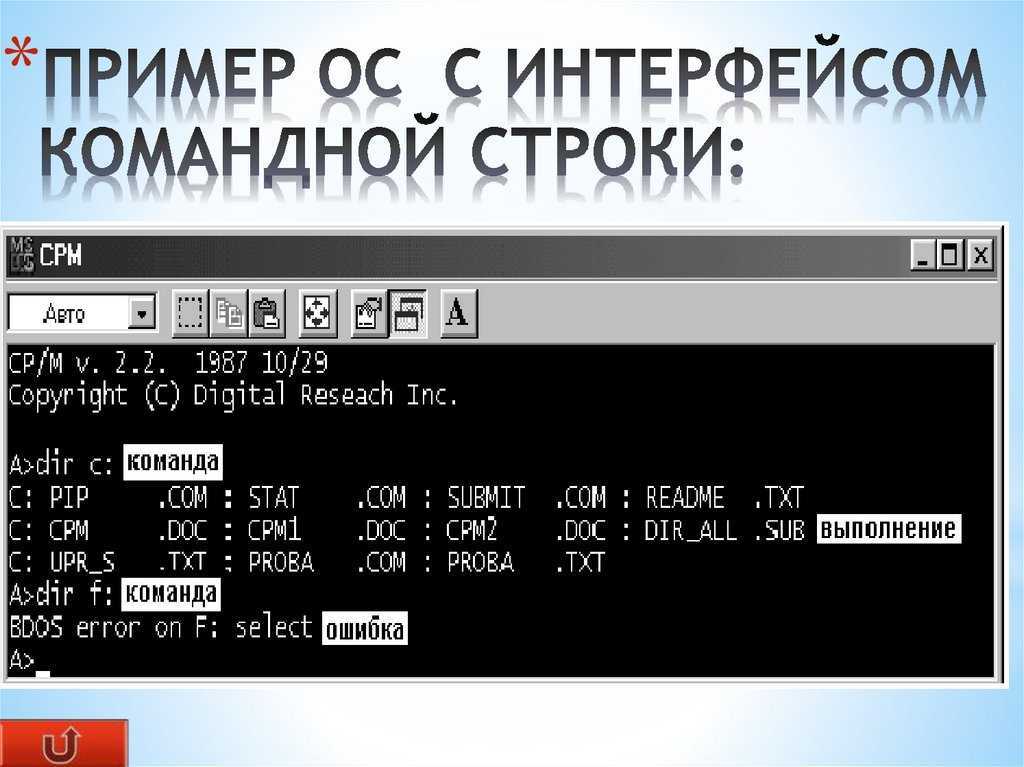
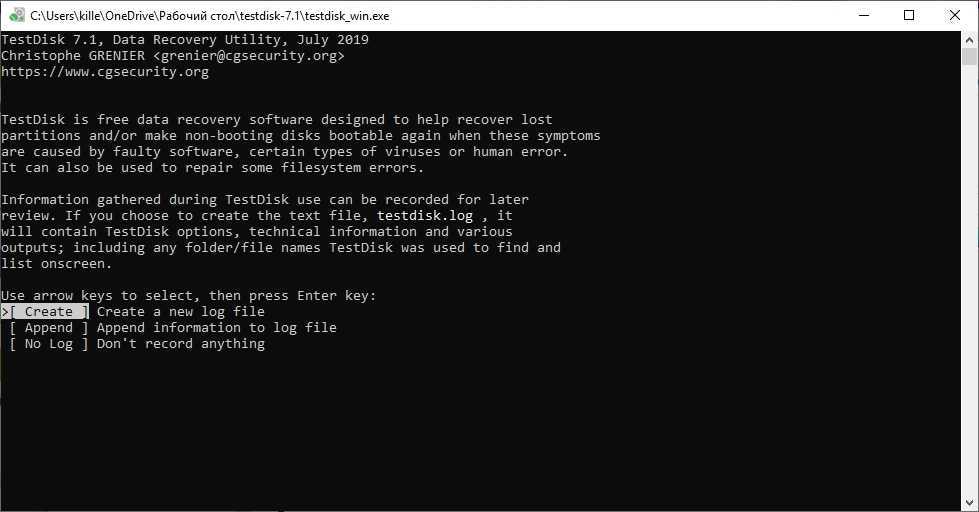
Параметры FTP
- -nr
- —dont-remove-listing
- Не удалять временные файлы .listing, генерируемые при загрузке по FTP. Эти файлы содержат информацию о папках серверов FTP. Неудаление поможет вам быстро определить обновление папок сервера (т.е. определять., что ваше зеркало является таковым).
Если вы не удаляете .listing, то помните о своей безопасности! Например, с таким именем можно создать символическую ссылку на /etc/passwd или что-то еще.
- -g on/off
- —glob=on/off
-
Включает или выключает использование специальных символов (маски) по протоколу FTP. Это может быть *, ?, и . Например:
wget ftp://gnjilux.srk.fer.hr/*.msg
По умолчанию использование символов маски разрешено, если URL содержит такие символы.
Вы можете также взять URL в кавычки. Это сработает только на серверах Unix FTP (и эмулирующих выход Unix "ls").
- —passive-ftp
- Включает пассивный режим FTP, когда соединение инициируется клиентом. Используется при наличии firewall.
- —retr-symlinks
- При рекурсивной загрузке папок FTP файлы, на которые указывают символические ссылки, не загружаются. Данный параметр отключает это.
Параметр —retr-symlinks работает сейчас только для файлов, не для папок.
Помните, что этот параметр не работает при загрузке одиночного файла.
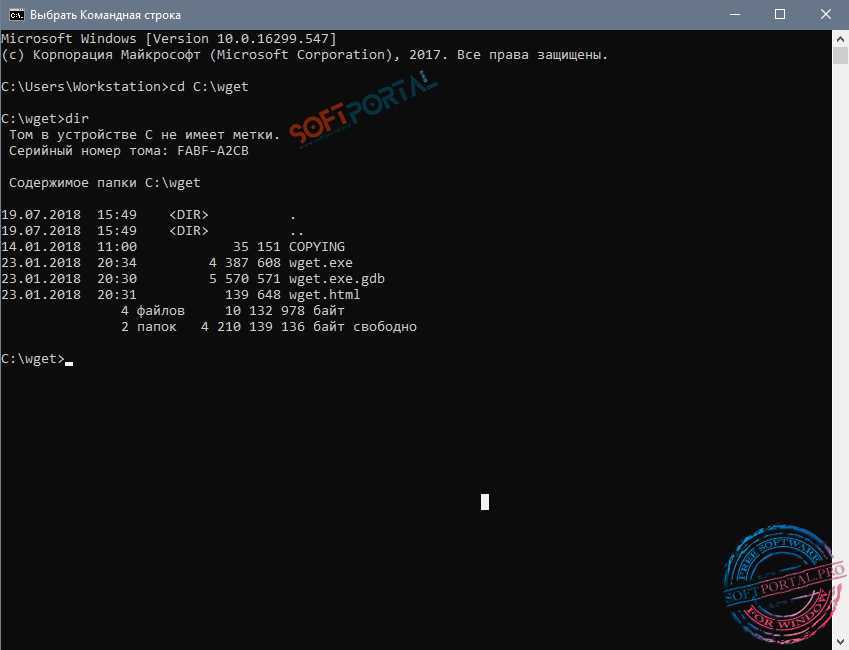
Install Wget
Check if Wget is installed
Open Terminal and type:
$ wget -V
If it is installed, it will return the version.
