin>
<Plugin filecount>
<Directory "/mnt/cache/backup/private">
Instance "backups"
</Directory>
</Plugin>
<Plugin interface>
Interface "eth0"
Interface "eth1"
</Plugin>
<Plugin rrdtool>
DataDir "/var/lib/collectd/rrd"
</Plugin>
Include "/etc/collectd/filters.conf"
Include "/etc/collectd/thresholds.conf"
Bitrix24
-
Объединить сотрудников даже самой большой команды в общем рабочем пространстве.
-
Наладить общение в живой ленте или чатах, совершать звонки аудио и видео, обмениваться файлами.
-
Создавать группы, проекты, доски, ставить задачи и подзадачи, назначить исполнителей.
-
Смотреть отчеты.
-
Хранить 5 ГБ файлов в облаке.
-
Настроить мобильную CRM.
-
Интегрировать Bitrix24 с Google Drive, Dropbox, Яндекс Диск, One Drive.
-
Редактировать документы в режиме онлайн в GoogleDocs и MS Office Online.
За что точно придется платить:
-
Настройка бизнес-процессов. Если у вас много регулярных процессов, например, согласование договоров, вам будет удобнее на платном тарифе.
-
Создание воронки продаж. В бесплатной версии можно построить только одну общую воронку.
-
Сквозная аналитика.
-
Полноценная IP-телефония. Если планируете контролировать количество и качество звонков – переходите на платный тариф. Бесплатно можно записать только 100 звонков, и места дается только 5 ГБ.
-
Интеграция CRM с 1C. Актуально для многих команд.
-
Настройка прав доступа (на всех уровнях: доступ к задачам, доступ к файлам и папкам, доступ к CRM, к телефонии…).
-
Ряд второстепенных, но приятных функций: регулярные задачи, шаблоны проектов и задач, наблюдатели и соисполнители, учет рабочего времени.
Бесплатная версия Bitrix24 вполне подходит для работы, если у вашей команды нет особых запросов. Если вам нужна только работа с задачами – спокойно оставайтесь на free-версии. Если же вы хотите построить в системе управления полноценные бизнес-процессы, создать воронки продаж, настроить сквозную аналитику, интегрироваться с 1С и почтой – выбирайте платный тариф. Платных тарифов целых 5, они заточены под разные цели. Однако, на наш взгляд, Bitrix24 настолько напичкан всевозможными функциями, что встает вопрос: всегда ли они действительно нужны и легко ли их применять на практике?
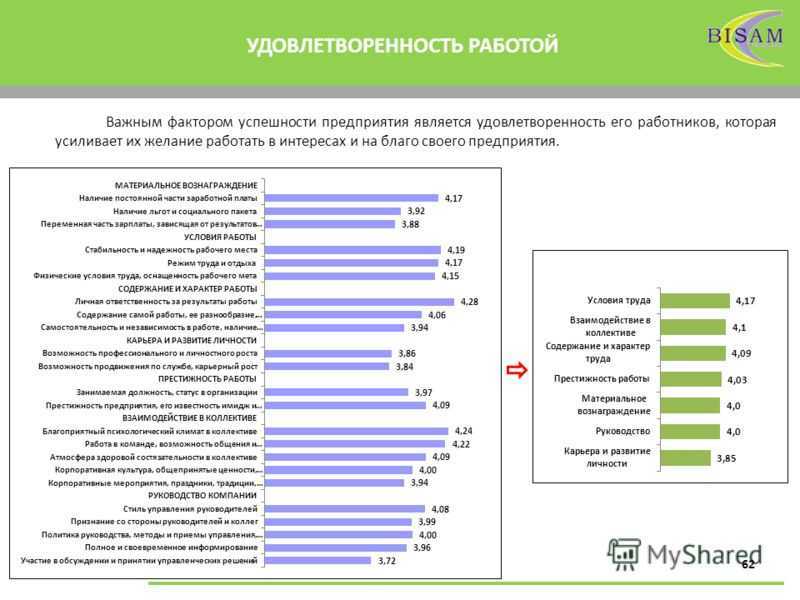
Зачем нужно отслеживать данные?
Для начала нужно разобраться, почему нужно отслеживать данные среды сервера или приложений.
Главная причина довольно проста: чем больше данных есть у пользователя, тем проще ему понять, что происходит с сервером в тот или иной момент. Благодаря этому можно создавать резервные копии достоверных данных и проследить, правильно ли работают внесенные в конфигурации изменения. Отслеживание статистики – дополнительный источник информации, которую невозможно получить из журналов приложения.
Большинство (но не все) систем журналирования не могут соотносить данные различных приложений или связывать события с определенным состоянием системы, потому что они в основном осуществляют автономный вывод данных приложения. Это может повлиять на целостность представления о подробностях событий системы.