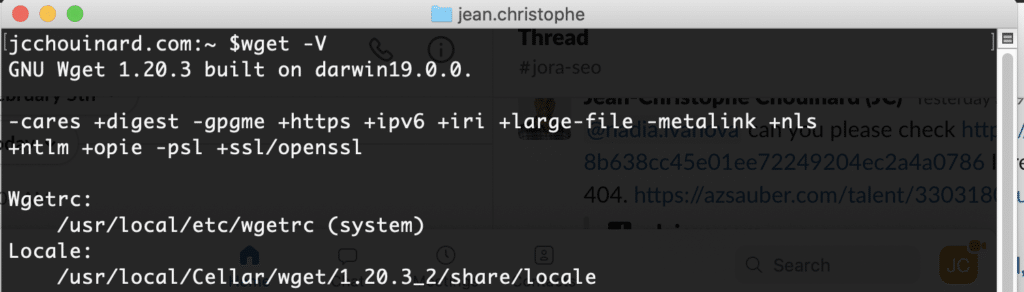
If not, follow the next steps to download wget on either Mac or Windows.
Download Wget on Mac
First, install Homebrew.
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Then, install wget.
$ brew install wget
Download Wget on Windows
To install and configure wget for Windows:
- Download wget for Windows and install the package.
- Copy the file into your folder.
- Open the command prompt (cmd.exe) and run to see if it is installed.
Here is a quick video showing you how to download wget on windows 10.
Яндекс.Браузер
Как и в вышеописанных случаях Яндекс.Браузер тоже можно достаточно просто оптимизировать и ускорить. Так как российский браузер разработан на движке WebKit, использующийся в Chrome от Google, большинство приемов, которые можно использовать в программе от «гугла» можно применить и в Яндексе.
В Яндекс.Браузере тоже есть раздел с экспериментальными настройками, для получения доступа к которому нужно ввести в адресную строку: browser://flags/. После этого мы увидим абсолютно тот же перечень свойств, что и в Chrome. Поэтому поднимаемся к описанию методов ускорения «хрома» и повторяем описанные там действия.
Кроме идентичного раздела с экспериментальными настройками, в Яндекс.Браузере есть свой диспетчер задач, который включается тем же сочетанием клавиш Shift + Esc. Открываем его и закрываем все ненужные плагины и расширения, влияющие на скорость работы.
Так как браузеры используют один движок, все расширения, что работают в «хроме», будут функционировать и в Яндексе. Поэтому отправляемся в пункт про браузер от Google и ставим те расширения, которые там описаны. Дополнения, к слову, ставятся из официального магазина Google Chrome.
В Яндексе есть еще одна крайне полезная функция, которая позволит в два клика ускорить работу браузера:
- Заходим в настройки браузера;
- Нажимаем «Включить турбо»;
- Готово.
Теперь все данные с открытых сайтов перед отправкой к вам будут сжиматься на серверах российской компании, что позволит значительно ускорить процесс путешествия по интернету. Особенно режим «Турбо» будет полезен тем, у кого не самый быстрый интернет.
Профессиональное использование
- *
-
Для хранение зеркала страницы (или папки FTP), то используйте —mirror (-m), что заменяет -r -l inf -N. Вы можете добавить Wget в crontab с запросом на проверку обновлений каждое воскресенье:
crontab 0 0 * * 0 wget --mirror http://www.gnu.org/ -o /home/me/weeklog
- *
-
Вы также хотите, чтобы ссылки конвертировались в локальные. Но после прочтения этого руководства, вы знаете, что при этом не будет работать сравнение по времени. Укажите Wget оставлять резервные копии HTML файлов перед конвертацией. Команда:
wget --mirror --convert-links --backup-converted http://www.gnu.org/ -o /home/me/weeklog
- *
-
А если не работает локальный просмотр файлов HTML с расширением, отличным от .html, например index.cgi, то нужно передать команду на переименование всех таких файлов (content-type = text/html) в имя.html.
wget --mirror --convert-links --backup-converted --html-extension -o /home/me/weeklog http://www.gnu.org/
С краткими аналогами команд:
wget -m -k -K -E http://www.gnu.org/ -o /home/me/weeklog
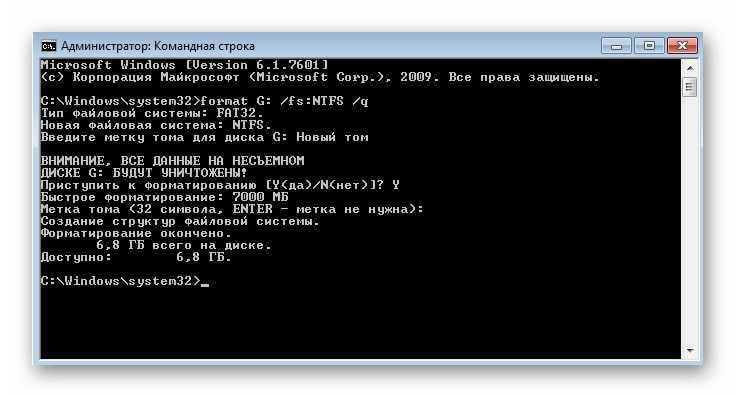
Отключение поисковика Windows
Поисковая система Windows 11 — главный подозреваемый в чрезмерной нагрузке, оказываемой на ЦП и диск компьютера. Аналогично «десятке» поисковик Windows 11 на постоянной основе отслеживает и индексирует все новые файлы, попадающие в систему. На компьютерах с мощным аппаратным обеспечением подобный процесс не должен вызывать каких бы то ни было проблем, а вот на ПК с бюджетными комплектующими дела обстоят куда более печально.
Некоторые пользователи утверждают, что из-за повышенной нагрузки их ПК начинает работать с жуткими тормозами либо и вовсе зависает намертво. Сильнее всего достается владельцам классических жестких дисков, впрочем, обладатели SSD тоже жалуются на проблемы с высокой нагрузкой.
Решение — отключение поисковой системы Windows 11. Верно, многие из вас постоянно пользуются поисковиком, но если он вызывает трудности в работе ПК — его нужно деактивировать. Чтобы отключить поисковик Windows 11, вам нужно сделать следующее:
- нажмите комбинацию клавиш Win+R, чтобы открыть окошко «Выполнить»;
- далее пропишите в пустой строке значение «services.msc» и нажмите Enter;
- найдите в списке службу «Windows Search» и дважды кликните на нее ЛКМ;
- попав в свойства службы, нажмите на кнопку «Остановить»;
- теперь выберите в ниспадающем меню типа запуска службы значение «Отключена» и сохраните внесенные изменения, нажав «Применить» и «OK»;
- закройте все открытые окна и перезагрузите ПК.
Теперь, когда поиск Windows 11 отключен, ваши ЦП и диск больше не будут подвергаться нагрузкам. Тем не менее если после отключения поиска ничего не изменилось… что же, двигаемся дальше.
Расширенное использование
- *
-
Если у Вас есть файл с URL, которые вы хотите загрузить, то используйте параметр -i:
wget -i I
Если вы укажете — вместо имени файла, то URL будут читаться из стандартного ввода (stdin).
- *
-
Создать пятиуровневую копию сайта GNU со структурой папок оригинала, с одной попыткой загрузки, сохранить сообщения в gnulog:
wget -r http://www.gnu.org/ -o gnulog
- *
-
Как и в примере выше, но с конвертированием ссылки в файлах HTML в локальные, для последующего автономного просмотра:
wget --convert-links -r http://www.gnu.org/ -o gnulog
- *
-
Загрузить одну страницу HTML и все файлы, требуемые для отображения последней (напр. рисунки, файлы каскадных стилей и т. д.). Также сконвертировать все ссылки на эти файлы:
wget -p --convert-links http://www.server.com/dir/page.html
Страница HTML будет сохранена в www.server.com/dir/page.html и рисунки, каскадные стили и прочее будет сохранено в папке www.server.com/, кроме случая, когда файлы будут загружаться с других серверов.
- *
-
Как и в примере выше, но без папки www.server.com/. Также все файлы будут сохранены в подпапках download/.
wget -p --convert-links -nH -nd -Pdownload http://www.server.com/dir/page.html
- *
-
Загрузить index.html с www.lycos.com, отображая заголовки сервера:
wget -S http://www.lycos.com/
- *
-
Сохранить заголовки в файл для дальнейшего использования.
wget -s http://www.lycos.com/ more index.html
- *
-
Загрузить два высших уровня wuarchive.wustl.edu в /tmp.
wget -r -l2 -P/tmp ftp://wuarchive.wustl.edu/
- *
-
Загрузить файлы GIF папки на HTTP сервере. Команда wget http://www.server.com/dir/*.gif не будет работать, так как маскировочные символы не поддерживаются при загрузке по протоколу HTTP. Используйте:
wget -r -l1 --no-parent -A.gif http://www.server.com/dir/
-r -l1 включает рекурсивную загрузку с максимальной глубиной 1. —no-parent выключает следование по ссылкам в родительскую папку, имеющую верхний уровень, -A.gif разрешает загружать только файлы с расширением .GIF. -A «*.gif» также будет работать.
- *
-
Предположим, что во время рекурсивной загрузки вам нужно было срочно выключить/перезагрузить компьютер. Чтобы не загружать уже имеющиеся файлы, используйте:
wget -nc -r http://www.gnu.org/
- *
-
Если вы хотите указать имя пользователя и пароль для сервера HTTP или FTP, используйте соответствующий синтаксис URL:
wget ftp://hniksic:mypassword@unix.server.com/.emacs
- *
-
Вы хотите, чтобы загружаемые документы шли в стандартный вывод, а не в файлы?
wget -O - http://jagor.srce.hr/ http://www.srce.hr/
Если вы хотите устроить конвейер и загрузить все сайты, ссылки на которые указаны на одной странице:
wget -O - http://cool.list.com/ | wget --force-html -i -
3) Download Files in the background (-b)
Use ‘-b’ option in wget command to download files in the background. This option becomes very useful where the file is too large and you want to use terminal for other tasks.
![Linux wget command guide [with examples]](https://smartshop124.ru/wp-content/uploads/6/7/3/673b7db138a35e4f746d1f75edc68dad.jpeg)
$ wget -b https://download.rockylinux.org/pub/rocky/8/isos/x86_64/Rocky-8.4-x86_64-dvd1.iso Continuing in background, pid 4505. Output will be written to ‘wget-log’.
As we can see above that downloading progress is capture in ‘wget-log’ file in user’s current directory. Use tail command to view status of download.
$ tail -f wget-log 2300K .......... .......... .......... .......... .......... 0% 48.1K 18h5m 2350K .......... .......... .......... .......... .......... 0% 53.7K 18h9m 2400K .......... .......... .......... .......... .......... 0% 52.1K 18h13m 2450K .......... .......... .......... .......... .......... 0% 58.3K 18h14m 2500K .......... .......... .......... .......... .......... 0% 63.6K 18h14m 2550K .......... .......... .......... .......... .......... 0% 63.4K 18h13m 2600K .......... .......... .......... .......... .......... 0% 72.8K 18h10m 2650K .......... .......... .......... .......... .......... 0% 59.8K 18h11m 2700K .......... .......... .......... .......... .......... 0% 52.8K 18h14m 2750K .......... .......... .......... .......... .......... 0% 58.4K 18h15m 2800K .......... .......... .......... .......... .......... 0% 58.2K 18h16m 2850K .......... .......... .......... .......... .......... 0% 52.2K 18h20m
Плагины в CMS слишком тяжелые
Внушительная часть ресурсов вашей VDS или виртуального хостинга могут уходить на поддержку CMS. То есть систему управления данными наподобие WordPress, Joomla или Drupal. А если установить в них увесистые плагины, то можно лишиться еще части ресурсов, выделенных на работу сайта.
Некоторые дополнения съедают слишком большое количество памяти, из-за чего резко падает скорость загрузки всего сайта. В этом случае не поможет кэширование и другие методы «ускорения» ресурса. Придется избавляться от «прожорливых» расширений.
Некоторые дополнения могут работать некорректно из-за сбоя при установке или обновлении. Стоит их переустановить или обновить в надежде на автоматическое исправление проблемы.
Проблемы на стороне клиента
Последнее, на что стоит сетовать — браузер пользователя. Бывает и так, что страницы долго открываются не у всех сразу, а только у конкретных людей. Повлиять на такого рода проблемы зачастую невозможно.
Все, что вы можете сделать, удобно подать им инструкцию по устранению общих проблем. Например, рассказать им, как удалить из браузера кэш, как очистить историю, переустановить или сменить браузер, проверить ОС антивирусом и т.п.
Но это стоит делать только в том случае, если вы на 100% уверены в наличии проблем на стороне клиента.
Зачастую же решить проблемы с медленной работой сайта и сервера помогают описанные выше методы. Задействовав сразу несколько, можно добиться весомого прироста.
И не забывайте, что производительность ресурса напрямую связана с удовлетворенностью клиентов, а их удовлетворенность влияет на ваш доход и репутацию сайта.
ОПИСАНИЕ
GNU Wget — это открыто распостраняемая утилита для загрузки файлов из интернет. Она поддерживает протоколы HTTP, HTTPS, и FTP, загрузку с серверов прокси по протоколу HTTP.
Wget может следовать по ссылкам страниц HTML и создавать локальные копии удаленных сайтов web, при этом возможно полное восстановление структуры папок сайта («recursive downloading» — рекурсивная загрузка). Во время такой работы Wget ищет файл с правами доступа для роботов (/robots.txt). Возможна также конвертация ссылок в загруженных файлах HTML для дальнейшего просмотра сайта в автономном режиме («off-line browsing»).
Проверка заголовков файлов: Wget может считывать заголовки файлов (это доступно по протоколам HTTP и FTP) и сравнивать их с заголовкам ранее загруженных файлов, после чего может загрузить новые версии файлов. Благодаря этому при использовании Wget можно реализовывать зеркальное хранение сайтов или набора файлов на FTP.