Предположим, сервер базы данных вышел из строя. Просмотрев журналы, можно заметить, что в 15:35 сервис MySQL был убит ошибкой ООМ (out of memory). Теперь понятно, что причиной сбоя стало использование памяти, но выяснить, что вызвало пик использования памяти в ранее стабильной системе, невозможно.
Если бы данные сервера и приложений отслеживались ранее, можно было бы собрать различные фрагменты системных данных воедино, чтобы понять, как именно выглядела среда на момент возникновения проблемы. Возможно, удалось бы обнаружить, что использование памяти постоянно возрастало, что и стало причиной ее нехватки. Владея информацией об использовании памяти на уровне приложений, можно определить, какие именно программы виновны в сбое. Кроме того, неестественный для системы пик использования может означать нечто совершенно иное.

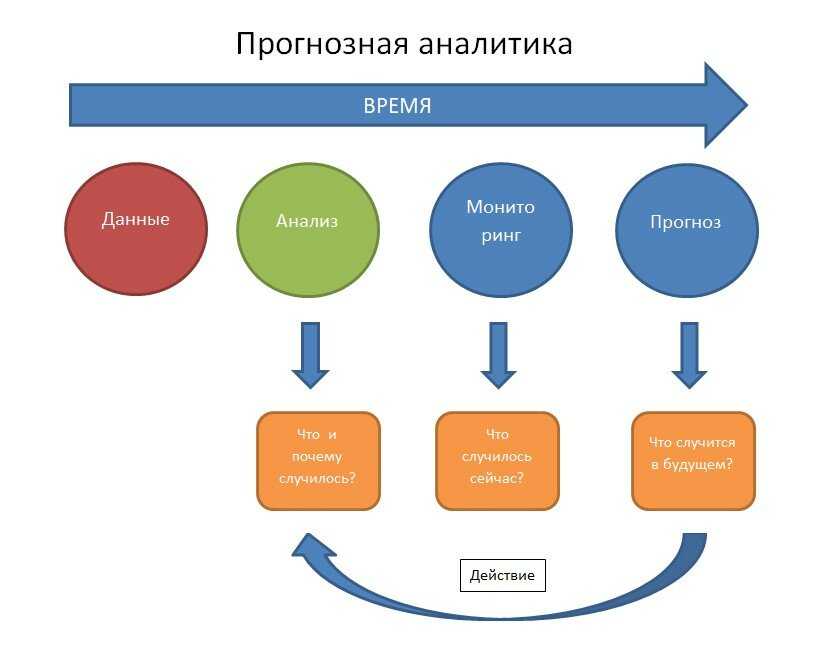
Другой пример: до и после развертывания среды система выглядит одинаково. Если новый код создает некоторые странные условия, можно отследить его влияние на компоненты и сравнить его производительность со старым кодом. Таким образом, можно определить части кода, которые удачнее предыдущего, и части, где были допущены ошибки.
Правильный подход к сбору статистики позволяет взглянуть на ОС как на систему данных, а не свободный набор несвязанных между собой компонентов
Configure Apache to Report Stats
In our configuration file, we enabled Apache stats tracking. We still need to configure Apache to allow this though.
In the Apache virtual hosts file that we have enabled for Graphite, we can add a simple location block that will tell Apache to report stats.
Open the file in your text editor:
Below the “content” location block, we are going to add another block so that Apache will serve statistics at the page. Add the following section:
<pre>
Alias /content/ /usr/share/graphite-web/static/
<Location “/content/”>
SetHandler None
</Location>
</pre>
Save and close the file when you are finished.
Now, we can reload Apache to get access to the new statistics:
We can check to make sure everything is working correctly by visiting the page in our web browser. We just need to go to our domain, followed by :
<pre>
http://<span class=“highlight”>domainnameor_IP</span>/server-status
</pre>
You should see a page that looks something like this:
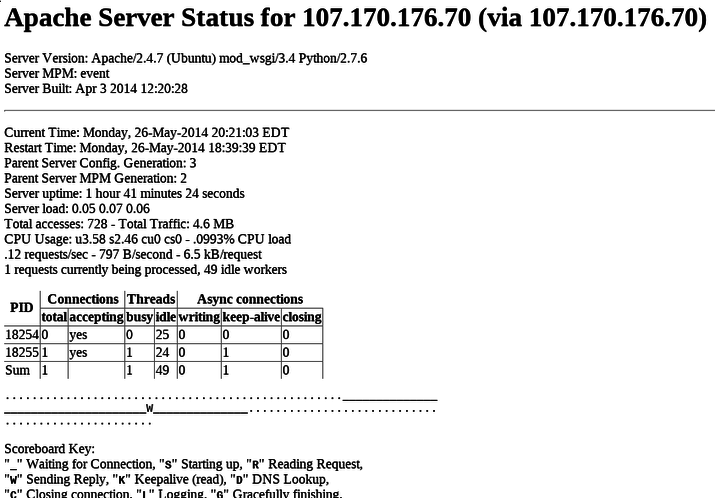
Caveats
Output buffering
A lot of programming environments (I/O-libraries, script interpreters) use buffered I/O when writing to the standard output. This may mean that data you’re printing to the collectd process may be delayed until a 4 kByte buffer gets filled (or something around that size), which can be several minutes later.