Wget разработан для медленных или нестабильных соединений: если во время загрузки возникнет проблема, то Wget будет пытаться продолжить загрузку файла. Если сервер, с которого загружается файл, поддерживает докачку файлоа, то Wget продолжит загружать файл именно с того места, где оборвалась загрузка.
Extract Web pages with Wget Commands
Download a File to a Specific Output Directory
Here replace by the output directory location where you want to save the file.
$ wget ‐P <YOUR-PATH> https://example.com/sitemap.xml
To output the file with a different name:
$ wget -O <YOUR-FILENAME.html> https://example.com/file.html
Identify yourself. Define your user-agent.
$ wget --user-agent=Chrome https://example.com/file.html
Extract as Google bot
$ wget --user-agent="Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://example.com/path
Extract Robots.txt only When it Changes
Let’s extract robots.txt only if the latest version in the server is more recent than the local copy.
First time that you extract use to keep a timestamps of the file.
$ wget -S https://example.com/robots.txt
Later, to check if the robots.txt file has changed, and download it if it has.
$ wget -N https://example.com/robots.txt
Convert Links on a Page
Convert the links in the HTML so they still work in your local version. (ex: to)
$ wget --convert-links https://example.com/path
Mirror a Single Webpage
To mirror a single web page so that it can work on your local.
$ wget -E -H -k -K -p --convert-links https://example.com/path
Add all urls in a file.
https://example.com/1 https://example.com/2 https://example.com/3
$ wget -i urls.txt
Limit Speed
To be a good citizen of the web, it is important not to crawl too fast by using and .
- : Wait 1 second between extractions.
- : Limit the download speed (bytes per second)
Extract Entire Site (Proceed with Caution)
Recursive mode extract a page, and follows the links on the pages to extract them as well.
This is extracting your entire site and can put extra load on your server. Be sure that you know what you do or that you involve the devs.
$ wget --recursive --page-requisites --adjust-extension --span-hosts --wait=1 --limit-rate=10K --convert-links --restrict-file-names=windows --no-clobber --domains example.com --no-parent example.com
- : Follow links in the document. The maximum depth is 5.
- : Get all assets (CSS/JS/images)
- : Save files with .html at the end.
- : Include necessary assets from offsite as well.
- : Wait 1 second between extractions.
- : Limit the download speed (bytes per second)
- : Convert the links in the HTML so they still work in your local version.
- : Modify filenames to work in Windows.
-
: Overwrite existing files.
- : Do not follow links outside this domain.
- : Do not ever ascend to the parent directory when retrieving recursively
-
: Specify the depth of crawling. is used for infinite.
Проблемы с интернетом-провайдером или сетью
Возможно, с вашим сайтом все в порядке, а скорость загрузки упала из-за проблем в сети.
Как понять, что есть сложности с работой сети
Данные от устройства посетителя сайта до сервера и обратно могут проходить через десятки промежуточных узлов. Причем иногда разные фрагменты данных (разные пакеты) могут ходить от одной точки в другую разными путями. Иногда те или иные узлы сети могут работать неверно и с задержкой передавать пакеты следующему узлу или не передавать их вовсе. Например, из-за работы фильтрующего ПО или оборудования.
Какие могут быть проблемы в работе сети:
- сеть провайдера перегружена,
- есть неполадки на сетевом оборудовании,
- ограничена полоса пропускания на том или ином узле,
- установлены ограничения на доступ к тому или иному ресурсу из вашей сети.
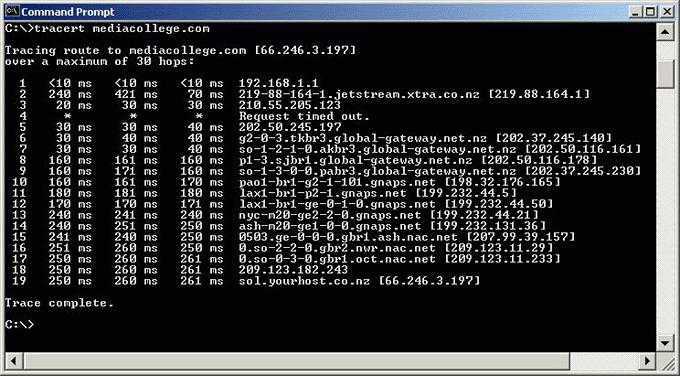
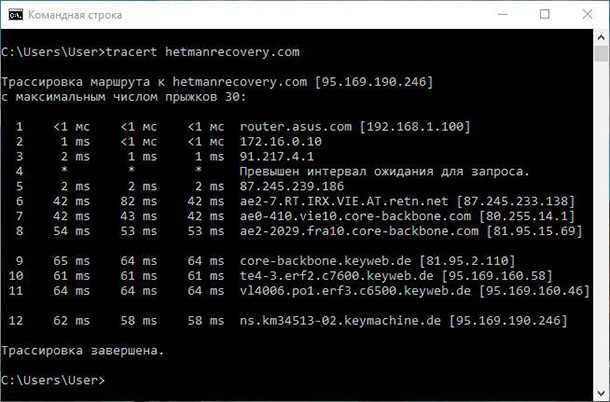
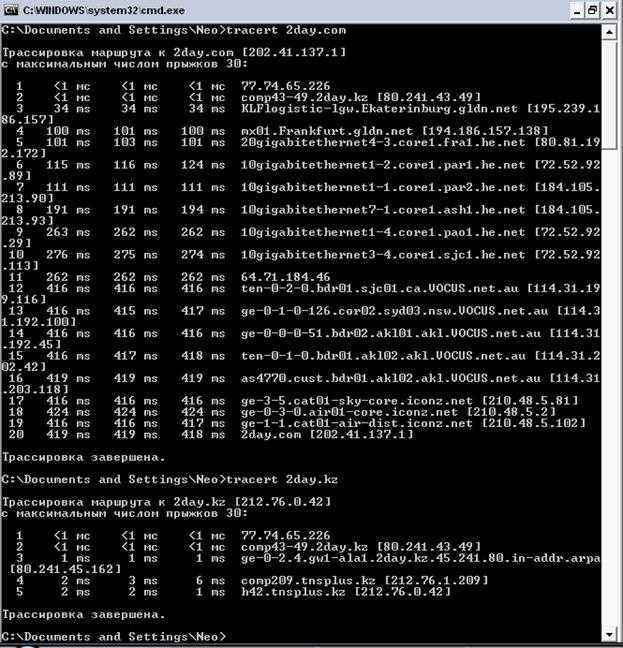
Проведите диагностику сетевых соединений с помощью утилит WinMTR или tracert (traceroute) и отправьте отчет в техподдержку вашего хостинг-провайдера. В ряде случаев такой тест может показать, есть ли проблемы с сетью между вашим устройством и сервером.
![Linux wget command guide [with examples]](https://smartshop124.ru/wp-content/uploads/b/4/5/b4554b4f17ca6a929038e3704638a635.jpeg)
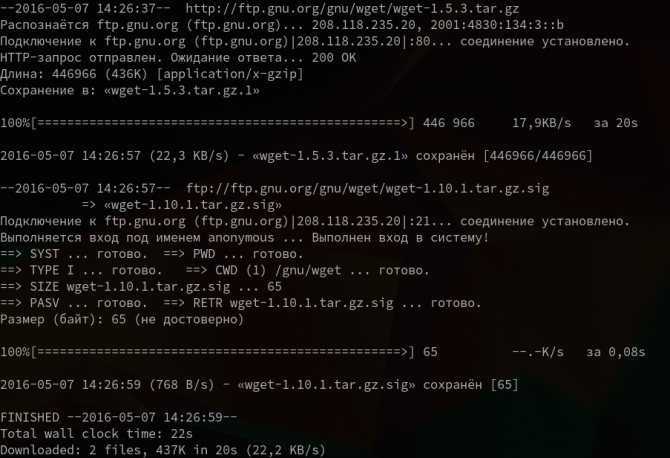
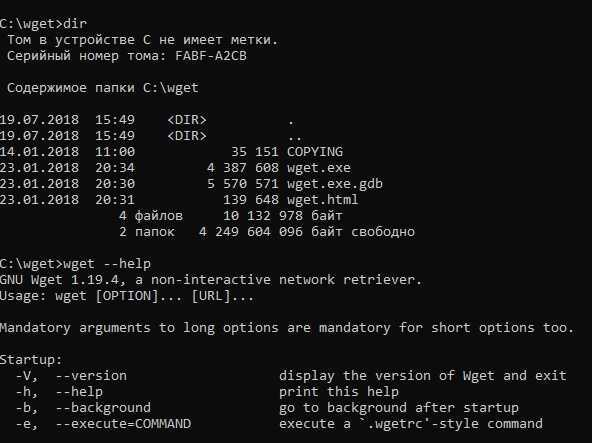
Basics of the wget Command in Linux
The wget utility comes pre-installed in most Linux distributions. However, if it is not the case for your system, you can download it using the package manager for your distribution.
To check this, we will ask the system to display the version of the wget command. This can be done by typing this in your terminal.
wget --version
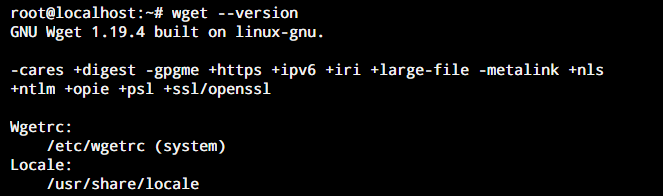
Wget Version
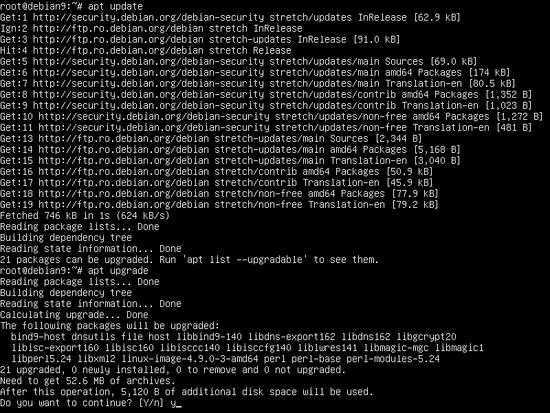
If this does not show you the version of wget command on your system, you need to install it. Before we begin to install wget command in Linux, we need to make sure that all our system repositories are up-to-date.
To do this, we need to update our default repositories using the apt package management service. Open the command line on your system and type the following.
sudo apt update
Now, you can install the wget command on your system depending on the distribution you are using.
For Debian and Ubuntu-based systems, use the following command.
sudo apt install wget
For CentOS and Fedora-based systems, use the following command.
sudo yum install wget
Настройка кэширования и устранения связанных неполадок
Кэширование — важная составляющая производительности любого сайта и веб-приложения. Тут можно работать сразу в двух направлениях: настроить кэширование данных на стороннем ресурсе (как в СDN-cистемах) и оптимизировать хранение кэша в браузере посетителей.
Можно подключиться к системе кэширования сайтов Cloudflare. Это стоит недорого и позволяет перенести всю нагрузку на их серверы. Они кэшируют даже скрипты и стили.
Во втором случае нужна настройка кэша на сервере и в браузере пользователя. Для сайтов, работающих на WordPress, есть плагины WP Super Cache и Proxy Cache Purge. С помощью них можно отправить запрос на удаление кэш-файлов с устройства пользователя. Таким образом, удастся избежать проблем, если вдруг скопившееся кэш-файлы повредятся и станут помехой при загрузке страницы.
Параметры рекурсивной загрузки
- -r
- —recursive
- Включить рекурсивную загрузку.
- -l depth
- —level=depth
- Максимальная глубина рекурсивной загрузки depth. По умолчанию ее значение равно 5.
- —delete-after
-
Удалять каждую страницу (локально) после ее загрузки. Используется для сохранения новых версий часто запрашиваемых страниц на прокси. Например:
wget -r -nd --delete-after http://whatever.com/~popular/page/
Параметр -r включает загрузку по умолчанию, параметр -nd отключает создание папок.
При указанном параметре —delete-after будет игнорироваться параметр —convert-links.
- -k
- —convert-links
- После завершения загрузки конвертировать ссылки в документе для просмотра в автономном режиме. Это касается не только видимых ссылок на другие документы, а ссылок на все внешние локальные файлы.
Каждая ссылка изменяется одним из двух способов:
-
- *
- Ссылки на файлы, загруженные Wget изменяются на соответствующие относительные ссылки.
Например: если загруженный файл /foo/doc.html, то ссылка на также загруженный файл /bar/img.gif будет выглядеть, как ../bar/img.gif. Этот способ работает, если есть видимое соотношение между папками одного и другого файла.
- *
- Ссылки на файлы, не загруженные Wget будут изменены на абсолютные адреса этих файлов на удаленном сервере.
Например: если загруженный файл /foo/doc.html содержит ссылку на /bar/img.gif (или на ../bar/img.gif), то ссылка в файле doc.html изменится на http://host/bar/img.gif.
-
Благодаря этому, возможен автономный просмотр сайта и файлов: если загружен файл, на который есть ссылка, то ссылка будет указывать на него, если нет — то ссылка будет указывать на его адрес в интернет (если такой существует). При конвертировании используются относительные ссылки, значит вы сможете переносить загруженный сайт в другую папку, не меняя его структуру.
Только после завершения загрузки Wget знает, какие файлы были загружены. Следовательно, при параметре -k конвертация произойдет только по завершении загрузки.
-
- -K
- —backup-converted
- Конвертировать ссылки обратно — убирать расширение .orig. Изменяет поведение опции -N.
- -m
- —mirror
- Включить параметры для зеркального хранения сайтов. Этот параметр равен нескольким параметрам: -r -N -l inf -nr. Для неприхотливого хранения зеркальных копий сайтов вы можете использовать данный параметр.
- -p
- —page-requisites
- Загружать все файлы, которые нужны для отображения страниц HTML. Например: рисунки, звук, каскадные стили.
По умолчанию такие файлы не загружаются. Параметры -r и -l, указанные вместе могут помочь, но т.к. Wget не различает внешние и внутренние документы, то нет гарантии, что загрузится все требуемое.