To avoid this problem is it advisable to flush this buffer before calling sleep. Many environments also provide means to disable buffering, for example the following will deactivate buffering on stdout using the standard C library:
/* This needs to be done before *anything* is written to STDOUT! */
status = setvbuf (stdout,
/* buf = */ NULL,
/* mode = */ _IONBF, /* unbuffered */
/* size = */ );
if (status != )
{
perror ("setvbuf");
exit (EXIT_FAILURE);
}
This Perl snipped will enable automatic flushing after each write:
# Enable auto flush $| = 1;
In Ruby you’d do something like:
# Enable auto flush STDOUT.sync = true
Heads up: While this behavior is merely confusing when you include timestamps in your messages, it may lead to invalid value lists if you use the (now) abbreviation: Since the time is only filled in when collectd receives the values, it may be several minutes late. If the same identifier is contained in the buffer multiple times, all values will bear the same time stamp and all but the first value will be lost.
Heads up 2: The stdout macro, which is specified by POSIX and used by many environments as the underlying I/O mechanism, behaves differently when connected to a terminal and to a pipe: When connected to a terminal, the output is «line buffered», i.e. the buffer is flushed when a newline is printed. When connected to a pipe, the stream is «fully buffered», i.e. output is only actually written if a fixed size buffer is full. This means that the output can actually appear immediately when testing the code in the command line, but still suffer from the problem when actually running with collectd.
Настроить Графана
адрес:http://127.0.0.1:3000 Учетная запись по умолчанию пароль # 127.0.0.1 — это IP-адрес сервера, на котором находится grafana. Если вы не можете получить к нему доступ, сначала убедитесь, что команда запуска grafana была выполнена успешно
Добавить источник данных InfluxDB
Возможные ошибки:
1. Ошибка при сохранении и тестировании:Является ли проблема конфигурации http ip базы данных несколько установлены на 127.0.0.1
2. Подскажите не сохранять приватные ссылки и не сохранять
Добавить график мониторинга
Я успешно настроил в начале, но не смог отобразить данные. Спасибо авторам следующей статьи за их инструкции:Ссылка ссылка
Хранение данных
Теперь инструмент collectd будет собирать данные сервисов. Отредактируйте настройки Graphite, чтобы программа могла правильно обрабатывать полученные данные.

Создайте конфигурационный файл для настройки сохранения метрик.
Добавьте в файл настройки, которые определяют сроки хранения и уровни детализации данных.
В данном руководстве Graphite будет хранить данные за 10 секунд в течение одного дня, данные за минуту в течение недели, а данные за 10 минут – в течение года. Такую политику можно настроить при помощи строк:
Примечание: Эти строки нужно поместить над политикой по умолчанию. В противном случае программа не будет их выполнять.
Setting the Storage Schema and Aggregation
Now that we have collectd configured to gather statistics about your services, we need to adjust Graphite to handle the data it receives correctly.
Let’s start by creating a storage schema definition. Open up the storage schema configuration file:
Inside, we need to add a definition that will dictate how long the information is kept, and how detailed the data should be at various levels.
We will tell Graphite to store collectd information at intervals of ten seconds for one day, at one minute for seven days, and intervals of ten minutes for one year.
This will give us a good balance between detailed information for recent activity and general trends over the long term. Collectd passes its metrics starting with the string , so we will match that pattern.
The policy we described can be added by adding these lines. Remember, add these above the default policy, or else they will never be applied:
Save and close the file when you are finished.
Настройка Apache
Согласно конфигурационному файлу collectd будет отслеживать статистику веб-сервера Apache. Теперь нужно настроить Apache для передачи статистических данных.
Переместите виртуальный хост для Graphite в каталог sites-available:
Добавьте в него небольшой блок настроек.
Откройте файл:
Сохраните и закройте файл.
Отключите стандартный виртуальный хост и включите новый хост:
Чтобы обновить настройки, перезапустите сервис:
Чтобы убедиться, что все работает должным образом, откройте в браузере:
На экране появится страница Apache Server Status, на которой вы увидите статистику веб-сервера.