Например, 1.html содержит тег "", со ссылкой на 1.gif, и тег "", ссылающийся на внешний документ 2.html. Страница 2.html аналогична, но ее рисунок — 2.gif и ссылается она на 3.html. Скажем, это продолжается до определенного числа.
wget -r -l 2 http://I/1.html
то 1.html, 1.gif, 2.html, 2.gif и 3.html загрузятся. Как видим, 3.html без 3.gif, т.к. Wget просто считает число прыжков, по которым он перешел, доходит до 2 и останавливается. А при параметрах:
wget -r -l 2 -p http://I/1.html
Все файлы и рисунок 3.gif страницы 3.html загрузятся. Аналогично
wget -r -l 1 -p http://I/1.html
приведет к загрузке 1.html, 1.gif, 2.html и 2.gif. Чтобы загрузить одну указанную страницу HTML со всеми ее элементами, просто не указывайте -r и -l:
wget -p http://I/1.html
При этом Wget будет себя вести, как при параметре -r, но будут загружены страница и ее вспомогательные файлы. Если вы хотите, чтобы вспомогательные файлы на других серверах (т.е. через абсолютные ссылки) были загружены, используйте:
wget -E -H -k -K -p http://I/I
И в завершении, нужно сказать, что для Wget внешняя ссылка — это URL, указанный в тегах "", "" и " ", кроме " ".
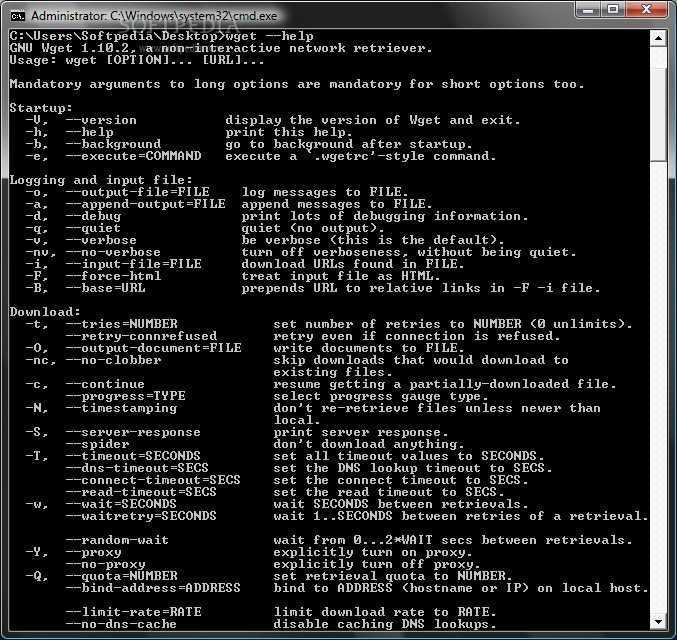
ОПЦИИ
Синтаксис опций очень свободный. У каждой опции, как правило есть как длинное, так и короткое имя. Их можно записывать как до URL, так и после. Между опцией и ее значением не обязательно ставить пробел, например вы можете написать -o log или -olog. Эти значения эквивалентны. Также если у опций нет параметров, не обязательно начинать каждую с дефиса, можно записать их все вместе: -drc и -d -r -c. Эти параметры wget тоже эквивалентны.
А теперь давайте перейдем к списку опций. У wget слишком много опций, мы разберем только основные.
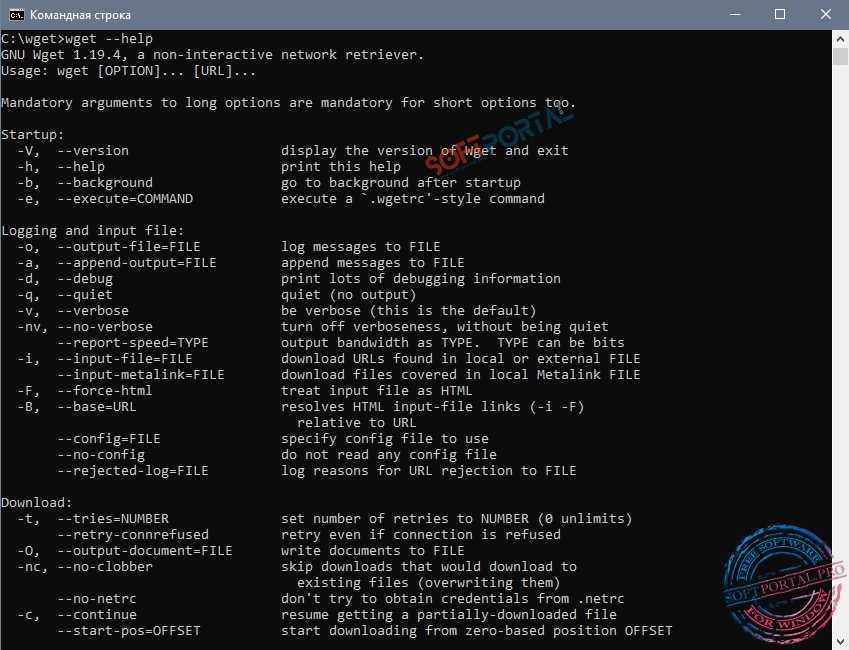
-V (—version) — вывести версию программы
-h (—help) — вывести справку
-b (—background) — работать в фоновом режиме
-o файл (—out-file) — указать лог файл
-d (—debug) — включить режим отладки
-v (—verbose) — выводить максимум информации о работе утилиты
-q (—quiet) — выводить минимум информации о работе
-i файл (—input-file) — прочитать URL из файла
—force-html — читать файл указанный в предыдущем параметре как html
-t (—tries) — количество попыток подключения к серверу
-O файл (—output-document) — файл в который будут сохранены полученные данные
-с (—continue) — продолжить ранее прерванную загрузку
-S (—server-response) — вывести ответ сервера
—spider — проверить работоспособность URL
-T время (—timeout) — таймаут подключения к серверу
—limit-rate — ограничить скорость загрузки
-w (—wait) — интервал между запросами
-Q (—quota) — максимальный размер загрузки
-4 (—inet4only) — использовать протокол ipv4
-6 (—inet6only) — использовать протокол ipv6
-U (—user-agent)— строка USER AGENT отправляемая серверу
-r (—recursive)- рекурсивная работа утилиты
-l (—level) — глубина при рекурсивном сканировании
-k (—convert-links) — конвертировать ссылки в локальные при загрузке страниц
-P (—directory-prefix) — каталог, в который будут загружаться файлы
-m (—mirror) — скачать сайт на локальную машину
-p (—page-requisites) — во время загрузки сайта скачивать все необходимые ресурсы
Кончено это не все ключи wget, но здесь и так слишком много теории, теперь давайте перейдем к практике. Примеры wget намного интереснее.
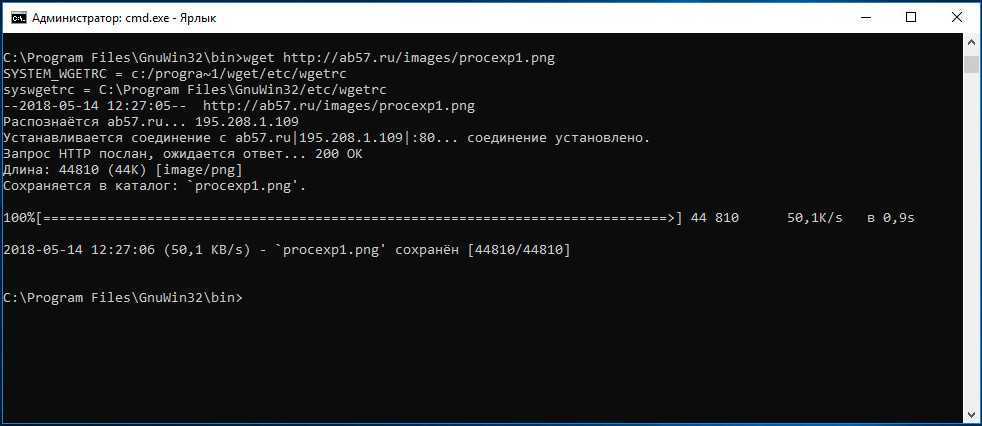
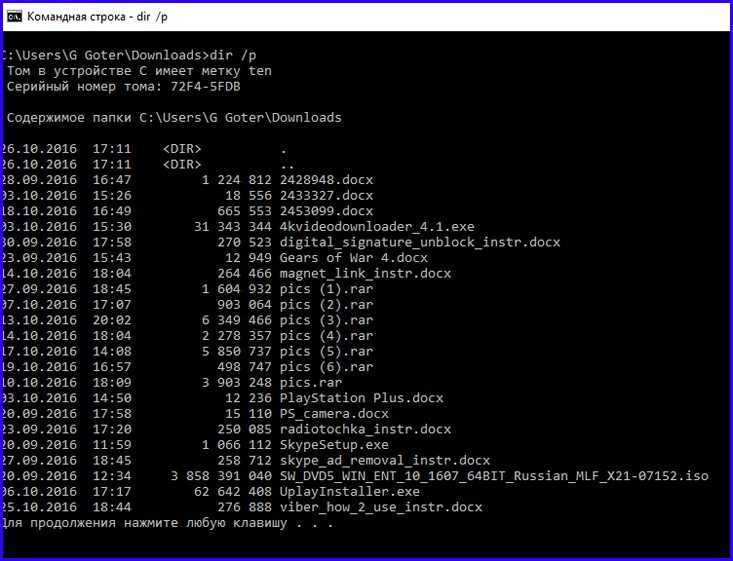
Скачать в текущую директорию
Пример скачивания
CentOS
Linux
с помощью wget.
Чтобы скачать что-нибудь полезное нужно найти где что-то полезное лежит
Я нахожусь в
Хельсинки
поэтому ближайший репозиторий CentOS это ftp.funet.fi
К вам может быть ближе какой-то другой репозиторий из списка
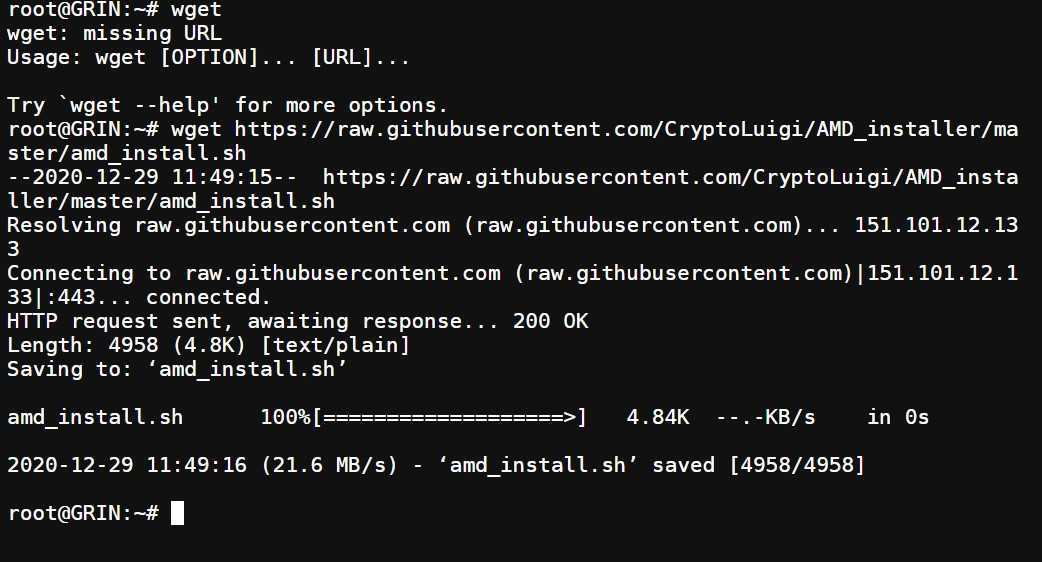
wget http://ftp.funet.fi/pub/mirrors/centos.org/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso
—2021-11-03 12:36:59— http://ftp.funet.fi/pub/mirrors/centos.org/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso
Resolving ftp.funet.fi (ftp.funet.fi)… 193.166.3.2, 2001:708:10:8::2
Connecting to ftp.funet.fi (ftp.funet.fi)|193.166.3.2|:80… connected.
HTTP request sent, awaiting response… 200 OK
Length: 4712300544 (4.4G) [application/x-iso9660-image]
Saving to: ‘CentOS-7-x86_64-DVD-2009.iso’
CentOS-7-x86_64-DVD 100% 4.39G 2.17MB/s in 23m 24s
2021-11-03 13:00:23 (3.20 MB/s) — ‘CentOS-7-x86_64-DVD-2009.iso’ saved [4712300544/4712300544]
В результате
CentOS-7-x86_64-DVD-2009.iso
скачан в текущую директорию
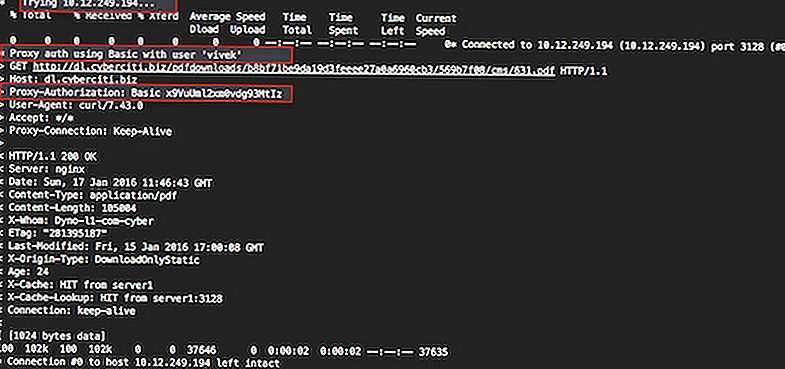
Downloading Files via Proxy
There are some situations where our system is running behind the proxy server, so in such situations first we need to set proxy and then we can use wget command to download file from the internet. To set proxy on the command line use the following variables and export command
$ export http_proxy=http://<Your-Proxy-IP>:<Proxy-Port> $ export https_proxy=http://<Your-Proxy-IP>:<Proxy-Port> $ export ftp_proxy=http://<Your-Proxy-IP>:<Proxy-Port>
In Case user name and password is required for proxy to work then use the followings
$ export http_proxy=http://<user-name>:<password>@<Your-Proxy-IP>:<Proxy-Port> $ export https_proxy=http://<user-name>:<password>@<Your-Proxy-IP>:<Proxy-Port> $ export ftp_proxy=http://<user-name>:<password>@<Your-Proxy-IP>:<Proxy-Port>
ОПЦИИ
Синтаксис опций очень свободный. У каждой опции, как правило есть как длинное, так и короткое имя. Их можно записывать как до URL, так и после. Между опцией и ее значением не обязательно ставить пробел, например вы можете написать -o log или -olog. Эти значения эквивалентны. Также если у опций нет параметров, не обязательно начинать каждую с дефиса, можно записать их все вместе: -drc и -d -r -c. Эти параметры wget тоже эквивалентны.
А теперь давайте перейдем к списку опций. У wget слишком много опций, мы разберем только основные.
-V (—version) — вывести версию программы
-h (—help) — вывести справку
-b (—background) — работать в фоновом режиме
-o файл (—out-file) — указать лог файл
-d (—debug) — включить режим отладки
-v (—verbose) — выводить максимум информации о работе утилиты
-q (—quiet) — выводить минимум информации о работе
-i файл (—input-file) — прочитать URL из файла
—force-html — читать файл указанный в предыдущем параметре как html
-t (—tries) — количество попыток подключения к серверу
-O файл (—output-document) — файл в который будут сохранены полученные данные
-с (—continue) — продолжить ранее прерванную загрузку
-S (—server-response) — вывести ответ сервера
—spider — проверить работоспособность URL
-T время (—timeout) — таймаут подключения к серверу
—limit-rate — ограничить скорость загрузки
-w (—wait) — интервал между запросами
-Q (—quota) — максимальный размер загрузки
-4 (—inet4only) — использовать протокол ipv4
-6 (—inet6only) — использовать протокол ipv6
-U (—user-agent)— строка USER AGENT отправляемая серверу
-r (—recursive)- рекурсивная работа утилиты
-l (—level) — глубина при рекурсивном сканировании
-k (—convert-links) — конвертировать ссылки в локальные при загрузке страниц
-P (—directory-prefix) — каталог, в который будут загружаться файлы
-m (—mirror) — скачать сайт на локальную машину
-p (—page-requisites) — во время загрузки сайта скачивать все необходимые ресурсы
Кончено это не все ключи wget, но здесь и так слишком много теории, теперь давайте перейдем к практике. Примеры wget намного интереснее.
Расширения
Как и в случае с Chrome, немаловажную роль в скорости работы Mozilla играют установленные вами расширения. Желательно перейти во вкладку с настройками браузера и отключить те дополнения, которыми вы не пользуетесь, а вместо них установить действительно полезные для вашей «оперативки». Вот парочка дополнений, которые смогут разгрузить ваш браузер и ОЗУ:
- OneTab. Как вы могли догадаться, это дополнение можно установить не только на Chrome, но и на Mozilla. Функциональность версий не отличается, поэтому если хотите бороться с «прожорливыми» вкладками, ставьте расширение и деактивируйте ненужные страницы.
- Auto Tab Discard. Схожее с OneTab приложение, которое позволяет экономить оперативную память путем контроля за неактивными вкладками. Вы можете выставить время, по истечении которого страницы будут закрываться. При этом, вы с легкостью сможете их вернуть в любой момент.
Отсутствие системы CDN
CDN расшифровывается как Content Delivery Network, что в переводе означает «сеть доставки контента». Это множество серверов по всей планете, на которых хранится один и тот же веб-сайт. И независимо от того, из какой части света посетитель заходит на ресурс, он получит данные с ближайшего сервера, что позитивно скажется на скорости загрузки.
Существует несколько провайдеров CDN-систем. Например, Cloudflare. Сервис дает возможность разместить свой сайт в нескольких частях планеты (конкретнее можно узнать на официальном сайте сервиса). Нередко вебмастера подгружают jQuery и другие компоненты с CDN-серверов, чтобы не тратить на их обработку ресурсы арендованного VDS.
Timeweb предлагает доступ к системе CDN вместе с защитой от DDoS-атак за небольшую дополнительную плату.
Параметры загрузки папок
- -nd
- —no-directories
- Не создавать структуру папок при рекурсивной загрузке. При указанном параметре, все файлы будут загружаться в одну папку. Если файл с данным именем уже существует, то он будет сохранен под именем ИмяФайла.n.
- -x
- —force-directories
- Противоположно параметру -nd — создавать структуру папок, начиная с главной страницы сервера. Например, wget -x http://fly.srk.fer.hr/robots.txt приведет к загрузке файла в папкуfly.srk.fer.hr.
- -nH
- —no-host-directories
-
Не создавать пустые папки в начале структуры. По умолчанию /pub/xemacs/. Если вы загрузите ее с параметром -r, то она сохранится под именем ftp.xemacs.org/pub/xemacs/. С параметром -nH из имени начальной папки вырежется ftp.xemacs.org/, и она будет называться pub/xemacs. А параметр —cut-dirs уберет number компонентов. Примеры работы параметра —cut-dirs:
Без параметров -> ftp.xemacs.org/pub/xemacs/ -nH -> pub/xemacs/ -nH --cut-dirs=1 -> xemacs/ -nH --cut-dirs=2 -> .
--cut-dirs=1 -> ftp.xemacs.org/xemacs/ ...
Если вы хотите просто избавиться от структуры папок, то вы можете заменить этот параметр на -nd и -P. В отличие от -nd, -nd работает с подкаталогами — например, при -nH —cut-dirs=1 подкаталог beta/ запишется, как xemacs/beta.
- -P prefix
- —directory-prefix=prefix
- Определяет начальную папку, в которой будет сохранена структура папок сайта (или просто файлы). По умолчанию этот параметр равен . (текущая папка).
Examples
Download a single file, basic usage:
wget https://www.example.com/file.zip
Continue Downloading a File
If a download only partially completed, continue/resume downloading it with the -c option:
wget -c https://www.example.com/file.zip
Download From a List of Files, Appending to Log
If you have a text file containing a list of URLs to download, you can pass it directly to wget and write a log of the results for later inspection:
wget -a log.txt -i url-list.txt
You could also use -o to write out the log file, and it will overwrite rather than append an existing log file if it’s already there.
Retry downloading a file and don’t’ print progress to the terminal:
wget -t 5 -q https://www.example.com/file.zip
Download From a List of Files, Waiting 6 Seconds Between Each Download, with a 12 Second Timeout
Wait between downloads to reduce server load, and abort if the server fails to respond within 12 seconds:
wget -w 6 -T 12 -i url-list.txt
Download a File from an FTPS Server which Requires a Username and Password
Download from an FTPS server with the username bob and the password boat:
wget --user=bob --password=boat ftps://ftp.example.com/file.zip
Download a File with a POST Request
Make an HTTP POST request instead of the default GET request, and send data. A blank string can be sent with –post-data:
wget --post-data="postcode=2000&country=Australia" https://www.example.com/file.zip
In this example, we’re sending two pieces of POST data – postcode and country.
Download Directory Recursively via FTP with a Depth Limit
Downloading recursively will download the contents of a folder and the contents of the folders in that folder. A depth limit of 3 is defined in this example – meaning that if a folder is nested within 3 other folders, it won’t be downloaded:
wget -r -l 3 ftps://ftp.example.com/path/to/folder
Cloning a Whole Web Page Using Wget
If you want to try and grab a whole webpage – including all images, styles, and scripts, you can use
wget -p https://www.example.com/page.html
Your success will vary – some modern web pages don’t really work well when ripped out of their native habitat.